Linux ———— 管理磁盘
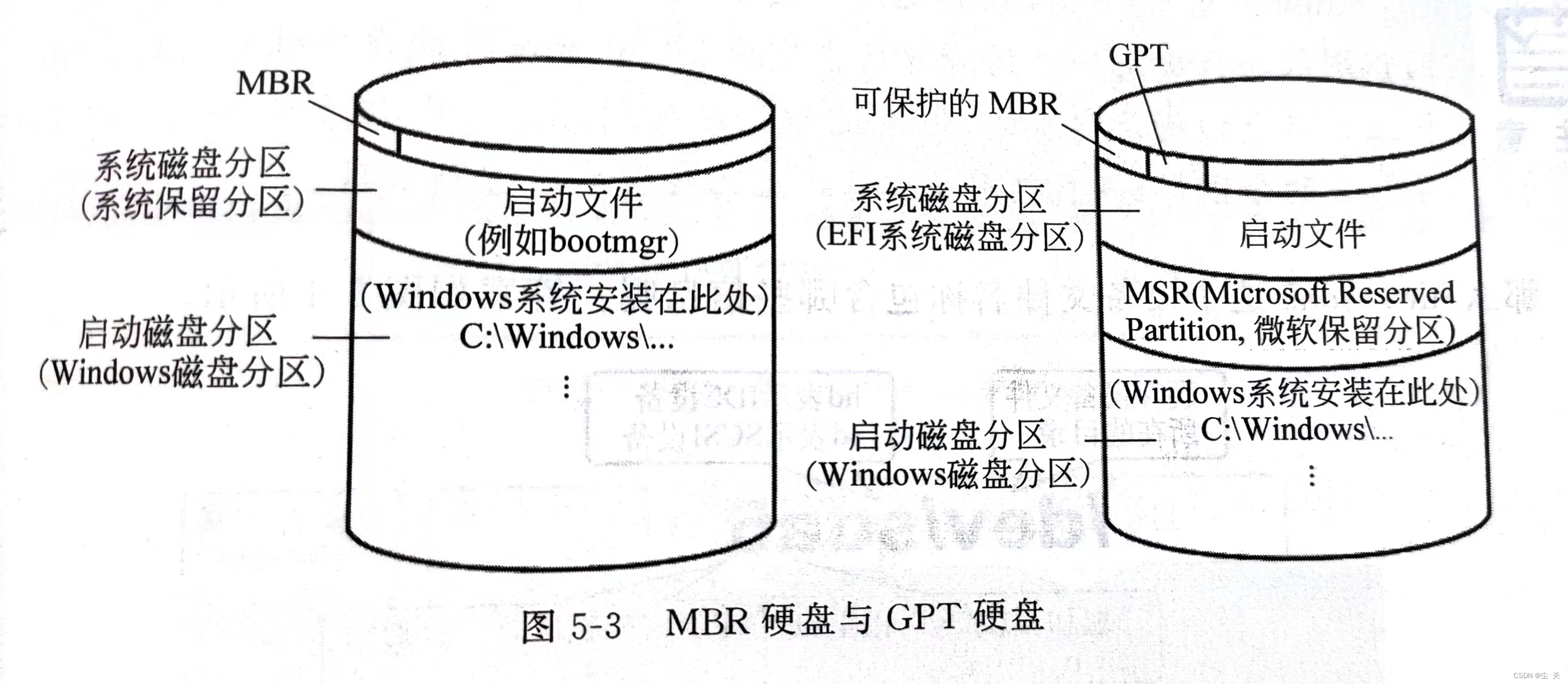
(一)MBR硬盘与GPT硬盘
硬盘按分区表的格式可以分为MBR硬盘与GPT硬盘两种硬盘格式。
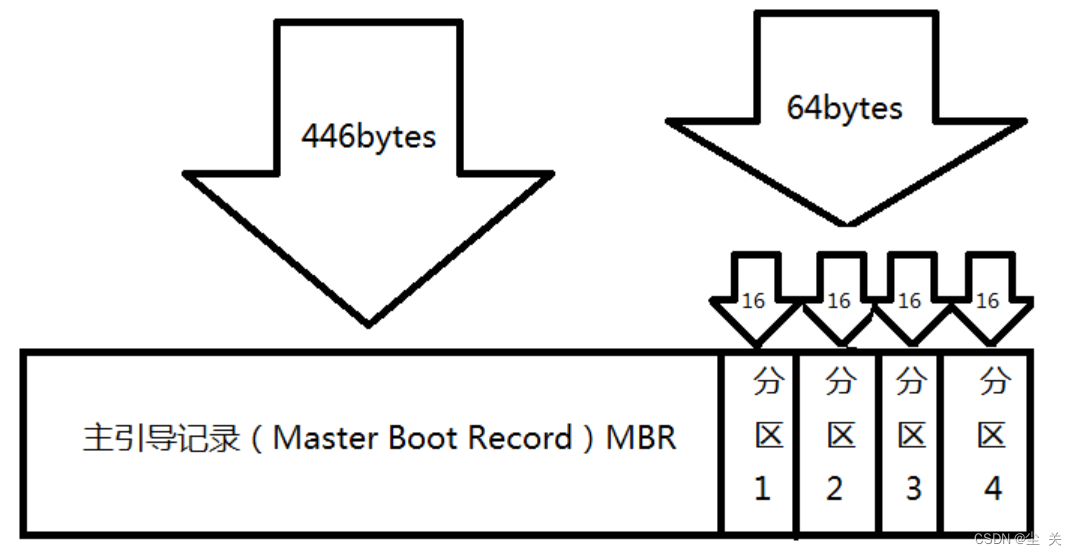
MBR 硬盘:使用的是旧的传统硬盘分区表格式,其硬盘分区表存储在MBR(Master Boot Record,主引导区记录)内。MBR位于硬盘最前端,计算机启动时,使用传统BIOS(基本输入输出系统,是固化在计算机主板上一个ROM芯片上的程序)的计算机,其BIOS会先读取MBR,并将控制权交给MBR内的程序代码,然后由此程序代码来继续后续的启动工作。MBR硬盘所支持的硬盘最大容量为2.2TB(1TB=1024GB)。
GPT硬盘:一种新的硬盘分区表格式,其硬盘分区表存储在GPT(GUID Partition Table)内,位于硬盘的前端,而且它有主分区表与备份分区表,可提供容错功能。使用新式 UEFI BIOS的计算机,其BIOS会先读取GPT,并将控制权交给GPT内的程序代码,然后由此程序代码来继续后续的启动工作。GPT硬盘所支持的硬盘最大容量可以超过2.2TB(1TB=1024GB)。
B站有个视频讲解了该内容十分详尽:【装机教程】超详细WIN10系统安装教程,官方ISO直装与PE两种方法教程,UEFI+GUID分区与Legacy+MBR分区_哔哩哔哩_bilibili
若是想了解MBR与GPT硬盘之间的区别可以查看:
MBR 与 GPT,哪种磁盘分区表更适合SSD固态硬盘 - 系统极客 (sysgeek.cn)
(二)物理设备的命名规则
Linux系统中的一切都是文件(万物皆文件),硬件设备也不例外。既然是文件,就必须有文件名称。系统内核中的udev设备管理器会自动把硬件名称规范起来,目的是让用户通过设备文件的名字可以猜出设备大致的属性以及分区信息等。这对于陌生的设备来说特别方便。另外,udev设备管理器的服务会一直以守护进程的形式运行并侦听内核发出的信号来管理/dev目录下的设备文件。Linux系统中常见的硬件设备的文件名称如表5-3所示。
表5-3
| 硬件设备 | 文件名称 |
| IDE设备 | /dev/hd[a-d] |
| SCSI/SATA/U盘 | /dev/sd[a-p] |
| 非易失性存储器标准(Non-Volatile Memory Express,NVMe)硬盘 | /dev/nvme0n[1-m],比如/dev/nvme0n1 就是第一个NVMe硬盘 |
| 软驱 | /dev/fd[0-1] |
| 打印机 | /dev/lp[0-15] |
| 光驱 | /dev/cdrom |
| 鼠标 | /dev/mouse |
| 磁带机 | /dev/st0或/dev/ht0 |
由于现在的IDE(Integrated Drive Electronics,电子集成驱动器)设备已经很少见了,所以一般的硬盘设备都会是以“/dev/sd”开头的。而一台主机上可以有多块硬盘,因此系统采用a~p来代表16块不同的硬盘(默认从a开始分配),而且硬盘的分区编号也有如下规定。
主分区或扩展分区的编号从1开始,到4结束。
逻辑分区从编号5开始。
注意:
学习LINUX系统中硬件设备的几个误区
误区1:设备名称理解错误
例如:/dev/sda表示主板上第一个插槽上的存储设备
真相: /dev目录中sda设备之所以是a,并不是由插槽决定的,而是由系统内核的识别顺序来决定的,而恰巧很多主板的插槽顺序就是系统内核的识别顺序,因此才会被命名为/dev/sda。大家以后在使用 iSCSI 网络存储设备时就会发现,明明主板上第二个插槽是空着的,但系统却能识别到/dev/sdb这个设备就是这个道理。
误区2:对分区名称的理解错误
例子 : 分区的编号代表分区的个数
真相 : 因为分区的数字编码不一定是强制顺延下来的,也有可能是手工指定的。因此sda3只能表示是编号为3的分区,而不能判断sda设备上已经存在了3个分区。
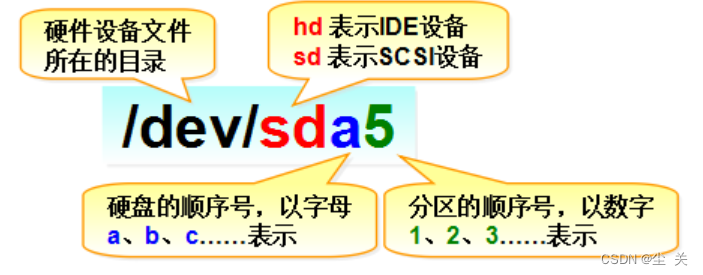
/dev/目录中保存的应当是硬件设备文件;sd表示是存储设备,a表示系统中同类接口中第一个被识别到的设备,5表示这个设备是一个逻辑分区。基于上述,“/dev/sda5”表示的就是“这是系统中第一块被识别到的硬件设备中分区编号为5的逻辑分区的设备文件”。
(三)硬盘分区
磁盘分区高质量博文:
Linux基础篇——Linux磁盘操作(磁盘基础知识、分类、分区、挂载、卸载、扩容)详解_linux中封盘是什么意思-CSDN博客
硬盘的使用规划

(四)使用硬盘管理工具fdisk
fdisk硬盘分区工具在DOS、Windows和Linux中都有相应的应用程序。在Linux系统中,fdisk是基于菜单的命令。对硬盘进行分区时,可以在fdish命令后直接加上要分区的硬盘作为参数。
fdiah命令的常见选项如下:
-
-a:调整硬盘启动分区。
-
- d:删除硬盘分区。
-
-l:列出所有支持的分区类型。
-
-m:列出所有命令。
-
-n:创建新分区。
-
-p:列出硬盘分区表。
-
-q:不保存更改,退出fdishk
-
-t:更改分区类型
-
-u:切换所显示的分区大小的单位
-
-w:把修改写入硬盘分区表,然后退出
-
-x:列出高级选项
创建主分区:
创建逻辑分区:
使用mkfs命令建立文件系统:
硬盘分区后,下一步的工作就是建立文件系统。类似于Windows下的格式化硬盘。在硬盘分区上建立文件系统会冲掉分区上的数据,而且不可恢复,因此在建立文件系统之前要确认分区上的数据不再使用。建立文件系统的命令是mkfs。
格式如下:mkfs [参数]文件系统
mkfs命令常用的参数选项如下:
-
-t:指定要创建的文件系统类型。
-
-c:建立文件系统前首先检查坏块。
-
-1file:从文件file中读硬盘坏块列表,file 文件一般是由硬盘坏块检查程序产生的。
-
-V:输出建立文件系统详细信息。
例如,在/dev/sdb1上建立xfs类型的文件系统,建立时检查硬盘坏块并显示详细信息。
使用fsck命令检查文件系统:
fsck命令主要用于检查文件系统的正确性,并对Linux硬盘进行修复。fsck命令的格
式如下:fsck 〔参数选项]文件系统
fsck 命令常用的参数选项如下:
-
-t:给定文件系统类型,若在/etc/fstab中已有定义或内核本身已支持,不需器加此项。
-
-s:一个一个地执行fsck命令进行检查。
-
-A:对/etc/fstab中所有列出来的分区进行检查。
-
-C:显示完整的检查进度。
-
-d:列出 fsck的debug结果。
-
-P:在同时有-A选项时,多个fsck的检查一起执行。
-
-a:如果枪查中发现错误,则自动修复
-
-r:如果检查有错误,询问是否修复。
删除分区
如果要删除硬盘分区,在fdisk菜单下输入d,并选择相应的硬盘分区即可。删除后输入w,保存退出。以/删除/dev/sdb3分区为例,操作如下。
(五)使用其他硬盘管理工具
dd命令:
建立和使用交换文件,当系统的交换区不能满足系统的要求而硬盘上有没有可用的空间时,可使用交换文件提供虚拟内存。
(1)在硬盘的根目录下建立一块大小为1024字节,块数为10240的名为swap的交换文件,该文件大小为1024*1240=10MB,命令如下:
# dd if=/dev/zero of=/swap bs=1024 count=10240
(2)建立/swap交换文件后,使用mkswap命令说明该文件用于交换空间
# mkswap /swap
(3)利用swapon命令可以激活交换空间,swapoff命令卸载被激活的交换空间
df命令:
df命令用来查看文件系统的硬盘空间占用情况,还可以利用该命令来获取硬盘被占用多少空间,以及目前还有多少空间等信息,获得文件系统的挂载位置。
df 命令的语法如下:df(参数选项]
df命令的常见参数选项如下:
-
-a:显示所有文件系统硬盘使用情况,包括0块的文件系统,如/proc文件系统。
-
- k:以k字节为单位显示。
-
-i:显示i节点信息。
-
-t:显示各指定类型的文件系统的硬盘空间使用情况。
-
-x:列出不是某一指定类型文件系统的硬盘空间使用情况(与t选项相反)。
-
-T:显示文件系统类型。
具体实例:
du命令:
du命令用于显示硬盘空间的使用情况。该命令逐级显示指定目录的每一级子目录占
用文件系统数据块的情况。
du命令的语法如下:du[参数选项][文件或目录名称]
du命令的参数选项如下:
-
-s:对每个name参数只给出占用的数据块总数。
-
-a:递归显示指定目录中各文件及子目录中各文件占用的数据块数
-
-b:以字节为单位列出硬盘空间使用情况(AS4.0中默认以KB为单位 )
-
-k:以1024字节为单位列出硬盘空间使用情况。
-
-c:在统计后加上一个总计(系统默认设置)
-
-l:计算所有文件大小,对硬链接文件重复计算
-
-x:跳过在不同文件系统上的目录,不予统计
例如,以字节为单位列出所有文件和目录的硬盘空间占用情况的命令如下所示;
root@ Server01 ~]du -ab
mount与umount命令
1) mount命令
在硬盘上建立好文件系统之后,还需要把新建立的文件系统挂载到系统上才能使用。这个过程称为挂载。文件系统所挂载到的目录被称为挂载点(mount point)。Linux系统中提供了/mnt和/media两个专门的挂载点。一般而言,挂载点应该是一个空目录,否则目录中原来的文件将被系统隐藏。通常将光盘和软盘挂载到/media/cdrom(或者/mnt/cdrom)和/media/floppy(或者/mnt/ floppy)中,其对应的设备文件名分别为/dev/cdrom和dev/fd0。
文件系统可以在系统引导过程中自动挂载,也可以手动挂载,手动挂载文件系统的挂载命令是mount。
该命令的语法格式如下:mount 选项 设备挂载点
mount 命令的主要选项如下:
-
-t:指定要挂载的文件系统的类型。
-
-r:如果不想修改要挂载的文件系统,可以使用该选项以只读方式挂载。
-
-a:挂载/etc/fstab文件中记录的设备。
2)umount 命令
文件系统可以被挂载也可以被卸载。卸载文件系统的命令是umount。
umountf格式为:umount 设备|挂载点
例如,卸载光盘的命令为:
[root@server0l ~] umount /media
[root@ Server0i ~]#umount /dev/cdrom
光盘在没有卸载之前,无法从驱动器中弹出。正在使用的文件系统不能卸载。
文件系统的自动挂载
在Linux中,当我们想要在每次开机时自动挂载某个文件系统,我们通常会编辑/etc/fstab文件。这个文件列出了哪些文件系统在启动时应该被挂载,以及如何挂载它们。
你可能注意到了,系统里的很多分区都是通过UUID来挂载的。那么,什么是UUID,为什么我们要使用它来挂载设备呢?
简单来说,UUID是一串独特的字符序列,它为系统中的每个设备提供了一个唯一的标签。这意味着无论你如何插拔或移动这些设备,它们的UUID都不会变。
想象一下,如果我们依赖设备名称(比如sda, sdb等)来挂载,那么设备的插拔或系统的变化可能导致这些名称变化,进而导致挂载失败。但是,如果我们使用UUID,就不用担心这些问题了。无论怎样,UUID都保持不变,为我们提供了一个稳定的挂载点。好奇你的设备的UUID是什么?只需在Linux终端中使用blkid命令就可以查看啦!
相关文章:
Linux ———— 管理磁盘
(一)MBR硬盘与GPT硬盘 硬盘按分区表的格式可以分为MBR硬盘与GPT硬盘两种硬盘格式。 MBR 硬盘:使用的是旧的传统硬盘分区表格式,其硬盘分区表存储在MBR(Master Boot Record,主引导区记录)内。MBR位于…...

文字的编码
1 字符的编码方式 1.1 ASCII 是“American Standard Code for Information Interchange”的缩写,美国信息交换标准代码。电脑毕竟是西方人发明的,他们常用字母就 26 个,区分大小写、加上标点符号也没超过 127 个,每个字符用一个字…...
21.9 Python 使用Selenium库
Selenium是一个自动化测试框架,主要用于Web应用程序的自动化测试。它可以模拟用户在浏览器中的操作,如打开网页、点击链接、填写表单等,并且可以在代码中实现条件判断、异常处理等功能。Selenium最初是用于测试Web应用程序的,但也…...
C++初阶2
目录 一,auto关键字 1-1,auto的使用 1-2,基于范围auto的for循环 二,nullptr的运用 三,C类的初步学习 3-1,类的引用 3-2,类的访问权限 3-3,类的使用 1,类中函数的…...

网络安全(黑客)—小白自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...

在win10下,使用torchviz对深度学习网络模型进行可视化
目录 1. 安装 graphviz 和 torchviz 2.安装 graphviz.exe 3.实例测试 4.如果你的电脑还是无法画图,并且出现了下面的报错: 5.参考文章: 1. 安装 graphviz 和 torchviz 首先打开 Anaconda prompt 进入自己的 pytorch 环境(图中 pt 是我自…...

【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
相关博客 【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer 【自然语言处理】【大模型】MPT模型结构源码解析(单机版) 【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版) 【自然语言处理】【大模型】BLOOM模型结构源码解析(…...
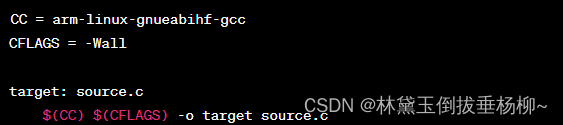
交叉编译工具链(以STM32MP1为例)
1.什么是交叉编译工具链? 在一个系统上进行编译,在另一个系统上进行执行 2.STM32MP1交叉编译工具链 3.交叉编译器内容 4.两种工具链模式 5.两种链接模式 6.工具使用 注意:OpenSTLinux已经提供了编译框架,不需要命令行手工编译 …...
使用 Pyro 和 PyTorch 的贝叶斯神经网络
一、说明 构建图像分类器已成为新的“hello world”。还记得当你第一次接触 Python 时,你的打印“hello world”感觉很神奇吗?几个月前,当我按照PyTorch 官方教程并为自己构建了一个运行良好的简单分类器时,我也有同样的感觉。 我…...

How to install the console system of i-search rpa on Centos 7
How to install the console system of i-search rpa on Centos 7 1、 准备1.1 、查看磁盘分区状态1.2、上传文件1.2.1、添加上传目录1.2.2、上传安装包1.2.3、解压安装包1.2.4、查看安装包结构 1.3、安装依赖包1.3.1、基础依赖包1.3.2 相关依赖 1.4、关闭防火墙1.5、解除SeLin…...
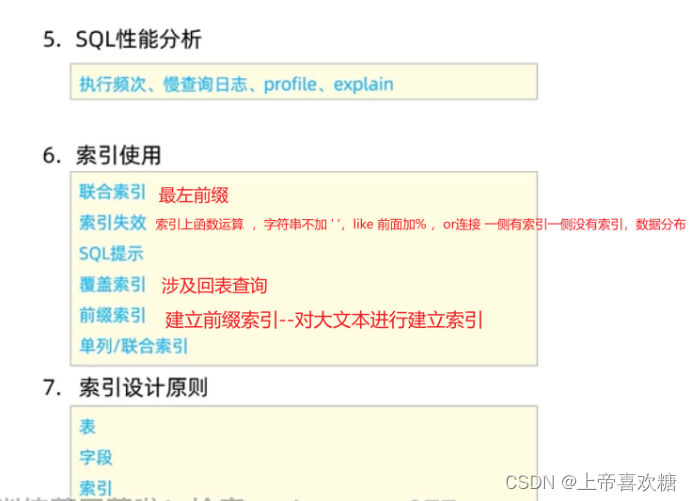
sql--索引使用 ---覆盖索引
覆盖索引 Select 后接 * 走id索引才是最优,使用二级索引则需要回表(性能稍差) 前缀索引 Create index 索引名 on 表名( 字段名( n ) ) n数字 n代表提取这个字符串的n个构建索引 ??那么 n 为几性能是最好的呢&…...

系统平台同一网络下不同设备及进程的话题通讯--DDS数据分发服务中间件
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 TODO:写完再整理 文章目录 系列文章目录前言(1)中间件的介绍(2)DDS介绍(3)发布者(4)订阅者(5)idl文件(定义msg结构体)(6)QoS(Quality of Service)策略(7)DDS测试工具介绍(…...

轻量级 IDE 文本编辑器 Geany 发布 2.0
Geany 是功能强大、稳定、轻量的开发者专用文本编辑器,支持 Linux、Windows 和 macOS,内置支持 50 多种编程语言。 2005 年Geany 发布首个版本 0.1。上周四刚好是 Geany 诞生 18 周年纪念日,官方发布了 2.0 正式版以表庆祝。 下载地址&#…...

好用工具分享 | tmux 终端会话分离工具
目录 1 tmux的安装 2 tmux的基本操作 2.1 启动与退出 2.2 分离会话 2.3 查看会话 2.4 重接会话 2.5 杀死会话 2.6 切换会话 tmux是一个 terminal multiplexer(终端复用器),它可以启动一系列终端会话。 我们使用命令行时,…...

计算机网络重点概念整理-第三章 数据链路层【期末复习|考研复习】
计算机网络复习系列文章传送门: 第一章 计算机网络概述 第二章 物理层 第三章 数据链路层 第四章 网络层 第五章 传输层 第六章 应用层 第七章 网络安全 计算机网络整理-简称&缩写 文章目录 前言三、数据链路层3.1 数据链路层的基础概念3.2 帧3.2.1 帧的概念3.2…...

迅速的更改conda 环境的名称!
快速的做法是,复制之前创建的环境 重新命名 然后再删除旧的环境即可!!! 因为之前已经装过环境了,只是名字不叫A而是B,所以现在把B(old_name)改成A(new_name)。 具体方法如下: 1. 复制出来一份…...

基本微信小程序的外卖点餐订餐平台
项目介绍 餐饮行业是一个传统的行业。根据当前发展现状,网络信息时代的全面普及,餐饮行业也在发生着变化,单就点餐这一方面,利用手机点单正在逐步进入人们的生活。传统的点餐方式,不仅会耗费大量的人力、时间…...
十大排序算法(C语言)
参考文献 https://zhuanlan.zhihu.com/p/449501682 https://blog.csdn.net/mwj327720862/article/details/80498455?ops_request_misc%257B%2522request%255Fid%2522%253A%2522169837129516800222848165%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&…...

iTransformer: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING
#论文题目:ITRANSFORMER: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING #论文地址:https://arxiv.org/abs/2310.06625 #论文源码开源地址:https://github.com/thuml/Time-Series-Library #论文所属会议:Mach…...

QT C++ AES字符串加密实现
使用方法:在.h中引入类库。然后在cpp中直接引入使用即可 类库的下载地址https://download.csdn.net/download/u012372365/88478671 具体代码: #include <QCoreApplication> #include <QTest> #ifdef __cplusplus #include "unit_tes…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...