TensorFlow图像多标签分类实例
接下来,我们将从零开始讲解一个基于TensorFlow的图像多标签分类实例,这里以图片验证码为例进行讲解。
在我们访问某个网站的时候,经常会遇到图片验证码。图片验证码的主要目的是区分爬虫程序和人类,并将爬虫程序阻挡在外。
下面的程序就是模拟人类识别验证码,从而使网站无法区分是爬虫程序还是人类在网站登录。
以图10.5所示的图片验证码为例,将这幅验证码图片标记为label=[3,8,8,7]。我们知道分类网络一般一次只能识别出一个目标,那么如何识别这个多标签的序列数据呢?
通过下面的TFRecord结构可以构建多标签训练数据集,从而实现多标签数据识别。

图10.5 图片验证码
以下为构造TFRecord多标签训练数据集的代码:
import tensorflow as tf
# 定义对整型特征的处理
def _int64_feature(value):return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 定义对字节特征的处理
def _bytes_feature(value):return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# 定义对浮点型特征的处理
def _floats_feature(value):return tf.train_Feature(float_list=tf.train.floatList(value=[value]))
# 对数据进行转换
def convert_to_record(name, image, label, map):filename = os.path.join(params.TRAINING_RECORDS_DATA_DIR,name + '.' + params.DATA_EXT)writer = tf.python_io.TFRecordWriter(filename)image_raw = image.tostring()map_raw = map.tostring()label_raw = label.tostring()example = tf.train.Example(feature=tf.train.Feature(feature={'image_raw': _bytes_feature(image_raw),'map_raw': _bytes_feature(map_raw),'1abel_raw': _bytes_feature(label_raw)}))writer.write(example.SerializeToString())writer.close()
通过上面的代码,我们构建了一条支持多标签的TFRecord记录,多幅验证码图片可以构建一个验证码的多标签数据集,用于后续的多标签分类训练。
通过前一步操作,我们得到了用于多标签分类的验证码数据集,现在需要构建多标签分类网络。
我们选择VGG网络作为特征提取网络骨架。通常越复杂的网络,对噪声的鲁棒性就越强。验证码中的噪声主要来自形变、粘连以及人工添加,VGG网络对这些噪声具有好的鲁棒性,代码如下:
import tensorflow as tf
tf.enable_eager_execution ()
def model_vgg(x, training = False):
# 第一组第一个卷积使用64个卷积核,核大小为3
conv1_1 = tf.layers.conv2d(inputs=x, filters=64,name="conv1_1",kernel_size=3, activation=tf.nn.relu, padding="same")
# 第一组第二个卷积使用64个卷积核,核大小为3
convl_2 = tf.layers.conv2d(inputs=conv1_1,filters=64, name="conv1_2",kernel_size=3, activation=tf.nn.relu,padding="same")
# 第一个pool操作核大小为2,步长为2
pooll = tf.layers.max_pooling2d(inputs=conv1_2, pool_size=[2, 2],strides=2, name= 'pool1')
# 第二组第一个卷积使用128个卷积核,核大小为3
conv2_1 = tf.layers.conv2d(inputs=pool1, filters=128, name="conv2_1",kernel_size=3, activation=tf.nn.relu, padding="same")
# 第二组第二个卷积使用64个卷积核,核大小为3
conv2_2 = tf.layers.conv2d(inputs=conv2_1, filters=128,name="conv2_2",kernel_size=3, activation=tf.nn.relu, padding="same")
# 第二个pool操作核大小为2,步长为2
pool2 = tf.layers.max_pooling2d(inputs=conv2_2, pool_size=[2, 2],strides=2, name="pool1")
# 第三组第一个卷积使用128个卷积核,核大小为3
conv3_1 = tf.layers.conv2d(inputs=pool2, filters=128, name="conv3_1", kernel_size=3, activation=tf.nn.relu, padding="same")
# 第三组第二个卷积使用128个卷积核,核大小为3
conv3_2 = tf.layers.conv2d(inputs=conv3_1, filters=128, name="conv3_2", kernel_size=3, activation=tf.nn.relu, padding="same")
# 第三组第三个卷积使用128个卷积核,核大小为3
conv3_3 = tf.layers.conv2d(inputs=conv3_2, filters=128, name="conv3_3", kernel_size=3, activation=tf.nn.relu, padding=" same")
# 第三个pool 操作核大小为2,步长为2
pool3 = tf.layers.max_pooling2d(inputs=conv3_3, pool_size=[2, 2], strides=2,name='pool3')
# 第四组第一个卷积使用256个卷积核,核大小为3
conv4_1 = tf.layers.conv2d(inputs-pool3, filters=256, name="conv4_1", kernel_size=3, activation=tf.nn.relu, padding="same")
# 第四组第二个卷积使用128个卷积核,核大小为3
conv4_2 = tf.layers.conv2d(inputs=conv4_1, filters=128, name="conv4_2", kernel_size=3, activation=tf.nn.relu, padding="same")
# 第四组第三个卷积使用128个卷积核,核大小为3
conv4_3 = tf.layers.conv2d(inputs=conv4_2, filters=128, name="cov4_3", kernel_size=3, activation=tf.nn.relu, padding="same" )
# 第四个pool操作核大小为2,步长为2
pool4 = tf.layers.max.pooling2d(inputs=conv4_3, pool_size=[2,2], strides=2, name='pool4')
# 第五组第一个卷积使用512个卷积核,核大小为3
conv5_1 = tf.layers.conv2d(inputs=pool4, filters=512, name="conv5_1", kernel_size=3, activation=tf.nn.relu, padding=" same")
# 第五组第二个卷积使用512个卷积核,核大小为3
conv5_2 = t.layers.conv2d(inputs=conv5_1, filters=512, name="conv5_2", kernel_size=3, activation=tf.nn.relu, padding="same")
# 第五组第三个卷积使用512个卷积核,核大小为3
conv5_3 = tf.layers.conv2d(inputs-conv5_2, filters=512, name="conv5_3", kernel_size=3, activation=tf.nn.relu, padding="same")
# 第五个pool操作核大小为2,步长为2
pool5 = tf.layers.max_pooling2d(inputs=conv5_3, pool_size=[2, 2], strides=2, name='pool5')
flatten = tf.layers.flatten(inputs=poo15, name="flatten")
上面是VGG网络的单标签分类TensorFlow代码,但这里我们需要实现的是多标签分类,因此需要对VGG网络进行相应的改进,代码如下:
# 构建输出为4096的全连接层
fc6 = tf.layers.dense(inputs=flatten, units=4096,
activation=tf.nn.relu, name='fc6')
# 为了防止过拟合,引入dropout操作
drop1 = tf.layers.dropout(inputs=fc6,rate=0.5, training=training)
# 构建输出为4096的全连接层
fc7 = tf.layers.dense(inputs=drop1, units=4096,
activation=tf.nn.relu, name='fc7')
# 为了防止过报合,引入dropout操作
drop2 = tf.layers.dropout(inputs=fc7, rate=0.5, training=training)
# 为第一个标签构建分类器
fc8_1 = tf.layers.dense(inputs=drop2, units=10,
activation=tf.nn.sigmoid, name='fc8_1')
# 为第二个标签构建分类器
fc8_2 = tf.layers.dense(inputs=drop2, units=10,
activation=tf.nn.sigmoid, name='fc8_2')
# 为第三个标签构建分类器
fc8_3 = tf.layers.dense(inputs=drop2, units=10,
activation=tf.nn.sigmoid, name='fc8_3')
# 为第四个标签构建分类器
fc8_4 = tf.layers.dense(inputs=drop2,units=10,
activation=tf.nn.sigmoid, name='fc8_4')
# 将四个标签的结果进行拼接操作
fc8 = tf.concat([fc8_1,fc8_2,fc8_3,fc8_4], 0)
这里的fc6和fc7全连接层是对网络的卷积特征进行进一步的处理,在经过fc7层后,我们需要生成多标签的预测结果。由于一幅验证码图片中存在4个标签,因此需要构建4个子分类网络。这里假设图片验证码中只包含10 个数字,因此每个网络输出的预测类别就是10类,最后生成4个预测类别为10的子网络。如果每次训练时传入64幅验证码图片进行预测,那么通过4个子网络后,分别生成(64,10)、(64,10)、(64,10)、(64,10) 4个张量。如果使用Softmax分类器的话,就需要想办法将这4个张量进行组合,于是使用tf.concat函数进行张量拼接操作。
以下是TensorFlow中tf.concat函数的传参示例:
tf.concat (
values,
axis,
name='concat'
)
通过fc8=tf.concat([fc8_1,fc8_2,fc8_3,fc8_4], 0)的操作,可以将前面的4个(64.10)张量变换成(256.10)这样的单个张量,生成单个张量后就能进行后面的Softmax分类操作了。
模型训练的第一个步骤就是读取数据,读取方式有两种:一种是直接读取图片进行操作,另一种是转换为二进制文件格式后再进行操作。前者实现起来简单,但速度较慢;后者实现起来复杂,但读取速度快。这里我们以后者二进制的文件格式介绍如何实现多标签数据的读取操作,下面是相关代码。
首先读取TFRecord文件内容:
tfr = TFrecorder()
def input_fn_maker(path, data_info_path, shuffle=False, batch_size = 1,
epoch = 1, padding = None) :
def input_fn():filenames = tfr.get_filenames(path=path, shuffle=shuffle)dataset=tfr.get_dataset(paths=filenames,data_info=data_info_path, shuffle = shuffle,batch_size = batch_size, epoch = epoch, padding = padding)iterator = dataset.make_one_shot_iterator ()return iterator.get_next()
return input_fn
# 原始图片信息
padding_info = ({'image':[30, 100,3,], 'label':[]})
# 测试集
test_input_fn = input_fn_maker('captcha_data/test/',
'captcha_tfrecord/data_info.csv',
batch_size = 512, padding = padding_info)
# 训练集
train_input_fn = input_fn_maker('captcha_data/train/',
'captcha_tfrecord/data_info.csv',
shuffle=True, batch_size = 128,padding = padding_info)
# 验证集
train_eval_fn = input_fn_maker('captcha_data/train/',
'captcha_tfrecord/data_info.csv',
batch_size = 512,adding = padding_info)
然后是模型训练部分:
def model_fn(features, net, mode):
features['image'] = tf.reshape(features['image'], [-1, 30, 100, 3])
# 获取基于net网络的模型预测结果
predictions = net(features['image'])
# 判断是预测模式还是训练模式
if mode == tf.estimator.ModeKeys.PREDICT:return tf.estimator.EstimatorSpec(mode=mode,predictions=predictions)
# 因为是多标签的Softmax,所以需要提前对标签的维度进行处理
lables = tf.reshape(features['label'], features['label'].shape[0]*4,))
# 初始化softmaxloss
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels,logits=logits)
# 训练模式下的模型结果获取
if mode ==tf.estimator.ModeKeys.TRAIN:# 声明模型使用的优化器类型optimizer = tf.train.AdamOptimizer(learning_rate=1e-3)train_op = optimizer.minimize(loss=loss,global_step=tf.train.get_global_step())return tf.estimator.EstimatorSpec(mode=mode,loss=loss, train_op=train_op)
# 生成评价指标
eval_metric_ops = {"accuracy": tf.metrics.accuracy(labels=features['label'],predictions=predictions["classes"]) }
return tf.estimator.EstimatorSpec(mode=mode, loss=loss,eval_metric_ops= eval_metric_ops)
多标签的模型训练流程与普通单标签的模型训练流程非常相似,唯一的区别就是需要将多标签的标签值拼接成一个张量,以满足Softmax分类操作的维度要求。
本文节选自《Python深度学习原理、算法与案例》。

相关文章:
TensorFlow图像多标签分类实例
接下来,我们将从零开始讲解一个基于TensorFlow的图像多标签分类实例,这里以图片验证码为例进行讲解。 在我们访问某个网站的时候,经常会遇到图片验证码。图片验证码的主要目的是区分爬虫程序和人类,并将爬虫程序阻挡在外。 下面…...

Python程序设计期末复习笔记
文章目录 一、数据存储1.1 倒计时1.2 os库1.3 字符串操作1.4 文件操作1.5 列表操作1.6 元组1.7 字典 二、文本处理及可视化2.1 jieba分词2.2 集合操作2.3 pdf文件读取2.4 参数传递2.5 变量作用域 三、数据处理分析3.1 Sumpy3.2 Matplotlib3.3 Numpy 四、Pandas4.1 索引操作4.2 …...

人大与加拿大女王大学金融硕士—与您共创辉煌
生活的本质就是有意识的活着,而生活的智慧就是活出了自己想要的样子,那些真正厉害的人,从来都在默默努力,伴随着金融人才的需求日益增长,中国人民大学与加拿大女王大学联合推出了人大女王金融硕士项目,旨在…...
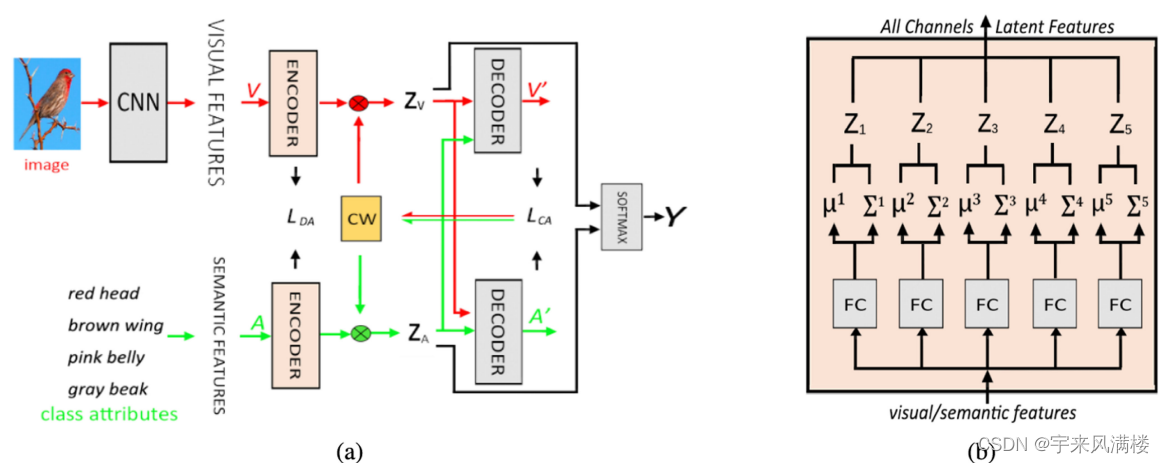
Generalized Zero-Shot Learning With Multi-Channel Gaussian Mixture VAE
L D A _{DA} DA最大化编码后两种特征分布之间的相似性 辅助信息 作者未提供代码...
)
10.30 知识总结(标签分类、css介绍等)
一、 标签的分类 1.1 单标签 img br hr <img /> 1.2 双标签 a h p div <a></a> 1.3 按照标签属性分类 1.3.1 块儿标签 即自己独自占一行 h1-h6 p div 1.3.2 行内(内联)标签 即自身文本有多大就占多大 a span u i b s 二、 标签的嵌套 标签之间是可以互相…...
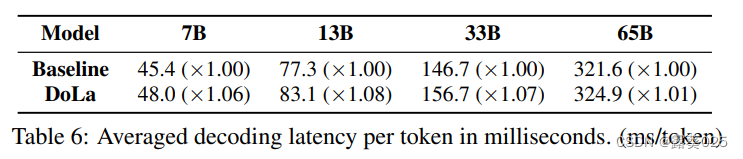
DoLa:对比层解码提高大型语言模型的事实性
DoLa:对比层解码提高大型语言模型的事实性 摘要1 引言2 方法2.1 事实知识在不同层级上演化2.2 动态早期层选择2.3 预测对比 3 实验3.1 任务3.2 实验设置3.3 多项选择3.3.1 TruthfulQA:多项选择3.3.2 FACTOR:维基、新闻 3.4 开放式文本生成3.4…...

解决由于找不到mfc140u.dll无法继续执行此代码问题的4个方法
mfc140u.dll是Microsoft Foundation Class(微软基础类库)中的一个动态链接库文件,它包含了许多用于实现Windows应用程序的基本功能。当我们在编写或运行基于MFC的程序时,如果系统中缺少这个文件,就会出现“找不到mfc14…...

MySQL高性能优化规范建议
当涉及到MySQL数据库的性能优化时,有许多方面需要考虑。以下是一些通用的MySQL性能优化规范建议: 合适的索引: 确保表中的字段使用了适当的索引。这能大幅提升检索速度。但避免过多索引,因为它会增加写操作的成本。 优化查询语句…...
pytorch 入门 (五)案例三:乳腺癌识别-VGG16实现
本文为🔗小白入门Pytorch内部限免文章 🍨 本文为🔗小白入门Pytorch中的学习记录博客🍦 参考文章:【小白入门Pytorch】乳腺癌识别🍖 原作者:K同学啊 在本案例中,我将带大家探索一下深…...

vue中electron与vue通信(fs.existsSync is not a function解决方案)
electron向vue发送消息 dist/main.js (整个文件配置在另一条博客里) win new BrowserWindow({width:1920,height:1080,webPreferences: {// 是否启用Node integrationnodeIntegration: true, // Electron 5.0.0 版本之后它将被默认false// 是否在独立 JavaScript 环境中运行…...

LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks翻译
论文《LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks》翻译 LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks翻译...

文件类漏洞总结, 文件包含, 文件上传, 文件下载
文件类漏洞总结 一, 文件包含 1. 文件包含绕过 实际环境中不是都是像$_GET[file]; incude $file 这样直接把变量传入包含函数的。 在很多时候包含的变量文件不是完全可控的,比如下面这段代码指定了前缀和后缀: <?php $file S_GET[filename]; include /opt/…...

SpringBoot篇---第四篇
系列文章目录 文章目录 系列文章目录一、springboot常用的starter有哪些二、 SpringBoot 实现热部署有哪几种方式?三、如何理解 Spring Boot 配置加载顺序? 一、springboot常用的starter有哪些 spring-boot-starter-web 嵌入tomcat和web开发需要servlet…...
 -- 在不同版本SpringBoot,选用不同的Knife4j相关的jar包)
Knife4j使用教程(一) -- 在不同版本SpringBoot,选用不同的Knife4j相关的jar包
目录 1. Knife4j的项目背景 2. Knife4j的选择 2.1 选用 Spring Boot 版本在 2.4.0~3.0.0之间 2.2 选用 Spring Boot 版本在 3.0.0之上...
Octave Convolution学习笔记 (附代码)
论文地址:https://export.arxiv.org/pdf/1904.05049 代码地址:https://gitcode.com/mirrors/lxtgh/octaveconv_pytorch/overview?utm_sourcecsdn_github_accelerator 1.是什么? OctaveNet网络属于paper《Drop an Octave: Reducing Spatia…...
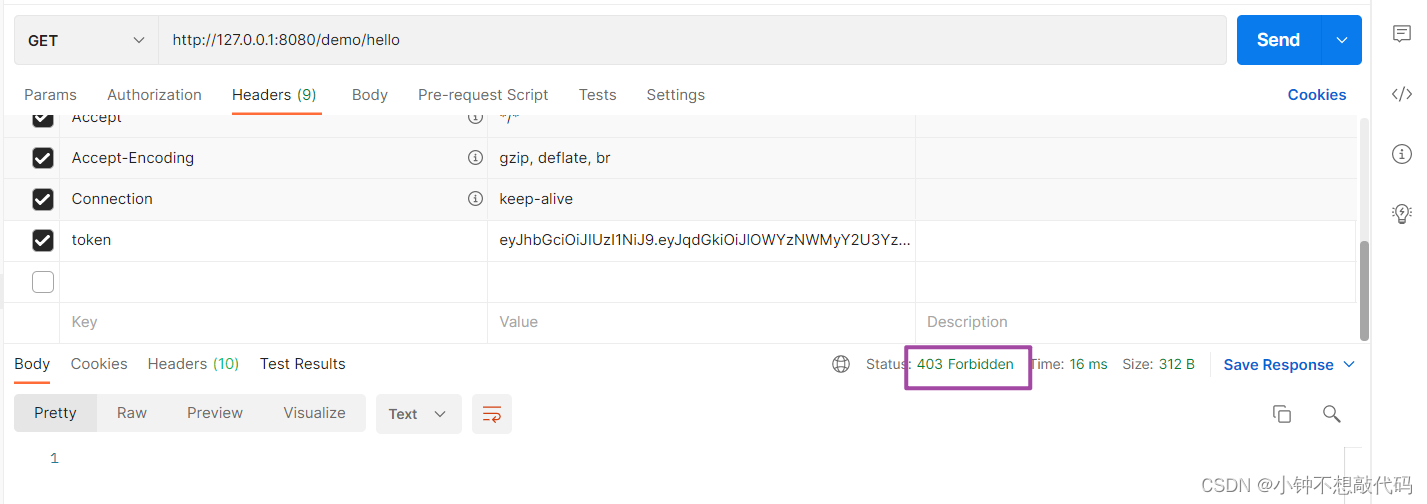
SpringSecurity 认证实战
一. 项目数据准备 1.1 添加依赖 <dependencies><!--spring security--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId></dependency><!--web起步依赖-…...
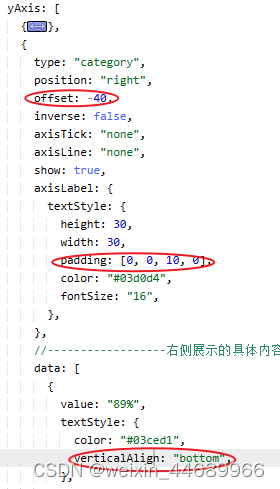
echarts中横向柱状图的数字在条纹上方
实现效果: 数字在条纹的上方 实现方法:这些数字是用新添加一个坐标轴来实现的 直接添加坐标轴数字显示是在条纹的正右边 所以需要配置一下偏移 完整代码 var option {grid: {left: "3%",right: "4%",bottom: "3%",cont…...

【仙逆】尸阴宗始祖现身,王林修得黄泉生窍诀,阿呆惊险逃生
【侵权联系删除】【文/郑尔巴金】 深度爆料最新集,王林终于成功筑基,这一集的《仙逆》动漫真是让人热血沸腾啊!在这个阶段,王林展现出了他的决心和毅力,成功地击杀了藤厉,并采取了夺基大法,从藤…...

C++二叉树剪枝
文章目录 C二叉树剪枝题目链接题目描述解题思路代码复杂度分析 C二叉树剪枝 题目链接 LCR 047. 二叉树剪枝 - 力扣(LeetCode) 题目描述 给定一个二叉树 根节点 root ,树的每个节点的值要么是 0,要么是 1。请剪除该二叉树中所有节…...
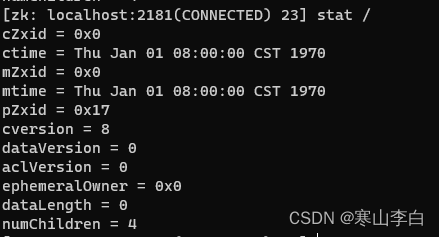
ZooKeeper中节点的操作命令(查看、创建、删除节点)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...