【大数据Hive】hive 表数据优化使用详解
目录
一、前言
二、hive 常用数据存储格式
2.1 文件格式-TextFile
2.1.1 操作演示
2.2 文件格式 - SequenceFile
2.2.1 操作演示
2.3 文件格式 -Parquet
2.3.1 Parquet简介
2.3.2 操作演示
2.4 文件格式-ORC
2.4.1 ORC介绍
2.4.2 操作演示
三、hive 存储数据压缩优化
3.1 数据压缩-概述
3.2 数据压缩的优缺点
3.2.1 压缩的优点
3.2.2 压缩的缺点
3.3 常用压缩格式和压缩算法
3.3.1 Hadoop中各种压缩算法性能对比
3.3.2 压缩参数设置
3.3 操作演示
3.3.1 设置压缩参数
3.3.2 创建表,指定为textfile格式
3.3.3 创建表,指定为orc格式
四、hive 存储优化
4.1 避免小文件生成
4.2 ORC文件索引
4.2.1 Row Group Index
4.2.2 核心参数设置
4.2.3 操作演示
4.2.4 Bloom Filter Index
4.2.5 操作演示
4.3 ORC矢量化查询
五、写在文末
一、前言
通过之前的学习了解到,hive本身并不存储数据,其数据存储的本质还是HDFS,所有的数据读写都基于HDFS的文件来实现,因此对于hive表数据的优化可以归结为对hdfs上面存储数据相关的优化,比如数据存储格式的选择等。
二、hive 常用数据存储格式
为了提高对HDFS文件读写的性能,Hive提供了多种文件存储格式:TextFile、SequenceFile、ORC、Parquet等,不同的文件存储格式具有不同的存储特点,有的可以降低存储空间,有的可以提高查询性能。
Hive的文件格式在建表时指定,默认是TextFile,在hive的建表语法树中,在 [STORED AS file_format] 这一项中可以进行指定;

2.1 文件格式-TextFile
TextFile是Hive中默认的文件格式,存储形式为按行存储。工作中最常见的数据文件格式就是TextFile文件,几乎所有的原始数据生成都是TextFile格式,所以Hive设计时考虑到为了避免各种编码及数据错乱的问题,选用了TextFile作为默认的格式。建表时如果不指定存储格式即为TextFile,导入数据时把数据文件拷贝至HDFS不进行处理。
TextFile格式优缺点对比:
| 优点 | 缺点 | 应用场景 |
| 1、最简单的数据格式,可以直接查看 2、可以使用任意的分隔符进行分割 3、便于和其他工具共享数据 4、可以搭配压缩一起使用 | 1、耗费存储空间,I/O性能较低 2、结合压缩时Hive不进行数据切分合并,不能进行并行操作,查询效率低 3、按行存储,读取列的性能差 | 1、适合于小量数据的存储查询 2、一般用于做第一层数据加载和测试使用 |
2.1.1 操作演示
在本地有一个2K大小的文件

建表并加载数据
create table tb_sogou_source(stime string,userid string,keyword string,clickorder string,url string
)row format delimited fields terminated by '\t';load data local inpath '/usr/local/soft/data/sogo.reduced' into table tb_sogou_source;执行过程
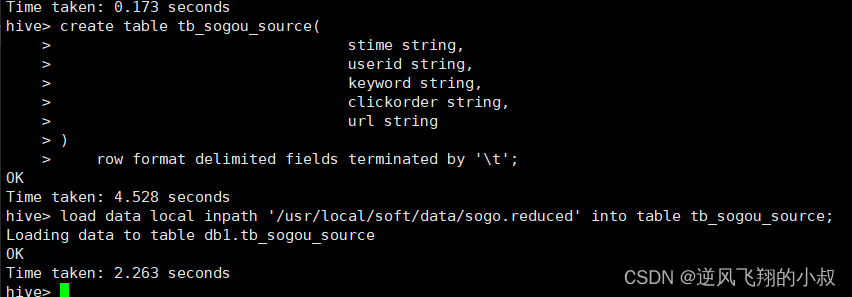
TextFile这种格式的文件的典型特征是,数据在hdfs上面文件大小与原文件保存不变,同时可以直接查看;

2.2 文件格式 - SequenceFile
SequenceFile是Hadoop里用来存储序列化的键值对即二进制的一种文件格式。SequenceFile文件也可以作为MapReduce作业的输入和输出,hive也支持这种格式。
| 优点 | 缺点 | 使用场景 |
| 1、以二进制的KV形式存储数据; 2、与底层交互更加友好,性能更快; 3、可压缩、可分割,优化磁盘利用率和I/O; 4、可并行操作数据,查询效率高; 5、也可以用于存储多个小文件 | 1、存储空间消耗最大; 2、与非Hadoop生态系统之外的工具不兼容; 3、构建SequenceFile需要通过TextFile文件转化加载 | 适合于小量数据,但是查询列比较多的场景 |
SequenceFile 底层存储架构图

2.2.1 操作演示
建表并加载数据
create table tb_sogou_seq(stime string,userid string,keyword string,clickorder string,url string
)row format delimited fields terminated by '\t'stored as sequencefile;insert into table tb_sogou_seq
select * from tb_sogou_source;执行过程
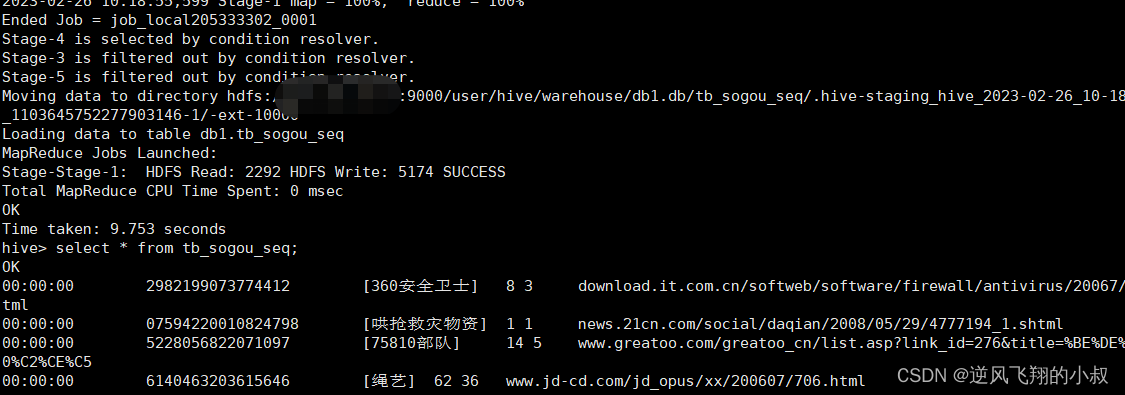
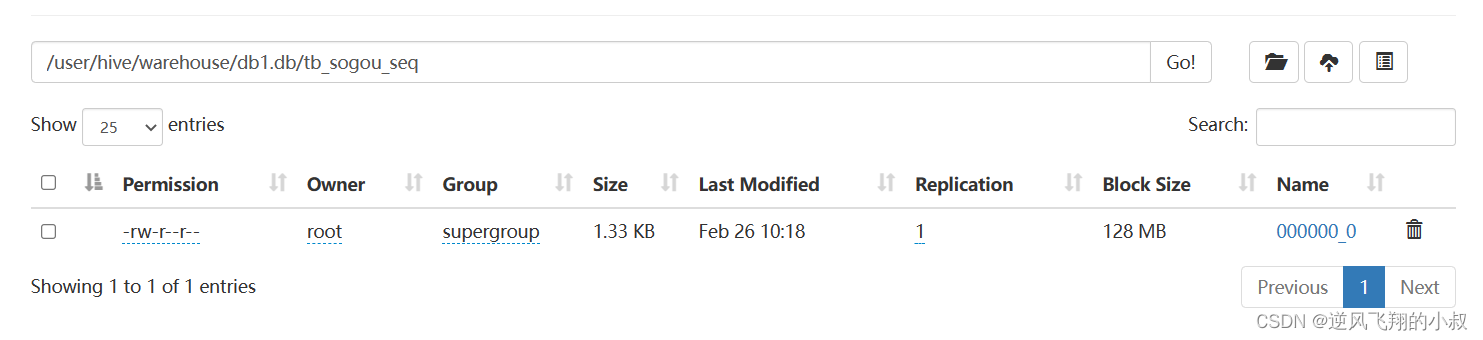
从文件大小来说,略有减小,但是这种文件下载之后是二进制格式的;
2.3 文件格式 -Parquet
2.3.1 Parquet简介
- Parquet是一种支持嵌套结构的列式存储文件格式,最早是由Twitter和Cloudera合作开发,2015年5月从Apache孵化器里毕业成为Apache顶级项目;
- 是一种支持嵌套数据模型对的列式存储系统,作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式;
- 通过数据编码和压缩,以及映射下推和谓词下推功能,Parquet的性能也较之其它文件格式有所提升;
优缺点对比
| 优点 | 缺点 | 使用场景 |
| 1、更高效的压缩和编码可压缩、可分割,优化磁盘利用率和I/O; 2、可用于多种数据处理框架 | 不支持update, insert, delete, ACID | 适用于字段数非常多,无更新,只取部分列的查询 |
2.3.2 操作演示
建表并加载数据
create table tb_sogou_parquet(stime string,userid string,keyword string,clickorder string,url string
)row format delimited fields terminated by '\t'stored as parquet;insert into table tb_sogou_parquet
select * from tb_sogou_source;执行过程
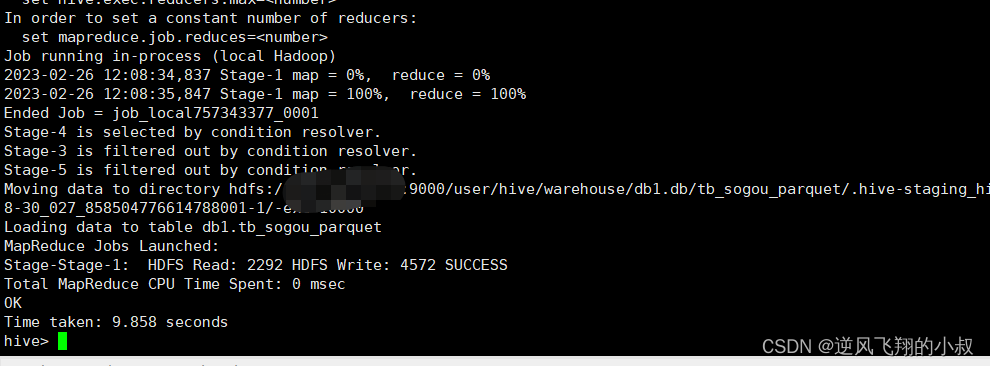
执行完成后,检查hdfs文件目录,对比原始文件可以看到这个压缩的比率还是很高的;

2.4 文件格式-ORC
2.4.1 ORC介绍
- ORC(OptimizedRC File)文件格式也是一种Hadoop生态圈中的列式存储格式;
- 它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度;
- 2015年ORC项目被Apache项目基金会提升为Apache顶级项目;
- ORC不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储;
- ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Hive、Spark SQL、Presto等查询引擎支持;
优缺点:
| 优点 | 缺点 | 应用场景 |
| 1、列式存储,存储效率非常高; 2、可压缩,高效的列存取; 3、查询效率较高,支持索引; 4、支持矢量化查询 | 1、加载时性能消耗较大; 2、需要通过text文件转化生成; 3、读取全量数据时性能较差 | 适用于Hive中大型的存储、查询 |
2.4.2 操作演示
建表并加载数据
create table tb_sogou_orc(stime string,userid string,keyword string,clickorder string,url string
)row format delimited fields terminated by '\t'stored as orc;insert into table tb_sogou_orc
select * from tb_sogou_source;执行过程
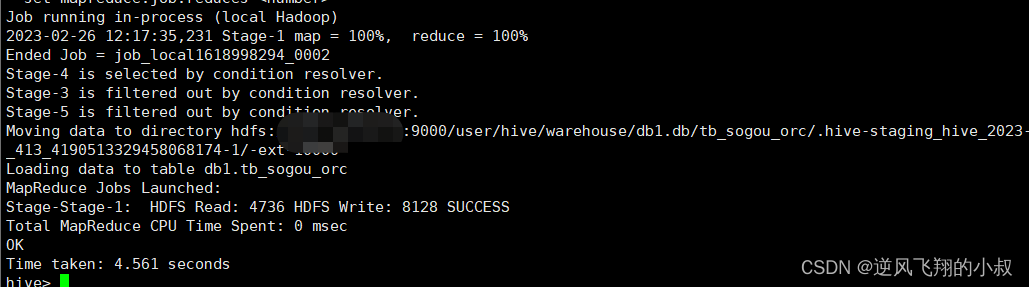
从hdfs文件目录下的数据来看,orc格式下文件仍然可以得到较大的压缩,使得存储空间大大降低;

三、hive 存储数据压缩优化
3.1 数据压缩-概述
Hive底层运行MapReduce程序时,磁盘I/O操作、网络数据传输、shuffle和merge要花大量的时间,尤其是数据规模很大和工作负载密集的情况下。鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助。
Hive压缩实际上说的就是MapReduce的压缩。
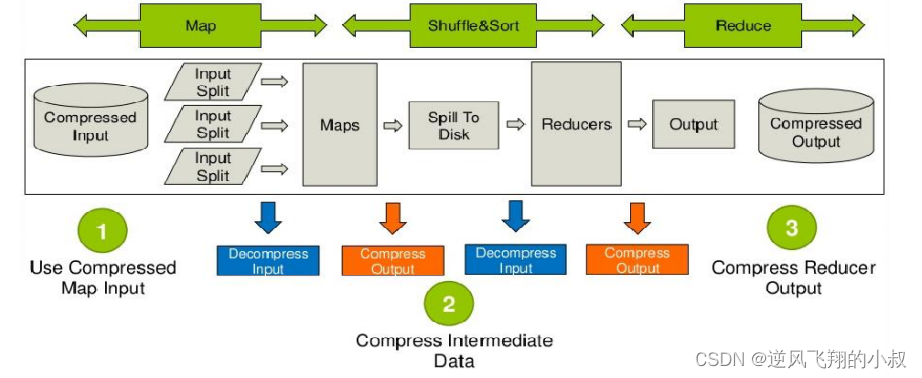
下图是hive在运行MR任务时数据压缩过程的运行架构图
3.2 数据压缩的优缺点
3.2.1 压缩的优点
- 减小文件存储所占空间;
- 加快文件传输效率,从而提高系统的处理速度;
- 降低IO读写的次数;
3.2.2 压缩的缺点
使用数据时需要先对文件解压,加重CPU负荷,压缩算法越复杂,解压时间越长
3.3 常用压缩格式和压缩算法
Hive中的压缩就是使用了Hadoop中的压缩实现的,所以Hadoop中支持的压缩在Hive中都可以直接使用。Hadoop中支持的压缩算法:
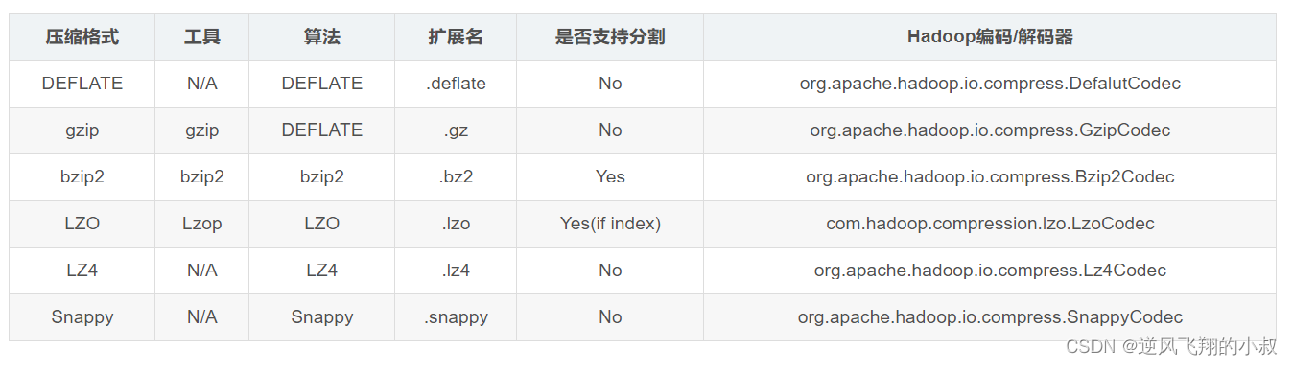
要想在Hive中使用压缩,需要对MapReduce和Hive进行相应的配置
3.3.1 Hadoop中各种压缩算法性能对比

3.3.2 压缩参数设置
--开启hive中间传输数据压缩功能
--1)开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
--2)开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
--3)设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;--开启Reduce输出阶段压缩
--1)开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
--2)开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
--3)设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
--4)设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;3.3 操作演示
3.3.1 设置压缩参数
使用上面的压缩参数

3.3.2 创建表,指定为textfile格式
指定为textfile格式,并使用snappy压缩
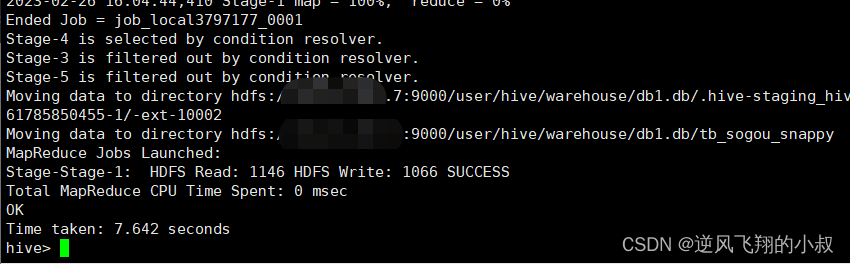
drop table tb_sogou_snappy;create table tb_sogou_snappystored as textfile
as select * from tb_sogou_source;执行过程
3.3.3 创建表,指定为orc格式
指定为orc格式,并使用snappy压缩
create table tb_sogou_orc_snappystored as orc tblproperties ("orc.compress"="SNAPPY")
as select * from tb_sogou_source;执行过程
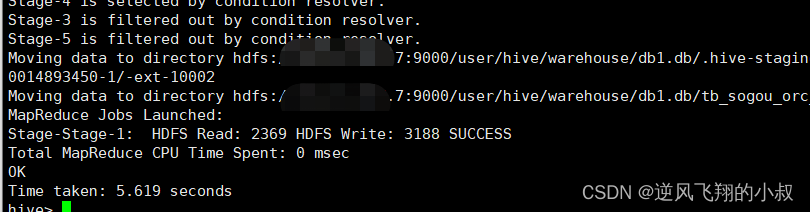
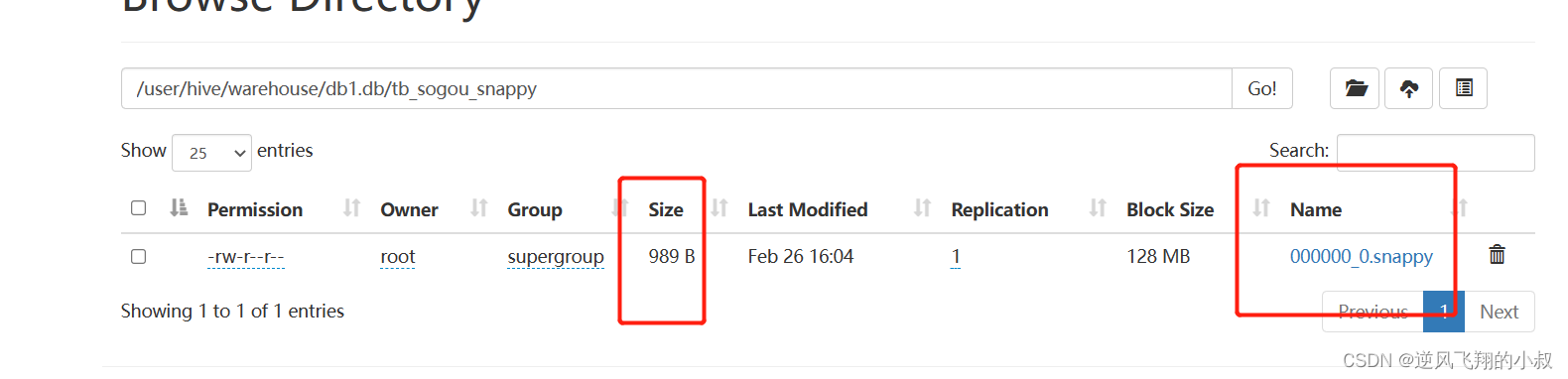
创建完成后,检查hdfs表的数据目录,可以发现数据目录的结尾会带有snappy,同时这个数据压缩比起上文更夸张了;
四、hive 存储优化
4.1 避免小文件生成
Hive的存储本质还是HDFS,HDFS是不利于小文件存储的,因为每个小文件会产生一条元数据信息,并且不利用MapReduce的处理,MapReduce中每个小文件会启动一个MapTask计算处理,导致资源的浪费,所以在使用Hive进行处理分析时,要尽量避免小文件的生成。
Hive中提供了一个特殊的机制,可以自动的判断是否是小文件,如果是小文件可以自动将小文件进行合并。
如下配置参数
-- 如果hive的程序,只有maptask,将MapTask产生的所有小文件进行合并
set hive.merge.mapfiles=true;-- 如果hive的程序,有Map和ReduceTask,将ReduceTask产生的所有小文件进行合并
set hive.merge.mapredfiles=true;-- 每一个合并的文件的大小(244M)
set hive.merge.size.per.task=256000000;-- 平均每个文件的大小,如果小于这个值就会进行合并(15M)
set hive.merge.smallfiles.avgsize=16000000;
如果遇到数据处理的输入是小文件的情况,怎么解决呢?Hive中也提供一种输入类CombineHiveInputFormat,用于将小文件合并以后,再进行处理。
设置Hive中底层MapReduce读取数据的输入类:将所有文件合并为一个大文件作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
4.2 ORC文件索引
在使用ORC文件时,为了加快读取ORC文件中的数据内容,ORC提供了两种索引机制:Row Group Index 和 Bloom Filter Index可以帮助提高查询ORC文件的性能;当用户写入数据时,可以指定构建索引,当用户查询数据时,可以根据索引提前对数据进行过滤,避免不必要的数据扫描。

4.2.1 Row Group Index
- 一个ORC文件包含一个或多个stripes(groups of row data),每个stripe中包含了每个column的min/max值的索引数据;
- 当查询中有大于等于小于的操作时,会根据min/max值,跳过扫描不包含的stripes;
- 而其中为每个stripe建立的包含min/max值的索引,就称为Row Group Index行组索引,也叫min-max Index大小对比索引,或者Storage Index;
Row Group Index 补充说明
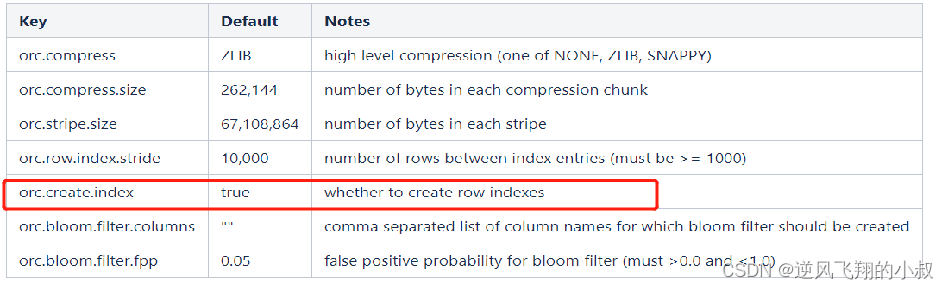
1、建立ORC格式表时,指定表参数’orc.create.index’=’true’之后,便会建立Row Group Index;
2、为了使Row Group Index有效利用,向表中加载数据时,必须对需要使用索引的字段进行排序;
4.2.2 核心参数设置
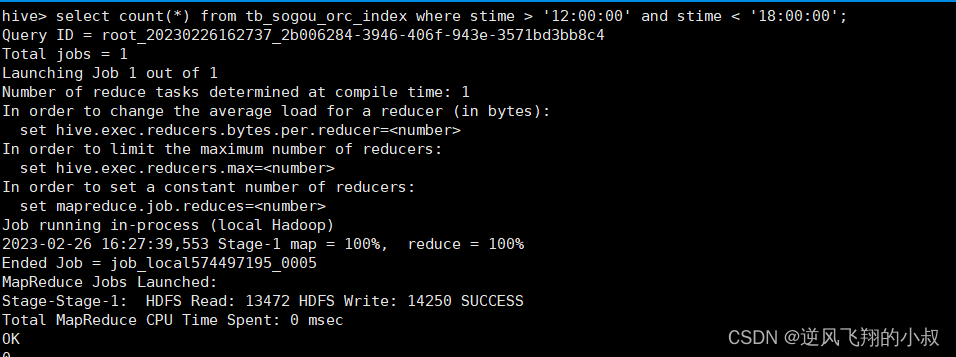
--1、开启索引配置set hive.optimize.index.filter=true;--2、创建表并制定构建索引create table tb_sogou_orc_index stored as orc tblproperties ("orc.create.index"="true")as select * from tb_sogou_source distribute by stime sort by stime;--3、当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询select count(*) from tb_sogou_orc_index where stime > '12:00:00' and stime < '18:00:00';4.2.3 操作演示
开启索引配置
set hive.optimize.index.filter=true;
创建表并制定构建索引
create table tb_sogou_orc_indexstored as orc tblproperties ("orc.create.index"="true")
as select * from tb_sogou_sourcedistribute by stimesort by stime;当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询
select count(*) from tb_sogou_orc_index where stime > '12:00:00' and stime < '18:00:00';执行结果
4.2.4 Bloom Filter Index
俗称布隆过滤器索引
- 建表时候通过表参数”orc.bloom.filter.columns”=”columnName……”来指定为哪些字段建立BloomFilter索引,在生成数据的时候,会在每个stripe中,为该字段建立BloomFilter的数据结构;
- 当查询条件中包含对该字段的等值过滤时候,先从BloomFilter中获取以下是否包含该值,如果不包含,则跳过该stripe;
4.2.5 操作演示
创建表指定创建布隆索引
create table tb_sogou_orc_bloom
stored as orc tblproperties ("orc.create.index"="true","orc.bloom.filter.columns"="stime,userid")
as select * from tb_sogou_source
distribute by stime
sort by stime;stime的范围过滤可以走row group index,userid的过滤可以走bloom filter index
selectcount(*)
from tb_sogou_orc_index
where stime > '12:00:00' and stime < '18:00:00'and userid = '3933365481995287' ;执行结果

4.3 ORC矢量化查询
Hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种Hive针对ORC文件操作的特性,目的是按照每批1024行读取数据,并且一次性对整个记录整合(而不是对单条记录)应用操作,提升了像过滤, 联合, 聚合等等操作的性能。
注意:要使用矢量化查询执行,就必须以ORC格式存储数据。
开启矢量化查询参数
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
五、写在文末
本文通过大量案例详细探讨了Hive中表的常用优化策略,希望对看到的小伙伴有用哦,本篇到此结束,感谢观看。
相关文章:
【大数据Hive】hive 表数据优化使用详解
目录 一、前言 二、hive 常用数据存储格式 2.1 文件格式-TextFile 2.1.1 操作演示 2.2 文件格式 - SequenceFile 2.2.1 操作演示 2.3 文件格式 -Parquet 2.3.1 Parquet简介 2.3.2 操作演示 2.4 文件格式-ORC 2.4.1 ORC介绍 2.4.2 操作演示 三、hive 存储数据压缩优…...

京东平台数据分析(京东销量):2023年9月京东吸尘器行业品牌销售排行榜
鲸参谋监测的京东平台9月份吸尘器市场销售数据已出炉! 根据鲸参谋电商数据分析平台的相关数据显示,今年9月,京东吸尘器的销量为19万,环比下滑约12%,同比下滑约25%;销售额为1.2亿,环比下滑约11%&…...
基于springboot实现休闲娱乐代理售票平台系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现休闲娱乐代理售票平台系统演示 摘要 网络的广泛应用给生活带来了十分的便利。所以把休闲娱乐代理售票管理与现在网络相结合,利用java技术建设休闲娱乐代理售票系统,实现休闲娱乐代理售票的信息化。则对于进一步提高休闲娱乐代理售票管…...

jvm对象内存划分
写此篇博客源于面试问到内存分配的细节,然后不明白问的是什么。回过头发现以前看过这块内容,只是有些印象,但是无法描述清楚。 额外概念了解 jvm内存空间是逻辑上连续的虚拟地址空间(虚拟内存中的概念)映射到物理内存…...
网络原理之TCP/IP
文章目录 应用层传输层UDP协议TCP协议TCP 的工作机制1. 确认应答2. 超时重传3. 连接管理TCP 的建立连接的过程(三次握手),和断开连接的过程(四次挥手)TCP 断开连接, 四次挥手 3. 滑动窗口5. 流量控制6. 拥塞控制7. 延时应答8. 捎带应答9. 面向字节流10. 异常情况 本章节主要讨论…...
Docker:数据卷挂载
Docker:数据卷挂载 1. 数据卷2. 数据卷命令补充 1. 数据卷 数据卷(volume)是一个虚拟目录,是容器内目录与宿主机目录之间映射的桥梁。 Nginx容器有自己独立的目录(Docker为每个镜像创建一个独立的容器,每个容器都是基于镜像创建的运行实例),…...

你会处理 go 中的 nil 吗
对于下面这段代码,我们知道 i 实际上的值就是 nil,所以 i nil 会生效 func main() {var i *int nilif i nil {fmt.Println("i is nil") // i is nil} }现在换一种写法,我们将 i 的类型改成 interface{},i nil 依然…...

高级深入--day42
注意:模拟登陆时,必须保证settings.py里的 COOKIES_ENABLED (Cookies中间件) 处于开启状态 COOKIES_ENABLED True 或 # COOKIES_ENABLED False 策略一:直接POST数据(比如需要登陆的账户信息) 只要是需要提供post数据的ÿ…...

mysql 计算两个坐标距离
方式一:st_distance_sphere 计算结果单位米 SELECT *, st_distance_sphere(point(lng,lat),point(lng,lat)) as distance FROM table mysql 版本5.7 以上 方式二:st_distance 计算结果单位是度 SELECT *, (st_distance(point(lng,lat),point(lng4,lat…...

String、StringBuffer、StringBuilder和StringJoiner
String、StringBuffer、StringBuilder和StringJoiner都是用于处理字符串的类,但它们在性能和使用方式上有一些区别。 String String是不可变的类,一旦创建就不能被修改。对String进行拼接或修改时,实际上是创建了一个新的String对象。适用于…...
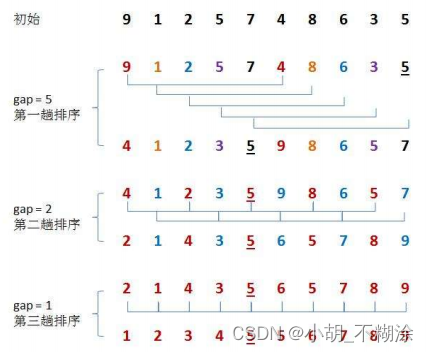
【数据结构】插入排序
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:浅谈数据结构 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 直接插入、希尔排序 1. 什么是排序2…...

Photoshop使用笔记总目录
Photoshop基础学习之工具学习 一、【Photoshop界面认识】 二、【 Photoshop常用快捷键】 三、【色彩模式与颜色填充】 四、【选区】 五、【视图】 六、【常用工具组】 七、【套索工具组】 八、【快速选择工具组】 九、【裁剪工具组】 十、【图框工具组】 十一、【吸取…...
最近面试遇到的高频面试题
大家好,我是 jonssonyan 互联网寒冬?金九银十真的不存在了么?虽说现在行情是差了一些,面试机会少了一些,但是大部分公司还是或多或少的招人,春招秋招都在进行。有人离职就有人入职。所以如果你还没约到面试…...

负载均衡有哪些算法,分别在nginx中如何配置?
负载均衡是用于分发传入的网络流量到多个后端服务器的技术,以确保无单个服务器过载,从而提高应用的可用性和响应时间。以下是一些常用的负载均衡算法,以及如何在Nginx中配置它们: 轮询 (Round Robin): 简介:…...
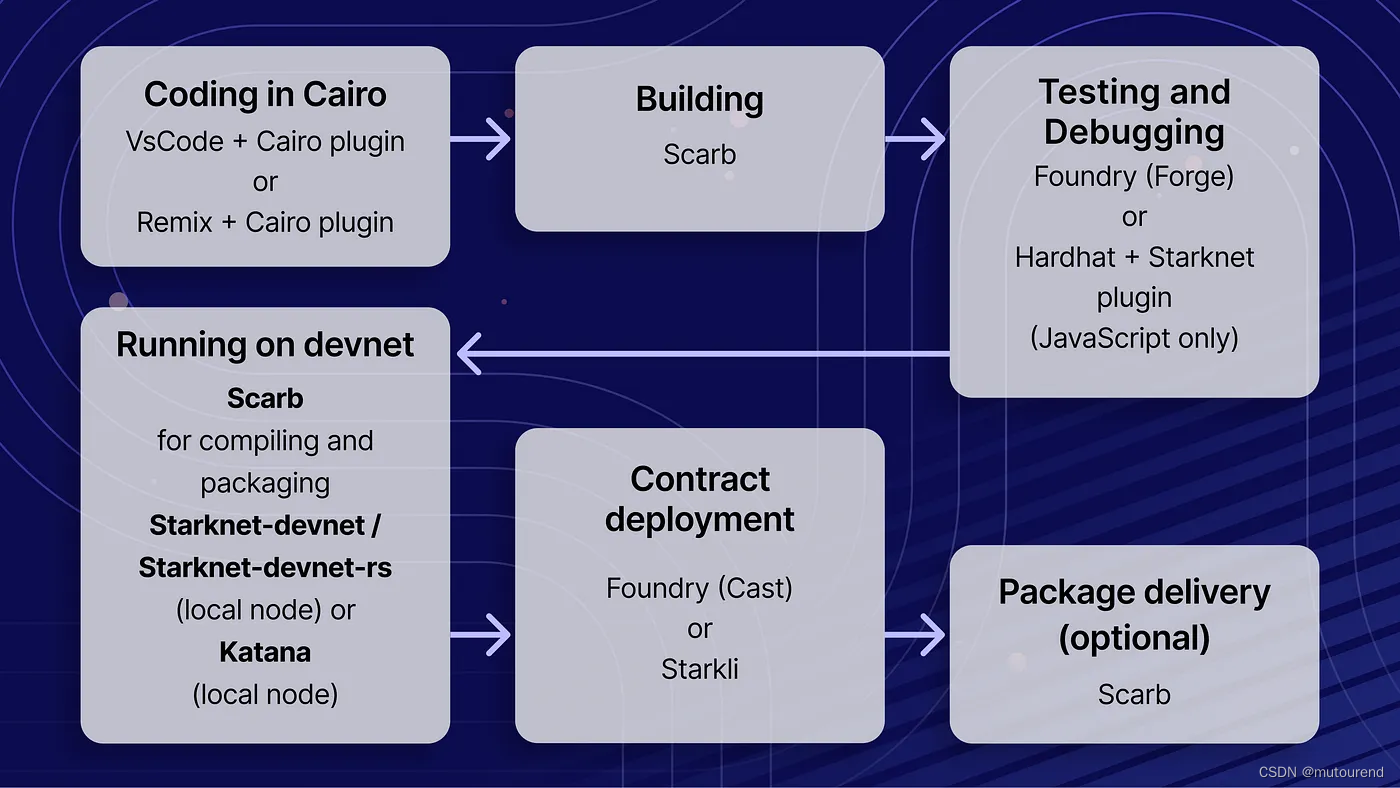
Starknet开发工具
1. 引言 目前Starknet的开发工具流可为: 1)Starkli:音为Stark-lie,为替换官方starknet-CLI的快速命令行接口。Starkli为单独的接口,可独自应用,而不是其它工具的组件。若只是想与Starknet交互࿰…...

Unity地面交互效果——1、局部UV采样和混合轨迹
大家好,我是阿赵。 这期开始,打算介绍一下地面交互的一些做法。 比如: Unity引擎制作沙地实时凹陷网格的脚印效果 或者: Unity引擎制作雪地效果 这些效果的实现,需要基于一些基础的知识。所以这一篇先介绍一下简单…...

基于STM32的示波器信号发生器设计
**单片机设计介绍,基于STM32的示波器信号发生器设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序文档 六、 文章目录 一 概要 基于STM32的示波器信号发生器是一种高性能的电子仪器,用于测试和分析电路中的电信号。在该系统中&a…...

案例分析大汇总
案例分析心得 2018-2022年的案例分析考试内容汇总(近五年) 架构设计题型 软件系统建模 数据库 Web 系统设计 2018年 胖/瘦客户端 C/S 架构非功能性需求 数据流图DFDE-R图Essential Use Cases(抽象用例),Real Use Cases(基础用例)信息工…...
)
MVCC(Multi-Version Concurrency Control,多版本并发控制)
是一种数据库管理系统中常用的并发控制技术,用于处理多个事务同时访问数据库数据时的数据一致性和隔离性。MVCC的主要目标是允许多个事务并发执行,同时保持数据的一致性,避免数据丢失或不一致。 MVCC 的核心思想是为每个事务维护多个版本的数…...
)
嵌入式面试2(c相关)
目录 1.C语言中static、const、volatile关键字用法区别; static的用法(定义和用途) const的用法(定义和用途) volatile (英文意思为易变的) 作用和用法: 2.C语言中,const 和 static 的区别,c…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...