【pandas技巧】group by+agg+transform函数
目录
1. group by+单个字段+单个聚合
2. group by+单个字段+多个聚合
3. group by+多个字段+单个聚合
4. group by+多个字段+多个聚合
5. transform函数
| students | grade | sex | score | money | |
|---|---|---|---|---|---|
| 0 | 小狗 | 小学部 | female | 95 | 844 |
| 1 | 小猫 | 小学部 | male | 93 | 836 |
| 2 | 小鸭 | 初中部 | male | 83 | 854 |
| 3 | 小兔 | 小学部 | female | 90 | 931 |
| 4 | 小花 | 小学部 | male | 81 | 853 |
| 5 | 小草 | 小学部 | male | 80 | 991 |
| 6 | 小狗 | 初中部 | female | 81 | 854 |
| 7 | 小猫 | 小学部 | male | 93 | 886 |
| 8 | 小鸭 | 小学部 | male | 88 | 983 |
| 9 | 小兔 | 小学部 | male | 86 | 891 |
| 10 | 小花 | 初中部 | male | 92 | 830 |
| 11 | 小草 | 初中部 | male | 84 | 948 |
1. group by+单个字段+单个聚合
1.1 方法一
# 求每个人的总金额:
total_money=df.groupby("students")["money"].sum().reset_index()
total_money1.2 方法二(使用agg)
df.groupby("students").agg({"money":"sum"}).reset_index()
#或者
df.groupby("students").agg({"money":np.sum}).reset_index()| students | money | |
|---|---|---|
| 0 | 小兔 | 1820 |
| 1 | 小狗 | 1711 |
| 2 | 小猫 | 1670 |
| 3 | 小花 | 1861 |
| 4 | 小草 | 1825 |
| 5 | 小鸭 | 1719 |
2. group by+单个字段+多个聚合
2.1 方法一(使用group by+merge)
mean_money = df.groupby("students")["money"].mean().reset_index()
mean_money.columns = ["students","mean_money"]
mean_money
total_mean = total_money.merge(mean_money)
total_mean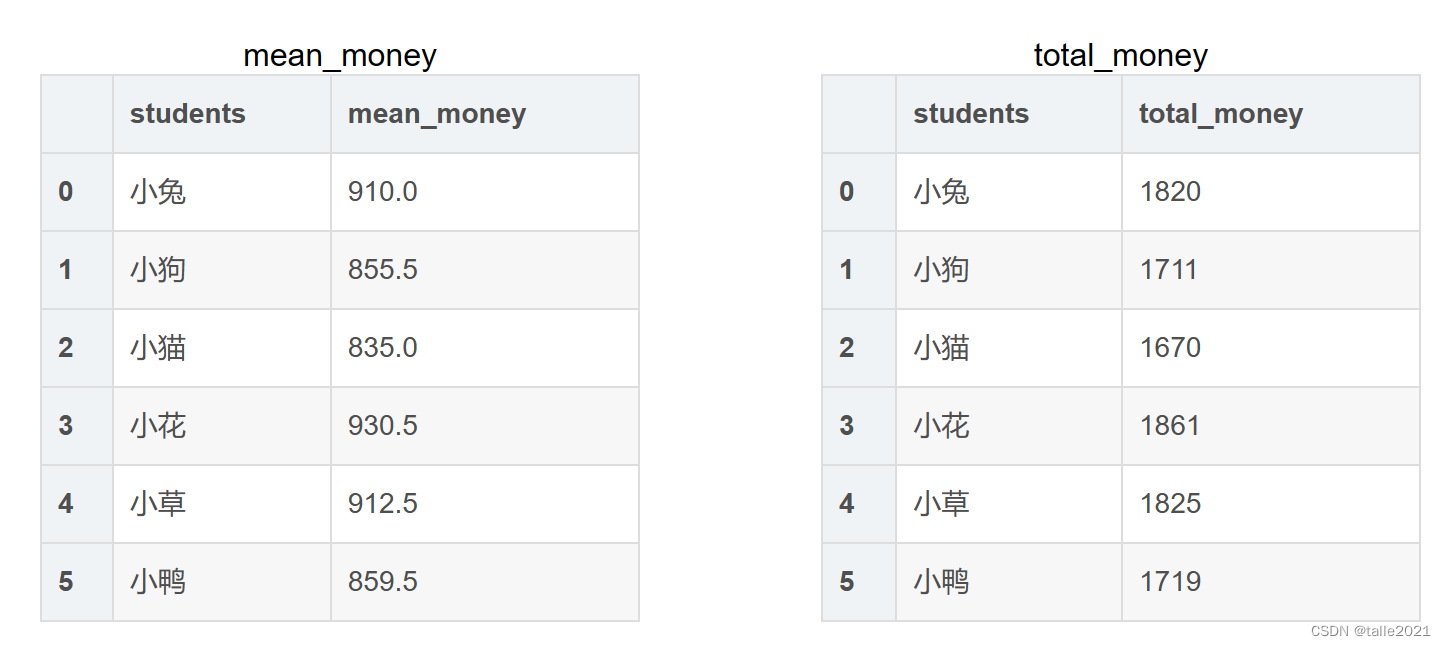
total_mean = total_money.merge(mean_money)
total_mean| students | total_money | mean_money | |
|---|---|---|---|
| 0 | 小兔 | 1820 | 910.0 |
| 1 | 小狗 | 1711 | 855.5 |
| 2 | 小猫 | 1670 | 835.0 |
| 3 | 小花 | 1861 | 930.5 |
| 4 | 小草 | 1825 | 912.5 |
| 5 | 小鸭 | 1719 | 859.5 |
2.2 方法二(使用group by+agg)
total_mean = df.groupby("students").agg(total_money=("money", "sum"),mean_money=("money", "mean")).reset_index()
total_mean| students | total_money | mean_money | |
|---|---|---|---|
| 0 | 小兔 | 1820 | 910.0 |
| 1 | 小狗 | 1711 | 855.5 |
| 2 | 小猫 | 1670 | 835.0 |
| 3 | 小花 | 1861 | 930.5 |
| 4 | 小草 | 1825 | 912.5 |
| 5 | 小鸭 | 1719 | 859.5 |
3. group by+多个字段+单个聚合
3.1 方法一
df.groupby(["students","grade"])["money"].sum().reset_index()| students | grade | money | |
|---|---|---|---|
| 0 | 小兔 | 初中部 | 1820 |
| 1 | 小狗 | 初中部 | 843 |
| 2 | 小狗 | 小学部 | 868 |
| 3 | 小猫 | 小学部 | 1670 |
| 4 | 小花 | 初中部 | 910 |
| 5 | 小花 | 小学部 | 951 |
| 6 | 小草 | 初中部 | 1825 |
| 7 | 小鸭 | 初中部 | 1719 |
3.2 方法二(使用agg)
df.groupby(["students","grade"]).agg({"money":"sum"}).reset_index()| students | grade | money | |
|---|---|---|---|
| 0 | 小兔 | 初中部 | 1820 |
| 1 | 小狗 | 初中部 | 843 |
| 2 | 小狗 | 小学部 | 868 |
| 3 | 小猫 | 小学部 | 1670 |
| 4 | 小花 | 初中部 | 910 |
| 5 | 小花 | 小学部 | 951 |
| 6 | 小草 | 初中部 | 1825 |
| 7 | 小鸭 | 初中部 | 1719 |
4. group by+多个字段+多个聚合
agg函数的使用的方法是:agg(新列名=("原列名", "统计函数"))
df.groupby(["students","grade"]).agg(total_money=("money", "sum"),mean_money=("money", "mean"),total_score=("score", "sum")).reset_index()| students | grade | total_money | mean_money | total_score | |
|---|---|---|---|---|---|
| 0 | 小兔 | 初中部 | 1820 | 910.0 | 192 |
| 1 | 小狗 | 初中部 | 843 | 843.0 | 88 |
| 2 | 小狗 | 小学部 | 868 | 868.0 | 93 |
| 3 | 小猫 | 小学部 | 1670 | 835.0 | 178 |
| 4 | 小花 | 初中部 | 910 | 910.0 | 95 |
| 5 | 小花 | 小学部 | 951 | 951.0 | 98 |
| 6 | 小草 | 初中部 | 1825 | 912.5 | 184 |
| 7 | 小鸭 | 初中部 | 1719 | 859.5 | 173 |
5. transform函数
5.1 方法一(使用groupby + merge)
df_1 = df.groupby("grade")["score"].mean().reset_index()
df_1.columns = ["grade", "average_score"]
df_1| grade | average_score | |
|---|---|---|
| 0 | 初中部 | 85.00 |
| 1 | 小学部 | 88.25 |
df_new1 = pd.merge(df, df_1, on="grade")
df_new1| students | grade | sex | score | money | average_score | |
|---|---|---|---|---|---|---|
| 0 | 小狗 | 小学部 | female | 95 | 844 | 88.25 |
| 1 | 小猫 | 小学部 | male | 93 | 836 | 88.25 |
| 2 | 小兔 | 小学部 | female | 90 | 931 | 88.25 |
| 3 | 小花 | 小学部 | male | 81 | 853 | 88.25 |
| 4 | 小草 | 小学部 | male | 80 | 991 | 88.25 |
| 5 | 小猫 | 小学部 | male | 93 | 886 | 88.25 |
| 6 | 小鸭 | 小学部 | male | 88 | 983 | 88.25 |
| 7 | 小兔 | 小学部 | male | 86 | 891 | 88.25 |
| 8 | 小鸭 | 初中部 | male | 83 | 854 | 85.00 |
| 9 | 小狗 | 初中部 | female | 81 | 854 | 85.00 |
| 10 | 小花 | 初中部 | male | 92 | 830 | 85.00 |
| 11 | 小草 | 初中部 | male | 84 | 948 | 85.00 |
5.2 方法二(使用groupby + map)
dic = df.groupby("grade")["score"].mean().to_dict()
dic{'初中部': 85.0, '小学部': 88.25}
df_new1["average_map_score"] = df["grade"].map(dic)
df_new1| students | grade | sex | score | money | average_score | average_map_score | |
|---|---|---|---|---|---|---|---|
| 0 | 小狗 | 小学部 | female | 95 | 844 | 88.25 | 88.25 |
| 1 | 小猫 | 小学部 | male | 93 | 836 | 88.25 | 88.25 |
| 2 | 小兔 | 小学部 | female | 90 | 931 | 88.25 | 85.00 |
| 3 | 小花 | 小学部 | male | 81 | 853 | 88.25 | 88.25 |
| 4 | 小草 | 小学部 | male | 80 | 991 | 88.25 | 88.25 |
| 5 | 小猫 | 小学部 | male | 93 | 886 | 88.25 | 88.25 |
| 6 | 小鸭 | 小学部 | male | 88 | 983 | 88.25 | 85.00 |
| 7 | 小兔 | 小学部 | male | 86 | 891 | 88.25 | 88.25 |
| 8 | 小鸭 | 初中部 | male | 83 | 854 | 85.00 | 88.25 |
| 9 | 小狗 | 初中部 | female | 81 | 854 | 85.00 | 88.25 |
| 10 | 小花 | 初中部 | male | 92 | 830 | 85.00 | 85.00 |
| 11 | 小草 | 初中部 | male | 84 | 948 | 85.00 | 85.00 |
5.3 方法三(使用transform一步到位)
df_new1["average_trans_score"] = df.groupby("grade")["score"].transform("mean")
df_new1| students | grade | sex | score | money | average_score | average_map_score | average_trans_score | |
|---|---|---|---|---|---|---|---|---|
| 0 | 小狗 | 小学部 | female | 95 | 844 | 88.25 | 88.25 | 88.25 |
| 1 | 小猫 | 小学部 | male | 93 | 836 | 88.25 | 88.25 | 88.25 |
| 2 | 小兔 | 小学部 | female | 90 | 931 | 88.25 | 85.00 | 85.00 |
| 3 | 小花 | 小学部 | male | 81 | 853 | 88.25 | 88.25 | 88.25 |
| 4 | 小草 | 小学部 | male | 80 | 991 | 88.25 | 88.25 | 88.25 |
| 5 | 小猫 | 小学部 | male | 93 | 886 | 88.25 | 88.25 | 88.25 |
| 6 | 小鸭 | 小学部 | male | 88 | 983 | 88.25 | 85.00 | 85.00 |
| 7 | 小兔 | 小学部 | male | 86 | 891 | 88.25 | 88.25 | 88.25 |
| 8 | 小鸭 | 初中部 | male | 83 | 854 | 85.00 | 88.25 | 88.25 |
| 9 | 小狗 | 初中部 | female | 81 | 854 | 85.00 | 88.25 | 88.25 |
| 10 | 小花 | 初中部 | male | 92 | 830 | 85.00 | 85.00 | 85.00 |
| 11 | 小草 | 初中部 | male | 84 | 948 | 85.00 | 85.00 | 85.00 |
相关文章:
【pandas技巧】group by+agg+transform函数
目录 1. group by单个字段单个聚合 2. group by单个字段多个聚合 3. group by多个字段单个聚合 4. group by多个字段多个聚合 5. transform函数 studentsgradesexscoremoney0小狗小学部female958441小猫小学部male938362小鸭初中部male838543小兔小学部female909314小花小…...
一文解读WordPress网站的各类缓存-老白博客
缓存是一种重要的WordPress优化手段,用于提高网站的性能和加载速度。减少计算量,有效提升响应速度,让有限的资源服务更多的用户。本文老白博客便从自己的使用简单给大家介绍下WordPress的缓存,包括 站点缓存(Page Cach…...

从零开始:开发直播商城APP的技术指南
时下,直播商城APP已经成了线上购物、电子商务的核心组成,本文将为您提供一个全面的技术指南,帮助您从零开始开发一个直播商城APP。我们将涵盖所有关键方面,包括技术堆栈、功能模块、用户体验和安全性。 第一部分:技术…...
GZ035 5G组网与运维赛题第6套
2023年全国职业院校技能大赛 GZ035 5G组网与运维赛项(高职组) 赛题第6套 一、竞赛须知 1.竞赛内容分布 竞赛模块1--5G公共网络规划部署与开通(35分) 子任务1:5G公共网络部署与调试(15分) …...

分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matla…...

【Qt】QString怎么转成int
2023年10月29日,周日晚上 第一种方法 这种方法会尝试将 QString 对象转换为 int 类型。如果转换成功,将返回转换后的 int 值;如果转换失败(例如,字符串中包含非数字字符),则返回 0。 QString…...

ubuntu 22.04 安装python-pcl
ubuntu 22.04 安装python-pcl 安装python-pcl修复bug 由于python-pcl库基本已经停止维护,所以Ubuntu22.04 在使用pip install python-pcl安装的时候会出现版本不适配的原因 安装python-pcl 使用Ubuntu22系统自带python3安装python-pcl,随后将下载的包拷…...

【题解】[GenshinOI Round 3 ]P9817 lmxcslD
题目传送门 分析 看到这道题我一开始是有点懵的,但是看了看数据范围,发现有几个点有 n 为质数 的特殊性质,结论先行,大胆猜测是不是可以贪心,所以先打了一个最傻的代码上去试试. void solve(){cin >> n >&…...
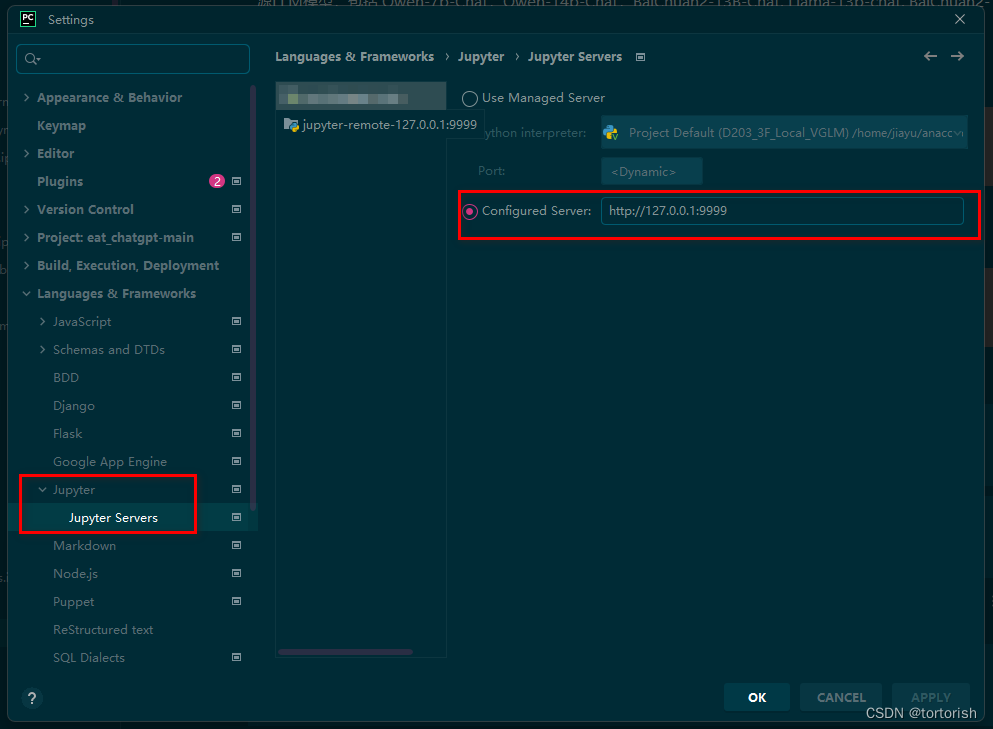
在pycharm中,远程操作服务器上的jupyter notebook
一、使用场景 现在我们有两台电脑,一台是拥有高算力的服务器,另一台是普通的轻薄笔记本电脑。如何在服务器上运行jupyter notebook,同时映射到笔记本电脑上的pycharm客户端中进行操作呢? 二、软件 pycharm专业版,jupy…...

SQL 运算符
SQL 运算符 运算符是保留字或主要用于 SQL 语句的 WHERE 子句中的字符,用于执行操作,例如:比较和算术运算。 这些运算符用于指定 SQL 语句中的条件,并用作语句中多个条件的连词。 常见运算符有以下几种: 算术运算符比…...

中间件安全-CVE 复现K8sDockerJettyWebsphere漏洞复现
目录 服务攻防-中间件安全&CVE 复现&K8s&Docker&Jetty&Websphere中间件-K8s中间件-Jetty漏洞复现CVE-2021-28164-路径信息泄露漏洞CVE-2021-28169双重解码信息泄露漏洞CVE-2021-34429路径信息泄露漏洞 中间件-Docker漏洞复现守护程序 API 未经授权访问漏洞…...

系列九、什么是Spring bean
一、什么是Spring bean 一句话,被Spring容器管理的bean就是Spring bean。...

轻量封装WebGPU渲染系统示例<4>-CubeMap/天空盒(源码)
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/version-1.01/src/voxgpu/sample/ImgCubeMap.ts 此示例渲染系统实现的特性: 1. 用户态与系统态隔离。 2. 高频调用与低频调用隔离。 3. 面向用户的易用性封装。 4. 渲染数据和渲染机制分离。 5. 用户…...

Linux 环境变量 二
目录 获取环境变量的后两种方法 环境变量具有全局属性 内建命令 和环境变量相关的命令 c语言访问地址 重新理解地址 地址空间 获取环境变量的后两种方法 main函数的第三个参数 :char* env[ ] 也是一个指针数组,我们可以把它的内容打印出来看看。 …...
Beyond Compare4 30天试用到期的解决办法
相信很多小伙伴都有在使用Beyond Compare 4软件,如果我们没有激活该软件,就只有30天的评估使用期,那么过了这30天后我们怎么继续使用呢?下面小编就来为大家介绍方法。 打开Beyond Compare4,提示已经超出30天试用期限制…...
sentinel规则持久化-规则同步nacos-最标准配置
官方参考文档: 动态规则扩展 alibaba/Sentinel Wiki GitHub 需要修改的代码如下: 为了便于后续版本集成nacos,简单讲一下集成思路 1.更改pom 修改sentinel-datasource-nacos的范围 将 <dependency><groupId>com.alibaba.c…...

【Linux】tail命令使用
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。 语法 tail [参数] [文件] tail命令 -Linux手册页 著者 由保罗鲁宾、大卫麦肯齐、伊恩兰斯泰勒和吉姆梅耶林撰写。 命令选项及作用 执行令 tail --help 执行命令结果 参…...

【数据结构】面试OJ题——时间复杂度2
目录 一:移除元素 思路: 二:删除有序数组中的重复项 思路: 三:合并两个有序数组 思路1: 什么?你不知道qsort() 思路2: 一:移除元素 27. 移…...
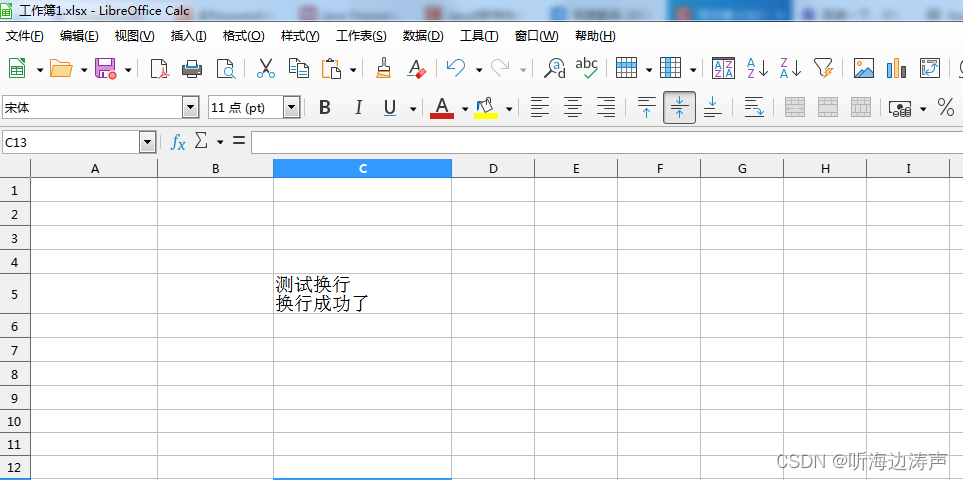
LibreOffice编辑excel文档如何在单元格中输入手动换行符
用WPS编辑excel文档的时候,要在单元格中输入手动换行符,可以先按住Alt键,然后回车。 而用LibreOffice编辑excel文档,要在单元格中输入手动换行符,可以先按住Ctrl键,然后回车。例如:...
ideaSSM在线商务管理系统VS开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 SSM 在线商务管理系统是一套完善的信息管理系统,结合SSM框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用SSM框架(MVC模式开发),系统具有完整的源代码 和数据库,系统主…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...