PostgreSQL基于Patroni方案的高可用启动流程分析
什么是Patroni
在很多生产环境中,分布式数据库以高可用性、数据分布性、负载均衡等特性,被用户广泛应用。而作为高可用数据库的解决方案——Patroni,是专门为PostgreSQL数据库设计的,一款以Python语言实现的高可用架构模板。该架构模板,旨在通过外部共享存储软件(kubernetes、etcd、etcd3、zookeeper、aws等),实现 PostgreSQL 集群的自动故障恢复、自动故障转移、自动备份等能力。
主要特点:
1.自动故障检测和恢复:Patroni 监视 PostgreSQL 集群的健康状态,一旦检测到主节点故障,它将自动执行故障恢复操作,将其中一个从节点晋升为主节点。
2.自动故障转移:一旦 Patroni 定义了新的主节点,它将协调所有从节点和客户端,以确保它们正确地切换到新的主节点,从而实现快速、无缝的故障转移。
3.一致性和数据完整性:Patroni 高度关注数据一致性和完整性。在故障切换过程中,它会确保在新主节点接管之前,数据不会丢失或受损。
4.外部共享配置存储:Patroni 使用外部键值存储(如 ZooKeeper、etcd 或 Consul)来存储配置和集群状态信息。这确保了配置的一致性和可访问性,并支持多个 Patroni 实例之间的协作。
5.支持多种云环境和物理硬件:Patroni 不仅可以在云环境中运行,还可以部署在物理硬件上,提供了广泛的部署选项。
Patroni架构解析
●DCS(Distributed Configuration Store ):是指分布式配置信息的存储位置,可支持kubernetes、etcd、etcd3、zookeeper、aws等存储媒介,由Patroni进行分布式配置信息的读写。
●核心Patroni:负责将分布式配置信息写入DCS中,并设置PostgreSQL节点的角色以及PostgreSQL配置信息,管理PostgreSQL的生命周期。
●PostgreSQL节点:各PostgreSQL节点,根据Patroni设置的PostgreSQL配置信息,生成主从关系链,以流复制的方式进行数据同步,最终生成一个PostgreSQL集群。
Patroni高可用源码分析
Patroni高可用启动流程
流程说明:
●加载集群信息,通过DCS支持的API接口,获取集群信息,主要内容如下:
○config:记录pg集群ID以及配置信息(包括pg参数信息、一些超时时间配置等),用于集群校验、节点重建等;
○leader:记录主节点选举时间、心跳时间、选举周期、最新的lsn等,用于主节点完成竞争后的信息记录;
○sync: 记录主节点和同步节点信息,由主节点记录,用于主从切换、故障转移的同步节点校验;
○failover: 记录最后一次故障转移的时间。
●集群状态检测,主要检测集群配置信息的内容校验,当前集群的整体状态及节点状态,判断通过什么方式来启动PostgreSQL;
●启动PostgreSQL,用于初始化PostgreSQL目录,根据集群信息设置相应的PostgreSQL配置信息,并启动;
●生成PostgreSQL集群,指将完成启动的PostgreSQL节点,通过设置主从角色,关联不同角色的PostgreSQL节点,最终生成完整的集群。
Patroni高可用启动流程分析
加载集群信息
加载集群信息,是高可用流程启动的第一步,也是生成PostgreSQL集群的最关键信息。
第一步,记载集群信息
…
try:self.load_cluster_from_dcs()self.state_handler.reset_cluster_info_state(self.cluster, self.patroni.nofailover)
except Exception:self.state_handler.reset_cluster_info_state(None, self.patroni.nofailover)raise
......
通过DCS接口加载集群信息
def load_cluster_from_dcs(self):
cluster = self.dcs.get_cluster()
# We want to keep the state of cluster when it was healthy
if not cluster.is_unlocked() or not self.old_cluster:self.old_cluster = cluster
self.cluster = clusterif not self.has_lock(False):self.set_is_leader(False)self._leader_timeline = None if cluster.is_unlocked() else cluster.leader.timeline
集群接口
def get_cluster(self, force=False):if force:self._bypass_caches()try:cluster = self._load_cluster()except Exception:self.reset_cluster()raise
self._last_seen = int(time.time())with self._cluster_thread_lock:self._cluster = clusterself._cluster_valid_till = time.time() + self.ttlreturn cluster
@abc.abstractmethod
def _load_cluster(self):"""Internally this method should build `Cluster` object whichrepresents current state and topology of the cluster in DCS.this method supposed to be called only by `get_cluster` method.
raise `~DCSError` in case of communication or other problems with DCS.If the current node was running as a master and exception raised,instance would be demoted."""
以Kubernetes作为DCS为例
def _load_cluster(self):stop_time = time.time() + self._retry.deadlineself._api.refresh_api_servers_cache()try:with self._condition:self._wait_caches(stop_time)
members = [self.member(pod) for pod in self._pods.copy().values()]nodes = self._kinds.copy()config = nodes.get(self.config_path)metadata = config and config.metadataannotations = metadata and metadata.annotations or {}# get initialize flaginitialize = annotations.get(self._INITIALIZE)# get global dynamic configurationconfig = ClusterConfig.from_node(metadata and metadata.resource_version,annotations.get(self._CONFIG) or '{}',metadata.resource_version if self._CONFIG in annotations else 0)# get timeline historyhistory = TimelineHistory.from_node(metadata and metadata.resource_version,annotations.get(self._HISTORY) or '[]')leader = nodes.get(self.leader_path)metadata = leader and leader.metadataself._leader_resource_version = metadata.resource_version if metadata else Noneannotations = metadata and metadata.annotations or {}# get last known leader lsnlast_lsn = annotations.get(self._OPTIME)try:last_lsn = 0 if last_lsn is None else int(last_lsn)except Exception:last_lsn = 0# get permanent slots state (confirmed_flush_lsn)slots = annotations.get('slots')try:slots = slots and json.loads(slots)except Exception:slots = None# get leaderleader_record = {n: annotations.get(n) for n in (self._LEADER, 'acquireTime','ttl', 'renewTime', 'transitions') if n in annotations}if (leader_record or self._leader_observed_record) and leader_record != self._leader_observed_record:self._leader_observed_record = leader_recordself._leader_observed_time = time.time()leader = leader_record.get(self._LEADER)try:ttl = int(leader_record.get('ttl')) or self._ttlexcept (TypeError, ValueError):ttl = self._ttlif not metadata or not self._leader_observed_time or self._leader_observed_time + ttl < time.time():leader = Noneif metadata:member = Member(-1, leader, None, {})member = ([m for m in members if m.name == leader] or [member])[0]leader = Leader(metadata.resource_version, None, member)# failover keyfailover = nodes.get(self.failover_path)metadata = failover and failover.metadatafailover = Failover.from_node(metadata and metadata.resource_version,metadata and (metadata.annotations or {}).copy())# get synchronization statesync = nodes.get(self.sync_path)metadata = sync and sync.metadatasync = SyncState.from_node(metadata and metadata.resource_version, metadata and metadata.annotations)return Cluster(initialize, config, leader, last_lsn, members, failover, sync, history, slots)
except Exception:logger.exception('get_cluster')raise KubernetesError('Kubernetes API is not responding properly')
上述集群信息中,主要以xxx-config、xxx-leader、xxx-failover、xxx-sync作为配置信息,具体内容如下:
●xxx-config
% kubectl get cm pg142-1013-postgresql-config -oyaml
apiVersion: v1
kind: ConfigMap
metadata:annotations:config: '{"loop_wait":10,"maximum_lag_on_failover":33554432,"postgresql":{"parameters":{"archive_command":"/bin/true","archive_mode":"on","archive_timeout":"1800s","autovacuum":"on","autovacuum_analyze_scale_factor":0.02,"autovacuum_max_workers":"3","autovacuum_naptime":"5min","autovacuum_vacuum_cost_delay":"2ms","autovacuum_vacuum_cost_limit":"-1","autovacuum_vacuum_scale_factor":0.05,"autovacuum_work_mem":"128MB","backend_flush_after":"0","bgwriter_delay":"200ms","bgwriter_flush_after":"256","bgwriter_lru_maxpages":"100","bgwriter_lru_multiplier":"2","checkpoint_completion_target":"0.9","checkpoint_flush_after":"256kB","checkpoint_timeout":"5min","commit_delay":"0","constraint_exclusion":"partition","datestyle":"iso,mdy","deadlock_timeout":"1s","default_text_search_config":"pg_catalog.english","dynamic_shared_memory_type":"posix","effective_cache_size":"32768","fsync":"on","full_page_writes":"on","hot_standby":"on","hot_standby_feedback":"off","huge_pages":"off","idle_in_transaction_session_timeout":"600000","lc_messages":"en_US.UTF-8","lc_monetary":"en_US.UTF-8","lc_numeric":"en_US.UTF-8","lc_time":"en_US.UTF-8","listen_addresses":"*","log_autovacuum_min_duration":"0","log_checkpoints":"on","log_connections":"off","log_disconnections":"off","log_error_verbosity":"default","log_line_prefix":"%t[%p]: [%l-1] %c %x %d %u %a %h","log_lock_waits":"on","log_min_duration_statement":"500","log_rotation_size":"0","log_statement":"none","log_temp_files":0,"log_timezone":"Asia/Shanghai","maintenance_work_mem":"32768","max_connections":"170","max_parallel_maintenance_workers":"2","max_parallel_workers":"2","max_parallel_workers_per_gather":"2","max_replication_slots":"10","max_standby_archive_delay":"30s","max_standby_streaming_delay":"30s","max_wal_senders":"10","max_wal_size":"2048","max_worker_processes":"8","old_snapshot_threshold":"-1","pg_stat_statements.max":"10000","pg_stat_statements.save":"on","pg_stat_statements.track":"all","pgaudit.log":"NONE","pgaudit.log_catalog":"on","pgaudit.log_client":"off","pgaudit.log_level":"log","pgaudit.log_parameter":"off","pgaudit.log_relation":"off","pgaudit.log_rows":"off","pgaudit.log_statement":"on","pgaudit.log_statement_once":"off","pgaudit.role":"","random_page_cost":"4","restart_after_crash":"on","synchronous_commit":"on","tcp_keepalives_count":"0","tcp_keepalives_idle":"900","tcp_keepalives_interval":"100","temp_buffers":"8MB","timezone":"Asia/Shanghai","track_activity_query_size":"1kB","track_functions":"all","track_io_timing":"off","unix_socket_directories":"/var/run/postgresql","vacuum_cost_delay":"0ms","vacuum_cost_limit":"200","wal_buffers":"2048","wal_compression":"on","wal_keep_segments":"128","wal_keep_size":"2048MB","wal_level":"replica","wal_log_hints":"on","wal_receiver_status_interval":"10s","wal_sender_timeout":"1min","wal_writer_delay":"200ms","wal_writer_flush_after":"1MB","work_mem":"4MB"},"use_pg_rewind":true,"use_slots":true},"retry_timeout":10,"synchronous_mode":true,"ttl":30}'initialize: "7289263672843878470"creationTimestamp: "2023-10-13T02:25:51Z"labels:application: spilocluster-name: pg142-1013-postgresqlname: pg142-1013-postgresql-confignamespace: defaultresourceVersion: "22858249"uid: dfa64d28-e939-4bdd-8db1-a3485fa09637
上述例子中,下有和2个参数,
1.定义集群的整体配置信息,这里包含了PostgreSQL配置参数以及集群参数(选举等待时间、允许的最大WAL延迟量、是否开启同步模式等)等;
2.定义了集群的ID,该值对应pg_controldata命令内的值,因此,所有集群内的PostgreSQL节点有相同的sys_id。
root@pg142-1013-postgresql-1:/home/postgres# pg_controldata | grep "Database system identifier"
Database system identifier: 7289263672843878470
●xxx-leader
% kubectl get cm pg142-1013-postgresql-leader -oyaml
apiVersion: v1
kind: ConfigMap
metadata:annotations:acquireTime: "2023-10-13T02:26:06.973552+00:00"leader: pg142-1013-postgresql-0optime: "67109192"renewTime: "2023-10-16T07:02:57.418940+00:00"transitions: "0"ttl: "30"creationTimestamp: "2023-10-13T02:26:07Z"labels:application: spilocluster-name: pg142-1013-postgresqlname: pg142-1013-postgresql-leadernamespace: defaultresourceVersion: "23286847"uid: cb235c85-6a21-454d-8320-222205eaa77f
上述下,各参数含义:
1.acquireTime:获取集群leader锁时间;
2.leader:集群leader锁的拥有者,这里表示某个PostgreSQL节点名称;
3.optime:集群leader的最新LSN的十进制数,这里;
4.renewTime:集群leader锁的拥有者心跳时间,心跳周期与xxx-config中的对应;
5.transitions:集群leader锁占用次数,一般发生在主从切换或故障转移场景,依次累加;
6.ttl:故障转移前的选举时间,即超过TTL时间下,没有获取到renewTime值更新,便触发选举,由新的节点占用leader锁。
●xxx-sync
% kubectl get cm pg142-1013-postgresql-sync -oyaml
apiVersion: v1
kind: ConfigMap
metadata:annotations:leader: pg142-1013-postgresql-1sync_standby: pg142-1013-postgresql-0creationTimestamp: "2023-10-16T06:54:39Z"labels:application: spilocluster-name: pg142-1013-postgresqlname: pg142-1013-postgresql-syncnamespace: defaultresourceVersion: "23288352"uid: 1c46e63b-8b90-4fc6-9596-8e2f71fba2ab
上述内容记录了2个信息:
1.leader:显示leader节点的名称;
2.sync_standby:显示同步节点的名称,多个同步节点以逗号分隔。
●xxx-failover
% kubectl get cm pg142-1013-postgresql-failover -oyaml
apiVersion: v1
kind: ConfigMap
metadata:creationTimestamp: "2023-10-16T07:16:03Z"labels:application: spilocluster-name: pg142-1013-postgresqlmanagedFields:- apiVersion: v1fieldsType: FieldsV1fieldsV1:f:metadata:f:labels:.: {}f:application: {}f:cluster-name: {}manager: Patronioperation: Updatetime: "2023-10-16T07:36:56Z"name: pg142-1013-postgresql-failovernamespace: defaultresourceVersion: "23290596"uid: 72d50c58-bc65-4b77-8870-93d0b8f8b7a2
上述内容,主要记录最后一次故障转移发生的时间。
集群状态检测
if self.is_paused():self.watchdog.disable()self._was_paused = Trueelse:if self._was_paused:self.state_handler.schedule_sanity_checks_after_pause()self._was_paused = Falseif not self.cluster.has_member(self.state_handler.name):self.touch_member()# cluster has leader key but not initialize keyif not (self.cluster.is_unlocked() or self.sysid_valid(self.cluster.initialize)) and self.has_lock():self.dcs.initialize(create_new=(self.cluster.initialize is None), sysid=self.state_handler.sysid)if not (self.cluster.is_unlocked() or self.cluster.config and self.cluster.config.data) and self.has_lock():self.dcs.set_config_value(json.dumps(self.patroni.config.dynamic_configuration, separators=(',', ':')))self.cluster = self.dcs.get_cluster()if self._async_executor.busy:return self.handle_long_action_in_progress()msg = self.handle_starting_instance()if msg is not None:return msg# we've got here, so any async action has finished.if self.state_handler.bootstrapping:return self.post_bootstrap()if self.recovering:self.recovering = Falseif not self._rewind.is_needed:# Check if we tried to recover from postgres crash and failedmsg = self.post_recover()if msg is not None:return msg# Reset some states after postgres successfully started upself._crash_recovery_executed = Falseif self._rewind.executed and not self._rewind.failed:self._rewind.reset_state()# The Raft cluster without a quorum takes a bit of time to stabilize.# Therefore we want to postpone the leader race if we just started up.if self.cluster.is_unlocked() and self.dcs.__class__.__name__ == 'Raft':return 'started as a secondary'
检测集群是否暂停
集群暂停,是指集群中的PostgreSQL节点不由Patroni管理,当集群异常时,不再出发故障转移等措施。
集群暂停一般由用户主动出发,可以用在单个PostgreSQL节点的维护上,触发方式:
root@pg142-1013-postgresql-0:/home/postgres# patronictl list
+ Cluster: pg142-1013-postgresql (7289263672843878470) ---+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+-------------------------+----------------+--------------+---------+----+-----------+
| pg142-1013-postgresql-0 | 10.244.117.143 | Leader | running | 3 | |
| pg142-1013-postgresql-1 | 10.244.165.220 | Sync Standby | running | 3 | 0 |
+-------------------------+----------------+--------------+---------+----+-----------+
root@pg142-1013-postgresql-0:/home/postgres# patronictl pause
Success: cluster management is paused
root@pg142-1013-postgresql-0:/home/postgres# patronictl list
+ Cluster: pg142-1013-postgresql (7289263672843878470) ---+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+-------------------------+----------------+--------------+---------+----+-----------+
| pg142-1013-postgresql-0 | 10.244.117.143 | Leader | running | 3 | |
| pg142-1013-postgresql-1 | 10.244.165.220 | Sync Standby | running | 3 | 0 |
+-------------------------+----------------+--------------+---------+----+-----------+Maintenance mode: on
上述,即表示当前集群已停止。此时,PostgreSQL进程仍然存活,如果故障,将需要用户自行启动。
集群暂停恢复方式:
root@pg142-1013-postgresql-0:/home/postgres# patronictl list
+ Cluster: pg142-1013-postgresql (7289263672843878470) ---+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+-------------------------+----------------+--------------+---------+----+-----------+
| pg142-1013-postgresql-0 | 10.244.117.143 | Leader | running | 3 | |
| pg142-1013-postgresql-1 | 10.244.165.220 | Sync Standby | running | 3 | 0 |
+-------------------------+----------------+--------------+---------+----+-----------+Maintenance mode: on
root@pg142-1013-postgresql-0:/home/postgres# patronictl resume
Success: cluster management is resumed
root@pg142-1013-postgresql-0:/home/postgres# patronictl list
+ Cluster: pg142-1013-postgresql (7289263672843878470) ---+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+-------------------------+----------------+--------------+---------+----+-----------+
| pg142-1013-postgresql-0 | 10.244.117.143 | Leader | running | 3 | |
| pg142-1013-postgresql-1 | 10.244.165.220 | Sync Standby | running | 3 | 0 |
+-------------------------+----------------+--------------+---------+----+-----------+
集群初始化检测
cluster has leader key but not initialize key通过命令,即可恢复集群。
在恢复集群后,需要对集群中PostgreSQL节点进行处理:
1.重新配置PostgreSQL的参数;
2.根据xxx-sync中最后一次记录的主、同步节点名称信息,在主节点上设置同步复制槽信息;
3.检测恢复后的PostgreSQL节点的是否变更,与最后一次xxx-config中的值,是否一致,否则将无法恢复集群。
if not (self.cluster.is_unlocked() or self.sysid_valid(self.cluster.initialize)) and self.has_lock():self.dcs.initialize(create_new=(self.cluster.initialize is None), sysid=self.state_handler.sysid)if not (self.cluster.is_unlocked() or self.cluster.config and self.cluster.config.data) and self.has_lock():self.dcs.set_config_value(json.dumps(self.patroni.config.dynamic_configuration, separators=(',', ':')))self.cluster = self.dcs.get_cluster()
集群初始化检测,主要检测2个方面的信息:
●集群当前存在leader节点,但xxx-config中的不存在,此时,需要将leader节点上PostgreSQL的sysid设置到xxx-config中;
●集群当前存在leader节点,但未获取到xxx-config信息,需要将leader节点上的配置信息和sysid都设置到xxx-config中,并重新获取集群信息。
该步骤的用途是,防止xxx-config文件被删除,导致从节点加载集群信息失败。
节点状态检测
检测当前PostgreSQL的进程启动到了什么阶段
if self._async_executor.busy:return self.handle_long_action_in_progress()
检测启动中的PostgreSQL是否出现异常
msg = self.handle_starting_instance()
if msg is not None:
return msg
节点状态检测,是通过检测PostgreSQL节点的当前运行状态,来确定是否需要进行具体的操作,节点状态检测的方式可分为2种:
1.通过PostgreSQL的运行状态确定;
2.通过异步进程(_async_executor)监听,当前节点处于什么阶段。
节点检测通过后基础操作
# we've got here, so any async action has finished.
if self.state_handler.bootstrapping:return self.post_bootstrap()if self.recovering:self.recovering = Falseif not self._rewind.is_needed:# Check if we tried to recover from postgres crash and failedmsg = self.post_recover()if msg is not None:return msg# Reset some states after postgres successfully started upself._crash_recovery_executed = Falseif self._rewind.executed and not self._rewind.failed:self._rewind.reset_state()# The Raft cluster without a quorum takes a bit of time to stabilize.# Therefore we want to postpone the leader race if we just started up.if self.cluster.is_unlocked() and self.dcs.__class__.__name__ == 'Raft':return 'started as a secondary'
节点状态检测通过后,需要对PostgreSQL进行操作:
1.PostgreSQL启动后操作
def post_bootstrap(self):with self._async_response:result = self._async_response.result# bootstrap has failed if postgres is not runningif not self.state_handler.is_running() or result is False:self.cancel_initialization()
if result is None:if not self.state_handler.is_leader():return 'waiting for end of recovery after bootstrap'self.state_handler.set_role('master')ret = self._async_executor.try_run_async('post_bootstrap', self.state_handler.bootstrap.post_bootstrap,args=(self.patroni.config['bootstrap'], self._async_response))return ret or 'running post_bootstrap'self.state_handler.bootstrapping = False
if not self.watchdog.activate():logger.error('Cancelling bootstrap because watchdog activation failed')self.cancel_initialization()
self._rewind.ensure_checkpoint_after_promote(self.wakeup)
self.dcs.initialize(create_new=(self.cluster.initialize is None), sysid=self.state_handler.sysid)
self.dcs.set_config_value(json.dumps(self.patroni.config.dynamic_configuration, separators=(',', ':')))
self.dcs.take_leader()
self.set_is_leader(True)
self.state_handler.call_nowait(ACTION_ON_START)
self.load_cluster_from_dcs()return 'initialized a new cluster'
上述操作,包括pg_rewind后的checkpoint检测、初始化DCS的xxx-config资源、生成xxx-leader资源、加载集群信息等。
2.恢复中的PostgreSQL检测是否需要执行pg_rewind
if self.recovering:
self.recovering = False
if not self._rewind.is_needed:# Check if we tried to recover from postgres crash and failedmsg = self.post_recover()if msg is not None:return msg# Reset some states after postgres successfully started up
self._crash_recovery_executed = False
if self._rewind.executed and not self._rewind.failed:self._rewind.reset_state()
pg_rewind命令用于将从节点的WAL与主节点的WAL拉齐,一般用于从节点WAL因异常后滞后于主节点WAL。
启动PostgreSQL
# is data directory empty?
if self.state_handler.data_directory_empty():self.state_handler.set_role('uninitialized')self.state_handler.stop('immediate', stop_timeout=self.patroni.config['retry_timeout'])# In case datadir went away while we were master.self.watchdog.disable()# is this instance the leader?if self.has_lock():self.release_leader_key_voluntarily()return 'released leader key voluntarily as data dir empty and currently leader'if self.is_paused():return 'running with empty data directory'return self.bootstrap() # new node
else:# check if we are allowed to joindata_sysid = self.state_handler.sysidif not self.sysid_valid(data_sysid):# data directory is not empty, but no valid sysid, cluster must be broken, suggest reinitreturn ("data dir for the cluster is not empty, ""but system ID is invalid; consider doing reinitialize")if self.sysid_valid(self.cluster.initialize):if self.cluster.initialize != data_sysid:if self.is_paused():logger.warning('system ID has changed while in paused mode. Patroni will exit when resuming'' unless system ID is reset: %s != %s', self.cluster.initialize, data_sysid)if self.has_lock():self.release_leader_key_voluntarily()return 'released leader key voluntarily due to the system ID mismatch'else:logger.fatal('system ID mismatch, node %s belongs to a different cluster: %s != %s',self.state_handler.name, self.cluster.initialize, data_sysid)sys.exit(1)elif self.cluster.is_unlocked() and not self.is_paused():# "bootstrap", but data directory is not emptyif not self.state_handler.cb_called and self.state_handler.is_running() \and not self.state_handler.is_leader():self._join_aborted = Truelogger.error('No initialize key in DCS and PostgreSQL is running as replica, aborting start')logger.error('Please first start Patroni on the node running as master')sys.exit(1)self.dcs.initialize(create_new=(self.cluster.initialize is None), sysid=data_sysid)
无数据目录启动
无数据目录启动,是指在执行初始化目录异常、恢复节点异常、WAL拉齐异常等场景下,会触发的流程:
1.设置角色,用于后续重新初始化集群;
2.立即停止当前PostgreSQL进程;
3.判断当前节点是否为主节点,主动释放主节点锁;
4.执行启动操作。
def bootstrap(self):if not self.cluster.is_unlocked(): # cluster already has leaderclone_member = self.cluster.get_clone_member(self.state_handler.name)member_role = 'leader' if clone_member == self.cluster.leader else 'replica'msg = "from {0} '{1}'".format(member_role, clone_member.name)ret = self._async_executor.try_run_async('bootstrap {0}'.format(msg), self.clone, args=(clone_member, msg))return ret or 'trying to bootstrap {0}'.format(msg)# no initialize key and node is allowed to be master and has 'bootstrap' section in a configuration fileelif self.cluster.initialize is None and not self.patroni.nofailover and 'bootstrap' in self.patroni.config:if self.dcs.initialize(create_new=True): # race for initializationself.state_handler.bootstrapping = Truewith self._async_response:self._async_response.reset()if self.is_standby_cluster():ret = self._async_executor.try_run_async('bootstrap_standby_leader', self.bootstrap_standby_leader)return ret or 'trying to bootstrap a new standby leader'else:ret = self._async_executor.try_run_async('bootstrap', self.state_handler.bootstrap.bootstrap,args=(self.patroni.config['bootstrap'],))return ret or 'trying to bootstrap a new cluster'else:return 'failed to acquire initialize lock'else:create_replica_methods = self.get_standby_cluster_config().get('create_replica_methods', []) \if self.is_standby_cluster() else Noneif self.state_handler.can_create_replica_without_replication_connection(create_replica_methods):msg = 'bootstrap (without leader)'return self._async_executor.try_run_async(msg, self.clone) or 'trying to ' + msgreturn 'waiting for {0}leader to bootstrap'.format('standby_' if self.is_standby_cluster() else '')
上述代码,表示启动的几种方式:
1.当前集群已有leader节点,当前PostgreSQL将以从节点从主节点上同步数据启动;
2.当前集群没有leader节点,当前PostgreSQL将以主节点启动,如果是备用集群,将以备用集群主节点启动;
3.当前集群为备用集群且没有主节点,从节点通过方式,一般通过协议流方式从主集群上进行数据同步。
有数据目录启动
有数据目录启动,主要校验集群ID与PostgreSQL节点sysid的一致性,触发的主要流程:
1.校验PostgreSQL节点sysid是否有效,如果无效,表示PostgreSQL出现了异常需要重启;
2.校验校验集群ID与PostgreSQL节点sysid是否一致,不一致将无法加入集群,如果集群已暂停,将会释放leader锁占用;
3.检验集群没有leader节点,当前节点将重新初始化集群,将sysid作为新的集群ID启动。
生成PostgreSQL集群
try:if self.cluster.is_unlocked():ret = self.process_unhealthy_cluster()else:msg = self.process_healthy_cluster()ret = self.evaluate_scheduled_restart() or msg
finally:# we might not have a valid PostgreSQL connection here if another thread# stops PostgreSQL, therefore, we only reload replication slots if no# asynchronous processes are running (should be always the case for the master)if not self._async_executor.busy and not self.state_handler.is_starting():create_slots = self.state_handler.slots_handler.sync_replication_slots(self.cluster,self.patroni.nofailover)if not self.state_handler.cb_called:if not self.state_handler.is_leader():self._rewind.trigger_check_diverged_lsn()self.state_handler.call_nowait(ACTION_ON_START)if create_slots and self.cluster.leader:err = self._async_executor.try_run_async('copy_logical_slots',self.state_handler.slots_handler.copy_logical_slots,args=(self.cluster.leader, create_slots))if not err:ret = 'Copying logical slots {0} from the primary'.format(create_slots)
生成PostgreSQL集群,主要根据当前集群是否存在主节点,判断走健康的集群流程还是非健康的集群流程。
非健康的集群流程
def process_unhealthy_cluster(self):"""Cluster has no leader key"""if self.is_healthiest_node():if self.acquire_lock():failover = self.cluster.failoverif failover:if self.is_paused() and failover.leader and failover.candidate:logger.info('Updating failover key after acquiring leader lock...')self.dcs.manual_failover('', failover.candidate, failover.scheduled_at, failover.index)else:logger.info('Cleaning up failover key after acquiring leader lock...')self.dcs.manual_failover('', '')self.load_cluster_from_dcs()if self.is_standby_cluster():# standby leader disappeared, and this is the healthiest# replica, so it should become a new standby leader.# This implies we need to start following a remote mastermsg = 'promoted self to a standby leader by acquiring session lock'return self.enforce_follow_remote_master(msg)else:return self.enforce_master_role('acquired session lock as a leader','promoted self to leader by acquiring session lock')else:return self.follow('demoted self after trying and failing to obtain lock','following new leader after trying and failing to obtain lock')else:# when we are doing manual failover there is no guaranty that new leader is ahead of any other node# node tagged as nofailover can be ahead of the new leader either, but it is always excluded from electionsif bool(self.cluster.failover) or self.patroni.nofailover:self._rewind.trigger_check_diverged_lsn()time.sleep(2) # Give a time to somebody to take the leader lockif self.patroni.nofailover:return self.follow('demoting self because I am not allowed to become master','following a different leader because I am not allowed to promote')return self.follow('demoting self because i am not the healthiest node','following a different leader because i am not the healthiest node')
非健康的集群流程,是确定leader节点的候选,首要条件必须找到一个健康的节点,如何判断健康的节点,主要有以下几个条件:
1.PostgreSQL集群状态非暂停;
2.PostgreSQL节点状态非启动中;
3.PostgreSQL节点允许故障转移;
4.PostgreSQL节点WAL与集群缓存中的(最后一次主节点同步的lsn值)的滞后量在允许的范围内。
def is_healthiest_node(self):
if time.time() - self._released_leader_key_timestamp < self.dcs.ttl:
logger.info(‘backoff: skip leader race after pre_promote script failure and releasing the lock voluntarily’)
return False
if self.is_paused() and not self.patroni.nofailover and
self.cluster.failover and not self.cluster.failover.scheduled_at:
ret = self.manual_failover_process_no_leader()
if ret is not None: # continue if we just deleted the stale failover key as a master
return ret
if self.state_handler.is_starting(): # postgresql still starting up is unhealthyreturn Falseif self.state_handler.is_leader():# in pause leader is the healthiest only when no initialize or sysid matches with initialize!return not self.is_paused() or not self.cluster.initialize\or self.state_handler.sysid == self.cluster.initializeif self.is_paused():return Falseif self.patroni.nofailover: # nofailover tag makes node always unhealthyreturn Falseif self.cluster.failover:# When doing a switchover in synchronous mode only synchronous nodes and former leader are allowed to raceif self.is_synchronous_mode() and self.cluster.failover.leader and \self.cluster.failover.candidate and not self.cluster.sync.matches(self.state_handler.name):return Falsereturn self.manual_failover_process_no_leader()if not self.watchdog.is_healthy:logger.warning('Watchdog device is not usable')return False# When in sync mode, only last known master and sync standby are allowed to promote automatically.all_known_members = self.cluster.members + self.old_cluster.membersif self.is_synchronous_mode() and self.cluster.sync and self.cluster.sync.leader:if not self.cluster.sync.matches(self.state_handler.name):return False# pick between synchronous candidates so we minimize unnecessary failovers/demotionsmembers = {m.name: m for m in all_known_members if self.cluster.sync.matches(m.name)}else:# run usual health checkmembers = {m.name: m for m in all_known_members}return self._is_healthiest_node(members.values())
…
def _is_healthiest_node(self, members, check_replication_lag=True):"""This method tries to determine whether I am healthy enough to became a new leader candidate or not."""
my_wal_position = self.state_handler.last_operation()if check_replication_lag and self.is_lagging(my_wal_position):logger.info('My wal position exceeds maximum replication lag')return False # Too far behind last reported wal position on masterif not self.is_standby_cluster() and self.check_timeline():cluster_timeline = self.cluster.timelinemy_timeline = self.state_handler.replica_cached_timeline(cluster_timeline)if my_timeline < cluster_timeline:logger.info('My timeline %s is behind last known cluster timeline %s', my_timeline, cluster_timeline)return False# Prepare list of nodes to run check againstmembers = [m for m in members if m.name != self.state_handler.name and not m.nofailover and m.api_url]if members:for st in self.fetch_nodes_statuses(members):if st.failover_limitation() is None:if not st.in_recovery:logger.warning('Master (%s) is still alive', st.member.name)return Falseif my_wal_position < st.wal_position:logger.info('Wal position of %s is ahead of my wal position', st.member.name)# In synchronous mode the former leader might be still accessible and even be ahead of us.# We should not disqualify himself from the leader race in such a situation.if not self.is_synchronous_mode() or st.member.name != self.cluster.sync.leader:return Falselogger.info('Ignoring the former leader being ahead of us')return True
当前节点为健康节点,因当前集群没有主节点,需要执行leader锁抢占。如果当前节点抢占leader锁失败,将作为从节点加入到集群中。
当前节点为异常节点,则会一直等待PostgreSQL节点正常后,参与集群的选举行为。
健康的集群流程
def process_healthy_cluster(self):if self.has_lock():if self.is_paused() and not self.state_handler.is_leader():if self.cluster.failover and self.cluster.failover.candidate == self.state_handler.name:return 'waiting to become master after promote...'
if not self.is_standby_cluster():self._delete_leader()return 'removed leader lock because postgres is not running as master'if self.update_lock(True):msg = self.process_manual_failover_from_leader()if msg is not None:return msg# check if the node is ready to be used by pg_rewindself._rewind.ensure_checkpoint_after_promote(self.wakeup)if self.is_standby_cluster():# in case of standby cluster we don't really need to# enforce anything, since the leader is not a master.# So just remind the role.msg = 'no action. I am ({0}), the standby leader with the lock'.format(self.state_handler.name) \if self.state_handler.role == 'standby_leader' else \'promoted self to a standby leader because i had the session lock'return self.enforce_follow_remote_master(msg)else:return self.enforce_master_role('no action. I am ({0}), the leader with the lock'.format(self.state_handler.name),'promoted self to leader because I had the session lock')else:# Either there is no connection to DCS or someone else acquired the locklogger.error('failed to update leader lock')if self.state_handler.is_leader():if self.is_paused():return 'continue to run as master after failing to update leader lock in DCS'self.demote('immediate-nolock')return 'demoted self because failed to update leader lock in DCS'else:return 'not promoting because failed to update leader lock in DCS'
else:logger.debug('does not have lock')lock_owner = self.cluster.leader and self.cluster.leader.nameif self.is_standby_cluster():return self.follow('cannot be a real primary in a standby cluster','no action. I am ({0}), a secondary, and following a standby leader ({1})'.format(self.state_handler.name, lock_owner), refresh=False)return self.follow('demoting self because I do not have the lock and I was a leader','no action. I am ({0}), a secondary, and following a leader ({1})'.format(self.state_handler.name, lock_owner), refresh=False)
健康的集群流程,是指当前的集群存在leader节点,对该流程的处理,主要有2个方向:
1.检测当前节点为主节点,进行更新leader锁操作,保持主节点心跳,避免从节点竞争锁,如果更新锁失败,将立即释放锁,让其他从节点抢占;
2.检测当前节点非主节点,作为从节点加入集群。
总结
综上所述,Patroni 是一个用于管理 PostgreSQL 数据库集群的高可用性(HA)管理工具,旨在确保数据库系统的连续可用性,以应对节点故障和维护操作等挑战。Patroni 提供了一系列关键功能和特点,使得它成为强大的高可用性解决方案。
总之,在很多场景中,Patroni能够保持PostgreSQL集群友好的运行,保证在集群异常的情况下,通过自动故障转移、数据同步和备份策略等功能,确保数据库集群的稳定性和可用性,使得应用程序能够持续访问数据,即使在节点故障或维护时也不会中断服务。
参考资源
Patroni配置参数https://patroni.readthedocs.io/en/latest/patroni_configuration.html
Patroni基于2.1.5分支源码https://github.com/zalando/patroni/tree/v2.1.5
相关文章:

PostgreSQL基于Patroni方案的高可用启动流程分析
什么是Patroni 在很多生产环境中,分布式数据库以高可用性、数据分布性、负载均衡等特性,被用户广泛应用。而作为高可用数据库的解决方案——Patroni,是专门为PostgreSQL数据库设计的,一款以Python语言实现的高可用架构模板。该架…...

opencv+yolov8实现监控画面报警功能
项目背景 最近停在门前的车被人开走了,虽然有监控,但是看监控太麻烦了,于是想着框选一个区域用yolov8直接检测闯入到这个区域的所有目标,这样1ms一帧,很快就可以跑完一天的视频 用到的技术 COpenCVYolov8 OnnxRunt…...
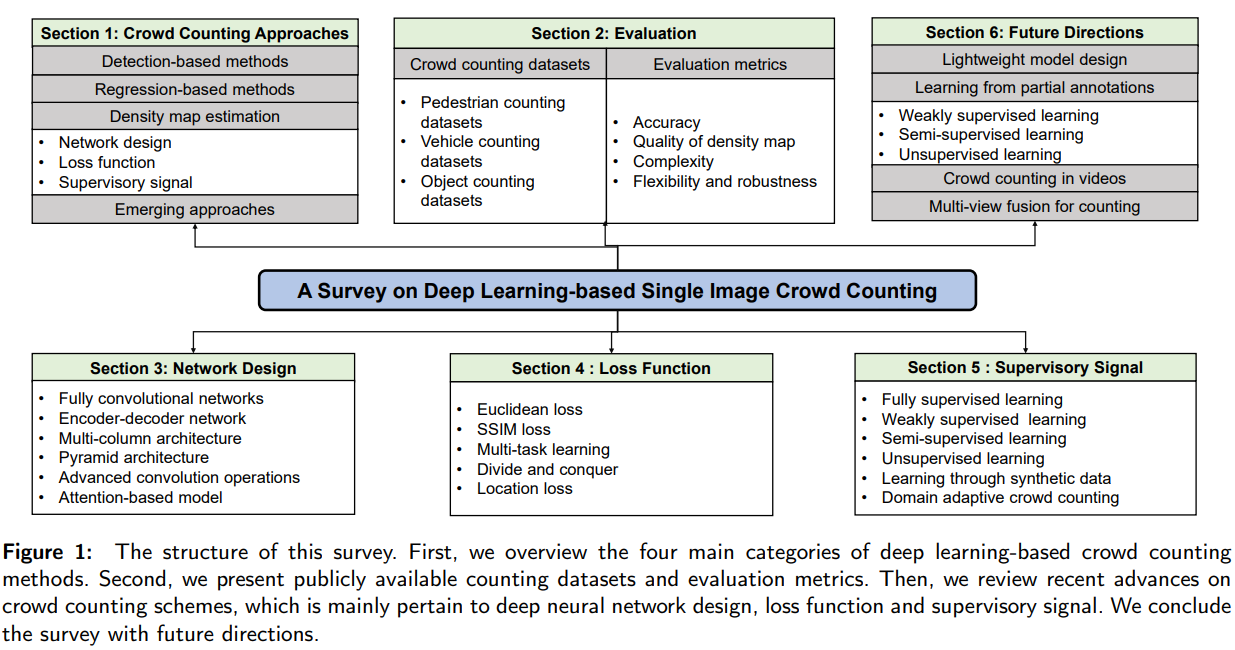
基于深度学习的单图像人群计数研究:网络设计、损失函数和监控信号
摘要 https://arxiv.org/pdf/2012.15685v2.pdf 单图像人群计数是一个具有挑战性的计算机视觉问题,在公共安全、城市规划、交通管理等领域有着广泛的应用。近年来,随着深度学习技术的发展,人群计数引起了广泛的关注并取得了巨大的成功。通过系统地回顾和总结2015年以来基于深…...

C++递归实现验证⼆叉搜索树
C递归实现验证⼆叉搜索树 文章目录 C递归实现验证⼆叉搜索树题目链接题目描述解题思路C算法代码: 题目链接 98. 验证二叉搜索树 - 力扣(LeetCode) 题目描述 给你⼀个⼆叉树的根节点root,判断其是否是⼀个有效的⼆叉搜索树。 有效⼆…...
♥ uniapp 环境搭建
♥ uniapp 环境搭建 开发uniapp需要用到的工具有两个: 1、用到的平台和地址: 需要了解的几个平台以及地址: (1)微信公众平台 https://mp.weixin.qq.com/ (2)微信开发文档 https://develo…...
,京东商品评论API接口,京东API接口)
京东商品链接获取京东商品评论数据(用 Python实现京东商品评论信息抓取),京东商品评论API接口,京东API接口
在网页抓取方面,可以使用 Python、Java 等编程语言编写程序,通过模拟 HTTP 请求,获取京东多网站上的商品详情页面评论内容。在数据提取方面,可以使用正则表达式、XPath 等方式从 HTML 代码中提取出有用的信息。值得注意的是&#…...
)
docker容器中安装ROS1/ROS2(不用配任何环境,10分钟搞定)
默认电脑已经安装了docker,没安装看这篇文章Docker 安装 (完整详细版) ROS和docker各种结合看官方文档 dockerTutorials 在OSRF中拉取想要的 ROS 版本 docker 镜像 网址为 拉取命令在这里 我是安装noetic版本,因为这个兼容比较多现有的工程 docker pul…...

如何解决ssh登录报错WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
原因: 当两个设备第一次进行链接时,会在~/.ssh/konwn_hosts 中将被连接设备的公钥信息进行保存,后续再次链接时OpenSSH会核对公钥来进行一个简单的验证 然而有时候被链接的那台设备系统被重装、IP 冲突等原因,会导致公钥信息没…...
Mysql5.7安装配置详细图文教程(msi版本)
博主介绍:✌全网粉丝5W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经验…...

运行dl4j-examples的主要一些依赖
直接从git获取dl4j-examples后本地无法用IJ直接运行样例,于是自己新建了一个springboot项目,主要使用了下面的一些依赖用来运行官方样例 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache…...

PSRAM伪静态RAM芯片APS6404L
PSRAM伪静态RAM能结合SRAM和DRAM的优点,即容量大,又接口驱动简单,PSRAM接口和SRAM一样简单,驱动简单;而存储形式则和DRAM一样,容量远大于SRAM,介于SRAM和DRAM之间。 PSRAM厂家也有很多,以AP用的最多。最常…...
低级语言汇编真的各个面不如汇编吗?
今日话题,低级语言汇编真的各个面不如C语言吗?C语言因其可移植性、开发效率和可读性而在各领域广泛使用,市场占有率极高。然而,汇编语言在特定场景下仍然具有独特优势,稳固地占据一席之地。如果你对这方面感兴趣&#…...

PyG edge index 转换回 邻接矩阵
PyG的edge index形式是 [ ( n o d e 1 , n o d e 2 ) , ( n o d e 1 , n o d e 3 ) . . . ] [(node_1,node_2), (node_1, node_3)...] [(node1,node2),(node1,node3)...]这种edge pair。 naive 直接for循环,吧edge index里面的位置填充1: imp…...

JavaSE19——file文件类
file文件类 在 Java File 类是 java.io 包中唯一代表磁盘文件本身的对象 File 类不能访问文件内容本身,如果需要访问文件内容本身,则需要使用输入/输出流。 File(String path):如果 path 是实际存在的路径,则该 File 对象表示的…...

mongodb记录
MongoDB导入导出和备份的命令工具从4.4版本开始不再自动跟随数据库一起安装,而是需要自己手动安装。 mongodump 不是内部或外部命令,也不是可运行的程序 下载mongodb命令工具 下载zip格式,解压后把bin目录下的文件全部复制粘贴到你MongoDB安…...

Go语言:数组和切片
Python中的数组(这里指的是List类型)及其切片Slice基本相同,但在Go语言中这两者差别很大。 1 数组 Go语言中的数组(Array)存放的是长度固定、类型固定并且存储位置连续的一系列元素。 1.1 声明 Go语言中数组的声明方式如下: arr1 : [5]string{"…...

OPENCV 闭运算实验示例代码morphologyEx()函数
void CrelaxMyFriendDlg::OnBnClickedOk() {hdc this->GetDC()->GetSafeHdc();// TODO: 在此添加控件通知处理程序代码string imAddr "c:/Users/actorsun/Pictures/";string imAddr1 imAddr"rice.png";Mat relax, positive;relax imread(imAddr1…...

UE4 体积云制作 学习笔记
首先Noise本来就是一张噪点图 云的扰动不能太大,将Scale调小,并将InputMin调整为0 形成这样一张扰动图 扰动需要根据材质在世界的位置进行调整,所以Position需要加上WorldPosition 材质在不同世界位置,噪点不同 除以一个数&#…...

visual studio编译QtAV
1.1 依赖环境 第一种方法: 下载编译好的ffmpeg-3.4.2-win64-dev和ffmpeg-3.4.2-win64-shared,解压得到 D:\qt-workspace\ffmpeg-3.4.2-win64-dev D:\qt-workspace\ffmpeg-3.4.2-win64-shared 第二种方法: QtAV官方有提供编译好的依赖库 QtAV-depends-windows-x86%2Bx64.7…...

喜报!CACTER邮件安全网关荣获2023鲲鹏应用创新大赛广东赛区三等奖
近期,2023鲲鹏应用创新大赛广东赛区暨广东省信息技术应用创新产业联盟创新大赛圆满落幕,Coremail凭借“基于鲲鹏CPU的邮件网关一体机解决方案”,荣获“金融行业方向”三等奖。 鲲鹏凌粤 展翅湾区 本届大赛广东区域赛以“鲲鹏凌粤 展翅湾…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...