Azure云工作站上做Machine Learning模型开发 - 全流程演示
目录
- 本文内容
- 先决条件
- 从“笔记本”开始
- 设置用于原型制作的新环境(可选)
- 创建笔记本
- 开发训练脚本
- 迭代
- 检查结果
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

本文内容
了解如何在 Azure 机器学习云工作站上使用笔记本开发训练脚本。 本教程涵盖入门所需的基础知识:
- 设置和配置云工作站。 云工作站由 Azure 机器学习计算实例提供支持,该实例预配置了环境以支持各种模型开发需求。
- 使用基于云的开发环境。
- 使用 MLflow 跟踪模型指标,所有都是在笔记本中完成的。
先决条件
若要使用 Azure 机器学习,你首先需要一个工作区。 如果没有工作区,请完成“创建开始使用所需的资源”以创建工作区并详细了解如何使用它。
从“笔记本”开始
工作区中的“笔记本”部分是开始了解 Azure 机器学习及其功能的好地方。 在这里,可以连接到计算资源、使用终端,以及编辑和运行 Jupyter Notebook 和脚本。
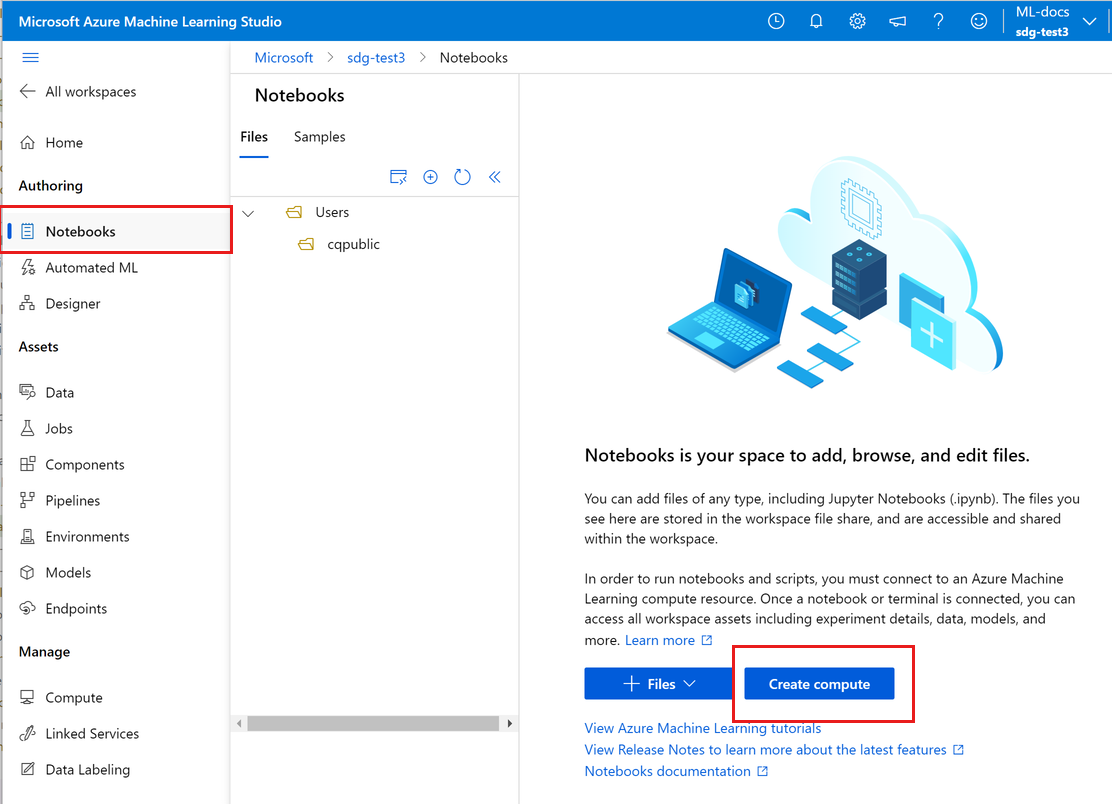
- 登录到 Azure 机器学习工作室。
- 选择你的工作区(如果它尚未打开)。
- 在左侧导航中,选择“笔记本”。
- 如果没有计算实例,屏幕中间会显示“创建计算”。 选择“创建计算”并填写表单。 可以使用所有默认值。 (如果已有计算实例,则会在该位置看到“终端”。本教程稍后会使用“终端”。)
设置用于原型制作的新环境(可选)
为使脚本运行,需要在配置了代码所需的依赖项和库的环境中工作。 本部分可帮助你创建适合代码的环境。 若要创建笔记本连接到的新 Jupyter 内核,请使用定义依赖项的 YAML 文件。
- 上传文件
上传的文件存储在 Azure 文件共享中,这些文件将装载到每个计算实例并在工作区中共享。
1. 使用右上角的 下载原始文件 按钮,将此 conda 环境文件 [workstation_env.yml](github.com) 下载到计算机。
1. 选择“添加文件”,然后选择“上传文件”,将其上传到工作区。
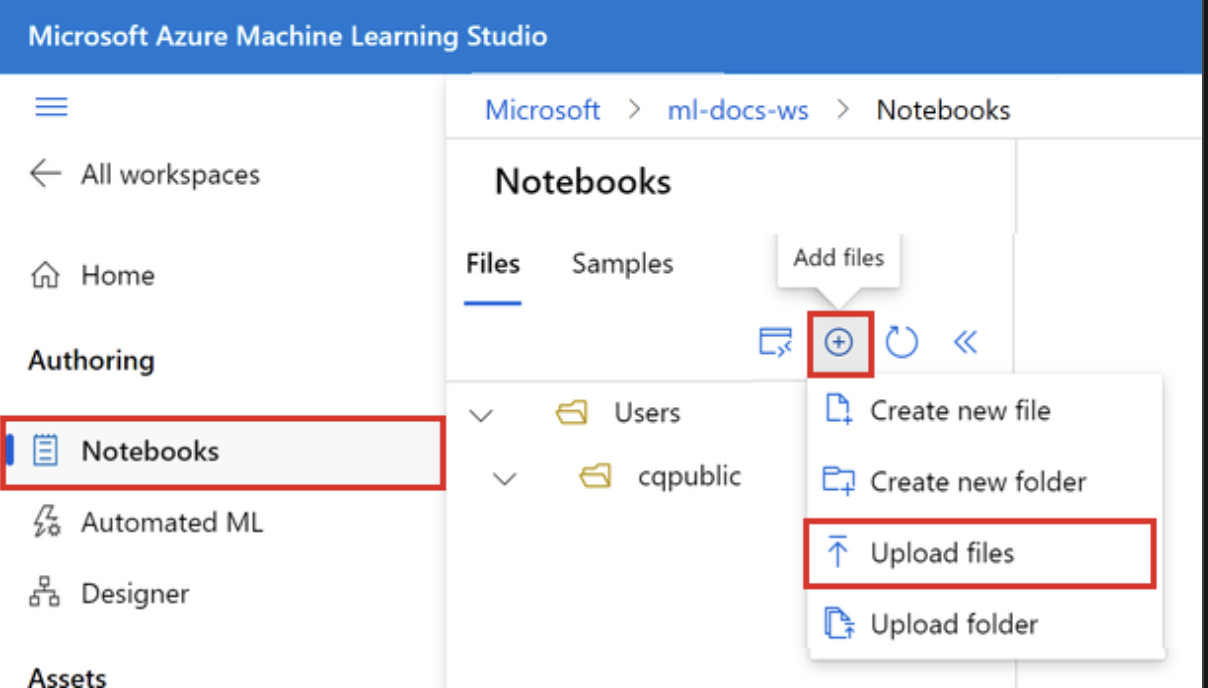
2. 选择“浏览并选择文件”。
3. 选择下载的 workstation_env.yml 文件。
4. 选择“上传”。
你将在“文件”选项卡的用户名文件夹下看到 workstation_env.yml 文件。请选择此文件以预览它,并查看它指定的依赖项。 你将看到如下所示的内容:
name: workstation_env
dependencies:- python=3.8- pip=21.2.4- scikit-learn=0.24.2- scipy=1.7.1- pandas>=1.1,<1.2- pip:- mlflow==2.4.1 - azureml-mlflow==1.51.0- psutil>=5.8,<5.9- ipykernel~=6.0- matplotlib- 创建内核
现在,使用 Azure 机器学习终端基于 workstation_env.yml 文件创建新的 Jupyter 内核。
1. 选择“终端”以打开终端窗口。 还可以从左侧命令栏打开终端:
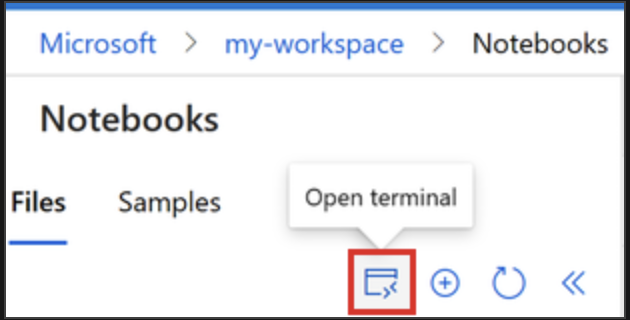
2. 如果计算实例已停止,请选择“启动计算”,并等待它运行。

3. 计算运行后,终端中会显示一条欢迎消息,可以开始键入命令。
4. 查看当前的 conda 环境。 活动环境标有 *。conda env list5. 如果为本教程创建了子文件夹,请立即运行 `cd` 转到该文件夹。
6. 根据提供的 conda 文件创建环境。 构建此环境需要几分钟时间。conda env create -f workstation_env.yml7. 激活新环境。conda activate workstation_env8. 验证正确的环境是否处于活动状态,再次查找标有 * 的环境。conda env list9. 基于活动环境创建新的 Jupyter 内核。python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env" 10. 关闭终端窗口。
创建笔记本
-
选择“添加文件”,然后选择“创建新文件”。
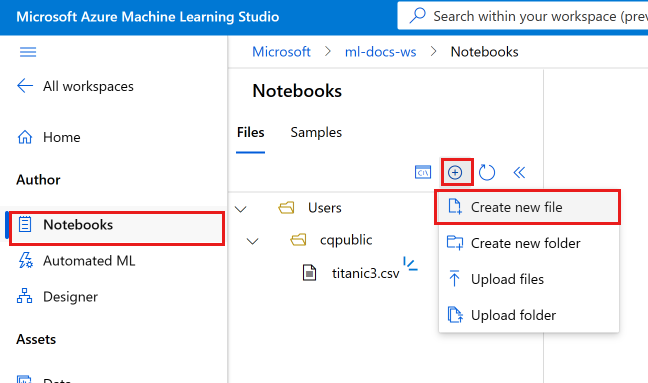
-
将新笔记本命名为 develop-tutorial.ipynb(或输入首选名称)。
-
如果计算实例已停止,请选择“启动计算”,并等待它运行。

-
你将在右上角看到笔记本已连接到默认内核。 如果创建了内核,请切换到使用 Tutorial Workstation Env 内核。
开发训练脚本
在本部分中,你将使用 UCI 数据集中准备好的测试和训练数据集开发一个 Python 训练脚本,用于预测信用卡默认付款。
此代码使用 sklearn 进行训练,使用 MLflow 来记录指标。
-
从可导入将在训练脚本中使用的包和库的代码开始。
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split -
接下来,加载并处理此试验的数据。 在本教程中,将从 Internet 上的一个文件读取数据。
# load the data credit_df = pd.read_csv("https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",header=1,index_col=0, )train_df, test_df = train_test_split(credit_df,test_size=0.25, ) -
准备好数据进行训练:
# Extracting the label column y_train = train_df.pop("default payment next month")# convert the dataframe values to array X_train = train_df.values# Extracting the label column y_test = test_df.pop("default payment next month")# convert the dataframe values to array X_test = test_df.values -
添加代码以使用
MLflow开始自动记录,以便可以跟踪指标和结果。MLflow具有模型开发的迭代性质,可帮助你记录模型参数和结果。 请回顾这些运行,比较并了解模型的性能。 这些日志还为你准备好从 Azure 机器学习中工作流的开发阶段转到训练阶段提供上下文。# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog() -
训练模型。
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}")mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()
注意
可以忽略 mlflow 警告。 你仍将获得需要跟踪的所有结果。
迭代
现在你已经有了模型结果,可能需要更改某些内容,然后重试。 例如,请尝试其他分类器技术:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifierprint(f"Training with data of shape {X_train.shape}")mlflow.start_run()
ada = AdaBoostClassifier()ada.fit(X_train, y_train)y_pred = ada.predict(X_test)print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()
注意
可以忽略 mlflow 警告。 你仍将获得需要跟踪的所有结果。
检查结果
现在,你已尝试两个不同的模型,请使用 MLflow 跟踪的结果来确定哪个模型更好。 可以引用准确性等指标,或者引用对方案最重要的其他指标。 可以通过查看 MLflow 创建的作业来更详细地了解这些结果。
-
在左侧导航栏中,选择“作业”。
-
选择“在云上开发教程”的链接。
-
显示了两个不同的作业,每个已尝试的模型对应一个。 这些名称是自动生成的。 将鼠标悬停在某个名称上时,如果要重命名该名称,请使用名称旁边的铅笔工具。
-
选择第一个作业的链接。 名称显示在顶部。 还可以在此处使用铅笔工具重命名它。
-
该页显示作业的详细信息,例如属性、输出、标记和参数。 在“标记”下,你将看到 estimator_name,其描述模型的类型。
-
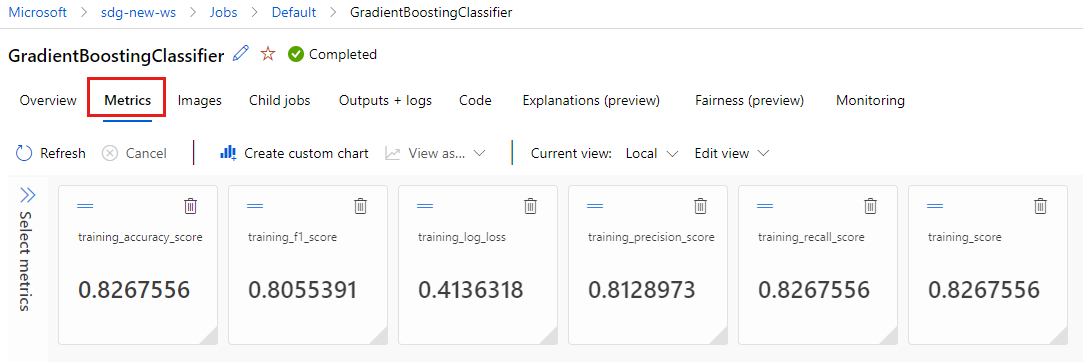
选择“指标”选项卡以查看
MLflow记录的指标。 (预期结果会有所不同,因为训练集不同。)
-
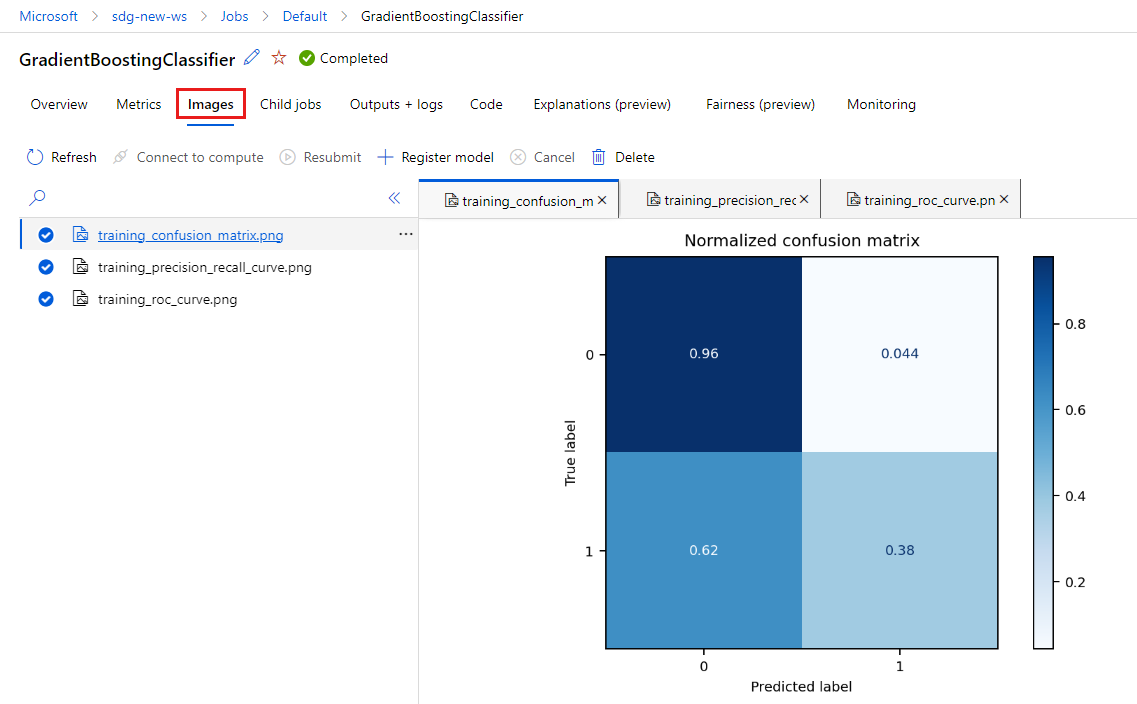
选择“图像”选项卡以查看
MLflow生成的图像。
-
返回并查看其他模型的指标和图像。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
Azure云工作站上做Machine Learning模型开发 - 全流程演示
目录 本文内容先决条件从“笔记本”开始设置用于原型制作的新环境(可选)创建笔记本开发训练脚本迭代检查结果 关注TechLead,分享AI全维度知识。作者拥有10年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕࿰…...
前端 : 用html ,css,js写一个你画我猜的游戏
1.HTML: <body><div id "content"><div id "box1">计时器</div><div id"box"><div id "top"><div id "box-top-left">第几题:</div><div id "box…...
Illustrator 2024(AI v28.0)
Illustrator 2024是一款功能强大的矢量图形编辑软件,由Adobe公司开发。它是设计师、艺术家和创意专业人士的首选工具,用于创建和编辑各种矢量图形、插图、图标、标志和艺术作品。 以下是Adobe Illustrator的主要功能和特点: 矢量图形编辑&…...

【Git企业开发】第二节.Git 的分支管理
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:Git企业级开发 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!࿰…...

第三章认识Node.js模块化开发
目录 认识Node.js 概述 作用 基本使用 Node.js的运行 Node.js的组成 Node.js的语法 Node.js全局对象 认识模块化开发 概述 场景 特点 模块成员的导入和导出 Node.js 模块化语法 导入模块 导出模块 ES6 模块化语法 导入模块 导出模块 项目 认识Node.js 概述…...

扩展Nginx的无限可能:掌握常见扩展模块和第三方插件的使用方法
Nginx是一款高性能的开源Web服务器和反向代理服务器。它具有模块化的架构,可以通过扩展模块和插件来增强其功能。在本文中,我将围绕Nginx的扩展模块和插件进行讲解,并提供一些常见的扩展模块和第三方插件的示例。 一、Nginx扩展模块 Nginx的…...

centos遇到的问题
lsof -i :8091 > 查看这个端口的线程 lsof : list open files 列出打开文件 -i : internet linux检测系统进程和服务: top : 实时监视系统的进程和资源的利用情况htop : top的增强版 问题: -bash: …...
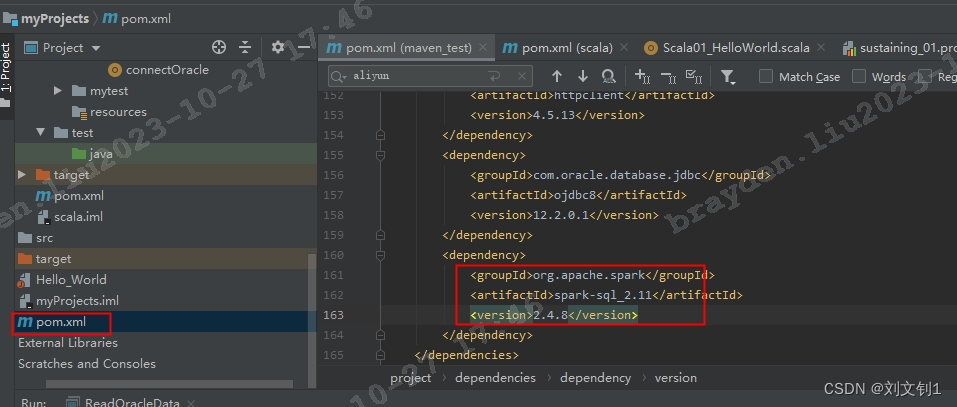
本机spark 通idea连接Oracle的坑
1. 报错:Exception in thread "main" java.lang.NoSuchMethodError: scala.Product.$init$(Lscala/Product;)V 查询网上资料,是idea引入的scala运行环境版本与idea默认的scala版本不一样 也就是写的项目中的pom的spark版本与idea默认的版本不…...
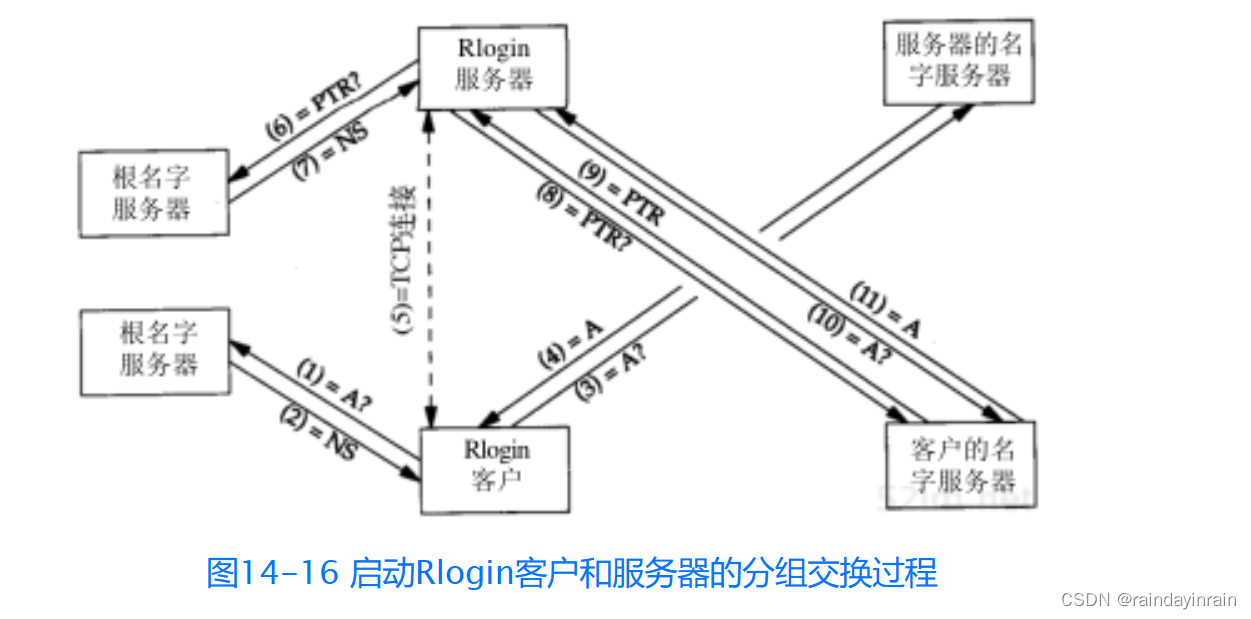
网络协议--DNS:域名系统
14.1 引言 域名系统(DNS)是一种用于TCP/IP应用程序的分布式数据库,它提供主机名字和IP地址之间的转换及有关电子邮件的选路信息。这里提到的分布式是指在Internet上的单个站点不能拥有所有的信息。每个站点(如大学中的系、校园、…...

计算机视觉注意力机制小盘一波 (学习笔记)
将注意力的阶段大改分成了4个阶段 1.将深度神经网络与注意力机制相结合,代表性方法为RAM ⒉.明确预测判别性输入特征,代表性方法为STN 3.隐性且自适应地预测潜在的关键特征,代表方法为SENet 4.自注意力机制 通道注意力 在深度神经网络中…...
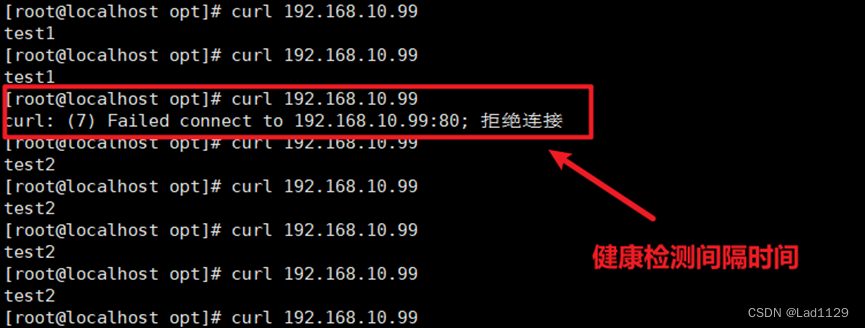
LVS+keepalive高可用集群
keepalive简介 keepalive为LVS应用延伸的高可用服务。lvs的调度器无法做高可用。但keepalive不是为lvs专门集群服务的,也可以为其他的的代理服务器做高可用。 keepalive在lvs的高可用集群,主调度器和备调度器(可以有多个) 一主两备或一主一备。 VRRP: k…...

Thread 和 Runnable 的区别
Thread 和 Runnable 接口的区别有四个: Thread 是一个类,Runnable 是接口,因为在 Java 语言里面的继承特性,接口可以支持多继承,而类只能单一继承。所以如果在已经存在继承关系的类里面要实现线程的话,只能…...

图神经网络和分子表征:5. Completeness
大家都知道 “两点确定一线,三点确定一平面”,那么多少个变量可以确定一个分子呢?这是最近顶刊们热烈讨论的话题。 (据笔者不完全统计)最早在 SphereNet (2022 ICLR)论文里,摘要上就…...

css-渐变色矩形
效果图: 代码: html: <!DOCTYPE html> <html><head><meta charset"utf-8"><meta name"viewport" content"initial-scale1.0, user-scalableno" /><title></title><link …...

使用easypoi-spring-boot-starter 4.1.1导入excel报错NoSuchMethodError和NoSuchMethodError
前言 使用easypoi进行excel的导入遇到的错误以及解决办法 easypoi项目地址:https://gitee.com/lemur/easypoi easypoi的Maven依赖: <dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-spring-boot-starter<…...
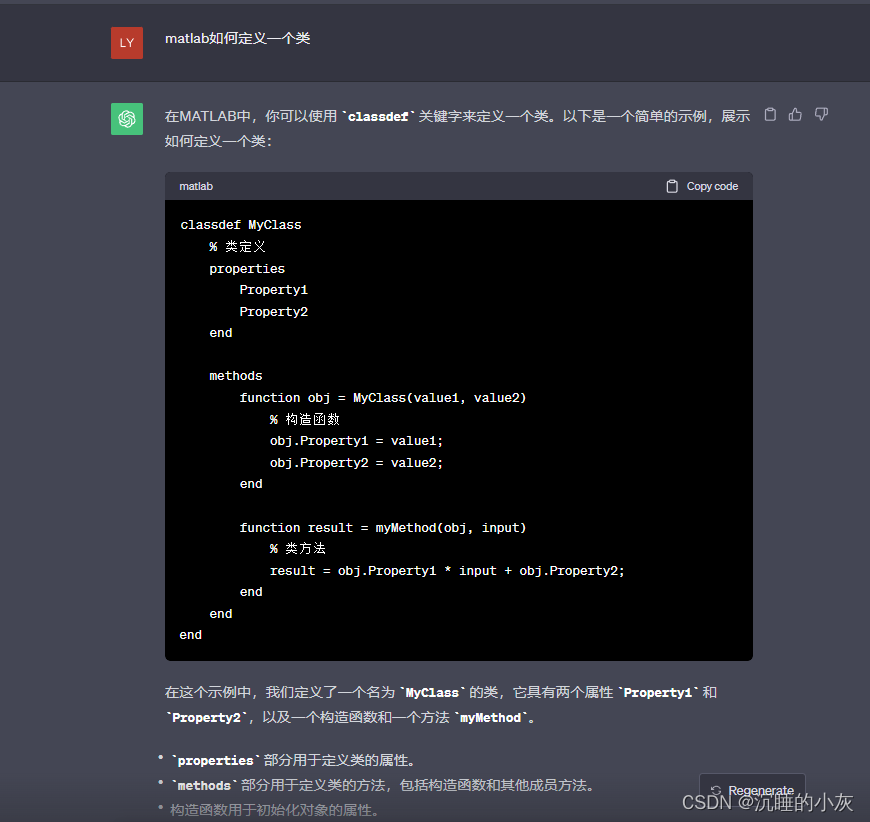
matlab中类的分别之handle类和value类——matlab无法修改类属性值的可能原因
写在之前(吐槽) 最近由于变化了一些工作方向,开始需要使用matlab进行开发,哎哟喂,matlab使用的我想吐,那个matlab编辑器又没代码提示,又没彩色,我只好用vscode进行代码编辑…...

3. t2t_vit inference
前言 对vit 进行fp16推理 参考链接: https://github.com/open-mmlab/mmpretrain/tree/master/configs/t2t_vit run code : https://mmclassification.readthedocs.io/en/latest/getting_started.html#inference-and-test-a-dataset https://mmclassification.readthedo…...
SpringMVC Day 05 : Spring 中的 Model
前言 欢迎来到 SpringMVC 系列教程的第五天!在之前的教程中,我们已经学习了如何使用控制器处理请求和返回视图。今天,我们将深入探讨 Spring 中的 Model。 在 Web 应用程序开发中,数据的传递和展示是非常重要的。SpringMVC 提供…...
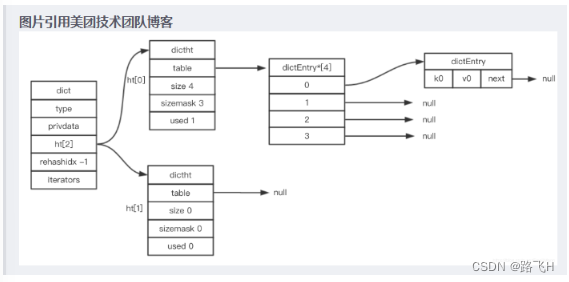
redis6.0源码分析:字典扩容与渐进式rehash
文章目录 字典数据结构结构设计dictType字典类型为什么字典有两个哈希表?哈希算法 扩容机制扩容前置知识字典存在几种状态?容量相关的关键字段定义字典的容量都是2的幂次方 扩容机制字典什么时候会扩容?扩容的阈值 & 扩容的倍数哪些方法会…...

【C++迭代器iterator】
迭代器 i t e r a t o r 迭代器iterator 迭代器iterator 在 容器 v e c t o r 容器vector 容器vector 中的使用 迭代器 i t e r a t o r 迭代器iterator 迭代器iterator 一般使用在 容器 v e c t o r 容器vector 容器vector 的 遍历 遍历 遍历,充当 遍历指针 遍…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

Python实现简单音频数据压缩与解压算法
Python实现简单音频数据压缩与解压算法 引言 在音频数据处理中,压缩算法是降低存储成本和传输效率的关键技术。Python作为一门灵活且功能强大的编程语言,提供了丰富的库和工具来实现音频数据的压缩与解压。本文将通过一个简单的音频数据压缩与解压算法…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...