【机器学习】PyTorch-MNIST-手写字识别
文章目录
- 前言
- 完成效果
- 一、下载数据集
- 手动下载
- 代码下载MNIST数据集:
- 二、 展示图片
- 三、DataLoader数据加载器
- 四、搭建神经网络
- 五、 训练和测试
- 第一次运行:
- 六、优化模型
- 第二次优化后运行:
- 七、完整代码
- 八、手写板实现输入识别功能
前言
注意:本代码需要安装PyTorch未安装请看之前的文章https://blog.csdn.net/qq_39583774/article/details/132070870
MNIST(Modified National Institute of Standards and Technology)是一个常用于机器学习和计算机视觉领域的数据集,用于手写数字识别。它包含了一系列28x28像素大小的灰度图像,每个图像都表示了一个手写的数字(0到9之间)。MNIST数据集共有60,000个训练样本和10,000个测试样本,可用于训练和测试各种图像分类算法。
通过使用MNIST数据集,研究人员和开发者可以测试和验证各种机器学习模型和算法的性能,特别是在图像分类领域。这个数据集成为了计算机视觉领域中的基准,许多研究论文和教程都使用它来演示各种图像处理和机器学习技术的效果。
完成效果
准确率有待提高,可能是因为测试数据集和训练数据集的数据是国外,写法有点不一样,如果你能提高这个模型的成功率可以分享给我,感谢。
一、下载数据集
下载可以使用代码也可以使用手动方式下载:
数据集网站:http://yann.lecun.com/exdb/mnist/
手动下载
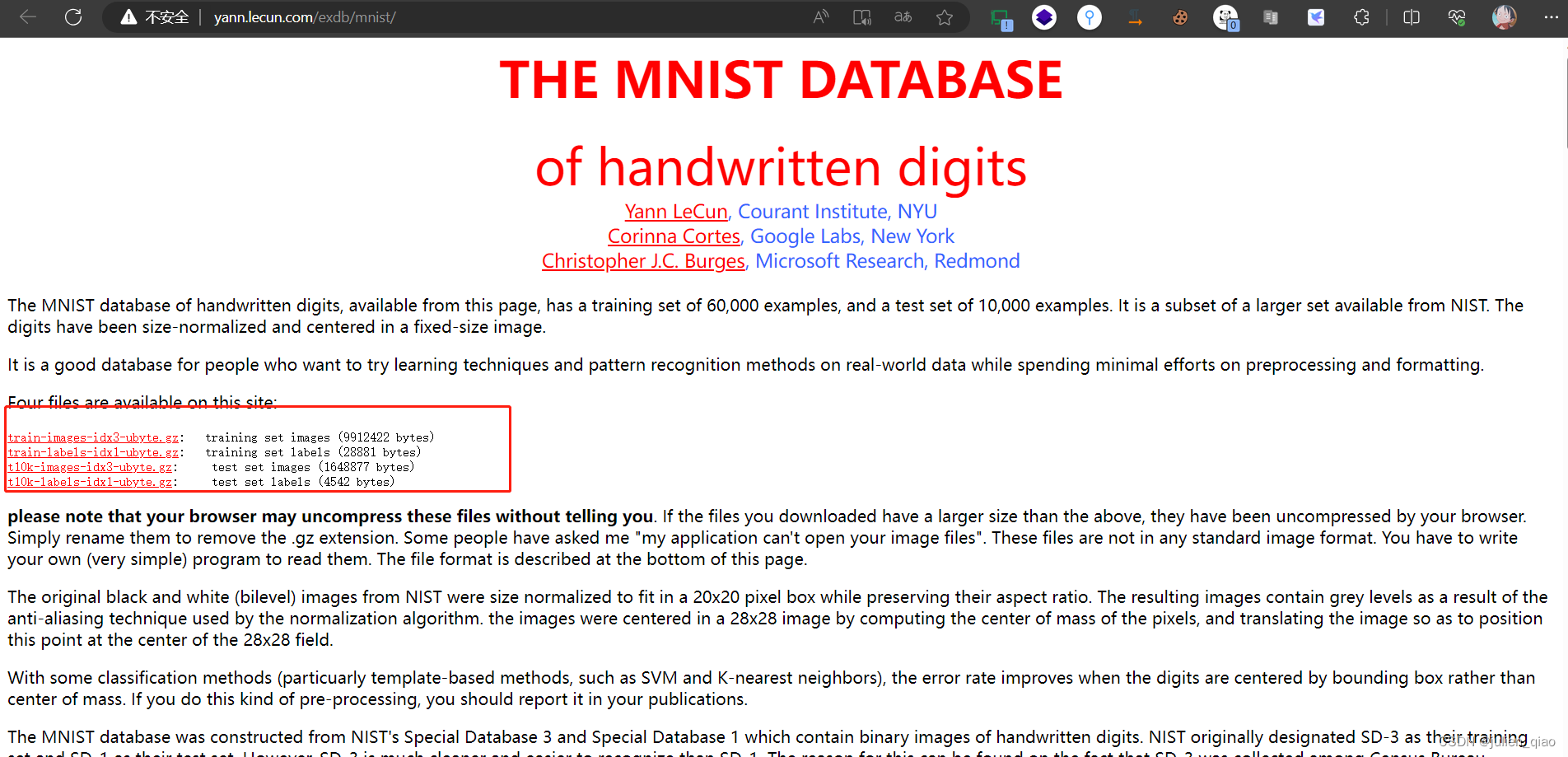
代码下载MNIST数据集:
#MNIST--手写字识别
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor#创建一个MNIST数据集的实例,其中包括训练图像和标签
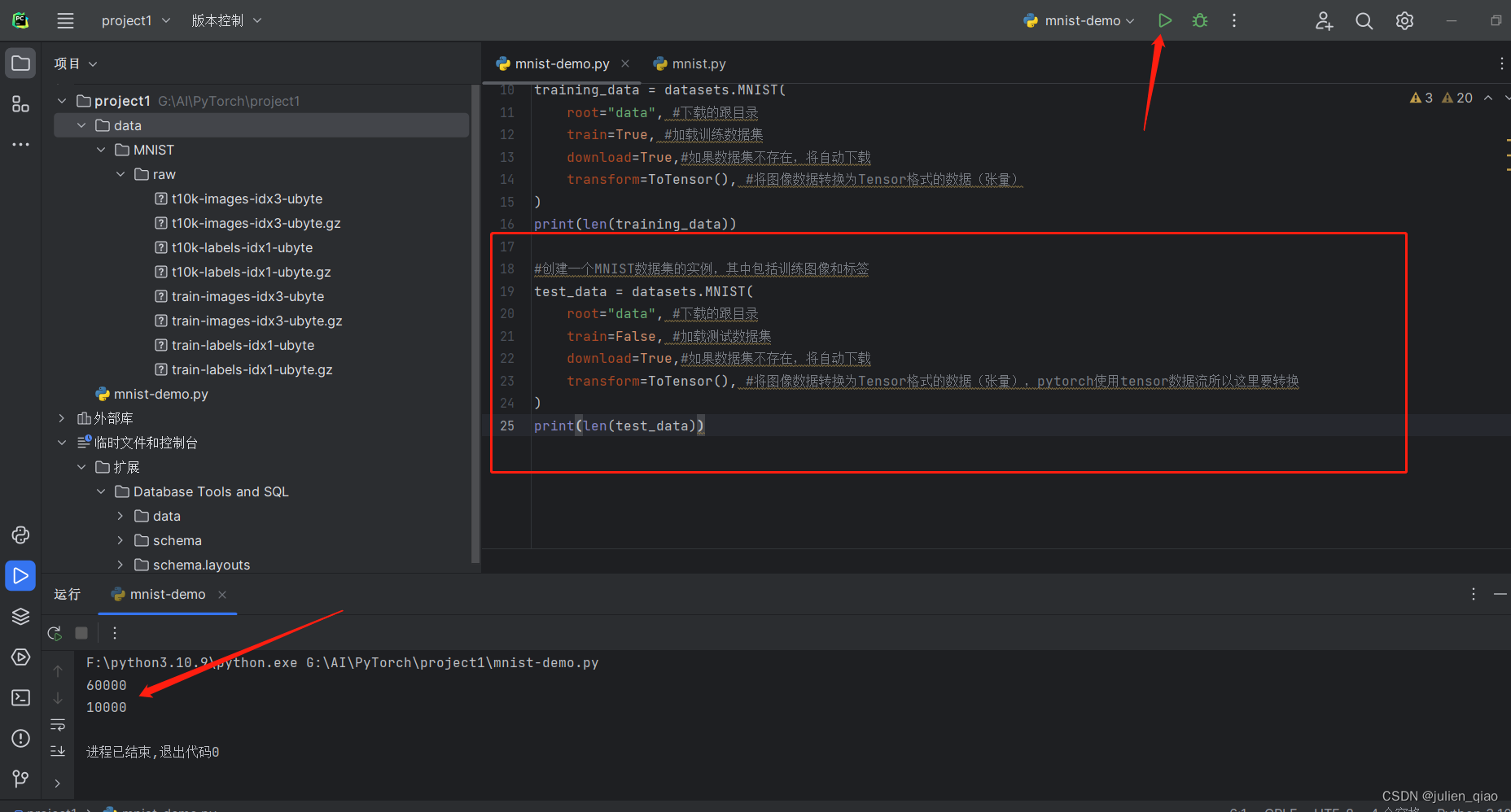
training_data = datasets.MNIST(root="data", #下载的跟目录train=True, #加载训练数据集download=True,#如果数据集不存在,将自动下载transform=ToTensor(), #将图像数据转换为Tensor格式的数据(张量),pytorch使用tensor数据流所以这里要转换
)
print(len(training_data))
运行:
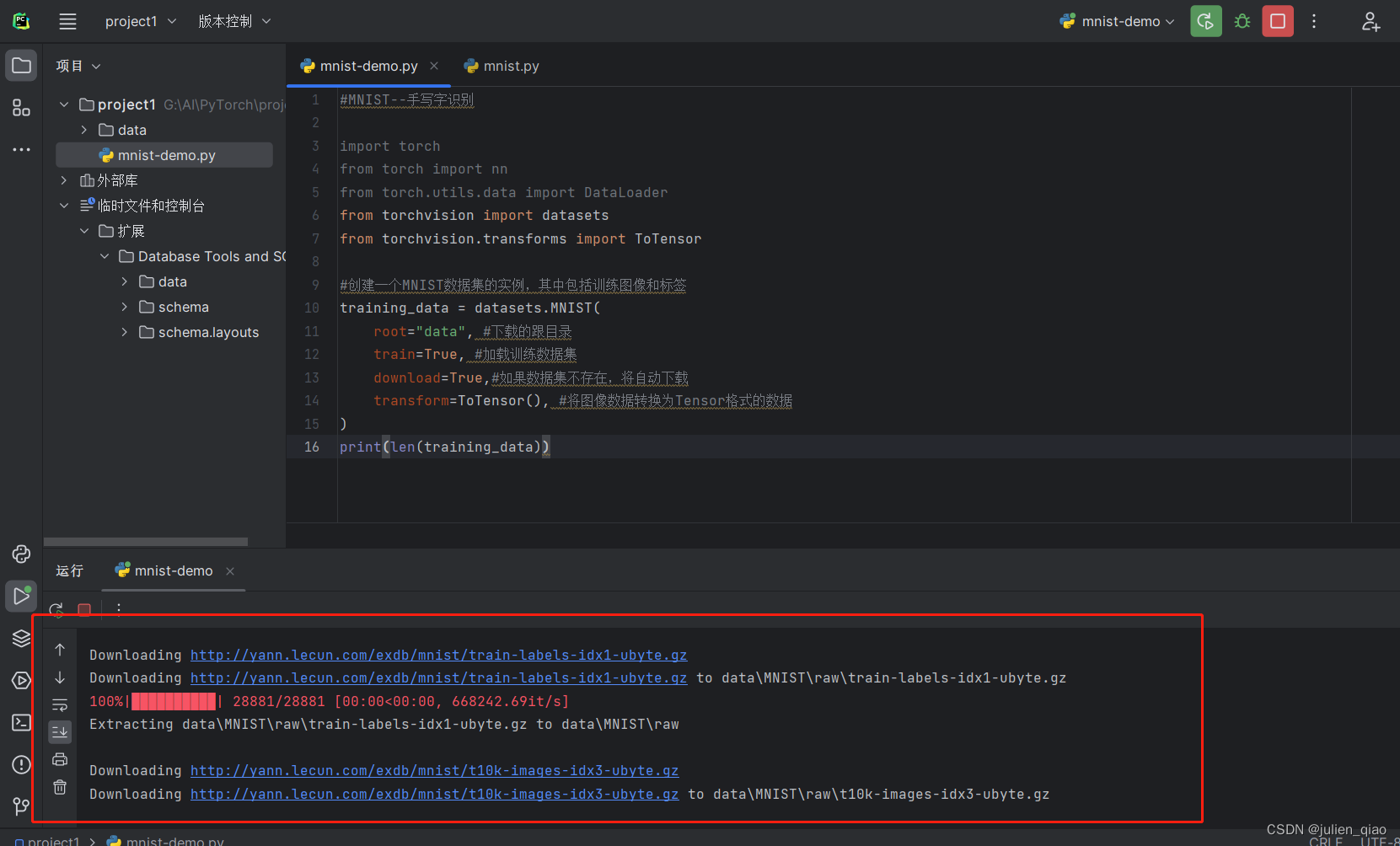
打印训练数量:

读取测试数据集:
代码下载工作原理:按住ctrl建跳转源代码
从上面看是通过爬虫方式下载,和我们的手动下载方式差不多

可以看到我们下载好的数据集:
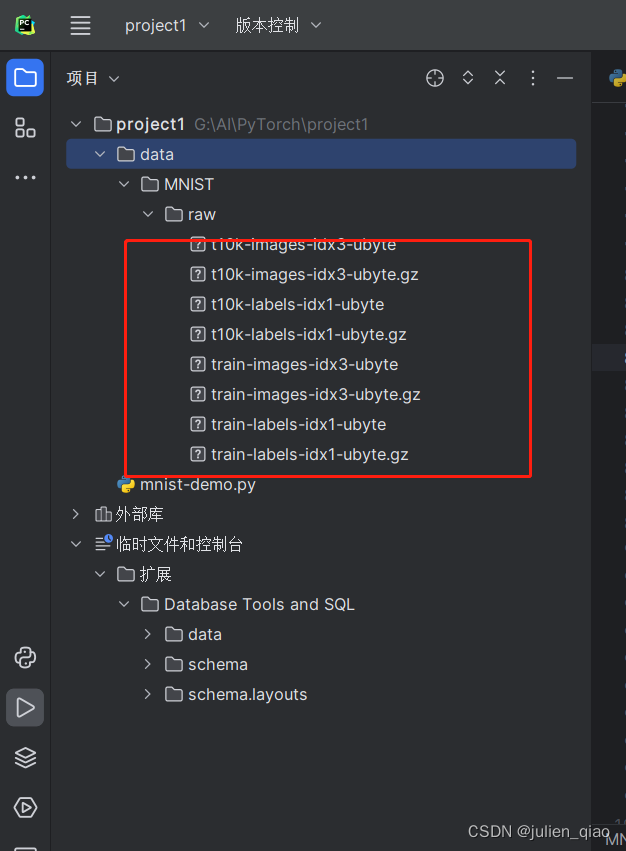
前言中我们有训练数据和测试数据上面是读取训练数据下面我们读取测试数据集:
test_data = datasets.MNIST(root="data", #下载的跟目录train=False, #加载测试数据集download=True,#如果数据集不存在,将自动下载transform=ToTensor(), #将图像数据转换为Tensor格式的数据(张量),pytorch使用tensor数据流所以这里要转换
)
print(len(test_data))
运行一下:
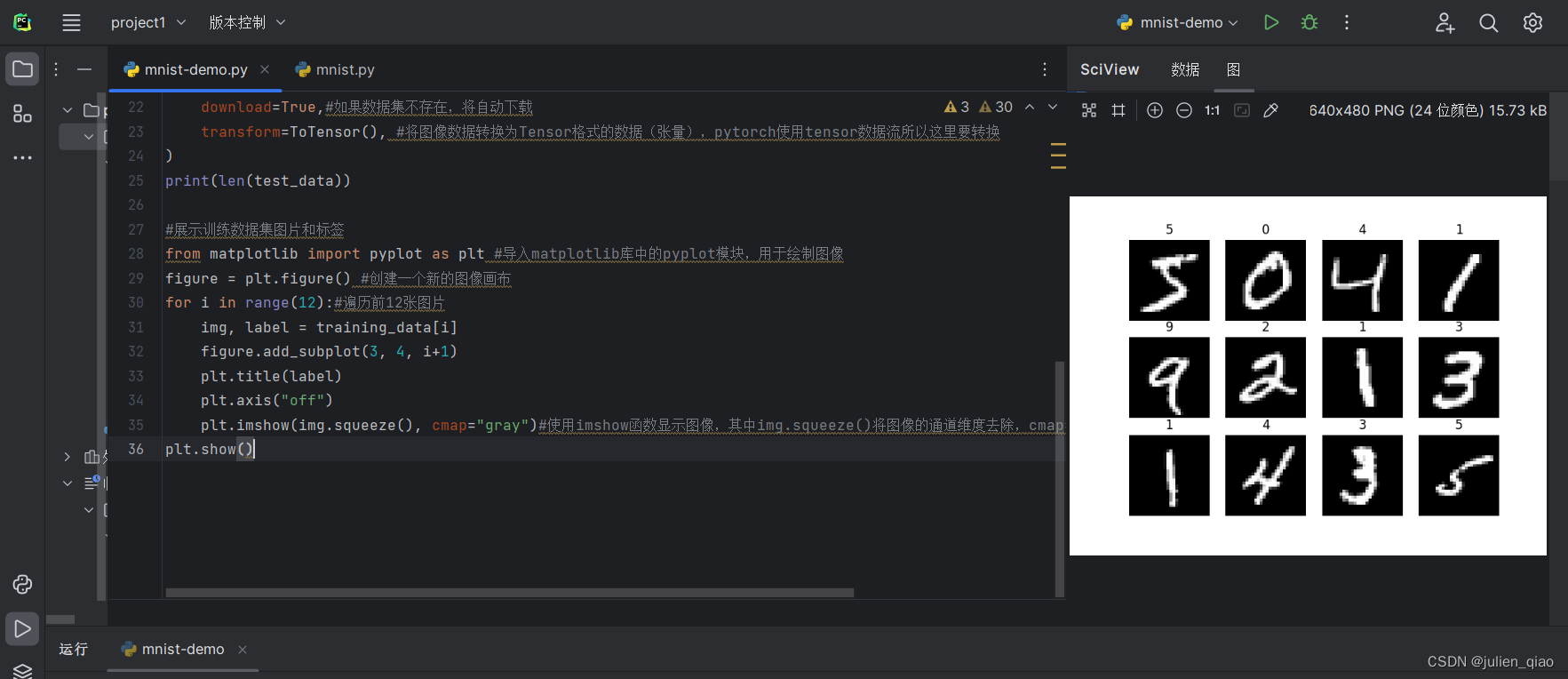
二、 展示图片
#展示训练数据集图片和标签
from matplotlib import pyplot as plt #导入matplotlib库中的pyplot模块,用于绘制图像
figure = plt.figure() #创建一个新的图像画布
for i in range(12):#遍历前12张图片0-12img, label = training_data[i]figure.add_subplot(3, 4, i+1)plt.title(label)plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")#使用imshow函数显示图像,其中img.squeeze()将图像的通道维度去除,cmap="gray"表示使用灰度颜色映射
plt.show()
三、DataLoader数据加载器
为什么要做这一步:因为数据集有6万个数据集,通过打包方式将64个为一组,打包起来一起传入,内存这样可以大大加快处理的速度,不然就是6万多个数据集一个一个传入导致速度变慢。
train_dataloader = DataLoader(training_data, batch_size=64)#创建一个训练数据加载器,将training_data(训练数据集)分成64张图像一组的批次
test_dataloader = DataLoader(test_data, batch_size=64)#创建一个测试数据加载器,将test_data(测试数据集)分成64张图像一组的批次。
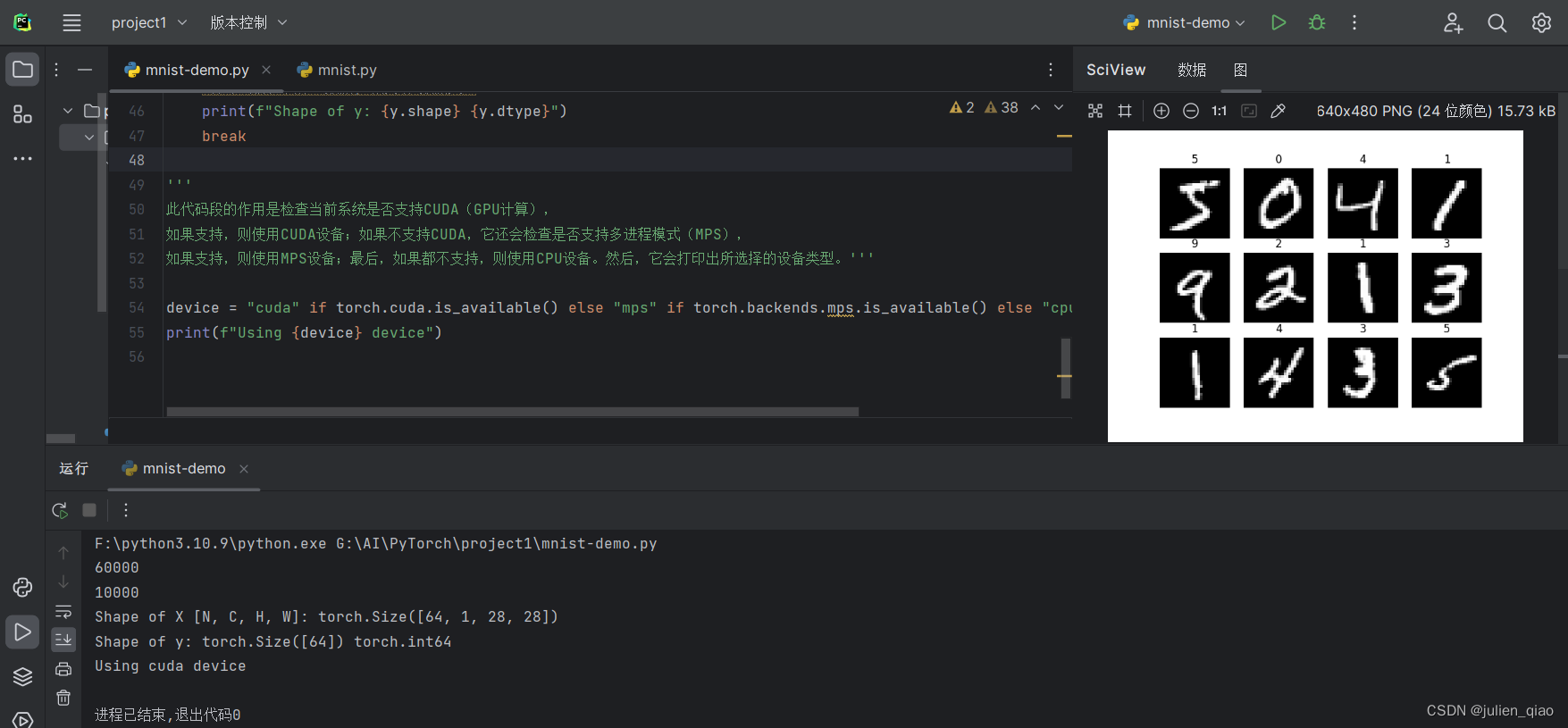
for X, y in test_dataloader:#X是表示打包好的每一个数据包#打印当前批次图像数据X的形状,其中N表示批次大小,C表示通道数,H和W表示图像的高度和宽度print(f"Shape of X [N, C, H, W]: {X.shape}")#打印当前批次标签数据y的形状和数据类型print(f"Shape of y: {y.shape} {y.dtype}")break#这里测试一下第一个组中的形状
'''
此代码段的作用是检查当前系统是否支持CUDA(GPU计算),
如果支持,则使用CUDA设备;如果不支持CUDA,它还会检查是否支持多进程模式(MPS),
如果支持,则使用MPS设备;最后,如果都不支持,则使用CPU设备。然后,它会打印出所选择的设备类型。'''device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
第一组中中有64张图像,大小为28*28,使用GPU计算
四、搭建神经网络
构造示意图:输出层为固定参数十个,因为数字数字0-9一共就十个
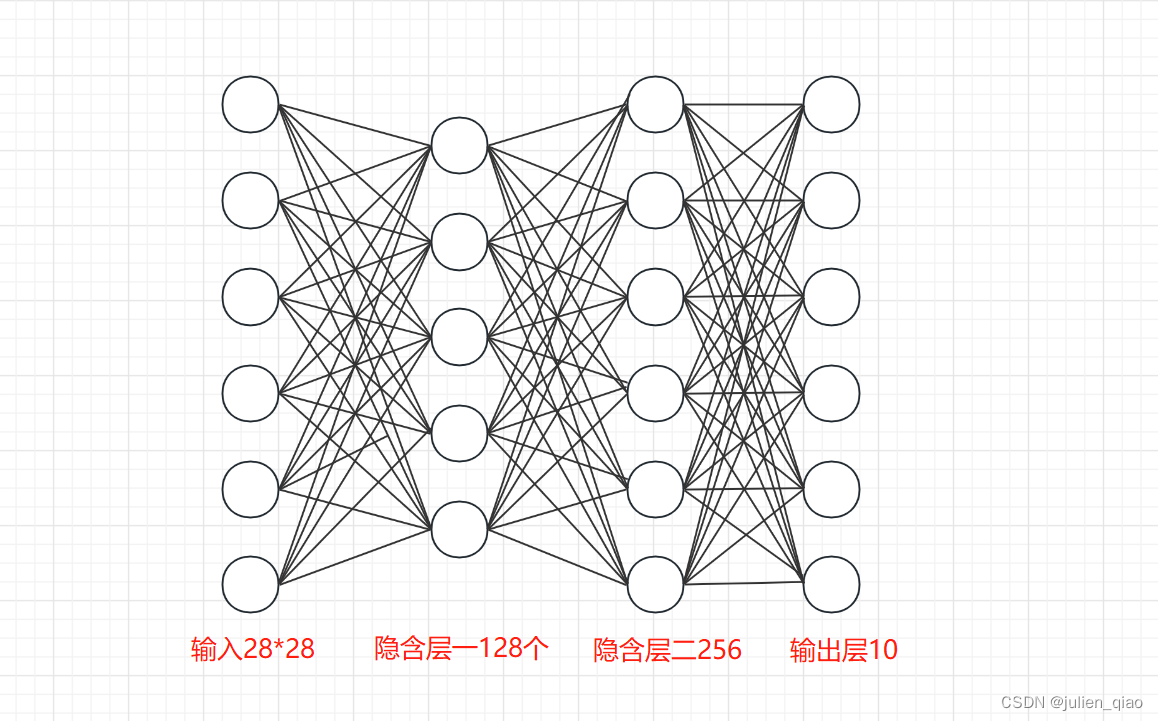
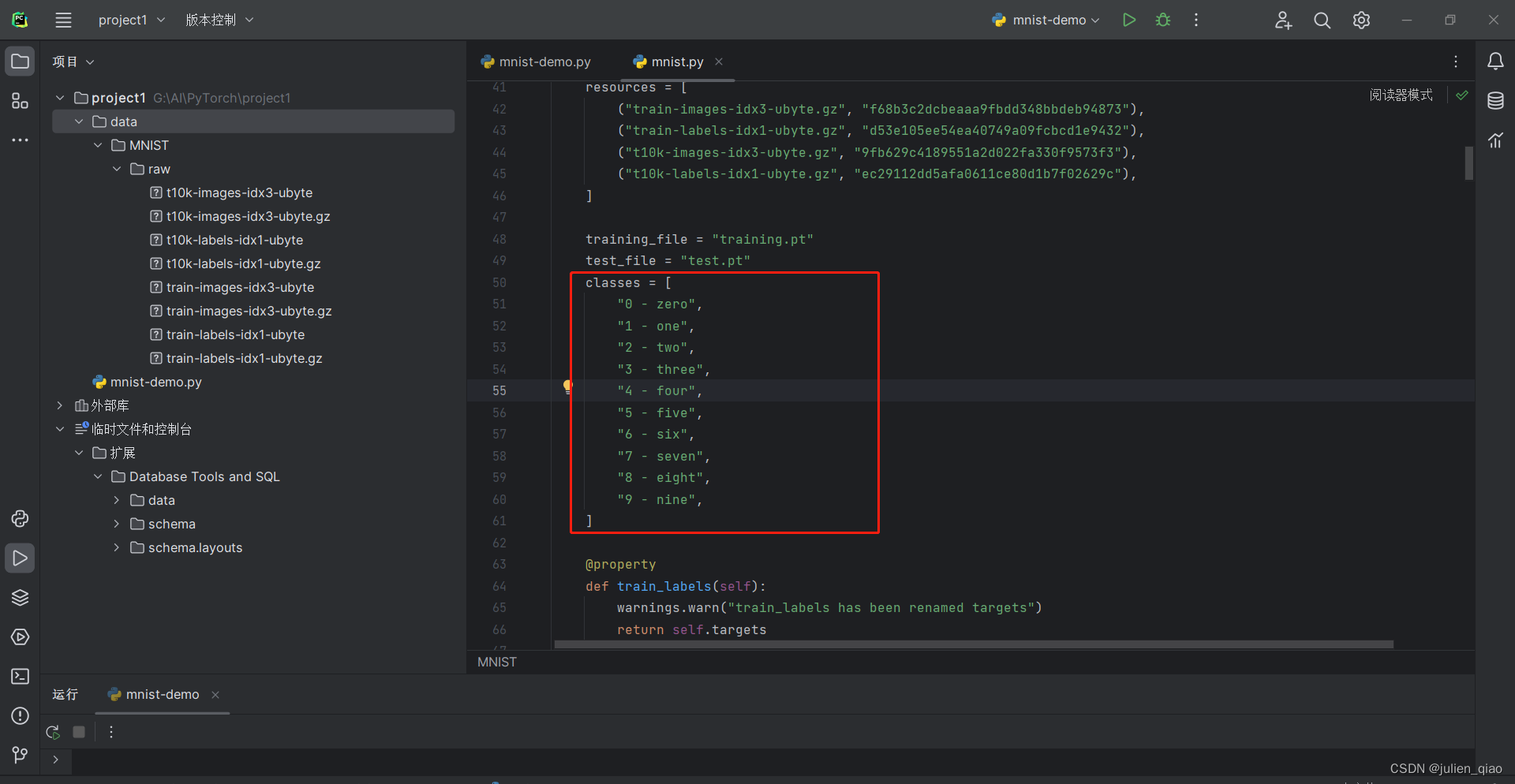
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # 将图像展平self.hidden1 = nn.Linear(28*28, 128) # 第一个隐藏层,输入维度为28*28,输出维度为128self.hidden2 = nn.Linear(128, 256) # 第二个隐藏层,输入维度为128,输出维度为256self.out = nn.Linear(256, 10) # 输出层,输入维度为256,输出维度为10(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 将输入图像展平x = self.hidden1(x) # 第一个隐藏层的线性变换x = torch.sigmoid(x) # 使用Sigmoid激活函数x = self.hidden2(x) # 第二个隐藏层的线性变换x = torch.sigmoid(x) # 使用Sigmoid激活函数x = self.out(x) # 输出层的线性变换(未经激活函数)return x # 返回模型的输出
model = NeuralNetwork().to(device)#传入对应设备,根据上面识别的设备进行传入,这里传入GPU
print(model)
从分类中也可以看出分类:
运行代码:
五、 训练和测试
#训练数据
def train(dataloader, model, loss_fn, optimizer):model.train()
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 model.eval()。
# 一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval() 。batch_size_num = 1for X, y in dataloader: #其中batch为每一个数据的编号X, y = X.to(device), y.to(device) #把训练数据集和标签传入cpu或GPUpred = model.forward(X) #自动初始化 w权值loss = loss_fn(pred, y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值optimizer.step() #根据梯度更新网络参数loss = loss.item() #获取损失值print(f"loss: {loss:>7f} [number:{batch_size_num}]")batch_size_num += 1
#测试数据
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval() #梯度管理test_loss, correct = 0, 0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存消耗。for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item() #correct += (pred.argmax(1) == y).type(torch.float).sum().item()a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号b = (pred.argmax(1) == y).type(torch.float)test_loss /= num_batches#计算正确率correct /= size#计算损失print(f"Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}")
# 多分类使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)#创建一个优化器,SGD为随机梯度下降算法??
#params:要训练的参数,一般我们传入的都是model.parameters()。
#lr:learning_rate学习率,也就是步长。
调用函数训练:
#训练模型
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
多次训练:
epochs = 5 #
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)# test(test_dataloader, model, loss_fn)
print("Done!")
test(test_dataloader, model, loss_fn)
第一次运行:
成功率只有可怜的16,loss高达2.2

六、优化模型
使用Adam(自适应矩估计):
修改代码118行:
# 多分类使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#创建一个优化器
防止梯度爆炸和梯度消失使用relu函数替换:
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # 将图像展平self.hidden1 = nn.Linear(28*28, 128) # 第一个隐藏层,输入维度为28*28,输出维度为128self.hidden2 = nn.Linear(128, 256) # 第二个隐藏层,输入维度为128,输出维度为256self.out = nn.Linear(256, 10) # 输出层,输入维度为256,输出维度为10(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 将输入图像展平x = self.hidden1(x) # 第一个隐藏层的线性变换x = torch.relu(x) # 使用Sigmoid激活函数/修改为relux = self.hidden2(x) # 第二个隐藏层的线性变换x = torch.relu(x) # 使用Sigmoid激活函数/修改为relux = self.out(x) # 输出层的线性变换(未经激活函数)return x # 返回模型的输出#传入GPU
model = NeuralNetwork().to(device)#传入对应设备,根据上面识别的设备进行传入
print(model)增加训练次数:
epochs = 15 #
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)# test(test_dataloader, model, loss_fn)
print("Done!")
test(test_dataloader, model, loss_fn)
第二次优化后运行:
成功率大大提高:
Accuracy: 97.67%, Avg loss: 0.12269500801303047

七、完整代码
#MNIST--手写字识别import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor#创建一个MNIST数据集的实例,其中包括训练图像和标签
training_data = datasets.MNIST(root="data", #下载的跟目录train=True, #加载训练数据集download=True,#如果数据集不存在,将自动下载transform=ToTensor(), #将图像数据转换为Tensor格式的数据(张量)
)
print(len(training_data))#创建一个MNIST数据集的实例,其中包括训练图像和标签
test_data = datasets.MNIST(root="data", #下载的跟目录train=False, #加载测试数据集download=True,#如果数据集不存在,将自动下载transform=ToTensor(), #将图像数据转换为Tensor格式的数据(张量),pytorch使用tensor数据流所以这里要转换
)
print(len(test_data))#展示训练数据集图片和标签
from matplotlib import pyplot as plt #导入matplotlib库中的pyplot模块,用于绘制图像
figure = plt.figure() #创建一个新的图像画布
for i in range(12):#遍历前12张图片img, label = training_data[i]figure.add_subplot(3, 4, i+1)plt.title(label)plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")#使用imshow函数显示图像,其中img.squeeze()将图像的通道维度去除,cmap="gray"表示使用灰度颜色映射
plt.show()#DataLoader数据加载器
train_dataloader = DataLoader(training_data, batch_size=64)#创建一个训练数据加载器,将training_data(训练数据集)分成64张图像一组的批次
test_dataloader = DataLoader(test_data, batch_size=64)#创建一个测试数据加载器,将test_data(测试数据集)分成64张图像一组的批次。
for X, y in test_dataloader:#X是表示打包好的每一个数据包#打印当前批次图像数据X的形状,其中N表示批次大小,C表示通道数,H和W表示图像的高度和宽度print(f"Shape of X [N, C, H, W]: {X.shape}")#打印当前批次标签数据y的形状和数据类型print(f"Shape of y: {y.shape} {y.dtype}")break'''
此代码段的作用是检查当前系统是否支持CUDA(GPU计算),
如果支持,则使用CUDA设备;如果不支持CUDA,它还会检查是否支持多进程模式(MPS),
如果支持,则使用MPS设备;最后,如果都不支持,则使用CPU设备。然后,它会打印出所选择的设备类型。'''device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # 将图像展平self.hidden1 = nn.Linear(28*28, 128) # 第一个隐藏层,输入维度为28*28,输出维度为128self.hidden2 = nn.Linear(128, 256) # 第二个隐藏层,输入维度为128,输出维度为256self.out = nn.Linear(256, 10) # 输出层,输入维度为256,输出维度为10(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 将输入图像展平x = self.hidden1(x) # 第一个隐藏层的线性变换x = torch.relu(x) # 使用Sigmoid激活函数/修改为relux = self.hidden2(x) # 第二个隐藏层的线性变换x = torch.relu(x) # 使用Sigmoid激活函数/修改为relux = self.out(x) # 输出层的线性变换(未经激活函数)return x # 返回模型的输出#传入GPU
model = NeuralNetwork().to(device)#传入对应设备,根据上面识别的设备进行传入
print(model)#训练数据
def train(dataloader, model, loss_fn, optimizer):model.train()
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 model.eval()。
# 一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval() 。batch_size_num = 1for X, y in dataloader: #其中batch为每一个数据的编号X, y = X.to(device), y.to(device) #把训练数据集和标签传入cpu或GPUpred = model.forward(X) #自动初始化 w权值loss = loss_fn(pred, y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值optimizer.step() #根据梯度更新网络参数loss = loss.item() #获取损失值print(f"loss: {loss:>7f} [number:{batch_size_num}]")batch_size_num += 1
#测试数据
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval() #梯度管理test_loss, correct = 0, 0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存消耗。for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item() #correct += (pred.argmax(1) == y).type(torch.float).sum().item()a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号b = (pred.argmax(1) == y).type(torch.float)test_loss /= num_batches#计算正确率correct /= size#计算损失print(f"Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}")# 多分类使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#创建一个优化器
#params:要训练的参数,一般我们传入的都是model.parameters()。
#lr:learning_rate学习率,也就是步长。#训练模型
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)epochs = 15 #
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)# test(test_dataloader, model, loss_fn)
print("Done!")
test(test_dataloader, model, loss_fn)
八、手写板实现输入识别功能
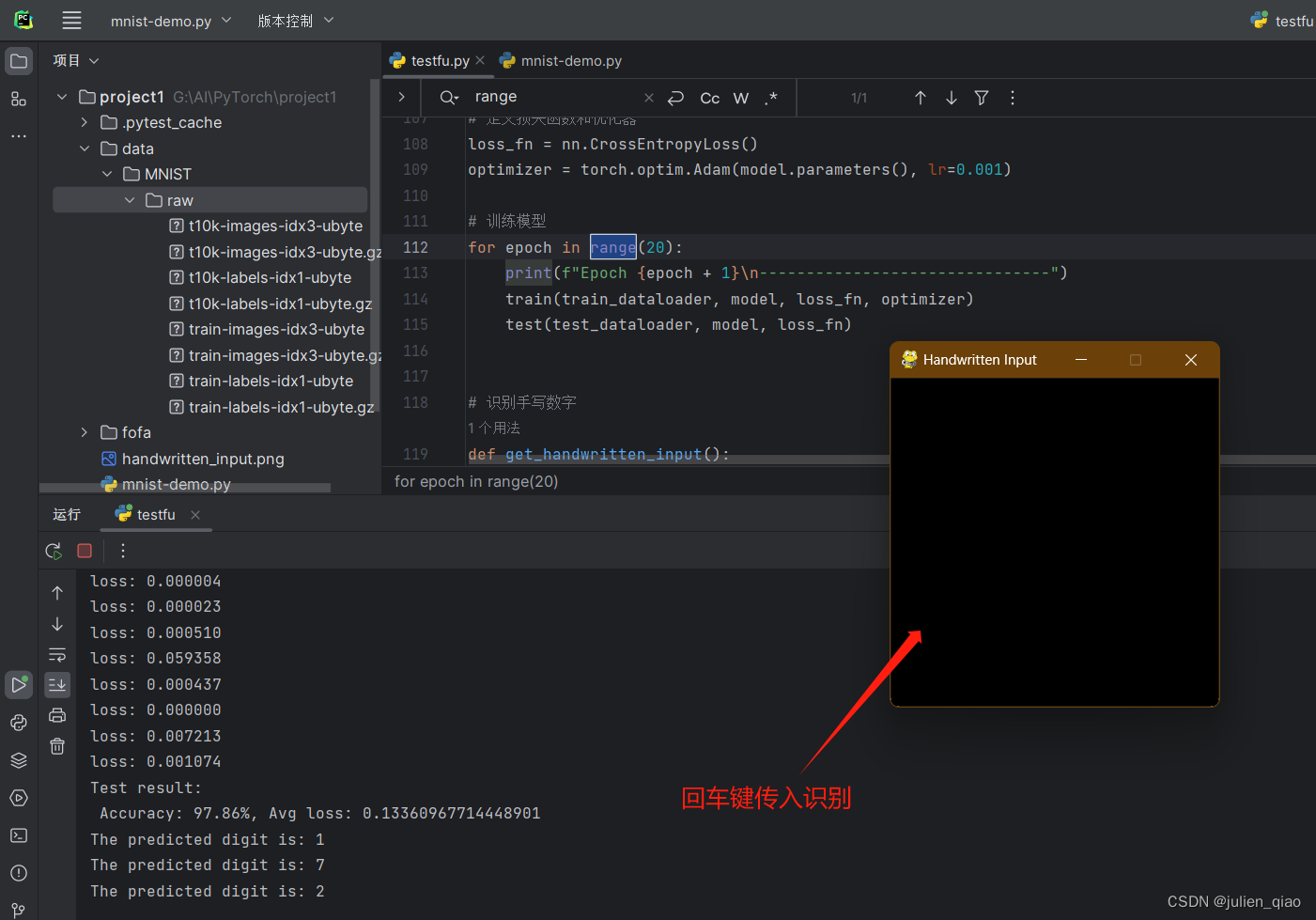
在原来的基础上实现,手写数字然后识别,训练完成后使用pygame做一个手写版实现手写,保存图片,然后将图片的大小修改为模型可以识别的大小,然后传入模型识别:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
from PIL import Image
import torchvision.transforms as transforms
import pygame
import sys ;sys.setrecursionlimit(sys.getrecursionlimit() * 5)
from pygame.locals import *# 创建一个MNIST数据集的实例
training_data = datasets.MNIST(root="data",train=True,download=True,transform=ToTensor(),
)test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor(),
)# 创建一个神经网络模型
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.hidden1 = nn.Linear(28 * 28, 128)self.hidden2 = nn.Linear(128, 256)self.out = nn.Linear(256, 10)def forward(self, x):x = self.flatten(x)x = self.hidden1(x)x = torch.relu(x)x = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x# 训练模型和测试模型的函数
def train(dataloader, model, loss_fn, optimizer):model.train()for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()loss = loss.item()print(f"loss: {loss:>7f}")def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test result: \n Accuracy: {(100 * correct)}%, Avg loss: {test_loss}")# 定义一个函数来识别手写数字
def recognize_handwritten_digit(image_path, model):image = Image.open(image_path).convert('L')preprocess = transforms.Compose([transforms.Resize((28, 28)),transforms.ToTensor(),])input_tensor = preprocess(image)input_batch = input_tensor.unsqueeze(0)input_batch = input_batch.to(device)with torch.no_grad():output = model(input_batch)_, predicted_class = torch.max(output, 1)return predicted_class.item()# 检查是否支持CUDA,然后选择设备
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")# 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 创建模型并传入设备
model = NeuralNetwork().to(device)# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(20):#训练次数print(f"Epoch {epoch + 1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)# 识别手写数字
def get_handwritten_input():pygame.init()# 设置窗口window = pygame.display.set_mode((280, 280))pygame.display.set_caption('Handwritten Input')window.fill((0, 0, 0)) # 设置背景为黑色drawing = Falselast_pos = Nonewhile True:for event in pygame.event.get():if event.type == QUIT:pygame.quit()sys.exit()elif event.type == MOUSEBUTTONDOWN:drawing = Trueelif event.type == MOUSEMOTION:if drawing:mouse_x, mouse_y = pygame.mouse.get_pos()if last_pos:pygame.draw.line(window, (255, 255, 255), last_pos, (mouse_x, mouse_y), 15) # 设置绘画颜色为白色last_pos = (mouse_x, mouse_y)elif event.type == MOUSEBUTTONUP:drawing = Falselast_pos = Nonepygame.display.update()if event.type == KEYDOWN and event.key == K_RETURN:pygame.image.save(window, 'handwritten_input.png')return 'handwritten_input.png'def main():while True: # 死循环保证程序一直运行,直到关闭image_path = get_handwritten_input()predicted_digit = recognize_handwritten_digit(image_path, model)print(f"The predicted digit is: {predicted_digit}")if __name__ == "__main__":main()
相关文章:
【机器学习】PyTorch-MNIST-手写字识别
文章目录 前言完成效果一、下载数据集手动下载代码下载MNIST数据集: 二、 展示图片三、DataLoader数据加载器四、搭建神经网络五、 训练和测试第一次运行: 六、优化模型第二次优化后运行: 七、完整代码八、手写板实现输入识别功能 前言 注意…...

玩转代码| Vue 中 JSX 的特性,这一篇讲的明明白白
目录 什么时候使用JSX JSX在Vue2中的基本使用 配置 文本插值 条件与循环渲染 属性绑定 事件绑定 v-show与v-model 插槽 使用自定义组件 在method里返回JSX JSX是一种Javascript的语法扩展,即具备了Javascript的全部功能,同时又兼具html的语义…...

(vue)el-descriptions 描述列表无效
(vue)el-descriptions 描述列表无效 原因:element 的版本不够 解决:运行下面两个命令 npm uninstall element-ui //卸载之前安装的版本 npm i element-ui -S //重新安装解决参考:https://blog.csdn.net/weixin_59769148/article/details/1…...

ios 苹果手机日期格式问题
目录 问题解决其他 问题 ios 无法识别的时间戳格式:2023-10-17 11:10:49 可识别的: 2023/10/17 11:10:49 解决 const startTime 2023/10/17 11:10:49 startTime.replace(/-/g, /)// 获取时间差值 export const useDateDiff (startTime , endTime …...
学习嵌入式系统的推荐步骤:
学习嵌入式系统的推荐步骤: 00001. 选择一款Linux发行版作为主要操作系统,如RedHat、Ubuntu、Fedora等。进入Linux后,使用终端进行任务操作。建议不要使用虚拟机,如有需要可考虑双系统安装。 00002. 00003. 学习C语言、数…...

勒索病毒LockBit2.0 数据库(mysql与sqlsever)解锁恢复思路分享
0.前言 今天公司服务器中招LockBit2.0勒索病毒,损失惨重,全体加班了一天基本解决了部分问题,首先是丢失的文件数据就没法恢复了,这一块没有理睬,主要恢复的是两个数据库,一个是16GB大小的SQLserver数据库&…...

超简单小白攻略:如何利用黑群晖虚拟机和内网穿透实现公网访问
文章目录 前言本教程解决的问题是:按照本教程方法操作后,达到的效果是前排提醒: 1. 搭建群晖虚拟机1.1 下载黑群晖文件vmvare虚拟机安装包1.2 安装VMware虚拟机:1.3 解压黑群晖虚拟机文件1.4 虚拟机初始化1.5 没有搜索到黑群晖的解…...
Ubuntu 16.04 LTS third maintenance update release
Ubuntu 16.04 LTS (Xenial Xerus)今天迎来的第三个维护版本更新中,已经基于Linux Kernel 4.10内核,而且Mesa图形栈已经升级至17.0版本。Adam Conrad表示:“像此前LTS系列相似,16.04.3对那些使用更新硬件的用户带来了硬件优化。该版…...
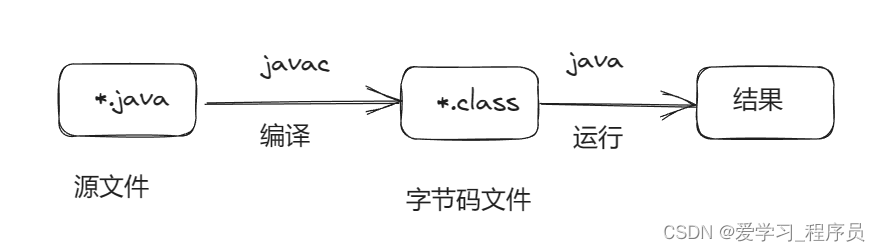
Java学习_day01_hello java
构成 JDK JDK是java开发者工具,由JRE和一些开发工具组成。JRE JRE是java运行环境,由JVM和java核心类库组成。JVM JVM是java虚拟机,主要用来运行字节码。 执行过程 由IDE或文本编辑器,编写源代码,并将文件保存为*.ja…...
UnitTesting 单元测试
1. 测试分为两种及详细介绍测试书籍: 1.1 Unit Test : 单元测试 - test the business logic in your app : 测试应用中的业务逻辑 1.2 UI Test : 界面测试 - test the UI of your app : 测试应用中的界面 1.3 测试书籍网址:《Testing Swift》 https://www.hackingwithswift.c…...

C++内存管理:其五、指针类型转换与嵌入式指针
一、内存池的缺陷 作者在上一版本里面介绍了链表实现内存池,其中有一个小缺陷:虽然较少了cookie的内存损耗,但是加入了一个额外的指针,仍然需要占用内存。我们仔细看内存池的设计思想,可以发现一个关键点:…...
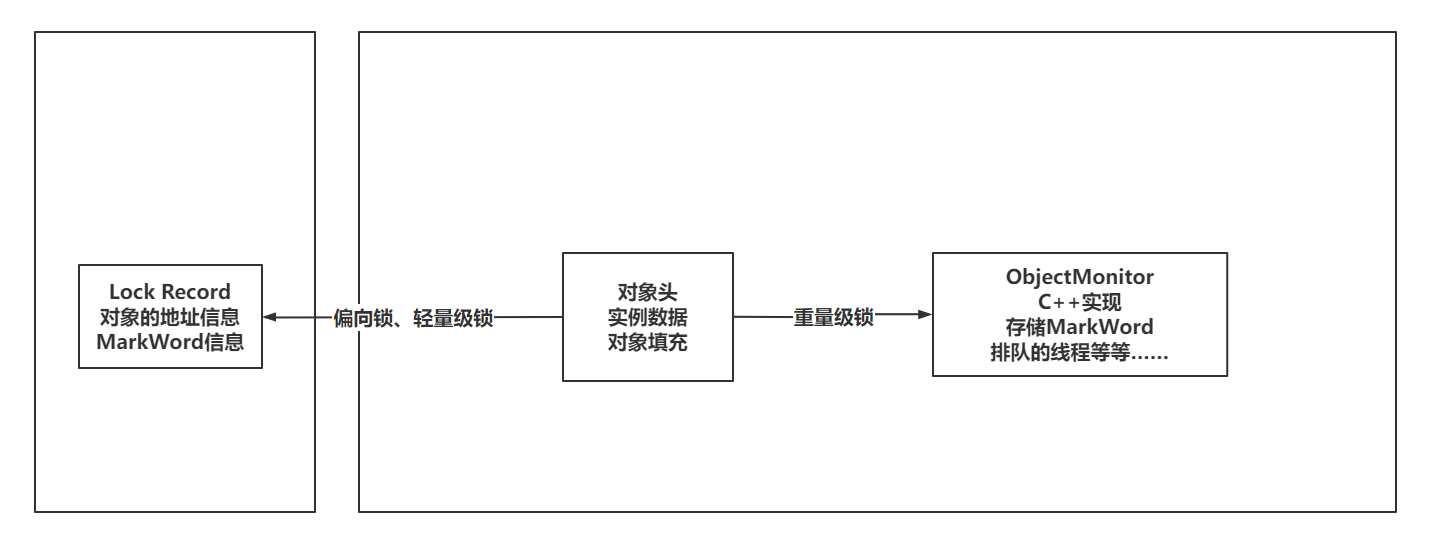
常见锁的分类
入职体验: 今天运维岗位刚入职,但是目前还没有办理入职手续,但是领导发了一堆资料!看了一下,非常多的新东西,只能说努力一把!!! 一、锁的分类 1.1 可重入锁、不可重入锁…...

vue 鼠标划入划出多传一个参数
// item可以传递弹窗显示数据, $event相关参数可以用来做弹窗定位用 mouseover"handleMouseOver($event, item)" mouseleave"handleMouseLeave($event, item)"举个栗子: 做一个hover提示弹窗组件(用的vue3框架 less插件) 可以将组件…...

svn项目同步到gitLab
安装git 确保安装了git 新建一个文件夹svn-git 在文件夹中新建userinfo.txt文件,映射svn用户,这个文件主要是用于将SVN用户映射为Git用户(昵称及其邮箱)。 userinfo.txt具体格式如下: admin admin <admin163.com> lis…...
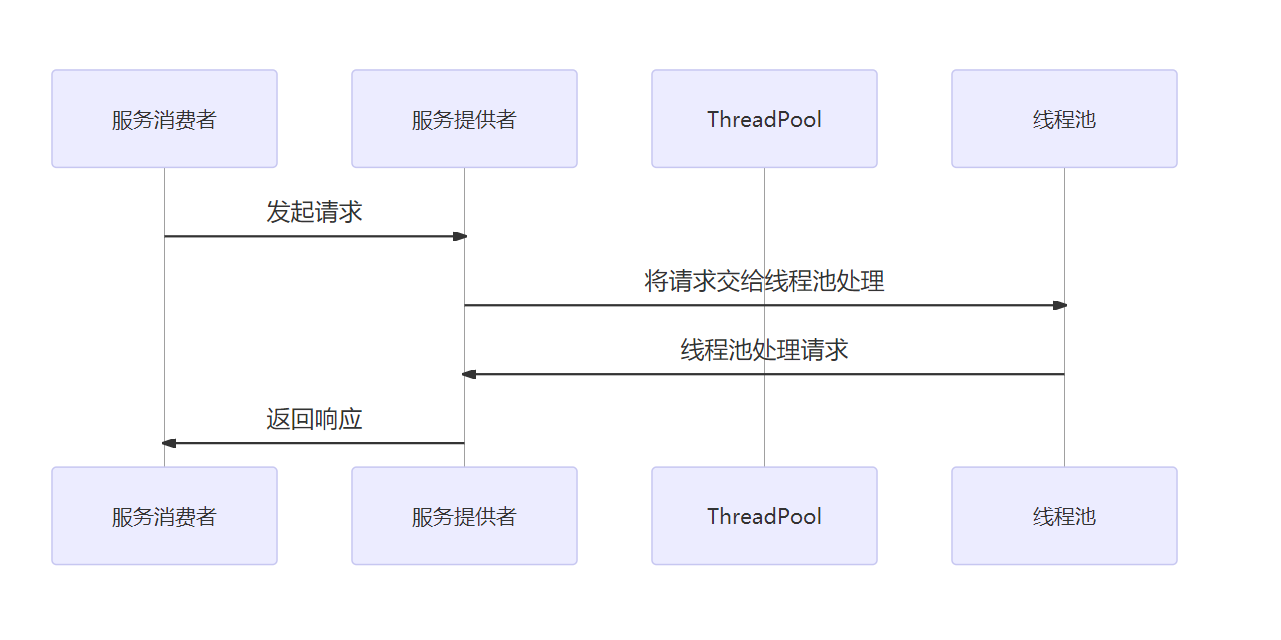
图解Dubbo,Dubbo 服务治理详解
目录 一、介绍1、介绍 Dubbo 服务治理的基本概念和重要性2、阐述 Dubbo 服务治理的实现方式和应用场景 二、Dubbo 服务治理的原理1、Dubbo 服务治理的架构设计2、Dubbo 服务治理的注册与发现机制3、Dubbo 服务治理的负载均衡算法 三、Dubbo 服务治理的实现方式1、基于 Docker 容…...

Css 如何取消a链接点击时的背景颜色
要取消 <a> 链接点击时的背景颜色,可以使用 CSS 的伪类 :active。你可以通过为 a:active 应用 background-color 属性设置为 transparent 或者 none,来取消点击时的背景色。下面是一个示例: a:active {background-color: transparent;…...

1.16.C++项目:仿muduo库实现并发服务器之HttpContext以及HttpServer模块的设计
文章目录 一、HttpContext模块二、HttpServer模块三、HttpContext模块实现思想(一)功能(二)意义(三)接口 四、HttpServer模块实现思想(一)功能(二)意义&#…...

ABAP 新增PO计划行时 新增行交货日期默认当前最大交期
ABAP 新增PO计划行时 新增行交货日期默认当前最大交期 DATA: ls_poitem TYPE mepoitem. DATA: ls_jhh TYPE meposchedule. DATA: ls_poitemc TYPE REF TO if_purchase_order_item_mm. DATA: is_persistent TYPE mmpur_bool. DATA: lt_eket TYPE TABLE OF eket. DATA: ls_e…...

VSCode怎么创建Java项目
首先安装好Java的开发环境:JDK在VSCode中安装适用于Java开发的插件。打开VSCode,点击左侧的扩展图标,搜索并安装Java Extension Pack插件。等待安装完成后,重启VSCode生效。创建一个新的Java项目,按下Ctrl Shift P&a…...

软件工程与计算(十四)详细设计中面向对象方法下的模块化
一.面向对象中的模块 1.类 模块化是消除软件复杂度的一个重要方法,每个代码片段相互独立,这样能够提高可维护性。在面向对象方法中,代码片段最重要的类,整个类的所有代码联合起来构成独立的代码片段。 模块化希望代码片段由两部…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...