Eureka处理流程
1、Eureka Server服务端会做什么
1、服务注册
Client服务提供者可以向Server注册服务,并且内部有二层缓存机制来维护整个注册表,注册表是Eureka Client的服务提供者注册进来的。
2、提供注册表
服务消费者用来获取注册表
3、同步状态
通过注册、心跳机制和 Eureka Server同步当前客户端的状态,这里就包括服务提供者和服务消费者。
2、Eureka Server的问题
问题:
1、Eureka Server的自我保护机制是怎么实现,怎么做到15分钟内,服务心跳失败比例高于85%。
2、自我保护机制触发后,有哪些功能会被开启
1、不再从注册列表中移除因为长时间没收到心跳而应该过期的服务,冷却时间是多久?
2、仍然能够接受新服务的注册和查询注册表请求,但是不会被同步到其它节点上
3、当网络稳定时,当前实例新的注册信息会被同步到其它节点中,怎么判断网络恢复
集群问题:
Eureka Server集群中,Eureka Server节点A和Eureka Server节点B是怎么通过P2P的方式完成服务注册表的同步?
Eureka Server集群中,同一个区域的Eureka Client,怎么做到优先和同区域内的Eureka Server进行通信的?
Eureka Client服务提供者,向Eureka Server注册,如果某个节点失败,自动切换到其他节点,是怎么做到的?
Eureka Server什么时候会自动退出自我保护模式?
二、源码概述
1、EurekaServer启动
@EnableEurekaServer->import(EurekaServerMarkerConfiguration)->注册Bean(EurekaServerMarkerConfiguration.Marker)->Marker激活了EurekaServerAutoConfiguration这个配置类
2、EurekaServerAutoConfiguration主要包含以下内容
1、创建Bean:【EurekaServerConfigBean】是一个配置类,EurekaServer的所有配置项都是EurekaServerConfigBean这个类里面。
2、创建Bean:【EurekaController】也就是我们通过url,可以访问EurekaServer后台。
3、创建Bean:【PeerAwareInstanceRegistry】处理注册表的类,这个类也会发布事件,发布了注册事件和取消事件(默认没有监听者需要自己实现)
4、创建Bean:【PeerEurekaNodes】初始化了集群节点集合
5、创建Bean:【EurekaServerContext】专业名称叫【EurekaServer上下文】,这个Bean的生成是基于上面创建的Bean: eureka server配置,注册表,集群节点集合来生成。而EurekaServerContext的作用就是初始化eurekaServer上下文,里面会做很多事情。
6、创建Bean:【EurekaServerBootstrap】Eureka Server的启动类
7、创建Bean:【FilterRegistrationBean】主要是对Jersey过滤器的包装,那么这个过滤器干嘛用的 ?
到此EurekaServerAutoConfiguration的创建Bean的任务完成了,但是EurekaServerAutoConfiguration里面还有一@Import(EurekaServerInitializerConfiguration)注解
3、EurekaServerInitializerConfiguration
EurekaServerInitializerConfiguration里面有个start方法,里面会拿到上面注册Bean:【EurekaServerBootstrap启动类】,来启动Eureak。
然后在通过生成的【EurekaServer上下文】开始初始化,初始化的时候会调用registry.syncUp方法,从相邻的eureka节点复制注册表,通过http调用相邻节点获取所有服务实例。
在通过上面的【PeerAwareInstanceRegistry】把实例注册到本地,这里的实例是指EurekaClient的服务提供者,同时PeerAwareInstanceRegistry里面还有一个【Timer】,这个是定时任务,清理30s没有续约的任务、服务剔除超过90s没过来续约的服务。
原文地址:跳转
三、下面通过代码原理说下实现逻辑
1、服务注册
2、服务续约
3、服务剔除
4、服务下线
5、服务发现
6、集群信息同步
1、服务注册
流程:服务提供者,请求EurekaServer端某个节点注册服务
EurekaClient端
Bean =【EurekaAutoServiceRegistration】
通过com.netflix.discovery.shared.transport.jersey.AbstractJerseyEurekaHttpClient#register向EurekaServer注册服务。
EurekaServer端
EurekaServer收到请求,请求进到ApplicationResource#addInstance方法,里面调用【Bean=PeerAwareInstanceRegistry】#register方法,
里面先发布一个Event事件,但是Spring没有监听这个事件,这个是留给我们自己拓展用的,在register里面还有一个很重要的事做,就是注册:
1、首先是设置服务的过期时间90s
2、调用父类完成服务注册,
3、在完成集群信息同步,同步给其他节点。重点看调用【父类完成注册】,先从注册表的集合中获取服务注册信息:
1、如果注册表存在,那么说明冲突了,就判断哪2个节点的活跃时间比较靠前,保留节点时间最新的节点
2、如果不存在就新建,将EurekaClient的服务提供者封装成InstanceInfo对象, InstanceInfo存放了注册信息,最后操作时间,注册时间,过期时间,
剔除时间等信息,再把这个InstanceInfo对象存到注册表中去。至此一个服务注册的流程就完成了注意:注册表是一个Map<String, Map<String, Lease<InstanceInfo>>>对象
1、最外层的key是AppName,注册进来的服务的服务名 , value = Map<String, Lease<InstanceInfo>> value表示这个服务名对应多个实例节点
2、Map<String, Lease<InstanceInfo>>这个Map,key是ip+端口,value是Lease<InstanceInfo>对象,也就是这个实例的更多信息,比如过期时间,最近活跃时间等等。
2、服务续约:
服务续约由Eureka-client端主动发起请求Eureka服务端,间隔时间30s,Eureka服务端收到请求,刷新节点的活跃时间。因为Eureka服务端,有定时任务,就是基于这个活跃时间来考虑是否剔除服务。
Eureka-client端
请求Eureka服务端,由DiscoveryClient#renew方法完成,主要是发送http请求,每隔30秒进行一次续约,
里面调用AbstractJerseyEurekaHttpClient#sendHeartBeat方法
Eureka-server端
在Eureka-server端服务续约的调用链与服务注册基本相同
InstanceRegistry#renew() -> PeerAwareInstanceRegistry#renew()-> AbstractInstanceRegistry # renew() 主要逻辑还是AbstractInstanceRegistry的renew方法renew的方法逻辑操作非常简单,它的本质就是修改服务的【最后更新时间】。将最后更新时间改为:【系统当前时间】+【服务的过期时间】
3、服务剔除
服务主要是Eureka服务端,通过定时任务检测注册节点的【活跃时间】,如果超过90s就会剔除。
Eureka-server端
当Eureka-server发现有的实例没有续约超过一定时间,则将该服务从注册列表剔除,该项工作由一个定时任务完成的。由下面方法完成
AbstractInstanceRegistry # postInit()定时任务前面说了在【EurekaServer上下文】初始化的时候,添加了一个Timer定时器,定时器关联的任务是EvictionTask的run方法,在执行任务中
调用剔除方法 evict(), 主要是拿到注册表的所有实例挨个遍历,判断【系统当前时间 > 最后更新时间+过期时间+预留时间】,
并且新建实例列表expiredLeases,用来存放过期的实例。当该条件成立时,认为服务过期(在Eureka中过期时间默认定义为3个心跳的时间,一个心跳是30秒,因此过期时间是90秒)。
将该过期实例放入上面创建的expiredLeases列表中。注意这里仅仅是将实例放入List中,并没有实际剔除。因为要判断是否超过阈值了,如果超过就从里面取随机数,随机剔除实例ID,注意expiredLeases里面存的是多个服务的实例,不是某一个服务的所有实例。下线的时候从里面取随机数,所以有可能某个服务的所有实例全部被剔除都有可能。在实际剔除任务前,需要提一下eureka的自我保护机制:
当1分钟内,心跳失败的服务大于一定比例时,会触发自我保护机制。这个值在Eureka中被定义为85%,一旦触发自我保护机制,
Eureka会尝试保护其服务注册表中的信息,不再删除服务注册表中的数据。1分钟是怎么统计数量的?哪些节点保留? 哪些节点删除?答:使用了随机算法进行剔除,
举个例子,假如当前共有100个服务,那么剔除阈值为85%,也就是最多剔除15个,如果list中有60个服务,那么就会从60个服务里面取15个。有可能一个服务的所有节点全部被剔除。剔除的节点被放到一个queue里面,这个里面存的是最近剔除的节点,在集群同步,或者拉取注册表的时候,要用到。
关于自我保护
首先是阈值是85%,比如100个,阈值是85%,那么一次最多剔除15个,当定时任务进来,发现100个里面有10个失效,那么10小于【最大阈值】,那就剔除10个,如果20个失效,20个大于15,所以最多剔除15个,这15个怎么选?
通过for循环15次,每次生成一个随机数,这个随机数是从20里面取,1、自我保护时期不能进行服务剔除操作
2、过期操作是分批进行
3、服务剔除是随机逐个剔除,均匀分布在所有应用中,其实也不算均匀,是随机抽
4、服务剔除是一个定时任务,默认60秒一次问题:自我保护时期不能进行服务剔除操作:这个是怎么做到的?首先是定义了2个变量,一个是【期望续约数】,一个是【前一分钟实际的续约数】。
这个【期望续约数】是通过公式算出来了,比如20个实例,正常情况下1分钟的话会续约40次,
那么期望的续约数应该是40*85%=34个,而如果实际契约数超过这个数量,比如35,
那么EurekaServer认为,服务恢复正常了,应该关闭自我保护机制。
注意:期望续约数是一个动态值,每次会重行计算的。比如服务下线或者上线,期望的数量是会加1或者减1的。问题:实际续约数是怎么算出来的?
因为剔除的定时任务是1分钟一次,所以有个定时任务专门设置【前一分钟实际续约数量】,MeasuredRate也是60秒一次,他里面定义了2个变量,一个是【一分钟内的续约】数,一个是【上一分钟的续约数】,服务每次注册就会加1,服务下线就减1,当定时任务跑的时候,就会把一分钟的续约数赋值给【上一分钟的续约数】,然后再把【一分钟内的续约】置0
自我保护机制,详细解读:跳转
代码流程:跳转
4、服务下线
当eureka-client关闭时,不会立刻关闭,需要先发请求给eureka-server服务端,告知自己要下线了。
Eureka-client端:
Eureka客户端请求EurekaServer服务端,通过DiscoveryClient#shutdown方法调用EurekaServer服务端
Eureka-server端
收到请求,进到AbstractInstanceRegistry#cancel方法, 最终还是调用了和服务剔除中一样的方法,remove掉了注册表中的实例
5、服务发现
是指EurekaClient 消费者,通过Http调用EurekaServer服务端接口,获取注册表信息
Eureka-client端:
DiscoveryClient#getInstances方法,可以根据服务id获取服务实例列表。那么这里就有一个问题了,我们还没有去调用微服务,那么服务列表是什么时候被拉取或缓存到本地的服务列表的呢?
EurekaDiscoveryClient # getInstances() -> DiscoveryClient # getInstancesByVipAddress() -> DiscoveryClient #getInstancesByVipAddress2() ->Applications # getInstancesByVirtualHostName() 这里居然不是走的http,是读的本地缓存。Applications中的getInstancesByVirtualHostName方法里面,有一个virtualHostNameAppMap的Map集合中已经保存了当前所有注册到eureka的服务列表。
private final Map<String, VipIndexSupport> virtualHostNameAppMap;
也就是说,在我们没有手动去调用服务的时候,该集合里面已经有值了,说明在Eureka-server项目启动后,会自动去拉取服务,并将拉取的服务缓存起来。那么追根溯源,来查找一下服务的发现究竟是什么时候完成的。回到DiscoveryClient这个类,
在它的构造方法中定义了任务调度线程池cacheRefreshExecutor,定义完成后,调用initScheduledTask方法,
通过fetchRegistry方法来拉取,不过分2种情况【增量拉取】还是【全量拉取】【全量拉取】:当缓存为null,或里面的数据为空,或强制时,进行全量拉取,执行getAndStoreFullRegistry方法
【增量拉取】: 只拉取修改的。执行getAndUpdateDelta方法,虽然这里是拉增量,但是如果没拉到数据,还是会拉全量的数据,然后就是更新操作,更新也有类型,是delete还是Modify,added,这里有个细节校验,就是拿hashCode和缓存的HashCode对比是否一致,如果一致,说明数据没有变动,如果不一致,那就说明本地和远程数据不一样,需要重新再拉一次,
对服务发现过程进行一下重点总结:
1、服务列表的拉取并不是在服务调用的时候才拉取,而是在项目启动的时候就有定时任务去拉取了,这点在DiscoveryClient的构造方法中能够体现;
2、服务的实例并不是实时的Eureka-server中的数据,而是一个本地缓存的数据;
3、缓存更新根据实际需求分为全量拉取与增量拉取。
6、集群信息同步
Eureka-server端:
集群信息同步发生在Eureka-server之间,之前提到在PeerAwareInstanceRegistryImpl类中,在执行register方法注册微服务实例完成后,
执行了集群信息同步方法replicateToPeers首先,遍历集群节点,用以给各个集群信息节点进行信息同步。最终发送http请求,请求各个EureakServer节点。
调用EurekaServer的ApplicationResource类里面的addInstance,注意EurekaClient注册的时候,也是调的这个方法,
单独注册时isReplication的值为false,集群同步时为true
Eureka三级缓存
服务端的缓存机制
服务端采用三级缓存(registry,readWriteCacheMap,readOnlyCacheMap)来存储注册表信息。
三级缓存的目的是为了将注册服务和获取服务区分开,避免了高并发的同时对一个缓存的读写操作,有效避免读写冲突。保证性能。
一级缓存 = ConcurrentHashMap<Key,Value> registry 服务一开始注册进来的地方
二级缓存 = Loading<Key,Value> readWriteCacheMap,本质上是guava的缓存,包含失效机制,保存服务信息的对外输出数据结构。
三级缓存 = ConcurrentHashMap<Key,Value> readOnlyCacheMap 本质上是HashMap,无过期时间,保存服务信息的对外输出数据结构。
设置缓存
(1)、客户端将服务信息注册在一级缓存registry中。(每30s一次心跳续约)
(2)、一级缓存registry收到注册信息后,先清空二级缓存readWriteCacheMap中的注册信息,然后在同步新数据给readWriteCacheMap二级缓存。
(3)、二级缓存按照30s一次的频率给三级缓存readOnlyCacheMap同步数据缓存获取
(4)、其他的客户端连接注册中心Server 30s一次的频率从三级缓存readOnlyCacheMap中获取,如果readOnlyCacheMap中获取不到,则直接去一级缓存registry中获取。缓存更新
(5)、一级缓存中默认每隔60s检查服务续期,如果90秒内服务还没有续期,则删除注册信息。同时同步给二级三级缓存。
(6)、服务下线时,一级缓存registry中的注册信息删除,同时删除二级缓存的数据。30s后二级同步三级缓存时发现二级缓存已失效,则删除三级缓存的注册表信息。则会期间会有时间的延迟。
(7)、二级缓存的默认有效期是180s(3min),3min后数据会失效,然后二级缓存数据清空。
三级缓存的弊端:
三级缓存的问题很明显,就是服务下线之后,不能及时通知到三级缓存中,注册信息的获取者(客户端)拿到的注册信息不是实时的。(当让客户端的获取也不是实时的,要间隔30s才会去主动获取)
相关文章:

Eureka处理流程
1、Eureka Server服务端会做什么 1、服务注册 Client服务提供者可以向Server注册服务,并且内部有二层缓存机制来维护整个注册表,注册表是Eureka Client的服务提供者注册进来的。 2、提供注册表 服务消费者用来获取注册表 3、同步状态 通过注册、心跳机制…...

排序算法
文章目录 P1271 【深基9.例1】选举学生会选择排序、冒泡排序、插入排序快速排序排序算法的应用[NOIP2006 普及组] 明明的随机数[NOIP2007 普及组] 奖学金P1781 宇宙总统 #mermaid-svg-Zo8AMme5IW1JlT6K {font-family:"trebuchet ms",verdana,arial,sans-serif;font-s…...

华为政企光传输网络产品集
产品类型产品型号产品说明 maintainProductEA5800-X15 典型配置 上行160G 下行64口GPON 16口XGS PONEA5800系列多业务接入设备定位为面向NG-PON的下一代OLT,基于分布式架构,运用虚拟接入技术,为用户提供宽带、无线、视频回传等多业务统一承…...

四路IC卡读卡器通信协议
1、摘要 Sle4442卡为256字节加密卡,存在读数据、写数据、保护数据以及密码操作。该卡在密码验证之前数据为只读状态,需要写入数据必须先进行密码验证,密码为3个字节,新卡初始密码为0xff,0xff,0xff。该读卡器…...

JavaFX作业
前言: 在写这个作业之前,尝试在JavaFX中添加全局快捷键,测试了大概5个小时,到处找教程换版本,结果最后还是没找到支持Java8以上的(也有可能是我自己的问题),最后只能退而求其次&…...

【使用Python编写游戏辅助工具】第五篇:打造交互式游戏工具界面:PySide6/PyQT高效构建GUI工具
前言 这里是【使用Python编写游戏辅助工具】的第五篇:打造交互式游戏工具界面:PySide6/PyQT高效构建GUI工具。本文主要介绍使用PySide6来实现构建GUI工具。 在前面,我们实现了两个实用的游戏辅助功能: 由键盘监听事件触发的鼠标连…...
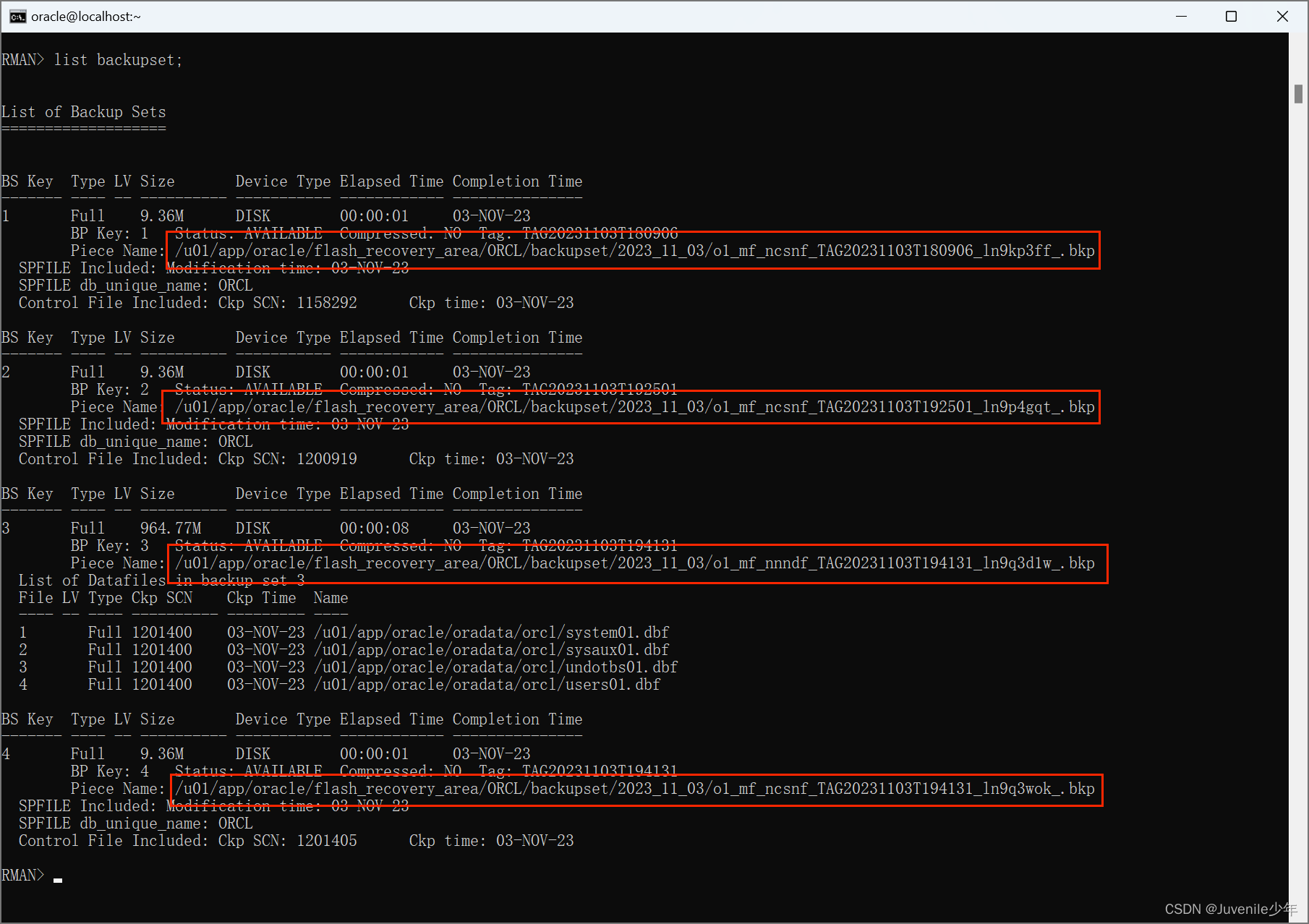
06.Oracle数据备份与恢复
Oracle数据备份与恢复 一、通过RMAN方式备份二、使用emp/imp和expdb/impdb工具进行备份和恢复三、使用Data guard进行备份与恢复 一、通过RMAN方式备份 通过 RMAN(Oracle 数据库备份和恢复管理器)方式备份 Oracle 数据库,可以使用以下步骤&a…...

大航海时代Ⅳ 威力加强版套装 HD Version (WinMac)中文免安装版
《大航海时代》系列的人气SRPG《大航海时代IV》以HD的新面貌再次登场!本作品以16世纪的欧洲“大航海时代”为舞台,玩家将以探险家、商人、军人等不同身份与全世界形形色色的人们一起上演出跌宕起伏的海洋冒险。游戏中玩家的目的是在不同的海域中掌握霸权…...
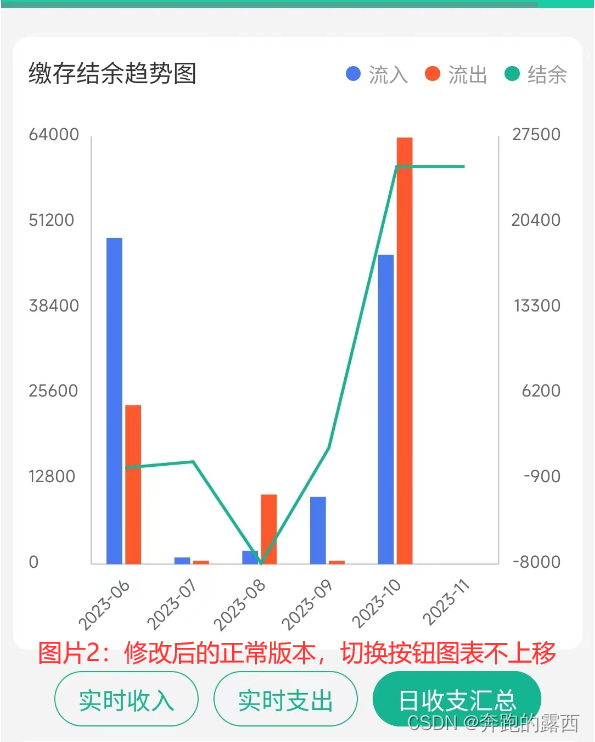
微信小程序 uCharts的使用方法
一、背景 微信小程序项目需要渲染一个柱状图,使用uCharts组件完成 uCharts官网指引👉:uCharts官网 - 秋云uCharts跨平台图表库 二、实现效果 三、具体使用 进入官网查看指南,有两种方式进行使用:分别是原生方式与组…...
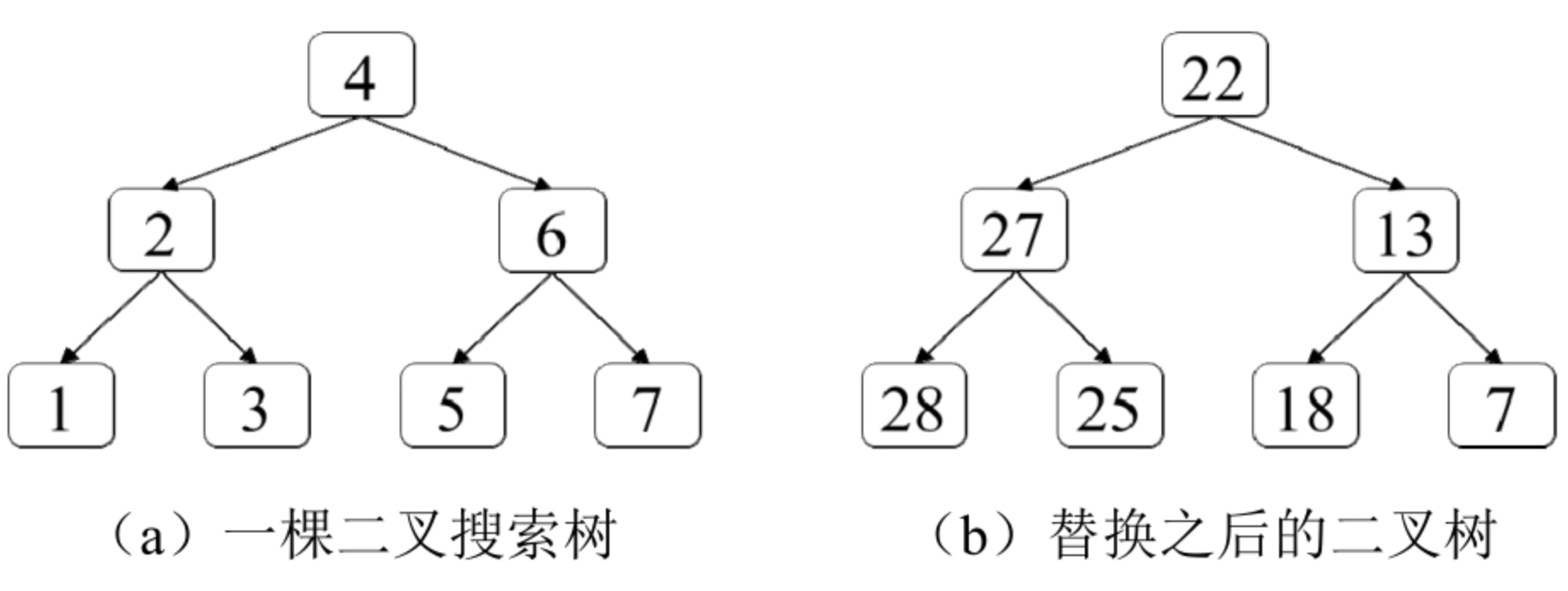
面试算法54:所有大于或等于节点的值之和
题目 给定一棵二叉搜索树,请将它的每个节点的值替换成树中大于或等于该节点值的所有节点值之和。假设二叉搜索树中节点的值唯一。例如,输入如图8.10(a)所示的二叉搜索树,由于有两个节点的值大于或等于6(即…...

七月论文审稿GPT第二版:从Meta Nougat、GPT4审稿到LongLora版LLaMA、Mistral
前言 如此前这篇文章《学术论文GPT的源码解读与微调:从chatpaper、gpt_academic到七月论文审稿GPT》中的第三部分所述,对于论文的摘要/总结、对话、翻译、语法检查而言,市面上的学术论文GPT的效果虽暂未有多好,可至少还过得去&am…...
:神经网络-搭建小实战和Sequential的使用)
PyTorch入门学习(十二):神经网络-搭建小实战和Sequential的使用
目录 一、介绍 二、先决条件 三、代码解释 一、介绍 在深度学习领域,构建复杂的神经网络模型可能是一项艰巨的任务,尤其是当您有许多层和操作需要组织时。幸运的是,PyTorch提供了一个方便的工具,称为Sequential API,…...

Linux shell编程学习笔记20:case ... esac、continue 和break语句
一、case ... esac语句说明 在实际编程中,我们有时会请到多条件多分支选择的情况,用if…else语句来嵌套处理不烦琐,于是JavaScript等语言提供了多选择语句switch ... case。与此类似,Linux Shell脚本编程中提供了case...in...esa…...

树莓派4无法进入桌面模式(启动后出现彩色画面,然后一直黑屏,但是可以正常启动和ssh)
本文记录了这段比较坎坷的探索之路,由于你的问题不一定是我最终解决方案的,可能是前面探索路上试过的,所以建议按顺序看排除前置问题。 双十一又买了个树莓派 4B,插上之前树莓派 4B 的 TF 卡直接就能使用(毕竟是一样规…...

花草世界生存技能
多菌灵 杀菌常用 阿维菌素 杀虫常用 除蚜虫 吡虫啉 有毒性 内吸性(植物吸收) 苦参碱 无毒,中药提取 内吸性药 吡虫啉,噻虫嗪、啶虫脒、苦参碱 栀子花 春秋花后修剪 牡丹 秋冬种植; 洛阳产地; 肥料 …...
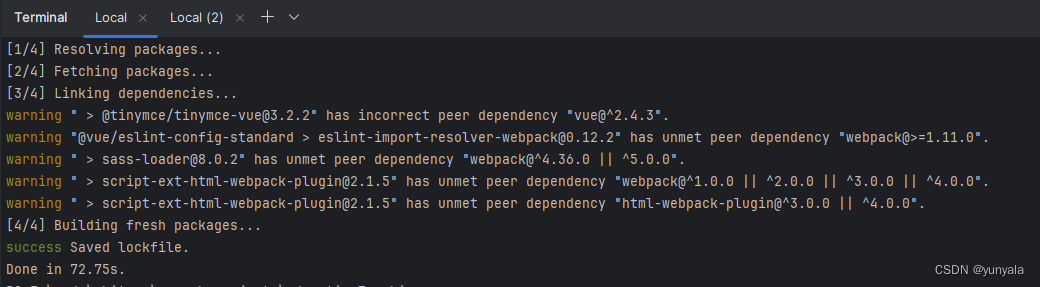
执行npm install时老是安装不成功node-sass的原因和解决方案
相信你安装前端项目所需要的依赖包(npm install 或 yarn install)时,有可能会出现如下报错: D:\code\**project > yarn install ... [4/4] Building fresh packages... [-/6] ⠁ waiting... [-/6] ⠂ waiting... [-/6] ⠂ wai…...

【MongoDB】集群搭建实战 | 副本集 Replica-Set | 分片集群 Shard-Cluster | 安全认证
文章目录 MongoDB 集群架构副本集主节点选举原则搭建副本集主节点从节点仲裁节点 连接节点添加副本从节点添加仲裁者节点删除节点 副本集读写操作副本集中的方法 分片集群分片集群架构目标第一个副本集第二个副本集配置集初始化副本集路由集添加分片开启分片集合分片删除分片 安…...
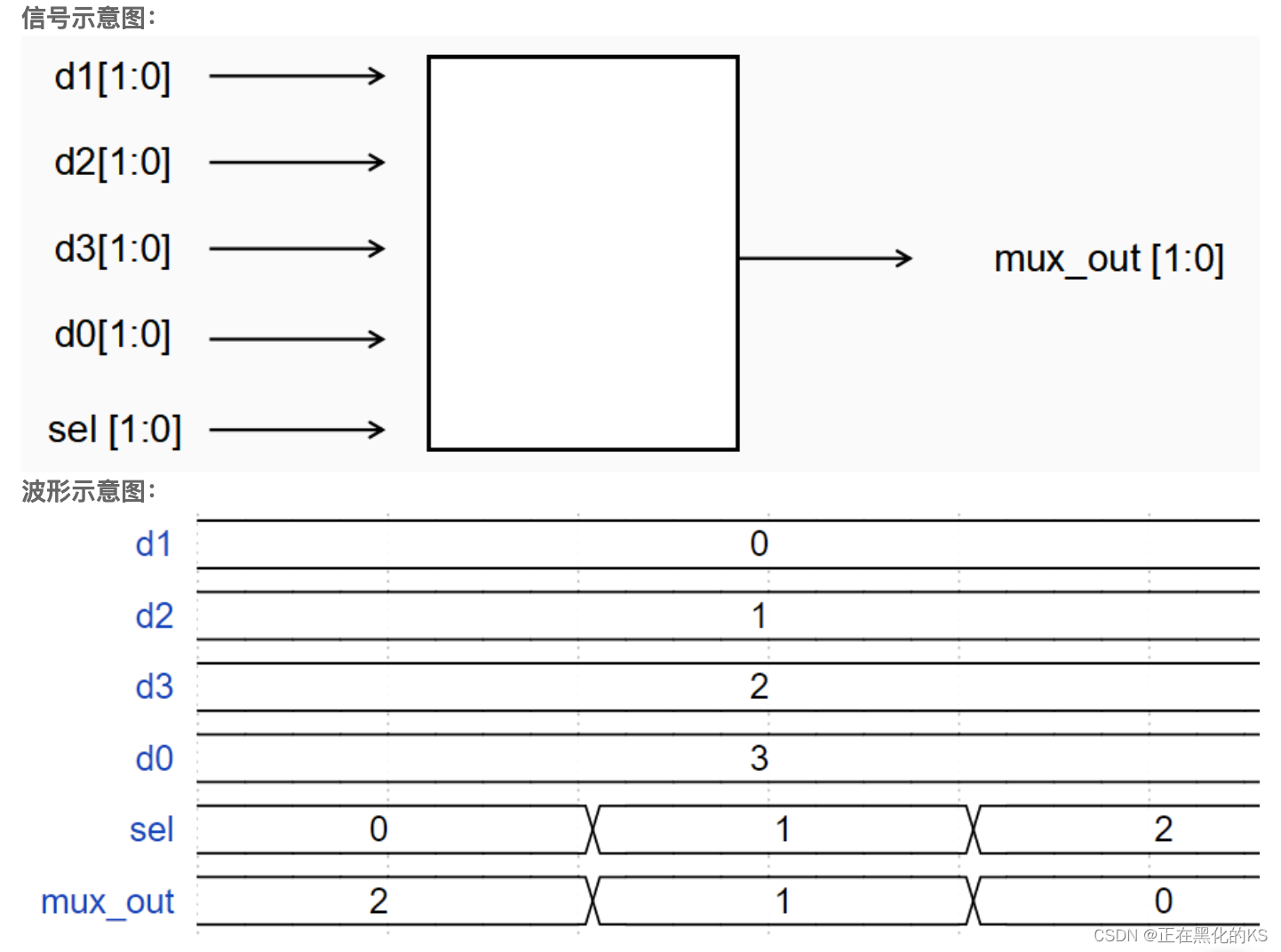
「Verilog学习笔记」四选一多路器
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 分析 通过波形示意图我们可以发现,当sel为0,1,2时,输出mux_out分别为d3,d2,d1,那么sel3…...
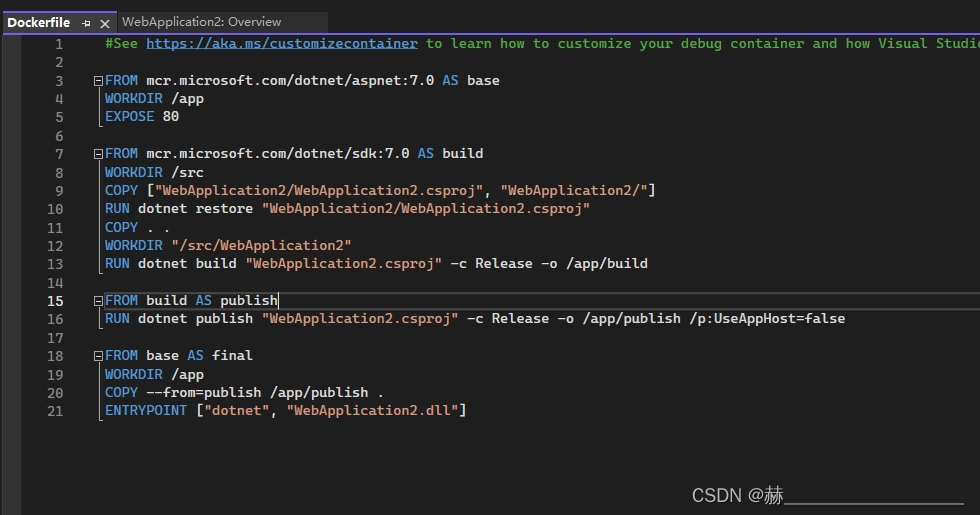
asp.net 创建docker容器
首先创建asp.net web api 创建完成后如下图 添加docker支持 添加docker支持 添加linux docker支持...

Linux项目自动化构建工具-make/Makefile使用
make/Makefile使用介绍 make是一个命令makefile是一个在当前目录下存在的一个具有特定格式的文本文件 下面我们设计一个场景,实现make命令对我们code.c文件进行编译和删除。 1 #include<stdio.h> 2 3 int main() 4 { 5 printf("hello,world!…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...