分布式-分布式缓存笔记
分布式系统缓存
缓存分类
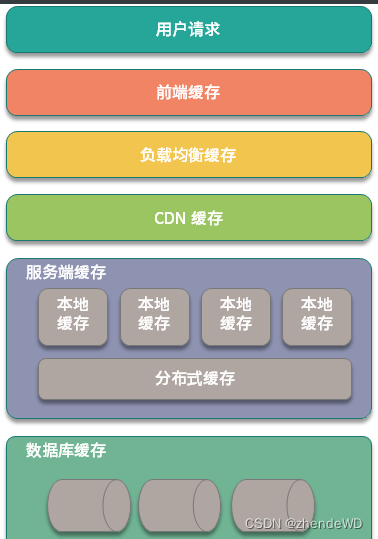
前端缓存
前端缓存包括页面和浏览器缓存,如果是 App,那么在 App 端也会有缓存。当你打开商品详情页,除了首次打开以外,后面重复刷新时,页面上加载的信息来自多种缓存。
页面缓存属于客户端缓存的一种,在第一次访问时,页面缓存将浏览器渲染的页面存储在本地,当用户再次访问相同的页面时,可以不发送网络连接,直接展示缓存的内容,以提升整体性能。
HTML5 支持了本地存储,本地存储包括 localStorage 和 sessionStorage。
- localStorage 没有时间限制,在同一个浏览器中,只要没被手动清理,数据会一直可用。
- sessionStorage 则和 session 的有效期内相关,关闭浏览器页面后缓存会被清空。
除了本地存储,HTML5 还支持离线缓存,也就是 Application Cache 技术,该技术可以实现应用离线的缓存,在暂时断网离线后仍然可以访问页面。
Application Cache 是基于 manifest 文件实现的缓存机制,浏览器会通过这个文件上的清单解析存储资源。
页面缓存一般用于数据更新比较少的数据,不会频繁修改。除了页面缓存,大部分浏览器自身都会实现缓存功能,比如查看某个商品信息,我如果要回到之前的列表页,点击后退功能,就会应用到浏览器缓存;另外对于页面中的图片和视频等,浏览器都会进行缓存,方便下次查看。
前端缓存还有 App 内的缓存,由于 App 是一个单独的应用,各级缓存会更加复杂,在 Android 和 iOS 开发中也有区别。客户端缓存是非常重要的优化手段,在开发中注意避免可能导致的问题就可以。
网络传输缓存
大多数业务请求都是通过 HTTP/HTTPS 协议实现的,它们工作在 TCP 协议之上,多次握手以后,浏览器和服务器建立 TCP 连接,然后进行数据传输,在传输过程中,会涉及多层缓存,比如 CDN 缓存等。
网络中缓存包括 CDN 缓存,CDN(Content Delivery Network,内容分发网络)实现的关键包括 内容存储 和 内容分发 ,
- 内容存储就是对数据的缓存功能
- 内容分发则是 CDN 节点支持的负载均衡。
前端请求在经过 DNS 之后,首先会被指向网络中最近的 CDN 节点,该节点从真正的应用服务器获取资源返回给前端,同时将静态信息缓存。在新的请求过来以后,就可以只请求 CDN 节点的数据,同时 CDN 节点也可以和服务器之间同步更新数据。
网络缓存还包括 负载均衡中的缓存 ,负载均衡服务器主要实现的是请求路由,也就是负载均衡功能;也可以实现部分数据的缓存,比如一些配置信息等很少修改的数据。
目前业务开发中大部分负载均衡都是通过 Nginx 实现的,用户请求在达到应用服务器之前,会先访问 Nginx 负载均衡器。如果发现有缓存信息,则直接返回给用户,如果没有发现缓存信息,那么 Nginx 会 回源 到应用服务器获取信息。
服务端缓存
前端请求经过负载均衡落到 Web 服务器之后,就进入服务端缓存,服务端缓存是缓存的重点,也是业务开发平时打交道最多的缓存。它还可以进一步分为 本地缓存 和 外部缓存 。
- 本地缓存也可以叫作 应用内缓存 ,比如 Guava 实现的各级缓存,或者 Java 语言中使用各类 Map 结构实现的数据存储,都属于本地缓存的范畴。应用内缓存的特点是随着服务重启后失效,作用时间很短,好处是应用比较灵活。
- 外部缓存就是 Redis、Memchaed 等 NoSQL 存储的分布式缓存,它也是在系统设计中对整体性能提升最大的缓存。但如果外部缓存使用不当,则会导致缓存穿透、缓存雪崩等业务问题。
数据库缓存
经过服务端缓存以后,数据其实并不是直接请求数据库持久层,在数据库层面,也可以有多级缓存。
在 Java 开发中,一般使用 MyBatis 或者 Hibernate 作为数据库访问的持久化层,这两个组件中都支持缓存的应用。
以 MyBatis 为例,MyBatis 为每个 SqlSession 都创建了 LocalCache,LocalCache 可以实现查询请求的缓存, 如果查询语句命中了 缓存 , 返回给用户,否则查询数据库, 并且 写入 LocalCache, 返回结果给用户。在实际开发中,数据库持久层的缓存非常容易出现数据不一致的情况,一般不推荐使用。
在数据库执行查询语句时,MySQL 会保存一个 Key-Value 的形式缓存在内存中,其中 Key 是查询语句,Value 是结果集。如果缓存 Key 被命中,则会直接返回给客户端,否则会通过数据库引擎 进行 查询,并且把结果缓存起来,方便下一次调用。虽然 MySQL 支持缓存,但是由于需要保证一致性,当数据有修改时,需要删除缓存。如果是某些更新特别频繁的数据,缓存的有效时间非常短,带来的优化效果并不明显。
避免缓存穿透、缓存击穿、缓存雪崩
缓存穿透
缓存穿透是指业务请求穿过了缓存层,落到持久化存储上。缓存被击穿以后,如果请求量比较大,则会导致数据库出现风险。
以双十一为例,由于各类促销活动的叠加,整体网站的访问量、商品曝光量会是平时的千倍甚至万倍。巨大的流量暴涨,单靠数据库是不能承载的,如果缓存不能很好的工作,可能会影响数据库的稳定性,继而直接影响整体服务。
场景
- 不合理的缓存失效策略
缓存失效策略如果设置不合理,比如设置了大量缓存在同一时间点失效,那么将导致大量缓存数据在同一时刻发生缓存穿透,业务请求直接打到持久化存储层。
- 外部用户的恶意攻击
外部恶意用户利用不存在的 Key,来构造大批量不存在的数据请求我们的服务,由于缓存中并不存在这些数据,因此海量请求全部穿过缓存,落在数据库中,将导致数据库崩溃。
解决
- 缓存空数据。针对数据库不存在的数据,在查询为空时,添加一个对应 null 的值到缓存中,这样在下次请求时,可以通过缓存的结果判断数据库中是否存在,避免反复的请求数据库。不过这种方式,需要考虑空数据的 Key 在新增后的处理。
- 布隆过滤器。布隆过滤器是应用非常广泛的一种数据结构,Bitmap,可以看作是一种特殊的布隆过滤器。使用布隆过滤器,可在缓存前添加一层过滤,布隆过滤器映射到缓存,在缓存中不存在的数据,会在布隆过滤器这一层拦截,从而保护缓存和数据库的安全。
缓存击穿
表现:前端请求大量的访问某个热点 Key,而这个热点 Key 在某个时刻恰好失效,导致请求全部落到数据库上。
二八定律:在任何一组东西中,最重要的只占其中一小部分,约 20%,其余 80% 尽管是多数,却是次要的,因此又称二八定律。
二八定律在缓存应用中也不能避免,往往是 20% 的缓存数据,承担了 80% 或者更高的请求,剩下 80% 的缓存数据,仅仅承担了 20% 的访问流量。
由于二八定律的存在,缓存击穿虽然可能只是一小部分数据失效,但这部分数据如果恰好是热点数据,还是会对系统造成非常大的危险。
缓存雪崩
- 大量的缓存数据在同一时刻失效,请求全部转发到数据库,将导致数据库压力过大,服务宕机;
- 缓存服务不稳定,比如负责缓存的 Redis 集群宕机。
出现缓存雪崩可能会直接导致大规模服务不可用,因为缓存失效时导致的雪崩,一方面是整体的数据存储链路,另一方面是服务调用链路,最终导致微服务整体的对外服务出现问题。
微服务本身就存在雪崩效应,在电商场景中,如果商品服务不可用,最终可能会导致依赖的订单服务、购物车服务、用户浏览等级联出现故障。
避免
- 明确缓存集群的容量峰值,通过合理的限流和降级,防止大量请求直接拖垮缓存;
- 做好缓存集群的高可用,以 Redis 为例,可以通过部署 RedisCluster、Proxy 等不同的缓存集群,来实现缓存集群高可用。
缓存稳定性
首先明确应用缓存的目的,大部分缓存都是内存数据库,并且可以支持非常高的 QPS,所以缓存应用,可以防止海量业务请求击垮数据库,保护正常的服务运行。
其次,在考虑缓存的稳定性时,要从两个方面展开,第一个是缓存的数据,第二个是缓存容器也就是缓存服务本身的稳定性。
缓存命中率:指落到缓存上的请求占整体请求总量的占比。缓存命中率在电商大促等场景中是一个非常关键的指标,要尽可能地提高缓存数据的命中率,一般要求达到 90% 以上,如果是大促等场景,会要求 99% 以上的命中率。
从缓存服务的层面,缓存集群本身也是一个服务,也会有集群部署,服务可用率,服务的最大容量等。在应用缓存时,要对缓存服务进行压测,明确缓存的最大水位,如果当前系统容量超过缓存阈值,就要通过其他的高可用手段来进行调整,比如服务限流,请求降级,使用消息队列等不同的方式。
先更新数据库,还是先更新缓存
数据不一致问题
缓存层和数据库存储层是独立的系统,在数据更新的时候,最理想的情况是缓存和数据库同时更新成功。但由于缓存和数据库是分开的,无法做到原子性的同时进行数据修改,可能出现缓存更新失败,或者数据库更新失败的情况,这时候会出现数据不一致,影响前端业务。
以电商中的商品服务为例,针对 C 端用户的大部分请求都是通过缓存来承载的,假设某次更新操作将商品详情 A 的价格从 1000 元更新为 1200 元,数据库更新成功,但是缓存更新失败。这时候就会出现 C 端用户在查看商品详情时,看到的还是 1000 元,实际下单时可能是别的价格,最终会影响用户的购买决策,影响平台的购物体验。
更新缓存方式
先更新数据库,再更新缓存
在写操作中,先更新数据库,更新成功后,再更新缓存。
问题:数据库更新成功以后,由于缓存和数据库是分布式的,更新缓存可能会失败,就会出现数据库是新的,但缓存中数据是旧的,出现不一致的情况。
先删缓存,再更新数据库
数据更新时,首先删除缓存,再更新数据库,这样可以在一定程度上避免数据不一致的情况。
并发场景,假如某次的更新操作,更新了商品详情 A 的价格,线程 A 进行更新时失效了缓存数据,线程 B 此时发起一次查询,发现缓存为空,于是查询数据库并更新缓存,然后线程 A 更新数据库为新的价格。
在这种并发操作下,缓存的数据仍然是旧的,出现业务不一致。
先更新数据库,再删缓存
缓存 + 数据库读写的模式( Cache Aside 方案)。具体操作是读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应,更新的时候,先更新数据库,数据库更新成功之后再删除缓存。
在 Cache Aside 方案中,调整了数据库更新和缓存失效的顺序,先更新数据库,再失效缓存。
目前大部分业务场景中都应用了读写分离,如果先删除缓存,在读写并发时,可能出现数据不一致。考虑这种情况:
- 线程 A 删除缓存,然后更新数据库主库;
- 线程 B 读取缓存,没有读到,查询从库,并且设置缓存为从库数据;
- 主库和从库同步。
在这种情况下,缓存里的数据就是旧的,所以建议先更新数据库,再失效缓存。当然,在 Cache Aside 方案中,也存在删除缓存失败的可能,因为缓存删除操作比较轻量级,可以通过多次重试等来解决。
缓存更新
为什么删除而不是更新缓存
删除一个数据,相比更新一个数据更加轻量级,出问题的概率更小。
在实际业务中,缓存的数据可能不是直接来自数据库表,也许来自多张底层数据表的聚合。比如上面提到的商品详情信息,在底层可能会关联商品表、价格表、库存表等,如果更新了一个价格字段,那么就要更新整个数据库,还要关联的去查询和汇总各个周边业务系统的数据,这个操作会非常耗时。
从另外一个角度,不是所有的缓存数据都是频繁访问的,更新后的缓存可能会长时间不被访问,所以说,从计算资源和整体性能的考虑,更新的时候删除缓存,等到下次查询命中再填充缓存,是一个更好的方案。
系统设计中有一个思想叫 Lazy Loading,适用于那些加载代价大的操作,删除缓存而不是更新缓存,就是懒加载思想的一个应用。
多级缓存如何更新
多级缓存是系统中一个常用的设计,比如在电商的商品信息展示中,可能会有多级缓存协同。
多级缓存之间同步数据
通过消息队列通知,在数据库更新后,通过事务性消息队列加监听的方式,失效对应的缓存。
多级缓存比较难保证数据一致性,通常用在对数据一致性不敏感的业务中,比如新闻资讯类、电商的用户评论模块等。
失效策略:缓存过期策略
页面置换算法
缓存技术对应到操作系统中,就是缓存页面的调度算法。
在操作系统中,文件的读取会先分配一定的页面空间,也就是Page,使用页面的时候首先去查询空间是否有该页面的缓存,如果有的话,则直接拿出来;否则就先查询,页面空间没有满,就把新页面缓存起来,如果页面空间满了,就删除部分页面,方便新的页面插入。
在操作系统的页面空间中,对应淘汰旧页面的机制不同,有不同页面调度方法,常见的有 FIFO、LRU、LFU 过期策略:
- FIFO(First In First Out,先进先出),根据缓存被存储的时间,离当前最远的数据优先被淘汰;
- LRU(Least Recently Used,最近最少使用),根据最近被使用的时间,离当前最远的数据优先被淘汰;
- LFU(Least Frequently Used,最不经常使用),在一段时间内,缓存数据被使用次数最少的会被淘汰。
内存淘汰策略
操作系统的页面置换算法,对应到分布式缓存中,就是缓存的内存淘汰策略,这里以 Redis 为例。当 Redis 节点分配的内存使用到达最大值以后,为了继续提供服务,Redis 会启动内存淘汰策略:
- noeviction,默认的策略,对于写请求会拒绝服务,直接返回错误,这种策略下可以保证数据不丢失;
- allkeys-lru,这种策略操作的范围是所有 key,使用 LRU 算法进行缓存淘汰;
- volatile-lru,这种策略操作的范围是设置了过期时间的 key,使用 LRU 算法进行淘汰;
- allkeys-random,这种策略下操作的范围是所有 key,会进行随机淘汰数据;
- volatile-random,这种策略操作的范围是设置了过期时间的 key,会进行随机淘汰;
- volatile-ttl,这种策略操作的范围是设置了过期时间的 key,根据 key 的过期时间进行淘汰,越早过期的越优先被淘汰。
缓存过期策略
内存淘汰是缓存服务层面的操作,过期策略定义的是具体缓存数据何时失效。
Redis 是 key-value 数据库,可以设置缓存 key 的过期时间,过期策略就是指当 Redis 中缓存的 key 过期了,Redis 如何处理。
- 定时过期
为每个设置过期时间的 key 都需要创建一个定时器,到过期时间就会立即清除。这种方式可以立即删除过期数据,避免浪费内存,但是需要耗费大量的 CPU 资源去处理过期的数据,可能影响缓存服务的性能。
- 惰性过期
可以类比懒加载的策略,这个就是懒过期,只有当访问一个 key 时,才会判断该 key 是否已过期,并且进行删除操作。这种方式可以节省 CPU 资源,但是可能会出现很多无效数据占用内存,极端情况下,缓存中出现大量的过期 key 无法被删除。
- 定期过期
这种方式是上面方案的整合,添加一个即将过期的缓存字典,每隔一定的时间,会扫描一定数量的 key,并清除其中已过期的 key。
合理的缓存配置,需要协调内存淘汰策略和过期策略,避免内存浪费,同时最大化缓存集群的吞吐量。另外,Redis 的缓存失效有一点特别关键,那就是如何避免大量主键在同一时间同时失效造成数据库压力过大的情况。
实现一个 LRU 缓存
在 Java 语言中实现 LUR 缓存,可以直接应用内置的 LinkedHashMap,重写对应的 removeEldestEntry() 方法,代码如下:
public class LinkedHashMapExtend extends LinkedHashMap { private int cacheSize; public LinkedHashMapExtend(int cacheSize){ super(); this.cacheSize=cacheSize; } @Override public boolean removeEldestEntry(Map.Entry eldest) { //重写移除逻辑 if(size()>cacheSize){ return true; } return false; } }
LinkedHashMap 的源码实现,在原生的 removeEldestEntry 实现中,默认返回了 false,也就是永远不会移除最“早”的缓存数据,只要扩展这个条件,缓存满了移除最早的数据,就实现了一个 LRU 策略.
使用原生的 Map 和双向链表来实现。
import java.util.HashMap; public class LRUCache { private int cacheSize; private int currentSize; private CacheNode head; private CacheNode tail; private HashMap<Integer,CacheNode> nodes; class CacheNode{ CacheNode prev; CacheNode next; int key; int value; } public LRUCache(int cacheSize){ cacheSize=cacheSize; currentSize=0; nodes=new HashMap<>(cacheSize); } public void set(Integer key,Integer value){ if(nodes.get(key)==null){ //添加新元素 CacheNode node=new CacheNode(); node.key=key; node.value=value; nodes.put(key,node); //移动到表头 moveToHead(node); //进行lru操作 if(currentSize>cacheSize) removeTail(); else currentSize++; }else{//更新元素值 CacheNode node=nodes.get(key); //移动到表头 moveToHead(node); node.value=value; } } private void removeTail() { if(tail!=null){ nodes.remove(tail.key); if(tail.prev!=null) tail.prev.next=null; tail=tail.prev; } } private void moveToHead(CacheNode node){ //链表中间的元素 if(node.prev!=null){ node.prev.next=node.next; } if(node.next!=null){ node.next.prev=node.prev; } //移动到表头 node.prev=null; if(head==null){ head=node; }else{ node.next=head; head.prev=node; } head=node; //更新tail //node就是尾部元素 if(tail==node){ //下移一位 tail=tail.prev; } //缓存里就一个元素 if(tail==null){ tail=node; } } public int get(int key){ if(nodes.get(key)!=null){ CacheNode node=nodes.get(key); moveToHead(node); return node.value; } return 0; } }
负载均衡:一致性哈希解决问题
高可用最常用的手段就是集群扩展。
缓存的集群高可用
目前 Redis 流行的集群方案有 官方 Cluster 方案、twemproxy 代理方案、哨兵模式、Codis 等方案。
缓存服务从单点扩展到集群以后,会产生缓存数据的分发问题,假设我们的缓存服务器有 3 台,每台缓存的数据是不相同的,那么在更新缓存时,放置在哪台机器上呢?根据 key 获取缓存时,该从哪台服务器上获取?这就涉及缓存的负载均衡策略。
关于缓存集群高可用的配置方式,有数据同步和不同步之分。
- 数据同步,所有节点之间数据都是一样的,不同节点互为副本,这种方式不需要关心缓存数据的分发,实现了缓存集群的最大可用,但是由于冗余了多份缓存数据,会造成比较多的服务器资源浪费;另外一方面,在更新缓存数据时,还要考虑不同节点之间的一致性。
- 数据不同步,就是每个缓存节点存储的数据不同,在缓存读写时使用一定的策略进行分发。在实际开发中,大部分都是应用数据不同步的方案,如果需要冗余数据,则可以通过缓存集群主从同步实现。
不同路由方案的扩容问题
哈希取模路由
最常见的方式是对缓存数据进行哈希,典型的操作就是通过对缓存 hash(缓存 Key)/ 节点数量。
假设我们有 5 台缓存服务器,伪代码如下:
//获取缓存服务器下标 public Integer getRoute(String key){ int cacheIndex = key.hashcode() % 5; return cacheIndex; }
哈希取模的方式,适合对固定数量的缓存集群进行路由,但是对横向扩展不友好。如果缓存机器数量发生变更过,比如从 5 台服务器调整为 10 台服务器,原来的缓存数据无法分配到正确机器,就会出现路由不正确,从而业务请求直接落到数据库上。
一致性哈希
在负载均衡策略中,可以应用一致性哈希,减少节点扩展时的数据失效或者迁移的情况。
一致性哈希是一种特殊的哈希算法。在使用一致性哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中 K 是关键字的数量,n 是槽位数量。然而在传统的哈希表中,添加或删除一个槽位几乎需要对所有关键字进行重新映射。
一致性哈希通过一个哈希环实现,Hash 环的基本思路是获取所有的服务器节点 hash 值,然后获取 key 的 hash,与节点的 hash 进行对比,找出顺时针最近的节点进行存储和读取。
以电商中的商品数据为例,假设我们有 4 台缓存服务器:
- A 服务器,地址 hash 结果是 100
- B 服务器,地址 hash 结果是 200
- C 服务器,地址 hash 结果是 300
- D 服务器,地址 hash 结果是 400
现在有某条数据的 Key 进行哈希操作,得到 200,则存储在 B 服务器;某条数据的 Key 进行哈希操作,得到 260,则存储在 C 服务器;某条数据的 Key 进行哈希操作,得到 500,则存储在 A 服务器。
一致性哈希算法在扩展时,只需要迁移少量的数据就可以。例如,我们刚才的例子中,如果 D 服务器下线,原先路由到 D 服务器的数据,只要顺时针迁移到 A 服务器就可以,其他服务器不受影响,我们只需要移动一台机器的数据即可。
问题:数据倾斜。
假设有 A、B、C 一直到 J 服务器,总共 10 台,组成一个哈希环。如果从 F 服务器一直到 J 服务器的 5 个节点宕机,那么这 5 台服务器原来的访问,都会被转移到服务器 A 之上,服务器的流量可能是原来的 5 倍或者更高,直到把服务器 A 打爆,这时候流量继续转移到 B 服务器,就出现缓存雪崩。
解决: 一个方案就是添加虚拟节点,对服务器节点也进行哈希操作,在整个哈希环上,均匀添加若干个节点。比如 a1 和 a2 都属于 A 节点,b1、b2 都属于 B 节点,这样在哈希时可以平衡各个节点的数据。
TreeMap 基于红黑树实现,元素默认按照 keys 的自然排序排列,对外开放了一个 tailMap(K fromKey) 方法,该方法可以返回比 fromKey 顺序的下一个节点,大大简化了一致性哈希的实现。
缓存高可用
Redis 的主从复制
集群实现依靠副本,副本之间的快速数据同步–主从复制。
Redis 的主从复制,可以将一台服务器的数据复制到其他节点,在 Redis 中,任何节点都可以成为主节点,通过 Slaveof 命令可以开启复制。
- 数据备份,通过实现主从节点之间的最终数据一致性,保证数据尽量不丢失。
- 读写分离,主节点作为写节点,从节点支持读请求。当主节点的系统水位不能承担前台业务请求并发量时,可以将请求路由到从节点,实现集群内的动态均衡。
Redis 的主从复制选举
当主节点发生故障宕机,需要运维工程师手动从从节点服务器列表中,选择一个晋升为主节点,并且需要更新上游客户端的配置。
在 Redis 集群中,依赖 Sentinel自动实现 Failover,也就是自动故障转移 。
Redis Sentinel——Redis 哨兵
主从复制场景,就可以依赖 Sentinel 进行集群监控。
Redis-Sentinel 是一个独立运行的进程,假如主节点宕机,它还可以进行主从之间的切换。主要实现了以下的功能:
- 不定期监控 Redis 服务运行状态
- 发现 Redis 节点宕机,可以通知上游的客户端进行调整
- 当发现 Master 节点不可用时,可以选择一个 Slave 节点,作为新的 Master 机器,并且更新集群中的数据同步关系
Sentinel 也存在单点问题,如果 Sentinel 宕机,高可用也就无法实现了,所以,Sentinel 必须支持集群部署。
Redis Sentine 方案是一个包含了多个 Sentinel 节点,以及多个数据节点的分布式架构。除了监控 Redis 数据节点的运行状态,Sentinel 节点之间还会互相监控,当发现某个 Redis 数据节点不可达时,Sentinel 会对这个节点做下线处理,如果是 Master 节点,会通过投票选择是否下线 Master 节点,完成故障发现和故障转移。
Sentinel 在操作故障节点的上下线时,还会通知上游的业务方,整个过程不需要人工干预,可以自动执行。
Redis Cluster 集群
Redis Cluster
官方的集群方案,是一种无中心的架构,可以整体对外提供服务。
在 Redis Cluster 集群中,所有 Redis 节点都可以对外提供服务,包括路由分片、负载信息、节点状态维护等所有功能都在 Redis Cluster 中实现。
Redis 各实例间通过 Gossip 通信,架构清晰、依赖组件少,方便横向扩展,有资料介绍 Redis Cluster 集群可以扩展到 1000 个以上的节点。
Redis Cluster 客户端直接连接服务器,避免了各种 Proxy 中的性能损耗,可以最大限度的保证读写性能。
Codis 方案
Codis 的实现和 Redis Cluster 不同,是一个“中心化的结构”,同时添加了 Codis Proxy 和 Codis Manager。Codis 设计中,是在 Proxy 中实现路由、数据分片等逻辑,Redis 集群作为底层的存储引擎,另外通过 ZooKeeper 维护节点状态。
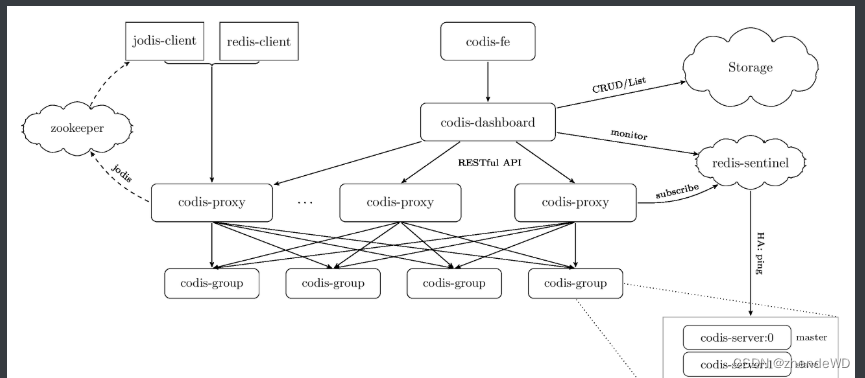
Codis 和官方的 Redis Cluster 实现思路截然不同,使用 Redis Cluster 方式,数据不经过 Proxy 层,直接访问到对应的节点。
Redis Cluster 划分了 16384 个槽位,每个节点负责其中的一部分数据,都会存储槽位的信息,当客户端链接时,会获得槽位信息。如果需要访问某个具体的数据 Key,就可以根据本地的槽位来确定需要连接的节点。
Redis Cluster 16384 个槽位。
相关文章:
分布式-分布式缓存笔记
分布式系统缓存 缓存分类 前端缓存 前端缓存包括页面和浏览器缓存,如果是 App,那么在 App 端也会有缓存。当你打开商品详情页,除了首次打开以外,后面重复刷新时,页面上加载的信息来自多种缓存。 页面缓存属于客户端…...

【反序列化漏洞-01】为什么要序列化
为什么要序列化百度百科上关于序列化的定义是,将对象的状态信息转换为可以存储或传输的形式(字符串)的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区(非关系型键值对形式的数据库Redis,与数组类似)。以后,可以通过…...

用c语言模拟实现常用字符串函数
目录 一.常用字符串函数介绍 1.strlen 2. strcpy 3.strcmp 4.strcat 5.strstr 二.模拟实现常用字符串函数 1.strlen 2.strcpy 3.strcmp 4.strcat 5.strstr 一.常用字符串函数介绍 1.strlen 字符串strlen是用来求字符串长度的,我们可以打开cpp网站查看有关…...
在 Flutter 中使用 webview_flutter 4.0 | 基础用法与事件处理
大家好,我是 17。 Flutter WebView 一共写了四篇文章 在 Flutter 中使用 webview_flutter 4.0 | 基础用法与事件处理在 Flutter 中使用 webview_flutter 4.0 | js 交互Flutter WebView 性能优化,让 h5 像原生页面一样优秀,已入选 掘金一周 …...
JavaWeb--Servlet
Servlet1 简介2 快速入门3 执行流程4 生命周期5 方法介绍6 体系结构7 urlPattern配置8 XML配置目标: 理解Servlet的执行流程和生命周期掌握Servlet的使用和相关配置 1 简介 Servlet是JavaWeb最为核心的内容,它是Java提供的一门动态web资源开发技术。 使…...
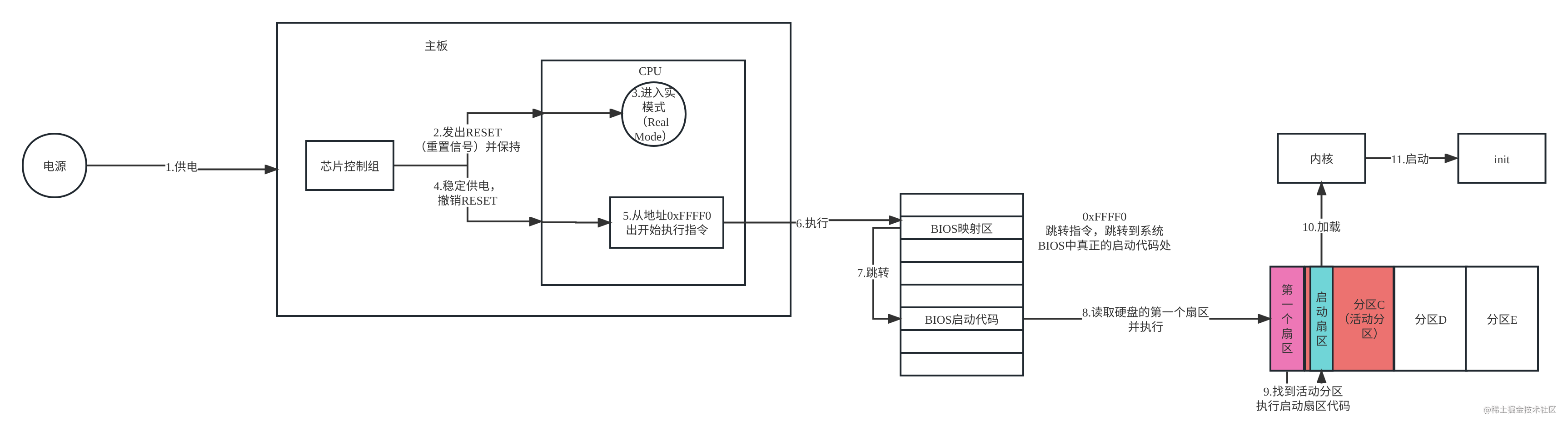
Linux启动过程
theme: channing-cyan 两种启动方式 传统启动方式(LEGACYMBR) 指传统BIOS启动方式,存在一些不足:比如最大只支持2TB磁盘,磁盘最多四个分区,且不支持图形操作 UEFIGPT方式 是新式的启动方式,…...

面试资料整理——C++
C/C难题的高赞回答「中文版」 https://mp.weixin.qq.com/s/KBEnrRVb1T6LfwHgaB4jiQ C/C难题的高赞回答「中文版」,帮你整理好了 https://mp.weixin.qq.com/s/o9MdENiasolVT-Fllag2_Q C语言与C面试知识总结 https://mp.weixin.qq.com/s/MGSoPqPv_OzyWBS5ZdnZgw 程…...
【ArcGIS Pro二次开发】(9):GeoProcessing工具和自定义工具的调用
ArcGIS Pro自带了1000种以上的GeoProcessing工具,几乎可以实现所有你想要做的事。 ArcGIS Pro的二次开发并不需要我们从底层做起,很多功能只要学会调用工具并组合使用,就完全可以实现。 下面介绍如何调用系统自带的GeoProcessing工具&#x…...

皕杰报表斜线单元格、图表里或导出pdf的中文显示小方块解决方案
在皕杰报表中,如果含有斜线的单元格、统计图的报表、或导出pdf时,汉字变成小方框,这往往是服务器端操作系统的中文安装包没有装全,导致报表里用到的字体在服务器端的操作系统里找不到,因此成了小方块。因为斜线单元格里…...

python读写hdfs文件的实用解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理…...

RK3399+FPGA+MIPI 方案细节之subLVDS to MIPI处理
#CROSSLINK系列 #CROSSLINK vs XO3L 总的来说XO3L的灵活性更强,更近似于一片通用的CPLD;CROSSLINK专用性更强。 针对subLVDS转换到MIPI的需求,CROSSLINK比较有优势,因为集成度更高,所以稳定性也更高。 #要点 #crossl…...
Vue组件是怎样挂载的
我们先来关注一下$mount是实现什么功能的吧: 我们打开源码路径core/instance/init.js: export function initMixin (Vue: Class<Component>) {......initLifecycle(vm)// 事件监听初始化initEvents(vm)initRender(vm)callHook(vm, beforeCreate)initInject…...

gcc: 编译选项:-fdelete-null-pointer-checks、-fno-delete-null-pointer-checks
文章目录 说明实例:Linux 里的使用chatGPT说明 这个说明写的有些理解不了,可能还是不太理解(有未知的东西在里面?)。但是从这个编译选项的命名上来看还是非常明确,就是删除不必要的空指针检查。使用时要小心了,这个优化超出了编译的界限! -fdelete-null-pointer-check…...
周赛334(前缀和、贪心+双指针、Dijkstra求最短路径、二分答案)
文章目录[6369. 左右元素和的差值](https://leetcode.cn/problems/left-and-right-sum-differences/)前缀和[6368. 找出字符串的可整除数组](https://leetcode.cn/problems/find-the-divisibility-array-of-a-string/)超长整数如何取余?[6367. 求出最多标记下标](ht…...

imx6ull——I2C驱动
I2C基本介绍 SCL 为高电平,SDA 出现下降沿:起始位 SCL 位高电平,SDA出现上升沿:停止位 主机——从机地址(ack)——寄存器地址(ack)——数据(ack) 重点:先是写,…...
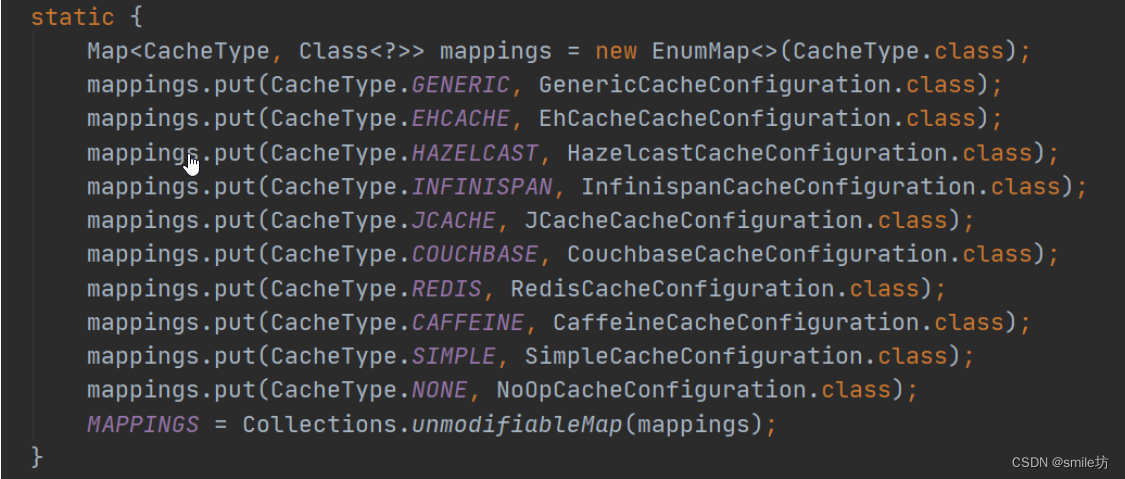
Spring Cache的基本使用与分析
概述 使用 Spring Cache 可以极大的简化我们对数据的缓存,并且它封装了多种缓存,本文基于 redis 来说明。 基本使用 1、所需依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-…...
【安全知识】——端口复用隐藏后门
作者名:白昼安全主页面链接: 主页传送门创作初心: 以后赚大钱座右铭: 不要让时代的悲哀成为你的悲哀专研方向: web安全,后渗透技术每日鸡汤: 精彩的人生是在有限的生命中实现无限价值端口复用是…...

Tina_Linux量产测试使用指南_new
OpenRemoved_Tina_Linux_量产测试_使用指南_new 1 概述 文档主要描述如何配置tinatest 并搭建量产测试环境。 1.1 编写目的 • 介绍量产配置方法; • 介绍量产测试环境搭建流程; • 介绍如何使用dragonMAT 软件; • 方便开发人员按照说明…...
STC32单片机 普通 I/O 口中断功能介绍和使用
STC32单片机 普通 I/O 口中断功能和使用✨STC32单片机普通 I/O 口中断,不是传统外部中断. 🔖手册上描述:STC32G 系列支持所有的 I/O 中断,且支持 4 种中断模式:下降沿中断、上升沿中断、低电平中断、高电平中断。每组 …...

计算机学生如何找到第一份实习?
作为一名计算机专业的学生,找到第一份实习是非常重要的一步,它不仅可以帮助你更好地了解行业,增加实践经验,还可以为即将到来的校招提供有力支持。计算机专业的校招,每年都在变得越来越卷。5年前,可能你只要…...
+情感韵律自然表达展示)
Qwen3-TTS语音合成惊艳效果:中文方言(粤语/川话)+情感韵律自然表达展示
Qwen3-TTS语音合成惊艳效果:中文方言(粤语/川话)情感韵律自然表达展示 1. 引言:当AI开口说方言,声音有了“灵魂” 想象一下,你正在开发一款面向全国用户的智能助手。当一位广东用户用粤语问“今日天气点样…...
)
实战避坑:YOLOv8训练某盾验证码障碍物检测模型(附完整数据集处理技巧)
基于YOLOv8的验证码障碍物检测实战指南 验证码识别一直是自动化领域的热门话题,而其中障碍物检测更是验证码破解的关键环节。本文将深入探讨如何利用YOLOv8这一前沿目标检测技术,高效解决验证码中的障碍物识别问题,并提供完整的数据集处理流程…...

STM32CubeIDE开发环境全攻略:从安装配置到高效开发
1. STM32CubeIDE开发环境概述 第一次接触STM32CubeIDE时,我被它的集成度惊艳到了。作为ST官方推出的免费开发工具,它完美融合了STM32CubeMX的图形化配置功能和Eclipse的强大代码编辑能力。相比传统的Keil或IAR,最大的优势就是一站式开发体验—…...

小白也能画火影:忍者绘卷Z-Image Turbo零基础入门到出图
小白也能画火影:忍者绘卷Z-Image Turbo零基础入门到出图 1. 为什么选择忍者绘卷Z-Image Turbo? 想画出专业级的火影忍者同人图却苦于不会画画?忍者绘卷Z-Image Turbo就是为你量身打造的AI绘画神器。这个基于Tongyi-MAI Z-Image底座的二次元…...
全攻略:从零基础到持证通关,附行业前瞻与实战秘籍)
2026最新Oracle Java认证(OCA/OCP)全攻略:从零基础到持证通关,附行业前瞻与实战秘籍
在Java开发领域,Oracle Java认证(OCA/OCP)始终是衡量开发者专业能力的“黄金标准”——OCA作为Java入门的权威敲门砖,夯实核心语法与基础素养;OCP作为进阶认证,彰显高级特性应用与实战开发能力,…...

Agentic Model实践:2026年,DeepMiner如何实现企业级可信智能体的数据全流程透明化?
代理式人工智能(Agentic AI)标志着AI从“被动的文本生成器”向“主动的任务执行者”的范式跃迁。与依赖单一指令的传统大语言模型(LLM)不同,代理式AI能够感知环境、规划复杂任务、调用工具、并基于反馈持续迭代&#x…...

构建智能问答系统:NLP-StructBERT与MySQL数据库的协同应用
构建智能问答系统:NLP-StructBERT与MySQL数据库的协同应用 你有没有遇到过这种情况?公司内部的知识库文档堆积如山,新员工问个问题,老员工得翻半天才能找到答案;或者你的产品客服每天要重复回答几百遍相同的问题&…...

从USBPcap驱动冲突到KMODE_EXCEPTION_NOT_HANDLED:一次Win11蓝屏的深度内核调试与修复实录
1. 当Win11突然蓝屏时发生了什么 那天早上我刚按下电源键,熟悉的Windows徽标还没完全显示出来,屏幕突然变成一片蓝色。这种蓝屏死机(BSOD)对Windows用户来说并不陌生,但这次出现的错误代码KMODE_EXCEPTION_NOT_HANDLED…...

EmbeddingGemma-300m开源可部署:Ollama镜像适配Apple M系列芯片原生运行教程
EmbeddingGemma-300m开源可部署:Ollama镜像适配Apple M系列芯片原生运行教程 1. 教程概述与价值 EmbeddingGemma-300m是谷歌推出的轻量级嵌入模型,专门为设备端部署优化。这个3亿参数的模型基于先进的Gemma 3架构,能够将文本转换为高质量的…...

ECharts异常检测实战指南:从数据噪声中挖掘关键信息
ECharts异常检测实战指南:从数据噪声中挖掘关键信息 【免费下载链接】echarts ECharts 是一款基于 JavaScript 的开源可视化库,提供了丰富的图表类型和交互功能,支持在 Web、移动端等平台上运行。强大的数据可视化工具,支持多种图…...