19 | 如何搞清楚事务、连接池的关系?正确配置是怎样的
事务的基本原理
在学习 Spring 的事务之前,你首先要了解数据库的事务原理,我们以 MySQL 5.7 为例,讲解一下数据库事务的基础知识。
我们都知道 当 MySQL 使用 InnoDB 数据库引擎的时候,数据库是对事务有支持的。而事务最主要的作用是保证数据 ACID 的特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),下面来一一解释。
原子性: 是指一个事务(Transaction)中的所有操作,要么全部完成,要么全部回滚,而不会有中间某个数据单独更新的操作。事务在执行过程中一旦发生错误,会被回滚(Rollback)到此次事务开始之前的状态,就像这个事务从来没有执行过一样。
一致性: 是指事务操作开始之前,和操作异常回滚以后,数据库的完整性没有被破坏。数据库事务 Commit 之后,数据也是按照我们预期正确执行的。即要通过事务保证数据的正确性。
持久性: 是指事务处理结束后,对数据的修改进行了持久化的永久保存,即便系统故障也不会丢失,其实就是保存到硬盘。
隔离性: 是指数据库允许多个连接,同时并发多个事务,又对同一个数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时,由于交叉执行而导致数据不一致的现象。而 MySQL 里面就是我们经常说的事务的四种隔离级别,即读未提交(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。
由于隔离级别是事务知识点中最基础的部分,我们就简单介绍一下四种隔离级别。但是它特别重要,你要好好掌握。
四种 MySQL 事务的隔离级别
Read Uncommitted(读取未提交内容):此隔离级别,表示所有正在进行的事务都可以看到其他未提交事务的执行结果。不同的事务之间读取到其他事务中未提交的数据,通常这种情况也被称之为脏读(Dirty Read),会造成数据的逻辑处理错误,也就是我们在多线程里面经常说的数据不安全了。在业务开发中,几乎很少见到使用的,因为它的性能也不比其他级别要好多少。
Read Committed(读取提交内容): 此隔离级别是指,在一个事务相同的两次查询可能产生的结果会不一样,也就是第二次查询能读取到其他事务已经提交的最新数据。也就是我们常说的不可重复读(Nonrepeatable Read)的事务隔离级别。因为同一事务的其他实例在该实例处理期间,可能会对其他事务进行新的 commit,所以在同一个事务中的同一 select 上,多次执行可能返回不同结果。这是大多数数据库系统的默认隔离级别(但不是 MySQL 默认的隔离级别)。
Repeatable Read(可重读): 这是 MySQL 的默认事务隔离级别,它确保同一个事务多次查询相同的数据,能读到相同的数据。即使多个事务的修改已经 commit,本事务如果没有结束,永远读到的是相同数据,要注意它与Read Committed 的隔离级别的区别,是正好相反的。这会导致另一个棘手的问题:幻读 (Phantom Read),即读到的数据可能不是最新的。这个是最常见的,我们举个例子来说明。
第一步:用工具打开一个数据库的 DB 连接,如图所示。
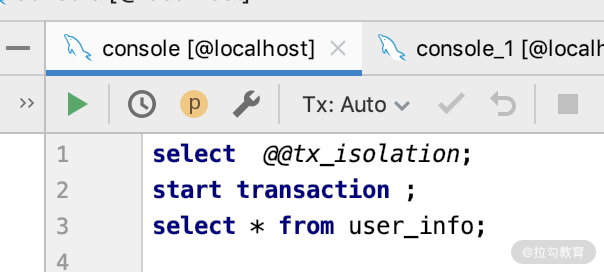
查看一下数据库的事务隔离级别。

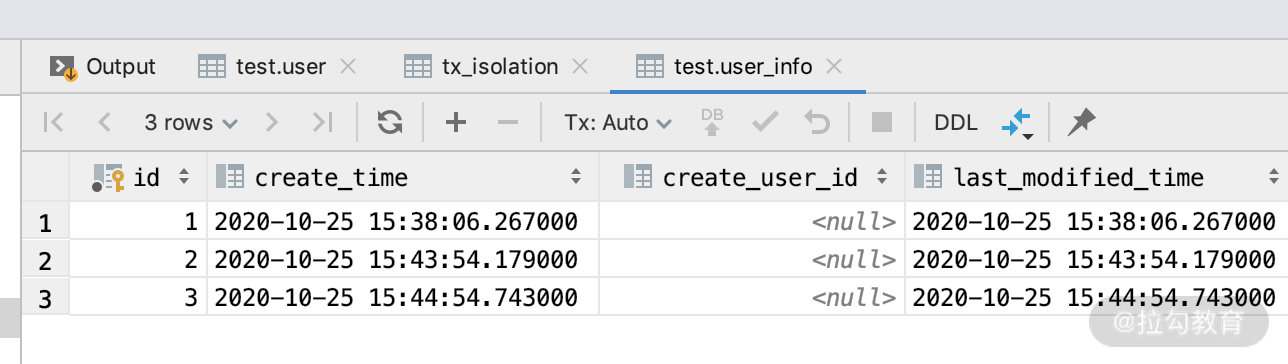
然后开启一个事务,查看一下 user_info 的数据,我们在 user_info 表里面插入了三条数据,如下图所示。
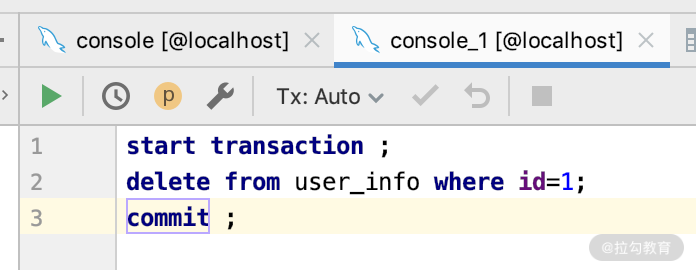
第二步:我们打开另外一个相同数据库的 DB 连接,删除一条数据,SQL 如下所示。
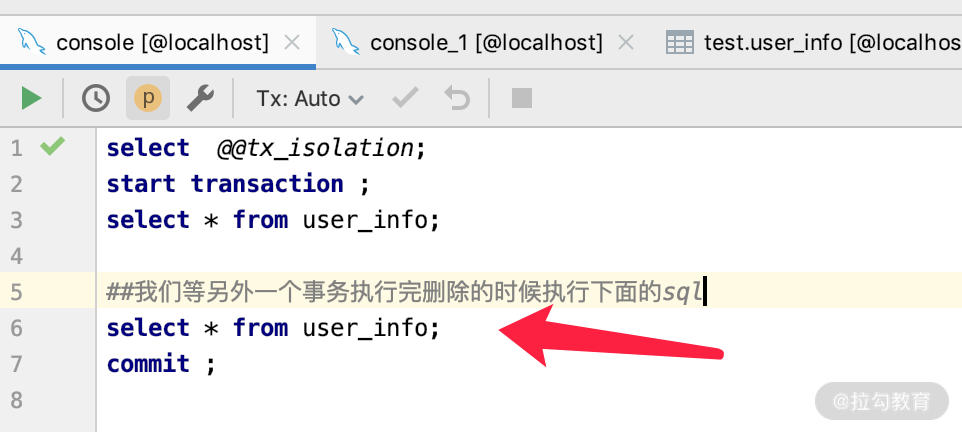
当删除执行成功之后,我们可以开启第三个连接,看一下数据库里面确实少了一条 ID=1 的数据。那么这个时候我们再返回第一个连接,第二次执行 select * from user_info,如下图所示,查到的还是三条数据。这就是我们经常说的可重复读。
Serializable(可串行化):这是最高的隔离级别,它保证了每个事务是串行执行的,即强制事务排序,所有事务之间不可能产生冲突,从而解决幻读问题。如果配置在这个级别的事务,处理时间比较长,并发比较大的时候,就会导致大量的 db 连接超时现象和锁竞争,从而降低了数据处理的吞吐量。也就是这个性能比较低,所以除了某些财务系统之外,用的人不是特别多。
数据库的隔离级别我们了解完了,并不复杂,这四种类型中,你能清楚地知道Read Uncommitted 和 Read Committed就可以了,一般这两个用得是最多的。
下面看一下数据的事务和连接是什么关系呢?
MySQL 事务与连接的关系
我们要搞清楚事务和连接池的关系,必须要先知道二者存在的前提条件。
- 事务必须在同一个连接里面的,离开连接没有事务可言;
- MySQL 数据库默认 autocommit=1,即每一条 SQL 执行完自动提交事务;
- 数据库里面的每一条 SQL 执行的时候必须有事务环境;
- MySQL 创建连接的时候默认开启事务,关闭连接的时候如果存在事务没有 commit 的情况,则自动执行 rollback 操作;
- 不同的 connect 之间的事务是相互隔离的。
知道了这些条件,我们就可以继续探索二者的关系了。在 connection 当中,操作事务的方式只有两种。
MySQL 事务的两种操作方式
第一种:用 BEGIN、ROLLBACK、COMMIT 来实现。
- BEGIN开始一个事务
- ROLLBACK事务回滚
- COMMIT事务确认
第二种:直接用 SET 来改变 MySQL 的自动提交模式。
- SET AUTOCOMMIT=0禁止自动提交
- SET AUTOCOMMIT=1开启自动提交
MySQL 数据库的最大连接数是什么?
而任何数据库的连接数都是有限的,受内存和 CPU 限制,你可以通过
show variables like ‘max_connections’ 查看此数据库的最大连接数、通过 show global status like ‘Max_used_connections’ 查看正在使用的连接数,还可以通过 set global max_connections=1500 来设置数据库的最大连接数。
除此之外,你可以在观察数据库的连接数的同时,通过观察 CPU 和内存的使用,来判断你自己的数据库中 server 的连接数最佳大小是多少。而既然是连接,那么肯定会有超时时间,默认是 8 小时。
这里我只是列举了 MySQL 数据库的事务处理原理,你可以用相同的思考方式看一下你在用的数据源的事务是什么机制的。
那么学习完了数据库事务的基础知识,我们再看一下 Spring 中事务的用法和配置是什么样的。
Spring 里面事务的配置方法
由于我们使用的是 Spring Boot,所以会通过 TransactionAutoConfiguration.java 加载 @EnableTransactionManagement 注解帮我们默认开启事务,关键代码如下图所示。
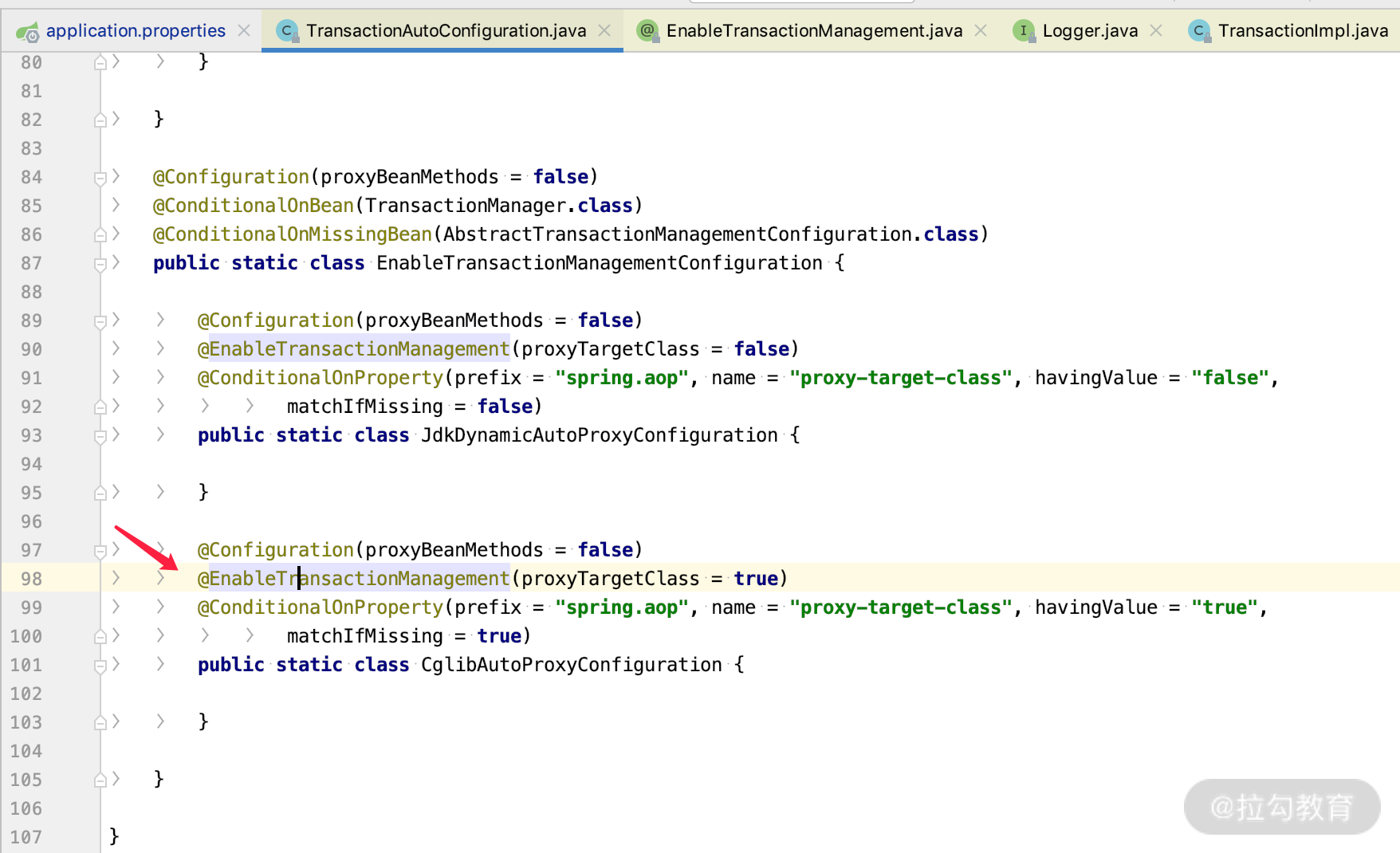
Spring 里面的事务有两种使用方式,常见的是直接通过 @Transaction 的方式进行配置,而我们打开 SimpleJpaRepository 源码类的话,会看到如下代码。
复制代码
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
...
@Transactional
@Override
public void deleteAll(Iterable<? extends T> entities) {
.....
我们仔细看源码的时候就会发现,默认情况下,所有 SimpleJpaRepository 里面的方法都是只读事务,而一些更新的方法都是读写事务。
所以每个 Respository 的方法是都是有事务的,即使我们没有使用任何加 @Transactional 注解的方法,按照上面所讲的 MySQL 的 Transactional 开启原理,也会有数据库的事务。那么我们就来看下 @Transactional 的具体用法。
默认 @Transactional 注解式事务
注解式事务又称显式事务,需要手动显式注解声明,那么我们看看如何使用。
按照惯例,我们打开 @Transactional 的源码,如下所示。
复制代码
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {@AliasFor("transactionManager")String value() default "";@AliasFor("value")String transactionManager() default "";Propagation propagation() default Propagation.REQUIRED;Isolation isolation() default Isolation.DEFAULT;int timeout() default TransactionDefinition.TIMEOUT_DEFAULT;boolean readOnly() default false;Class<? extends Throwable>[] rollbackFor() default {};String[] rollbackForClassName() default {};Class<? extends Throwable>[] noRollbackFor() default {};String[] noRollbackForClassName() default {};
}
针对 @Transactional 注解中常用的参数,我列了一个表格方便你查看。
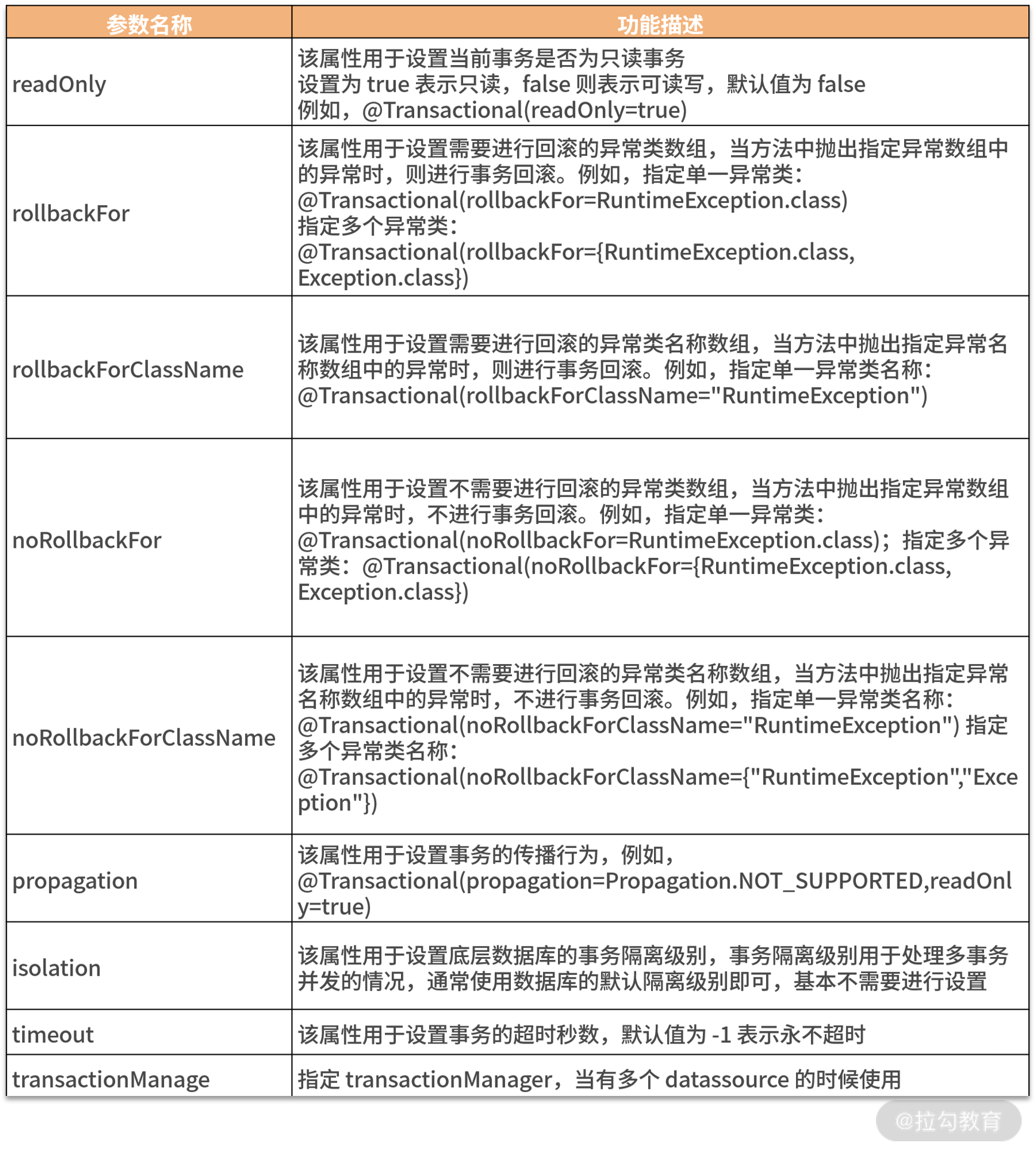
其他属性你基本上都可以知道是什么意思,下面重点说一下隔离级别和事务的传播机制。
隔离级别 Isolation isolation() default Isolation.DEFAULT:默认采用数据库的事务隔离级别。其中,Isolation 是个枚举值,基本和我们上面讲解的数据库隔离级别是一样的,如下图所示。

propagation:代表的是事务的传播机制,这个是 Spring 事务的核心业务逻辑,是 Spring 框架独有的,它和 MySQL 数据库没有一点关系。所谓事务的传播行为是指在同一线程中,在开始当前事务之前,需要判断一下当前线程中是否有另外一个事务存在,如果存在,提供了七个选项来指定当前事务的发生行为。我们可以看 org.springframework.transaction.annotation.Propagation 这类的枚举值来确定有哪些传播行为。7 个表示传播行为的枚举值如下所示。
复制代码
public enum Propagation {REQUIRED(0),SUPPORTS(1),MANDATORY(2),REQUIRES_NEW(3),NOT_SUPPORTED(4),NEVER(5),NESTED(6);
}
- REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这个值是默认的。
- SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
- NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 REQUIRED。
设置方法:通过使用 propagation 属性设置,例如下面这行代码。
复制代码
@Transactional(propagation = Propagation.REQUIRES_NEW)
虽然用法很简单,但是也有使用 @Transactional 不生效的时候,那么在哪些场景中是不可用的呢?
@Transactional 的局限性
这里列举的是一个当前对象调用对象自己里面的方法不起作用的场景。
我们在 UserInfoServiceImpl 的 save 方法中调用了带事务的 calculate 方法,代码如下。
复制代码
@Component
public class UserInfoServiceImpl implements UserInfoService {@Autowiredprivate UserInfoRepository userInfoRepository;/*** 根据UserId产生的一些业务计算逻辑*/@Override@Transactional(transactionManager = "db2TransactionManager")public UserInfo calculate(Long userId) {UserInfo userInfo = userInfoRepository.findById(userId).get();userInfo.setAges(userInfo.getAges()+1);//.....等等一些复杂事务内的操作userInfo.setTelephone(Instant.now().toString());return userInfoRepository.saveAndFlush(userInfo);}/*** 此方法调用自身对象的方法,就会发现calculate方法上面的事务是失效的*/public UserInfo save(Long userId) {return this.calculate(userId);}
}
当在 UserInfoServiceImpl 类的外部调用 save 方法的时候,此时 save 方法里面调用了自身的 calculate 方法,你就会发现 calculate 方法上面的事务是没有效果的,这个是 Spring 的代理机制的问题。那么我们应该如何解决这个问题呢?可以引入一个类 TransactionTemplate,我们看下它的用法。
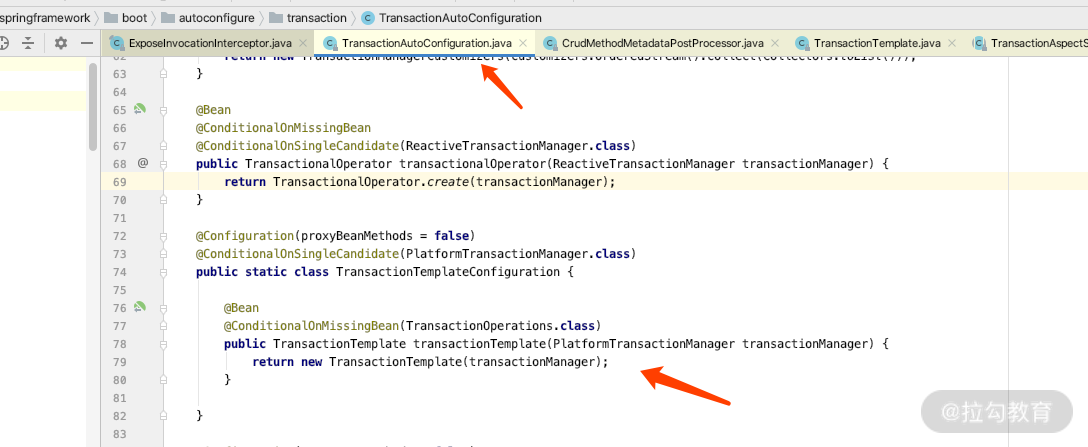
TransactionTemplate 的用法
此类是通过 TransactionAutoConfiguration 加载配置进去的,如下图所示。
我们通过源码可以看到此类提供了一个关键 execute 方法,如下图所示。
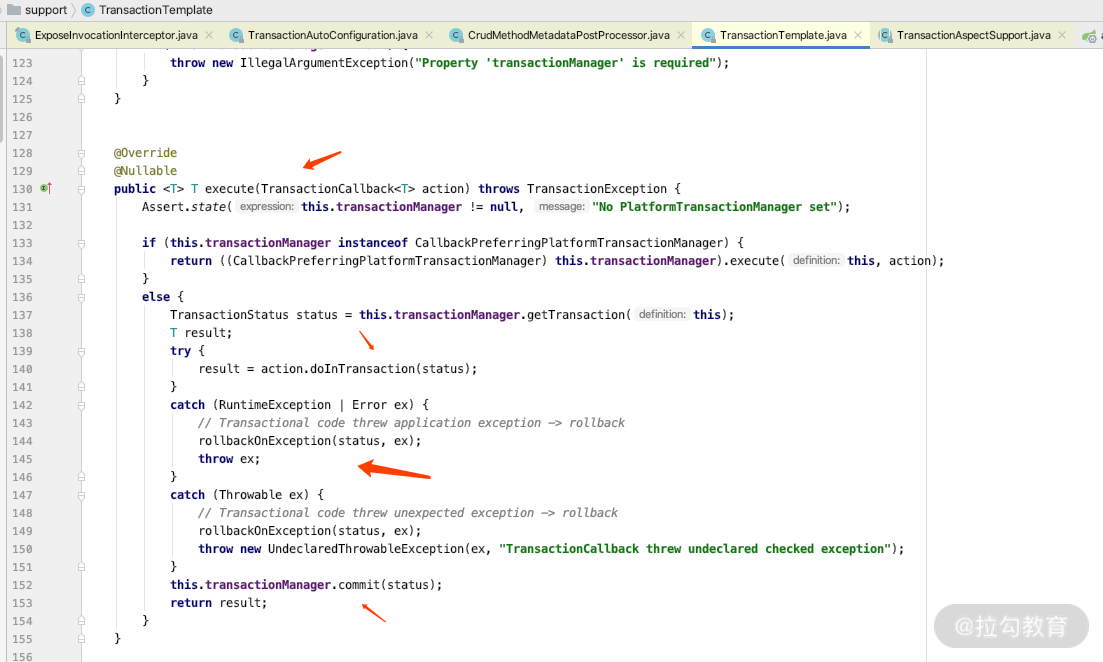
这里面会帮我们处理事务开始、rollback、commit 的逻辑,所以我们用的时候就非常简单,把上面的方法做如下改动。
复制代码
public UserInfo save(Long userId) {return transactionTemplate.execute(status -> this.calculate(userId));
}
此时外部再调用我们的 save 方法的时候,calculate 就会进入事务管理里面去了。当然了,我这里举的例子很简单,你也可以通过下面代码中的方法设置隔离级别和传播机制,以及超时时间和是否只读。
复制代码
transactionTemplate = new TransactionTemplate(transactionManager);
//设置隔离级别
transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_REPEATABLE_READ);
//设置传播机制
transactionTemplate.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
//设置超时时间
transactionTemplate.setTimeout(1000);
//设置是否只读
transactionTemplate.setReadOnly(true);
我们也可以根据 transactionTemplate 的实现原理,自己实现一个 TransactionHelper,一起来看一下。
自定义 TransactionHelper
第一步:新建一个 TransactionHelper 类,进行事务管理,代码如下。
复制代码
/*** 利用spring进行管理*/
@Component
public class TransactionHelper {/*** 利用spring 的机制和jdk8的function机制实现事务*/@Transactional(rollbackFor = Exception.class) //可以根据实际业务情况,指定明确的回滚异常public <T, R> R transactional(Function<T, R> function, T t) {return function.apply(t);}
}
第二步:直接在 service 中就可以使用了,代码如下。
复制代码
@Autowiredprivate TransactionHelper transactionHelper;==/*** 调用外部的transactionHelper类,利用transactionHelper方法上面的@Transaction注解使事务生效*/public UserInfo save(Long userId) {return transactionHelper.transactional((uid)->this.calculate(uid),userId);}
上面我介绍了显式事务,都是围绕 @Transactional 的显式指定的事务,我们也可以利用 AspectJ 进行隐式的事务配置。
隐式事务 / AspectJ 事务配置
只需要在我们的项目中新增一个类 AspectjTransactionConfig 即可,代码如下。
复制代码
@Configuration
@EnableTransactionManagement
public class AspectjTransactionConfig {public static final String transactionExecution = "execution (* com.example..service.*.*(..))";//指定拦截器作用的包路径@Autowiredprivate PlatformTransactionManager transactionManager;@Beanpublic DefaultPointcutAdvisor defaultPointcutAdvisor() {//指定一般要拦截哪些类AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();pointcut.setExpression(transactionExecution);//配置advisorDefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor();advisor.setPointcut(pointcut);//根据正则表达式,指定上面的包路径里面的方法的事务策略Properties attributes = new Properties();attributes.setProperty("get*", "PROPAGATION_REQUIRED,-Exception");attributes.setProperty("add*", "PROPAGATION_REQUIRED,-Exception");attributes.setProperty("save*", "PROPAGATION_REQUIRED,-Exception");attributes.setProperty("update*", "PROPAGATION_REQUIRED,-Exception");attributes.setProperty("delete*", "PROPAGATION_REQUIRED,-Exception");//创建InterceptorTransactionInterceptor txAdvice = new TransactionInterceptor(transactionManager, attributes);advisor.setAdvice(txAdvice);return advisor;}
}
这种方式,只要符合我们上面的正则表达规则的 service 方法,就会自动添加事务了;如果我们在方法上添加 @Transactional,也可以覆盖上面的默认规则。
不过这种方法近两年使用的团队越来越少了,因为注解的方式其实很方便,并且注解 @Transactional 的方式更容易让人理解,代码也更简单,你了解一下就好了。
上面的方法介绍完了,那么一个方法经历的 SQL 和过程都有哪些呢?我们通过日志分析一下。
通过日志分析配置方法的过程
大致可以分为以下几个步骤。
第一步,我们在数据连接中加上 logger=Slf4JLogger&profileSQL=true,用来显示 MySQL 执行的 SQL 日志,如图所示。

第二步,打开 Spring 的事务处理日志,用来观察事务的执行过程,代码如下。
复制代码
# Log Transactions Details
logging.level.org.springframework.orm.jpa=DEBUG
logging.level.org.springframework.transaction=TRACE
logging.level.org.hibernate.engine.transaction.internal.TransactionImpl=DEBUG
# 监控连接的情况
logging.level.org.hibernate.resource.jdbc=trace
logging.level.com.zaxxer.hikari=DEBUG
第三步,我们执行一个 saveOrUpdate 的操作,详细的执行日志如下所示。

通过日志可以发现,我们执行一个 saveUserInfo 的动作,由于在其中配置了一个事务,所以可以看到 JpaTransactionManager 获得事务的过程,图上黄色的部分是同一个连接里面执行的 SQL 语句,其执行的整体过程如下所示。
- get connection:从事务管理里面,获得连接就 begin 开始事务了。我们没有看到显示的 begin 的 SQL,基本上可以断定它利用了 MySQL 的 connection 初始化事务的特性。
- set autocommit=0:关闭自动提交模式,这个时候必须要在程序里面 commit 或者 rollback。
- select user_info:看看 user_info 数据库里面是否存在我们要保存的数据。
- update user_info:发现数据库里面存在,执行更新操作。
- commit:执行提交事务。
- set autocommit=1:事务执行完,改回 autocommit 的默认值,每条 SQL 是独立的事务。
我们这里采用的是数据库默认的隔离级别,如果我们通过下面这行代码,改变默认隔离级别的话,再观察我们的日志。
复制代码
@Transactional(isolation = Isolation.READ_COMMITTED)
你会发现在开始事务之前,它会先改变默认的事务隔离级别,如图所示。

而在事务结束之后,它还会还原此链接的事务隔离级别,又如下图所示。

如果你明白了 MySQL 的事务原理的话,再通过日志分析可以很容易地理解 Spring 的事务原理。我们在日志里面能看到 MySQL 的事务执行过程,同样也能看到 Spring 的 TransactionImpl 的事务执行过程。这是什么原理呢?我们来详细分析一下。
Spring 事务的实现原理
这里我重点介绍一下 @Transactional 的工作机制,这个主要是利用 Spring 的 AOP 原理,在加载所有类的时候,容器就会知道某些类需要对应地进行哪些 Interceptor 的处理。
例如我们所讲的 TransactionInterceptor,在启动的时候是怎么设置事务的、是什么样的处理机制,默认的代理机制又是什么样的呢?
Spring 事务源码分析
我们在 TransactionManagementConfigurationSelector 里面设置一个断点,就会知道代理的加载类 ProxyTransactionManagementConfiguration 对事务的处理机制。关键源码如下图所示。
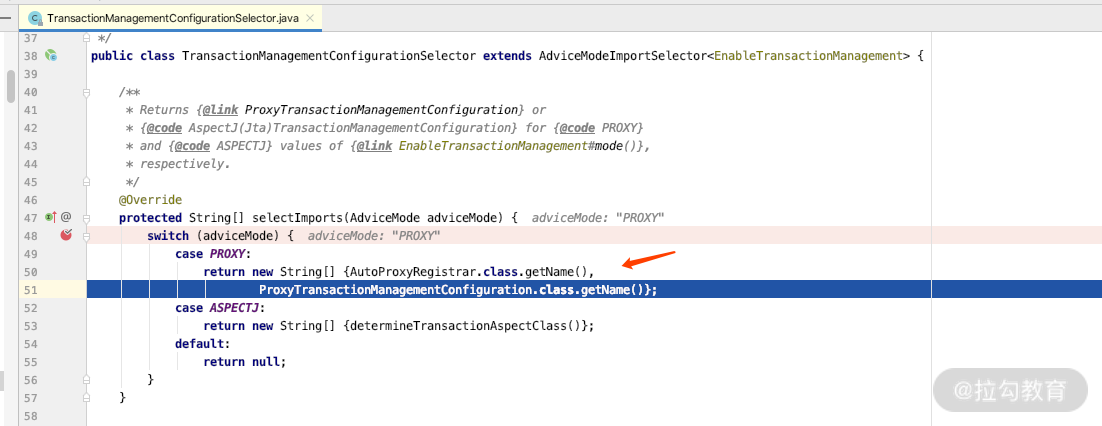
而我们打开 ProxyTransactionManagementConfiguration 的话,就会加载 TransactionInterceptor 的处理类,关键源码如下图所示。
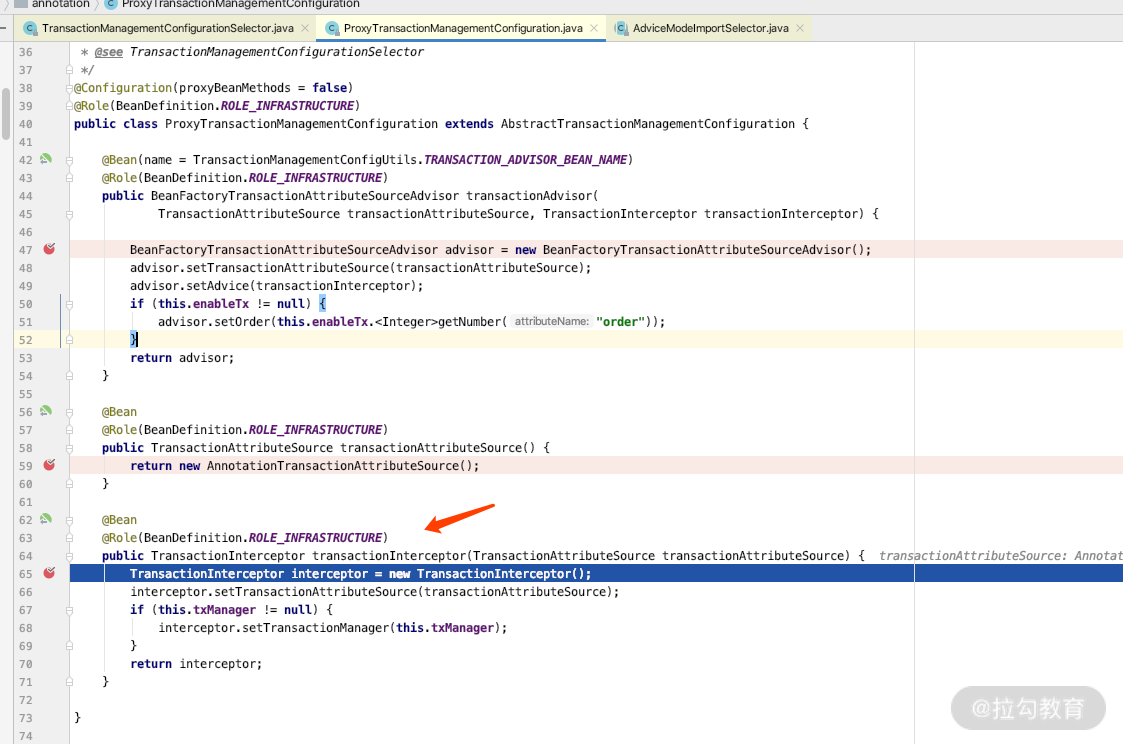
如果继续加载的话,里面就会加载带有 @Transactional 注解的类或者方法。关键源码如下图所示。
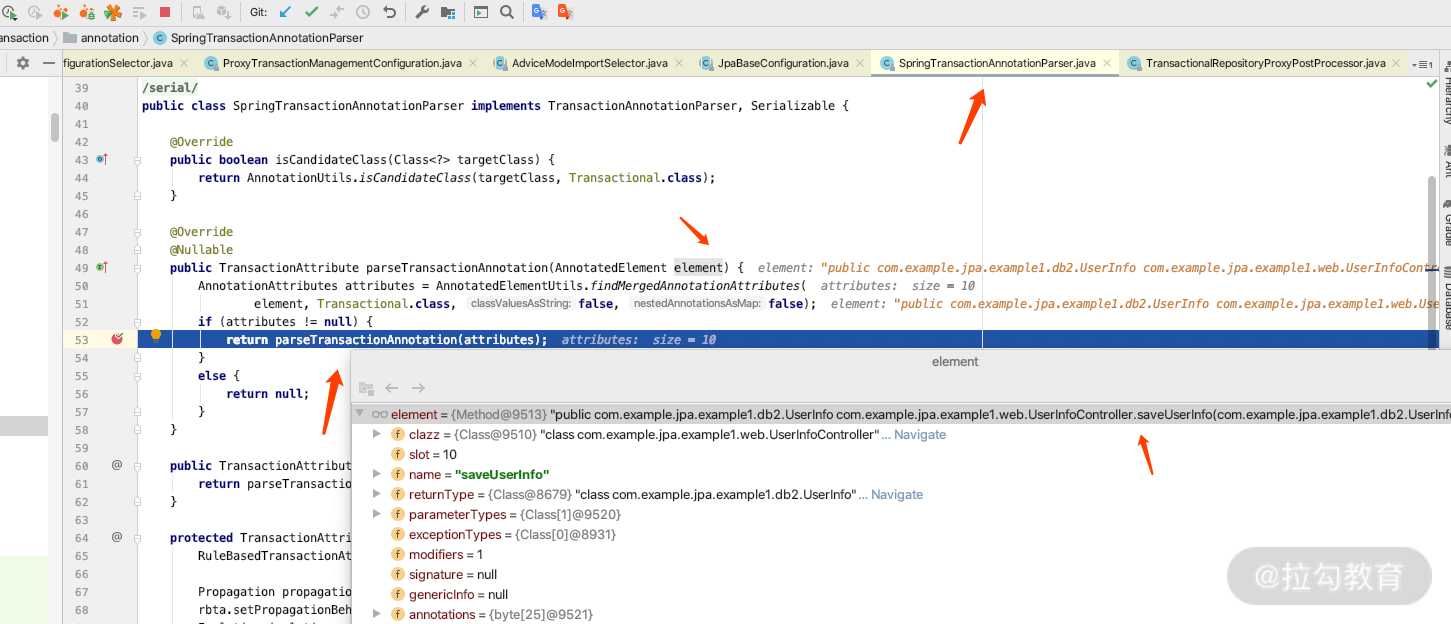
加载期间,通过 @Trnsactional 注解来确定哪些方法需要进行事务处理。
复制代码
o.s.orm.jpa.JpaTransactionManager : Creating new transaction with name
而运行期间通过上面这条日志,就可以找到 JpaTransactionManager 里面通过 getTransaction 方法创建的事务,然后再通过 debuger 模式的 IDEA 线程栈进行分析,就能知道创建事务的整个过程。你可以一步一步地去断点进行查看,如下图所示。

如上图,我们可以知道 createTransactionIfNecessary 是用来判断是否需要创建事务的,有兴趣的话你可以点击进去看看,如下图所示。
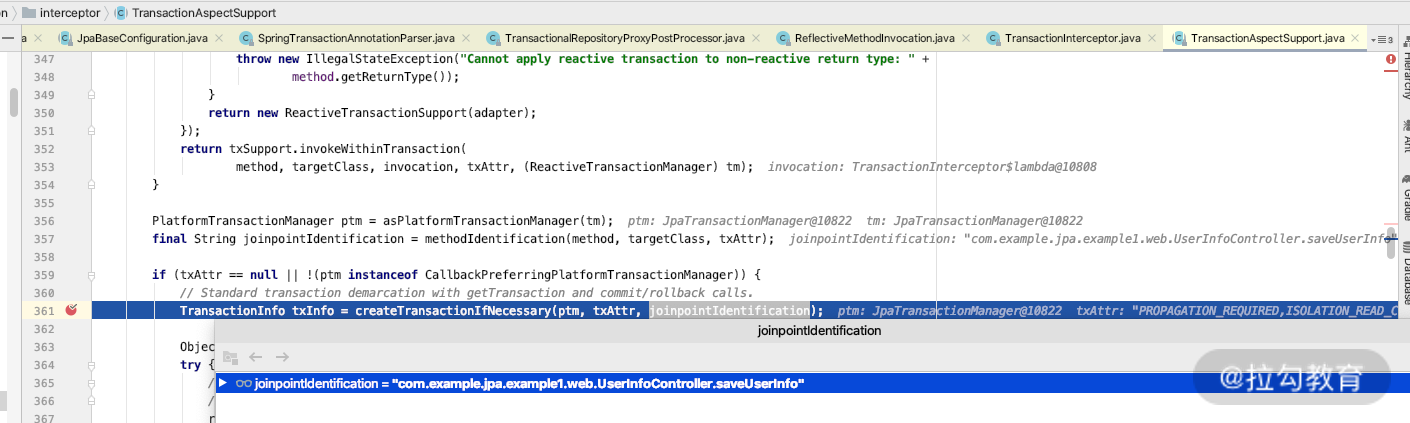
我们继续往下面 debug 的话,就会找到创建事务的关键代码,它会通过调用 AbstractPlatformTransactionManager 里面的 startTransaction 方法开启事务,如下图所示。
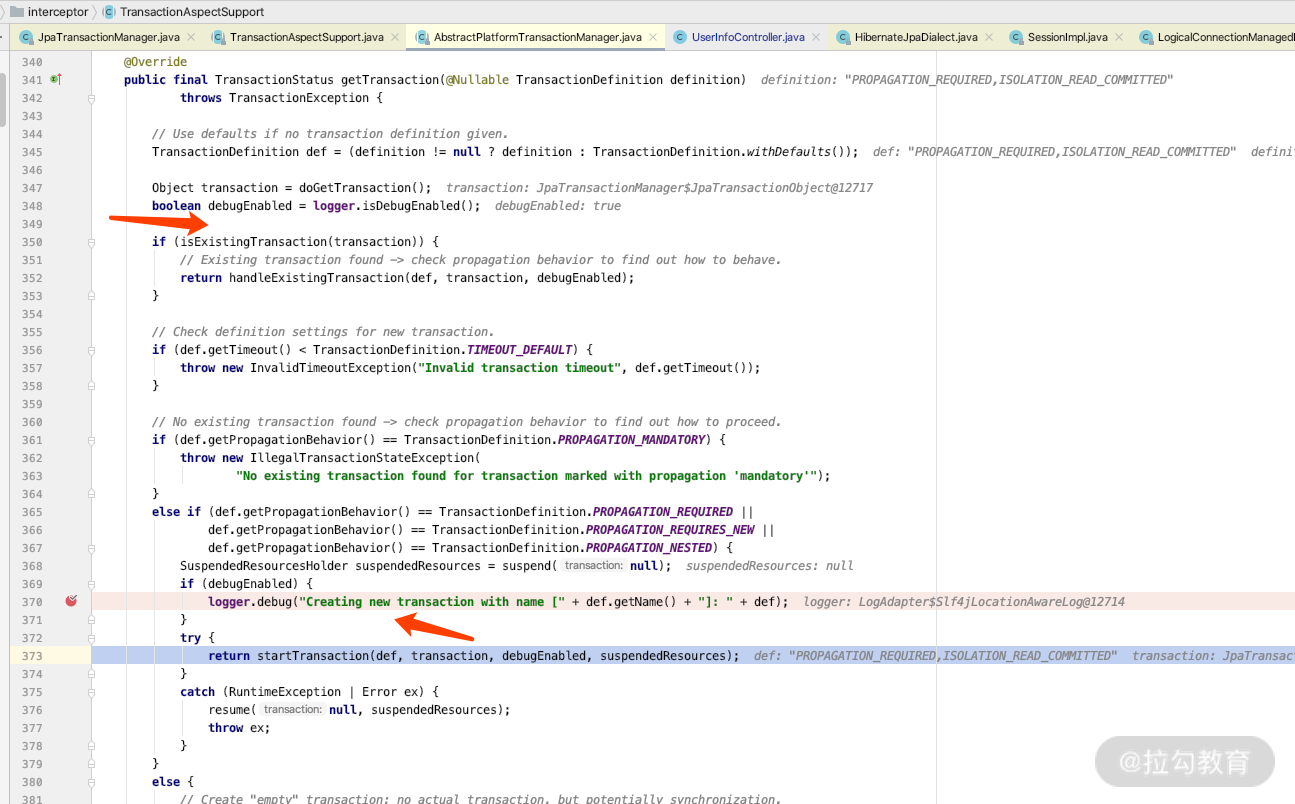
然后我们就可以继续往下断点进行分析了。断点走到最后的时候,你就可以看到开启事务的时候,必须要从我们的数据源里面获得连接。看一下断点的栈信息,这里有几个关键的 debug 点。如下图所示。
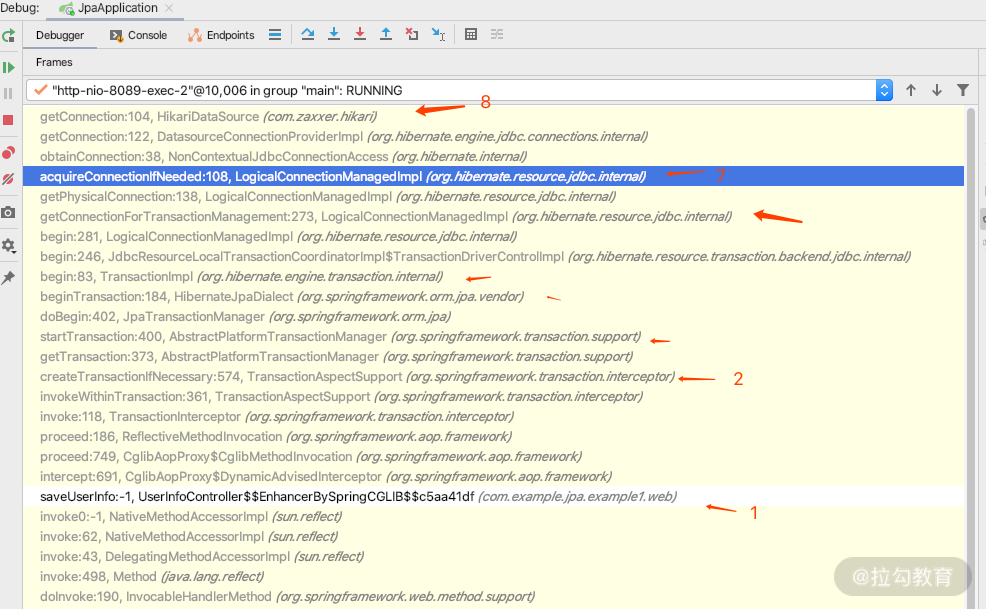
其中,
第一处:是处理带 @Transactional 的注解的方法,利用 CGLIB 进行事务拦截处理;
第二处:是根据 Spring 的事务传播机制,来判断是用现有的事务,还是创建新的事务;
第七处:是用来判断是否现有连接,如果有直接用,如果没有就从第八处的数据源里面的连接池中获取连接,第七处的关键代码如下。
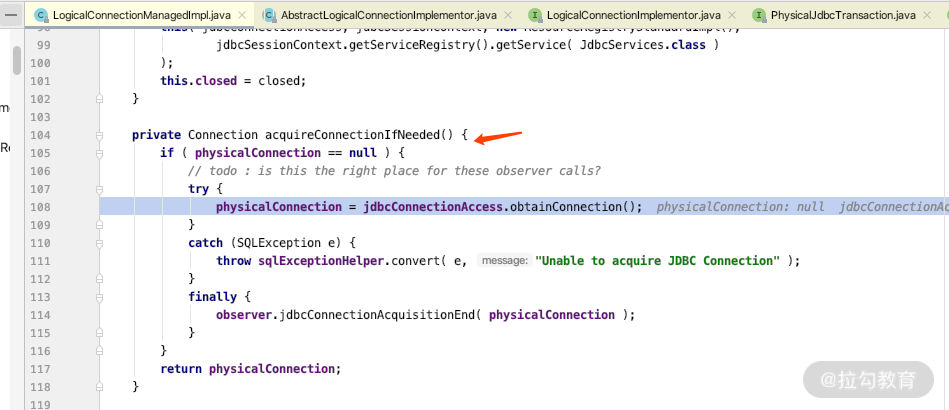
到这里,我们介绍完了事务获得连接的关键时机,那么还需要知道它是在什么时间释放连接到连接池里面的。我们在 LogicalConnectionManagedImpl 的 releaseConnection 方法中设置一个断点,如下图所示。
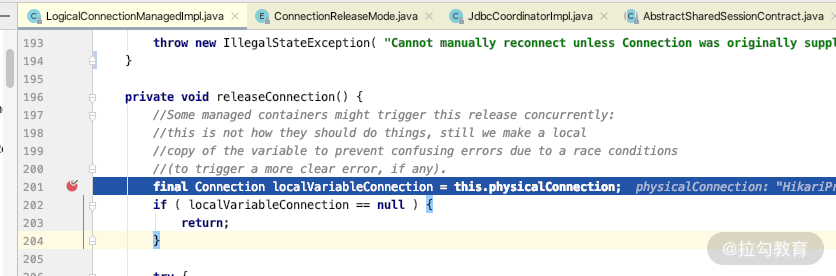
然后观察断点线性的执行方法,你会发现,在事务执行之后,它会将连接释放到连接池里面。
我们通过上面的 saveOrUpdate 的详细执行日志,可以观察出来,事务是在什么时机开启的、数据库连接是什么时机开启的、事务是在什么时机关闭的,以及数据库连接是在什么时机释放的,如果你没看出来,可以再仔细看一遍日志。
所以,Spring 中的事务和连接的关系是,开启事务的同时获取 DB 连接;事务完成的时候释放 DB 连接。通过 MySQL 的基础知识可以知道数据库连接是有限的,那么当我们给某些方法加事务的时候,都需要注意哪些内容呢?
事务和连接池在 JPA 中的注意事项
我们在“17 | DataSource 为何物?加载过程是怎样的?”中对数据源的介绍时,说过数据源的连接池不能配置过大,否则连接之前切换就会非常耗费应用内部的 CPU 和内存,从而降低应用对外提供 API 的吞吐量。
所以当我们使用事务的时候,需要注意如下 几个事项:
- 事务内的逻辑不能执行时间太长,否则就会导致占用 db 连接的时间过长,会造成数据库连接不够用的情况;
- 跨应用的操作,如 API 调用等,尽量不要在有事务的方法里面进行;
- 如果在真实业务场景中有耗时的操作,也需要带事务时(如扣款环节),那么请注意增加数据源配置的连接池数;
- 我们通过 MVC 的应用请求连接池数量,也要根据连接池的数量和事务的耗时情况灵活配置;而 tomcat 默认的请求连接池数量是 200 个,可以根据实际情况来增加或者减少请求的连接池数量,从而减少并发处理对事务的依赖。
相关文章:
19 | 如何搞清楚事务、连接池的关系?正确配置是怎样的
事务的基本原理 在学习 Spring 的事务之前,你首先要了解数据库的事务原理,我们以 MySQL 5.7 为例,讲解一下数据库事务的基础知识。 我们都知道 当 MySQL 使用 InnoDB 数据库引擎的时候,数据库是对事务有支持的。而事务最主要的作…...

备忘录模式-撤销功能的实现
在idea写代码的过程中,会经常用到一个快捷键——“crtl z”,即撤销功能。“备忘录模式”则为撤销功能提供了一个设计方案。 1 备忘录模式 备忘录模式提供一种状态恢复机制。在不破坏封装的前提下,捕获对象内部状态并在该对象之外保存这个状态。可以在…...
C++入门(二)
文章目录 一、缺省参数1、概念2、缺省参数分类1、全缺省参数2、半缺省参数 3、特性总结 二、函数重载1、引入函数重载2、函数重载概念3、函数重载分类4、C支持函数重载的原理--名字修饰(name Mangling) 三、 引用1、引用概念2、引用特性3、 常引用4、 使用场景1、做参数2、做返…...
【软件设计师】面向对象类图的六种关系
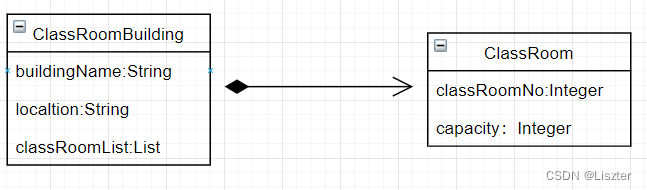
面向对象类图的六种关系(继承、实现、依赖、关联、聚合、组合) 1、泛化(继承)2、实现3、依赖4、关联5、聚合6、组合 面向对象类图的六种关系(继承、实现、依赖、关联、聚合、组合) 进行面向对象设计时&…...
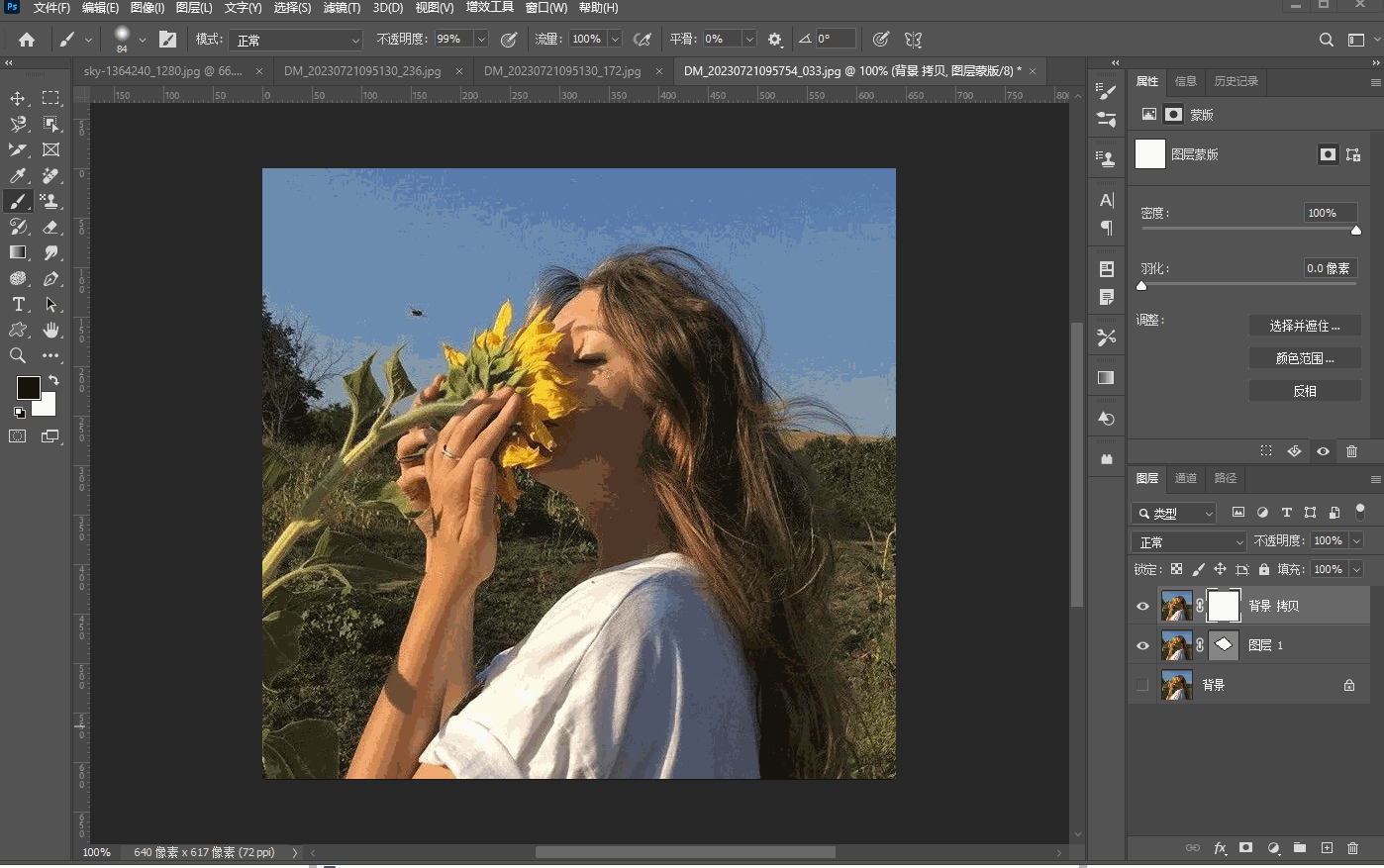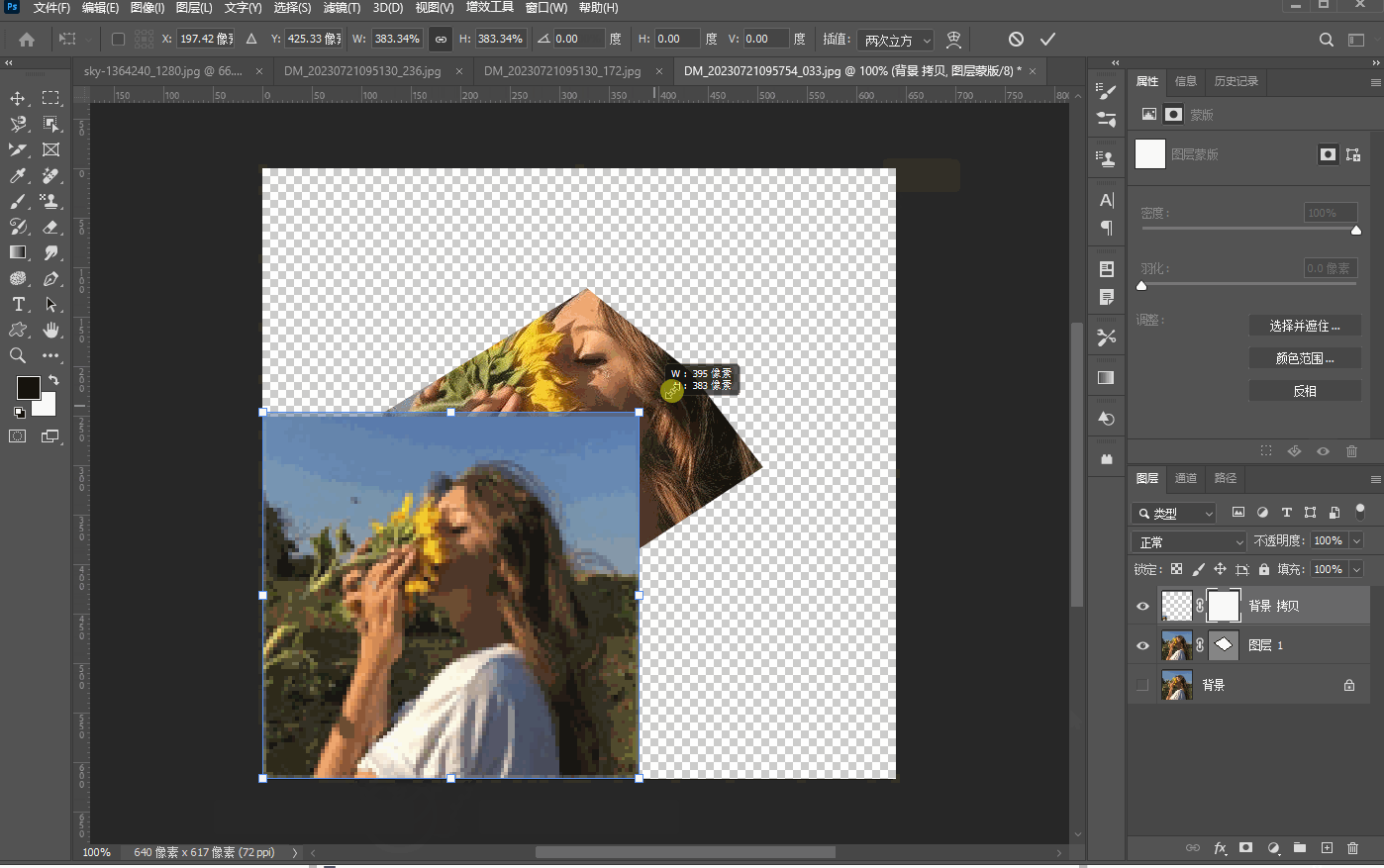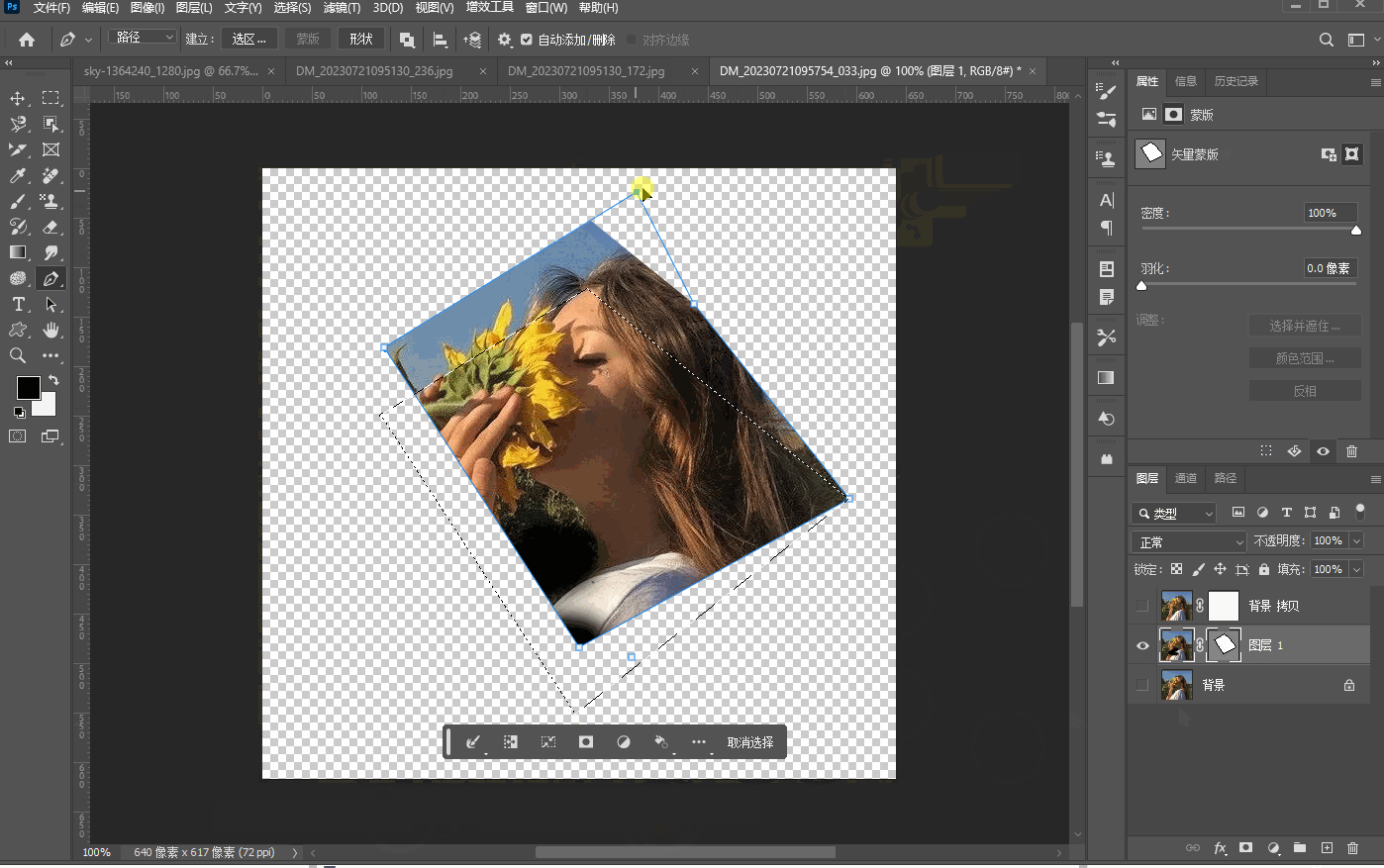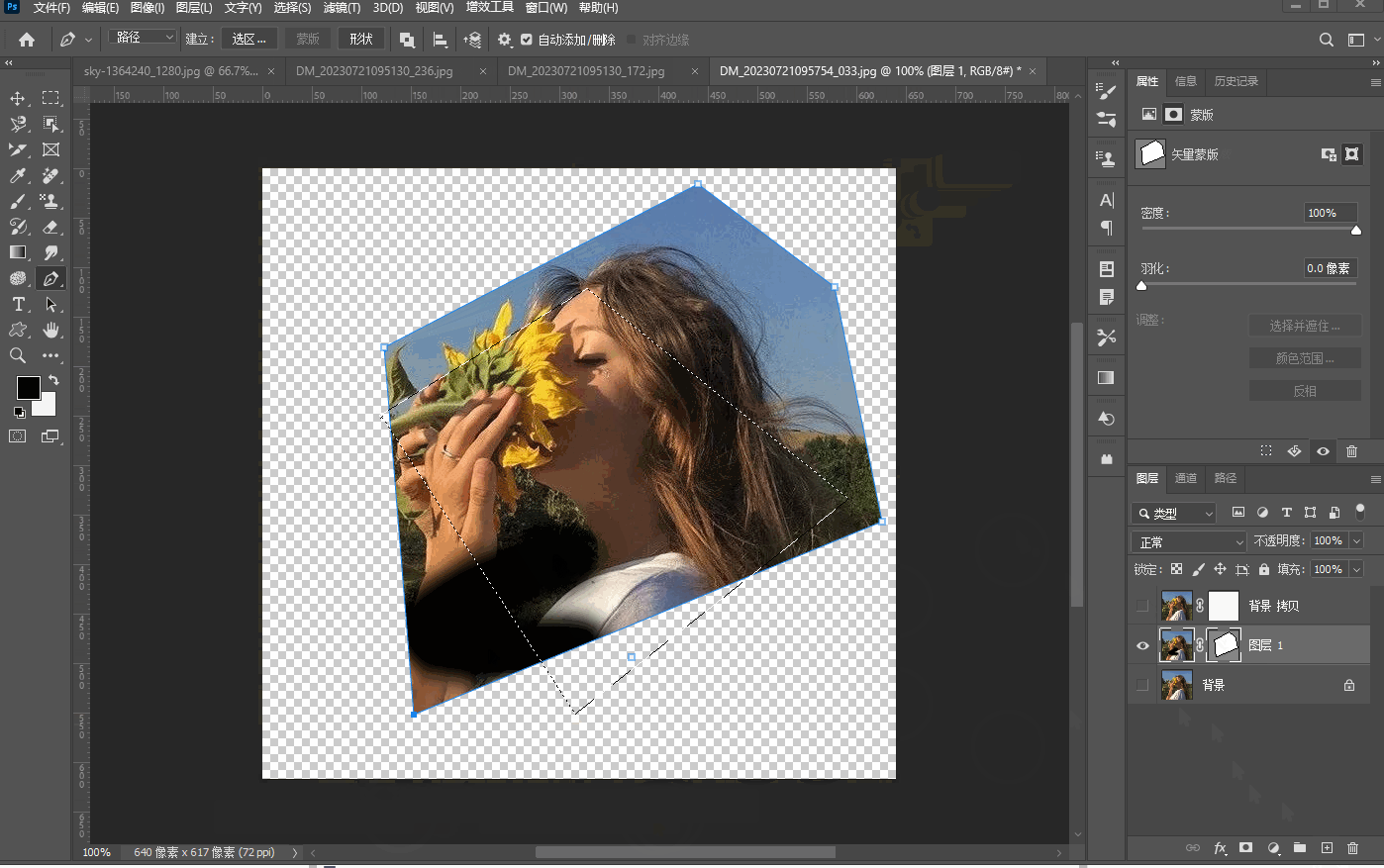
二十七、【四种蒙版】
文章目录 图层蒙版剪贴蒙版快速蒙版矢量蒙版 图层蒙版 在当前图层加上蒙版,黑色画笔的可以让当前图层消失,白色的画笔可以让当前图层出现: 无论填充什么样的颜色,蒙板只有黑白灰三种颜色。模板最简单应用就是我们在插入图形的时候…...
目录最新无死角讲解)
卡尔曼家族从零解剖-(00)目录最新无死角讲解
讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解的 卡尔曼家族从零解剖 链接 :卡尔曼家族从零解剖-(00)目录最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/133846882 文末正下方中心提供了本人 联系…...
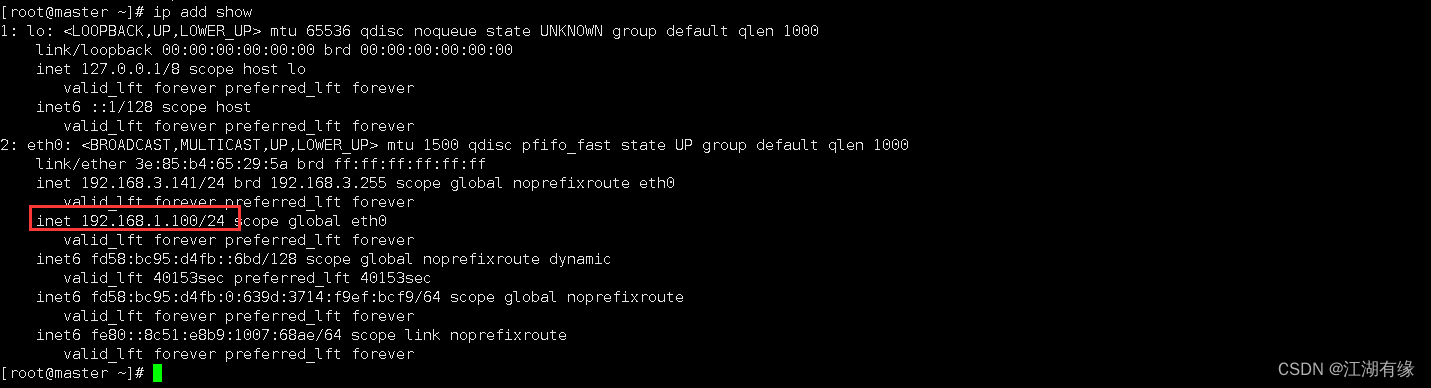
Linux系统之ip命令的基本使用
Linux系统之ip命令的基本使用 一、ip命令介绍1.1 ip命令简介1.2 ip命令的由来1.3 ip命令的安装包 二、ip命令使用帮助2.1 ip命令的help帮助信息2.2 ip命令使用帮助 三、查看网络信息3.1 显示当前网络接口信息3.2 显示网络设备运行状态3.3 显示详细设备信息3.4 查看路由表3.5 查…...

【推荐算法】ctr cvr联合建模问题合集
ctr和cvr分开建模相比ctcvr的优势? 在电商搜索推荐排序中,将ctr和cvr分开建模,相比直接建模ctcvr的优势是什么? - 萧瑟的回答 - 知乎 总结: 1、ctr的数据可以试试获取,能实时训练。但是cvr存在延迟现象&…...

安装njnx --chatGPT
gpt: 要在 Debian 11 上安装 Nginx(通常称为 "nginx"),您可以使用 apt 包管理器执行以下步骤: 1. **登录到您的 Debian 11 服务器**。您可以使用 SSH 客户端以 root 或具有管理员权限的用户身份登录。 2. **更新软件…...
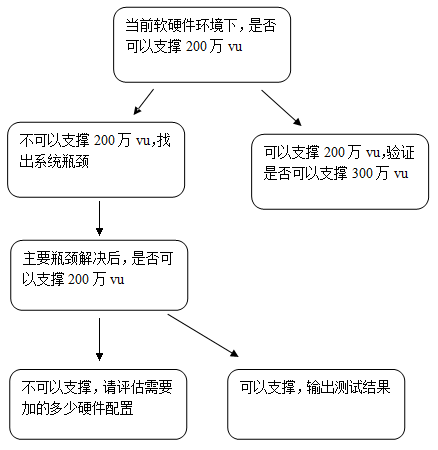
性能测试需求分析
1、客户方提出 客户方能提出明确的性能需求,说明对方很重视性能测试,这样的企业一般是金融、电信、银行、医疗器械等;他们一般对系统的性能要求非常高,对性能也非常了解。提出需求也比较明确。 曾经有一个银行项目,已经…...
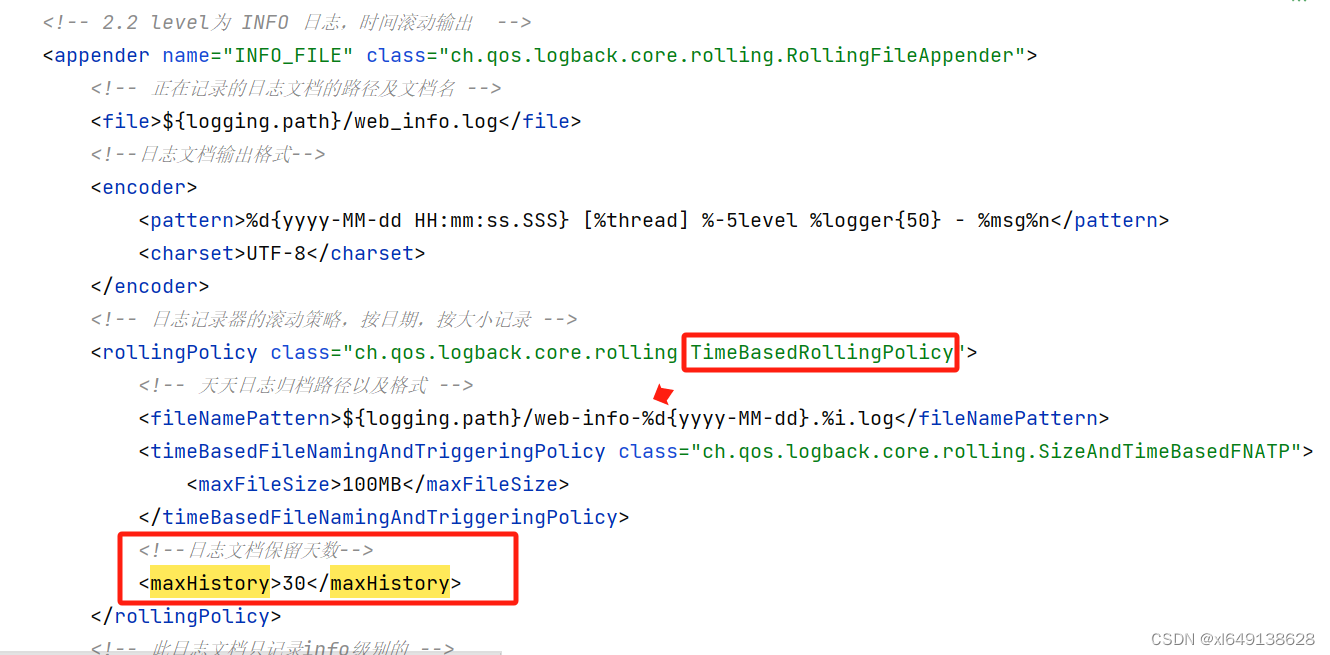
logback服务器日志删除原理分析
查看以下的logback官方文档 Chapter 4: Appendershttps://logback.qos.ch/manual/appenders.html 按文档说明,maxHistory是设置保存归档日志的最大数量,该数量的单位受到fileNamePattern里的值%d控制,如果有多个%d,只能有一个主%d࿰…...

到底什么才是真正的商业智能(BI)
随着人工智能、云计算、大数据、互联网、物联网等新一代信息化、数字化技术在各行各业内开始大规模的应用,社会上的数字化、信息化程度不断加深,而数据价值也在这样的刺激下成为了个人、机构、企业乃至国家的重要战略资源,成为了继土地、劳动…...

Pulsar Manager配置自定义认证插件访问
Pulsar Manager配置自定义认证插件访问 Pulsar Manager和dashboard部署和启用认证 pulsar自定义认证插件开发 前面博客讲了以token方式访问pulsar 这节博客讲如何配置自定义认证插件的方式访问pulsar #启动pulsar-manager docker run --name pulsar-manager -dit \-p 9527:…...

Java SimpleDateFormat linux时间字符串转时间轴的坑
Mon Oct 16 09:51:28 2023 这是linux 的 date命令得到的时间,要转换称时间戳。 EEE MMM dd HH:mm:ss yyyy 这样的格式,看起来就是正确的,可是就是报错 Unparseable date: "Mon Oct 16 09:51:28 2023" 下面是正确的代码 String[…...
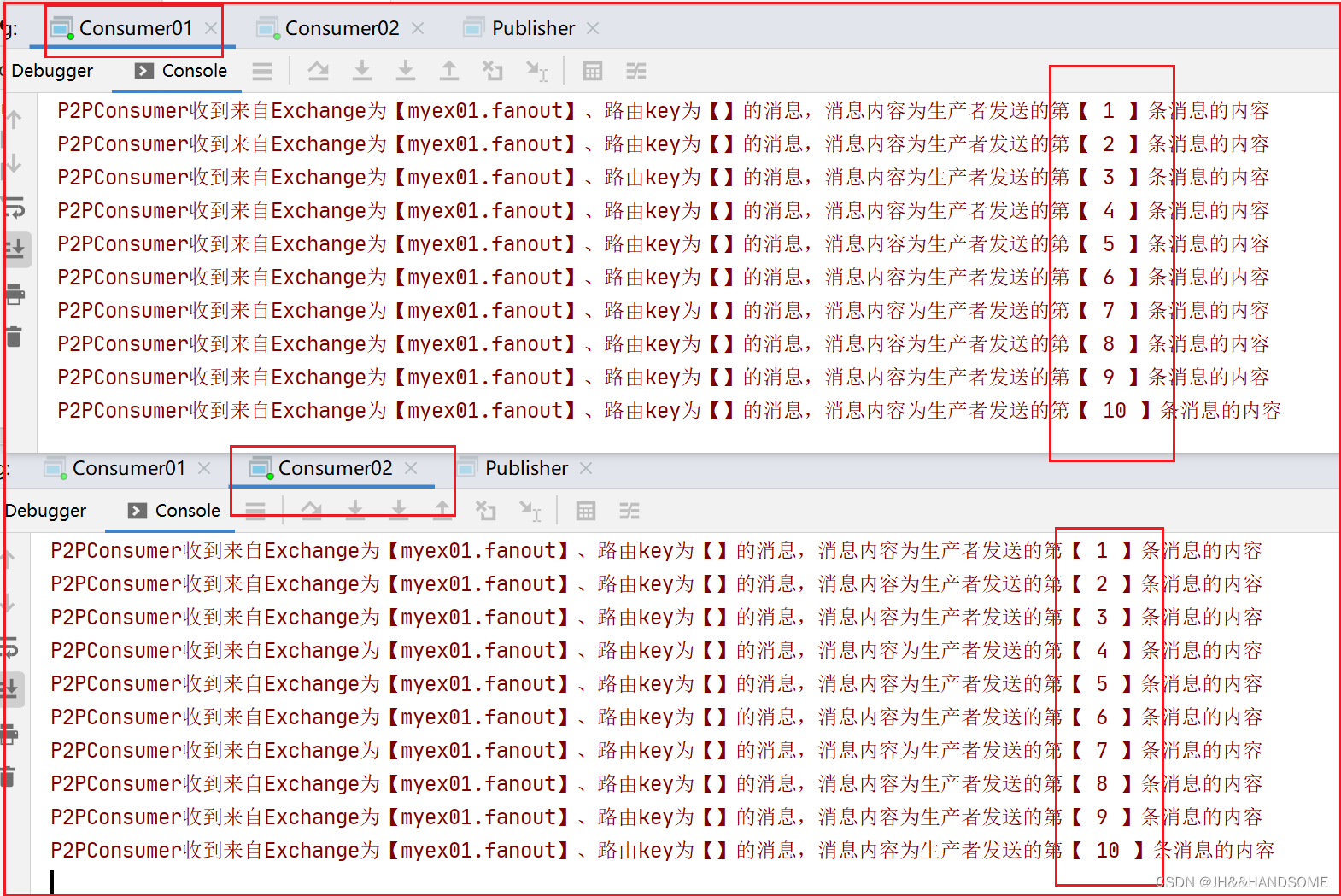
202、RabbitMQ 之 使用 fanout 类型的Exchange 实现 Pub-Sub 消息模型---fanout类型就是广播类型
目录 ★ 使用 fanout 类型的Exchange 实现 Pub-Sub 消息模型代码演示:生产者:producer消费者:Consumer01消费者:Consumer02测试结果 完整代码ConnectionUtilPublisherConsumer01Consumer02pom.xml ★ 使用 fanout 类型的Exchange …...
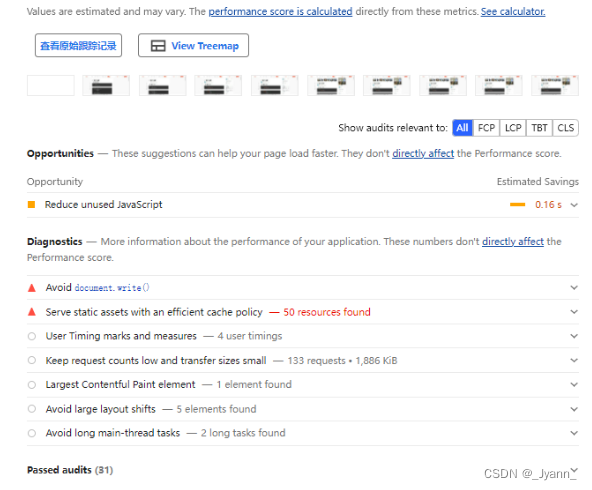
web 性能优化详解(Lighthouse工具、优化方式、强缓存和协商缓存、代码优化、算法优化)
1.性能优化包含的方面 优化性能概念宽泛,可以从信号、系统、计算机原理、操作系统、网络通信、DNS解析、负载均衡、页面渲染。只要结合一个实际例子讲述清楚即可。 2.什么是性能? Web 性能是客观的衡量标准,是用户对加载时间和运行时的直观…...
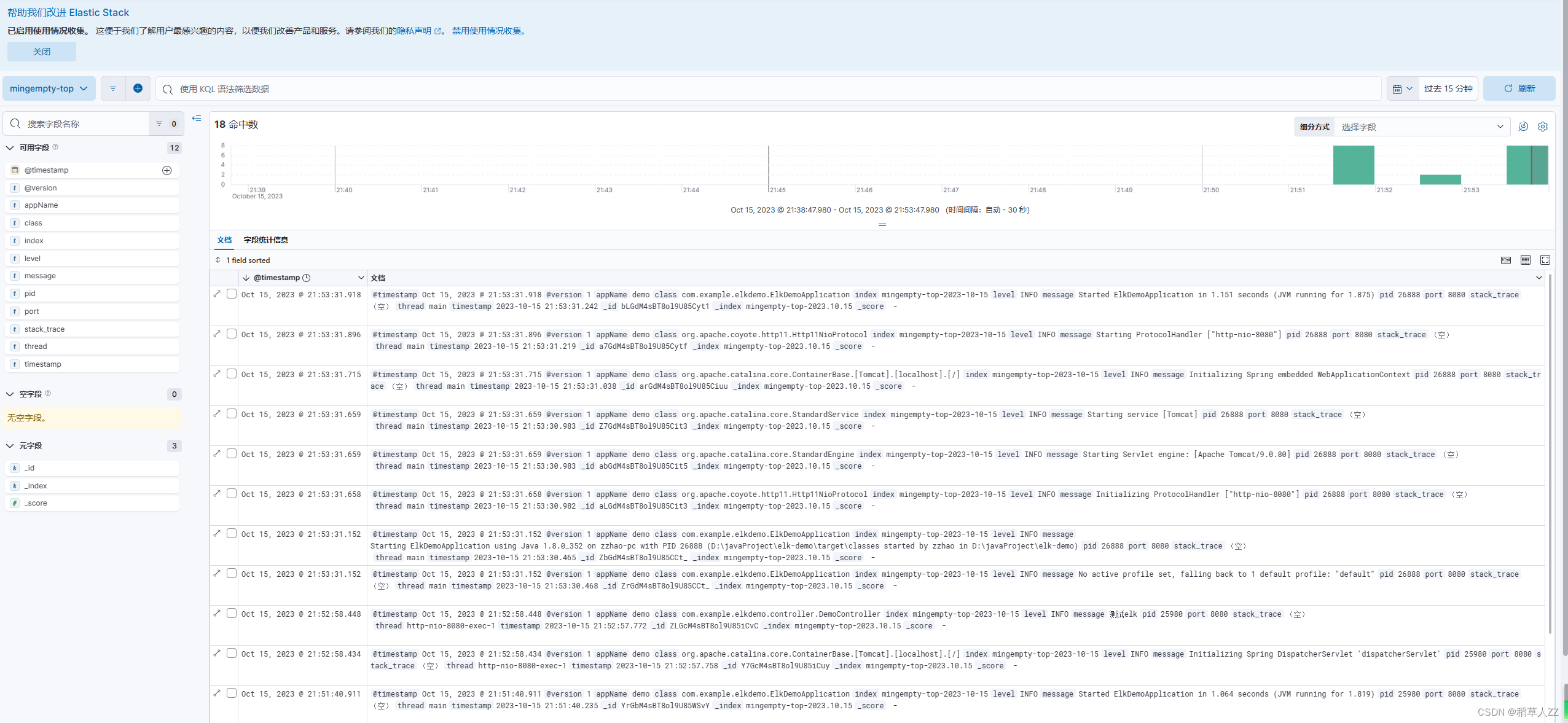
docker-compose部署elk(8.9.0)并开启ssl认证
docker部署elk并开启ssl认证 docker-compose部署elk部署所需yml文件 —— docker-compose-elk.yml部署配置elasticsearch和kibana并开启ssl配置基础数据认证配置elasticsearch和kibana开启https访问 配置logstash创建springboot项目进行测试kibana创建视图,查询日志…...
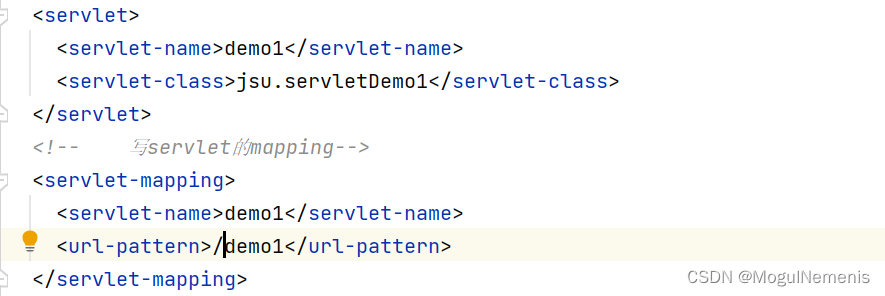
解决java.lang.IllegalArgumentException: servlet映射中的<url pattern>[demo1]无效
当我使用tomcat启动使用servlet项目时,出现了报错: java.lang.IllegalArgumentException: servlet映射中的<url pattern>[demo1]无效 显示路径错误,于是去检查Web.xml中的配置,发现是配置文件的路径写错了,少写了…...

软件测试学习(三)易用性测试、测试文档、软件安全性测试、网站测试
目录 易用性测试 用户界面测试 优秀Ul由什么构成 符合标准和规范 直观 一致 灵活 舒适 正确 实用 为有残疾障碍的人员测试:辅助选项测试 测试文档 软件文档的类型 文档测试的重要性 软件安全性测试 了解黑客的动机 威胁模式分析 网站测试 网页基…...
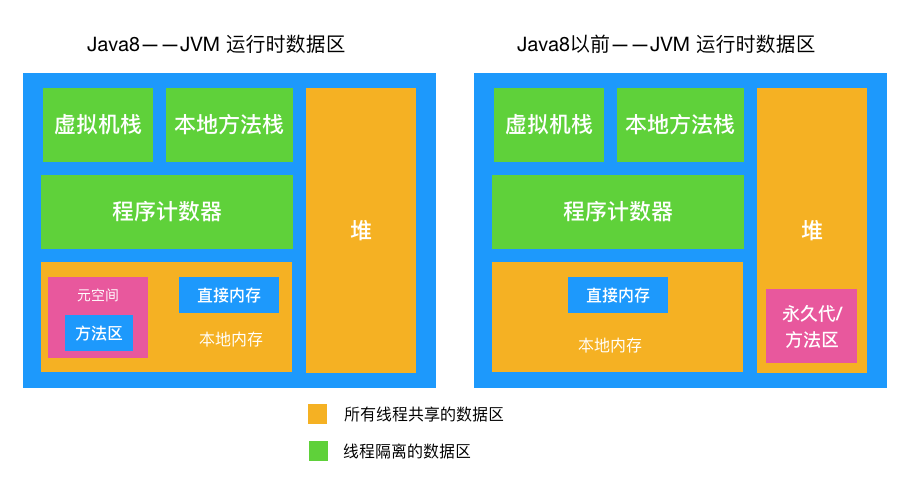
Java中,对象一定在堆中分配吗?
在我们的日常编程实践中,我们经常会遇到各种类型的对象,比如字符串、列表、自定义类等等。这些对象在内存中是如何存储的呢? 你可能会毫不犹豫地回答:“在堆中!”如果你这样回答了,那你大部分情况下是正确…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...