EfficientViT:高分辨率密集预测的多尺度线性关注
标题:EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
论文:https://arxiv.org/abs/2205.14756
中文版:【读点论文】EfficientViT: Enhanced Linear Attention for High-Resolution Low-Computation将softmax注意力转变为线性注意力_羞儿的博客-CSDN博客
代码:https://codeload.github.com/mit-han-lab/efficientvit/zip/refs/heads/master
目录
一、摘要
二、主要贡献
三、方法论
3.1 Multi-Scale Linear Attention(多尺度线性注意力)
3.2 EfficientViT架构
四、实验
4.1 消融研究
4.2 语义分割实验
五、总结
一、摘要
研究背景:高分辨率密集预测使许多有吸引力的现实世界的应用,如计算摄影,自动驾驶等,然而,巨大的计算成本使得部署最先进的高分辨率密集预测模型的硬件设备上的困难。
主要工作:本文提出了一种新的多尺度线性attention的高分辨率视觉模型——EfficientViT。与之前的高分辨率密集预测模型依赖于大量的softmax关注、硬件低效的大核卷积或复杂的拓扑结构来获得良好的性能不同,多尺度线性attention只需要轻量级和硬件高效的操作就能实现全局接受场和多尺度学习(高分辨率密集预测的两个理想特征)。
研究成果:因此,在各种硬件平台(包括移动CPU、边缘GPU和云GPU)上,EfficientViT比以前的最先进型号提供了显著的性能提升。在Cityscapes(数据集)上没有性能损失的情况下,EfficientViT分别比SegFormer和SegNeXt提供了高达13.9倍和6.2倍的GPU延迟减少。对于超分辨率,EfficientViT比Restormer提供高达6.4倍的加速,同时提供0.11dB的PSNR增益。
二、主要贡献
1. 引入了一个新的多尺度线性注意力模块,用于高效的高分辨率稠密预测。它实现了全局感受野和多尺度学习,同时保持了良好的硬件效率。据我们所知,我们的工作是第一个证明线性注意力对高分辨率密集预测的有效性。
2. 我们设计了高效vit,一个新的高分辨率系列基于视觉模型,提出了多尺度线性注意模块。
3. EfficientViT在不同硬件平台(移动的CPU,边缘GPU和云GPU)上的语义分割,超分辨率,分割任何东西和ImageNet分类方面都比以前的SOTA模型有显著的加速。
三、方法论
3.1 Multi-Scale Linear Attention(多尺度线性注意力)
多尺度线性注意力仅通过硬件高效的操作同时实现了全局感受野和多尺度学习。基于多尺度线性注意力,作者提出了一种新的用于高分辨率密集预测的Vision transformer模型EfficientVit。

动机:从性能角度来看,全局感受野和多尺度学习是必不可少的。以前的 SOTA 高分辨率密集预测模型通过启用这些特征提供了较强的性能,但不能提供良好的效率。多尺度线性注意力模块通过用轻微的性能损失换取显著的效率提升来解决这个问题。
方法:使用ReLU线性注意力来实现全局感受野,而不是繁重的softmax注意力。
ReLU线性注意力的公式推导:
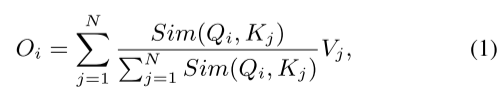
![]()
由传统的softmax注意力公式和Relu注意力相似度计算函数(相似度计算函数替换为Relu版的),可得:

由矩阵乘法的结合律,可得:

推导最终结论:由公式(3)所示,只需要计算![]() 和
和![]()
一次,就可以对每个Query重用它们(多头attention机制查询无关问题的最终解???),从而只需要O(N)的计算代价和O(N)的内存。
ReLU线性注意力的局限性:如下图所示,softmax 注意和 ReLU 线性注意的注意图。由于缺乏非线性相似函数,ReLU 线性注意不能生成集中的注意图,捕获局部信息的能力较弱。(ReLU线性注意缺点暴露)

解决方案:
1. 为了减轻其局限性,我们提出用卷积增强 ReLU 线性注意力。具体来说,在每个 FFN 层中插入深度卷积。如下图所示,其中 ReLU 线性注意力捕获上下文信息,FFN+DWConv 捕获局部信息。
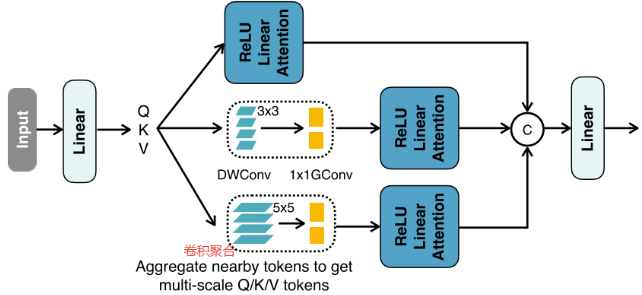
2. 将邻近的 Q/K/V token信息聚合(拼接)成多尺度token,以增强 ReLU 线性注意的多尺度学习能力(这里多尺度是指通道方向上的不同尺度,所以聚合能多尺度学习能力)。
具体来说,将所有DWConv融合成单个DWConv组,将所有 1x1 Convs合并成单个1x1的卷积组,组数为3 × #head,每组通道数为d。得到多尺度token后,对其进行ReLU线性注意力,提取多尺度全局特征。最后,将特征沿头部维度进行连接,并将其提供给最终的线性层以融合特征。
(本质上是使用nn.Conv2d()函数中的groups参数,将输入和输出通道分成几组进行卷积操作,学习通道方向上的不同尺度的信息。)
Q:感受野和注意力机制有什么关系?
A:注意力机制可以通过计算不同位置之间的关系,来捕捉长距离依赖关系,从而扩大感受野,提高网络的感知能力。
代码如下:
轻量权重多尺度注意力模块
# 轻量权重多尺度注意力
class LiteMLA(nn.Module):r"""Lightweight multi-scale linear attention"""def __init__(self,in_channels: int,out_channels: int,heads: int or None = None,heads_ratio: float = 1.0,dim=8,use_bias=False,norm=(None, "bn2d"),act_func=(None, None),kernel_func="relu",scales: tuple[int, ...] = (5,),eps=1.0e-15,):super(LiteMLA, self).__init__()self.eps = epsheads = heads or int(in_channels // dim * heads_ratio)total_dim = heads * dimuse_bias = val2tuple(use_bias, 2)norm = val2tuple(norm, 2)act_func = val2tuple(act_func, 2)self.dim = dimself.qkv = ConvLayer(in_channels,3 * total_dim,1,use_bias=use_bias[0],norm=norm[0],act_func=act_func[0],)self.aggreg = nn.ModuleList([nn.Sequential(nn.Conv2d(3 * total_dim,3 * total_dim,scale,padding=get_same_padding(scale),groups=3 * total_dim,bias=use_bias[0],),nn.Conv2d(3 * total_dim, 3 * total_dim, 1, groups=3 * heads, bias=use_bias[0]),)for scale in scales]) # nn.Conv2d()函数中的groups参数是指将输入和输出通道分成几组进行卷积操作self.kernel_func = build_act(kernel_func, inplace=False) # Relu激活函数self.proj = ConvLayer(total_dim * (1 + len(scales)),out_channels,1,use_bias=use_bias[1],norm=norm[1],act_func=act_func[1],)@autocast(enabled=False)def relu_linear_att(self, qkv: torch.Tensor) -> torch.Tensor:B, _, H, W = list(qkv.size())if qkv.dtype == torch.float16:qkv = qkv.float()qkv = torch.reshape(qkv,(B,-1,3 * self.dim,H * W,),)qkv = torch.transpose(qkv, -1, -2)q, k, v = (qkv[..., 0 : self.dim],qkv[..., self.dim : 2 * self.dim],qkv[..., 2 * self.dim :],)# lightweight linear attentionq = self.kernel_func(q) # 进行relu激活k = self.kernel_func(k) # 进行relu激活# linear matmultrans_k = k.transpose(-1, -2)v = F.pad(v, (0, 1), mode="constant", value=1) # 进行维度扩展kv = torch.matmul(trans_k, v) # 按推导公式计算out = torch.matmul(q, kv)out = out[..., :-1] / (out[..., -1:] + self.eps)out = torch.transpose(out, -1, -2)out = torch.reshape(out, (B, -1, H, W))return outdef forward(self, x: torch.Tensor) -> torch.Tensor:# generate multi-scale q, k, vqkv = self.qkv(x) # 获取Q、K、V,由1x1卷积得到multi_scale_qkv = [qkv]for op in self.aggreg: # 卷积聚合,学习通道上的多尺度信息multi_scale_qkv.append(op(qkv))multi_scale_qkv = torch.cat(multi_scale_qkv, dim=1) # Q、K、V拼接out = self.relu_linear_att(multi_scale_qkv) # 重新等分划分为Q,K,V,馈入ReLU线性注意力out = self.proj(out) # 1x1卷积输出,模拟线性层return out
3.2 EfficientViT架构

如上图所示,
Backbone(骨干):由输入层和四个阶段组成,特征图大小逐渐减小,通道数量逐渐增加。在阶段3和4中插入EfficientViT模块。对于下采样,我们使用步幅为2的MBConv。
Head(分割头):P2、P3和P4表示阶段2、3和4的输出,形成特征图的金字塔。为了简单和高效,使用1x 1卷积和标准上采样操作(例如,双线性/双三次上采样)以匹配它们的空间和信道大小并经由加法来融合它们。简单的头部设计,其包括若干MBConv块和输出层(即,预测和上采样)。
代码如下:
Backbone(骨干)
class EfficientViTBackbone(nn.Module):# Backbone:input_stem + stage1 + stage2 + stage3 + stage4def __init__(self,width_list: list[int],depth_list: list[int],in_channels=3,dim=32,expand_ratio=4,norm="bn2d",act_func="hswish",) -> None:super().__init__()self.width_list = []# input stemself.input_stem = [ConvLayer(in_channels=3,out_channels=width_list[0],stride=2,norm=norm,act_func=act_func,) # 3x3卷积 -> 下采2倍]for _ in range(depth_list[0]):block = self.build_local_block( # 构建DSConv模块,捕捉局部信息in_channels=width_list[0],out_channels=width_list[0],stride=1,expand_ratio=1,norm=norm,act_func=act_func,)self.input_stem.append(ResidualBlock(block, IdentityLayer())) # 增加残差in_channels = width_list[0]self.input_stem = OpSequential(self.input_stem) # 把input_stem阶段各模块按顺序添加到ModuleList中self.width_list.append(in_channels) # 把每个模块的通道数添加到width_list# stagesself.stages = []# # # stages1for w, d in zip(width_list[1:3], depth_list[1:3]):stage = []for i in range(d):stride = 2 if i == 0 else 1block = self.build_local_block( # 构建MBConv模块,捕捉局部信息in_channels=in_channels,out_channels=w,stride=stride,expand_ratio=expand_ratio,norm=norm,act_func=act_func,)block = ResidualBlock(block, IdentityLayer() if stride == 1 else None) # 增加残差stage.append(block)in_channels = wself.stages.append(OpSequential(stage))self.width_list.append(in_channels)for w, d in zip(width_list[3:], depth_list[3:]):stage = []# # # stages2block = self.build_local_block( # 构建MBConv模块,捕捉局部信息in_channels=in_channels,out_channels=w,stride=2,expand_ratio=expand_ratio,norm=norm,act_func=act_func,fewer_norm=True,)stage.append(ResidualBlock(block, None))in_channels = w# # # stages3、4for _ in range(d):stage.append(EfficientViTBlock( # EfficientViTBlock模块,多尺度注意力提取上下文特征in_channels=in_channels,dim=dim,expand_ratio=expand_ratio,norm=norm,act_func=act_func,))self.stages.append(OpSequential(stage))self.width_list.append(in_channels)self.stages = nn.ModuleList(self.stages) # nn.ModuleList,用于存储不同的模块,并自动将每个模块的参数添加到网络中# 构建DSConv 或 MBConv —> 局部信息@staticmethoddef build_local_block(in_channels: int,out_channels: int,stride: int,expand_ratio: float,norm: str,act_func: str,fewer_norm: bool = False,) -> nn.Module:if expand_ratio == 1:block = DSConv( # DSConv模块in_channels=in_channels,out_channels=out_channels,stride=stride,use_bias=(True, False) if fewer_norm else False,norm=(None, norm) if fewer_norm else norm,act_func=(act_func, None),)else:block = MBConv( # MBConv模块,Mobile倒置残差瓶颈卷积 -> 2倍下采样in_channels=in_channels,out_channels=out_channels,stride=stride,expand_ratio=expand_ratio,use_bias=(True, True, False) if fewer_norm else False,norm=(None, None, norm) if fewer_norm else norm,act_func=(act_func, act_func, None),)return blockdef forward(self, x: torch.Tensor) -> dict[str, torch.Tensor]:output_dict = {"input": x}output_dict["stage0"] = x = self.input_stem(x)for stage_id, stage in enumerate(self.stages, 1): # 网络的backboneoutput_dict["stage%d" % stage_id] = x = stage(x)output_dict["stage_final"] = xreturn output_dictDSConv模块
class DSConv(nn.Module):def __init__(self,in_channels: int,out_channels: int,kernel_size=3,stride=1,use_bias=False,norm=("bn2d", "bn2d"),act_func=("relu6", None),):super(DSConv, self).__init__()use_bias = val2tuple(use_bias, 2)norm = val2tuple(norm, 2)act_func = val2tuple(act_func, 2)self.depth_conv = ConvLayer(in_channels,in_channels,kernel_size,stride,groups=in_channels,norm=norm[0],act_func=act_func[0],use_bias=use_bias[0],)self.point_conv = ConvLayer(in_channels,out_channels,1,norm=norm[1],act_func=act_func[1],use_bias=use_bias[1],)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.depth_conv(x)x = self.point_conv(x)return xMBConv模块
# MBConv
class MBConv(nn.Module):def __init__(self,in_channels: int,out_channels: int,kernel_size=3,stride=1,mid_channels=None,expand_ratio=6,use_bias=False,norm=("bn2d", "bn2d", "bn2d"),act_func=("relu6", "relu6", None),):super(MBConv, self).__init__()use_bias = val2tuple(use_bias, 3)norm = val2tuple(norm, 3)act_func = val2tuple(act_func, 3)mid_channels = mid_channels or round(in_channels * expand_ratio)self.inverted_conv = ConvLayer(in_channels,mid_channels,1,stride=1,norm=norm[0],act_func=act_func[0],use_bias=use_bias[0],)self.depth_conv = ConvLayer(mid_channels,mid_channels,kernel_size,stride=stride,groups=mid_channels,norm=norm[1],act_func=act_func[1],use_bias=use_bias[1],)self.point_conv = ConvLayer(mid_channels,out_channels,1,norm=norm[2],act_func=act_func[2],use_bias=use_bias[2],)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.inverted_conv(x) # 512x = self.depth_conv(x) # 512x = self.point_conv(x) # 256return xEfficientViTBlock模块
# EfficientViTBlock模块 —> 提取上下文特征
class EfficientViTBlock(nn.Module):def __init__(self,in_channels: int,heads_ratio: float = 1.0,dim=32,expand_ratio: float = 4,norm="bn2d",act_func="hswish",):super(EfficientViTBlock, self).__init__()self.context_module = ResidualBlock(LiteMLA( # 轻量权重多尺度注意力in_channels=in_channels,out_channels=in_channels,heads_ratio=heads_ratio,dim=dim,norm=(None, norm),),IdentityLayer(),)local_module = MBConv(in_channels=in_channels,out_channels=in_channels,expand_ratio=expand_ratio,use_bias=(True, True, False),norm=(None, None, norm),act_func=(act_func, act_func, None),)self.local_module = ResidualBlock(local_module, IdentityLayer()) # 添加残差连接def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.context_module(x) # 轻量多尺度注意力 -> 全局上下文特征x = self.local_module(x) # 深度卷积 -> 局部特征return x
四、实验
数据集:Cityscapes 和 ADE20K数据集。
评价指标:mIoU、Params和MAC(乘加累积操作数)。
4.1 消融研究
(1)EfficientViT模块的性能测试

mIoU和MAC在Cityscapes上测量,输入分辨率为1024x2048。重新调整模型的宽度,使它们具有相同的MAC,由上表所示,多尺度学习和全局感受野对于获得良好的语义分割性能至关重要。
(2)ImageNet上的主干性能对比
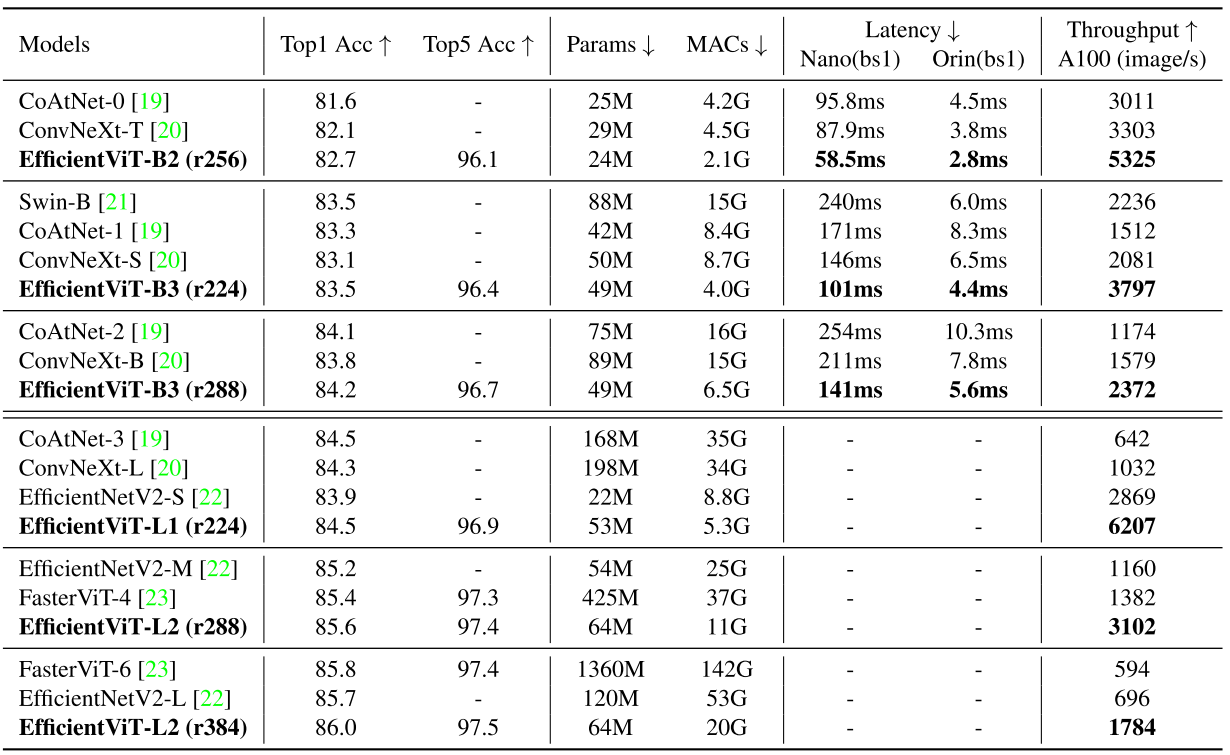
EfficientViT-L2-r384在ImageNet上获得了86.0的top-1精度,比EfficientNetV 2-L提供了+0.3的精度增益,在A100 GPU上提供了2.6倍的加速。
4.2 语义分割实验
与先进语义分割模型在Cityscapes数据集上的对比。

与SegFormer相比,EfficientViT在mIoU更高的边缘GPU(Jetson AGX Orin)上获得了高达13倍的MAC数节省和高达8.8倍的延迟减少。与SegNeXt相比,EfficientViT在边缘GPU上提供高达2.0倍的MAC减少和3.8倍的加速,同时保持更高的mIoU。
五、总结
1. 本文针对高分辨率稠密预测的有效架构设计,引入了一个轻量级的多尺度注意力模块,它同时实现了全局感受野,以及具有轻量级和硬件高效操作的多尺度学习,从而在各种硬件设备上提供了显着的加速,而不会比SOTA高分辨率密集预测模型带来性能损失。
2. 多尺度线性注意力,使用ReLU线性注意力来实现全局感受野,通过FFN+DWConv 捕获局部信息和卷积聚合捕获多尺度信息,以此克服ReLU线性注意力轻量化所带来的缺点。
相关文章:
EfficientViT:高分辨率密集预测的多尺度线性关注
标题:EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction 论文:https://arxiv.org/abs/2205.14756 中文版:【读点论文】EfficientViT: Enhanced Linear Attention for High-Resolution Low-Computation将soft…...

每日一道算法题:26. 删除有序数组中的重复项
难度 简单 题目 给你一个 非严格递增排列 的数组 nums ,请你原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。 考虑 nums 的唯一元素的数量为…...
吴恩达《机器学习》2-2->2-4:代价函数
一、代价函数的概念 代价函数是在监督学习中用于评估模型的性能和帮助选择最佳模型参数的重要工具。它表示了模型的预测输出与实际目标值之间的差距,即建模误差。代价函数的目标是找到使建模误差最小化的模型参数。 二、代价函数的理解 训练集数据:假设我…...
)
软考 系统架构设计师系列知识点之设计模式(6)
接前一篇文章:软考 系统架构设计师系列知识点之设计模式(5) 所属章节: 老版(第一版)教材 第7章. 设计模式 第2节. 设计模式实例 相关试题 1. 设计模式描述了一个出现在特定设计语境中的设计再现问题&…...
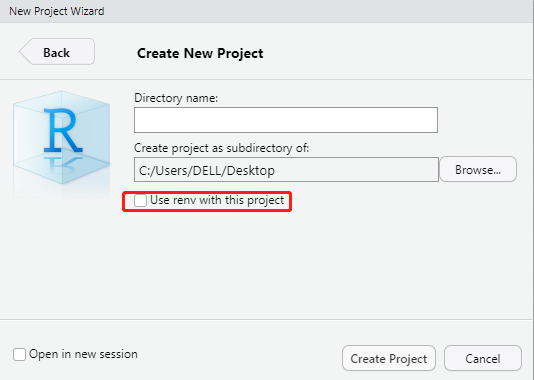
use renv with this project create a git repository
目录 1-create a git repository 2-Use renv with this project 今天在使用Rstudio过程中,发现有下面两个新选项(1)create a git repository (2) Use renv with this project. 选中这两个选项后,创建新项目,在项目目…...

摄像头种类繁多,需要各自APP
老外报怨吾APP不能用之后,吾按照提供的图片买了一个。昨天到货以后,心想这下你小子可被我逮住了,非解决你不可…… 吾APP当然不能用。老外声称能用的APP也不能用。又下载了一个,还是不能用。 最后只能老老实实的想办法从Google P…...
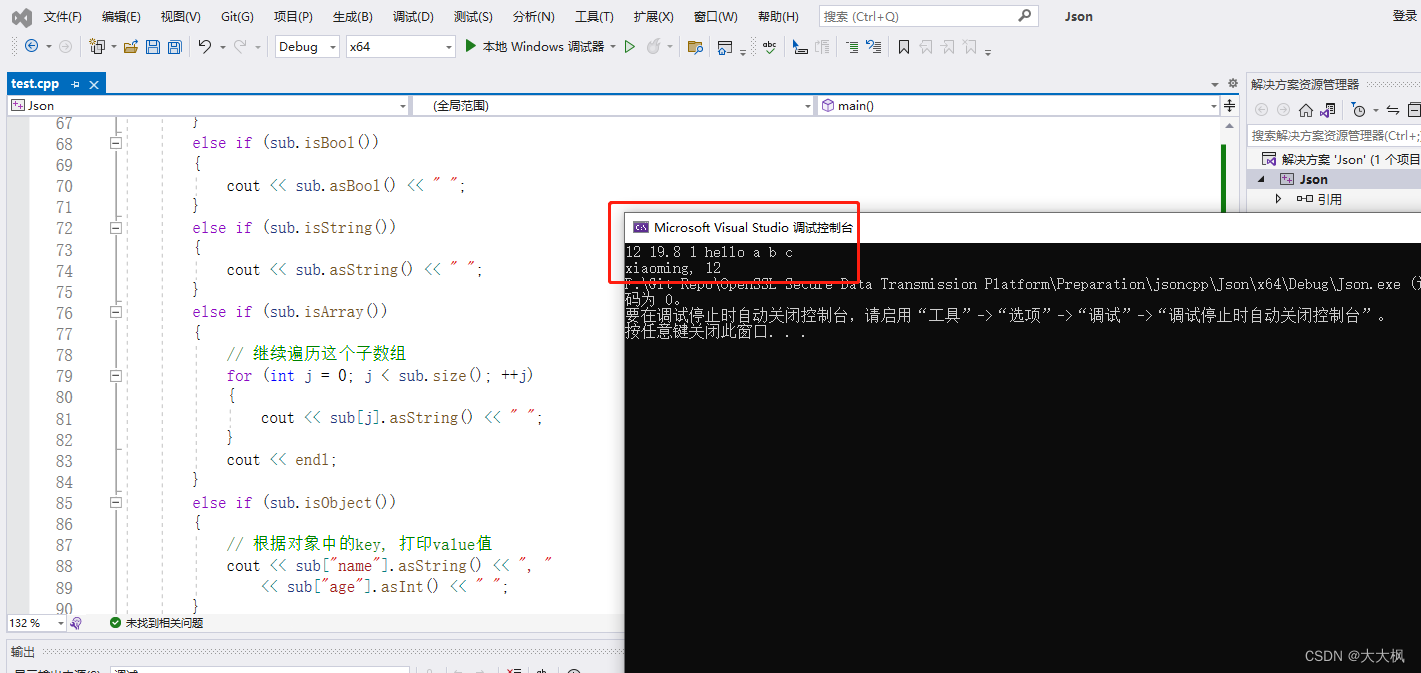
Openssl数据安全传输平台010:jasoncpp 0.10.7的编译 - Windows-vs2022 / Ubuntu/ Centos8 -含测试代码
文章目录 0. 代码仓库1 安装1.1 windows 下的安装1.2 Linux 下的安装1.2.1 相关环境配置问题1.2.2 准备安装1.2.2.1 安装scons1.2.2.2 安装jsoncppUbuntu系统下Centos8系统下 2 编译 c 测试文件: json-test.cpp2.1 配置库文件2.2 配置VS2.3 Winsows系统下cpp文件测试…...

GSCoolink GSV6182 带嵌入式MCU的MIPI D-PHY转HDMI 2.0
Gscoolink GSV6182是一款高性能、低功耗的MIPI D-PHY到HDMI 2.0转换器。通过集成基于RISC-V的增强型微控制器,GSV6182创造了一种具有成本效益的解决方案,提供了上市时间优势。MIPI D-PHY接收器支持CSI-2版本1.3和DSI版本1.3,每条通道最高可达…...
ABBYY FineReader PDF15免费版图片文件识别软件
ABBYY全称为“ABBYY FineReader PDF”, ABBYY FineReader PDF集优秀的文档转换、PDF 管理和文档比较于一身。 首先这款软件OCR文字识别功能十分强大,话不多说,直接作比较。下图是某文字识别软件识别一串Java代码的结果,识别的结果就不多评价…...

如何使用手机蓝牙设备作为电脑的解锁工具像动态锁那样,蓝牙接近了电脑,电脑自动解锁无需输入开机密码
环境: Win10 专业版 远程解锁 蓝牙解锁小程序 问题描述: 如何使用手机蓝牙设备作为电脑的解锁工具像动态锁那样,蓝牙接近了电脑,电脑自动解锁无需输入开机密码 手机不需要拿出来,在口袋里就可以自动解锁ÿ…...

几道面试题记录20231023
1, JVM优化 -Xms-Xmx -Xmn -Xss -XX:PermSize -XX:MaxPermSize -NewRatio -SuvriorRatio 收集器配置: 一般:串行收集 Serial 吞吐优先:并行收集Pramllel 响应优先:并发收集Conc 2,支付掉单如何解决? 因为网络等原…...

c++ 线程安全的string类
非安全string 说明 c标准未规定stl容器以及字符串的线程安全性,故std::string在多线程下是不安全的。 代码示例 #include <iostream> #include <stdio.h> using namespace std;std::string *sp nullptr;void Read() {for(int i 0; i < 100000;…...

linux上安装apktool反编译apk解析AndroidManifest.xml得到首页Activity
需求 在linux系统上反编译安卓app, 有些应用需要知道其主页Activity用于adb指令打开其主页。 安装 自动安装脚本 #!/bin/bashwget https://raw.githubusercontent.com/iBotPeaches/Apktool/master/scripts/linux/apktool -O ./apktool wget https://bitbucket.org/iBotPeac…...

代码随想录算法训练营第4天| 24. 两两交换链表中的节点、19.删除链表的倒数第N个节点、面试题 02.07. 链表相交 、142.环形链表II
JAVA语言编写 24. 两两交换链表中的节点 谷歌、亚马逊、字节、奥多比、百度 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。…...

【面向对象程序设计】Java大作业 汽车租赁管理系统V4.0
前言 自己大二时候使用JavaMysql写的租车系统大作业V4.0黑窗口版的一个记录,简简单单的黑窗口,不是炫酷的前后端分离也没用GUI,但功能完善,该有都有,当时得分也还是挺不错的 技术栈 Java (jdk8)Mysql 资源包内容 …...

golang模拟QQ退出后自动重启
模拟QQ退出后自动重启,go build xxx.go 打包成exe运行。 processName 为你所需要的进程exe processNamePath 为你所需要的进程路径 package mainimport ("bytes""errors""fmt""os""os/exec""regexp"&…...

jQuery中ajax如何使用
jQuery中ajax如何使用及代码详解 1. 引言 在现代Web开发中,使用Ajax进行异步数据交互变得非常普遍。而在jQuery中,提供了便捷的方法来实现Ajax请求,简化了开发过程。本文将介绍jQuery中如何使用Ajax以及通过代码详解其使用方法。 2. Ajax简介…...

redis集群的多key原子性操作如何实现?
1、背景 在单实例redis中,我们知道多key原子性操作可以用lua脚本或者multi命令来实现。 比如说有一个双删场景,要保证原子性同时删除k1和k2。 可以用lua双删 EVAL "redis.call(del, KEYS[1]);redis.call(del, KEYS[2])" 2 k1 k2也可以用事务…...

密码学与网络安全:量子计算的威胁与解决方案
第一章:引言 在当今数字化世界中,网络安全一直是一个备受关注的话题。密码学作为网络安全的基石,扮演着至关重要的角色。然而,随着科学技术的不断进步,特别是量子计算的崛起,传统密码学的基础受到了严重威…...
GoLong的学习之路(十二)语法之标准库 flag的使用
上回书说到,fmt的标准库的一些常用的使用函数。这次说flag的使用,以下这些库要去做了解。不然GG,Go语言内置的flag包实现了命令行参数的解析,flag包使得开发命令行工具更为简单。 文章目录 os.Argsflag包flag.Type()flag.TypeVar(…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...