Java高级-集合-Collection部分

本篇讲解java集合
集合
集合框架的概述
-
集合、数组都是对多个数据进行存储操作的结构,简称
Java容器。说明:此时的存储,主要指的是内存层面的存储,不涉及到持久化的存储(.txt,.jpg,.avi,数据库中)
-
数组的缺陷
-
数组在存储多个数据方面的特点
- 一旦初始化以后,其长度就确定了。
- 数组一旦定义好,其元素的类型也就确定了。我们也就只能操作指定类型的数据了。
-
数组在存储多个数据方面的缺点
-
一旦初始化以后,其长度就不可修改。
-
数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。
-
获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用
-
数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足。
-
-
Java 集合可分为 Collection 和 Map 两种体系
Collection
|----Collection接口:单列集合,用来存储一个一个的对象|----List接口:存储有序的、可重复的数据。 -->“动态”数组|----ArrayList、LinkedList、Vector|----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”|----HashSet、LinkedHashSet、TreeSet|----Map接口:双列集合,用来存储一对(key - value)一对的数据 -->高中函数:y = f(x)|----HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
Collection接口方法测试
- 添加
add(Object obj)addAll(Collection coll)
- 获取有效元素的个数
int size()
- 清空集合
void clear()
- 是否是空集合
boolean isEmpty()
- 是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否是同一个对象boolean containsAll(Collection c):也是调用元素的equals方法来比较的。拿两个集合的元素挨个比较。
- 删除
boolean remove(Object obj):通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素boolean removeAll(Collection coll):取当前集合的差集
- 取两个集合的交集
boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响c
- 集合是否相等
boolean equals(Object obj)
- 转成对象数组
Object[] toArray()
- 获取集合对象的哈希值
hashCode()
- 遍历
iterator():返回迭代器对象,用于集合遍历
方法示例,这里我们使用ArrayList来作演示
Collection coll = new ArrayList();//add(Object e):将元素e添加到集合coll中
coll.add("AA");
coll.add("BB");
coll.add(123);//自动装箱
coll.add(new Person("琪亚娜", 20));//Person是自定义的一个类//size():获取添加的元素的个数
System.out.println(coll.size());//4//addAll(Collection coll1):将coll1集合中的元素添加到当前的集合中
Collection coll1 = new ArrayList();
coll1.add(456);
coll1.add("CC");
coll.addAll(coll1);System.out.println(coll.size());//6
System.out.println(coll);//[AA, BB, 123, Wed Feb 08 16:40:55 CST 2023, 456, CC]//clear():清空集合元素
coll.clear();//isEmpty():判断当前集合是否为空
System.out.println(coll.isEmpty());//true//contains(Object obj):判断obj是否存在于集合中
System.out.println(coll.contains(new Person("hengxing",18)));//true,因为我们重写了Person的equals方法//containsAll(Collection coll1):判断形参coll1中的所有元素是否都存在于当前集合中。
Collection coll2 = Arrays.asList("hello", 123, new Person("琪亚娜", 20));
System.out.println(coll.containsAll(coll2));//true
System.out.println(coll);//[123, hello, 17:24, 456, Person{name='琪亚娜', age=20}]//remove(Object obj):从当前集合中移除obj元素。
coll.remove("hello");
System.out.println(coll);//[123, 17:24, 456, Person{name='琪亚娜', age=20}]//removeAll(Collection coll1):差集:从当前集合中移除coll2中所有的元素。
Collection coll2 = Arrays.asList("hello", 123, new Person("琪亚娜", 20));
coll.removeAll(coll2);
System.out.println(coll);//[17:24, 456]//retainAll(Collection coll1):交集:获取当前集合和coll1集合的交集,并返回给当前集合
Collection coll1 = new ArrayList();
coll1.add(123);
coll1.add("hello");
coll.retainAll(coll1);
System.out.println(coll);//equals(Object obj):要想返回true,需要当前集合和形参集合的元素都相同。
//此时,coll1是一个和coll集合完全相同的集合
System.out.println(coll.equals(coll1));//true//hashCode():返回当前对象的哈希值
System.out.println(coll.hashCode());//-816743945//集合 --->数组:toArray()
Object[] array = coll.toArray();
System.out.println(Arrays.toString(array));//[123, hello, 17:24, 456, Person{name='琪亚娜', age=20}]//拓展:数组 ---> 集合:调用Arrays类的静态方法asList()
List strings = Arrays.asList(new String[]{"hello","hi"});
System.out.println(strings);//[hello, hi]
//注意:int型数组会被认为是一个元素
List ints = Arrays.asList(new int[]{1,2,3});
System.out.println(ints);//[[I@6477463f],这里[I@6477463f是其中一个元素,左右有中括号包围,说明使用了toString()
//为了看的更清楚,写了下面这个例子,你可以看出,第一个元素[I@3d71d552是一个一维数组和地址
System.out.println(Arrays.asList(new int[]{1, 2, 3}, 12));//[[I@3d71d552, 12]
//解决办法:
//1.使用包装类
List integers = Arrays.asList(new Integer[]{1, 2, 3});
System.out.println(integers);//[1, 2, 3]
//2.直接放入数组元素
List ints2 = Arrays.asList(1, 2, 3, 4);
System.out.println(ints2);//[1, 2, 3, 4]
迭代器接口
Iterator对象称为迭代器(设计模式的一种),主要用于遍历 Collection 集合中的元素。
GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生。类似于“公交车上的售票员”、“火车上的乘务员”、“空姐”。
Collection接口继承了java.lang.Iterable接口,该接口有一个iterator()方法,那么所
有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象。
Iterator 仅用于遍历集合,Iterator 本身并不提供承装对象的能力。如果需要创建Iterator 对象,则必须有一个被迭代的集合。
⭐集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
常用方法

在调用
it.next()方法之前必须要调用it.hasNext()进行检测。若不调用,且下一条记录无效,直接调用
it.next()会抛出NoSuchElementException异常。
Collection coll = new ArrayList();
coll.add(123);
coll.add("hello");
coll.add(LocalTime.of(17,24));
coll.add(456);
coll.add(new Person("琪亚娜", 20));Iterator iterator = coll.iterator();
while (iterator.hasNext()){//hasNext(): 判断是否还有下一个元素System.out.println(iterator.next());//next(): 1.指针下移 2.将下移以后集合位置上的元素返回
}
/*
123
hello
17:24
456
Person{name='琪亚娜', age=20}
*/iterator = coll.iterator();
while (iterator.hasNext()){if ("hello".equals(iterator.next())){iterator.remove();}
}//会删除hello这一项
/*
123
17:24
456
Person{name='琪亚娜', age=20}
*/
Iterator可以删除集合的元素,但是是遍历过程中通过迭代器对象的remove方法,不是集合对象的remove方法。
如果还未调用next()或在上一次调用 next 方法之后已经调用了 remove 方法,再调用remove都会报IllegalStateException。
常见错误
//错误方式一:
Iterator iterator = coll.iterator();
while((iterator.next()) != null){System.out.println(iterator.next());
}//错误方式二:
//集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
while (coll.iterator().hasNext()){System.out.println(coll.iterator().next());
}
增强for循环foreach
Java 5.0 提供了foreach循环迭代访问Collection和数组。
- 遍历操作不需获取Collection或数组的长度,无需使用索引访问元素。
- 遍历集合的底层调用Iterator完成操作。
foreach还可以用来遍历数组。
for(集合元素的类型 局部变量 : 集合对象)或者for(数组元素的类型 局部变量 : 数组对象)
Collection coll = new ArrayList();
coll.add(123);
coll.add("hello");
coll.add(LocalTime.of(17,24));
coll.add(456);
coll.add(new Person("琪亚娜", 20));for (Object obj : coll) {System.out.println(obj);
}int[] ints = {1, 2, 3, 4, 5};
for (int i : ints) {System.out.println(i);
}
面试题
int[] ints = {1, 2, 3, 4, 5};
for (int i : ints) {i = 1;
}//并不会修改原先数组中的数据,因为这个i是你新声明的。
List子接口
鉴于Java中数组用来存储数据的局限性,我们通常使用List替代数组
List集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引。
List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
JDK API中List接口的实现类常用的有:ArrayList、LinkedList和Vector。
ArrayList:作为List接口的主要实现类;线程不安全的,效率高;底层使用Object[] elementData存储
-
`LinkedList`:对于频繁的插入、删除操作,使用此类效率比`ArrayList`高;底层使用双向链表存储 -
`Vector`:作为List接口的古老实现类;线程安全的,效率低;底层使用`Object[] elementData`存储
面试题:
ArrayList、LinkedList、Vector三者的异同?同:三个类都是实现了List接口,存储数据的特点相同:存储有序的、可重复的数据
不同:见上
ArrayList源码分析
-
JDK 7.0中
ArrayList list = new ArrayList();//底层创建了长度是10的Object[]数组elementDatalist.add(123);//elementData[0] = new Integer(123);…
list.add(11);//如果此次的添加导致底层elementData数组容量不够,则扩容。默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中。
结论:建议开发中使用带参的构造器:
ArrayList list = new ArrayList(int capacity),避免扩容影响效率 -
JDK 8.0中
ArrayList的变化ArrayList list = new ArrayList();//底层Object[] elementData初始化为{}.并没有创建长度为10的数组list.add(123);//第一次调用add()时,底层才创建了长度10的数组,并将数据123添加到elementData[0]…
后续的添加和扩容操作与JDK 7.0无异。
-
小结
JDK 7.0中的
ArrayList的对象的创建类似于单例的饿汉式,而JDK 8.0中的ArrayList的对象的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
LinkedList源码分析
LinkedList list = new LinkedList();内部声明了Node类型的first和last属性,默认值为null
list.add(123);将123封装到Node中,创建了Node对象。
其中,Node定义为:体现了LinkedList的双向链表的特性
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}
}
Vector源码分析
JDK 7.0和JDK 8.0中通过Vector()构造器创建对象时,底层都创建了长度为10的数组。
List常用方法
void add(int index, Object ele):在index位置插入ele元素
boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
Object get(int index):获取指定index位置的元素
int indexOf(Object obj):返回obj在集合中首次出现的位置
int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
Object remove(int index):移除指定index位置的元素,并返回此元素
Object set(int index, Object ele):设置指定index位置的元素为ele(覆盖之前的记录)
List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
总结:
- 增:
add(Object obj) - 删:
remove(int index) / remove(Object obj) - 改:
set(int index, Object ele) - 查:
get(int index) - 插:
add(int index, Object ele) - 长度:
size() - 遍历:
- Iterator迭代器方式
- 增强for循环
- 普通的循环
面试题
@Test
public void testListRemove() {List list = new ArrayList();list.add(1);list.add(2);list.add(3);updateList(list);System.out.println(list);//会输出什么?
}private void updateList(List list) {list.remove(2);
}
答案是[1,2]
这道题的重点是,区分List中remove(int index)和remove(Object obj)
我们这里传入的是int型的数据,根据重载原则,会执行remove(int index),而不是自动装箱后使用remove(Object obj)。如果我们想删掉2这个数据(使用对象删除)那可以手动装箱:
list.remove(new Integer(2));
Set子接口
|----Collection接口:单列集合,用来存储一个一个的对象|----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”|----HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值|----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历对于频繁的遍历操作,LinkedHashSet效率高于HashSet.|----TreeSet:可以按照添加对象的指定属性,进行排序。
存储无序的、不可重复的数据
- Set接口是Collection的子接口,set接口没有提供额外的方法
- Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set 集合中,则添加操作失败。
- Set 判断两个对象是否相同不是使用
==运算符,而是根据equals()方法
Set的特性及HashSet
以HashSet为例说明:
-
无序性:不等于随机性。存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。
-
不可重复性:保证添加相同的元素按照
equals()判断时,不能返回true。即:相同的元素只能添加一个。
二、添加元素的过程
以HashSet为例:
我们向
HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),判断数组此位置上是否已经有元素:
- 如果此位置上没有其他元素,则元素a添加成功。 —>情况1
- 如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
- 如果hash值不相同,则元素a添加成功。—>情况2
- 如果hash值相同,进而需要调用元素a所在类的equals()方法:
equals()返回true,元素a添加失败
equals()返回false,则元素a添加成功。—>情况3对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
- JDK 7.0 :元素a放到数组中,指向原来的元素。
- JDK 8.0:原来的元素在数组中,指向元素a
总结:七上八下
HashSet底层:数组+链表的结构。
Set对数据的要求
- 向Set(主要指:
HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals() - 重写的
hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
重写两个方法的小技巧:对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。

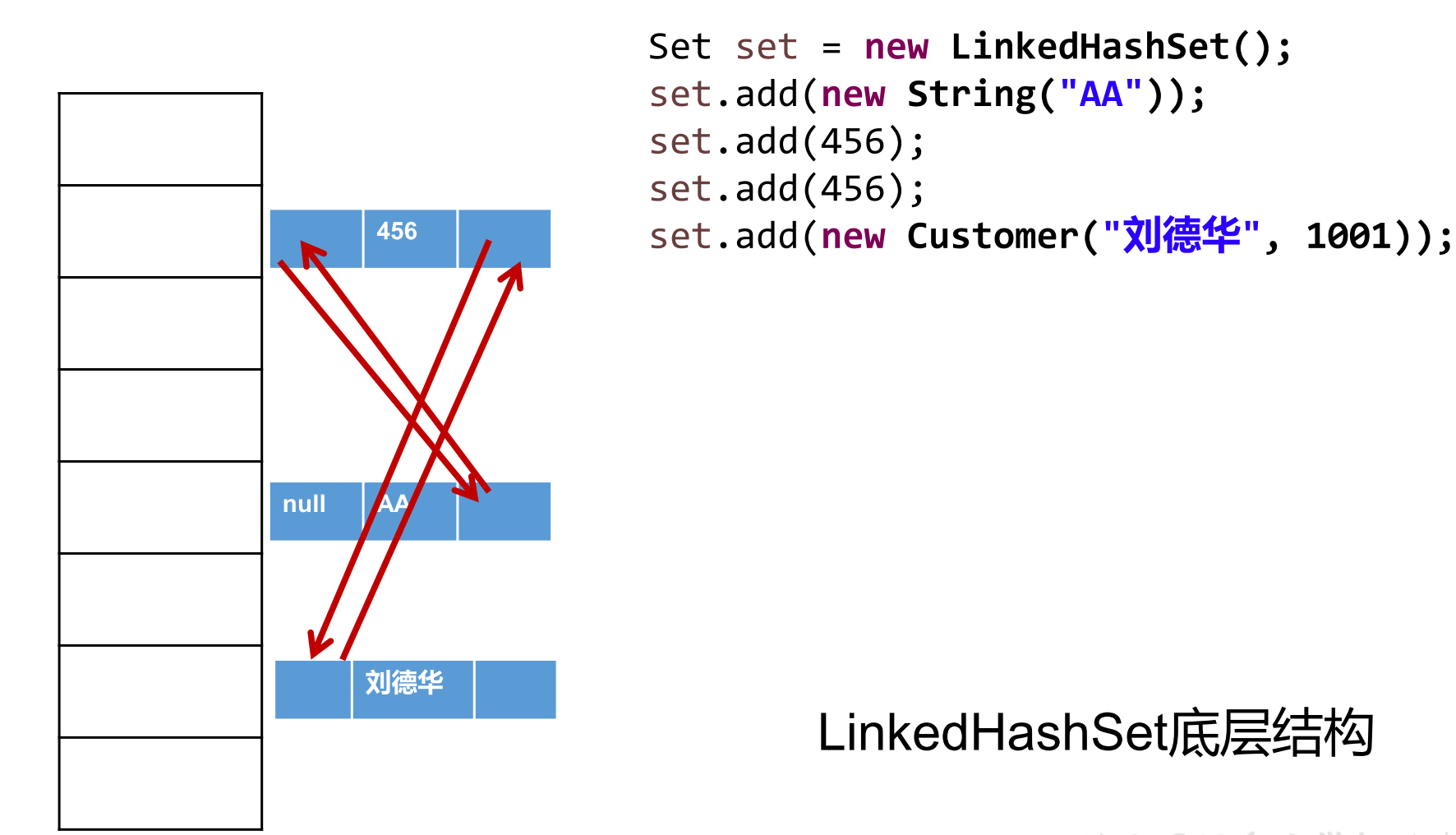
LinkedHashSet介绍
LinkedHashSet作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。
优点是:对于频繁的遍历操作,LinkedHashSet效率高于HashSet
TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。
TreeSet底层使用红黑树结构存储数据
参考:红黑树介绍
TreeSet两种排序方法:自然排序和定制排序。默认情况下,TreeSet采用自然排序。
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列
如果试图把一个对象添加到
TreeSet时,则该对象的类必须实现Comparable接口。
Comparable 的典型实现:
BigDecimal、BigInteger以及所有的数值型对应的包装类:按它们对应的数值大小进行比较Character:按字符的unicode值来进行比较Boolean:true对应的包装类实例大于false对应的包装类实例String:按字符串中字符的unicode值进行比较Date、Time:后边的时间、日期比前面的时间、日期大
自然排序实现
自然排序中,比较两个对象是否相同的标准为:compareTo()返回0.不再是equals().
//在Person类中去实现Comparable接口
@Override
public int compareTo(Object o) {if (!(o instanceof Person)){throw new RuntimeException("类型不匹配。");}Person person = (Person) o;int compare = this.name.compareTo(person.name);if (compare == 0){return this.age - person.age;}return compare;
}
TreeSet treeSet = new TreeSet();
treeSet.add(new Person("琪亚娜",12));
treeSet.add(new Person("芽衣",13));
treeSet.add(new Person("布洛尼亚",11));
treeSet.add(new Person("李素裳",24));
treeSet.add(new Person("李素裳",25));
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()){System.out.println(iterator.next());
}
/*
Person{name='布洛尼亚', age=11}
Person{name='李素裳', age=24}
Person{name='李素裳', age=25}
Person{name='琪亚娜', age=12}
Person{name='芽衣', age=13}
*/
定制排序实现
//先按年龄升序排,相同的不要
Comparator comparator = new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if (!(o1 instanceof Person && o2 instanceof Person)){throw new RuntimeException("输入的类型不匹配");}Person p1 = (Person) o1;Person p2 = (Person) o2;return p1.getAge() - p2.getAge();}
};
TreeSet treeSet = new TreeSet(comparator);//调用有参构造器,传入定制排序对象
treeSet.add(new Person("琪亚娜",12));
treeSet.add(new Person("芽衣",13));
treeSet.add(new Person("布洛尼亚",11));
treeSet.add(new Person("李素裳",24));
treeSet.add(new Person("李素裳1",24));//年龄相同,不可存入
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()){System.out.println(iterator.next());
}
/*Person{name='布洛尼亚', age=11}
Person{name='琪亚娜', age=12}
Person{name='芽衣', age=13}
Person{name='李素裳', age=24}*/
一些问题
-
集合Collection中存储的如果是自定义类的对象,需要自定义类重写哪个方法?为什么?
对于
List:重写equals(),因为list通过equals()判断元素是否重复对于
Set:重写equals()和hashCode(),因为Set通过hashCode()确定存储位置,再通过equals()确定是否重复对于
TreeSet:重写compareTo()或compare(),自然排序使用compareTo(),定制排序使用compare() -
ArrayList,LinkedList,Vector三者的相同点与不同点相同点:三者都是无序,不可重复的数据
不同点:Vector是线程安全的,效率低,
ArrayList线程不安全,效率高,Vector与ArrayList底层都是通过数组实现的LinkedList线程不安全,是链表实现,插入删除效率高于ArrayList,但随机存取的效率反而低于ArrayList,需要根据场景选择。
练习题
//练习:在List内去除重复数字值,要求尽量简单
public static List duplicateList(List list) {HashSet set = new HashSet();set.addAll(list);return new ArrayList(set);
}
@Test
public void test2(){List list = new ArrayList();list.add(new Integer(1));list.add(new Integer(2));list.add(new Integer(2));list.add(new Integer(4));list.add(new Integer(4));List list2 = duplicateList(list);for (Object integer : list2) {System.out.println(integer);}
}
我们通常利用Set不可重复的特性过滤重复数据。
第二题,考察Set的特性和增加删除的细节
@Test
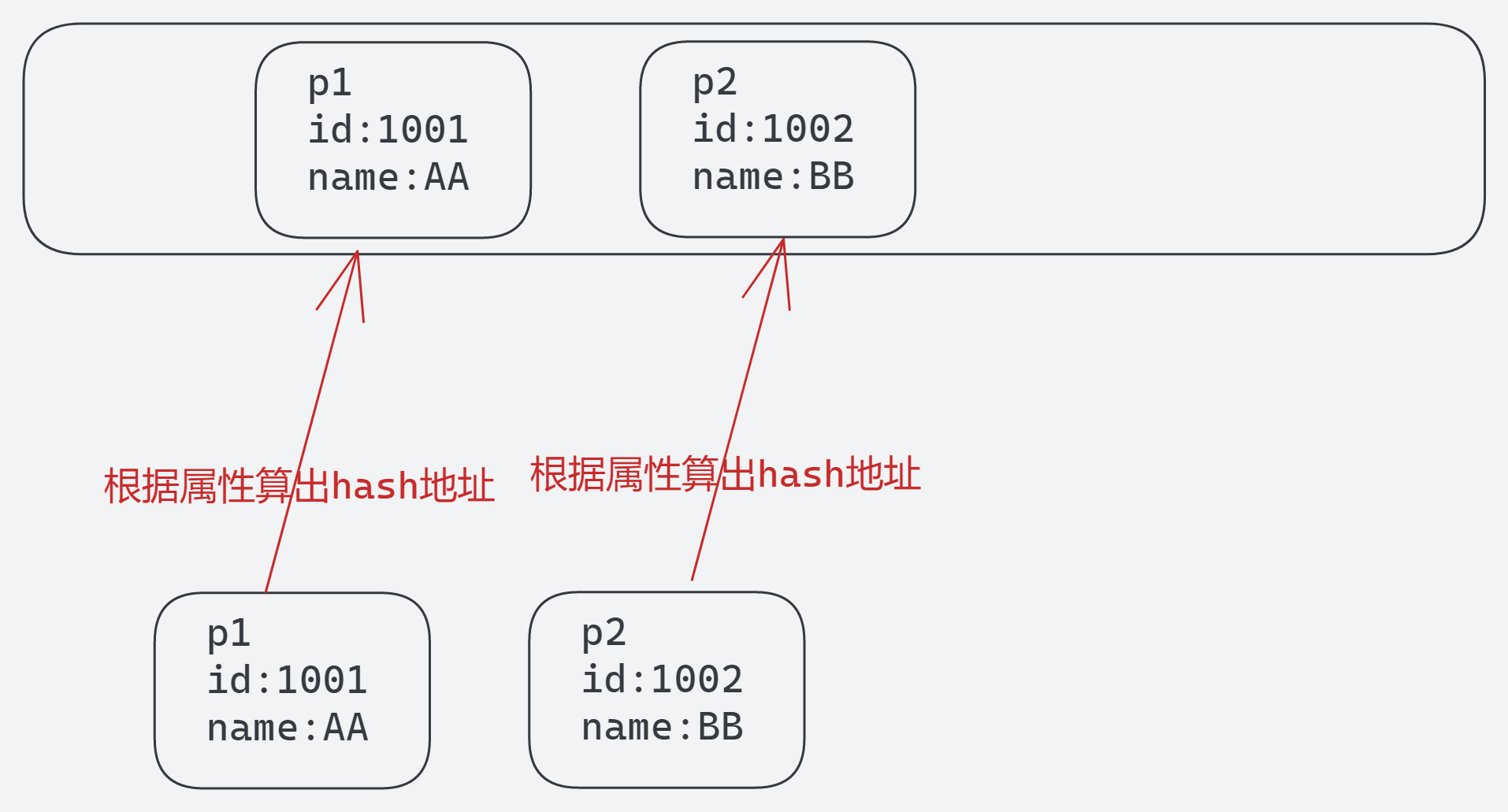
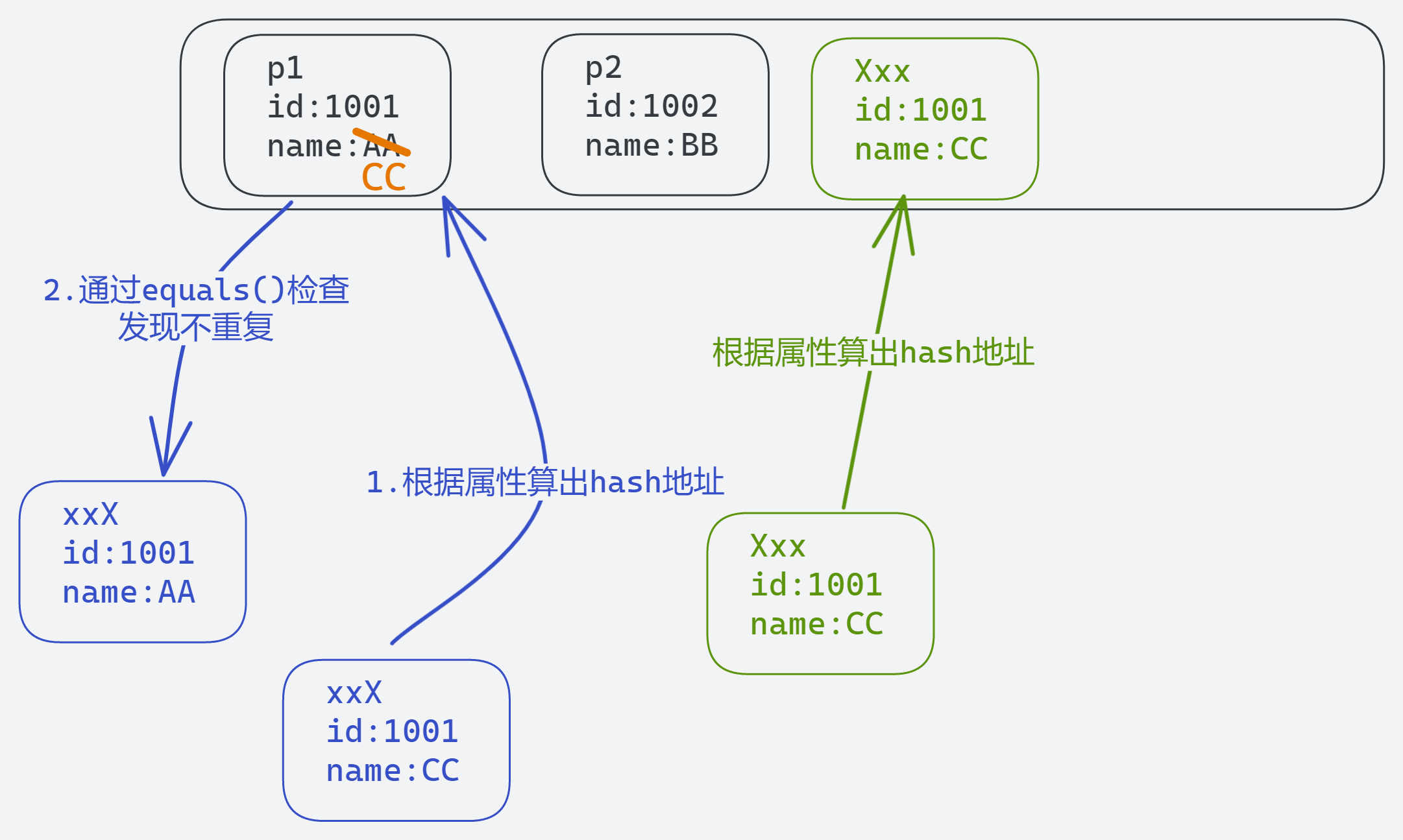
public void test3(){HashSet set = new HashSet();Person p1 = new Person(1001,"AA");Person p2 = new Person(1002,"BB");//第一部分set.add(p1);set.add(p2);System.out.println(set);//第二部分p1.name = "CC";set.remove(p1);System.out.println(set);//第三部分set.add(new Person(1001,"CC"));System.out.println(set);//第四部分set.add(new Person(1001,"AA"));System.out.println(set);}
输出结果
[Person{id=1002, name='BB'}, Person{id=1001, name='AA'}]
[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}]
[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}]
[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}, Person{id=1001, name='AA'}]
第一部分,通过属性算出hash地址,注意存储的是地址值
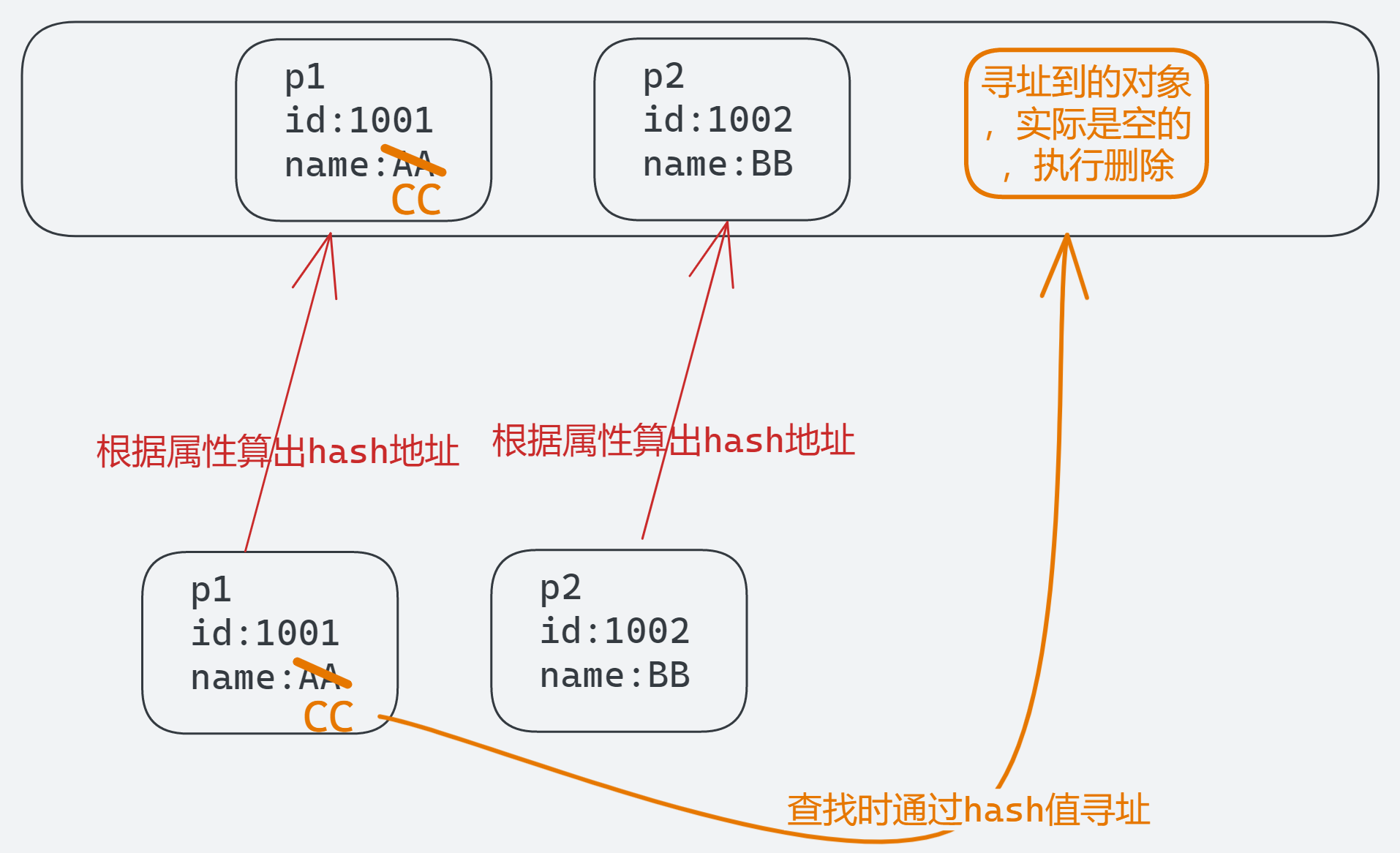
第二部分,修改p1的属性,修改后再执行删除,删除时是通过hash寻址的,虽然找到的地址并没有实际对象,但是还是进行删除,此时并没删除真正的p1对象。
所以输出[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}]
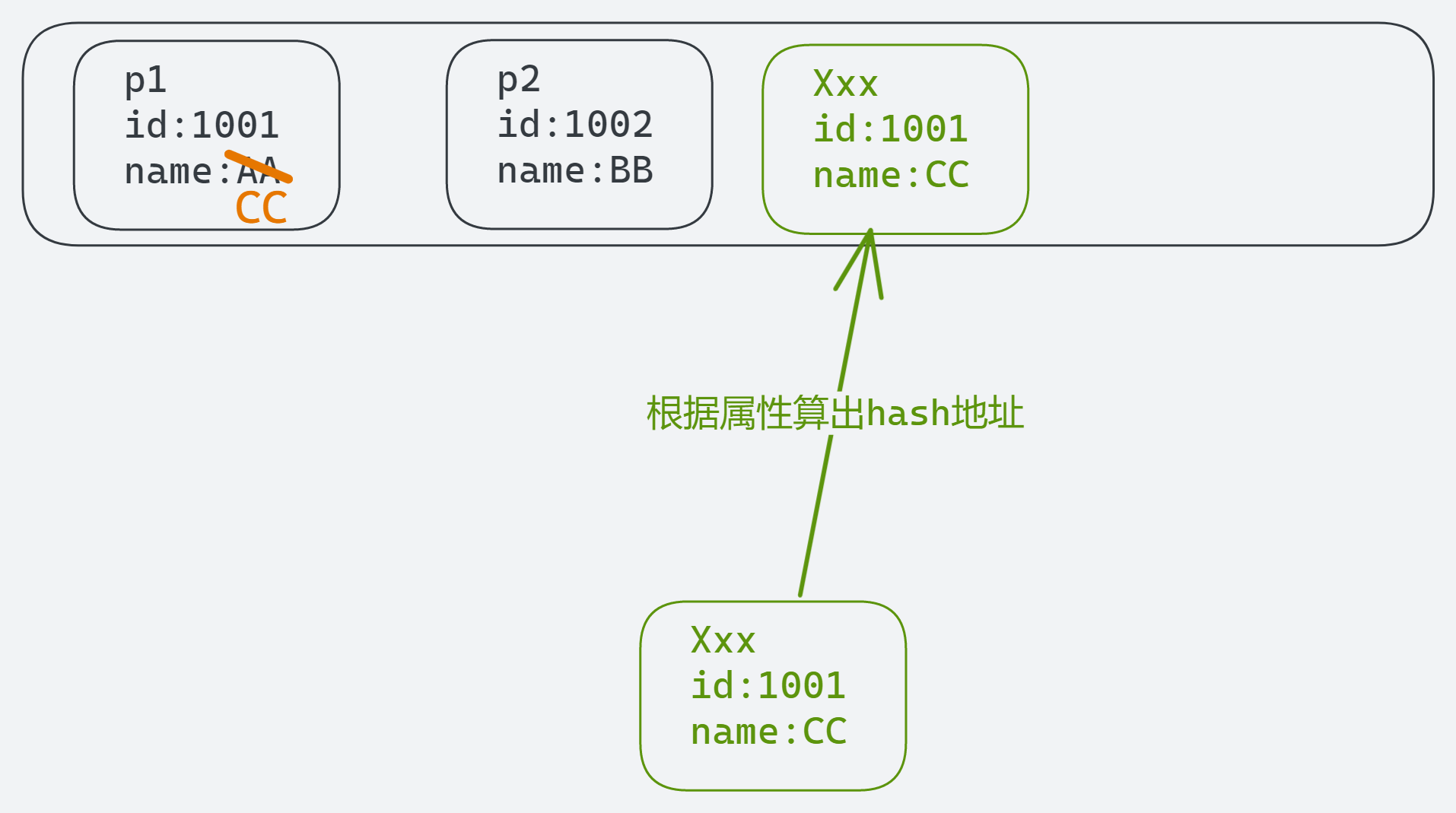
第三部分,通过hash值算出地址,由于hash值不重复,Set认为这个对象和p1并不重复,成功存入
所以输出[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}]
第四部分,通过hash值算出地址,发现已经有元素,执行equals()算法发现元素属性不重复,成功存入
所以输出[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}, Person{id=1001, name='AA'}]
相关文章:
Java高级-集合-Collection部分
本篇讲解java集合 集合 集合框架的概述 集合、数组都是对多个数据进行存储操作的结构,简称Java容器。 说明:此时的存储,主要指的是内存层面的存储,不涉及到持久化的存储(.txt,.jpg,.avi,数据库中…...
Android性能优化:getResources()与Binder交火导致的界面卡顿优化
欢迎:https://juejin.cn/post/7198430801851531324/ 欢迎:https://nasdaqgodzilla.github.io/2023/02/10/Android%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%EF%BC%9AgetResources-%E4%B8%8EBinder%E4%BA%A4%E7%81%AB%E5%AF%BC%E8%87%B4%E7%9A%84%E7%95%8C%E…...

常见的内存操作函数
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言学习者 ✈️专栏:C语言航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&a…...

python关键字
文章目录1 and、or、not2 if、elif、else3 for、while4 True、False5 continue、break6 pass7 try、except、finally、raise8 import、from、as9 def、return10 class11 lambda12 del13 global、nonlocal14 in、is15 None16 assert17 with18 yield1 and、or、not and、or、not…...
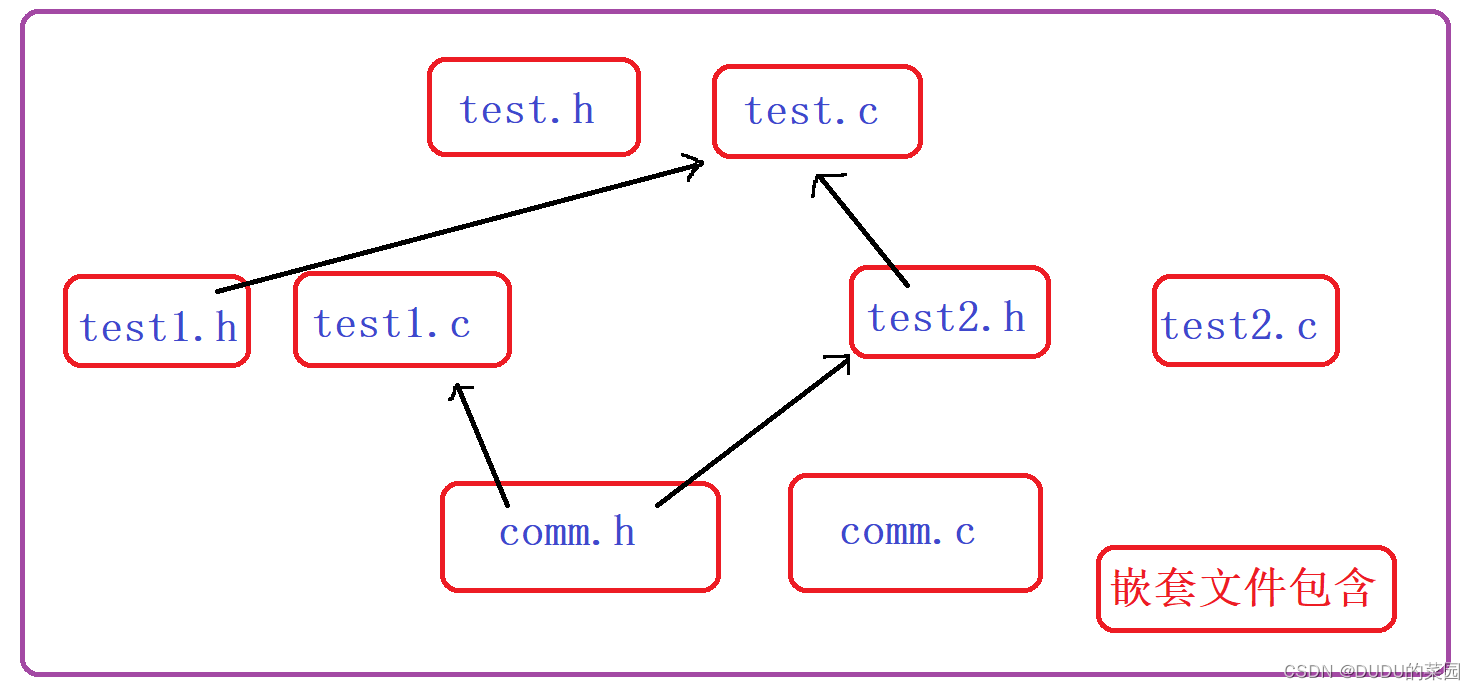
C语言 | 预处理知识详解 #预处理指令有哪些?他们如何使用?宏和函数有哪些区别?...#
文章目录前言预定义符号介绍预处理指令#define#define替换规则预处理指令 #undef宏和函数的对比宏和函数的对比图命名约定命令行定义条件编译预处理指令 #include嵌套文件包含其他预处理指令写在最后前言 上篇文章介绍了一个程序运行的 编译与链接 ,其中编译阶段有个…...
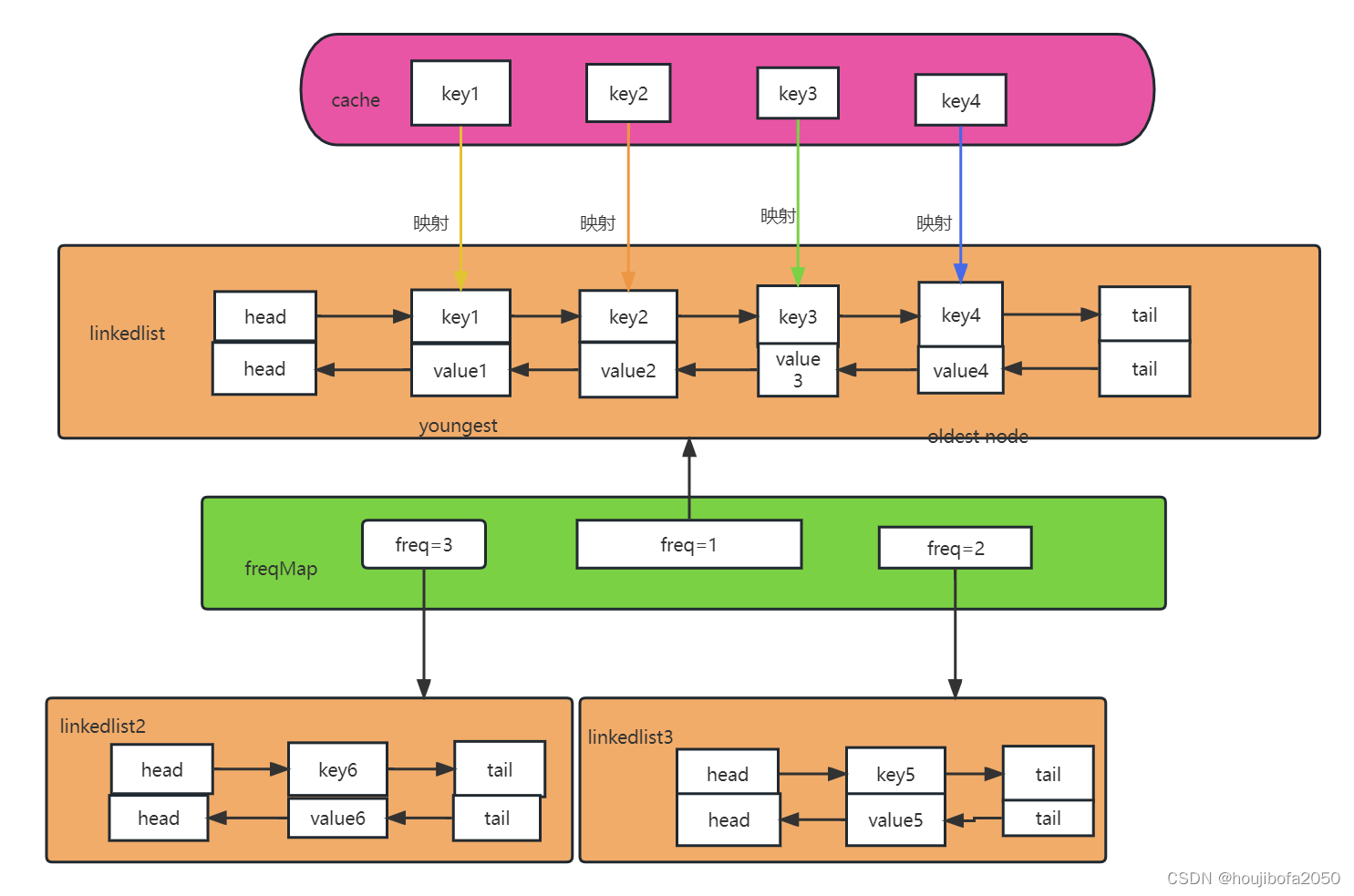
如何实现LFU缓存(最近最少频率使用)
目录 1.什么是LFU缓存? 2.LFU的使用场景有哪些? 3.LFU缓存的实现方式有哪些? 4.put/get 函数实现具体功能 1.什么是LFU缓存? LFU缓存是一个具有指定大小的缓存,随着添加元素的增加,达到容量的上限&…...
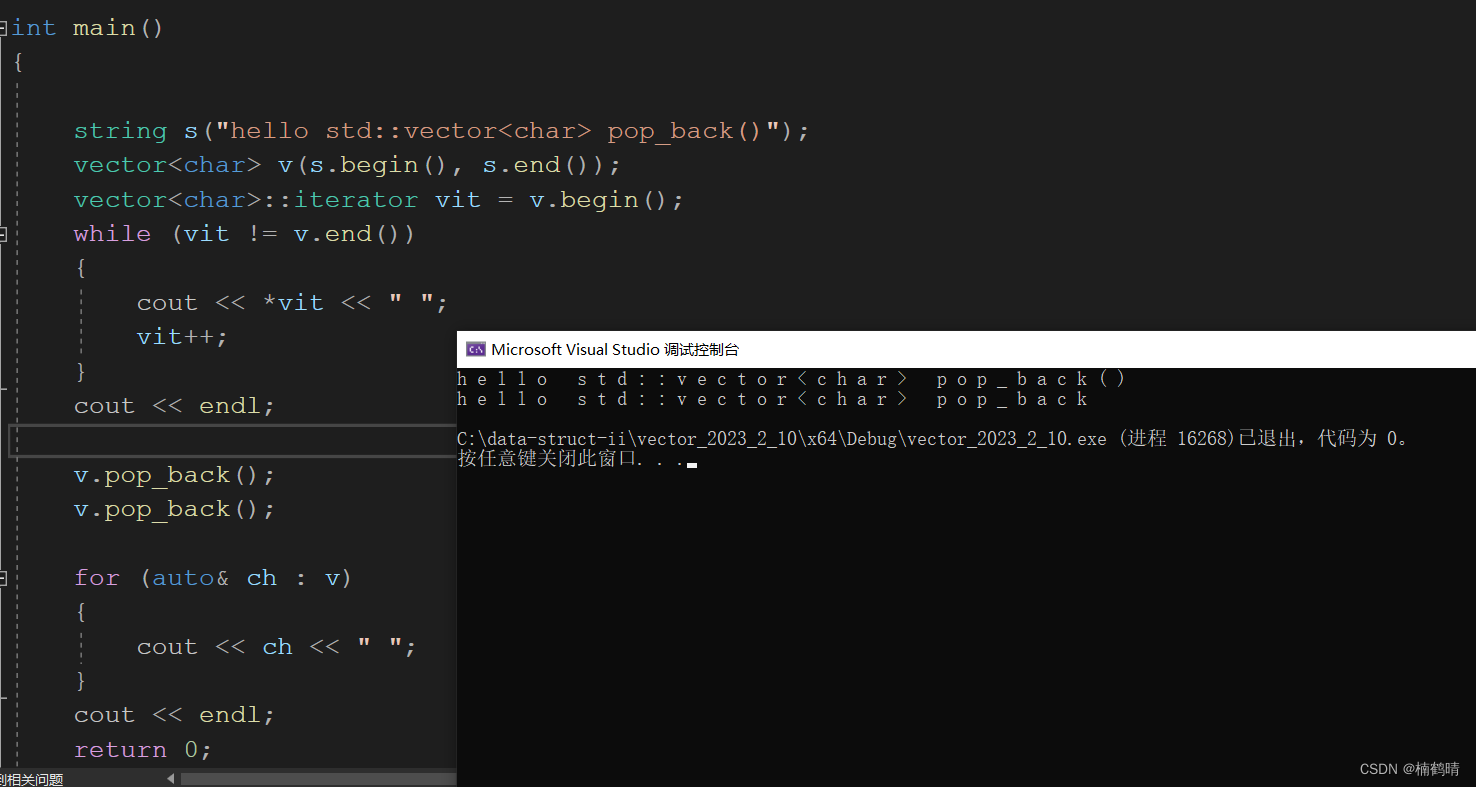
【C++之容器篇】精华:vector常见函数的接口的熟悉与使用
目录前言一、认识vector1. 介绍2. 成员类型二、默认成员函数(Member functions)1. 构造函数2. 拷贝构造函数vector (const vector& x);3. 析构函数4. 赋值运算符重载函数三、迭代器(Iterators)1. 普通对象的迭代器2. const对象…...
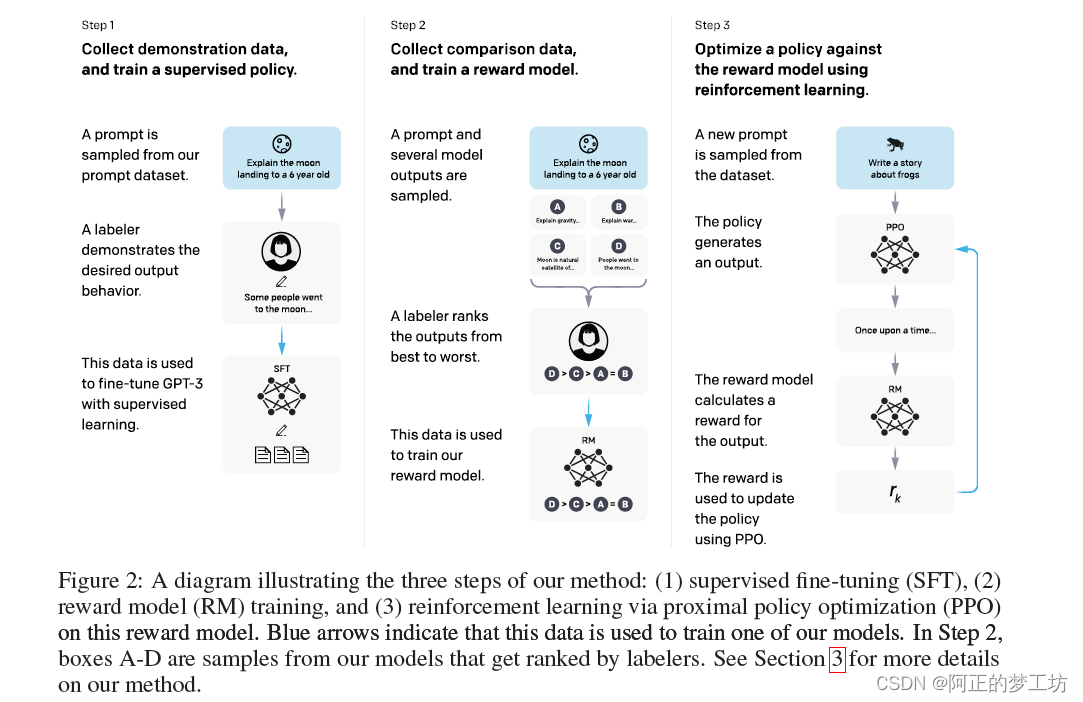
InstructGPT
文章目录Abstract 给定人类的命令,并且用人工标注想要的结果,构成数据集,使用监督学习来微调GPT-3。 然后,我们对模型输出进行排名,构成新的数据集,我们利用强化学习来进一步微调这个监督模型。 我们把产…...
)
RTOS之一环境搭建(基于TM4C123GXL)
硬件TM4C123GXLBOOSTXL-EDUMKII keil5micriumOSA软件安装:1 ARM-MDK(MDK538aMDK_Stellaris_ICDI_AddOn)MDK538a链接:https://www.keil.com/demo/eval/arm.htmICDI链接:https://documentation-service.arm.com/static/60509bd61da8f8344a2ca1b…...
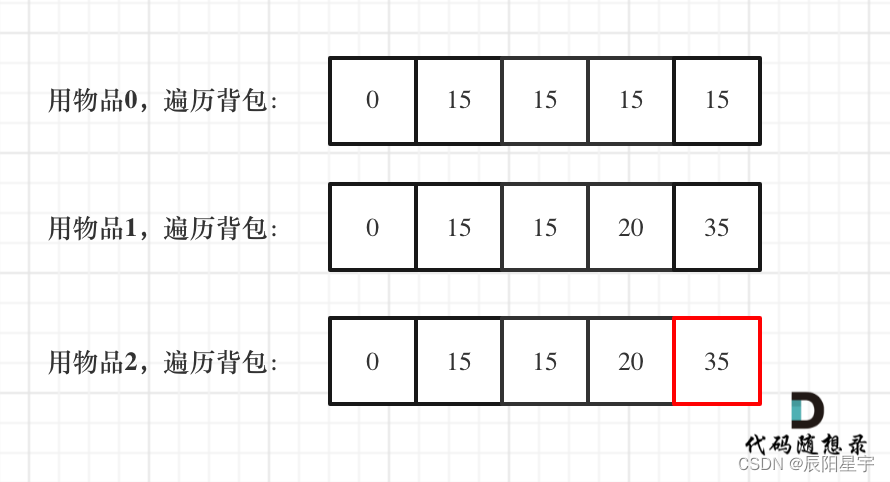
151、【动态规划】AcWing ——2. 01背包问题:二维数组+一维数组(C++版本)
题目描述 原题链接:2. 01背包问题 解题思路 (1)二维dp数组 动态规划五步曲: (1)dp[i][j]的含义: 容量为j时,从物品1-物品i中取物品,可达到的最大价值 (2…...

DS期末复习卷(二)
选择题 1.下面关于线性表的叙述错误的是( D )。 (A) 线性表采用顺序存储必须占用一片连续的存储空间 (B) 线性表采用链式存储不必占用一片连续的存储空间 © 线性表采用链式存储便于插入和删除操作的实现 (D) 线性表采用顺序存储便于插…...
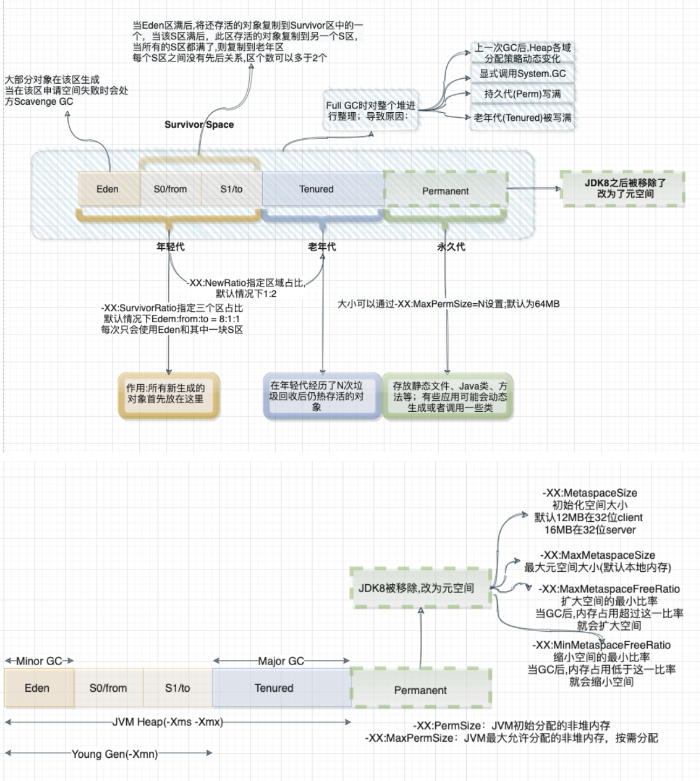
大数据技术架构(组件)31——Spark:Optimize--->JVM On Compute
2.1.9.4、Optimize--->JVM On Compute首要的一个问题就是GC,那么先来了解下其原理:1、内存管理其实就是对象的管理,包括对象的分配和释放,如果显式的释放对象,只要把该对象赋值为null,即该对象变为不可达.GC将负责回…...
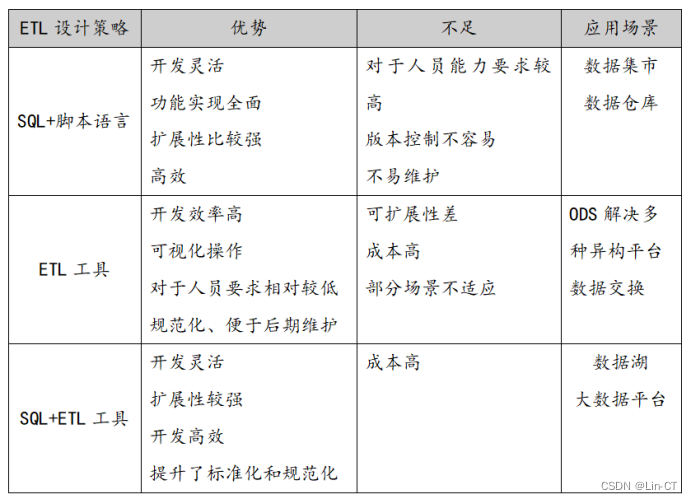
ETL基础概念及要求详解
ETL基础概念及要求详解概念ETL与ELT数据湖与数据仓库ETL应用场景ETL具体流程及操作要求抽取清洗转换加载ETL设计模式SQL脚本语言ETL工具设计ETL工具SQLETL接口设计要求明确接口属性约定接口形式确定接口抽取方法规范接口格式概念 ETL即Extract(抽取)Tra…...

刷题记录:牛客NC23054华华开始学信息学 线段树+分块
传送门:牛客 题目描述: 题目latex公式较多,此处省略 输入: 10 6 1 1 1 2 4 6 1 3 2 2 5 7 1 6 10 2 1 10 输出: 3 5 26这道题让我体验到的线段树相对于树状数组的常数巨大 我们倘若直接用单点修改的话,如果D过小比如1那么我们足足要加n次,时间复杂度爆…...

二叉搜索树(查找,插入,删除)
目录 1.概念 2.性质 3.二叉搜索树的操作 1.查找 2.插入 3.删除(难点) 1.概念 二叉搜索树又称二叉排序树.利用中序遍历它就是一个有顺序的一组数. 2.性质 1.若它的左子树不为空,则左子树上所有节点的值都小于根节点的值 2.若它的右子树不为空,则右子树上所有节点的值都…...

C# PictureEdit 加载图片
方法一: 如果要加载的图片的长宽比不是太过失衡, 1.可以改变picturebox的SizeMode属性为 PictureBoxSizeMode.StretchImage, 2.或者Dev控件 PictureEdit的SizeMode属性为Zoom。(zoom:缩放;clip剪短;stret…...
3种方法设置PDF“打开密码”,总有一种适合你
PDF文件是我们工作中经常用到的文件之一,对于重要的文件,设置“打开密码”是一种很好的保护方式。下面就来说说,设置PDF“打开密码”有哪三种方法? 方法一:在线网站加密 市面上有很多可以直接在线上加密PDF文件的产品…...
-计算机网络(笔记))
第三章 数据链路层(点到点的传输服务)-计算机网络(笔记)
计算机网络 第三章 数据链路层(点到点的传输服务) 数据链路层属于计算机网络的低层。数据链路层使用的信道主要有以下两种类型: (1)点到点信道。这种信道使用一对一的点到点通信方式。 (2)广…...

volatile关键字与CAS机制
volatile关键字 volatile关键字可以对类的成员变量与静态变量进行修饰 volatile关键字的作用 1.保证被修饰属性的可见性,被修饰后的属性如果被更改后其他线程是会立即可见的 2.保证被修饰属性的有序性,被修饰后的属性禁止修改指令执行的顺序 注意:volatile关键字不能保证属性…...

LeetCode题解 动态规划(四):416 分割等和子集;1049 最后一块石头的重量 II
背包问题 下图将背包问题做了分类 其中之重点,是01背包,即一堆物件选哪样不选哪样放入背包里。难度在于,以前的状态转移,多只用考虑一个变量,比如爬楼梯的阶层,路径点的选择,这也是能用滚动数组…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...