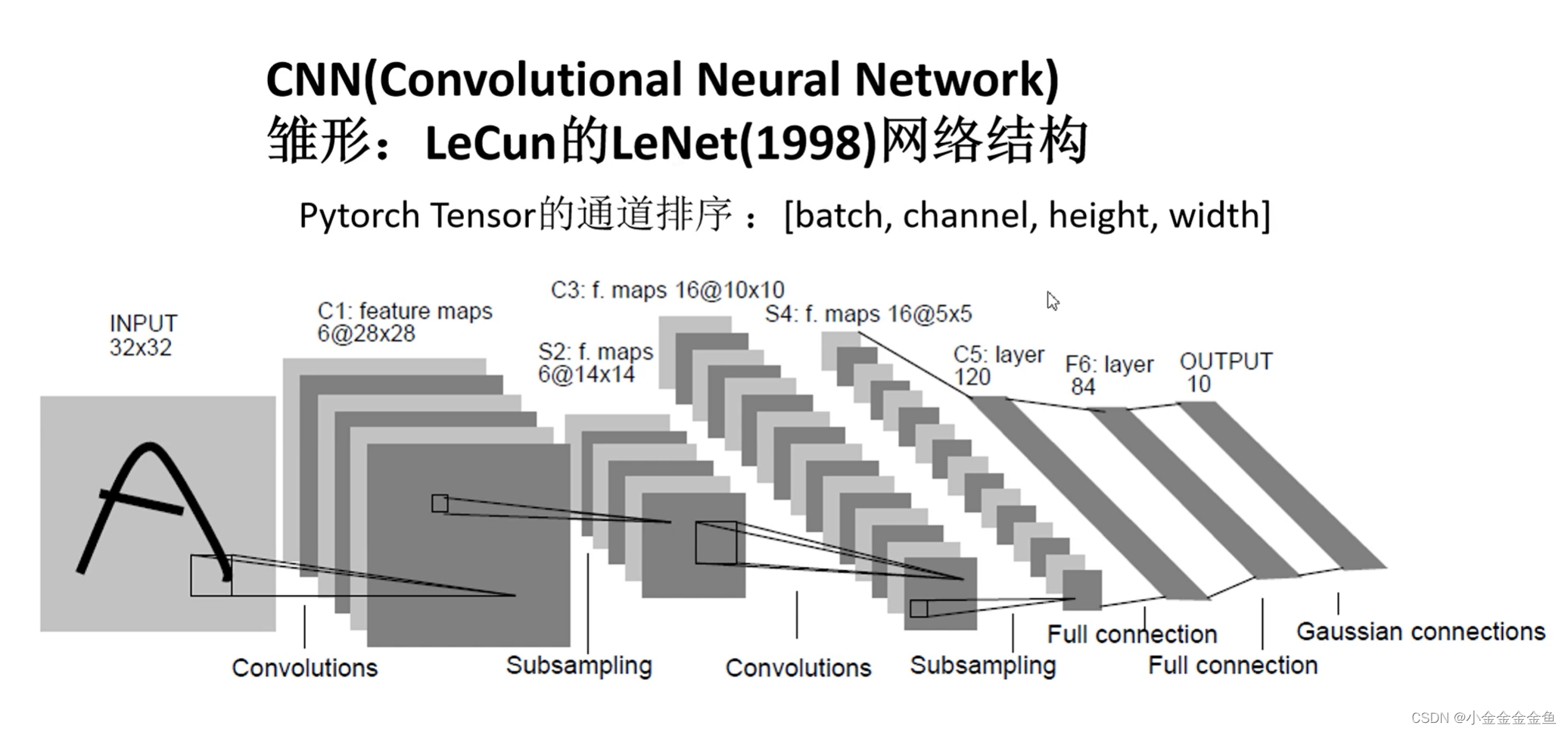
人工智能学习07--pytorch09--LeNet
参考:
视频:
https://www.bilibili.com/video/BV187411T7Ye/?spm_id_from=333.999.0.0&vd_source=b425cf6a88c74ab02b3939ca66be1c0d
博客:https://blog.csdn.net/STATEABC/article/details/123661612?utm_medium=distribute.pc_feed_404.none-task-blog-2defaultBlogCommendFromBaiduRate-8-123661612-blog-null.pc_404_mixedpudn&depth_1-utm_source=distribute.pc_feed_404.none-task-blog-2defaultBlogCommendFromBaiduRate-8-123661612-blog-null.pc_404_mixedpud
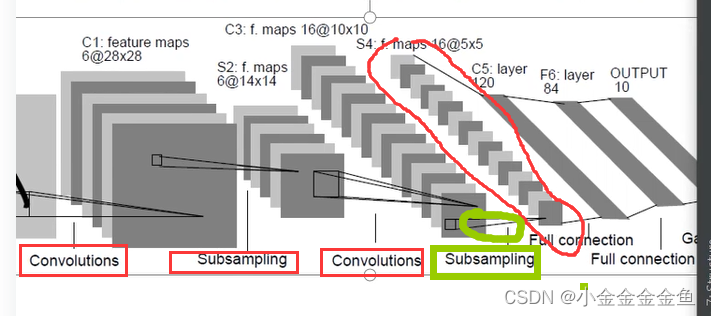
搭建网络
- 在pytorch中搭建模型:
1、先写一个类,继承nn.Module
2、在类中实现两个方法:
①**init(self) 初始化函数**:
实现在搭建网络过程中需要使用到的一些网络层结构
②forward(self,x):
定义正向传播的过程
实例化这个类之后,将参数传递到实例中,进行正向传播。按照forward里面的这个顺序来运行。
import torch.nn as nn
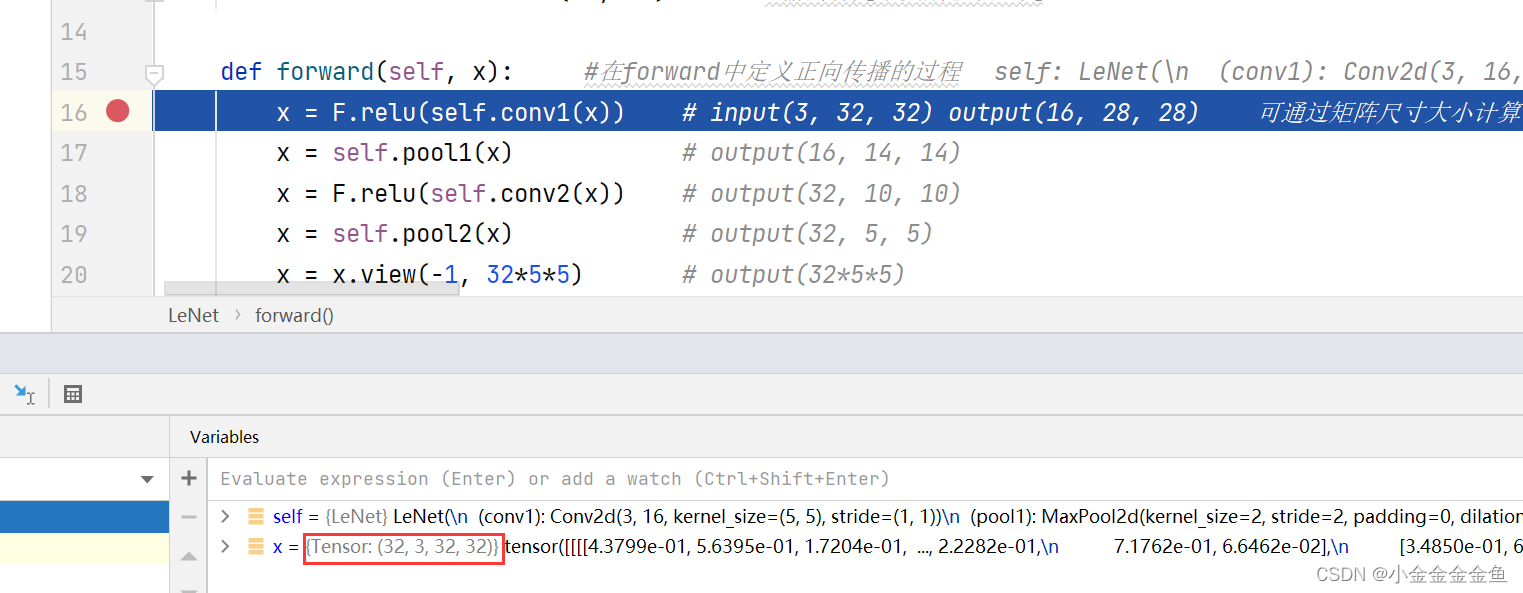
import torch.nn.functional as Fclass LeNet(nn.Module): #在Pytorch中搭建模型首先要定义一个类,这个类要继承于nn.Module这个副类def __init__(self): #在该类中首先要初始化函数,实现在搭建网络过程中需要使用到的网络层结构,#然后在forward中定义正向传播的过程super(LeNet, self).__init__() #super能够解决在多重继承中调用副类可能出现的问题self.conv1 = nn.Conv2d(3, 16, 5) #这里输入深度为3,卷积核个数为16,大小为5x5self.pool1 = nn.MaxPool2d(2, 2) #最大池化核大小为2x2,步长为2self.conv2 = nn.Conv2d(16, 32, 5) #经过Conv2d的16个卷积核处理后,输入深度变为16self.pool2 = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(32*5*5, 120) #全连接层的输入是一维的向量,因此将输入的特征矩阵进行展平处理(32x5x5),然后根据网络设置输出self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10) #输出有几个类别就设置几def forward(self, x): #在forward中定义正向传播的过程x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28) 可通过矩阵尺寸大小计算公式得x = self.pool1(x) # output(16, 14, 14)x = F.relu(self.conv2(x)) # output(32, 10, 10)x = self.pool2(x) # output(32, 5, 5)x = x.view(-1, 32*5*5) # output(32*5*5)x = F.relu(self.fc1(x)) # output(120)x = F.relu(self.fc2(x)) # output(84)x = self.fc3(x) # output(10)return x-
init(self)
①super:在定义类的过程中继承了nn.Module类。super:在多层继承中调用父类可能出现的问题。
②第一个卷积层: self.conv1 = nn.Conv2d(3, 16, 5):
通过nn.Conv2d函数(使用2d卷积,对输入的数据进行处理)来构建卷积层。参数:
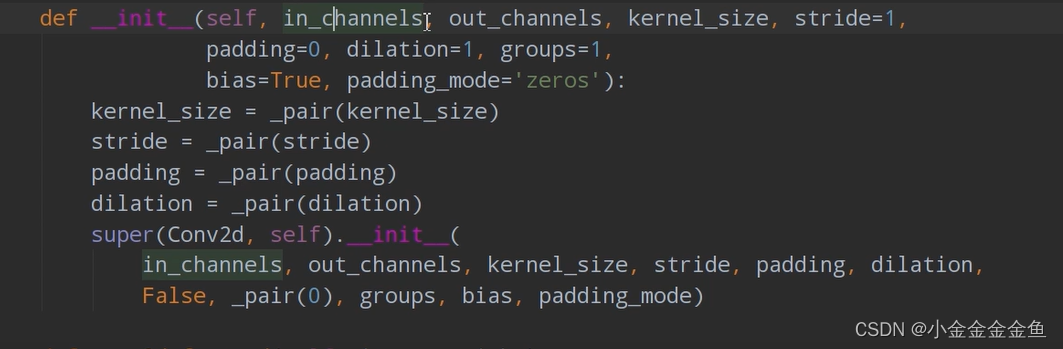
1 in_channels 输入特征矩阵的深度(如:3:R,G,B)
2 out_channels 使用卷积核的个数(使用几个卷积核,就会生成一个深度为多少维的特征矩阵)
3 kernel_size 卷积核大小
4 stride 步长,默认等于1
5 padding 在四周补数时默认等于0
6 dilation groups 比较高阶,暂时用不到
7 bias 偏置,True默认使用
self.conv1 = nn.Conv2d(3, 16, 5)
↓
输入深度为3,卷积核个数为16,大小为5x5
③计算输出图片的大小:
( padding=0 )
(32-5)/1+1 = 28
所以输出的是16x28x28(16个卷积核,所以channel变成16了)
如果写了batch,那就是输出(banchx16x28x28)
④定义下采样层:self.pool1 = nn.MaxPool2d(2, 2) :
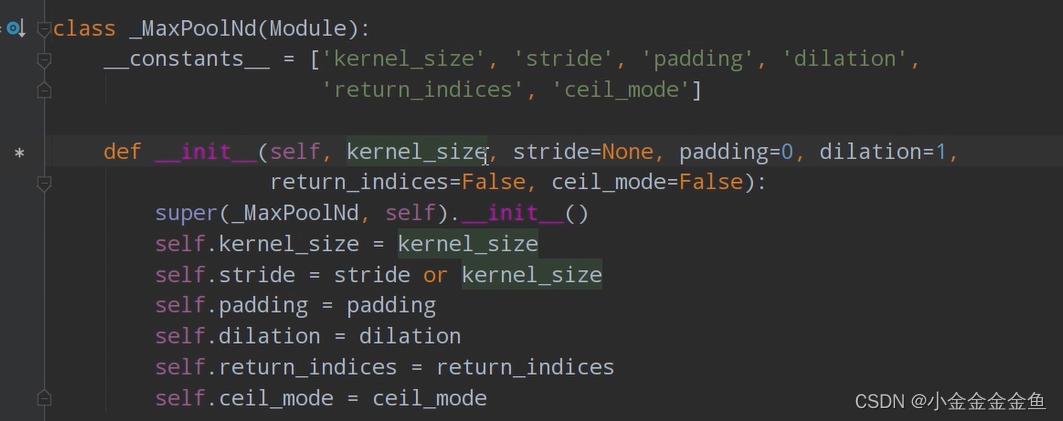
1 kernel_size 池化核大小
2 stride 如果不去指定步长,则采用与池化核大小一样的步距
self.pool1 = nn.MaxPool2d(2, 2)
↓
采用池化核大小2x2,步长为2的最大池化操作
⑤计算池化层输出:(28-2)/2+1=14,即宽度高度缩减为输入的一半
池化层,只改变特征矩阵的高和宽,不影响深度(16)
⑥第二个卷积层:self.conv2 = nn.Conv2d(16, 32, 5)
输入深度16,采用32个卷积核,尺寸5x5
(14-5+0)/1+1 = 10
所以输出为32x10x10
⑦第二个下采样层:nn.MaxPool2d(2, 2)
(10-2)/2+1 = 5
所以输出为(32x5x5)的尺寸
⑧第一个全连接层:self.fc1 = nn.Linear(32x5x5, 120)
全连接层的输入为一维向量,所以要把特征矩阵展平变成一维向量。
↓所以第一个全连接层的输入为32x5x5,有120个参数
⑨第二个全连接层:self.fc2 = nn.Linear(120, 84)
输入为上个全连接层的输出(120个节点)
第二层这里设置84个节点(看顶上的网络结构图,按照这个神经网络的定义来构建这个网络)
⑩self.fc3 = nn.Linear(84, 10)
84就是上一层定义的84个节点。
输出需要根据训练集来弄。这里是10(使用cifar10训练–>具有10个类别的分类任务)。 -
forward(self,x) 定义前向传播
x:输入的数据:按照以下排列顺序的数据↓
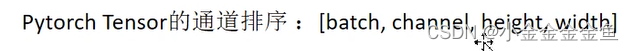
①x = F.relu(self.conv1(x))
数据x经过定义的卷积层1
将得到的输出通过relu激活函数
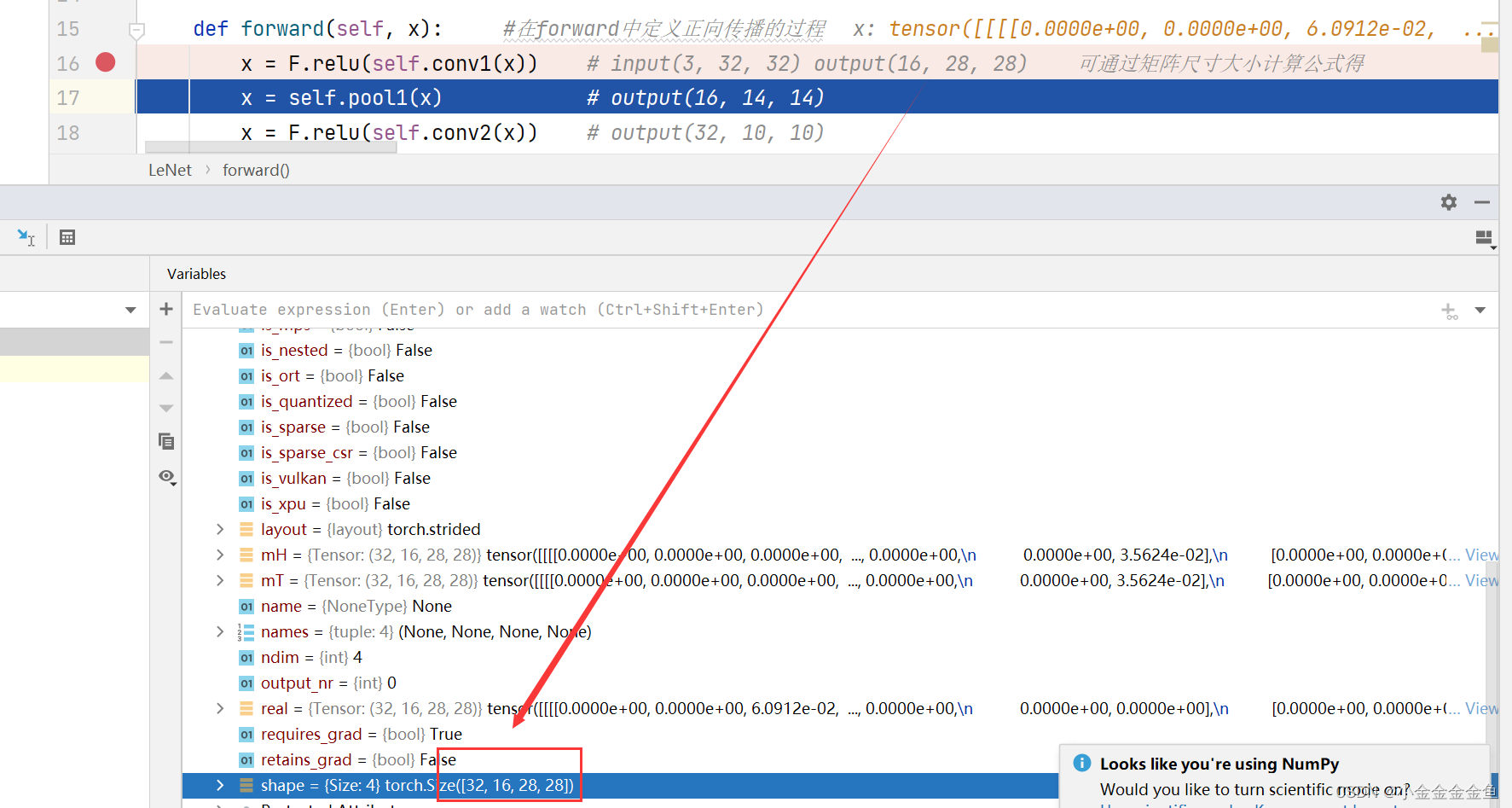
②x = self.pool1(x)
将输出通过下采样1层
③x = F.relu(self.conv2(x))
……
④x = self.pool2(x)
……
到了这里
要和全连接层进行拼接,将特征矩阵展平变成一维向量↓
⑤x = x.view(-1, 32x5x5)
将特征矩阵展平变成一维向量
-1 第一个维度,自动推理,为batch
3255展平后节点个数
-1是xpython里view(x,y)函数的一个可选取值,x这一项置为-1,就会自动根据整个向量的维度和后面的y计算x这项
-1表示不确定展开成几行,但是知道要展开成32x5x5列,因为一共就是32x5x5,所以是一行,即一维向量
-1是代表自动推理,函数自己计算那个维度的大小
⑥x = F.relu(self.fc1(x))
将数据通过全连接层1+它的激活函数
⑦x = F.relu(self.fc2(x))
……
⑧x = self.fc3(x)
通过全连接层3得到最终的输出
为什么这里没有用Softmax这个函数?
对于分类问题,一般会在最后接上一个softmax层,让输出转化成为一个概率分布。
但是在训练网络过程中,计算卷积交叉熵的过程中,已经在它的内部(优化器SGD中)实现了softmax方法,所以这里不用再添加了。
测试
# 实例化 ↑ 后进行测试 ↓
import torch
input1 =torch.rand([32,3,32,32]) #定义随机生成数据的shape batch,深度,高度,宽度
model = LeNet() #实例化模型
print(model)
output = model(input1) #将数据输入到网络中进行正向传播

将input变量传输类的实例model,为什么会自动调用forward() ?
在nn.mldule类中,有一个call方法调用了forward函数,所以所有的nn.module子类中默认调用forward函数
【
实例后得到的实例当成一个函数调用的时候(例如:model(),此处model是实例)会调用实例所属类的__call__方法,而_call__方法中调用了forward方法
】
训练:
cifar10数据集
提前下载复制到当前目录的data文件夹里面
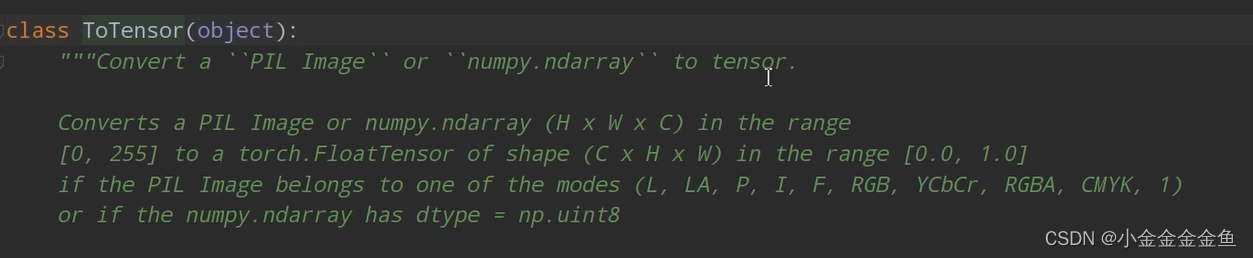
transform = transforms.Compose( # 通过transforms.Compose函数将使用的预处理方法打包成一个整体[transforms.ToTensor(),# 将PIL图像或numpy数据转化成tensor,即将shape (H x W x C) in the range [0, 255]转换成shape (C x H x W) in the range [0.0, 1.0]transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 标准化的过程
transform,对图像进行预处理
Compose函数把用到的一些预处理方法打包成一个整体
- ToTensor
 - Normalize
- Normalize
标准化,使用均值或者标准差来标准化tensor

# 导入50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录,这里是当前目录的data文件夹下train=True, # 如果是True,就会导入cifar10训练集的样本download=True, # 第一次运行时为True,下载数据集,下载完成后改为Falsetransform=transform) # 预处理过程
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集batch_size=50, # 每批训练的样本数shuffle=False, # 是否打乱训练集num_workers=0) # 使用线程数,在windows下设置为0
通过CIFAR10函数导入训练集,将训练集的每一个图像通过transform预处理函数进行预处理
# 10000张测试图片
# 第一次使用时要将download设置为True才会自动去下载数据集
test_set = torchvision.datasets.CIFAR10(root='./data', train=False,download=False, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=4,shuffle=False, num_workers=0)
# 获取测试集中的图像和标签,用于accuracy计算
test_data_iter = iter(test_loader)
test_image, val_label = test_data_iter.next()
将test_loader转化为可迭代的迭代器
通过next方法可获取到一批数据,其中包含图像、图像对应的标签值
发现.next()这里报错,改为了:
test_image, test_label = test_data_iter.next()
# 导入标签
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
iindex[0]对应plane
模型
net = LeNet() #实例化模型
loss_function = nn.CrossEntropyLoss()
#定义损失函数,在nn.CrossEntropyLoss中已经包含了Softmax函数
optimizer = optim.Adam(net.parameters(), lr=0.001)
#定义优化器,这里使用Adam优化器,net是定义的LeNet,parameters将LeNet所有可训练的参数都进行训练,lr=learning rate- nn.CrossEntropyLoss() 损失函数

可以看出已经内置了softmax函数 - optim.Adam(net.parameters(), lr=0.001) 优化器
使用Adam优化器
net.parameters():把net(LeNet)中可训练的参数都进行训练
lr学习率
有GPU时使用GPU,无GPU时使用CPU训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
net = LeNet() #实例化模型
# net.to(device) #将网络分配到指定的device中
loss_function = nn.CrossEntropyLoss() #定义损失函数,在nn.CrossEntropyLoss中已经包含了Softmax函数
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,这里使用Adam优化器,net是定义的LeNet,parameters将LeNet所有可训练的参数都进行训练,lr=learning rate# 对应的,需要用to()函数来将Tensor在CPU和GPU之间相互移动,分配到指定的device中计算for epoch in range(5): # loop over the dataset multiple times #将训练集迭代的次数(5轮)running_loss = 0.0 #累加训练过程的损失# time_start = time.perf_counter()for step, data in enumerate(train_loader, start=0): #遍历训练集样本# get the inputs; data is a list of [inputs, labels]inputs, labels = data #将得到的数据分离成输入(图片)和标签# zero the parameter gradientsoptimizer.zero_grad() #将历史损失梯度清零,如果不清除历史梯度,就会对计算的历史梯度进行累加(通过这个特性能够变相实现一个很大的batch)# forward + backward + optimizeoutputs = net(inputs) # 将图片放入网络正向传播,得到输出# outputs = net(inputs.to(device)) # 将inputs分配到指定的device中# loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中loss = loss_function(outputs, labels) #计算损失,outputs为网络预测值,labels为输入图片对应的真实标签loss.backward() #将loss进行反向传播optimizer.step() #进行参数更新# print statisticsrunning_loss += loss.item() #计算完loss完之后将其累加到running_loss# 累加损失,因为希望每500次迭代计算一个损失:if step % 500 == 499: # print every 500 mini-batches #每隔500次打印一次训练的信息with torch.no_grad():# with是一个上下文管理器:在接下来的计算中,不要计算每个节点中误差的损失梯度。否则即使在测试阶段中也会计算# 会自动生成前向的传播图,这会占用大量内存,测试时应该禁用# outputs = net(val_image.to(device)) # 将test_image分配到指定的device中outputs = net(test_image) # [batch, 10] [0]为batchpredict_y = torch.max(outputs, dim=1)[1] #寻找输出的最大的index。在维度1上进行最大值的预测,[1]为index索引,[0]为batch# accuracy = (predict_y == test_label.to(device)).sum().item() / test_label.size(0) # 将test_label分配到指定的device中accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0) #将预测的标签类别与真实的标签类别进行比较,在相同的地方返回值为1,否则为0,用此计算预测对了多少样本print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, step + 1, running_loss / 500, accuracy))# print('%f s' % (time.perf_counter() - time_start))running_loss = 0.0print('Finished Training')
- enumerate就是c++里面的枚举,返回每一批数据的data和这一批data对应的步数index。
start=0说明从0开始
得到数据后,将数据分离成图像和标签:inputs, labels = data - optimizer.zero_grad()
将历史损失梯度清零

如果不清除历史梯度,就会对计算的历史梯度进行累加(通过这个特性能够变相实现一个很大的batch)
一般情况下,batch_size是根据硬件设备来设置的。数值设置的越大,训练效果就越好。但一般由于硬件设备受限,内存不足,所以不可能用很大的batch训练。所以用这种梯度清零的方法来实现很大batch的训练:
一次性计算多个小的batch的损失梯度,变相得到一个很大的batch的图片的损失梯度。再对这个大batch的梯度进行反向传播。 - accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0)
torch.eq(predict_y, test_label) 相同的地方返回True(1),否则返回False(0)。
sum:求和,计算本次测试中预测对了多少个样本 - running_loss = 0.0
清零,进行下一轮
save_path = './Lenet.pth' #保存权重
torch.save(net.state_dict(), save_path) #将网络的所有参数及逆行保存
保存网络所有参数
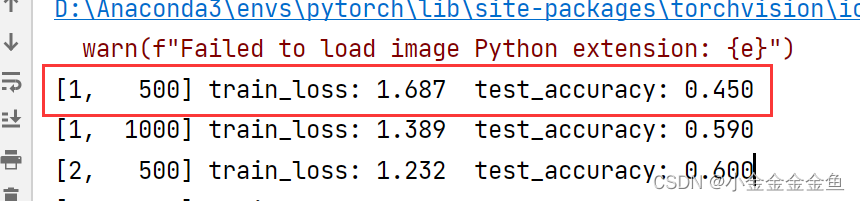
在第一个epoch中的第500步,训练的损失是1.687,测试准确率是0.450
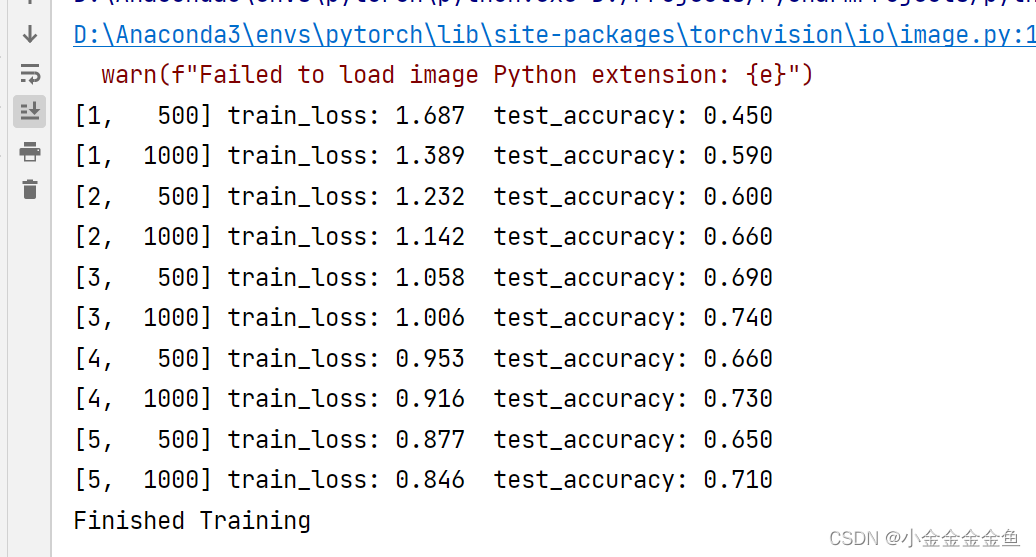
最终准确率0.710
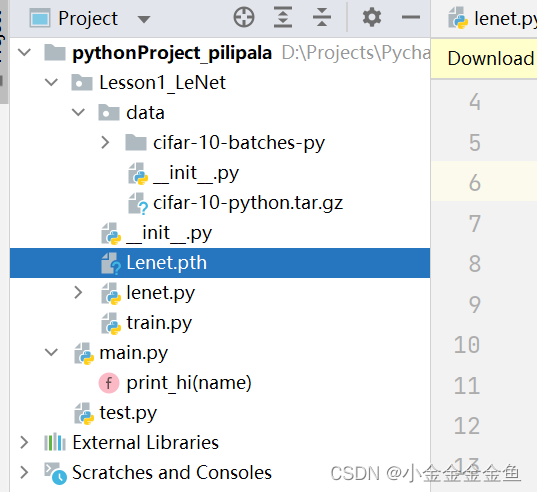
可以看到已经生成了本次训练的模型权重文件
测试:
调用模型权重进行预测
transform = transforms.Compose([transforms.Resize((32, 32)), #首先需resize成跟训练集图像一样的大小transforms.ToTensor(), #转化成tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) #标准化处理classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')net = LeNet() #实例化网络
net.load_state_dict(torch.load('Lenet.pth')) #载入保存的权重文件im = Image.open('plane.png') #导入要测试的图片
# PIL图像导入的可是一般都是宽度,高度,通道,要正向传播则要转变成pytorch tensor的格式
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W] #对数据增加一个新维度,因为tensor的参数是[batch, channel, height, width]with torch.no_grad():outputs = net(im) #把图像传入网络predict = torch.max(outputs, dim=1)[1].numpy() #寻找输出汇总的最大尺度对应的index(索引),把它传入classes
print(classes[int(predict)])
或者使用softmax得到一个概率分布:
with torch.no_grad():outputs = net(im) #把图像传入网络# predict = torch.max(outputs, dim=1)[1].numpy() #寻找输出汇总的最大尺度对应的index(索引),把它传入classespredict = torch.softmax(outputs, dim=1) #使用softmax函数 因为输出的是[channel,第一个维度],所以dim=1
# print(classes[int(predict)])
print(predict)


tensorboard
先用测试图片试了一下
发现以前用这个就行:
tensorboard --logdir=logs --port=6007
但是这次不灵了,换成这个:
tensorboard --logdir=D:\Projects\PycharmProjects\pythonProject_pilipala\Lesson1_LeNet\logs --port=6007
就是换成了那个logs文件的绝对路径
把loss的变化图像做出来了:
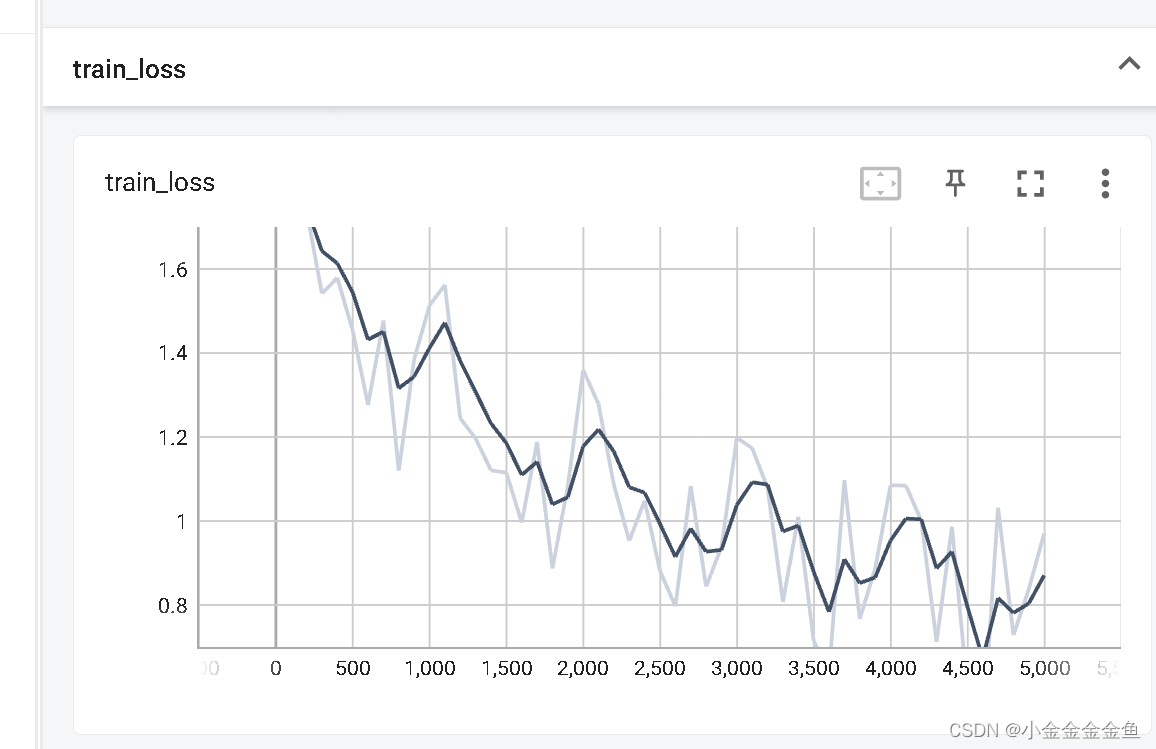
import torch
import torchvision
import torch.nn as nn
from lenet import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.tensorboard import SummaryWritertransform = transforms.Compose( # 通过transforms.Compose函数将使用的预处理方法打包成一个整体[transforms.ToTensor(),# 将PIL图像或numpy数据转化成tensor,即将shape (H x W x C) in the range [0, 255]转换成shape (C x H x W) in the range [0.0, 1.0]transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 标准化的过程# 导入50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录,这里是当前目录的data文件夹下train=True, # 如果是True,就会导入cifar10训练集的样本download=False, # 第一次运行时为True,下载数据集,下载完成后改为Falsetransform=transform) # 预处理过程
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集batch_size=50, # 每批训练的样本数shuffle=False, # 是否打乱训练集num_workers=0) # 使用线程数,在windows下只能设置为0# 10000张测试图片
# 第一次使用时要将download设置为True才会自动去下载数据集
test_set = torchvision.datasets.CIFAR10(root='./data', train=False,download=False, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=100,shuffle=False, num_workers=0)# 添加tensorboard-------------------------------------------------
writer = SummaryWriter("logs_train_cifar10")# 获取测试集中的图像和标签,用于accuracy计算
test_data_iter = iter(test_loader)
# 将test_loader转化为可迭代的迭代器
test_image, test_label = test_data_iter.__next__()
# 通过next方法可获取到一批数据,其中包含图像、图像对应的标签值# 导入标签
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')net = LeNet() #实例化模型
loss_function = nn.CrossEntropyLoss() #定义损失函数,在nn.CrossEntropyLoss中已经包含了Softmax函数
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,这里使用Adam优化器,net是定义的LeNet,parameters将LeNet所有可训练的参数都进行训练,lr=learning rate# 使用下面语句可以在有GPU时使用GPU,无GPU时使用CPU进行训练
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# print(device)net = LeNet() #实例化模型
# net.to(device) #将网络分配到指定的device中
loss_function = nn.CrossEntropyLoss() #定义损失函数,在nn.CrossEntropyLoss中已经包含了Softmax函数
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,这里使用Adam优化器,net是定义的LeNet,parameters将LeNet所有可训练的参数都进行训练,lr=learning rate# 对应的,需要用to()函数来将Tensor在CPU和GPU之间相互移动,分配到指定的device中计算
# 记录训练的次数
total_train_step = 0
for epoch in range(5): # loop over the dataset multiple times #将训练集迭代的次数(5轮)running_loss = 0.0 #累加训练过程的损失# time_start = time.perf_counter()for step, data in enumerate(train_loader, start=0): #遍历训练集样本# get the inputs; data is a list of [inputs, labels]inputs, labels = data #将得到的数据分离成输入(图片)和标签# zero the parameter gradientsoptimizer.zero_grad() #将历史损失梯度清零,如果不清除历史梯度,就会对计算的历史梯度进行累加(通过这个特性能够变相实现一个很大的batch)# forward + backward + optimizeoutputs = net(inputs) # 将图片放入网络正向传播,得到输出# outputs = net(inputs.to(device)) # 将inputs分配到指定的device中# loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中loss = loss_function(outputs, labels) #计算损失,outputs为网络预测值,labels为输入图片对应的真实标签loss.backward() #将loss进行反向传播optimizer.step() #进行参数更新# ------------------tensorboard--------------------------total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("训练次数:{},loss:{}".format(total_train_step,loss.item())) # 或者loss.item() .item():把tensor数据类型转化为真实数字# 逢百记录writer.add_scalar("train_loss",loss.item(),total_train_step)# --------------------------------------------# print statisticsrunning_loss += loss.item() #计算完loss完之后将其累加到running_loss# 累加损失,因为希望每500次迭代计算一个损失:if step % 500 == 499: # print every 500 mini-batches #每隔500次打印一次训练的信息with torch.no_grad():# with是一个上下文管理器:在接下来的计算中,不要计算每个节点中误差的损失梯度。否则即使在测试阶段中也会计算# 会自动生成前向的传播图,这会占用大量内存,测试时应该禁用# outputs = net(val_image.to(device)) # 将test_image分配到指定的device中outputs = net(test_image) # [batch, 10] [0]为batchpredict_y = torch.max(outputs, dim=1)[1] #寻找输出的最大的index。在维度1上进行最大值的预测,[1]为index索引,[0]为batch# accuracy = (predict_y == test_label.to(device)).sum().item() / test_label.size(0) # 将test_label分配到指定的device中accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0) #将预测的标签类别与真实的标签类别进行比较,在相同的地方返回值为1,否则为0,用此计算预测对了多少样本print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, step + 1, running_loss / 500, accuracy))# print('%f s' % (time.perf_counter() - time_start))running_loss = 0.0print('Finished Training')
# --------------------------------------------
writer.close()# tensorboard --logdir=logs_train_cifar10 --port=6007
# tensorboard --logdir=D:\Projects\PycharmProjects\pythonProject_pilipala\Lesson1_LeNet\logs_train_cifar10 --port=6007
# --------------------------------------------
save_path = './Lenet.pth' #保存权重
torch.save(net.state_dict(), save_path) #将网络的所有参数及逆行保存相关文章:
人工智能学习07--pytorch09--LeNet
参考: 视频: https://www.bilibili.com/video/BV187411T7Ye/?spm_id_from333.999.0.0&vd_sourceb425cf6a88c74ab02b3939ca66be1c0d 博客:https://blog.csdn.net/STATEABC/article/details/123661612?utm_mediumdistribute.pc_feed_404.…...

java泛型编程初识
java泛型编程初识1.泛型解决的是什么问题2.泛型实例化语句3.自定义泛型1)自定义泛型类或接口2)自定义泛型方法4.泛型使用中的继承和通配1)通配2)继承使用限制1.泛型解决的是什么问题 很多类、接口、方法中逻辑相同,只是操作的对象类型不同,这个时候就可…...

代码随想录算法训练营 || 贪心算法 1005 134 135
Day291005.K次取反后最大化的数组和力扣题目链接给定一个整数数组 A,我们只能用以下方法修改该数组:我们选择某个索引 i 并将 A[i] 替换为 -A[i],然后总共重复这个过程 K 次。(我们可以多次选择同一个索引 i。)以这种方…...

Spring框架面试题
springboot的自动装配原理 主类上的SpringBootApplication存在EnableAutoConfiguration,EnableAutoConfiguration会导入AutoConfigurationImportSelector组件,其AutoConfigurationImportSelector$AutoConfigurationGroup#process()方法会读取当前应用所有…...
纯x86汇编实现的多线程操作系统实践 - 第五章 AP的守护执行
AP的32位保护模式代码的后半部分从0x8001C000开始执行,完成的工作主要有:初始化必要的中断给BSP发送启动成功的消息创建各AP的系统进程创建各AP的用户进程循环显示各AP中用户进程执行的时间比例5.1 初始化中断5.1.1总体初始化各AP调用init_interrupt_fun…...

2023年全国最新高校辅导员精选真题及答案7
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 71.在北京曾经发现一处战国时期的遗址,从中出土了燕、韩、赵、魏等国铸币3876…...
使用windwow windbg 吃透64位分页内存管理
前言 分页基础概念是操作系统基础知识,网上已经有太多太多了。所以本文记录使用windwow内核调试工具验证理论知识。 具体可以参阅intel volume3的 4.1.1 Four Paging Modes章节。 简而言之:CR0.PG 0表示不开启分页.并且根据CR4各种标志开启不同类别的…...
Java知识复习(五)JVM虚拟机
1、虚拟机的自动内存管理和C/C的区别 C/C开发程序时需要为每一个new操作去写对应的delete/free操作,不容易出现内存泄漏和溢出问题。而Java程序将内存控制权交给了Java虚拟机 2、JVM的运行机制 1、Java程序的具体运行过程如下: Java源文件被编译器编…...
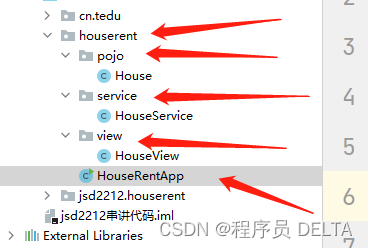
房屋出租管理系统
1. 铺垫 1.1 项目真实开发的过程 上来要做什么???? 有电脑—》配环境(JDK、IDEA、MAVEN……) 这个项目:房屋管理系统 从什么角度出发,第一步做什么?? 架构 …...

2023年全国最新食品安全管理员精选真题及答案6
百分百题库提供食品安全管理员考试试题、食品安全员考试预测题、食品安全管理员考试真题、食品安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 51.制定《中华人民共和国食品安全法》的目的是为了保证食品安全…...

C++中的文件操作
文件操作 所有数据程序运行结束后都会释放通过文件可以将数据持久化头文件文件类型分为两种 文本文件—文件以文本的ASCII码形式存储在计算机中二进制文件—文件以文本的二进制存储在计算机中 操作文件的三大类 ofstream—写操作ifstream—读操作fstream—读写操作 文本文件 写…...
监控生产环境中的机器学习模型
简介 一旦您将机器学习模型部署到生产环境中,很快就会发现工作还没有结束。 在许多方面,旅程才刚刚开始。你怎么知道你的模型的行为是否符合你的预期?下周/月/年,当客户(或欺诈者)行为发生变化并且您的训练…...

15s了解什么是物联网技术
目录 15s了解什么是物联网技术 15s了解什么是物联网技术 什么是物联网技术。 简单地说,物联网就是把所有的物体连接起来,相互作用,形成一个互联互通的网络,这就是物联网。如果说互联网是我们身体的虚拟大脑,那么物联网就是我们身体的感知系统,就像眼睛和耳朵-样,让我们…...

敲出来的真理-mysql备份大全,备份命令,还原命令,定时备份
mysqldump命令全量备份数据全量标准语句格式mysqldump -h主机名 -P端口 -u用户名 -p密码 –database 数据库名 > 文件名.sql 1.备份全部数据库的数据和结构mysqldump -uroot -p123456 -A > /data/mysqlDump/mydb.sql2.备份全部数据库的结构(加 -d 参数&#x…...
ATTCK实战系列-红队评估(一)
from ATT&CK实战系列-红队评估(一) 环境搭建 下载地址:http://vulnstack.qiyuanxuetang.net/vuln/detail/2/ 将三个虚拟机启动起来 除了windows 7那个主机,其他都只设置成仅主机模式 windows 7添加两个网卡,一个是仅主机,一个是NAT …...
学python的第二天---差分
一、改变数组元素(差分)方法一:差分数组map(int,input().split())for b in arr[:n]:print(1 if b else 0,end )方法二:区间合并interval.sort(keylambda x:x[0])二、差分a [0] list(map(int, input().split())) a[n 1:]三、差…...
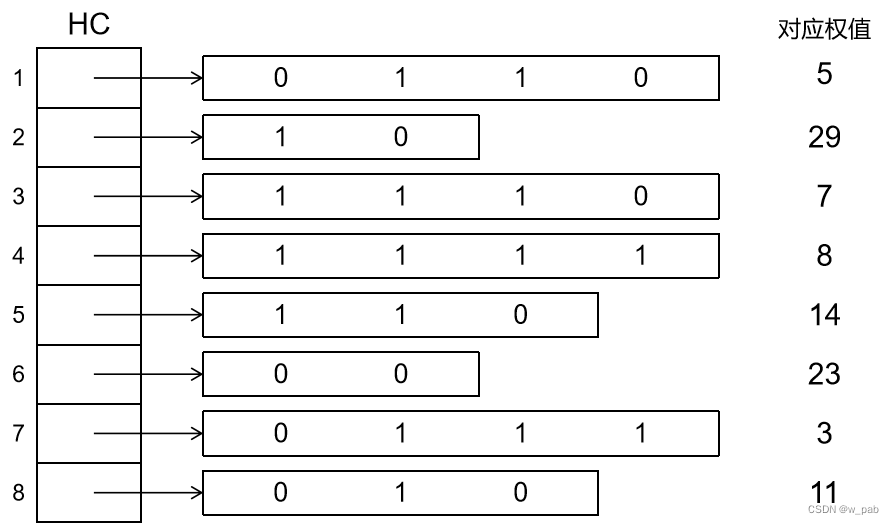
数据结构入门5-2(数和二叉树)
目录 注: 树的存储结构 1. 双亲表示法 2. 孩子表示法 3. 重要:孩子兄弟法(二叉树表示法) 森林与二叉树的转换 树和森林的遍历 1. 树的遍历 2. 森林的遍历 哈夫曼树及其应用 基本概念 哈夫曼树的构造算法 1. 构造过程 …...

把Redis当作队列来用,到底合适吗?
文章目录 前言从最简单的开始:List 队列发布/订阅模型:Pub/Sub趋于成熟的队列:Stream1) Stream 是否支持「阻塞式」拉取消息?2) Stream 是否支持发布 / 订阅模式?3) 消息处理时异常,Stream 能否保证消息不丢失,重新消费?4) Stream 数据会写入到 RDB 和 AOF 做持久化吗?…...

Python学习-----项目设计1.0(设计思维和ATM环境搭建)
目录 前言: 项目开发流程 MVC设计模式 什么是MVC设计模式? ATM项目要求 ATM项目的环境搭建 前言: 我个人学习Python大概也有一个月了,在这一个月中我发布了许多关于Python的文章,建立了一个Python学习起步的专栏…...
python网络爬虫(理论+实战)——爬虫实战:指定关键词的百度新闻爬取)
(九)python网络爬虫(理论+实战)——爬虫实战:指定关键词的百度新闻爬取
系列文章目录 (1)python网络爬虫—快速入门(理论+实战)(一) (2)python网络爬虫—快速入门(理论+实战)(二) (3) python网络爬虫—快速入门(理论+实战)(三) (4)python网络爬虫—快速入门(理论+实战)(四) (5)...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...