【Mysql】Mysql中表连接的原理
连接简介
在实际工作中,我们需要查询的数据很可能不是放在一张表中,而是需要同时从多张表中获取。下面我们以简单的两张表为例来进行说明。
连接的本质
为方便测试说明,,先创建两个简单的表并给它们填充一点数据:
mysql> CREATE TABLE t1 (m1 int, n1 char(1));
Query OK, 0 rows affected (0.12 sec)
mysql> CREATE TABLE t2 (m2 int, n2 char(1));
Query OK, 0 rows affected (0.13 sec)
mysql> INSERT INTO t1 VALUES(1, 'a'), (2, 'b'), (3, 'c');
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> INSERT INTO t2 VALUES(2, 'b'), (3, 'c'), (4, 'd');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
以上是建立的两个表 t1 和 t2 ,两个表都有两个列,一个是 INT 类型的,一个是 CHAR(1) 类型的,填充的表数据如下:
mysql> SELECT * FROM t1;
+------+------+
| m1 | n1 |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM t2;
+------+------+
| m2 | n2 |
+------+------+
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
3 rows in set (0.00 sec)
连接的本质就是把各个连接表中的记录都取出来并将依次匹配的组合加入结果集并返回给用户。所以我们把 t1 和t2 两个表连接起来的过程如下图所示:
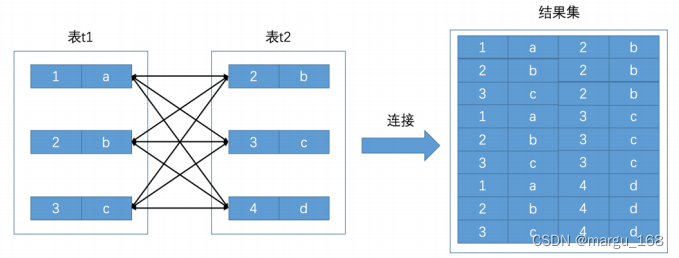
这个过程看起来就是把 t1 表的记录和 t2 的记录连起来组成新的更大的记录,所以这个查询过程称之为连接查询。连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合,这样的组合集就可以称之为笛卡尔积 。因为表 t1 中有3条记录,表 t2 中也有3条记录,所以这两个表连接之后的笛卡尔积就有 3×3=9 行记录。在 MySQL 中,连接查询的语法也很随意,只要在 FROM 语句后边跟多个表名就好了,比如我们把 t1 表和 t2 表连接起来的查询语句可以写成这样:
mysql> SELECT * FROM t1, t2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 1 | a | 2 | b |
| 2 | b | 2 | b |
| 3 | c | 2 | b |
| 1 | a | 3 | c |
| 2 | b | 3 | c |
| 3 | c | 3 | c |
| 1 | a | 4 | d |
| 2 | b | 4 | d |
| 3 | c | 4 | d |
+------+------+------+------+
9 rows in set (0.00 sec)
连接过程简介
理论上我们可以连接任意数量张表,但是如果没有任何限制条件的话,这些表连接起来产生的 笛卡尔积可能是非常巨大的。比方说3个100行记录的表连接起来产生的 笛卡尔积就有 100×100×100=1000000 行数据!所以在连接的时候过滤掉特定记录组合是有必要的,在连接查询中的过滤条件可以分成两种:
- 涉及单表的条件
这种只设计单表的过滤条件我们之前都提到过一万遍了,我们之前也一直称为搜索条件 ,比如 t1.m1 > 1是只针对 t1 表的过滤条件, t2.n2 < ‘d’ 是只针对 t2 表的过滤条件。 - 涉及两表的条件
比如 t1.m1 = t2.m2 、 t1.n1 < t2.n2 等,这些条件中涉及到了两个表,我们稍后会分析这种过滤条件是如何使用的.
下边我们就要看一下携带过滤条件的连接查询的大致执行过程了,比方说下边这个查询语句:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < ‘d’;
在这个查询中我们指明了这三个过滤条件: - t1.m1 > 1
- t1.m1 = t2.m2
- t2.n2 < ‘d’
这个连接查询的大致执行过程如下:
1 . 首先确定第一个需要查询的表,这个表称之为驱动表 。单表中执行查询语句按照前一章节的方式进行,只需要选取代价最小的那种访问方法去执行单表查询语句就好了(依次是const、ref、ref_or_null、range、index、all这些执行方法中选取代价最小的去执行查询)。此处假设使用 t1 作为驱动表,那么就需要到 t1 表中找满足 t1.m1 > 1 的记录,因为表中的数据太少,我们也没在表上建立二级索引,所以此处查询 t1 表的访问方法应该为all,也就是采用全表扫描的方式执行单表查询。关于如何提升连接查询的性能我们之后再说,现在先把基本概念搞清楚。所以查询过程就如下图所示:
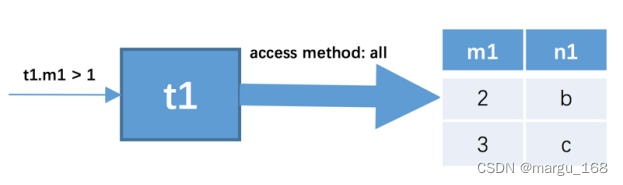
我们可以看到, t1 表中符合 t1.m1 > 1 的记录有两条。
2 . 针对上一步骤中从驱动表产生的结果集中的每一条记录,分别需要到 t2 表中查找匹配的记录,所谓匹配的记录 ,指的是符合过滤条件的记录。因为是根据 t1 表中的记录去找 t2 表中的记录,所以 t2 表也可以被称之为被驱动表 。上一步骤从驱动表中得到了2条记录,所以需要查询2次 t2 表。此时涉及两个表的列的过滤条件 t1.m1 = t2.m2 就派上用场了: - 当 t1.m1 = 2 时,过滤条件 t1.m1 = t2.m2 就相当于 t2.m2 = 2 ,所以此时 t2 表相当于有了 t2.m2 =2 、 t2.n2 < ‘d’ 这两个过滤条件,然后到 t2 表中执行单表查询。
- 当 t1.m1 = 3 时,过滤条件 t1.m1 = t2.m2 就相当于 t2.m2 = 3 ,所以此时 t2 表相当于有了 t2.m2 =3 、 t2.n2 < ‘d’ 这两个过滤条件,然后到 t2 表中执行单表查询。
所以整个连接查询的执行过程就如下图所示:
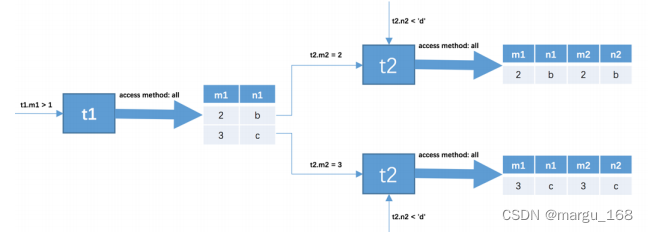
也就是说整个连接查询最后的结果只有两条符合过滤条件的记录:
| m1 | n1 | m2 | n2 |
|---|---|---|---|
| 2 | b | 2 | b |
| 3 | c | 3 | c |
| 从上边两个步骤可以看出来,我们上边唠叨的这个两表连接查询共需要查询1次 t1 表,2次 t2 表。当然这是在特定的过滤条件下的结果,如果我们把 t1.m1 > 1 这个条件去掉,那么从 t1 表中查出的记录就有3条,就需要查询3次 t2 表了。也就是说在两表连接查询中,驱动表只需要访问一次,被驱动表可能被访问多次。 |
内连接和外连接
为方便大家理解,我们先创建两个比较实用的表,
CREATE TABLE student (
number INT NOT NULL AUTO_INCREMENT COMMENT '学号',
name VARCHAR(5) COMMENT '姓名',
major VARCHAR(30) COMMENT '专业',
PRIMARY KEY (number)
) Engine=InnoDB CHARSET=utf8 COMMENT '学生信息表';
Query OK, 0 rows affected (0.12 sec)CREATE TABLE score (
number INT COMMENT '学号',
subject VARCHAR(30) COMMENT '科目',
score TINYINT COMMENT '成绩',
PRIMARY KEY (number, score)
) Engine=InnoDB CHARSET=utf8 COMMENT '学生成绩表';
Query OK, 0 rows affected (0.18 sec)
我们新建了一个学生信息表和一个学生成绩表,然后我们向上述两个表中插入一些数据,插入后两表中的数据如下:
mysql> insert into student values(20230101,'张三','石油工程'),(20230102,'李四','测控技术'),(20230103,'王五','通信工程');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> insert into score values(20230101,'高等数学','76'),(20230102,'模拟电路','92'),(20230102,'模拟电路','86'),(20230102,'高等数学','95');
Query OK, 4 rows affected (0.06 sec)
Records: 4 Duplicates: 0 Warnings: 0mysql> select * from student;
+----------+--------+--------------+
| number | name | major |
+----------+--------+--------------+
| 20230101 | 张三 | 石油工程 |
| 20230102 | 李四 | 测控技术 |
| 20230103 | 王五 | 通信工程 |
+----------+--------+--------------+
3 rows in set (0.00 sec)mysql> select * from score;
+----------+--------------+-------+
| number | subject | score |
+----------+--------------+-------+
| 20230101 | 高等数学 | 76 |
| 20230102 | 模拟电路 | 86 |
| 20230102 | 模拟电路 | 92 |
| 20230102 | 高等数学 | 95 |
+----------+--------------+-------+
4 rows in set (0.00 sec)
现在我们想把每个学生的考试成绩都查询出来就需要进行两表连接了(因为 score 中没有姓名信息,所以不能单纯只查询 score 表)。连接过程就是从 student 表中取出记录,在 score 表中查找 number 相同的成绩记录,所以过滤条件就是 student.number = socre.number ,整个查询语句就是这样:
mysql> SELECT * FROM student, score WHERE student.number = score.number;
+----------+--------+--------------+----------+--------------+-------+
| number | name | major | number | subject | score |
+----------+--------+--------------+----------+--------------+-------+
| 20230101 | 张三 | 石油工程 | 20230101 | 高等数学 | 76 |
| 20230102 | 李四 | 测控技术 | 20230102 | 模拟电路 | 86 |
| 20230102 | 李四 | 测控技术 | 20230102 | 模拟电路 | 92 |
| 20230102 | 李四 | 测控技术 | 20230102 | 高等数学 | 95 |
+----------+--------+--------------+----------+--------------+-------+
4 rows in set (0.00 sec)
字段有点重复,我们精简一下:
mysql> SELECT s1.number, s1.name, s1.major , s2.subject, s2.score FROM student AS s1, score AS s2 where s1.number = s2.number;
+----------+--------+--------------+--------------+-------+
| number | name | major | subject | score |
+----------+--------+--------------+--------------+-------+
| 20230101 | 张三 | 石油工程 | 高等数学 | 76 |
| 20230102 | 李四 | 测控技术 | 模拟电路 | 86 |
| 20230102 | 李四 | 测控技术 | 模拟电路 | 92 |
| 20230102 | 李四 | 测控技术 | 高等数学 | 95 |
+----------+--------+--------------+--------------+-------+
4 rows in set (0.00 sec)
从上述查询结果中我们可以看到,各个同学对应的各科成绩就都被查出来了,可是有个问题, 王五同学,也就是学号为 20230103的同学因为某些原因没有参加考试,所以在 score 表中没有对应的成绩记录。那如果老师想查看所有同学的考试成绩,即使是缺考的同学也应该展示出来,但是到目前为止我们介绍的连接查询是无法完成这样的需求的。我们稍微思考一下这个需求,其本质是想:驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。为了解决这个问题,就有了内连接和外连接的概念:
- 对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接 。(交集?)
- 对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。
在 MySQL 中,根据选取驱动表的不同,外连接仍然可以细分为2种:- 左外连接
选取左侧的表为驱动表。 - 右外连接
选取右侧的表为驱动表。
可是这样仍然存在问题,即使对于外连接来说,有时候我们也并不想把驱动表的全部记录都加入到最后的结果集。这就犯难了,有时候匹配失败要加入结果集,有时候又不要加入结果集,怎么解决呢,其实把过滤条件分为两种这个问题就解决了,放在不同地方的过滤条件是有不同语义的:
- 左外连接
- WHERE 子句中的过滤条件
WHERE 子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合 WHERE 子句中的过滤条件的记录都不会被加入最后的结果集。 - ON 子句中的过滤条件
对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配 ON 子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用 NULL 值填充。
需要注意的是,这个ON子句是专门为外连接驱动表中的记录在被驱动表找不到匹配记录时应不应该把该记录加入结果集这个场景下提出的,所以如果把 ON 子句放到内连接中, MySQL 会把它和 WHERE 子句一样对待,也就是说:内连接中的WHERE子句和ON子句是等价的。
一般情况下,我们都把只涉及单表的过滤条件放到 WHERE 子句中,把涉及两表的过滤条件都放到 ON 子句中,我们也一般把放到 ON 子句中的过滤条件也称之为连接条件 。
注意:左外连接和右外连接简称左连接和右连接。
左(外)连接的语法
左(外)连接的语法还是挺简单的,比如我们要把 t1 表和 t2 表进行左外连接查询可以这么写:
SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
其中中括号里的 OUTER 单词是可以省略的。对于 LEFT JOIN 类型的连接来说,我们把放在左边的表称之为外表或者驱动表,右边的表称之为内表或者被驱动表。所以上述例子中 t1 就是外表或者驱动表, t2 就是内表或者被驱动表。需要注意的是,对于左(外)连接和右(外)连接来说,必须使用 ON 子句来指出连接条件。了解了左(外)连接的基本语法之后,再次回到我们上边那个现实问题中来,看看怎样写查询语句才能把所有的学生的成绩信息都查询出来,即使是缺考的考生也应该被放到结果集中:
mysql> SELECT s1.number, s1.name, s2.subject, s2.score FROM student AS s1 LEFT JOIN score AS s2 ON s1.number = s2.number;
+----------+--------+--------------+-------+
| number | name | subject | score |
+----------+--------+--------------+-------+
| 20230101 | 张三 | 高等数学 | 76 |
| 20230102 | 李四 | 模拟电路 | 86 |
| 20230102 | 李四 | 模拟电路 | 92 |
| 20230102 | 李四 | 高等数学 | 95 |
| 20230103 | 王五 | NULL | NULL |
+----------+--------+--------------+-------+
5 rows in set (0.00 sec)
从结果集中可以看出来,虽然 王五并没有对应的成绩记录,但是由于采用的是连接类型为左(外)连接,所以仍然把她放到了结果集中,只不过在对应的成绩记录的各列使用 NULL 值填充而已。
右(外)连接的语法
右(外)连接和左(外)连接的原理是一样一样的,语法也只是把 LEFT 换成 RIGHT 而已:
SELECT * FROM t1 RIGHT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
只不过驱动表是右边的表,被驱动表是左边的表。
mysql> SELECT s1.number, s1.name, s2.subject, s2.score FROM score AS s2 right JOIN student AS s1 ON s1.number = s2.number;
内连接的语法
内连接和外连接的根本区别就是在驱动表中的记录不符合 ON 子句中的连接条件时不会把该记录加入到最后的结果集,我们最开始说的那些连接查询的类型都是内连接。不过之前仅仅提到了一种最简单的内连接语法,就是直接把需要连接的多个表都放到 FROM 子句后边。其实针对内连接,MySQL提供了好多不同的语法,我们以 t1和 t2 表为例:
SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件];
也就是说在 MySQL 中,下边这几种内连接的写法都是等价的:
- SELECT * FROM t1,t2;
- SELECT * FROM t1 JOIN t2;
- SELECT * FROM t1 INNER JOIN t2;
- SELECT * FROM t1 CROSS JOIN t2;
现在我们虽然介绍了很多种内连接 的书写方式,不过熟悉一种就好了,我们推荐 INNER JOIN 的形式书写内连接(因为 INNER JOIN 语义很明确,可以和 LEFT JOIN 和 RIGHT JOIN 很轻松的区分开)。这里需要注意的是,由于在内连接中ON子句和WHERE子句是等价的,所以内连接中不要求强制写明ON子句。
我们前边说过,连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。不论哪个表作为驱动表,两表连接产生的笛卡尔积肯定是一样的。而对于内连接来说,由于凡是不符合 ON 子句或WHERE 子句中的条件的记录都会被过滤掉,其实也就相当于从两表连接的笛卡尔积中把不符合过滤条件的记录给踢出去,所以对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果。但是对于外连接来说,由于驱动表中的记录即使在被驱动表中找不到符合 ON 子句连接条件的记录,所以此时驱动表和被驱动表
的关系就很重要了,也就是说左外连接和右外连接的驱动表和被驱动表不能轻易互换。
连接的原理
嵌套循环连接(Nested-Loop Join)
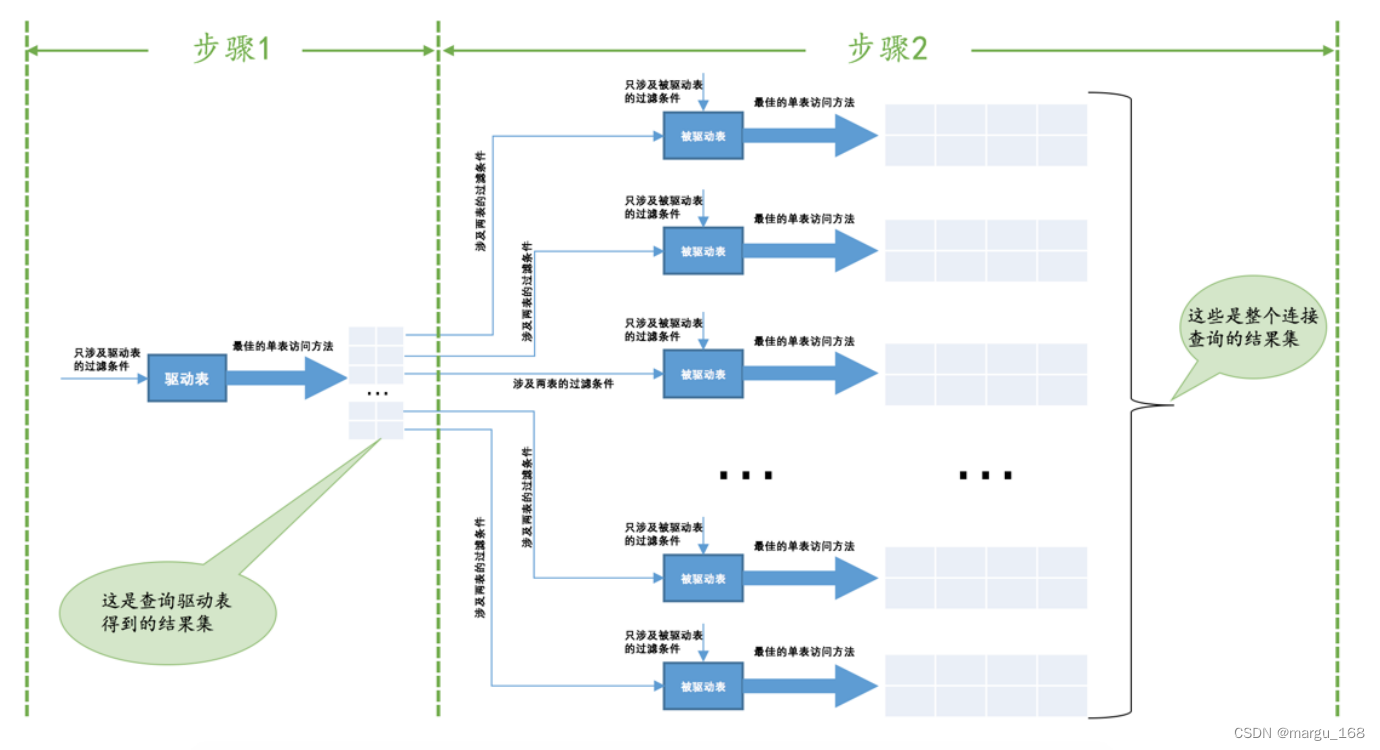
我们前边说过,对于两表连接来说,驱动表只会被访问一遍,但被驱动表却要被访问到好遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。对于内连接来说,选取哪个表为驱动表都没关系,而外连接的驱动表是固定的,也就是说左(外)连接的驱动表就是左边的那个表,右(外)连接的驱动表就是右边的那个表。我们上边已经大致介绍过 t1 表和 t2 表执行内连接查询的大致过程,大致过程如下:
- 步骤1:选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
- 步骤2:对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。
通用的两表连接过程如下图所示:
如果有3个表进行连接的话,那么 步骤2 中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表,
重复上边过程,也就是 步骤2 中得到的结果集中的每一条记录都需要到 t3 表中找一找有没有匹配的记录,用伪
代码表示一下这个过程就是这样:
for each row in t1 { #此处表示遍历满足对t1单表查询结果集中的每一条记录
for each row in t2 { #此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的
每一条记录
for each row in t3 { #此处表示对于某条t1和t2表的记录组合来说,对t3表进行单表查询
if row satisfies join conditions, send to client
}
}
}
这个过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为 嵌套循环连接 ( Nested-Loop Join ),这是最简单,也是最笨拙的一种连接查询算法。
使用索引加快连接速度
我们知道在嵌套循环连接的步骤2 中可能需要访问多次被驱动表,如果访问被驱动表的方式都是全表扫描的话,那得要扫描很多次了。 但是别忘了,查询 t2 表其实就相当于一次单表扫描,我们可以利用索引来加快查询速度。回顾一下最开始介绍的 t1 表和 t2 表进行内连接的例子:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < ‘d’;
我们使用的其实是 嵌套循环连接 算法执行的连接查询,再把上边那个查询执行过程表拉下来给大家看一下:
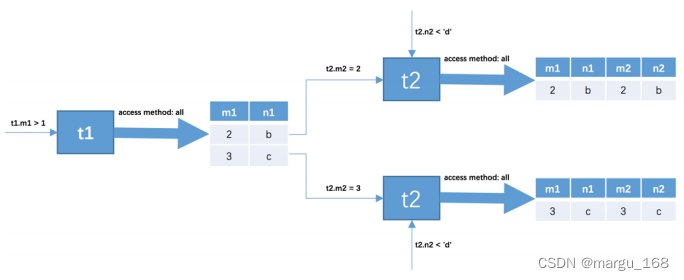
查询驱动表 t1 后的结果集中有两条记录, 嵌套循环连接 算法需要对被驱动表查询2次:
- 当 t1.m1 = 2 时,去查询一遍 t2 表,对 t2 表的查询语句相当于:
SELECT * FROM t2 WHERE t2.m2 = 2 AND t2.n2 < ‘d’; - 当 t1.m1 = 3 时,再去查询一遍 t2 表,此时对 t2 表的查询语句相当于:
SELECT * FROM t2 WHERE t2.m2 = 3 AND t2.n2 < ‘d’;
可以看到,原来的 t1.m1 = t2.m2 这个涉及两个表的过滤条件在针对 t2 表做查询时关于 t1 表的条件就已经确定了,所以我们只需要单单优化对 t2 表的查询了,上述两个对 t2 表的查询语句中利用到的列是 m2 和 n2 列,我们可以:
- 在 m2 列上建立索引,因为对 m2 列的条件是等值查找,比如 t2.m2 = 2 、 t2.m2 = 3 等,所以可能使用到ref (refs复数,多个)的访问方法,假设使用 ref 的访问方法去执行对 t2 表的查询的话,需要回表之后再判断 t2.n2 < d 这个条件是否成立。
这里有一个比较特殊的情况,就是假设 m2 列是 t2 表的主键或者唯一二级索引列,那么使用 t2.m2 = 常数值这样的条件从 t2 表中查找记录的过程的代价就是常数级别的。我们知道在单表中使用主键值或者唯一二级索引列的值进行等值查找的方式称之为 const ,而设计 MySQL 的人把在连接查询中对被驱动表使用主键值或者唯一二级索引列的值进行等值查找的查询执行方式称之为: eq_ref 。 - 在 n2 列上建立索引,涉及到的条件是 t2.n2 < ‘d’ ,可能用到 range 的访问方法,假设使用 range 的访问
方法对 t2 表的查询的话,需要回表之后再判断在 m2 列上的条件是否成立。
假设 m2 和 n2 列上都存在索引的话,那么就需要从这两个里边儿挑一个代价更低的去执行对 t2 表的查询。当然,建立了索引不一定使用索引,只有在 二级索引 + 回表 的代价比全表扫描的代价更低时才会使用索引。
另外,有时候连接查询的查询列表和过滤条件中可能只涉及被驱动表的部分列,而这些列都是某个索引的一部分,这种情况下即使不能使用 eq_ref 、 ref 、 ref_or_null 或者 range 这些访问方法执行对被驱动表的查询的话,也可以使用索引扫描,也就是 index 的访问方法来查询被驱动表。所以我们建议在真实工作中最好不要使用 * 作为查询列表,最好把实际需要用到的列作为查询列表。
基于块的嵌套循环连接(Block Nested-Loop Join)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足。现实生活中的表可不像 t1 、t2 这种只有3条记录,成千上万条记录都是少的,几百万、几千万甚至几亿条记录的表到处都是。内存里可能并不能完全存放的下表中所有的记录,所以在扫描表前边记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前边的记录从内存中释放掉。我们前边又说过,采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个 I/O 代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
当被驱动表中的数据非常多时,每次访问被驱动表,被驱动表的记录会被加载到内存中,在内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉。然后再从驱动表结果集中拿出另一条记录,再一次把被驱动表的记录加载到内存中一遍,周而复始,驱动表结果集中有多少条记录,就得把被驱动表从磁盘上加载到内存中多少次。所以我们可不可以在把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。所以设计 MySQL 的人提出了一个
join buffer 的概念, join buffer 就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个 join buffer 中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和 join buffer 中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的 I/O 代价。使用 join buffer 的过程如下图所示:
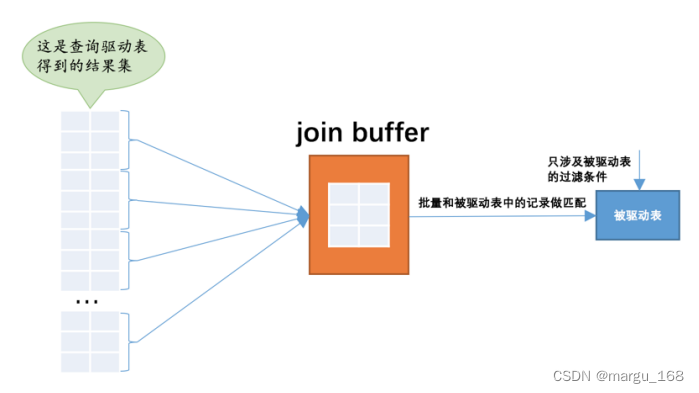
最好的情况是 join buffer 足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。设计 MySQL 的人把这种加入了 join buffer 的嵌套循环连接算
法称之为 基于块的嵌套连接(Block Nested-Loop Join)算法。
这个 join buffer 的大小是可以通过启动参数或者系统变量 join_buffer_size 进行配置,默认大小为 262144字节 (也就是 256KB ),最小可以设置为128字节 。当然,对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大 join_buffer_size 的值来对连接查询进行优化。
另外需要注意的是,驱动表的记录并不是所有列都会被放到 join buffer 中,只有满足查询列表中的列和过滤条件中的列才会被放到 join buffer 中,最后强调说明,最好不要把 * 作为查询列表,只需要把我们实际需要使用到的列放到查询列表就好了,这样就可以在 join buffer 中一次性放置更多的记录。
更多关于mysql的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出
相关文章:
【Mysql】Mysql中表连接的原理
连接简介 在实际工作中,我们需要查询的数据很可能不是放在一张表中,而是需要同时从多张表中获取。下面我们以简单的两张表为例来进行说明。 连接的本质 为方便测试说明,,先创建两个简单的表并给它们填充一点数据: …...

Java配置47-Spring Eureka 未授权访问漏洞修复
文章目录 1. 背景2. 方法2.1 Eureka Server 添加安全组件2.2 Eureka Server 添加参数2.3 重启 Eureka Server2.4 Eureka Server 升级版本2.5 Eureka Client 配置2.6 Eureka Server 添加代码2.7 其他问题 1. 背景 项目组使用的 Spring Boot 比较老,是 1.5.4.RELEASE…...

6.Spark共享变量
概述 共享变量 共享变量的工作原理Broadcast VariableAccumulator 共享变量 共享变量的工作原理 通常,当给 Spark 操作的函数(如 mpa 或 reduce) 在 Spark 集群上执行时,函数中的变量单独的拷贝到各个节点上,函数执行时,使用…...

FaceChain开源虚拟试衣功能,打造更便捷高效的试衣新体验
简介 虚拟试衣这个话题由来已久,电商行业兴起后,就有相关的研发讨论。由其所见即所得的属性,它可以进一步提升用户服装购买体验。它既可以为商家做商品展示服务,也可以为买家做上身体验服务,这让同时具备了 B 和 C 的两…...

java的几种对象: PO,VO,DAO,BO,POJO
概述 对象释意使用备注PO(persistant object)持久对象可以看成是与数据库中的表相映射的Java对象,最简单的PO就是对应数据库中某个表中的一条记录。PO中应该不包含任何对数据库的操作VO(view object)表现层对象主要对…...
【使用Python编写游戏辅助工具】第三篇:鼠标连击器的实现
前言 这里是【使用Python编写游戏辅助工具】的第三篇:鼠标连击器的实现。本文主要介绍使用Python来实现鼠标连击功能。 鼠标连击是指在很短的时间内多次点击鼠标按钮,通常是鼠标左键。当触发鼠标连击时,鼠标按钮会迅速按下和释放多次…...

C++二分查找算法的应用:最小好进制
本文涉及的基础知识点 二分查找 题目 以字符串的形式给出 n , 以字符串的形式返回 n 的最小 好进制 。 如果 n 的 k(k>2) 进制数的所有数位全为1,则称 k(k>2) 是 n 的一个 好进制 。 示例 1: 输入:n “13” 输出:“3” …...
2022年12月 Python(三级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python等级考试(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 列表L1中全是整数,小明想将其中所有奇数都增加1,偶数不变,于是编写了如下图所示的代…...

行业安卓主板-基于RK3568/3288/3588的AI视觉秤/云相框/点餐机/明厨亮灶行业解决方案(一)
AI视觉秤 单屏Al秤集成独立NPU,可达0.8Tops算力,令AI运算效率大幅提升,以实现生鲜商品快速准确识别,快速称重打印标签,降低生鲜门店运营成本,缓解高峰期称重排队拥堵的现象,提高称重效率&#…...

fo-dicom缺少DicomJpegLsLosslessCodec
VS2019,fo-dicom v4.0.8 using Dicom.Imaging.Codec; ... DicomJpegLsLosslessCodec //CS0103 当前上下文中不存在名称“DicomJpegLsLosslessCodec” 但官方文档的确存在该类的说明DicomJpegLsLosslessCodec 尝试:安装包fo-dicom.Codecs,注…...

跳跳狗小游戏
欢迎来到程序小院 跳跳狗 玩法:一直弹跳的狗狗,鼠标点击屏幕左右方向键进行弹跳,弹到不同物品会有不同的分数减扣,规定的时间3分钟内完成狗狗弹跳,快去跳跳狗吧^^。开始游戏https://www.ormcc.com/play/gameStart/198…...
CoDeSys系列-4、基于Ubuntu的codesys运行时扩展包搭建Profinet主从环境
CoDeSys系列-4、基于Ubuntu的codesys运行时扩展包搭建Profinet主从环境 文章目录 CoDeSys系列-4、基于Ubuntu的codesys运行时扩展包搭建Profinet主从环境一、前言二、资料收集三、Ubuntu18.04从安装到更换实时内核1、下载安装Ubuntu18.042、下载安装实时内核,解决编…...

shell_70.Linux调整谦让度
调整谦让度 1.nice 命令 (1)nice 命令允许在启动命令时设置其调度优先级。要想让命令以更低的优先级运行,只需用nice 命令的-n 选项指定新的优先级即可: $ nice -n 10 ./jobcontrol.sh > jobcontrol.out & [2] 16462 $ $ ps -p 16462 -o pid,…...
【jvm】虚拟机栈
目录 一、背景二、栈与堆三、声明周期四、作用五、特点(优点)六、可能出现的异常七、设置栈内存大小八、栈的存储单位九、栈运行原理十、栈帧的内部结构10.1 说明10.2 局部变量表10.3 操作数栈10.4 动态链接10.5 方法返回地址10.6 一些附加信息 十一、代…...

Flink SQL Over 聚合详解
Over 聚合定义(⽀持 Batch\Streaming):**特殊的滑动窗⼝聚合函数,拿 Over 聚合 与 窗⼝聚合 做对⽐。 窗⼝聚合:不在 group by 中的字段,不能直接在 select 中拿到 Over 聚合:能够保留原始字段…...

【鸿蒙软件开发】ArkUI之容器组件Counter(计数器组件)、Flex(弹性布局)
文章目录 前言一、Counter1.1 子组件1.2 接口1.3 属性1.4 事件 1.5 示例代码二、Flex弹性布局到底是什么意思? 2.1 权限列表2.2 子组件2.3 接口参数 2.4 示例代码示例代码1示例代码2 总结 前言 Counter容器组件:计数器组件,提供相应的增加或…...
:神经网络-线性层及其他层介绍)
PyTorch入门学习(十一):神经网络-线性层及其他层介绍
目录 一、简介 二、PyTorch 中的线性层 三、示例:使用线性层构建神经网络 四、常见的其他层 一、简介 神经网络是由多个层组成的,每一层都包含了一组权重和一个激活函数。每层的作用是将输入数据进行变换,从而最终生成输出。线性层是神经…...
农业水土环境与面源污染建模及对农业措施响应
目录 专题一 农业水土环境建模概述 专题二 ArcGIS入门 专题三 农业水土环境建模流程 专题四 DEM数据制备流程 专题五 土地利用数据制备流程 专题六 土壤数据制备流程 专题七 气象数据制备流程 专题八 农业措施数据制备流程 专题九 参数率定与结果验证 专题十 模型结…...

回归预测 | Matlab实现MPA-BP海洋捕食者算法优化BP神经网络多变量回归预测(多指标、多图)
回归预测 | Matlab实现MPA-BP海洋捕食者算法优化BP神经网络多变量回归预测(多指标、多图) 目录 回归预测 | Matlab实现MPA-BP海洋捕食者算法优化BP神经网络多变量回归预测(多指标、多图)效果一览基本介绍程序设计参考资料 效果一览…...

扫地机器人遇瓶颈?科沃斯、石头科技“突围”
曾经,扫地机器人行业也曾有过高光时刻,而如今,扫地机器人已然告别高增长阶段,增速开始放缓。据中怡康零售推总数据显示,2023年上半年,中国扫地机器人市场规模为63.6亿元人民币,同比下滑了0.6%&a…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...