符尧:别卷大模型训练了,来卷数据吧!【干货十足】
大家好,我是HxShine。
今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程(data engineering)包括mix ratio(数据混合比例) + data format(数据格式) + data curriculum(数据课程)以及模型规模对speed of grokking的影响,同时用一个生动的随机数生成的例子讨论语言模型学习的本质,干货十足,分享给大家~
一、概述
Title:An Initial Exploration of Theoretical Support for Language Model Data Engineering. Part 1: Pretraining
文章地址:https://yaofu.notion.site/An-Initial-Exploration-of-Theoretical-Support-for-Language-Model-Data-Engineering-Part-1-Pretraini-dc480d9bf7ff4659afd8c9fb738086eb
1 Motivation
- 最近大模型开源社区研究热点开始从model engineering转移到data engineering,大家开始意识到数据质量的重要性。
- data engineering的理论还不太成熟,例如:好数据的准确定义是什么?,如何优化数据的结构组成?我们的优化目标是什么?
- 对data engineering进行理论分析可以帮助我们在正式跑实验前预测每个task最终的performance,openai在gpt4的技术报告中提到了这点,非常有意义。
2 Methods
本文不提出优化数据的具体方法,仅讨论数据工程(data engineering)时应该解决的问题是什么,以及指导我们的基本原则。具体来说,我们讨论预训练和 SFT 数据优化的以下目标:
- 预训练阶段数据优化:找到最优的混合比例+数据格式+数据课程=>使学习速度最大化。
- 监督微调/指令阶段调整数据优化:寻找最小的query-response pairs(最小的训练数据)=>使用户偏好分布的覆盖范围最大。
3 Conclusion
- 解释了可能更好的衡量评估指标speed of grokking(获取某技能的速度)是什么,其可能更具有泛化性并且更贴近于特定的skill能力。
- 分析mix ratio(数据混合比例) + data format(数据格式) + data curriculum(数据课程?)以及模型规模对speed of grokking的影响。
- 讨论llm模型最终学习到的是什么,以及可能的一些更好衡量模型效果的metrics。
二、详细内容
1 预训练能力评估指标:speed of grokking(获取某技能的速度)
1.1 grokking是什么?
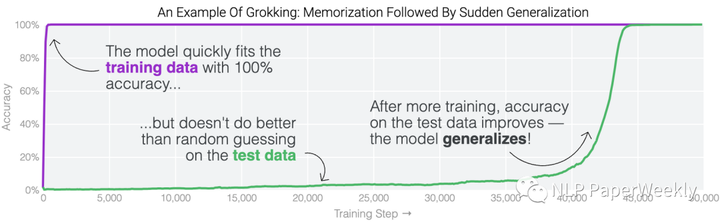
Aggregating curves of different skills lead to an overall loss curve.[1]
如上图,在训练开始时,模型记忆了训练数据,但测试精度比较低并且没有变化。随着训练的进行,从第35k步到第45k步有一个相变期,模型突然从记忆过渡到泛化,在测试集上显示出 100% 的准确率。学习过程中的这种阶段性变化被称为“grokking”。
1.2 speed of grokking和loss函数的优缺点是什么?
通常预训练模型评估指标:下一个单词预测损失(考虑到它与无损压缩的联系,信息量很大),但是loss函数并不能反映其在具体下游任务上的性能表现。
本文提到的评估指标:考虑speed of grokking摸索速度(模型获得特定技能的速度)可能是一个不错的选择替代指标。
说明:模型学习不同粒度技能的速度是不一样的,例如以下技能的难易程度不一样,模型能够学会解决这些问题所需要的时间也不一样,通过比较不同data engineering方法学习同一技能的速度(speed of grokking),可能是一个不错的评估方式。
不同粒度的技能对比:
- 单一技能:如两位数加法 => 难度低,学习速度块
- 聚合技能:一位数加法+两位数加法+两位数减法+…… => 难度中,模型所需要的学习时间中等
- 下游表现:GSM8k 数学作业题表现 => 难度大,模型所需要的学习时间最长
2 数据因素对speed of grokking的影响
本节主要讨论观察到的影响学习速度的数据因素,重点关注data format, mixture, and curriculum 这几个方面对模型的影响。
2.1 Format of data(训练数据格式)对模型的影响
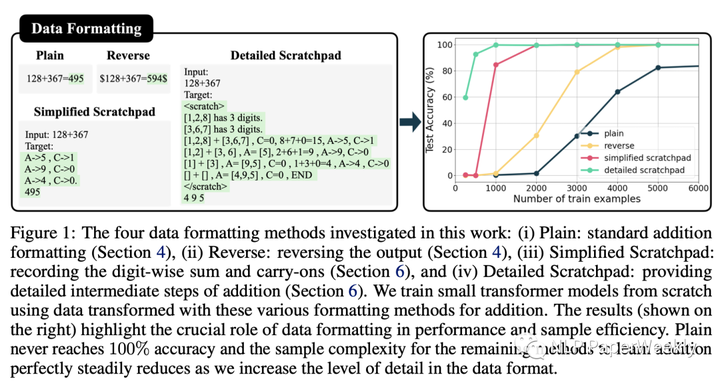

Different format of the data gives different speed of learning. Also note that they are the same data — same equation same answer, only the formats are different.[2]
数据说明:
- Plain:没有任何COT中间结果
- Reverse:倒过来
- Simplified Scratchpad:提供部分中间COT推理结果作为训练数据
- Detailed Scratchpad:提供详细的COT推理结果作为训练数据
结果:
- 利用越详细的COT中间结果来训练模型,模型学习的速度越快。
- 并不是其他Format of data不能学习到最终的结果(2,3,4的精度最后都到100%了),而是看谁的学习速度最快。
2.2 Curriculum of data(数据课程:按照一定的课程顺序编排训练数据,使模型学到的效果最佳)
什么是data curriculum?
假设:我们想要模型具备文本生成和代码生成能力,我们有 10B 文本和 10B 代码,计算资源只允许我们训练 10B 数据。希望使模型的代码生成能力最强。以下是三种可能的解决方案:
- 方法1(仅限代码):直接馈送10B代码数据
- 方法2(均匀混合):将5B文本和5B代码数据均匀混合,然后将它们同时输入模型
- 方法3(data curriculum):先输入5B文本,然后输入5B代码
哪一个能表现得最好?
- 如果模型从文本数据中学习的技能对代码数据没有帮助,那么我们可以直接执行方法1,仅利用代码数据来 训练模型,就像StarCoder和AlphaCode的情况一样。
- 如果模型从文本数据中学习的技能可以转移到代码数据中,那么我们可能想做方法2,均匀混合
- 如果学习代码技能需要模型先有文本技能,也就是说文本和代码之间有依赖关系,并且文本必须先有,那么我们需要做方法3,data curriculum(数据课程)。Codex 和 CodeLLaMA 就是这种情况(尽管他们可能不是故意选择这样做的)。
参考结论
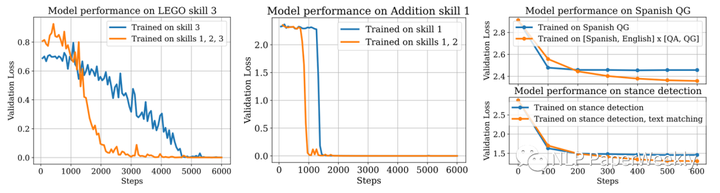

Different source of data induces different skills. Training on a particular ordering of data can give faster learning speed than training on skill-specific data.[3]
(a):想提高skill 3任务的效果,对比只在skill 3数据上训练和在skill 1,2,3数据上训练,发现在skill 1,2,3任务上训练收敛的速度更快。
(b):想提高skill 1任务的效果,对比只在skill 1数据上训练和在skill 1,2数据上训练,发现在skill 1,2任务上训练收敛的速度更快。
(c):想提上Spanish QG的效果,对比只在Spanish语料和同时在【spanish、English】语料训练,发现在【spanish、English】语料收敛速度慢点,但是最终效果更好。
(d):stance detection任务,也是在stance detection和text matching数据上同时修炼,最终的效果更好。
总结:叠加其他类型的数据,按照一定顺序来训练模型,可能比只在单一任务上训练效果更好,收敛速度更快。
2.3 Mix ratio(各部分数据比例对模型的影响)
LLaMA各部分数据占比
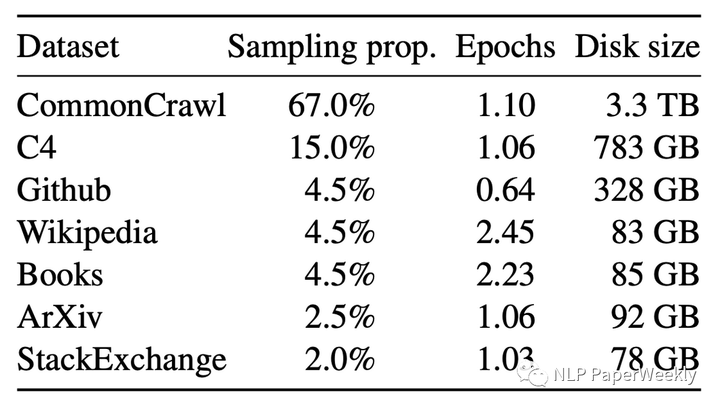
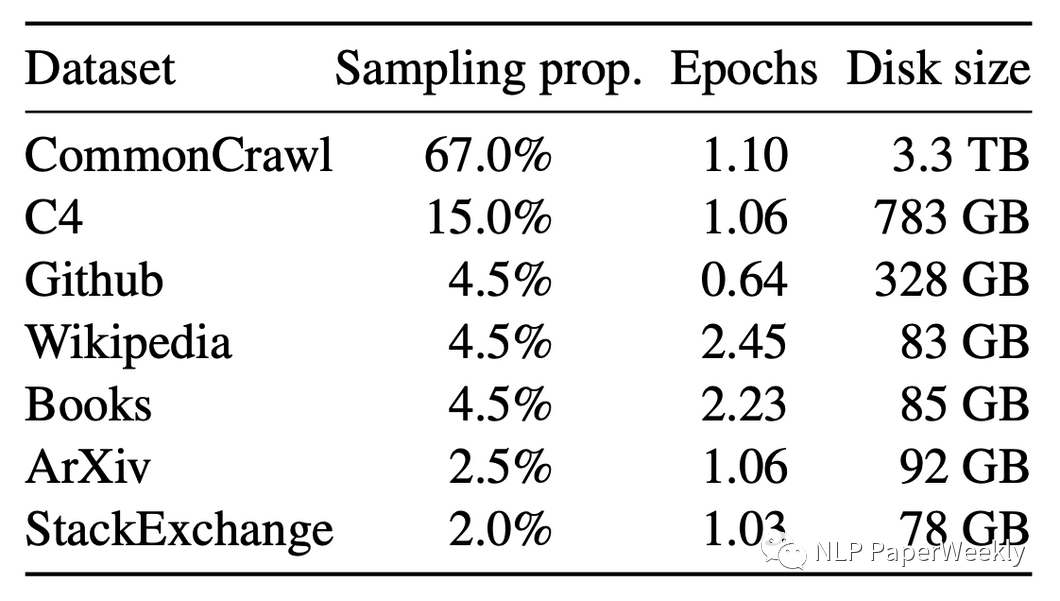
LLaMA data mix ratio. This ratio down weights code data like Github and StackExchange, also it down weights paper data like Arxiv.[4]
总结:
- LLaMA数据中Github的数据占比不高,他的coding表现也不太好,而starcode,大部分采用code数据训练,在coding task上效果比较好。
- LLaMA数据中Paper类的训练数据像Arxiv比较少,看起来科学推理效果也不高,而Galactica模型,大部分采用papers的数据,在科学推理上效果比较好。
不同的mix ratio可能造成不同的speed of learning:
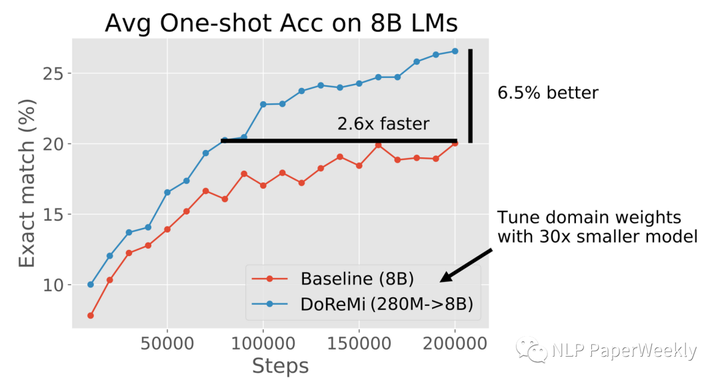
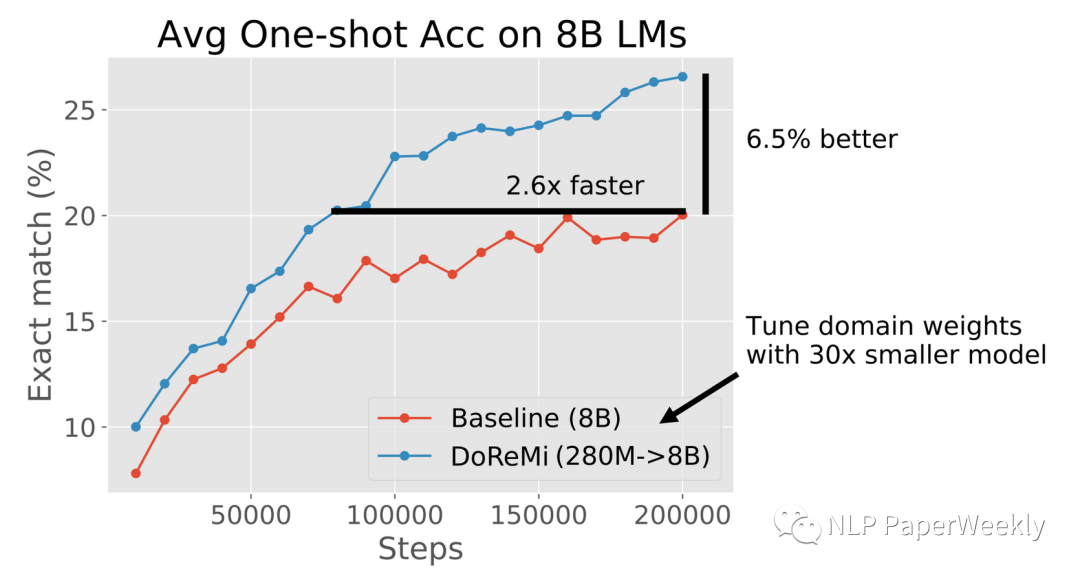
Different mix ratio of data improves speed of learning.[5]
结论:好的混合比例pile提上了模型的表现,使其有更好的学习曲线,让模型能给更快的从数据中进行学习。
2.4 Caveat:model scaling(模型尺寸大小对数据工程的影响):小于30B模型上data engineering有效果不代表大于70B的模型上该方法也会有效果
例如:代码数据真的能提升模型的推理能力吗?
- 7B模型:添加代码数据后,可以提升符号推理像Symbolic reasoning, like BABI and BBH-Algorithmic的效果,以及提升符号数据和语言数据的翻译能力,像such as structure-to-text or text-to-sql能力。
- 70B模型:对BBH-Algorithmic效果没有提升
- 代码数据对自然语言推理,像Natural language reasoning, like BBH-Language数据效果没有提升,对数学推理,像Math reasoning, like GSM8K的效果也没有提升。
总结:代码数据对小模型像7B模型的推理能力可能有一定帮助,但对大模型70B就没有帮助了。一些其他的观察也有出现这样的情况。如果真是这样,那可能不需要来做数据工程了,像data format / curriculum / mix ratio都没必要再做了,只需要做一些数据清洗工作就够了。
3 其他
3.1 不同skll学习曲线和整体loss曲线的关系
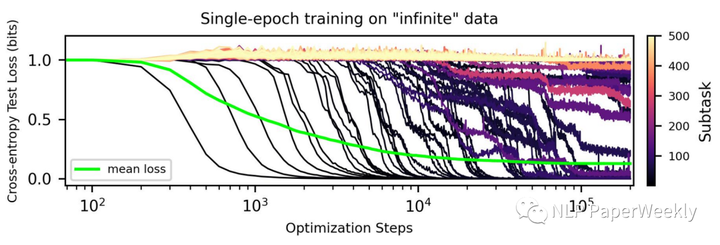
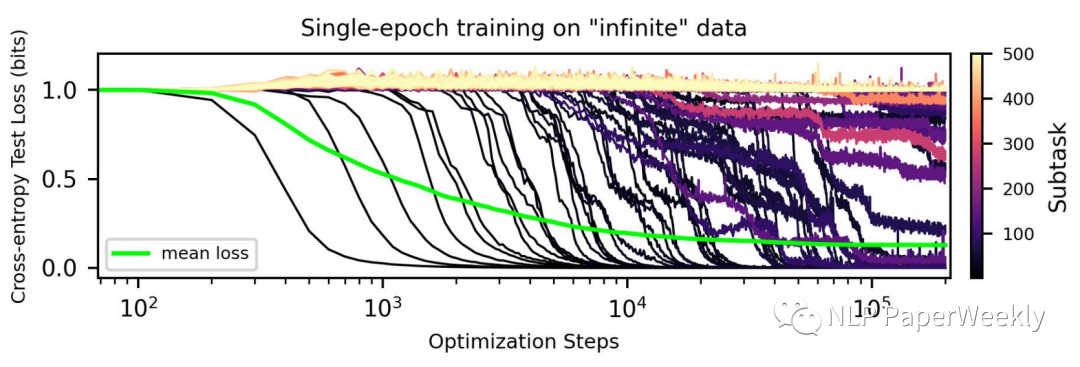
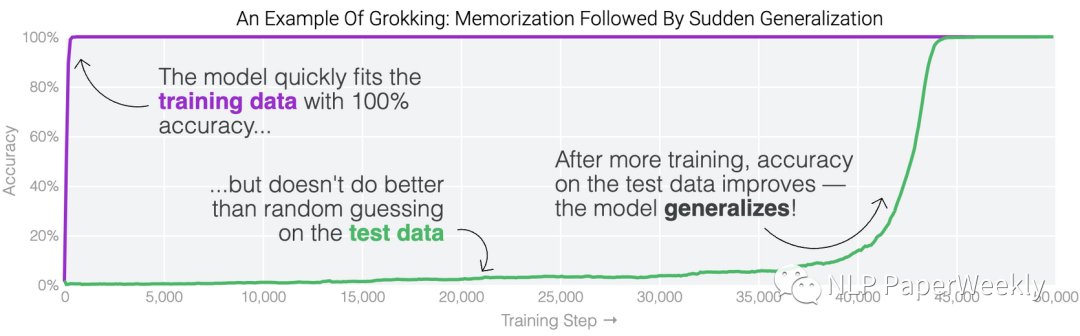
Aggregating curves of different skills lead to an overall loss curve.[6]
总结:
- 单技能的学习曲线通常表现出相变形状(在某个时间节点突然顿悟了)
- 模型学习不同skill的speed是不同的
- 集成多个skill到一块,我们可以获得一个平滑的log形状的loss曲线,说明loss函数可能只能反映一个整体的表现,而非每个具体task的效果。
3.2 loss和single-skill accuracy评价指标的优缺点
- LOSS:优点:可预测,和整体表现强相关,能解释成压缩比例。缺点:不能直接翻译成下游任务的表现。
- Single-skill accuracy(meso or macro level):只能衡量single skill的效果。
- 其他可能的metrics:
- 与能力方向很好地结合(比如推理)Aligns well with a direction of capability (say reasoning)
- 可以从第一原理推导出来(如信息论)Can be derived from first principles (like information theory)
- 衡量我们与“真正的生成过程”的接近程度,例如某种相互信息 Measures how close we are to the “true generative process”, like some sort of mutual information
3.3 模型学习是真正人类生存语言的过程而非记住数据(以随机数生成为例)
说明:这里以随机数无损压缩揭示了模型学习真实的生成的过程,说明模型是学习生成过程,而非随机生成的100B或者50B的随机数
- 随机数生成算法。例如,[Python随机数生成算法](https://github.com/python/cpython/blob/3.11/Lib/random.py)有904行代码,31.4 kb 磁盘内存。
- 使用此算法生成 100B 伪随机数。
- 将这100B随机数发送给朋友并要求朋友对其进行压缩。
- 在不了解底层生成过程(算法)的情况下,如果使用一些常见的压缩软件(例如 gzip),他们最终可能会得到 50B 左右的文件,压缩率很低。
- 如果以某种方式弄清楚了随机数生成算法和初始种子,只需存储算法和种子,只需要 31.4kb 磁盘内存,这是极高的压缩比。
- 大型神经网络及其学习算法,类似于上述过程,使用大量观察来恢复底层生成过程(数据生成算法)。压缩比/训练损失越高,他们恢复潜在生成过程的可能性就越大。
三、总结
本文回顾了语言模型学习的一些现象grokking, log-linear scaling law, emergent abilities,以及影响学习速度的数据因素data format, mix ratio, and curriculum(数据格式、混合比例和课程)。
总结1: 数据工程的目标是建立一种理论并指导我们做数据(以及其他重要的学习因素),以便我们可以在没写一行代码时就可预测每项任务的最终表现(而不仅仅是预训练损失)。例如OpenAI 报道称,在 GPT-4 的开发过程中,他们在实验前预测了 HumanEval 的性能。我们相信这种预测可以通过一个未知定理来统一,该定理能够预先预测所有下游性能。
总结2: 不同的data format, mix ratio, and curriculum确实可能会提升模型的学习速度,甚至最终的效果。例如为了提升代码能力,code-LLaMA2先在文本数据上训练,然后在代码数据上训练。
总结3: 一些数据工程对小模型有提升,但不意味着在大尺寸的模型上也有效果。例如code数据只对7B大小的模型的推理能力有帮助,对70B的模型效果没有提升。
模型4: 语言模型学习的是真正的语言生成过程,而非记住数据。这里以随机数压缩的例子说明模型之所以能够学习,是因为模型学习在无损压缩的角度下近似真实的生成过程。
总结5: 不同skill模型学习的speed是不一样的,模型的loss函数不能真正反映模型学习各种task的能力,它只是一个整体的表现评估指标。
四、参考
[1] Michaud E J, Liu Z, Girit U, et al. The quantization model of neural scaling[J]. arXiv preprint arXiv:2303.13506, 2023.
[2] Lee N, Sreenivasan K, Lee J D, et al. Teaching Arithmetic to Small Transformers[J]. arXiv preprint arXiv:2307.03381, 2023.
[3] Chen M F, Roberts N, Bhatia K, et al. Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models[J]. arXiv preprint arXiv:2307.14430, 2023.
[4] Touvron H, Martin L, Stone K, et al. Llama 2: Open foundation and fine-tuned chat models[J]. arXiv preprint arXiv:2307.09288, 2023.
[5] Xie S M, Pham H, Dong X, et al. DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining[J]. arXiv preprint arXiv:2305.10429, 2023.
[6] Michaud E J, Liu Z, Girit U, et al. The quantization model of neural scaling[J]. arXiv preprint arXiv:2303.13506, 2023.
五、更多文章精读
LLama2详细解读 | Meta开源之光LLama2是如何追上ChatGPT的?
大模型开源之光LLaMA2今天发布了,再来读下LLaMA1原文吧
Meta AI | 指令回译:如何从大量无标签文档挖掘高质量大模型训练数据?
TOT(Tree of Thought) | 让GPT-4像人类一样思考
OpenAI | Let’s Verify Step by Step详细解读
进技术交流群请添加我微信:FlyShines
请备注昵称+公司/学校+研究方向,否则不予通过
如果觉得文章能够帮助到你,点赞是对我最好的支持!
相关文章:
符尧:别卷大模型训练了,来卷数据吧!【干货十足】
大家好,我是HxShine。 今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程(data engineering)包括mix ratio(数据混合…...

2023年中国半导体检测仪器设备销售收入、产值及市场规模分析[图]
半导体测试设备是一种用于电子与通信技术领域的电子测量仪器。随着技术发展,半导体芯片晶体管密度越来越高,相关产品复杂度及集成度呈现指数级增长,这对于芯片设计及开发而言是前所未有的挑战,随着芯片开发周期的缩短,…...

诊断DLL——Visual Studio安装与dll使用
文章目录 Visual Studio安装一、DLL简介二、使用步骤1.新建VS DLL工程2.生成dll文件3.自定义函数然后新建一个function.h文件,声明这个函数。4.新建VS C++ console工程,动态引用DLL编写代码,调用dll三、extern "C" __declspec(dllexport)总结Visual Studio安装 官…...

专业课138,总分390+,西工大,西北工业大学827信号与系统考研分享
数学一 考研数学其实严格意义上已经没有难度大小年之分了,说21年难的会说22年简单,说22年简单的做23年又会遭重,所以其实只是看出题人合不合你的口味罢了,建议同学不要因偶数年而畏惧,踏踏实实复习。资料方面跟谁就用…...

css3链接
你可以使用CSS3来自定义链接(超链接)的样式,以改变它们的外观。以下是一些用于自定义链接的常见CSS3样式规则: 链接的颜色: a { color: #0077b6; /* 设置链接的文字颜色 */ } 这个规则可以改变链接的文字颜色。你可以根据需要设置…...

第五章 运输层 | 计算机网络(谢希仁 第八版)
文章目录 第五章 运输层5.1 运输层协议概述5.1.1 进程之间的通信5.1.2 运输层的两个主要协议5.1.3 运输层的端口 5.2 用户数据报协议UDP5.2.1 UDP概述5.2.2 UDP的首部格式 5.3 传输控制协议TCP概述5.3.1 TCP最主要的特点5.3.2 TCP的连接 5.4 可靠传输的工作原理5.4.1 停止等待协…...

CustomTabBar 自定义选项卡视图
1. 用到的技术点 1) Generics 泛型 2) ViewBuilder 视图构造器 3) PreferenceKey 偏好设置 4) MatchedGeometryEffect 几何效果 2. 创建枚举选项卡项散列,TabBarItem.swift import Foundation import SwiftUI//struct TabBarItem: Hashable{ // let ico…...

卡片翻转效果的实现思路
卡片翻转效果的实现思路 HTML 基础布局 <div class"card"><img class"face" src"images/chrome_eSCSt8hUpR.png" /><p class"back"><span>背面背景</span></p> </div>布局完成后如下所示…...
blob和ArrayBuffer格式图片如何显示
首先blob格式图片 <template> <div> <img :src"imageURL" alt"Image" /> </div> </template> <script> export default { data() { return { imageBlob: null, // Blob格式的图片 imageURL: null // 图…...

MySQL学习(四)——事务与存储引擎
文章目录 1. 事务1.1 概念1.2 事务操作1.2.1 未设置事务1.2.2 控制事务 1.3 事务四大特性1.4 并发事务问题1.5 事务隔离级别 2. 存储引擎2.1 MySQL体系结构2.2 存储引擎2.3 存储引擎的特点2.3.1 InnoDB2.3.2 MyISAM2.3.3 Memory2.3.4 区别和比较 1. 事务 1.1 概念 事务 是一组…...
3.3 Tessellation Shader (TESS) Geometry Shader(GS)
一、曲面细分着色器的应用 海浪,雪地等 与置换贴图的结合 二、几何着色器的应用 几何动画 草地等(与曲面着色器结合) 三、着色器执行顺序 1.TESS的输入与输出 输入 Patch,可以看成是多个顶点的集合,包含每个顶点的属…...

C++:超越C语言的独特魅力
W...Y的主页😊 代码仓库分享💕 🍔前言: 今天我们依旧来完善补充C,区分C与C语言的区别。上一篇我们讲了关键字、命名空间、C的输入与输出、缺省参数等知识点。今天我们继续走进C的世界。 目录 函数重载 函数重载概…...

【LeetCode】27. 移除元素
1 问题 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新…...

AWS SAP-C02教程4--身份与联合身份认证
AWS的账号和权限控制一开始接触的时候觉得很复杂,不仅IAM、Identiy Federation、organization,还有Role、Policy等。但是其实先理清楚基本一些概念,然后在根据实际应用场景去理解设计架构,你就会很快掌握这一方面的内容。 AWS的账号跟其它一些云或者说一些SAAS产品的账号没…...

Mybatis Plus入门进阶:特殊符号、动态条件、公共语句、关联查询、多租户插件
前言 Mybatis Plus入门进阶:特殊符号、动态条件、公共语句、关联查询、多租户插件 隐藏问题:批量插入saveBatch 文章目录 前言注意点动态条件xml公共语句关联查询动态表名使用自定义函数主键生成策略saveBatch插件:多租户TenantLineInnerInte…...

Webpack 什么是loader?什么是plugin?loader与plugin区别是什么?
什么是loader?什么是plugin? loader 本质为一个函数,将文件编译成可执行文件。webpack完成的工作是将依赖分析与tree shinking对于类似.vue或.scss结尾的文件无法编译理解这就需要实现一个loader完成文件转译成js、html、css、json等可执行文…...
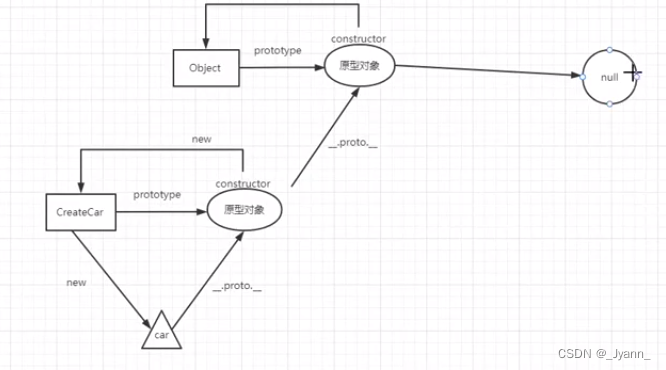
js面向对象(工厂模式、构造函数模式、原型模式、原型和原型链)
1.封装 2. 工厂模式 function createCar(color, style){let obj new Object();obj.color color;obj.style style;return obj;}var car1 createCar("red","car1");var car2 createCar("green","car2"); 3. 构造函数模式 // 创建…...

grid网格布局,比flex方便太多了,介绍几种常用的grid布局属性
使用flex布局的痛点 如果使用justify-content: space-between;让子元素两端对齐,自动分配中间间距,假设一行4个,如果每一行都是4的倍数那没任何问题,但如果最后一行是2、3个的时候就会出现下面的状况: /* flex布局 两…...

企业如何凭借软文投放实现营销目标?
数字时代下,软文投放成为许多企业营销的主要方式,因为软文投放成本低且效果持续性强,最近也有不少企业来找媒介盒子进行软文投放,接下来媒介盒子就来给大家分享下,企业在软文投放中需要掌握哪些技巧,才能实…...

【AI】深度学习——循环神经网络
神经元不仅接收其他神经元的信息,也能接收自身的信息。 循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络,可以更方便地建模长时间间隔的相关性 常用的参数学习可以为BPTT。当输入序列比较…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...
Xcode 16 集成 cocoapods 报错
基于 Xcode 16 新建工程项目,集成 cocoapods 执行 pod init 报错 ### Error RuntimeError - PBXGroup attempted to initialize an object with unknown ISA PBXFileSystemSynchronizedRootGroup from attributes: {"isa">"PBXFileSystemSynchro…...
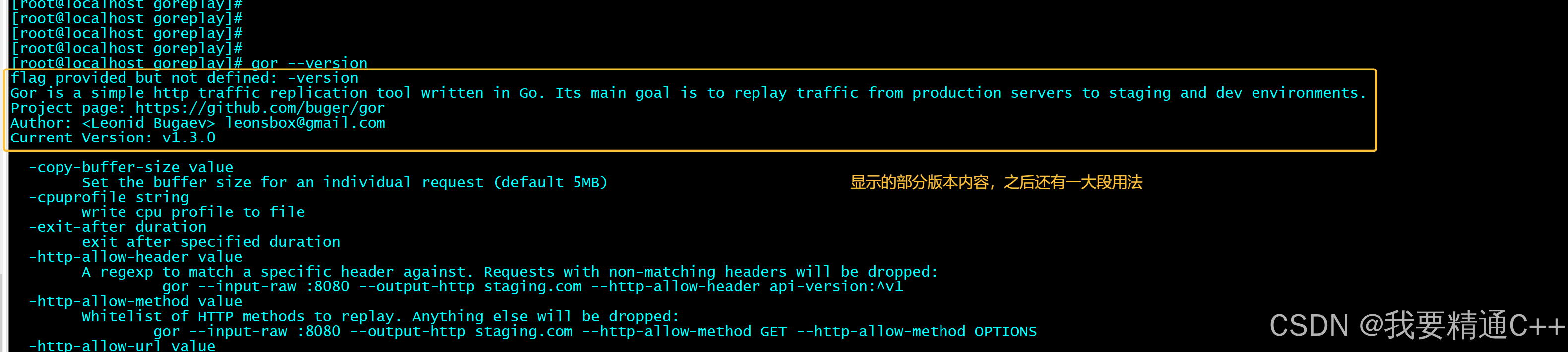
goreplay
1.github地址 https://github.com/buger/goreplay 2.简单介绍 GoReplay 是一个开源的网络监控工具,可以记录用户的实时流量并将其用于镜像、负载测试、监控和详细分析。 3.出现背景 随着应用程序的增长,测试它所需的工作量也会呈指数级增长。GoRepl…...
qt+vs Generated File下的moc_和ui_文件丢失导致 error LNK2001
qt 5.9.7 vs2013 qt add-in 2.3.2 起因是添加一个新的控件类,直接把源文件拖进VS的项目里,然后VS卡住十秒,然后编译就报一堆 error LNK2001 一看项目的Generated Files下的moc_和ui_文件丢失了一部分,导致编译的时候找不到了。因…...
李沐--动手学深度学习--GRU
1.GRU从零开始实现 #9.1.2GRU从零开始实现 import torch from torch import nn from d2l import torch as d2l#首先读取 8.5节中使用的时间机器数据集 batch_size,num_steps 32,35 train_iter,vocab d2l.load_data_time_machine(batch_size,num_steps) #初始化模型参数 def …...

HTML中各种标签的作用
一、HTML文件主要标签结构及说明 1. <!DOCTYPE html> 作用:声明文档类型,告知浏览器这是 HTML5 文档。 必须:是。 2. <html lang“zh”>. </html> 作用:包裹整个网页内容,lang"z…...