《Python机器学习》基础代码
1,要学习Python机器学习,第一步就是读入数据,这里我们以读入excel的数据为例,利用jupyter notebook来编码,具体教程看这个视频
推荐先上传到jupyter notebook,再用名字.xlsx来导入
Jupyter notebook导入Excel数据的两种方法介绍_哔哩哔哩_bilibili
2,同一目录下的代码互相关联,也就是你在这个项目里import的库或者初始化的变量,可以在下一个项目使用,所以提交单个代码时可能会报错
目录
1,Pandas的数据加工处理
2,空气质量监测数据预处理
3,空气质量检测数据基本分析
1,Pandas的数据加工处理
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df1 = DataFrame({'key':['a','d','c','a','b','d','c'],'var1':range(7)}) #基于字典建立数据框
print('df1的数据:\n{0}'.format(df1))
df2 = DataFrame({'key':['a','b','c','c'],'var2':[0,1,2,2]})
print('df2的数据:\n{0}'.format(df2))
df = pd.merge(df1,df2,on='key',how='outer')
df.iloc[0,2]=np.NaN
df.iloc[5,1]=np.NaN
print('合并后的数据:\n{0}'.format(df))
df = df.drop_duplicates()
print('删除重复数据行后的数据:\n{0}'.format(df))
print('判断是否为缺失值:\n{0}'.format(df.isnull()))
print('判断是否不为缺失值:\n{0}'.format(df.notnull()))
print('删除缺失值后的数据:\n{0}'.format(df.dropna()))
fill_value=df[['var1','var2']].apply(lambda x:x.mean())
print('以均值替代缺失值:\n{0}'.format(df.fillna(fill_value)))1,
第4,6行,字典的优势在于引入键,通过键访问数据更灵活
从数据集的角度,key和var1两个键对应两个变量(即数据集的两个列)
两组值则对应数据集两列的取值
df1行索引取值范围0至6,列索引名为key和var1
注意!基于字典建立数据库的“字典”,各组键的值的个数要相等,否则有些样本观测在某个变量上没有具体取值
2,
第8行,pandas.merge()将两个数据框按指定关键字横向合并,也就是这个关键字这一列合并了,其他不变,但是个数会增多
.iloc[]=numpy.NaN指定样本观测的某变量为NaN,NaN在Numpy表示缺失值,不参与数据建模分析
3,
.drop_duplicates()剔除在所有变量上都重复取值的样本观测
.isnull(),.notnull(),判断是否为NaN,输出True或False
.dropna()剔除取NaN的样本观测
.apply() + lambda计算各变量均值
.apply()实现循环处理,lambda告知了循环处理的步骤
.fillna()将所有NaN替换为指定值
df1的数据:key var1
0 a 0
1 d 1
2 c 2
3 a 3
4 b 4
5 d 5
6 c 6
df2的数据:key var2
0 a 0
1 b 1
2 c 2
3 c 2
合并后的数据:key var1 var2
0 a 0.0 NaN
1 a 3.0 0.0
2 d 1.0 NaN
3 d 5.0 NaN
4 c 2.0 2.0
5 c NaN 2.0
6 c 6.0 2.0
7 c 6.0 2.0
8 b 4.0 1.0
删除重复数据行后的数据:key var1 var2
0 a 0.0 NaN
1 a 3.0 0.0
2 d 1.0 NaN
3 d 5.0 NaN
4 c 2.0 2.0
5 c NaN 2.0
6 c 6.0 2.0
8 b 4.0 1.0
判断是否为缺失值:key var1 var2
0 False False True
1 False False False
2 False False True
3 False False True
4 False False False
5 False True False
6 False False False
8 False False False
判断是否不为缺失值:key var1 var2
0 True True False
1 True True True
2 True True False
3 True True False
4 True True True
5 True False True
6 True True True
8 True True True
删除缺失值后的数据:key var1 var2
1 a 3.0 0.0
4 c 2.0 2.0
6 c 6.0 2.0
8 b 4.0 1.0
以均值替代缺失值:key var1 var2
0 a 0.0 1.4
1 a 3.0 0.0
2 d 1.0 1.4
3 d 5.0 1.4
4 c 2.0 2.0
5 c 3.0 2.0
6 c 6.0 2.0
8 b 4.0 1.02,空气质量监测数据预处理
import numpy as np
import pandas as pd
from pandas import Series,DataFramedata=pd.read_excel('北京市空气质量数据.xlsx') #pandas.read_excel()将excel格式数据读入数据框
data=data.replace(0,np.NaN) #数据框函数.replace(0,numpy.NaN)将0替换为缺失值NaN
data['年']=data['日期'].apply(lambda x:x.year) #.apply(lambda x:x.year)基于'日期'变量得到年份
month=data['日期'].apply(lambda x:x.month)
quarter_month={'1':'一季度','2':'一季度','3':'一季度', #建立一个关于月份和季度的字典quarter_month'4':'二季度','5':'二季度','6':'二季度','7':'三季度','8':'三季度','9':'三季度','10':'四季度','11':'四季度','12':'四季度'}
data['季度']=month.map(lambda x:quarter_month[str(x)]) #month.map(lambda x:quarter_month...)将month中的1,2,3等月份映射到相应季度标签变量
bins=[0,50,100,150,200,300,1000] #生成一个列表bins,用于对后续AQI分组,它描述了AQI和空气质量等级的数值对应关系
data['等级']=pd.cut(data['AQI'],bins,labels=['一级优','二级良','三级轻度污染','四级中度污染','五级重度污染','六级严重污染'])
print('对AQI的分组结果:\n{0}'.format(data[['日期','AQI','等级','季度']])) #pandas.cut()对AQI分组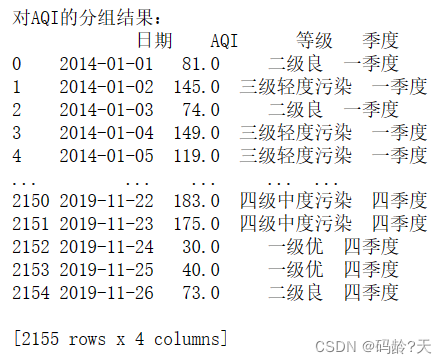
3,空气质量检测数据基本分析
import pandas as pd
data=pd.read_excel('北京市空气质量数据.xlsx') #pandas.read_excel()将Excel格式数据读入数据框
month=data['日期'].apply(lambda x:x.month) #基于日期变量, 得到每个样本观测的月份
quarter_month={'1':'一季度','2':'一季度','3':'一季度','4':'二季度','5':'二季度','6':'二季度','7':'三季度','8':'三季度','9':'三季度', #建立一个关于月份和季度的字典'10':'四季度','11':'四季度','12':'四季度'}
data['季度']=month.map(lambda x:quarter_month[str(x)]) #.map()将序列month中月份映射到对应季度标签上
bins=[0,50,100,150,200,300,1000] #列表bins, 描述AQI
data['等级']=pd.cut(data['AQI'],bins,labels=['一级优','二级良','三级轻度污染','四级中度污染','五级重度污染','六级严重污染'])
print('各季度的AQI和Pm2.5的均值:\n{0}'.format(data.loc[:,['AQI','PM2.5']].groupby(data['季度']).mean()))
print('各季度AQI和PM2.5的描述统计量:\n',data.groupby(data['季度'])['AQI','PM2.5'].apply(lambda x:x.describe()))def top(df, n = 10, column='AQI'):return df.sort_values(by=column, ascending=False)[:n]
print('空气质量最差的5天:\n',top(data,n=5)[['日期','AQI','PM2.5','等级']])
print('各季度空气质量最差3天:\n',data.groupby(data['季度']).apply(lambda x:top(x, n=3)[['日期','AQI','PM2.5','等级']]))
print('各季度空气质量情况:\n',pd.crosstab(data['等级'],data['季度'],margins=True,margins_name='总计',normalize=False))各季度的AQI和Pm2.5的均值:AQI PM2.5
季度
一季度 109.125693 77.083179
三季度 98.731884 49.438406
二季度 108.766972 54.744954
四季度 109.400387 77.046422
各季度AQI和PM2.5的描述统计量:AQI PM2.5
季度
一季度 count 541.000000 541.000000mean 109.125693 77.083179std 80.468322 73.141507min 0.000000 0.00000025% 48.000000 24.00000050% 80.000000 53.00000075% 145.000000 109.000000max 470.000000 454.000000
三季度 count 552.000000 552.000000mean 98.731884 49.438406std 45.637813 35.425541min 0.000000 0.00000025% 60.000000 23.00000050% 95.000000 41.00000075% 130.250000 67.000000max 252.000000 202.000000
二季度 count 545.000000 545.000000mean 108.766972 54.744954std 50.129711 36.094890min 0.000000 0.00000025% 71.000000 27.00000050% 98.000000 47.00000075% 140.000000 73.000000max 500.000000 229.000000
四季度 count 517.000000 517.000000mean 109.400387 77.046422std 84.248549 76.652706min 0.000000 0.00000025% 55.000000 25.00000050% 78.000000 51.00000075% 137.000000 101.000000max 485.000000 477.000000
空气质量最差的5天:日期 AQI PM2.5 等级
1218 2017-05-04 500 0 六级严重污染
723 2015-12-25 485 477 六级严重污染
699 2015-12-01 476 464 六级严重污染
1095 2017-01-01 470 454 六级严重污染
698 2015-11-30 450 343 六级严重污染
各季度空气质量最差3天:日期 AQI PM2.5 等级
季度
一季度 1095 2017-01-01 470 454 六级严重污染45 2014-02-15 428 393 六级严重污染55 2014-02-25 403 354 六级严重污染
三季度 186 2014-07-06 252 202 五级重度污染211 2014-07-31 245 195 五级重度污染183 2014-07-03 240 190 五级重度污染
二季度 1218 2017-05-04 500 0 六级严重污染1219 2017-05-05 342 181 六级严重污染103 2014-04-14 279 229 五级重度污染
四季度 723 2015-12-25 485 477 六级严重污染699 2015-12-01 476 464 六级严重污染698 2015-11-30 450 343 六级严重污染
各季度空气质量情况:季度 一季度 三季度 二季度 四季度 总计
等级
一级优 145 96 38 108 387
二级良 170 209 240 230 849
三级轻度污染 99 164 152 64 479
四级中度污染 57 72 96 33 258
五级重度污染 48 10 14 58 130
六级严重污染 21 0 2 23 46
总计 540 551 542 516 2149pd.get_dummies(data['等级']) #pandas.get_dummies()得到分类型变量等级的虚拟变量
data.join(pd.get_dummies(data['等级'])) #数据框的.join()将原始数据与虚拟变量按行索引横向合并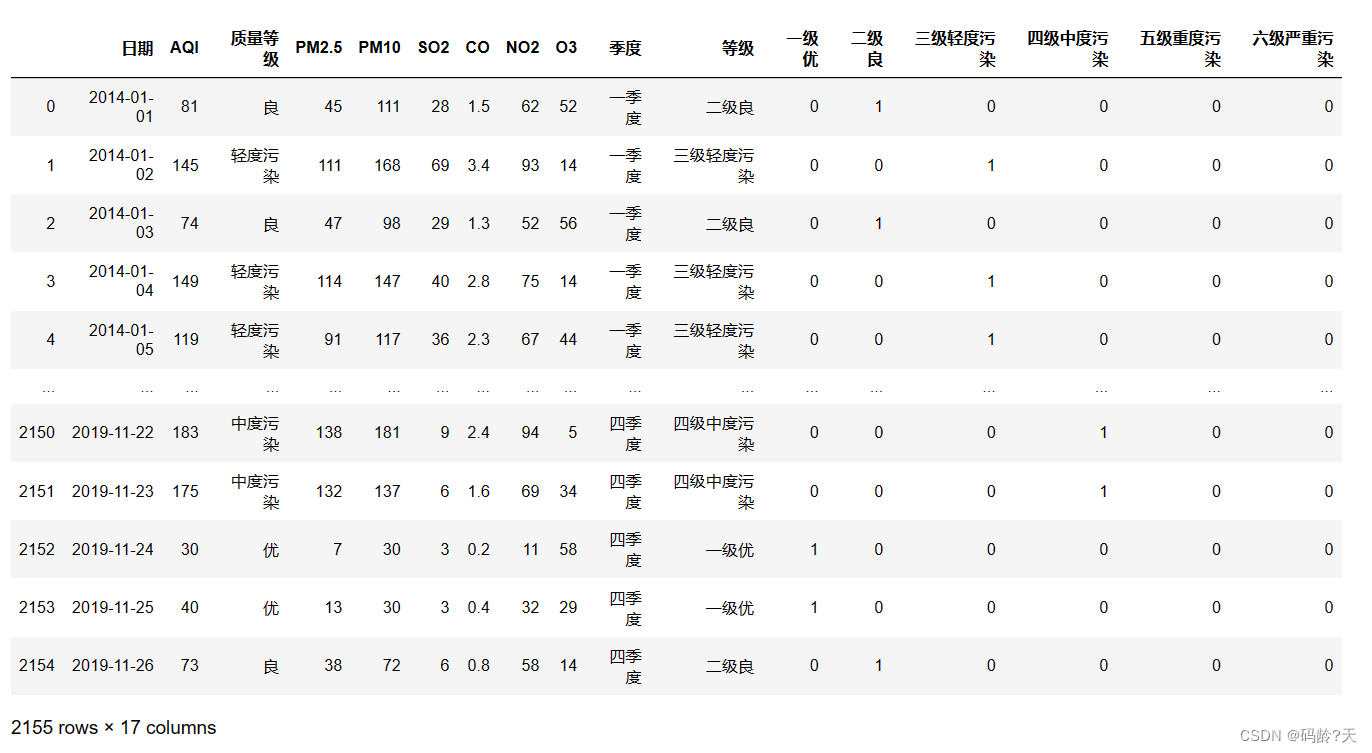
import numpy as np #导入numpy库
np.random.seed(123)#随机数种子
sampler=np.random.randint(0,len(data),10) #numpy.random.randint()指定范围随机抽取指定个数
print(sampler)
sampler=np.random.permutation(len(data))[:10] #numpy.random.permutation()随机打乱重排, 再抽取前10个
print(sampler)data.take(sampler) #数据框.take()基于指定随机数获得数据集的一个随机子集
data.loc[data['质量等级']=='优',:] #数据框访问方式,抽取满足指定条件的行的数据子集
相关文章:
《Python机器学习》基础代码
1,要学习Python机器学习,第一步就是读入数据,这里我们以读入excel的数据为例,利用jupyter notebook来编码,具体教程看这个视频 推荐先上传到jupyter notebook,再用名字.xlsx来导入 Jupyter notebook导入Excel数据的两种方法介绍_哔哩哔哩_bilibili 2,…...

【前端】JS异步加载
文章目录为什么要异步加载如何实现异步加载参考为什么要异步加载 两个原因其实是一个意思。 原因1: JS是单线程的语言,它会同步的执行代码,从上往下执行 但是,一旦网络不好,或要加载的js文件过大的话,会…...

【MySQL】SQL语言的五个部分
DQL 数据查询语言(Data Query Language,DQL):DQL主要用于数据的查询,其基本结构是使用SELECT子句,FROM子句和WHERE子句的组合来查询一条或多条数据。 DML 数据操作语言(Data Manipulation La…...

详细的IO面试题汇总
IO 流简介 IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因此称为 IO 流。IO 流在…...

在Linux终端管理你的密码!
大家好,我是良许。 现在是互联网时代,我们每天都要跟各种 APP 、网站打交道,而这些东西基本上都需要注册才可以使用。 但是账号一多,我们自己都经常记不清对应的密码了。有些小伙伴就一把梭,所有的账号密码都是一样。…...
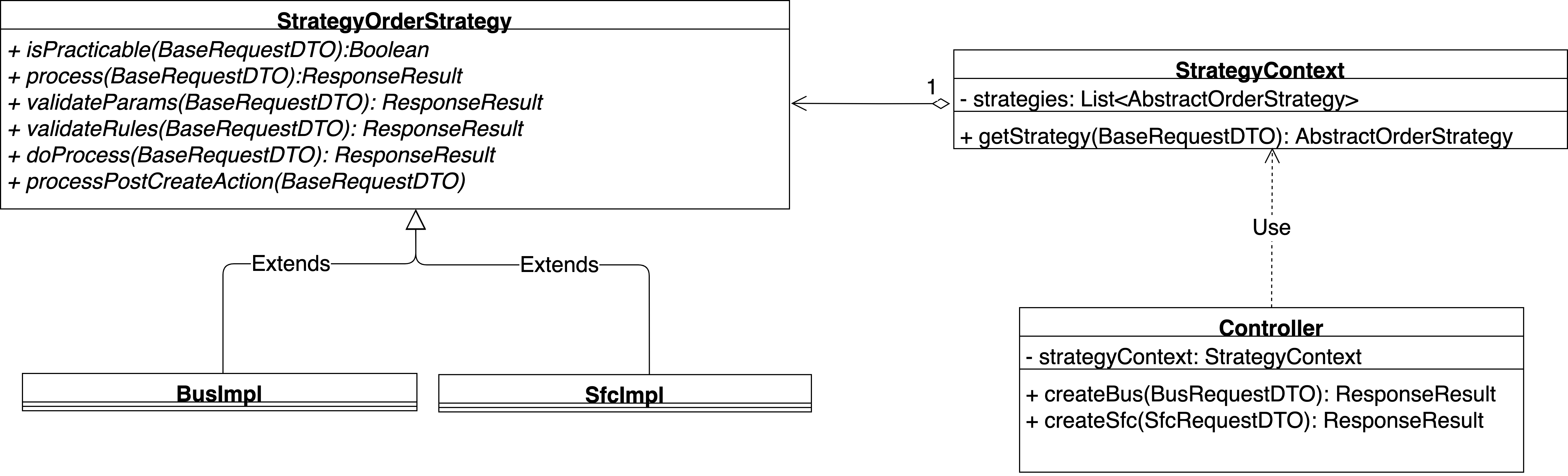
【设计模式】策略模式在Java工程中应用
在之前的文章中,曾经给大家介绍过策略模式:【设计模式】策略模式,在该篇文章中,我们曾很清楚的说到,策略模式主要解决的问题是:在有多种算法相似的情况下,解决使用 if...else 所带来的复杂和难以…...

Linux驱动开发工程师需要掌握哪些技能?
一、前言 Linux驱动开发是一项高度技术性的工作,需要深厚的编程技能和对计算机硬件的深入理解。随着物联网、人工智能等领域的快速发展,Linux驱动开发工程师的需求日益增加。在这篇文章中,我将为您介绍一条Linux驱动开发工程师的学习路线&am…...
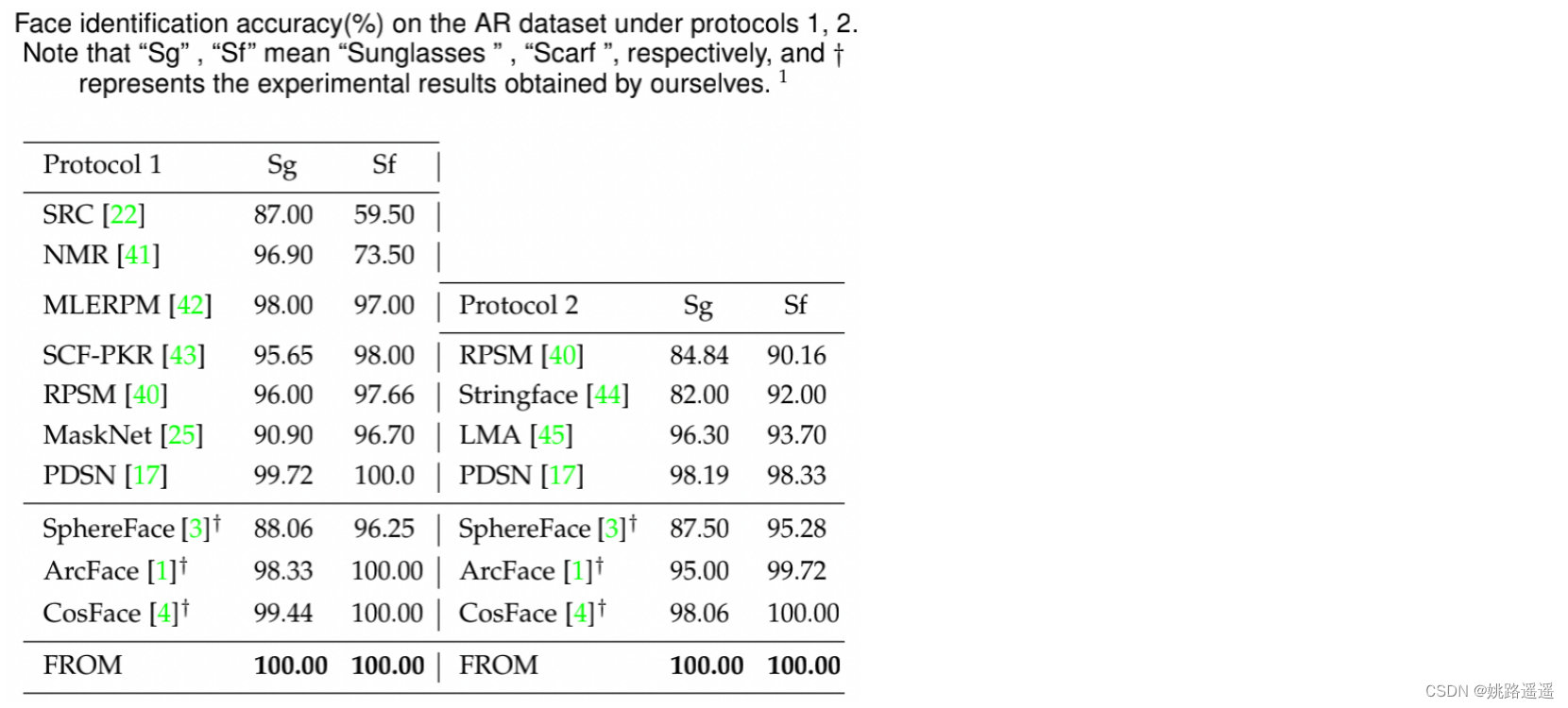
【人脸识别】FROM:提升遮挡状态下的人脸识别效果
论文题目:《End2End Occluded Face Recognition by Masking Corrupted Features》 论文地址:https://arxiv.org/pdf/2108.09468v3.pdf 代码地址:https://github.com/haibo-qiu/from 1.前言 人脸识别技术已经取得了显著的进展,主要…...

浏览器缓存
什么是缓存? 当第一次访问网站的时候,比如www.baidu.com,电脑会图片,文件等下载下来,当第二次访问网站的时候,网站就会直接被加载出来. 缓存的好处? 减轻服务器压力,减少请求的放松.提高性能,在本地打开资源肯定比在服务器上获取要快减少宽带的消耗,当我们使用缓存时,只会…...

【软考 系统架构设计师】论文范文③ 论数据访问层设计技术及其应用
>>回到总目录<< 文章目录 论数据访问层设计技术及其应用范文摘要正文论数据访问层设计技术及其应用 在信息系统的开发与建设中,分层设计是一种常见的架构设计方法,区分层次的目的是为了实现“高内聚低耦合”的思想。分层设计能有效简化系统复杂性,使设计结构清…...

802.11 MCS 的最低SNR分析
常常看到这样的表格: 那么这个SNR如何而来? 看看RSSI和SNR的关系,它们之间隔了一个noise floor。从表格看得出,这个底噪在-80~-90之间。 而SNR的核心,也有类似的原因,它和BER有关。...

用于C++的对象关系映射库—YB.ORM
1 介绍YB.ORM YB.ORM 旨在简化与关系数据库交互的 C 应用程序的开发。 对象关系映射器(ORM) 通过将数据库表映射到类并将表行映射到应用程序中的对象来工作,这种方法可能不是对每个数据库应用程序都是最佳的,但它被证明在需要复杂逻辑和事务处理的应用程…...
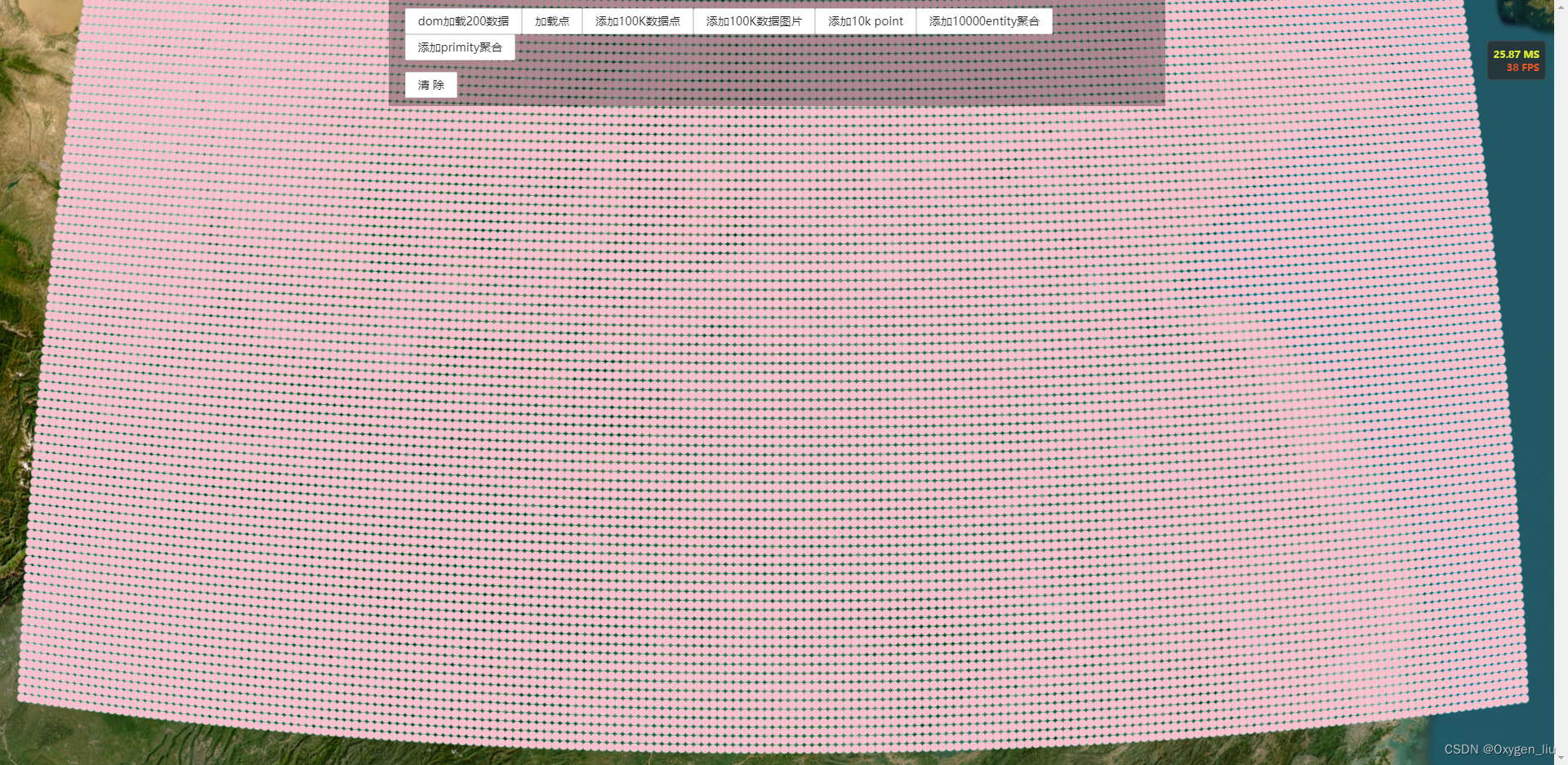
Cesium 100K数据加载 支持弹窗 动态更改位置
前言:今天总结关于point、label、billboard海量数据加载。后续会研究下大量model加载以及大bim(几百G上T)模型记载 海量点加载 弹窗 加载点位时,不加载弹窗。点击点位时在加载弹窗,及有效的减少加载量,优化性能。 const handler …...

MySQL管理表
在创建表时需要提前了解mysql里面的数据类型 常见的数据类型 创建表 创建表方式1: 格式: CREATE TABLE [IF NOT EXISTS] 表名( 字段1, 数据类型 [约束条件] [默认值], 字段2, 数据类型 [约束条件] [默认值], 字段3, 数据类型 [约束条件] [默认值], ………...

【Java 面试合集】打印一个int整数的32位表示
打印一个int整数的32位表示 1. 概述 嗨,大家好【Java 面试合集】又来了,今天给大家分享的主题是打印一个int整数的32位表示. 2. 32位分析 2.1 为什么是32位呢 不知道看到这篇文章的各位是否都知道,一个int类型的表示方式就是32位呢&#x…...
这样在管理后台里实现 403 页面实在是太优雅了
前言403 页面通常表示无权限访问,与 404 页面代表着不同含义。而大部分管理后台框架仅提供了 404 页面的支持,但却忽略了对 403 页面的处理,有的框架虽然也有对 403 页面的处理,但处理效果却不尽人意。那怎么样的 403 页面才是即好…...

c++提高篇——STL常用算法
STL常用算法一、常用遍历算法一、for_each 遍历容器二、transform 搬运容器到另一个容器中二、常用查找算法一、find二、find_if三、adjacent_find四、binary_search五、count六、count_if三、常用排序算法一、sort二、random_shuffle三、 merage四、reverse四、常用拷贝和替换…...
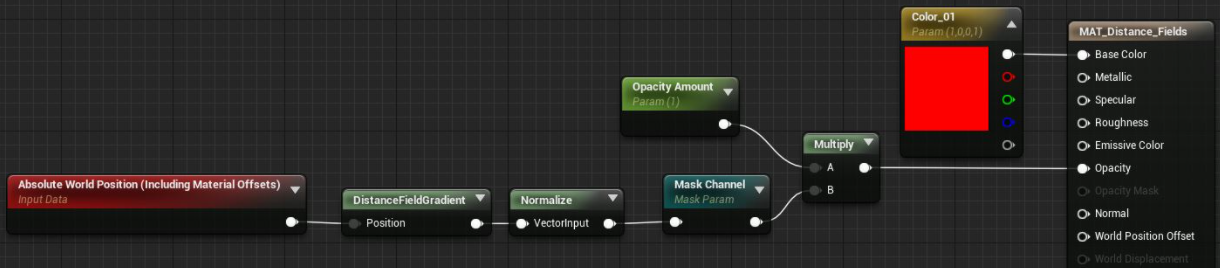
Materials - DistanceField Nodes
以前的相关笔记,归档发布;距离场相关节点:DistanceToNearestSurface节点:求出传入的Position位置到最近的面的距离并输出,在没有Position输入的时候,默认值会直接使用World Position:Position的…...
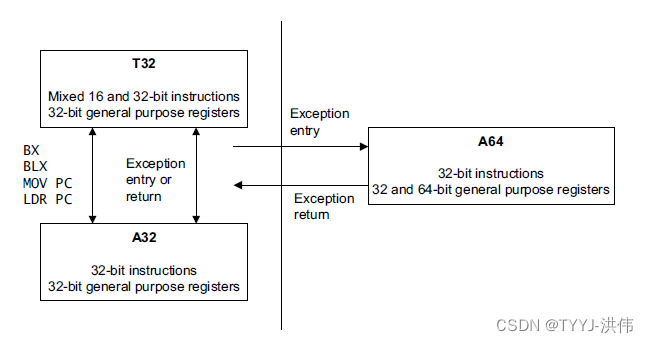
【ARMv8 编程】ARMv8 指令集介绍
ARMv8 架构中引入的最重要的变化之一是增加了 64 位指令集。该指令集补充了现有的 32 位指令集架构。这种增加提供了对 64 位宽整数寄存器和数据操作的访问,以及使用 64 位长度的内存指针的能力。新指令被称为 A64,以 AArch64 执行状态执行。ARMv8 还包括…...
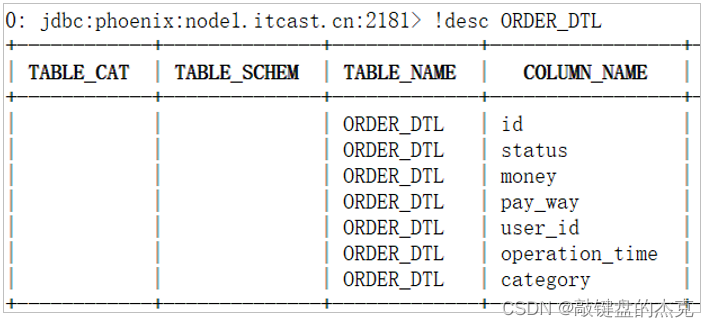
大数据之Phoenix基本介绍
文章目录前言一、Phoenix简介二、Phoenix入门(一)创建表语法(二)查看表信息(三)删除表(四)大小写问题前言 #博学谷IT学习技术支持# 上篇文章介绍了Phoenix环境搭建,点击…...

Qwen3.5-4B-Claude-Opus部署教程:模型路径软链失效时的容错加载机制
Qwen3.5-4B-Claude-Opus部署教程:模型路径软链失效时的容错加载机制 1. 模型概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是基于Qwen3.5-4B的推理蒸馏模型,特别强化了结构化分析、分步骤回答以及代码与逻辑类问题的处理能力。该版本以GG…...

OpenClaw硬件监控:nanobot定时报告系统资源使用情况
OpenClaw硬件监控:nanobot定时报告系统资源使用情况 1. 为什么需要自动化硬件监控 去年夏天,我的开发机因为内存泄漏问题突然宕机,导致一个重要的线上演示被迫推迟。当时我就意识到,手动检查系统资源的方式既不及时也不可靠。直…...

用快马AI快速原型设计:9·1免费素材库管理界面十分钟搭建指南
最近在帮朋友设计一个免费素材库的管理界面,需求是要快速搭建一个能展示"91免费素材"的网页应用。作为一个经常需要验证设计想法的开发者,我发现用InsCode(快马)平台可以大大缩短原型开发时间。下面分享下我是如何在十分钟内完成这个素材库管理…...

通义千问3-Reranker-0.6B优化升级:调整批处理大小和自定义指令,性能再提升5%
通义千问3-Reranker-0.6B优化升级:调整批处理大小和自定义指令,性能再提升5% 1. 为什么需要优化重排序模型性能? 在信息检索和问答系统中,重排序模型扮演着至关重要的角色。它负责对初步检索得到的文档进行二次排序,…...

深入对比:在Vivado中设计异步复位、同步复位和带使能D触发器的实战差异与选型建议
深入对比:在Vivado中设计异步复位、同步复位和带使能D触发器的实战差异与选型建议 当你在设计一个状态机或数据流水线时,是否曾为选择哪种D触发器而犹豫不决?异步复位、同步复位还是带使能的D触发器,每种设计都有其独特的应用场景…...

编译原理避坑指南:自顶向下语法分析的5个常见错误及解决方法
编译原理避坑指南:自顶向下语法分析的5个常见错误及解决方法 第一次接触自顶向下语法分析时,我盯着那个无限循环的递归文法整整三天没想明白——为什么明明按照教材步骤操作,程序却始终报错?直到助教指出我忽略了间接左递归的隐蔽…...

为ROS开发准备:在拯救者Y7000上搭建Win11+Ubuntu22.04双系统全流程
拯救者Y7000 Win11与Ubuntu22.04双系统配置:ROS开发环境搭建实战手册 在机器人操作系统(ROS)开发领域,稳定的Linux环境是必不可少的基石。对于使用拯救者Y7000这类高性能笔记本的开发者而言,如何在保留Windows11系统的…...

智慧生鲜配送:揭秘生鲜配送商城APP功能版块设计
在数字化消费浪潮中,生鲜配送商城APP成为居民采购食材的重要渠道。其功能版块设计聚焦用户需求,通过智能化、便捷化的操作体验,打造高效生鲜购物场景。以下揭秘其核心功能玩法,解析如何实现“从指尖到餐桌”的流畅服务。一、首页&…...

洛谷 P1507:NASA的食物计划 ← 二维费用0/1背包问题
【题目来源】 https://www.luogu.com.cn/problem/P1507 【题目背景】 NASA(美国航空航天局)因为航天飞机的隔热瓦等其他安全技术问题一直大伤脑筋,因此在各方压力下终止了航天飞机的历史,但是此类事情会不会在以后发生࿰…...

海康WEBSDK无插件版实战:零基础构建WEB端网络摄像机实时监控系统
1. 环境准备:5分钟搞定基础配置 第一次接触海康WEBSDK无插件版时,我也被那些专业术语吓到过。但实际操作后发现,只要准备好三样东西就能开工:一台能联网的电脑、海康网络摄像机、以及从官网下载的开发包。这里分享几个新手容易踩的…...