10000字!图解机器学习特征工程
文章目录
- 引言
- 特征工程
- 1.特征类型
- 1.1 结构化 vs 非结构化数据
- 1.2 定量 vs 定性数据
- 2.数据清洗
- 2.1 数据对齐
- 2.2 缺失值处理
原文链接:https://www.showmeai.tech/article-detail/208
作者:showmeAI
引言
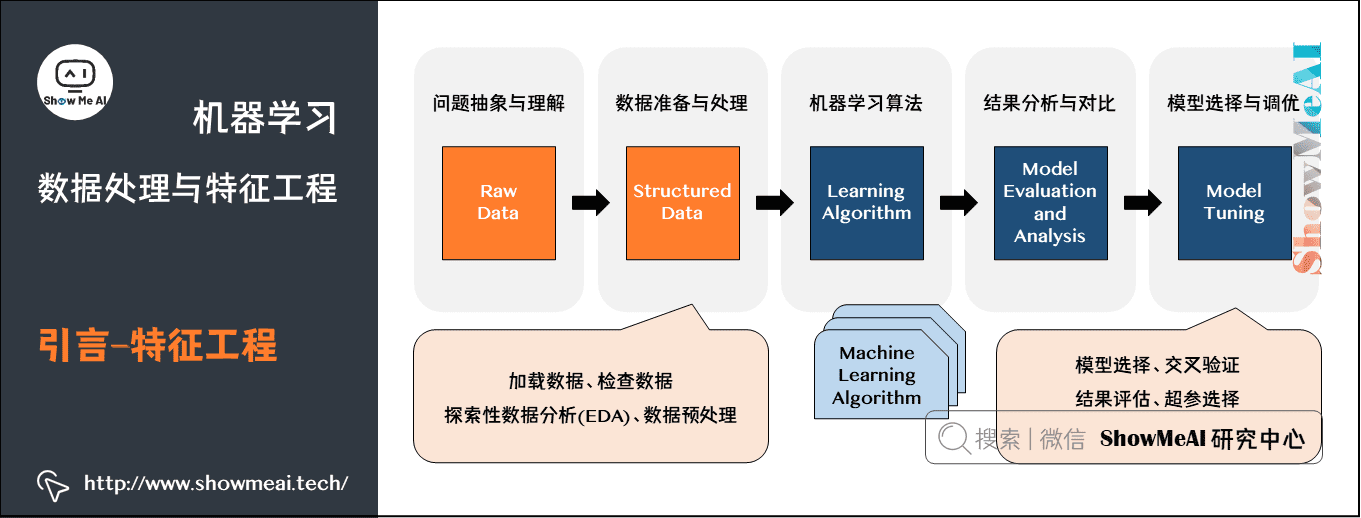
上图为大家熟悉的机器学习建模流程图,ShowMeAI在前序机器学习实战文章 Python机器学习算法应用实践中和大家讲到了整个建模流程非常重要的一步,是对于数据的预处理和特征工程,它很大程度决定了最后建模效果的好坏,在本篇内容汇总,我们给大家展开对数据预处理和特征工程的实战应用细节做一个全面的解读。
特征工程
首先我们来了解一下「特征工程」,事实上大家在ShowMeAI的实战系列文章 Python机器学习综合项目-电商销量预估 和 Python机器学习综合项目-电商销量预估<进阶> 中已经看到了我们做了特征工程的处理。
如果我们对特征工程(feature engineering)做一个定义,那它指的是:利用领域知识和现有数据,创造出新的特征,用于机器学习算法;可以手动(manual)或自动(automated)。
- 特征:数据中抽取出来的对结果预测有用的信息。
- 特征工程:使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
在业界有一个很流行的说法:
数据与特征工程决定了模型的上限,改进算法只不过是逼近这个上限而已。

这是因为,在数据建模上,「理想状态」和「真实场景」是有差别的,很多时候原始数据并不是规矩干净含义明确充分的形态:
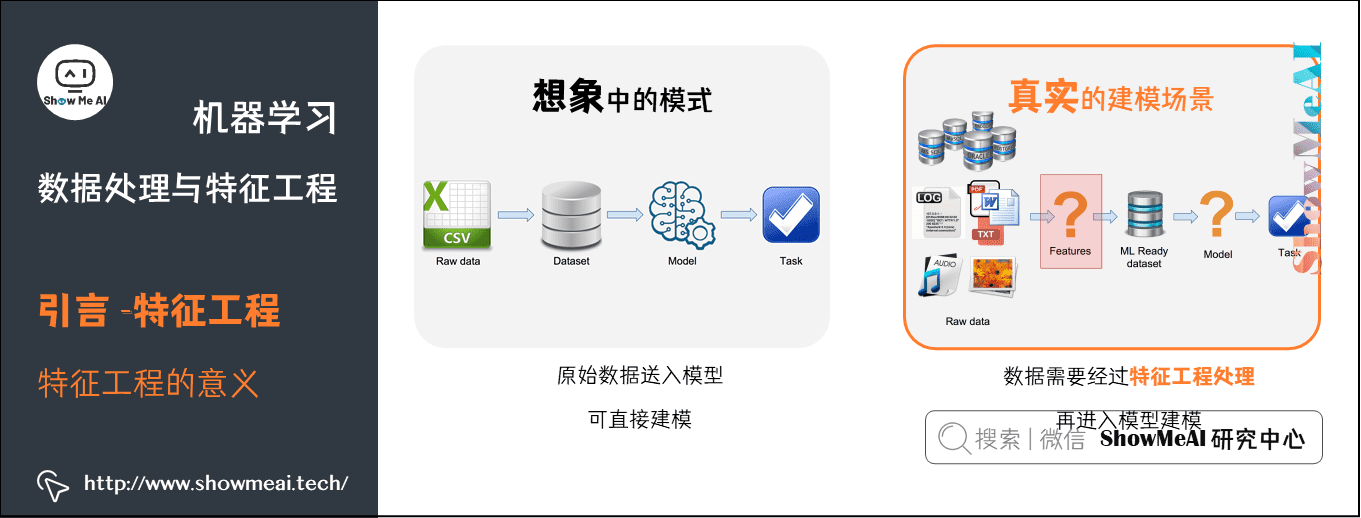
而特征工程处理,相当于对数据做一个梳理,结合业务提取有意义的信息,以干净整齐地形态进行组织:

特征工程有着非常重要的意义:
- 特征越好,灵活性越强。只要特征选得好,即使是一般的模型(或算法)也能获得很好的性能,好特征的灵活性在于它允许你选择不复杂的模型,同时运行速度也更快,也更容易理解和维护。
- 特征越好,构建的模型越简单。有了好的特征,即便你的参数不是最优的,你的模型性能也能仍然会表现的很好,所以你就不需要花太多的时间去寻找最优参数,这大大的降低了模型的复杂度,使模型趋于简单。
- 特征越好,模型的性能越出色。显然,这一点是毫无争议的,我们进行特征工程的最终目的就是提升模型的性能。
本篇内容,ShowMeAI带大家一起来系统学习一下特征工程,包括「特征类型」「数据清洗」「特征构建」「特征变换」「特征选择」等板块内容。
我们这里用最简单和常用的Titanic数据集给大家讲解。
Titanic数据集是非常适合数据科学和机器学习新手入门练习的数据集,数据集为1912年泰坦尼克号沉船事件中一些船员的个人信息以及存活状况。我们可以根据数据集训练出合适的模型并预测新数据(测试集)中的存活状况。
Titanic数据集可以通过 seaborn 工具库直接加载,如下代码所示:
import pandas as pd
import numpy as np
import seaborn as snsdf_titanic = sns.load_dataset('titanic')
其中数据集的数据字段描述如下图所示:

1.特征类型
在具体演示Titanic的数据预处理与特征工程之前,ShowMeAI再给大家构建一些关于数据的基础知识。
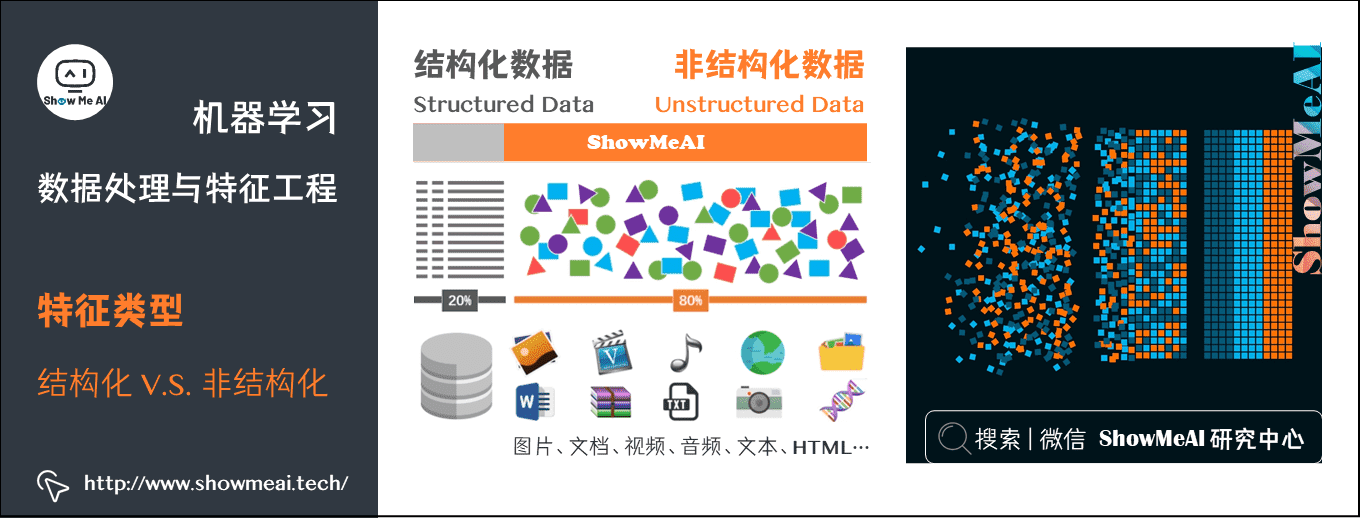
1.1 结构化 vs 非结构化数据
数据可以分为「结构化数据」和「非结构化数据」,比如在互联网领域,大部分存储在数据库内的表格态业务数据,都是结构化数据;而文本、语音、图像视频等就属于非结构化数据。
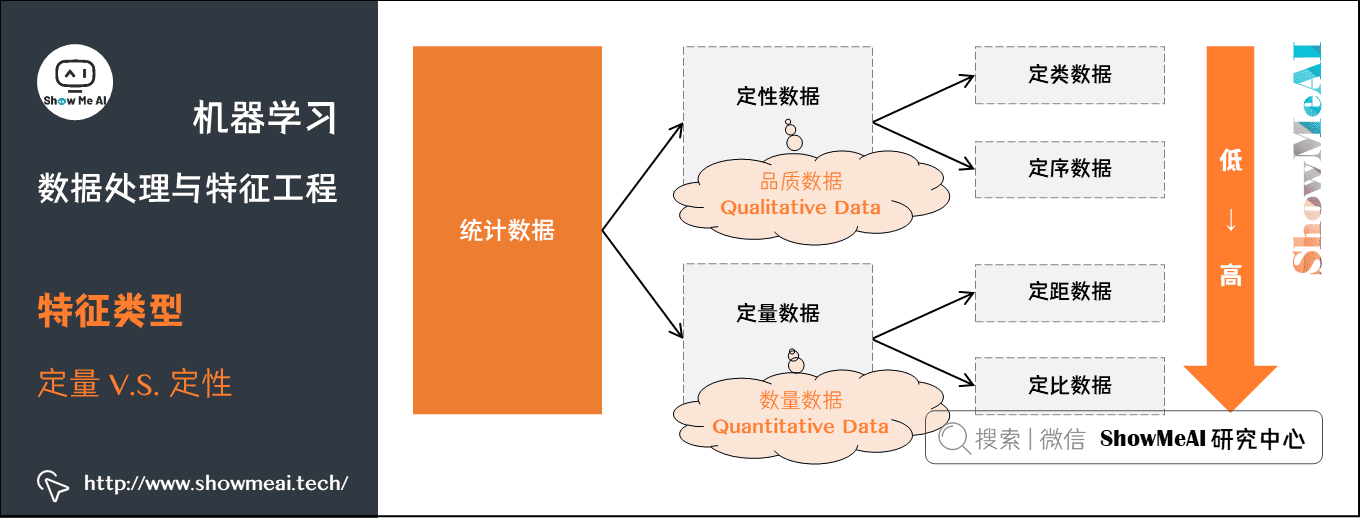
1.2 定量 vs 定性数据
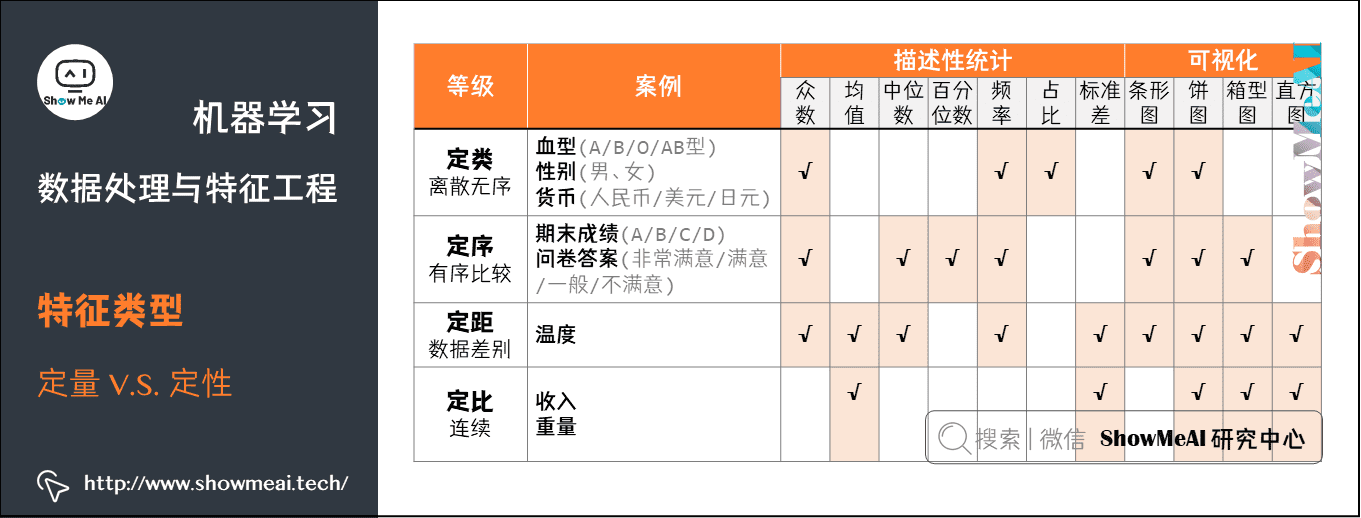
对于我们记录到的数据,我们通常又可以以「定量数据」和「定性数据」对齐进行区分,其中:
- 定量数据:指的是一些数值,用于衡量数量与大小。
例如高度,长度,体积,面积,湿度,温度等测量值。 - 定性数据:指的是一些类别,用于描述物品性质。
例如纹理,味道,气味,颜色等。
如下图是两类数据示例以及它们常见的处理分析方法的总结:
2.数据清洗
实际数据挖掘或者建模之前,我们会有「数据预处理」环节,对原始态的数据进行数据清洗等操作处理。因为现实世界中数据大体上都是不完整、不一致的「脏数据」,无法直接进行数据挖掘,或者挖掘结果差强人意。
「脏数据」产生的主要成因包括:
- 篡改数据
- 数据不完整
- 数据不一致
- 数据重复
- 异常数据
数据清洗过程包括数据对齐、缺失值处理、异常值处理、数据转化等数据处理方法,如下图所示:

下面我们注意对上述提到的处理方法做一个讲解。
2.1 数据对齐
采集到的原始数据,格式形态不一,我们会对时间、字段以及相关量纲等进行数据对齐处理,数据对齐和规整化之后的数据整齐一致,更加适合建模。如下图为一些处理示例:

(1) 时间
- 日期格式不一致【2022-02-20、20220220、2022/02/20、20/02/2022】。
- 时间戳单位不一致,有的用秒表示,有的用毫秒表示。
- 使用无效时间表示,时间戳使用0表示,结束时间戳使用FFFF表示。
(2) 字段 - 姓名写了性别,身份证号写了手机号等。
(3) 量纲 - 数值类型统一【如1、2.0、3.21E3、四】。
- 单位统一【如180cm、1.80m】。
2.2 缺失值处理
数据缺失是真实数据中常见的问题,因为种种原因我们采集到的数据并不一定是完整的,我们有一些缺失值的常见处理方式:
- 不处理(部分模型如XGBoost/LightGBM等可以处理缺失值)。
- 删除缺失数据(按照样本维度或者字段维度)。
- 采用均值、中位数、众数、同类均值或预估值填充。
具体的处理方式可以展开成下图:

下面回到我们的Titanic数据集,我们演示一下各种方法:
我们先对数据集的缺失值情况做一个了解(汇总分布):
df_titanic.isnull().sum()
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
(1) 删除
最直接粗暴的处理是剔除缺失值,即将存在遗漏信息属性值的对象 (字段,样本/记录) 删除,从而得到一个完备的信息表。优缺点如下:
- 优点:简单易行,在对象有多个属性缺失值、被删除的含缺失值的对象与初始数据集的数据量相比非常小的情况下有效;
- 不足:当缺失数据所占比例较大,特别当遗漏数据非随机分布时,这种方法可能导致数据发生偏离,从而引出错误的结论。
在我们当前Titanic的案例中,embark_town字段有 2 个空值,考虑删除缺失处理下。
df_titanic[df_titanic["embark_town"].isnull()]
df_titanic.dropna(axis=0,how='any',subset=['embark_town'],inplace=True)

(2) 数据填充
第2大类是我们可以通过一些方法去填充缺失值。比如基于统计方法、模型方法、结合业务的方法等进行填充。

① 手动填充
根据业务知识来进行人工手动填充。
② 特殊值填充
将空值作为一种特殊的属性值来处理,它不同于其他的任何属性值。如所有的空值都用unknown填充。一般作为临时填充或中间过程。
代码实现
df_titanic['embark_town'].fillna('unknown', inplace=True)
③ 统计量填充
若缺失率较低,可以根据数据分布的情况进行填充。常用填充统计量如下:
- 中位数:对于数据存在倾斜分布的情况,采用中位数填补缺失值。
- 众数:离散特征可使用众数进行填充缺失值。
- 平均值:对于数据符合均匀分布,用该变量的均值填补缺失值。
中位数填充——fare:缺失值较多,使用中位数填充
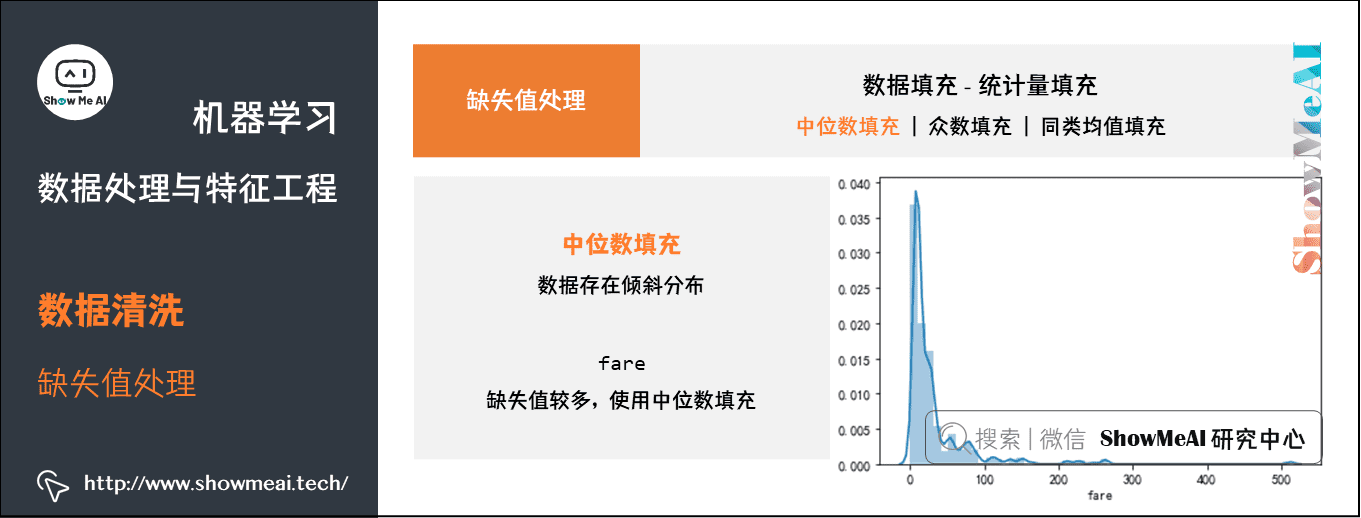
df_titanic['fare'].fillna(df_titanic['fare'].median(), inplace=True)
众数填充——embarked:只有两个缺失值,使用众数填充
df_titanic['embarked'].isnull().sum()
#执行结果:2
df_titanic['embarked'].fillna(df_titanic['embarked'].mode(), inplace=True)
df_titanic['embarked'].value_counts()
#执行结果:
#S 64
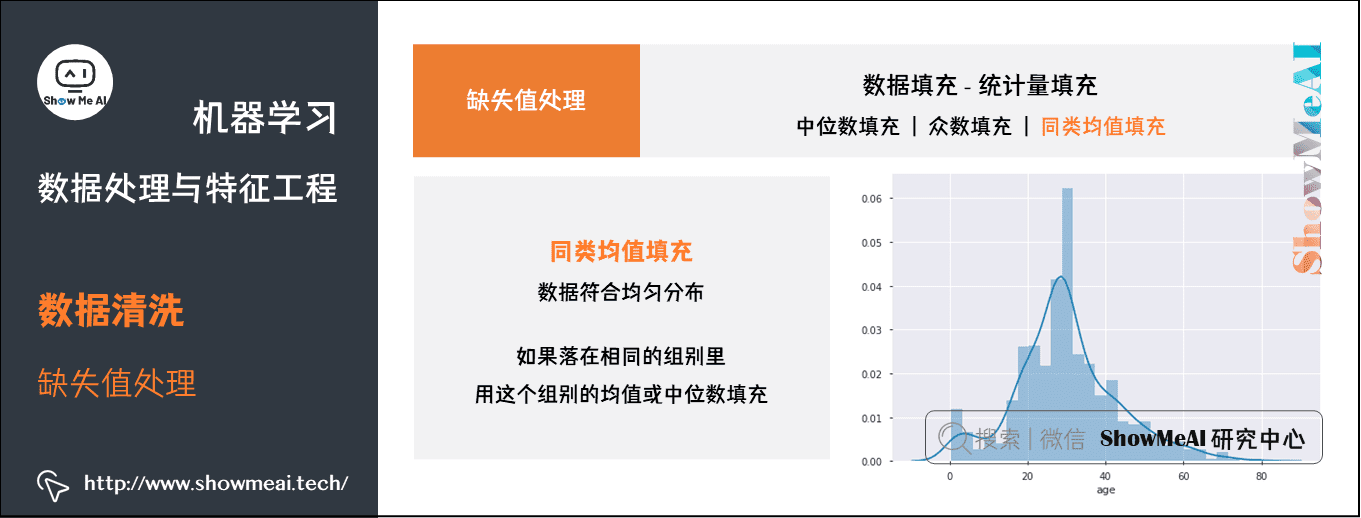
同类均值填充
age:根据 sex、pclass 和 who 分组,如果落在相同的组别里,就用这个组别的均值或中位数填充。
df_titanic.groupby(['sex', 'pclass', 'who'])['age'].mean()
age_group_mean = df_titanic.groupby(['sex', 'pclass', 'who'])['age'].mean().reset_index()
def select_group_age_median(row):condition = ((row['sex'] == age_group_mean['sex']) &(row['pclass'] == age_group_mean['pclass']) &(row['who'] == age_group_mean['who']))return age_group_mean[condition]['age'].values[0]
df_titanic['age'] =df_titanic.apply(lambda x: select_group_age_median(x) if np.isnan(x['age']) else x['age'],axis=1)
④ 模型预测填充
如果其他无缺失字段丰富,我们也可以借助于模型进行建模预测填充,将待填充字段作为Label,没有缺失的数据作为训练数据,建立分类/回归模型,对待填充的缺失字段进行预测并进行填充。
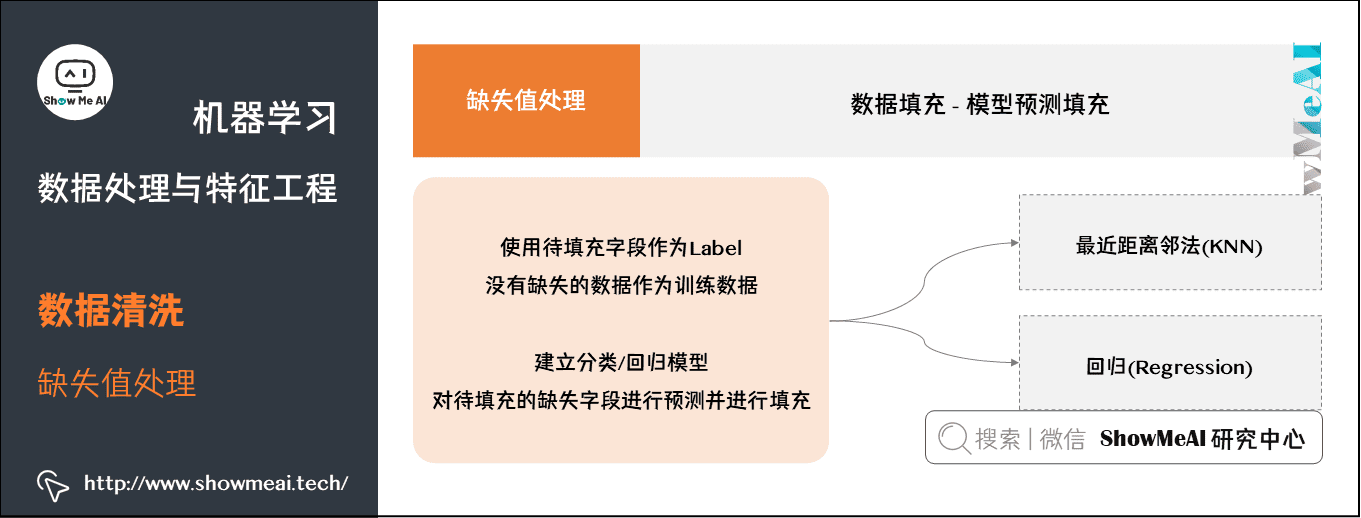
最近距离邻法(KNN)
- 先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的 公式 个样本,将这 公式 个值加权平均/投票来估计该样本的缺失数据。
回归(Regression)
- 基于完整的数据集,建立回归方程。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关时会导致有偏差的估计,常用线性回归。
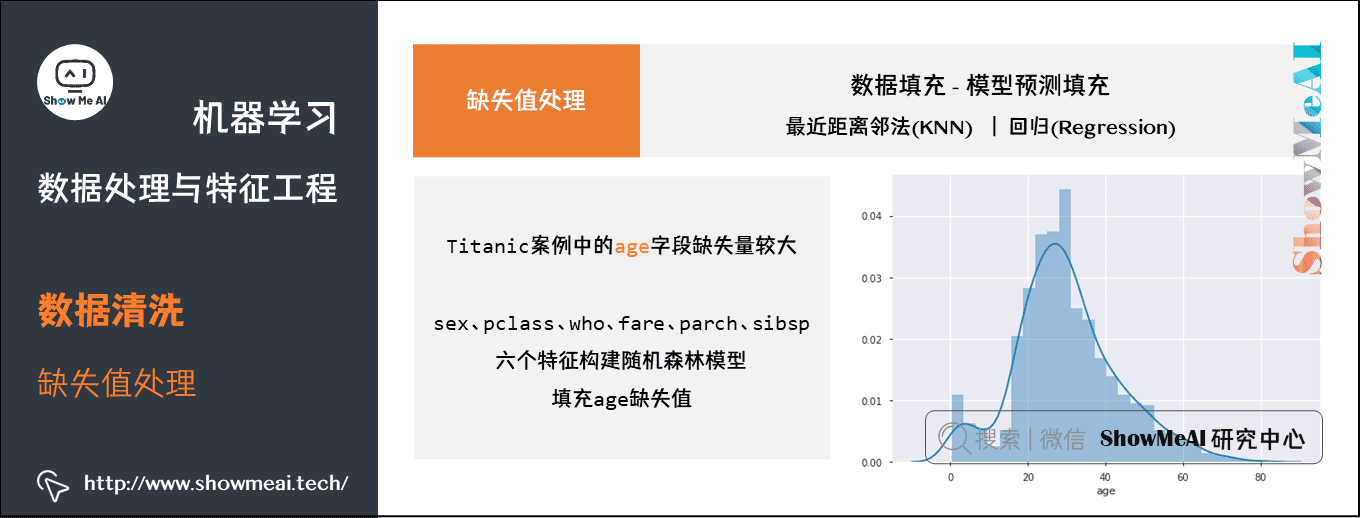
我们以 Titanic 案例中的 age 字段为例,讲解一下:
- age 缺失量较大,这里我们用 sex、pclass、who、fare、parch、sibsp 六个特征构建随机森林模型,填充年龄缺失值。
df_titanic_age = df_titanic[['age', 'pclass', 'sex', 'who','fare', 'parch', 'sibsp']] df_titanic_age = pd.get_dummies(df_titanic_age) df_titanic_age.head()# 乘客分成已知年龄和未知年龄两部分 known_age = df_titanic_age[df_titanic_age.age.notnull()] unknown_age = df_titanic_age[df_titanic_age.age.isnull()] # y 即目标年龄 y_for_age = known_age['age'] # X 即特征属性值 X_train_for_age = known_age.drop(['age'], axis=1) X_test_for_age = unknown_age.drop(['age'], axis=1) from sklearn.ensemble import RandomForestRegressor rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1) rfr.fit(X_train_for_age, y_for_age) # 用得到的模型进行未知年龄结果预测 y_pred_age = rfr.predict(X_test_for_age) # 用得到的预测结果填补原缺失数据 df_titanic.loc[df_titanic.age.isnull(), 'age'] = y_pred_agesns.distplot(df_titanic.age)
相关文章:
10000字!图解机器学习特征工程
文章目录 引言特征工程1.特征类型1.1 结构化 vs 非结构化数据1.2 定量 vs 定性数据 2.数据清洗2.1 数据对齐2.2 缺失值处理 原文链接:https://www.showmeai.tech/article-detail/208 作者:showmeAI 引言 上图为大家熟悉的机器学习建模流程图,…...

Java 官方提供了哪几种线程池,分别有什么特点?
JDK 中提供了 5 中不同线程池的创建方式: newCachedThreadPool newCachedThreadPool, 是一种可以缓存的线程池,它可以用来处理大量短期的突发流量。 它的特点有三个,最大线程数是 Integer.MaxValue,线程存活时间是 60 …...

DTI-ALPS处理笔记
DTI-ALPS处理笔记 前言: 前段时间刚好学习了一下DTI-ALPS处理(diffusion tensor image analysis along the perivascular space ),记录一下,以便后续学习。ALPS是2017年发表在《Japanese Journal of Radiology》的一篇文章首次提出的 (文章地址),主要用于无创评估脑内淋…...
LVS集群-NAT模式
集群的概念: 集群:nginx四层和七层动静分离 集群标准意义上的概念:为解决特定问题将多个计算机组合起来形成一个单系统 集群的目的就是为了解决系统的性能瓶颈。 垂直扩展:向上扩展,增加单个机器的性能,…...
微服务技术导学
文章目录 微服务结构认识微服务技术栈 微服务结构 技术: 解决异常定位: 持续集成,解决自动化的部署: 总结如下: 认识微服务 微服务演变: 技术栈 SpringCloud与SpringBoot版本对应关系...

p5.js 开发点彩画派的绘画工具
本文简介 点赞 关注 收藏 学会了 这几天在整理书柜时看到这套书,看到梵高,想起他的点彩画。 想到点彩画派,不得不提的一个画家叫乔治皮埃尔秀拉。据说梵高也模仿过他的画作。 我引用一下维基百科对点彩画派的解析: 点彩画派&…...

Java工具库——Commons IO的50个常用方法
工具库介绍 Commons IO(Apache Commons IO)是一个广泛用于 Java 开发的开源工具库,由Apache软件基金会维护和支持。这个库旨在简化文件和流操作,提供了各种实用工具类和方法,以便更轻松地进行输入输出操作。以下是 Com…...

Git: 仓库clone和用户配置
git clone 两种方式clone远程仓库到本地。 通过ssh 命令格式: git clone gitxxxxxx.git使用这种方法需要提前创建ssh秘钥。 首先打开一个git控制台,输入命令 ssh-keygen -t ed25519 -C “xxxxxxxxxx.com”输入命令后需要点击四次回车,其…...

构建外卖小程序:技术要点和实际代码
1. 前端开发 前端开发涉及用户界面设计和用户交互。HTML、CSS 和 JavaScript 是构建外卖小程序界面的主要技术。 <!-- HTML 结构示例 --> <header><h1>外卖小程序</h1><!-- 其他导航元素 --> </header> <main><!-- 菜单显示 -…...

ubuntu安装配置svn
目录 简介安装SVN 启动模式方式1:单库svnserve方式方式2:多库svnserve方式 SVN 创建版本库1.svn 服务配置文件 svnserve.conf2.用户名口令文件 passwd3.权限配置文件4.多库方式运行 SVN 检出操作SVN 解决冲突SVN 提交操作SVN 版本回退SVN 查看历史信息1.svn log2.svn diff3.svn…...
『Jmeter入门万字长文』 | 从环境搭建、脚本设计、执行步骤到生成监控报告完整过程
『Jmeter入门万字长文』 | 从环境搭建、脚本设计、执行步骤到生成监控报告完整过程 1 Jmeter安装1.1 下载安装1.2 Jmeter汉化1.2.1 临时修改1.2.2 永久修改 1.3 验证环境 2 测试对象2.1 测试对象说明2.2 测试对象安装2.2.1 下载安装2.2.2 启动测试对象服务2.2.3 访问测试对象2.…...
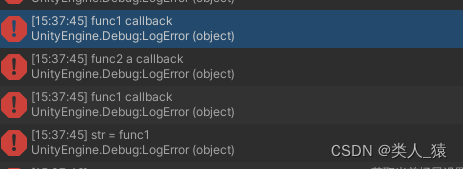
Unity C#中LuaTable、LuaArrayTable、LuaDictTable中数据的增删改查
LuaTable、LuaArrayTable、LuaDictTable中数据的增删改查 介绍Lua表lua表初始化lua移除引用lua中向表中添加数据lua中表中移除数据lua表中连接数据lua表中数据排序获取lua表长度获取表中最大值 UnityC#中LuaTableUnityC#中LuaArrayTable、LuaDictTable、LuaDictTable<K,V>…...

Spring常见面试题
https://blog.csdn.net/a745233700/article/details/80959716?ops_request_misc%257B%2522request%255Fid%2522%253A%2522169847982516800213061720%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id169847982516800213061720&biz_id0&…...
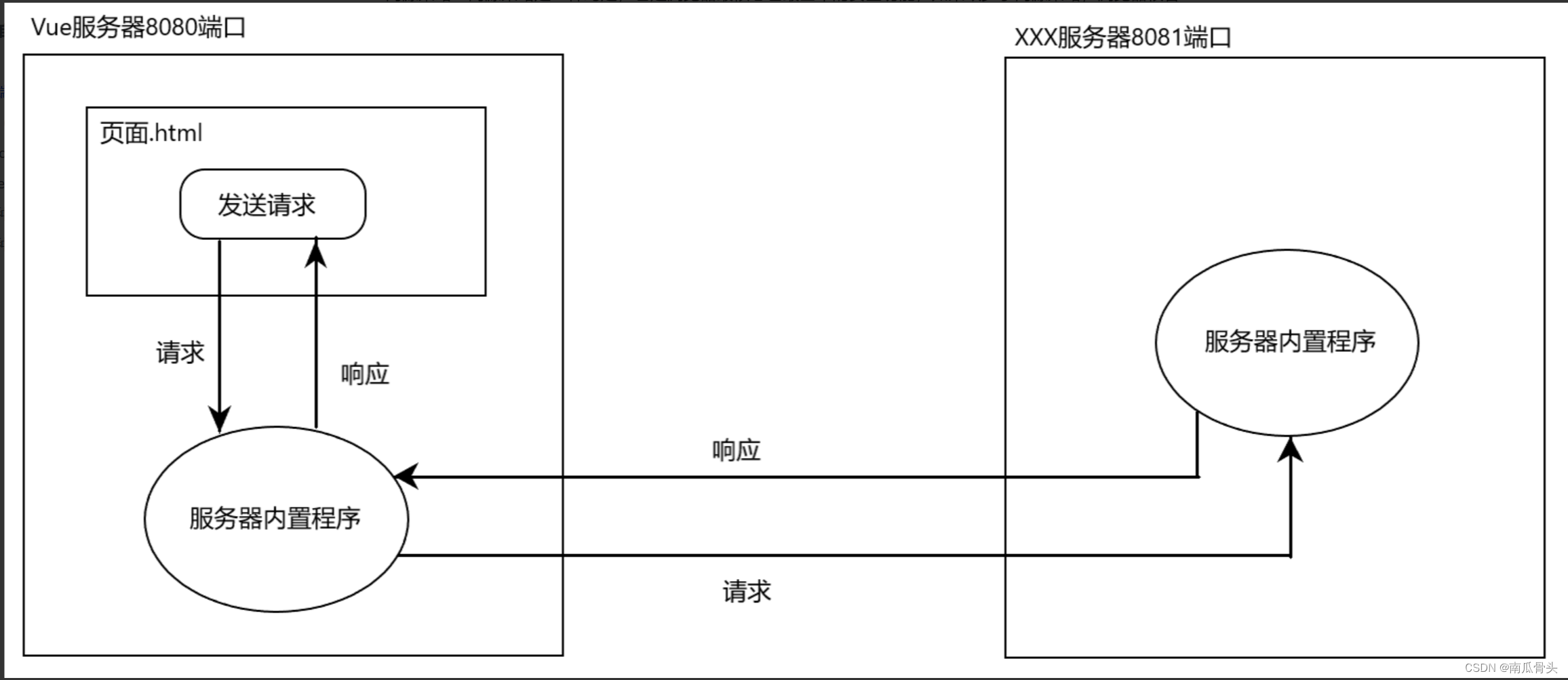
通过Vue自带服务器实现Ajax请求跨域(vue-cli)
通过Vue自带服务器实现Ajax请求跨域(vue-cli) 跨域 原理:从A页面访问到B页面,并且要获取到B页面上的数据,而两个页面所在的端口、协议和域名中哪怕有一个不对等,那么这种行为就叫跨域。注意:类…...

Vue2-计算属性的用法
题记 vue2计算属性的用法 反转字符串 <!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>实例</title> <script src"https://cdn.staticfile.org/vue/2.2.2/vue.min.js"></script> </hea…...

SM3加密udf
SM3加密udf maven xml <dependencies> <!-- 配置日志 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.5</version> </dep…...

ce从初阶到大牛(两台主机免密登录)
一、配置ssh远程连接 实现两台linux主机之间通过公钥验证能够互相实现免密登陆 1.确认服务程序是否安装 rpm -qa | grep ssh 2.是否启动 ps -aux | grep ssh 3.生成非对称公钥 ssh-keygen -t rsa 4.公钥发送到客户端 cd /root/.ssh/ ssh-copy-id root192.168.170.134 因为…...

CS224W2.3——传统基于特征的方法(图层级特征)
前两篇中我们讨论了节点层级的特征表示、边层级的特征表示: CS224W2.1——传统基于特征的方法(节点层级特征)CS224W2.2——传统基于特征的方法(边层级特征) 在这篇中,我们将重点从整个图中提取特征。换句话说,我们想要描述整个图结构的特征…...
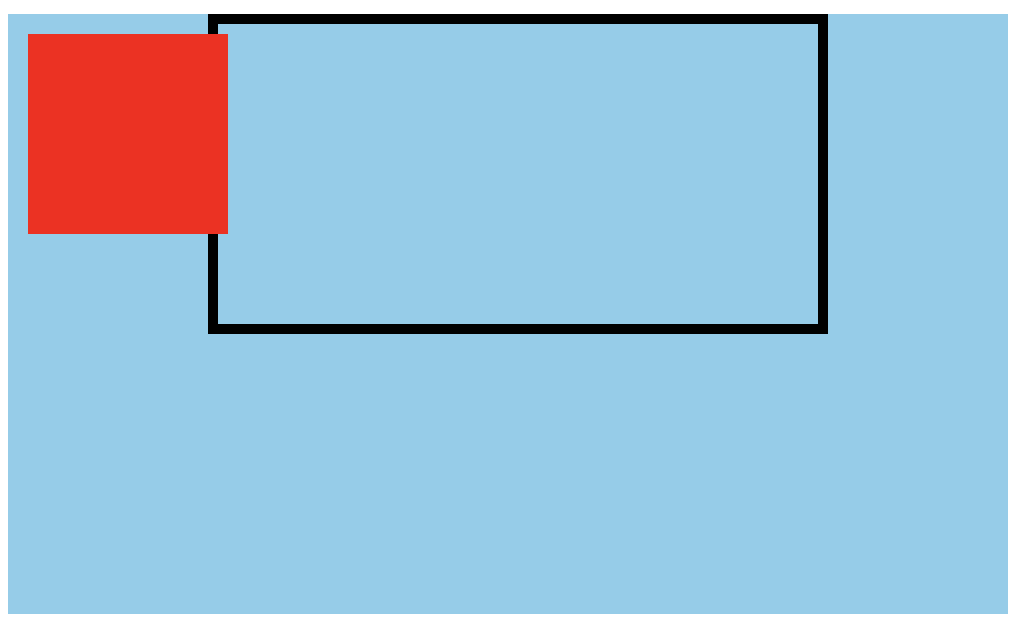
【CSS】包含块
CSS规范中的包含块 包含块的内容: 元素的尺寸和位置,会受它的包含块所影响。 对于一些属性,例如 width, height, padding, margin,绝对定位元素的偏移值(比如 position 被设置为 absolute 或 fixed)&…...

[SpringCloud] Nacos 简介
目录 一、Nacos,启动! 1、安装 Nacos 2、运行 Nacos 3、Nacos 服务注册 二、Nacos 服务多级存储模型 1、服务跨集群分配 2、NacosRule 负载均衡(优先本地) 3、服务实例的权重设置 4、环境隔离 三、Nacos 注册中心细节分…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...