JAVA面试题简单整理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、重载和重写的区别
- 一、&和&&的区别
- 一、get和post请求的区别 delete、put
- 一、cookie和session的区别
- 一、@Autowired和@Resource区别
- 一、==”和equals 最大的区别是
- 一、IOC控制反转
- 一、什么是AOP?
- 一、AOP为什么叫切面编程?
- 一、为什么叫控制反转?
- 一、IOC和DI的区别?
- 一、Redis 持久化机制
- 一、缓存雪崩
- 一、缓存穿透
- 一、单线程的redis为什么这么快
- 一、redis的数据类型,以及每种数据类型的使用场景
- 一、SpringBoot和SpringCloud区别
- 一、总结一下SpringCloud结果核心组件
- 一、Spring的bean默认是单例多例
- 一、创建线程有哪几种方式?
- 一、runnable 和 callable 有什么区别
- 一、线程的 run() 和 start() 有什么区别
- 一、说一下 spring mvc 运行流程
- 一、spring mvc 有哪些组件
- 一、说一下list,set,map的区别
- 一、MySQL的事务
- 一、如何做 MySQL 的性能优化?
- 一、sql慢查询
- 一、通过MySQL命令查看有多少慢查询
- 一、HashMap和HashTable区别
- 一、ArrayList和LinkedList的区别如下
- 一、final、finally、finalize 有什么区别
- 一、说一下堆栈的区别
- 一、springbuilder和springbuffer
- 一、事务特性
- 一、事务的隔离级别
- 一、Mybatis 和 Hibernate 的区别
- 一、MySQL索引类型以及方法
- 一、查看索引是否生效
前言
提示:(不定期更新)
提示:以下是本篇文章正文内容,下面案例可供参考
一、重载和重写的区别
重载: 发生在同一类中,函数名必须一样,参数类型、参数个数、参数顺序、返回值、修饰符可以不一样。
重写: 发生在父子类中,函数名、参数、返回值必须一样,访问修饰符必须大于等于父类,异常要小于等于父类,父类方法是private不能重写。
一、&和&&的区别
&&: 如果一边为假,就不比较另一边。具有短路行
&: 两边都为假,结果才为假,多用于位运算。
一、get和post请求的区别 delete、put
get相对不安全,数据放在url中(请求行),post放在body中(请求体),相对安全。
get传送的数据量小,post传送的数据量大。
get效率比post高,是form的默认提交方法。
一、cookie和session的区别
存储位置不同:cookie放在客户端电脑,session放在服务器端内存的一个对象
存储容量不同:cookie <=4KB,一个站点最多保存20个cookie,session是没有上限的,但是性能考虑不要放太多,而且要设置session删除机制
存储数据类型不同:cookie只能存储ASCll字符串,session可以存储任何类型的数据
隐私策略不同:cookie放在本地,别人可以解析,进行cookie欺骗,session放在服务器,不存在敏感信息泄露
有效期不同:可以设置cookie的过期时间,session依赖于jsessionID的cookie,默认时间为-1,只需要关闭窗口就会失效
一、@Autowired和@Resource区别
1.提供方不同
@Autowired 是Spring提供的,@Resource 是J2EE提供的。
2.装配时默认类型不同
@Autowired只按type装配,@Resource默认是按name装配。
3、使用区别
(1)@Autowired与@Resource都可以用来装配bean,都可以写在字段或setter方法上
(2)@Autowired默认按类型装配,默认情况下必须要求依赖对象存在,如果要允许null值,
可以设置它的required属性为false。如果想使用名称装配可以结合@Qualifier注解进行使用。
一、==”和equals 最大的区别是
“==”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。
equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重写之后比较的是对象的值。
一、IOC控制反转
它是一种思想而不是一种技术实现。
作用:Java开发领域对象的创建及管理的问题。
例如:现有类A依赖类B
**传统的开发方式: 往往是在类A手动通过new关键字来new一个B对象出来
**使用IOC思想的开发方式:**不通过new关键字来创建对象,
而是通过IOC容器(spring框架)来帮助我们实例化对象。
我们需要哪个对象,直接从IOC容器里面拿就行
一、什么是AOP?
AOP:面向切面编程,AOP是OOP(面向对象编程)的延续。
例子:现有三个类,a、b、c,这三个类中都有 q 和 qq 两个方法。
通过 OOP 思想中的继承,我们可以提取出一个 Animal(哎里某) 的父类,然后将 q 和 qq 方法放入父类中,
a,b,c,通过继承Animal类即可自动获得q() 和qq() 方法。
这样将会少些很多重复的代码。
一、AOP为什么叫切面编程?
切:指的是横切逻辑,原有业务逻辑代码不动,只能操作横切逻辑代码,所以面向横切编程
面:横切逻辑代码往往影响的是很多个方法,每个方法如同一个点,多个点构成一个面。这里有一个面的概念
一、为什么叫控制反转?
控制:指的是对象的创建的权力
反转:指的控制权交给外部环境(Spring框架、IOC容器)
一、IOC和DI的区别?
IOC是一种设计思想或者说是一种某种模式。
这个设计思想就是将原本在程序中手动创建对象的控制权,
交由Spring框架来管理,IOC在其他语言中也有应用,并非Spring特有**。
IOC容器时Spring实现IOC的载体,IOC实际上就是一个Map(key,value),Map中存放的是各种对象**
IOC最常见以及最合理的实现方式叫依赖注入(简称DI)
一、Redis 持久化机制
Redis是一个支持持久化的内存数据库,通过持久化机制把内存中的数据同步到硬盘文件来保证数据持久化。
当Redis重启后通过把硬盘文件重新加载到内存,就能达到恢复数据的目的。
实现:单独创建fork()一个子进程,将当前父进程的数据库数据复制到子进程的内存中,
然后由子进程写入到临时文件中,持久化的过程结束了,再用这个临时文件替换上次的快照文件,然后子进程退出,内存释放。
RDB是Redis默认的持久化方式。按照一定的时间周期策略把内存的数据以快照的形式保存到硬盘的二进制文件。
即Snapshot快照存储,对应产生的数据文件为dump.rdb,通过配置文件中的save参数来定义快照的周期。
( 快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。)
AOF:Redis会将每一个收到的写命令都通过Write函数追加到文件最后,
类似于MySQL的binlog。当Redis重启是会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。
当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复
一、缓存雪崩
我们可以简单的理解为:由于原有缓存失效,新缓存未到期间
(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),
所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,
严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决办法:
大多数系统设计者考虑用加锁( 最多的解决方案)或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,
从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开。
一、缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,
在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。
这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
解决办法;
最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,
一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),
我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,
这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
一、单线程的redis为什么这么快
(一)纯内存操作
(二)单线程操作,避免了频繁的上下文切换
(三)采用了非阻塞I/O多路复用机制
一、redis的数据类型,以及每种数据类型的使用场景
回答:一共五种
(一)String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。
(二)hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,
以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
(三)list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,
做基于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适—取行情信息。就也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
(四)set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?
因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
(五)sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作
一、SpringBoot和SpringCloud区别
SpringBoot专注于快速方便的开发单个个体微服务。
SpringCloud是关注全局的微服务协调整理治理框架,
它将SpringBoot开发的一个个单体微服务整合并管理起来,
为各个微服务之间提供,配置管理、服务发现、断路器、路由、
微代理、事件总线、全局锁、决策竞选、
分布式会话等等集成服务SpringBoot可以离开SpringCloud独立使用开发项目,
但是SpringCloud离不开SpringBoot ,属于依赖的关系SpringBoot专注于快速、
方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
一、总结一下SpringCloud结果核心组件
Eureka:服务启动时,Eureka会将服务注册到EurekaService,并且EurakeClient还可以返回过来从EurekaService拉去注册表,从而知道服务在哪里
Ribbon:服务间发起请求的时候,基于Ribbon服务做到负载均衡,从一个服务的对台机器中选择一台
Feign:基于fegin的动态代理机制,根据注解和选择机器,拼接Url地址,发起请求
Hystrix:发起的请求是通过Hystrix的线程池来走,不同的服走不同的线程池,实现了不同的服务调度隔离,避免服务雪崩的问题
Zuul:如果前端后端移动端调用后台系统,统一走zull网关进入,有zull网关转发请求给对应的服务
一、Spring的bean默认是单例多例
默认是单例,是并发不安全的,以Controller举例,问题根源在于,
我们可能会在Controller中定义成员变量,如此一来,多个请求来临,
进入的都是同一个单例的Controller对象,并对此成员变量的值进行修改操作
因此会互相影响,无法达到并发安全(不同于线程隔离的概念,后面会解释到)的效果。
一、创建线程有哪几种方式?
继承 Thread (思瑞的)重写 run 方法;
实现 Runnable 接口;
实现 Callable 接口。
一、runnable 和 callable 有什么区别
runnable 没有返回值,callable 可以拿到有返回值,callable 可以看作是 runnable 的补充。
一、线程的 run() 和 start() 有什么区别
start() 方法用于启动线程,run() 方法用于执行线程的运行时代码。run() 可以重复调用,而 start() 只能调用一次。
try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
finally 一定会执行,即使是 catch 中 return 了,catch 中的 return 会等 finally 中的代码执行完之后,才会执行
一、说一下 spring mvc 运行流程
springMVC是一个基于注解型的MVC框架。
它的核心控制器是dispatcherServlet,在web.xml中配置。
用户发起的请求都会被核心控制器拦截,进入springMVC的核心配置文件spring-servlet.xml。
在这个xml中,主要配置的是注解的开启和扫描信息。
首先要开启注解模式,并且指定注解所在的路径。
当请求到达后,springMVC会根据请求的action名称,
通过ActionMapping去找到对应的controller类中的requestMapping注解,
这个注解中有一个value值,需要与请求的名称保持一致。所以请求可以到达action层。
当然,springMVC也有自己的拦截器Interceptor。如果需要完成自定义拦截器,
则需要写一个类,去继承handlerInterceptor类。
重写里面的preHandler方法,在这方法中,
通过返回true或者fasle来决定请求继续执行还是被拦截
一、spring mvc 有哪些组件
前置控制器 DispatcherServlet。
映射控制器 HandlerMapping。
处理器 Controller。
模型和视图 ModelAndView。
一、说一下list,set,map的区别
List:
1.可以允许重复的对象。
2.可以插入多个null元素。
3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
4.常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList 最为流行,它提供了使用索引的随意访问,
而 LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适。Set:
1.不允许重复对象
2无序容器,你无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序。
3. 只允许一个 null 元素
4.Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于
HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其
compare() 和 compareTo() 的定义进行排序的有序容器。
Map:
1.Map不是collection的子接口或者实现类。Map是一个接口。
2.Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
3. TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
4. Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
5.Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。>>(HashMap、TreeMap最常用)
一、MySQL的事务
1、原子性(Atomicity):
事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,
会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位
2、一致性(Consistency):
事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
3、隔离性(Isolation):
同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,
在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability):
事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
一、如何做 MySQL 的性能优化?
不要把 select 子句写成 select *
对 order by 排序的字段设置索引,可以大大加快数据库执行的速度
尽量少用 or 运算符,因为逻辑或运算符也会让数据库跳过索引
尽量少用 in 和 not in 运算符,原因和 or 运算符一样,都属于逻辑或关系
1.对查询进行优化, 尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2. 尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3. 尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4. 尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
查询索引是否生效可以用expalin( A可丝不勒)方法查询type是否生效
索引并不是越多越好,索引固然可以提高相应的 select 的效率,
但同时也降低了 insert 及 update 的效率,
因为 insert 或 update 时有可能会重建索引,
所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过6个,
若太多则应考虑一些不常使用到的列上建的索引是否有必要
一、sql慢查询
一直慢的原因:
索引没有设计好、SQL 语句没写好、MySQL 选错了索引’
mysql慢查询优化
第一步:开启mysql慢查询日志,通过慢查询日志定位到执行较慢的SQL语句。
查看是否开启慢查询
show variables(外瑞bo死) like ‘slow(死咯)_query%’;
1.low_query_log 慢查询开启状态 OFF 未开启 ON 为开启
2.slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
第二步:利用explain关键字可以模拟优化器执行SQL查询语句,来分析SQL查询语句。
第三步:通过查询的结果进行优化
一、通过MySQL命令查看有多少慢查询
show globalstatus like ‘%Slow_queries%’;
| Slow_queries | 1 |
优化方式
(1)首先分析语句,看看是否包含了额外的数据,可能是查询了多余的行并抛弃掉了,也可能是加了结果中不需要的列,要对SQL语句进行分析和重写。
(2)分析优化器中索引的使用情况,要修改语句使得更可能的命中索引。比如使用组合索引的时候符合最左前缀匹配原则。not in,not like都不会走索引,可以优化为in.
(3)如果对语句的优化已经无法执行,可以考虑表中的数据是否太大,如果是的话可以横向和纵向的切表。
一、HashMap和HashTable区别
(1)线程安全性不同
HashMap是线程不安全的,HashTable是线程安全的,
产生时间:Hashtable是java发布时提供的键值映射的数据结构,HashMap是在JDK1.2推出时才有的
继承的父类:HashMap继承自AbstractMap类,HashTable继承自Dictionary类
对外提供接口:Hashtable比HashMap多提供了elments() 和contains() 两个方法
一、ArrayList和LinkedList的区别如下
ArrayList的实现是基于数组,LinkedList的实现是基于双向链表。
对于随机访问,ArrayList优于LinkedList,ArrayList可以根据下标以O(1)时间复杂度对元素进行随机访问。
而LinkedList的每一个元素都依靠地址指针和它后一个元素连接在一起,
在这种情况下,查找某个元素的时间复杂度是O(n)
对于插入和删除操作,LinkedList优于ArrayList,因为当元素被添加到LinkedList任意位置的时候,
不需要像ArrayList那样重新计算大小或者是更新索引。
LinkedList比ArrayList更占内存,因为LinkedList的节点除了存储数据,
还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
一、final、finally、finalize 有什么区别
final
final关键字主要用在三个地方:变量、方法、类;
final修饰的变量是常量不能被修改;
final修饰的方法是私有(private)不可被调用;
final修饰的类不能被继承,类中的所有成员方法都被指定为final方法;
finally
finally:是 try{} catch{} finally{} 最后一部分,表示不论发生任何情况都会执行,finally 部分可以省略,
但如果 finally 部分存在,则一定会执行 finally 里面的代码。
finalize
finalize: 是 Object 类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法。
一、说一下堆栈的区别
功能方面:堆是用来存放对象的,栈是用来执行程序的。
共享性:堆是线程共享的,栈是线程私有的。
空间大小:堆大小远远大于栈。
一、springbuilder和springbuffer
1.springbuilder是可变的,他不是线程安全的
2.springbuffer是可变的线程是安全的,所以他的开销比stringbuilder大
3.stringbuffer是线程安全的所有的方法都是同步的,stringbuilder没有对方法加锁,所有stringbubuffer性能好于stringbuilder
4.StringBuffer每次toString都会使⽤toStringCache值来构造⼀个字符串,⽽StringBuilder则每次都需要复制⼀次字节数组,再构造⼀个字符串
一、事务特性
1. 原子性(Atomic)
一个事务包含多个操作,这些操作要么全部执行,要么全都不执行。实现事务的原子性,要支持回滚操作,在某个操作失败后,回滚到事务执行之前的状态。
回滚实际上是一个比较高层抽象的概念,大多数DB在实现事务时,是在事务操作的数据快照上进行的(比如,MVCC),并不修改实际的数据,如果有错并不会提交,所以很自然的支持回滚。
而在其他支持简单事务的系统中,不会在快照上更新,而直接操作实际数据。可以先预演一边所有要执行的操作,如果失败则这些操作不会被执行,通过这种方式很简单的实现了原子性。
- 一致性(Consistency)
一致性是指事务使得系统从一个一致的状态转换到另一个一致状态。事务的一致性决定了一个系统设计和实现的复杂度。事务可以不同程度的一致性:
强一致性:读操作可以立即读到提交的更新操作。
弱一致性:提交的更新操作,不一定立即会被读操作读到,此种情况会存在一个不一致窗口,指的是读操作可以读到最新值的一段时间。
最终一致性:是弱一致性的特例。事务更新一份数据,最终一致性保证在没有其他事务更新同样的值的话,最终所有的事务都会读到之前事务更新的最新值。
如果没有错误发生,不一致窗口的大小依赖于:通信延迟,系统负载等。
其他一致性变体还有:
单调一致性:如果一个进程已经读到一个值,那么后续不会读到更早的值。
会话一致性:保证客户端和服务器交互的会话过程中,读操作可以读到更新操作后的最新值。 - 隔离性(Isolation)
并发事务之间互相影响的程度,比如一个事务会不会读取到另一个未提交的事务修改的数据。在事务并发操作时,可能出现的问题有:
脏读:事务A修改了一个数据,但未提交,事务B读到了事务A未提交的更新结果,如果事务A提交失败,事务B读到的就是脏数据。
不可重复读:在同一个事务中,对于同一份数据读取到的结果不一致。比如,事务B在事务A提交前读到的结果,和提交后读到的结果可能不同。
不可重复读出现的原因就是事务并发修改记录,要避免这种情况,最简单的方法就是对要修改的记录加锁,这回导致锁竞争加剧,影响性能。
另一种方法是通过MVCC可以在无锁的情况下,避免不可重复读。
幻读:在同一个事务中,同一个查询多次返回的结果不一致。事务A新增了一条记录,事务B在事务A提交前后各执行了一次查询操作,
发现后一次比前一次多了一条记录。 幻读是由于并发事务增加记录导致的,这个不能像不可重复读通过记录加锁解决,
因为对于新增的记录根本无法加锁。需要将事务串行化,才能避免幻读。 - 持久性(Durability)
事务提交后,对系统的影响是永久的。
一、事务的隔离级别
未提交读(Read Uncommitted):事务可以读取未提交的数据,也称作脏读(Dirty Read)。一般很少使用。
提交读(Read Committed):是大都是 DBMS (如:Oracle, SQLServer)默认事务隔离。
执行两次同意的查询却有不同的结果,也叫不可重复读。
可重复读(Repeable Read):是 MySQL 默认事务隔离级别。
能确保同一事务多次读取同一数据的结果是一致的。可以解决脏读的问题,
但理论上无法解决幻读(Phantom Read)的问题。
可串行化(Serializable):是最高的隔离级别。强制事务串行执行,
会在读取的每一行数据上加锁,这样虽然能避免幻读的问题,但也可能导致大量的超时和锁争用的问题。
很少会应用到这种级别,只有在非常需要确保数据的一致性且可以接受没有并发的应用场景下才会考虑。
一、Mybatis 和 Hibernate 的区别
Hibernate和MyBatis都是实现了ORM思想的框架,但是
Hibernate一个是全封装,mybatis是半封装,
使用hibernate做单表查询操作的时候比较简单
(因为hibernate是针对对象进行操作的),
但是多表查询起来就比较繁琐了,比如说5张表10张表做关联查询,
就算是有SQLquery那后续的维护工作也比较麻烦,
还有就是Hibernate在Sql优化上执行效率上会远低于MyBatis
(因为hibernate会把表中所有的字段查询出来,比较消耗性能)
我们以前在做传统项目方面用过hibernate,
但是现在基本上都在用mybatis.
在开发效率上 mybatis 可能要稍逊于 hibernate
一、MySQL索引类型以及方法
mysql索引类型:FULLTEXT、NORMAL、SPATIAL、UNIQUE
mysql索引方法:btree 和 hash
一、Normal 普通索引
表示普通索引,大多数情况下都可以使用
二、Unique 唯一索引
表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,
可设置为unique
约束唯一标识数据库表中的每一条记录,即在单表中不能用每条记录是唯一的(例如身份证就是唯一的),Unique(要求列唯一)和Primary Key(primary key = unique + not null 列唯一)约束均为列或列集合中提供了唯一性的保证,Primary Key是拥有自动定义的Unique约束,但是每个表中可以有多个Unique约束,但是只能有一个Primary Key约束。
mysql中创建Unique约束
三、Full Text 全文索引
表示全文收索,在检索长文本的时候,效果最好,短文本建议使用Index,但是在检索的时候数据量比较大的时候,现将数据放入一个没有全局索引的表中,然后在用Create Index创建的Full Text索引,要比先为一张表建立Full Text然后在写入数据要快的很多
FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
四、SPATIAL 空间索引
空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
一、查看索引是否生效

相关文章:
JAVA面试题简单整理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、重载和重写的区别一、&和&&的区别一、get和post请求的区别 delete、put一、cookie和session的区别一、Autowired和Resource区别一、”和equals…...

dd命令用法学习,是一个功能强大的工具
dd 命令是一个功能强大的工具,它有许多参数可以用来控制其行为。以下是 dd 命令中常用的一些参数: - ifinputfile:指定输入文件的路径。 - ofoutputfile:指定输出文件的路径。 - bssize:设置每个块的大小。可以使用不同…...

Games104现代游戏引擎笔记 网络游戏进阶架构
Character Movement Replication 角色位移同步 玩家2的视角看玩家1的移动是起伏一截一截,并且滞后的 interpolation:内插值,在两个旧的但已知的状态计算 extrapolation:外插值,本质是预测 内插值:但网络随着…...

Apollo 快速上手指南:打造自动驾驶解决方案
快速上手 概述云端体验登录云端仿真环境 打开DreamView播放离线数据包PNC Monitor 内置的数据监视器cyber_monitor 实时通道信息视图福利活动 主页传送门:📀 传送 概述 Apollo 开放平台是一个开放的、完整的、安全的平台,将帮助汽车行业及自…...
笔记——预处理器)
C现代方法(第14章)笔记——预处理器
文章目录 第14章 预处理器14.1 预处理器的工作原理14.2 预处理指令14.3 宏定义14.3.1 简单的宏14.3.2 带参数的宏14.3.3 #运算符14.3.4 ##运算符14.3.5 宏的通用属性14.3.6 宏定义中的圆括号14.3.7 创建较长的宏14.3.8 预定义宏14.3.9 C99中新增的预定义宏14.3.10 空的宏参数(C…...

Kafka KRaft模式探索
1.概述 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。其核心组件包含Producer、Broker、Consumer,以及依赖的Zookeeper集群。其中Zookeeper集群是Kafka用来负责集群元数据的管理、控制器的选举等。 2.内容…...
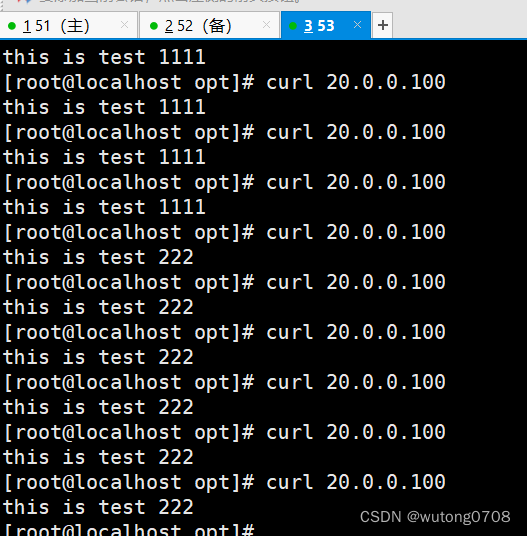
LVS-keepalived实现高可用
概念: 本章核心: Keepalived为LVS应运而生的高可用服务。LVS的调度无法做高可用,预算keepalived这个软件,实现了调度器的高可用。 但是:Keeplived不是专门为LVS集群服务的,也可以做其他服务器的高可用 LVS…...

Linux内核驱动开发的需要掌握的知识点
Linux内核驱动开发是一项复杂而有挑战性的任务,需要掌握多方面的知识和技能。下面是一些需要掌握的关键知识点,这些知识将有助于你成功地开发Linux内核驱动程序。 1. Linux内核基础知识 首先,了解Linux内核的基础知识至关重要。这包括Linux…...
nginx 动静分离 防盗链
一、动静分离环境准备静态资源配置(10.36.192.169)安装nginx修改配置文件重启nginx 动态资源配置(192.168.20.135)yum安装php修改nginx配置文件重启nginx nginx代理机配置(192.168.20.134)修改nginx子自配置文件重启nginx 客户端访问 二、防盗链nginx防止…...
)
MYSQL(索引篇)
一、什么是索引 索引是一种数据结构,它用来帮助MYSQL更高效的获取数据 采用索引可以提高数据检索的效率,降低IO成本 通过索引对数据排序,降低数据排序成本,降低CPU消耗 常见的有:B树索引、B树索引、哈希索引。其中Inno…...
Java API访问HDFS
一、下载IDEA 下载地址:https://www.jetbrains.com/idea/download/?sectionwindows#sectionwindows 拉到下面使用免费的IC版本即可。 运行下载下来的exe文件,注意安装路径最好不要安装到C盘,可以改成其他盘,其他选项按需勾选即可…...

高三高考免费试卷真题押题知识点合集
发表于安徽 温馨提示:有需要的真题试卷可联系本人,百卷内上免费资源。 感觉有用的下方三连,谢谢 。 免费版卷有6-60卷每卷平均4-30页 高三免费高三地理高三英语高三化学高三物理高三语文高三历史高三政治高三数学高三生物 付费版卷有1…...
 不起效 原因)
css 计算函数属性:calc() 不起效 原因
踩坑:注意事项(- 减号或加号前后需要空格!!!) calc(100% - 251px); 这里错误写法中-两边没加空格,导致width不生效。但并不是所有运算符间都需要加空格,只有 和 - 需要加空格,因为运算允许负…...

2、TB6600驱动器介绍【51单片机控制步进电机-TB6600系列】
摘要:本节介绍TB6600驱动器界面及关键参数设置 一、驱动器功能界面 二、关键参数 输入电压:DC9-42V 输出电流:0.5-4A 最大功耗:160W 细分设置:1,2/A,2/B,4,8,16,32 工作温度:-10~45C 信号口驱动电流&…...

Vue3:将表格数据下载为excel文件
需求 将表格数据或者其他形式的数据下载为excel文件 技术栈 Vue3、ElementPlus、 实现 1、安装相关的库 下载xlsx 和 file-saver 库 npm install -S file-saver npm install -S xlsx引入XLSX库和FileSaver库 import XLSX from xlsx; import FileSaver from file-saver;…...
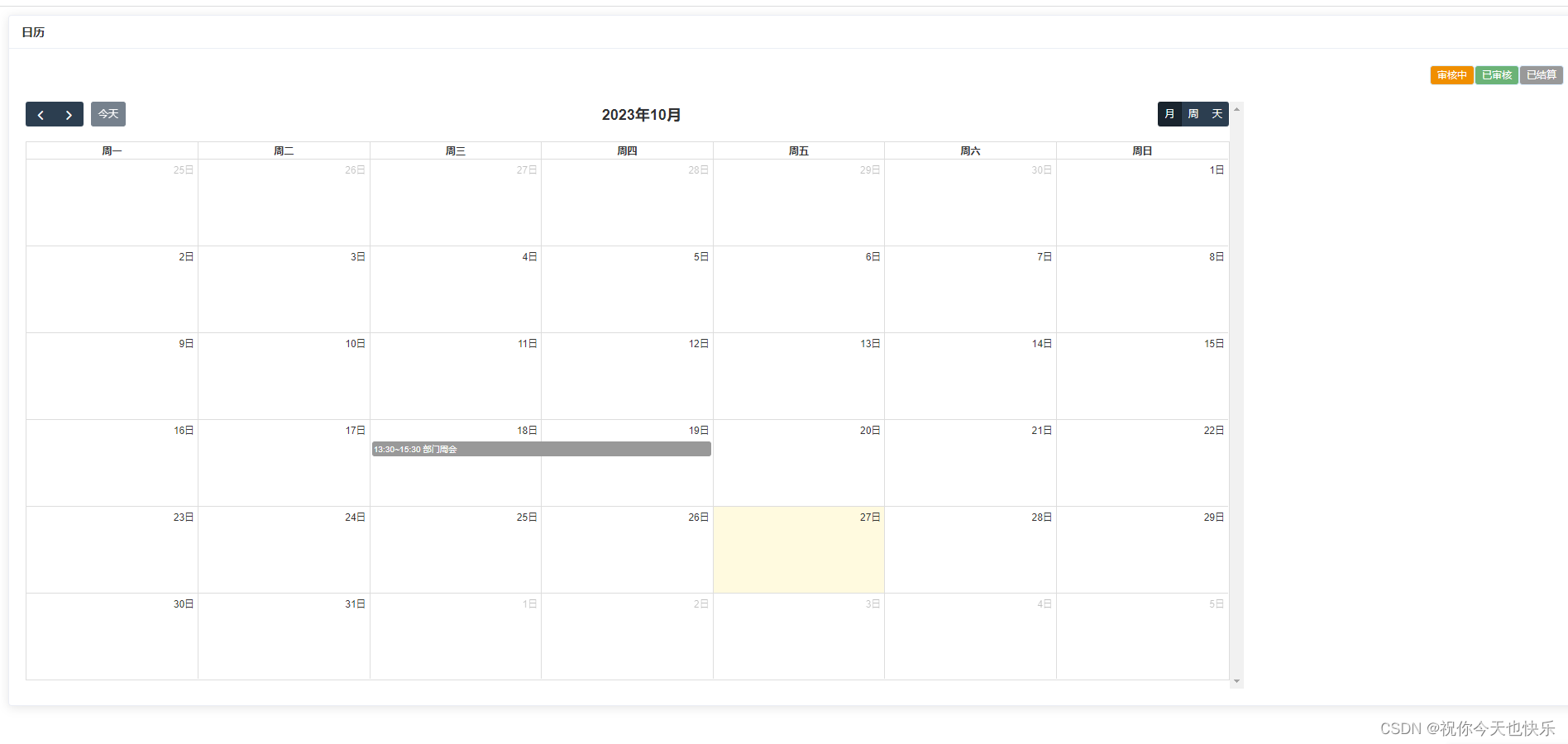
vue+Fullcalendar
vueFullcalendar: vueFullcalendar项目代码https://gitee.com/Oyxgen404/vue--fullcalendar.git...

Spring定时任务+webSocket实现定时给指定用户发送消息
生命无罪,健康万岁,我是laity。 我曾七次鄙视自己的灵魂: 第一次,当它本可进取时,却故作谦卑; 第二次,当它在空虚时,用爱欲来填充; 第三次,在困难和容易之…...
:数组(1))
C语言学习笔记(六):数组(1)
0,问题的引入 怎么保存一个学生的成绩 float a; 怎么保存一个班(10人)的学生的成绩 float a,b,c,d......; float a1,a2,a3,........; 这样太麻烦了 -》“数组” 1,数组 什么是数组ÿ…...

apk反编译修改教程系列-----修改apk中的图片 任意更换apk桌面图片【三】
往期教程: apk反编译修改教程系列-----修改apk应用名称 任意修改名称 签名【一】 apk反编译修改教程系列-----任意修改apk版本号 版本名 防止自动更新【二】 这次实例演示下如何更换apk安装后的桌面图标图片。其实这个步骤前面我有一个教程贴。这次针对步骤做个补…...

【IO面试题 五】、 Serializable接口为什么需要定义serialVersionUID变量?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官: Serializable接口为什么…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...