帧间快速算法论文阅读
Low complexity inter coding scheme for Versatile Video Coding (VVC)
通过分析相邻CU的编码区域,预测当前CU的编码区域,以终止不必要的分割模式。

𝐶𝑈1、𝐶𝑈2、𝐶𝑈3、𝐶𝑈4 表示当前CU(CU0) 的相邻CU。根据空间相关性,当前CU的面积预测为
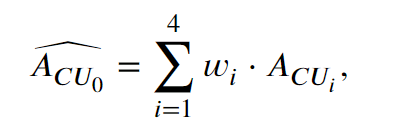
w i w_i wi的值分别为0.3,0.2,0.3,0.2 。(考虑到水平方向和垂直方向的相关性大于对角线方向的相关性)
当预测面积高于当前CU一定程度时,说明当前CU足够小,可以提前停止分裂。反之,如果预测面积较小,则该CU可以分裂为4个子CU。公式如下:
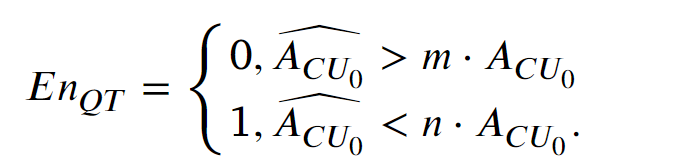
参数𝑚、𝑛分别设置为4和1/8。
值为1时,确定当前CU在QT结构下分裂为4个子CU
进一步利用在预测过程中生成的时间最优编码模式来缩小候选模式以加速编码过程。
在编码过程中,BT_H和BT_V先于TT_H和TT_V执行。如果选择BT_H作为二叉树结构下的最优模式,则意味着当前CU可以通过水平分裂获得更好的编码性能,所以不需要执行TT_V。
利用相邻预测模式的分布来测量当前CU的运动复杂度,基于此可以提前跳过不必要的预测模式。
在VVC帧间编码中,有五种预测模式:SKIP、inter、affine、merge_geo和intra。对于SKIP模式,没有残差和运动矢量被传输到解码器侧,这意味着当前CU的纹理和运动特征是简单的。同时,如果CU采用帧内模式编码,则表明CU的运动特征比较复杂,运动估计对于CU来说是无效的。一般来说,不同的模式对应不同的内容,具有不同的运动信息。
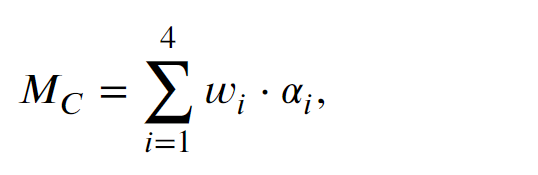
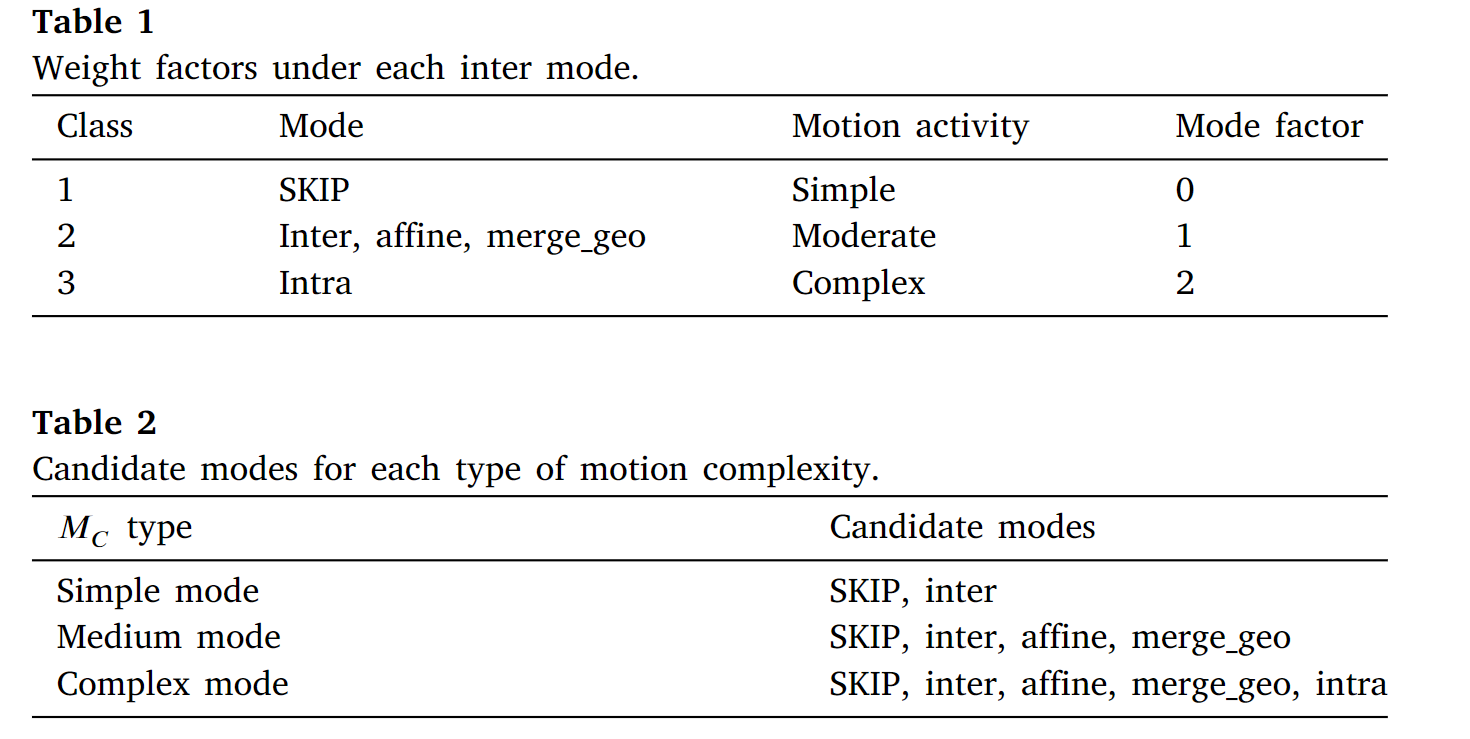

𝑇ℎ1和𝑇ℎ2分别设置为0.5和1
算法流程图:

实验结果:

节省 40.08% 的时间,BDPSNR 降低 0.07 dB,BDBR 提高 1.56%。
“FoodMarket4”的时间节省最多为 48.19%,而“RaceHorses”的时间节省最少为 35.95%。
由于“FoodMarket4”中的运动复杂度相对低于“Racehorses”中的运动复杂度,因此“FoodMarket4”中节省了更多时间,并且具有更好的编码性能。
高分辨率的序列比低分辨率的序列可以节省更多的时间。例如,分辨率为 3840 × 2160 的 A1 序列可节省 45.96% 的时间,而分辨率为 416 × 240 的 D 序列可节省 36.25% 的时间。
原因是高分辨率的序列提供了更多的细节,这表明编码内容的空间相关性很高。
复杂度低??分辨率??
CNN-based Prediction of Partition Path for VVC Fast Inter Partitioning Using Motion Fields
我们提出了一种基于卷积神经网络(CNN)的方法来加速 VVC 中的内部划分过程。首先,引入了从分区路径导出的具有嵌套多类型树(QTMT)分区的四叉树的新颖表示。其次,我们开发了一个基于 U-Net 的 CNN,将多尺度运动矢量场作为编码树单元(CTU)级别的输入。 CNN 推理的目的是预测率失真优化 (RDO) 过程中的最佳划分路径。为了实现这一目标,我们将 CTU 划分为网格,并预测网格每个单元的四元树 (QT) 深度和多类型树 (MT) 分割决策。第三,引入了一种有效的分区剪枝算法,以在每个分区级别使用 CNN 预测来跳过不必要的分区路径的 RDO 评估。最后,设计了一种自适应阈值选择方案,使复杂性和效率之间的权衡具有可扩展性。实验表明,该方法在RandomAccess Group Of Picture 32(RAGOP32)配置下可以实现16.5%至60.2%的加速,而就BD速率而言,效率下降了0.44%至4.59%,超越了其他状态最先进的解决方案。此外,我们的方法是该领域最轻的方法之一,这确保了它对其他编码器的适用性。
BD速率下降??
我们提出了一种新颖的基于分区路径的 CTU 级别 QTMT 分区表示,作为 QT 深度图加上三个 MT 分区图,很好地适应了 VVC 中复杂的分区方案。
在 QTMT 分区内,需要注意的是,MT 分割的子节点禁止 QT 分割。因此,VVC 中最优分割路径的搜索可以被概念化为一个连续的两步决策过程,包括一系列 QT 分割和随后的一系列 MT 分割
MT 分割的子节点禁止 QT 分割
考虑到VTM中QT分割和MT分割的最大数量通常设置为4和3,任何分区都可以通过一个QT深度图(即QTdepthMap)和三个MT分割图(即MTsplitMap)依次有效地描述。 QTdepthMap 和 MTsplitMap 中的每个元素对应于 8x8 和 4x4 区域,该区域与 VTM 中 QT 分割和 MT 分割的最小子 CU 的尺寸对齐
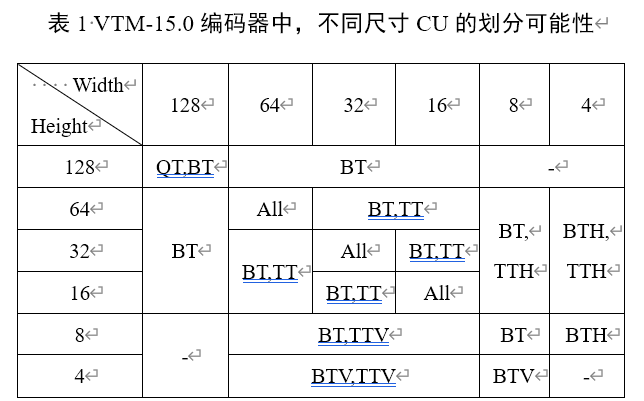
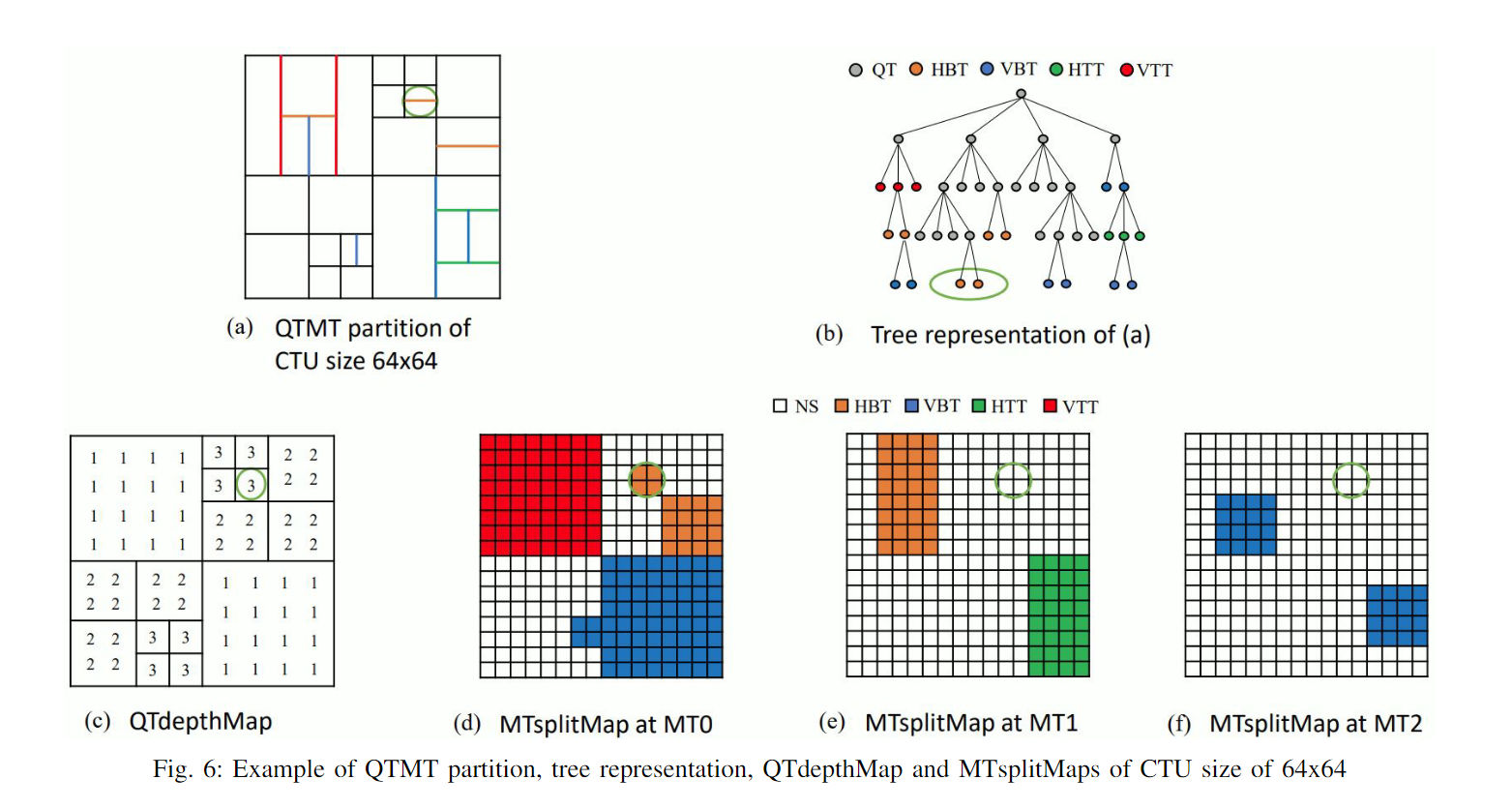
所以训练网络的目的就是为了得到QTdepthMap和3个 MTsplitMap。 MTsplitMap 的每个元素被分为五个类,对应于五种分割类型,从而产生三个尺寸为 32x32x5 的 MT 输出。
我们设计了一个基于 U-Net 的 CNN 模型,以运动向量的多尺度场作为输入,以有效预测 QT 深度图以及不同 MT 级别的分割决策
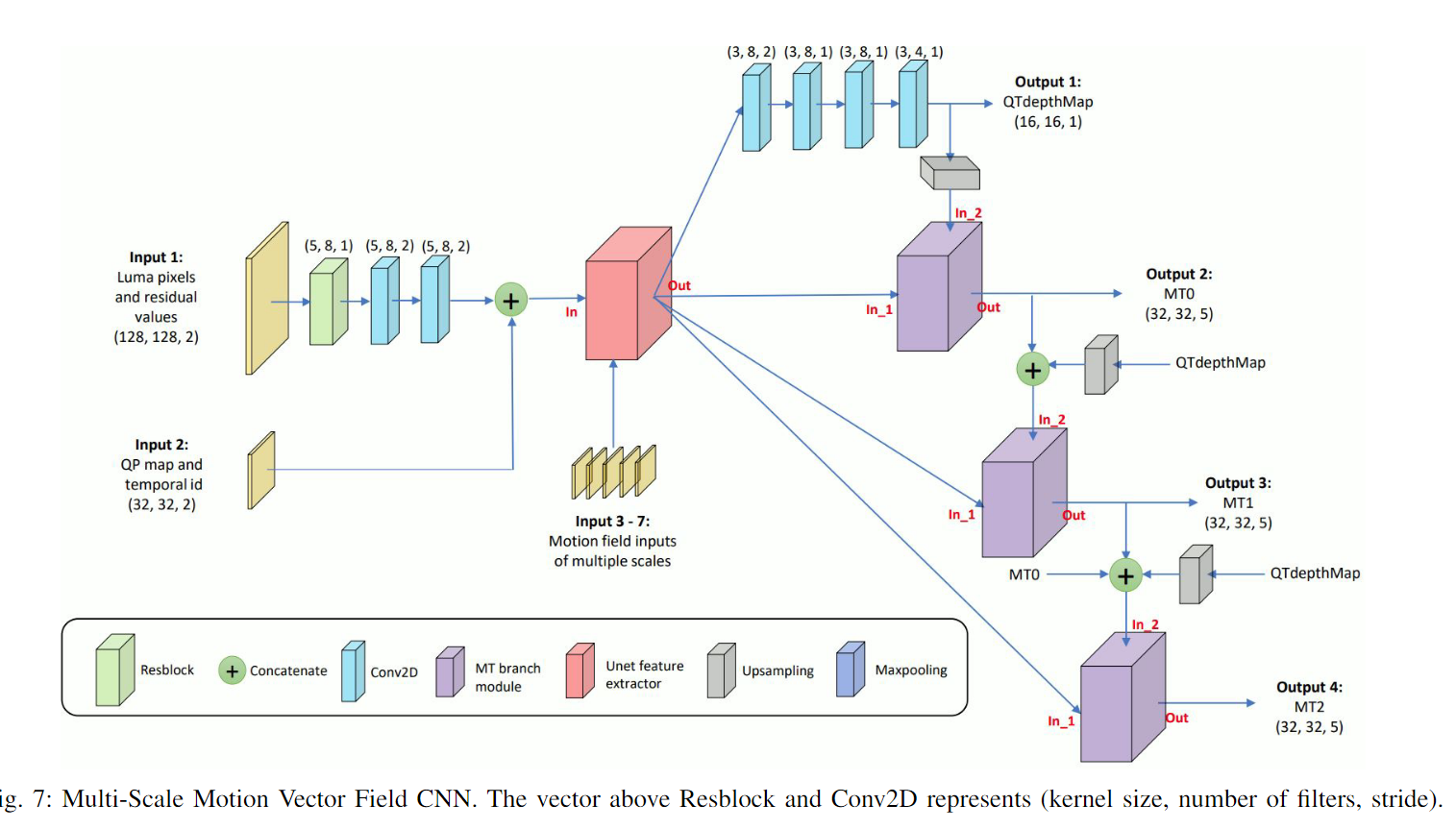
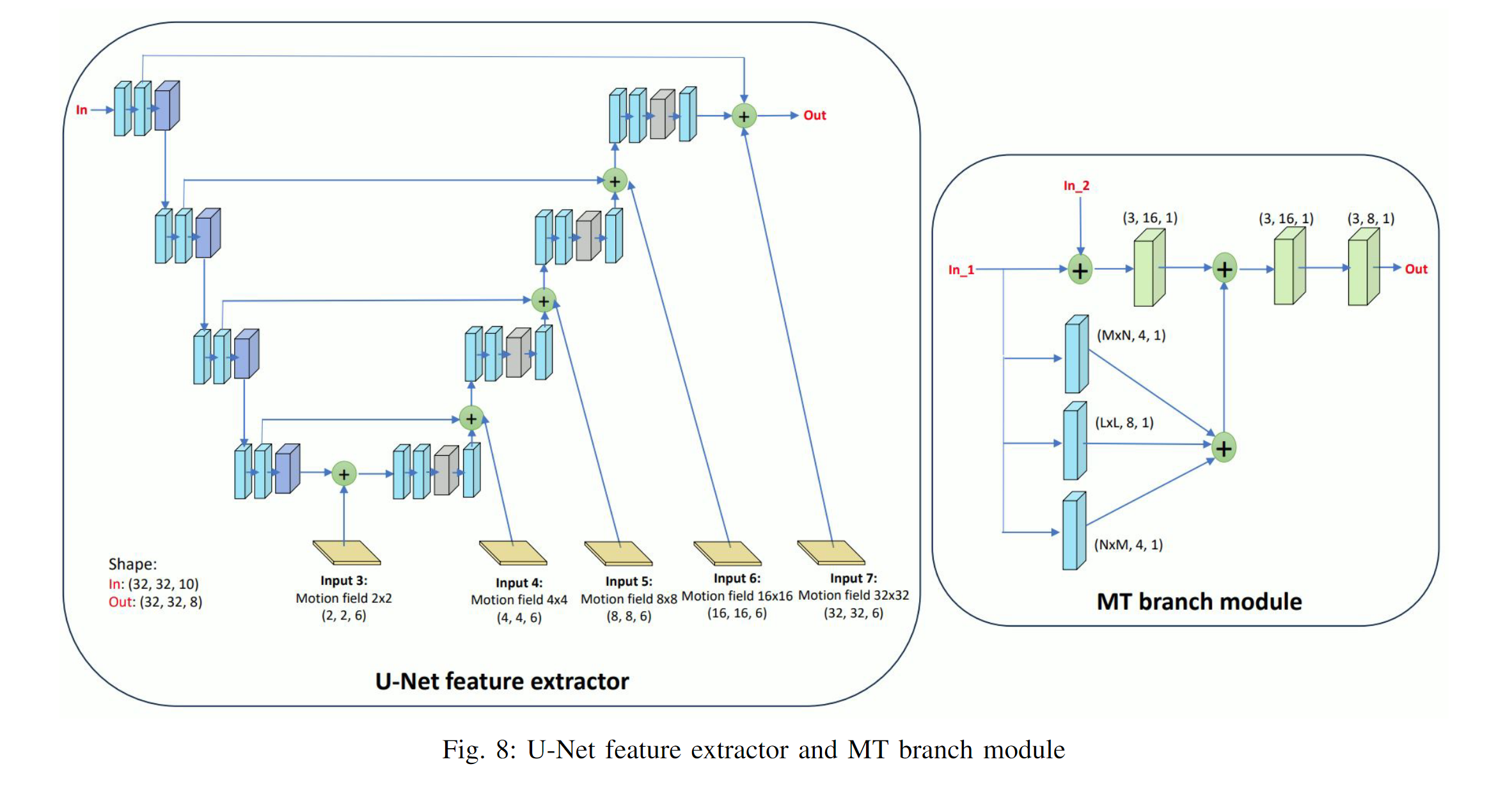
由于每个级别的分割取决于先前的分割,因此我们采用分层多分支预测机制。 QTdepthMap是在通过四个卷积层从U-Net提取的特征后进行预测的。对于 MT 分支,模块的两个输入是 U-Net 提取的特征和先前分区级别的输出。
MT分支模块包含内核大小MxN、LxL和NxM的分支。 (M,N,L)的值对于分支MT0设置为(5,7,9),对于分支MT1设置为(3,5,7),对于分支MT2设置为(1,3,3)。在更深的 MT 级别上,会在较小的 CU 上进行拆分。因此,应用较小的内核尺寸来提取更精细的特征。
Multi-Scale Motion Vector Field
In this paper, we have introduced a CNN model based on a novel input feature called MS-MVF.Our MS-MVF at five scales is presented as Input 3-7 in Figure 8. To compute MS- MVF, we divide the 128x128 CTU into multiple scale sub- blocks ranging from 4x4 pixels to 64x64 pixels, and perform motion estimation on these sub-blocks.Each motion vector of sub-block comprises a vertical and horizontal motion value, along with the associated Sum of Absolute Differences (SAD) cost value as the third element.By concatenating elements pointing to reference frame of L0 with those of L1, each sub- block corresponds to 6 elements in the motion vector field.For example, the motion vector field input for 8x8-pixel scale has dimensions of 16x16x6
在本文中,我们介绍了一种基于称为 MS-MVF 的新颖输入特征的 CNN 模型。我们在五个尺度上的 MS-MVF 显示为图 8 中的输入 3-7。为了计算 MS-MVF,我们将 128x128 CTU 划分为从 4x4 像素到 64x64 像素的多个尺度子块,并对这些子块执行运动估计- 块。子块的每个运动向量包括垂直和水平运动值,以及作为第三元素的相关绝对差和(SAD)成本值。通过将指向L0的参考帧的元素与L1的参考帧的元素连接起来,每个子块对应于运动矢量场中的6个元素。例如,8x8 像素尺度的运动矢量场输入的尺寸为 16x16x6
4到64,所以有5个输入
分区间预测的一个重大挑战是大运动搜索空间,它跨越 RAGOP32 配置中不同参考帧的多达 6 个 384x384 像素区域。**最先进的方法通常采用来自参考帧的运动场或像素作为机器学习模型的输入特征。**值得注意的是,在[19]和[21]中,使用的一个关键特征是运动场,它包括为每个 4x4 子块计算的运动向量,引用最近的帧。如[19]中所述,这个运动场与最佳分区密切相关。在另一种方法中,Tissier 等人在 [15] 中选择在最近的帧中利用两个参考 CTU
选择使用 MS-MVF 作为 CNN 输入而不是运动场和参考像素是基于以下原因。首先,MS-MVF 包含当前 CTU 的关键运动信息,这对于帧间预测和帧间分区都至关重要。与使用参考像素作为 CNN 输入相比,CNN 模型可以更有效地解释此信息。其次,MS-MVF 的多尺度性质与 U-Net 的多级结构非常吻合,并且可以有效地利用这种结构。本质上,MS-MVF 表示不同分辨率下的运动特征,允许与相同分辨率尺度下从 CTU 像素提取的特征相结合
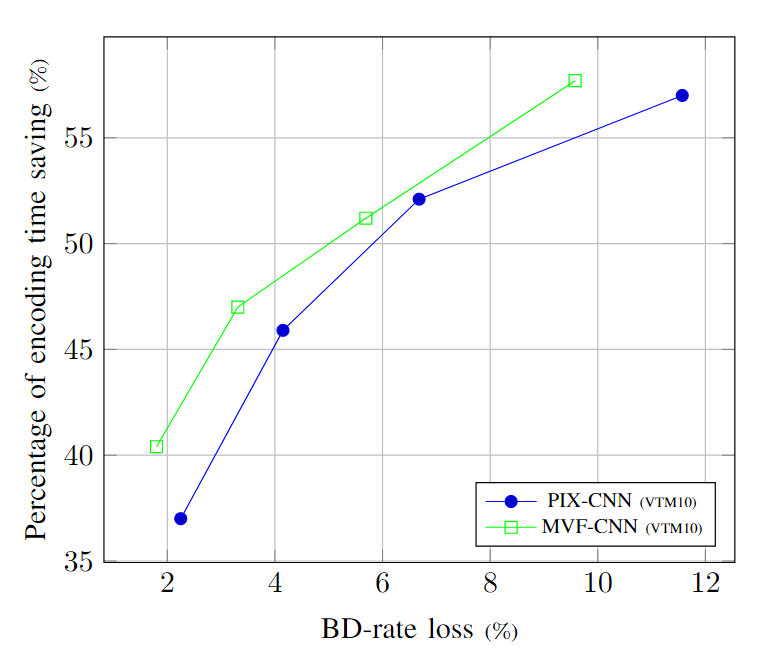
为了证明 MS-MVF 输入的有效性,我们进行了一项涉及两个 CNN 模型训练的实验。这些模型之间的唯一区别在于它们的输入:第一个模型 PIX-CNN 将两个参考 CTU 的像素作为输入,而第二个模型 MVF-CNN 使用我们提出的 MS-MVF 作为输入。两个模型共享与图 7 相同的架构。训练数据集包含从 [33] 的 200 个序列的 RAGOP32 编码中随机选择的 250k 个样本,分辨率为 540p。图 9 中的性能评估基于通用测试条件 (CTC) 的 C 类序列。结果一致表明,MVF-CNN 在所有四个数据点上均优于 PIX-CNN,这证明了使用 MS-MVF 输入相对于像素输入的优势
CNN 预测的后处理,权衡速度和编码损失

我们引入两个参数Thm和QTskip来调节加速损失权衡。具体来说,Thm是分裂概率的阈值。QTskip代表我们是否应该加速RDO QT 分割与否。增加 Thm 值并将 QTskip 设置为 true 将导致更大的加速,但代价是增加编码损失
第一步怎么算呢
在图10的流程图中,如果算法1执行后SkipMT为真,我们直接检查CandSplit。在这种情况下,编码器对CU进行RDO,并用QT分割CU,因为CandSplit仅包含NS和QT。如果 SkipMT 为 false,那么我们将验证 NS 是否是 CandList 中的唯一选择。如果是这种情况,我们会将概率最高的 MT 分割添加到列表中。接下来,如果由于CU形状或快捷方式而不允许QT拆分CU,我们直接进行CandSplit的检查。如果QT拆分可行,我们参考QTskip来决定是否将QT添加到CandList中。将 QTskip 设置为 true 表示我们将始终检查 QT(如果可能)。这是为了纠正预测 QTdepthpred 值小于实际地面实况值的潜在错误。然而,这是以牺牲一些加速度为代价的。最后,我们在 CU 上执行 RDO,并按 CandSplit 列表中的 split 类型对其进行分区。然后对下一个 CU 重复分区搜索,并重新应用上述算法。
这里在MT划分后又加了QT划分,那前面的那个MT后不进行QT是什么意思
A.预测精度评估
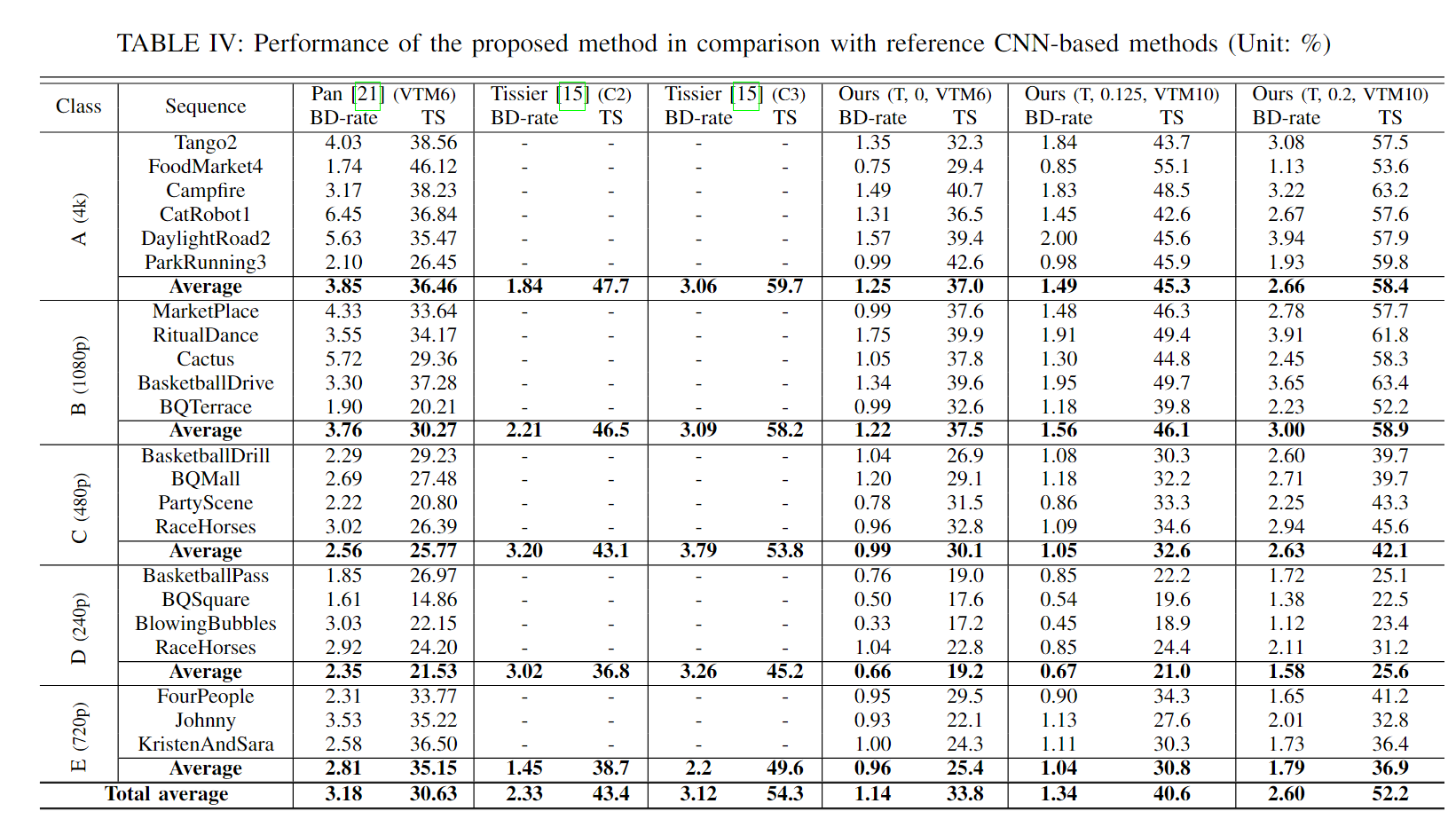
在CU层面,我们的算法可以分为两个决策:SkipMT的决策和CandSplit列表的决策。为了评估基于模型输出的决策精度,我们执行了编码,收集了真实数据划分和 CNN 输出。分析是在所有 CTC 序列的前 64 帧上进行的,不包括具有 QP 22、27、32、37 的 D 类。表 II 和图 12 中呈现的这些决策的准确性是通过对四个 QP 和各种测试序列进行平均来计算的。
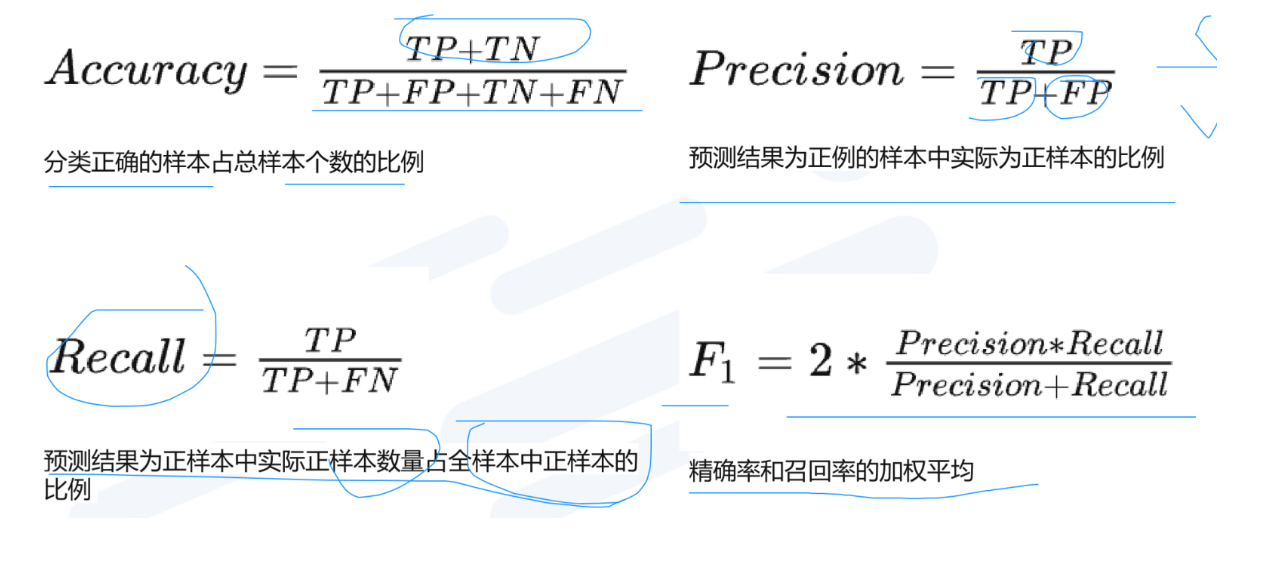
正确肯定(True Positive,TP)︰预测为真,实际为真
正确否定(True Negative,TN)︰预测为假,实际为假
错误肯定(False Positive,FP)︰预测为真,实际为假
错误否定(False Negative,FN)︰预测为假,实际为真
- 正确率 —— 提取出的正确信息条数 / 提取出的信息条数
- 召回率 —— 提取出的正确信息条数 / 样本中的信息条数
如果当前CU需要进一步分割QT并且SkipMT等于False,则SkipMT的这个决策被分类为假阴性(FN)
TP:skipMT等于true,CU需要进一步分割QT
TN:skipMT等于false,CU不需要进一步分割QT
FP:skipMT等于false,CU需要进一步分割QT



一般来说,我们的模型在 QT 深度范围从 0 到 2 时表现出很强的性能,如表 II 所示。随着 QT 深度的增加,精度和 F1 分数都会降低。在 QT 深度 3 处,精度和 F1 分数分别下降至 25% 和 40%,这表明该级别的 SkipMT 决策不太可靠。这些观察结果可以用两个原因来解释
首先,决策规模随着 QT 深度的增加而减小。更明确地说,QT 深度 0 处的 SkipMT 决策是通过计算 QTdepthMap 中 256 个值的平均值在 CTU 尺度上做出的。然而,QT 深度 3 的决策仅依赖于 16x16 CU 内 QTdepthMap 的 4 个值。因此,较小尺度的决策对错误预测的 QT深度映射值的弹性较差,导致较高 QT 深度的总体精度较低
其次,较高 QT 深度的决策明显比较低 QT 深度的决策更不平衡。 QT 深度为 3 时,真实情况的正例仅占 0.02%,而 QT 深度为 0 时,正例的比例为 49.65%。总之,模型的训练方式使其在 QT 较大时倾向于做出负面的 SkipMT 决策深处。这解释了随着 QT 深度增加而精度下降的原因。
值得注意的是,加速水平可能会根据不同的序列类别(例如分辨率)而变化,这与其他基于 CNN 的方法是一致的。正如[6]中所讨论的,超出图片边界的CTU被称为部分CTU。与常规 CTU 相比,这些部分 CTU 需要不同的分区搜索方案。因此,部分 CTU 的编码不会加速,因为基于 CNN 的方法不适用于它们。一般来说,对于较低的分辨率,部分CTU占据的帧区域的比例较大,导致在较小的分辨率上使用快速分区方法时加速较小。这可以部分解释在 D 类中观察到的有限加速度,该加速度被排除在整体性能计算之外。更具体地说,我们的方法往往在较高分辨率(例如 A 类和 B 类)上表现更好,而在较低分辨率(例如 C 类、D 类和 E 类)上比最先进的方法获得的加速更少。研究和改进这方面可能是未来工作的重点。
VIII. CONCLUSION
In this study, we propose a machine learning-based method to accelerate VVC inter partitioning.Our method leverages a novel representation of the QTMT partition structure based on partition path, consisting of QTdepthMap and MTsplitMaps.Our work is structured as follows.Firstly, we have built a large scale inter partition dataset.Secondly, a novel Unet- based model that takes MS-MVF as input is trained to predict the partition paths of CTU.Thirdly, we develop a scalable acceleration algorithm based on thresholds to utilize the output of the model.Finally, we speed up the VTM10 encoder under RAGOP32 configuration by 16.5%∼60.2% with BD-rate loss of 0.44%∼4.59%.This performance surpasses state-of-the- art methods in terms of coding efficiency and complexity trade-off.Notably, our method is among the most lightweight methods in the field, making it possible to adapt our approach to faster codecs.
在本研究中,我们提出了一种基于机器学习的方法来加速 VVC 间分区。我们的方法利用基于分区路径的 QTMT 分区结构的新颖表示,由 QTdepthMap 和 MTsplitMap 组成。我们的工作结构如下。首先,我们建立了一个大规模的分区间数据集。其次,训练一种以 MS-MVF 作为输入的基于 Unet 的新型模型来预测 CTU 的分区路径。第三,我们开发了一种基于阈值的可扩展加速算法来利用模型的输出。最后,我们将 RAGOP32 配置下的 VTM10 编码器加速了 16.5%∼60.2%,BD 速率损失为 0.44%∼4.59%。在编码效率和复杂性权衡方面,这种性能超越了最先进的方法。值得注意的是,我们的方法是该领域最轻量级的方法之一,使得我们的方法能够适应更快的编解码器。
For future work, we intend to investigate how video resolution influences partitioning acceleration, aiming to boost the speed-up of our method on lower resolutions.Furthermore, there is still acceleration potential lying in the selection of inter coding modes at the CU level, as discussed in [44].An extension of our approach could be the incorporation of fast inter coding mode selection algorithm into our method to further accelerate the inter coding process.
对于未来的工作,我们打算研究视频分辨率如何影响分区加速,旨在提高我们的方法在较低分辨率下的速度。此外,如[44]中所讨论的,CU级别帧间编码模式的选择仍然存在加速潜力。我们的方法的扩展可以是将快速帧间编码模式选择算法合并到我们的方法中,以进一步加速帧间编码过程。
相关文章:
帧间快速算法论文阅读
Low complexity inter coding scheme for Versatile Video Coding (VVC) 通过分析相邻CU的编码区域,预测当前CU的编码区域,以终止不必要的分割模式。 𝐶𝑈1、𝐶𝑈2、𝐶𝑈3、&#x…...

mooc单元测验第一单元
TCP和OSI参考模型对比 OSI参考模型与TCP/IP参考模型(计算机网络)_osi模型 tcpip模型_李桥桉的博客-CSDN博客 会话层和物理层...
AOC显示器出问题了?别担心,简单重置一下就OK了
你的AOC显示器有问题吗?它是被卡在特定的屏幕上还是根本不显示任何图像?如果你的显示器出现任何问题,只需简单重置即可解决问题。 重置AOC显示器可以帮助解决一系列问题,例如颜色或显示设置问题、输入源检测问题以及其他与软件相…...
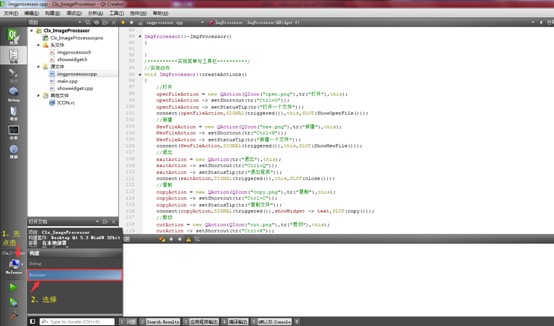
ok-解决qt5发布版本,直接运行exe缺少各种库的问题
已实验第二种方法可用。 工具:电脑必备、QT下的windeployqt Qt 官方开发环境使用的动态链接库方式,在发布生成的exe程序时,需要复制一大堆 dll,如果自己去复制dll,很可能丢三落四,导致exe在别的电脑里无法…...
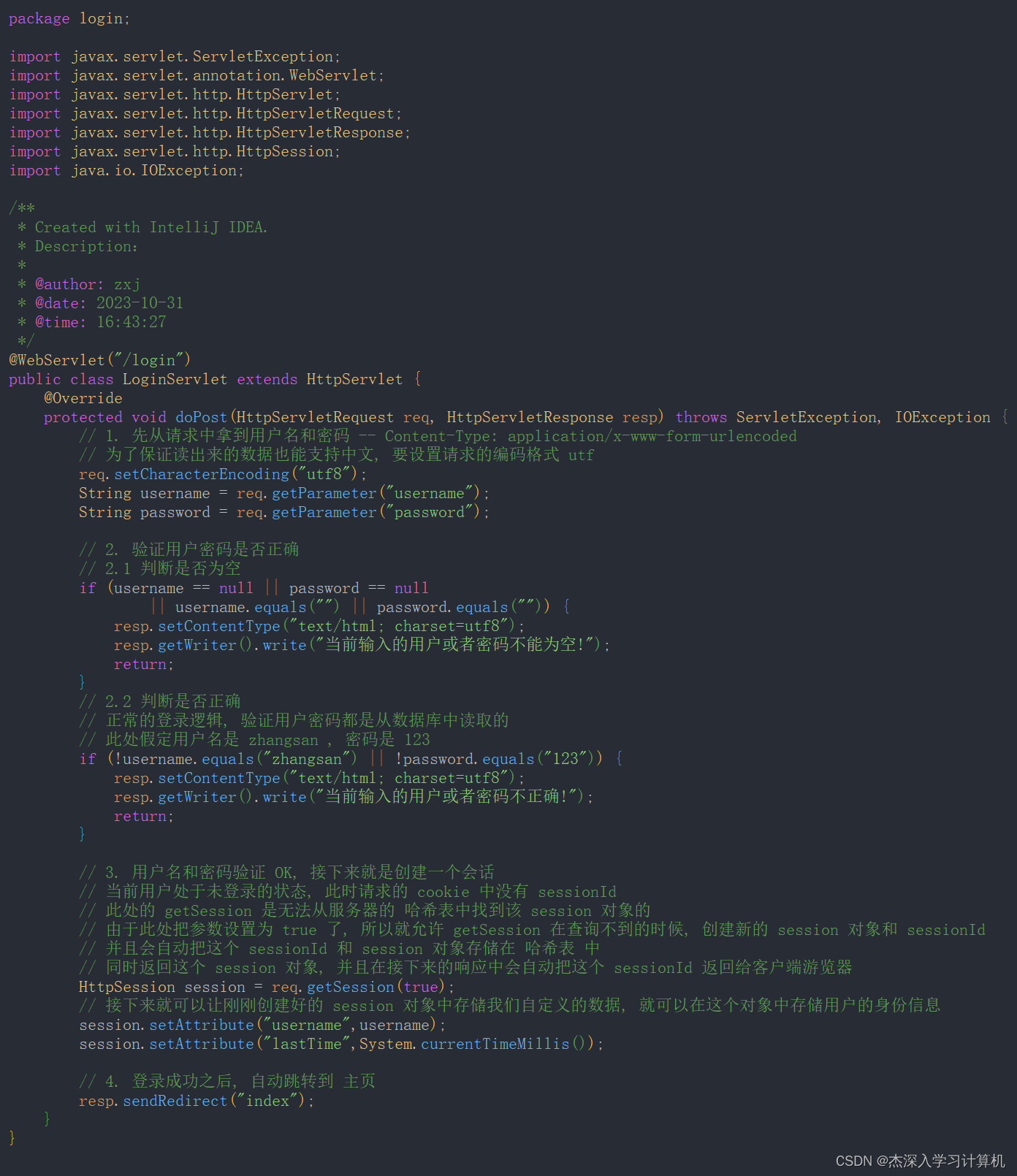
【JavaEE】cookie和session
cookie和session cookie什么是 cookieServlet 中使用 cookie相应的API Servlet 中使用 session 相应的 API代码示例: 实现用户登陆Cookie 和 Session 的区别总结 cookie 什么是 cookie cookie的数据从哪里来? 服务器返回给浏览器的 cookie的数据长什么样? cookie 中是键值对…...

关于CSS的几种字体悬浮的设置方法
关于CSS的几种字体悬浮的设置方法 1. 鼠标放上动态的2. 静态的(位置看上悬浮)2.1 参考QQ邮箱2.2 参考知乎 1. 鼠标放上动态的 效果如下: 代码如下: <!DOCTYPE html> <html lang"en"> <head><met…...
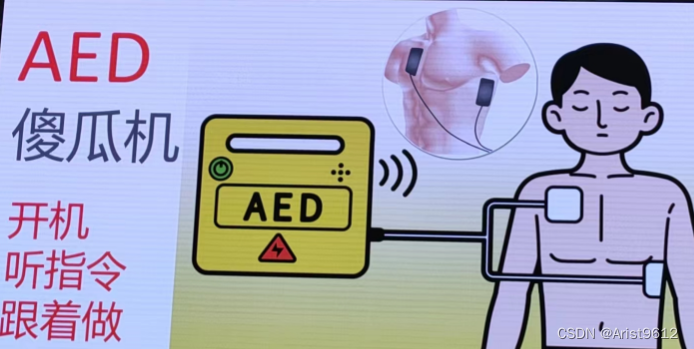
心脏骤停急救赋能
文章目录 0. 背景知识1. 遇到有人突然倒地怎么办1.1 应急反应系统1.2 高质量CPR1.2.1 胸外按压1.2.2 人工呼吸 1.3 AED除颤1.3.1 AED用法 1.4 高级心肺复苏1.5 入院治疗1.6 康复 0. 背景知识 中国每30s就有人倒地,他们可能是工作压力大的年轻人(工程师群…...

Android 13.0 根据app包名授予app监听系统通知权限
1.概述 在13.0的系统rom产品定制化开发中,在一些产品rom定制化开发中,系统内置的第三方app需要开启系统通知权限,然后可以在app中,监听系统所有通知,来做个通知中心的功能,所以需要授权获取系统通知的权限,然后来顺利的监听系统通知。来做系统通知的功能,接下来来实现…...
校园招聘系统
校园管理系统 公共模块学生端游客端企业联系人端校内管理员端超级管理员端企业端 公共模块 登录 用户可以通过验证码、账号密码进行登录。 个人中心 学生端 学生主要为查看招聘信息以及投递等。 首页 简历详情投递 双选会公司详情 公告通知 学生端主要为这些等等…...

SpringBoot-SpringCache缓存
文章目录 Spring Cache 介绍常用注解 Spring Cache 介绍 Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。 Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现,…...
服务器带宽忽然暴增,不停的触发告警
问题: 线上环境,服务器的外网下行带宽达到某个阈值,触发告警,查了下服务器的带宽监控信息,是从某个时间开始突然串上去的,然后监控图形非常有规律,都是每秒达到顶峰后,又立马下去了…...

Linux学习笔记之二(环境变量)
Linux learning note 1、环境变量1.1、修好PATH环境变量 1、环境变量 环境变量(environment variables)即系统运行的一些环境参数。主要的环境变量有以下这些: PATH:决定了系统查找可执行文件的目录范围。HOME:指定当前用户的主目录路径。U…...
)
设计模式——备忘录模式(Memento Pattern)
文章目录 一、备忘录模式定义二、例子2.1 菜鸟例子2.1.1 定义副本类2.1.2 定义对象2.1.3 定义CareTaker 类2.1.3 使用 2.2 JDK —— Date 三、其他设计模式 一、备忘录模式定义 类型: 行为型模式 目的: 保存一个对象的某个状态,以便在适当的…...

C++ 代码实例:多项式除法简单计算工具
文章目录 前言代码仓库代码说明核心片段 结果总结参考资料作者的话 前言 C 代码实例:多项式除法简单计算工具。 代码仓库 yezhening/Programming-examples: 编程实例 (github.com)Programming-examples: 编程实例 (gitee.com) 代码 说明 由于代码篇幅较多&#…...

MySql表自修改报错:You can‘t specify target table ‘student‘ for update in FROM clause
文章目录 一、发现问题二、场景1:在where条件中查询了修改表的数据三、场景2:在set语句中查询了修改表的数据 一、发现问题 在一次准备处理历史数据sql时,出现这么一个问题:You cant specify target table 表名 for update in FR…...
LeetCode 热题100——链表专题
一、俩数相加 2.俩数相加(题目链接) 思路:这题题目首先要看懂,以示例1为例 即 342465807,而产生的新链表为7->0->8. 可以看成简单的从左向右,低位到高位的加法运算,4610,逢…...

植物花粉深度学习图片数据集大合集
最近收集了一波有关于植物花粉的图片数据集,可以用于相关深度学习模型的搭建,废话不多说,上数据集!!! 1、23种花粉类型805张花粉图像数据集 关于此数据:花粉种类和类型的分类是法医抱粉学、考…...
面试算法48:序列化和反序列化二叉树
题目 请设计一个算法将二叉树序列化成一个字符串,并能将该字符串反序列化出原来二叉树的算法。 分析 先考虑如何将二叉树序列化为一个字符串。需要逐个遍历二叉树的每个节点,每遍历到一个节点就将节点的值序列化到字符串中。以前序遍历的顺序遍历二叉…...
【Python基础】Python编程入门自学笔记,基础大全,一篇到底!
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
windows自动登陆
新建文本粘贴下面代码,另存为注册表文件 Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Driver Signing] "Policy"hex:00[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon]"DefaultUserN…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...
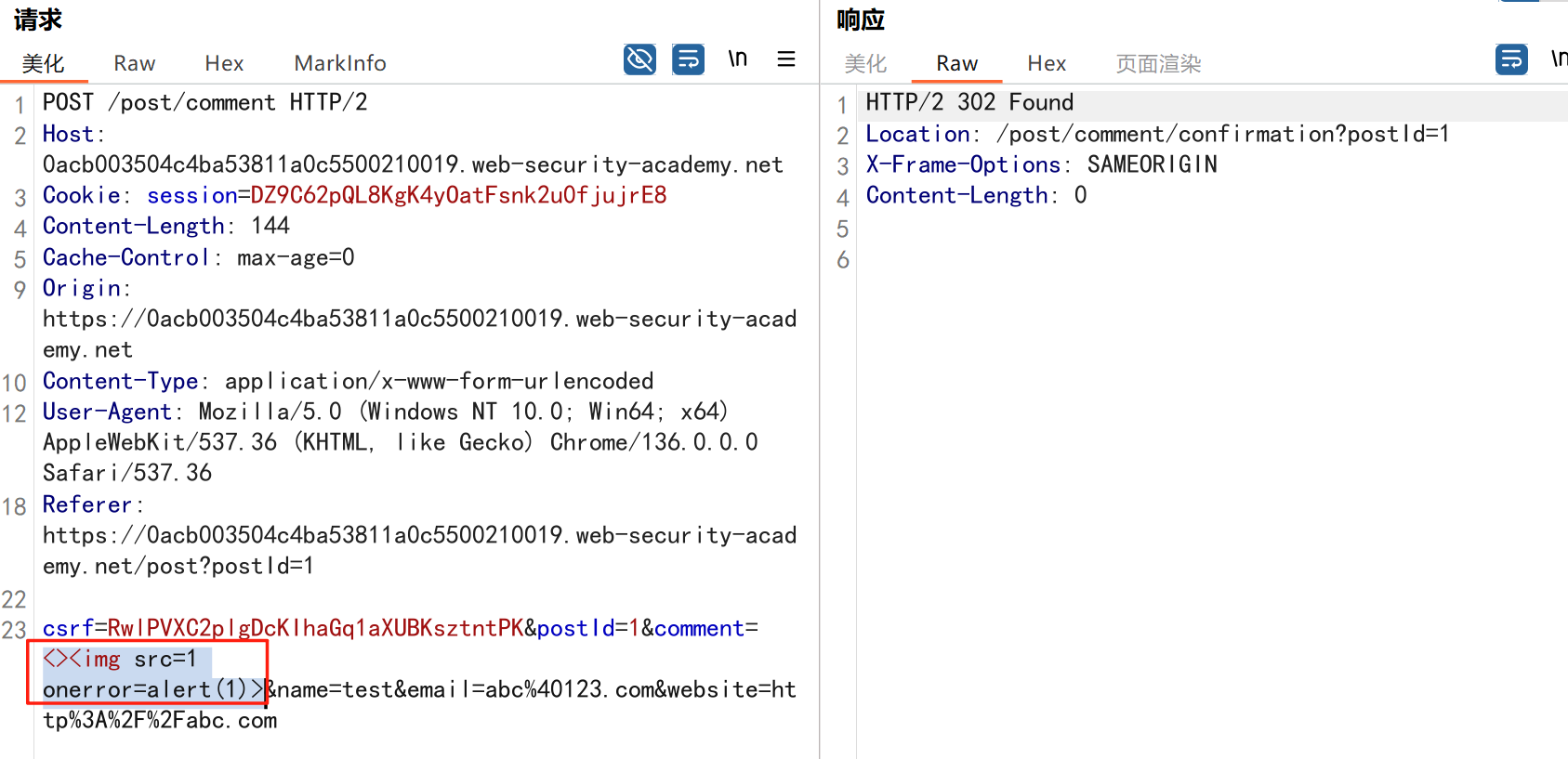
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...