机器学习---使用 TensorFlow 构建神经网络模型预测波士顿房价和鸢尾花数据集分类
1. 预测波士顿房价
1.1 导包
from __future__ import absolute_import
from __future__ import division
from __future__ import print_functionimport itertoolsimport pandas as pd
import tensorflow as tftf.logging.set_verbosity(tf.logging.INFO)最后一行设置了TensorFlow日志的详细程度:
tf.logging.DEBUG:最详细的日志级别,用于记录调试信息。
tf.logging.INFO:用于记录一般的信息性消息,比如训练过程中的指标和进度。
tf.logging.WARN:用于记录警告消息,表示可能存在潜在问题,但不会导致程序终止。
tf.logging.ERROR:仅记录错误消息,表示程序遇到了错误并可能终止执行。
tf.logging.FATAL:记录严重错误消息,并终止程序的执行。
1.2 处理数据集
COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age","dis", "tax", "ptratio", "medv"]
FEATURES = ["crim", "zn", "indus", "nox", "rm","age", "dis", "tax", "ptratio"]
LABEL = "medv"training_set = pd.read_csv("boston_train.csv", skipinitialspace=True,skiprows=1, names=COLUMNS)
test_set = pd.read_csv("boston_test.csv", skipinitialspace=True,skiprows=1, names=COLUMNS)
prediction_set = pd.read_csv("boston_predict.csv", skipinitialspace=True,skiprows=1, names=COLUMNS)定义了一些列名和特征,并使用pd.read_csv函数读取了训练集、测试集和预测集的数据。
pd.read_csv函数来读取CSV文件,并将其转换为Pandas数据帧。

1.3 创建DNNRegressor对象
feature_cols = [tf.feature_column.numeric_column(k) for k in FEATURES]
regressor = tf.estimator.DNNRegressor(feature_columns=feature_cols,hidden_units=[50,50,50],model_dir="./boston_model")tf.feature_column.numeric_column函数用于创建一个表示数值特征的特征列。在这种情况下,它
会遍历FEATURES列表中的每个特征名称,并为每个特征创建一个数值特征列。
创建DNNRegressor对象的参数:
feature_columns:这是包含特征列的列表,用于定义输入的特征。在这里,您传递了之前创建
的feature_cols,它包含了用于模型训练的数值特征列。
hidden_units:这是一个整数列表,用于定义隐藏层的结构。在这个例子中,您定义了一个具
有3个隐藏层的DNN模型,每个隐藏层都有50个神经元。
model_dir:这是模型保存的目录路径。在这里,您指定了"./boston_model"作为模型保存的目录。

1.4 创建输入函数
def get_input_fn(data_set, num_epochs=None, shuffle=True):return tf.estimator.inputs.pandas_input_fn(x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),y = pd.Series(data_set[LABEL].values),num_epochs=num_epochs,shuffle=shuffle)该输入函数将Pandas数据帧作为输入,并将其转换为TensorFlow的输入格式。具体而言,它将特
征数据集(由FEATURES列表指定的列)转换为x,将标签数据(由LABEL指定的列)转换为y。
1.5 训练评估预测
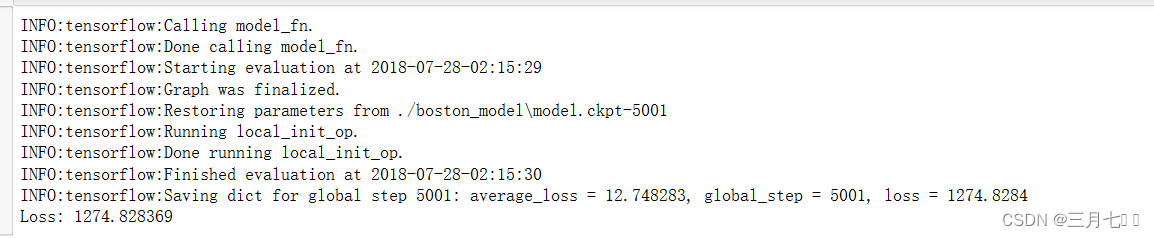
regressor.train(input_fn=get_input_fn(training_set), steps=5000)
ev = regressor.evaluate(input_fn=get_input_fn(test_set, num_epochs=1, shuffle=False))
loss_score = ev["loss"]
print("Loss: {0:f}".format(loss_score))
y = regressor.predict(input_fn=get_input_fn(prediction_set, num_epochs=1, shuffle=False))
# .predict() returns an iterator of dicts; convert to a list and print
# predictions
predictions = list(p["predictions"] for p in itertools.islice(y, 6))
print("Predictions: {}".format(str(predictions)))steps参数指定了训练的迭代步数,即模型将对训练数据执行多少次梯度下降更新。
使用get_input_fn获取输入函数,该函数将测试集(test_set)作为输入数据。num_epochs参数设
置为1,表示测试集只会被迭代一次,shuffle参数被设置为False,表示测试集不需要进行洗牌。
然后提取评估结果中的损失值(loss),并将其赋值给loss_score变量。
通过迭代预测结果的字典形式,将预测值提取出来,并将其存储在predictions列表中。


2. 鸢尾花数据集分类
import tensorflow as tf
import pandas as pdCOLUMN_NAMES = ['SepalLength', 'SepalWidth','PetalLength', 'PetalWidth', 'Species']# Import training dataset
training_dataset = pd.read_csv('iris_training.csv', names=COLUMN_NAMES, header=0)
train_x = training_dataset.iloc[:, 0:4]
train_y = training_dataset.iloc[:, 4]# Import testing dataset
test_dataset = pd.read_csv('iris_test.csv', names=COLUMN_NAMES, header=0)
test_x = test_dataset.iloc[:, 0:4]
test_y = test_dataset.iloc[:, 4]# Setup feature columns
columns_feat = [tf.feature_column.numeric_column(key='SepalLength'),tf.feature_column.numeric_column(key='SepalWidth'),tf.feature_column.numeric_column(key='PetalLength'),tf.feature_column.numeric_column(key='PetalWidth')
]# Build Neural Network - Classifier
classifier = tf.estimator.DNNClassifier(feature_columns=columns_feat,# Two hidden layers of 10 nodes each.hidden_units=[10, 10],# The model is classifying 3 classesn_classes=3)# Define train function
def train_function(inputs, outputs, batch_size):dataset = tf.data.Dataset.from_tensor_slices((dict(inputs), outputs))dataset = dataset.shuffle(1000).repeat().batch(batch_size)return dataset.make_one_shot_iterator().get_next()# Train the Model.
classifier.train(input_fn=lambda:train_function(train_x, train_y, 100),steps=1000)# Define evaluation function
def evaluation_function(attributes, classes, batch_size):attributes=dict(attributes)if classes is None:inputs = attributeselse:inputs = (attributes, classes)dataset = tf.data.Dataset.from_tensor_slices(inputs)assert batch_size is not None, "batch_size must not be None"dataset = dataset.batch(batch_size)return dataset.make_one_shot_iterator().get_next()# Evaluate the model.
eval_result = classifier.evaluate(input_fn=lambda:evaluation_function(test_x, test_y, 100))print('\nAccuracy: {accuracy:0.3f}\n'.format(**eval_result))首先导入所需的库,包括 TensorFlow 和 Pandas。然后,定义了一个包含特征列的列
表 columns_feat,用于描述输入数据的特征。接下来,通过 Pandas 读取训练集和测试集的数
据,并将其分为输入特征和输出类别。
然后,使用 tf.estimator.DNNClassifier 类构建了一个多层感知机神经网络分类器。该分类器具
有两个隐藏层,每个隐藏层包含10个节点,输出层用于分类3个类别的鸢尾花。
然后,定义了一个训练函数 train_function 和一个评估函数 evaluation_function,用于转换输
入数据并创建 TensorFlow 数据集。训练函数将训练数据转换为 Dataset 对象,并进行随机化、重
复和分批处理。评估函数将测试数据转换为 Dataset 对象,并进行分批处理。
最后,通过调用 classifier.train 方法来训练模型,使用训练函数作为输入函数,并指定训练步
数。然后,通过调用 classifier.evaluate 方法来评估模型的性能,使用评估函数作为输入函数,
并指定评估时的批大小。评估结果包括准确率,并通过 print 函数进行输出。
相关文章:
机器学习---使用 TensorFlow 构建神经网络模型预测波士顿房价和鸢尾花数据集分类
1. 预测波士顿房价 1.1 导包 from __future__ import absolute_import from __future__ import division from __future__ import print_functionimport itertoolsimport pandas as pd import tensorflow as tftf.logging.set_verbosity(tf.logging.INFO) 最后一行设置了Ten…...

铁合金电炉功率因数补偿装置设计
摘要 由于国内人民生活水平的提高,科技不断地进步,控制不断地完善,从而促使功率因数补偿装置在电力等系统领域占据主导权,也使得功率因数补偿控制系统被广泛应用。在铁合金电炉系统设计领域中,功率因数补偿控制成为目前…...

表格识别软件:科技革新引领行业先锋,颠覆性发展前景广阔
表格识别软件的兴起背景可以追溯到数字化和自动化处理的需求不断增加的时期。传统上,手动处理纸质表格是一项费时费力的工作,容易出现错误,效率低下。因此,开发出能够自动识别和提取表格数据的软件工具变得非常重要。 随着计算机…...
【Redis】高并发分布式结构服务器
文章目录 服务端高并发分布式结构名词基本概念评价指标1.单机架构缺点 2.应用数据分离架构应用服务集群架构读写分离/主从分离架构引入缓存-冷热分离架构分库分表(垂直分库)业务拆分⸺微服务 总结 服务端高并发分布式结构 名词基本概念 应⽤࿰…...

微信小程序拍照页面自定义demo
api文档 <template><div><imagemode"widthFix"style"width: 100%; height: 300px":src"imageSrc"v-if"imageSrc"></image><camerav-else:device-position"devicePosition":flash"flash&qu…...
单目标应用:进化场优化算法(Evolutionary Field Optimization,EFO)求解微电网优化MATLAB
一、微网系统运行优化模型 微电网优化模型介绍: 微电网多目标优化调度模型简介_IT猿手的博客-CSDN博客 二、进化场优化算法EFO 进化场优化算法(Evolutionary Field Optimization,EFO)由Baris Baykant Alagoz等人于2022年提出&…...

推荐算法面试
当然可以,请看下面的解释和回答: 一面(7.5) 问题:推荐的岗位和其他算法岗(CV,NLP)有啥区别? 解释: 面试官可能想了解你对不同算法岗位的理解,包…...

长图切图怎么切
用PS的切片工具 切片工具——基于参考线的切片——ctrl+shift+s 过长的图片怎么切 ctrl+alt+i 查看图片的长宽看图片的长宽来切成两个板块(尽量中间切成两半)用选区工具选中下半部分的区域——在选完时不…...
动手学深度学习 - 学习环境配置
学习环境配置 1、安装 Miniconda1.1 下载 miniconda31.2 环境变量配置1.3 安装成功测试1.4 配置文件1.5 使用conda创建、使用、删除环境1.6 conda 常用命令 2、使用 miniconda 安装 d2l2.1 下载 d2l 安装包2.2 安装 d2l 1、安装 Miniconda 参考: https://www.jb51.n…...
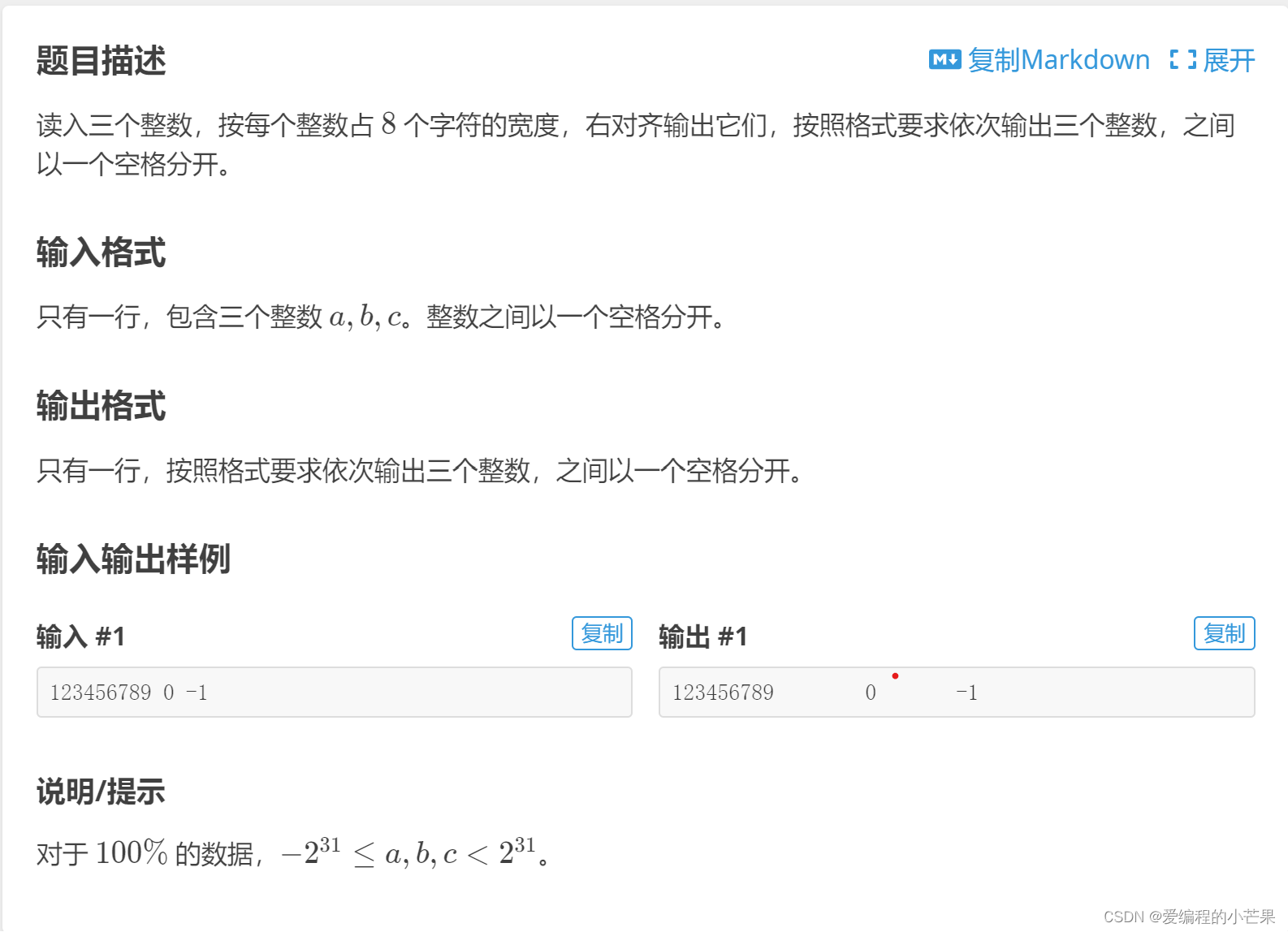
洛谷 B2004 对齐输出 C++代码
目录 推荐专栏 题目描述 AC Code 切记 推荐专栏 http://t.csdnimg.cn/Z1tCAhttp://t.csdnimg.cn/Z1tCA 题目描述 题目网址:对齐输出 - 洛谷 AC Code #include<bits/stdc.h> using namespace std; typedef long long ll; int main() { int a,b,c;cin&g…...
)
seccomp学习 (1)
文章目录 0x01. seccomp规则添加原理A. 默认规则B. 自定义规则 0x02. seccomp沙箱“指令”格式实例Task 01Task 02 0x03. 总结 今天打了ACTF-2023,惊呼已经不认识seccomp了,在被一道盲打题折磨了一整天之后,实在是不想面向题目高强度学习了。…...
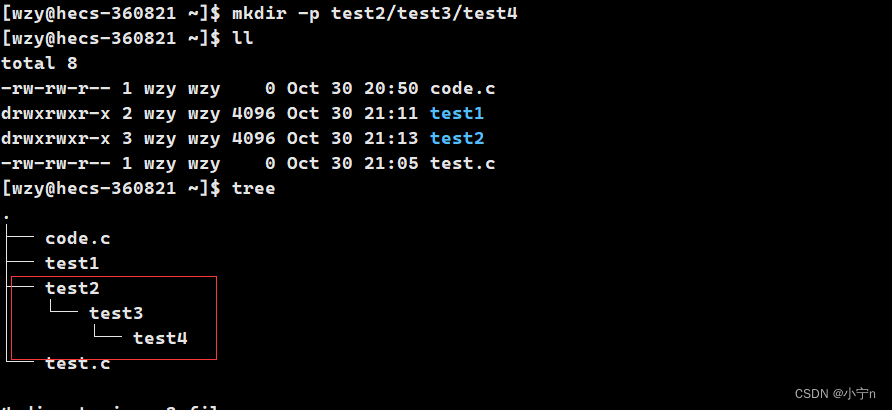
Linux指令【上】
目录 目录结构 ls cd stat touch mkdir whoami 查看当前帐号是谁 who 查看当前有哪些人在使用 pwd 当前的工作目录 目录结构 目录结构就是一颗多叉树的样子 路径 我们从 / 目录开始,定位一个叶子文件的…...
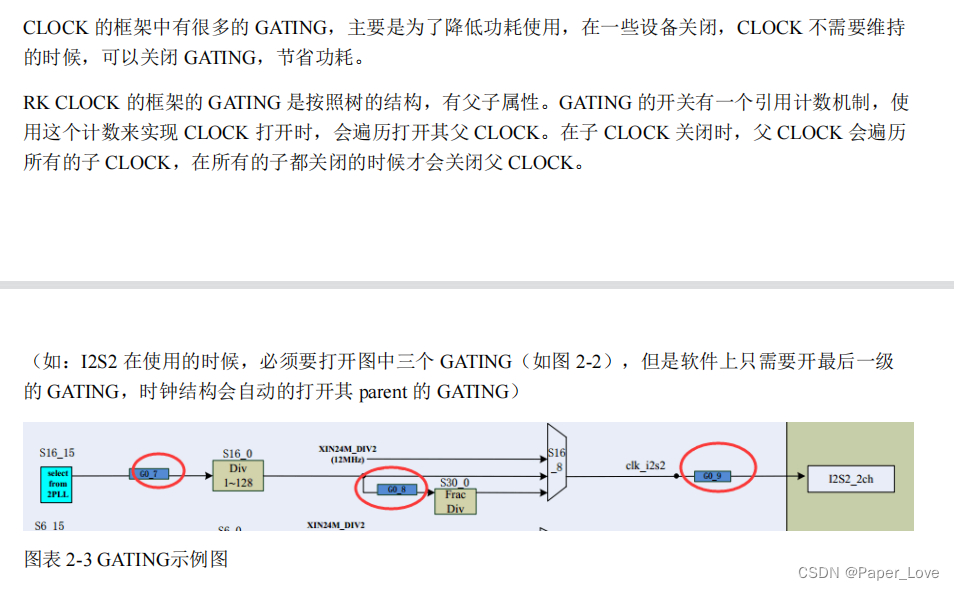
RK3568-clock
pll锁相环 总线 gating rk3568.dtsi pmucru: clock-controller@fdd00000 {compatible = "rockchip,rk3568-pmucru";reg = <0x0 0xfdd00000 0x0 0x1000>;rockchip,grf = <&grf>;rockchip,pmugrf = <&pmugrf>;#clock-cells = <1>;#re…...
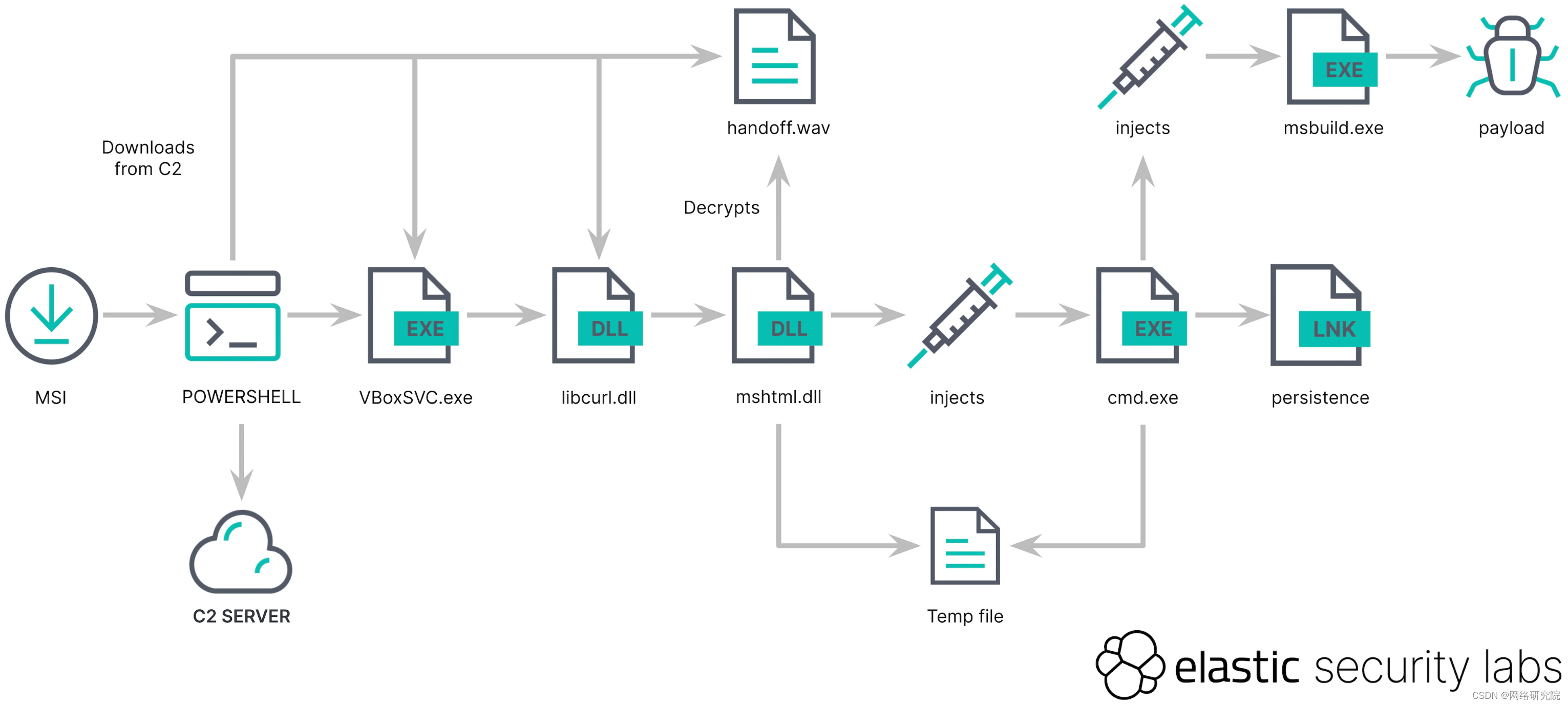
新恶意软件使用 MSIX 软件包来感染 Windows
人们发现,一种新的网络攻击活动正在使用 MSIX(一种 Windows 应用程序打包格式)来感染 Windows PC,并通过将隐秘的恶意软件加载程序放入受害者的 PC 中来逃避检测。 Elastic Security Labs 的研究人员发现,开发人员通常…...

干货!数字IC后端入门学习笔记
很多同学想要了解IC后端,今天大家分享了数字IC后端的学习入门笔记,供大家学习参考。 很多人对于后端设计的概念比较模糊,需要做什么也都不甚清楚。 有的同学认为就是跑跑 flow、掌握各类工具。 事实上,后端设计的工作远不止于此。…...
力扣:144. 二叉树的前序遍历(Python3)
题目: 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 来源:力扣(LeetCode) 链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 示例: 示例 1: 输…...

【数据挖掘 | 数据预处理】缺失值处理 重复值处理 文本处理 确定不来看看?
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...
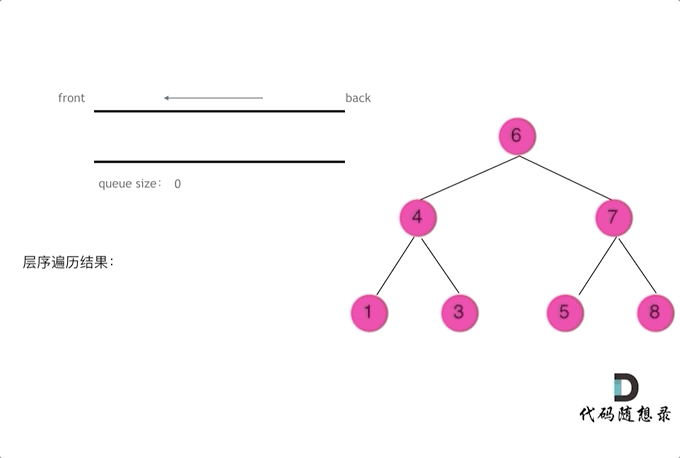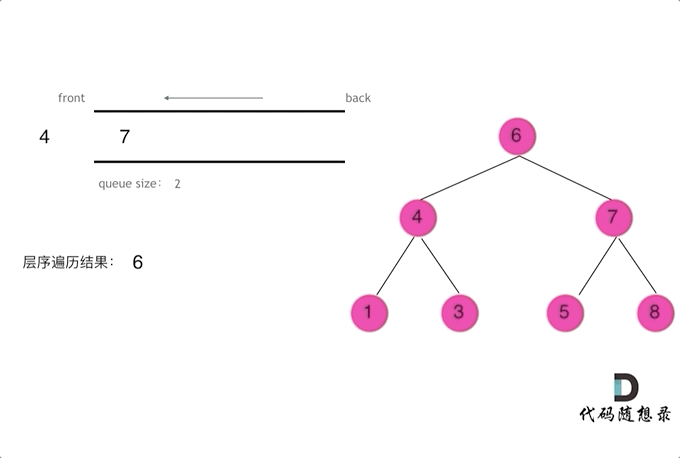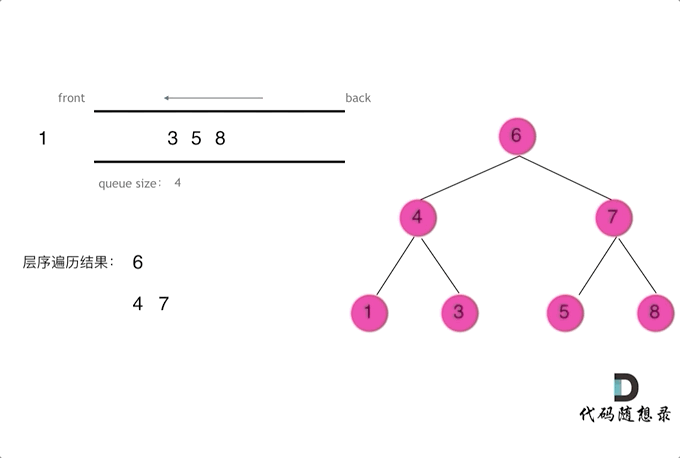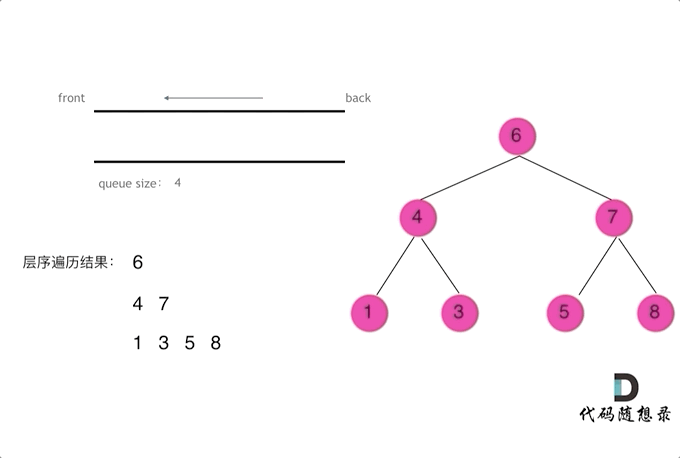
二叉树问题——前/中/后/层遍历(递归与栈)
摘要 博文主要介绍二叉树的前/中/后/层遍历(递归与栈)方法 一、前/中/后/层遍历问题 144. 二叉树的前序遍历 145. 二叉树的后序遍历 94. 二叉树的中序遍历 102. 二叉树的层序遍历 二、二叉树遍历递归解析 // 前序遍历递归LC144_二叉树的前序遍历 class Solution {publi…...

Nor Flash和Nand Flash的区别——笔记
NorFlash:串行存储器、读取速度比较快(比NandFlash快),适合用于存储程序代码和执行代码,但NorFlash写入速度比较慢、容量比较小。数据线和地址线是分开的。 NandFlash:并行存储器、写入速度比较快…...
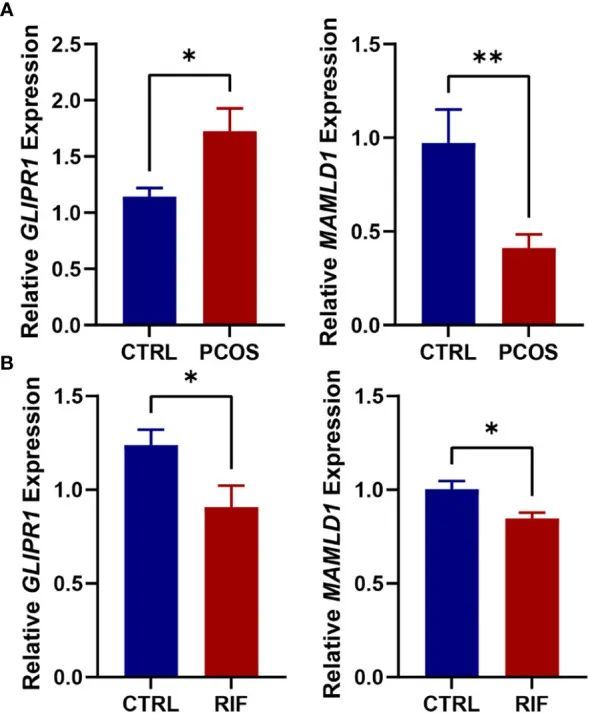
7+共病思路。WGCNA+多机器学习+实验简单验证,易操作
今天给同学们分享一篇共病WGCNA多机器学习实验的生信文章“Shared diagnostic genes and potential mechanism between PCOS and recurrent implantation failure revealed by integrated transcriptomic analysis and machine learning”,这篇文章于2023年5月16日发…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...