scrapy框架爬取数据(创建一个scrapy项目+xpath解析数据+通过pipelines管道实现数据保存+中间件)
目录
一、创建一个scrapy项目
二、xpath解析数据
三、通过pipelines管道实现数据保存
四、中间件
一、创建一个scrapy项目
1.创建一个文件夹:C06
在终端输入以下命令:
2.安装scrapy:pip install scrapy
3.来到文件夹下:cd C06
4.创建项目:scrapy startproject C06L02(项目名称)
5.切换到C06L02下:cd C06L02/C06L02
切换到spiders下:cd spiders
6.创建爬虫名称和输入爬取链接:scrapy genspider app https://product.cheshi.com/rank/2-0-0-0-1/
(若是crawlspider爬虫字类实现全站爬取:scrapy genspider -t crawl app http://seller.cheshi.com/jinan/
7.注意看爬虫文件(新生成的app.py)链接是否一致
8.运行爬虫文件:scrapy crawl app
9.若想要消除日志文件,在settings.py中添加命令:LOG_LEVEL="ERROR"
若想要绕过ROBOTS协议,在settings.py中添加命令:ROBOTSTXT_OBEY=False
10.简单的scrapy项目的app.py文件代码如下:
import scrapyclass AppSpider(scrapy.Spider):name = "app"allowed_domains = ["product.cheshi.com"]started_urls = ["http://product.cheshi.com/rank/2-0-0-0-1/"]def parse(self, response):print(response.text)若是crawlspider爬虫字类实现全站爬取:
import scrapy
from scrapy.linkextractors import linkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass AppSpider(CrawlSpider):name = "app"allowed_domains = ["product.cheshi.com"]started_urls = ["http://product.cheshi.com/jinan"]rules = (Rule(linkExtractor(allow=r"seller.cheshi.com/\d+", deny=r"seller.cheshi.com/\d+/.+"),callback="parse_item",follow=True),)def parse(self, response):print(response.url)11.user-agent配置:在settings.py文件中将user-agent注释内容展开,添加需要内容
二、xpath解析数据
在app.py文件中修改parse函数
import scrapyclass AppSpider(scrapy.Spider):name = "app"allowed_domains = ["product.cheshi.com"]started_urls = ["http://product.cheshi.com/rank/2-0-0-0-1/"]def parse(self, response):cars = response.xpath('//ul[@class="condition_list_con"]/li')for car in cars:title = car.xpath('./div[@class="m_detail"]//a/text()').get()price = car.xpath('./div[@class="m_detail"]//b/text()').get()若实现分页爬取则为以下代码
import scrapy
from ..items import C06L10Itemclass AppSpider(scrapy.Spider):name = "app"allowed_domains = ["book.douban.com"]started_urls = ["http://book.douban.com/latest"]def parse(self, response):books = response.xpath('//ul[@class="chart-dashed-list"]/li')for book in books:link = book.xpath('.//h2/a/@href').get()yield scrapy.Request(url=link,callback=self.parse_details)next_url = response.xpath('//*[@id="content"]/div/div[1]/div[4]/span[4]/a/@href').get()if next_url is not None:next_url = response.urljoin(next_url)print(next_url)yield scrapy.Request(url=next_url, callback=self.parse)else:next_url = response.xpath('//*[@id="content"]/div/div[1]/div[4]/span[3]/a/@href').get()next_url = response.urljoin(next_url)print(next_url)yield scrapy.Request(url=next_url, callback=self.parse)def parse_details(self, reponse):item = C06L10Item()item["title"] = response.xpath('//*[id="wrapper"]/h1/span/text()').get()item["publisher"] = response.xpath('//*[id="info"]/a[1]/text()').get()yield item
三、通过pipelines管道实现数据保存
1.在items.py文件中定义数据模型
import scrapyclass C06L04Item(scrapy.Item):title = scrapy.Field()price = scrapy.Field()2.在app.py文件中添加如下代码
import scrapy
from ..items import C06L04Itemclass AppSpider(scrapy.Spider):name = "app"allowed_domains = ["product.cheshi.com"]started_urls = ["http://product.cheshi.com/rank/2-0-0-0-1/"]def parse(self, response):item = C06L04Item()cars = response.xpath('//ul[@class="condition_list_con"]/li')for car in cars:item["title"] = car.xpath('./div[@class="m_detail"]//a/text()').get()item["price"] = car.xpath('./div[@class="m_detail"]//b/text()').get()yield item3.在settings.py文件中展开被注释掉的ITEM_PIPELINES,无需修改
4.修改pipelines.py文件代码
from itemadapter import ItemAdapterclass C06L04Pipeline:def process_item(self, item, spider):# print(item["title"],item["price"])return item若想要保存成文件添加以下代码
from itemadapter import ItemAdapterclass C06L04Pipeline:def __init__(self):self.f = open("data.tet", "w")def process_item(self, item, spider):self.f.write(item["title"]+item["price"]+"\n")return itemdef __del__(self):self.f.close()存储为mongodb形式为如下代码
from itemadapter import ItemAdapter
import pymongoclass C06L04Pipeline:def __init__(self):self.client = pymongo.MongoClient("mongodb://localhost:27017")self.db = self.client["cheshi"]self.col = self.db["cars"]def process_item(self, item, spider):res = self.col.insert_one(dict(item))print(res.inserted_id)return itemdef __del__(self):print("end")四、中间件
1.Middleware的应用:随机User-Agent、代理IP、使用Selenium、添加Cookie
2.动态User-Agent
打开settings.py文件中注释掉的DOWNLOADER_MIDDLEWARES
在middlewares.py文件中添加如下代码(只显示修改部分):
import randomdef process_request(self, request, spider):uas = ["User-Agent:Mxxxxxxxxxxxxxxxxxxxxxxxx","User-Agent:Mxxxxxxxxxxxxxxxxxxxxxxxx","User-Agent:Mxxxxxxxxxxxxxxxxxxxxxxxx","User-Agent:Mxxxxxxxxxxxxxxxxxxxxxxxx",]request.headers["User-Agent"] = random.choice(uas)2.代理IP
具体操作略去,例如:快代理-隧道代理-python-scrapy的文档中心有具体的书写方式
相关文章:
)
scrapy框架爬取数据(创建一个scrapy项目+xpath解析数据+通过pipelines管道实现数据保存+中间件)
目录 一、创建一个scrapy项目 二、xpath解析数据 三、通过pipelines管道实现数据保存 四、中间件 一、创建一个scrapy项目 1.创建一个文件夹:C06 在终端输入以下命令: 2.安装scrapy:pip install scrapy 3.来到文件夹下:cd C06 4.创建…...

你被骗了吗?别拿低价诱骗机器视觉小白,4000元机器视觉系统怎么来的?机器视觉工程师自己组装一个2000元不到,还带深度学习
淘宝闲鱼,大家搜搜铺价格,特别是机器视觉小白。 机架:(新的)200元以下。(看需求,自己简单打光,买个50元的。如果复杂,就拿给供应商免费打光) 相机,镜头:&am…...

计算机毕业设计选题推荐-大学生校园兼职微信小程序/安卓APP-项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

如何使用 Docker 搭建 Jenkins 环境?从安装到精通
不少兄弟搭 jenkins 环境有问题,有的同学用 window, 有的同学用 mac, 有的同学用 linux。 还有的同学公司用 window, 家里用 mac,搭个环境头发掉了一地。。。 这回我们用 docker 去搭建 jenkins 环境,不管你是用的是什么系统&…...
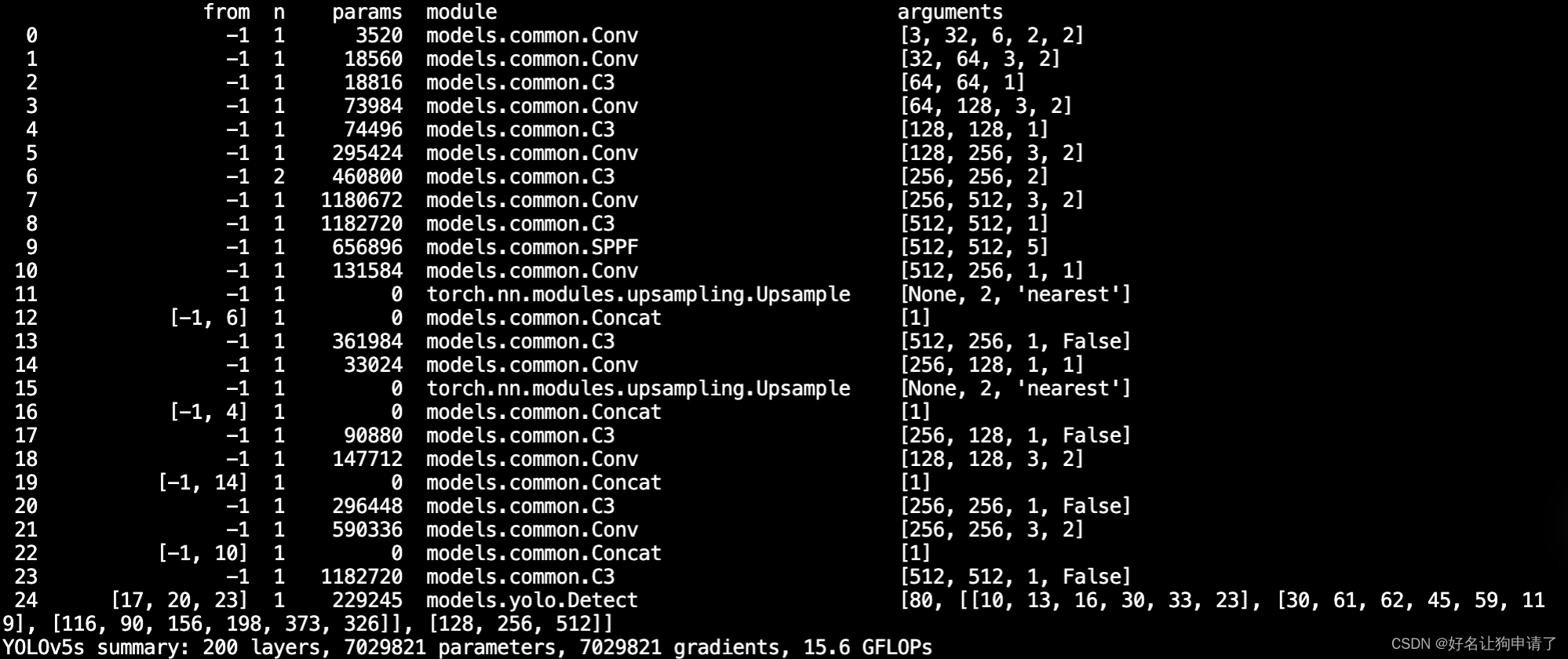
YOLOv5配置文件之 - yaml
在YOLOv5的目录中,models文件夹里存储了YOLO的模型配置。 ./models/yolov5.yaml 定义了YOLOv5s网络结构的定义文件 yaml的主要内容 参数配置 nc: 80 类别数量 depth_multiple: 0.33 模型深度缩放因子 width_multiple: 0.50 控制卷积特征图的通道个数 anchors配…...

HBuilderX实现安卓真机调试
1. 简介 HBuilderX 简称 HX,HBuilder,H 是 HTML 的缩写,Builder 是建设者。是为前端开发者服务的通用 IDE,或者称为编辑器。与 vscode、sublime、webstorm 类似。 它可以开发普通 web 项目,也可以开发 DCloud 出品的 u…...
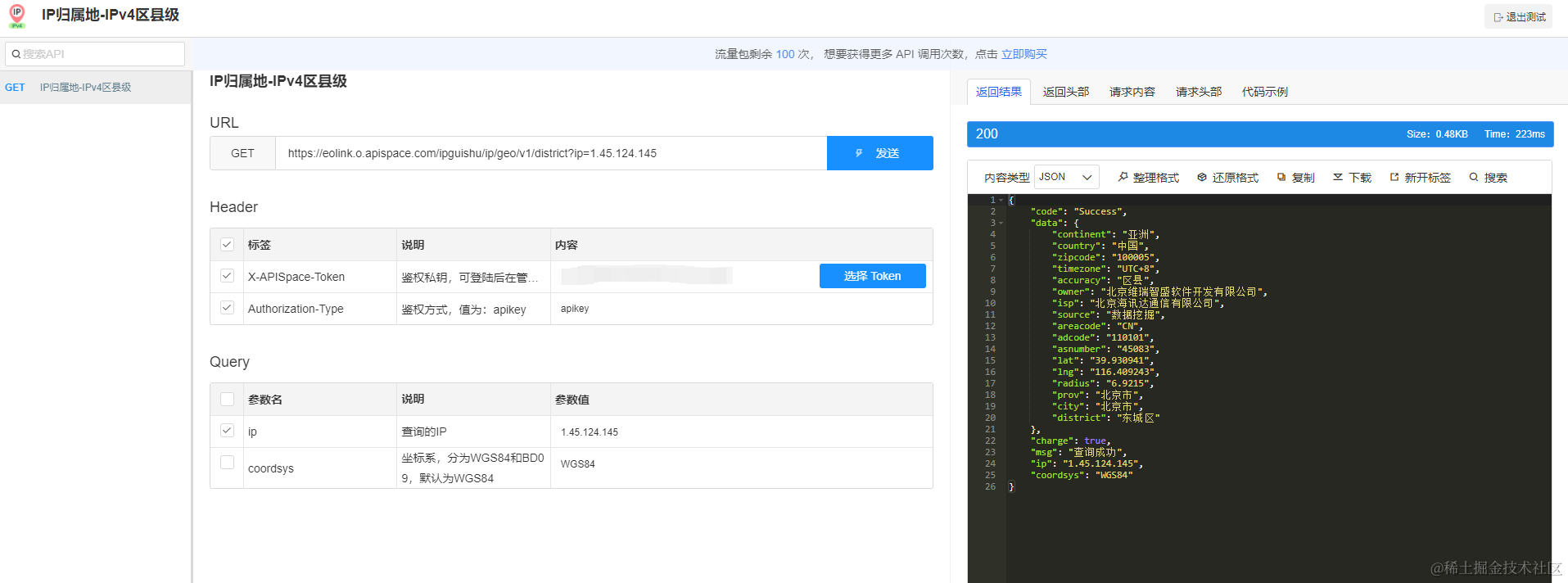
如何使用IP归属地查询API加强网络安全
引言 在当今数字化时代,网络安全对于个人和组织来说至关重要。恶意网络活动的威胁不断增加,因此采取有效的措施来加强网络安全至关重要。其中之一是利用IP归属地查询API。这个工具可以为您的网络安全策略提供宝贵的信息,帮助您更好地保护自己…...
Nginx 实战指南:暴露出请求的真实 IP
🔭 嗨,您好 👋 我是 vnjohn,在互联网企业担任 Java 开发,CSDN 优质创作者 📖 推荐专栏:Spring、MySQL、Nacos、Java,后续其他专栏会持续优化更新迭代 🌲文章所在专栏&…...

golang工程— grpc-gateway健康检查和跨域配置
grpc健康检查网关跨域配置 grpc健康检查 grpc健康检查使用 服务端配置 import ("google.golang.org/grpc/health""google.golang.org/grpc/health/grpc_health_v1" )//添加健康检查服务,多路复用 grpc_health_v1.RegisterHealthServer(s, health.NewSe…...

怎么样把握单片机的实际应用?说几句大实话
关注我们 你听说小米的大动作了吗? 没错,小米终于揭开了新操作系统的面纱。 小米澎湃OS暨小米14系列新品发布会于10月26日19:00举行,小米14手机系列、小米首款血压手表、小米Watch S3...... 今天主要讲的是自研7年的小米澎湃系统 没…...

PostgreSQL在云端:部署、管理和扩展你的数据库
随着云计算技术的迅猛发展,将数据库迁移到云端已经成为许多企业的首选。而在众多数据库管理系统中,PostgreSQL因其稳定性、灵活性和可扩展性而成为了不少企业的首选之一。 部署PostgreSQL在云端 将PostgreSQL部署在云端是一个相对简单的过程。云服务提供…...
Maven进阶系列-继承和聚合
Maven进阶系列-继承和聚合 文章目录 Maven进阶系列-继承和聚合1. 继承2. 继承的作用2.1 在父工程中配置依赖的统一管理2.2 在父工程中声明自定义属性2.3 父工程中必须要继承的配置 3. 聚合4. 聚合的作用 1. 继承 Maven工程之间存在继承关系,例如工程B继承工程A&…...
)
Lintcode 3715 · Lowest Common Ancestor V (最小祖先好题)
3715 Lowest Common Ancestor VPRE Algorithms Medium This topic is a pre-release topic. If you encounter any problems, please contact us via “Problem Correction”, and we will upgrade your account to VIP as a thank you. Description Given a binary tree wit…...

SQL LIKE 运算符
SQL LIKE 运算符 在WHERE子句中使用LIKE运算符来搜索列中的指定模式。 有两个通配符与LIKE运算符一起使用: % - 百分号表示零个,一个或多个字符_ - 下划线表示单个字符 注意: MS Access使用问号(?)而不是…...

AR眼镜定制开发-智能眼镜的主板硬件、软件
AR眼镜定制开发是一项复杂而又重要的工作,它需要准备相关的硬件设备和软件。这些设备包括多个传感器、显示装置和处理器等。传感器用于捕捉用户的动作和环境信息,如摄像头、陀螺仪、加速度计等;显示装置则用于将虚拟信息呈现给用户;处理器用于处理和协调…...
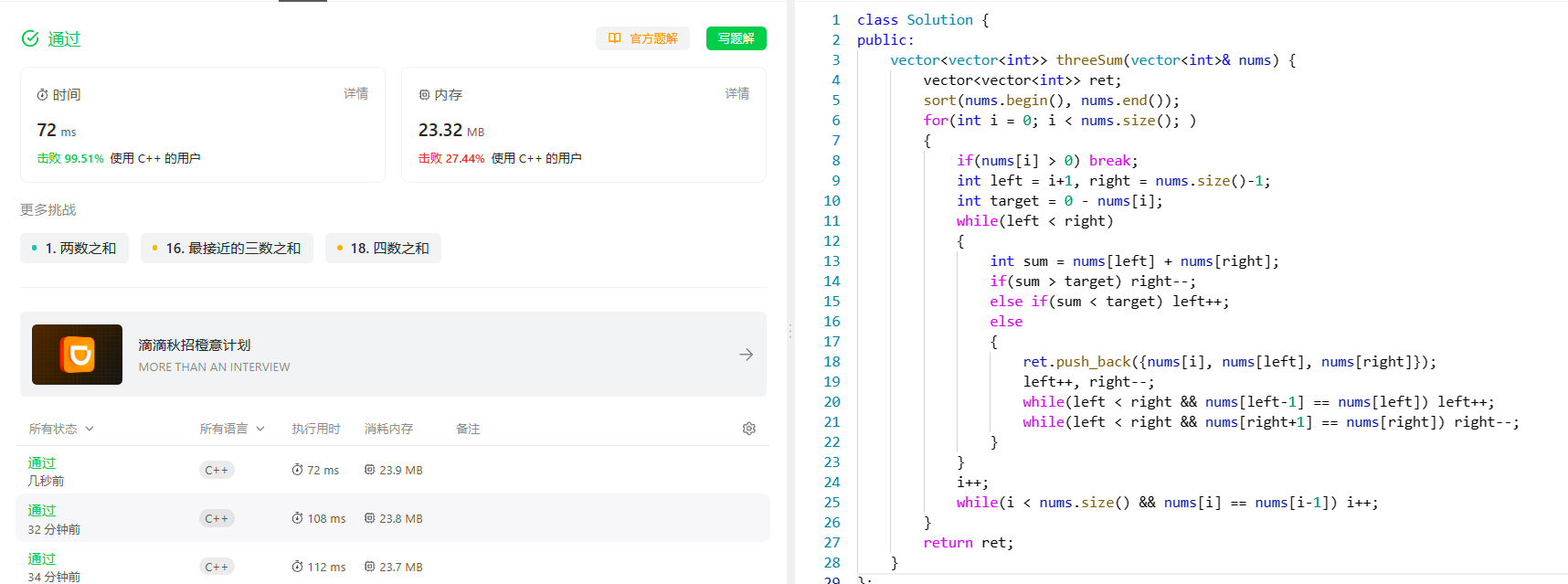
[双指针] (三) LeetCode LCR 179. 查找总价格为目标值的两个商品 和 15. 三数之和
[双指针] (三) LeetCode LCR 179. 查找总价格为目标值的两个商品 和 15. 三数之和 文章目录 [双指针] (三) LeetCode LCR 179. 查找总价格为目标值的两个商品 和 15. 三数之和查找总价格为目标值的两个商品题目分析解题思路代码实现总结 三数之和题目分析解题思路代码实现总结 …...

左移测试,如何确保安全合规还能实现高度自动化?
「云原生安全既是一种全新安全理念,也是实现云战略的前提。 基于蚂蚁集团内部多年实践,云原生PaaS平台SOFAStack发布完整的软件供应链安全产品及解决方案,包括静态代码扫描Pinpoint,软件成分分析SCA,交互式安全测试IA…...
mysql 增删改查基础命令
数据库是企业的重要信息资产,在使用数据库时,要注意(查和增,无所谓,但是删和改,要谨慎! ) 数据库管理系统(DBMS) :实现对数据的有效组织,管理和存取的系统软件 mysgl 数据库是一个系统, 是一个人机系统,硬件, gs,数据库…...

C# 使用 AES 加解密文件
[作者:张赐荣] 对称加密是一种加密技术,它使用相同的密钥来加密和解密数据。换句话说,加密者和解密者需要共享同一个密钥,才能进行通信。 对称加密的优点是速度快,效率高,适合大量数据的加密。对称加密的缺点是密钥的管…...
SSM培训报名管理系统开发mysql数据库web结构java编程计算机网页源码eclipse项目
一、源码特点 SSM 培训报名管理系统是一套完善的信息系统,结合SSM框架完成本系统,对理解JSP java编程开发语言有帮助系统采用SSM框架(MVC模式开发),系统具有完整的源代码和数据库,系统主 要采用B/S模式开…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...