什么是大模型?一文读懂大模型的基本概念
大模型是指具有大规模参数和复杂计算结构的机器学习模型。本文从大模型的基本概念出发,对大模型领域容易混淆的相关概念进行区分,并就大模型的发展历程、特点和分类、泛化与微调进行了详细解读,供大家在了解大模型基本知识的过程中起到一定参考作用。
本文目录如下:
· 大模型的定义
· 大模型相关概念区分
· 大模型的发展历程
· 大模型的特点
· 大模型的分类
· 大模型的泛化与微调
1. 大模型的定义
大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
ChatGPT对大模型的解释更为通俗易懂,也更体现出类似人类的归纳和思考能力:大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。

那么,大模型和小模型有什么区别?
小模型通常指参数较少、层数较浅的模型,它们具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的场景,例如移动端应用、嵌入式设备、物联网等。
而当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,其表现出了一些未能预测的、更复杂的能力和特性,模型能够从原始训练数据中自动学习并发现新的、更高层次的特征和模式,这种能力被称为“涌现能力”。而具备涌现能力的机器学习模型就被认为是独立意义上的大模型,这也是其和小模型最大意义上的区别。
相比小模型,大模型通常参数较多、层数较深,具有更强的表达能力和更高的准确度,但也需要更多的计算资源和时间来训练和推理,适用于数据量较大、计算资源充足的场景,例如云端计算、高性能计算、人工智能等。
2. 大模型相关概念区分:
大模型(Large Model,也称基础模型,即Foundation Model),是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。
超大模型:超大模型是大模型的一个子集,它们的参数量远超过大模型。
大语言模型(Large Language Model):通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
GPT(Generative Pre-trained Transformer):GPT 和ChatGPT都是基于Transformer架构的语言模型,但它们在设计和应用上存在区别:GPT模型旨在生成自然语言文本并处理各种自然语言处理任务,如文本生成、翻译、摘要等。它通常在单向生成的情况下使用,即根据给定的文本生成连贯的输出。
ChatGPT:ChatGPT则专注于对话和交互式对话。它经过特定的训练,以更好地处理多轮对话和上下文理解。ChatGPT设计用于提供流畅、连贯和有趣的对话体验,以响应用户的输入并生成合适的回复。
3. 大模型的发展历程
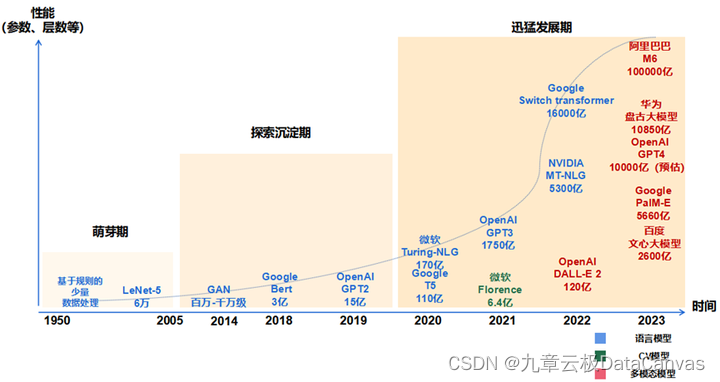
萌芽期(1950-2005):以CNN为代表的传统神经网络模型阶段
· 1956年,从计算机专家约翰·麦卡锡提出“人工智能”概念开始,AI发展由最开始基于小规模专家知识逐步发展为基于机器学习。
· 1980年,卷积神经网络的雏形CNN诞生。
· 1998年,现代卷积神经网络的基本结构LeNet-5诞生,机器学习方法由早期基于浅层机器学习的模型,变为了基于深度学习的模型,为自然语言生成、计算机视觉等领域的深入研究奠定了基础,对后续深度学习框架的迭代及大模型发展具有开创性的意义。
探索沉淀期(2006-2019):以Transformer为代表的全新神经网络模型阶段
· 2013年,自然语言处理模型 Word2Vec诞生,首次提出将单词转换为向量的“词向量模型”,以便计算机更好地理解和处理文本数据。
· 2014年,被誉为21世纪最强大算法模型之一的GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。
· 2017年,Google颠覆性地提出了基于自注意力机制的神经网络结构——Transformer架构,奠定了大模型预训练算法架构的基础。
· 2018年,OpenAI和Google分别发布了GPT-1与BERT大模型,意味着预训练大模型成为自然语言处理领域的主流。在探索期,以Transformer为代表的全新神经网络架构,奠定了大模型的算法架构基础,使大模型技术的性能得到了显著提升。
迅猛发展期(2020-至今):以GPT为代表的预训练大模型阶段
· 2020年,OpenAI公司推出了GPT-3,模型参数规模达到了1750亿,成为当时最大的语言模型,并且在零样本学习任务上实现了巨大性能提升。随后,更多策略如基于人类反馈的强化学习(RHLF)、代码预训练、指令微调等开始出现, 被用于进一步提高推理能力和任务泛化。
· 2022年11月,搭载了GPT3.5的ChatGPT横空出世,凭借逼真的自然语言交互与多场景内容生成能力,迅速引爆互联网。
· 2023年3月,最新发布的超大规模多模态预训练大模型——GPT-4,具备了多模态理解与多类型内容生成能力。在迅猛发展期,大数据、大算力和大算法完美结合,大幅提升了大模型的预训练和生成能力以及多模态多场景应用能力。如ChatGPT的巨大成功,就是在微软Azure强大的算力以及wiki等海量数据支持下,在Transformer架构基础上,坚持GPT模型及人类反馈的强化学习(RLHF)进行精调的策略下取得的。
4. 大模型的特点
· 巨大的规模: 大模型包含数十亿个参数,模型大小可以达到数百GB甚至更大。巨大的模型规模使大模型具有强大的表达能力和学习能力。
· 涌现能力:涌现(英语:emergence)或称创发、突现、呈展、演生,是一种现象,为许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。引申到模型层面,涌现能力指的是当模型的训练数据突破一定规模,模型突然涌现出之前小模型所没有的、意料之外的、能够综合分析和解决更深层次问题的复杂能力和特性,展现出类似人类的思维和智能。涌现能力也是大模型最显著的特点之一。
· 更好的性能和泛化能力: 大模型通常具有更强大的学习能力和泛化能力,能够在各种任务上表现出色,包括自然语言处理、图像识别、语音识别等。
· 多任务学习: 大模型通常会一起学习多种不同的NLP任务,如机器翻译、文本摘要、问答系统等。这可以使模型学习到更广泛和泛化的语言理解能力。
· 大数据训练: 大模型需要海量的数据来训练,通常在TB以上甚至PB级别的数据集。只有大量的数据才能发挥大模型的参数规模优势。
· 强大的计算资源: 训练大模型通常需要数百甚至上千个GPU,以及大量的时间,通常在几周到几个月。
· 迁移学习和预训练: 大模型可以通过在大规模数据上进行预训练,然后在特定任务上进行微调,从而提高模型在新任务上的性能。
· 自监督学习: 大模型可以通过自监督学习在大规模未标记数据上进行训练,从而减少对标记数据的依赖,提高模型的效能。
· 领域知识融合: 大模型可以从多个领域的数据中学习知识,并在不同领域中进行应用,促进跨领域的创新。
· 自动化和效率:大模型可以自动化许多复杂的任务,提高工作效率,如自动编程、自动翻译、自动摘要等。
5. 大模型的分类
按照输入数据类型的不同,大模型主要可以分为以下三大类:
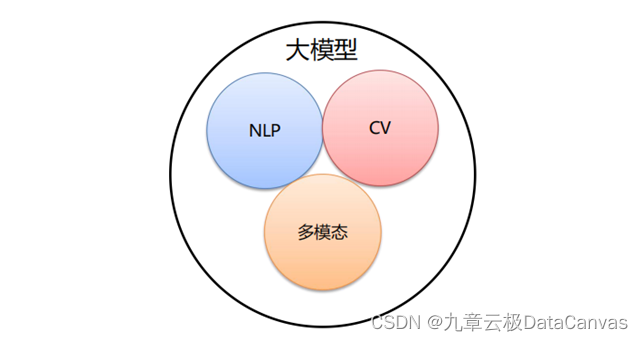
· 语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT系列(OpenAI)、Bard(Google)、文心一言(百度)。
· 视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。例如:VIT系列(Google)、文心UFO、华为盘古CV、INTERN(商汤)。
· 多模态大模型:是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了NLP和CV的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。例如:DingoDB多模向量数据库(九章云极DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
按照应用领域的不同,大模型主要可以分为L0、L1、L2三个层级:
· 通用大模型L0:是指可以在多个领域和任务上通用的大模型。它们利用大算力、使用海量的开放数据与具有巨量参数的深度学习算法,在大规模无标注数据上进行训练,以寻找特征并发现规律,进而形成可“举一反三”的强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于AI完成了“通识教育”。
· 行业大模型L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度,相当于AI成为“行业专家”。
· 垂直大模型L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。
6. 大模型的泛化与微调
模型的泛化能力:是指一个模型在面对新的、未见过的数据时,能够正确理解和预测这些数据的能力。在机器学习和人工智能领域,模型的泛化能力是评估模型性能的重要指标之一。
什么是模型微调:给定预训练模型(Pre-trained model),基于模型进行微调(Fine Tune)。相对于从头开始训练(Training a model from scatch),微调可以省去大量计算资源和计算时间,提高计算效率,甚至提高准确率。
模型微调的基本思想是使用少量带标签的数据对预训练模型进行再次训练,以适应特定任务。在这个过程中,模型的参数会根据新的数据分布进行调整。这种方法的好处在于,它利用了预训练模型的强大能力,同时还能够适应新的数据分布。因此,模型微调能够提高模型的泛化能力,减少过拟合现象。
常见的模型微调方法:
· Fine-tuning:这是最常用的微调方法。通过在预训练模型的最后一层添加一个新的分类层,然后根据新的数据集进行微调。
· Feature augmentation:这种方法通过向数据中添加一些人工特征来增强模型的性能。这些特征可以是手工设计的,也可以是通过自动特征生成技术生成的。
· Transfer learning:这种方法是使用在一个任务上训练过的模型作为新任务的起点,然后对模型的参数进行微调,以适应新的任务。
大模型是未来人工智能发展的重要方向和核心技术,未来,随着AI技术的不断进步和应用场景的不断拓展,大模型将在更多领域展现其巨大的潜力,为人类万花筒般的AI未来拓展无限可能性。
相关文章:
什么是大模型?一文读懂大模型的基本概念
大模型是指具有大规模参数和复杂计算结构的机器学习模型。本文从大模型的基本概念出发,对大模型领域容易混淆的相关概念进行区分,并就大模型的发展历程、特点和分类、泛化与微调进行了详细解读,供大家在了解大模型基本知识的过程中起到一定参…...
数据结构之队的实现
𝙉𝙞𝙘𝙚!!👏🏻‧✧̣̥̇‧✦👏🏻‧✧̣̥̇‧✦ 👏🏻‧✧̣̥̇:Solitary-walk ⸝⋆ ━━━┓ - 个性标签 - :来于“云”的“羽球人”。…...
【实战Flask API项目指南】之三 路由和视图函数
实战Flask API项目指南之 路由和视图函数 本系列文章将带你深入探索实战Flask API项目指南,通过跟随小菜的学习之旅,你将逐步掌握 Flask 在实际项目中的应用。让我们一起踏上这个精彩的学习之旅吧! 前言 当小菜踏入Flask后端开发的世界时&…...

mediasoup udp端口分配策略
mediasoup-worker多进程启动时,rtcMinPort/rtcMaxPort可以使用相同的配置。 for (let i 0; i < numWorkers; i) { let worker await mediasoup.createWorker({ logLevel: config.mediasoup.worker.logLevel, logTags: config.mediasoup.work…...
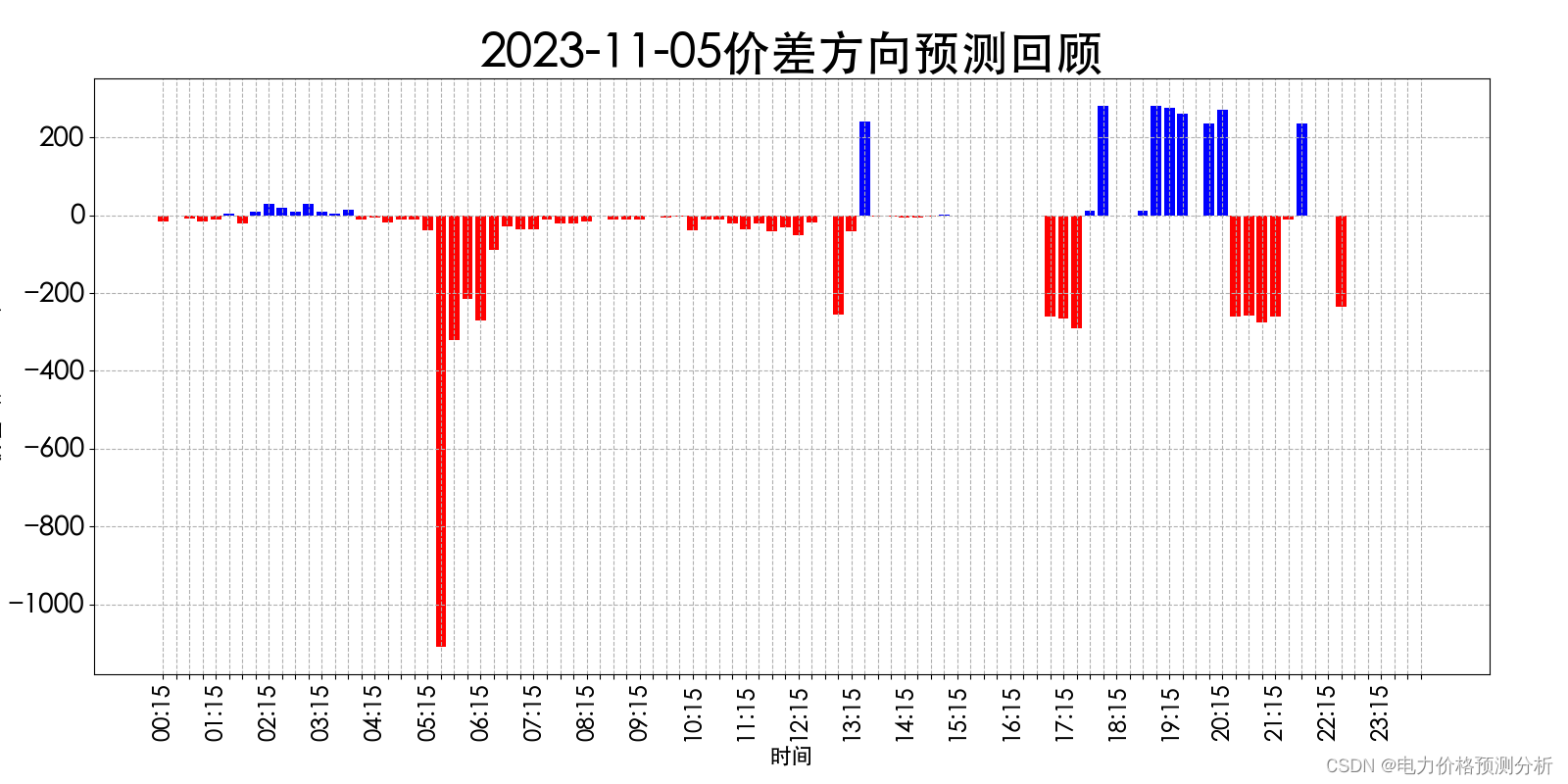
山西电力市场日前价格预测【2023-11-07】
日前价格预测 预测说明: 如上图所示,预测明日(2023-11-07)山西电力市场全天平均日前电价为318.54元/MWh。其中,最高日前电价为514.01元/MWh,预计出现在18: 00。最低日前电价为192.95元/MWh,预计…...
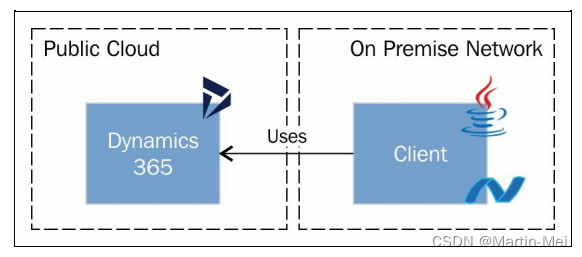
Microsoft Dynamics 365 CE 扩展定制 - 5. 外部集成
本章内容包括: 使用.NET从其他系统连接到Dynamics 365使用OData(Java)从其他系统连接到Dynamics 365使用外部库从外部源检索数据使用web应用程序连接到Dynamics 365运行Azure计划任务设置Azure Service Bus终结点与Azure Service Bus构建近乎实时的集成使用来自Azure服务总线…...
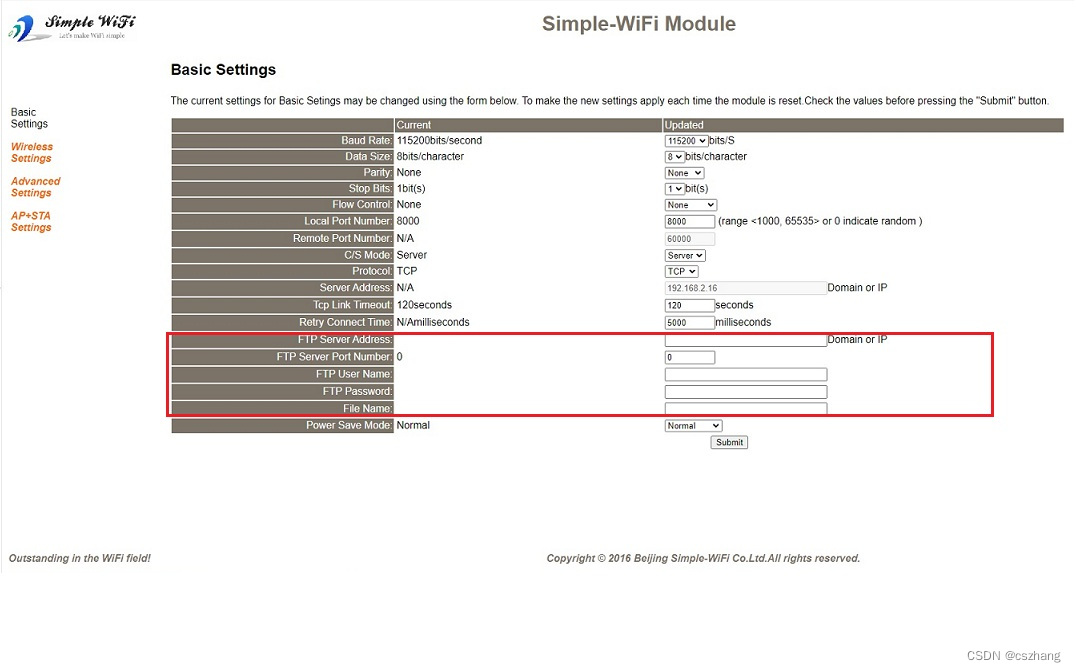
手机升级STM32单片机,pad下载程序,手机固件升级单片机,局域网程序下载,STM32单片机远程下载升级
STM32单片机,是我们最常见的一种MCU。通常我们在使用STM32单片机都会遇到程序在线升级下载的问题。 STM32单片机的在线下载通常需要以下几种方式完成: 1、使用ST提供的串口下载工具,本地完成固件的升级下载。 2、自行完成系统BootLoader的编写…...
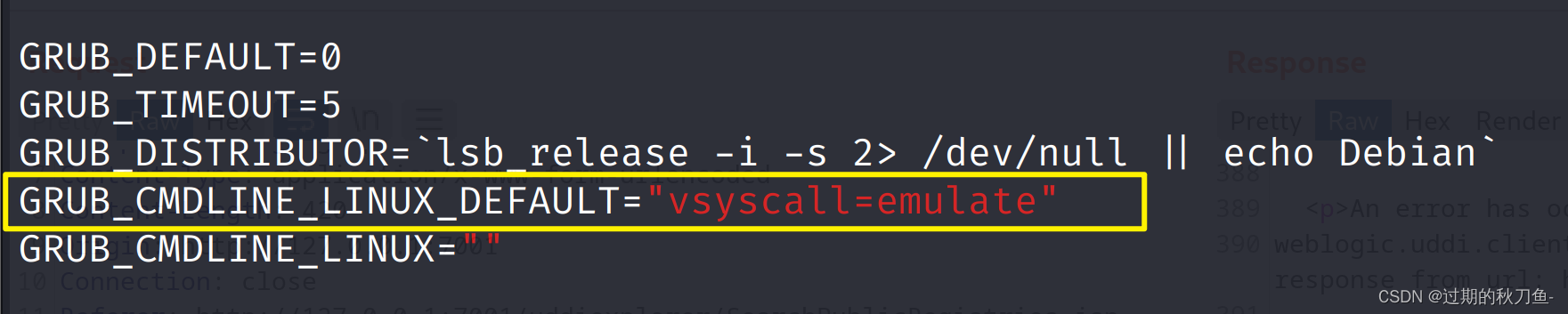
【漏洞复现】weblogic-SSRF漏洞
感谢互联网提供分享知识与智慧,在法治的社会里,请遵守有关法律法规 文章目录 漏洞测试注入HTTP头,利用Redis反弹shell 问题解决 Path : vulhub/weblogic/ssrf 编译及启动测试环境 docker compose up -dWeblogic中存在一个SSRF漏洞࿰…...

FreeSWTCH dialplan check nosdp
应朋友要求写一段dialplan,如果没有sdp(sip_profile打开了3pcc),马上回486,当然如果有sdp,dialplan正常往下走 我试了试,貌似不太复杂,如下: <!-- check no sdp --&…...
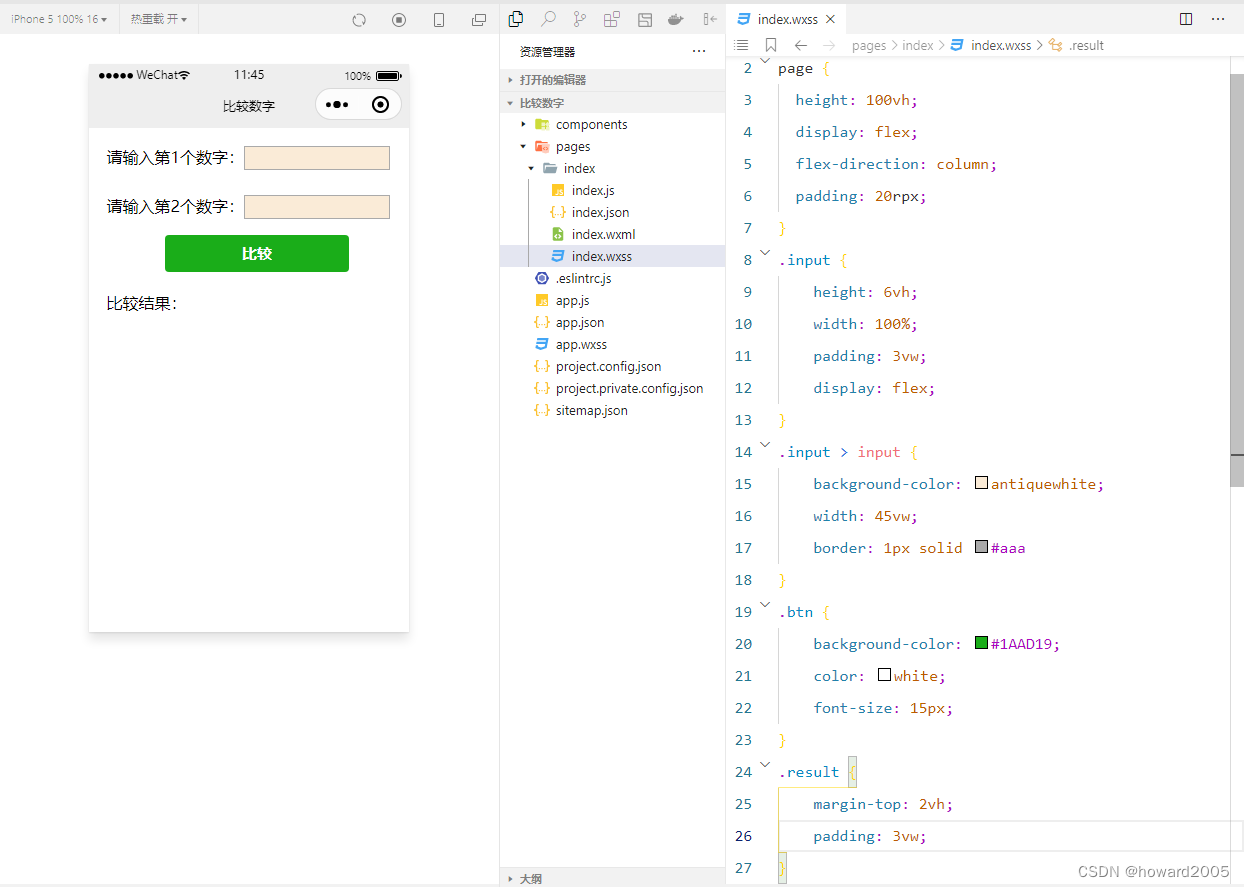
微信小程序案例3-1 比较数字
文章目录 一、运行效果二、知识储备(一)Page()函数(二)数据绑定(三)事件绑定(四)事件对象(五)this关键字(六)setData()方法࿰…...
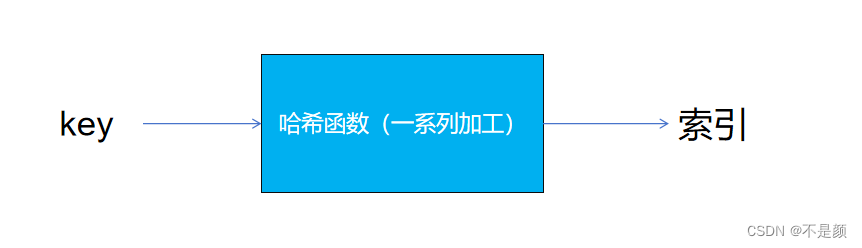
哈希表----数据结构
引入 如果你是一个队伍的队长,现在有 24 个队员,需要将他们分成 6 组,你会怎么分?其实有一种方法是让所有人排成一排,然后从队头开始报数,报的数字就是编号。当所有人都报完数后,这 24 人也被分…...

可达矩阵-邻接矩阵-以及有向图的python绘制
参考1 自定义输入矩阵来绘制 根据参考代码, 自定义 代码如下: # 编程实现有向图连通性的判断 from pylab import mplmpl.rcParams[font.sans-serif] [SimHei] mpl.rcParams[axes.unicode_minus] False import numpy as np import networkx as nx imp…...

react typescript @别名的使用
1、config/webpack.config.js中找到alias,添加: path.resolve(src) ,如下: alias: {// Support React Native Web// https://www.smashingmagazine.com/2016/08/a-glimpse-into-the-future-with-react-native-for-web/"react-native&qu…...

C++性能优化笔记-6-C++元素的效率差异-7-类型转换
C元素的效率差异 类型转换signed与unsigned转换整数大小转换浮点精度转换整数到浮点转换浮点到整数转换指针类型转换重新解释对象的类型const_caststatic_castreinterpret_castdynamic_cast转换类对象 类型转换 在C语法中,有几种方式进行类型转换: // …...

c#中switch常用模式
声明模式 首先检查value的类型,然后根据类型输出相应的消息 public void ShowMessage(object value) {switch (value){case int i: Console.WriteLine($"value is int:{i}"); break;case long l: Console.WriteLine($"value is long:{l}"); b…...

Flink SQL 常用作业sql
目录 flink sql常用配置kafka source to mysql sink窗口函数 开窗datagen 自动生成数据表tumble 滚动窗口hop 滑动窗口cumulate 累积窗口 grouping sets 多维分析over 函数TopN flink sql常用配置 设置输出结果格式 SET sql-client.execution.result-modetableau;kafka source…...
nodejs国内镜像及切换版本工具nvm
淘宝 NPM 镜像站(http://npm.taobao.org)已更换域名,新域名: Web 站点:https://npmmirror.com Registry Endpoint:https://registry.npmmirror.com 详见: 【望周知】淘宝 NPM 镜像换域名了&…...

用Rust和Scraper库编写图像爬虫的建议
本文提供一些有关如何使用Rust和Scraper库编写图像爬虫的一般建议: 1、首先,你需要安装Rust和Scraper库。你可以通过Rustup或Cargo来安装Rust,然后使用Cargo来安装Scraper库。 2、然后,你可以使用Scraper库的Crawler类来创建一个…...

Java 语言环境搭建
JDK 是一种用于构建在 Java 平台上发布的应用程序、Applet 和组件的开发环境,即编写 Java 程序必须使用 JDK,它提供了编译和运行 Java 程序的环境。 在安装 JDK 之前,首先要到 Oracle 网站获取 JDK 安装包。JDK 安装包被集成在 Java SE 中&a…...
酷开科技 | 酷开系统里萌萌哒小维在等你!
在一片金黄淡绿的颜色中,深秋的脚步更近了,在这个气候微凉的季节里,你是不是更想拥有一种温暖的陪伴呢?酷开科技智慧AI语音功能更懂你,贴心的小维用心陪伴你的每一天。 01.全天候陪伴 在酷开系统中,只要你…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...

二维FDTD算法仿真
二维FDTD算法仿真,并带完全匹配层,输入波形为高斯波、平面波 FDTD_二维/FDTD.zip , 6075 FDTD_二维/FDTD_31.m , 1029 FDTD_二维/FDTD_32.m , 2806 FDTD_二维/FDTD_33.m , 3782 FDTD_二维/FDTD_34.m , 4182 FDTD_二维/FDTD_35.m , 4793...

从实验室到产业:IndexTTS 在六大核心场景的落地实践
一、内容创作:重构数字内容生产范式 在短视频创作领域,IndexTTS 的语音克隆技术彻底改变了配音流程。B 站 UP 主通过 5 秒参考音频即可克隆出郭老师音色,生成的 “各位吴彦祖们大家好” 语音相似度达 97%,单条视频播放量突破百万…...