【深度学习】【NLP】如何得到一个分词器,如何训练自定义分词器:从基础到实践
文章目录
- 什么是分词?
- 分词算法
- 使用Python训练分词器
- 步骤1:选择分词算法
- 步骤2:准备训练语料
- 步骤3:配置分词器参数
- 步骤4:训练分词器
- 步骤5:测试和使用分词器
- 代码示例:使用SentencePiece训练分词器
- 分词算法的训练要素,如何训练好
- 合并分词表
- baichuan-7B 的分词
- 通义千问
- 智谱
在自然语言处理(NLP)领域,分词是一个重要的预处理步骤,它将文本切分成有意义的子词或标记。合适的分词工具可以对NLP任务产生深远的影响,而如何训练一个自定义分词器也是一个关键的课题。本篇博客将引导您了解不同分词算法,深入探讨分词工具的原理,然后演示如何使用Python代码训练自己的分词器。
什么是分词?
分词是将文本划分为更小的单元,如单词、子词或标记的过程。在中文分词中,这些单元通常是词汇,而在英文中,可以是单词或子词。分词是NLP的基础,它对文本的理解和处理具有关键作用。
分词算法
在NLP中,有多种分词算法可供选择。以下是一些常见的分词算法,这些分词算法各有其优势,取决于具体的应用场景和需求。以下是它们的一些特点:
-
BPE(Byte-Pair Encoding):
- 优势:BPE是一种无监督算法,能够适用于多种语言,包括中文和英文。它基于字符级别的处理,对于分词的划分灵活性较高,适用于不同领域的文本。
- 中英文混合分词:BPE可以用于中英文混合分词,但需要适当调整参数和词表来满足中文语言的需求。
-
WordPiece:
- 优势:WordPiece是一种基于BPE的算法,它在选择字符对合并时考虑标记的可能性。这使得它在处理NLP任务时表现更好,如机器翻译和文本生成。对于英文和中文等多语言情境,WordPiece通常具有很好的性能。
- 中英文混合分词:WordPiece同样适合中英文混合分词,而且在考虑标记的可能性时,能更好地处理多语言文本。
-
Unigram:
- 优势:Unigram采用概率模型来选择标记,这使得它能够生成带概率的多个子词分段。这对于语言生成任务或需要模糊匹配的场景可能有益。
- 中英文混合分词:Unigram同样可以用于中英文混合分词,但需要注意参数设置和模型训练。
-
SentencePiece:
- 优势:SentencePiece结合了BPE和Unigram的优点,可以从原始文本开始训练分词模型,适用于多种语言。它非常灵活,适用于多样化的文本处理需求,包括中英文。
- 中英文混合分词:SentencePiece同样适合中英文混合分词,并且容易进行多语言训练。
关于哪个更适合中英文一起的分词,选择取决于具体情况。WordPiece和SentencePiece通常被认为对于多语言处理更强大,因为它们考虑到了标记的可能性,这对于处理多语言文本的一致性和性能提升有好处。 Unigram和BPE也可以用于中英文混合分词,但可能需要更多的调整和参数设置来满足特定需求。最终的选择应基于实际需求和性能测试。
使用Python训练分词器
以下是使用Python训练自定义分词器的步骤:
步骤1:选择分词算法
首先,选择适合您需求的分词算法。如果需要针对特定语料库或任务训练分词器,可以考虑使用SentencePiece来灵活满足需求。
步骤2:准备训练语料
收集和准备训练语料,这是训练自定义分词器的基础。语料库的大小和质量将影响分词器的性能。
步骤3:配置分词器参数
针对所选的分词算法,配置参数,如词表大小、字符覆盖率等。这些参数的选择应根据语料和任务的特点来确定。
步骤4:训练分词器
使用选择的分词算法和参数,训练自定义分词器。这通常涉及编写Python代码来调用分词库的API,并传递训练语料。
步骤5:测试和使用分词器
训练完成后,测试分词器的性能,确保它能够有效切分文本。然后,您可以将训练好的分词器用于NLP任务,如文本分类、情感分析等。
代码示例:使用SentencePiece训练分词器
下面是一个使用SentencePiece库来训练分词器的Python代码示例:
import sentencepiece as spm# 训练SentencePiece模型
spm.SentencePieceTrainer.train(input='corpus.txt', # 输入文件model_prefix='custom_tokenizer', # 模型前缀vocab_size=5000, # 词汇表大小model_type='unigram', # 模型类型# 其他参数...
)# 加载训练好的模型
sp = spm.SentencePieceProcessor()
sp.load('custom_tokenizer.model')# 使用分词器
text = "这是一个示例句子"
tokens = sp.encode_as_pieces(text)
print(tokens)
在训练一个分词器时,下面是一些重要的参数,其中一些参数对模型的性能和行为产生显著影响:
-
model_type:模型类型,可以选择BPE、char、word、unigram。这决定了分词器使用哪种分词算法。不同类型适用于不同的任务和文本类型。
-
vocab_size:词汇表大小,这个参数决定了词表中包含多少标记。太小的词汇表可能导致词汇覆盖不足,而太大的词汇表可能会增加训练时间。
-
character_coverage:指定模型中覆盖的字符数,通常设置为一个小数,如0.9995。这可以帮助控制词汇表的大小。
-
max_sentence_length:最大句子长度,决定了句子在分词时的最大长度。过长的句子可能需要截断或拆分。
-
num_threads:进程个数,控制训练时的并行度,影响训练速度。
-
unk_id、bos_id、eos_id、pad_id:这些参数定义了特殊标记的ID。例如,unk_id表示未知标记的ID,bos_id表示句子的开头,eos_id表示句子的结尾,pad_id表示填充标记。
-
split_by_unicode_script、split_by_number、split_by_whitespace、split_digits:这些参数用于控制在哪些情况下进行拆分,例如,是否在不同的字符脚本之间、数字之间、空格之间、数字和字母之间拆分。
-
use_all_vocab:是否使用所有词汇。设置为0时,只使用出现频率高的标记。
这些参数是分词器训练中的关键配置,它们直接影响模型的性能和行为。根据具体任务和语料库,你需要谨慎选择和调整这些参数以获得最佳的分词效果。不同的参数设置可能适用于不同的应用场景,因此需要根据需求进行实验和调整。
这段代码演示了如何使用SentencePiece来训练一个自定义分词器,加载模型,并将其应用于文本。
HuggingFace的Tokenizers也实现了分词算法,具体使用可以参考如下:
from tokenizers import (ByteLevelBPETokenizer,BPETokenizer,SentencePieceBPETokenizer,BertWordPieceTokenizer)tokenizer = SentencePieceBPETokenizer()
tokenizer.train(["../blog_test.txt"], vocab_size=500, min_frequency=2)output = tokenizer.encode("This is a test")
print(output.tokens)
分词算法的训练要素,如何训练好
在训练大模型分词器时,有几个关键因素需要考虑,这些因素可以总结如下:
-
词表大小设置:词表大小应该与语料库的大小匹配。具体的设置可以参考一些大型模型,如ChatGPT和Chinese-LLaMA模型,它们通常采用词表大小在5万到13万之间。合理的词表大小直接影响了模型参数数量和训练速度。较大的词表可能需要更多的资源来训练和部署,但能够更好地覆盖不同领域和语言的内容。
-
语料库的充实性:语料库的质量和数量对分词器的性能至关重要。使用丰富和多样化的语料库可以更好地适应各种领域和专业术语,以产生更符合通用语义的切分结果。特别是在垂直领域或特殊领域的应用中,充足的领域特定语料库对于保持高质量的分词结果非常重要。
-
词汇量大小的平衡:选择词汇表的大小需要在模型质量和效率之间取得平衡。较大的词汇表可以提高模型的语言表示能力,但也会增加模型的参数量。在拥有足够计算资源和充足语料库的情况下,可以考虑使用较大的词汇表以提高模型的性能。
合并分词表
由transformers库的教程https://transformers.run/intro/2021-12-11-transformers-note-2/也可以得知:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenizer.save_pretrained("./models/bert-base-cased/")
调用 Tokenizer.save_pretrained() 函数会在保存路径下创建三个文件:
special_tokens_map.json:映射文件,里面包含 unknown token 等特殊字符的映射关系;
tokenizer_config.json:分词器配置文件,存储构建分词器需要的参数;
vocab.txt:词表,一行一个 token,行号就是对应的 token ID(从 0 开始)。
博客https://blog.51cto.com/u_16116809/6321388提到一个tips:LLaMA模型预训练中文语料特别少,可以把中文学到的vocab.txt分词表加入到原有的里面,我理解,special_tokens_map.json是通用的,tokenizer_config.json里面写的一些分词算法配置如果中英文一样也就无所谓,所以就能合并vocab.txt分词表。
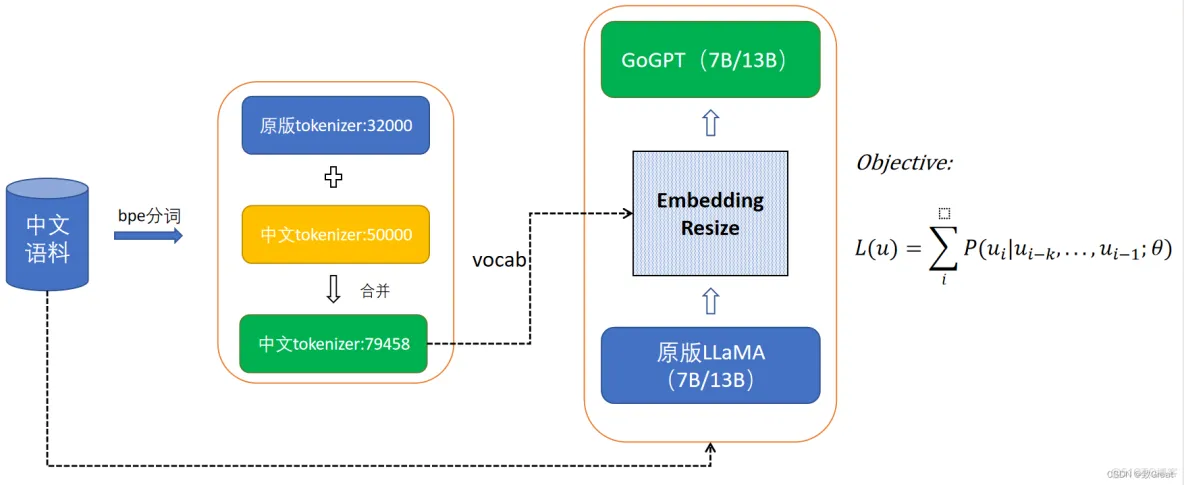
baichuan-7B 的分词
看得出来,针对不同领域,分词算法也是一个研究点,baichuan-7B看起来还是挺厉害的:
https://github.com/baichuan-inc/baichuan-7B#%E5%88%86%E8%AF%8D
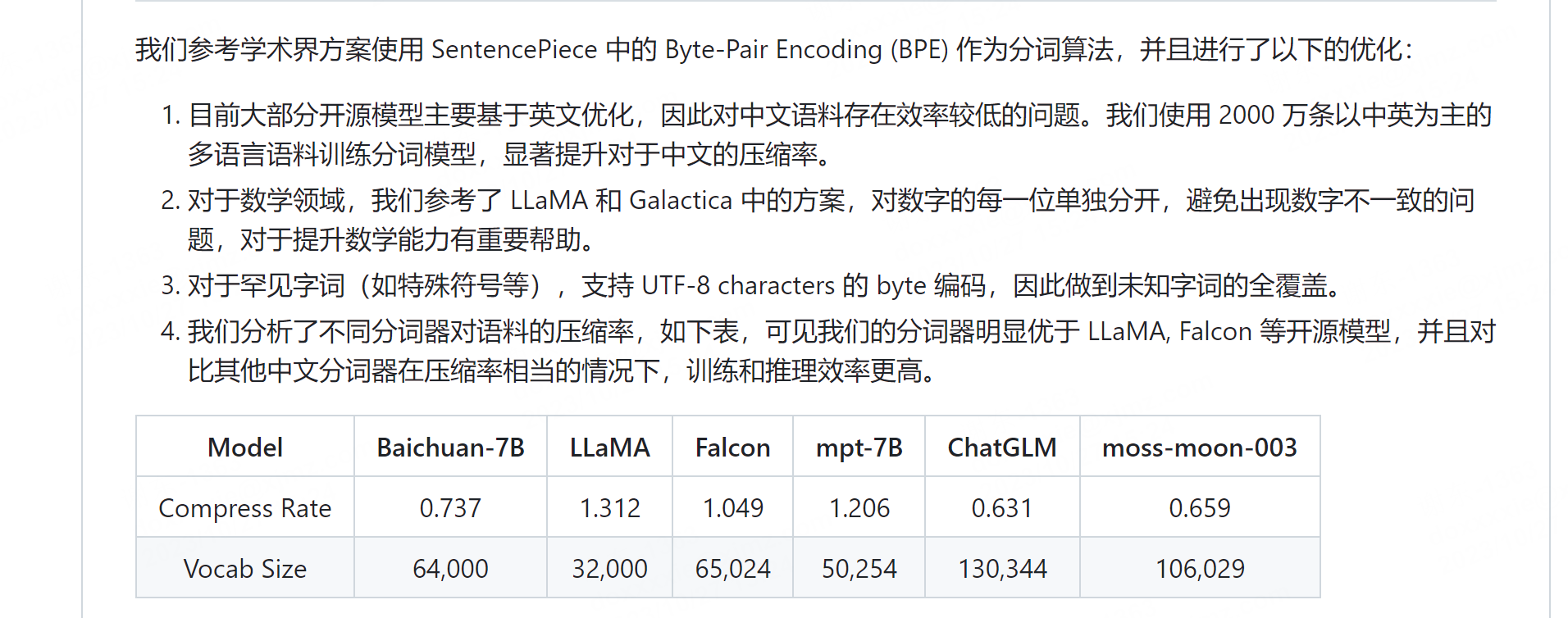
通义千问
https://modelscope.cn/organization/qwen
https://huggingface.co/Qwen/Qwen-7B-Chat
智谱
https://github.com/THUDM/ChatGLM2-6B
参考:
https://blog.51cto.com/u_16116809/6321388
https://github.com/yanqiangmiffy/how-to-train-tokenizer
https://github.com/baichuan-inc/baichuan-7B#%E5%88%86%E8%AF%8D
相关文章:
【深度学习】【NLP】如何得到一个分词器,如何训练自定义分词器:从基础到实践
文章目录 什么是分词?分词算法使用Python训练分词器步骤1:选择分词算法步骤2:准备训练语料步骤3:配置分词器参数步骤4:训练分词器步骤5:测试和使用分词器 代码示例:使用SentencePiece训练分词器…...

线程池的线程回收
线程池 线程池里面分为核心线程和非核心线程。 核心线程是常驻在线程池里面的工作线程,它有两种方式初始化: 向线程池里面添加任务的时候,被动初始化 主动调用 prestartAllCoreThreads 方法 当线程池里面的队列满了的情况下,为了增…...

【2023.10.25练习】数据库-函数1
任务描述 本关任务:编写函数fun_1完成学生选课操作。输入参数:学号、课程名,函数返回值:操作结果。 如果该生已有该门课程的选修记录,则函数返回-1;如果该门课程无先修课,则将选课信息添加到选…...
基于水循环算法的无人机航迹规划-附代码
基于水循环算法的无人机航迹规划 文章目录 基于水循环算法的无人机航迹规划1.水循环搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用水循环算法来优化无人机航迹规划。 1.水循环…...
JVM调优(10)JVM的运行时数据区
一、概述 对于 C C 来说,在内存管理领域,JVM既拥有最高的权利,但是同时他们又是从事最基础工作的劳动人员,因为他们担负着每一个对象从开始到结束的维护责任。而对于Java来说,再虚拟机自动内存管理的帮助下࿰…...

Python网络爬虫介绍
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium 什么是网络爬虫? 网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者)ÿ…...

iOS QR界面亮度调整
亮度调事,不久在QR界面切换的时候还要考虑进入前台后台时的操作 1.QR界面功能实现代码。 QR界面- (void)viewWillAppear:(BOOL)animated {[super viewWillAppear:animated];[[NSUserDefaults standardUserDefaults] setValue:([UIScreen mainScreen].brightness) …...
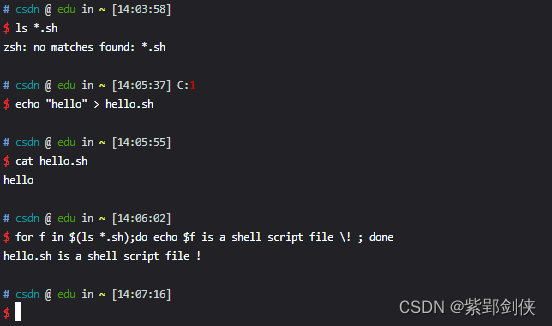
Linux shell编程学习笔记17:for循环语句
Linux Shell 脚本编程和其他编程语言一样,支持算数、关系、布尔、字符串、文件测试等多种运算,同样也需要进行根据条件进行流程控制,提供了if、for、while、until等语句。 之前我们探讨了if语句,现在我们来探讨for循环语句。 Li…...

Go语言用Resty库编写的音频爬虫代码
目录 一、Go语言与Resty库简介 二、音频爬虫的实现 1、确定抓取目标 2、使用Resty发送HTTP请求 3、解析响应数据 4、下载音频文件 5、并发下载音频文件 三、注意事项 总结 随着互联网的飞速发展,网络爬虫逐渐成为数据获取和分析的重要工具。在音频领域&…...

AWTK 液体流动效果控件发布
液体流动效果控件。 主要特色: 支持水平和垂直方向。支持正向和反向流动。支持设置头尾的图片。支持设置流动的图片。支持设置速度的快慢。支持启停操作。 准备 获取 awtk 并编译 git clone https://github.com/zlgopen/awtk.git cd awtk; scons; cd -运行 生成…...

对mysql的联合索引的深刻理解
背景 对mysql的联合索引的考察是Java程序员面试高频考点!必须深刻理解掌握否则容易丢分非常可惜。 技术难点 考察对最左侧匹配原理理解。 原理 暂且不表。网上讲这非常多。我理解就是,B树每个非叶子节点的值都是有序存放索引的值。 比如对A、B、C …...
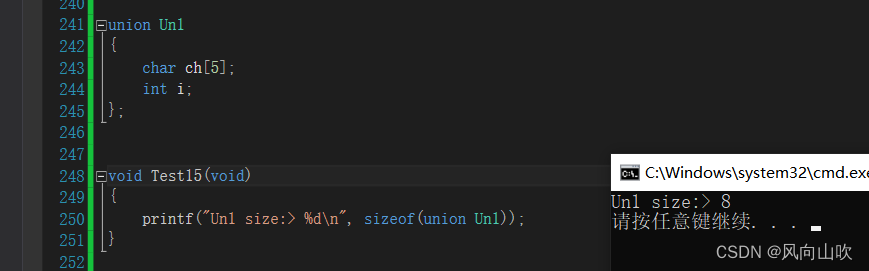
C的自定义类型
目录 1. 结构体 1.1. 结构体类型的声明 1.1.1. 特殊声明 2. 结构的自引用 3. 结构体变量的定义和初始化 4. 结构体内存对齐 4.1. 结构体内存对齐 4.2. 修改默认对齐数 5. 结构体传参 6. 结构体实现位段(位段的填充&可移植性) 6.1. 什么是位…...

我的创作纪念日 - 2048
机缘 昨天刚刚收到 C 站的 1024 勋章: 今天爬山途中就又收到了 CSDN 的创作 2048 天纪念推送: 虽然 1024、2048 这些数字对普通人来说可能没有意义,但对于程序员来说却有不一样的情结。感谢 C 站这波细心的操作,替程序员的我们记…...
拿捏面试官,高频接口自动化测试面试题总结(附答案)狂收offer...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 面试题࿱…...
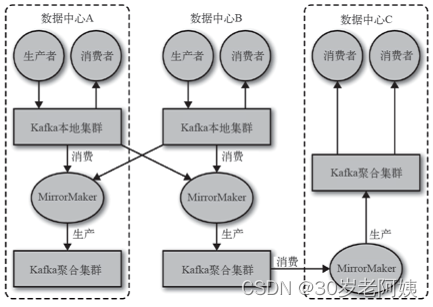
大数据-Storm流式框架(六)---Kafka介绍
Kafka简介 Kafka是一个分布式的消息队列系统(Message Queue)。 官网:Apache Kafka 消息和批次 kafka的数据单元称为消息。消息可以看成是数据库表的一行或一条记录。 消息由字节数组组成,kafka中消息没有特别的格式或含义。 消息有可选的键&#x…...

自动驾驶的未来展望和挑战
自动驾驶技术是一项引人瞩目的创新,将在未来交通领域产生深远影响。然而,随着技术的不断演进,自动驾驶也面临着一系列挑战和障碍。本文将探讨自动驾驶的未来发展方向、技术面临的挑战,以及自动驾驶对社会和环境的潜在影响。 自动驾…...

2.11、自定义图融合过程与量化管线
introduction 介绍如何自定义量化优化过程,以及如何手动调用优化过程 code from typing import Callable, Iterableimport torch import torchvisionfrom ppq import (BaseGraph, QuantizationOptimizationPass,QuantizationOptimizationPipeline, QuantizationSetting,Tar…...

Linux——文件权限属性和权限管理
文件权限属性和权限管理 本章思维导图: 注:本章思维导图对应的Xmid文件和.png文件都以传到“资源” 文章目录 文件权限属性和权限管理1. sudo提权和sudoers文件1.1 sudo提权和成为root的区别 2. 权限2.1 Linux群体2.1.1 为什么要有所属组2.1.2 修改文件…...
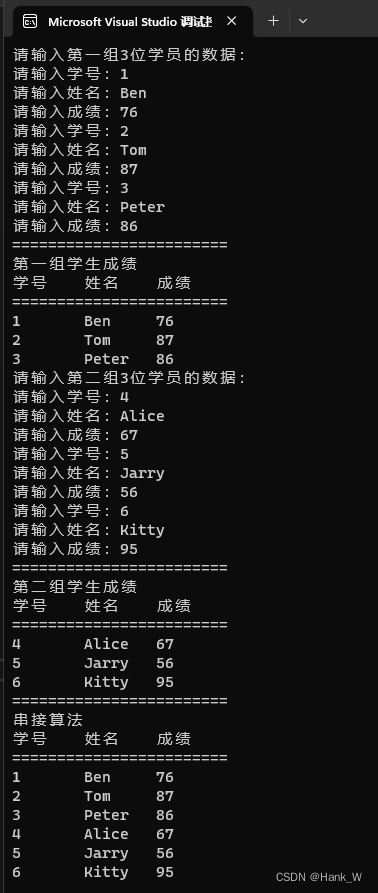
数组与链表算法-单向链表算法
目录 数组与链表算法-单向链表算法 C代码 单向链表插入节点的算法 C代码 单向链表删除节点的算法 C代码 对单向链表进行反转的算法 C代码 单向链表串接的算法 C代码 数组与链表算法-单向链表算法 在C中,若以动态分配产生链表节点的方式,则可以…...

Oracle(6) Control File
一、oracle控制文件介绍 1、ORACLE控制文件概念 Oracle控制文件是Oracle数据库的一个重要元素,用于记录数据库的结构信息和元数据。控制文件包含了数据库的物理结构信息、数据字典信息、表空间和数据文件的信息等。在Oracle数据库启动时,控制文件会被读…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...