Spark Streaming

第1章 SparkStreaming 概述
1.1 Spark Streaming 是什么
Spark 流使得构建可扩展的容错流应用程序变得更加容易。
**Spark Streaming 用于流式数据的处理。**Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。

和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作 DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此得名“离散化”)。所以简单来将,DStream 就是对 RDD 在实时数据处理场景的一种封装。
1.2 Spark Streaming 的特点
➢ 易用

➢ 容错

➢ 易整合到 Spark 体系

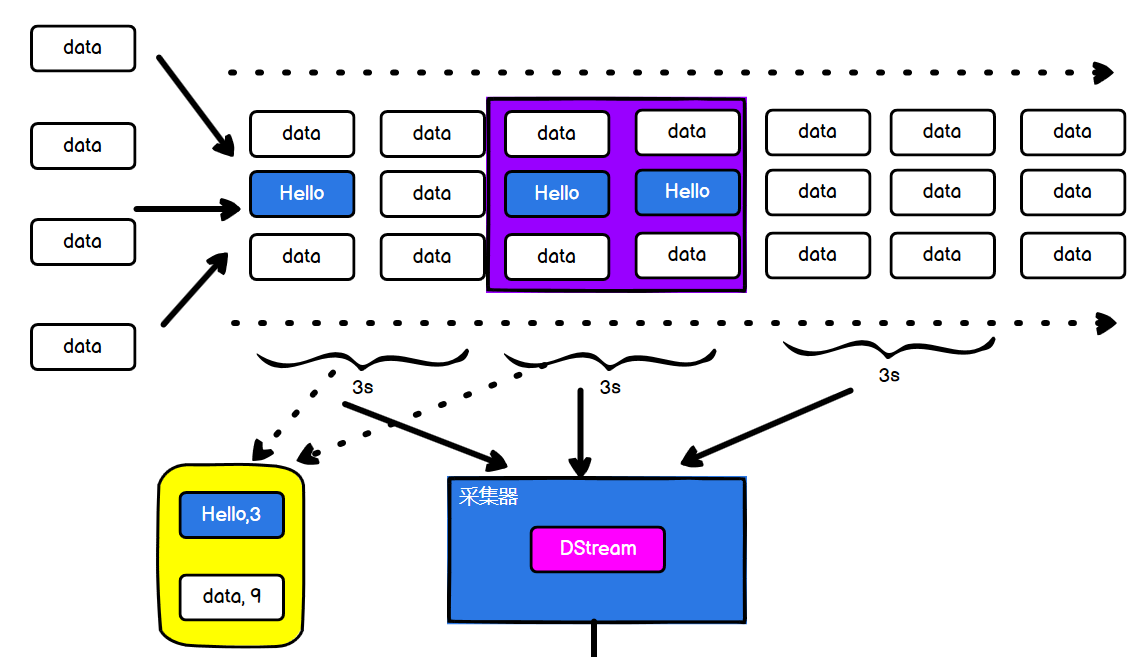
1.3 Spark Streaming 架构
1.3.1 架构图
➢ 整体架构图

➢ SparkStreaming 架构图

1.3.2 背压机制
Spark 1.5 以前版本,用户如果要限制 Receiver 的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer 数据生产高于 maxRate,当前集群处理能力也高于 maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5 版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即 Spark Streaming Backpressure): 根据JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。
为了更好的协调数据接收速率与资源处理能力,1.5 版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即 Spark Streaming Backpressure): 根据JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。
第 2 章 Dstream 入门
2.1 WordCount 案例实操
➢ 需求:使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并统计不同单词出现的次数
1) 添加依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.0.0</version>
</dependency>2) 编写代码
package spark.streamingimport org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}/*** @author Lucaslee* @create 2023-02-23 14:12*/
object streaming_wordCount {def main(args: Array[String]): Unit = {// TODO 创建环境对象//1.初始化 Spark 配置信息val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")//2.初始化 SparkStreamingContext// StreamingContext创建时,需要传递两个参数// 第一个参数表示环境配置// 第二个参数表示批量处理的周期(采集周期)val ssc = new StreamingContext(sparkConf, Seconds(3))// TODO 逻辑处理// 获取端口数据val line = ssc.socketTextStream("hadoop102", 9999)val word = line.flatMap(words=>{words.split(" ")})val wordCount = word.map((_, 1)).reduceByKey(_ + _)wordCount.print()// TODO 关闭环境// 由于SparkStreaming采集器是长期执行的任务,所以不能直接关闭// 如果main方法执行完毕,应用程序也会自动结束。所以不能让main执行完毕//ssc.stop()// 1. 启动采集器ssc.start()// 2. 等待采集器的关闭ssc.awaitTermination()}
}
3) 启动程序并通过 netcat 发送数据:
nc -lk 9999
hello spark2.2 WordCount 解析
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,DStream 是一系列连续的 RDD 来表示。每个 RDD 含有一段时间间隔内的数据。

对数据的操作也是按照 RDD 为单位来进行的

计算过程由 Spark Engine 来完成

第 3 章 DStream 创建
3.1 RDD 队列
3.1.1 用法及说明
测试过程中,可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到这个队列中的 RDD,都会作为一个 DStream 处理。
3.1.2 案例实操
➢ 需求:循环创建几个 RDD,将 RDD 放入队列。通过 SparkStream 创建 Dstream,计算WordCount
1) 编写代码
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}import scala.collection.mutableobject SparkStreaming02_Queue {def main(args: Array[String]): Unit = {// TODO 创建环境对象// StreamingContext创建时,需要传递两个参数// 第一个参数表示环境配置val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")// 第二个参数表示批量处理的周期(采集周期)val ssc = new StreamingContext(sparkConf, Seconds(3))//3.创建 RDD 队列val rddQueue = new mutable.Queue[RDD[Int]]()//4.创建 QueueInputDStreamval inputStream = ssc.queueStream(rddQueue,oneAtATime = false)val mappedStream = inputStream.map((_,1))val reducedStream = mappedStream.reduceByKey(_ + _)reducedStream.print()//7.启动任务ssc.start()//8.循环创建并向 RDD 队列中放入 RDDfor (i <- 1 to 5) {rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)Thread.sleep(2000)}ssc.awaitTermination()}
}
结果展示
-------------------------------------------
Time: 1539075280000 ms
-------------------------------------------
(4,60)
(0,60)
(6,60)
(8,60)
(2,60)
(1,60)
(3,60)
(7,60)
(9,60)
(5,60)
-------------------------------------------
Time: 1539075284000 ms
-------------------------------------------
(4,60)
(0,60)
(6,60)
(8,60)
(2,60)
(1,60)
(3,60)
(7,60)
(9,60)
(5,60)
-------------------------------------------
Time: 1539075288000 ms
-------------------------------------------
(4,30)
(0,30)
(6,30)
(8,30)
(2,30)
(1,30)
(3,30)
(7,30)
(9,30)
(5,30)
-------------------------------------------
Time: 1539075292000 ms
-------------------------------------------3.2 自定义数据源
3.2.1 用法及说明
需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
3.2.2 案例实操
需求:自定义数据源,实现监控某个端口号,获取该端口号内容。
1) 自定义数据源
class CustomerReceiver(host: String, port: Int) extendsReceiver[String](StorageLevel.MEMORY_ONLY) {//最初启动的时候,调用该方法,作用为:读数据并将数据发送给 Sparkoverride def onStart(): Unit = {new Thread("Socket Receiver") {override def run() {receive()}}.start()}//读数据并将数据发送给 Sparkdef receive(): Unit = {//创建一个 Socketvar socket: Socket = new Socket(host, port)//定义一个变量,用来接收端口传过来的数据var input: String = null//创建一个 BufferedReader 用于读取端口传来的数据val reader = new BufferedReader(new InputStreamReader(socket.getInputStream,StandardCharsets.UTF_8))//读取数据input = reader.readLine()//当 receiver 没有关闭并且输入数据不为空,则循环发送数据给 Sparkwhile (!isStopped() && input != null) {store(input)input = reader.readLine()}//跳出循环则关闭资源reader.close()socket.close()//重启任务restart("restart")}override def onStop(): Unit = {}
}2) 使用自定义的数据源采集数据
object FileStream {def main(args: Array[String]): Unit = {//1.初始化 Spark 配置信息val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")//2.初始化 SparkStreamingContextval ssc = new StreamingContext(sparkConf, Seconds(5))//3.创建自定义 receiver 的 Streamingval lineStream = ssc.receiverStream(new CustomerReceiver("hadoop102", 9999))//4.将每一行数据做切分,形成一个个单词val wordStream = lineStream.flatMap(_.split("\t"))//5.将单词映射成元组(word,1)val wordAndOneStream = wordStream.map((_, 1))//6.将相同的单词次数做统计val wordAndCountStream = wordAndOneStream.reduceByKey(_ + _)//7.打印wordAndCountStream.print()//8.启动 SparkStreamingContextssc.start()ssc.awaitTermination()}
}
小练习
package spark.streamingimport org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}import java.util.Random/*** @author Lucaslee* @create 2023-02-23 14:55*/
object DIY_Receiver {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val messageDS: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver())messageDS.print()ssc.start()ssc.awaitTermination()}/*自定义数据采集器1. 继承Receiver,定义泛型, 传递参数2. 重写方法*/class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY) {private var flg = true//最初启动的时候,调用该方法,作用为:读数据并将数据发送给 Sparkoverride def onStart(): Unit = {new Thread(new Runnable {override def run(): Unit = {while ( flg ) {// 在这里改采集逻辑val message = "采集的数据为:" + new Random().nextInt(10).toStringstore(message)Thread.sleep(500)}}}).start()}override def onStop(): Unit = {flg = false;}}}
3.3 Kafka 数据源(面试、开发重点)
3.3.1 版本选型
**ReceiverAPI:**需要一个专门的 Executor 去接收数据,然后发送给其他的 Executor 做计算。存在的问题,接收数据的 Executor 和计算的 Executor 速度会有所不同,特别在接收数据的 Executor速度大于计算的 Executor 速度,会导致计算数据的节点内存溢出。早期版本中提供此方式,当前版本不适用
**DirectAPI:**是由计算的 Executor 来主动消费 Kafka 的数据,速度由自身控制。
3.3.2 Kafka 0-8 Receiver 模式(当前版本不适用)
1) 需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
2)导入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-8_2.11</artifactId><version>2.4.5</version>
</dependency>3)编写代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object ReceiverAPI {def main(args: Array[String]): Unit = {//1.创建 SparkConfval sparkConf: SparkConf = newSparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(3))//3.读取 Kafka 数据创建 DStream(基于 Receive 方式)val kafkaDStream: ReceiverInputDStream[(String, String)] =KafkaUtils.createStream(ssc,"linux1:2181,linux2:2181,linux3:2181","atguigu",Map[String, Int]("atguigu" -> 1))//4.计算 WordCountkafkaDStream.map { case (_, value) =>(value, 1)}.reduceByKey(_ + _).print()//5.开启任务ssc.start()ssc.awaitTermination()}
}3.3.3 Kafka 0-8 Direct 模式(当前版本不适用)
1)需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
2)导入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-8_2.11</artifactId><version>2.4.5</version>
</dependency>3)编写代码(自动维护 offset)
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectAPIAuto02 {val getSSC1: () => StreamingContext = () => {val sparkConf: SparkConf = newSparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")val ssc = new StreamingContext(sparkConf, Seconds(3))ssc}def getSSC: StreamingContext = {//1.创建 SparkConfval sparkConf: SparkConf = newSparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(3))//设置 CKssc.checkpoint("./ck2")//3.定义 Kafka 参数val kafkaPara: Map[String, String] = Map[String, String](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->"linux1:9092,linux2:9092,linux3:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu")//4.读取 Kafka 数据val kafkaDStream: InputDStream[(String, String)] =KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc,kafkaPara,Set("atguigu"))//5.计算 WordCountkafkaDStream.map(_._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()//6.返回数据ssc}def main(args: Array[String]): Unit = {//获取 SSCval ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck2", () =>getSSC)//开启任务ssc.start()ssc.awaitTermination()}
}
4)编写代码(手动维护 offset)
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils,OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectAPIHandler {def main(args: Array[String]): Unit = {//1.创建 SparkConfval sparkConf: SparkConf = newSparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(3))//3.Kafka 参数val kafkaPara: Map[String, String] = Map[String, String](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->"hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu")//4.获取上一次启动最后保留的 Offset=>getOffset(MySQL)val fromOffsets: Map[TopicAndPartition, Long] = Map[TopicAndPartition,Long](TopicAndPartition("atguigu", 0) -> 20)//5.读取 Kafka 数据创建 DStreamval kafkaDStream: InputDStream[String] = KafkaUtils.createDirectStream[String,String, StringDecoder, StringDecoder, String](ssc,kafkaPara,fromOffsets,(m: MessageAndMetadata[String, String]) => m.message())//6.创建一个数组用于存放当前消费数据的 offset 信息var offsetRanges = Array.empty[OffsetRange]//7.获取当前消费数据的 offset 信息val wordToCountDStream: DStream[(String, Int)] = kafkaDStream.transform { rdd=>offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesrdd}.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)//8.打印 Offset 信息wordToCountDStream.foreachRDD(rdd => {for (o <- offsetRanges) {println(s"${o.topic}:${o.partition}:${o.fromOffset}:${o.untilOffset}")}rdd.foreach(println)})//9.开启任务ssc.start()ssc.awaitTermination()}
}3.3.4 Kafka 0-10 Direct 模式(使用)
1)需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
2)导入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version>
</dependency>
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.10.1</version>
</dependency>3)编写代码
package spark.streaming
import java.util.Randomimport org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}/*** @author Lucaslee* @create 2023-02-23 15:14*/
object SparkStreaming04_Kafka {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(3))//3.定义 Kafka 参数val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop103:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")//kafka消费者,需要在集群中启动kafka生产者进行数据的生产在观察控制台打印结果//4.读取 Kafka 数据创建 DStreamval kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))//5.将每条消息的 KV 取出kafkaDataDS.map(_.value()).print()ssc.start()ssc.awaitTermination()}
}
打开一个Kafka生产者进程生产数据,然后观察控制台输出数据
查看 Kafka 消费进度
bin/kafka-consumer-groups.sh --describe --bootstrap-server linux1:9092 --group
atguigu
第 4 章 DStream 转换
DStream 上的操作与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种 Window 相关的原语。
4.1 无状态转化操作
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。注意,针对键值对的 DStream 转化操作(比如reduceByKey())要添加 import StreamingContext._才能在 Scala 中使用。

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。
例如:reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
4.1.1 Transform
Transform 允许 DStream 上执行任意的 RDD-to-RDD 函数。即使这些函数并没有在 DStream的 API 中暴露出来,通过该函数可以方便的扩展 Spark API。该函数每一批次调度一次。其实也就是对 DStream 中的 RDD 应用转换。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}object SparkStreaming06_State_Transform {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val lines = ssc.socketTextStream("localhost", 9999)// transform方法可以将底层RDD获取到后进行操作// 1. DStream功能不完善// 2. 需要代码周期性的执行// Code : Driver端val newDS: DStream[String] = lines.transform(rdd => {// Code : Driver端,(周期性执行)rdd.map(str => {// Code : Executor端str})})// Code : Driver端val newDS1: DStream[String] = lines.map(data => {// Code : Executor端data})ssc.start()ssc.awaitTermination()}}
4.1.2 join
两个流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的 RDD 进行 join,与两个 RDD 的 join 效果相同。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object JoinTest {def main(args: Array[String]): Unit = {//1.创建 SparkConfval sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("JoinTest")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(5))//3.从端口获取数据创建流val lineDStream1: ReceiverInputDStream[String] =ssc.socketTextStream("linux1", 9999)val lineDStream2: ReceiverInputDStream[String] =ssc.socketTextStream("linux2", 8888)//4.将两个流转换为 KV 类型val wordToOneDStream: DStream[(String, Int)] = lineDStream1.flatMap(_.split(" ")).map((_, 1))val wordToADStream: DStream[(String, String)] = lineDStream2.flatMap(_.split("")).map((_, "a"))//5.流的 JOINval joinDStream: DStream[(String, (Int, String))] =wordToOneDStream.join(wordToADStream)//6.打印joinDStream.print()//7.启动任务ssc.start()ssc.awaitTermination()}
}package com.atguigu.bigdata.spark.streamingimport org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}object SparkStreaming06_State_Join {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(5))val data9999 = ssc.socketTextStream("localhost", 9999)val data8888 = ssc.socketTextStream("localhost", 8888)val map9999: DStream[(String, Int)] = data9999.map((_,9))val map8888: DStream[(String, Int)] = data8888.map((_,8))// 所谓的DStream的Join操作,其实就是两个RDD的joinval joinDS: DStream[(String, (Int, Int))] = map9999.join(map8888)joinDS.print()ssc.start()ssc.awaitTermination()}}
4.2 有状态转化操作
4.2.1 UpdateStateByKey
UpdateStateByKey 原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加 wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey 操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,需要做下面两步:
1.定义状态,状态可以是一个任意的数据类型。
定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用 updateStateByKey 需要对检查点目录进行配置,会使用检查点来保存状态。
更新版的 wordcount
1) 编写代码
package spark.streaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}object SparkStreaming05_State {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))// 设置检查点路径ssc.checkpoint("cp")// 无状态数据操作,只对当前的采集周期内的数据进行处理// 在某些场合下,需要保留数据统计结果(状态),实现数据的汇总// 使用有状态操作时,需要设定检查点路径val datas = ssc.socketTextStream("hadoop102", 9999)val wordToOne = datas.map((_,1))//val wordToCount = wordToOne.reduceByKey(_+_)// updateStateByKey:根据key对数据的状态进行更新// 传递的参数中含有两个值// 第一个值表示相同的key的value数据// 第二个值表示缓存区相同key的value数据val state = wordToOne.updateStateByKey(( seq:Seq[Int], buff:Option[Int] ) => {val newCount = buff.getOrElse(0) + seq.sumOption(newCount)})state.print()ssc.start()ssc.awaitTermination()}}
2) 启动程序并向 9999 端口发送数据
nc -lk 9999
Hello World
Hello Scala3) 结果展示
-------------------------------------------
Time: 1504685175000 ms
-------------------------------------------
-------------------------------------------
Time: 1504685181000 ms
-------------------------------------------
(shi,1)
(shui,1)
(ni,1)
-------------------------------------------
Time: 1504685187000 ms
-------------------------------------------
(shi,1)
(ma,1)
(hao,1)
(shui,1)4.2.2 WindowOperations
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前 Steaming 的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
➢ 窗口时长:计算内容的时间范围;
➢ 滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集周期大小的整数倍。
WordCount 第三版:3 秒一个批次,窗口 12 秒,滑步 6 秒。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}object SparkStreaming06_State_Window {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val lines = ssc.socketTextStream("localhost", 9999)val wordToOne = lines.map((_,1))// 窗口的范围应该是采集周期的整数倍// 窗口可以滑动的,但是默认情况下,一个采集周期进行滑动// 这样的话,可能会出现重复数据的计算,为了避免这种情况,可以改变滑动的滑动(步长)val windowDS: DStream[(String, Int)] = wordToOne.window(Seconds(6), Seconds(6))val wordToCount = windowDS.reduceByKey(_+_)wordToCount.print()ssc.start()ssc.awaitTermination()}}
关于 Window 的操作还有如下方法:
(1)window(windowLength, slideInterval): 基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream;
(2)countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;
(3)reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
(4)reduceByKey****AndWindow(func, windowLength, slideInterval, [numTasks]): 当在一个(K,V)对的 DStream 上调用此函数,会返回一个新(K,V)对的 DStream,此处通过对滑动窗口中批次数据使用 reduce 函数来整合每个 key 的 value 值。
(5)reduceByKeyAndWindow(func,** invFunc**, windowLength, slideInterval, [numTasks]): 这个函数是上述函数的变化版本,每个窗口的 reduce 值都是通过用前一个窗的 reduce 值来递增计算。通过 reduce 进入到滑动窗口数据并”反向 reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对 keys 的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的 reduce 函数”,也就是这些 reduce 函数有相应的”反 reduce”函数(以参数 invFunc 形式传入)。如前述函数,reduce 任务的数量通过可选参数来配置。
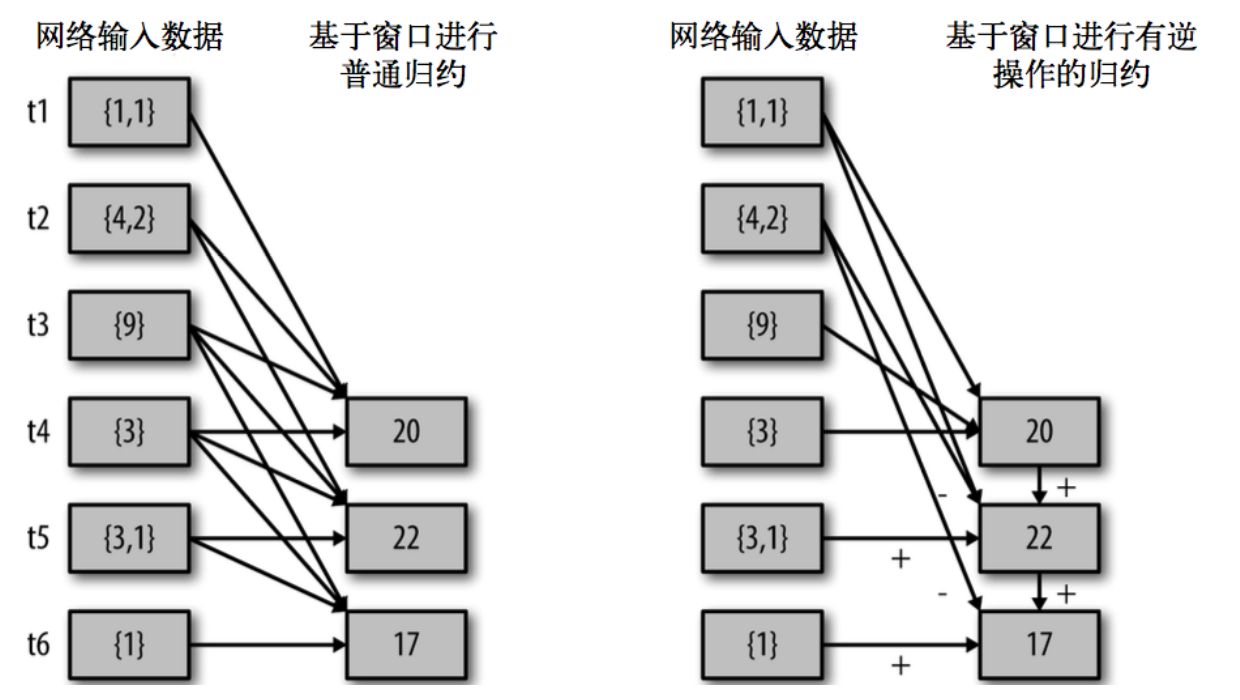
val ipDStream = accessLogsDStream.map(logEntry => (logEntry.getIpAddress(), 1))
val ipCountDStream = ipDStream.reduceByKeyAndWindow({(x, y) => x + y},{(x, y) => x - y},Seconds(30),Seconds(10))//加上新进入窗口的批次中的元素 //移除离开窗口的老批次中的元素 //窗口时长// 滑动步长countByWindow()和 countByValueAndWindow()作为对数据进行计数操作的简写。
countByWindow()返回一个表示每个窗口中元素个数的 DStream,而 countByValueAndWindow()返回的 DStream 则包含窗口中每个值的个数。
案例
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}object SparkStreaming06_State_Window1 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))ssc.checkpoint("cp")val lines = ssc.socketTextStream("localhost", 9999)val wordToOne = lines.map((_,1))// reduceByKeyAndWindow : 当窗口范围比较大,但是滑动幅度比较小,那么可以采用增加数据和删除数据的方式// 无需重复计算,提升性能。val windowDS: DStream[(String, Int)] =wordToOne.reduceByKeyAndWindow((x:Int, y:Int) => { x + y},(x:Int, y:Int) => {x - y},Seconds(9), Seconds(3))windowDS.print()ssc.start()ssc.awaitTermination()}}
第 5 章 DStream 输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。如果 StreamingContext 中没有设定输出操作,整个 context 就都不会启动。(没有输出直接报错)
输出操作如下:
➢ print():在运行流程序的驱动结点上打印 DStream 中每一批次数据的最开始 10 个元素。这用于开发和调试。在 Python API 中,同样的操作叫 print()。
➢ saveAsTextFiles(prefix, [suffix]):以 text 文件形式存储这个 DStream 的内容。每一批次的存储文件名基于参数中的 prefix 和 suffix。”prefix-Time_IN_MS[.suffix]”。
➢ saveAsObjectFiles(prefix, [suffix]):以 Java 对象序列化的方式将 Stream 中的数据保存为SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python中目前不可用。
➢ saveAsHadoopFiles(prefix, [suffix]):将 Stream 中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。Python API 中目前不可用。
➢ foreachRDD(func):这是最通用的输出操作,即将函数 func 用于产生于 stream 的每一个RDD。其中参数传入的函数 func 应该实现将每一个 RDD 中数据推送到外部系统,如将RDD 存入文件或者通过网络将其写入数据库。
通用的输出操作 foreachRDD(),它用来对 DStream 中的 RDD 运行任意计算。这和 transform()有些类似,都可以让我们访问任意 RDD。在 foreachRDD()中,可以重用我们在 Spark 中实现的所有行动操作。比如,常见的用例之一是把数据写到诸如 MySQL 的外部数据库中。
注意:
连接不能写在 driver 层面(序列化)
如果写在 foreach 则每个 RDD 中的每一条数据都创建,得不偿失;
增加 foreachPartition,在分区创建(获取)。
第 6 章 优雅关闭
流式任务需要 7*24 小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所有配置优雅的关闭就显得至关重要了。
使用外部文件系统来控制内部程序关闭。
➢ MonitorStop
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.streaming.{StreamingContext, StreamingContextState}
class MonitorStop(ssc: StreamingContext) extends Runnable {override def run(): Unit = {val fs: FileSystem = FileSystem.get(new URI("hdfs://linux1:9000"), newConfiguration(), "atguigu")while (true) {tryThread.sleep(5000)catch {case e: InterruptedException =>e.printStackTrace()}val state: StreamingContextState = ssc.getStateval bool: Boolean = fs.exists(new Path("hdfs://linux1:9000/stopSpark"))if (bool) {if (state == StreamingContextState.ACTIVE) {ssc.stop(stopSparkContext = true, stopGracefully = true)System.exit(0)}}}}
}package com.atguigu.bigdata.spark.streamingimport org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}object SparkStreaming08_Close {def main(args: Array[String]): Unit = {/*线程的关闭:val thread = new Thread()thread.start()thread.stop(); // 强制关闭*/val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val lines = ssc.socketTextStream("localhost", 9999)val wordToOne = lines.map((_,1))wordToOne.print()ssc.start()// 如果想要关闭采集器,那么需要创建新的线程// 而且需要在第三方程序中增加关闭状态new Thread(new Runnable {override def run(): Unit = {// 优雅地关闭// 现实中应该这样写// 计算节点不在接收新的数据,而是将现有的数据处理完毕,然后关闭// Mysql : Table(stopSpark) => Row => data// Redis : Data(K-V)// ZK : /stopSpark// HDFS : /stopSpark/*while ( true ) {if (true) {// 获取SparkStreaming状态val state: StreamingContextState = ssc.getState()if ( state == StreamingContextState.ACTIVE ) {ssc.stop(true, true)}}Thread.sleep(5000)}*/// 这是测试代码Thread.sleep(5000)val state: StreamingContextState = ssc.getState()if ( state == StreamingContextState.ACTIVE ) {ssc.stop(true, true)}System.exit(0)}}).start()ssc.awaitTermination() // block 阻塞main线程}}
➢ SparkTest
恢复数据
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkTest {def createSSC(): _root_.org.apache.spark.streaming.StreamingContext = {val update: (Seq[Int], Option[Int]) => Some[Int] = (values: Seq[Int], status:Option[Int]) => {//当前批次内容的计算val sum: Int = values.sum//取出状态信息中上一次状态val lastStatu: Int = status.getOrElse(0)Some(sum + lastStatu)}val sparkConf: SparkConf = newSparkConf().setMaster("local[4]").setAppName("SparkTest")//设置优雅的关闭sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")val ssc = new StreamingContext(sparkConf, Seconds(5))ssc.checkpoint("./ck")val line: ReceiverInputDStream[String] = ssc.socketTextStream("linux1", 9999)val word: DStream[String] = line.flatMap(_.split(" "))val wordAndOne: DStream[(String, Int)] = word.map((_, 1))val wordAndCount: DStream[(String, Int)] = wordAndOne.updateStateByKey(update)wordAndCount.print()ssc}def main(args: Array[String]): Unit = {val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck", () =>createSSC())new Thread(new MonitorStop(ssc)).start()ssc.start()ssc.awaitTermination()}
}
package com.atguigu.bigdata.spark.streamingimport org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}object SparkStreaming09_Resume {def main(args: Array[String]): Unit = {val ssc = StreamingContext.getActiveOrCreate("cp", ()=>{val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val lines = ssc.socketTextStream("localhost", 9999)val wordToOne = lines.map((_,1))wordToOne.print()ssc})ssc.checkpoint("cp")ssc.start()ssc.awaitTermination() // block 阻塞main线程}}
第 7 章 SparkStreaming 案例实操
7.1 环境准备
7.1.1 pom 文件
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba/druid --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.10</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version>
</dependency>
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.10.1</version>
</dependency>
</dependencies>7.2 实时数据生成模块
➢ JDBCUtil(工具类)
package spark.utilimport java.sql.{Connection, PreparedStatement, ResultSet}
import java.util.Properties
import javax.sql.DataSource
import com.alibaba.druid.pool.DruidDataSourceFactoryobject JDBCUtil {//初始化连接池var dataSource: DataSource = init()//初始化连接池方法def init(): DataSource = {val properties = new Properties()properties.setProperty("driverClassName", "com.mysql.jdbc.Driver")properties.setProperty("url", "jdbc:mysql://hadoop102:3306/spark2023?useUnicode=true&characterEncoding=UTF-8")properties.setProperty("username", "root")properties.setProperty("password", "123456")properties.setProperty("maxActive", "50")DruidDataSourceFactory.createDataSource(properties)}//获取 MySQL 连接def getConnection: Connection = {dataSource.getConnection}//执行 SQL 语句,单条数据插入def executeUpdate(connection: Connection, sql: String, params: Array[Any]): Int= {var rtn = 0var pstmt: PreparedStatement = nulltry {connection.setAutoCommit(false)pstmt = connection.prepareStatement(sql)if (params != null && params.length > 0) {for (i <- params.indices) {pstmt.setObject(i + 1, params(i))}}rtn = pstmt.executeUpdate()connection.commit()pstmt.close()} catch {case e: Exception => e.printStackTrace()}rtn}//执行 SQL 语句,批量数据插入def executeBatchUpdate(connection: Connection, sql: String, paramsList:Iterable[Array[Any]]): Array[Int] = {var rtn: Array[Int] = nullvar pstmt: PreparedStatement = nulltry {connection.setAutoCommit(false)pstmt = connection.prepareStatement(sql)for (params <- paramsList) {if (params != null && params.length > 0) {for (i <- params.indices) {pstmt.setObject(i + 1, params(i))}pstmt.addBatch()}}rtn = pstmt.executeBatch()connection.commit()pstmt.close()} catch {case e: Exception => e.printStackTrace()}rtn}//判断一条数据是否存在def isExist(connection: Connection, sql: String, params: Array[Any]): Boolean ={var flag: Boolean = falsevar pstmt: PreparedStatement = nulltry {pstmt = connection.prepareStatement(sql)for (i <- params.indices) {pstmt.setObject(i + 1, params(i))}flag = pstmt.executeQuery().next()pstmt.close()} catch {case e: Exception => e.printStackTrace()}flag}//获取 MySQL 的一条数据def getDataFromMysql(connection: Connection, sql: String, params: Array[Any]):Long = {var result: Long = 0Lvar pstmt: PreparedStatement = nulltry {pstmt = connection.prepareStatement(sql)for (i <- params.indices) {pstmt.setObject(i + 1, params(i))}val resultSet: ResultSet = pstmt.executeQuery()while (resultSet.next()) {result = resultSet.getLong(1)}resultSet.close()pstmt.close()} catch {case e: Exception => e.printStackTrace()}result}//主方法,用于测试上述方法def main(args: Array[String]): Unit = {}
}
➢ MockData(Kafka数据生产者)
package spark.testimport java.util.{Properties, Random}
import scala.collection.mutable.ListBuffer
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}/*** @author Lucaslee* @create 2023-02-24 11:31*/
object SparkStreaming10_MockData {def main(args: Array[String]): Unit = {// 生成模拟数据 (生产者)// 格式 :timestamp area city userid adid// 含义: 时间戳 区域 城市 用户 广告// Application => Kafka => SparkStreaming => Analysisval prop = new Properties()// 添加配置prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092")prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](prop)while ( true ) {mockdata().foreach(data => {// 向Kafka中生成数据val record = new ProducerRecord[String, String]("atguigu", data)producer.send(record)println(data)})Thread.sleep(2000)}}def mockdata() = {val list = ListBuffer[String]()val areaList = ListBuffer[String]("华北", "华东", "华南")val cityList = ListBuffer[String]("北京", "上海", "深圳")for ( i <- 1 to new Random().nextInt(50) ) {val area = areaList(new Random().nextInt(3))val city = cityList(new Random().nextInt(3))var userid = new Random().nextInt(6) + 1var adid = new Random().nextInt(6) + 1list.append(s"${System.currentTimeMillis()} ${area} ${city} ${userid} ${adid}")}list}
}
➢ ConsumerData(Kafka数据消费者)
package spark.test
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}/*** @author Lucaslee* @create 2023-02-24 11:33*/
object SparkStreaming11_Req1 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))// 消费者消费数据val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu11","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))kafkaDataDS.map(_.value()).print()ssc.start()ssc.awaitTermination()}}
7.3 需求一:广告黑名单
实现实时的动态黑名单机制:将每天对某个广告点击超过 100 次的用户拉黑。注:黑名单保存到 MySQL 中。
7.3.1 思路分析
1)读取 Kafka 数据之后,并对 MySQL 中存储的黑名单数据做校验;
2)校验通过则对给用户点击广告次数累加一并存入 MySQL;
3)在存入 MySQL 之后对数据做校验,如果单日超过 100 次则将该用户加入黑名单。


7.3.2 MySQL 建表
创建库 spark2020
1)存放黑名单用户的表
CREATE TABLE black_list (userid CHAR(1) PRIMARY KEY);2)存放单日各用户点击每个广告的次数
CREATE TABLE user_ad_count (
dt varchar(255),
userid CHAR (1),
adid CHAR (1),
count BIGINT,
PRIMARY KEY (dt, userid, adid)
);7.3.3 需求实现
package spark.test
import java.sql.ResultSet
import java.text.SimpleDateFormat
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import spark.util.JDBCUtilimport scala.collection.mutable.ListBufferobject SparkStreaming11_Req1_BlackList {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu2","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))val adClickData = kafkaDataDS.map(kafkaData => {val data = kafkaData.value()val datas = data.split(" ")AdClickData(datas(0),datas(1),datas(2),datas(3),datas(4))})val ds = adClickData.transform(rdd => {// TODO 通过JDBC周期性获取黑名单数据val blackList = ListBuffer[String]()val conn = JDBCUtil.getConnectionval pstat = conn.prepareStatement("select userid from black_list")val rs: ResultSet = pstat.executeQuery()while ( rs.next() ) {blackList.append(rs.getString(1))}rs.close()pstat.close()conn.close()// TODO 判断点击用户是否在黑名单中val filterRDD = rdd.filter(data => {!blackList.contains(data.user)})// TODO 如果用户不在黑名单中,那么进行统计数量(每个采集周期)filterRDD.map(data => {val sdf = new SimpleDateFormat("yyyy-MM-dd")val day = sdf.format(new java.util.Date( data.ts.toLong ))val user = data.userval ad = data.ad(( day, user, ad ), 1) // (word, count)}).reduceByKey(_+_)})ds.foreachRDD(rdd => {rdd.foreach{case ( ( day, user, ad ), count ) => {println(s"${day} ${user} ${ad} ${count}")if ( count >= 30 ) {// TODO 如果统计数量超过点击阈值(30),那么将用户拉入到黑名单val conn = JDBCUtil.getConnectionval pstat = conn.prepareStatement("""|insert into black_list (userid) values (?)|on DUPLICATE KEY|UPDATE userid = ?""".stripMargin)pstat.setString(1, user)pstat.setString(2, user)pstat.executeUpdate()pstat.close()conn.close()} else {// TODO 如果没有超过阈值,那么需要将当天的广告点击数量进行更新。val conn = JDBCUtil.getConnectionval pstat = conn.prepareStatement("""| select| *| from user_ad_count| where dt = ? and userid = ? and adid = ?""".stripMargin)pstat.setString(1, day)pstat.setString(2, user)pstat.setString(3, ad)val rs = pstat.executeQuery()// 查询统计表数据if ( rs.next() ) {// 如果存在数据,那么更新val pstat1 = conn.prepareStatement("""| update user_ad_count| set count = count + ?| where dt = ? and userid = ? and adid = ?""".stripMargin)pstat1.setInt(1, count)pstat1.setString(2, day)pstat1.setString(3, user)pstat1.setString(4, ad)pstat1.executeUpdate()pstat1.close()// TODO 判断更新后的点击数据是否超过阈值,如果超过,那么将用户拉入到黑名单。val pstat2 = conn.prepareStatement("""|select| *|from user_ad_count|where dt = ? and userid = ? and adid = ? and count >= 30""".stripMargin)pstat2.setString(1, day)pstat2.setString(2, user)pstat2.setString(3, ad)val rs2 = pstat2.executeQuery()if ( rs2.next() ) {val pstat3 = conn.prepareStatement("""|insert into black_list (userid) values (?)|on DUPLICATE KEY|UPDATE userid = ?""".stripMargin)pstat3.setString(1, user)pstat3.setString(2, user)pstat3.executeUpdate()pstat3.close()}rs2.close()pstat2.close()} else {// 如果不存在数据,那么新增val pstat1 = conn.prepareStatement("""| insert into user_ad_count ( dt, userid, adid, count ) values ( ?, ?, ?, ? )""".stripMargin)pstat1.setString(1, day)pstat1.setString(2, user)pstat1.setString(3, ad)pstat1.setInt(4, count)pstat1.executeUpdate()pstat1.close()}rs.close()pstat.close()conn.close()}}}})ssc.start()ssc.awaitTermination()}// 广告点击数据case class AdClickData( ts:String, area:String, city:String, user:String, ad:String )}对jdbc操作进行操作
package spark.testimport java.sql.ResultSet
import java.text.SimpleDateFormat
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import spark.util.JDBCUtilimport scala.collection.mutable.ListBufferobject SparkStreaming11_Req1_BlackList1 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu3","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))val adClickData = kafkaDataDS.map(kafkaData => {val data = kafkaData.value()val datas = data.split(" ")AdClickData(datas(0),datas(1),datas(2),datas(3),datas(4))})val ds = adClickData.transform(rdd => {// TODO 通过JDBC周期性获取黑名单数据val blackList = ListBuffer[String]()val conn = JDBCUtil.getConnectionval pstat = conn.prepareStatement("select userid from black_list")val rs: ResultSet = pstat.executeQuery()while ( rs.next() ) {blackList.append(rs.getString(1))}rs.close()pstat.close()conn.close()// TODO 判断点击用户是否在黑名单中val filterRDD = rdd.filter(data => {!blackList.contains(data.user)})// TODO 如果用户不在黑名单中,那么进行统计数量(每个采集周期)filterRDD.map(data => {val sdf = new SimpleDateFormat("yyyy-MM-dd")val day = sdf.format(new java.util.Date( data.ts.toLong ))val user = data.userval ad = data.ad(( day, user, ad ), 1) // (word, count)}).reduceByKey(_+_)})ds.foreachRDD(rdd => {// rdd. foreach方法会每一条数据创建连接// foreach方法是RDD的算子,算子之外的代码是在Driver端执行,算子内的代码是在Executor端执行// 这样就会涉及闭包操作,Driver端的数据就需要传递到Executor端,需要将数据进行序列化// 数据库的连接对象是不能序列化的。// RDD提供了一个算子可以有效提升效率 : foreachPartition// 可以一个分区创建一个连接对象,这样可以大幅度减少连接对象的数量,提升效率rdd.foreachPartition(iter => {val conn = JDBCUtil.getConnectioniter.foreach{case ( ( day, user, ad ), count ) => {}}conn.close()})rdd.foreach{case ( ( day, user, ad ), count ) => {println(s"${day} ${user} ${ad} ${count}")if ( count >= 30 ) {// TODO 如果统计数量超过点击阈值(30),那么将用户拉入到黑名单val conn = JDBCUtil.getConnectionval sql = """|insert into black_list (userid) values (?)|on DUPLICATE KEY|UPDATE userid = ?""".stripMarginJDBCUtil.executeUpdate(conn, sql, Array( user, user ))conn.close()} else {// TODO 如果没有超过阈值,那么需要将当天的广告点击数量进行更新。val conn = JDBCUtil.getConnectionval sql = """| select| *| from user_ad_count| where dt = ? and userid = ? and adid = ?""".stripMarginval flg = JDBCUtil.isExist(conn, sql, Array( day, user, ad ))// 查询统计表数据if ( flg ) {// 如果存在数据,那么更新val sql1 = """| update user_ad_count| set count = count + ?| where dt = ? and userid = ? and adid = ?""".stripMarginJDBCUtil.executeUpdate(conn, sql1, Array(count, day, user, ad))// TODO 判断更新后的点击数据是否超过阈值,如果超过,那么将用户拉入到黑名单。val sql2 = """|select| *|from user_ad_count|where dt = ? and userid = ? and adid = ? and count >= 30""".stripMarginval flg1 = JDBCUtil.isExist(conn, sql2, Array( day, user, ad ))if ( flg1 ) {val sql3 = """|insert into black_list (userid) values (?)|on DUPLICATE KEY|UPDATE userid = ?""".stripMarginJDBCUtil.executeUpdate(conn, sql3, Array( user, user ))}} else {val sql4 = """| insert into user_ad_count ( dt, userid, adid, count ) values ( ?, ?, ?, ? )""".stripMarginJDBCUtil.executeUpdate(conn, sql4, Array( day, user, ad, count ))}conn.close()}}}})ssc.start()ssc.awaitTermination()}// 广告点击数据case class AdClickData( ts:String, area:String, city:String, user:String, ad:String )}7.4 需求二:广告点击量实时统计
描述:实时统计每天各地区各城市各广告的点击总流量,并将其存入 MySQL。
7.4.1 思路分析
1)单个批次内对数据进行按照天维度的聚合统计;
2)结合 MySQL 数据跟当前批次数据更新原有的数据。
7.4.2 MySQL 建表
CREATE TABLE area_city_ad_count (
dt VARCHAR(255),
area VARCHAR(255),
city VARCHAR(255),
adid VARCHAR(255),count BIGINT,
PRIMARY KEY (dt,area,city,adid)
);7.4.3 代码实现
package spark.testimport org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import spark.util.JDBCUtilimport java.text.SimpleDateFormatobject SparkStreaming12_Req2 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu4","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))val adClickData = kafkaDataDS.map(kafkaData => {val data = kafkaData.value()val datas = data.split(" ")AdClickData(datas(0),datas(1),datas(2),datas(3),datas(4))})val reduceDS = adClickData.map(data => {val sdf = new SimpleDateFormat("yyyy-MM-dd")val day = sdf.format(new java.util.Date( data.ts.toLong ))val area = data.areaval city = data.cityval ad = data.ad( ( day, area, city, ad ), 1 )}).reduceByKey(_+_)reduceDS.foreachRDD(rdd => {rdd.foreachPartition(iter => {val conn = JDBCUtil.getConnectionval pstat = conn.prepareStatement("""| insert into area_city_ad_count ( dt, area, city, adid, count )| values ( ?, ?, ?, ?, ? )| on DUPLICATE KEY| UPDATE count = count + ?""".stripMargin)iter.foreach{case ( ( day, area, city, ad ), sum ) => {pstat.setString(1,day )pstat.setString(2,area )pstat.setString(3, city)pstat.setString(4, ad)pstat.setInt(5, sum)pstat.setInt(6,sum )pstat.executeUpdate()}}pstat.close()conn.close()})})ssc.start()ssc.awaitTermination()}// 广告点击数据case class AdClickData( ts:String, area:String, city:String, user:String, ad:String )}
7.5 需求三:最近一小时广告点击量
结果展示:
1:List [15:50->10,15:51->25,15:52->30]
2:List [15:50->10,15:51->25,15:52->30]
3:List [15:50->10,15:51->25,15:52->30]7.5.1 思路分析
1)开窗确定时间范围;
2)在窗口内将数据转换数据结构为((adid,hm),count);
3)按照广告 id 进行分组处理,组内按照时分排序。
7.5.2 代码实现
➢ 实现1
package spark.testimport java.text.SimpleDateFormat
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*** @author Lucaslee* @create 2023-02-24 13:15*/
object SparkStreaming13_Req3 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(5))val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu5","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))val adClickData = kafkaDataDS.map(kafkaData => {val data = kafkaData.value()val datas = data.split(" ")AdClickData(datas(0),datas(1),datas(2),datas(3),datas(4))})// 最近一分钟,每10秒计算一次// 12:01 => 12:00// 12:11 => 12:10// 12:19 => 12:10// 12:25 => 12:20// 12:59 => 12:50// 55 => 50, 49 => 40, 32 => 30// 55 / 10 * 10 => 50// 49 / 10 * 10 => 40// 32 / 10 * 10 => 30// 这里涉及窗口的计算val reduceDS = adClickData.map(data => {val ts = data.ts.toLongval newTS = ts / 10000 * 10000( newTS, 1 )}).reduceByKeyAndWindow((x:Int,y:Int)=>{x+y}, Seconds(60), Seconds(10))reduceDS.print()ssc.start()ssc.awaitTermination()}// 广告点击数据case class AdClickData( ts:String, area:String, city:String, user:String, ad:String )}
➢ 实现2(小优化)
package spark.testimport java.io.{File, FileWriter, PrintWriter}
import java.text.SimpleDateFormat
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}import scala.collection.mutable.ListBuffer
/*** @author Lucaslee* @create 2023-02-24 13:18*/
object SparkStreaming13_Req31 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(5))val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu6","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))val adClickData = kafkaDataDS.map(kafkaData => {val data = kafkaData.value()val datas = data.split(" ")AdClickData(datas(0),datas(1),datas(2),datas(3),datas(4))})// 最近一分钟,每10秒计算一次// 12:01 => 12:00// 12:11 => 12:10// 12:19 => 12:10// 12:25 => 12:20// 12:59 => 12:50// 55 => 50, 49 => 40, 32 => 30// 55 / 10 * 10 => 50// 49 / 10 * 10 => 40// 32 / 10 * 10 => 30// 这里涉及窗口的计算val reduceDS = adClickData.map(data => {val ts = data.ts.toLongval newTS = ts / 10000 * 10000( newTS, 1 )}).reduceByKeyAndWindow((x:Int,y:Int)=>{x+y}, Seconds(60), Seconds(10))//reduceDS.print()reduceDS.foreachRDD(rdd => {val list = ListBuffer[String]()val datas: Array[(Long, Int)] = rdd.sortByKey(true).collect()datas.foreach{case ( time, cnt ) => {val timeString = new SimpleDateFormat("mm:ss").format(new java.util.Date(time.toLong))list.append(s"""{"xtime":"${timeString}", "yval":"${cnt}"}""")}}// 输出文件val out = new PrintWriter(new FileWriter(new File("E:\\java\\project\\sparkproject\\output\\adclick.json")))out.println("["+list.mkString(",")+"]")out.flush()out.close()})ssc.start()ssc.awaitTermination()}// 广告点击数据case class AdClickData( ts:String, area:String, city:String, user:String, ad:String )}
相关文章:
Spark Streaming
第1章 SparkStreaming 概述1.1 Spark Streaming 是什么Spark 流使得构建可扩展的容错流应用程序变得更加容易。**Spark Streaming 用于流式数据的处理。**Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字…...

[kubernetes]-k8s通过psp限制nvidia-plugin插件的使用
导语: k8s通过psp限制nvidia-plugin插件的使用。刚开始接触psp 记录一下 后续投入生产测试了再完善。 通过apiserver开启psp 静态pod会自动更新 # PSP(Pod Security Policy) 在默认情况下并不会开启。通过将PodSecurityPolicy关键词添加到 --enbale-admission-plu…...
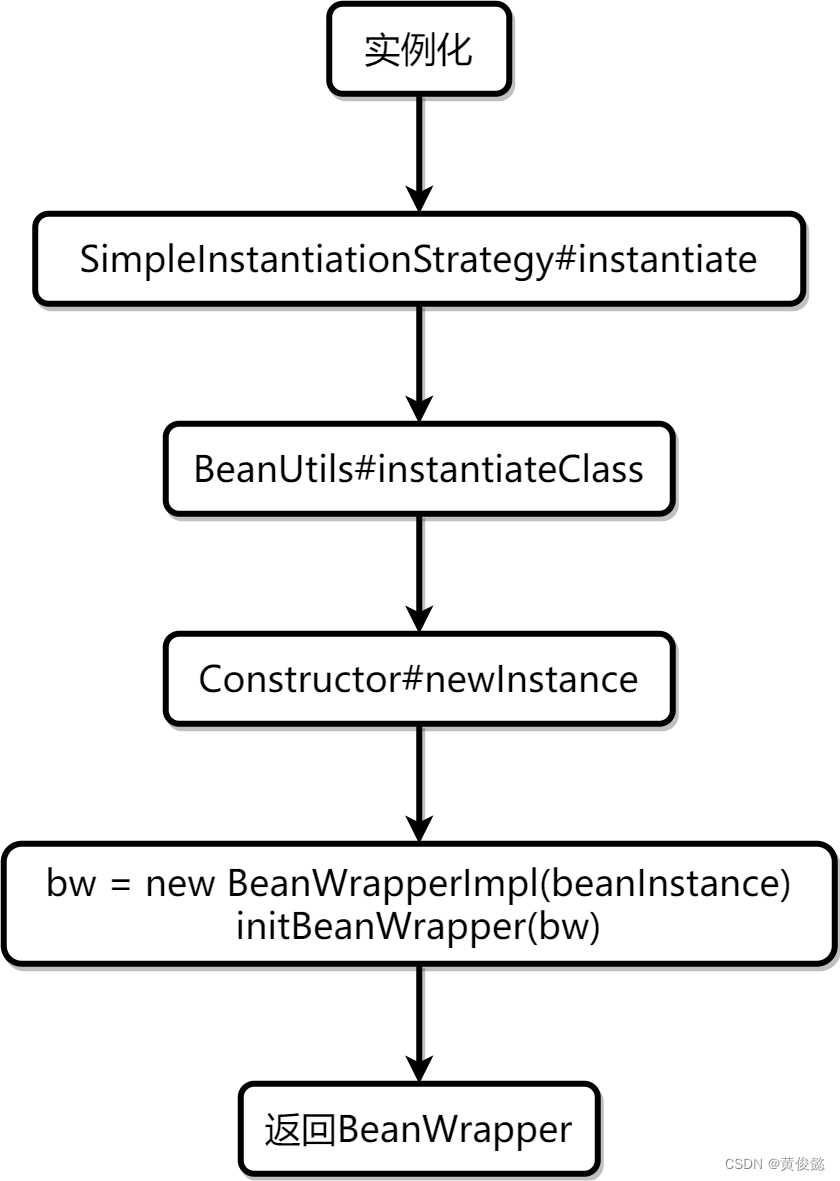
简单易懂又非常牛逼的Spring源码解析,推断构造与bean的实例化
简单易懂又非常牛逼的Spring源码解析,推断构造与bean的实例化原理解析实例化bean的入口工厂方法实例化推断构造初次筛选二次筛选bean的实例化代码走读实例化bean的入口createBeanInstance方法内部的流程推断构造初次筛选二次筛选bean的实例化总结往期文章࿱…...
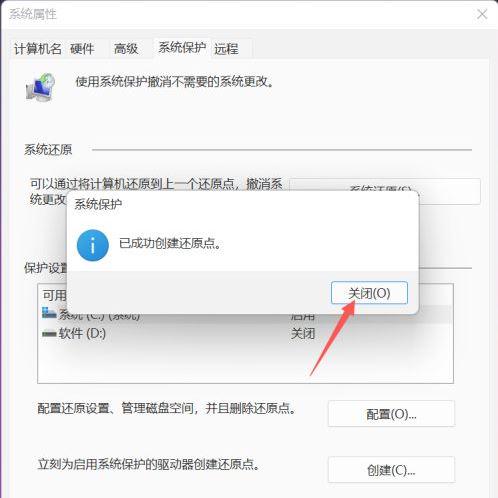
Win11的两个实用技巧系列清理磁盘碎片、设置系统还原点的方法
Win11如何清理磁盘碎片?Win11清理磁盘碎片的方法磁盘碎片过多,会影响电脑的运行速度,所以需要定期清理,这篇文章将以Win11为例,给大家分享的整理磁盘碎片方法相信很多用户都会发现,随着电脑使用时间的增加,…...
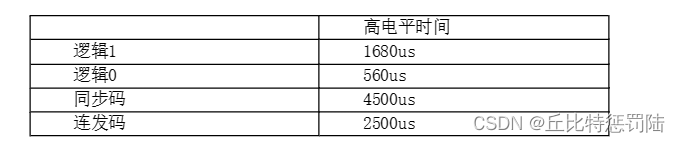
嵌入式 STM32 红外遥控
目录 红外遥控 NEC码的位定义 硬件设计 软件设计 源码程序 红外遥控 红外遥控是一种无线、非接触控制技术,具有抗干扰能力强,信息传输可靠,功耗低,成本低,容易实现等显著的特点,被诸多电子设备特别…...
【java web篇】使用JDBC操作数据库
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...

华为OD机试题,用 Java 解【最小步骤数】问题
最近更新的博客 华为OD机试题,用 Java 解【停车场车辆统计】问题华为OD机试题,用 Java 解【字符串变换最小字符串】问题华为OD机试题,用 Java 解【计算最大乘积】问题华为OD机试题,用 Java 解【DNA 序列】问题华为OD机试 - 组成最大数(Java) | 机试题算法思路 【2023】使…...

JAVA中 throw 和 throws 的区别含案例
JAVA中 throw 和 throws 的区别含案例 在 Java 中,throw 和 throws 是两个关键字,它们用于处理异常。 throw 关键字用于抛出一个异常对象。一旦抛出异常,程序将停止执行当前方法的剩余代码,并尝试寻找与该异常匹配的 catch 块来…...

基于SpringCloud的可靠消息最终一致性05:保存并发送事务消息
在有了分布式事务的解决方案、项目的需求、骨架代码和基础代码,做好了所有的准备工作之后,接下来就可以继续深入了解「核心业务」了。 在前面了解分布式事务时,可靠消息最终一致性方案的流程图是这样的: 图三十一:可靠消息最终一致性 整个的流程是: 1、业务处理服务在事务…...

SQL语句大全(详解)
SQL前言1 DDL1.1 显示所包含的数据库1.2 创建数据库1.3 删除数据库1.4 使用数据库1.4.1 创建表1.4.2 查看表的结构1.4.3 查看当前数据库下的所有表1.4.4 基础的增删改查1.4.4.1 删除表1.4.4.2 添加列1.4.4.3 修改表名1.4.4.4 修改数据类型1.4.4.5 修改列名和数据类型2 DML2.1 给…...

视频营销活动中7个常见的错误
如今,越来越多的企业在社交媒体平台上开展视频营销活动。与其他传统营销策略不同,视频营销可以为企业带来更多的销售机会。随着越来越多的视频社交媒体平台的出现,营销人员更应该抓住这个机会。但在开始视频创作之前,您需要有一个…...

MapReduce小试牛刀
部署完hadoop单机版后,试下mapreduce是怎么分析处理数据的 Word Count Word Count 就是"词语统计",这是 MapReduce 工作程序中最经典的一种。它的主要任务是对一个文本文件中的词语作归纳统计,统计出每个出现过的词语一共出现的次…...

2023年全国最新工会考试精选真题及答案7
百分百题库提供工会考试试题、工会考试预测题、工会考试真题、工会证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 21.会员大会或会员代表大会与职工代表大会或职工大会须分别行使职权,()…...
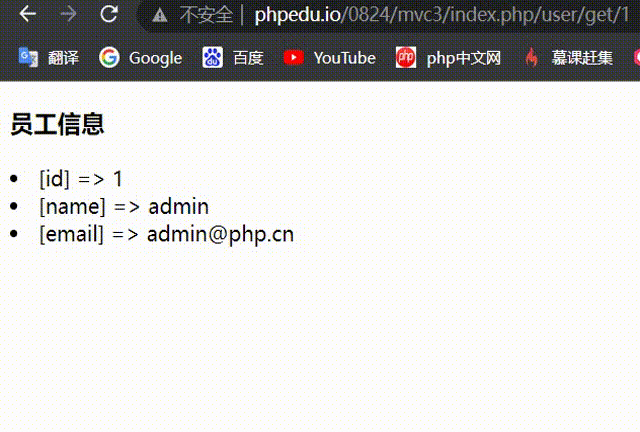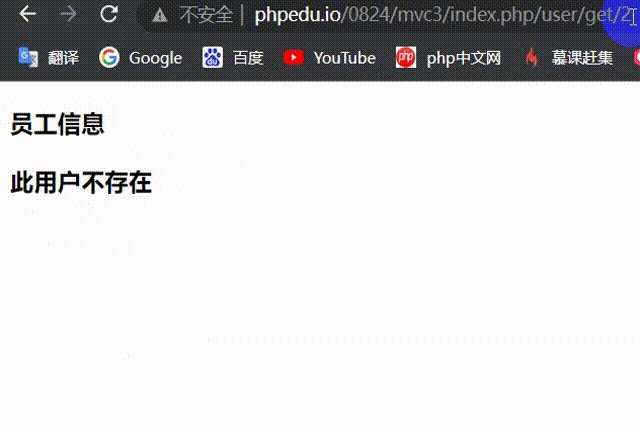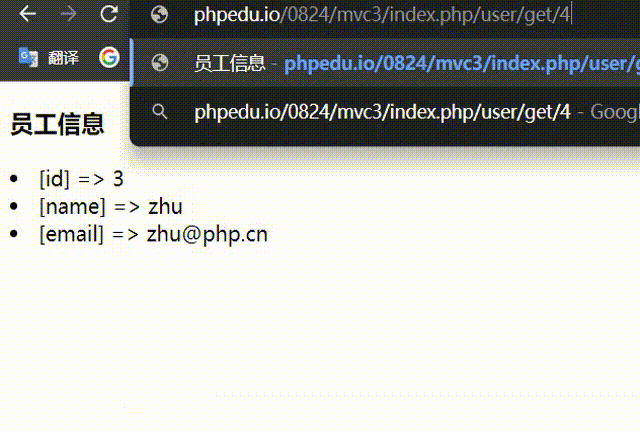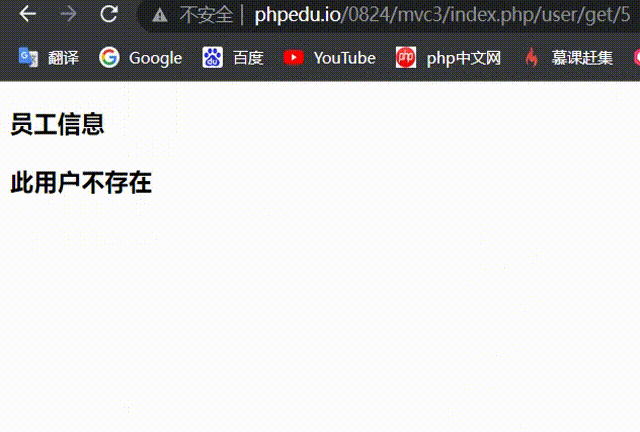
13-mvc框架原理与实现方式
1、mvc原理 # mvc 与框架## 1.mvc 是什么1. m:model,模型(即数据来源),主要是针对数据库操作 2. v:view,视图,html 页面。视图由一个一个模板构成(模板是视图的一个具体展现或载体,视图是模板的一个抽象) 3. c:controller,控制器,用于mv之间的数据交互## 2.最简单的 mvc 就是一…...

弹性盒子布局
目录一、弹性盒子属性二、认识flex的坐标轴三、简单学习父级盒子属性三、属性说明3.1、flex-grow一、弹性盒子属性 说明: div的默认样式:display:block 块盒子 display:flex弹性盒子(可以控制下级盒子的位置) 当两种盒子单独出现…...
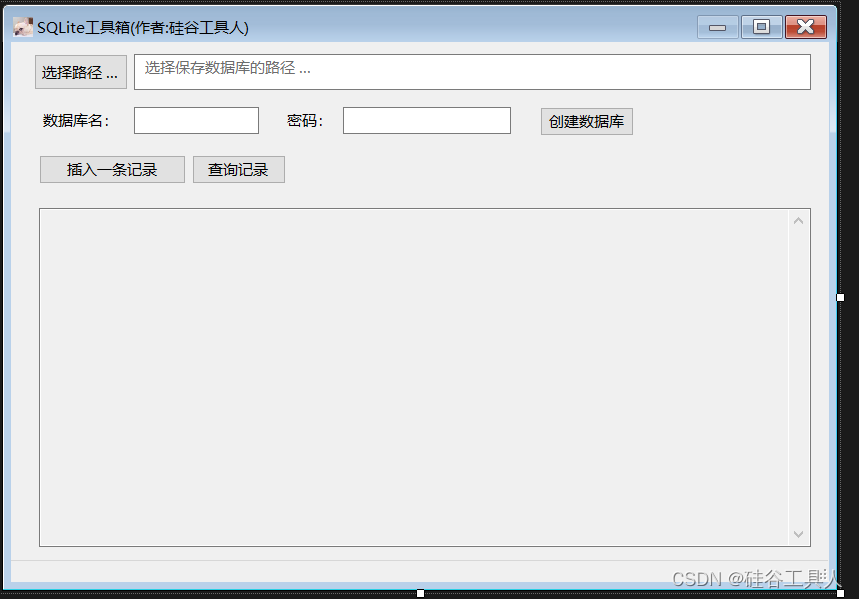
C# Sqlite数据库加密
sqlite官方的数据库加密是收费的,而且比较贵。 幸亏微软提供了一种免费的方法。 1 sqlite加密demo 这里我做了一个小的demo演示如下: 在界面中拖入数据库名、密码、以及保存的路径 比如我选择保存路径桌面的sqlite目录,数据库名guigutool…...

高压放大器在声波谐振电小天线收发测试系统中的应用
实验名称:高压放大器在声波谐振电小天线收发测试系统中的应用研究方向:信号传输测试目的:声波谐振电小天线颠覆了传统电小天线以电磁波谐振作为理论基础的天线发射和接收模式,它借助声波谐振实现电磁信号的辐射或接收。因为同频的…...
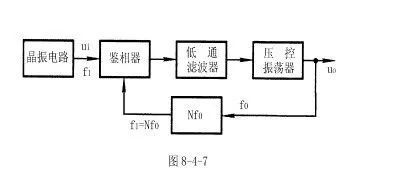
锁相环的组成和原理及应用
一.锁相环的基本组成 许多电子设备要正常工作,通常需要外部的输入信号与内部的振荡信号同步,利用锁相环路就可以实现这个目的。 锁相环路是一种反馈控制电路,简称锁相环(PLL)。锁相环的特点是:利用外部输入的参考信号控制环路内…...

[C++]string类模拟实现
目录 前言: 1. string框架构造 2. 默认函数 2.1 构造函数 2.2 析构函数 2.3 拷贝构造 2.4 赋值重载 3. 迭代器 4. 整体程序 前言: 本篇文章模拟实现了C中string的部分功能,有助于大家了解和熟悉string类,虽然这个类不难实…...

一个更适合Java初学者的轻量级开发工具:BlueJ
Java是世界上最流行的编程语言之一,它被广泛用于从Web开发到移动应用的各种应用程序。大部分Java工程师主要是用IDEA、Eclipse为主,这两个开发工具由于有强大的能力,所以复杂度上就更高一些。如果您刚刚开始使用Java,或者您更适合…...

AI系统-21AI芯片之NoC总线
在大型SoC芯片,特别是AI SoC中,存在多个异构核子系统,非常的大和复杂。对应芯片设计中,一个重要的技术就是NoC,要想富先修路,NoC就是通信的路。而且SoC把很多硬件模块集成到一个芯片上就是为了让路好走&…...

Kronos金融市场基础模型:从技术原理到量化交易系统构建
Kronos金融市场基础模型:从技术原理到量化交易系统构建 【免费下载链接】Kronos Kronos: A Foundation Model for the Language of Financial Markets 项目地址: https://gitcode.com/GitHub_Trending/kronos14/Kronos 金融市场的复杂性和波动性一直是投资者…...

Visual C++ Redistributable开源项目故障排除终极指南:从问题诊断到系统优化
Visual C Redistributable开源项目故障排除终极指南:从问题诊断到系统优化 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 开源项目故障排除是开发者…...

Spring AI实战:从零构建智能聊天与图像生成应用
1. Spring AI初探:你的第一个智能聊天应用 记得第一次接触AI聊天功能时,我盯着那个能对答如流的对话框看了足足十分钟。现在用Spring AI框架,只需要四步就能实现同样的效果。先创建一个标准的Spring Boot项目,这个不用多说&#x…...

手把手调试Linux DRM:如何用ftrace和debugfs深入connector的生命周期
深入Linux DRM调试:用ftrace与debugfs剖析connector全生命周期 当一块崭新的显示板卡接入系统时,DRM驱动中的connector如同一位尽职的接线员,负责建立显示设备与内核之间的通信桥梁。但在实际开发中,我们常会遇到热插拔检测失灵、…...

从Vaihingen数据集到训练样本:高分辨率遥感影像语义分割全流程实战
1. 初识Vaihingen数据集:遥感语义分割的黄金标准 第一次接触Vaihingen数据集时,我被它5厘米的超高分辨率震撼到了。这个由ISPRS提供的基准数据集,虽然只包含38张60006000像素的影像,但每张都清晰地展现了德国小镇Vaihingen的街道、…...

OpenClaw备份策略:Qwen3.5-9B重要数据自动同步到私有云盘
OpenClaw备份策略:Qwen3.5-9B重要数据自动同步到私有云盘 1. 为什么需要自动化备份方案 作为一个经常需要处理大量文档和代码的技术写作者,我经历过太多次因为系统崩溃或误操作导致工作成果丢失的惨痛教训。传统的备份方案要么需要手动操作(…...

Python金融数据获取终极指南:用mootdx高效处理通达信股票数据
Python金融数据获取终极指南:用mootdx高效处理通达信股票数据 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在量化投资和金融数据分析领域,获取稳定、免费的股票数据一直…...

嵌入式开发硬件知识体系与核心技能解析
嵌入式开发中的硬件知识体系构建1. 嵌入式开发的技术架构1.1 嵌入式系统技术分类现代嵌入式系统开发主要分为两大技术方向:嵌入式硬件开发:聚焦电路原理设计、PCB布局及硬件系统集成嵌入式软件开发:包含驱动层开发和应用程序开发两个层级1.2 …...

电源键按下去后发生了什么?用Wireshark+日志分析揭秘操作系统启动的隐藏细节
电源键背后的技术探秘:用Wireshark与日志分析揭开系统启动的黑盒 当你按下电源键的那一刻,整台计算机仿佛被注入了生命。但在这个看似简单的动作背后,隐藏着一场精密编排的技术交响乐。作为运维工程师或开发者,理解这个过程不仅有…...