大数据技术生态全景一览
大数据技术生态全景一览
- 大数据平台ETL数据接入
- 大数据平台海量数据存储
- 大数据平台通用计算
- 大数据平台各场景的分析运算
- 分布式协调服务
- 任务流调度引擎
大数据平台ETL数据接入
大数据有很多的产品,琳琅满目。从架构图上就能看出产品很多。这些产品它们各自的功能是什么,它们又是怎么样相互配合来完成一整套的数据存储,包括分析计算任务。这里要给大家进行一个讲解与分析。
我们按照数据处理的流程,从下往上给大家进行依次的讲解。
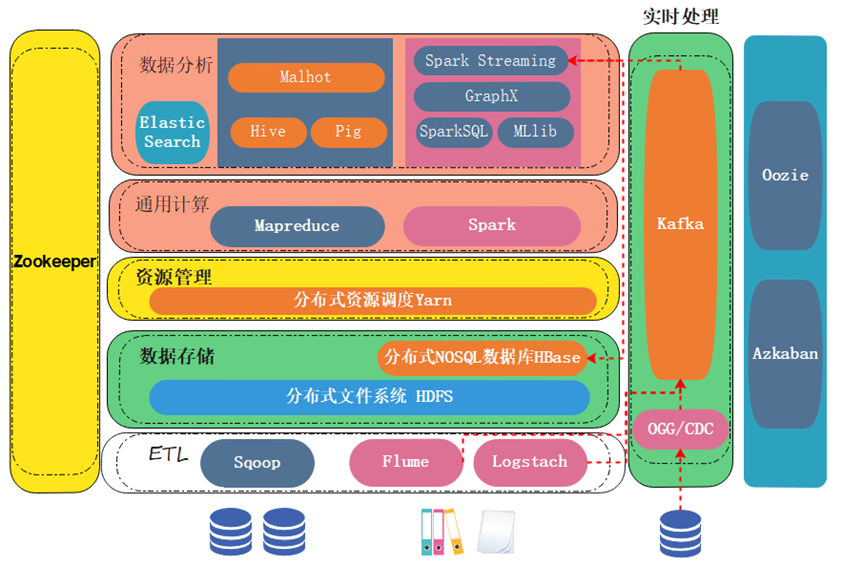
首先我们看数据源,数据有结构化数据,存在关系型数据库里的数据,它以二维表的形式进行存储;还有一些非结构化、半结构化数据,比如日志 json属于半结构化数据,图片视频音频属于非结构化数据。
对于结构化数据来说,一般通过sqoop组件进行抽取,把数据抽取到大数据存储平台。
大数据存储平台主流的选型是HDFS,因为它已经非常成熟了,并且经过很多年的一个打磨。
Sqoop会通过jdbc的方式,连接到数据库,对数据库进行直接抽取后做一个导出。将数据导出到HDFS中。
Sqoop在抽取的时,一般是T+1的。什么叫T+1?就是今天产生的数据,可能明天才能导入到大数据平台,它的时效性比较低一些。
像数据仓库,它其实是每天凌晨0点才会把昨天新生成的数据统一进行一个导入。
对于这种非结构化半结构化数据,它们其实就是文件,例如图片、视频、日志、json。这种文件一般来说,它们会实时产生。比如监控的摄像头,它会实时产生图片或者视频;日志会实时在服务器端生成。
实时产生的数据要进行实时抽取,这个时候肯定就不能用sqoop了,这些数据会通过flume或者logstash进行实时的监控。一旦这些非结构化半结构化数据产生,它们就会立即被抽取到大数据的存储平台。
但是按照我们前面讲过的一个知识点,实时产生的数据在架构设计上来说,我们要先给它推送到一个消息队列中进行缓冲,起到一个抗压的作用。
这个消息队列,常用的选型就是Kafka,它能扛住数据源的并发压力。扛住压力以后,实时产生的数据一定是要先经过大数据平台的处理,处理完以后再把结果存到大数据存储平台。这样才能发挥实时数据的一个价值。
所以这种实时数据,它不是直接往大数据平台存,而是先经过消息队列缓存抗压后,再由大数据平台处理,最终将计算结果保存起来。
有的同学这个时候想了,那结构化的数据,如果它也想进行实时的一个抽取,可不可以实现?当然可以,这个时候它要用到另外一种方式,目前有CDC和Ogg。Ogg是Oracle特有的,CDC是开源的。
它们可以监控,数据库里的结构化数据,当数据一旦发生变化,它们就会监控到变动的数据,并将数据抽到Kafka或其它消息队列中。再交给大数据平台进行一个处理。
它们为什么能够进行实时的一个监控?其实它们监控的是数据库的日志,比如说Mysql会有binlog,其他的数据库也有它们特有的日志文件,当我们在对数据库做一些数据新增、修改删除的操作的时候,数据库会先把这样的一个操作记录在日志中,以保证容灾。之后再往数据库里面进行一个持久化写入。
我们直接监控数据库的日志,数据的实时的变更就可以立马获取到,而且不影响数据库的性能,因为日志本身就是一个文件。这是CDC和Ogg,它做的一个事情。
所以在数据源这里,结构化数据可以使用T+1的方式,隔一段时间抽一次,导入到大数据平台。非结构化半结构化数据,当然也可以通过flume和logstach定时(T+1)把它们抽到大数据平台。
但非结构化与半结构化数据的应用场景,更多的是实时去抽取,并传送到消息队列kafka中。结构化数据通过cdc、ogg,也实时抽取到kafka。
这样的话我们不管是结构化数据,还是非结构化半结构化数据,都可以满足t+1与实时抽取方式的需要。
大数据平台海量数据存储
那数据最终会存储到我们的hdfs中,但hdfs它本质上是一个文件系统,生产上使用起来并不能适合所有场景。生产中没有见过,我们直接把数据存到文件系统里面。
我们一般会选择把数据存到数据库里,hbase就是一个分布式的nosql数据库。它是基于hdfs建立的,虽然数据最终它也是存在hdfs中,但是它上层搭建了一个数据库,这个数据库用起来易用性会更好。
这样的话你抽取过来的数据,可以直接存到hdfs里,也可以存到hbase中,就看具体的应用场景来具体对待。
大数据平台通用计算
那数据存储起来以后,我们要基于这个数据做一些运算。运算的时候,可以用mapreduce也可以用spark。
Mapreduce它计算起来要慢一些,Spark相对快一些。不管使用哪种计算框架,它们的计算任务要移动到数据节点进行一个运算。
怎么能够把计算任务分发到数据节点,要通过中间资源管理层的一些框架来完成。这里最常用的是分布式资源调度框架YARN。
YARN这个框架,它在部署的时候是和数据存储的框架部署在一起的。比如说我们底层的hdfs,它是用来做存储的有三个节点,于是YARN它也装在这三个节点上,并且管理的这三个节点的计算资源。计算资源一般包含CPU、内存,还有一些环境变量。
MapReduce和Spark计算任务,要移动到数据节点进行运算,这个时候Yarn就可以直接在数据节点上分配给这些计算任务一些计算资源;它们就可以顺利的紧贴数据运算。
运算完成之后,Yarn又可以把资源进行一个回收。所以大数据的移动计算这一块的实现,就是通过资源管理层它来完成的。
大数据平台各场景的分析运算
虽然我们在做计算的时候,有了MapReduce有了Spark,但是用起来还是不够好用,易用性还是不够好。
因为我们在开发的时候,针对于这种结构化数据,一般我们习惯用什么?用SQL。一些非结构化半结构化数据,我们习惯用一些API。
但是现在你把数据抽取到大数据平台以后,这些SQL API都不能用了。你只能用它提供的MapReduce和spark去进行一个数据处理,对于我们来说就很难用。
而且之前我们的业务系统用的SQL,用的一些API,你是不是都要进行一个迁移。迁移的时候这个工作量就很大了。
为了让我们的数据开发,或者数据分析这样的一个过程更加易用。大数据这里其实提供了很多的一些易用框架,比方说Hive,它其实完成的就是帮你把SQL转换成底层的mapreduce。
当然Hive也可以转换成Spark,计算的效率会更高。
这样的话你原来的结构化数据,存到大数据平台后,之前是用SQL进行开发的,现在依然可以用SQL。由Hive帮你把SQL转换成通用计算,转化完成之后通用计算的mapreduce或者spark再通过资源管理调度到我们的数据节点,紧贴数据完成整个计算任务。
Pig也是相同的情况,Pig有它的一些API,你使用它的API进行开发。它会把这些API转换成MapReduce任务,当然Pig比较早就停止维护了。
还有malhot,它是做机器学习的,用它提供的机器学习的API,然后它帮你转换成MapReduce。
所以数据分析这一层,它们完全是用于提高我们易用性而诞生的一些框架。
而根据它们转换的计算任务的不同,如果默认是转换mapreduce的,它们就属于hadoop生态圈。
因为hadoop包含三个组件,除了hdfs、mapreduce之外,在hadoop 2.x的时候增加了一个YARN。
默认兼容hadoop的,就属于hadoop生态圈。当然有一些框架其实刚开始诞生的时候是兼容hadoop的,后面因为spark它的性能更高,用的公司更多一些;所以hadoop生态圈有一些框架,比如说hive它也可以运行在spark上面。
当然spark也有它的一些生态,spark sql帮你把sql转换成spark任务;Mllib是做机器学习的;GraphX是作图计算的。
spark streaming是做流计算的,就是实时处理,我们一般称为实时流处理或者实时流计算,它计算得到的结果我们会给它存到hdfs里或者hbase里,当然我们一般会存储在hbase里。
因为实时的结果,如果存到hdfs里的话它会产生一些小文件问题。hdfs对于小文件来说是很敏感的,它很容易把管理节点的内存给占满,而且也会导致后续计算的一个效率下降。所以实时计算完得到的结果会存到hbase中。
hbase虽然说数据最终也存到hdfs,但是它是一个数据库,它解决了小文件问题。它并没有小文件问题带来的这些隐患。
这一部分是spark生态圈,我们之后在做开发的时候,大部分同学可能直接用spark或者mapreduce进行编程相对会比较少一些。我们可能更多的是用上层的,易用性比较高的组件来进行一些相关的开发。
还有一些是独立开发的组件(非Hadoop、Spark生态圈),比如说elasticsearch它是做搜索与检索的,数据存到elasticsearch里面以后可以进行一些模糊查询、精确匹配、语义匹配等一些操作。
为什么说它是独立的?因为elasticsearch有它自己的通用计算,也有它自己的资源管理,包括数据存储层。所以它并不依赖hadoop,它也不依赖spark。这个产品里面,它本身就包含这几层。所以它属于一个独立的产品。
分布式协调服务
最左边有一个zookeeper,zookeeper对大数据的各个产品其实是非常重要的。很多产品比如说hdfs、hbase都要依赖zookeeper。
它是干嘛的?它是一个分布式的协调服务。
因为大数据的产品它都是分布式,也就是运行在多个节点上的。比方说我们某一个大数据组件,它突然新增的一个节点上来,zookeeper就会识别到,然后通知我们之前的3个节点说,你现在的集群规模变成了4。
突然这个节点挂掉了,zookeeper也会通知另外三个节点说,好,你现在有一个节点挂掉了,节点数现在变成了3。
包括说我们的集群里面,有多个管理节点,但是这些管理节点它只有一个能够管理当前集群,其他的都是备用节点。这样的话究竟由谁来进行管理?谁来做备份?zookeeper可以进行一个选举。
比如说选第一个,作为当前的管理节点,另外两个做备份。管理节点挂掉以后,zookeeper又可以从剩下的两个备用节点里面再选出一个来,让它来进行集群的一个接管。
所以zookeeper的作用其实是很大的,我们用到的这些大数据产品,只要想要在分布式环境下进行协调,都可以依赖zookeeper来完成这样的一个诉求。
而且像一些组件是必须依赖zookeeper的,比如说kafka它在搭建之前,zookeeper必须要进行安装。
任务流调度引擎
最右边有两个任务的调度组件,一个叫oozie一个叫azkaban。azkaban相对比较新一些,它俩是用来调度我们的计算任务的,比如说我们在大数据集群里面的任务,它如果有一个先后顺序,比如说任务1完成以后,我们任务2才可以执行,任务2执行完成以后再任务3。
如果有一个严格的先后顺序,可以由oozie和azkaban来进行一个限定。再比如计算任务,如果我们要进行定时,比如说让它每天凌晨0点的时候定时执行,就可以由oozie或azkaban来完成。
所以它们主要是来完成这种任务流的管理和调度的。
OK,那大数据的整个产品就先介绍到这里,当然大数据的产品不止这些,大家要慢慢归纳,整体的架构是一致的,可以定位到它所属的分层后基本就明白它的职责。那我们下期再会!B站配套视频传送:大数据技术生态全景一览
相关文章:
大数据技术生态全景一览
大数据技术生态全景一览大数据平台ETL数据接入大数据平台海量数据存储大数据平台通用计算大数据平台各场景的分析运算分布式协调服务任务流调度引擎大数据平台ETL数据接入 大数据有很多的产品,琳琅满目。从架构图上就能看出产品很多。这些产品它们各自的功能是什么…...

CI/CD | 深入研究Jenkins后,我挖掘出了找到了摆脱低效率低下的方法
在本系列的第一篇文章中,您已经了解了一些关于如何管理Jenkins的内容,主要是为无序的人带来秩序。在这篇文章中,我将更深入地探讨我效率低下的问题,提出我们工作流中一些安全性、治理和合规性的挑战。这不仅仅是你在网站上或展览横…...

刷LeetCode
文章目录滑动窗口算法1 涉及知识点 :unordered_set 容器2 参数详情3 例题滑动窗口算法 滑动的窗口,每次记录下窗口的状态,再找出符合条件的窗口使用滑动窗口减少时间复杂度 1 涉及知识点 :unordered_set 容器 说明:…...
Spring 大白话系列:工厂
Spring 大白话系列:工厂 “工厂模式,大家都很熟悉了。说到底,就是解除创建对象和使用对象之间的耦合。这东西没啥啊。” 教室里,老师傅听到小明在嘀嘀咕咕的。老师走过去问: “有什么问题呢小明同学?” 小…...

喜讯!华秋电子荣获第六届“蓝点奖”十佳分销商奖
2 月 25 日,由深圳市电子商会主办的2023 中国电子信息产业创新发展交流大会暨第六届蓝点奖颁奖盛典在深圳隆重举行。 图:华秋商城渠道总监杨阳(右三) 深圳市电子商会连续六年举办“蓝点奖”评选活动,旨在表彰对电子信…...

Linux概述
1:Linux概述1.1:操作系统常见操作系统有:Windows、MacOS、Linux。名称描述Windows微软公司研发的收费操作系统。分为两类:用户操作系统、Server操作系统。用户操作系统:win 95、win 98、win NT、win Me、win xp、vista…...
中级嵌入式系统设计师2015下半年上午试题及答案解析
中级嵌入式系统设计师2015下半年上午试题 单项选择题 1、CPU是在______结束时响应DMA请求的。 A.一条指令执行 B.一段程序 C.一个时钟周期 D.一个总线周期 2、虚拟存储体系由______两级存储器构成。 A.主存-辅存 B.寄存器-Cache C.寄存器-主存...

华为OD机试模拟题 用 C++ 实现 - 删除指定目录(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)) 文章目录 最近更新的博客使用说明删除指定目录题目输入输出示例一输入输出说明Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为…...
【正点原子FPGA连载】第二十章AXI4接口之DDR读写实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第二十章AXI4接口…...
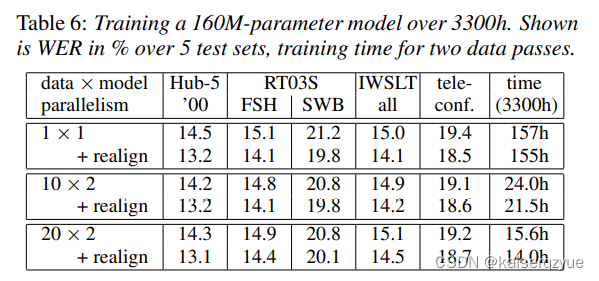
超出认知的数据压缩 用1-bit数据来表示32-bit的梯度 语音识别分布式机器学习 梯度压缩 论文精读
说明 介绍1−bit1-bit1−bit论文内容。 原文链接:1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs | Semantic Scholar ABS 实验证明在分布式机器学习的过程中能够通过将同步所传递的梯度进行量化…...

深度剖析指针(上)——“C”
各位CSDN的uu们你们好呀,今天,小雅兰的内容是指针噢,在学习C语言的过程中,指针算是一个比较重要的内容,当然,难度也是比较大的,那么现在就让小雅兰来带大家进入指针的世界吧 字符指针 数组指针…...

学习 Python 之 Pygame 开发魂斗罗(六)
学习 Python 之 Pygame 开发魂斗罗(六)继续编写魂斗罗1. 创建碰撞类2. 给地图添加碰撞体3. 让人物可以掉下去4. 实现人物向下跳跃5. 完整的代码继续编写魂斗罗 在上次的博客学习 Python 之 Pygame 开发魂斗罗(五)中,我…...

LeetCode题解:1238. 循环码排列,归纳法,详细注释
原题链接: https://leetcode.cn/problems/circular-permutation-in-binary-representation/ 前置条件: 在解题之前,请先一定要阅读89.格雷编码的题解格雷编码可以满足题目的条件“p[i] 和 p[i1] 的二进制表示形式只有一位不同”,…...

全新后门文件Nev-3.exe分析
一、 样本发现: 蜜罐 二、 内容简介: 通过公司的蜜罐告警发现一个Nev-3.exe可执行文件文件,对该样本文件进行分析发现,该可执行程序执行后会从远程服务器http://194.146.84.2:4395/下载一个名为“3”的压缩包,解压后…...

线性回归系数解释
线性回归系数解释线性回归系数1、R2R^2R2(R方,R-Square)2、Adj−R2Adj-R^2Adj−R2(调整后的 R 方)3、标准误差4、FFF 值5、FFF 显著度6、置信区间7、PPP 值线性回归系数 回归模型得到后会有多个系数,这些系…...
 A~D)
22.2.27打卡 Codeforces Round #852 (Div. 2) A~D
A Yet Another Promotion 题面翻译 题目描述 共 ttt 组数据,每组数据中,你需要买 nnn 公斤苹果,第一天单价为 aaa ,但每买 mmm 公斤赠送一公斤;第二天单价为 bbb 。求最小花费。 输入输出格式 第一行一个正整数 …...
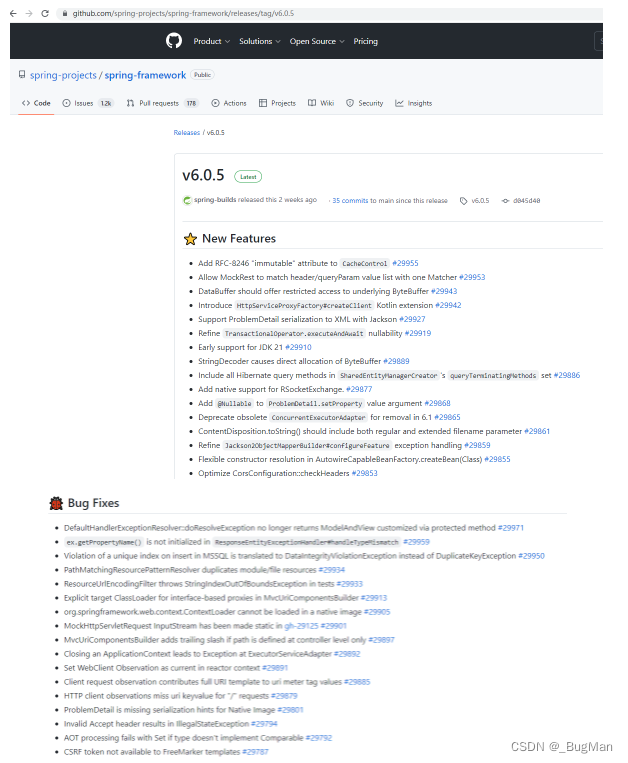
如何查看Spring Boot各版本的变化
目录 1.版本 2.基础特性和使用 3.新增特性和Bug修复 1.版本 打开Spring官网,点进Spring Boot项目我们会发现在不同版本后面会跟着不同的标签: 这些标签对应不同的版本,其意思如下: GA正式版本,通常意味着该版本已…...

程序员是否要加入创业公司?
我从1月份入职到2月份离职,历时一个半月。短暂的体验了一段创业生活,更准确的说是一段“待在”创业团队的生活,因为我发现创业本身跟我关系不大。一个半月的就业经历,对任何人来说都不是一个好选择,当然也不是我所期望…...
2023软件测试工程师全新技术栈,吃透这些,起薪就是25k~
相信每个准备软件测试面试的同学,不管你是大学刚毕业,满心憧憬着进入公司实习、非计算机行业转行软件测试、自学测试就业还是培训后就业,都会面临着众多的疑问和不解,那就是该怎么走出着第一步,今天本文一次性告诉你&a…...

【ChatGPT情商大考验】ChatGPT教我谈恋爱
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

antV L7 无底图模式实战:打造纯净3D地图可视化
1. 认识antV L7的无底图模式 第一次接触antV L7的无底图模式时,我完全被它的简洁震撼到了。想象一下,当你需要在地图上突出显示某个特定区域的数据时,周围那些无关的底图元素反而会分散注意力。无底图模式就像给你的数据一个干净的画布&#…...

基于粒子群算法的IEEE33节点配电网无功优化及其结果分析
基于粒子群算法的配电网无功优化 基于IEEE33节点配电网,以无功补偿器的接入位置和容量作为优化变量,以牛拉法进行潮流计算,以配电网网损最小为优化目标,通过优化求解,得到最佳接入位置和容量,优化结果如下所…...

SEO数据分析资源网
SEO数据分析资源网:揭秘成功的关键 在当前数字化竞争日益激烈的环境中,SEO(搜索引擎优化)已经成为企业提升在线可见度和吸引客户的重要手段。SEO并不是一蹴而就的事情,而是需要不断的数据分析和调整。今天,…...

瑞斯康达Raisecom交换机VLAN与ERPS实战配置指南
1. 瑞斯康达交换机基础配置入门 第一次接触瑞斯康达交换机的朋友可能会被命令行界面吓到,其实它的操作逻辑和主流厂商设备非常相似。以Gazelle系列交换机为例,默认登录账号密码都是raisecom,这个设计对新手特别友好——至少不用像某些品牌设备…...
,分为免费的 Community 版和功能更全面的 Professional 版)
PyCharm 是 JetBrains 推出的专业 Python 集成开发环境(IDE),分为免费的 Community 版和功能更全面的 Professional 版
PyCharm 是 JetBrains 推出的专业 Python 集成开发环境(IDE),分为免费的 Community 版和功能更全面的 Professional 版。其核心优势在于深度集成多种现代开发工具链: ✅ Python 支持:智能代码补全、实时错误检查、重构…...

Amazon日本站、欧洲站A+内容翻译怎么做?跨马翻译在多站点运营中的实际应用
【一、从一次上架被拒说起】上个月帮一个做家居品类的卖家朋友处理欧洲站上架问题,他花了两周精心设计的A页面被Amazon审核退回,原因只有一句话:"Please ensure all images contain text in the target marketplace language."&…...

轻量级跨平台安卓应用安装工具:APK-Installer极简高效使用指南
轻量级跨平台安卓应用安装工具:APK-Installer极简高效使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows系统上运行安卓应用通常面临两大痛…...

ble sig mesh消息格式分析
蓝牙 Mesh (Bluetooth SIG Mesh) 的数据格式采用分层结构,每一层都有其特定的数据单元和职责 一.承载层 (Bearer Layer) 承载层定义了消息如何在物理媒介上传输。蓝牙 Mesh 主要支持两种承载方式: 广播承载 (Advertising Bearer): 使用 BLE 广播包来传输…...

别再只改Keycloak登录密码了!从一次‘误报’漏洞,聊聊真正的中间件安全加固
从Keycloak密码事件看中间件安全:超越弱口令的防御体系 上周团队收到一份来自第三方安全机构的漏洞扫描报告,其中赫然标注着我们的Keycloak服务存在"弱口令漏洞"。令人困惑的是,我们早已将默认的admin/admin密码修改为包含大小写字…...

HiFloat8:高性能训练之路
Float8单数据格式FP8/HiF8训练算法介绍Float8混合精度训练策略随着预训练模型(尤其是基于Transformer架构的大语言模型)参数规模突破千亿级,训练过程面临愈发严重的算力和内存瓶颈,成本极高。在此背景下,8位浮点逐渐成…...