致敬白衣天使,学习Python读取
名字:阿玥的小东东
学习:Python、c++
主页:阿玥的小东东
故事设定:现在学校要求对所有同学进行核酸采集,每位同学先在宿舍内等候防护人员(以下简称“大白”)叫号,叫到自己时去停车场排队等候大白对自己进行采集,采集完之后的样本由大白统一有序收集并储存。
名词解释:
- 学生:所有的学生是一个大文件,每个学生是其中的一行数据
- 宿舍:硬盘
- 停车场:内存
- 核酸采集:数据处理
- 样本:处理后的数据
- 大白:程序
学生数量特别少的情况
当学生数量特别少时,可以考虑将所有学生统一叫到停车场等候,再依次进行核酸采集。
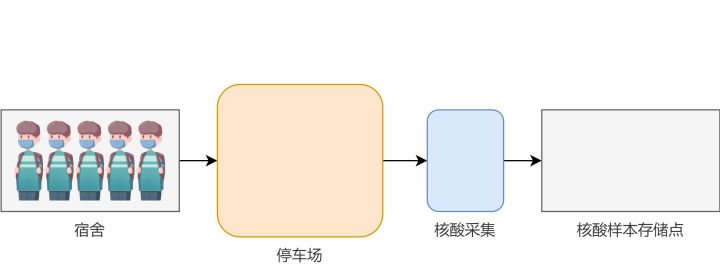
方法一:简单情况
此时的程序可以模拟为:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
注意,在第19行中,大白一次性把所有同学都叫到了停车场中。这种做法在学生比较少时做起来很快,但是如果学生特别多,停车场装不下怎么办?
停车场空间不够时怎么办?
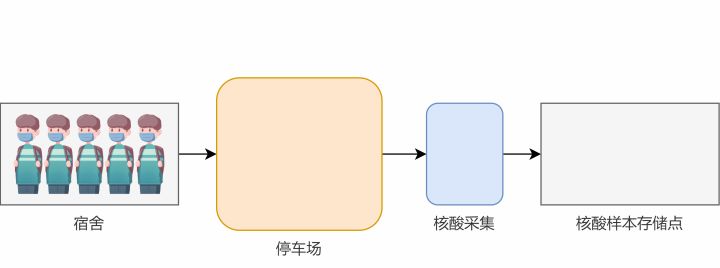
方法二:边读边处理
一般来说,由于停车场空间有限,我们不会采用一次性把所有学生都叫到停车场中,而是会一个一个地处理,这样可以节约内存空间。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
这里pick_one_student函数中的返回值是用yield返回的,一次只会返回一名同学。
不过,这种做法虽然确保了停车场不会满员,但是这种做法在人数特别多的时候就不再适合了。虽然可以保证完成任务,但由于每次只能采集一个同学,程序的执行并不高。特别是当你的CPU有多个核时,会浪费机器性能,出现一核有难,其它围观的现象。
怎么加快执行效率?
大家可能也已经注意到了,刚刚我们的场景中,不论采用哪种方法,都只有一名大白在工作。那我们能不能加派人手,从而提高效率呢?
答案当然是可行的。我们现在先考虑增加两名大白,使得一名大白专注于叫号,安排学生进入停车场,另外一名大白专注于采集核酸,最后一名大白用于存储核酸样本。
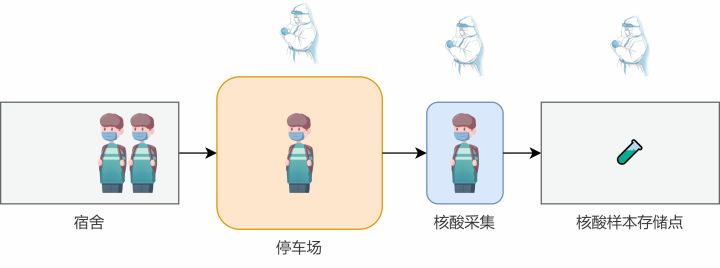
方法三
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
|
这份代码中,我们引入了多进程的思路,将每个大白看作一个进程,并使用了队列Queue作为进程间通信的媒介。stu_queue表示学生叫号进停车场的队列,store_queue表示已经采集过的待存储核酸样本的队列。
此外,为了控制进程的停止,我们在pick_student和 process函数的最后都向各自队列中添加了None作为结束标志符。
假设有1w名学生(student_names.txt文件有1w行),经过测试后发现上述方法的时间如下:
- 方法一:1m40.716s
- 方法二:1m40.717s
- 方法三:1m41.097s
咦?不是做了分工吗?怎么速度还变慢了?经笔者观察,这是因为叫号的大白速度太快了(文件读取速度快)通常是TA已经齐活了,另外俩人还在吭哧吭哧干活呢,体现不出来分工的优势。如果这个时候我们对法二和法三的叫号做延时操作,每个学生叫号之后停滞10ms再叫下一位学生,则方法三的处理时间几乎不变,而方法二的时间则会延长至3m21.345s。
怎么加快处理速度?
上面提到,大白采核酸的时间较长,往往上一个人的核酸还没采完,下一个人就已经在后面等着了。我们能不能提高核酸采集这个动作(数据处理)的速度呢?其实一名大白执行一次核酸采集的时间我们几乎无法再缩短了,但是我们可以通过增加人手的方式,来达到这个目的。就像去银行办业务,如果开放的窗口越多,那么每个人等待的时间就会越短。这里我们也采取类似的策略,增加核酸采集的窗口。
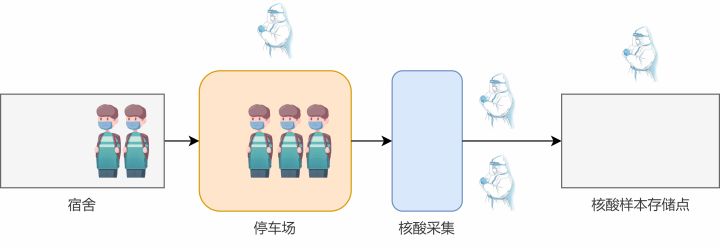
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
|
总耗时 0m4.160s !我们来具体看看其中的细节部分:
首先我们将CPU核数 - 3作为采核酸的大白数量。这里减3是为其它工作进程保留了一些资源,你也可以根据自己的具体情况做调整
这次我们在 Queue中增加了 maxsize参数,这个参数是限制队列的最大长度,这个参数通常与你的实际内存情况有关。如果数据特别多时要考虑做些调整。这里我采用10倍的工作进程数目作为队列的长度
注意这里pick_student函数中要为每个后续的工作进程都添加一个结束标志,因此最后会有个for循环
我们把之前放在process函数中的结束标志提取出来,放在了最外侧,使得所有工作进程均结束之后再关闭最后的store_p进程
结语
总结来说,如果你的数据集特别小,用法一;通常情况下用法二;数据集特别大时用法四。
相关文章:
致敬白衣天使,学习Python读取
名字:阿玥的小东东 学习:Python、c 主页:阿玥的小东东 故事设定:现在学校要求对所有同学进行核酸采集,每位同学先在宿舍内等候防护人员(以下简称“大白”)叫号,叫到自己时去停车场排…...
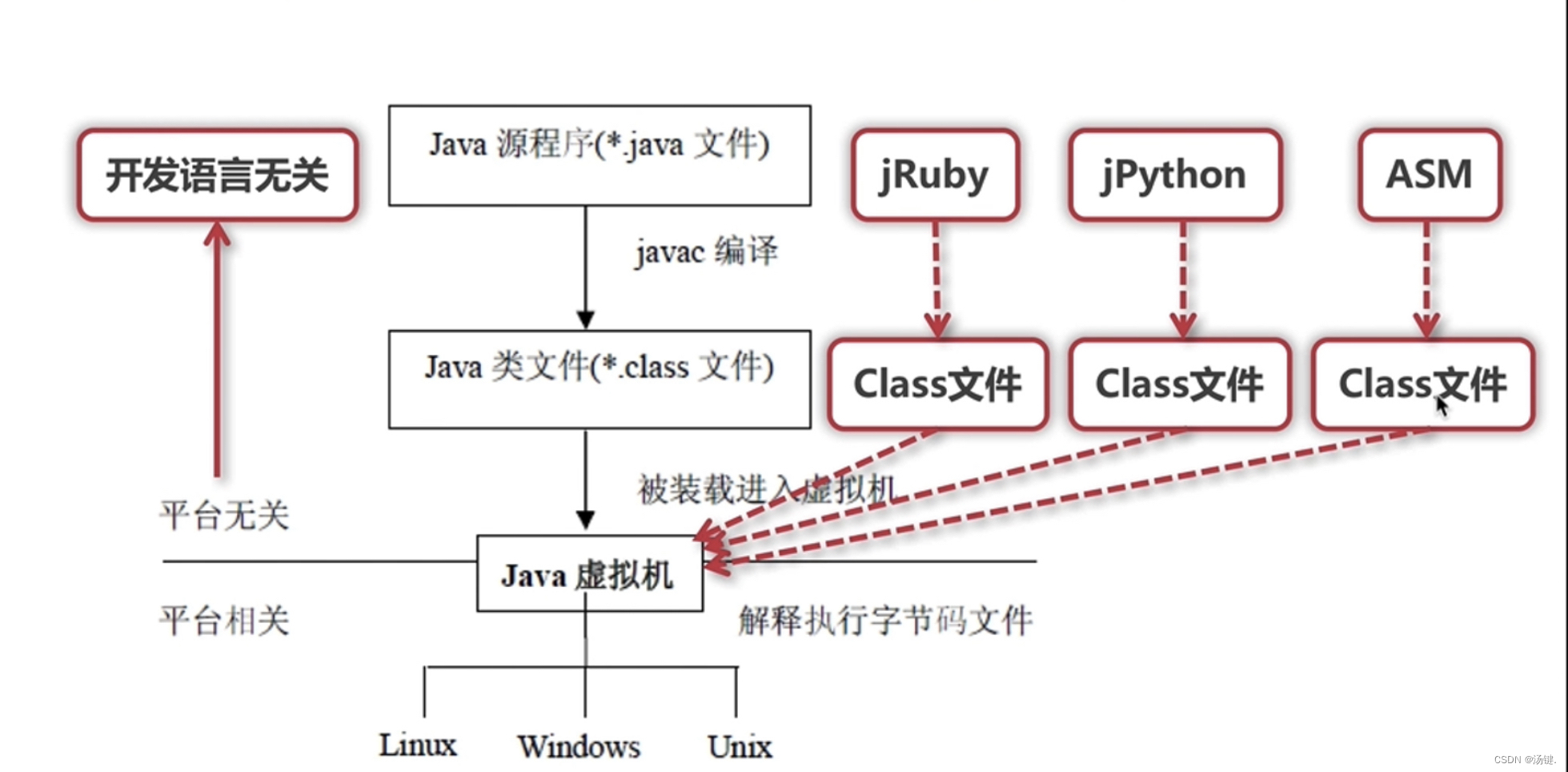
JVM - 认识JVM规范
目录 重识JVM JVM规范作用及其核心 JVM 整体组成 理解ClassFile结构 ASM开发 重识JVM JVM概述JVM: Java Virtual Machine,也就是Java虚拟机所谓虚拟机是指: 通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的计算机系统…...

文献阅读笔记 # CodeBERT: A Pre-Trained Model for Programming and Natural Languages
《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》EMNLP 2020 (CCF-B)作者主要是来自哈工大、中山大学的 MSRA 实习生和 MSRA、哈工大的研究员。资源:code | pdf相关资源:RoBERTa-base | CodeNN词汇: bimodal: 双模态…...

openHarmony的UI开发
自适应布局 拉伸能力 Blank在容器主轴方向上,空白填充组件具有自动填充容器空余部分的能力。仅当父组件为Row/Column时生效,即是线性布局。这样便可以在两个固定宽度或高度的组件中间添加一个Blank(),将剩余空间占满,从而实现…...
【JavaSE】深入HashMap
文章目录1. HashMap概述2. 哈希冲突3. 树化与退化3.1 树化的意义3.2 树的退化4. 二次哈希5. put方法源码分析6. key的设计7. 并发问题参考 如何防止因哈希碰撞引起的DoS攻击_hashmap dos攻击_双子孤狼的博客-CSDN博客 为什么 HashMap 要用 h^(h >>&#…...
)
华为机试题:HJ62 查找输入整数二进制中1的个数(python)
文章目录博主精品专栏导航知识点详解1、input():获取控制台(任意形式)的输入。输出均为字符串类型。1.1、input() 与 list(input()) 的区别、及其相互转换方法2、print() :打印输出。1、整型int() :将指定进制…...

代码随想录训练营一刷总结|
分为几个大部分: 数组 最先接触的部分,虽然说感觉是最简单的,但是需要掌握好基础,特别是小心循环。这里面需要再仔细看的就是螺旋矩阵那一块,其他的在后续刷的时候能用一种方法一次a就行。 链表 需要注意链表的基础…...

CSS中的几种尺寸单位
一、尺寸单位 CSS 支持多种尺寸单位,包括: px:像素,固定大小单位em:相对于当前元素字体大小的单位rem:相对于根元素(HTML)字体大小的单位%:相对于父元素的百分比单位vh…...
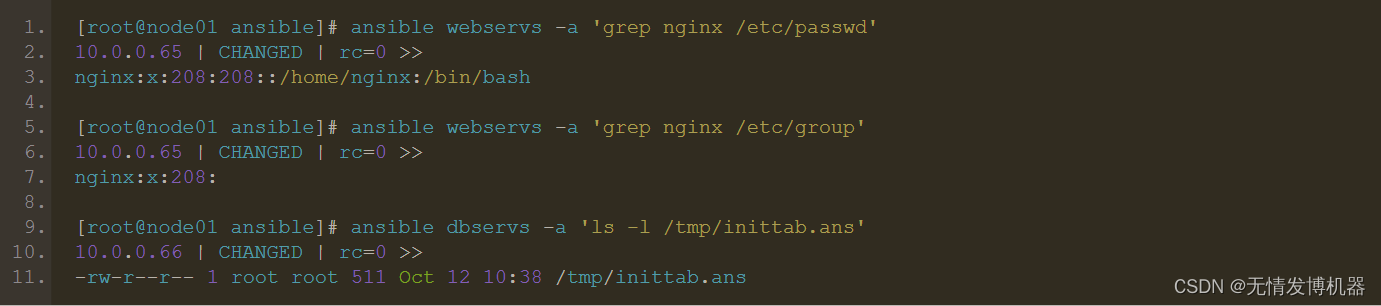
运维必会:ansible剧本(piaybook)
playbooks 概述以及实例操作 Playbooks 组成部分: Inventory Modules Ad Hoc Commands Playbooks Tasks: 任务,即调用模块完成的某些操作 Variables: 变量 Templates: 模板 Handlers: 处理器,由某时间触发执行的操作 Roles: 角色 YAML 介绍…...
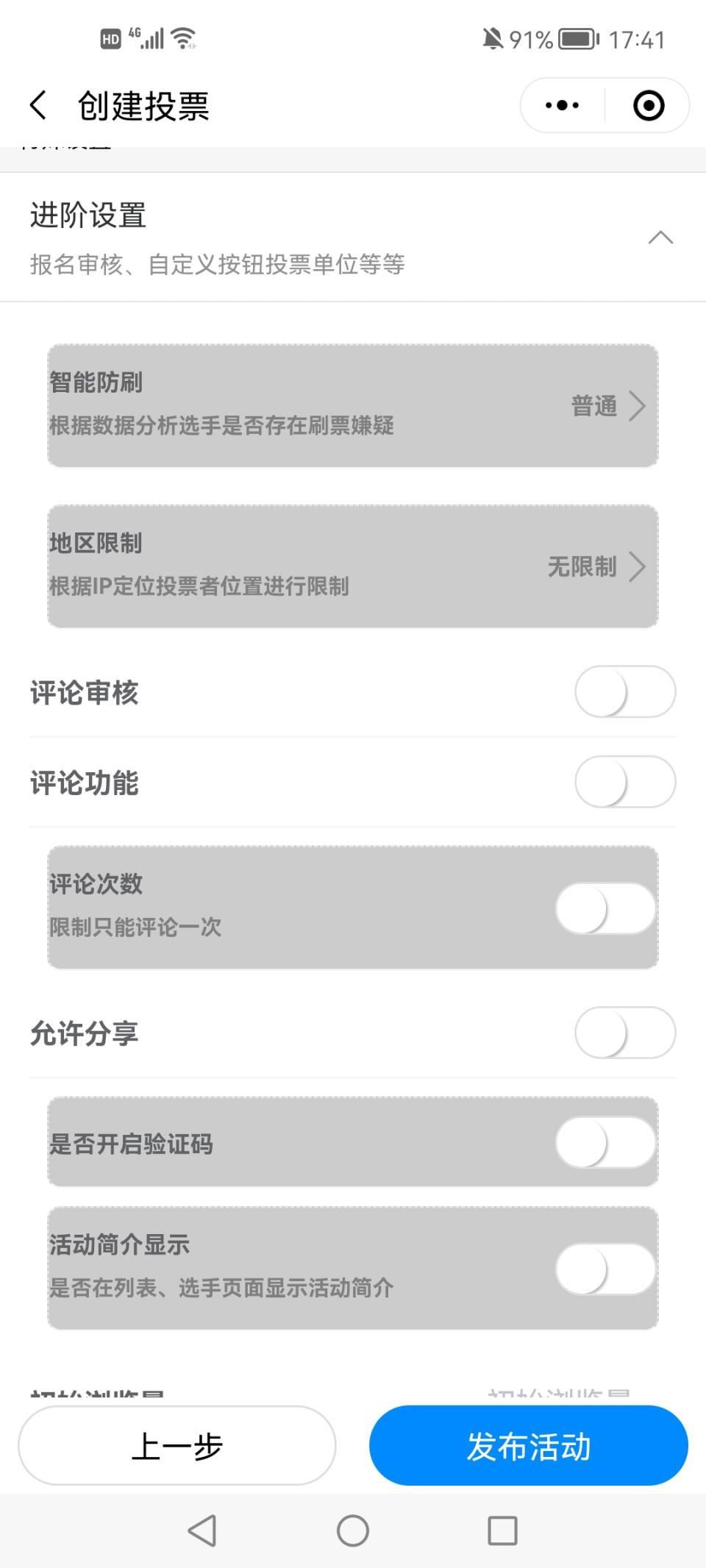
活动星投票午间修身自习室制作在线投票投票制作网页
“午间修身自习室”网络评选投票_免费小程序投票推广_小程序投票平台好处手机互联网给所有人都带来不同程度的便利,而微信已经成为国民的系统级别的应用。现在很多人都会在微信群或朋友圈里转发投票,对于运营及推广来说找一个合适的投票小程序能够提高工…...

C#泛型:高级静态语言的效率利器
文章目录引入类型约束子类泛型常用的泛型数据结构前文提要: 💎超快速成,零基础掌握C#开发中最重要的概念💎抽丝剥茧,C#面向对象快速上手💎Winform,最友好的桌面GUI框架💎懂了委托&a…...

澳大利亚访问学者申请流程总结
澳大利亚访问学者申请需要注意些什么?下面知识人网小编整理澳大利亚访问学者申请流程总结。1、取得wsk英语成绩,现在都是先买票再上车了。2、联系外导,申请意向接收函(email)。3、向留学基金委CSC提出申请。4、获批后,申请正式邀请…...
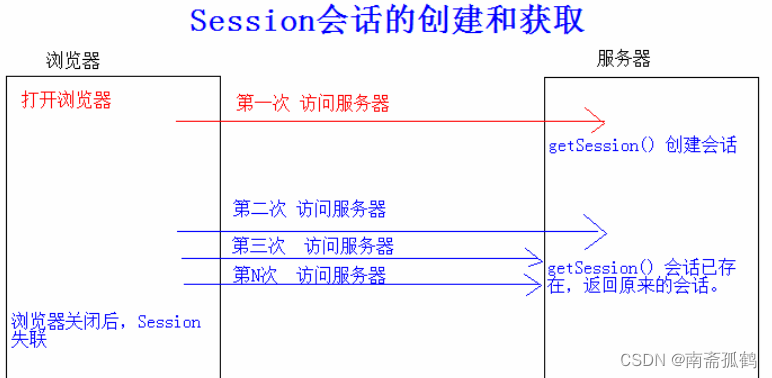
cookie和Session的作用和比较
目录 什么是cookie cookie的工作原理 什么是session Session的工作原理 为什么会有session和cookie cookie和session如何配合工作 cookie和Session作用 什么是会话 什么是cookie cookie是web服务器端向我们客户端发送的一块小文件,该文件是干嘛的呢…...
测试员都是背锅侠?测试人员避“锅”攻略,拿走不谢
最近发生了一起生产事故,究其根源,事故本身属于架构或者需求层面需要规避的问题,测试人员的责任其实是非常小的,但实际情况是:相关测试人员因此承担了很大的压力,成为质量问题的“背锅侠”。 实际上&#…...
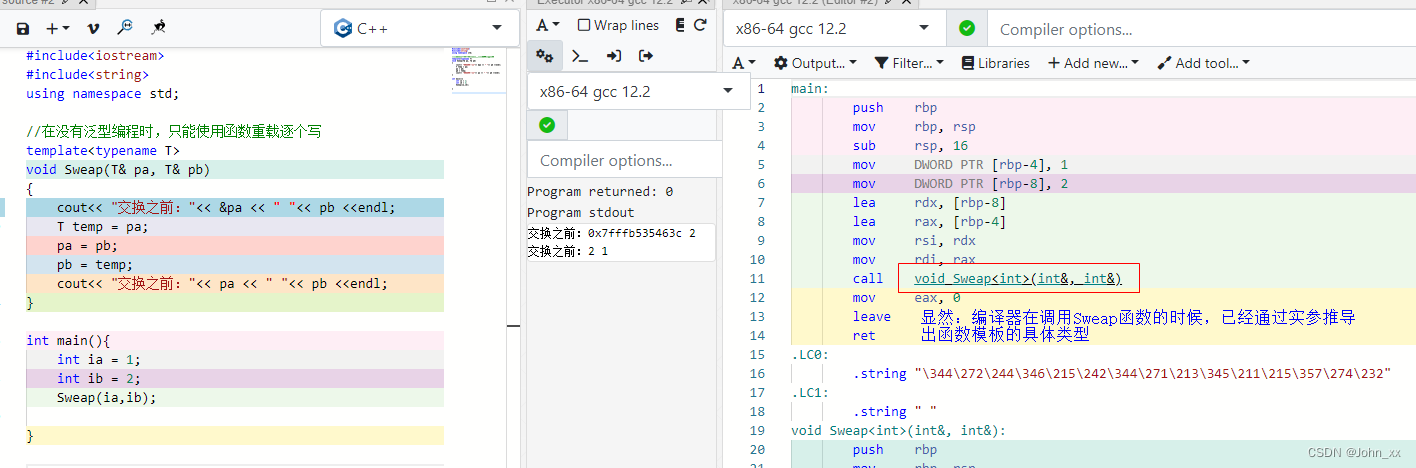
C++: C++模板<template>
C template content😊前言😁模板💕1、泛型编程😍2、函数模板😒2.1:函数模板概念👌2.2:函数模板的格式😘2.3:函数模板原理😁2.4:函数模…...

chmod命令详解
用法:chmod [选项]… 模式[,模式]… 文件… 或:chmod [选项]… 八进制模式 文件… 或:chmod [选项]… --reference参考文件 文件… Change the mode of each FILE to MODE. With --reference, change the mode of each FILE to that of R…...
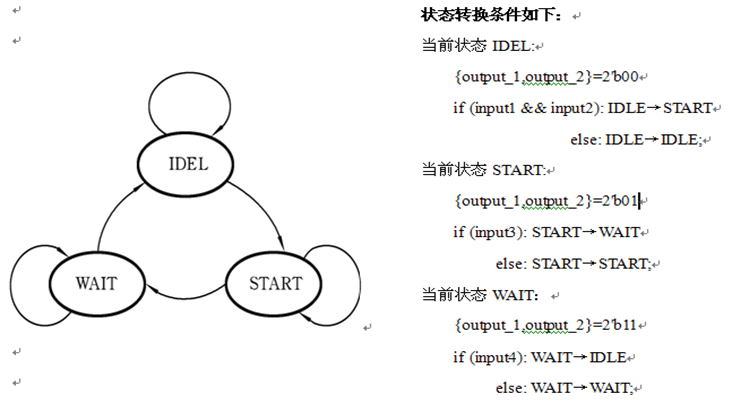
状态机设计中的关键技术
⭐本专栏针对FPGA进行入门学习,从数电中常见的逻辑代数讲起,结合Verilog HDL语言学习与仿真,主要对组合逻辑电路与时序逻辑电路进行分析与设计,对状态机FSM进行剖析与建模。 🔥文章和代码已归档至【Github仓库…...

单片机开发---ESP32S3移植NES模拟器(二)
书接上文 《单片机开发—ESP32-S3模块上手》 《单片机开发—ESP32S3移植lvgl触摸屏》 《单片机开发—ESP32S3移植NES模拟器(一)》 暖场视频,小时候称这个为—超级曲线射门!!!!!&am…...
微信小程序nodej‘s+vue警局便民服务管理系统
本文首先介绍了设计的背景与研究目的,其次介绍系统相关技术,重点叙述了系统功能分析以及详细设计,最后总结了系统的开发心得在Internet高速发展的今天,我们生活的各个领域都涉及到计算机的应用,其中包括“最多跑一次”微信小程序的网络应用,在外国小程序的使用已经是很普遍的方…...

第18章 MongoDB $type 操作符教程
MongoDB $type 操作符 描述 在本章节中,咱们将继续讨论MongoDB中条件操作符 $type。 $type操作符是基于BSON类型来检索集合中匹配的数据类型,并return 结果。 MongoDB 中可以使用的类型如下表所示: 类型数字备注Double1 String2 Object3…...

使用Taotoken CLI工具一键配置开发环境,简化团队协作的接入流程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境,简化团队协作的接入流程 在团队协作开发大模型应用时,一个常见的挑…...

终极指南:使用RPFM免费工具快速制作《全面战争》游戏模组
终极指南:使用RPFM免费工具快速制作《全面战争》游戏模组 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https://…...

Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极指南
Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极指南 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

终极FFXIV模组管理器:TexTools完全使用指南与实战教程
终极FFXIV模组管理器:TexTools完全使用指南与实战教程 【免费下载链接】FFXIV_TexTools_UI 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_TexTools_UI 你是否厌倦了在《最终幻想14》中与其他玩家穿着相同的装备?是否梦想着为你的光之战士…...

Cursor Pro破解工具完整指南:5步实现机器标识重置与永久Pro功能解锁
Cursor Pro破解工具完整指南:5步实现机器标识重置与永久Pro功能解锁 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve rea…...

终极Enigma Virtual Box解包指南:evbunpack完全解析与实战应用
终极Enigma Virtual Box解包指南:evbunpack完全解析与实战应用 【免费下载链接】evbunpack Enigma Virtual Box Unpacker / 解包、脱壳工具 项目地址: https://gitcode.com/gh_mirrors/ev/evbunpack Enigma Virtual Box解包工具evbunpack是一个专门用于解包E…...

为什么说Full Page Screen Capture是Chrome网页截图的终极解决方案?
为什么说Full Page Screen Capture是Chrome网页截图的终极解决方案? 【免费下载链接】full-page-screen-capture-chrome-extension One-click full page screen captures in Google Chrome 项目地址: https://gitcode.com/gh_mirrors/fu/full-page-screen-capture…...

10分钟掌握AppImageLauncher:让Linux应用管理像Windows一样简单的完整指南
10分钟掌握AppImageLauncher:让Linux应用管理像Windows一样简单的完整指南 【免费下载链接】AppImageLauncher Helper application for Linux distributions serving as a kind of "entry point" for running and integrating AppImages 项目地址: http…...

构建多智能体系统时如何通过统一网关管理不同模型的调用与鉴权
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多智能体系统时如何通过统一网关管理不同模型的调用与鉴权 在开发集成多个AI智能体的复杂系统时,工程师常常面临一…...

5步解决Windows包管理器Winget安装难题:专业修复指南
5步解决Windows包管理器Winget安装难题:专业修复指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_mirrors/wi/w…...