C的自定义类型
目录
1. 结构体
1.1. 结构体类型的声明
1.1.1. 特殊声明
2. 结构的自引用
3. 结构体变量的定义和初始化
4. 结构体内存对齐
4.1. 结构体内存对齐
4.2. 修改默认对齐数
5. 结构体传参
6. 结构体实现位段(位段的填充&可移植性)
6.1. 什么是位段
6.2. 位段的内存分配
2. 枚举
2.1. 枚举
2.2. 枚举常量的优点
3. 联合
3.1. 联合
3.2. 判断大小端
3.3. 联合大小的计算
1. 结构体
首先,为什么要求这些自定义类型呢?在C语言中,其标准已经为我们提供了许多的内置类型,int、char、double等等,但是,有些情况下,人们发现单单靠这些内置类型无法满足现实世界各种复杂的情况,例如,如果我们要描述一本书,我们是不是应该描述它的书名、作者、出版社等等各种信息,我们发现如果此时只有内置类型,是不可能达成类似这种复杂需求的,于是C赋予了程序员们一种权利,可以定义自定义类型。而结构体就是自定义类型中的一种。
1.1. 结构体类型的声明
首先,我们看看结构体的声明是怎样的呢?
// 假如我要描述一本书
struct book
{char book_name[20];char author_name[10];int book_pages;//... 各种信息
}; // 注意这里的 ; 不可漏掉上面的struct book就是一个结构体类型的声明。
1.1.1. 特殊声明
在声明结构体类型时,C标准允许可以不完全声明:
struct
{int x;int y;int z;
}target; //并且此时只能在这里定义这个类型的变量struct
{int x;int y;int z;
}*p; // 定义了一个这个结构体类型指针的变量上面的类型就是一个匿名结构体类型,有人看到这两个匿名结构体的成员变量完全一样,那能不能这样做呢?
void Test1(void)
{p = &x;
}首先,这样做是不好的。编译器对于匿名结构体的处理是:如果匿名结构体的成员变量一样,编译器也认为它们是不同的类型。
2. 结构的自引用
结构体的自引用简单理解就是:结构体类型中的成员变量包含一个结构体类型的指针变量。
struct Node
{int val;struct Node next;
};上面的代码可行吗? 答案是,不可行。为什么呢?struct Node这个自定义类型中包含一个类型为struct Node的成员next,而这个成员也是一个自定义类型struct Node,那它里面也有一个struct Node类型的成员啊,这种无穷包含自己,在编译器看来是一种非法行为,因为此时这个类型的大小无法确定。
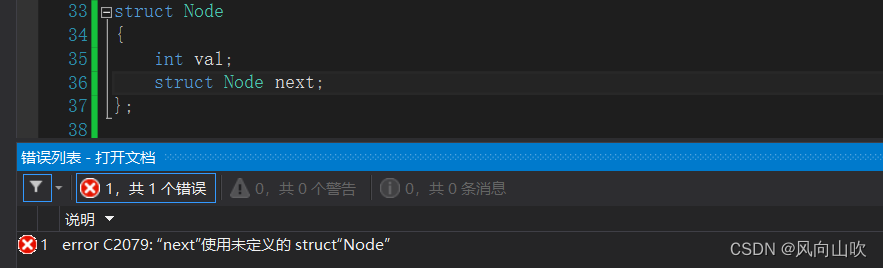
正确的自引用是这样的:
struct Node
{int val;struct Node* next;
};而我们直到typedef可以对一种数据类型进行重命名,那么它可以对结构体类型重命名吗?当然可以。例如如下:
typedef struct Node
{int val;struct Node* next;
}Node;上面的代码的意思是什么呢?就是定义了一个struct Node的结构体类型,我们对这个结构体类型重命名为 Node,即 Node 等价于 struct Node,它们代表着同一种类型。
然而,有人看到这里就会突发奇想,他说既然Node和 struct Node代表着同一种类型,那么可不可以这样呢?
typedef struct Node
{int val;Node* next;
}Node; // 走到这里才代表对struct Node进行重命名为 Node首先,说答案,上面这种声明是非法的,因为此时的这个成员变量next的类型还没有完成重命名,也就是先有鸡还是先有蛋的问题,只有走完这个类型重命名语句,才会对struct Node进行重命名为 Node,不可以在重命名之前就使用重命名后的类型。因此正确的命名是如下这种形式:
typedef struct Node
{int val;struct Node* next;
}Node;然而,有时候我们会在书中看到这样的声明风格:
typedef struct Node
{int val;struct Node* next;
}Node,*PNode;其实很简单,
这里的Node等价于struct Node
PNode就相当于 struct Node*
3. 结构体变量的定义和初始化
struct Book
{char book_name[20];int book_pages;double price;
}b1 = {"XqianC语言",531,33.3}; // 声明 + 定义了一个struct Book类型的全局变量struct Node
{struct Book b;struct Node* next;
}n1 = { {"wangwuLinux",843,55.5},NULL }; // 定义一个结构体嵌套类型的全局变量void Test3(void)
{struct Book b2; // 定义一个struct Book类型的局部变量// 给b2的成员变量赋值b2.book_name[20] = "lisiC++";b2.book_pages = 632;b2.price = 44.4; // 定义 + 初始化struct Node n2 = { { "cuihuaMySql", 483, 66.6 }, NULL }; // 定义一个结构体嵌套类型的局部变量
}4. 结构体内存对齐
4.1. 结构体内存对齐
首先,我们看看下面的这两个类型:
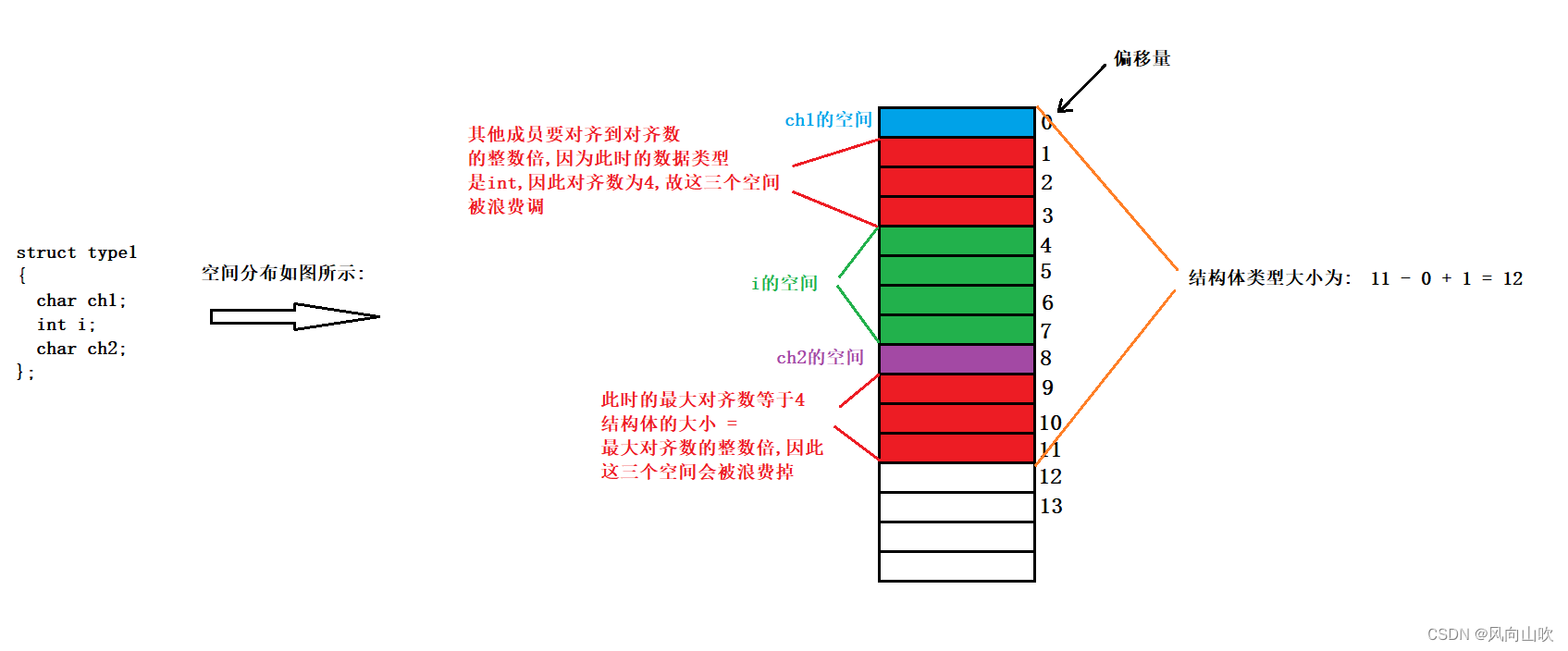
struct type1
{char ch1;int i;char ch2;
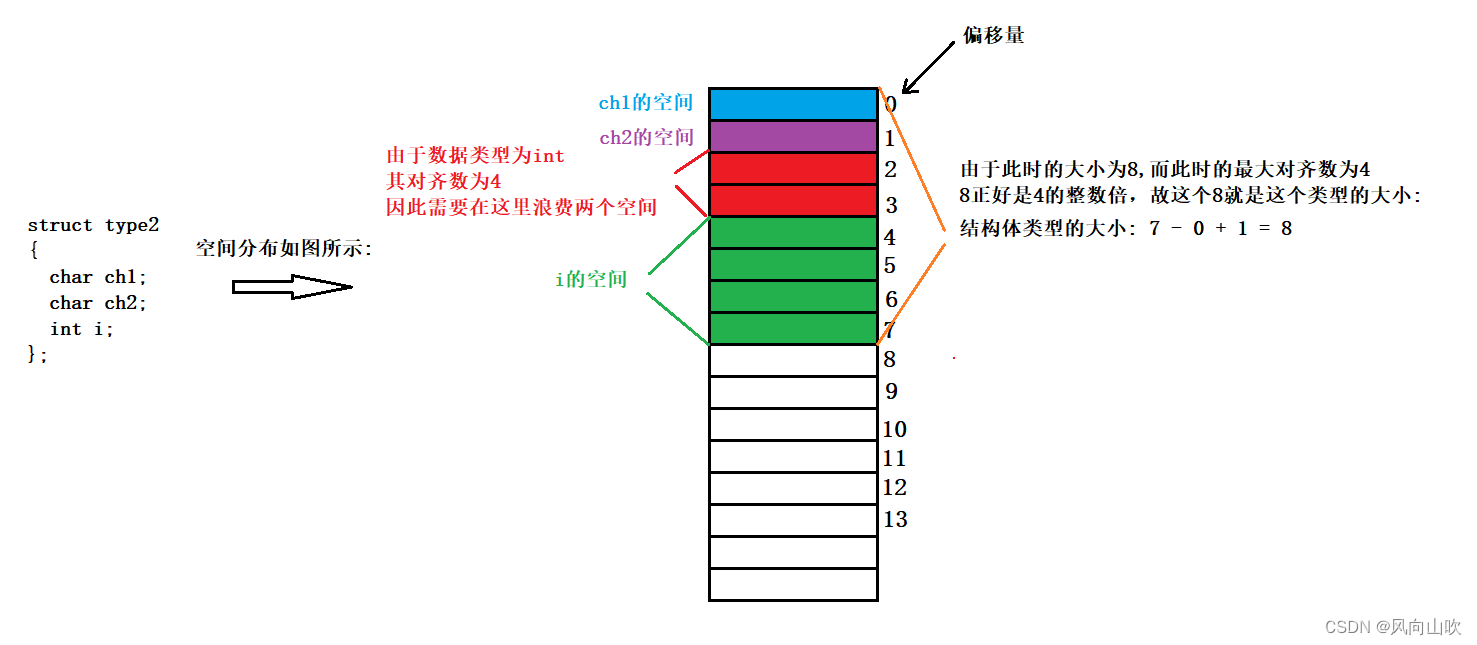
};struct type2
{char ch1;char ch2;int i;
};现在要求我们计算着两个类型分别是多大,即:
void Test4(void)
{printf("struct type1 size = %d\n", sizeof(struct type1));printf("struct type2 size = %d\n", sizeof(struct type2));
}有人一看这两个类型,诶,这两个类型的成员变量除了顺序不一样,其他都是一样的啊,让我算的话,它们的大小难道不应该是 两个 char + 一个 int类型的大小,即等于6吗?OK,让我们看看它的结果是多少呢?

出人意料,诶,怎么回事,不是6就是算了,怎么这两个类型的大小还不一样。为了解决这个问题,我们要引出一个东西,称之为结构体内存对齐规则。
那么结构体内存对齐规则是什么呢?如下:
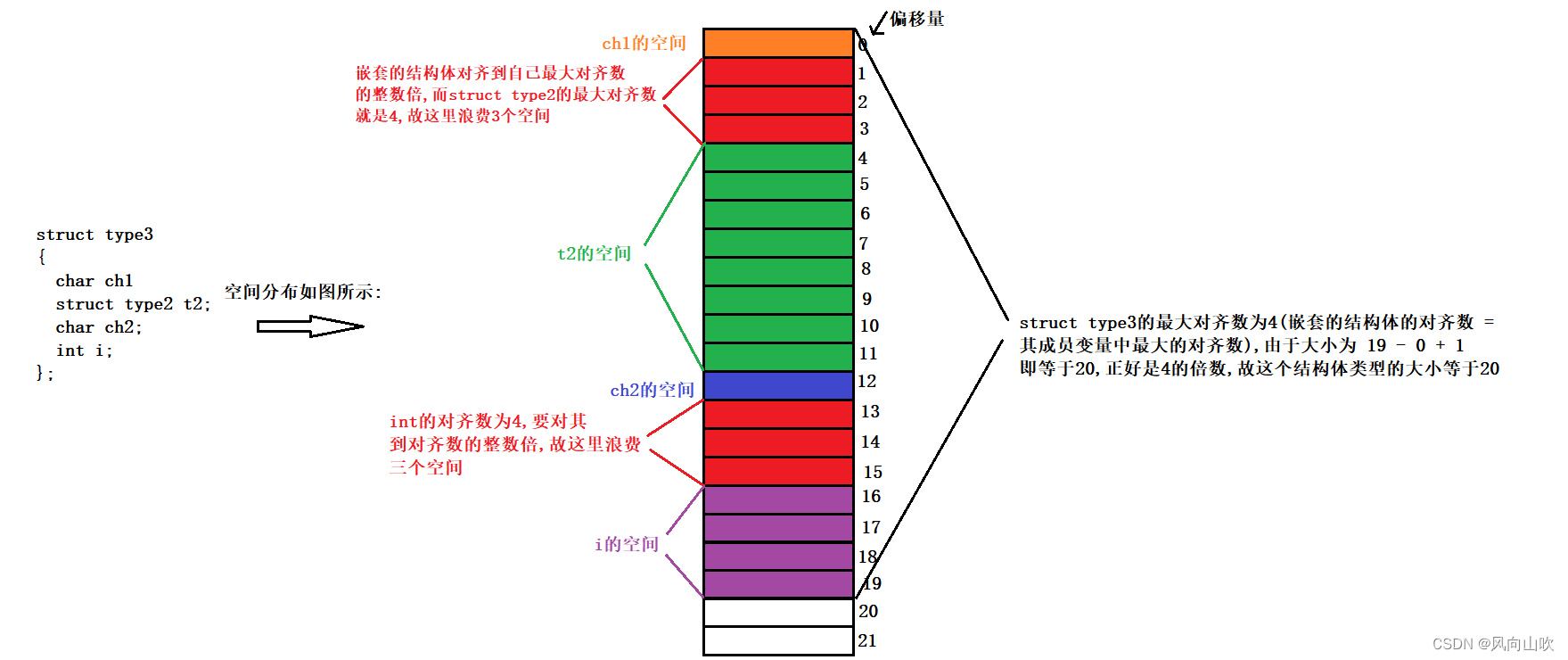
1. 第一个成员在与结构体变量偏移量为0的地址处。2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。对齐数 = 编译器默认的对齐数 与 该成员变量类型大小 的较小值vs下默认对齐数为83. 结构体总大小为最大对齐数的整数倍。最大对齐数:所有成员变量类型大小中的最大值。4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
有了结构体内存对齐规则,我们就可以分析上面这两个结构体类型的大小为何如此了,分析如下:
声明:为了更好理解下面的图,由于结构体对齐规则导致没有使用的空间用红色表示
对struct type1的分析如下:
对struct type2的分析如下:
有了对上面的理解,我们试着去计算下面这个结构体类型的大小:
struct type3
{char ch1struct type2 t2;char ch2;int i;
};
为了验证上面结构体成员的偏移量是否与预期正确,我们可以用offsetof,它是一个宏,可以帮助我们计算一个结构体中某个成员变量相对于起始位置的偏移量。
// 原型如下
// 其包含在 #include <stddef.h>
// structName --- 结构体名字
// memberName --- 成员变量名字
size_t offsetof( structName, memberName );void Test5(void)
{printf("ch1 offset: %d\n", offsetof(struct type3, ch1));printf("t2 offset: %d\n", offsetof(struct type3, t2));printf("ch2 offset: %d\n", offsetof(struct type3, ch2));printf("i offset: %d\n", offsetof(struct type3, i));
}结果如下:
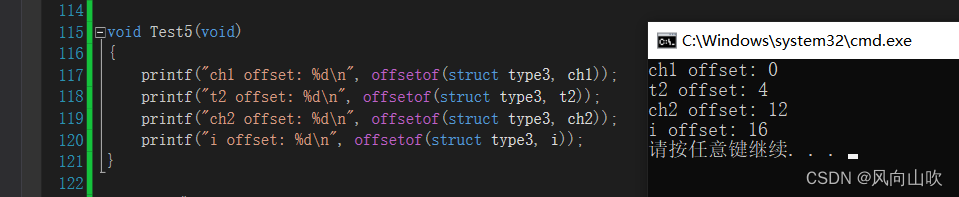
很显然,符合我们的预期。
那么为什么要存在内存对齐:
1. 平台原因(移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。2. 性能原因: 数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。总体来说,结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,如果我们既要满足对齐,又要节省空间,该如何做呢?
答案是:让占用空间小的结构体成员尽量集中在一起,例如:
struct type1
{char ch1;int i;char ch2;
};struct type2
{char ch1;char ch2;int i;
};struct type1和struct type2的成员变量是一样的,但是它们的大小确是不一样的,前者占12个字节,后者占8个字节,原因就在于struct type2中的较小成员集中在了一起,节省了一定的空间。
4.2. 修改默认对齐数
我们知道,VS下的默认对齐数是8,但是我们却可以显式的修改其默认对齐数。
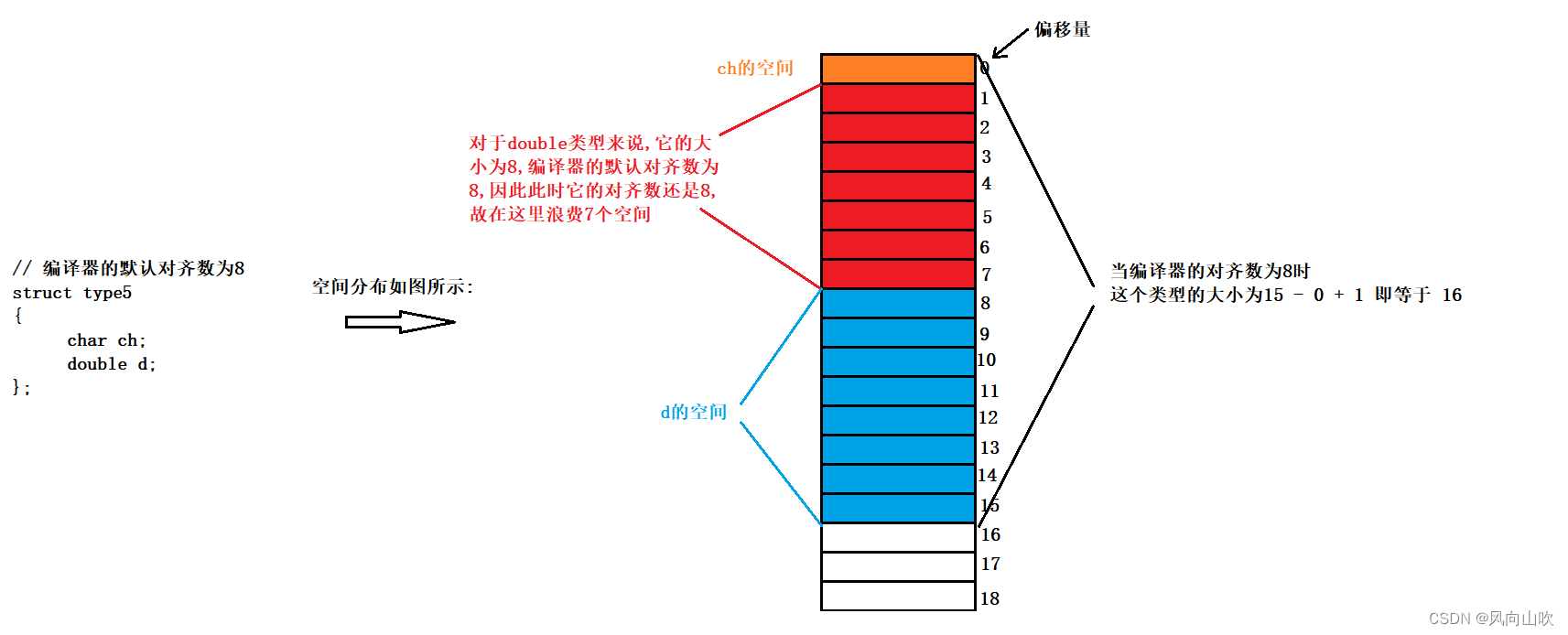
// 编译器的默认对齐数为8
struct type5
{ char ch; double d;
};
#pragma pack(4) // 将编译器的对齐数修改为4
struct type5
{char ch;double d;
};
#pragma pack() // 取消设置的对齐数,还原为默认对齐数
#pragma pack(1) // 将编译器的对齐数修改为1,就意味着不对齐.此时的大小就是9
struct type5
{char ch;double d;
};
#pragma pack() // 取消设置的对齐数,还原为默认对齐数结构体在对齐方式不合适的时候,我们可以自己更改默认对齐数。
5. 结构体传参
struct Info
{int data[1000];char* name[1000];
};// 结构体传参
void print1(struct Info tmp)
{//...
}// 结构体的地址传参
void print2(struct Info* p_tmp)
{//...
}void Test7(void)
{struct Info information = { { 1, 2, 3 }, {NULL} };print1(information); // 不推荐,值传递传参的压栈系统开销过大print2(&information); // 推荐,址传递传参的压栈系统开销很小
}对于结构体的传参,我们推荐采用以传结构体地址的方式;因为函数在传参的时候,会将其参数压栈,在时间上和空间上都会有消耗,如果我们传递一个结构体对象,当这个结构体很大的时候,参数压栈的系统开销就会很大,会导致性能的降低,而如果传递一个结构体指针,其大小是固定的(32位下4个字节、64位下8个字节),可以节省系统的开销,一定程度上提高性能。
结论:结构体传参尽量传结构体的地址。
6. 结构体实现位段(位段的填充&可移植性)
6.1. 什么是位段
1. 位段的成员必须是 int 、 unsigned int 或 signed int或者char(char也是属于整形家族) 。2. 位段的成员名后边有一个冒号和一个数字。
struct bit
{int a : 2;int b : 5;int c : 10;int d : 30;
};上面就是一个位段,我们可以看到,位段的成员后面有一个冒号和一个数字,这个数字代表着你这个成员占用了几个bit位,例如:a这个成员就会占用2个bit位。那么位段的大小如何计算呢?位段需要进行内存对齐吗?
首先,对于位段我们应该知道,其主要作用是:节省空间;而我们知道结构体的内存对齐是以空间换取时间的一种方式,很显然,这就与位段的初衷相矛盾了,故位段是不会有内存对齐的。
void Test8(void)
{printf("bit size = %d\n", sizeof(struct bit));
}那么上面这个位段是多大呢?

可以看到这个位段共占用了8个字节,的确节省了空间。那么位段究竟是如何分配内存的呢?
6.2. 位段的内存分配
1. 位段的成员可以是 int、unsigned int、 signed int、 或者是 char( 属于整形家族)类型2. 位段的空间上是按照需要以 4 个字节( int )或者 1 个字节( char )的方式来开辟的。3. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段
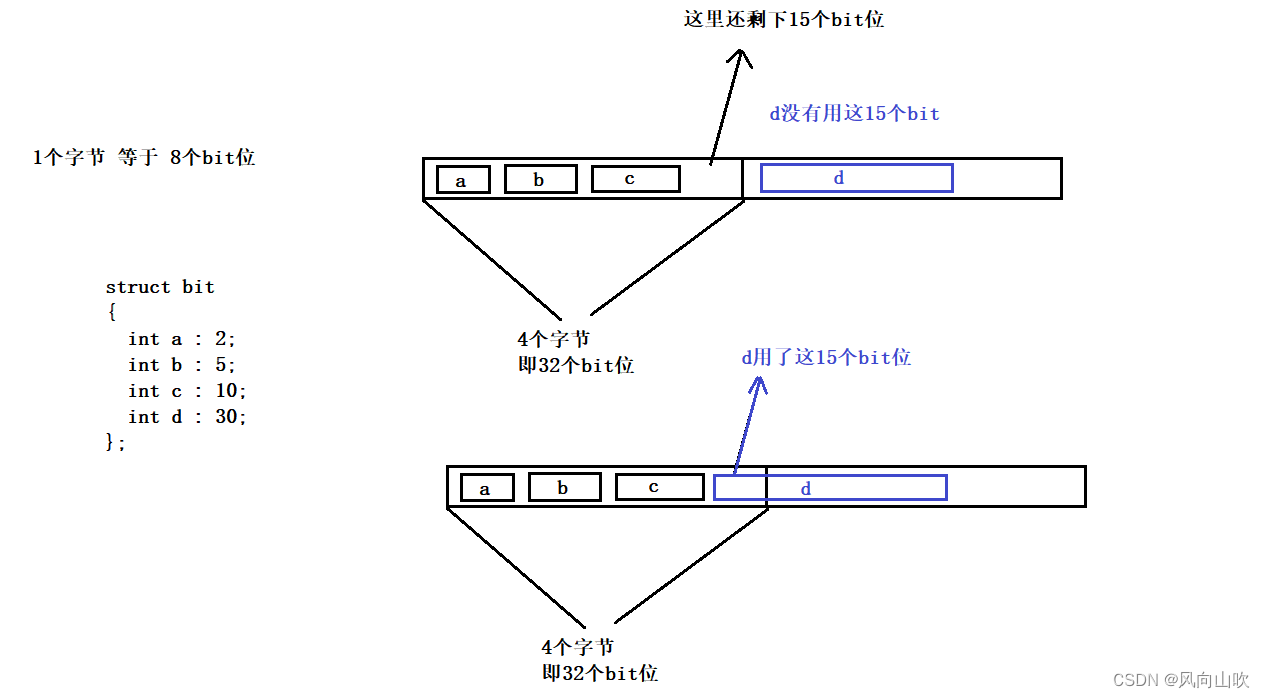
之所以说位段是不跨平台的,是由于当出现上面这种情况时,我们不知道它的内存分配是怎样的,例如:上面剩余了15个bit位,d到底有没有使用它,是不确定的,标准并没有明确规定是否使用这个15个bit。因此,对于位段的使用要小心,如果要求程序具有移植性,那么尽量减少位段的使用。
位段的跨平台问题1. int 位段被当成有符号数还是无符号数是不确定的。2. 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机器会出问题。3. 位段中的成员在内存中从左向右分配,还是从右向左分,配标准尚未定义(vs下是从右向左分配的)。4. 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的(vs下没有利用剩余的空间)
总结:
位段较结构体相比,位段可以达到同样的效果,但是可以很好的节省空间,但由于标准对许多细节并没有明确规定,存在跨平台的问题,其可移植性是有待商榷。
2. 枚举
2.1. 枚举
枚举(enum)是一种用于定义一组相关常量的数据类型。它可以帮助开发人员更清晰地表示某个值的取值范围,并提供更好的可读性和可维护性。
在枚举类型中,我们可以定义一组具体的命名常量,也称为枚举成员。每个枚举成员都有一个与之关联的值,它可以是数字(如整数)或者是其他数据类型(如字符串)。枚举成员之间用逗号隔开。
使用枚举,我们可以通过给定的枚举成员来表示某个特定的取值。这有助于编写更可读的代码,并减少硬编码所带来的错误。此外,枚举还可以作为函数参数、变量和属性的类型,增加代码的类型安全性。
enum color
{RED,YELLOW,BILU
};上面的enum color 就是一种枚举类型,{}中的内容是枚举类型的可能取值,也称之为枚举常量,这些枚举常量都是有值的,默认从0开始,依次递增1,当然在定义的时候也可以赋初值,例如:
enum color
{RED = 5,YELLOW = 3,BLACK, // 这里的BLACK没有赋初值,那么就是YELLOW + 1,即等于4BILU = 7 // 注意,最后一项的枚举常量不加,
};2.2. 枚举常量的优点
为什么要使用枚举常量呢?它与#define定义的符号常量有什么区别呢?
枚举常量的优点:
1. 增加代码的可读性和可维护性2. 和 #define 定义的标识符比较枚举有类型检查,更加严谨。枚举常量是属于一种枚举类型的,它是具有类型检查的,与符号常量相比更为严谨3. 防止了命名污染(封装)4. 便于调试,宏定义的符号常量在预编译阶段就被替换了。5. 使用方便,一次可以定义多个常量
因此,我们推荐使用枚举常量,以减少宏定义的标识符的使用
3. 联合
3.1. 联合
联合(union)是一种特殊的 自定义类型 ,它可用于在同一内存空间中存储不同的数据类型。它允许使用同一块内存来存储多种类型的数据,但同一时间只能使用其中的一种类型数据。联合与结构体非常相似,都可以定义多个成员,但联合只分配给它成员中最大的元素所需要的内存空间(需要考虑内存对齐,当最大成员的大小不是最大对齐数的整数倍时,就需要内存对齐)。因此,联合可以通过不同的成员来表示同一块内存中的数据,这使得它在一定程度上可以节省内存空间。
联合体的特征就是:联合的成员共用同一块空间(所以联合也叫共用体),示例如下:
union Un
{char ch;int i;
};那么上面这个联合体的大小是多少呢?
void Test10(void)
{printf("Un size: %d\n", sizeof(union Un));
}
联合的大小是由其最大的成员决定的,例如上面的这个联合,其最大成员是一个int类型,又因为此时这个联合体的最大对齐数就是4,因此上面这个联合的大小就是4。
void Test11(void)
{union Un u;printf("u address: %p\n", &u);printf("ch address: %p\n", &(u.ch));printf("i address: %p\n", &(u.i));
}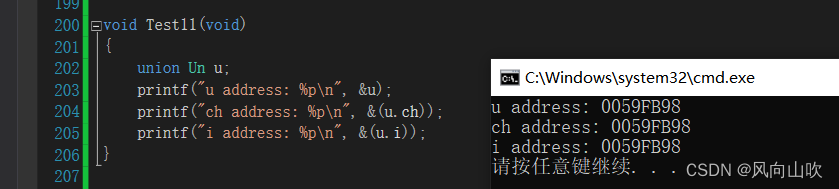
可以发现,联合对象和它的成员的地址是一样的,也就是说,其内存分配如图所示:
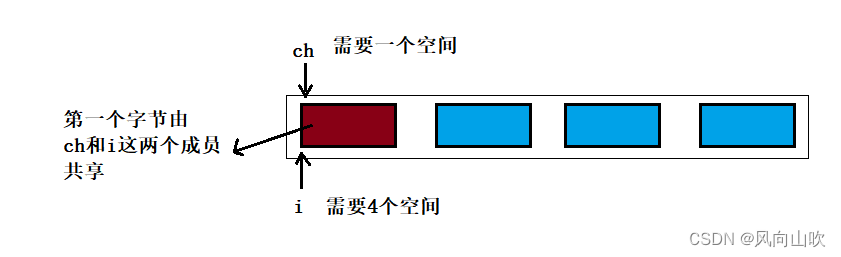
联合的特定是成员共享同一块空间,但这也限制了在同一时刻只可以使用一种成员。例如:
union Un
{char ch;int i;
};
void Test12(void)
{union Un u;u.i = 0x11223344;u.ch = 0x66;
}

在使用联合时,改变其中一个成员变量,另一个成员变量也会被修改,因此一般情况下,联合在某一时刻下是单独使用一个成员变量的 。
3.2. 判断大小端
什么叫大端,什么叫小端呢?
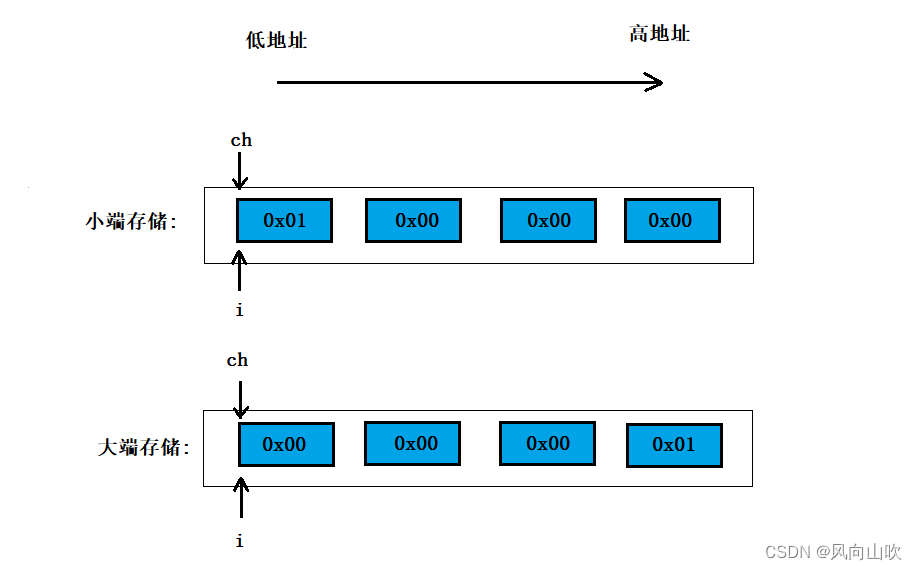
大端(Big Endian)和小端(Little Endian)是用于描述存储和处理多字节数据的方式。
大端字节序(Big Endian)是指将最高有效字节(Most Significant Byte,MSB)存储在最低地址处,最低有效字节(Least Significant Byte,LSB)存储在最高地址处。也就是说,数据的高位字节存储在低位地址,低位字节存储在高位地址。
小端字节序(Little Endian)则相反,它是指将最低有效字节(LSB)存储在最低地址处,最高有效字节(MSB)存储在最高地址处。也就是说,数据的低位字节存储在低位地址,高位字节存储在高位地址。
void Test13(void)
{int i = 0x12345678;// 对于0x12345678的大端字节序和小端字节序// 低地址 <---------------> 高地址// 大端字节序:// 0x12 0x34 0x56 0x78// 小端字节序:// 0x78 0x56 0x34 0x12
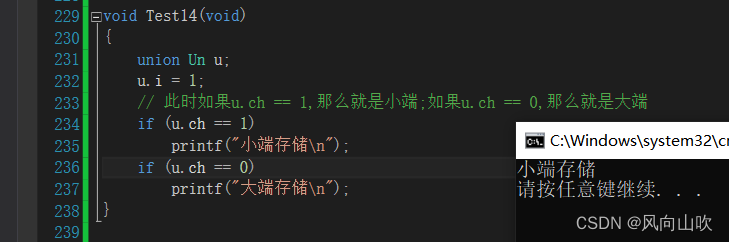
}利用联合的特性(其成员共有同一块空间),我们就可以判断某个机器下是大段还是小端存储,那么如何判断呢?
union Un
{char ch;int i;
};void Test14(void)
{union Un u;u.i = 1;// 此时如果u.ch == 1,那么就是小端;如果u.ch == 0,那么就是大端if (u.ch == 1)printf("小端存储\n");if (u.ch == 0)printf("大端存储\n");
}
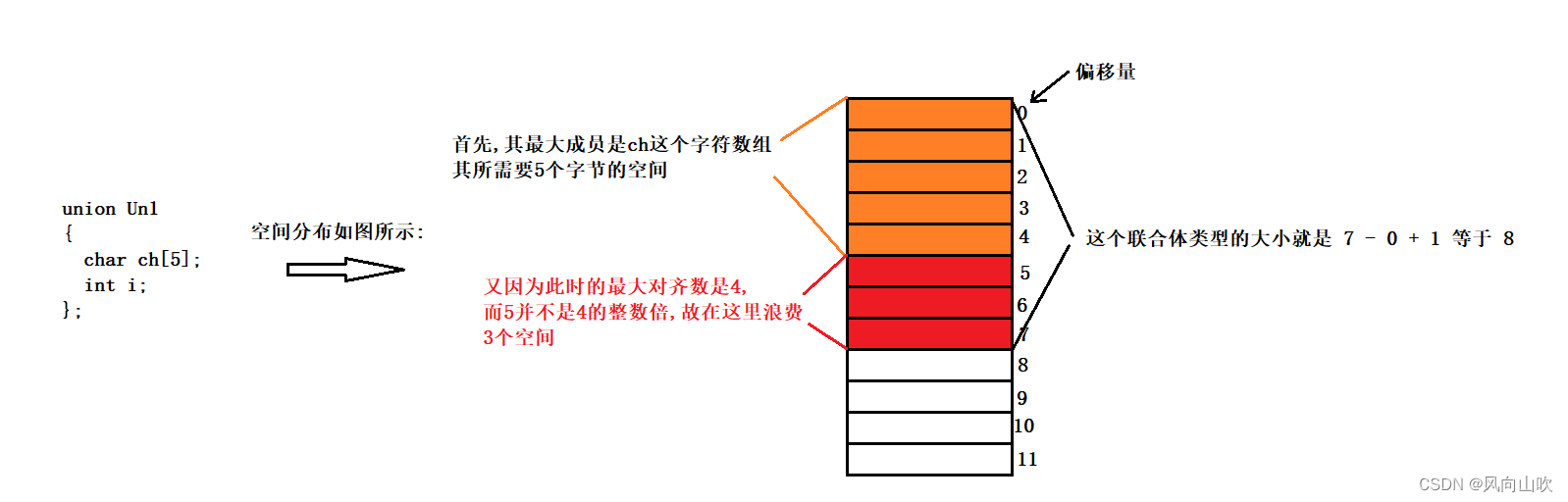
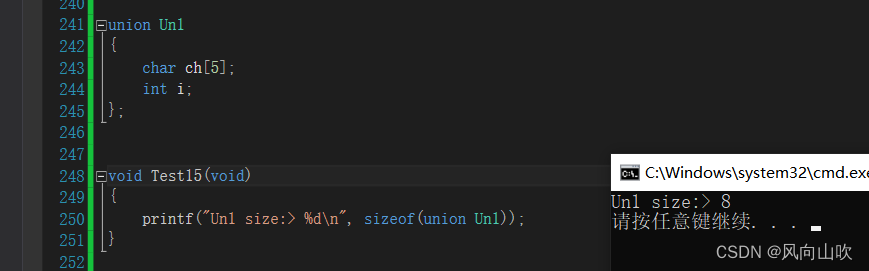
3.3. 联合大小的计算
union Un1
{char ch[5];int i;
};上面的联合体是多大呢?注意,联合体的的大小首先是要保证能够存放最大成员,其次如果最大成员所占空间大小不是其最大对齐数的整数倍,那么需要内存对齐。例如上面的:
至此,C语言的自定义类型到此结束。
相关文章:
C的自定义类型
目录 1. 结构体 1.1. 结构体类型的声明 1.1.1. 特殊声明 2. 结构的自引用 3. 结构体变量的定义和初始化 4. 结构体内存对齐 4.1. 结构体内存对齐 4.2. 修改默认对齐数 5. 结构体传参 6. 结构体实现位段(位段的填充&可移植性) 6.1. 什么是位…...

我的创作纪念日 - 2048
机缘 昨天刚刚收到 C 站的 1024 勋章: 今天爬山途中就又收到了 CSDN 的创作 2048 天纪念推送: 虽然 1024、2048 这些数字对普通人来说可能没有意义,但对于程序员来说却有不一样的情结。感谢 C 站这波细心的操作,替程序员的我们记…...
拿捏面试官,高频接口自动化测试面试题总结(附答案)狂收offer...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 面试题࿱…...
大数据-Storm流式框架(六)---Kafka介绍
Kafka简介 Kafka是一个分布式的消息队列系统(Message Queue)。 官网:Apache Kafka 消息和批次 kafka的数据单元称为消息。消息可以看成是数据库表的一行或一条记录。 消息由字节数组组成,kafka中消息没有特别的格式或含义。 消息有可选的键&#x…...

自动驾驶的未来展望和挑战
自动驾驶技术是一项引人瞩目的创新,将在未来交通领域产生深远影响。然而,随着技术的不断演进,自动驾驶也面临着一系列挑战和障碍。本文将探讨自动驾驶的未来发展方向、技术面临的挑战,以及自动驾驶对社会和环境的潜在影响。 自动驾…...

2.11、自定义图融合过程与量化管线
introduction 介绍如何自定义量化优化过程,以及如何手动调用优化过程 code from typing import Callable, Iterableimport torch import torchvisionfrom ppq import (BaseGraph, QuantizationOptimizationPass,QuantizationOptimizationPipeline, QuantizationSetting,Tar…...

Linux——文件权限属性和权限管理
文件权限属性和权限管理 本章思维导图: 注:本章思维导图对应的Xmid文件和.png文件都以传到“资源” 文章目录 文件权限属性和权限管理1. sudo提权和sudoers文件1.1 sudo提权和成为root的区别 2. 权限2.1 Linux群体2.1.1 为什么要有所属组2.1.2 修改文件…...
数组与链表算法-单向链表算法
目录 数组与链表算法-单向链表算法 C代码 单向链表插入节点的算法 C代码 单向链表删除节点的算法 C代码 对单向链表进行反转的算法 C代码 单向链表串接的算法 C代码 数组与链表算法-单向链表算法 在C中,若以动态分配产生链表节点的方式,则可以…...

Oracle(6) Control File
一、oracle控制文件介绍 1、ORACLE控制文件概念 Oracle控制文件是Oracle数据库的一个重要元素,用于记录数据库的结构信息和元数据。控制文件包含了数据库的物理结构信息、数据字典信息、表空间和数据文件的信息等。在Oracle数据库启动时,控制文件会被读…...
吴恩达《机器学习》2-5->2-7:梯度下降算法与理解
一、梯度下降算法 梯度下降算法的目标是通过反复迭代来更新模型参数,以便最小化代价函数。代价函数通常用于衡量模型的性能,我们希望找到使代价函数最小的参数值。这个过程通常分为以下几个步骤: 初始化参数: 随机或设定初始参数…...
方法)
Pytorch detach()方法
detach() 是 PyTorch 中的一个方法,用于从计算图中分离(detach)张量。它可以将一个张量从当前计算图中分离出来,返回一个新的张量,该张量与原始张量共享相同的底层数据,但不再追踪梯度信息。 当你需要在计…...
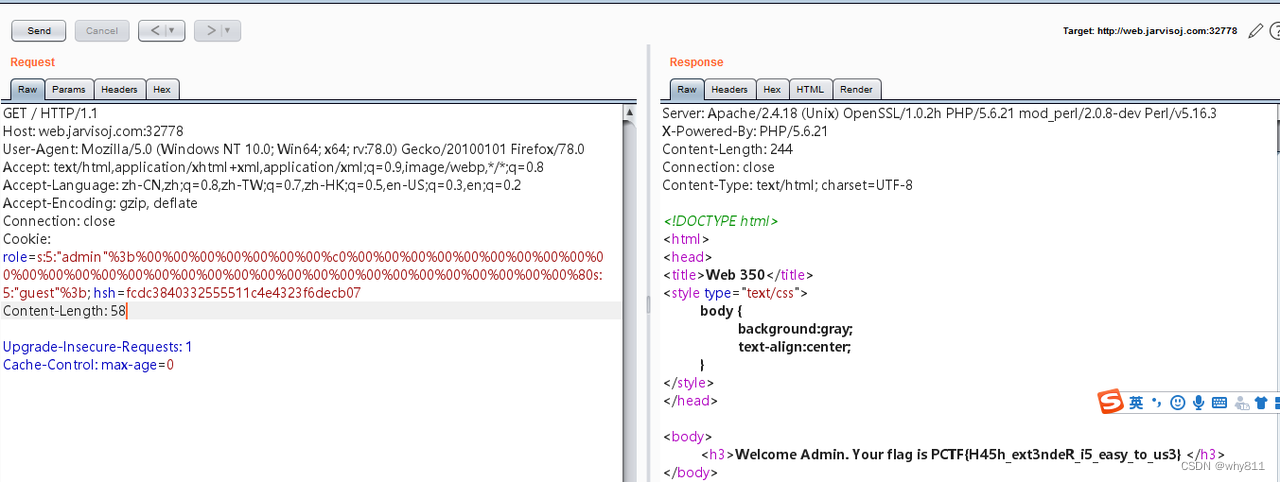
CTF-php特性绕过
注意:null0 正确 nullflase 错误 Extract变量覆盖 <?php$flagxxx; extract($_GET);if(isset($shiyan)){ $contenttrim(file_get_contents($flag));//trim移除引号if($shiyan$content){ echoctf{xxx}; }else{ echoOh.no;} }?> extract() 函数从数组中将…...

人脸识别测试数据分析
一个人脸识别研究小组对若干名学生做了人脸识别的测试,将测试结果写入到一个文件 dir_50.txt 中,每一行是一张照片的识别结果“_照片编号”“.jpg”的字符串组合,示例如下: [1709020621, 0]_116.jpg [1709020621]_115.jpg [17706…...
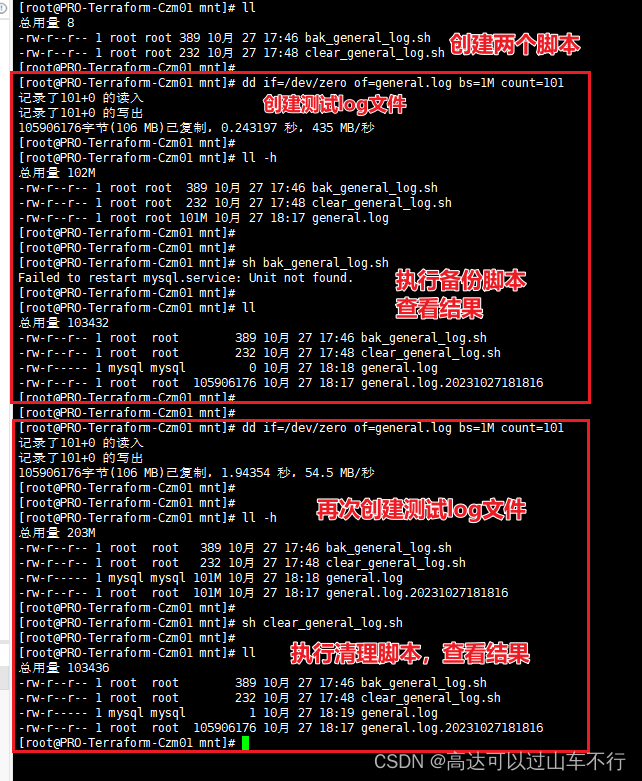
MySQL 5.7限制general_log日志大小
背景 需求: 在MySQL 5.7.41中开启general_log 并限制其大小,避免快速增长占用硬盘空间。 解决: 通过定时任务,执行简单的脚本,判断general_log 日志的大小,实现对通用查询日志的“每日备份”或“每日清…...
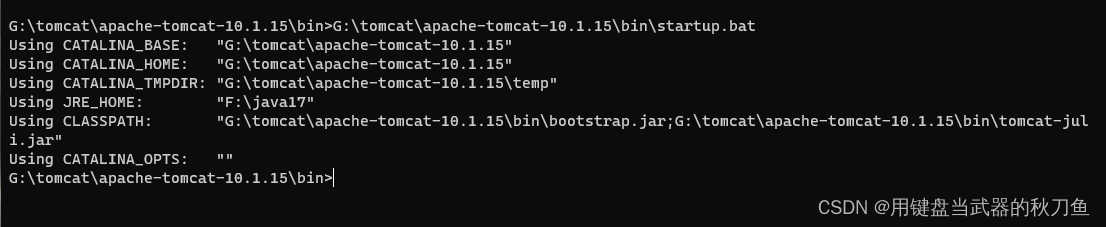
tomcat9~10猫闪退个人经验
java版本17与8 8版本有jre,java17没有jre 所以在java8版本中将jre和jdk路径一同添加环境是不会出现闪退的,tomcat9没有闪退 但是在10就闪退了,因为java版本太低 java17没有jre,但是可以通过一种方法添加jre到java17的目录 完…...
Linux之J2EE的项目部署及发布
目录 前言 一、会议OA单体项目windows系统部署 1.检验工作 1. 检验jar项目包是否可以运行 2. 验证数据库脚本是否有误 3. 测试项目功能 2. 部署工作 2.1 传输文件 2.2 解压项目及将项目配置到服务器中 2.3 配置数据库 2.4 在服务器bin文件下点击startup.bat启动项目 …...
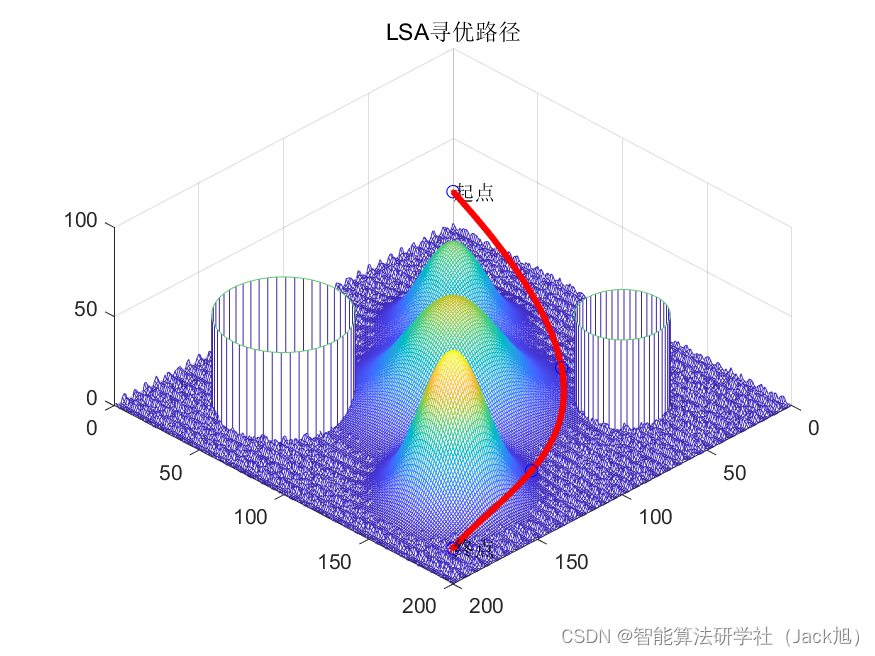
基于闪电搜索算法的无人机航迹规划-附代码
基于闪电搜索算法的无人机航迹规划 文章目录 基于闪电搜索算法的无人机航迹规划1.闪电搜索搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用闪电搜索算法来优化无人机航迹规划。 …...

【网络安全 --- 文件上传靶场练习】文件上传靶场安装以及1-5关闯关思路及技巧,源码分析
一,前期准备环境和工具 1,vmware 16.0安装 若已安装,请忽略 【网络安全 --- 工具安装】VMware 16.0 详细安装过程(提供资源)-CSDN博客文章浏览阅读186次,点赞9次,收藏2次。【网络安全 --- 工…...
BUUCTF刷题记录
[BJDCTF2020]Easy MD51 进入题目页面,题目提示有一个链接,应该是题目源码 进入环境,是一个查询框,无论输入什么都没有回显,查看源码也没什么用 利用bp抓包查看有没有什么有用的东西 发现响应的Hint那里有一个sql语句&…...

黑客技术(网络安全)—小白自学
目录 一、自学网络安全学习的误区和陷阱 二、学习网络安全的一些前期准备 三、网络安全学习路线 四、学习资料的推荐 想自学网络安全(黑客技术)首先你得了解什么是网络安全!什么是黑客! 网络安全可以基于攻击和防御视角来分类&am…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...