[论文阅读]PV-RCNN++
PV-RCNN++
PV-RCNN++: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection
论文网址:PV-RCNN++
论文代码:PV-RCNN++
简读论文
这篇论文提出了两个用于3D物体检测的新框架PV-RCNN和PV-RCNN++,主要的贡献如下:
-
提出PV-RCNN框架,通过voxel-to-keypoint scene encoding和keypoint-to-grid RoI feature abstraction两步深度融合基于point的set abstraction和基于voxel的sparse convolution的特征学习策略,以发挥两者的优势。
-
提出PV-RCNN++框架,通过以下两种改进使检测更准确、高效:
(1) 提出sectorized proposal-centric keypoint sampling策略,可以更快速生成更具代表性的关键点。
(2) 提出VectorPool聚合模块,可以在大规模点云上进行更有效和高效的局部特征聚合。 -
在Waymo开放数据集上,提出的检测器取得了state-of-the-art的性能,特别是PV-RCNN++在150米×150米的检测范围内可以达到10 FPS的推理速度。
主要创新点有:
-
提出voxel-to-keypoint scene encoding,使用voxel set abstraction模块将多尺度的voxel特征聚合到少量关键点中,保留精确的点位置信息。
-
提出keypoint-to-grid RoI feature abstraction,通过RoI-grid pooling模块将关键点特征聚合到proposal对应的RoI grid点上,获得全局上下文信息。
-
提出sectorized proposal-centric keypoint sampling策略,可以快速生成更具代表性的关键点。
-
提出VectorPool模块,使用局部向量表示编码位置敏感特征,进行更高效的局部特征聚合。
总体来说,该论文通过深度融合点表示和voxel表示的特征学习策略,以及一些提高效率和效果的新模块,取得了SOTA的3D物体检测性能。
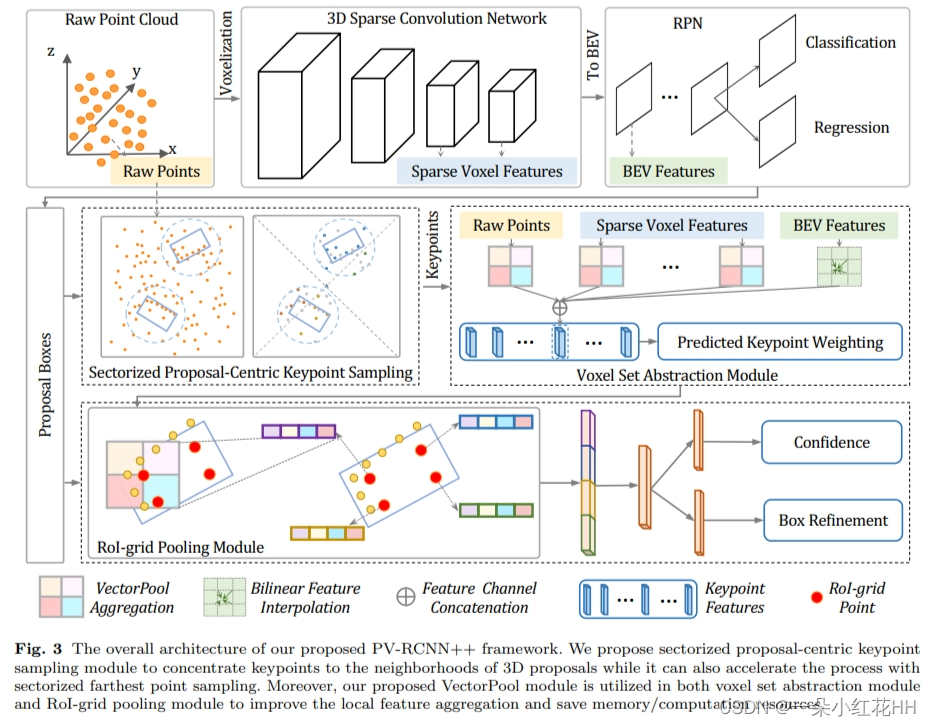
PV-RCNN++采样策略
sectorized proposal-centric keypoint sampling策略主要包含以下两个步骤:
-
Proposal-centric filtering:利用提议框信息对原始点云进行过滤,只保留提议框附近的点,以减少后续采样的规模和计算量。具体地,设原始点云为P,提议框集为D,然后计算每个点p到其最近提议框中心的距离,保留距离在最大框尺寸的一半+额外radius之内的点,构成过滤后的候选点集P’。
-
Sectorized sampling:将P’划分为多个sector,每个sector在球坐标系下占据一定角度范围的点,然后对每个sector平行进行最远点采样,获得采样结果。该策略基于激光雷达点云的径向分布特性,可以将全局采样问题分解为多个局部采样子问题,减少每个采样的规模,实现加速。
相比传统的全局最远点采样,该策略的优点有:
- 提案框滤波可以减少采样规模,将关键点集中在更重要的区域。
- 分sector采样,可以平行执行,加速采样过程。
- 最远点采样可以生成更均匀分布的关键点。
实验结果显示,该采样策略可以使关键点生成加速3倍,同时 também 提高了检测性能。关键点的覆盖率实验也证明其可以生成更均匀分布的关键点。
整体来说,该采样策略通过提案框过滤和分sector采样,实现了在保证关键点分布 uniform 的同时,大大减少了采样计算量,是该网络获得速度提升的关键。
PV-RCNN++聚合模块
VectorPool模块主要用于大规模点云的局部特征聚合,具体步骤如下:
-
对中心点周围区域进行立方体划分,划分为n x n y n z个子体素。
-
对每个子体素,使用三个最近邻点的内容加权平均得到体素内部特征。
-
对每个子体素特征,使用独立的卷积核进行编码,得到位置敏感特征。
-
按空间顺序连接所有子体素的位置编码特征,得到局部向量表示。
-
通过多层感知机网络进一步处理vectors,得到聚合后的局部特征。
相比传统的set abstraction模块,该模块具有以下优点:
-
采用子体素表示特征可以大大降低内存和计算量。
-
位置编码可以保留局部结构信息。
-
权重平均避免了empty voxels的特征归零问题。
-
独立卷积核进行位置敏感编码。
实验结果显示,该模块使检测框架的内存消耗减少约30%,同时也提升了检测性能。
因此,VectorPool模块通过局部向量表示和位置编码,实现了对大规模点云高效和高质量的局部特征聚合。这为提升检测网络的效率提供了重要支撑。
摘要
3D目标检测由于其在各个领域的广泛应用,越来越受到工业界和学术界的关注。本文提出了基于point-voxel区域的卷积神经网络 (PV-RCNN),用于点云上的 3D 目标检测。首先,提出了一种新颖的 3D 检测器 PV-RCNN,它通过两个新颖的步骤(即体素到关键点场景)深度集成基于点的集合抽象和基于体素的稀疏卷积的特征学习,从而提高了 3D 检测性能编码和关键点到网格 RoI 特征抽象。其次,提出了一种先进的框架 PV-RCNN++,用于更高效、更准确的 3D 对象检测。它包含两个主要改进:以扇区为中心的提案采样,用于有效生成更具代表性的关键点,以及 VectorPool 聚合,用于以更少的资源消耗更好地聚合局部点特征。通过这两种策略,我们的 PV-RCNN++ 比 PVRCNN 快约 3 倍,同时还实现了更好的性能。实验表明,我们提出的PV-RCNN++框架在大规模且竞争激烈的Waymo开放数据集上实现了最先进的3D检测性能,在150m×150m的检测范围内具有10 FPS的推理速度。
引言
点云上的 3D 目标检测旨在从一组 3D 点中定位和识别 3D 物体,这是 3D 场景理解的一项基本任务,广泛应用于自动驾驶、智能交通系统和机器人等许多实际应用中。与图像上的二维检测方法相比,点云的稀疏性和不规则性使得直接在点云的 3D 检测上应用二维检测技术具有挑战性。
为了应对这些挑战,大多数现有的 3D 检测方法将点转换为规则体素,这样可以使用传统的 2D/3D 卷积神经网络和经过充分研究的 2D 检测头进行处理。但体素化操作不可避免地会带来量化误差,从而降低其定位精度。相比之下,基于点的方法自然地在特征提取中保留了准确的点位置,但在处理大规模点时通常需要大量计算。也有一些现有的方法简单地将这两种策略结合起来,在第一阶段采用基于体素的方法进行特征提取和 3D 提案生成,然后在第二阶段补偿细粒度提案细化的量化误差。然而,这种简单的堆叠组合忽略了其基本算子的深度融合(例如稀疏卷积和集合抽象),并且无法充分探索两种策略的特征交叉以充分利用两个世界。
因此,本文提出了一个统一的框架,即基于点-体素区域的卷积神经网络(PV-RCNN),通过深度集成体素和点表示的特征学习策略来充分利用两者的特征学习策略。其原理在于,基于体素的策略可以更有效地编码多尺度特征并从大规模点云生成高质量的3D建议,而基于点的策略可以通过灵活的感受野保留准确的位置信息,以进行精细的处理以及细粒度的提案细化。本文证明了本文提出的点-体素交织框架可以通过深度融合点和体素表示的特征学习来有效提高 3D 检测性能。
首先,本文介绍本文最初的 3D 检测框架 PV-RCNN,它是点云上的两阶段 3D 检测器。它由两个新颖的点-体素特征聚合步骤组成。第一步是体素到关键点场景编码,其中采用具有稀疏卷积的 3D 体素 CNN 进行特征学习和提案生成。然后通过基于点的集合抽象将多尺度体素特征概括为一小组关键点,其中具有准确点位置的关键点通过距原始点最远的点来采样。第二步是关键点到网格 RoI 特征抽象,本文提出 RoI-grid pooling 模块将上述关键点特征聚合回每个提案的常规 RoI 网格。它对多尺度上下文信息进行编码,以形成用于提案细化的规则网格特征。这两个步骤在基于点的集合抽象和基于体素的稀疏卷积之间建立了特征交织,实验证明这可以提高模型的表示能力和检测性能。
其次,本文在PV-RCNN之上提出了一种先进的两阶段检测网络PV-RCNN++,以实现更准确、高效和实用的3D物体检测。 PV-RCNN++的改进在于两个方面。第一个方面是一种新颖的以提案为中心的扇区化关键点采样策略,本文将有限数量的关键点集中在 3D 提案内及其周围,以编码更有效的场景特征。同时,考虑到LiDAR点的径向分布,本文提出在不同扇区并行进行点采样,这加快了关键点采样过程,同时也保证了关键点的均匀分布。本文提出的关键点采样策略比具有二次复杂度的普通最远点采样更快、更有效。整个框架的效率由此得到极大的提升,这对于百万点的大规模3D场景尤为重要。第二个方面是一个新颖的局部特征聚合模块,VectorPool聚合,用于在点云上更有效和高效的局部特征编码。本文认为局部区域中的相对点位置对于描述局部几何来说是稳健、有效和有区别的特征。本文建议将 3D 局部空间分割为规则且紧凑的子体素,其特征依次连接以形成超特征向量。不同位置的子体素特征使用单独的内核权重进行编码,以生成位置敏感的局部特征。这样,不同的局部位置信息用超特征向量中的不同特征通道进行编码。与集合抽象相比,由于紧凑的局部特征表示,本文的 VectorPool 聚合可以有效地处理大量的中心点。本文的 PV-RCNN++ 在基于体素的主干和 RoI 网格池化模块中配备了 VectorPool 聚合,比以前的同类产品更内存友好、速度更快,具有更好的性能,这有助于在资源有限的情况建立实用的 3D 检测器设备。
简而言之,本文的贡献有三方面:1)本文的 PV-RCNN 采用两种新颖的策略,体素到关键点场景编码和关键点到网格 RoI 特征抽象,深度融合了基于点和体素的优点。 2)本文的PV-RCNN++在更实用的3D检测系统上迈出了一步,具有更好的性能、更少的资源消耗和更快的运行速度。这是通过提出的以提案为中心的扇区化关键点采样来实现的,以更快的速度获得更具代表性的关键点,并且还通过新颖的 VectorPool 聚合来实现,以更少的资源消耗和更有效的表示来实现大量中心点的本地聚合。 (3) 本文提出的 3D 检测器超越了所有已发布的方法,在具有挑战性的大规模 Waymo 开放数据集上具有显着的优势。特别是, PV-RCNN++ 在 150m × 150m 检测范围内以 10 FPS 的推理速度实现了最先进的结果。
相关工作
基于二维图像的3D目标检测 : 基于图像的 3D 检测旨在从单目图像或立体图像估计 3D 边界框。 Mono3D使用地平面假设生成 3D 提案,并通过利用图像中的语义知识对其进行评分。以下工作(Mousavian et al 2017;Li et al 2019a)将 2D 和 3D 框之间的关系合并为几何约束。 M3D-RPN引入了具有深度感知卷积的 3D 区域提议网络。 (Chabot 等人,2017 年;Murthy 等人,2017 年;Manhardt 等人,2019 年)根据从 CAD 模型获得的线框模板预测 3D 框。 RTM3D执行粗略关键点检测来定位 3D 对象。在立体方面,Stereo R-CNN利用立体 RPN 来关联左右图像的提案。 DSGN引入了可微分 3D 体积来学习端到端优化管道中的深度信息和语义线索。 LIGA-Stereo提出从训练有素的 LiDAR 探测器中学习良好的几何特征。基于伪激光雷达的方法将图像像素转换为人工点云,基于激光雷达的检测器可以对其进行操作以进行 3D 框估计。这些基于图像的 3D 检测方法存在深度估计不准确的问题,并且只能生成粗略的 3D 边界框。
最近,除了单目图像或立体图像的基于图像的 3D 检测之外,对周围摄像机的全面场景理解也引起了很多关注,其中通常采用众所周知的鸟瞰图(BEV)表示来更好地理解场景。来自多个周围图像的特征融合。 LSS 和 CaDDN 预测深度分布,将 2D 图像特征“提升”为 BEV 特征图以进行 3D 检测。他们的后续工作学习基于深度的隐式投影,将图像特征投影到 BEV 空间。其他一些论文还探索了 Transformer 结构,通过交叉注意力将图像特征从透视图投影到 BEV 空间,例如 DETR3D 、PETR 、BEVFormer 、PolarFormer 等。虽然这些工作通过将多视图图像投影到统一的BEV空间极大地提高了基于图像的3D检测的性能,但不准确的深度估计仍然是基于图像的3D检测的主要挑战。
点云表示学习 : 最近,点云上的表示学习对于提高 3D 分类和分割的性能引起了广泛关注。在 3D 检测方面,以前的方法通常将点投影到常规 2D 像素或 3D 体素,以便使用 2D/3D CNN 对其进行处理。 (Yan et al 2018; Shi et al 2020b) 采用稀疏卷积来有效地从点云中学习稀疏体素特征。(Qi et al 2017a,b)提出PointNet直接从原始点学习点特征,其中集合抽象通过设置不同的搜索半径来实现灵活的感受野。 (Liu et al 2019) 将体素 CNN 和point多层感知机网络相结合,以实现高效的点特征学习。相比之下,本文的 PV-RCNN 利用基于体素(即 3D 稀疏卷积)和基于点(即集合抽象)策略的优势,能够通过密集的 BEV 检测头和灵活的感受野生成高质量的 3D 提案在 3D 空间中提高 3D 检测性能。
使用点云进行3D目标检测 : 大多数现有的3D检测方法可以根据学习点云特征的不同策略大致分为三类,即基于体素的方法、基于点的方法以及点和体素相结合的方法。
基于体素的方法将点云投影到规则网格以解决不规则数据格式问题。 MV3D项目指向 2D 鸟瞰网格并放置大量预定义的 3D 锚点以生成 3D 框,以及以下工作(Ku et al 2018;Liang et al 2018、2019;Vora et al 2020;Yoo et al) al 2020;Huang et al 2020)开发更好的多传感器融合策略。 (Yang et al 2018b,a;Lang et al 2019)引入了更高效的鸟瞰视图表示框架,而(Ye et al 2020)提出融合多个尺度的网格特征。 MVF(Zhou et al 2020)在将点投影到pillars表示之前集成了鸟瞰图和透视图的 2D 特征(Lang et al 2019)。其他一些论文(Song and Xiao 2016;Zhou and Tuzel 2018;Wang et al 2022a)将点划分为 3D 体素,由 3D CNN 处理。 (Yan et al 2018) 引入了 3D 稀疏卷积 (Graham et al 2018),以实现高效的 3D 体素处理。 (Kuang et al 2020)利用多个检测头来检测不同尺度的 3D 物体。此外,(Wang et al 2020;Chen et al 2019a)根据无锚范式预测边界框参数。这些基于网格的方法通常对于准确的 3D 提案生成非常有效,但感受野受到 2D/3D 卷积核大小的限制。
基于点的方法直接从原始点检测 3D 对象。 F-PointNet (Qi et al 2018) 应用 PointNet (Qi et al 2017a,b) 从基于 2D 图像框的裁剪点进行 3D 检测。 PointRCNN(Shi et al 2019)仅通过获取 3D 点直接从原始点生成 3D 提案,一些论文(Qi et al 2019;Cheng et al 2021;Wang et al 2022b)通过探索不同的特征分组来遵循基于点的流程生成 3D 盒子的策略。 3DSSD(Yang et al 2020)在原始点上引入了基于混合特征距离的最远点采样。这些基于点的方法大多基于PointNet系列,特别是集合抽象(Qi et al 2017b),它为点云特征学习提供了灵活的感受野。然而,将这些基于点的方法扩展到大规模点云具有挑战性,因为它们通常比上述基于体素的方法消耗更多的内存/计算资源。
还有一些作品同时使用基于点和基于体素的表示。 STD(Yang et al 2019)将逐点特征转换为密集体素以细化建议。 Fast Point R-CNN(Chen et al 2019b)将深度体素特征与原始点融合以进行 3D 检测。 Part-A2-Net(Shi et al 2020b)通过基于体素的 RoI 感知池聚合逐点零件位置,以提高 3D 检测性能。然而,这些方法通常只是简单地转换两种表示之间的特征,并且不会从这两种表示的具体基本操作中融合更深层次的特征。相比之下,本文的 PV-RCNN 框架探索如何通过学习基于点(即集合抽象)和基于体素(即稀疏卷积)的特征学习模块来深度聚合特征,以提高 3D 检测性能。
PV-RCNN:基于点-体素特征集抽象的 3D 目标检测
大多数最先进的 3D 检测器(Shi et al 2020b;Yin et al 2021;Sheng et al 2021)采用 3D 稀疏卷积来从不规则点学习代表性特征,这得益于其处理大规模点的效率和有效性。然而,由于不可或缺的体素化过程,3D 稀疏卷积网络会丢失准确的点信息。相比之下,基于点的方法 (Qi et al 2017a,b) 自然地保留了准确的点位置,并且可以通过灵活的感受野捕获丰富的上下文信息,其中准确的点位置对于估计准确的 3D 边界框至关重要。
在本节中,将简要回顾本文最初的 3D 检测框架 PV-RCNN(Shi et al 2020a),用于从点云进行 3D 对象检测。它深度集成了基于体素的稀疏卷积和基于点的集合抽象操作,以实现两全其美。
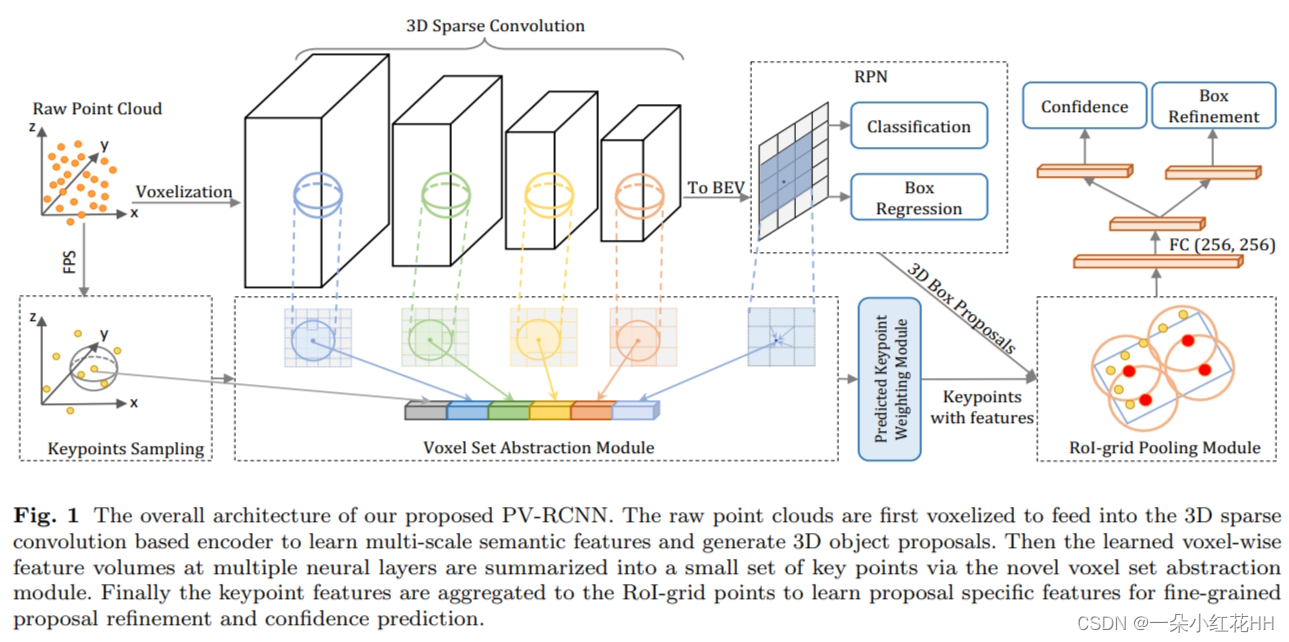
如图 1 所示,PV-RCNN 是一个两阶段 3D 检测框架,采用稀疏卷积的 3D 体素 CNN 作为高效特征编码和提案生成的主干,然后生成提案-对齐特征,通过两个新颖的步骤交织点体素特征来预测准确的 3D 边界框,这两个步骤是体素到关键点场景编码和关键点到网格 RoI 特征抽象。
体素特征编码和建议生成
为了处理大规模点云上的 3D 对象检测,本文采用具有稀疏卷积的 3D 体素 CNN(Graham et al 2018)作为主干网络来生成初始 3D 建议。
输入点P首先被划分为空间分辨率为L×W×H的小体素,其中通过对内部点的坐标进行平均来直接计算非空体素特征。该网络利用一系列 3D 稀疏卷积将点逐渐转换为具有 1×、2×、4×、8× 下采样大小的特征量。本文按照(Yan et al 2018)沿 Z 轴堆叠 3D 特征量以获得 L/8 × W/8 鸟瞰特征图,该特征图可以与 2D 检测头自然结合(Liu et al 2016;Yin et al 2021)用于生成高质量的 3D 提案。
值得注意的是,每个级别的稀疏特征量可以被视为一组稀疏体素特征向量,并且这些多尺度语义特征被视为本文接下来的体素到关键点场景编码步骤的输入。
体素到关键点场景编码
考虑到多尺度场景特征,本文建议将这些特征总结为少量关键点,作为将特征从上述 3D 体素 CNN 传播到细化网络的信使。
关键点采样 : 本文简单地采用(Qi et al 2017b)中的最远点采样算法来采样少量关键点 K = { pi | pi ∈ R3 }n i=1来自原始点 P 的 ,其中 n 是超参数(例如,对于 Waymo 开放数据集,n=4,096 (Sun et al 2020))。它鼓励关键点均匀分布在非空体素周围,并且可以代表整个场景。
体素集抽象模块 : 为了聚合从 3D 特征量到关键点的多尺度语义特征,本文提出了体素集抽象(VSA)模块。采用集合抽象(Qi et al 2017b)来聚合体素特征量。主要区别在于,周围的局部点现在是来自 3D 体素 CNN 的常规体素语义特征,而不是具有 PointNet 学习特征的相邻原始点。
具体来说,本文将 3D 体素 CNN 第 k 层中非空体素的数量表示为 Nk,体素方面的特征和 3D 坐标表示为
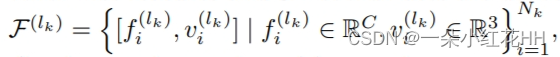 其中C表示特征维度的数量。
其中C表示特征维度的数量。
对于每个关键点 pi ∈ K,为了检索相邻体素特征向量的集合,首先在半径 rk 内的第 k 层识别其相邻非空体素:
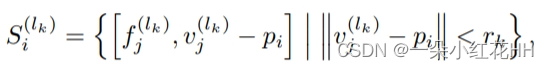
其中 [f(lk) j , v(lk) j ] ∈ F(lk),与局部相对位置 v(lk) j −pi 连接起来表示 f(lk) j 在该局部区域中的相对位置。然后,相邻集合 S(lk) i 内的特征由 PointNet-block(Qi 等人 2017a)聚合,以生成关键点特征:

其中 SharedMLP(·) 表示共享多层感知器 (MLP) 网络,用于编码体素特征和相对位置,max{·} 进行排列不变特征聚合,将不同数量的相邻体素特征映射到单个关键点特征 f (pvk)。这里利用多个半径来捕获更丰富的上下文信息。
上述体素特征聚合是在3D体素CNN的不同级别的输出上进行的,并且将不同尺度的聚合特征连接起来以获得关键点pi的多尺度语义特征:
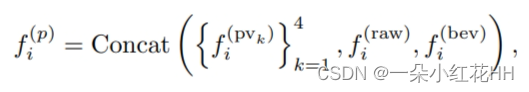
其中 i ∈ {1, . , n}, 且 k ∈ {1, . , 4} 表示关键点特征是从 3D 体素 CNN 的四级体素特征聚合而来。请注意,关键点特征通过两个额外的信息源进一步丰富,其中原始点特征 f(raw) i 被聚合。 弥补点体素化的量化损失,同时在8×下采样的2D特征图上通过双线性插值获得2D鸟瞰特征f(bev) i,以实现沿高度轴更大的感受野。
预测关键点权重 : 直观上,属于前景对象的关键点应该对提案细化贡献更大,而来自背景区域的关键点应该贡献较少。因此,本文提出了一个预测关键点加权(PKW)模块,通过点分割的额外监督来重新加权关键点特征:

其中 MLP(·) 是一个三层 MLP 网络,具有 sigmoid 函数来预测前景置信度。它使用默认参数进行focal loss训练 (Lin et al 2018),并且可以直接从 3D 框注释生成分割标签,如 (Shi et al 2019) 中所示。请注意,这个 PKW 模块对于本文的框架来说是可选的,因为它只会带来很小的收益。
关键点特征 F = { f§ i }n i=1 不仅融合了 3D 体素主干网络的多尺度语义特征,而且还通过其 3D 关键点坐标自然地保留了准确的位置信息 K = {pi}n i=1 ,为后续的细粒度提案细化提供了强大的保留整个场景的3D结构信息的能力。
关键点到网格 RoI 特征抽象
给定聚合的关键点特征及其 3d 坐标,在这一步中,本文提出关键点到网格 RoI 特征抽象,以生成准确的提案对齐特征,以进行细粒度提案细化。
通过集合抽象进行 RoI 网格池化 : 本文提出了 RoI-grid pooling 模块,通过采用多尺度局部特征分组将关键点特征聚合到 RoI-grid 点。对于每个给定的 3D 提案,根据 3D 提案框均匀采样 6 × 6 × 6 网格点,然后将其展平并表示为 G = {gi}6×6×6=216 i=1 。为了将关键点的特征聚合到 RoI 网格点,首先将网格点 gi 的相邻关键点识别为:
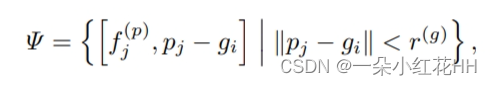
其中 pj ∈ K 且 f§ j ∈ F。本文连接 pj − gi 来指示半径为 r(g) 的球内的局部相对位置。然后采用与方程
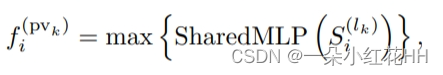
类似的过程总结邻近关键点特征集Ψ,得到网格点gi的特征为:

请注意,本文设置了多个半径 r(g) 并聚合具有不同感受野的关键点特征,这些特征连接在一起以捕获更丰富的多尺度上下文信息。接下来,同一 RoI 的所有 RoI-grid 特征 {f(g) i }216 i=1 可以通过具有 256 个特征维度的两层 MLP 进行矢量化和变换,以表示该提案框的整体特征。
本文提出的 RoI 网格池化操作可以比之前的 RoI 池化/RoI 对齐操作聚合更丰富的上下文信息(Shi et al 2019;Yang et al 2019;Shi et al 2020b)。这是因为由于 RoI 网格点的相邻球重叠,单个关键点可以对多个 RoI 网格点做出贡献,并且通过捕获 3D RoI 之外的上下文关键点特征,它们的感受野甚至超出了 RoI 边界。相比之下,以前最先进的方法要么简单地平均提案中的所有点状特征作为 RoI 特征(Shi et al 2019),要么由于非常稀疏的点状特征而将许多无信息的零池化为 RoI 特征特征(Shi et al 2020b;Yang et al 2019)。
提案细化 : 给定上述 RoI 对齐特征,细化网络学习预测相对于 3D 建议框的大小和位置(即中心、大小和方向)残差。采用两个兄弟子网络进行置信度预测和提案细化。每个子网络由两层 MLP 和线性预测层组成。按照(Shi et al 2020b)进行基于 IoU 的置信度预测。采用二元交叉熵损失来优化 IoU 分支,同时使用 smooth-L1 损失来优化框残差。
PV-RCNN++:使用 PV-RCNN 框架更快更好的 3D 检测
尽管本文提出的 PV-RCNN 3D 检测框架实现了最先进的性能(Shi et al 2020a),但在处理大规模点云时却遇到了效率问题。为了使 PV-RCNN 框架更实用于现实世界的应用,提出了一种先进的 3D 检测框架,即 PVRCNN++,以更少的资源消耗实现更准确、更高效的 3D 对象检测。
如图 3 所示,本文提出了两个新颖的模块来提高 PV-RCNN 框架的准确性和效率。一种是以扇区提案为中心的策略,用于更快更好的关键点采样,另一种是 VectorPool 聚合模块,用于从大规模点云进行更有效和高效的局部特征聚合。采用这两个模块来替换 PV-RCNN 中的对应模块。
以提案为中心的扇区抽样,实现高效且具有代表性的关键点抽样
关键点采样对于 PV-RCNN 框架至关重要,因为关键点连接了点体素表示并严重影响提案细化的性能。然而,以前的关键点采样算法有两个主要缺点。 (i) 最远点采样由于其二次复杂度而非常耗时,这阻碍了PV-RCNN的训练和推理速度,特别是对于大规模点云上的关键点采样。 (ii) 它会生成大量的背景关键点,这些背景关键点通常对提案细化无用,因为 RoI-grid pooling 模块只能检索提案周围的关键点。
为了减轻这些缺点,本文提出了以扇区化提案为中心(SPC)的关键点采样,以从更集中的邻近提案区域中均匀地采样关键点,同时也比普通的最远点采样算法快得多。它主要由两个新颖的步骤组成,即以提案为中心的过滤和扇区化采样。
以提案为中心的过滤 : 为了更好地将关键点集中在更重要的区域,并降低下一次采样过程的复杂性,本文首先采用以提案为中心的过滤步骤。
具体来说,本文将许多 Np 3D 提案表示为 D = {[ci, di] | ci ∈ R3, di ∈ R3}Np i=1,其中ci和di分别是每个提案框的中心和大小。将候选关键点 P’ 限制为所有提案的相邻点集:
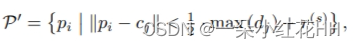
该步骤不仅降低了后续关键点采样的时间复杂度,而且集中了有限数量的关键点以更好地对提案的相邻区域进行编码。
扇区关键点采样 : 为了进一步并行化加速关键点采样过程,如图4所示,本文提出了扇区化关键点采样策略,该策略利用LiDAR点的径向分布来更好地并行化和加速关键点采样过程。
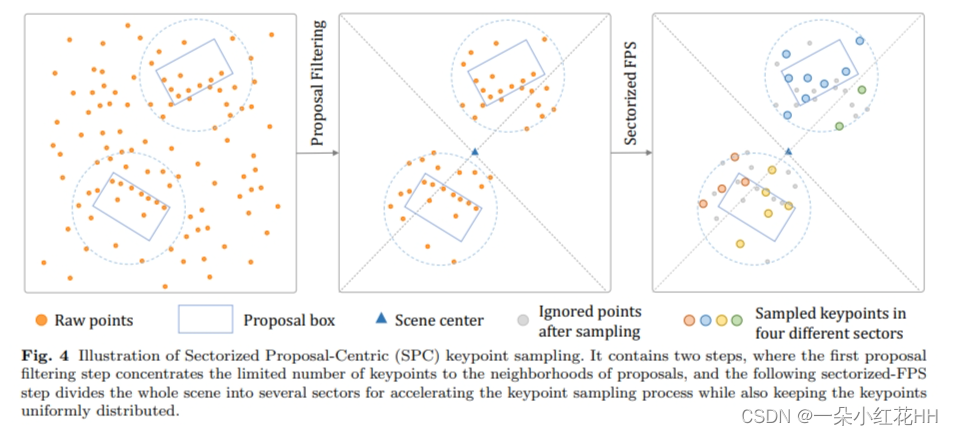
具体来说,本文将以提案为中心的点集P’分为以场景中心为中心的s个扇区,第k个扇区的点集可以表示为
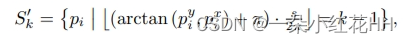
值得注意的是,通过考虑 LiDAR 传感器生成的点的径向分布,本文基于扇区的组划分可以大致在每组中产生相似数量的点,这对于加快关键点采样至关重要,因为整体运行时间取决于得分最多的组。
因此,本文提出的关键点采样算法大大降低了|P|的关键点采样规模。到更小的maxk∈{1,…,s} |S’ k|,这不仅有效地加速了关键点采样过程,而且通过将关键点集中到更重要的邻近区域来增加关键点特征表示的能力3D 提案。
尽管所提出的扇区化关键点采样是为 LiDAR 传感器量身定制的,但其背后的主要思想,即在空间组中进行 FPS 以加速操作,对于其他类型的传感器也有效。需要注意的是,点群生成应基于空间分区,以保持整体均匀分布。将点随机分组,同时确保组间点数平衡,会损害模型性能。
用于保留结构的局部特征学习的局部向量表示
点云的局部特征聚合在PV-RCNN框架中起着重要作用,因为它是在体素集抽象和RoI网格池提案过滤扇区化FPS模块中深度集成点体素特征的基本操作。然而,本文观察到 PV-RCNN 框架中的集合抽象在大规模点云上可能非常耗时和资源消耗,因为它在每个局部点的逐点特征分别。此外,集合抽象中的最大池化操作放弃了局部点的空间分布信息,损害了点云局部聚合特征的表示能力。
因此,本文提出了 VectorPool 聚合模块,用于大规模点云上的局部特征聚合,它可以更好地保留局部邻域的空间点分布,并且比常用的集合抽象花费更少的内存/计算资源。PV-RCNN++框架采用它作为基本模块,以实现更有效和高效的3D物体检测。
点云上的 VectorPool 聚合 : 在本文提出的 VectorPool 聚合模块中,建议通过使用单独的内核权重和单独的特征通道对不同的空间区域进行编码来生成位置敏感的局部特征,然后将其连接为单个向量表示以显式地表示局部点特征的空间结构。
具体来说,给定一个目标中心点 qk,首先识别其立方相邻区域内的支撑点,可以表示为
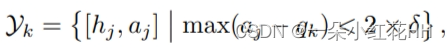
请注意,本文将原始立方空间的一半长度加倍,以包含更多相邻点,用于该目标点的局部特征聚合。
为了为以 qk 为中心的局部立方邻域生成位置敏感特征,本文将其相邻立方空间分割为 nx ×ny ×nz 小局部子体素。受(Qi et al 2017b)的启发,利用反距离加权策略通过考虑距 Yk 的三个最近邻来插值第 t 个子体素的特征,其中 t ∈ {1,… , nx ×ny ×nz} 表示每个子体素的索引,将其相应的子体素中心表示为 vt ∈ R3。然后可以生成第 t 个子体素的特征为:
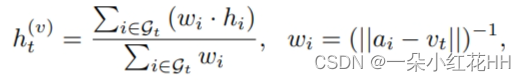
结果 h(v) t 对该局部立方体中的特定第 t 个局部子体素的局部特征进行编码。
还有两种其他替代策略可以通过简单地平均每个子体素内的特征或通过随机选择每个子体素内的一个点来聚合局部子体素的特征。它们都在空子体素中生成大量空特征,这可能会降低性能。相比之下,本文基于插值的策略即使在空的局部体素上也可以生成更有效的特征。
不同局部子体素中的那些特征可能代表非常不同的局部特征。因此,建议使用单独的局部内核权重对不同的局部子体素进行编码,以捕获位置敏感特征,而不是像(Qi et al 2017b)中那样使用共享参数 MLP 来编码局部特征,如下所示
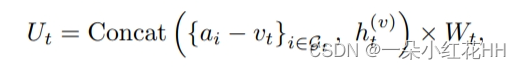
最后,直接根据局部子体素特征 Ut 沿每个 3D 轴的空间顺序对其进行排序,并将它们的特征依次连接以生成最终的局部向量表示:
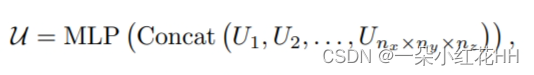
其中 U ∈ RCout 。内部顺序串联通过简单地将不同位置的特征分配到相应的特征通道来对结构保留的局部特征进行编码,这自然地保留了以qk为中心的相邻空间中的局部特征的空间结构,最终处理该局部向量表示使用多个MLP将局部特征编码到Cout特征通道以进行后续处理。
值得注意的是,本文的 VectorPool 聚合模块还可以与(Sun et al 2018)中的通道缩减技术相结合,通过在进行 VectorPool 聚合之前汇总输入特征通道来进一步减少计算/内存资源。
与集合抽象相比, VectorPool 聚合可以通过采用通道求和并利用 MLP 之前提出的局部向量表示来大大减少所需的计算和内存资源。此外,本文提出的局部向量表示可以对具有不同特征通道的位置敏感特征进行编码,而不是像集合抽象中那样对局部逐点特征进行最大池化,从而为局部特征学习提供更有效的表示。
PV-RCNN++ 上的 VectorPool 聚合 : 本文提出的 VectorPool 聚合集成在 PVRCNN++ 检测框架中,以取代体素集抽象模块和 RoI 网格池模块中的集抽象。由于本文的 VectorPool 聚合操作,实验表明 PVRCNN++ 不仅比 PV-RCNN 框架消耗更少的内存和计算资源,而且还实现了更好的 3D 检测性能。
结论
在本文中,提出了两个新颖的框架,名为 PV-RCNN 和 PV-RCNN++,用于从点云进行精确的 3D 对象检测。PV-RCNN框架采用了一种新颖的体素集抽象模块,将多尺度3D体素CNN特征和基于PointNet的特征深度集成到一小组关键点中,然后将学习到的判别性关键点特征聚合到RoI-网格点通过我们提出的 RoI 网格池模块来捕获更丰富的上下文信息以进行提案细化。 PVRCNN++ 进一步改进了 PV-RCNN 框架,通过新颖的以扇区提案为中心的关键点采样策略有效地生成更具代表性的关键点,并且还配备了本文提出的 VectorPool 聚合模块来学习体素集抽象模块和RoI-网格池模块。因此,PV-RCNN++最终以比原始PV-RCNN框架更快的运行速度获得了更好的性能。
最终的 PV-RCNN++ 框架显着优于之前的 3D 检测方法,并在大规模 Waymo 开放数据集的验证集和测试集上实现了最先进的性能,并且已经设计和进行了大量的实验来深入研究本文提议的框架的各个组成部分。
相关文章:
[论文阅读]PV-RCNN++
PV-RCNN PV-RCNN: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection 论文网址:PV-RCNN 论文代码:PV-RCNN 简读论文 这篇论文提出了两个用于3D物体检测的新框架PV-RCNN和PV-RCNN,主要的贡献如下: 提出P…...
测试老鸟整理,Postman加密接口测试-Rsa/Aes对参数加密(详细总结)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 一些问题 postma…...

JavaScript使用对象
对象(object)是最基本、最通用的类型,具有复合性结构,属于引用型数据,对象的结构具有弹性,内部的数据是无序的,每个成员被称为属性。在JavaScript中,对象是一个泛化的概念,任何值都可以转换为对…...
微带线的ABCD矩阵的推导、转换与级联-Matlab计算实例
微带线的ABCD矩阵的推导、转换与级联-Matlab计算实例 散射参数矩阵有实际的物理意义,但是其无法级联计算,但是ABCD参数和传输散射矩阵可以级联计算,在此先简单介绍ABCD参数矩阵的基本用法。 1、微带线的ABCD矩阵的推导 其他的一些常用的二端…...
“网站不安全”该如何解决
当我们的网站被客户访问的时候,经常会出现提示不安全的情况,导致客户的不信任,从而出现客户流失的现象,这种情况我们应该如何解决呢? 首先,我们要确定网站会出现不安全的原因,一般来说ÿ…...

gitlab数据备份和恢复
gitlab数据备份 sudo gitlab-rake gitlab:backup:create备份文件默认存放在/var/opt/gitlab/backups路径下, 生成1697101003_2023_10_12_12.0.3-ee_gitlab_backup.tar 文件 gitlab数据恢复 sudo gitlab-rake gitlab:backup:restore BACKUP1697101003_2023_10_12_…...
嵌入式Linux和stm32区别? 之间有什么关系吗?
嵌入式Linux和stm32区别? 之间有什么关系吗? 主要体现在以下几个方面: 1.硬件资源不同 单片机一般是芯片内部集成flash、ram,ARM一般是CPU,配合外部的flash、ram、sd卡存储器使用。最近很多小伙伴找我,说想要一些嵌…...

【Redis】String字符串类型-内部编码使用场景
文章目录 内部编码使用场景缓存功能计数功能共享会话手机验证码 内部编码 字符串类型的内部编码有3种: int:8个字节(64位)的⻓整型,存储整数embstr:压缩字符串,适用于表示较短的字符串raw&…...

电脑发热发烫,具体硬件温度达到多少度才算异常?
环境: 联想E14 问题描述: 电脑发热发烫,具体硬件温度达到多少度才算异常? 解决方案: 电脑硬件的温度正常范围会因设备类型和使用的具体硬件而有所不同。一般来说,以下是各种硬件的正常温度范围: CPU:正…...

计算机网络第4章-IPv6和寻址
IP地址的分配 为了获取一块IP地址用于一个组织的子网内,于是我们向ISP联系,ISP则会从已分给我们的更大 地址块中提供一些地址。 例如,ISP也许已经分配了地址块200.23.16.0/20。 该ISP可以依次将该地址块分成8个长度相等的连续地址块&…...
Lazarus安装和入门资料
azarus-2.2.6-fpc-3.2.2-win64 下载地址 Lazarus 基础教程 - Lazarus Tutorials for Beginners Lazarus Tutorial #1 - Learning programming_哔哩哔哩_bilibili https://www.devstructor.com/index.php?pagetutorials Lazarus是一款开源免费的object pascal语言RAD IDE&…...

mediapipe流水线分析 二
目标检测 Graph 一 流水线上游输入处理 1 TfLiteConverterCalculator 将输入的数据转换成tensorflow api 支持的Tensor TfLiteTensor 并初始化相关输入输出节点 ,该类的业务主要通过 interpreter std::unique_ptrtflite::Interpreter interpreter_ nullptr; 实现…...
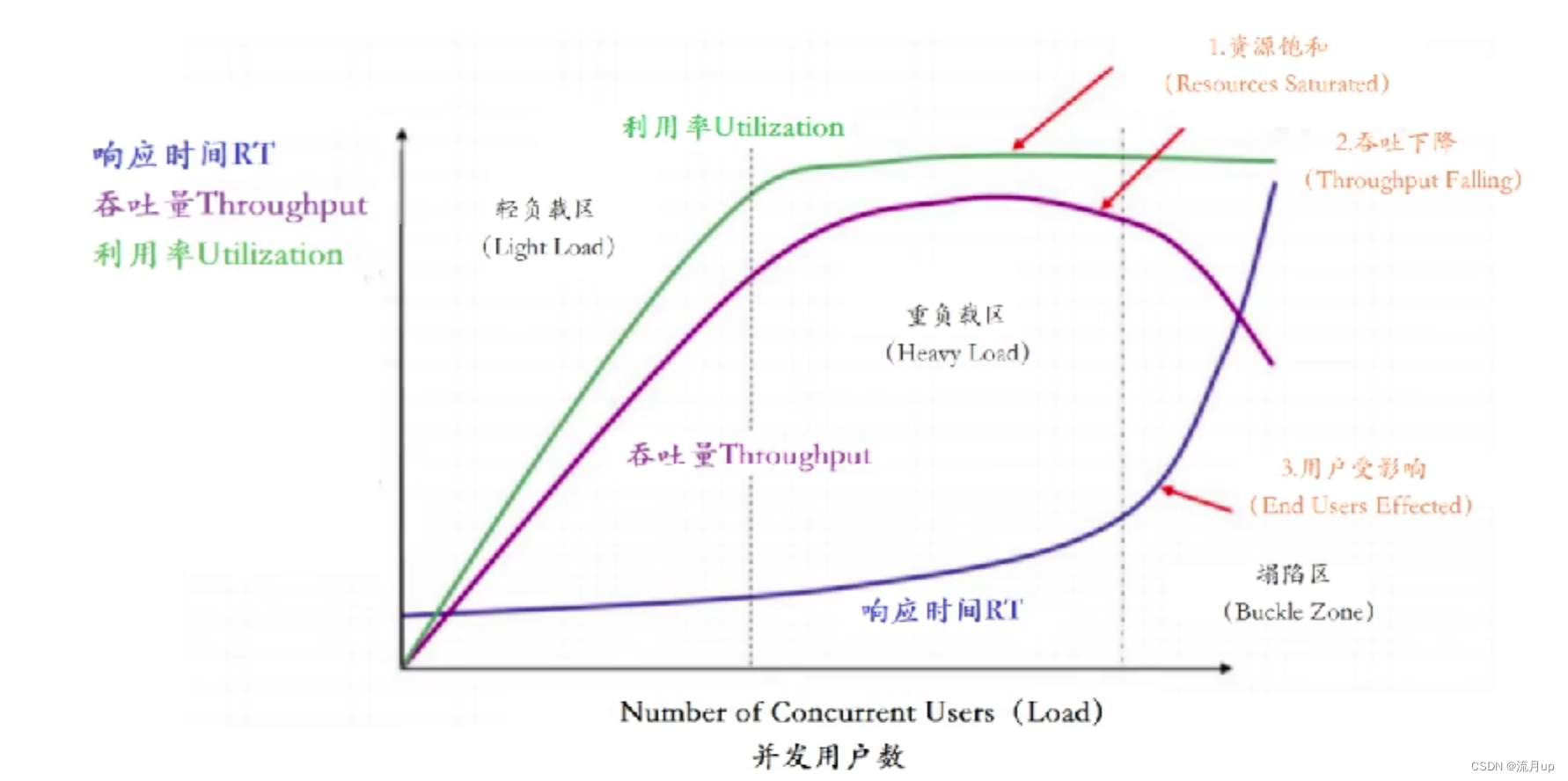
1.性能优化
概述 今日目标: 性能优化的终极目标是什么压力测试压力测试的指标 性能优化的终极目标是什么 用户体验 产品设计(非技术) 系统性能(快,3秒不能更久了) 后端:RT,TPS,并发数 影响因素01:数据库读写,RPCÿ…...
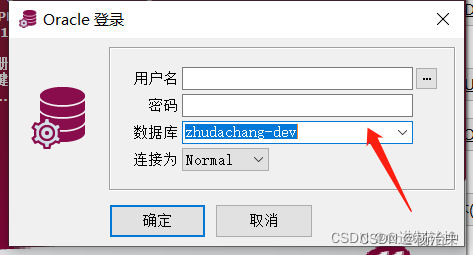
使用Plsql+oracle client 连接 Oracle数据库
2011年入职老东家X煤集团的时候,在csnd上写了一篇blog,题目叫“什么是ERP”,从此跳入DBA了这个烂坑,目前公司的数据库一部分是Oracle,另一部分是MySQL的,少量MSSQL,还需要捡起来一部分ÿ…...
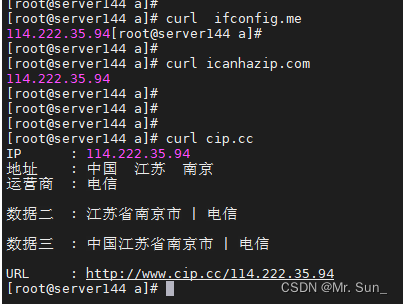
centos获取服务器公网ip
查看公网IP 用下面几个命令: #curl ifconfig.me #curl icanhazip.com #curl cip.cc...

思谋科技进博首秀:工业多模态大模型IndustryGPT V1.0正式发布
大模型技术正在引领新一轮工业革命,但将其应用于工业制造,仍面临许多挑战,专业知识的缺乏是关键难点。11月5日,香港中文大学终身教授、思谋科技创始人兼董事长贾佳亚受邀参加第六届中国国际进口博览会暨虹桥国际经济论坛开幕式。虹…...
Wsl2 Ubuntu在不安装Docker Desktop情况下使用Docker
目录 1. 前提条件 2.安装Distrod 3. 常见问题 3.1.docker compose 问题无法使用问题 3.1. docker-compose up报错 参考文档 1. 前提条件 win10 WSL2 Ubuntu(截止202308最新版本是20.04.xx) 有不少的博客都是建议直接安装docker desktop,这样无论在windows…...
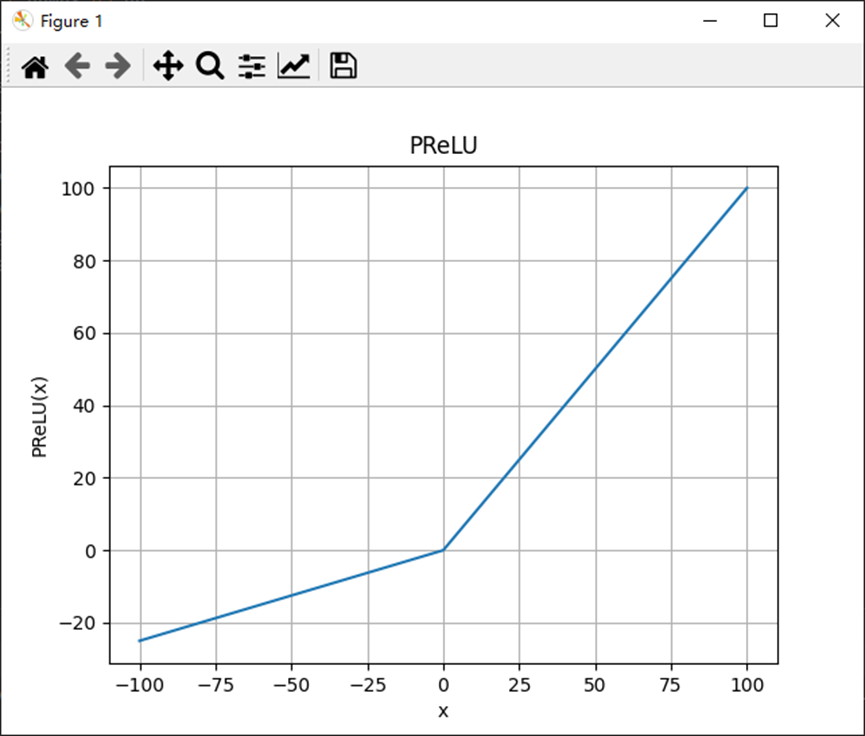
pytorch之relu激活函数
目录 1、relu 2、relu6 3、leaky_relu 4、ELU 5、SELU 6、PReLU 1、relu ReLU(Rectified Linear Unit)是一种常用的神经网络激活函数,它在PyTorch中被广泛使用。ReLU函数接受一个输入值,如果该值大于零,则返回该…...
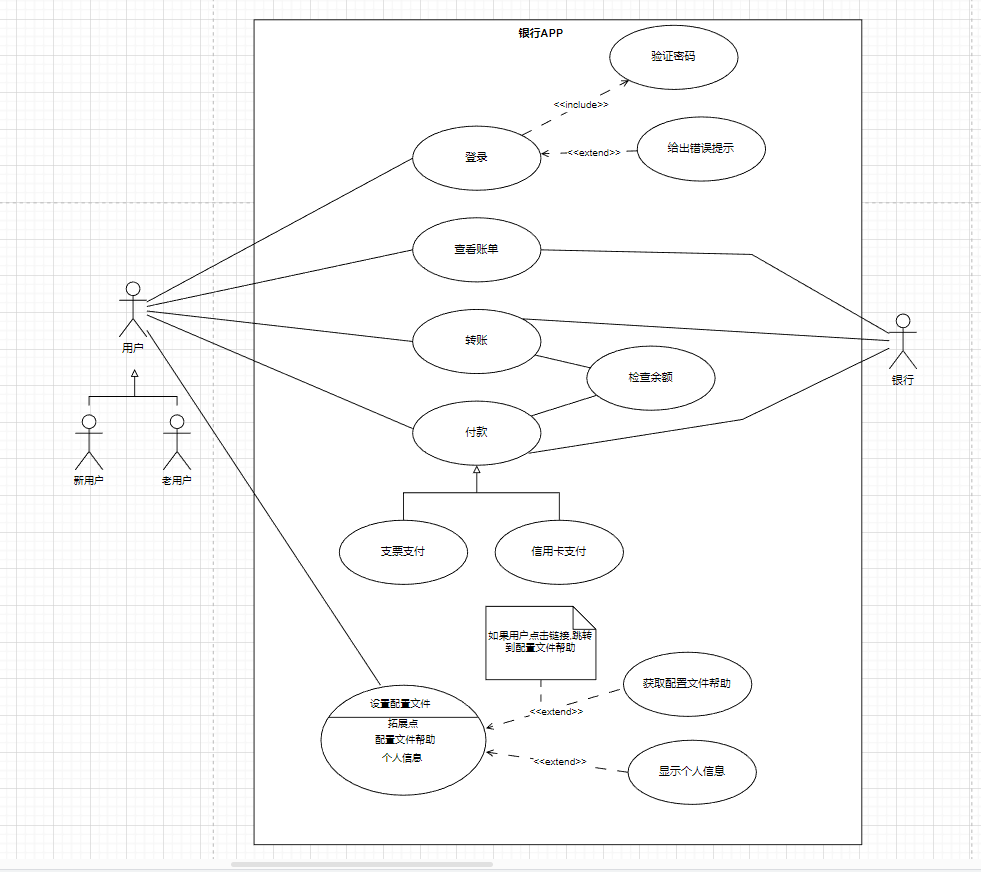
UML---用例图
UML–用例图 0.用例图简介 用例图是一种UML(统一建模语言)的图形化表示方法,用于描述系统的功能和行为。它可以帮助系统分析师和开发人员理解系统的需求,用例图由参与者、用例和它们之间的关系组成。 1.用例图的组成部分 系统…...

后端配置跨域怎么配置
在后端配置跨域,需要在服务器的代码中添加相应的设置。以下是几种常见的后端语言的跨域配置方式: Node.js 在使用 Node.js 的 Express 框架时,可以使用 cors 中间件来处理跨域问题。安装 cors 中间件后,在代码中添加如下设置&am…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...
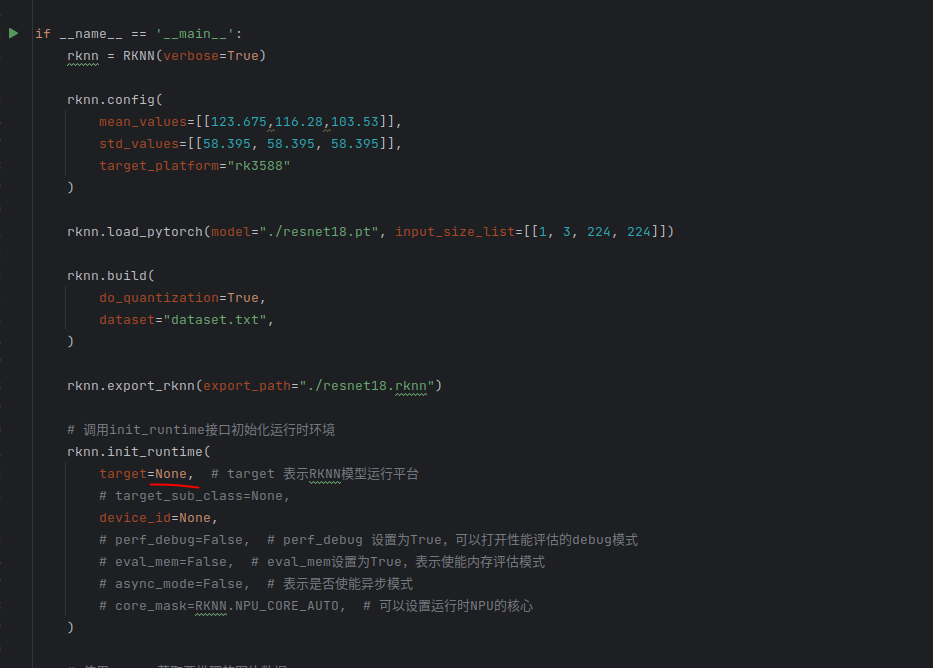
rknn toolkit2搭建和推理
安装Miniconda Miniconda - Anaconda Miniconda 选择一个 新的 版本 ,不用和RKNN的python版本保持一致 使用 ./xxx.sh进行安装 下面配置一下载源 # 清华大学源(最常用) conda config --add channels https://mirrors.tuna.tsinghua.edu.cn…...