OpenCV #以图搜图:感知哈希算法(Perceptual hash algorithm)的原理与实验
1. 介绍
感知哈希算法(Perceptual Hash Algorithm,简称pHash) 是哈希算法的一种,主要用来做相似图片的搜索工作。
2. 原理
感知哈希算法(pHash)首先将原图像缩小成一个固定大小的像素图像,然后将图像转换为灰度图像,通过使用离散余弦变换(DCT)来获取频域信息。然后,根据DCT系数的均值生成一组哈希值。最后,利用两组图像的哈希值的汉明距离来评估图像的相似度。
魔法: 概括地讲,感知哈希算法一共可细分八步:
- 缩小图像: 将目标图像缩小为一个固定的大小,通常为32x32像素。作用是去除各种图像尺寸和图像比例的差异,只保留结构、明暗等基本信息,目的是确保图像的一致性,降低计算的复杂度。
- 图像灰度化: 将缩小的图像转换为灰度图像。
- 离散余弦变换(DCT): 感知哈希算法的核心是应用离散余弦变换。DCT将图像从空间域(像素级别)转换为频域,得到32×32的DCT变换系数矩阵,以捕获图像的低频信息。
- 缩小DCT: 经过DCT变换后,图像的频率特征集中在图像的左上角,保留系数矩阵左上角的8×8系数子矩阵(因为虽然DCT的结果是32×32大小的矩阵,但左上角8×8的矩阵呈现了图片中的最低频率)。
- 计算灰度均值: 计算DCT变换后图像块的均值,以便后面确定每个块的明暗情况。
- 生成二进制哈希值: 如果块的DCT系数高于均值,表示为1,否则表示为0(由于我们只提取了DCT矩阵左上角的8×8系数子矩阵,所以,最后会得到一个64位的二进制值(8x8像素的灰度图像))。
- 生成哈希值: 由于64位二进制值太长,所以按每4个字符为1组,由2进制转成16进制。这样就转为一个长度为16的字符串。这个字符串也就是这个图像可识别的哈希值,也叫图像指纹,即这个图像所包含的特征。
- 哈希值比较: 通过比较两个图像的哈希值的汉明距离(Hamming Distance),就可以评估图像的相似度,距离越小表示图像越相似。
3. 实验
第一步:缩小图像
将目标图像缩小为一个固定的大小,通常为32x32像素。作用是去除各种图像尺寸和图像比例的差异,只保留结构、明暗等基本信息,目的是确保图像的一致性,降低计算的复杂度。
1)读取原图
# 测试图片路径
img_path = 'img_test/apple-01.jpg'# 通过OpenCV加载图像
img = cv2.imread(img_path)# 通道重排,从BGR转换为RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)

2)缩放原图
使用 OpenCV 的 resize 函数将图像缩放为32x32像素。
# 缩小图像:使用OpenCV的resize函数将图像缩放为32x32像素,采用Cubic插值方法进行图像重采样
img_32 = cv2.resize(img, (32, 32), cv2.INTER_CUBIC)

OpenCV 的 cv2.resize() 函数提供了4种插值方法,以根据图像的尺寸变化来进行图像重采样。
- cv2.INTER_NEAREST: 最近邻插值,也称为最近邻算法。它简单地使用最接近目标像素的原始像素的值。虽然计算速度快,但可能导致图像质量下降。
- cv2.INTER_LINEAR: 双线性插值,通过对最近的4个像素进行线性加权来估计目标像素的值。比最近邻插值更精确,但计算成本略高。
- cv2.INTER_CUBIC: 双三次插值,使用16个最近像素的加权平均值来估计目标像素的值。通常情况下,这是一个不错的插值方法,适用于图像缩小。
- cv2.INTER_LANCZOS4: Lanczos插值,一种高质量的插值方法,使用Lanczos窗口函数。通常用于缩小图像,以保留图像中的细节和纹理。
第二步:图像灰度化
将缩小的图像转换为灰度图像。
# 图像灰度化:将彩色图像转换为灰度图像。
img_gray = cv2.cvtColor(img_32, cv2.COLOR_BGR2GRAY)
print(f"缩放32x32的图像中每个像素的颜色=\n{img_gray}")
输出打印:
缩放32x32的图像中每个像素的颜色=
[[253 253 253 ... 253 253 253][253 253 253 ... 253 253 253][253 253 253 ... 253 253 253]...[253 253 253 ... 253 253 253][253 253 253 ... 253 253 253][253 253 253 ... 253 253 253]]

第三步:离散余弦变换(DCT)
感知哈希算法的核心是应用离散余弦变换。DCT将图像从空间域(像素级别)转换为频域,得到32×32的DCT变换系数矩阵,以捕获图像的低频信息。这里我们使用 OpenCV 的 cv2.dct 函数来执行DCT。
# 离散余弦变换(DCT):计算图像的DCT变换,得到32×32的DCT变换系数矩阵
img_dct = cv2.dct(np.float32(img_gray))
print(f"灰度图像离散余弦变换(DCT)={img_dct}")
这行代码执行了离散余弦变换(DCT),它将图像数据从空间域(像素级别)转换为频域,以便在频域上分析图像。
- cv2.dct: 这是 OpenCV 库中的函数,用于执行离散余弦变换。DCT是一种数学变换,类似于傅里叶变换,它将图像分解为不同频率的分量。
- np.float32(img_gray): 这是将灰度图像 img_gray 转换为32位浮点数的操作。DCT通常需要浮点数作为输入。
- img_dct: 这是存储DCT变换后结果的变量。在执行DCT后,img_dct 将包含图像的频域表示。
基于DCT的图像感知哈希算法是一种能够有效感知图像全局特征的算法,将图片认为是一个二维信号,包含了表现大范围内的亮度变化小的低频部分与局部范围亮度变化剧烈的高频部分,而高频部分一般存在大量的冗余和相关性。通过DCT变换,可以将高能量信息集中到图像的左上角区域。可以理解为图像的特征频率区域。
# 离散余弦变换(DCT):计算图像的DCT变换,得到32×32的DCT变换系数矩阵
img_dct = cv2.dct(np.float32(img_gray))
print(f"灰度图像离散余弦变换(DCT)={img_dct}")# 缩放DCT系数
dct_scaled = cv2.normalize(img_dct, None, 0, 255, cv2.NORM_MINMAX)
img_dct_scaled = dct_scaled.astype(np.uint8)# 显示DCT系数的图像
plt.imshow(img_dct_scaled, cmap='gray')
plt.show()
如下图,将图像进行DCT后得到其变换结果,图像左上角变化明显,而右下角几乎没有变化。

第四步:缩小DCT
经过DCT变换后,图像的频率特征集中在图像的左上角,保留系数矩阵左上角的8×8系数子矩阵(因为虽然DCT的结果是32×32大小的矩阵,但左上角8×8的矩阵呈现了图片中的最低频率)。
备注: 这里为什么要缩放DCT?以及其它缩放方式有哪些?不同缩放方式结果有何不同?不进行缩放DCT会怎么样?等等问题,我们在文末对比解答。
# 离散余弦变换(DCT):计算图像的DCT变换,得到32×32的DCT变换系数矩阵
img_dct = cv2.dct(np.float32(img_gray))
# print(f"灰度图像离散余弦变换(DCT)={img_dct}")# 缩放DCT:将DCT系数的大小显式地调整为8x8,然后它计算调整后的DCT系数的均值,并生成哈希值。
img_dct.resize(8, 8)# 缩放DCT系数
dct_scaled = cv2.normalize(dct_roi, None, 0, 255, cv2.NORM_MINMAX)
img_dct_scaled = dct_scaled.astype(np.uint8)# 显示DCT系数的图像
plt.imshow(img_dct_scaled, cmap='gray')
plt.show()

第五步:计算灰度均值
计算DCT变换后图像块的均值,以便后面确定每个块的明暗情况。
# 计算灰度均值:计算DCT变换后图像块的均值
img_avg = np.mean(img_dct)
print(f"DCT变换后图像块的均值={img_avg}")
输出打印:
DCT变换后图像块的均值=7.814879417419434
第六步:生成二进制哈希值
如果块的DCT系数高于均值,表示为1,否则表示为0。
由于我们只提取了DCT矩阵左上角的8×8系数子矩阵(图片特征频率区域),所以,最后会得到一个64位的二进制值(8x8像素的灰度图像)。
# 生成二进制哈希值
img_hash_str = ''
for i in range(8):for j in range(8):if img_dct[i, j] > img_avg:img_hash_str += '1'else:img_hash_str += '0'
print(f"图像的二进制哈希值={img_hash_str}")
或者,使用等价的 lambda 表达式。效果一样。
img_hash_str = ""
for i in range(8):img_hash_str += ''.join(map(lambda i: '0' if i < img_avg else '1', img_dct[i]))
print(f"图像的二进制哈希值={img_hash_str}")
输出打印:
图像的二进制哈希值=1011000010001000100000100010000000001000000000001000000000000000
第七步:图像可识别的哈希值
由于64位二进制值太长,所以按每4个字符为1组,由2进制转成16进制。这样就转为一个长度为16的字符串。这个字符串也就是这个图像可识别的哈希值,也叫图像指纹,即这个图像所包含的特征。
# 生成图像可识别哈希值
img_hash = ''
for i in range(0, 64, 4):img_hash += ''.join('%x' % int(img_hash_str[i: i + 4], 2))
print(f"图像可识别的哈希值={img_hash}")
输出打印:
图像可识别的哈希值=b088822008008000
第八步:哈希值比较
通过比较两个图像的哈希值的汉明距离(Hamming Distance),就可以评估图像的相似度,距离越小表示图像越相似。
def hamming_distance(s1, s2):# 检查这两个字符串的长度是否相同。如果长度不同,它会引发 ValueError 异常,因为汉明距离只适用于等长的字符串if len(s1) != len(s2):raise ValueError("Input strings must have the same length")distance = 0for i in range(len(s1)):# 遍历两个字符串的每个字符,比较它们在相同位置上的值。如果发现不同的字符,将 distance 的值增加 1if s1[i] != s2[i]:distance += 1return distance
4. 测试
我们来简单测试一下基于感知哈希算法的以图搜图 – 基于一张原图找最相似图片,看看效果如何。
这里,我准备了10张图片,其中9张是苹果,但形态不一,1张是梨子。

输出打印:
图片名称:img_test/apple-01.jpg,图片HASH:b080000088000000,与图片1的近似值(汉明距离):0
图片名称:img_test/apple-02.jpg,图片HASH:a080000018000000,与图片1的近似值(汉明距离):2
图片名称:img_test/apple-03.jpg,图片HASH:b020000080000000,与图片1的近似值(汉明距离):2
图片名称:img_test/apple-04.jpg,图片HASH:a480000020000000,与图片1的近似值(汉明距离):4
图片名称:img_test/apple-05.jpg,图片HASH:a400000044000000,与图片1的近似值(汉明距离):5
图片名称:img_test/apple-06.jpg,图片HASH:f881000084000000,与图片1的近似值(汉明距离):4
图片名称:img_test/apple-07.jpg,图片HASH:e408000090000000,与图片1的近似值(汉明距离):6
图片名称:img_test/apple-08.jpg,图片HASH:cad9522236480010,与图片1的近似值(汉明距离):13
图片名称:img_test/apple-09.jpg,图片HASH:b000000098000000,与图片1的近似值(汉明距离):2
图片名称:img_test/pear-001.jpg,图片HASH:e0000000c8000000,与图片1的近似值(汉明距离):3
耗时:0.08439445495605469
汉明距离:两个长度相同的字符串在相同位置上的字符不同的个数。

简单的测试分析:
| 原图 | 相似图片 | 相似值(汉明距离) | 相似图片特点 | 相似图片与原图Hash对比结果 |
|---|---|---|---|---|
| 图片01 | 图片01 | 0 | 自己 | 自己与自己相似度100% |
| 图片01 | 图片02、03、09 | 2 | 主体形状、位置、背景基本相似 | 最相似。相同背景、相同物体、同相位置下最相似。 |
| 图片01 | 图片pear-001 | 3 | 黄色的梨子 | 意外相似。相似搜索并不能识别物体/内容。 |
| 图片01 | 图片04、图片06 | 4 | 原图像的180度旋转图;多主体 | 比较相似。对于多主体、原图旋转变换相似搜索友好,因为经过DCT变换后,图像的能量特征集中在图像的左上角。 |
| 图片01 | 图片05 | 5 | 青苹果(2D) | 比较相似。对于2D的扁平相似图片搜索也相对友好。 |
| 图片01 | 图片07 | 6 | 背景差异、多色调 | 勉强相似。对于背景差异、多色调的图片开始查找吃力。 |
| 图片01 | 图片08 | 10以上 | 背景差异、多色调 | 较难分辨。复杂背景差异、多色调的图片较难与原图相似。 |
10张测试图片中,汉明距离在5以内的有8张图片;汉明距离在10以外只有1张图片。
从抽样简单测试结果看,感知哈希算法表现更友好、更准确。
备注:如果汉明距离0,则表示这两张图片非常相似;如果汉明距离小于5,则表示有些不同,但比较相近;如果汉明距离大于10,则表明是完全不同的图片。
5. 总结
经过实验和测试,感知哈希算法的撸棒性更好。总体与均值哈希算法(aHash)差不多,区别在于二值化方式不一样。
特点: 传统
优点: 简单、相对准确、计算效率高;感知哈希考虑了图像的全局特征,对图像的尺寸和旋转变化具有一定的鲁棒性;适用于快速图像相似性搜索。
缺点: 对一些局部变化不够敏感;对于复杂、多色调的图像较难辨别,属于一种外观相似的相似度计算。
6. 实验代码
"""
以图搜图:感知哈希算法(Perceptual Hash Algorithm,简称pHash)的原理与实现
测试环境:win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1
实验时间:2023-10-22
"""import cv2
import time
import numpy as np
import matplotlib.pyplot as pltdef get_hash(img_path):# 读取图像:通过OpenCV的imread加载图像# 缩小图像:使用OpenCV的resize函数将图像缩放为32x32像素,采用Cubic插值方法进行图像重采样img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)img = cv2.resize(img, (32, 32), cv2.INTER_CUBIC)# 图像灰度化:将彩色图像转换为灰度图像。img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# print(f"缩放32x32的图像中每个像素的颜色=\n{img_gray}")# 离散余弦变换(DCT):计算图像的DCT变换,得到32×32的DCT变换系数矩阵img_dct = cv2.dct(np.float32(img_gray))# print(f"灰度图像离散余弦变换(DCT)={img_dct}")# 缩放DCT:将DCT系数的大小显式地调整为8x8。然后它计算调整后的DCT系数的均值,并生成哈希值。# dct_roi = img_dct[0:8, 0:8]img_dct.resize(8, 8)# 计算灰度均值:计算DCT变换后图像块的均值img_avg = np.mean(img_dct)# print(f"DCT变换后图像块的均值={img_avg}")"""# # 生成二进制哈希值# img_hash_str = ''# for i in range(8):# for j in range(8):# if img_dct[i, j] > img_avg:# img_hash_str += '1'# else:# img_hash_str += '0'# print(f"图像的二进制哈希值={img_hash_str}")# # 生成图像可识别哈希值# img_hash = ''# for i in range(0, 64, 4):# img_hash += ''.join('%x' % int(img_hash_str[i: i + 4], 2))# print(f"图像可识别的哈希值={img_hash}")"""img_hash_str = ""for i in range(8):img_hash_str += ''.join(map(lambda i: '0' if i < img_avg else '1', img_dct[i]))# print(f"图像的二进制哈希值={img_hash_str}")# 生成图像可识别哈希值img_hash = ''.join(map(lambda x:'%x' % int(img_hash_str[x : x + 4], 2), range(0, 64, 4)))# print(f"图像可识别的哈希值={img_hash}")return img_hash# 汉明距离:计算两个等长字符串(通常是二进制字符串或位字符串)之间的汉明距离。用于确定两个等长字符串在相同位置上不同字符的数量。
def hamming_distance(s1, s2):# 检查这两个字符串的长度是否相同。如果长度不同,它会引发 ValueError 异常,因为汉明距离只适用于等长的字符串if len(s1) != len(s2):raise ValueError("Input strings must have the same length")distance = 0for i in range(len(s1)):# 遍历两个字符串的每个字符,比较它们在相同位置上的值。如果发现不同的字符,将 distance 的值增加 1if s1[i] != s2[i]:distance += 1return distance# --------------------------------------------------------- 测试 ---------------------------------------------------------time_start = time.time()img_1 = 'img_test/apple-01.jpg'
img_2 = 'img_test/apple-02.jpg'
img_3 = 'img_test/apple-03.jpg'
img_4 = 'img_test/apple-04.jpg'
img_5 = 'img_test/apple-05.jpg'
img_6 = 'img_test/apple-06.jpg'
img_7 = 'img_test/apple-07.jpg'
img_8 = 'img_test/apple-08.jpg'
img_9 = 'img_test/apple-09.jpg'
img_10 = 'img_test/pear-001.jpg'img_hash1 = get_hash(img_1)
img_hash2 = get_hash(img_2)
img_hash3 = get_hash(img_3)
img_hash4 = get_hash(img_4)
img_hash5 = get_hash(img_5)
img_hash6 = get_hash(img_6)
img_hash7 = get_hash(img_7)
img_hash8 = get_hash(img_8)
img_hash9 = get_hash(img_9)
img_hash10 = get_hash(img_10)distance1 = hamming_distance(img_hash1, img_hash1)
distance2 = hamming_distance(img_hash1, img_hash2)
distance3 = hamming_distance(img_hash1, img_hash3)
distance4 = hamming_distance(img_hash1, img_hash4)
distance5 = hamming_distance(img_hash1, img_hash5)
distance6 = hamming_distance(img_hash1, img_hash6)
distance7 = hamming_distance(img_hash1, img_hash7)
distance8 = hamming_distance(img_hash1, img_hash8)
distance9 = hamming_distance(img_hash1, img_hash9)
distance10 = hamming_distance(img_hash1, img_hash10)time_end = time.time()print(f"图片名称:{img_1},图片HASH:{img_hash1},与图片1的近似值(汉明距离):{distance1}")
print(f"图片名称:{img_2},图片HASH:{img_hash2},与图片1的近似值(汉明距离):{distance2}")
print(f"图片名称:{img_3},图片HASH:{img_hash3},与图片1的近似值(汉明距离):{distance3}")
print(f"图片名称:{img_4},图片HASH:{img_hash4},与图片1的近似值(汉明距离):{distance4}")
print(f"图片名称:{img_5},图片HASH:{img_hash5},与图片1的近似值(汉明距离):{distance5}")
print(f"图片名称:{img_6},图片HASH:{img_hash6},与图片1的近似值(汉明距离):{distance6}")
print(f"图片名称:{img_7},图片HASH:{img_hash7},与图片1的近似值(汉明距离):{distance7}")
print(f"图片名称:{img_8},图片HASH:{img_hash8},与图片1的近似值(汉明距离):{distance8}")
print(f"图片名称:{img_9},图片HASH:{img_hash9},与图片1的近似值(汉明距离):{distance9}")
print(f"图片名称:{img_10},图片HASH:{img_hash10},与图片1的近似值(汉明距离):{distance10}")print(f"耗时:{time_end - time_start}")
7. 疑难杂症
是否有很多问号?
为什么要缩放DCT?DCT缩放方式有哪些?不同DCT缩放方式有何不同?不进行DCT缩放效果会怎么样?
对于这些问题,我们来通过下面三组对比分析,一探究竟。
7.1 过程对比
方式一: DCT变换后,无DCT特征频率区域缩放
方式二: DCT变换后,将DCT系数显式调整为8x8
方式三: DCT变换后,只提取DCT系数左上角8x8像素

从上图的DCT变换过程来看,从原图读取,到缩小到指定大小的像素图像,再到像素图像灰度化,对于图像的加工结果都是一样的。区别仅在于对灰度图像使用离散余弦变换(DCT)之后,对DCT系数的使用方式不一样。
7.2 结果对比
1)纵向对比
同一张图片使用不同DCT变换方式获得的哈希值结果:
方式一:离散余弦变换DCT变换后,无DCT特征频率区域缩放,获得图像的二进制哈希值=b3c3c682c9306640
方式二:离散余弦变换DCT变换后,将DCT系数显式调整为8x8,获得图像的二进制哈希值=b080000088000000
方式三:离散余弦变换DCT变换后,只提取DCT系数左上角8x8像素,获得图像的二进制哈希值=b088822008008000
从上述的DCT变换结果来看,同一张图片获得图像的二进制哈希值各不一样。
- 方式一与方式二、方式三的结果相差较大。
- 方式二与方式三的结果也不尽一致。
2)横向对比
不同图片使用相同DCT变换方式获得的哈希值结果:

从上图的DCT变换结果来看,不同图片使用不同方式的DCT变换,最终查找的相似图片结果都不尽相同。
- 从DCT变换方式维度看,方式二,将DCT系数显示调整为8x8的查找效果最好。方式三其次。方式一最次。
- 从DCT变换方式的计算效率来看,方式二与方式三耗时相当,计算效率较高;而方式一,由于无DCT特征频率区域缩放,所以计算量最大,效率最次。
7.3 代码对比
"""
以图搜图:感知哈希算法(Perceptual Hash Algorithm,简称pHash)的原理与实现
测试环境:win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1
实验时间:2023-10-22
"""# ---------------------------------------------------------------------------------------------------------------------
# 测试:为什么要缩放DCT?DCT缩放方式有哪些?不同DCT缩放方式有何不同?不进行DCT缩放效果会怎么样?
# ---------------------------------------------------------------------------------------------------------------------import cv2
import time
import numpy as np
import matplotlib.pyplot as plt# DCT变换后:无特征频率区域缩放,使用整个32x32图像块的频率分布,计算整个DCT系数的均值,并根据这个均值生成哈希值。
def get_pHash1(img_path):img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)# plt.imshow(img, cmap='gray')# plt.show()img = cv2.resize(img, (32, 32), cv2.INTER_CUBIC)# plt.imshow(img, cmap='gray')# plt.show()img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# plt.imshow(img_gray, cmap='gray')# plt.show()img_dct = cv2.dct(np.float32(img_gray))# 显示DCT系数的图像# dct_scaled = cv2.normalize(img_dct, None, 0, 255, cv2.NORM_MINMAX)# img_dct_scaled = dct_scaled.astype(np.uint8)# plt.imshow(img_dct_scaled, cmap='gray')# plt.show()img_avg = np.mean(img_dct)# print(f"DCT变换后图像块的均值={img_avg}")img_hash_str = get_img_hash_binary(img_dct, img_avg)# print(f"图像的二进制哈希值={img_hash_str}")img_hash = get_img_hash(img_hash_str)return img_hash# DCT变换后:将DCT系数的大小显式地调整为8x8,使用8x8的DCT系数块的频率分布,计算调整后的DCT系数的均值,并生成哈希值。
def get_pHash2(img_path):img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)# plt.imshow(img, cmap='gray')# plt.show()img = cv2.resize(img, (32, 32), cv2.INTER_CUBIC)# plt.imshow(img, cmap='gray')# plt.show()img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# plt.imshow(img_gray, cmap='gray')# plt.show()img_dct = cv2.dct(np.float32(img_gray))img_dct.resize(8, 8)# 显示DCT系数的图像# dct_scaled = cv2.normalize(img_dct, None, 0, 255, cv2.NORM_MINMAX)# img_dct_scaled = dct_scaled.astype(np.uint8)# plt.imshow(img_dct_scaled, cmap='gray')# plt.show()img_avg = np.mean(img_dct)# print(f"DCT变换后图像块的均值={img_avg}")img_hash_str = get_img_hash_binary(img_dct, img_avg)# print(f"图像的二进制哈希值={img_hash_str}")img_hash = get_img_hash(img_hash_str)return img_hash# DCT变换后:只提取DCT系数的左上角8x8块的信息,然后计算这个块的均值。此法只考虑图像一小部分的频率分布,并生成哈希值。
def get_pHash3(img_path):img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)# plt.imshow(img, cmap='gray')# plt.show()img = cv2.resize(img, (32, 32), cv2.INTER_CUBIC)# plt.imshow(img, cmap='gray')# plt.show()img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# plt.imshow(img_gray, cmap='gray')# plt.show()img_dct = cv2.dct(np.float32(img_gray))dct_roi = img_dct[0:8, 0:8]# 显示DCT系数的图像# dct_scaled = cv2.normalize(dct_roi, None, 0, 255, cv2.NORM_MINMAX)# img_dct_scaled = dct_scaled.astype(np.uint8)# plt.imshow(img_dct_scaled, cmap='gray')# plt.show()img_avg = np.mean(dct_roi)# print(f"DCT变换后图像块的均值={img_avg}")img_hash_str = get_img_hash_binary(dct_roi, img_avg)# print(f"图像的二进制哈希值={img_hash_str}")img_hash = get_img_hash(img_hash_str)return img_hashdef get_img_hash_binary(img_dct, img_avg):img_hash_str = ''for i in range(8):img_hash_str += ''.join(map(lambda i: '0' if i < img_avg else '1', img_dct[i]))# print(f"图像的二进制哈希值={img_hash_str}")return img_hash_strdef get_img_hash(img_hash_str):img_hash = ''.join(map(lambda x:'%x' % int(img_hash_str[x : x + 4], 2), range(0, 64, 4)))# print(f"图像可识别的哈希值={img_hash}")return img_hash# 汉明距离:计算两个等长字符串(通常是二进制字符串或位字符串)之间的汉明距离。用于确定两个等长字符串在相同位置上不同字符的数量。
def hamming_distance(s1, s2):# 检查这两个字符串的长度是否相同。如果长度不同,它会引发 ValueError 异常,因为汉明距离只适用于等长的字符串if len(s1) != len(s2):raise ValueError("Input strings must have the same length")distance = 0for i in range(len(s1)):# 遍历两个字符串的每个字符,比较它们在相同位置上的值。如果发现不同的字符,将 distance 的值增加 1if s1[i] != s2[i]:distance += 1return distance# ======================================== 测试场景一 ========================================# img = 'img_test/apple-01.jpg'# img_hash1 = get_phash1(img)
# img_hash2 = get_phash2(img)
# img_hash3 = get_phash3(img)# print(f"方式一:DCT变换后,无DCT特征频率区域缩放,获得图像的二进制哈希值={img_hash1}")
# print(f"方式二:DCT变换后,将DCT系数显式调整为8x8,获得图像的二进制哈希值={img_hash2}")
# print(f"方式三:DCT变换后,只提取DCT系数左上角8x8像素,获得图像的二进制哈希值={img_hash3}")# ======================================== 测试场景二 ========================================time_start = time.time()img_1 = 'img_test/apple-01.jpg'
img_2 = 'img_test/apple-02.jpg'
img_3 = 'img_test/apple-03.jpg'
img_4 = 'img_test/apple-04.jpg'
img_5 = 'img_test/apple-05.jpg'
img_6 = 'img_test/apple-06.jpg'
img_7 = 'img_test/apple-07.jpg'
img_8 = 'img_test/apple-08.jpg'
img_9 = 'img_test/apple-09.jpg'
img_10 = 'img_test/pear-001.jpg'# ------------------------------------- 测试场景二:方式一 --------------------------------------# img_hash1 = get_pHash1(img_1)
# img_hash2 = get_pHash1(img_2)
# img_hash3 = get_pHash1(img_3)
# img_hash4 = get_pHash1(img_4)
# img_hash5 = get_pHash1(img_5)
# img_hash6 = get_pHash1(img_6)
# img_hash7 = get_pHash1(img_7)
# img_hash8 = get_pHash1(img_8)
# img_hash9 = get_pHash1(img_9)
# img_hash10 = get_pHash1(img_10)# ------------------------------------- 测试场景二:方式二 --------------------------------------img_hash1 = get_pHash2(img_1)
img_hash2 = get_pHash2(img_2)
img_hash3 = get_pHash2(img_3)
img_hash4 = get_pHash2(img_4)
img_hash5 = get_pHash2(img_5)
img_hash6 = get_pHash2(img_6)
img_hash7 = get_pHash2(img_7)
img_hash8 = get_pHash2(img_8)
img_hash9 = get_pHash2(img_9)
img_hash10 = get_pHash2(img_10)# ------------------------------------- 测试场景二:方式三 --------------------------------------# img_hash1 = get_pHash3(img_1)
# img_hash2 = get_pHash3(img_2)
# img_hash3 = get_pHash3(img_3)
# img_hash4 = get_pHash3(img_4)
# img_hash5 = get_pHash3(img_5)
# img_hash6 = get_pHash3(img_6)
# img_hash7 = get_pHash3(img_7)
# img_hash8 = get_pHash3(img_8)
# img_hash9 = get_pHash3(img_9)
# img_hash10 = get_pHash3(img_10)distance1 = hamming_distance(img_hash1, img_hash1)
distance2 = hamming_distance(img_hash1, img_hash2)
distance3 = hamming_distance(img_hash1, img_hash3)
distance4 = hamming_distance(img_hash1, img_hash4)
distance5 = hamming_distance(img_hash1, img_hash5)
distance6 = hamming_distance(img_hash1, img_hash6)
distance7 = hamming_distance(img_hash1, img_hash7)
distance8 = hamming_distance(img_hash1, img_hash8)
distance9 = hamming_distance(img_hash1, img_hash9)
distance10 = hamming_distance(img_hash1, img_hash10)time_end = time.time()print(f"图片名称:{img_1},图片HASH:{img_hash1},与图片1的近似值(汉明距离):{distance1}")
print(f"图片名称:{img_2},图片HASH:{img_hash2},与图片1的近似值(汉明距离):{distance2}")
print(f"图片名称:{img_3},图片HASH:{img_hash3},与图片1的近似值(汉明距离):{distance3}")
print(f"图片名称:{img_4},图片HASH:{img_hash4},与图片1的近似值(汉明距离):{distance4}")
print(f"图片名称:{img_5},图片HASH:{img_hash5},与图片1的近似值(汉明距离):{distance5}")
print(f"图片名称:{img_6},图片HASH:{img_hash6},与图片1的近似值(汉明距离):{distance6}")
print(f"图片名称:{img_7},图片HASH:{img_hash7},与图片1的近似值(汉明距离):{distance7}")
print(f"图片名称:{img_8},图片HASH:{img_hash8},与图片1的近似值(汉明距离):{distance8}")
print(f"图片名称:{img_9},图片HASH:{img_hash9},与图片1的近似值(汉明距离):{distance9}")
print(f"图片名称:{img_10},图片HASH:{img_hash10},与图片1的近似值(汉明距离):{distance10}")print(f"耗时:{time_end - time_start}")
如上代码,这三种方法获取到的图像二进制哈希值之所以不同,是因为它们在DCT变换后的处理方式不同:
- get_pHash1 方法: 这种方法首先将图像进行灰度化,然后执行DCT变换。接着,它计算整个DCT系数的均值,并根据这个均值生成哈希值。这意味着它考虑了整个32x32图像块的频率分布。
- get_pHash2 方法: 这种方法在执行DCT后,将DCT系数的大小显式地调整为8x8。然后它计算调整后的DCT系数的均值,并生成哈希值。这个方法只考虑了8x8的DCT系数块的频率分布。
- get_pHash3 方法: 这种方法与 get_pHash2 类似,但它只提取了DCT系数的左上角8x8块的信息(即ROI,感兴趣区域),然后计算这个块的均值。这个方法只考虑了图像的一个小部分频率分布。
由于这些方法考虑的DCT系数区域不同,它们生成的哈希值会有差异。一般来说,get_pHash1 方法考虑了整个图像块的频率分布,因此哈希值可能更稳定,但它也可能受到图像整体性的影响。而 get_pHash2 和 get_pHash3 方法只考虑了一个小块的频率信息,所以哈希值可能更容易受到图像的局部特征影响。
选择哪种方法取决于你的应用需求。如果你希望更稳定的哈希值,get_pHash1 可能是一个不错的选择。如果你希望更灵敏地检测局部特征,get_pHash2 或 get_pHash3 可能更适合。
8. 系列书签
OpenCV #以图搜图:均值哈希算法(Average Hash Algorithm)原理与实验
相关文章:
OpenCV #以图搜图:感知哈希算法(Perceptual hash algorithm)的原理与实验
1. 介绍 感知哈希算法(Perceptual Hash Algorithm,简称pHash) 是哈希算法的一种,主要用来做相似图片的搜索工作。 2. 原理 感知哈希算法(pHash)首先将原图像缩小成一个固定大小的像素图像,然后…...
Android多张图片rotation旋转角度叠加/重叠堆放
Android多张图片rotation旋转角度叠加/重叠堆放 <?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app"http://schemas.android.com/apk/res-auto"…...
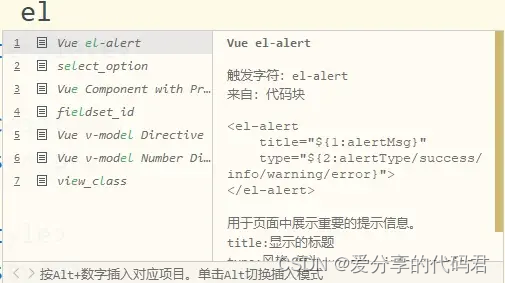
HBuilderX 自定义语法提示
在开发实践中,会使用到各种第三方组件,比如Element UI,通常的做法是到官网中复制模板再在本地根据设计要求进行修改,或是从其它已经实现的组件中复制相似的内容。但每次复制粘贴确实比较麻烦。 在HBuilderx中可以设置代码块来创建…...

Leetcode—2562.找出数组的串联值【简单】
2023每日刷题(十四) Leetcode—2562.找出数组的串联值 实现代码 long long findTheArrayConcVal(int* nums, int numsSize){int left 0;int right numsSize - 1;long long sum 0;while(left < right) {if(left right) {sum nums[left];break;}…...

T0外部计数输入
/*----------------------------------------------- 内容:通过外部按键计数进入中断执行LED取反 ------------------------------------------------*/ #include<reg52.h> //包含头文件,一般情况不需要改动,头文件包含特殊功能寄存器的…...
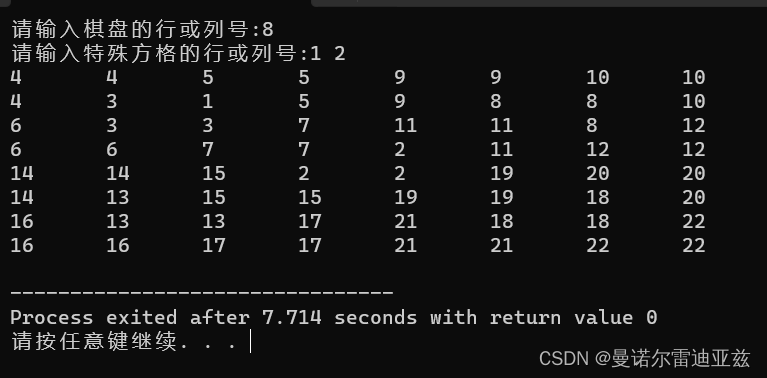
分治法求解棋盘覆盖问题
分治法求解棋盘覆盖问题 如何应用分治法求解棋盘覆盖问题呢?分治的技巧在于如何划分棋盘,使划分后的子棋盘的大小相同,并且每个子棋盘均包含一个特殊方格,从而将原问题分解为规模较小的棋盘覆盖问题。 基本思路 棋盘覆盖问题是…...

爱写bug的小邓程序员个人博客
博客网址: http://www.006969.xyz 欢迎来到我的个人博客,这里主要分享我对于前后端相关技术的学习笔记、项目实战经验以及一些技术感悟。 在我的博客中,你将看到以下主要内容: 技术文章 我将会分享我在学习前后端技术过程中的一些感悟&am…...

selenium判断元素可点击、可见、可选
1、判断元素是否可以点击 判断元素是否可以点击,WebElement对象调用is_enabled() is_enabled()方法返回一个布尔值,若可点击返回:True。若不可点击则返回:False from selenium import webdriver import time from selenium.web…...

计算机网络重点概念整理-第六章 应用层【期末复习|考研复习】
计算机网络复习系列文章传送门: 第一章 计算机网络概述 第二章 物理层 第三章 数据链路层 第四章 网络层 第五章 传输层 第六章 应用层 第七章 网络安全 计算机网络整理-简称&缩写 文章目录 前言六、应用层6.1 网络应用模型6.1.1 客户/服务器模式C/S模型6.1.2 P…...

html2pdf
页面布局时将需要保存在同一页pdf的dom元素用div包裹,并为该div添加class类名,例如.convertPDF,如果有多页创建多个.convertPDF这个div,再循环保存pdf即可 用到了html2canvas和JsPdf这两个插件,自行站内搜索安装 pdf页…...

css中页面元素隐藏
display:nonevisibility:hiddenopcity:0页面中不存在存在存在重排会不会不会重绘会会不一定自身绑定事件不触发不触发能触发transition不支持支持支持子元素可复原不能能不能被遮挡的元素可触发事件能能不能 其他: 1.设置height,width,margi…...

dp三步问题
三步问题 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 class Solution { public:int waysToStep(int n) {vector<int> dp(n1,1);if(n1) return 1;dp[1]1;dp[2]2;for(int i3; i<n1; i){dp[i] ((dp[i-1]dp[i-2])%1000000007dp[i-3])%100…...

结构体和联合体嵌套访问
在JSON项目中,使用了联合体和结构体之间的嵌套,但是在访问内部的联合体和结构体的时候出现了问题,这篇文章作为记录,也希望能帮助遇到相同问题的好伙伴。 struct lept_value {union {struct str{char *s;size_t len;};double n;}…...

Linux ———— 管理磁盘
(一)MBR硬盘与GPT硬盘 硬盘按分区表的格式可以分为MBR硬盘与GPT硬盘两种硬盘格式。 MBR 硬盘:使用的是旧的传统硬盘分区表格式,其硬盘分区表存储在MBR(Master Boot Record,主引导区记录)内。MBR位于…...

文字的编码
1 字符的编码方式 1.1 ASCII 是“American Standard Code for Information Interchange”的缩写,美国信息交换标准代码。电脑毕竟是西方人发明的,他们常用字母就 26 个,区分大小写、加上标点符号也没超过 127 个,每个字符用一个字…...
21.9 Python 使用Selenium库
Selenium是一个自动化测试框架,主要用于Web应用程序的自动化测试。它可以模拟用户在浏览器中的操作,如打开网页、点击链接、填写表单等,并且可以在代码中实现条件判断、异常处理等功能。Selenium最初是用于测试Web应用程序的,但也…...
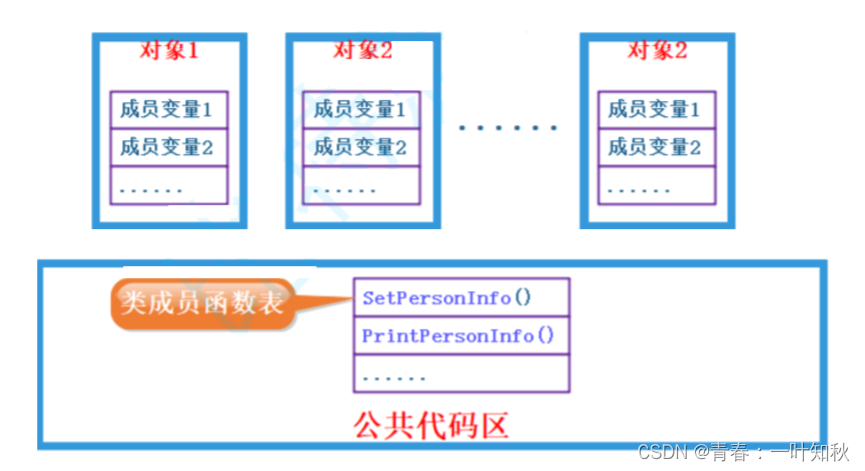
C++初阶2
目录 一,auto关键字 1-1,auto的使用 1-2,基于范围auto的for循环 二,nullptr的运用 三,C类的初步学习 3-1,类的引用 3-2,类的访问权限 3-3,类的使用 1,类中函数的…...

网络安全(黑客)—小白自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...

在win10下,使用torchviz对深度学习网络模型进行可视化
目录 1. 安装 graphviz 和 torchviz 2.安装 graphviz.exe 3.实例测试 4.如果你的电脑还是无法画图,并且出现了下面的报错: 5.参考文章: 1. 安装 graphviz 和 torchviz 首先打开 Anaconda prompt 进入自己的 pytorch 环境(图中 pt 是我自…...

【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
相关博客 【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer 【自然语言处理】【大模型】MPT模型结构源码解析(单机版) 【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版) 【自然语言处理】【大模型】BLOOM模型结构源码解析(…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...