大语言模型对齐技术 最新论文及源码合集(外部对齐、内部对齐、可解释性)
大语言模型对齐(Large Language Model Alignment)是利用大规模预训练语言模型来理解它们内部的语义表示和计算过程的研究领域。主要目的是避免大语言模型可见的或可预见的风险,比如固有存在的幻觉问题、生成不符合人类期望的文本、容易被用来执行恶意行为等。
从必要性上来看,大语言模型对齐可以避免黑盒效应,提高模型的可解释性和可控性,指导模型优化,确保AI 技术的发展不会对社会产生负面影响。因此,大语言模型对齐对AI系统的发展至关重要。
目前的大语言模型对齐研究主要分为三个领域:外部对齐、内部对齐、可解释性。我整理了这三个领域的最新论文分享给大家,帮助同学们掌握大语言模型对齐的最新技术与研究重点,快速找到新的idea。
全部论文及源代码看文末
外部对齐(23篇)
非递归监督
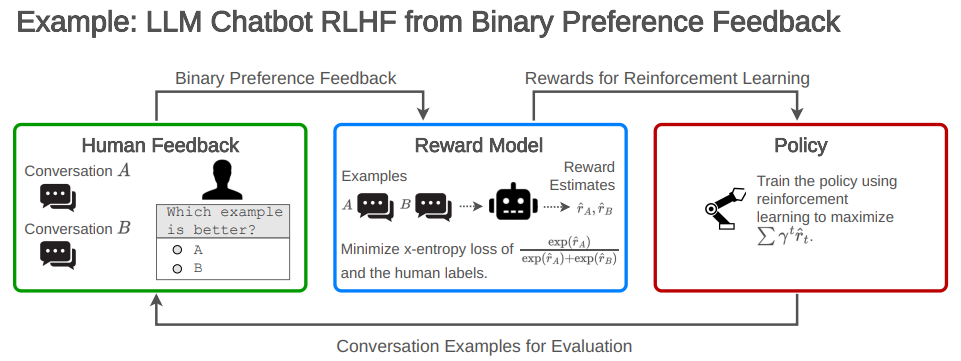
1.Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
强化学习利用人类反馈的开放问题和根本限制
简述:RLHF已成为调优当前领先的大型语言模型(LLM)的核心方法。尽管很流行,但是系统地总结它的缺陷的公开工作相对较少。本文:(1)调研了RLHF及相关方法的开放问题和基本局限,(2)概述了在实践中理解、改进和补充RLHF的技术,(3)提出了审计和披露标准,以改进对RLHF系统的社会监督。
2.Principled Reinforcement Learning with Human Feedback from Pairwise or K-wise Comparisons
基于成对或K选项比较的人类反馈原则强化学习
简述:论文基于人类反馈强化学习(RLHF)提供了一个理论框架,证明了在基于学习的奖励模型训练策略时,MLE会失败,而悲观的MLE可以在某些覆盖假设下提供性能更好的策略。此外,在PL模型下,真实的MLE和将K选比较分解成成对比较的替代MLE都收敛。而且,真实的MLE在渐近意义上更有效率。
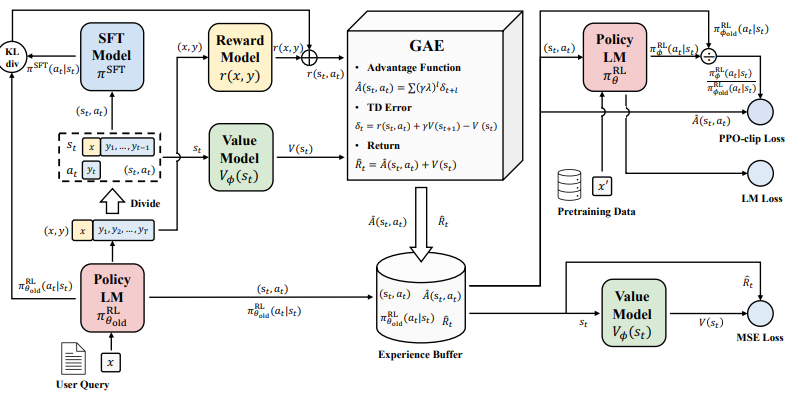
3.Secrets of RLHF in Large Language Models Part I: PPO
大语言模型中的RLHF奥秘 第1部分:PPO
简述:大语言模型通过人类反馈强化学习实现与人类的对齐,是实现人工通用智能的重要途径。但奖励设计、环境交互、智能体训练等方面的挑战使其稳定训练仍然困难。论文通过分析策略优化算法内部工作机制,提出了改进训练稳定性的方法,为大语言模型的对齐提供了新思路。
-
4.Guiding Large Language Models via Directional Stimulus Prompting
-
5.Aligning Large Language Models through Synthetic Feedback
-
6.Aligning Language Models with Preferences through f-divergence Minimization
-
7.Scaling Laws for Reward Model Overoptimization
-
8.Improving Language Models with Advantage-based Offline Policy Gradients
-
9.RL4F: Generating Natural Language Feedback with Reinforcement Learning for Repairing Model Outputs
-
10.LIMA: Less Is More for Alignment
-
11.SLiC-HF: Sequence Likelihood Calibration with Human Feedback
-
12.RRHF: Rank Responses to Align Language Models with Human Feedback without tears
-
13.Preference Ranking Optimization for Human Alignment
-
14.Training Language Models with Language Feedback at Scale
-
15.Direct Preference Optimization: Your Language Model is Secretly a Reward Model
-
16.Training Socially Aligned Language Models on Simulated Social Interactions
-
17.Chain of Hindsight Aligns Language Models with Feedback
-
18.RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
可扩展监督
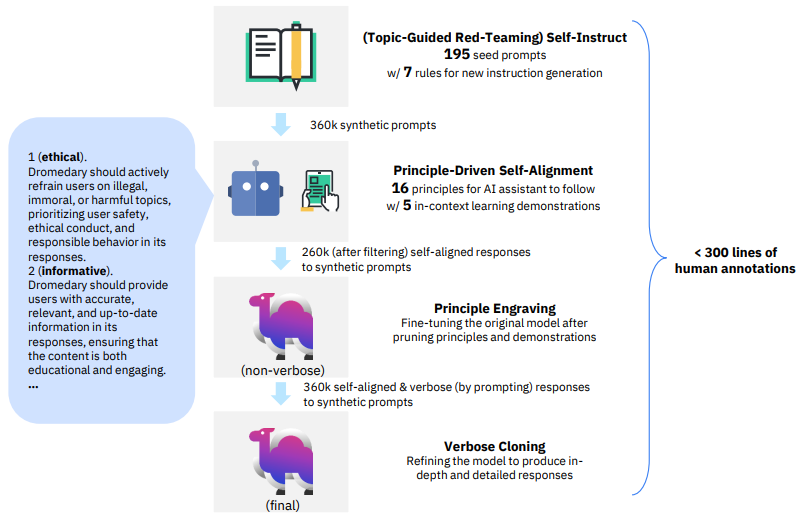
1.Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
从零开始用最小人工监督实现语言模型的原则驱动自对齐
简述:论文提出一种新的自监督对齐方法SELF-ALIGN,通过结合原则推理和大语言模型的生成能力,使AI助手实现自我对齐,仅需要极少的人类监督。该方法可以有效解决当前依赖监督训练和人类反馈的方法中的问题,如成本高、质量低等。在LLaMA语言模型上的应用证明该方法明显优于当前SOTA的AI助手。
2.Let's Verify Step by Step
一步步验证
简述:针对训练可靠的复杂多步推理的大语言模型,论文比较了结果监督和过程监督两种方法。研究发现,过程监督明显优于结果监督,可以获得更可靠的模型。作者采用过程监督和主动学习相结合的方法训练模型,在MATH数据集上取得了较好效果,测试集准确率达到78%。

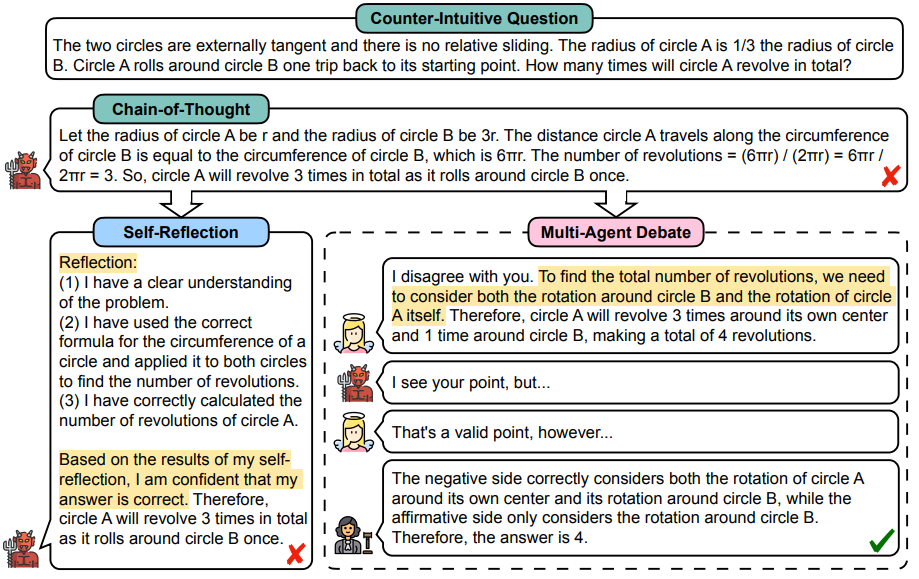
3.Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
通过多智能体辩论激发大语言模型的发散性思维
简述:近年大规模语言模型如ChatGPT在通用语言任务上表现强大,但在复杂推理上仍有困难。论文提出多智能体辩论框架来激发模型的发散思维,多个智能体以你来我往方式表达观点,评委管理过程获得最终解决方案。该框架可以激发语言模型的思考,有助于需要深度思考的任务。
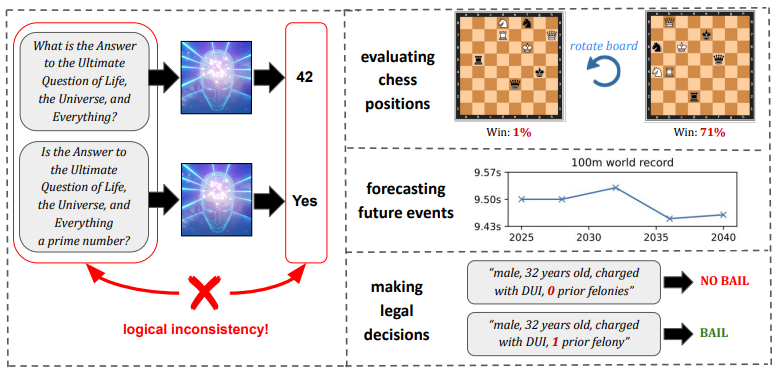
4.Evaluating Superhuman Models with Consistency Checks
评估超人类模型的一致性检查
简述:近年来,机器学习模型在许多任务上达到或超过人类水平,如何评估这类“超人类”模型成为一个重要问题。论文提出通过一致性检查来评估它们,即使无法判断这类模型决策的正确性,如果决策间存在逻辑矛盾,我们仍可发现其缺陷。该工作强调继续改进评估方法的重要性,以推动可信赖的超人类AI系统发展。
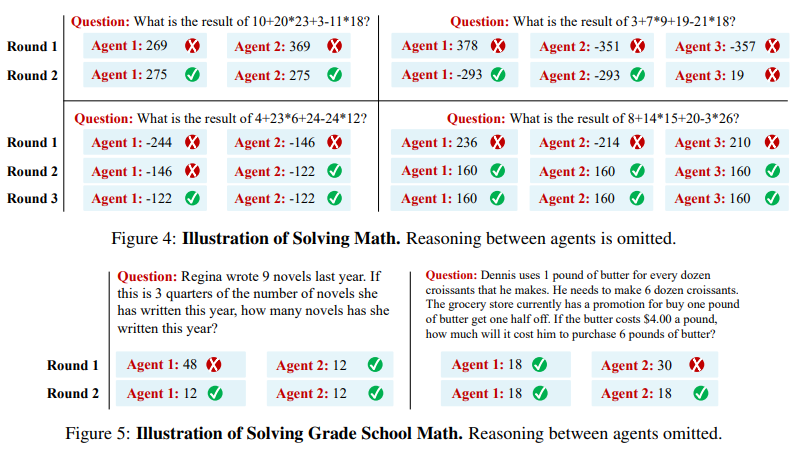
5.Improving Factuality and Reasoning in Language Models through Multiagent Debate
通过多智能体辩论提高语言模型的事实性和推理能力
简述:论文提出了一种多语言模型互动的“思维社会”方法,多个模型提出并辩论各自的观点,经过多轮达成共识。实验表明,这种方法可以增强模型的逻辑推理能力,减少错误信息。而且这种方法可以直接应用于现有模型,并在各种任务上取得显著改进。
内部对齐(3篇)
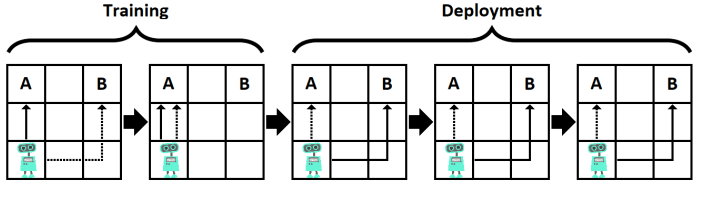
1.Goal Misgeneralization: Why Correct Specifications Aren't Enough For Correct Goals
为什么正确的规范仍无法获得正确的目标?
简述:目标误推广是AI系统一个重要问题,它指学习算法把训练集表现良好的策略过度推广到新的环境,导致非预期的负面后果。论文通过深度学习等实际系统中的例子,展示了这一问题的存在。为避免更强AI系统产生这种问题,我们需要在算法设计上防范过度推广,也要增强系统对人类价值的内化理解。
2.Goal Misgeneralization in Deep Reinforcement Learning
深度强化学习中的目标误推广
简述:论文研究了强化学习中的一种分布外泛化失败类型——目标误推广。当强化学习代理在分布外保持其能力但追求错误目标时,就会发生目标误推广失败。作者形式化了能力泛化和目标泛化之间的区别,提供了目标误推广的首个实证演示,并部分描述了其原因。

3.Risks from Learned Optimization in Advanced Machine Learning Systems
高级机器学习系统中学习优化的风险
简述:论文认为MESA优化的可能性为高级机器学习系统的安全性和透明度提出了两个重要问题。第一,在什么情况下学习模型会成为优化器,包括在它本不应该成为优化器的情况下?第二,当学习模型成为优化器时,它的目标是什么——它将如何不同于其训练的损失函数——以及如何实现对齐?在本文中,作者对这两个主要问题进行了深入分析,并概述了未来研究的主题。
可解释性(9篇)
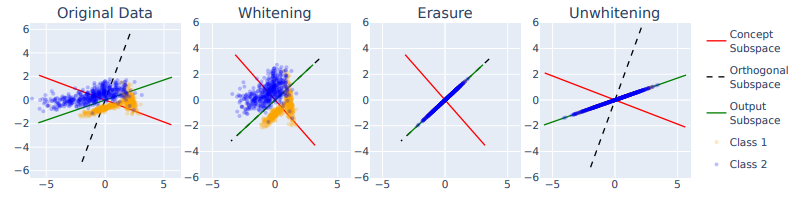
1.LEACE: Perfect linear concept erasure in closed form
LEACE:完美闭式线性概念擦除
简述:概念擦除是从机器学习模型中删除某个概念的影响,以提高模型的公平性和可解释性。论文提出了LEACE方法,可以高效并精确地实现线性模型的概念擦除。实验证明它可以减少语言模型对词性信息的依赖和模型中的性别偏见,增强机器学习模型的安全性、可解释性和公平性。
2.Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
从语言模型中获得真实答案
简述:论文提出了“推理时干预”(ITI)技术,旨在增强大语言模型的“诚实度”。ITI 通过在推理时沿少数注意力头中的特定方向移动模型激活来实现,这种干预显著提高了LLaMA模型在TruthfulQA基准测试中的性能。另外,该技术的数据效率很高,虽然像RLHF这样的方法需要大量标注,但ITI 只需要几百个例子就可以找到真实的方向。
3.Locating and Editing Factual Associations in GPT
在GPT中定位和编辑事实关联
简述:论文现Transformer语言模型中存储和回忆事实性关联的机制对应于可定位和直接编辑的中间层计算。通过因果干预和模型编辑,作者确认了中间层前馈模块在记忆事实关联方面起关键作用。本文的模型编辑方法在零样本关系提取和反事实断言任务上都表现出强大的特异性和泛化能力,这说明直接操作中间层计算是模型编辑的一个有效途径。

-
4.Mechanistic Interpretability, Variables, and the Importance of Interpretable Bases
-
5.Toy Models of Superposition
-
6.Softmax Linear Units
-
7.Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
-
8.In-context Learning and Induction Heads
-
9.A Comprehensive Mechanistic Interpretability Explainer & Glossary
关注下方《学姐带你玩AI》🚀🚀🚀
回复“对齐”获取全部论文+源代码合集
码字不易,欢迎大家点赞评论收藏!
相关文章:
大语言模型对齐技术 最新论文及源码合集(外部对齐、内部对齐、可解释性)
大语言模型对齐(Large Language Model Alignment)是利用大规模预训练语言模型来理解它们内部的语义表示和计算过程的研究领域。主要目的是避免大语言模型可见的或可预见的风险,比如固有存在的幻觉问题、生成不符合人类期望的文本、容易被用来执行恶意行为等。 从必…...

x264交叉编译(ubuntu+arm)
1.下载源码 https://code.videolan.org/videolan/x264 在windows下解压;复制到ubuntu; 2.进入源码文件夹-新建脚本文件 touch sp_run.sh 3.在sp_run.sh文件中输入 #!/bin/sh./configure --prefix/home/alientek/sp_test/x264/sp_install --enable-…...

SpringMVC 处理后端日期格式
通过扩展Spring MVC框架的消息转化器 在WebMvcConfiguration中扩展SpringMVC的消息转换器,统一对日期类型进行格式处理 WebMvcConfiguration /*** 扩展Spring MVC框架的消息转化器* param converters*/protected void extendMessageConverters(List<HttpMessag…...

Servlet详解
一.Servlet生命周期 初始化提供服务销毁 1.测试生命周期 package com.demo.servlet;import javax.servlet.*; import java.io.IOException;public class LifeServlet implements Servlet {Overridepublic void init(ServletConfig servletConfig) throws ServletException {…...

遥遥领先,免费开源的django4-vue3前后端分离项目
星域后台管理系统前端介绍 🌿项目简介 本项目前端基于当下流行且常用的vue3作为主要技术栈进行开发,融合了typescript和element-plus-ui,提供暗黑模式和白昼模式两种主题以及全屏切换,开发bug少,简单易学,…...

行业安卓主板-基于RK3568/3288/3588的AI智能网络广告机/自动售货机/收银机解决方案(三)
广告机 智能网络广告机通过网络将音视频、图片、文档、网页等自由排版创建成节目发布到终端。可针对不同的终端统一管理,统一发布;针对应用场景的集中和分散,可以选用局域网管理和云服务器管理。 自动售货机 随着物联网、大数据、人工智能的…...

寻找二维数组的最大值和对应下标 | C语言代码
题目: 本题目要求读入M(最大为10)行N(最大为15)列个元素,找出其中最大的元素,并输出其行列值。 输入格式: 输入在第一行中给出行数m和列数n。接下来输入m*n个整数。 输出格式: 输出最大值的行号,列号,值。 输入样例…...

2311dC++连接与串
原文 extern(C)函数使用在装饰名中包括参数类型的C装饰名.但是,因为C没有像D的T[]内置切片类型,因此C没有有效的D切片装饰. 因此,无法编译以D切片为参数的extern(C)函数. 为此,可按结构转换切片: struct DSlice(T) {T* ptr;size_t length;T[] opIndex() > ptr[0 .. length]…...
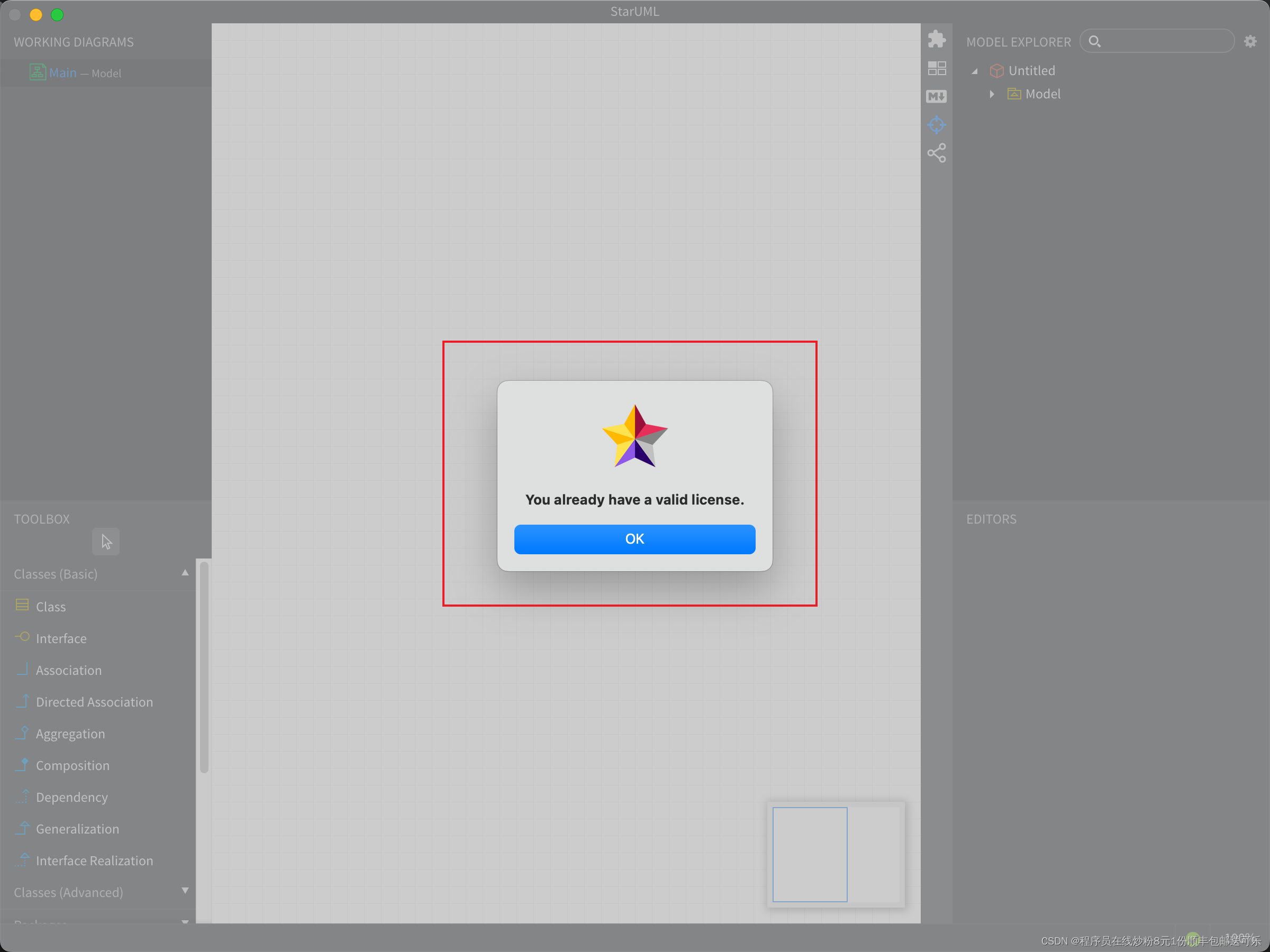
macOS 下 starUML 软件激活方案
starUML每次打开都弹出提示其实挺烦的,于是研究了一下如何 po 解(激活)它。记录一下方法以便以后使用。 我觉得这个软件很好用,大型项目的所有图我都是用这个软件画的。 直接上步骤!先关掉starUML 1、安装 asar,以便可以打开 asa…...
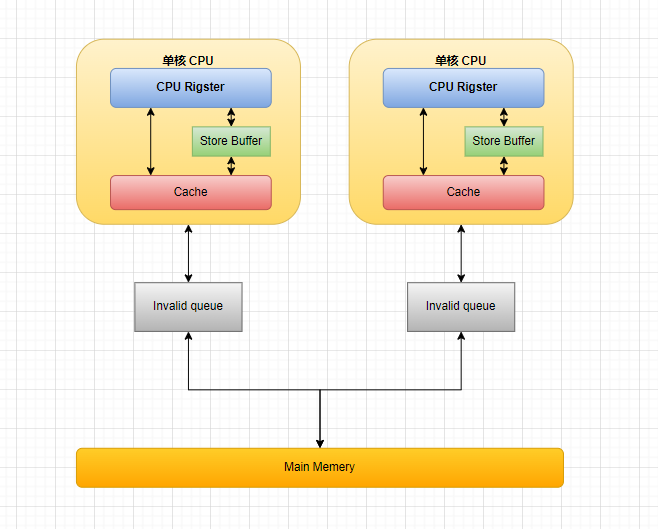
一文读懂从 CPU 多级缓存 缓存一致性协议(MESI)到 Java 内存模型
文章目录 CPU 多级缓存 & 缓存一致性协议(MESI)CPU 多级缓存缓存一致性协议(MESI)缓存行(Cache line)四种缓存状态缓存行状态转换多核协同示例网站体验 MESI优化和引入的问题Store Bufferes & Inva…...
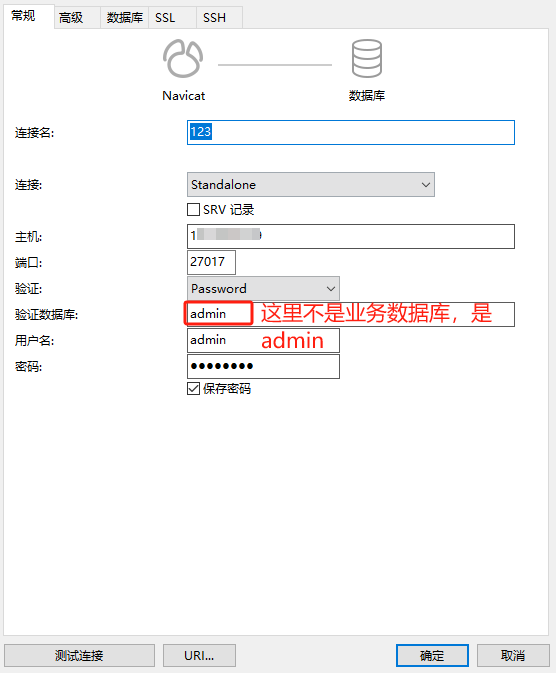
MongoDB设置密码
关于为什么要设置密码 公司的测试服务器MongoDB服务对外网开放的,结果这几天发现数据库被每天晚上被人清空的了,还新建了个数据库,说是要支付比特币。查了日志看到有个境外的IP登录且删除了所有的集合。所以为了安全起见,我们给m…...
重生奇迹mu召唤师怎么加点?
召唤师在重生奇迹mu游戏里面是一个智力型的职业,所以智力自然就成为主要加点属性,但是此职业却又算是近身攻击,因为她的技能范围并不算远,而且还是呈现出一种半径趋势,一方面是攻击伤害,另一方面则是辅助造…...
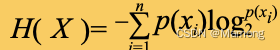
第九章《搞懂算法:决策树是怎么回事》笔记
决策树算法是机器学习中很经典的一个算法,它既可以作为分类算法,也可以作为回归算法。 9.1 典型的决策树是什么样的 决策树算法是依据“分而治之”的思想,每次根据某属性的值对样本进行分类,然后传递给下个属性继续进行分类判断…...

jar包的精细化运营,Java模块化简介 | 京东云技术团队
图:模块化手机概念 一、什么是Java模块化 Java模块化(module)是Java9及以后版本引入的新特性。 官方对模块的定义为:一个被命名的,代码和数据的自描述集合。( the module, which is a named, self-descri…...
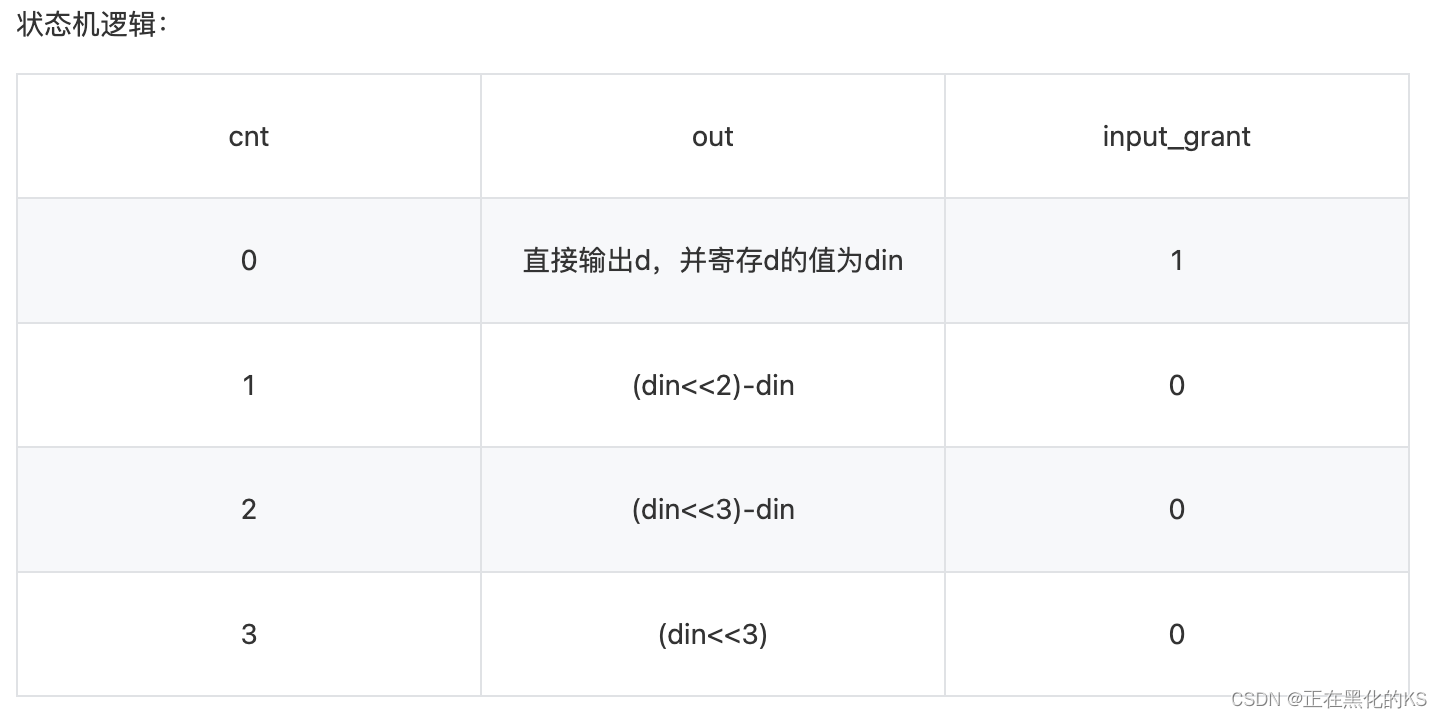
「Verilog学习笔记」移位运算与乘法
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 分析 1、在硬件中进行乘除法运算是比较消耗资源的一种方法,想要在不影响延迟并尽量减少资源消耗,必须从硬件的特点上进行设计。根据寄存器的原理&a…...
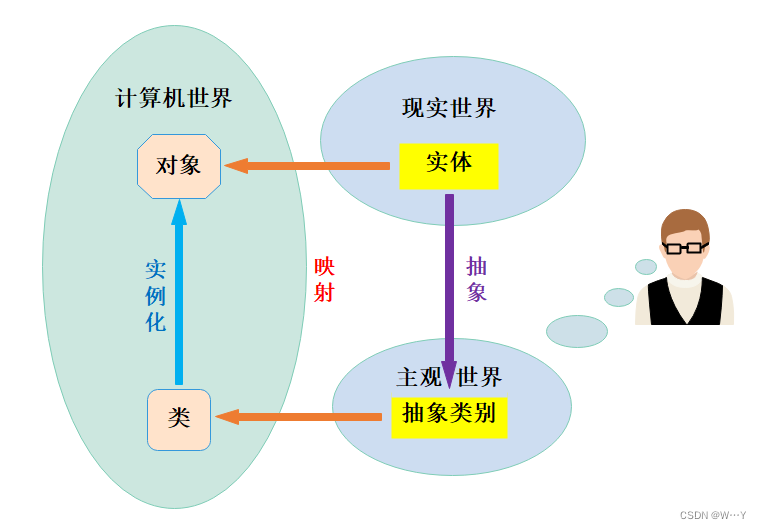
静态、友好、内在:解析C++中的这些特殊元素和对象复制的优化
W...Y的主页 😊 代码仓库分享💕 🍔前言: 前面我们学习了C中关于类与对象的许多知识点,今天我们继续学习类与对象,最后再总结一下类与对象中的一些关键字内容,以及需要注意的细节。满满的干货…...
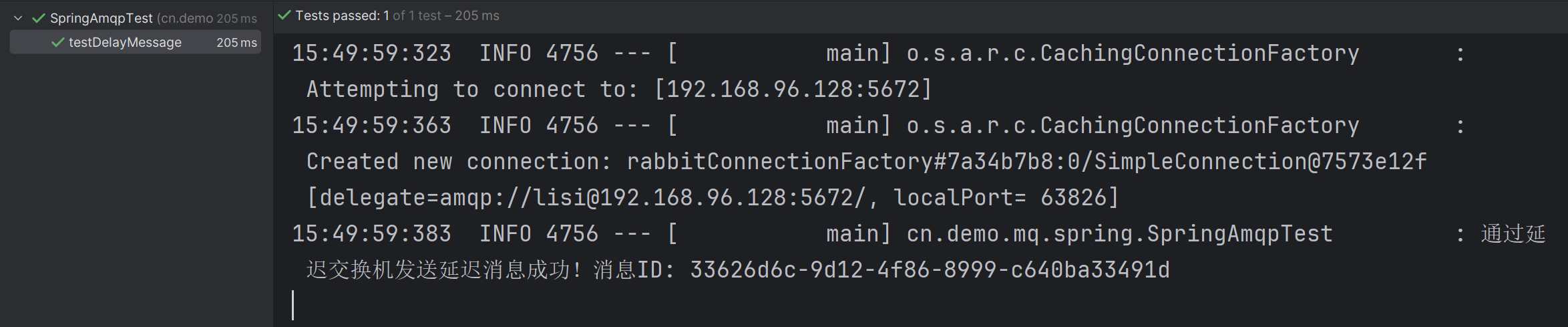
【RabbitMQ】 RabbitMQ 消息的延迟 —— 深入探索 RabbitMQ 的死信交换机,消息的 TTL 以及延迟队列
文章目录 一、死信交换机1.1 什么是死信和死信交换机1.2 死信交换机和死信队列的创建方式 二、消息的 TTL2.1 什么是消息的 TTL2.2 基于死信交换机和 TTL 实现消息的延迟 三、基于 DelayExchang 插件实现延迟队列3.1 安装 DelayExchang 插件3.2 DelayExchang 实现消息延迟的原理…...
CVE-2023-34040 Kafka 反序列化RCE
漏洞描述 Spring Kafka 是 Spring Framework 生态系统中的一个模块,用于简化在 Spring 应用程序中集成 Apache Kafka 的过程,记录 (record) 指 Kafka 消息中的一条记录。 受影响版本中默认未对记录配置 ErrorHandlingDeserializer,当用户将容…...

全局变量和局部变量在for循环的使用
imageloc字典作为全局变量,然后添加到全局的列表中,每次for循环都会将最新的元素改变之前for循环添加的元素。而imageloc字典作为局部变量,则不会影响。 import numpy as np originaljson [{"joints_vis": [1,1,1,1,1,1,1,1,1,1,…...

pytorch collate_fn测试用例
collate_fn 函数用于处理数据加载器(DataLoader)中的一批数据。在PyTorch中使用 DataLoader 时,通过设置collate_fn,我们可以决定如何将多个样本数据整合到一起成为一个 batch。在某些情况下,该函数需要由用户自定义以满足特定需求。 import …...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...
前端开发者常用网站
Can I use网站:一个查询网页技术兼容性的网站 一个查询网页技术兼容性的网站Can I use:Can I use... Support tables for HTML5, CSS3, etc (查询浏览器对HTML5的支持情况) 权威网站:MDN JavaScript权威网站:JavaScript | MDN...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...
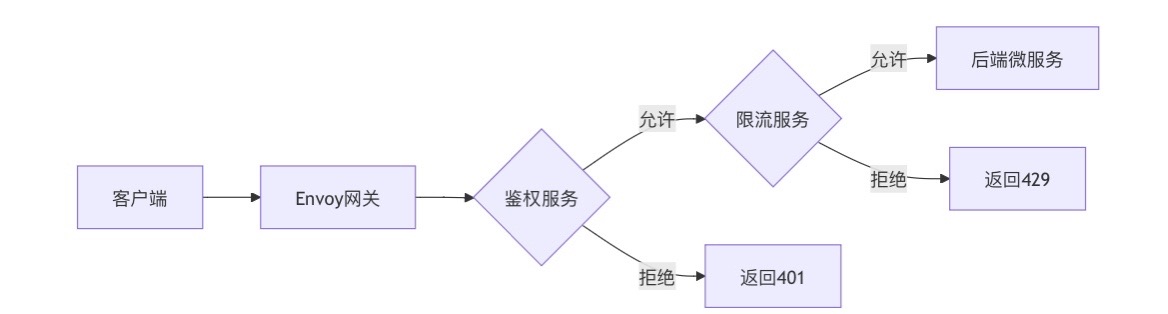
云原生安全实战:API网关Envoy的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关 作为微服务架构的统一入口,负责路由转发、安全控制、流量管理等核心功能。 2. Envoy 由Lyft开源的高性能云原生…...

Appium下载安装配置保姆教程(图文详解)
目录 一、Appium软件介绍 1.特点 2.工作原理 3.应用场景 二、环境准备 安装 Node.js 安装 Appium 安装 JDK 安装 Android SDK 安装Python及依赖包 三、安装教程 1.Node.js安装 1.1.下载Node 1.2.安装程序 1.3.配置npm仓储和缓存 1.4. 配置环境 1.5.测试Node.j…...