项目解读_v2
1. 项目介绍
- 如果使用task2-1作为示例时, 运行process.py的过程中需要确认 process调用的是函数
preprocess_ast_wav2vec(wav, fr)
1.1 任务简介
首个开源的儿科呼吸音数据集, 通过邀请11位医师标注;
数字听诊器的采样频率和量化分辨率分别为8 kHz和16位。
儿童参与者的呼吸音弱于成人呼吸音。此外,在胸前采集时,呼吸音受心音的影响很大。因此,呼吸声音是在四个背面位置获取的,包括左后部、左外侧、右后部和右侧(图 4)。每个位置的收集持续时间持续超过 9 秒,以确保至少两个呼吸周期。

292位参与测试者,共8.2个小时。
-
总共2683个录音文件record level, 被标记出了9089个呼吸音event level; (对比icbhi2017是920个录音文件)
-
录音文件被标记为 事件级别 event level 用于 task 1 任务, 和 record level, 用于task2 任务;
任务总共包含两大类,分别如下
# Important Assumption (used in model/metric.py)
# Normal is always index 0
# PQ, if exists, is index 1def resp_classes(task, level):assert task in (1,2), 'Task has to be either 1 or 2.'assert level in (1,2), 'Level has to be either 1 or 2.'if task==1:if level==1:CLASSES = ('Normal', 'Adventitious') # 2 classelif level==2: # 7 classCLASSES = ('Normal', 'Rhonchi', 'Wheeze', 'Stridor', 'Coarse Crackle', 'Fine Crackle', 'Wheeze & Crackle') elif task==2:if level==1: # 3 class;CLASSES = ('Normal', 'Poor Quality', 'Adventitious')elif level==2: # 5 class;CLASSES = ('Normal', 'Poor Quality', 'CAS', 'DAS', 'CAS & DAS')return CLASSES
5
两类任务上的平均时间, The mean duration of respiratory sound events and records are 1.3s and 11s, respectively.
对于任务1,事件级别的音频, 在训练集中总共 6656份音频;
task1-1: 二分类任务: normal: 5159, Adventitious: 1497; 对异常类中的样本,随机扩充, 扩充到和正常样本数目相同;
task1-2: 七分类任务:the number of Normal, Rhonchi,Wheeze, Stridor, Coarse Crackle, Fine Crackle, and Wheeze & Crackle are 6,887, 53, 865, 17, 66, 1,167, and 34, respectively.
对于任务2, 录音级别的音频, 在训练集中总共1949 份音频;
task2-1: 3分类任务: normal: 1303, Adventitious:469 ‘Poor Quality’: 177 '对异常类中的样本,随机扩充, 扩充到和正常样本数目相同;
task2-2: 5 分类任务:
normal: 1303, ‘Poor Quality’: 177 , CAS,126, DAS: 248; CAS&DAS:95

icbhi 数据集0

task1, 事件级别的分类, event level :
训练集: 6656份音频事件
测试集: 对应了2433份音频事件;
task2,录音级别的分类, record level,
训练集: 包含1949录音, (注意, 后续通过筛选 task2, 减少为1772 份录音;)
测试集: 734份录音,
1.2 数据预处理
preprocess.py 数据预处理, 详细的分析过程参考第9节;
其中,根据task_config.json 中的配置 data_loader, input_dir 选项中的是 task1 对应processed_wav2vec or task2 对应processed_ast_wav2vec,
根据上述不同的任务, preprocess() 函数将调用 不同的预处理函数, processed_wav2vec() or processed_ast_wav2vec(),
1.3 Dataset 数据集的创建
创建Dataset的子类,用于创建数据集;
在__getitem() 中,生成 训练样本 以及该样本的标签 label;
注意,这里的训练样本,即可以是原始的音频数据;
又可以是,经过处理后的特征,使用该特征直接进行输入到网络中进行训练。
并且在 __getitem__() 使用数据增强, 可以使得每一个 batch 都采用不同的数据增强的方式;
# location, data/SPRSound/Dataset.py
from torch.utils.data import Dataset
# RespDataLoader 中调用当前类 RespDataset();class RespDataset(Dataset):def __init__(self, data_dir, task, input_dir=None):assert task in (1,2)self.task = tasktask_file_name = 'task1.csv' if task==1 else 'task2_filtered.csv'# task_file_name = f'task{task}.csv'self.csv = pd.read_csv(join(data_dir, task_file_name))self.input_dir = input_dirif input_dir is None: # note, 这里使用的原始划分的音频文件;if task == 1: # 若果没有指定 input dir 用于训练的音频文件, 则 clip 中存放的是task1 的事件级别的检测任务;self.dir = join(data_dir, 'clip')else: # 如果, task2, 使用wav 文件,其中存放的是record 记录级别的事件;self.dir = join(data_dir, 'wav')else: # note , 这里是自定义 的文件夹;self.dir = join(data_dir, input_dir)def __len__(self):return len(self.csv)def __getitem__(self, index): # 这里获取的是音频, 和对应的label;entry = self.csv.iloc[index]wav_name = entry['wav_name']target = (entry[f'label_{self.task}1'], entry[f'label_{self.task}2'])if self.input_dir is None:wav, _ = torchaudio.load(join(self.dir, wav_name))else:wav = torch.load(join(self.dir, wav_name), map_location='cpu')# # normalize# wav = (wav-37.3)/(2.3*2)return wav, target1.4 项目流程
train.py(): 是整个项目的执行过程的载体;
依次的顺序是,
- 实例化 训练集和验证集;
- 模型实例化:
- 损失函数和评价指标的设定;
- 可学习参数, 优化器以及学习率参数配置;
- 实例化训练类,
- 调度训练类中的
trian函数, 开始训练;
2. DataLoader加载器的实例化
训练集加载器 train_loader 和验证集加载器 valid_dataLoader 分别通过调用, 以下函数进行实现;
data_loader = config.init_obj('data_loader', module_data)
valid_data_loader = data_loader.split_validation()
## 2.0 三个类之间的继承关系;
RespDataLoader(BaseDataLoader) 继承自 BaseDataLoader(DataLoader),
BaseDataLoader(DataLoader) 继承自pytorch 中DataLoader(),
2.1 class BaseDataLoader()
note: 后面的子类RespDataLoader(),在使用 super().__init__()函数时,将会重新对当前父类BaseDataLoader()进行初始化, 注意, 在传入super().__init__() 中的参数时, 传入了自定义的collate_fn() 函数
# location: base/base_data_loader.py
from torch.utils.data import DataLoader# 根据 RespDataLoader 中传来的 dataset, 完成训练集 和测试集的划分;
class BaseDataLoader(DataLoader): def __init__(self, dataset, bt, shuffle, validation_split, num_workers, collate_fn= default_collate)初始化,训练集测试集的分配比率;# 分别获取训练集, 验证集的下标索引;self.sampler, self.valid_sampler = self._split_sampler(self.validation_split)# 注意到,这里的初始化参数通过子类RespDataLoader中, 重新传入参数赋值进来, 尤其关注到 collate_fn# 被重新赋值;self.init_kwargs = {'dataset': dataset,'batch_size':bt,'shuffle':shuffle,'collate_fn':collate_fn,'num_workers':num_workers,}def _split_sampler(self, split):# 将整体数据集,重新划分为训练集和测试集, # 获取各自训练和验证集上,所对应的下标索引;def split_validation(self):# 用于获取验证集的数据,通过 属性,下标索引, # 传入 DataLoader() return DataLoader(sampler = self.valid_sampler, **self.init_kwargs)2.2 class RespDataLoader()
# location: data_loader/data_loaders.pydef resp_classes(task, level):根据当前任务, 返回当前任务上每个类别所对应的标签;from data.SPRSound import Datasetsclass RespDataLoader(BaseDataLoader):def __init__(self, ...):初始化,当前任务上的类别标签属性;dataset = Datasets.RespDataset(data_dir, task= task, input_dir=input_dir)# 使用当前类中的属性重新初始化父类BaseDataLoader , 对父类中的 __init__() 函数重新初始化;super().__init__(dataset, bt, shuffle, validation_split, num_workers, collate_fn=self.collate_fn)def collate_fn(self, batch):tensors, targets = [], []获取一个batch 中的 tensor, 以及对应的label;# 此处,需要搞清楚,这里的 tensor 到底对应的 特征级别的 tensor, 用于后续直接输入到网络模型中;# 还是这里tensor 依然代表的是音频数据的 tensor; return tensors, targets2.3 train_dataLoader的实例化:
data_loader = config.init_ob(data_loader, module_data), 其中 参数配置中的data_loader是指,Json 配置文件中,指定的类 RespDataLoader, 通过将该类实例化为对象的过程中, 逐个在 重新初始化其父类, 最终将pytorch中的 DataLoader() 该基类重新初始化, 流程如下:
-
data_loader = config.init_ob(data_loader, module_data) -
—>
RespDataLoader(BaseDataLoader), 调用两个函数:
- 获取当前任务的整体数据集,dataset =
Datasets.RespDataset(); - 通过重新初始化其父类,获得训练集和测试集的样本下标索引; 具体讲来,其中的
super().__init__(dataset, bt, shuffle, validation_split, num_workers, collate_fn= self.collate_fn)通过传入参数,重新初始化其父类BaseDataLoader(),下面进入父类中进行初始化,
- —->
BaseDataLoader(DataLoader), 初始化的过程中,分两步走:
-
self.sampler, self.valid_sampler = self._split_sampler(self.validation_split)分别生成训练集,和测试集的下标索引。 -
重新初始化所对应的父类
DataLoader(), 通过传入super().__init__(sampler= self.sampler, **self.init_kwargs)其中**self.init_kwargs包含了上一个子类传入的自定义collate_fn方法; -
上一步中的,将训练集的下标索引,
self.sampler, 和collate_fn函数传入到了DataLoader()中, 从而获取了训练集;
经过 DataLoader() 该函数中,存在 collate_fn 函数
批处理函数 collate_fn
批处理函数 collate_fn 负责对每一个采样出的 batch 中的样本进行处理。默认的 collate_fn 会进行如下操作:
- 添加一个新维度作为 batch 维;
- 自动地将 NumPy 数组和 Python 数值转换为 PyTorch 张量;
- 保留原始的数据结构,例如输入是字典的话,它会输出一个包含同样键 (key) 的字典,但是将值 (value) 替换为 batched 张量(如何可以转换的话)。
例如,如果样本是包含 3 通道的图像和一个整数型类别标签,即 (image, class_index),那么默认的 collate_fn 会将这样的一个元组列表转换为一个包含 batched 图像张量和 batched 类别标签张量的元组。
我们也可以传入手工编写的 collate_fn 函数以对数据进行自定义处理,例如前面我们介绍过的 padding 操作。
参考阅读:https://transformers.run/intro/2021-12-14-transformers-note-3/#dataloaders
2.4 valid_dataLoader的实例化:
valid_data_loader = data_loader.split_validation()
调用 BaseDataLoader()中的 BaseDataLoader().split_validation()函数,
该函数内部,传入了测试集的下标索引, 并且同样传入了 collate_fn()函数,通过 **self.init_kwargs函数;
然后通过调用 pytorch 中的 DataLoader() 获取数据集, DataLoader(sampler = self.valid_sampler, **self.init_kwargs),
3. 载入模型
model = config.init_obj('arch', module_arch)
通过关键字arch 获取Json 配置文件中的模型架构名称,
-
以及在当前任务上属于几分类问题,
-
该模型输入的 shape 形状;
之后,通过 getattr(module, module_name)(*args, **module_args) 进入当前调用的模型的初始化函数中去,
class ASTModel(nn.Module)def __init__():# 完成该模型的初始化;
3.1 light cnn
3.2 预训练的 ResNet18,
3.3 预训练的AST Model
预训练的 Audio Spectrogram Transformer 模型,
AST 在 AudioSet 上的音频分类任务上已经证明了它在 10 个 YouTube 视频片段中的音频类数据集 [23]。
该项目中,期望 AST 比基于图像的分类器,可以学习到用于音频分类的更好的呼吸音特征。
4. 损失函数与评价指标的设定
设置当前任务上的损失函数和评价指标,同样是通过Json 文件中去设置的;
"loss": {"type": "cross_entropy","args": {"weight": [0.2, 0.5, 0.3]}},"metrics": ["accuracy", "specificity", "sensitivity_task2", "score_task2"],
# 评价指标,包含4个方面, 精度, 特异度, 敏感度, 分数;
criterion = config.init_ftn('loss', module_loss, device=device)
metric = [getattr(module_metric, met) for met in config['metrics']]
5. 优化器以及学习率的配置
确认可学习参数, 构建优化器, 学习率;
trainable_params = filter(lambda p: p.requires_grad, model.parameters() )# optimizer 中配置好, 优化器,学习率,可学习参数等信息;
optimizer = config.init_obj('optimizer', torch.optim, trainable_params)
lr_scheduler = config.init_obj('lr_scheduler', torch.optim.lr_sheduler, optimizer)同样,通过调用config_中的参数, 取出其中 优化器以及学习率对应的参数信息;
"optimizer": {"type": "Adam","args":{"lr": 0.0001,"weight_decay": 0,"amsgrad": true}},"lr_scheduler": {"type": "StepLR","args": {"step_size": 50,"gamma": 0.1}},
6. 实例化训练类
训练类的继承关系,
Trainer()继承自父类BaseTrainer(), 而 BaseTrainer() 则是最初的基类;
-
trainer = Trainer():实例化训练类,通过实例化, 该类 Trainer(),trainer = Trainer(传入模型,损失函数, 优化器, 训练集和测试集)
# 实例化,训练类;
trainer = Trainer(model, criterion, metrics, optimizer,config = config, device = device,data_loader=data_loader, valid_data_loader=valid_data_loader,lr_scheduler=lr_scheduler )6.1 class BaseTrainer()
# current location: base/base_trainer.pyfrom logger import TensorboardWriterclass BaseTrainer:def __init__():初始以下各类属性, 模型, 损失函数, 评价指标;优化器, epoch 数目; 监视器,用于监控模型的性能,保存住最佳模型,通过 min , val loss 来判断最佳;可视化实例;def _train_epoch():由子类, 重写进行覆盖; 由下面的 train() 函数调用def train():train该函数, 在实例化子类Trainer()后,被调用,作为训练函数的调用接口函数;并且其自身,调用上面的 _train_epoch()函数;监听模型性能: 根据指标的变化, 保存当前模型的权重文件;调用下面的_save_checkpoiont()保存当前模型的训练过程;def _save_checkpoint():保存模型的训练信息,包含模型的参数权重, 状态字典; 当前epoch 数目, 优化器参数;def _resume_checkpoint();从保存的训练信息中, 加载模型,继续训练;6.2 class Trainer()
Trainer()继承自父类BaseTrainer()
# current location: trainer/trainer.pyfrom base import BaseTrainer class Trainer(BaseTrainer):def __init__(): 该初始化函数中, 设置属性,用来 传入训练集, 验证集; 模型;传入当前任务上的评价指标;# 传入参数, 重新初始化其父类 BaseTrainer 中的初始化函数;super().__init__(model, criterion, metric_ftns, optimizer, config) def _train_epoch(): 该函数,重写了父类中 _trian_epoch()中的方法;是网络训练的主体部分, 整个训练过程,在这个函数中体现出来;并将当前epoch 上训练得到的,结果保存在log 中;for bt_idx, (data, target) in enumerate(self.data_loader):...def _valid_epoch();用于每个epoch 训练结束时, 在_train_epoch() 函数中被调用,得到当前epoch 上的验证精度;def _progress():当前epoch 时, 每个batch 达到 self.log_step() 进行打印输出信息, 在_train_epoch() 函数中被调用;def _createConfusionMatrix():构建了混淆矩阵, 并且以热力图的形式保存,当前未找到,调用关系;6.3 训练流程
训练过程, 下面的第7节,对训练过程进行展开。
trainer.train()
由于 Trainer(BaseTrainer) Trainer 继承自BaseTrainer, 所以 trainer.train() 其中的 train() 函数是来自于父类中的函数;
所以 trainer.train() 其实调用的是BaseTrainer.train() 中的 train() 函数;
调用流程:
-
trainer. train()–>BaseTrainer.train() -
BaseTrainer.train()该train() 函数中调用 –>self._train_epoch() , 该函数在子类Trainer()中重写,并实现; -
_train_epoch()中调用 —>self.data_loader (), 而 data_loader 中每个batch 的数据加载流程 ,
7 . 训练过程
7.1 训练过程总览
训练过程,按照如下步骤进行分析:
- 训练过程中, 数据获取的流程
- 将优化器中的参数对应的梯度重新置零;
- 数据输入到模型中进行推理, 得到预测值;
- 将预测值和 标签输入到损失函数中,算出loss;
- 将损失开始反向传播,
- 更新优化器中的梯度
- 更新自定义的评价指标的中的性能参数;
- 将以上训练中性能信息 记录到
tensorboard以及 logger 中; - 当前一个 epoch 训练完成后, 开始在验证集上,进行一次验证,调用验证函数;
- 打印信息,保存权重;
self.data_loader 每次取一个batch 的数据时候调用,最终会调用到 RespDataLoader().collate_fn() 类中的自定义函数,
该函数用于将取出的音频文件,以及对应的标签,打包成一个 batch 的张量数据进行返回。
训练集和测试集data_loder, valid_data_loader 都是来自于同一个类(RespDataLoader)的实例化对象, 故这里只以分析 data_loader为例子,
for idx, (data, target) in enumerate(self.data_loader):data, target = data.to(self.device), target.to(self.device),取出数据的过程, 首先执行了便是 DataLoader() 中的 __iter__() 魔法函数;
然后,依次调用函数, 一直到调用到 Dataset() 子类中的 __getitem__() 方法,取出数据;
# 当对 data_loader 使用 enumerate() 函数时,
# 1. 将自动调用 DataLoader 类中的 迭代器函数 __iter__(self),
# 该函数返回的是一个可迭代对象;# We quote '_BaseDataLoaderIter' since it isn't defined yet and the definition can't be moved up
# since '_BaseDataLoaderIter' references 'DataLoader'.
def __iter__(self) -> '_BaseDataLoaderIter':# When using a single worker the returned iterator should be# created everytime to avoid reseting its state# However, in the case of a multiple workers iterator# the iterator is only created once in the lifetime of the# DataLoader object so that workers can be reusedif self.persistent_workers and self.num_workers > 0:if self._iterator is None:self._iterator = self._get_iterator()else:self._iterator._reset(self)return self._iteratorelse:return self._get_iterator()self._get_iterator() : 根据是否使用多进程,选择调用 单进程数据加载器, 还是选择多进程数据加载器;
def _get_iterator(self) -> '_BaseDataLoaderIter':if self.num_workers == 0:return _SingleProcessDataLoaderIter(self)else:self.check_worker_number_rationality()return _MultiProcessingDataLoaderIter(self)
7.2 训练中- 获取数据的流程:
data_loader 训练集是 RespDataLoader的一个实例化对象, 通过先后继承父类 BaseDataLoader(), DataLoader()
当每次从 self.data_loader 中取出一个batch 的数据时, 发生了如下调用事件,
-
调用 –> 私有类中的魔法函数
_BaseDataLoaderIter(object).__next__():该函数中继续调用– >
self._next_data()
上述的意思即,在该__next__() 魔法函数中调用了 self._next_data(),
_BaseDataLoaderIter(object)自身类中,该 _next_data()私有方法没有实现,
而是 在其子类_SingleProcessDataLoaderIter(_BaseDataLoaderIter)._next_data()中实现了, 故调用其子类中的该方法。
故这里的实际调用关系是:
—> _BaseDataLoaderIter(object).__next__():
––> 私有单线程类中的方法 _SingleProcessDataLoaderIter(_BaseDataLoaderIter)._next_data()
# location: `torch.utils.data.dataloader.py`中,class _SingleProcessDataLoaderIter(_BaseDataLoaderIter):def __init__(self, loader):super(_SingleProcessDataLoaderIter, self).__init__(loader)assert self._timeout == 0assert self._num_workers == 0self._dataset_fetcher = _DatasetKind.create_fetcher(self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last)def _next_data(self):index = self._next_index() # may raise StopIterationdata = self._dataset_fetcher.fetch(index) # may raise StopIterationif self._pin_memory:data = _utils.pin_memory.pin_memory(data)return data-
1 而
_SingleProcessDataLoaderIter(_BaseDataLoaderIter)._next_data()该方法在实现过程中调用 如下函数:—>
self._next_index(), 当前子类中并没有实现,通过继承使用父类(_BaseDataLoaderIter)中的该方法,而该父类中
self._next_index()方法 则继续调用如下方法, –>
return next(self._sampler_iter),继续调用–>
torch.utils.data.sampler.py中类BatchSampler.__iter__(), 该函数实现了取出一个 batch 批次的数据,所对应的下标索引。2.2 在
self._next_index(), 调用完成之后,获取了一个batch 数据的下标索引, 则继续调用
self._dataset_fetcher.fetch(index),—-> 该函数的实现则是调用了
_MapDatasetFetcher(_BaseDatasetFetcher).fetch()方法# location: torch.utils.data._utils.fetch.py 中class _MapDatasetFetcher(_BaseDatasetFetcher):def __init__(self, dataset, auto_collation, collate_fn, drop_last):super(_MapDatasetFetcher, self).__init__(dataset, auto_collation, collate_fn, drop_last)def fetch(self, possibly_batched_index):if self.auto_collation: # 注意到, 这里通过self.dataset 该属性,获取了该下标所对应的数据;data = [self.dataset[idx] for idx in possibly_batched_index]else:data = self.dataset[possibly_batched_index]return self.collate_fn(data)注意上面的
fetch()该方法通过self.dataset属性, 找到当前下标所对应的数据,通过
index获取data,发生如下的调用关系事件: —> fetch(index) –>
data = self.dataset[index]—> 此时,会返回到
Dataset().__getitem__(),而该
__getitem()方法,通常是由在子类中实现,这里是RespDataset(Dataset),至此, 通过当前下标索引
index, 获取data, 注意的这里的data, 指的是在数据集上,所对应的音频数据以及标签;这里需要通过数据预处理部分,
process.py来确认,到底特征级别还是音频级别注意,这里获取的音频文件, 如果是自定义的方式,生成的
self.input_dir, 这里的音频可能便是特征级别的数据;比如输入的
input_dir= processed_ast_wav2vec, 则是自定义的音频数据,则代表的是特征,这里此时wav= (768, 128),
class RespDataset(Dataset):def __init__():读入当前任务task 所对应的 .csv 文件,csv 文件,包含了音频以及对应的标签信息;读入音频文件, 根据传入的音频文件夹的位置;def __len__():返回csv 文件的长度,即当前任务上音频的总个数, 包括训练集和验证集;def __getitem__(self, index): # 这里获取的是音频, 和对应的label;entry = self.csv.iloc[index]wav_name = entry['wav_name']target = (entry[f'label_{self.task}1'], entry[f'label_{self.task}2'])if self.input_dir is None:wav, _ = torchaudio.load(join(self.dir, wav_name))else:wav = torch.load(join(self.dir, wav_name), map_location='cpu')# # normalize# wav = (wav-37.3)/(2.3*2)return wav, target2.3 在执行完, data = self.dataset(index) –>self.dataset.__getitem(index) 后,
则继续执行类 _MapDatasetFetcher(_BaseDatasetFetcher) 中的最后一个方法, return self.collate_fn(data);
7.3 collate_fn()的传递过程
2.4 而collate_fn() 该函数经历怎样的传递过程呢? 首先该方法在 RespDataLoader(BaseDataLoader).collate_fn() 中定义的,
在DataLoader 中调用 __iter()后, 继续调用自身类中的私有函数_get_iterator() 函数,该函数中继续调用到_SingleProcessDataLoaderIter()
之后collate_fn(),便在以下的各个类中进行传递 :
_SingleProcessDataLoaderIter() —> _DatasetKind —> _MapDatasetFetcher;
终于,来到了最初在 RespDataLoader().collate_fn() 中设置的方法, 该方法的作用,是将获取的数据和标签打包成一个 batch 的数据,
然后进行返回, 返回的过程便是一个弹栈的过程:
先返回到 –> _SingleProcessDataLoaderIter()._next_data() 中 data= self._dataset_fetcher.fetch(index) ;
–> _BaseDataLoaderIter.__next__() 该魔法函数中的的 data = self._next_data()
—> 回到训练过程中的 for batch_idx, (data, target) in enumerate(self.data_loader):
至此,训练过程中, 训练集数据的提取过程分析完毕;
class RespDataLoader(BaseDataLoader):def __init__(self, data_dir, batch_size, shuffle=True, validation_split=0.0, num_workers=1, training=True, task=1, level=1, input_dir='processed'):self.CLASSES = resp_classes(task, level)self.CLASS2INT = {label:i for (i, label) in enumerate(self.CLASSES)}self.LEVEL = level# note, dataset 获取训练集和 测试集;dataset = Datasets.RespDataset(data_dir, task=task, input_dir=input_dir)super().__init__(dataset, batch_size, shuffle, validation_split, num_workers, collate_fn=self.collate_fn)# 这里根据预处理,获取用于输入的 训练样本 和 标签;def collate_fn(self, batch):tensors, targets = [], []# Gather in lists, and encode labels as indicesfor wave, label in batch:label = label[self.LEVEL-1] # 根据级别,获取当前的label 标签;tensors += [wave]targets += [torch.LongTensor([self.CLASS2INT[label]])]# Group the list of tensors into a batched tensortensors = torch.stack(tensors)targets = torch.stack(targets)targets.squeeze_(1)return tensors, targets训练过程中, 每次从训练集(
self.data_loader)或者验证集(self.valid_data_loader)中取出一个batch 的数据时,会执行
RespDataLoader().collate_fn()函数, 用于返回一个batch 的数据。
8. DataLoader与_BaseDataLoaderIter()
当创建一个 DataLoader() 实例化对象的时候, 实际是在通过 _BaseDataLoaderIter 来迭代数据集,
这样的设计方式,是为了将数据集 和 迭代数据的过程进行分离,
DataLoader(): 用于管理 dataset, 兵准备好 迭代数据之前所需要的设置;
_BaseDataLoaderIter: 则是执行,实际的迭代过程, 包括了从线程中获取数据;
这种将 数据集本身 与迭代数据过程的方法 进行分离的方式,
可以通过继承类_BaseDataLoaderIter方式, 自定义一个子类,在该子类中重写 数据迭代的方式,从而更多的控制数据迭代的过程。
8.1 DataLoader
当在 DataLoader() 调用其中的魔法函数 __iter() 时, 该魔法函数返回的实际上是一个一个_BaseDataLoaderIter,
# We quote '_BaseDataLoaderIter' since it isn't defined yet and the definition can't be moved up# since '_BaseDataLoaderIter' references 'DataLoader'.def __iter__(self) -> '_BaseDataLoaderIter':# When using a single worker the returned iterator should be# created everytime to avoid reseting its state# However, in the case of a multiple workers iterator# the iterator is only created once in the lifetime of the# DataLoader object so that workers can be reusedif self.persistent_workers and self.num_workers > 0:if self._iterator is None:self._iterator = self._get_iterator()else:self._iterator._reset(self)return self._iteratorelse:return self._get_iterator()
__iter() 继续调用自身类中的私有函数 _get_iterator() 函数, 可以看到,此时根据是否启用多线程,
将会返回不同的线程迭代数据集的方式, num_worker==0, 则使用(单进程)主进程完成数据的迭代,
而无论是 单进程_SingleProcessDataLoaderIter(_BaseDataLoaderIter) 还是多进程,他们都是继承的同一个父类_BaseDataLoaderIter,
def _get_iterator(self) -> '_BaseDataLoaderIter':if self.num_workers == 0:return _SingleProcessDataLoaderIter(self)else:self.check_worker_number_rationality()return _MultiProcessingDataLoaderIter(self)8.2 _BaseDataLoaderIter
可以看到,这两个类都是继承自_BaseDataLoaderIter,
_SingleProcessDataLoaderIter(_BaseDataLoaderIter)
_MultiProcessingDataLoaderIter(_BaseDataLoaderIter)
8.3 _SingleProcessDataLoaderIter()
# location: torch.utils.data.dataloader.pyclass _SingleProcessDataLoaderIter(_BaseDataLoaderIter):def __init__(self, loader):super(_SingleProcessDataLoaderIter, self).__init__(loader)assert self._timeout == 0assert self._num_workers == 0self._dataset_fetcher = _DatasetKind.create_fetcher(self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last)def _next_data(self):index = self._next_index() # may raise StopIterationdata = self._dataset_fetcher.fetch(index) # may raise StopIterationif self._pin_memory:data = _utils.pin_memory.pin_memory(data)return data可以看到,在执行 data = self._dataset_fetcher.fetch(index) 过程中,调用了私有类_DatasetKind中的 create_fetcher方法;
# location: torch.utils.data.dataloader.py
class _DatasetKind(object):Map = 0Iterable = 1@staticmethoddef create_fetcher(kind, dataset, auto_collation, collate_fn, drop_last):if kind == _DatasetKind.Map:return _utils.fetch._MapDatasetFetcher(dataset, auto_collation, collate_fn, drop_last)else:return _utils.fetch._IterableDatasetFetcher(dataset, auto_collation, collate_fn, drop_last)create_fetcher方法中,则继续调用私有类, _MapDatasetFetcher()
#location: torch.utils.data._utils.fetch.pyclass _MapDatasetFetcher(_BaseDatasetFetcher):def __init__(self, dataset, auto_collation, collate_fn, drop_last):super(_MapDatasetFetcher, self).__init__(dataset, auto_collation, collate_fn, drop_last)def fetch(self, possibly_batched_index):if self.auto_collation:data = [self.dataset[idx] for idx in possibly_batched_index]else:data = self.dataset[possibly_batched_index]return self.collate_fn(data)可以,看到从_SingleProcessDataLoaderIter() 开始,
collate_fn 该方法就一直被传递过来,中间在以下的各个类中进行传递如下过程 :
_SingleProcessDataLoaderIter() —> _DatasetKind —> _MapDatasetFetcher;
9. 数据预处理
数据预处理,其实是整个项目的最开始,由于篇幅会较多,故放在这里分析;
task1, 事件级别的分类, event level :
训练集: 6656份音频事件
测试集: 对应了2433份音频事件;
task2,录音级别的分类, record level,
训练集: 包含1949录音, (注意, 后续通过筛选 task2, 减少为1772 份录音;)
测试集: 734份录音,
需要注意的是, 在不同的预处理函数中, 对于不同音频长度的音频, 并没有统一到相同的音频长度;
都是经过相同的函数,然后通过reshape的方式, 使得所有的特征形状相同。
preprocess.py 数据预处理, 用于将 clip 事件级别的6656份音频事件, 与 wav 录音级别的包含1949录音,
即 事件级别的6656份音频事件 + 录音级别的包含1949录音 = 8605 份音频;
都是是将将训练集上 事件级别音频+ 录音级别音频;
经过预处理函数之后(调用不同的 9.1-9.5 预处理函数),存放在同一个文件夹下面 preprocessed_file。
之后,在task_config.json 中的配置 data_loader时候, 选项中的 input_dir是便是上述生成的preprocessed_file文件。
if __name__ == '__main__':REC_DIR = "wav"CLIP_DIR = "clip"# PROC_DIR = "processed_wav2vec"PROC_DIR = "processed_ast"if not exists(PROC_DIR):makedirs(PROC_DIR)for dir in (REC_DIR, CLIP_DIR):print(f" \n Processing waves in {dir}/ folder")for wav_name in tqdm(listdir(dir)):wav, fr = load(join(dir, wav_name))# 如果,输入到预处理函数中,不需要经过AST model, 则需要将下行注释,用于将tensor 转化成 numpy;wav = wav.squeeze().cpu().detach().numpy()processed = preprocess(wav,fr)torch.save(processed, join(PROC_DIR, wav_name))tips:
-
如果使用task2-1作为示例时, 运行process.py的过程中需要确认 process调用的是函数
preprocess_ast_wav2vec(wav, fr)根据上述不同的任务, preprocess() 函数将调用 不同的预处理函数,
processed_wav2vec()orprocessed_ast_wav2vec(), 或者是下面五中不同的预处理函数中的其中一个;
9.1 preprocess_stft
for task 1-1:
processed_ast_wav2vec 预处理函数,
提取出的特征向量表示维度为 (1, 224, 224),
经过 collate_fn 之后, 输出(bt, 1, 224, 224),
输入到 light cnn 中;
9.2 preprocess_wavelet
processed_ast_wav2vec 预处理函数,
提取出的特征向量表示维度为 (3, 224, 224),
经过 collate_fn 之后, 输出(bt, 3, 224, 224),
9.3 preprocess_ast
processed_ast预处理函数,
提取出的特征向量表示维度为(256, 128) , 通过reshape 将帧数统一到相同长度. 128 代表n_filters 的个数;
经过 collate_fn 之后, 输出(bt, 256, 128),
9.4 processed_ast_wav2vec
wav2vec2,是一个在960小时音频上面训练好的,语音编码表示向量;试验中,使用AST Model 的预训练权重,
输入音频后,提取AST网络模型中最后一层的输出,来代表这一份音频的编码向量;
processed_ast_wav2vec 预处理函数,
提取出的特征向量表示维度为( 768, 128)
经过 collate_fn()之后, 输出( BT , 768, 128);
之后,输入到 AST Model 中;
9.5 processed_wav2vec
for task 1-1:
当使用:processed_wav2vec 预处理函数,
提取出的特征向量表示维度为 (1, 224, 224),
此时 ,原始的 Dataset() .getitem() 取出的便是该项。
经过 collate_fn 之后, 输出(bt, 1, 224, 224),
输入到 light cnn 中;
注意在config_task 中, 需要根据 arch` 中的配置参数,比如其中的
arch: 参数
"arch": {"type": "ASTModel", # 规定了网络模型架构;"args": {"label_dim":3, # 输出的几分类;"input_fdim":128, # 规定了网络模型 输入的尺寸;"input_tdim":768,"audioset_pretrain": true}},"data_loader": {"type": "RespDataLoader", # 规定了数据加载器;"args":{"data_dir": "data/SPRSound/","batch_size": 16,"shuffle": true,"validation_split": 0.2,"num_workers": 2,"task":2,"level":1,"input_dir":"processed_ast_wav2vec"}},
相关文章:
项目解读_v2
1. 项目介绍 如果使用task2-1作为示例时, 运行process.py的过程中需要确认 process调用的是函数 preprocess_ast_wav2vec(wav, fr) 1.1 任务简介 首个开源的儿科呼吸音数据集, 通过邀请11位医师标注; 数字听诊器的采样频率和量化分辨率分…...
杀毒软件哪个好,杀毒软件有哪些
安全杀毒软件是一种专门用于检测、防止和清除计算机病毒、恶意软件和其他安全威胁的软件。这类软件通常具备以下功能: 1. 实时监测:通过实时监测计算机系统,能够发现并防止病毒、恶意软件等安全威胁的入侵。 2. 扫描和清除:可以…...

Ubuntu上安装配置Nginx
要在 Ubuntu 上安装 Nginx,请按照以下步骤进行操作: 打开终端:可以使用快捷键 Ctrl Alt T 打开终端,或者在开始菜单中搜索 “Terminal” 并点击打开。 更新软件包列表:在终端中运行以下命令,以确保软件包…...
C++之string
C之string #include <iostream>using namespace std;/*string();//创建一个空的字符串string(const char* s);//使用字符串s初始化string(const string& str);//使用一个string对象初始化另外一个string对象string(int n,char c);//使用n个字符c初始化*/void test1()…...

多线程---单例模式
文章目录 什么是单例模式?饿汉模式懒汉模式版本一:最简单的懒汉模式版本二:考虑懒汉模式存在的线程安全问题版本三:更完善的解决线程安全问题版本四:解决指令重排序问题 什么是单例模式? 单例模式…...

SpringBoot相比于Spring的优点(自动配置和依赖管理)
自动配置 例子见真章 我们先看一下我们Spring整合Druid的过程,以及我们使用SpringBoot整合Druid的过程我们就知道我们SpringBoot的好处了。 Spring方式 Spring方式分为两种,第一种就是我们使用xml进行整合,第二种就是使用我们注解进行简化…...

SAP SPAD新建打印纸张
SAP SPAD新建打印纸张 1.事务代码SPAD 2.完全管理-设备类型-页格式-显示(创建格式页) 3.按标准A4纸张为模板参考创建。同一个纸张纵向/横向各创建1次(创建格式页) 4.完全管理-设备类型-格式类型-显示(创建格式类型࿰…...

C# 图解教程 第5版 —— 第11章 结构
文章目录 11.1 什么是结构11.2 结构是值类型11.3 对结构赋值11.4 构造函数和析构函数11.4.1 实例构造函数11.4.2 静态构造函数11.4.3 构造函数和析构函数小结 11.5 属性和字段初始化语句11.6 结构是密封的11.7 装箱和拆箱(*)11.8 结构作为返回值和参数11…...
车载电子电器架构 —— 基于AP定义车载HPC
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...
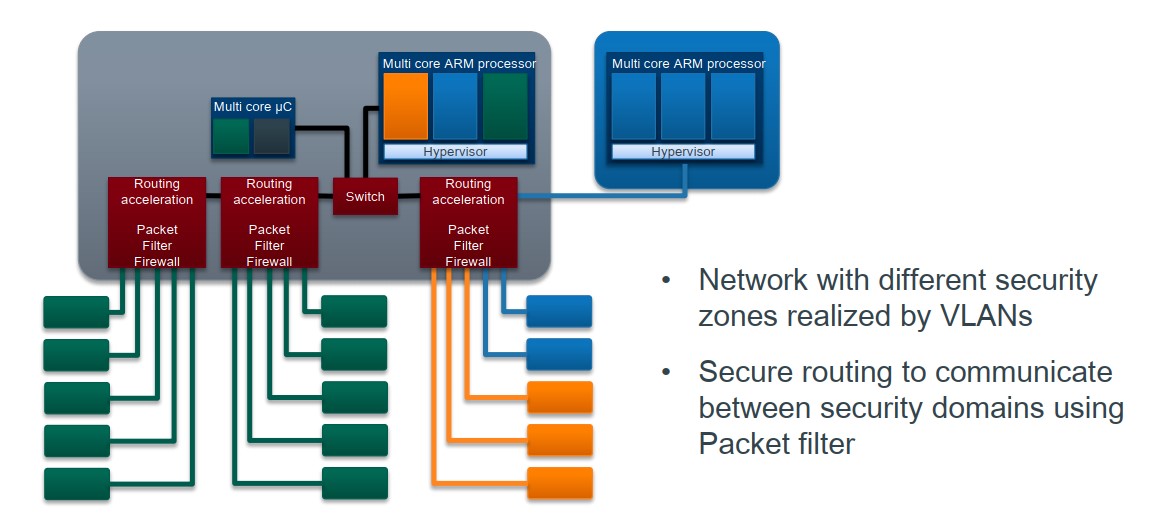
Redis原理-IO模型和持久化
高性能IO模型 为什么单线程Redis能那么快 一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。另一方面,就是 Redis 采用了多路复用机制&#…...

PID控制示例
PID控制简单示例 import numpy as np import matplotlib.pyplot as plt import copy# 定义曲线函数 y sin(x) def target_curve(x):return np.sin(x)class PID:def __init__(self, kp, ki, kd):self.kp kpself.ki kiself.kd kdself.ep 0.0self.ei 0.0self.ed 0.0self.d…...

GoLand GC(垃圾回收机制)简介及调优
GC(Garbage Collector)垃圾回收机制及调优 简单理解GC机制 其实gc机制特别容易理解,就是物理内存的自动清理工。我们可以把内存想象成一个房间,程序运行时会在这个房间里存放各种东西,但有时候我们会忘记把不再需要的东西拿出去,…...

AI:40-基于深度学习的森林火灾识别
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌本专栏包含以下学习方向: 机器学习、深度学…...

37基于MATLAB平台的图像去噪,锐化,边缘检测,程序已调试通过,可直接运行。
基于MATLAB平台的图像去噪,锐化,边缘检测,程序已调试通过,可直接运行。 37matlab边缘检测图像处理 (xiaohongshu.com)...

通过Metasploit+Ngrok穿透内网长期维持访问外网Android设备
前言: 因为之前作为小白我不会在Kali Linux里面把IP映射出外网,卡在那个地方很久,后来解决了这个问题就写方法出来和大家分享分享。 环境: Kali Linux系统(https://www.kali.org/downloads/) Metasploit Ngrok Linux64位的端口转发工具(htt…...

STM32 CubeMX配置USB HID功能,及安装路径
STM32CubeMX学习笔记(46)——USB接口使用(HID自定义设备) STM32CubeMX实现STM32 USBHID双向64字节通信(下位机部分) STM32 USB HID设置(STM32CubeMX) 关于keil 5安装出现Fail to set path to Software Packs.问题解决方法...
【错误解决方案】ModuleNotFoundError: No module named ‘transformers‘
1. 错误提示 在python程序中,尝试导入一个名为transformers的模块,但Python提示找不到这个模块。 错误提示:ModuleNotFoundError: No module named ‘transformers‘ 2. 解决方案 所遇到的问题是Python无法找到名为transformers的模块&am…...

Mac 配置环境变量
Mac 配置环境变量 修改配置文件 vim ~/.bash_profile i进入编辑模式. Esc:wq 保存文件 esc:q 退出 如:jdk环境变量配置 JAVA_HOME/Library/Java/JavaVirtualMachines/jdk1.8.0_361.jdk/Contents/Home CLASSPATH J A V A H O M E / l i b / t o o l…...
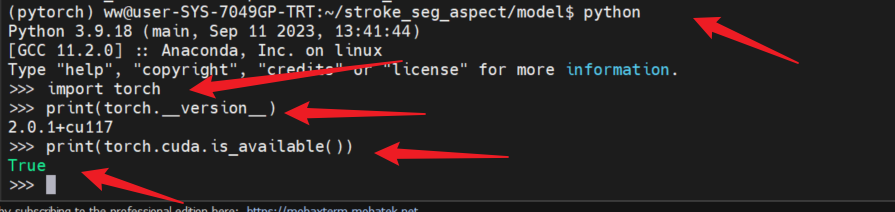
如何在linux服务器上安装Anaconda与pytorch,以及pytorch卸载
如何在linux服务器上安装Anaconda与pytorch,以及pytorch卸载 1,安装anaconda1.1 下载anaconda安装包1.2 安装anaconda1.3 设计环境变量1.4 安装完成验证 2 Anaconda安装pytorch2.1 创建虚拟环境2.2 查看现存环境2.3 激活环境2.4 选择合适的pytorch版本下…...
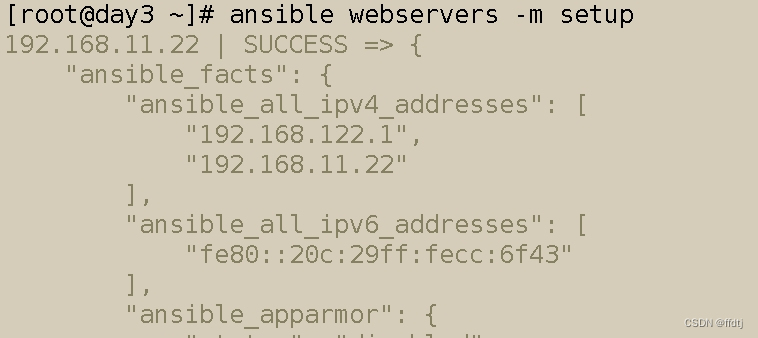
ansble
ansble概述 Ansible是一款自动化运维工具,基于Python开发,具有批量系统配置,批量程序部署, 批量运行命令等功能。 Ansible的很多模块在执行时都会先判断目标节点是否要执行任务,所以,可以放心大胆地让Ansible去执行任务…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...