【C++】string类的模拟实现
当你将放弃作为一种习惯,你一辈子也不会有出息…

文章目录
- 一、Default member functions
- 1.Constructor
- 2.Copy constructor(代码重构:传统写法和现代写法)
- 3.operator=(代码重构:传统写法和现代写法)
- 4.destructor
- 二、Other member functions
- 1.Iterators
- 1.1 begin() && end()
- 2.Capacity
- 2.1 size() && capacity()
- 2.2 resize()
- 2.3 reserve()
- 2.4 clear()
- 3.Element access
- 3.1 operator[]
- 4.Modifiers(画重点)
- 4.1 push_back()
- 4.2 append()
- 4.3 operator+=()
- 4.4 insert()(头插时的bug集中区)
- 4.5 erase()
- 4.6 swap()
- 5.String operations
- 5.1 find()
- 5.2 c_str()
- 三、Non-member function overloads
- 1.operator<<
- 2.operator>>
- 3.getline()
- 4.swap()
一、Default member functions
1.Constructor
1.
库里面的构造函数实现了多个版本,我们这里就实现最常用的参数为const char *的版本,为了同时支持无参的默认构造,这里就不在多写一个无参的默认构造,而是用全缺省的const char *参数来替代无参和const char *参数的两个构造函数版本。
2.
_size代表数组中有效字符的个数,在vs下_capacity代表数组中有效字符所占空间的大小,在g++下包含了标识字符\0的空间大小,我们这里就实现和vs编译器一样的_capacity,然后在底层实际开空间的时候多开一个空间存放字符串的\0就可以。
3.
代码中利用了strlen和strcpy来进行字符串有效字符的计算和字符串的拷贝,值得注意的是strcpy在拷贝时会自动将字符串末尾的\0也拷贝过去。
// '\0' -- 字符0,ascll码值为0
// "\0" -- 字符串有两个\0,因为默认有一个\0
// "" -- 有一个\0,字符串默认以\0结尾
//将无参构造函数和有参构造函数搞一块儿,整个全缺省参数的构造函数就可以直接替代前面两个构造函数了。
string(const char* str = "")//默认的缺省值是\0字符串,如果是\0字符,那就相当于ascll码值0,那其实就是nullptr,strlen在nullptr中找\0时就会报错,崩溃//:_str(str)//权限会放大,不能这样初始化。
{//std::string:标准中未规定需要\0作为字符串结尾。编译器在实现时既可以在结尾加\0,也可以不加。(因编译器不同)_size = strlen(str);_capacity = _size;_pstr = new char[_capacity + 1];//capacity存的是有效字符,只是在实际开空间的时候多开一个位置给\0strcpy(_pstr, str);
}
/*string()
{_pstr = new char[1];_size = _capacity = 0;_pstr[0] = '\0';
}*/
2.Copy constructor(代码重构:传统写法和现代写法)
1.
传统写法就是我们自己手动给被拷贝对象开辟一块与拷贝对象相同大小的空间,然后手动将s的数据拷贝到新空间,最后再手动将不涉及资源申请的成员变量进行赋值。
2.
现代写法就是我们自己不去手动开空间,手动进行成员变量的赋值,而是将这些工作交给其他的接口去做,就是去找一个打工人,让打工人去替我们做这份工作,在下面代码中,构造函数就是这个打工人。
所以构造出来的tmp和s就拥有一样大小的空间和数据,然后我们再调用string类的swap成员函数,进行被拷贝对象this和tmp对象的交换,这样只需两行代码就能解决拷贝构造的实现,但真的解决了吗?
补充:如果要进行两个对象的交换,不要调用std里的swap,因为会进行三次深拷贝,效率非常低,所以我们利用某一个对象的swap类成员函数来进行两个对象的交换。

3.
实际上,还需要一个初始化列表,因为s2的内容不初始化,则s2的_pstr就是野指针,随机指向一块不属于他的空间,这块空间应该属于操作系统,那么在交换完毕之后,tmp的_pstr就变为了空指针,在出函数作用域之后tmp对象会被销毁自动调用析构函数,则释放野指针所指向的空间就会发生越界访问,程序就会崩溃,所以最好的解决办法就是利用初始化列表先将this的成员变量初始化一下,对于有资源的_pstr我们利用nullptr来进行初始化,避免出现野指针。
4.
可能会有人有疑问,释放nullptr指向的空间时,程序不会崩吗?实际上无论是delete、delete[]还是free,他们在内部实现的时候,如果遇到空指针则什么都不做,也就是没有任何事情发生,因为这也没有做的理由,空指针指向的空间没有任何数据,我为什么要处理它呢?只有说一个空间中有数据需要清理的时候,也就是这个指针不为空的时候,free和delete、delete[]才有处理它的理由。
//string s2(s1)
/*string(const string& s)//传统写法
{_pstr = new char[s._capacity + 1];_capacity = s._capacity;_size = s._size;//类里面不受访问限定符private/public/protected的限制strcpy(_pstr, s._pstr);
}*/
string(const string& s)//现代写法:_pstr(nullptr),_size(0), _capacity(0)
{//重构代码:不改变代码外在行为的前提下,对代码做出修改,以改进程序的内部结构。string tmp(s._pstr);//调用构造函数,tmp和s有一样大的空间和一样的值//下面不可以用赋值,要不然tmp析构的时候,this的_pstr又变成野指针了,this被析构时又会发生问题了。//库 里面的swap代价太大,需要不断进行实例化swap模板//swap(_pstr, tmp._pstr);//swap(_capacity, tmp._capacity);//swap(_size, tmp._size);//交换之后,tmp的_pstr就变成野指针了,出了函数栈帧tmp销毁时就会野指针访问,用初始化列表可以解决。//this->swap(tmp);swap(tmp);//可以不用this指针调用,因为在类里面,swap默认的左边第一个参数就是this,直接调用就可以。//如果要交换两个对象时不要用swap(s1,s2)这个代价大,应该用s1.swap(s2),如果用库的swap则会发生三次深拷贝。//总结:内置类型调算法库里面的swap,自定义类型调成员函数swap
}
3.operator=(代码重构:传统写法和现代写法)
1.
赋值重载的传统写法和拷贝构造非常的相似,都是我们自己手动开空间,手动进行无资源申请的成员变量的赋值,手动进行数据的拷贝。但需要额外关注的一点是,一个对象可能被多次赋值,那我们就需要对原来可能存在的资源进行释放,所以需要手动delete[]或者调用clear()函数来进行原来可能存在的资源的释放。
2.
现代写法就是我们可以找打工人,让自己少手动进行操作,这时候的打工人有两种,一种是构造函数,一种是拷贝构造函数,但在这个地方不需要担心临时对象销毁时析构可能造成的野指针访问问题,因为赋值重载针对的是两个已经被构造出来的对象,就算你什么参数都不传,也有缺省值\0给你顶着,所以就不会出现野指针,而拷贝构造出现野指针的原因是被拷贝的对象还没有被构造出来,类成员变量都是随机值,所以就有野指针,为了避免这样的问题,我们才在拷贝构造中加入了初始化列表,以防止野指针的出现。
实际上,只要一个对象被构造出来,哪怕这个对象是调用无参构造函数构造出来的,那么这个对象也没有野指针,因为即使是空对象在底层中他的数组中都会有一个\0标识字符,标识这个对象对应的串是一个空串,只要这个数据有效,那么指向数据空间的指针也就有效,就不会有析构野指针的问题出现。
3.
我们继续把话题捞回来,所以只要让打工人拷贝构造构造出来tmp,然后我们再利用类成员函数swap将tmp和this对象进行交换,则赋值工作就完成了,本质和拷贝构造是一样的,都是先让一个打工人帮我们搞好一个和拷贝对象一样的对象,然后再用自己的对象和打工人搞好的这个对象进行交换,等离开函数时打工人搞的对象就被销毁,this对象成功就完成了赋值工作。
4.
其实还有一个最为简洁的办法就是用传值传递,这样的话,函数参数天然的就是我们的打工人拷贝构造函数搞出来的对象,那我们实际上什么都不用做,直接调用swap函数进行this和参数对象的交换即可,以后我们写赋值重载就用这个最简洁的方法。
//s2=s1
//string& operator=(const string& s)//传统写法
//{
// if (this != &s)//不要自己给自己赋值
// {
// delete[] _pstr;//清空掉s2原有的数据,然后进行赋值
// _pstr = new char[s._capacity + 1];
// strcpy(_pstr, s._pstr);// _size = s._size;
// _capacity = s._capacity;// }
// return *this;
//}
//string& operator=(const string& s)//现代写法
//{
// //代码重构
// if (this != &s)
// {
// //string tmp(s._pstr);
// string tmp(s);//调用拷贝构造或者构造函数
// swap(tmp);
// }
// return *this;
//}
string& operator=(string s)//现代写法的另一种更为常用的写法,s是现成的打工人,身份地位和tmp一样
//传值传参不存在权限的放大和缩小,指针和引用才有权限的放大和缩小,传值只是权限的平移,无论是const还是非const,直接拷贝就行
{ swap(s);return *this;
}
4.destructor
1.
析构函数的实现就比较简单了,只要将指针指向的空间进行释放,然后将其置为空指针,防止野指针的误操作,然后再将剩余两个成员变量赋值为0即可完成工作。
~string()
{//delete和free内部实现中都有一个特征,他们内部会检查指针,如果指针为空,则什么都不做。所以delete[]或free空指针不会报错delete[] _pstr;_pstr = nullptr;_size = _capacity = 0;
}
二、Other member functions
1.Iterators
1.1 begin() && end()
1.
现阶段我们无法完全透彻的理解迭代器,但是目前我们确实可以将其理解为指针,所以在模拟实现这里我们用typedef来将iterator定义为char型的指针类型。而对于begin和end来说较为简单,只要返回首元素和末尾的\0元素对应的地址就可以,而_size对应的下标正好就是\0,所以直接返回就好。
typedef char* iterator;iterator begin()const
{return _pstr;
}
iterator end()const
{return _pstr + _size;
}
2.
实际上C++11的新特性基于范围的for循环,他的本质实现就是迭代器,所以只要有begin()和end()这两个返回迭代器的函数,我们就可以使用范围for,范围for代码的执行实际上可以理解为宏的替换,就是在执行for时,编译器会在这个地方作处理,等到实际执行时,执行的就是迭代器,并且范围for只能调用begin和end,这是写死的,如果这两个函数的名字变一下,那范围for就用不了了,因为局部的返回迭代器的函数名有问题。
void test_string1()
{string s1("hello world");cout << s1.c_str() << endl;for (size_t i = 0; i < s1.size(); i++){s1[i]++;}cout << s1.c_str() << endl;string::iterator it1 = s1.begin();while (it1 != s1.end()){(*it1)--;it1++;}cout << s1.c_str() << endl;for (auto ch : s1){cout << ch << " ";}cout << endl;//范围for就是用迭代器实现的,在编译范围for的代码之前先将代码替换为迭代器的实现,有点类似于宏.//所以在实际编译的时候编译的是替换之后的迭代器的代码,替换的迭代器必须是begin和end,如果我们将自己的begin改成Begin,//则iterator的调用还可以进行,但范围for就无法通过,因为范围for只能调用begin()和end(),这是写死的。//范围for调用我们自己写的迭代器的原因是因为,它会先去局部找,然后再去全局找,局部有我们自己实现的begin和end,则范围for就会//自动调用。//只要一个容器有迭代器,那么这个容器就可以支持范围for,迭代器必须是原模原样的begin和end
}
2.Capacity
2.1 size() && capacity()
size_t size()const//利用public的函数让类外能够访问到类中的private成员
{return _size;
}
size_t capacity()const
{return _capacity;
}
2.2 resize()
1.
对于resize来说,根据所传空间大小的值来看,可以分为插入数据和删除数据两种情况,对于插入数据直接调用reserve提前预留好空间,然后搞一个for循环将字符ch尾插到数组里面去,最后再在数组末尾插入一个\0标识字符,此刻就体现出来为什么我们在reserve开空间的时候要多开一个空间了,因为这个空间就是给\0留的。
2.
对于删除数据就比较简单了,直接在n位置插入\0即可,依旧采用惰性删除的方式,然后重置一下_size的大小为n即可。
void resize(size_t n, char ch = '\0')//resize需要开空间和初始化,我们将初始化的ch默认缺省为\0
{//分三种情况,删除数据,不扩容增加数据,扩容增加数据,后两种情况可以合起来,因为是插入数据if (n > _size)//插入数据{reserve(n);//插入数据,调用扩容接口for (size_t i = _size; i < n; i++){_pstr[i] = ch;}_size = n;_pstr[_size] = '\0';}else//删除数据{_pstr[n] = '\0';_size = n;}
}
2.3 reserve()
1.
reserve的参数代表你要将数组的现有的有效字符所占空间大小调整为的大小,注意是有效字符,这是不包含标识字符的,而在具体实现的时候,我们在底层多开一个空间给\0,在C++中所有的扩容都是异地扩容,而不是原地扩容,所以每一次扩容都需要进行原数据拷贝到新空间,代价确实很大。
void reserve(size_t n)
{//reserve尽量不要缩容,最好是扩容。//下面代码只有扩容,如果是缩容,则什么都不做。if (n > _capacity){char* tmp = new char[n + 1];//开空间的时候多开一个给\0,n代表的是有效字符的大小strcpy(tmp, _pstr);delete[] _pstr;_pstr = tmp;_capacity = n;}
}
2.4 clear()
1.
这里的clear实现的很巧,我们只要将_size搞成0,然后将第一个元素赋值为\0就完成资源的清理了,之后如果进行元素的修改操作,那么直接进行覆盖即可,这实际上是一种惰性删除的方式。
void clear()
{_size = 0;_pstr[0] = '\0';
}
3.Element access
3.1 operator[]
1.
对于operator[]来说,调用它时既有可能进行写操作,又有可能进行读操作,所以为了适应const和非const对象,operator[]应该实现两个版本的函数,并且这个函数对待越界访问的态度就是assert直接断言,而at对于越界访问的态度是抛异常。
//普通对象:可读可写
char& operator[](size_t pos)//operator[]是可能读和可能写的,所以需要实现两个版本
{assert(pos < _size);return _pstr[pos];
}
//const对象:只读
char& operator[](size_t pos)const//只读的版本
{assert(pos < _size);return _pstr[pos];
}
4.Modifiers(画重点)
4.1 push_back()
1.
push_back有一个需要注意的地方就是在扩容的地方,如果是一个空对象进行push_back的话,我们采取的二倍扩容就有问题,因为0*2还是0,所以对于空对象的情况我们应该给他一个初始的capacity值,这里我们就给成4,其他情况的话只要空间满了我们就二倍扩容,采用和g++一样的策略。
2.
很容易忘记的就是在尾插字符之后,忘记补\0了,千万不要忘记这里,否则在打印的时候就会有麻烦了。
我个人认为,忘记尾插\0的原因还是对字符串不够敏感,对于它的组成还是迷迷糊糊的,你只要记住一个字符串就是由有效字符和结尾的标识字符组成的,这样无论你在进行什么样的字符串操作之后,你肯定就会想一下,哎呀,操作完之后这个字符串好像没有标识字符啊,这会出问题的呀,那我应该补上啊。
在理解字符串之后,相信你肯定不会忘记补\0了就。
void push_back(char ch)
{if (_size == _capacity){int new_capacity = _capacity == 0 ? 4 : _capacity * 2;reserve(new_capacity);}_pstr[_size] = ch;_size++;_pstr[_size] = '\0';
}
4.2 append()
1.
对于append的实现,我们其实可以直接调用strcpy接口来进行字符串的尾插,并且我们知道strcpy是会将\0也拷贝过去的,这样的话,我们就不需要在末尾手动补充\0了。
2.
值得注意的是,string系列的字符串函数是不会进行自动扩容的,所以我们需要判断一下是否需要进行扩容,在空间预留好的情况下进行字符串的尾插,调整strcpy的插入位置为_pstr+_size即可实现字符串尾插的工作。
void append(const char* str)
{//string系列的库函数是不会自动扩容的,都需要在有足够空间的情况下进行操作,strcat是行不通的在这里,因为空间不一定够size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);//这里开空间不需要加1,只需要传有效字符的个数就可以了,底层实际多开一个\0空间的工作交给reserve}strcpy(_pstr + _size, str);//strcpy会把\0也拷贝过去_size += len;
}
4.3 operator+=()
1.
string类的修改模块儿中的yyds函数,我们也只实现两个最常用的版本,参数分别为字符和字符串的版本。
在已实现push_back和append的情况下,我们直接进行函数复用即可。
string& operator+=(char ch)
{push_back(ch);return *this;
}
string& operator+=(const char* str)
{append(str);return *this;//返回对象的引用
}
4.4 insert()(头插时的bug集中区)
1.
insert的逻辑还是很简单的,总体来说就是先判段是否需要进行扩容,然后就是向后挪动数据,最后将目标数据插入到对应的位置即可。但是实现起来坑还是非常多的,出现坑的情况实际就是因为头插,在这种情况下,insert如果不控制好处理的逻辑,很容易就会出现bug。
2.
如果end被定义为字符的下标,那么就应该将end位置元素挪到end+1位置上去,如果进行头插的话,end=0会继续进入循环,循环结束之后end会变为-1,回到while的判断位置,此刻就出现问题了,如果我们的end是size_t定义的,那么-1会被认为是无符号整数,进行隐式类型转换,由于-1的补码是全1,被当作无符号整数的话,它的原码就被看作是全1了,那就是四十二亿九千万大小,程序会陷入死循环。所以我们可以不用size_t来定义end,防止发生隐式类型转换。
改用int定义end的话,稍不注意又会出现问题,因为-1在和size_t定义的pos进行比较时,又会发生隐式类型转换,因为比较运算符也是运算,只要是运算就有可能出现隐式类型转换,那么-1就又会被转为无符号整型,程序就又会陷入死循环,所以如果采取int方式定义的end,那么在比较时就需要将size_t的pos强转为int类型来和int类型的end进行比较。ps:强转这种方法很好用,十分推荐。
3.
如果你不想将end定义为int类型,想继续使用size_t类型,那就需要将end定义为字符将要被挪动到的位置的下标,所以我们就将end-1位置的元素挪到end位置上去,在while循环条件的判断位置,我们用end来和pos位置进行比较,end应该大于pos的位置,一旦end=pos我们就跳出循环,这样就不会出现bug了。
string& insert(size_t pos, char ch)//pos位置不可能是一个负数,所以我们用size_t来进行定义
{assert(pos <= _size);//==_size就相当于在\0位置插入数据,也就是尾插if (_size == _capacity){int new_capacity = _capacity == 0 ? 4 : _capacity * 2;reserve(new_capacity);}//挪动数据/*int end = _size;while (end >= (int)pos)//可以用int类型的end,然后再将pos强转为int类型即可。{_pstr[end + 1] = _pstr[end];--end;}*/size_t end = _size + 1;//end表示需要被挪动的数据应该被挪动到的位置。//但如果将类型改为int,也会报错,因为会发生隐式类型转换,需要将while的判断条件调整一下while (end > pos)//如果进行头插,这里就会出现问题,end会减到-1,然后去end>=pos位置进行判断,但是end是size_t类型:死循环//如果改为int,这里会用-1和size_t的pos进行比较,int会隐式类型转换为size_t,程序会死循环{_pstr[end] = _pstr[end - 1];--end;}_pstr[pos] = ch;_size++;return *this;
}
4.
对于字符串的插入逻辑也是相同的,我们需要提前预留好存放字符串的有效字符的空间大小,然后进行挪动字符串,最后将字符串的所有有效字符插入到对应的位置上去即可。
5.
插入字符串的情况种类和上面插入字符一样,我推荐使用字符的位置来作为end的定义,将end下标的元素挪到end+len之后的位置上去,因为我们只插入有效字符,所以strlen的结果刚好满足我们的要求,同样在while判断条件进行比较的时候,还是要讲pos强转为int类型来和end进行比较,这样的逻辑非常的清晰明了。
6.
在使用size_t作为end类型的情况下,我们需要用字符将要被挪动到的位置来作为end的定义,然后将end-len位置的元素赋值到end位置上去,我们可以将判断条件控制为end>pos+len-1,因为pos+len位置是pos位置元素需要被挪动到的位置,-1之后就是需要存放的字符串的最后一个有效字符的位置,所以我们应该将条件控制为end>pos+len-1或者是end>=pos+len,这两种条件都成立。
7.
与插入字符稍有不同的是,我们插入的字符串是有标识字符作为结尾的,所以在进行字符串拷贝到数组里面时,我们需要控制不要将\0拷贝进去,因为原来数组的末尾就有\0,这个时候就不适合用strcpy函数来进行拷贝,可以使用strncpy然后传有效字符大小作为拷贝字符串的字符个数,这样就可以解决不拷贝\0的问题。
string& insert(size_t pos, const char* str)
{//1.判断空间是否足够,不够就扩容size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);//这里开空间不需要加1,只需要传有效字符的个数就可以了,底层实际躲开一个\0空间的工作交给reserve}//2.挪动数据然后插入字符串。// (1)还是用下面强转的方式简单int end = _size;//用int就是为了防止end为-1时,循环还能继续进行从而发生死循环while (end >= (int)pos)//这样的代码是可以支持头插的。因为end是int,pos也被强转为int了。{_pstr[end + len] = _pstr[end];end--;}//(2)这个思考起来太麻烦了//size_t end = _size + len;//end表示数据将要被向后挪动到的位置。//while (end > pos + len - 1)//end位置和pos原有数据应该被挪动到的位置进行比较//while (end >= pos + len)//也可以,因为这里的等于时end位置不会为0,进入循环结束之后,就会跳出循环,而不是变为-1继续判断//{// _pstr[end] = _pstr[end - len];// end--;//}// 不要用strcpy,因为strcpy会把\0也拷贝进去。可以使用strncpy或者memcpy,memmove比memcpy可以多处理内存重叠的情况。//但如果是两个字符串的拷贝,就不存在内存重叠的情况,直接用memcpy就够了,不用memmovestrncpy(_pstr + pos, str, len);_size += len;//不要忘了将_size+=,如果不+=,那么扩容就无法正常进行return *this;
}
4.5 erase()
1.
erase的参数分别为删除的起始位置和需要删除的长度,库中实现时,如果你不传则默认使用缺省值npos,转换过来的意思就是,如果你不传删除长度,那就默认从删除的起始位置开始将后面的所有字符都进行删除。
2.
如果len+pos之后的下标大于或者等于_size的话,那处理结果和没传删除长度参数一样,都是将pos位置之后的元素全部删除,我们依旧采用惰性删除的方式来进行删除,直接将pos位置下标对应的元素赋值为\0即可。
3.
对于仅删除字符串的部分字符情况的话,我们可以利用strcpy来进行,将pos+len之后的字符串直接覆盖到pos位置,这样实际上就完成了删除的工作。
string& erase(size_t pos, size_t len = npos)
{assert(pos <= _size);if (len == npos || len + pos >= _size )//pos代表pos位置之前还有几个有效数据{_pstr[pos] = '\0';_size = pos;}else{strcpy(_pstr + pos, _pstr + pos + len);_size -= len;}return *this;//如果不搞引用返回的话,则会发生浅拷贝因为我们没写拷贝构造,临时对象离开函数会被销毁,则对象s1指向空间为OS,越界访问。
}
4.
对于静态成员变量,我们知道必须在类外定义,类内只是声明,定义时不加static关键字。但如果静态成员变量有了const修饰之后,情况就不一样了,它可以在类内直接进行定义,值得注意的是,这样的特性只针对于整型,如果你换成浮点型就不适用了。我们的npos就是const static修饰的成员变量,可以直接在类内进行定义。
class string
{
public:private://类模板不支持分离编译,因为用的地方进行了实例化,但用的地方只有声明没有定义,而有定义的地方却没有实例化,所以发生链接错误//1.如果在定义的地方进行了实例化,则通过.h文件找到方法之后,方法已经发生实例化了,那么就不会发生链接错误。//2.或者直接将声明和定义放到.hpp文件中,只要用的地方包含了.hpp文件,则类定义的地方就会进行实例化。char* _pstr;size_t _size;//理论上不可能为负数,所以我们用size_t类型进行定义size_t _capacity;//如果在调用构造函数的时候没有显示传参初始化成员变量,则成员变量会利用C++11的缺省值在构造函数的初始化列表进行初始化const static size_t npos = -1;//静态成员变量在类中声明,定义必须在类外面,因为它属于整个类。但const修饰的静态成员变量可以直接在类中进行定义,算特例。//但const修饰静态成员变量在类中可以进行定义的特性,只针对于整型类型,换个类型就不支持了。***给整型开绿灯***//const static double X ;};
4.6 swap()
类成员函数swap的实现非常简单,只需要调用std里面的swap将对象的内置类型的每个成员变量进行交换,即完成对象的交换工作。
void swap(string& str)
{std::swap(_pstr, str._pstr);std::swap(_capacity, str._capacity);std::swap(_size, str._size);
}
5.String operations
5.1 find()
1.
对于字符的查找,遍历一遍即可,如果找不到我们就返回npos,找到就返回下标
2.
对于字串的查找,我们调用strstr来进行解决,如果找到就利用指针-指针来返回字串的首元素下标,找不到就返回npos。
size_t find(const char ch, size_t pos = 0)const
{assert(pos < _size);while (pos < _size)//一般来说不会查找空字符,所以这里就不加={if (_pstr[pos] == ch){return pos;}pos++;}return npos;//找不到返回npos
}
size_t find(const char* str, size_t pos = 0)const
{assert(pos < _size);const char* p = strstr(_pstr + pos, str);if (p == nullptr)return npos;return p - _pstr;
}
5.2 c_str()
c_str是C++为了兼容C语言增加的一个接口,其作用就是返回string类对象的成员变量,也就是char *的指针。
const char* c_str()
{return _pstr;
}
三、Non-member function overloads
1.operator<<
1.
类外获得类内私有成员变量,一般有两种方法,一种是通过友元函数来进行解决,另一种是调用公有成员函数来访问私有成员变量。
这里的流插入重载还是非常简单的,我们利用范围for就可以输出字符串的每个字符,最后返回ostream类对象的引用即可,以此来符合连续流插入的情景。
ostream& operator<<(ostream& out, const string& s)
{//返回值是ostream&,这样可以连续使用cout//流插入和流提取必须重载成全局的,而且得是友元。(这句话是错误的,必须是全局但不一定得是友元因为可以用public函数获取private)for (auto ch : s)//会被替换为迭代器,*迭代器拿到ch的值{out << ch;ch++;}/*for (size_t i = 0; i < s.size(); i++){out << s[i];}*/return out;
}
2.operator>>
1.
对于流提取的重载和getline的实现就不一样了,流提取是以空格和\n作为间隔标志的 ,所以在实现时如果遇到这两个字符我们就跳出while循环。
2.
cin和scanf是读取不了空格的,所以一旦我们流提取一个含有空格的字符串到某个对象时,就会发生问题,缓冲区里的空格和换行符是直接过滤的,所以等到in读取完缓冲区字符之后,in就一直让我输入,程序会陷入死循环,永远跳不出while循环。最本质的原因就是scanf和cin在读取的时候会自动过滤掉空格和换行符,所以in从缓冲区里拿到的字符永远都不可能是空格和换行符,那么while循环就永远都跳不出来,程序必然会崩溃。

3.
所以为了避免这种问题的出现,我们不采用in读取缓冲区字符的方法,而是使用in对象的类成员还是get()来进行字符的读取,get()是可以拿到所有的字符的,等到拿出来空格或换行符的时候,我们就跳出循环,结束get继续对缓冲区字符的读取。
4.
但我们知道+=字符的本质就是push_back,如果我们输入的字符串非常非常的长的话,就会导致频繁的调用+=,而频繁的调用push_back势必会进行多次的扩容,频繁扩容那就会降低效率,所以这样低效率的代码是写库的人不可接受的。
所以实际在库中实现流提取时,用了buff数组作为一个缓冲来解决频繁扩容带来的效率降低的问题。
5.
利用reserve来提前预留空间,降低频繁扩容的做法是不可取的,因为我们不知道用户在输入的时候会输入多少字符的字符串,所以如果空间开大了就会浪费,开小了又不够。
那什么时候用reserve呢?需要提前知道预留空间的大小才适合用reserve来提前预留空间。
6.
我们用buff来存储get从缓冲区中提出来的字符,等到buff数组满了之后,我们再将数组中的内容统一+=到对象是里面去,这样就可以减少输入字符串过长带来的效率降低,如果输入的字符过短,没有达到buff数组的大小的时候,我们就将buff里面存在的字符+=到对象s即可。
7.
在具体实现的时候,其实这里还存在bug,如果你用if和else的语句来进行判断的话,会出问题,当buff满了的时候,get读取出来的字符肯定是+=不了的,因为需要进入另一个分支语句进行buff数组内容+=到对象里面,那此刻get读取出来的字符就无法尾插到对象里面,buff数组+=过后,get继续进行读取,原来的字符就被过滤掉了,还没来得及尾插到对象里面,就又读取新的字符了。
所以在这样的逻辑情况下,实际存储到对象里面的字符是要比我们输入的字符个数少的,因为每一次进行buff内容的append时,当前读取的字符会被过滤掉,然后又重新读取新的字符。
8.
所以我们应该换一种逻辑,就是当append尾插buff内容的时候,原有字符依旧不会被过滤掉,而是重新再赋值到buff里面,这样的逻辑也好说,只要用if语句控制即可,不要用if else这样的分支语句,只用if则可以保证每一次get读取出来的字符都能被插入到buff里面,然后等buff满了的时候再统一append到对象s里面。
如果buff没有满,不要忘了将buff里面仅存的字符+=到对象s里面去
istream& operator>>(istream& in, string& s)//这里不能用const了,因为要将控制台输入后的内容拷贝到对象s里面
{s.clear();//上来就清空一下,这样就可以支持已初始化对象的流提取了/*char ch;in >> ch;*///流提取就是从语言级缓冲区中拿数据,但是他拿不到空格和换行符,因为istream类的流提取重载就是这么规定的//所以要解决的话,我们就不用流提取重载,我们改用istream类的get()函数来一个一个获取缓冲区里面的每个字符。char ch = in.get();while (ch != ' ' && ch != '\n'){s += ch;//如果输入到缓冲区里的字符串非常非常的长,那么+=就需要频繁的扩容,则效率就会降低。// //in >> ch;ch = in.get();//C++的get()和C语言的getchar()的功能是一样的,都是获取缓冲区的字符}//方法1.reserve解决方案//reserve大了,空间浪费,如果小了,一旦字符串又过大,则还会需要频繁的扩容,reserve可以,但是不是特别好的方法。//方法2.开辟buff数组/*如果你输入的字符个数过于少,有效字符的个数不到127的话,跳出while循环之后,我们还需要另外判断,再将buff中还没有满的数据 += 到对象s里面去。如果输入的字符个数过于多,无需担心,我们以127个有效字符为一组,每组满了就将这一组的数据 += 到对象s里面去,库里面大概就是这么实现的。*/char buff[128] = { '\0' };size_t i = 0;char ch = in.get();while (ch != ' ' && ch != '\n'){//if (i < 127)//这里的大小必须是127,最后得留一个位置给\0,要不然没有标识字符,字符串的结尾具体在哪里找不到,打印出错//{// buff[i++] = ch;//}//else//{// s += buff;// i = 0;//}//ch = in.get();//上面这种逻辑,输入的有效字符个数超过127或者更大的时候,实际存到s里面的字符个数会变少,下面的逻辑是正确的。if(i == 127){s += buff;//+=的字符串buff是以\0结尾的i = 0;}buff[i++] = ch;ch = in.get();}if (i >= 0)//i代表已经插入的有效字符的个数,个数对应的下标位置正好是最后一个有效元素的下一个位置。{buff[i] = '\0';s += buff;//将上面插入的\0之前的字符串+=到对象s里。}return in;
}
3.getline()
1.
这里实现getline的时候,有一点小问题,对于istream类的对象在传参时,不能使用传值拷贝,编译器会自动删除掉istream类的拷贝构造,防止出现浅拷贝等不确定的问题,如果想要进行解决,则需要用引用,或者自己实现深拷贝的拷贝构造函数。
2.
getline和cin>>不同的地方在于,cin>>是以空格和\n作为分隔符,而getline是以\n作为分隔符的,所以在模拟实现的时候不能使用流提取来进行字符的读取,应该用istream类中的读取字符的成员函数get()来进行缓冲区的字符读取。
3.
在实现内部,我们利用+=来进行string类对象的字符的尾插。
istream& getline(istream& in, string& s)
//vs编译器会将istream类的默认构造自动删除,防止出现浅拷贝等不确定问题,所以需要用引用或者自己定义深拷贝的拷贝构造函数。
{char ch = in.get();while (ch != '\n'){s += ch;ch = in.get();//get()一点一点从缓冲区里面拿字符,直到遇到\n,这才是getline,遇到空格和\n的应该是>>}return in;
}
4.swap()
1.
std中的swap实际上是支持内置类型和自定义类型的函数模板,并且对于内置类型的定义,也支持了像自定义类型一样的拷贝构造、赋值重载等用法,但在平常写代码中对于内置类型我们还是用原来的写法,下面的模板写法只是为了方便兼容内置和自定义类型。
template <class T> void swap ( T& a, T& b )
{T c(a); a=b; b=c;
}
void test_string9()
{//下面这样的写法是为了支持函数模板,有时候模板参数可能是自定义类型或内置类型,所以为了兼容内置类型,就搞了这样的写法。int i(10);//等价于int i = 10;int j = int();//匿名对象的赋值重载
}

相关文章:
【C++】string类的模拟实现
当你将放弃作为一种习惯,你一辈子也不会有出息… 文章目录一、Default member functions1.Constructor2.Copy constructor(代码重构:传统写法和现代写法)3.operator(代码重构:传统写法和现代写法ÿ…...
——STL容器)
笔记(一)——STL容器
容器分类:序列式容器:每个元素都有固定位置,取决于插入的时机和地点,和元素无关,如vector、deque、list、stack、queue。关联式容器:元素位置取决于特定的排序准则,和插入顺序无关,如…...

红黑树
红黑树是一个相对的平衡,减少了旋转的消耗 一个节点不是红的就是黑的根节点是黑的一个节点是红的,孩子是黑的(没有连续的红色节点)对于每个节点,从该节点到后代节点的简单路径,都包含相同的黑色࿰…...
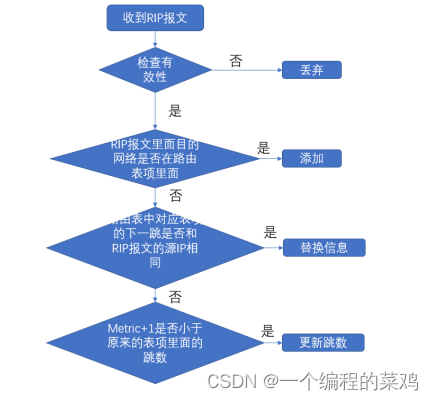
RIP路由协议的更新(电子科技大学TCP/IP第二次实验)
一.实验目的 1、掌握 RIP 协议在路由更新时的发送信息和发送方式 2、掌握 RIP 协议的路由更新算法 二.预备知识 1、静态路由选择和动态路由选择 2、内部网关协议和外部网关协议 3、距离向量路由选择 三.实验原理 RIP 协议(…...

基于JWT实现用户身份认证
常见场景 账号/密码登录、手机号验证码登录、微信扫码登录 解决方案 基于Session认证方案 什么是session认证方案 服务端生成httpsession认证(内存-sessionId)sessionId写到浏览器cookie浏览器请求的header中自动带sessionId到服务端服务端校验sessionId是否合法 优点 .…...
)
SaltStack 远程命令执行漏洞(CVE-2020-16846)
目录 (一)漏洞描述 (二)漏洞复现 1、在vulhub上启动docker 2、访问docker靶机 https /ip:8000...

SAP 详细解析成本收集器
成本收集器作为成本对象,主要应用于按期间进行成本核算的情况,在这种情况下会把产品创建为成本收集器,实际成本的收集和差异的结算全部按照成本收集器进行处理,财务的成本分析也针对成本收集器进行。 成本收集器是按期间核算&am…...

Vision Transformer学习了什么-WHAT DO VISION TRANSFORMERS LEARN? A VISUAL EXPLORATION
WHAT DO VISION TRANSFORMERS LEARN? A VISUAL EXPLORATION 文章地址 代码地址 摘要 视觉转换器( Vision Transformers,ViTs )正在迅速成为计算机视觉的事实上的架构,但我们对它们为什么工作和学习什么知之甚少。虽然现有研究对卷积神经网络的机制进…...

一种全新的图像滤波理论的实验(三)
一、前言 2023年02月22日,我发布了滤波后,为针对异常的白色和黑色像素进行处理的实验,本次发布基于上下文处理的方案的实验,目的是通过基于加权概率模型滤波后,在逆滤波时直接修复大量的白色和黑色的异常像素…...
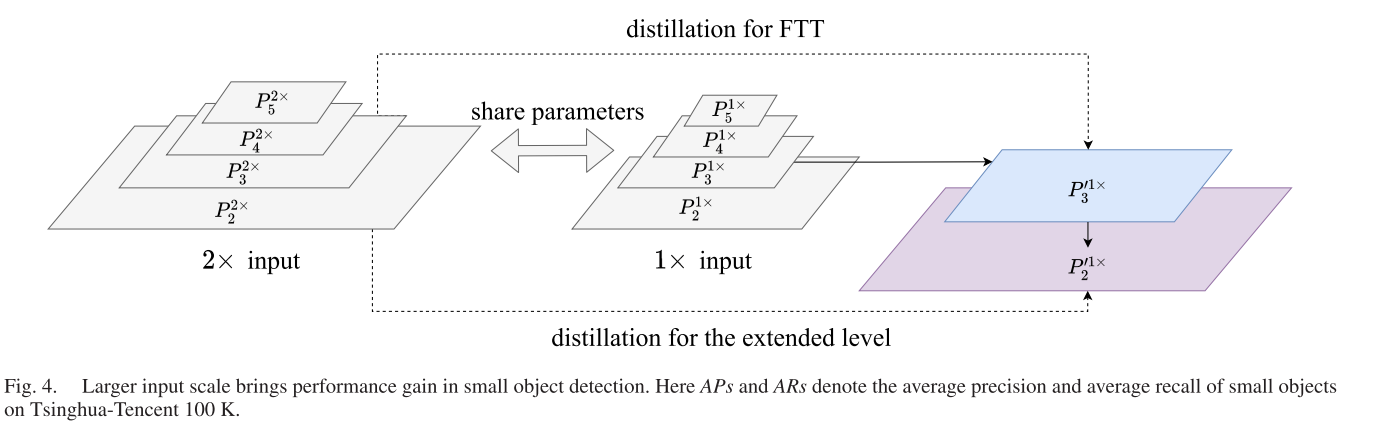
CV——day79 读论文:基于小目标检测的扩展特征金字塔网络
Extended Feature Pyramid Network for Small Object DetectionI. INTRODUCTIONII. RELATED WORKA. 深层物体探测器B. 跨尺度特征C. 目标检测中的超分辨率III. OUR APPROACHA. 扩展特征金字塔网络B. 特征纹理传输C. 交叉分辨蒸馏IV. EXPERIMENTSA. Experimental Settings1&…...
智能家居项目(五)测试串口功能
目录 一、写一个单独测试串口的demo 二、直接运行上一篇智能家居的代码 一、写一个单独测试串口的demo 1、TTL串口与树莓派的连接方式 (1)TTL的RXD和TXD针脚连接到树莓的TXD和RXD上(T–>R R–>T),交叉连&…...

2023年全国最新道路运输从业人员精选真题及答案7
百分百题库提供道路运输安全员考试试题、道路运输从业人员考试预测题、道路安全员考试真题、道路运输从业人员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 71.根据《中华人民共和国安全生产法》,生产经营单位…...

python的所有知识点(含讲解),不看就亏死了
目录 简介 特点 搭建开发环境 版本 hello world 注释 文件类型 变量 常量 数据类型 运算符和表达式 控制语句 数组相关 函数相关 字符串相关 文件处理 对象和类,注:不是那个对象!!!!&…...

【Servlet篇】Response对象详细解读
文章目录Response 继承体系Response 设置响应数据设置响应行数据设置响应头数据设置响应体数据Response 重定向Response 响应字符数据Response 响应字节数据Response 继承体系 前面说到,我们使用 Request 对象来获取请求数据,使用 Response 对象来设置响…...

SAP FICO期初开账存货导入尾差
一、问题 1.AFS物料网格级别库存导入先除再乘有尾差: 旧系统数据迁移自两个系统:一个管理数量账(网格级别),一个管理金额账(物料级别) 2.MB52分工厂与MB5L分工厂统计差异: M…...
微信商城小程序怎么做_分享实体店做微信商城小程序制作步骤
各行各业都在用微商城小程序开店,不管是餐饮店还是便利店,还是五金店。都是可以利用微信小程序开一个线上店铺。实现线上跟线下店铺更加全面的结合。维护好自己的老客户。让您的客户给您拉新,带来新客户。小程序经过这几年的快速发展和不断升…...

【moment.js】时间格式化插件
Moment.js 用于在JavaScript中解析,验证,操作和显示日期和时间。是一款在项目中使用频率极高的时间格式化工具,Ant Design Vue 组件中就是使用它来处理时间的。 安装 npm install moment --save # npm yarn add moment # Ya…...

微信小程序开发【壹】
随手拍拍💁♂️📷 日期: 2023.02.24 地点: 杭州 介绍: 2023.02.24上午十点,路过学院的教学楼时🏢,突然看见了一团粉红色。走进一看是一排梅花🌸,赶在它们凋零前,将它们定格在我的相…...

2 k-近邻算法
0 问题引入 想一想:下面图片中有三种豆,其中三颗豆品种未知,如何判断他们类型? 1 KNN概述 1.1 KNN场景 电影可以按照题材分类,那么如何区分 动作片 和 爱情片 呢? 动作片:打斗次数更多爱情…...
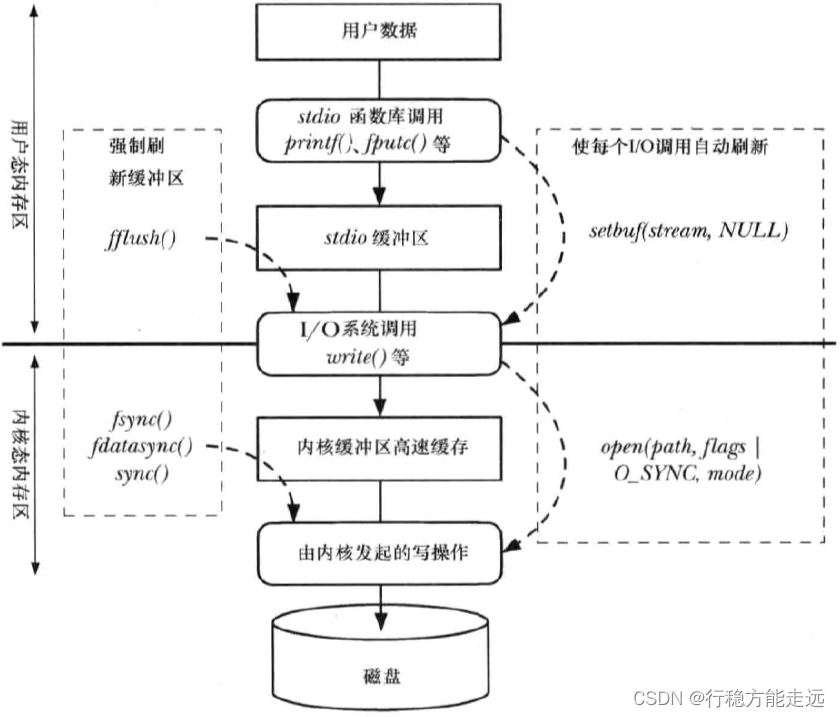
深入探究文件I/O
目录Linux 系统如何管理文件静态文件与inode文件打开时的状态返回错误处理与errnostrerror 函数perror 函数exit、_exit、_Exit_exit()和_Exit()函数exit()函数空洞文件概念实验测试O_APPEND 和O_TRUNC 标志O_TRUNC 标志O_APPEND 标志多次打开同一个文件验证一些现象多次打开同…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...
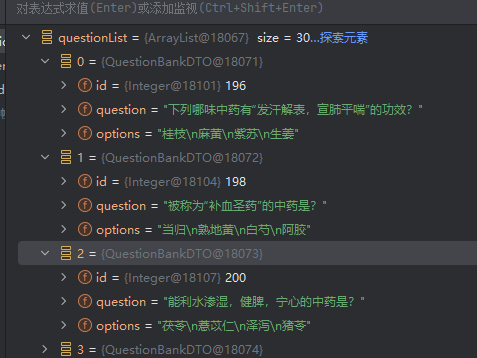
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...

边缘计算网关提升水产养殖尾水处理的远程运维效率
一、项目背景 随着水产养殖行业的快速发展,养殖尾水的处理成为了一个亟待解决的环保问题。传统的尾水处理方式不仅效率低下,而且难以实现精准监控和管理。为了提升尾水处理的效果和效率,同时降低人力成本,某大型水产养殖企业决定…...
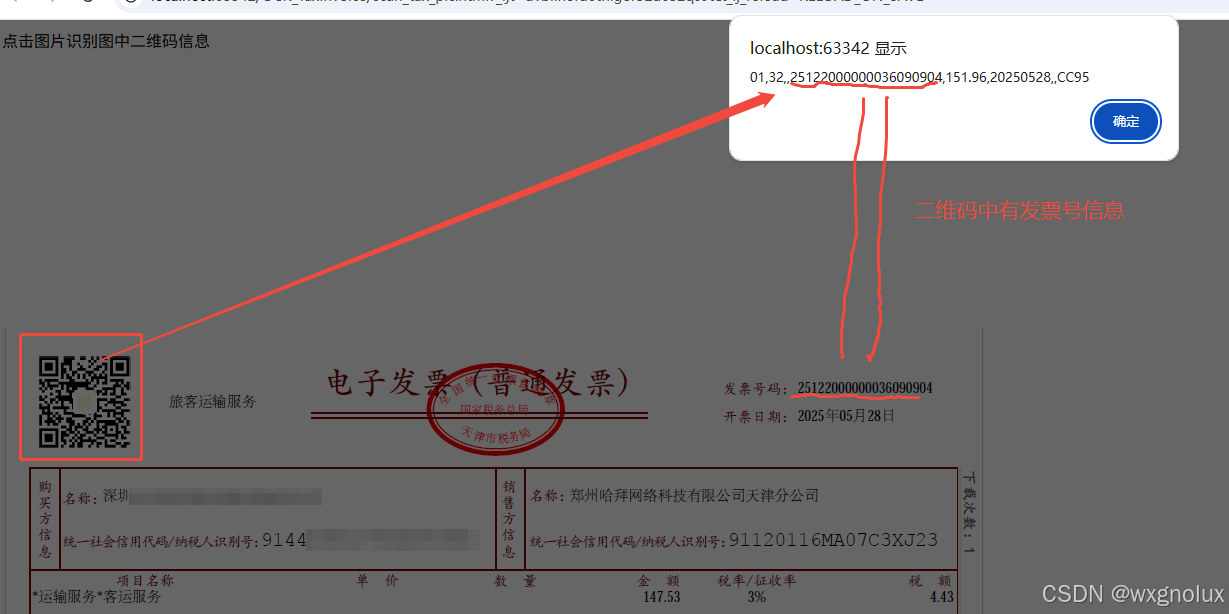
网页端 js 读取发票里的二维码信息(图片和PDF格式)
起因 为了实现在报销流程中,发票不能重用的限制,发票上传后,希望能读出发票号,并记录发票号已用,下次不再可用于报销。 基于上面的需求,研究了OCR 的方式和读PDF的方式,实际是可行的ÿ…...
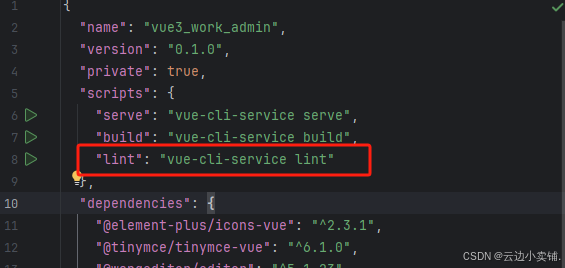
运行vue项目报错 errors and 0 warnings potentially fixable with the `--fix` option.
报错 找到package.json文件 找到这个修改成 "lint": "eslint --fix --ext .js,.vue src" 为elsint有配置结尾换行符,最后运行:npm run lint --fix...

多模态大语言模型arxiv论文略读(112)
Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文标题:Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文作者:Jea…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(八)
uboot启动异常及解决 网络问题及解决 打开STM32CubeMX选中ETH1 - A7NS(Linux)Mode:RGMII(Reduced GMII)勾选ETH 125MHz Clock Input修改GPIO引脚如图所示 Net: No ethernet found.生成代码后,修改u-boot下…...
自动化立体仓库堆垛机控制系统STEP7 OB1功能块
1、堆垛机控制系统STEP7硬件组态如下图 CPU CPU 314C-2 PN/DP 6ES7 314-6EH04-0AB0 SM 338 POS-INPUT AO2x12Bit 6ES7 332-5HB01-0AB0 2、堆垛机控制系统STEP7内部变量 前进HMI M 0.0 BOOL 后退HMI M 0.1 BOOL 上升HMI M 0.2 B…...

Oracle 19c RAC集群ADG搭建
1、将主库的pfile和passwdfile发送到备库 #主库一节点操作 scp -P1234 /tmp/pfile2025.ora bak_ip:/home/oracle sco -P1234 /oracle/app/oracle/product/19.0.0/db/dbs/orapw$ORACLE_SID bak_ip:/oracle/app/oracle/product/19.0.0/db/dbs 2、备库修改参数文件成standby相关…...