Prescriptive Analytics for Flexible Capacity Management
3
本节根据Netessine等人(2002年)和Bassok等人(1999年)对我们解决的容量规划问题进行了正式描述。考虑一家以pi(I=1,…,I)的单价提供I服务的公司。在每个计划周期t∈{1,…,t}(例如,一周中的每一天)中,对每个服务i的需求是不确定的,我们将其建模为由Di t表示的随机变量。Di T的I×T分布是未知的,但该公司可以访问一组数据SN={(d1,x1),…,(dn,xN)},其中包含需求d N=(dN,1,…,d N,T)∈d⊆R I×T的最新历史观测值,其中每日需求d N,T=(dn,t1,…,dn,tI),以及向量~xN∈X \8838R p表示的特征的相应观测值。例如,这些特征描述了季节性(日、月、周、季)、天气条件和其他可预测需求的独立可观察变量。为了提供各种服务i,公司使用不同的资源j=1。。。,一、 我们称之为服务线。
1服务i由服务线j=i提供,但也可以由任何服务线j≤i提供,尽管单位利润较低。因此,存在服务线的层次结构,其中j=1是最灵活的服务线,因为它可以提供所有服务i=1。。。,一、 当服务需求未知时,公司必须在T期规划期的第一个阶段之前确定服务线的容量。在我们的背景下,能力是一周的人员配置水平(即T=5),在一周的每一天T都是恒定的。我们用q=(q1,…,qI)表示在规划期的每个周期t∈{1,……,t}中可用的恒定容量,用fj表示每单位容量j的固定成本。除此固定成本外,我们假设使用一单位容量j时产生的可变成本vj。在每个时期t,公司首先观察该时期的需求,然后将实现的需求dt=(dt1,…,dtI)分配给给定的产能q。公司因未满足服务需求i而产生单位罚款成本ci,并在使用服务线j满足服务需求时实现单位贡献边际ai,j。贡献边际定义为ai,j=pi−vj+ci,我们假设j<i时ai,i≥ai,j,当服务线j=i时,满足类型i的需求更有利可图,如果服务线j<i时,需求得到升级和满足,则利润更低。公司的目标是确定假设实现的需求dT在每个周期T中最优地分配给服务线j,则T期规划范围最大化预期利润。设yi,j表示一旦观察到需求,服务线j所完成的服务量i。公司的产能规划问题可由以下两阶段随机优化问题表示:
(1)
该公式与Netessine等人(2002)提出的公式在一个小方面有所不同:尽管出于可处理性的原因,他们在第2阶段假设了一个单周期分配问题,但在给定第1阶段确定的容量q的情况下,我们对在每个周期t∈{1,…,t}中独立做出的多个分配决策进行建模。由于第2阶段的连续分配决策是独立的,我们还可以证明利润函数∏(q)是凹的。
提案1。(1)中定义的利润函数∏(q)在q中共同凹。
2在大多数实际情况下,给定X=X的非平稳、依赖于特征的需求D的分布是未知的,传统的方法是首先估计条件分布,然后解决问题1。
4 规范分析方法
与先估计需求D的特征相关的多变量分布然后解决问题1的传统方法不同,规定性分析方法直接规定了当给定新的特征向量x时使损失最小化的最优决策q(~x)。
在容量规划问题中,损失函数可以定义为
(2)
其中∏(q,d)表示与需求实际化d下的产能决策q相关的利润,∏*(d)=maxq∏( q,d是事后最优利润。该定义确保L(~q,d)≥0。
提案2。损失函数L(q,d)在q中是联合凸的。
已经提出了两种方法来解决确定q(x)的规定性分析问题。第一种方法是通过从函数空间F中选择一个函数来最小化真实风险R(q(·)),该函数被定义为X×D的联合分布上的预期损失,我们假设该函数空间是Banach空间,从而定义了一个范数,并且方程3中存在最小值,函数~q(?):X→ Q,其从特征空间X映射到决策空间Q:
(3)
知道这样一个函数q(·),就可以为特征向量x∈x的每个新观测值确定容量决策q(x)∈q。第二种方法通过求解
(4)
对于每个新的~x。
由于既不知道X×D的联合概率分布,也不知道D的条件概率分布,给定X=X,(3)和(4)不能直接求解。然而,对于能够访问由需求和特征的历史观察组成的数据集SN的决策者,可以推导出(3)和(4)的规定性分析方法。ERM的成熟机器学习原理提出,可以使用最小化经验风险RN(q(·))的函数~q ERM(·)来规定能力,而不是真实风险R(~q)(参见BK和BR):
(5)
BK提出了基于局部学习技术的ERM方法的许多替代方案,这些方法采用从特征中导出一些权重wn(x)∈[0,1]的常见形式,并“针对数据的重新加权优化决策[q]”(BK,第11页),如(6)所示:
(6)
在最一般的术语中,该方法近似于(4),可以被视为SAA(wSAA)的加权形式。权重函数wn(·)可以被认为是一个相似函数;因此,它与kERM方法中使用的内核函数K(·,·)有很强的相似性,我们将在第4.2节中看到。显然,wSAA方法的性能取决于相似函数的选择。BK基于k近邻回归、核回归、局部线性回归、回归树和随机森林构建了许多权重函数。
我们事先不知道ERM方法或wSAA方法是否更适合我们的特定容量规划问题,我们无法就其性能差异提出任何索赔。BK提出了许多支持本地学习方法的论点,并描述了应用于OR/MS问题的ERM方法的局限性。我们表明,ERM方法适用于解决(3)中所述的规定性分析问题,并且它还具有一些特性,包括外推能力、通用近似特性和性能保证,这可能使它成为一个具有类似吸引力的选择。
4.1基于问题6的加权样本平均近似方法
我们将容量规划问题的wSAA方法表述为:
(7)
我们忽略了∏*(d),因为它与~q无关。
提案3。wSAA方法的目标函数在~q中是联合凸的。
对于任何给定的权重函数wn(~x)≥0,wSAA方法(7)是一个线性程序。
使用BK中给出的结果,我们展示了我们的特定wSAA方法对于与BK相同的权重函数类的渐近最优性3,即基于k近邻(kNN)、(递归)核方法和局部线性方法的权重函数(见G.1节中的命题10)。
显然,函数q(x)的渐近最优性是规定分析方法的理想性质。然而,这些wSAA方法的收敛速度可能容易受到维度的诅咒;也就是说,它可能随着特征向量x的维数p呈指数下降。我们无法证明任意分布(X,D)的这种情况,因为无法导出~q wSAA(~X)收敛速度的一般表达式(Györfi等人(2002))。
然而,我们可以证明,对于特定类别的分布和一般损失函数,单个较低的收敛速度4在p中呈指数下降。
提案4。假设Q=D=R,并且从分布(~X,D)∈P(l,C)绘制出数据集SN iid。对于损失函数L(q,d)=|q−d|2,q wSAA的单个较低收敛率如下
(8)
命题4指出,我们通常不能期望q wSAA(~x)的收敛速度快于N−2l+1 2l+p,后者在p上呈指数下降(详见Györfi等人(2002))。因此,在具有大量特征p的大数据系统中,收敛可能会很慢,并且达到一定性能水平所需的观测值N可能会很高。
因此,在我们的问题背景下,在需求数据的历史观测数量相对较少的情况下,我们不能期望有超过N≈260个相关观测(假设一个观测描述了一周,而五年以上的数据不再相关),并且特征的数量p可能较大,收敛可能较慢,并且渐近最优性的性质似乎具有有限的实际相关性。BK报告的仅具有三个特征的程式化设置的实验结果表明,他们的wSAA方法在超过104次观察后收敛到完全信息最优。
对于观测值明显较少的情况,如我们的情况,渐近最优性的性质不允许对方法的性能进行推断。
在BK的数值实验中,基于随机森林的权重函数(无法显示wSAA的渐近最优性)导致了最佳性能。与可以显示渐近最优性的权重函数相反(见命题10),随机森林权重函数是从数据中学习的,隐含地识别了最相关的特征子集,因此可以提供更好的相似性度量,尤其是在历史观测数量较少的情况下。基于这些考虑和BK给出的数值结果,我们建议使用BK引入的随机森林权重函数:
(9)
对于具有L棵树和Rl(x)的随机林,树L的终端节点包含x。(9)中的分子捕获特征向量x和xn被分配给树l中的相同终端节点,而分母捕获~x的终端节点中的训练样本数。权重wn RF(~x)被计算为随机森林中所有L棵树的该分数的平均值。该定义确保了权重的归一化,使得P n wn RF(~x)=1。
通过设计,wSAA方法规定了可行的解决方案,因为它们依赖于对~x的每个新实例在可行集Q上的重新优化。虽然这显然是一个有吸引力的房产,但在我们的环境中,它可能会有负面影响,因为需求可能会有强烈的负面或积极的趋势。假设标量值需求实现和容量决策,我们可以证明,q wSAA(~x)限于单个需求实现dn(n=1,…,n)的最优解的凸组合-参见第G.1节中的命题11,因此它在过去可能是最优的可行解之间进行插值。然而,在需求出现积极或消极趋势的情况下,插值可能会导致处方不如基于允许外推的方法的处方(更多说明和讨论请参见第G.2节)。正如我们在下面讨论的,与wSAA相比,ERM方法允许外推,但不能保证可行的解决方案。
6
本节将wSAA和kERM应用于物流服务提供商的能力规划问题。我们使用历史需求数据和案例公司成本参数的实际值来证明这些方法的适用性,并将其性能与两种传统的两步方法和不包含特征数据的传统SAA方法进行比较。为了阐明方法性能的潜在驱动因素,并产生超出案例公司特定参数设置的见解,我们提供了额外的数值分析结果,其中我们改变了模型的(外生)成本参数,同时保持了案例公司的历史需求和特征数据。这些分析的结果为这些方法的性能驱动因素提供了见解,并使我们能够评估其稳健性。
6.1
我们的研究灵感来自于我们与德国一家物流服务提供商的合作,该服务提供商收集、分拣和递送邮件(信件、包裹)、报纸、广告材料等。我们专注于大约15名员工在公司主要设施中进行的分拣操作。该公司平均每天收到约175000件物品,这些物品是手动分拣(服务线3)、半自动分拣(服务线路2)或全自动分拣(1)。虽然每个服务线都有足够的分拣机容量,但这些机器的操作和手动分拣需要一定的人员配置(即容量)。
三条服务线的劳动力成本和所需技能水平不同,因为全自动分拣机的操作需要高技能员工,而半自动和手动分拣的技能要求较低。由于服务线1的员工也可以运营服务线2和3,服务线2的员工也可运营服务线3,因此公司有一个升级选项,如第3节所述。每周,公司必须确定下一周每条生产线的人员配置水平(产能),这将导致每条服务线每天的固定和恒定产能(t=1,…,t=5)。第t天到达的需求由指定服务线的员工处理,而超过指定服务线员工能力的需求可以“升级”为更昂贵的服务线员工。如果有必要,所有在t天到达的物品都必须在当天结束前处理,加班不仅在工资方面成本高昂,而且由于其对员工挽留的负面影响,这也是非常不可取的。该公司面临劳动力供应的严重短缺,因此他们希望限制加班,以保持员工满意度。
过去,该公司采用相对简单的方法来进行产能决策。根据历史需求,他们获得了不同邮件数量的估计值将这些转换为单个工作日的容量需求,作为每周容量计划的基础。这一过程主要是以人工方式进行的,并强烈依赖于规划者以往的经验和专业知识;该公司没有使用复杂的工具进行预测或产能规划。临时产能调整(通过转换或重新安排班次,或招聘额外临时工)经常发生。
利用公司提供的信息,我们获得了公司收入和成本的估计值(表1)。每项分类的收入约为0.1欧元。每个工人的(全额)成本为每小时15欧元至40欧元,具体取决于技能设置和其他因素。与公司一起,我们定义了每项未分类项目0.05欧元的罚款成本,以反映加班对员工满意度的负面影响。9我们还假设产能使用成本vj=0,因为计划产能是固定的,必须在整个星期内支付。
因为它类似于第3节中描述的产能规划问题,我们可以采用传统的两步方法,即估计多变量需求分布和求解两阶段随机优化模型,如(1)所述,以确定接下来一周三条生产线的“最佳”产能。这种方法的实际困难主要源于第1节所述的多变量需求分布的估计。我们通过对案例公司需求数据的一些描述性分析来支持第1节中的论点。图1a描绘了2014年至2017年所有三条生产线的每日需求(换算为所需工时)。我们观察了这三个时间序列表明需求是非平稳的。更详细的分析表明,时间序列包含不同频率的季节性叠加(第B节),三条生产线的日需求变化差异很大。为了突出这些每日需求的变化,图1b描绘了去趋势化和去季节化的时间使用TBATS模型获得的系列(详见B节)。
在这四年中,三条服务线每日需求的变异系数(CV)从中等到低,从服务线2的CV2=0.25到服务线1的CV1=0.17不等。整个时间段内的相关系数(CC)相对较低,所有三种服务线组合的相关系数约为0.18。尽管在所有观察中,CV和CC都是低到中等的,但在较短的时间段内,我们观察到了显著的变化(见B节),但我们不知道它们是随机发生的还是可以通过某些特征来解释。对该公司专家的采访表明,其中一些变化可能是可预测的。例如,在每年的第50周和第51周,服务线1和3的需求通常高度相关,因为大量的年终商务邮件(服务线1)和私人假日邮件(服务线路3)到达。另一方面,由于私人邮件增加,临近公共假期往往会导致负相关,而商业邮件减少,因为企业员工往往在这段时间休假。我们期望有许多这样的关系,并且在适当的特征下,它们可能是可预测的。
然而,很难将这些关系结合到多变量需求分布的估计中,这说明了需要能够隐式结合特征相关分布的规定性方法。
6.2需求数据和特征工程
案例公司向我们提供了一个历史数据集,其中包含2014年至2017年期间每一天每一条服务线i的邮件数量需求数据,以解决我们描述的规划问题。根据这些历史数据,我们构建了一个数据集SN={(d1,x1),…,(dN,xN)},其中需求矩阵dn以工时为单位,N=209周,特征向量~xN∈R162。
作为特征向量~xn的元素,我们首先构建了描述观察到的需求的时间维度的基于日期的特征。特别是,我们使用了年份号以及包含特定星期的一年中的半年、季度和月份作为特征。周数也可能是一个相关的特征,因为我们从与专家的访谈中了解到,在临近年底的几周内,需求量很高(见第6.1节)。我们将滞后需求(例如,一年前同一周内每条服务线的需求量)纳入第二组特征,以说明时间序列的连续性。第三组特征编码了公共假日的信息,这些信息也已知会影响需求(见第6.1节)。我们构建了公共假日指标和相关指标(例如,如果公共假日是在感兴趣的一周之前或之后的几天)。我们的分析中包括的162个特征的详细描述及其重要性分析见第C节。
6.3评估程序
我们将生成的数据集SN分为N=157周的训练数据(2014-2016年)和52周的测试数据(2017年),以便于进行样本外性能评估。由于特征的数量p>N,我们面临一个高维问题。我们评估并比较了以下方法的处方性能:1。kERM:通过用随机森林内核(13)求解(12)来估计处方函数(11),并为测试周期的每一周规定容量决策。
2.wSAA:用测试期间每周的随机森林权重(9)求解(7)。
3.SAA:通过求解wn(~x)=1/N的(7)来估计训练数据集的SAA处方。
4.SVR-SEO10:使用随机森林核(13)训练支持向量回归模型,估计样本残差的CV和CC,并预测多变量需求分布
5.ARIMA-SEO10:训练ARIMA时间序列模型,估计样本残差的CV和CC,并预测测试期间每周的多变量需求分布。
按照与SVR-SEO相同的步骤求解(1)。
我们通过在测试期间的每一天解决问题1的第二阶段,确定了所有规定产能决策的最大可实现利润,总利润为所有周的每周利润之和。我们还计算了测试期间的事后最优利润∏*(d),因此我们可以报告所有方法的最优利润∆∏,abs=∏*(d)−∏(~q,d)的绝对差距。
相关文章:

Prescriptive Analytics for Flexible Capacity Management
3 本节根据Netessine等人(2002年)和Bassok等人(1999年)对我们解决的容量规划问题进行了正式描述。考虑一家以pi(I1,…,I)的单价提供I服务的公司。在每个计划周期t∈{1,……...

超简单的待办事项列表管理器todo
什么是 todo ? todo 是一个自托管的 todo web 应用程序,可让您以简单且最少的方式跟踪您的 todo。📝 老苏觉得和之前介绍的 KissLists 比较像 文章传送门:最简单的共享列表服务器KissLists 官方提供了 Demo 演示站点:https://tod…...

在C#中初测OpencvSharp4
一、配置OpenCV 首先,我们新建一个工程,然后就是给这个工程配置OpenCV了,最简单的方法还是Nuget,来我们右键一个Nuget: 打开Nuget后,你可以直接输入OpenCVSharp4来查找,当然,如果你…...
(DFS))
洛谷P1123 取数游戏(C++)(DFS)
目录 1.题目 题目描述 输入格式 输出格式 输入输出样例 说明/提示 2.AC 1.题目 题目描述 一个N \times MNM的由非负整数构成的数字矩阵,你需要在其中取出若干个数字,使得取出的任意两个数字不相邻(若一个数字在另外一个数字相邻88个格…...

Python Qt6快速入门-嵌入PyQtGraph图表
嵌入PyQtGraph 文章目录 嵌入PyQtGraph1、PyQtGraph介绍2、创建PyQtGraph小部件3、绘图样式配置3.1 背景颜色3.2 线条颜色、线宽和样式配置3.3 线标记(Line Markers)3.4 绘制标题3.5 轴标题3.6 图例(Legends)3.7 轴范围限制3.8 绘制多组数据3.10 画布清空4、更新数据5、总结1、…...
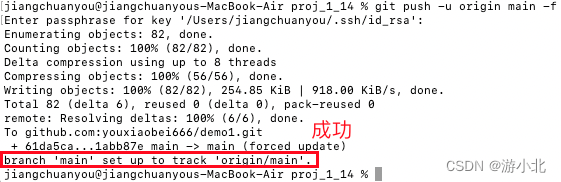
Mac电脑_GitHub提交项目至仓库
第一步(准备工作): Mac 电脑自带 git , 无需安装 1. 创建一个项目 demo1 在 github 上 2. 创建 ssh 密钥 打开终端: ssh-keygen -t rsa -C "your_emailyouremail.com" 此处输入两次密码, 直接…...

Android自定义View实现横向的双水波纹进度条
效果图:网上垂直的水波纹进度条很多,但横向的很少,将垂直的水波纹改为水平的还遇到了些麻烦,现在完善后发布出来,希望遇到的人少躺点坑。思路分析整体效果可分为三个,绘制圆角背景和圆角矩形,绘…...
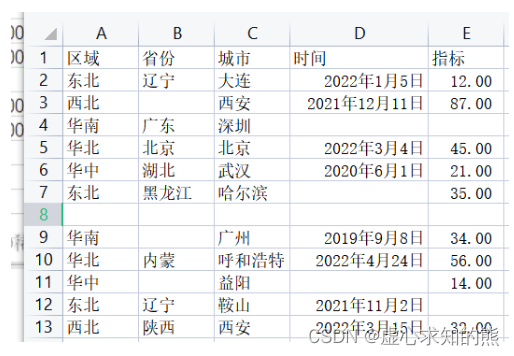
Python 之 Pandas 分组操作详解和缺失数据处理
文章目录一、groupby 分组操作详解1. Groupby 的基本原理2. agg 聚合操作3. transform 转换值4. apply二、pandas 缺失数据处理1. 缺失值类型1.1 np.nan1.2 None1.3 NA 标量2. 缺失值处理2.1 查看缺失值的情形2.2 缺失值的判断2.3 删除缺失值2.4 缺失值填充在开始之前ÿ…...

【人工智能 AI】什么是人工智能? What is Artificial Intelligence
目录 Introduction to Artificial Intelligence人工智能概论 What is Artificial Intelligence? 什么是人工智能?...

17、触发器
文章目录1 触发器概述2 触发器的创建2.1 创建触发器语法2.2 代码举例3 查看、删除触发器3.1 查看触发器3.2 删除触发器4 触发器的优缺点4.1 优点4.2 缺点4.3 注意点尚硅谷MySQL数据库教程-讲师:宋红康 我们缺乏的不是知识,而是学而不厌的态度 在实际开发…...

内核并发消杀器(KCSAN)技术分析
一、KCSAN介绍KCSAN(Kernel Concurrency Sanitizer)是一种动态竞态检测器,它依赖于编译时插装,并使用基于观察点的采样方法来检测竞态,其主要目的是检测数据竞争。KCSAN是一种检测LKMM(Linux内核内存一致性模型)定义的数据竞争(data race)的工…...

蓄水池抽样算法
蓄水池抽样,也称水塘抽样,是随机抽样算法的一种。基本抽样问题有一批数据(假设为一个数组,可以逐个读取),要从中随机抽取一个数字,求抽得的数字下标。常规的抽样方法是,先读取所有的…...

数据结构预算法之买股票最好时机动态规划(可买卖多次)
一.题目二.思路在动规五部曲中,这个区别主要是体现在递推公式上,其他都和上一篇文章思路是一样的。所以我们重点讲一讲递推公式。这里重申一下dp数组的含义:dp[i][0] 表示第i天持有股票所得现金。dp[i][1] 表示第i天不持有股票所得最多现金如…...
)
华为OD机试真题Java实现【蛇形矩阵】真题+解题思路+代码(20222023)
蛇形矩阵 蛇形矩阵是由1开始的自然数依次排列成的一个矩阵上三角形。 例如,当输入5时,应该输出的三角形为: 1 3 6 10 15 2 5 9 14 4 8 13 7 12 11请注意本题含有多组样例输入。 🔥🔥🔥🔥🔥👉👉👉👉👉👉 华为OD机试(Java)真题目录汇总 输入描述:…...
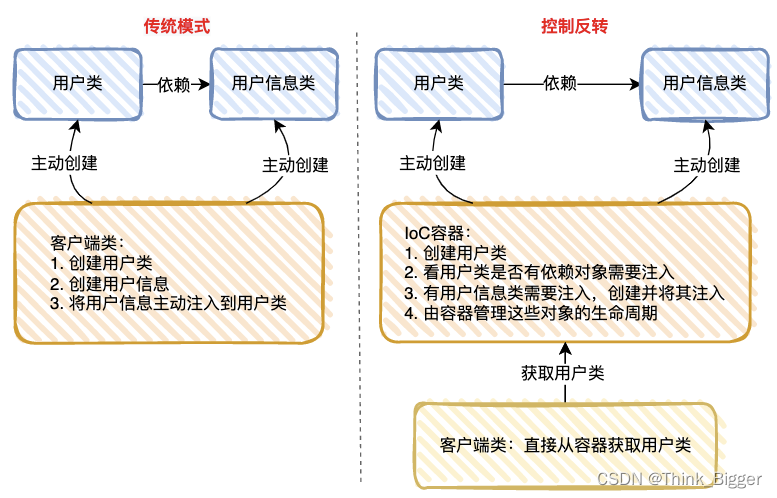
spring Bean的生命周期 IOC
文章目录 1. 基础知识1.1 什么是 IoC ?2. 扩展方法3. 源码入口1. 基础知识 1.1 什么是 IoC ? IoC,控制反转,想必大家都知道,所谓的控制反转,就是把 new 对象的权利交给容器,所有的对象都被容器控制,这就叫所谓的控制反转。 IoC 很好地体现了面向对象设计法则之一 —…...

详解cors跨域
文章目录同源策略cors基本概念cors跨域方式简单请求 simple request非简单请求- 预检请求CORS兼容情况CORS总结同源策略 在以前的一篇博客中有介绍,同源策略是一种安全机制,为了预防某些恶意的行为,限制浏览器从不同源文档和脚本进行交互的行…...
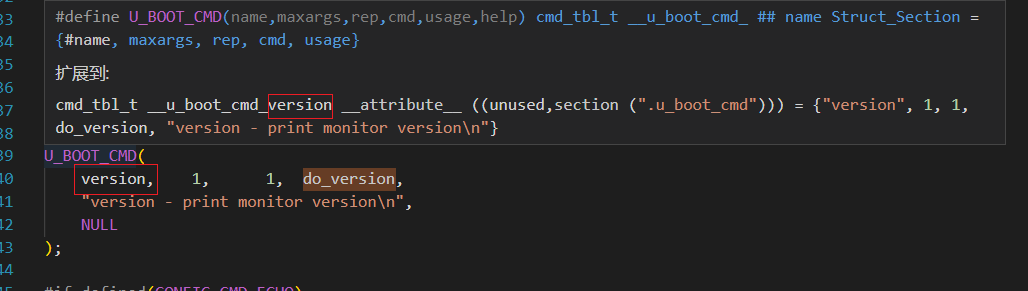
ARM uboot 源码分析7 - uboot的命令体系
一、uboot 命令体系基础 1、使用 uboot 命令 (1) uboot 启动后进入命令行环境下,在此输入命令按回车结束,uboot 会收取这个命令然后解析,然后执行。 2、uboot 命令体系实现代码在哪里 (1) uboot 命令体系的实现代码在 uboot/common/cmd_xx…...

物理服务器与云服务器备份相同吗?
自从云计算兴起以来,服务器备份已经从两阶段的模拟操作演变为由云服务器备份软件执行的复杂的多个过程。但是支持物理服务器和虚拟服务器之间的备份相同吗?主要区别是什么?我们接下来将详细讨论这个问题。 物理服务器与云服务器备份的区别 如果您不熟悉虚拟服务器…...

【Linux】system V共享内存 | 消息队列 | 信号量
🌠 作者:阿亮joy. 🎆专栏:《学会Linux》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录👉system V共…...

FSC的宣传许可 答疑
【FSC的宣传许可 答疑】问:已经采购了认证产品但没有贴FSC标签,是否可以申请宣传许可?答:不可以。要宣传您采用了FSC认证产品的前提条件之一是产品必须是认证且贴有标签的。如果产品没有贴标,则不可申请宣传许可。您的…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

aardio 自动识别验证码输入
技术尝试 上周在发学习日志时有网友提议“在网页上识别验证码”,于是尝试整合图像识别与网页自动化技术,完成了这套模拟登录流程。核心思路是:截图验证码→OCR识别→自动填充表单→提交并验证结果。 代码在这里 import soImage; import we…...
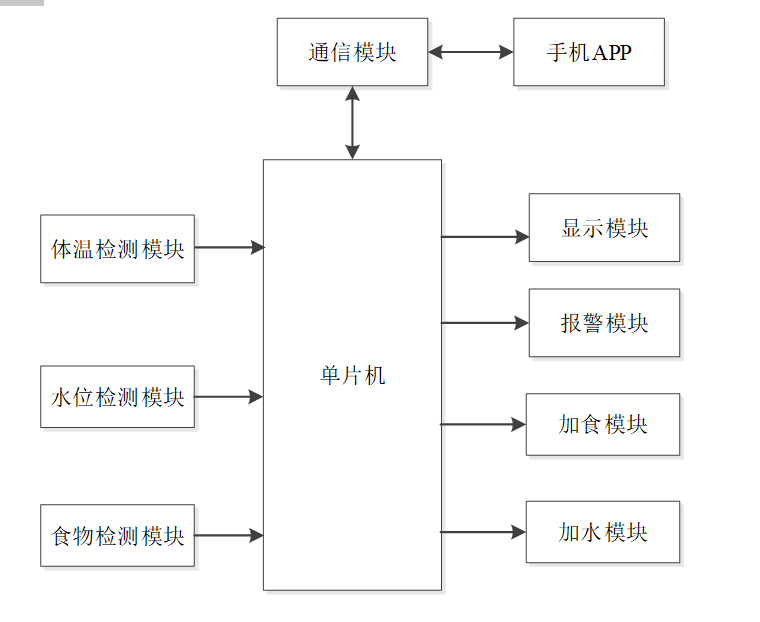
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...