大数据Hadoop教程-学习笔记05【Apache Hive DML语句与函数使用】
- 视频教程:哔哩哔哩网站:黑马大数据Hadoop入门视频教程 总时长:14:22:04
- 教程资源: https://pan.baidu.com/s/1WYgyI3KgbzKzFD639lA-_g 提取码: 6666
- 【P001-P017】大数据Hadoop教程-学习笔记01【大数据导论与Linux基础】【17p】
- 【P018-P037】大数据Hadoop教程-学习笔记02【Apache Hadoop、HDFS】【20p】
- 【P038-P050】大数据Hadoop教程-学习笔记03【Hadoop MapReduce与Hadoop YARN】【13p】
- 【P051-P068】大数据Hadoop教程-学习笔记04【数据仓库基础与Apache Hive入门】【18p】
- 【P069-P083】大数据Hadoop教程-学习笔记05【Apache Hive DML语句与函数使用】【15p】
- 【P084-P096】大数据Hadoop教程-学习笔记06【Hadoop生态综合案例:陌陌聊天数据分析】【13p】
目录
01【Hive SQL DML语法之加载数据】
P069【01-课程内容大纲与学习的目标】
P070【02-Hive SQL-DML-Load加载数据操作】
P071【03-Hive SQL-DML-Insert插入数据】
02【Hive SQL DML语法之查询数据】
P072【04-Hive SQL-DML-Select查询--语法树与学习环境准备】
P073【05-Hive SQL-DML-Select查询--列表达式与distinct去重】
P074【06-Hive SQL-DML-Select查询--Where条件过滤】
P075【07-Hive SQL-DML-Select查询--聚合操作aggregate】
P076【08-Hive SQL-DML-Select查询--Group by分组及语法限制】
P077【09-Hive SQL-DML-Select查询--Having过滤操作】
P078【10-Hive SQL-DML-Select查询--Order by排序】
P079【11-Hive SQL-DML-Select查询--Limit限制语法】
P080【12-Hive SQL-DML-Select查询--执行顺序梳理】
03【Hive SQL Join关联查询】
P081【13-Hive SQL Join关联查询】
04【Hive SQL中的常用函数使用入门】
P082【14-Hive函数概述及分类标准】
P083【15-Hive常用的内置函数】
01【Hive SQL DML语法之加载数据】
P069【01-课程内容大纲与学习的目标】
目录
- Hive SQL DML语法之加载数据
- Hive SQL DML语法之查询数据
- Hive SQL Join关联查询
- Hive SQL中的函数使用
学习目标
- 掌握Hive SQL Load加载数据语句
- 掌握Hive SQL Insert插入数据语句
- 掌握Hive SQL Select基础查询语句
- 掌握Hive SQL Join查询语句
- 掌握Hive SQL 常用函数的使用
P070【02-Hive SQL-DML-Load加载数据操作】
连接成功
Last login: Thu Feb 23 22:01:26 2023 from 192.168.88.1
[root@node1 ~]# pwd
/root
[root@node1 ~]# ll
总用量 84
-rw-r--r-- 1 root root 2 2月 21 21:14 1.txt
-rw-r--r-- 1 root root 4 2月 22 11:03 666.txt
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
-rw-r--r-- 1 root root 34 2月 21 21:36 hello.txt
-rw------- 1 root root 66920 2月 23 22:05 nohup.out
[root@node1 ~]# mkdir hivedata
[root@node1 ~]# cd hivedata/
[root@node1 hivedata]# ll
总用量 0
[root@node1 hivedata]# vim 1.txt
[root@node1 hivedata]# cat 1.txt
1,allen,18
2,james,22
3,kobe,33
[root@node1 hivedata]# jps
7949 Jps
[root@node1 hivedata]# start-all.sh
Starting namenodes on [node1]
上一次登录:五 2月 24 10:54:43 CST 2023从 192.168.88.1pts/1 上
Starting datanodes
上一次登录:五 2月 24 11:00:11 CST 2023pts/0 上
Starting secondary namenodes [node2]
上一次登录:五 2月 24 11:00:14 CST 2023pts/0 上
Starting resourcemanager
上一次登录:五 2月 24 11:00:21 CST 2023pts/0 上
Starting nodemanagers
上一次登录:五 2月 24 11:00:32 CST 2023pts/0 上
[root@node1 hivedata]# jps
8432 NameNode
9640 NodeManager
9944 Jps
9420 ResourceManager
8622 DataNode
[root@node1 hivedata]# nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore
[root@node1 ~]# jps
8432 NameNode
9640 NodeManager
11515 RunJar
9420 ResourceManager
14333 Jps
8622 DataNode
[root@node1 ~]# nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
[1] 14827
[root@node1 ~]# nohup: 忽略输入并把输出追加到"nohup.out"[root@node1 ~]# jps
8432 NameNode
15045 Jps
9640 NodeManager
11515 RunJar
14827 RunJar
9420 ResourceManager
8622 DataNode
[root@node1 ~]# 连接成功
Last login: Fri Feb 24 11:00:35 2023
[root@node1 ~]# jps
8432 NameNode
9640 NodeManager
11515 RunJar
9420 ResourceManager
14333 Jps
8622 DataNode
[root@node1 ~]# nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
[1] 14827
[root@node1 ~]# nohup: 忽略输入并把输出追加到"nohup.out"[root@node1 ~]# jps
8432 NameNode
15045 Jps
9640 NodeManager
11515 RunJar
14827 RunJar
9420 ResourceManager
8622 DataNode
[root@node1 ~]# hadoop fs -put 1.txt /user/hive/warehouse/itheima.db/t_1
[root@node1 ~]# cat 1.txt
1
[root@node1 ~]# cd hivedata/
[root@node1 hivedata]# hadoop fs -put 1.txt /user/hive/warehouse/itheima.db/t_1
put: `/user/hive/warehouse/itheima.db/t_1/1.txt': File exists
[root@node1 hivedata]# hadoop fs -put 1.txt /user/hive/warehouse/itheima.db/t_1
[root@node1 hivedata]# 连接成功
Last login: Fri Feb 24 10:57:54 2023 from 192.168.88.1
[root@node3 ~]# /export/server/apache-hive-3.1.2-bin/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> ! connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000> use itheima;
INFO : Compiling command(queryId=root_20230224110613_71182481-e89c-49d0-819f-02beec470edd): use itheima
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224110613_71182481-e89c-49d0-819f-02beec470edd); Time taken: 1.394 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224110613_71182481-e89c-49d0-819f-02beec470edd): use itheima
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224110613_71182481-e89c-49d0-819f-02beec470edd); Time taken: 0.08 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (1.841 seconds)
0: jdbc:hive2://node1:10000> create table t_1(id int, name string, age int) row format delimited fields terminated by ',';
INFO : Compiling command(queryId=root_20230224111148_4be457ef-f056-4714-9e5e-c1870296f045): create table t_1(id int, name string, age int) row format delimited fields terminated by ','
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224111148_4be457ef-f056-4714-9e5e-c1870296f045); Time taken: 0.225 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224111148_4be457ef-f056-4714-9e5e-c1870296f045): create table t_1(id int, name string, age int) row format delimited fields terminated by ','
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224111148_4be457ef-f056-4714-9e5e-c1870296f045); Time taken: 2.87 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (3.142 seconds)
0: jdbc:hive2://node1:10000> hadoop fs -put 1.txt /user/hive/warehouse/itheima.db/t_1
. . . . . . . . . . . . . .> ;
Error: Error while compiling statement: FAILED: ParseException line 1:0 cannot recognize input near 'hadoop' 'fs' '-' (state=42000,code=40000)
0: jdbc:hive2://node1:10000> select * from t_1;
INFO : Compiling command(queryId=root_20230224111528_87b64e1a-d9dd-4c7b-ac15-c73bb7830cc7): select * from t_1
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_1.id, type:int, comment:null), FieldSchema(name:t_1.name, type:string, comment:null), FieldSchema(name:t_1.age, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224111528_87b64e1a-d9dd-4c7b-ac15-c73bb7830cc7); Time taken: 2.749 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224111528_87b64e1a-d9dd-4c7b-ac15-c73bb7830cc7): select * from t_1
INFO : Completed executing command(queryId=root_20230224111528_87b64e1a-d9dd-4c7b-ac15-c73bb7830cc7); Time taken: 0.005 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------+-----------+----------+
| t_1.id | t_1.name | t_1.age |
+---------+-----------+----------+
| 1 | NULL | NULL |
+---------+-----------+----------+
1 row selected (3.728 seconds)
0: jdbc:hive2://node1:10000> select * from t_1;
INFO : Compiling command(queryId=root_20230224111713_190a3ed2-60b4-497a-b492-14e3d04ab944): select * from t_1
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_1.id, type:int, comment:null), FieldSchema(name:t_1.name, type:string, comment:null), FieldSchema(name:t_1.age, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224111713_190a3ed2-60b4-497a-b492-14e3d04ab944); Time taken: 0.298 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224111713_190a3ed2-60b4-497a-b492-14e3d04ab944): select * from t_1
INFO : Completed executing command(queryId=root_20230224111713_190a3ed2-60b4-497a-b492-14e3d04ab944); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------+-----------+----------+
| t_1.id | t_1.name | t_1.age |
+---------+-----------+----------+
| 1 | allen | 18 |
| 2 | james | 22 |
| 3 | kobe | 33 |
+---------+-----------+----------+
3 rows selected (0.464 seconds)
0: jdbc:hive2://node1:10000> LOCAL本地是哪里?
本地文件系统指的是Hiveserver2服务所在机器的本地Linux文件系统,不是Hive客户端所在的本地文件系统。
node1:安装hive、启动了metastore服务与hiveServer2服务
node3:客户端
load data local,local:不是客户端所在的本地,而是hive服务器所在的本地;只要访问的是node1这台服务器上运行的hive服务,加载数据时local本地指的就是从node1这台linux加载的本地文件系统。
node1
start-all.sh
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
jps
node3
/export/server/apache-hive-3.1.2-bin/bin/beeline
! connect jdbc:hive2://node1:10000
root
node3
use itheima;
show tables;
load data local inpath '/root/hivedata/students.txt' into table itheima.student_local;
select * from student_local;
[root@node3 ~]# /export/server/apache-hive-3.1.2-bin/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> ! connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000> use itheima;
INFO : Compiling command(queryId=root_20230224150749_0991ca1a-f503-44a6-a7f1-74ac128de061): use itheima
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224150749_0991ca1a-f503-44a6-a7f1-74ac128de061); Time taken: 0.028 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224150749_0991ca1a-f503-44a6-a7f1-74ac128de061): use itheima
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224150749_0991ca1a-f503-44a6-a7f1-74ac128de061); Time taken: 0.015 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.127 seconds)
0: jdbc:hive2://node1:10000> show tables;
INFO : Compiling command(queryId=root_20230224150754_7e131858-4f7a-45c5-ac4c-197fb0ef187b): show tables
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=root_20230224150754_7e131858-4f7a-45c5-ac4c-197fb0ef187b); Time taken: 0.028 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224150754_7e131858-4f7a-45c5-ac4c-197fb0ef187b): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224150754_7e131858-4f7a-45c5-ac4c-197fb0ef187b); Time taken: 0.009 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------------------+
| tab_name |
+---------------------+
| student_hdfs |
| student_local |
| t_1 |
| t_archer |
| t_archer1 |
| t_team_ace_player |
| t_team_ace_player2 |
+---------------------+
7 rows selected (0.11 seconds)
0: jdbc:hive2://node1:10000> load data local inpath '/root/hivedata/students.txt' into table itheima.student_local;
INFO : Compiling command(queryId=root_20230224151134_e01df8a4-14fb-4474-bc35-f751d8a54bcd): load data local inpath '/root/hivedata/students.txt' into table itheima.student_local
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224151134_e01df8a4-14fb-4474-bc35-f751d8a54bcd); Time taken: 0.183 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224151134_e01df8a4-14fb-4474-bc35-f751d8a54bcd): load data local inpath '/root/hivedata/students.txt' into table itheima.student_local
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table itheima.student_local from file:/root/hivedata/students.txt
INFO : Starting task [Stage-1:STATS] in serial mode
INFO : Completed executing command(queryId=root_20230224151134_e01df8a4-14fb-4474-bc35-f751d8a54bcd); Time taken: 0.571 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.77 seconds)
0: jdbc:hive2://node1:10000> select * from student_local;
INFO : Compiling command(queryId=root_20230224151258_71d2f260-469d-483b-a451-3e34008ab22e): select * from student_local
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student_local.num, type:int, comment:null), FieldSchema(name:student_local.name, type:string, comment:null), FieldSchema(name:student_local.sex, type:string, comment:null), FieldSchema(name:student_local.age, type:int, comment:null), FieldSchema(name:student_local.dept, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224151258_71d2f260-469d-483b-a451-3e34008ab22e); Time taken: 0.352 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224151258_71d2f260-469d-483b-a451-3e34008ab22e): select * from student_local
INFO : Completed executing command(queryId=root_20230224151258_71d2f260-469d-483b-a451-3e34008ab22e); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+--------------------+---------------------+--------------------+--------------------+---------------------+
| student_local.num | student_local.name | student_local.sex | student_local.age | student_local.dept |
+--------------------+---------------------+--------------------+--------------------+---------------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
| 95004 | 张立 | 男 | 19 | IS |
| 95005 | 刘刚 | 男 | 18 | MA |
| 95006 | 孙庆 | 男 | 23 | CS |
| 95007 | 易思玲 | 女 | 19 | MA |
| 95008 | 李娜 | 女 | 18 | CS |
| 95009 | 梦圆圆 | 女 | 18 | MA |
| 95010 | 孔小涛 | 男 | 19 | CS |
| 95011 | 包小柏 | 男 | 18 | MA |
| 95012 | 孙花 | 女 | 20 | CS |
| 95013 | 冯伟 | 男 | 21 | CS |
| 95014 | 王小丽 | 女 | 19 | CS |
| 95015 | 王君 | 男 | 18 | MA |
| 95016 | 钱国 | 男 | 21 | MA |
| 95017 | 王风娟 | 女 | 18 | IS |
| 95018 | 王一 | 女 | 19 | IS |
| 95019 | 邢小丽 | 女 | 19 | IS |
| 95020 | 赵钱 | 男 | 21 | IS |
| 95021 | 周二 | 男 | 17 | MA |
| 95022 | 郑明 | 男 | 20 | MA |
+--------------------+---------------------+--------------------+--------------------+---------------------+
22 rows selected (0.581 seconds)
0: jdbc:hive2://node1:10000> select * from student_hdfs;
INFO : Compiling command(queryId=root_20230224152251_0333fd6a-7ecb-49dd-b5eb-d792308f8e23): select * from student_hdfs
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student_hdfs.num, type:int, comment:null), FieldSchema(name:student_hdfs.name, type:string, comment:null), FieldSchema(name:student_hdfs.sex, type:string, comment:null), FieldSchema(name:student_hdfs.age, type:int, comment:null), FieldSchema(name:student_hdfs.dept, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224152251_0333fd6a-7ecb-49dd-b5eb-d792308f8e23); Time taken: 0.244 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224152251_0333fd6a-7ecb-49dd-b5eb-d792308f8e23): select * from student_hdfs
INFO : Completed executing command(queryId=root_20230224152251_0333fd6a-7ecb-49dd-b5eb-d792308f8e23); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------+--------------------+-------------------+-------------------+--------------------+
| student_hdfs.num | student_hdfs.name | student_hdfs.sex | student_hdfs.age | student_hdfs.dept |
+-------------------+--------------------+-------------------+-------------------+--------------------+
+-------------------+--------------------+-------------------+-------------------+--------------------+
No rows selected (0.299 seconds)
0: jdbc:hive2://node1:10000> load data inpath '/students.txt' into table itheima.student_hdfs;
INFO : Compiling command(queryId=root_20230224152540_1eafbf79-52a6-4846-8b2a-e1412b020807): load data inpath '/students.txt' into table itheima.student_hdfs
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224152540_1eafbf79-52a6-4846-8b2a-e1412b020807); Time taken: 0.073 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224152540_1eafbf79-52a6-4846-8b2a-e1412b020807): load data inpath '/students.txt' into table itheima.student_hdfs
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table itheima.student_hdfs from hdfs://node1:8020/students.txt
INFO : Starting task [Stage-1:STATS] in serial mode
INFO : Completed executing command(queryId=root_20230224152540_1eafbf79-52a6-4846-8b2a-e1412b020807); Time taken: 0.468 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.552 seconds)
0: jdbc:hive2://node1:10000> select * from student_hdfs;
INFO : Compiling command(queryId=root_20230224152626_dcf0cf77-73b5-4e51-ab0e-64d00653c5db): select * from student_hdfs
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student_hdfs.num, type:int, comment:null), FieldSchema(name:student_hdfs.name, type:string, comment:null), FieldSchema(name:student_hdfs.sex, type:string, comment:null), FieldSchema(name:student_hdfs.age, type:int, comment:null), FieldSchema(name:student_hdfs.dept, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224152626_dcf0cf77-73b5-4e51-ab0e-64d00653c5db); Time taken: 0.255 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224152626_dcf0cf77-73b5-4e51-ab0e-64d00653c5db): select * from student_hdfs
INFO : Completed executing command(queryId=root_20230224152626_dcf0cf77-73b5-4e51-ab0e-64d00653c5db); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------+--------------------+-------------------+-------------------+--------------------+
| student_hdfs.num | student_hdfs.name | student_hdfs.sex | student_hdfs.age | student_hdfs.dept |
+-------------------+--------------------+-------------------+-------------------+--------------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
| 95004 | 张立 | 男 | 19 | IS |
| 95005 | 刘刚 | 男 | 18 | MA |
| 95006 | 孙庆 | 男 | 23 | CS |
| 95007 | 易思玲 | 女 | 19 | MA |
| 95008 | 李娜 | 女 | 18 | CS |
| 95009 | 梦圆圆 | 女 | 18 | MA |
| 95010 | 孔小涛 | 男 | 19 | CS |
| 95011 | 包小柏 | 男 | 18 | MA |
| 95012 | 孙花 | 女 | 20 | CS |
| 95013 | 冯伟 | 男 | 21 | CS |
| 95014 | 王小丽 | 女 | 19 | CS |
| 95015 | 王君 | 男 | 18 | MA |
| 95016 | 钱国 | 男 | 21 | MA |
| 95017 | 王风娟 | 女 | 18 | IS |
| 95018 | 王一 | 女 | 19 | IS |
| 95019 | 邢小丽 | 女 | 19 | IS |
| 95020 | 赵钱 | 男 | 21 | IS |
| 95021 | 周二 | 男 | 17 | MA |
| 95022 | 郑明 | 男 | 20 | MA |
+-------------------+--------------------+-------------------+-------------------+--------------------+
22 rows selected (0.313 seconds)
0: jdbc:hive2://node1:10000> P071【03-Hive SQL-DML-Insert插入数据】
create table t_2(id int, name string);
insert into table t_2 values(1, "zhangsan"); 语法支持,但运行速度太慢!
select * from t_2;

0: jdbc:hive2://node1:10000> create table t_2(id int, name string);
INFO : Compiling command(queryId=root_20230224154557_9d1559c6-d7df-42cb-a0e2-5957691cf26e): create table t_2(id int, name string)
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224154557_9d1559c6-d7df-42cb-a0e2-5957691cf26e); Time taken: 0.027 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224154557_9d1559c6-d7df-42cb-a0e2-5957691cf26e): create table t_2(id int, name string)
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224154557_9d1559c6-d7df-42cb-a0e2-5957691cf26e); Time taken: 0.109 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.164 seconds)
0: jdbc:hive2://node1:10000> insert into table t_2 values(1, "zhangsan");
INFO : Compiling command(queryId=root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a): insert into table t_2 values(1, "zhangsan")
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col1, type:int, comment:null), FieldSchema(name:col2, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a); Time taken: 0.773 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a): insert into table t_2 values(1, "zhangsan")
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a
INFO : Total jobs = 3
INFO : Launching Job 1 out of 3
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1677220144667_0001
INFO : Executing with tokens: []
INFO : The url to track the job: http://node1:8088/proxy/application_1677220144667_0001/
INFO : Starting Job = job_1677220144667_0001, Tracking URL = http://node1:8088/proxy/application_1677220144667_0001/
INFO : Kill Command = /export/server/hadoop-3.3.0/bin/mapred job -kill job_1677220144667_0001
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2023-02-24 15:49:20,742 Stage-1 map = 0%, reduce = 0%
INFO : 2023-02-24 15:49:32,536 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.82 sec
INFO : 2023-02-24 15:49:54,617 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 10.2 sec
INFO : MapReduce Total cumulative CPU time: 10 seconds 200 msec
INFO : Ended Job = job_1677220144667_0001
INFO : Starting task [Stage-7:CONDITIONAL] in serial mode
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Starting task [Stage-4:MOVE] in serial mode
INFO : Moving data to directory hdfs://node1:8020/user/hive/warehouse/itheima.db/t_2/.hive-staging_hive_2023-02-24_15-48-28_204_7443762290621652108-3/-ext-10000 from hdfs://node1:8020/user/hive/warehouse/itheima.db/t_2/.hive-staging_hive_2023-02-24_15-48-28_204_7443762290621652108-3/-ext-10002
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table itheima.t_2 from hdfs://node1:8020/user/hive/warehouse/itheima.db/t_2/.hive-staging_hive_2023-02-24_15-48-28_204_7443762290621652108-3/-ext-10000
INFO : Starting task [Stage-2:STATS] in serial mode
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 10.2 sec HDFS Read: 15250 HDFS Write: 241 SUCCESS
INFO : Total MapReduce CPU Time Spent: 10 seconds 200 msec
INFO : Completed executing command(queryId=root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a); Time taken: 88.299 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (89.096 seconds)
0: jdbc:hive2://node1:10000> select * from t_2;
INFO : Compiling command(queryId=root_20230224155036_23fdd103-4a07-4232-aa48-c94335756fe3): select * from t_2
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_2.id, type:int, comment:null), FieldSchema(name:t_2.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224155036_23fdd103-4a07-4232-aa48-c94335756fe3); Time taken: 0.224 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224155036_23fdd103-4a07-4232-aa48-c94335756fe3): select * from t_2
INFO : Completed executing command(queryId=root_20230224155036_23fdd103-4a07-4232-aa48-c94335756fe3); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------+-----------+
| t_2.id | t_2.name |
+---------+-----------+
| 1 | zhangsan |
+---------+-----------+
1 row selected (0.275 seconds)
0: jdbc:hive2://node1:10000> show databases;use itheima;------------Hive SQL-DML-Load加载数据-----------------step1:建表
--建表student_local 用于演示从本地加载数据
create table student_local(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
--建表student_HDFS 用于演示从HDFS加载数据
create table student_HDFS(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';--建议使用beeline客户端 可以显示出加载过程日志信息
--step2:加载数据
-- 从本地加载数据 数据位于HS2(node1)本地文件系统 本质是hadoop fs -put上传操作
LOAD DATA LOCAL INPATH '/root/hivedata/students.txt' INTO TABLE student_local;
--从HDFS加载数据 数据位于HDFS文件系统根目录下 本质是hadoop fs -mv 移动操作
--先把数据上传到HDFS上 hadoop fs -put /root/hivedata/students.txt /
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS;------------Hive SQL-DML-Insert插入数据-------------------step1:创建一张源表student
drop table if exists student;
create table student(num int,name string,sex string,age int,dept string)
row format delimited fields terminated by ',';--step2:加载数据
load data local inpath '/root/hivedata/students.txt' into table student;select * from student;--step3:创建一张目标表 只有两个字段
create table student_from_insert(sno int, sname string);--使用insert+select插入数据到新表中
insert into table student_from_insert select num, name from student;select * from student_from_insert;02【Hive SQL DML语法之查询数据】
P072【04-Hive SQL-DML-Select查询--语法树与学习环境准备】
Select语法树
- 从哪里查询取决于FROM关键字后面的table_reference,这是我们写查询SQL的首先要确定的事即你查询谁?
- 表名和列名不区分大小写。


------------Hive SQL select查询基础语法------------
--创建表t_usa_covid19
drop table if exists t_usa_covid19;
CREATE TABLE t_usa_covid19(count_date string,county string,state string,fips int,cases int,deaths int)
row format delimited fields terminated by ",";--将数据load加载到t_usa_covid19表对应的路径下
load data local inpath '/root/hivedata/us-covid19-counties.dat' into table t_usa_covid19;--1、select_expr
--查询所有字段或者指定字段
select * from t_usa_covid19;P073【05-Hive SQL-DML-Select查询--列表达式与distinct去重】
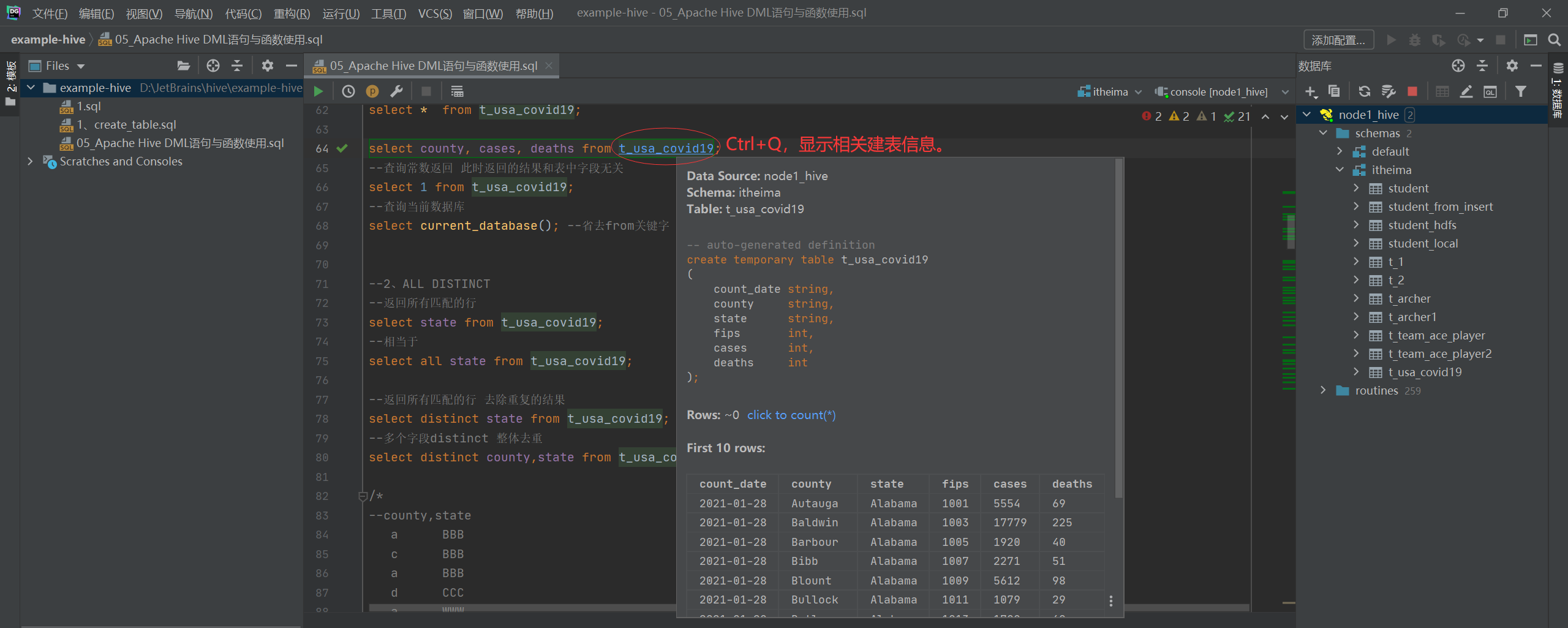
--1、select_expr
--查询所有字段或者指定字段
select * from t_usa_covid19;select county, cases, deaths from t_usa_covid19;
--查询常数返回 此时返回的结果和表中字段无关
select 1 from t_usa_covid19;
--查询当前数据库
select current_database(); --省去from关键字--2、ALL DISTINCT
--返回所有匹配的行
select state from t_usa_covid19;
--相当于
select all state from t_usa_covid19;--返回所有匹配的行 去除重复的结果
select distinct state from t_usa_covid19;
--多个字段distinct 整体去重
select distinct county,state from t_usa_covid19;/*
--county, statea BBBc BBBa BBBd CCCa WWWa BBBc BBBd CCC
*/P074【06-Hive SQL-DML-Select查询--Where条件过滤】
--3、WHERE CAUSE
select * from t_usa_covid19 where 1 > 2; -- 1 > 2 返回false
select * from t_usa_covid19 where 1 = 1; -- 1 = 1 返回true--找出来自于California州的疫情数据
select * from t_usa_covid19 where state = 'California';
--where条件中使用函数 找出州名字母长度超过10位的有哪些
select * from t_usa_covid19 where length(state) >10 ;P075【07-Hive SQL-DML-Select查询--聚合操作aggregate】
--4、聚合操作
select county from t_usa_covid19;
select count(county) from t_usa_covid19;
--统计美国总共有多少个县county
select county as itcast from t_usa_covid19;
--学会使用as给查询返回的结果起个别名
select count(county) as county_cnts from t_usa_covid19;
--去重distinct
select count(distinct county) as county_cnts from t_usa_covid19;--统计美国加州有多少个县
select count(county) from t_usa_covid19 where state = "California";
--统计德州总死亡病例数
select sum(deaths) from t_usa_covid19 where state = "Texas";
--统计出美国最高确诊病例数是哪个县
select max(cases) from t_usa_covid19;P076【08-Hive SQL-DML-Select查询--Group by分组及语法限制】
--5、GROUP BYselect * from t_usa_covid19;--根据state州进行分组 统计每个州有多少个县county
select count(county) from t_usa_covid19 where count_date = "2021-01-28" group by state;--想看一下统计的结果是属于哪一个州的
select state,count(county) as county_nums from t_usa_covid19 where count_date = "2021-01-28" group by state;--再想看一下每个县的死亡病例数,我们猜想很简单呀 把deaths字段加上返回 真实情况如何呢?
select state,count(county),sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" group by state;
--很尴尬 sql报错了org.apache.hadoop.hive.ql.parse.SemanticException:Line 1:27 Expression not in GROUP BY key 'deaths'--为什么会报错??group by的语法限制
--结论:出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段。
--deaths不是分组字段 报错
--state是分组字段 可以直接出现在select_expr中--被聚合函数应用
select state,count(county),sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" group by state;P077【09-Hive SQL-DML-Select查询--Having过滤操作】
--6、having
--统计2021-01-28死亡病例数大于10000的州
select state,sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" and sum(deaths) >10000 group by state;
--where语句中不能使用聚合函数,语法报错,所以使用having函数!--先where分组前过滤,再进行group by分组, 分组后每个分组结果集确定 再使用having过滤
select state,sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" group by state having sum(deaths) > 10000;
--这样写更好 即在group by的时候聚合函数已经作用得出结果 having直接引用结果过滤 不需要再单独计算一次了
select state,sum(deaths) as cnts from t_usa_covid19 where count_date = "2021-01-28" group by state having cnts> 10000;P078【10-Hive SQL-DML-Select查询--Order by排序】
--7、order by
--根据确诊病例数升序排序 查询返回结果
select * from t_usa_covid19 ;
select * from t_usa_covid19 order by cases;
--不写排序规则 默认就是asc升序
select * from t_usa_covid19 order by cases asc;--根据死亡病例数倒序排序 查询返回加州每个县的结果
select * from t_usa_covid19 where state = "California" order by cases desc;P079【11-Hive SQL-DML-Select查询--Limit限制语法】
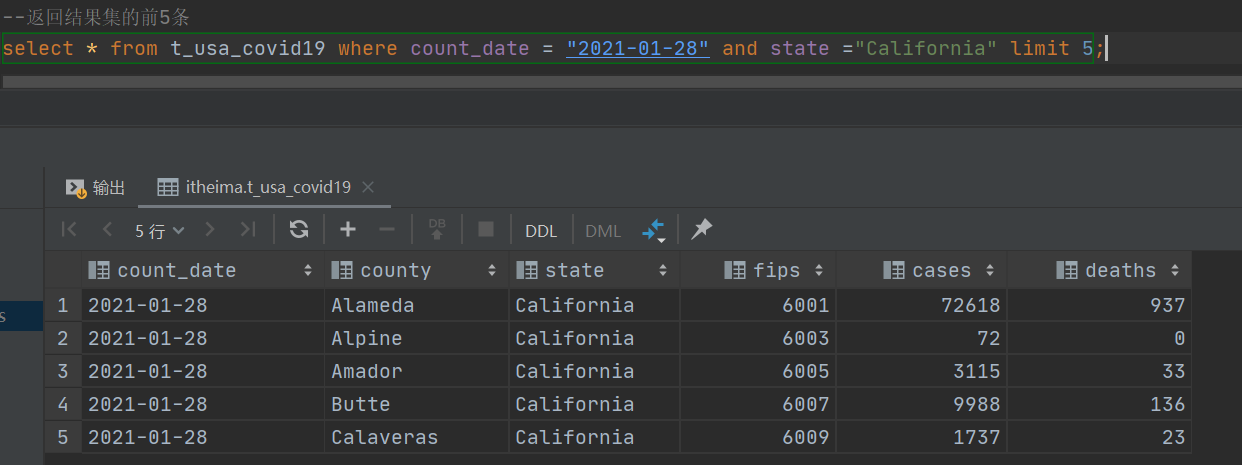
--8、limit
--没有限制返回2021.1.28 加州的所有记录
select * from t_usa_covid19 where count_date = "2021-01-28" and state ="California";--返回结果集的前5条
select * from t_usa_covid19 where count_date = "2021-01-28" and state ="California" limit 5;--返回结果集从第1行开始 共3行
select * from t_usa_covid19 where count_date = "2021-01-28" and state ="California" limit 2,3;
--注意 第一个参数偏移量是从0开始的P080【12-Hive SQL-DML-Select查询--执行顺序梳理】
--执行顺序
select state,sum(deaths) as cnts from t_usa_covid19
where count_date = "2021-01-28"
group by state
having cnts> 10000
limit 2;03【Hive SQL Join关联查询】
P081【13-Hive SQL Join关联查询】
在Hive中,使用最多最重要的两种join分别是:inner join(内连接)、left join(左连接)。
employee.txt
1201,gopal,manager,50000,TP
1202,manisha,cto,50000,TP
1203,khalil,dev,30000,AC
1204,prasanth,dev,30000,AC
1206,kranthi,admin,20000,TPemployee_address.txt
1201,288A,vgiri,jublee
1202,108I,aoc,ny
1204,144Z,pgutta,hyd
1206,78B,old city,la
1207,720X,hitec,nyemployee_connection.txt
1201,2356742,gopal@tp.com
1203,1661663,manisha@tp.com
1204,8887776,khalil@ac.com
1205,9988774,prasanth@ac.com
1206,1231231,kranthi@tp.com
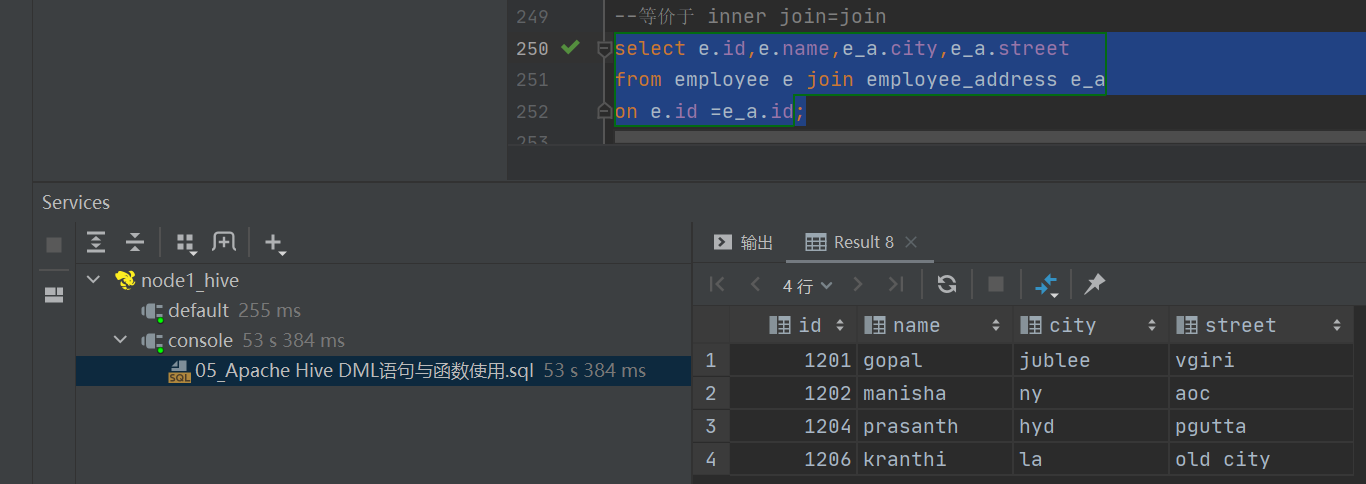
------------Hive Join SQL 语法------------
--Join语法练习 建表
drop table if exists employee_address;
drop table if exists employee_connection;
drop table if exists employee;--table1: 员工表
CREATE TABLE employee(id int,name string,deg string,salary int,dept string) row format delimited
fields terminated by ',';--table2:员工家庭住址信息表
CREATE TABLE employee_address (id int,hno string,street string,city string
) row format delimited
fields terminated by ',';--table3:员工联系方式信息表
CREATE TABLE employee_connection (id int,phno string,email string
) row format delimited
fields terminated by ',';--加载数据到表中
load data local inpath '/root/hivedata/employee.txt' into table employee;
load data local inpath '/root/hivedata/employee_address.txt' into table employee_address;
load data local inpath '/root/hivedata/employee_connection.txt' into table employee_connection;select * from employee;select * from employee_address;select * from employee_connection;--1、inner join
select e.id,e.name,e_a.city,e_a.street
from employee e inner join employee_address e_a
on e.id =e_a.id;--等价于 inner join=join
select e.id,e.name,e_a.city,e_a.street
from employee e join employee_address e_a
on e.id =e_a.id;--等价于 隐式连接表示法
select e.id,e.name,e_a.city,e_a.street
from employee e , employee_address e_a
where e.id = e_a.id;--2、left join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left join employee_connection e_conn
on e.id = e_conn.id;--等价于 left outer join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left outer join employee_connection e_conn
on e.id = e_conn.id;04【Hive SQL中的常用函数使用入门】
P082【14-Hive函数概述及分类标准】
概述
Hive内建了不少函数,用于满足用户不同使用需求,提高SQL编写效率。
- 使用show functions查看当下可用的所有函数;
- 通过describe function extended funcname来查看函数的使用方式。
分类标准
Hive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数UDF(User-Defined Functions):
- 内置函数可分为:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
- 用户定义函数根据输入输出的行数可分为3类:UDF、UDAF、UDTF。
P083【15-Hive常用的内置函数】
概述
- 内置函数(build-in)指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数。
- 官方文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
- 内置函数根据应用归类整体可以分为8大种类型,我们将对其中重要的,使用频率高的函数使用进行详细讲解。
- String Functions,字符串函数
- Date Functions,日期函数
- Mathematical Functions,数学函数
- Conditional Functions,条件函数
-----------------Hive 常用的内置函数----------------------
show functions;
describe function extended count;------------String Functions 字符串函数------------
select length("itcast");
select reverse("itcast");select concat("angela", "baby");
--带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('itcast', 'cn'));--字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len])
select substr("angelababy", -2); --pos是从1开始的索引,如果为负数则倒着数
select substr("angelababy", 2, 2);
--分割字符串函数: split(str, regex)
--split针对字符串数据进行切割,返回的是数组array,可以通过数组的下标取内部的元素,注意下标是从0开始的
select split('apache hive', ' ');
select split('apache hive', ' ')[0];
select split('apache hive', ' ')[1];----------- Date Functions 日期函数 -----------------
--获取当前日期: current_date
select current_date();
--获取当前UNIX时间戳函数: unix_timestamp
select unix_timestamp();
--日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp("2011-12-07 13:01:03");
--指定格式日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp('20111207 13:01:03', 'yyyyMMdd HH:mm:ss');
--UNIX时间戳转日期函数: from_unixtime
select from_unixtime(1618238391);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');--日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff('2012-12-08', '2012-05-09');
--日期增加函数: date_add
select date_add('2012-02-28', 10);
--日期减少函数: date_sub
select date_sub('2012-01-1', 10);----Mathematical Functions 数学函数-------------
--取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926, 4);
--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);-----Conditional Functions 条件函数------------------
--使用之前课程创建好的student表数据
select * from student limit 3;--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1 = 2, 100, 200);
select if(sex = '男', 'M', 'W') from student limit 3;--空值转换函数: nvl(T value, T default_value)
select nvl("allen", "itcast");
select nvl(null, "itcast");--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
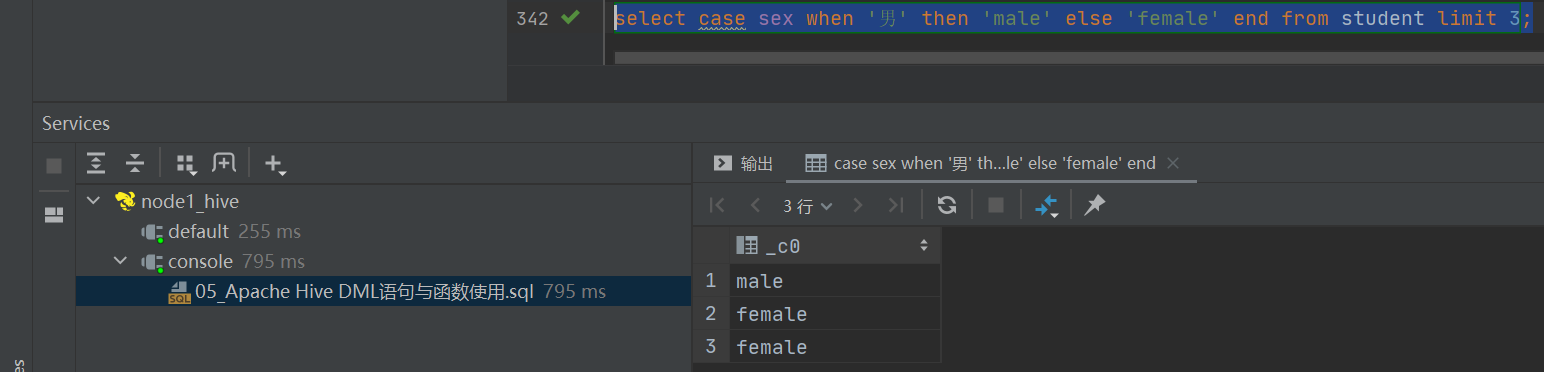
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when '男' then 'male' else 'female' end from student limit 3;相关文章:
大数据Hadoop教程-学习笔记05【Apache Hive DML语句与函数使用】
视频教程:哔哩哔哩网站:黑马大数据Hadoop入门视频教程 总时长:14:22:04教程资源: https://pan.baidu.com/s/1WYgyI3KgbzKzFD639lA-_g 提取码: 6666【P001-P017】大数据Hadoop教程-学习笔记01【大数据导论与Linux基础】【17p】【P018-P037】大…...

Unity动画转Three.js动画
一:应用场景 在工作中,由于算法给到的动画文件是Unity的.anim格式动画文件,这个格式不能直接在Web端用Three.js引擎运行。因此需要将.anim格式的动画文件转换为Three.js的AnimationClip动画对象。 二:.ANIM格式与AnimationClip对…...

07_MySQL的单行函数
1. 函数的理解1.1 什么是函数函数在计算机语言的使用中贯穿始终,函数的作用是什么呢?它可以把我们经常使用的代码封装起来,需要的时候直接调用即可。这样既提高了代码效率 ,又提高了可维护性 。在 SQL 中我们也可以使用函数对检索…...

QML 第一个应用程序Window
1.创建QML工程 新建文件或者项目-->选择Qt Quick Application 然后生成了一个默认的Window 2.main.cpp中如何加载的qml文件 QQmlApplicationEngine提供了从单个QML文件加载应用程序的便捷方式。 此类结合了QQmlEngine和QQmlComponent,以提供一种方便的方式加载…...
)
RedisAI编译安装(一)
1.概述 RedisAI 是一个 Redis 模块,用于执行深度学习/机器学习模型并管理其数据。它的目的是成为模型服务的“主力”,通过为流行的 DL/ML 框架和无与伦比的性能提供开箱即用的支持。RedisAI 遵循数据局部性原则,最大限度地提高计算吞吐量并减…...
换掉 Maven,我就用Gradle,急速编译
相信使用Java的同学都用过Maven,这是一个非常经典好用的项目构建工具。但是如果你经常使用Maven,可能会发现Maven有一些地方用的让人不太舒服: Maven的配置文件是XML格式的,假如你的项目依赖的包比较多,那么XML文件就…...

22.2.26打卡 Codeforces Round #853 (Div. 2)
A题极端考虑, 只要存在一个前缀数组的最大公约数小于等于2, 将其放在数组最前端, 那么保证能够满足题目要求数据范围这么小, 果断暴力Serval and Mochas Array题目描述Mocha likes arrays, and Serval gave her an array consisting of positive integers as a gift.Mocha thin…...
结构体字节对齐、偏移量
复习下struct的大小、成员偏移量offsetof,说下我的理解: 64位下默认对齐数default8原则1:struct中每一个成员变量tmp的对齐数realmin{default,tmp} struct Student {int num;//0char name[8];double score; } stu; 这个结构体stu中&#x…...
全网最全——Java 数据类型
一、数据类型方法论 程序本质上是对数据的处理(逻辑运算),因此任何语言都需先解决如何表征【数据】这个核心概念。数据作为抽象的概念,天然的包含2个方面属性: 类型:类型决定了数据只能和同类型的数据进行…...
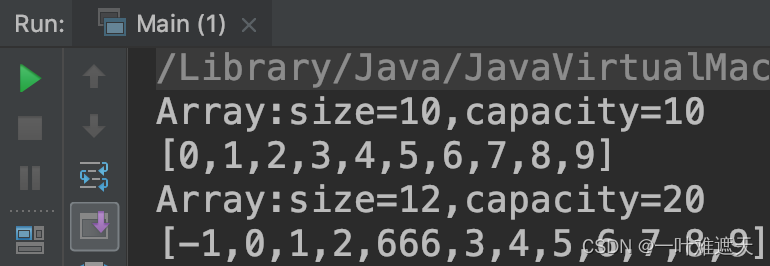
数据结构基础之动态数组
目录 前言 1、Java中的数组 2、实现动态数组 2.1、基本类结构设计 2.2、添加元素 2.3、查询&修改元素 2.4、包含&搜索&删除 2.5、数组扩容 前言 今天我们来学习一下关于数据结构的一些基础知识,数据结构研究的是数据如何在计算机中进行组织和存…...

【跟我一起读《视觉惯性SLAM理论与源码解析》】第九章 地图点、关键帧以及图结构
这一章主要讲了一些基本内容,包括ORB-SLAM2中地图点,关键帧图结构的问题 地图点和特征点的关系?有时候地图点对应不同帧上的特征点,特征点可以通过三角化得到地图点地图点的几个属性,平均观测方向,以及观测…...
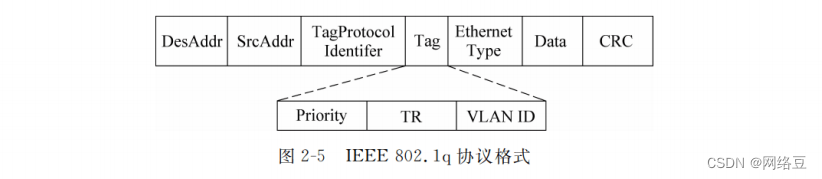
网络安全——数据链路层安全协议(2)
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.局域网数据链路层安全协议 1.IEEE 802.10 (1)IEE…...

【华为OD机试模拟题】用 C++ 实现 - 热点网络统计(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 去重求和(2023.Q1) 文章目录 最近更新的博客使用说明热点网络统计【华为OD机试模拟题】题目输入输出描述示例一输入输出示例二输入输出Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出…...
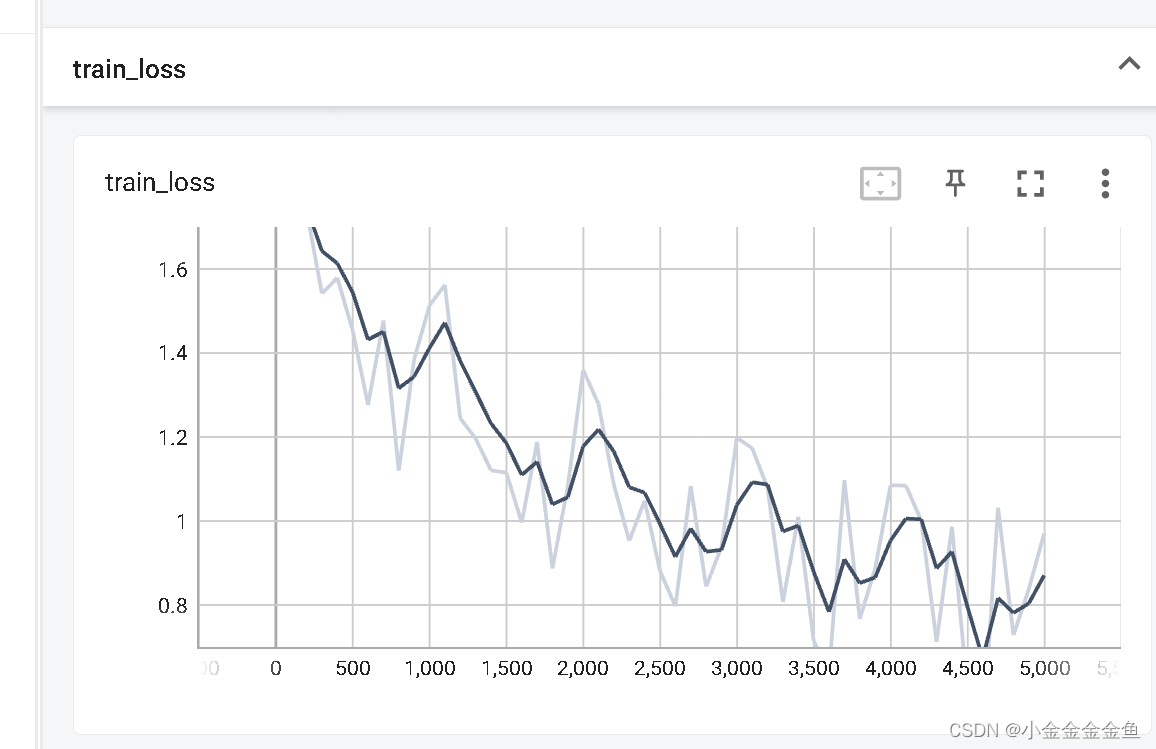
人工智能学习07--pytorch09--LeNet
参考: 视频: https://www.bilibili.com/video/BV187411T7Ye/?spm_id_from333.999.0.0&vd_sourceb425cf6a88c74ab02b3939ca66be1c0d 博客:https://blog.csdn.net/STATEABC/article/details/123661612?utm_mediumdistribute.pc_feed_404.…...

java泛型编程初识
java泛型编程初识1.泛型解决的是什么问题2.泛型实例化语句3.自定义泛型1)自定义泛型类或接口2)自定义泛型方法4.泛型使用中的继承和通配1)通配2)继承使用限制1.泛型解决的是什么问题 很多类、接口、方法中逻辑相同,只是操作的对象类型不同,这个时候就可…...

代码随想录算法训练营 || 贪心算法 1005 134 135
Day291005.K次取反后最大化的数组和力扣题目链接给定一个整数数组 A,我们只能用以下方法修改该数组:我们选择某个索引 i 并将 A[i] 替换为 -A[i],然后总共重复这个过程 K 次。(我们可以多次选择同一个索引 i。)以这种方…...

Spring框架面试题
springboot的自动装配原理 主类上的SpringBootApplication存在EnableAutoConfiguration,EnableAutoConfiguration会导入AutoConfigurationImportSelector组件,其AutoConfigurationImportSelector$AutoConfigurationGroup#process()方法会读取当前应用所有…...
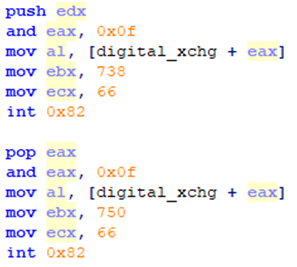
纯x86汇编实现的多线程操作系统实践 - 第五章 AP的守护执行
AP的32位保护模式代码的后半部分从0x8001C000开始执行,完成的工作主要有:初始化必要的中断给BSP发送启动成功的消息创建各AP的系统进程创建各AP的用户进程循环显示各AP中用户进程执行的时间比例5.1 初始化中断5.1.1总体初始化各AP调用init_interrupt_fun…...

2023年全国最新高校辅导员精选真题及答案7
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 71.在北京曾经发现一处战国时期的遗址,从中出土了燕、韩、赵、魏等国铸币3876…...
使用windwow windbg 吃透64位分页内存管理
前言 分页基础概念是操作系统基础知识,网上已经有太多太多了。所以本文记录使用windwow内核调试工具验证理论知识。 具体可以参阅intel volume3的 4.1.1 Four Paging Modes章节。 简而言之:CR0.PG 0表示不开启分页.并且根据CR4各种标志开启不同类别的…...

【鸿蒙PC命令行移植适配】rsync 三方库鸿蒙化适配后在鸿蒙PC运行的完整实践
欢迎加入 开源鸿蒙跨平台开发者社区,与大家一起共建鸿蒙化 C/C 三方库生态。 1. 前言 本教程面向 C/C 开发者,带你完成 rsync 三方库的鸿蒙平台适配,并能够在鸿蒙PC上进行验证。 通过本教程,你将掌握: 使用 lycium…...

Fashion-MNIST实战:从数据加载到模型评估的完整流程
1. 为什么选择Fashion-MNIST作为入门项目 如果你刚开始接触深度学习中的图像分类任务,Fashion-MNIST绝对是最佳选择之一。这个数据集包含了10类时尚单品的灰度图片,每张图片都是28x28像素大小。相比经典的MNIST手写数字数据集,Fashion-MNIST的…...

软件开发公司如何利用AI低代码开发平台提升项目交付能力
一、软件外包行业的现状与转型压力 软件开发公司作为数字化转型的重要参与者,在当前市场环境下正面临着前所未有的挑战。客户需求日益复杂、交付周期不断压缩、人力成本持续上升、竞争格局日趋激烈,这些因素使得传统的外包开发模式难以为继。对于…...

实测对比:不同品牌X7R/X5R陶瓷电容在Buck电路中的纹波抑制效果
实测对比:TDK、Murata、国巨X7R/X5R陶瓷电容在2MHz Buck电路中的纹波抑制表现 当你在设计一款紧凑型消费电子产品的电源模块时,输入电容的选择往往决定了整个系统的稳定性和效率。特别是在2MHz这样的高频Buck电路中,陶瓷电容的选型更是一门需…...
)
HTML+CSS+JS打造动态新年倒计时网页(附完整源码)
1. 项目概述与效果预览 想要在网页上展示一个酷炫的新年倒计时效果吗?用HTMLCSSJS三件套就能轻松实现!这个项目将带你从零开始打造一个动态数字时钟节日特效背景交互音效的完整页面。最终效果会显示距离新年的精确倒计时(天/时/分/秒…...

嵌入式硬件项目技术文章转化规范说明
项目标题与正文内容严重偏离嵌入式硬件技术主题,不具备转化为合格技术文章的基础条件。所给内容为职场随笔类人文评论文章,混杂公众号运营话术、知乎风格叙事、个人职业感悟及若干无关技术短语(如“单片机启动文件.s有什么作用”)…...

2025年FontForge字体设计终极指南:10个革新方向助你打造专业字体
2025年FontForge字体设计终极指南:10个革新方向助你打造专业字体 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge FontForge作为一款免费开源的字体编辑器…...

VMware虚拟机中部署Qwen3:Windows主机下的Linux开发测试环境
VMware虚拟机中部署Qwen3:Windows主机下的Linux开发测试环境 对于很多使用Windows系统的开发者来说,想在本地跑一些基于Linux环境的AI项目,常常会遇到环境配置复杂、依赖冲突等问题。直接在Windows上折腾,往往事倍功半。今天&…...

Qwen3.5-27B惊艳效果:复杂场景多物体识别+关系推理+自然语言描述
Qwen3.5-27B惊艳效果:复杂场景多物体识别关系推理自然语言描述 你有没有遇到过这样的情况?看到一张复杂的照片,里面有好多东西,它们之间好像有某种联系,但你很难用一句话把整个场景描述清楚。比如一张公园的照片&…...

Z-Image-Turbo-rinaiqiao-huiyewunv开源大模型实践:二次元垂直领域微调模型本地化范本
Z-Image-Turbo-rinaiqiao-huiyewunv开源大模型实践:二次元垂直领域微调模型本地化范本 想亲手打造一个只属于你的二次元角色吗?比如,让《辉夜大小姐想让我告白》中的日奈娇(辉夜大小姐)按照你的想象,摆出各…...