MySQL---表的增查改删(CRUD进阶)
文章目录
- 数据库约束
- 表的设计
- 一对一
- 一对多
- 多对多
- 新增
- 查询
- 聚合查询
- 分组查询
- 联合查询
- 内连接
- 外连接
- 自连接
- 子查询
- 合并查询
数据库约束
数据库约束就是指:程序员定义一些规则对数据库中的数据进行限制。这样数据库会在新增和修改数据的时候按照这些限制,对数据进行校验。如果校验不通过,则直接报错。
数据库的约束类型有很多,以下我们将一一介绍:
- not null:表示被指定的某列不能为NULL,必须填信息。
//在不加 not null约束时,可以插入空值
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)mysql> insert into student values(NULL, NULL);
Query OK, 1 row affected (0.00 sec)// 重新定义表结构 给 id 字段加上 not null约束
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)mysql> create table student (id int not null, name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)//有 not null 约束后不能插入空值
mysql> insert into student values (NULL, NULL);
ERROR 1048 (23000): Column 'id' cannot be null- unique:表示被指定的列该字段的值必须唯一
//创建学生表 使id有unique约束mysql> create table student (id int unique, name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | UNI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)// 不能插入相同值
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.00 sec)mysql> insert into student values(1, '张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'id'- default:表示未给该字段赋值时,数据库赋予该字段的默认值
//对 id 和 name 分别设置默认值 0 和 未命名
mysql> create table student (id int default 0, name varchar(20) default '未命名');
Query OK, 0 rows affected (0.01 sec)mysql> desc student;
+-------+-------------+------+-----+-----------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+-----------+-------+
| id | int(11) | YES | | 0 | |
| name | varchar(20) | YES | | 未命名 | |
+-------+-------------+------+-----+-----------+-------+
2 rows in set (0.00 sec)// 演示 name 默认值为 未命名
mysql> insert into student (id) values (1);
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+------+-----------+
| id | name |
+------+-----------+
| 1 | 未命名 |
+------+-----------+
1 row in set (0.00 sec)//演示 id 默认值为 0
mysql> insert into student (name) values ('张三');
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+------+-----------+
| id | name |
+------+-----------+
| 1 | 未命名 |
| 0 | 张三 |
+------+-----------+
2 rows in set (0.00 sec)注:MySQL给的默认值是 NULL
- primary key:表示主键,即区分该行和其他行的唯一标识,方便定位每一条记录
//对 id 设置为主键mysql> create table student (id int primary key,name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)//插入数据进行演示,可以看出//一 主键不能为空
mysql> insert into student values(null, null);
ERROR 1048 (23000): Column 'id' cannot be null//二 主键的值必须唯一 不能重复
mysql> insert into student values(1,'张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'mysql> insert into student values(1,'张三');
Query OK, 1 row affected (0.00 sec)- 自增主键:因为主键的值必须要填还不能重复,MySQL就提供了一个功能来自动生成主键的值
//对 id 设置自增主键mysql> create table student (id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> desc student;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)// 自增主键可以把主键写为空值 因为系统最后会自动赋值
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
+----+--------+
1 row in set (0.00 sec)//如果给主键填空值,主键会按自增主键自动生成;如果给主键填指定值,主键就是指定值
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
+----+--------+
4 rows in set (0.00 sec)//如果给主键填空值,主键会按自增主键自动生成;如果给主键填指定值,主键就是指定值
mysql> insert into student values (100,'张三');
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+-----+--------+
| id | name |
+-----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
| 100 | 张三 |
+-----+--------+
5 rows in set (0.00 sec)mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+-----+--------+
| id | name |
+-----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
| 100 | 张三 |
| 101 | 张三 |
+-----+--------+
6 rows in set (0.00 sec)
注:
- MySQL在自增主键的时候,就必须先记录下目前主键值是多少了然后再+1,当我们手动指定一个主键值使它与记录下的、目前的主键值差距较大后,下次自增会在哪个数值上+1实现自增呢?MySQL里简单粗暴的做法是:选择主键里的最大值,然后在最大值的基础上自增。这样能保证绝对不会重复;
- 如果在多线程情况下,自增主键可能会不安全。于是又提出了一个自增主键的方法:唯一 id = 时间戳(ms) + 机房编号 + 主机编号 + 随机因子(这里的 + 表示字符串拼接),这样就保证了主键的唯一性。
- foreign key:表示外键,即连接该表和其他表的一个媒介,描述了两张表的关联关系
mysql> create table class (classId int primary key,className varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> create table student (studentId int primary key, name varchar(20), classId int, foreign key (classId) references class (classId));
Query OK, 0 rows affected (0.01 sec)mysql>
mysql> desc student;
+-----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+-------+
| studentId | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| classId | int(11) | YES | MUL | NULL | |
+-----------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)注:
- 学生在班级里,即可以理解为学生被班级约束。被约束的表称为子表,约束别人的表称为父表;
- 把所有字段都定义完后,再写外键约束。注意外键约束的写法!
//父表为空时往子表里插入数据就会报错 因为对子表没有产生约束mysql> insert into student values(1,'张三',1);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`java`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `class` (`classId`))// 假设已经在父表里插入了三条数据 我们现在往子表里插入外键4
// 也会报错 因为子表超出了父表对它的约束
mysql> insert into student values(1,'张三',4);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`java`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `class` (`classId`))注:
- 在外键的约束下,每次插入、删除数据的时候,都得对父表进行查询,这是一个低效的操作。为了解决这个问题,MySQL就要求:在建立外键约束时,外键必须是另一张表的主键或者unique,这样会建立索引让查询更高效。
- 父表对子表产生限制,相应的子表也会对父表产生限制。父表对子表的限制是子表不能随意的插入和修改;子表对父表的限制是不能随意的修改和删除。
- check:表示保证插入的值必须符合check条件
//插入的数据只能是 男或女
check (sex ='男' or sex='女')
注:MySQL使用时不报错,但是会忽略该约束。(该约束不起作用)
表的设计
一对一
以教务系统为例,学生表有学号姓名班级等属性,教务系统上的用户表有账号密码等属性,每一个学生有且仅有一个教务系统的账号,并且教务系统上的一个账号仅对应一个学生,像这种关系就是一对一的关系。
那么如何在数据库表示这种一对一的关系呢?
方案1:把学生表与用户表放在一个表中一一对应。
方案2:学生表中增加一列,存放学生在教务系统上的账号,在教务系统用户表增加一列,存放学生的学号。
一对多
还是以教务系统为例,如学生与班级之间的关系就是一个一对多的关系,一个学生原则上只能在一个班级中,一个班级容纳多名学生。
那么如何在数据库表示这种一对多的关系呢?
方案1:在班级表中增加一列,存放一个班里面所有学生的学号。但是MySQL不支持这种方案,因为SQL中没有类似于数组的类型。
方案2:在一个学生表中增加一列,存放学生所在的班级。
多对多
还是以教务系统为例,如学生与课程之间的关系就是一个典型的多对多的关系,一个学生可以学习多门课程,一门课程中有多名学生学习。
那么如何在数据库表示这种多对多的关系呢?
只有一种方案:建立一个关联表,来关联学生表和课程表,这个关联表中有两列,一列用来存放学生学号,另一列存放课程编号,这样两表可以通过这一个关联表来实现多对多的一个关系。
新增
//把查询结果作为新增的数据
insert into 表1 select 列名 from 表2;
//创建表1
mysql> create table student (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> insert into student values (1,'张三'),(2,'李四'),(3,'王五');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0//创建表2
mysql> create table student2 (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)//查看表1当前的信息
mysql> select * from student;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)//明确表2现在为空
mysql> select * from student2;
Empty set (0.00 sec)//将表1的数据全部插入表2
mysql> insert into student2 select * from student;
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from student2;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)注:
- 先进行查询操作再进行插入操作。
- 要求表2查询结果的列数、类型 和 表1的列数、类型匹配 不要求列名匹配。
查询
聚合查询
聚合查询依赖于聚合函数,而聚合函数都是针对行与行之间进行计算的,在这里我们先认识一下相关的聚合函数,这些都是SQL的内置函数,即库函数;可以直接使用:
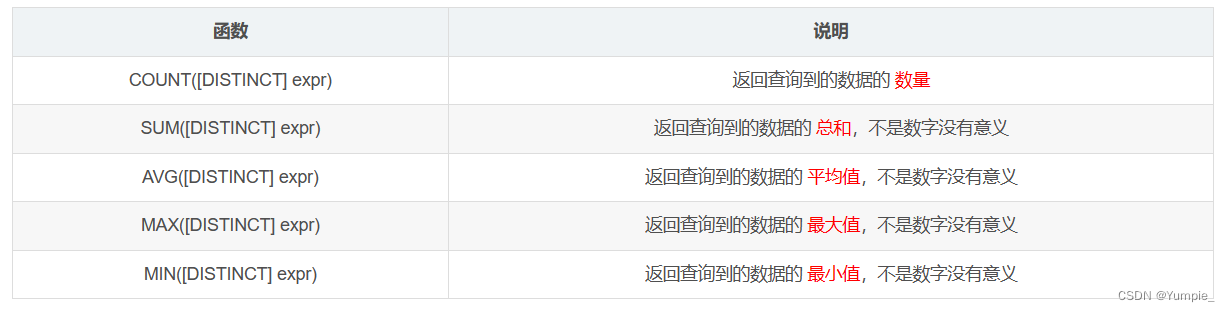
- 使用count函数:
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | zhangsan | 67.0 | 98.0 | 56.0 |
| 2 | lisi | 87.5 | 78.0 | 77.0 |
| 3 | wangwu | 88.0 | 98.5 | 90.0 |
| 4 | zhaoliu | 82.0 | 84.0 | 67.0 |
| 5 | sunqi | 55.5 | 85.0 | 45.0 |
| 6 | zhouba | 70.0 | 73.0 | 78.5 |
| 7 | wujiu | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)//count函数既可以使用count(*) 又可以使用count(列名)
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)mysql> select count(name) from exam_result;
+-------------+
| count(name) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)count(*) 和 count(列名) 的区别://插入一条空数据
mysql> insert into exam_result values(null, null, null, null, null);
Query OK, 1 row affected (0.00 sec)mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | zhangsan | 67.0 | 98.0 | 56.0 |
| 2 | lisi | 87.5 | 78.0 | 77.0 |
| 3 | wangwu | 88.0 | 98.5 | 90.0 |
| 4 | zhaoliu | 82.0 | 84.0 | 67.0 |
| 5 | sunqi | 55.5 | 85.0 | 45.0 |
| 6 | zhouba | 70.0 | 73.0 | 78.5 |
| 7 | wujiu | 75.0 | 65.0 | 30.0 |
| NULL | NULL | NULL | NULL | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 8 |
+----------+
1 row in set (0.00 sec)mysql> select count(name) from exam_result;
+-------------+
| count(name) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)//我们看到 count(*) 和 count(列名) 的查询结果不同
注:count(*)会把NULL值也统计到总行数中;count(列名)不会把NULL值统计到总行数中
- 使用sum函数:
mysql> select sum(english) from exam_result;
+--------------+
| sum(english) |
+--------------+
| 443.5 |
+--------------+
1 row in set (0.00 sec)//聚合函数也可以结合条件查询mysql> select sum(english) from exam_result where english < 60;
+--------------+
| sum(english) |
+--------------+
| 131.0 |
+--------------+
1 row in set (0.00 sec)- 使用avg函数:
mysql> select avg(math) from exam_result;
+-----------+
| avg(math) |
+-----------+
| 83.07143 |
+-----------+
1 row in set (0.00 sec)- 使用max函数 和 使用min函数
mysql> select max(math) from exam_result;
+-----------+
| max(math) |
+-----------+
| 98.5 |
+-----------+
1 row in set (0.00 sec)mysql> select min(math) from exam_result;
+-----------+
| min(math) |
+-----------+
| 65.0 |
+-----------+
1 row in set (0.00 sec)注:
- 在聚合函数中进行计算时,NULL不会参与计算。
- 对于带有条件的聚合查询,先会按照条件进行筛选,再把筛选后得到的结果进行聚合。
分组查询
select 列名 from 表名 where 条件 group by 列名;
mysql> select * from student;
+------+--------+--------+-------+
| id | name | gender | score |
+------+--------+--------+-------+
| 1 | 张三 | 男 | 95 |
| 2 | 李四 | 女 | 75 |
| 3 | 王五 | 男 | 85 |
| 4 | 赵六 | 女 | 65 |
+------+--------+--------+-------+
4 rows in set (0.00 sec)mysql> select gender, max(score), min(score), avg(score) from student group by gender;
+--------+------------+------------+------------+
| gender | max(score) | min(score) | avg(score) |
+--------+------------+------------+------------+
| 女 | 75 | 65 | 70.0000 |
| 男 | 95 | 85 | 90.0000 |
+--------+------------+------------+------------+
2 rows in set (0.00 sec)注:
- 分组查询是指:指定某一列作为分组的依据,把列名相同的分为一组,即把表中的若干行分为好几组;
- 分组规则就是:把某些具有相同字段值的行作为一组。
//复杂的查询情况下,对查询的顺序进行理解。
mysql> select gender, avg(score) from student where name != '赵六' group by gender having avg(score) > 80;
+--------+------------+
| gender | avg(score) |
+--------+------------+
| 男 | 90.0000 |
+--------+------------+
1 row in set (0.00 sec)注:
- 通常情况下,都会把select 后的第一个列名 与 group by 后面的列名保持一致。
- 这个SQL语句的执行顺序是:先对where条件进行筛选,再通过列值进行分组,再对分好的几组进行having条件的筛选,最后显示出要查找的列信息。
联合查询
联合查询也叫多表查询,是把多个表的记录合并在一起,进行综合查询。
联合查询的核心概念是:笛卡尔积。
笛卡尔积就是把俩个表中的所有记录,进行排列组合,穷举出所有可能的结果。
笛卡尔积后的列数就是几张表的列数之和,笛卡尔积后的行数就是几张表的行数之积
笛卡尔积中包含了大量的无效数据,当指定合理的筛选条件时,就可以把有效的数据挑选出来得到一个有用的数据表,这个筛选的过程就是”联合查询“的过程。
内连接
select 列名 from 表1,表2 where 条件 and 其他条件;
select 列名 from 表1 inner join 表2 on 条件 and 其他条件;
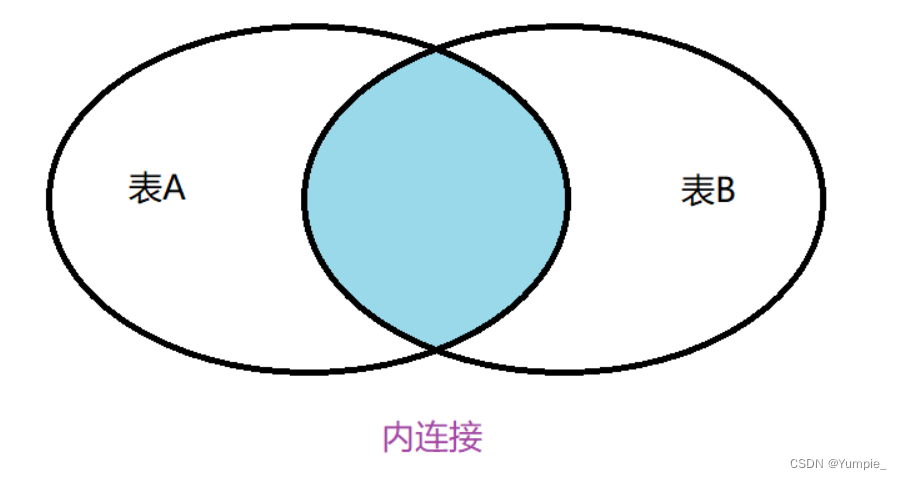
-- 创建部门表
CREATE TABLE department(did int (4) NOT NULL PRIMARY KEY, dname varchar(20)
);-- 创建员工表
CREATE TABLE employee (eid int (4) NOT NULL PRIMARY KEY, ename varchar (20), eage int (2), departmentid int (4) NOT NULL
);-- 向部门表插入数据
INSERT INTO department VALUES(1001,'财务部');
INSERT INTO department VALUES(1002,'技术部');
INSERT INTO department VALUES(1003,'行政部');
INSERT INTO department VALUES(1004,'生活部');
-- 向员工表插入数据
INSERT INTO employee VALUES(1,'张三',19,1003);
INSERT INTO employee VALUES(2,'李四',18,1002);
INSERT INTO employee VALUES(3,'王五',20,1001);
INSERT INTO employee VALUES(4,'赵六',20,1004);//使用join on 查询
select ename,dname from department inner join employee on department.did=employee.departmentid;//使用where查询
select ename,dname from department,employee where department.did = employee.departmentid;外连接
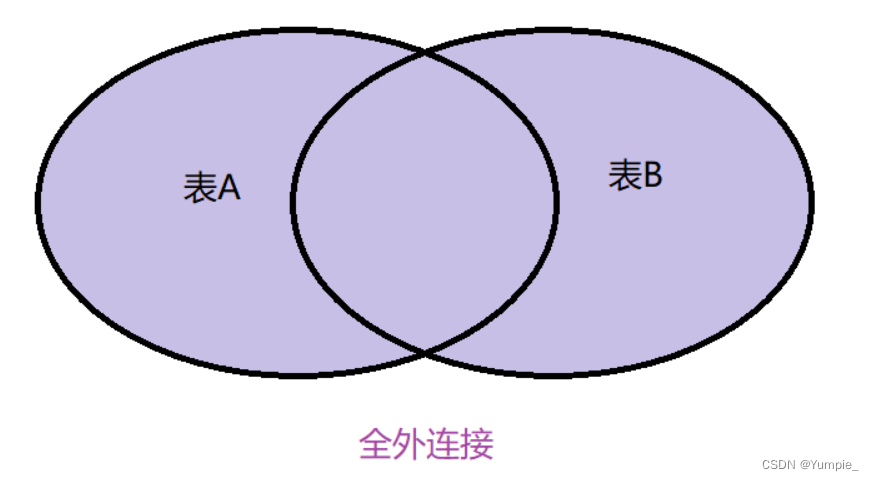
外连接分为左外连接和右外连接及全外连接(SQL不支持)
select 列名 from 表1 left join 表2 on 条件; // 左外连接
select 列名 from 表2 right join 表2 on 条件; // 右外连接
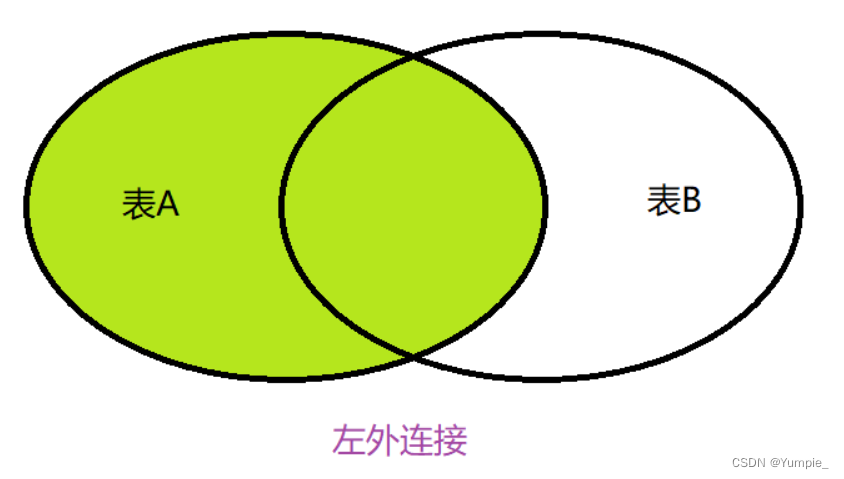
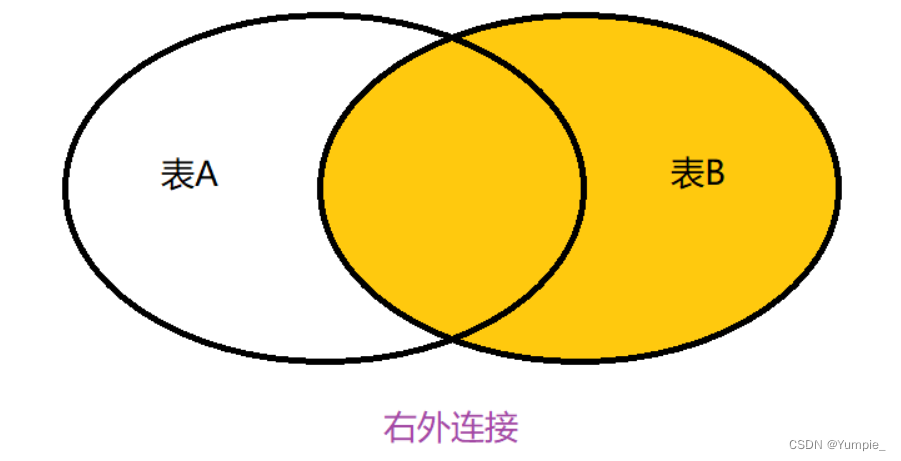
-- 创建班级表
CREATE TABLE class(cid int (4) NOT NULL PRIMARY KEY, cname varchar(20)
);-- 创建学生表
CREATE TABLE student (sid int (4) NOT NULL PRIMARY KEY, sname varchar (20), sage int (2), classid int (4) NOT NULL
);
-- 向班级表插入数据
INSERT INTO class VALUES(1001,'Java');
INSERT INTO class VALUES(1002,'C++');
INSERT INTO class VALUES(1003,'Python');
INSERT INTO class VALUES(1004,'PHP');-- 向学生表插入数据
INSERT INTO student VALUES(1,'张三',20,1001);
INSERT INTO student VALUES(2,'李四',21,1002);
INSERT INTO student VALUES(3,'王五',24,1002);
INSERT INTO student VALUES(4,'赵六',23,1003);
INSERT INTO student VALUES(5,'Jack',22,1009);//左外连接
select cid,cname,sname from class left join student on class.cid=student.classid;
//右外连接
select cid,cname,sname from class right join student on class.cid=student.classid;
注:进行左外连接查询和右外连接查询时,必须要加上查询条件。因为,只有加上条件才能得到在一个表中存在但是在另一个表中不存在的信息。
自连接
自连接:自己和自己连接,同一张表和自己进行笛卡尔积。
SQL里面指定条件查询都是按照列和列之间进行筛选,难以进行 行和行之间筛选,自连接操作能把按列筛选转化为按行筛选。
//查找哪个学生的3号课程分数高于1号课程
mysql> select s1.student_id from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;
子查询
子查询是指:在select语句中嵌套其他的SQL语句一起进行查询,也叫嵌套查询。
- 单行子查询:返回一行记录的子查询
mysql> select name from student where classes_id = (select classes_id from student where name = 'zhangsan');
注:此处的子查询可以任意级别的嵌套。
- 多行子查询:返回多行记录的子查询
//查询语文或英语课程的成绩信息
mysql> select * from score where course_id in (select id from course where name = '语文' or name = '英文');
合并查询
合并查询:把两个查询的结果集合,合并到一起。可以使用集合操作符 union 和 union all,注意两个结果集合查询的字段应该相同。
- union:该操作符用于取得两个结果集合的并集,会自动去除掉结果集合中的重复行。
//查询 id<3 或者 名字为英文的课程mysql> select * from course where id < 3 or name = '英文';
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 6 | 英文 |
+----+--------------------+
3 rows in set (0.00 sec)mysql> select * from course where id < 3 union select * from course where name = '英文';
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 6 | 英文 |
+----+--------------------+
3 rows in set (0.00 sec)- union all:和union的唯一区别是如果有重复记录,union all 不会去重
最后总结一下SQL查询中各个关键字的执行先后顺序:from > on> join > where > group by > with > having >select > distinct > order by > limit
相关文章:
MySQL---表的增查改删(CRUD进阶)
文章目录 数据库约束表的设计一对一一对多多对多 新增查询聚合查询分组查询联合查询内连接外连接自连接子查询合并查询 数据库约束 数据库约束就是指:程序员定义一些规则对数据库中的数据进行限制。这样数据库会在新增和修改数据的时候按照这些限制,对数…...
《HelloGitHub》第 91 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣、入门级的开源项目。 github.com/521xueweihan/HelloGitHub 这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 Python、…...

jvm线上异常排查流程
1. Linux命令 jps 找出当前运行实例 2. jinfo -flags pid(java运行id) 打印出当前设置的jvm内存参数情况 3.jstat -gcutil pid 1000 10 每秒打印一次当前jvm的gc运行情况,一共打印10次 4.将gc日志下载进行分析:到底是因为什么原因导致一直…...

python项目之酒店客房入侵检测系统的设计与实现
项目简介 酒店客房入侵检测系统的设计与实现实现了以下功能: 1、控制台: 控制台是整个系统的首页面。在控制台中,酒店的客房管理人员能够在该页面中查看到当前的空余客房数量、当前在店的客房人数、当前的已用客房数量、当前酒店全部的客房…...

C++ 学习系列 -- 标准库常用得 algorithm function
一 前言 c 标准库中提供了许多操作数据结构:vector、list、deque、map、set 等函数,学习并了解这些常用函数对于我们理解 c 的一些设计模式有着重要的作用。 二 常用的 algorithm function 源码 源代码位置: bits/stl_algo.h 1. accumu…...

[论文笔记]E5
引言 今天又带来一篇文本匹配/文本嵌入的笔记:Text Embeddings by Weakly-Supervised Contrastive Pre-training。中文题目是 基于弱监督对比预训练计算文本嵌入。 本篇工作提出了E5模型(EmbEddings from bidirEctional Encoder rEpresentations)。该模型以带弱监督信号的对…...

k8s 1.28版本:使用StorageClass动态创建PV,SelfLink 问题修复
k8s中提供了一套自动创建 PV 的机制,就是基于 StorageClass 进行的,通过 StorageClass 可以实现仅仅配置 PVC,然后交由 StorageClass 根据 PVC 的需求动态创建 PV。 问题: 使用 k8s 1.28版本,通过 kubectl get pv…...
漏洞复现-dedecms文件上传(CVE-2019-8933)
dedecms文件上传_CVE-2019-8933 漏洞信息 Desdev DedeCMS 5.7SP2版本中存在安全漏洞CVE-2019-8933文件上传漏洞 描述 Desdev DedeCMS(织梦内容管理系统)是中国卓卓网络(Desdev)公司的一套基于PHP的开源内容管理系统&#x…...

vue分片上传
<template><div><input type"file" id"input" /><button click"uploadFile">上传</button></div> </template><script lang"ts" setup> let chunkSize1024 * 1024,index0; const upl…...

【大数据Hive】hive 表数据优化使用详解
目录 一、前言 二、hive 常用数据存储格式 2.1 文件格式-TextFile 2.1.1 操作演示 2.2 文件格式 - SequenceFile 2.2.1 操作演示 2.3 文件格式 -Parquet 2.3.1 Parquet简介 2.3.2 操作演示 2.4 文件格式-ORC 2.4.1 ORC介绍 2.4.2 操作演示 三、hive 存储数据压缩优…...

京东平台数据分析(京东销量):2023年9月京东吸尘器行业品牌销售排行榜
鲸参谋监测的京东平台9月份吸尘器市场销售数据已出炉! 根据鲸参谋电商数据分析平台的相关数据显示,今年9月,京东吸尘器的销量为19万,环比下滑约12%,同比下滑约25%;销售额为1.2亿,环比下滑约11%&…...
基于springboot实现休闲娱乐代理售票平台系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现休闲娱乐代理售票平台系统演示 摘要 网络的广泛应用给生活带来了十分的便利。所以把休闲娱乐代理售票管理与现在网络相结合,利用java技术建设休闲娱乐代理售票系统,实现休闲娱乐代理售票的信息化。则对于进一步提高休闲娱乐代理售票管…...

jvm对象内存划分
写此篇博客源于面试问到内存分配的细节,然后不明白问的是什么。回过头发现以前看过这块内容,只是有些印象,但是无法描述清楚。 额外概念了解 jvm内存空间是逻辑上连续的虚拟地址空间(虚拟内存中的概念)映射到物理内存…...
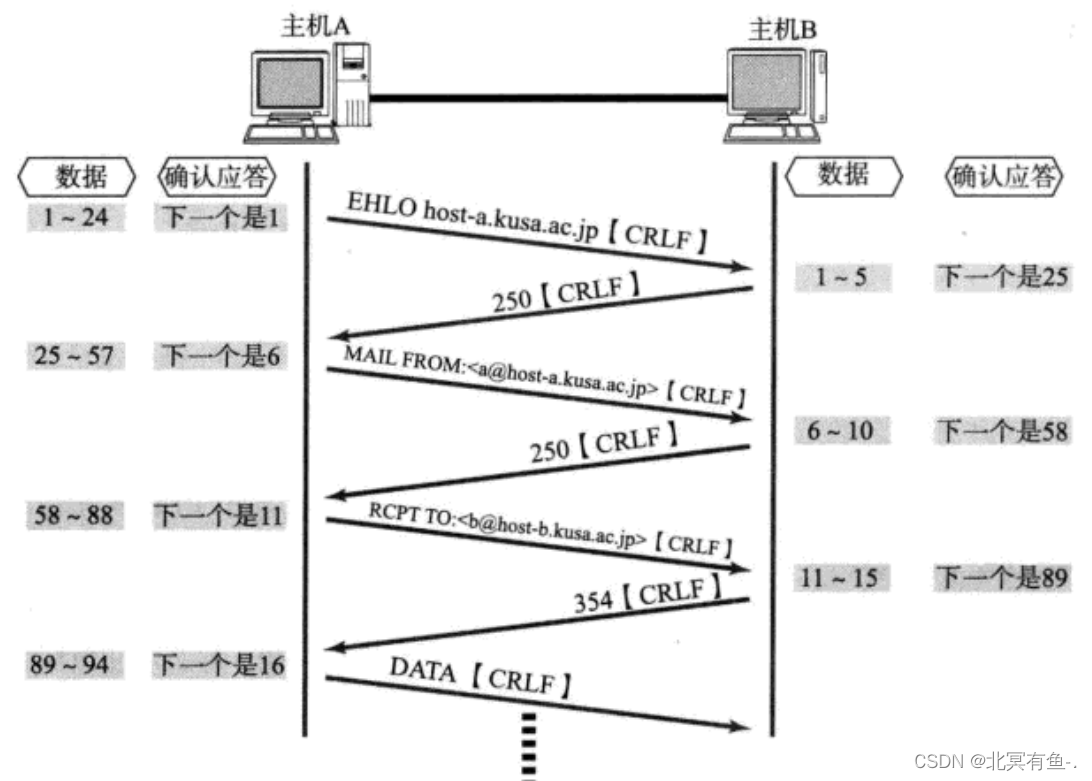
网络原理之TCP/IP
文章目录 应用层传输层UDP协议TCP协议TCP 的工作机制1. 确认应答2. 超时重传3. 连接管理TCP 的建立连接的过程(三次握手),和断开连接的过程(四次挥手)TCP 断开连接, 四次挥手 3. 滑动窗口5. 流量控制6. 拥塞控制7. 延时应答8. 捎带应答9. 面向字节流10. 异常情况 本章节主要讨论…...
Docker:数据卷挂载
Docker:数据卷挂载 1. 数据卷2. 数据卷命令补充 1. 数据卷 数据卷(volume)是一个虚拟目录,是容器内目录与宿主机目录之间映射的桥梁。 Nginx容器有自己独立的目录(Docker为每个镜像创建一个独立的容器,每个容器都是基于镜像创建的运行实例),…...

你会处理 go 中的 nil 吗
对于下面这段代码,我们知道 i 实际上的值就是 nil,所以 i nil 会生效 func main() {var i *int nilif i nil {fmt.Println("i is nil") // i is nil} }现在换一种写法,我们将 i 的类型改成 interface{},i nil 依然…...

高级深入--day42
注意:模拟登陆时,必须保证settings.py里的 COOKIES_ENABLED (Cookies中间件) 处于开启状态 COOKIES_ENABLED True 或 # COOKIES_ENABLED False 策略一:直接POST数据(比如需要登陆的账户信息) 只要是需要提供post数据的ÿ…...

mysql 计算两个坐标距离
方式一:st_distance_sphere 计算结果单位米 SELECT *, st_distance_sphere(point(lng,lat),point(lng,lat)) as distance FROM table mysql 版本5.7 以上 方式二:st_distance 计算结果单位是度 SELECT *, (st_distance(point(lng,lat),point(lng4,lat…...

String、StringBuffer、StringBuilder和StringJoiner
String、StringBuffer、StringBuilder和StringJoiner都是用于处理字符串的类,但它们在性能和使用方式上有一些区别。 String String是不可变的类,一旦创建就不能被修改。对String进行拼接或修改时,实际上是创建了一个新的String对象。适用于…...
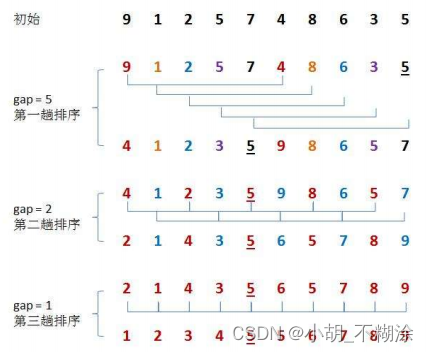
【数据结构】插入排序
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:浅谈数据结构 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 直接插入、希尔排序 1. 什么是排序2…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...