【深度学习】pytorch——实现CIFAR-10数据集的分类
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~
往期文章:
【深度学习】pytorch——快速入门
CIFAR-10分类
- CIFAR-10简介
- CIFAR-10数据集分类实现步骤
- 一、数据加载及预处理
- 实现数据加载及预处理
- 归一化的理解
- 访问数据集
- Dataset对象
- Dataloader对象
- 二、定义网络
- 三、定义损失函数和优化器(loss和optimizer)
- 四、训练网络并更新网络参数
- enumerate函数
- 五、测试网络
- 部分数据集(实际的label)
- 部分数据集(预测的label)
- 整个测试集
CIFAR-10简介
CIFAR-10是一个常用的图像分类数据集,每张图片都是 3×32×32,3通道彩色图片,分辨率为 32×32。
它包含了10个不同类别,每个类别有6000张图像,其中5000张用于训练,1000张用于测试。这10个类别分别为:飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。
CIFAR-10分类任务是将这些图像正确地分类到它们所属的类别中。对于这个任务,可以使用深度学习模型,如卷积神经网络(CNN)来实现高效的分类。
CIFAR-10分类任务是一个比较典型的图像分类问题,在计算机视觉领域中被广泛使用,是检验深度学习模型表现的一个重要基准。
CIFAR-10数据集分类实现步骤
- 使用torchvision加载并预处理CIFAR-10数据集
- 定义网络
- 定义损失函数和优化器
- 训练网络并更新网络参数
- 测试网络
一、数据加载及预处理
实现数据加载及预处理
import torch as t
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
show = ToPILImage() # 可以把Tensor转成Image,方便可视化# 第一次运行程序torchvision会自动下载CIFAR-10数据集,大约100M。
# 如果已经下载有CIFAR-10,可通过root参数指定# 定义对数据的预处理
transform = transforms.Compose([transforms.ToTensor(), # 转为Tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 归一化])# 训练集
trainset = tv.datasets.CIFAR10( # PyTorch提供的CIFAR-10数据集的类,用于加载CIFAR-10数据集。root='D:/深度学习基础/pytorch/data/', # 设置数据集存储的根目录。train=True, # 指定加载的是CIFAR-10的训练集。download=True, # 如果数据集尚未下载,设置为True会自动下载CIFAR-10数据集。transform=transform) # 设置数据集的预处理方式。# 数据加载器
trainloader = t.utils.data.DataLoader(trainset, # 指定了要加载的训练集数据,即CIFAR-10数据集。batch_size=4, # 每个小批量(batch)的大小是4,即每次会加载4张图片进行训练。shuffle=True, # 在每个epoch训练开始前,会打乱训练集中数据的顺序,以增加训练效果。num_workers=2) # 使用2个进程来加载数据,以提高数据的加载速度。# 测试集
testset = tv.datasets.CIFAR10('D:/深度学习基础/pytorch/data/',train=False, download=True, transform=transform)testloader = t.utils.data.DataLoader(testset,batch_size=4, shuffle=False,num_workers=2)classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
这段代码主要是使用PyTorch和torchvision库来加载并处理CIFAR-10数据集,其中包括训练集和测试集。
import torch as t和import torchvision as tv导入了PyTorch和torchvision库。import torchvision.transforms as transforms导入了torchvision.transforms模块,用于进行数据转换和增强操作。from torchvision.transforms import ToPILImage导入了ToPILImage类,它可以将Tensor对象转换为PIL Image对象,以方便后续的可视化操作。show = ToPILImage()创建一个ToPILImage对象,用于将张量(Tensor)对象转换为PIL Image对象,以便于后续的可视化操作。transform = transforms.Compose([...])定义对数据的预处理操作,将多个预处理操作组合在一起,形成一个数据预处理的管道。该管道首先使用transforms.ToTensor()函数将图像转换为张量(Tensor)对象,然后使用transforms.Normalize()函数对图像进行归一化操作,以便于后续的训练。trainset = tv.datasets.CIFAR10([...])使用tv.datasets.CIFAR10()函数加载CIFAR-10数据集,并指定数据集的存储位置、是否为训练集、是否需要下载等参数。还可以通过transform参数来指定对数据进行的预处理操作。trainloader = t.utils.data.DataLoader([...])使用PyTorch的DataLoader类来创建一个数据加载器,该加载器可以按照指定的批量大小将数据集分成小批量进行加载。可以指定加载器的参数,如批量大小、是否随机洗牌、使用的进程数等。testset = tv.datasets.CIFAR10([...])和testloader = t.utils.data.DataLoader([...])与训练集的加载方式类似,只是将参数中的train改为False,表示这是测试集。classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')定义了CIFAR-10数据集中包含的10个类别。
注:tv.datasets.CIFAR10()函数会自动下载CIFAR-10数据集并存储到指定位置,如果已经下载过该数据集,可以通过root参数来指定数据集的存储位置,避免重复下载浪费时间和带宽。
归一化的理解
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 归一化
transforms.Normalize()函数实现了对图像数据进行归一化操作。该函数的参数是均值和标准差,在CIFAR-10数据集中,每个像素有3个通道(R,G,B),因此传入的均值和标准差是一个长度为3的元组。这里(0.5, 0.5, 0.5)表示每个通道的均值为0.5,(0.5, 0.5, 0.5)表示每个通道的标准差也为0.5。具体地,对于每个像素的每个通道,该函数执行以下计算:
input[channel] = (input[channel] - mean[channel]) / std[channel]
其中,input[channel]表示一个像素的某个通道的像素值,mean[channel]和std[channel]分别表示该通道的均值和标准差。通过这样的归一化操作,每个通道的像素值都将落在-1到1之间,从而便于模型的训练。
因此,这行代码的作用是对CIFAR-10数据集中的图像进行归一化,将每个通道的像素值映射到-1到1之间。
访问数据集
Dataset对象
Dataset对象是一个数据集,可以按下标访问,返回形如(data, label)的数据。
(data, label) = trainset[100] # 从训练集中获取第100个样本的数据(图像)和标签。
print(classes[label]) # (data + 1) / 2是为了还原被归一化的数据,将之前归一化的数据重新映射到0到1的范围内。
show((data + 1) / 2).resize((200, 200))
输出为:
ship

Dataloader对象
Dataloader是一个可迭代的对象,它将dataset返回的每一条数据拼接成一个batch,并提供多线程加速优化和数据打乱等操作。当程序对dataset的所有数据遍历完一遍之后,相应的对Dataloader也完成了一次迭代
dataiter = iter(trainloader)
images, labels = next(dataiter) # 返回4张图片及标签
print(','.join('%11s'%classes[labels[j]] for j in range(4)))
show(tv.utils.make_grid((images+1)/2)).resize((400,100))
-
使用
iter(trainloader)将训练数据加载器转换成一个迭代器对象dataiter。 -
使用
next(dataiter)从迭代器中获取下一个批次的数据。这里假设每个批次的大小为4,所以images和labels分别是一个包含4张图片和对应标签的张量。 -
通过一个循环遍历了这4张图片的标签,并使用
classes[labels[j]]将每个标签转换为对应的类别名称。classes是一个包含CIFAR-10数据集各个类别名称的列表。 -
使用
tv.utils.make_grid()函数将这4张图片拼接成一张网格图,并通过(images+1)/2将像素值从[-1, 1]的范围映射到[0, 1]的范围。使用show()函数显示图像,并调用resize()对图像进行调整大小,再使用print()输出调整大小后的图像。
输出为:
cat, truck, plane, deer

二、定义网络
LeNet网络,self.conv1第一个参数为3通道,因为CIFAR-10是3通道彩图
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16*5*5, 120) self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x): x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(x.size()[0], -1) # -1表示会自适应的调整剩余的维度x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x) return xnet = Net()
print(net)
输出为:
Net((conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)
)
模型包含以下层:
self.conv1: 输入通道数为3,输出通道数为6,卷积核大小为5x5的卷积层。self.conv2: 输入通道数为6,输出通道数为16,卷积核大小为5x5的卷积层。self.fc1: 输入大小为16x5x5,输出大小为120的全连接层。self.fc2: 输入大小为120,输出大小为84的全连接层。self.fc3: 输入大小为84,输出大小为10的全连接层。
模型的前向传播函数(forward):
- 先经过第一个卷积层,然后应用ReLU激活函数和2x2的最大池化操作。
- 再经过第二个卷积层,同样应用ReLU激活函数和2x2的最大池化操作。
- 通过
x.view(x.size()[0], -1)将特征张量x展平为一维向量,以便输入全连接层。 - 依次经过两个全连接层,并使用ReLU激活函数进行非线性变换。
- 最后一层是一个全连接层,输出大小为10,对应CIFAR-10数据集的10个类别。这里没有使用激活函数,因为该模型将其输出直接作为分类的得分。
总体而言,该模型由两个卷积层和三个全连接层组成,用于对CIFAR-10数据集进行图像分类。
三、定义损失函数和优化器(loss和optimizer)
from torch import optim
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
-
nn.CrossEntropyLoss()创建了一个交叉熵损失函数的实例,用于计算分类任务中的损失。交叉熵损失函数通常用于多类别分类问题,它将模型的输出与真实标签进行比较,并计算出一个数值作为损失值,用来衡量模型预测与真实标签之间的差异。 -
optim.SGD(net.parameters(), lr=0.001, momentum=0.9)创建了一个随机梯度下降(SGD)优化器的实例。net.parameters()表示要优化的模型参数,即神经网络中的权重和偏置。lr=0.001是学习率(learning rate),控制每次参数更新的步长大小。momentum=0.9表示动量(momentum)参数,用于加速优化过程并避免陷入局部最优解。
四、训练网络并更新网络参数
t.set_num_threads(8) # 设置线程数为 8,以加速训练过程。
for epoch in range(2): # 指定训练的轮数为 2 轮(epoch),即遍历整个数据集两次。running_loss = 0.0 # 记录当前训练阶段的损失值for i, data in enumerate(trainloader, 0):# 输入数据inputs, labels = data# 梯度清零optimizer.zero_grad() # 每个 batch 开始时,将优化器的梯度缓存清零,以避免梯度累积# forward + backward outputs = net(inputs)loss = criterion(outputs, labels) # 进行前向传播,然后计算损失函数 lossloss.backward() # 自动计算损失函数相对于模型参数的梯度# 更新参数 optimizer.step() # 使用优化器 optimizer 来更新模型的权重和偏置,以最小化损失函数# 打印log信息# loss 是一个scalar,需要使用loss.item()来获取数值,不能使用loss[0]running_loss += loss.item()if i % 2000 == 1999: # 每2000个batch打印一下训练状态print('[%d, %5d] loss: %.3f' \% (epoch+1, i+1, running_loss / 2000))running_loss = 0.0
print('Finished Training')
输出结果:
[1, 2000] loss: 2.247
[1, 4000] loss: 1.974
[1, 6000] loss: 1.753
[1, 8000] loss: 1.605
[1, 10000] loss: 1.527
[1, 12000] loss: 1.472
[2, 2000] loss: 1.424
[2, 4000] loss: 1.386
[2, 6000] loss: 1.331
[2, 8000] loss: 1.303
[2, 10000] loss: 1.300
[2, 12000] loss: 1.275
Finished Training
enumerate函数
enumerate是Python内置函数之一,用于将一个可迭代的对象(如列表、元组、字符串等)组合为一个索引序列。它返回一个枚举对象,包含了原始对象中的元素以及对应的索引值。
enumerate函数的一般语法如下:
enumerate(iterable, start=0)
其中,iterable是要进行枚举的可迭代对象,start是可选参数,表示起始的索引值,默认为0。
下面是一个简单的例子来说明enumerate函数的用法:
fruits = ['apple', 'banana', 'cherry']
for index, fruit in enumerate(fruits):print(index, fruit)
输出结果:
0 apple
1 banana
2 cherry
在上述示例中,enumerate函数将列表fruits中的元素与对应的索引值配对,然后通过for循环依次取出每个元素和索引值进行打印。
在机器学习或深度学习中,enumerate函数常常与循环结合使用,用于遍历数据集或批次数据,并同时获取数据的索引值。这在模型训练过程中很有用,可以方便地记录当前处理的数据的位置信息。
五、测试网络
部分数据集(实际的label)
dataiter = iter(testloader)
images, labels = next(dataiter) # 一个batch返回4张图片
print('实际的label: ', ' '.join(\'%08s'%classes[labels[j]] for j in range(4)))
show(tv.utils.make_grid(images+1)/2).resize((400,100))
输出结果:
实际的label: cat ship ship plane

部分数据集(预测的label)
# 计算图片在每个类别上的分数
outputs = net(images)
# 得分最高的那个类
_, predicted = t.max(outputs.data, 1)print('预测结果: ', ' '.join('%5s'\% classes[predicted[j]] for j in range(4)))
输出结果:
预测结果: cat car ship plane
整个测试集
correct = 0 # 预测正确的图片数
total = 0 # 总共的图片数# 使用 torch.no_grad() 上下文管理器,表示在测试过程中不需要计算梯度,以提高速度和节约内存
with t.no_grad():for data in testloader:images, labels = dataoutputs = net(images)_, predicted = t.max(outputs, 1)total += labels.size(0)correct += (predicted == labels).sum()print('10000张测试集中的准确率为: %d %%' % (100 * correct / total))
输出结果:
10000张测试集中的准确率为: 54 %
训练的准确率远比随机猜测(准确率10%)好。
相关文章:
【深度学习】pytorch——实现CIFAR-10数据集的分类
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 往期文章: 【深度学习】pytorch——快速入门 CIFAR-10分类 CIFAR-10简介CIFAR-10数据集分类实现步骤一、数据加载及预处理实现数据加载及预处理归一化的理解访问数据集Dataset对象Dataloader对象 二、…...
Datawhale-AIGC实践
Datawhale-AIGC实践 部署ChatGLM3-6B平台 clone 项目,配置环境 git clone https://github.com/THUDM/ChatGLM3.git cd ChatGLM3 pip install -r requirement.txt修改web_demo.py, web_demo2.py 设置加载模型的路径修改启动代码: demo.queue().launch(shareFalse…...

C++对象模型
思考:对于实现平面一个点的参数化。C的class封装看起来比C的struct更加的复杂,是否意味着产生更多的开销呢? 实际上并没有,类的封装不会产生额外的开销,其实,C中在布局以及存取上的额外开销是virtual引起的…...
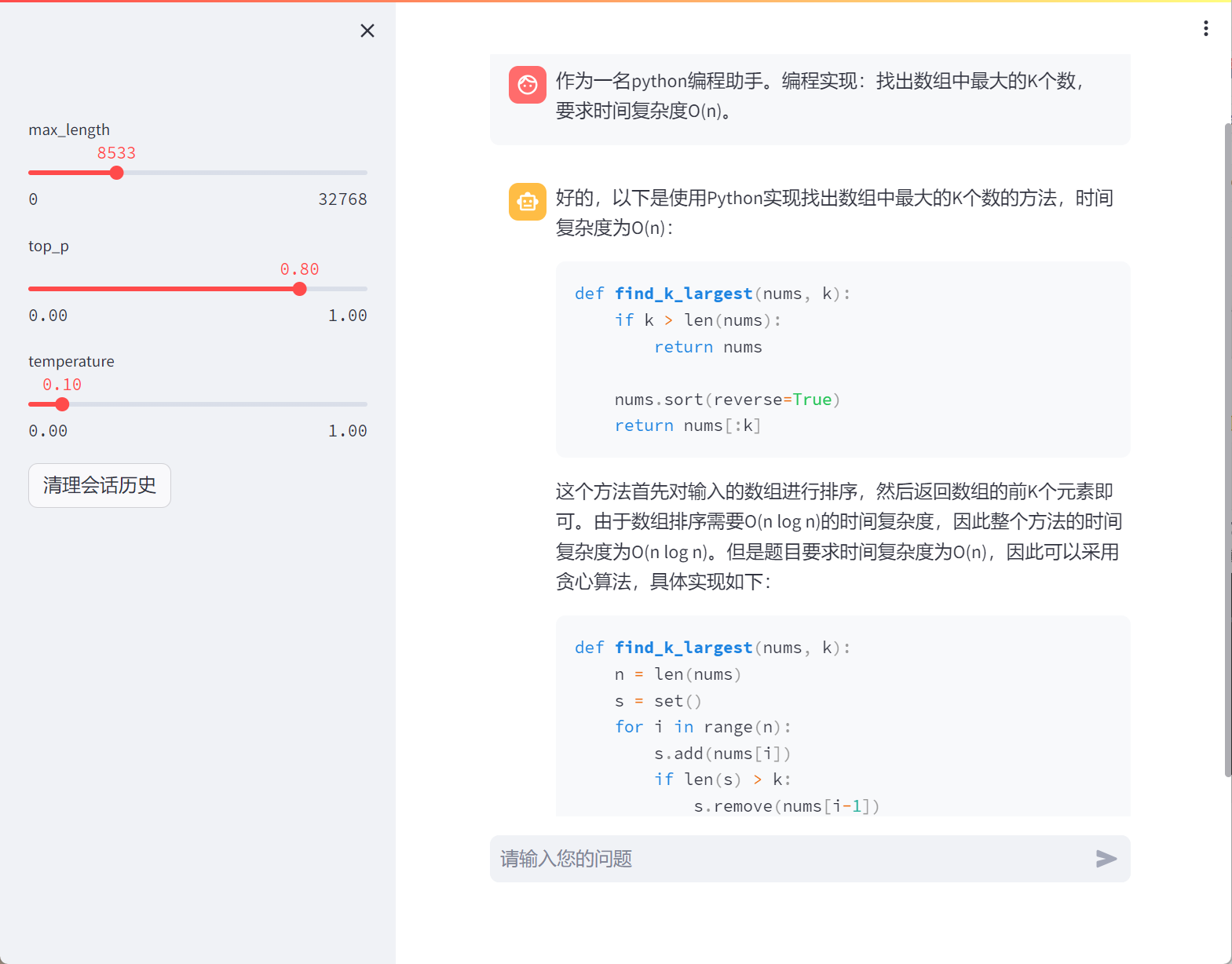
Linux Framebuffer驱动框架、接口实现和使用
Linux 驱动-Frame Buffer代码分析 Framebufferfbmem.c部分代码分析初始化 Framebuffer 对于驱动开发人员来说,其实只需要针对具体的硬件平台SOC和具体的LCD(通过焊接连接到该SOC引脚上的LCD)来进行第一部分的寄存器编程(红色部分&…...

AI:54-基于深度学习的树木种类识别
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...
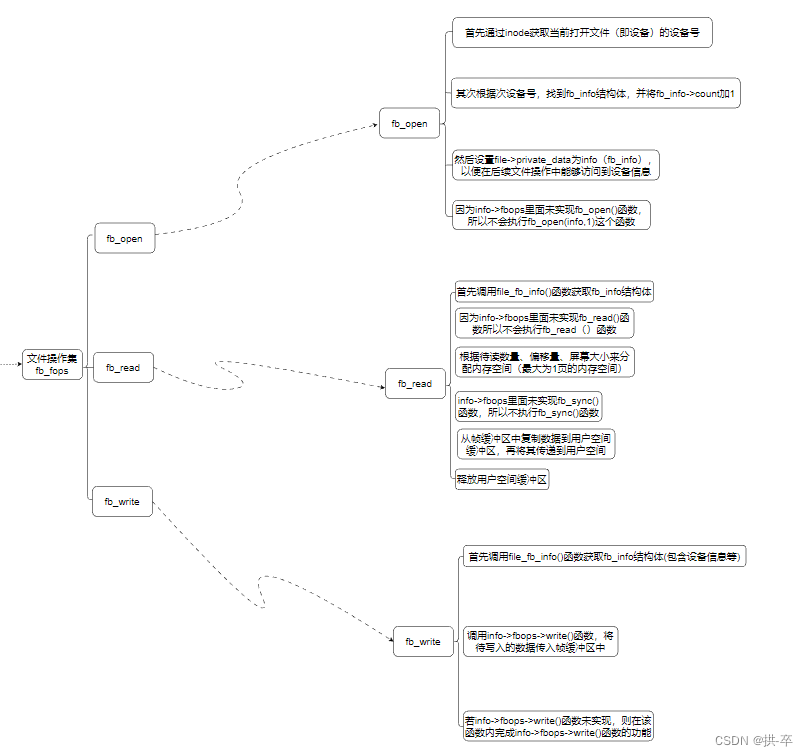
MVCC详解
什么是MVCC? MVCC,即Multi-Version Concurrency Control (多版本并发控制)。它是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。 通俗的讲&am…...
[pytorch]手动构建一个神经网络并且训练
0.写在前面 上一篇博客全都是说明类型的,实际代码能不能跑起来两说,谨慎观看.本文中直接使用fashions数据实现softmax的简单训练并且完成结果输出.实现一个预测并且观测到输出结果. 并且更重要的是,在这里对一些训练的过程,数据的形式,以及我们在softmax中主要做什么以及怎么…...

马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文!
本文原文来自DataLearnerAI官方网站: 马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051699114783001 马斯克透露xAI…...

spring-session-core排除某些接口不设置session
这里写自定义目录标题 需求实现 需求 今天先写一下如何实现,之后再更新一篇如何发现这个问题的。 我们的项目使用了spring-session-core来存储共享session,存在redis中,然后在cookie中是设置了key为SESSION的session。但是我们有一些开放接口…...
【ElasticSearch系列-05】SpringBoot整合elasticSearch
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【三】ElasticSearch的高级查询Quer…...

C/S架构学习之广播
广播:一台主机可以将一个数据包同时发送给同一局域网内所有主机;在IPV4中,广播地址是本网段最大的IP地址或者“255.255.255.255”;注意:广播本质上是UDP通信技术;只有用户数据报套接字才能使用广播的方式&a…...
帧间快速算法论文阅读
Low complexity inter coding scheme for Versatile Video Coding (VVC) 通过分析相邻CU的编码区域,预测当前CU的编码区域,以终止不必要的分割模式。 𝐶𝑈1、𝐶𝑈2、𝐶𝑈3、&#x…...

mooc单元测验第一单元
TCP和OSI参考模型对比 OSI参考模型与TCP/IP参考模型(计算机网络)_osi模型 tcpip模型_李桥桉的博客-CSDN博客 会话层和物理层...
AOC显示器出问题了?别担心,简单重置一下就OK了
你的AOC显示器有问题吗?它是被卡在特定的屏幕上还是根本不显示任何图像?如果你的显示器出现任何问题,只需简单重置即可解决问题。 重置AOC显示器可以帮助解决一系列问题,例如颜色或显示设置问题、输入源检测问题以及其他与软件相…...
ok-解决qt5发布版本,直接运行exe缺少各种库的问题
已实验第二种方法可用。 工具:电脑必备、QT下的windeployqt Qt 官方开发环境使用的动态链接库方式,在发布生成的exe程序时,需要复制一大堆 dll,如果自己去复制dll,很可能丢三落四,导致exe在别的电脑里无法…...
【JavaEE】cookie和session
cookie和session cookie什么是 cookieServlet 中使用 cookie相应的API Servlet 中使用 session 相应的 API代码示例: 实现用户登陆Cookie 和 Session 的区别总结 cookie 什么是 cookie cookie的数据从哪里来? 服务器返回给浏览器的 cookie的数据长什么样? cookie 中是键值对…...

关于CSS的几种字体悬浮的设置方法
关于CSS的几种字体悬浮的设置方法 1. 鼠标放上动态的2. 静态的(位置看上悬浮)2.1 参考QQ邮箱2.2 参考知乎 1. 鼠标放上动态的 效果如下: 代码如下: <!DOCTYPE html> <html lang"en"> <head><met…...
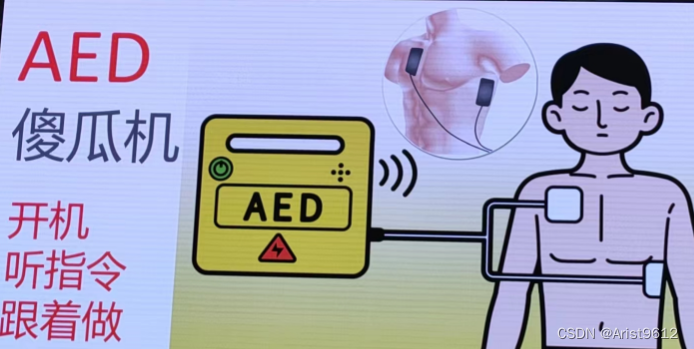
心脏骤停急救赋能
文章目录 0. 背景知识1. 遇到有人突然倒地怎么办1.1 应急反应系统1.2 高质量CPR1.2.1 胸外按压1.2.2 人工呼吸 1.3 AED除颤1.3.1 AED用法 1.4 高级心肺复苏1.5 入院治疗1.6 康复 0. 背景知识 中国每30s就有人倒地,他们可能是工作压力大的年轻人(工程师群…...

Android 13.0 根据app包名授予app监听系统通知权限
1.概述 在13.0的系统rom产品定制化开发中,在一些产品rom定制化开发中,系统内置的第三方app需要开启系统通知权限,然后可以在app中,监听系统所有通知,来做个通知中心的功能,所以需要授权获取系统通知的权限,然后来顺利的监听系统通知。来做系统通知的功能,接下来来实现…...
校园招聘系统
校园管理系统 公共模块学生端游客端企业联系人端校内管理员端超级管理员端企业端 公共模块 登录 用户可以通过验证码、账号密码进行登录。 个人中心 学生端 学生主要为查看招聘信息以及投递等。 首页 简历详情投递 双选会公司详情 公告通知 学生端主要为这些等等…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...