Spark新特性与核心概念
一、Sparkshuffle
(1)Map和Reduce
在shuffle过程中,提供数据的称之为Map端(Shuffle Write),接受数据的称之为Redeuce端(Shuffle Read),在Spark的两个阶段中,总是前一个阶段产生一批Map提供数据,下一阶段产生一批Reduce接收数据。
(2)Shuffle管理器
①HashShuffleManager
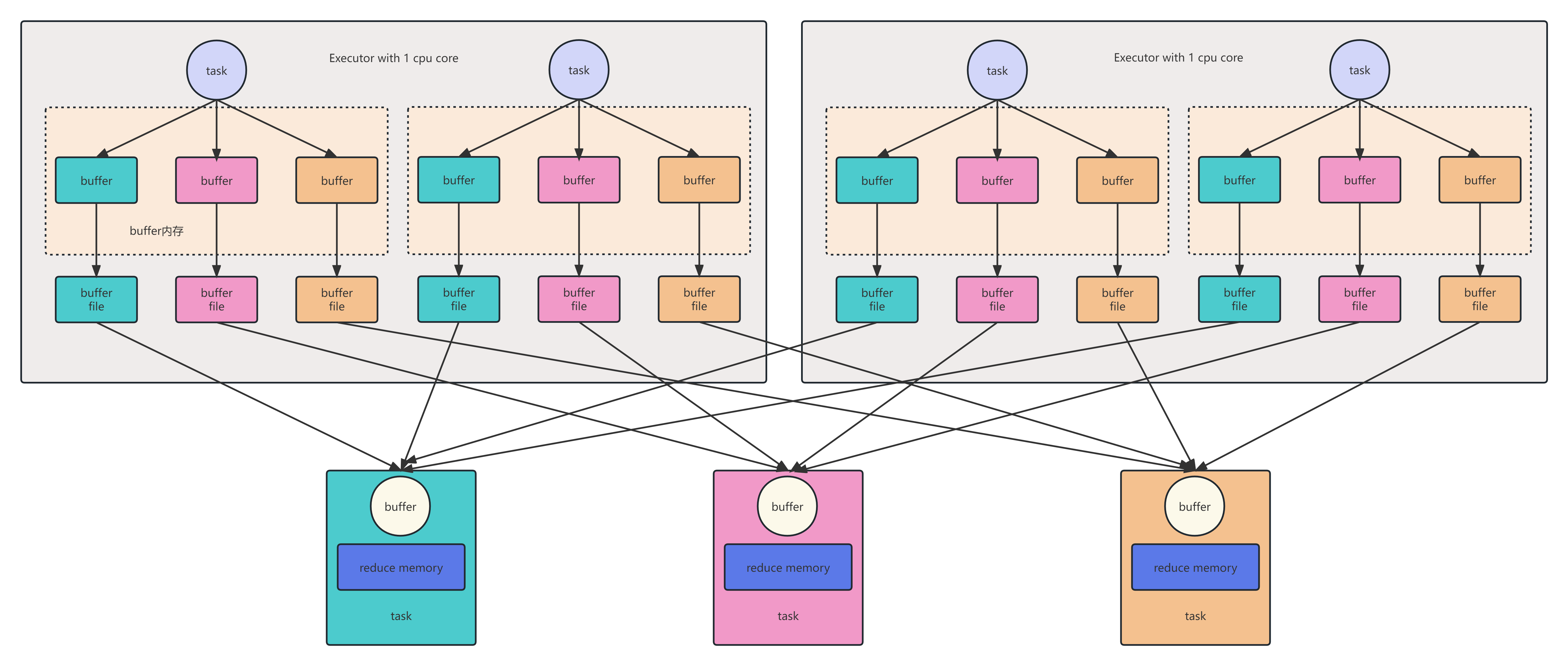
HashShuffleManager是Spark的一个组件,用于实现在节点之间进行数据分发和合并。它的主要作用是将数据进行随机哈希分区,然后将不同分区的数据发送到不同的节点上进行处理,最后将结果合并返回给调用方。HashShuffleManager的优点是能够高效地处理大规模数据集,同时保证数据的顺序性和数据安全性。它一共分为两种,一种有优化,一种无优化。
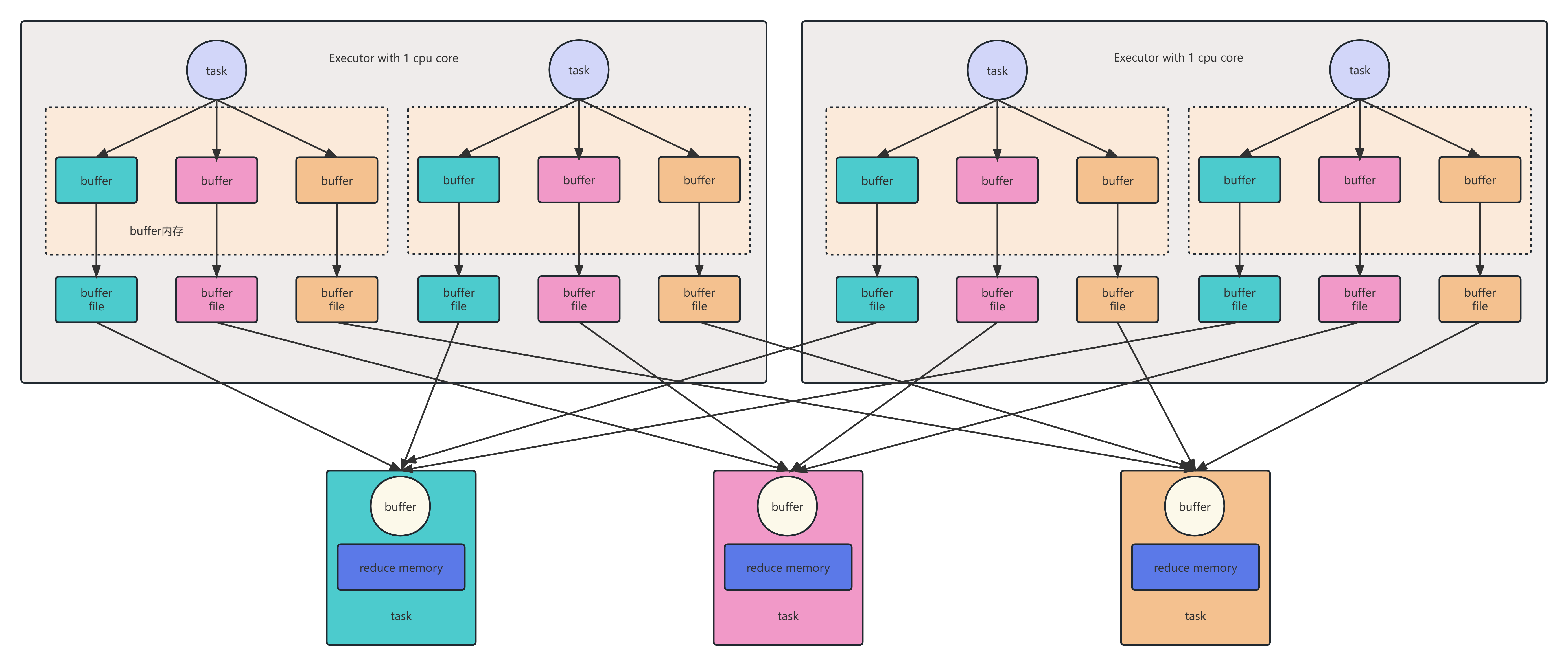
优化后的和未优化的一致,不同点在于
1. 在一个Executor内, 不同Task是共享Buffer缓冲区
2. 这样减少了缓冲区乃至写入磁盘文件的数量, 提高性能

②SortShuffleManager
SortShuffleManager是Spark的一个组件,用于实现在节点之间进行数据分发和合并。与HashShuffleManager不同的是,SortShuffleManager使用的是排序方式进行数据分发和合并。相对于HashShuffleManager,SortShuffleManager的优点是能够更好地保证数据的有序性,减少数据倾斜的情况,提高数据处理效率。但是,SortShuffleManager需要进行排序操作,需要占用更多的计算资源和时间。因此,在不同的使用场景下,可以选择合适的ShuffleManager来实现数据分发和合并。
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。

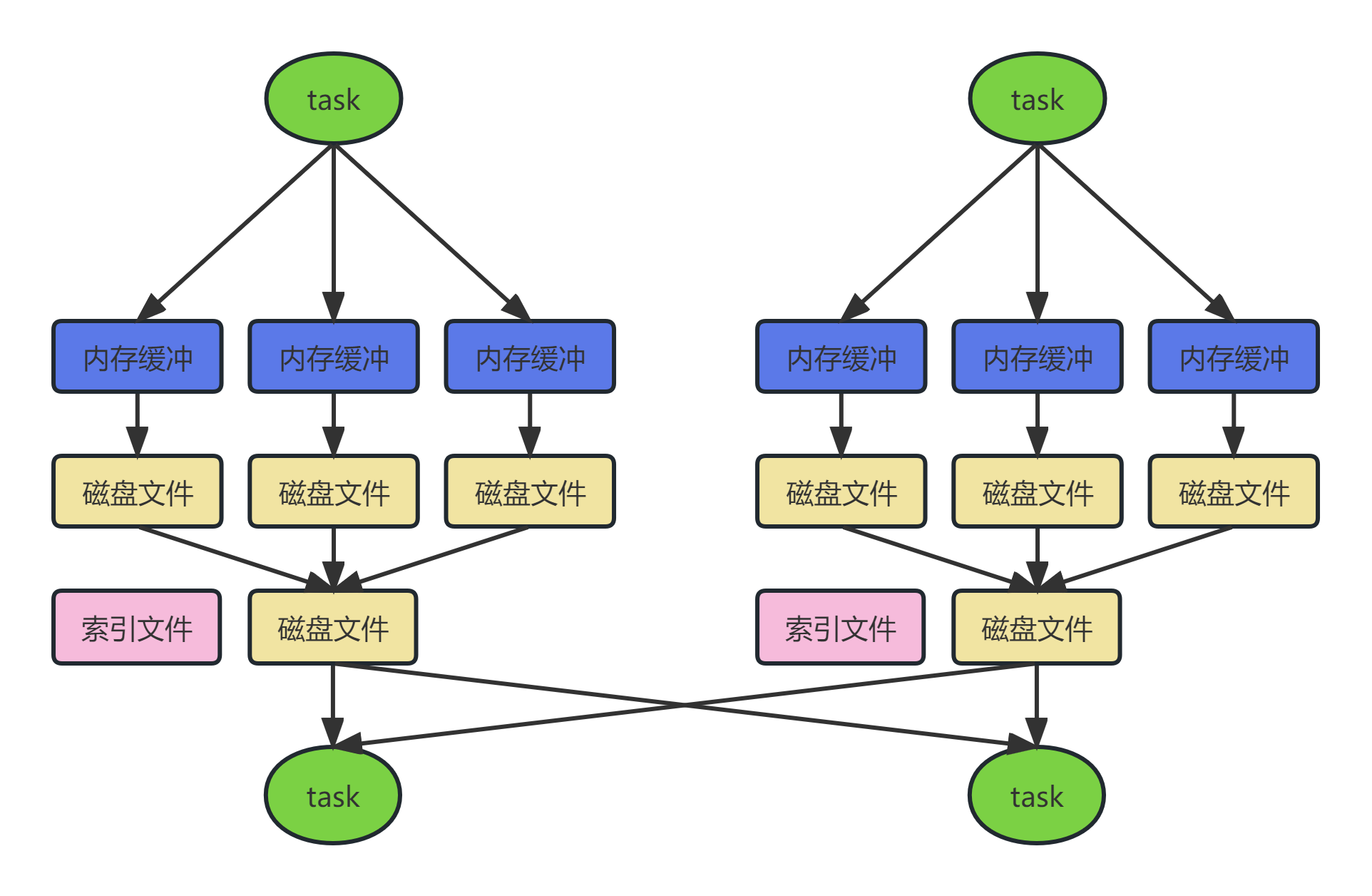
bypass运行机制的触发条件如下:
(1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
(2)不是聚合类的shuffle算子(比如reduceByKey)。
同普通机制基本类同, 区别在于, 写入磁盘临时文件的时候不会在内存中进行排序而是直接写,最终合并为一个task一个最终文件。
与普通模式IDE区别在于:
第一,磁盘写机制不同。
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
二、Spark3新特性概览
(1)Adaptive Query Execution 自适应查询(SparkSQL)
由于缺乏或者不准确的数据统计信息(元数据)和对成本的错误估算(执行计划调度)导致生成的初始执行计划不理想。在Spark3.x版本提供Adaptive Query Execution自适应查询技术,通过在”运行时”对查询执行计划进行优化,允许Planner在运行时执行可选计划,这些可选计划将会基于运行时数据统计进行动态优化,从而提高性能。
Adaptive Query Execution AQE主要提供了三个自适应优化:
①动态合并Shuffle Partitions
②动态调整Join策略
③动态优化倾斜Join(Skew Joins)
开启AQE方式:
set spark.sql.adaptive.enabled = true;
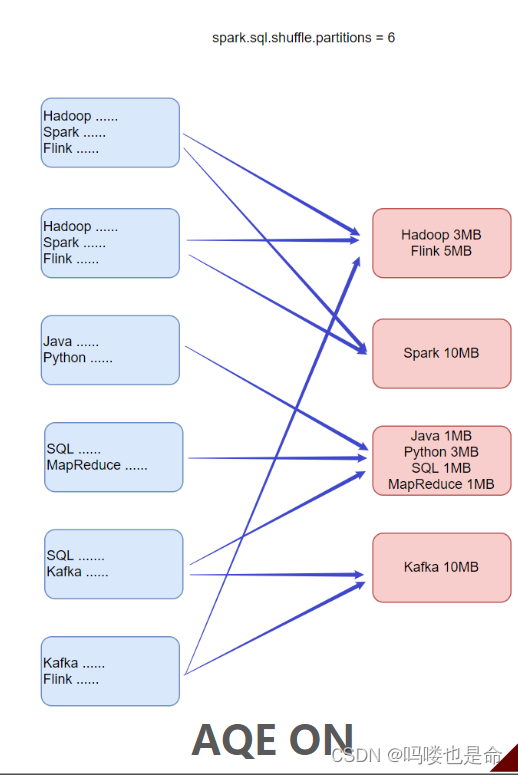
①动态合并Dynamically coalescing shuffle partitions
可以动态调整shuffle分区的数量。用户可以在开始时设置相对较多的shuffle分区数,AQE会在运行时将相邻的小分区合并为较大的分区。

②动态调整Join策略Dynamically switching join strategies
此优化可以在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行计划性能不佳的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能。
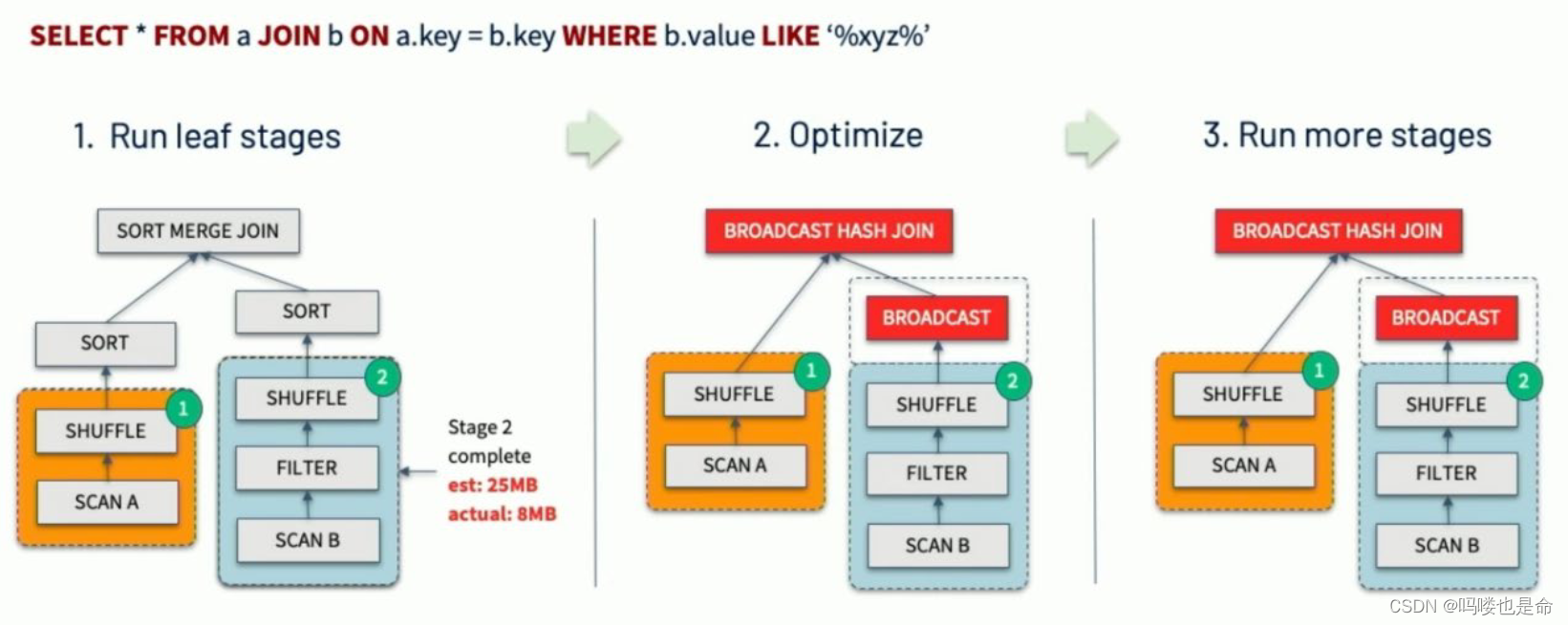
③动态优化倾斜Join
skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测至J任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更好的整体性能。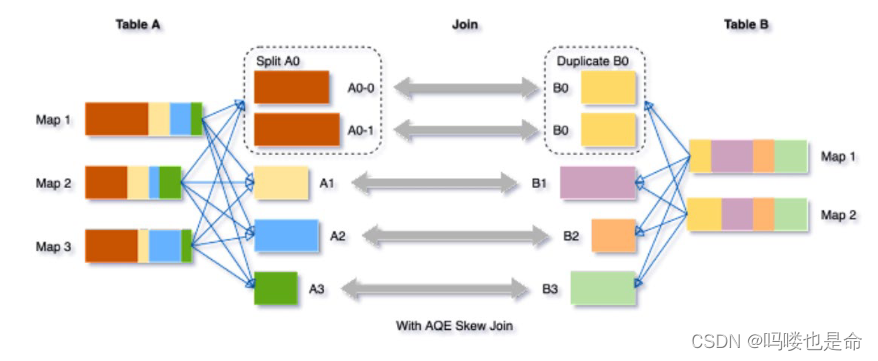
触发条件:
1.分区大小> spark.sql.adaptive.skewJoin.skewedPartitionFactor (default=10) * "median partition size(中位数分区大小)"
2.分区大小 > spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes (default = 256MB)
④AQE总结
1.AQE的开启通过: spark.sql.adaptive.enabled设置为true开启。
2.AQE是自动化优化机制,无需我们设置复杂的参数调整,开启AQE符合条件即可自动化应用AQE优化。
3.AQE带来了极大的SparkSQL性能提升。

(2)Dynamic Partition Pruning动态分区裁剪(SparkSQL)
当优化器在编译时无法识别可跳过的分区时,可以使用"动态分区裁剪",即基于运行时推断的信息来进一步进行分区裁剪。这在星型模型中很常见,星型模型是由一个或多个并且引用了任意数量的维度表的事实表组成。在这种连接操作中,我们可以通过识别维度表过滤之后的分区来裁剪从事实表中读取的分区。在一个TPC-DS基准测试中,102个查询中有60个查询获得2到18倍的速度提升。
(3)增强的Python APl: PySpark和Koalas
Python现在是Spark中使用较为广泛的编程语言,因此也是Spark 3.0的重点关注领域。Databricks有68%的notebook命令是用Python写的。PySpark在 Python Package lndex上的月下载量超过500万。
很多Python开发人员在数据结构和数据分析方面使用pandas APl,但仅限于单节点处理。Databricks会持续开发Koalas——基于Apache Spark的pandas API实现,让数据科学家能够在分布式环境中更高效地处理大数据。
经过一年多的开发,Koalas实现对pandas API将近80%的覆盖率。Koalas每月PyPI下载量已迅速增长到85万,并以每两周一次的发布节奏快速演进。虽然Koalas可能是从单节点pandas代码迁移的最简单方法,但很多人仍在使用PySpark API,也意味着
PySpark API也越来越受欢迎。

三、Spark核心概述

相关文章:
Spark新特性与核心概念
一、Sparkshuffle (1)Map和Reduce 在shuffle过程中,提供数据的称之为Map端(Shuffle Write),接受数据的称之为Redeuce端(Shuffle Read),在Spark的两个阶段中,总…...
设计模式_状态模式
状态模式 介绍 设计模式定义案例问题堆积在哪里解决办法状态模式一个对象 状态可以发生改变 不同的状态又有不同的行为逻辑游戏角色 加载不同的技能 每个技能有不同的:攻击逻辑 攻击范围 动作等等1 状态很多 2 每个状态有自己的属性和逻辑每种状态单独写一个类 角色…...

css 某个元素被挤的显示不完整,如何显示完整
加一行 flex-shrink: 0;解决...

pve lxc debian 11安装docker遇到bash: sudo: command not解决办法
pve创建LXC容器,使用debian 11模版,安装完成后正常换源、安装依赖 然后添加Docker 的官方 GPG 密钥时出错: $ curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/debian/gpg | sudo apt-key add - 提示 bash: sudo: command not …...

springboot的缓存和redis缓存,入门级别教程
一、springboot(如果没有配置)默认使用的是jvm缓存 1、Spring框架支持向应用程序透明地添加缓存。抽象的核心是将缓存应用于方法,从而根据缓存中可用的信息减少执行次数。缓存逻辑是透明地应用的,对调用者没有任何干扰。只要使用…...
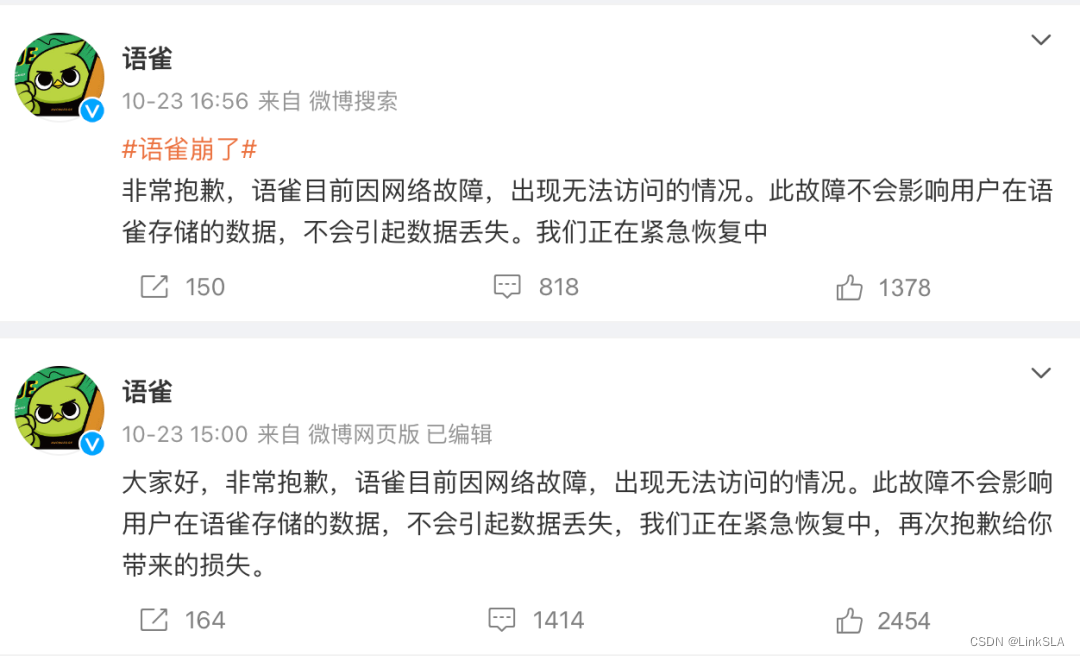
语雀P0级时间爆发,留给运维的时间不多了?
事件背景 打工人的焦虑,已经延伸到在线文档了。近日,语雀P0级故障想必大家都有所体会,宕机近8小时,笔记、离线同步完全不可用。作为用户尤其担心我的文档资料是否会因此消失。 这泼天的8小时,放眼互联网界也是相当炸裂…...
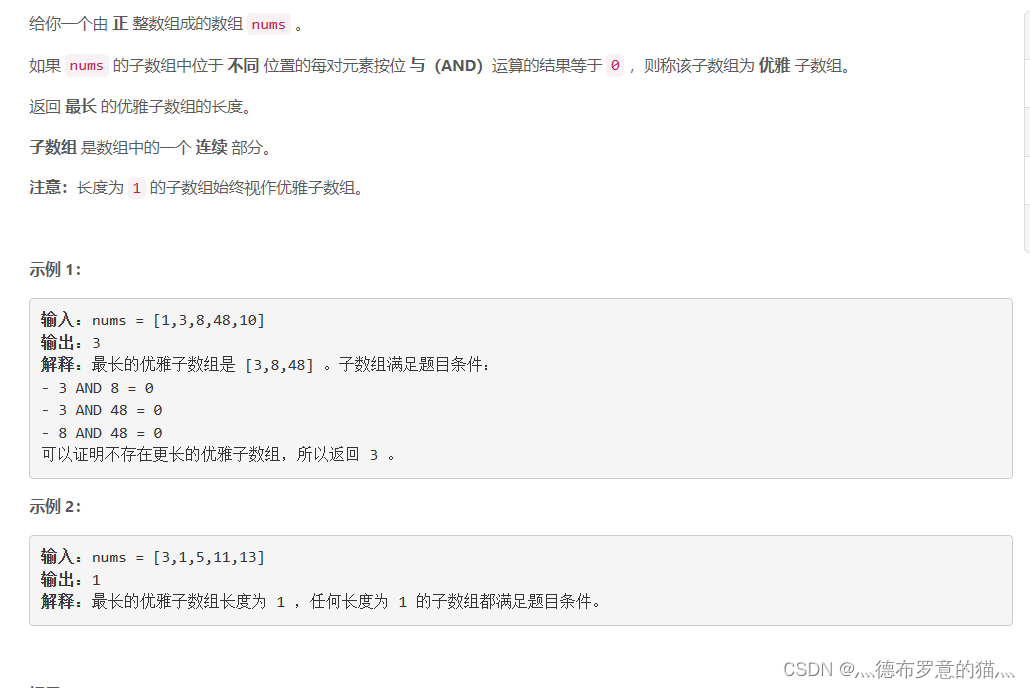
LeetCode 2401.最长优雅子数组 ----双指针+位运算
数据范围1e5 考虑nlog 或者n的解法,考虑双指针 因为这里要求的是一段连续的数组 想起我们的最长不重复连续子序列 然后结合一下位运算就好了 是一道双指针不错的题目 class Solution { public:int longestNiceSubarray(vector<int>& nums) {int n nums…...

NOIP2023模拟6联测27 无穷括号序列
题目大意 小 C C C有一个括号序列 A A A,其长度为 m m m,且序列元素只包含左右括号。他想生成一个无限长的括号序列 B B B,由于 B B B的长度为正无穷,所以其下标可以为任意整数(可以为负)。为了由 A A A生…...
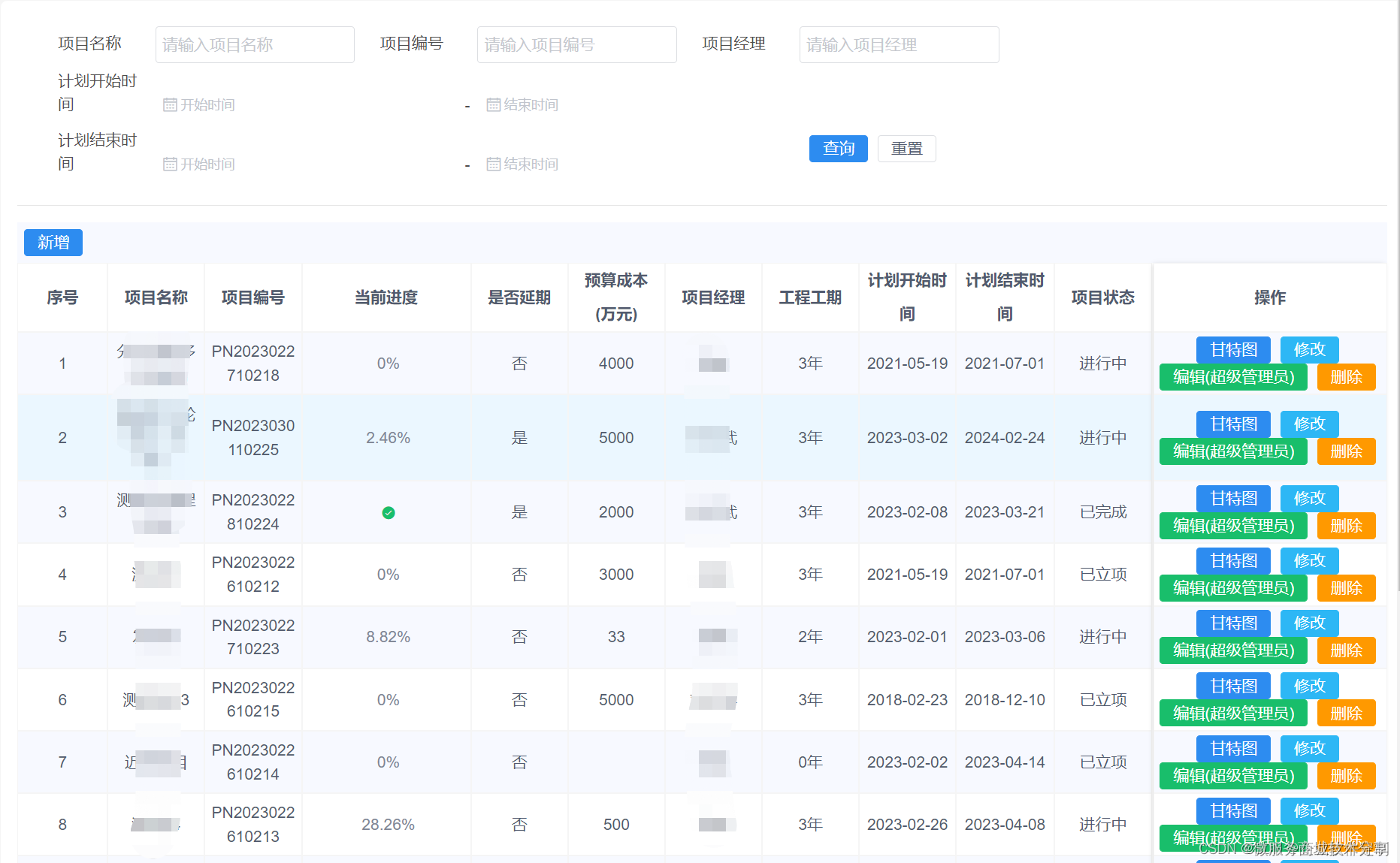
java spring cloud 工程企业管理软件-综合型项目管理软件-工程系统源码
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显示…...
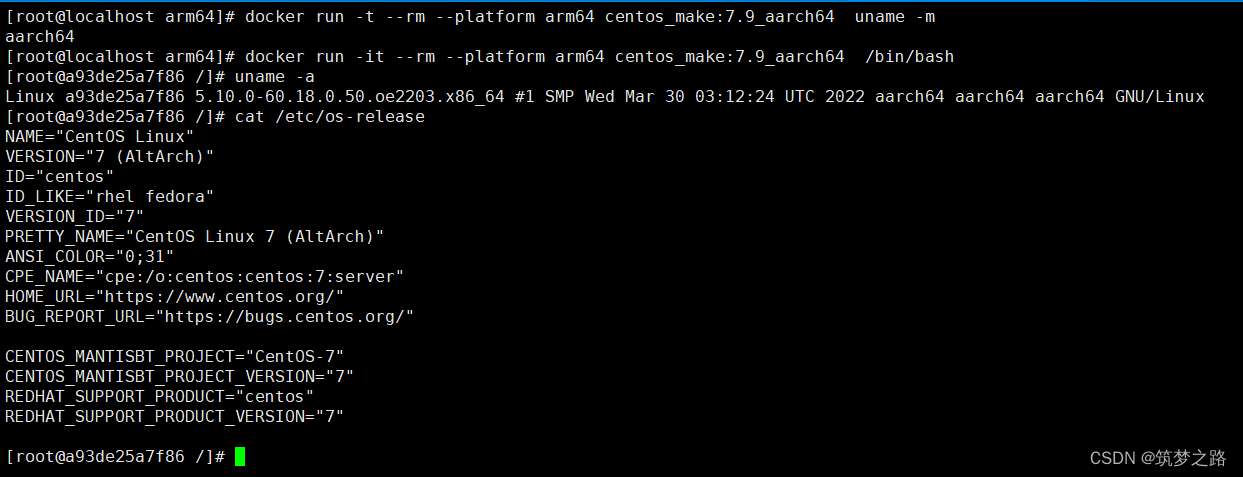
openEuler 22.03 x86架构下docker运行arm等架构的容器——筑梦之路
为什么要这样做? 随着国产化的普及,国家政策对信创产业的支持,尤其一些金融证券行业、政府单位等,逐渐开始走国产化信创的路线,越来越多接触到国产 CPU (arm 平台,比如华为的鲲鹏处理器…...

【Java】HashMap常见的面试题
HashMap常见面试题 1.HashMap key 是否可以是为 我们自定义对象?——可以 2.HashMap 存储数据 有序还是无序?——无序 3.HashMap key 是否可以存放 null值?如果可以的话 存放在 数组中那个位置?——可以;存放在 index0的位置 4.Ha…...
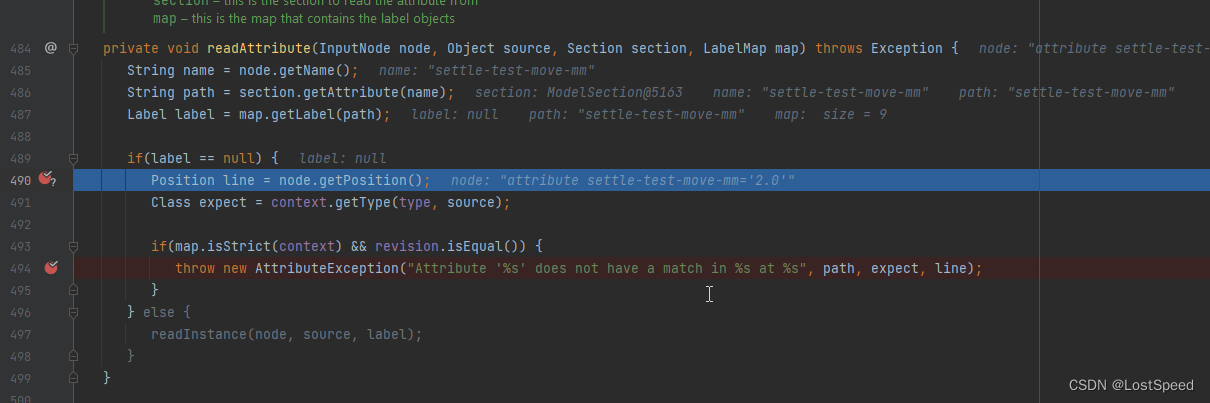
openpnp - src - 配置文件载入过程的初步分析
文章目录 openpnp - src - 配置文件载入过程的初步分析概述笔记自己编译用的git版本报错截图问题1 - 怎么在调试状态下, 定位到抛异常的第一现场?结合单步调试找到的现场, 来分析报错的原因openpnp配置文件读取的流程END openpnp - src - 配置文件载入过程的初步分析 概述 从…...
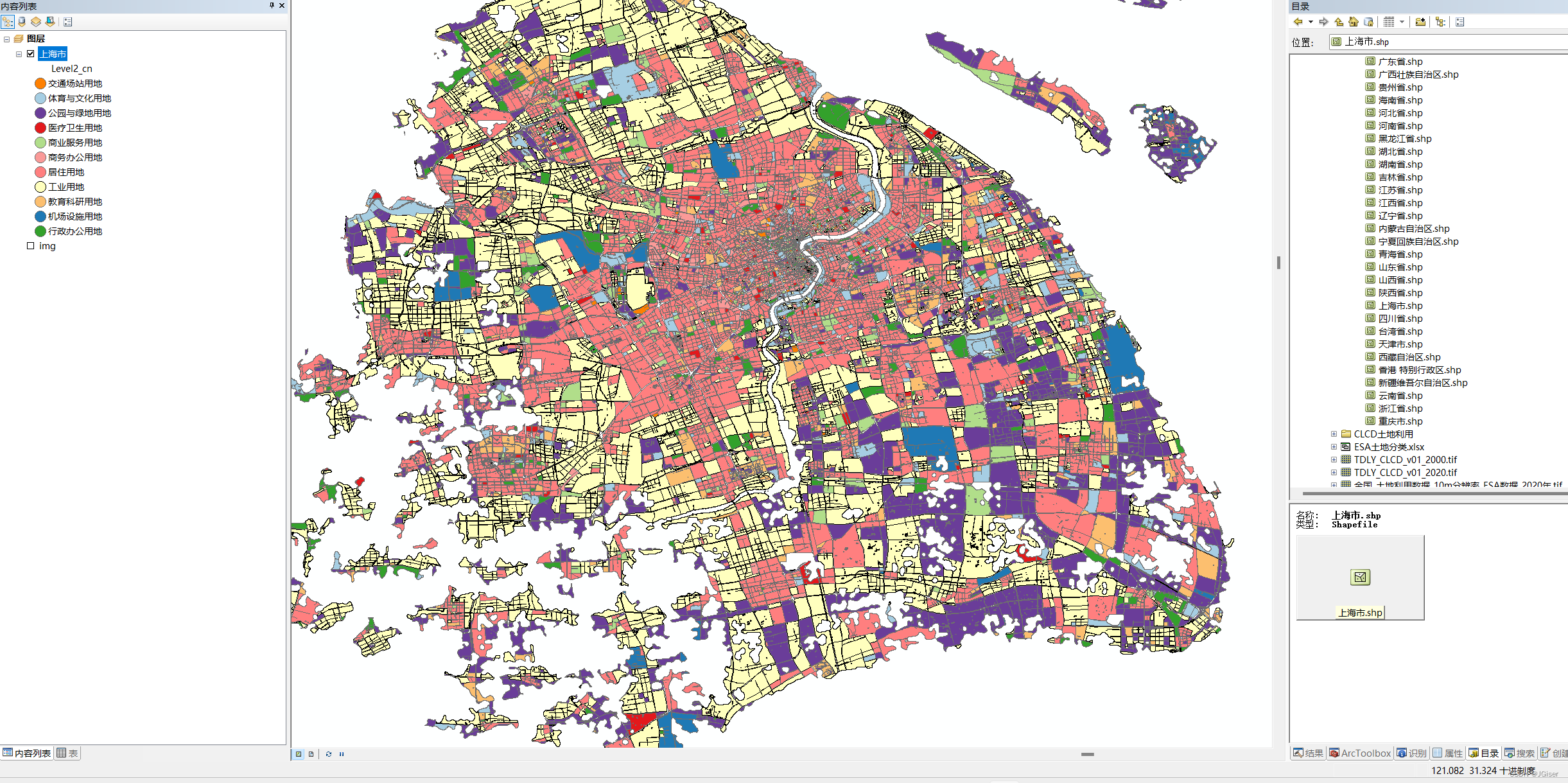
中国各城市土地利用类型(城市功能)数据集(shp)
中国各城市土地利用类型(城市功能)数据集 时间:2018年 全国范围的城市用地类型数据(居住/商业/交通用地等共计11类) 分类:居住用地、商业用地、工业用地、医疗设施用地、体育文化设施用地、交通场站用地、绿地等用地类型 含城市编码、一级分类5个、二级分类11个 数据按…...
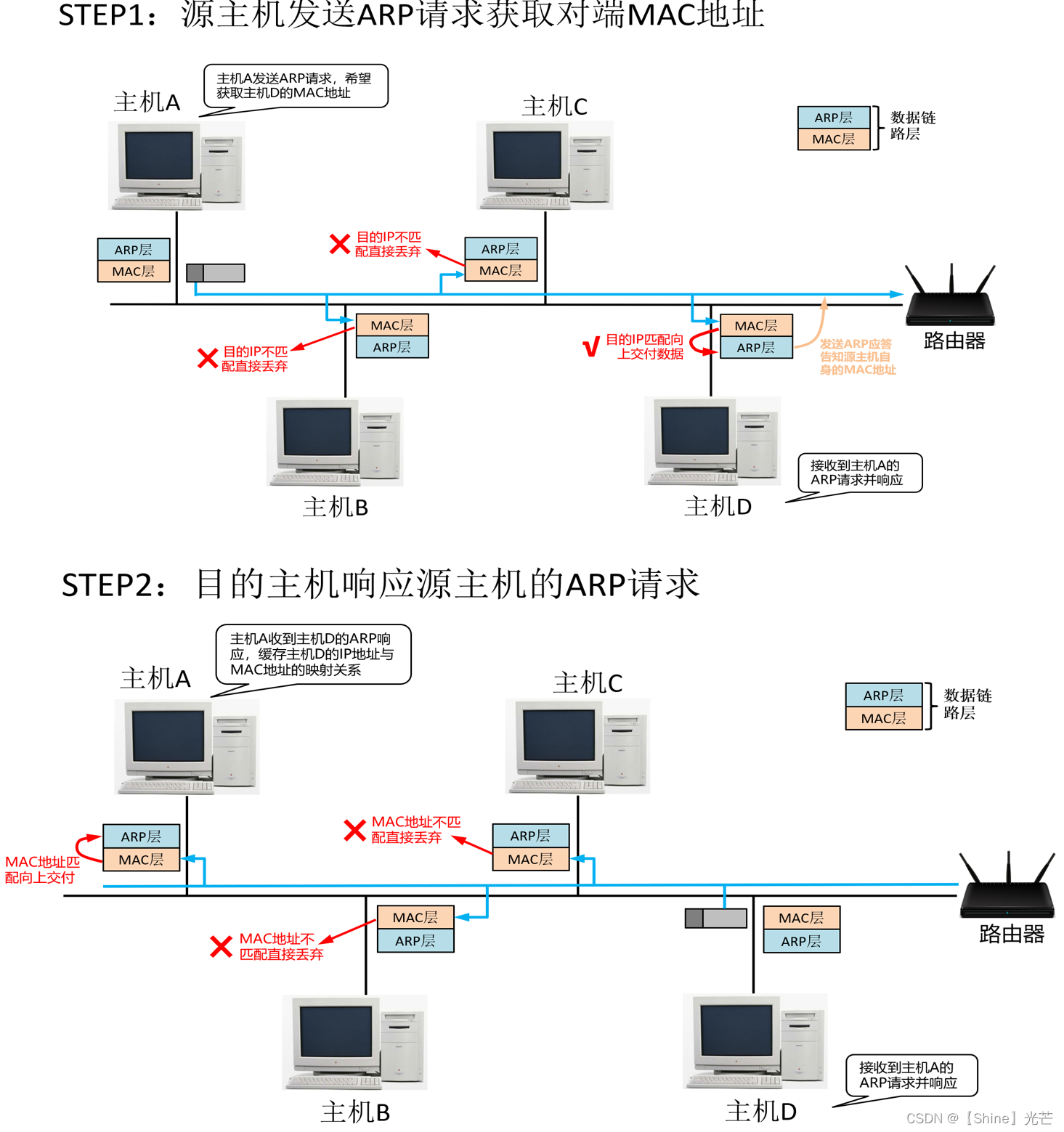
Linux网络编程:数据链路层
目录 一. 数据链路层概述 二. 以太网 2.1 以太网的概念 2.2 以太网数据帧 2.3 对于MAC地址的认识 2.4 数据碰撞问题 三. MTU和MSS 3.1 什么是MTU 3.2 MTU对UDP的影响 3.3 MTU对TCP的影响(MSS的概念) 四. ARP协议 4.1 ARP协议的作用 4.2 ARP数…...

python 线程 超时时间
python 线程 超时时间_mob649e815f0f18的技术博客_51CTO博客...
)
LeetCode:274. H 指数、275. H 指数 II(C++)
目录 274. H 指数 题目描述: 实现代码与解析: 排序暴力 275. H 指数 II 题目描述: 实现代码与解析: 二分 比较简单,不再写解析,注意二分的时候,r指针为n,含义为个数…...

多线程及锁
1.lock锁和synchronized锁的区别。 1:Synchronized 是Java的一个关键字,而Lock是java.util.concurrent.Locks 包下的一个接口; 2:Synchronized 使用过后,会自动释放锁,而Lock需要手动上锁、手动释放锁&am…...

C++ 写一个Data类的注意问题
Data类 声明和定义分离的一些问题 声明里面我们不带缺省参数,定义我们给缺省参数,如下面两段代码: Data.h#pragma once #include<iostream> using namespace std; class Data { public:Data(int year,int month,int day);private:in…...
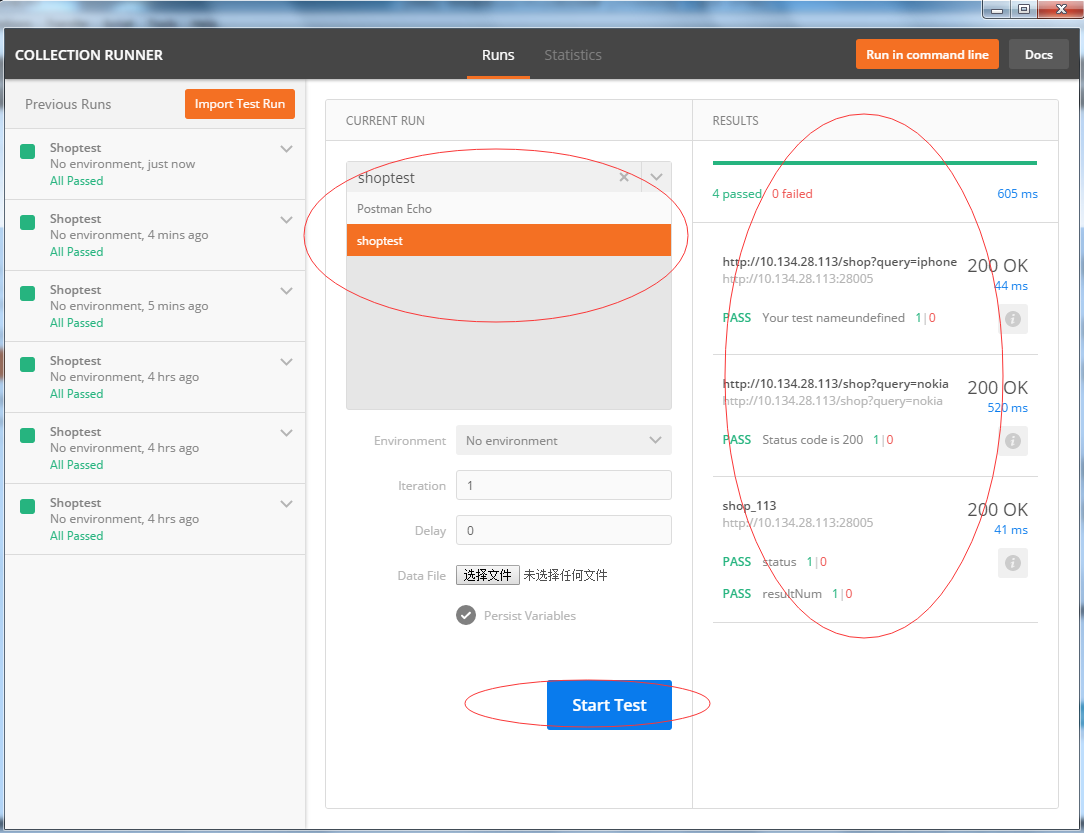
postman做接口测试
之前搞自动化接口测试,由于接口的特性,要验证接口返回xml中的数据,所以没找到合适的轮子,就自己用requests造了个轮子,用着也还行,不过就是case管理有些麻烦,近几天又回头看了看postman也可以玩…...
-29)
hdlbits系列verilog解答(always块)-29
文章目录 一、问题描述二、verilog源码三、仿真结果一、问题描述 由于数字电路由用网线连接的逻辑门组成,因此任何电路都可以表示为模块和赋值语句的某种组合。然而,有时这不是描述电路的最方便方式。过程procedure(其中 always 的块就是一个示例)提供了描述电路的替代语法…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...
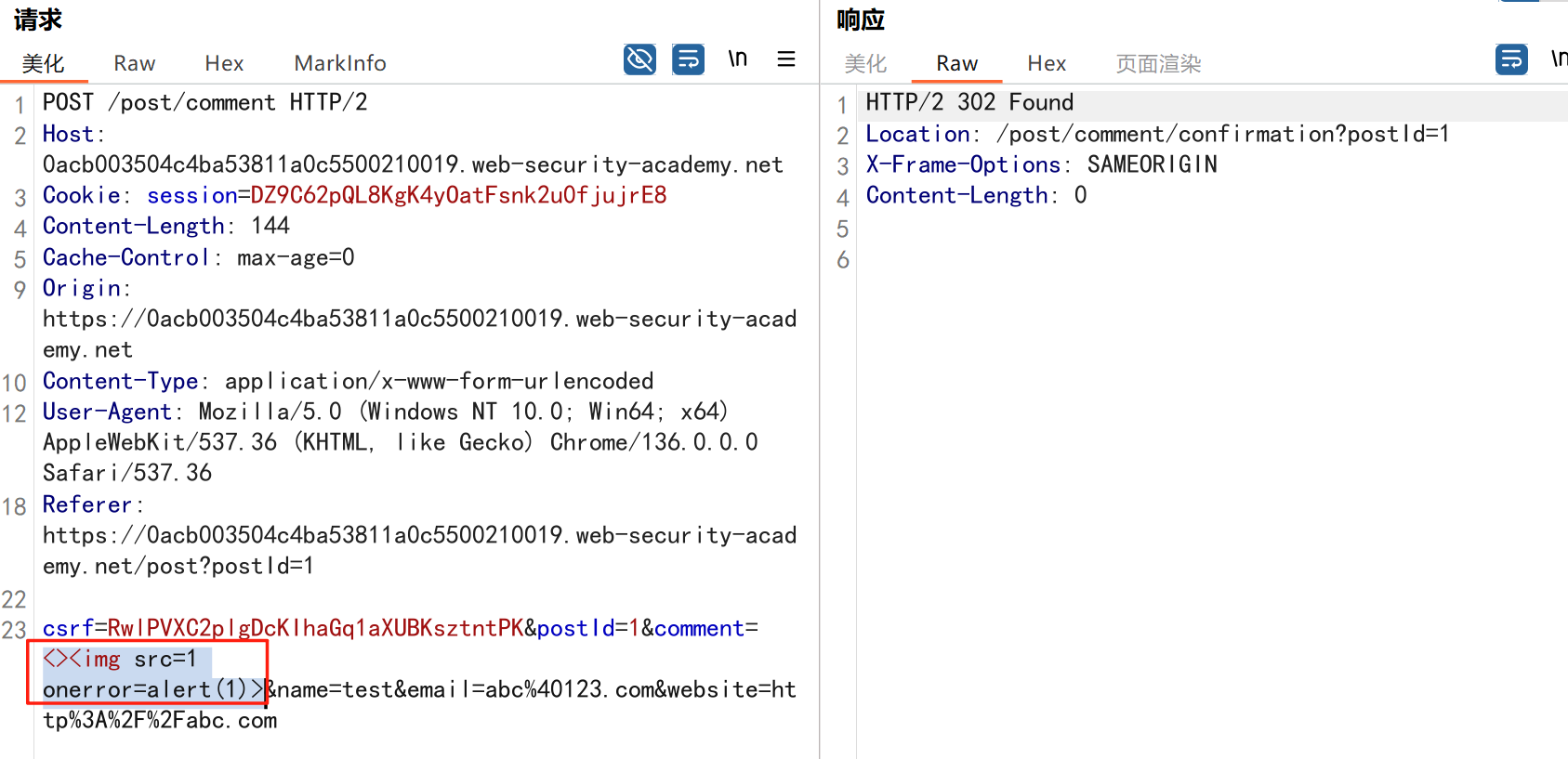
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...
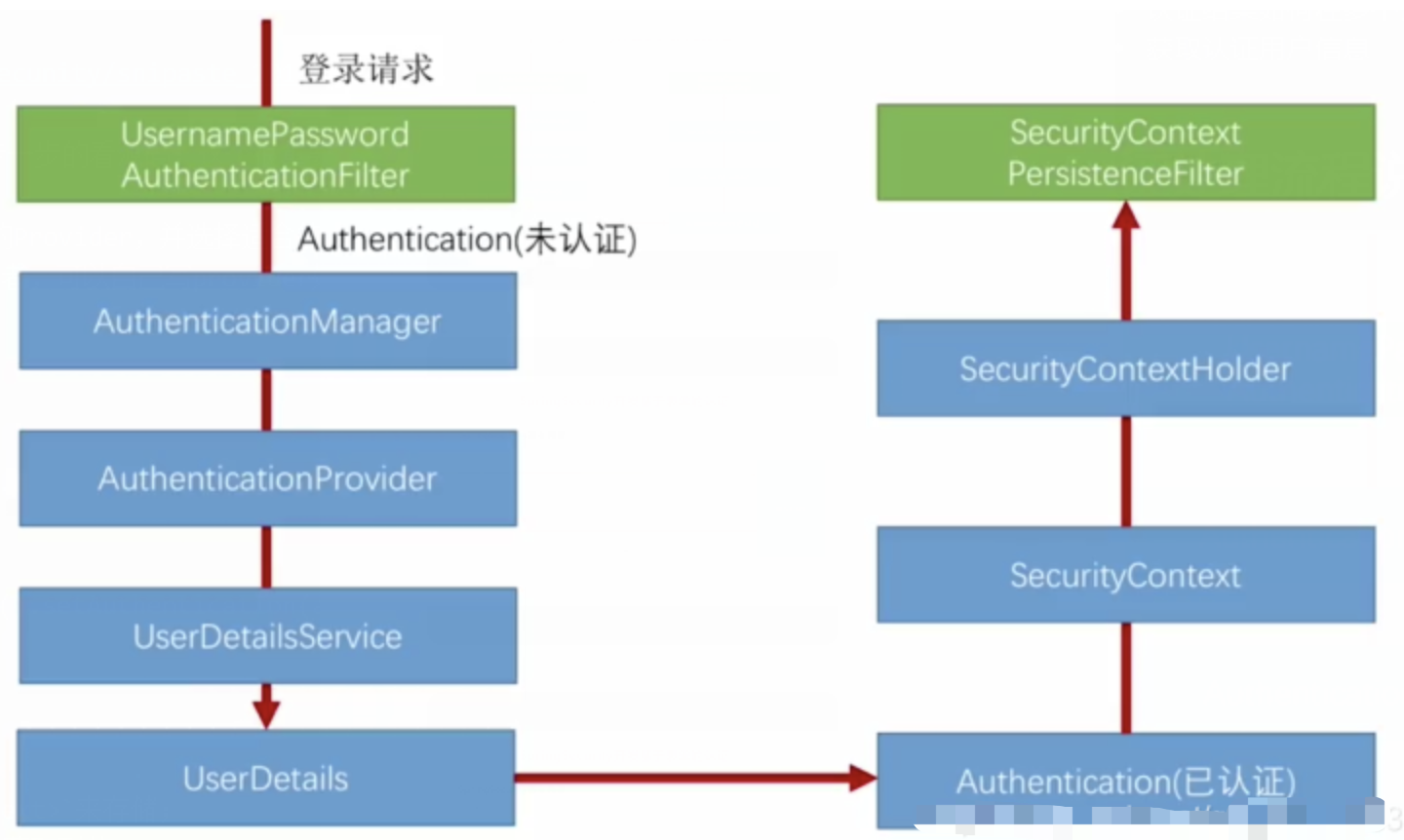
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...