超出认知的数据压缩 用1-bit数据来表示32-bit的梯度 语音识别分布式机器学习 梯度压缩 论文精读
说明
介绍1−bit1-bit1−bit论文内容。
原文链接:1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs | Semantic Scholar
ABS
实验证明在分布式机器学习的过程中能够通过将同步所传递的梯度进行量化(从323232位到111位),同时加上量化容错机制能够很好的加快整个训练过程。最值得注意的时,模型的收敛情况并没有收到影响。
本文将该发现与SGD,AdaGradSGD,AdaGradSGD,AdaGrad, 自动批量选择, 双缓冲区,模型并行技术相结合设计了。意料之外的是,量化甚至能让精度有一个很小的提升。
不同的模型在使用该方法后加速效果明显。
1 Introduction and Related Work
现在上下文相关的深度神经网络模型基本都是通过反向传播进行训练(常用的例如SGDSGDSGD),而上述的模型的训练是非常耗时的。
注:上下文相关的神经网络应该是指类似与解决翻译问题所用的模型。
使用分布式训练上述的模型已经取得了一定成功。(这里介绍了一部分相关工作,这里不进行赘述)
在分布式训练中,一个非常重要的问题就是带宽瓶颈的问题:即各个节点训练一定时间之后需要进行数据的发送(这不管是模型并行还是数据并行都会发生),而这个过程交换的数据量往往取决于模型的大小,而现在使用的模型一般都比较大,所以网络的带宽成为了分布式机器学习的一个瓶颈。
缓解这个方法一般有两类方法:
- 增加批量大小,这样每轮会进行的计算会增加,而参与通信的时间会相对减少;
- 减少每一次通信的数据交换量。
本文提出的方法属于第二种,同时本文更多关注的是将量化方法应用于数据并行的分布式训练中。
2 Data-Parallel Deterministically Distributed SGD Training
通常采用BPBPBP进行模型的训练,过程可以被概述为下列的两个方程:
KaTeX parse error: Undefined control sequence: \part at position 114: …^{t+N-1}\frac {\̲p̲a̲r̲t̲ ̲F_{\lambda}(o(\…
上述过程对应反向传播求导和梯度下降进行更新。
2.1 Data-Parallel Distributed SGD
上述的方程可以进行分布式计算,只需要将方程(2)(2)(2)的梯度计算部分按照节点的个数,让每个处理一部分数据,然后进行梯度的计算,计算完成后,相加即可得到某个时刻的梯度。
perfectoverlapperfect\ overlapperfect overlap:选取合适的工作节点个数能够让计算和数据交换进行最优的并行化,也就是通信资源和计算资源同时饱和。
Tcalc(K^)=Tcomm(K^)T_{calc}(\hat K)=T_{comm}(\hat K) Tcalc(K^)=Tcomm(K^)
也就是选取KKK让每轮的通信时间和计算时间相等,这样当通信完成是下一轮的计算也完成可以继续进行通信。
计算时间可以被分解成固定的计算时间和可变的计算时间两部分。固定的计算时间一般是完成一些必要的操作时间所花费的时间,而可变计算时间往往会根据模型的大小,批量大小发生改变。
Figure1Figure\ 1Figure 1展示了当节点个数下降到通信时间与计算时间相等时获得的加速。
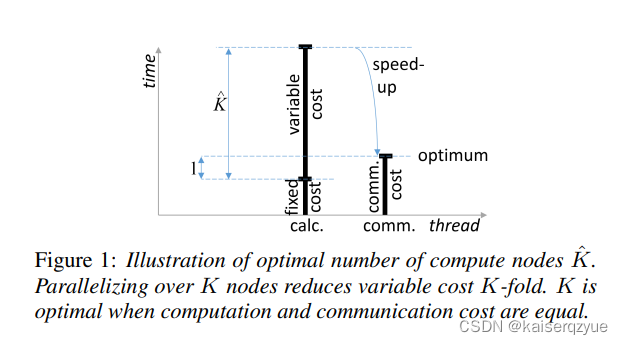
K^\hat KK^可以通过如下公式进行计算:
K^=N/2∗Tcalcfrm+C∗Tcalcpost1ZTcommfloat−Tcalcupd\hat K = \frac {N/2*T^{frm}_{calc}+C*T^{post}_{calc}}{\frac 1 ZT^{float}_{comm}-T^{upd}_{calc}} K^=Z1Tcommfloat−TcalcupdN/2∗Tcalcfrm+C∗Tcalcpost
各参数的含义:(设模型的大小为MMM)
- NNN:批量的大小。
- TcalcfrmT^{frm}_{calc}Tcalcfrm:计算梯度所花费的时间,大约为MFLOPS\frac M {FLOPS}FLOPSM。
- CCC:一个常量,使用特殊方法处理所携带的常数。
- TcalcpostT^{post}_{calc}Tcalcpost:后续进行处理所需要的时间,例如使用AdaGrad,momentumAdaGrad, momentumAdaGrad,momentum需要花费的额外时间(需要和CCC相乘才能获取实际时间),大约为Mr\frac M rrM,rrr为内存的带宽。
- ZZZ:数据传输之前的压缩率,在本文中将323232位压缩成111位,那么Z=32Z=32Z=32。
- TcommfloatT_{comm}^{float}Tcommfloat:不压缩梯度进行通信所需要花费的时间,大约为Mb\frac M bbM,bbb为两个结点之间的网络带宽。
- TcalcupdT^{upd}_{calc}Tcalcupd:参数服务器将受到的梯度用于更新所需要的时间,大约为Mr\frac M rrM。
上面的公式的理解:
分母是实际进行通信的时间,分子计算所有NNN个数据会花费的时间,而前面的推断需要让每个结点的计算时间和通信时间相等,由于在分布式机器学习中每个结点拥有的数据量是相同的,所以分子的计算时间除以KKK就是每个结点的计算时间,让两者相等并将KKK移到方程的一边即可得到上面的公式。上面计算时间的计算出现了一个除以222,这在下一小节会解释。
2.2 Double Buffering with Half Batches
上一节的公式里面出现了除以222是因为使用了双缓冲区。整个过程将每一个批量会分成大小相等的两部分放入缓冲区中,当前一部分计算完成后,开始计算后一部分,这个时候前一部分即可进行通信,当后一部分计算完成的时候,即可进行通信,此时又可以从缓冲区读取下一个批量的前一部分,所以每次实际上只计算了整个批量的一半,所以上面会出现除以222。
2.3 Potential Faster-Than-Fixed-Cost Communication
当通信时间降到固定计算时间之下时,那么此时上面的计算公式将不再适用。此时整个系统的限制在于固定的计算时间,通信很难饱和。此时在使用双缓冲区就没有什么意义了,因为此时的通信带宽是足够的,而双缓冲区是为了缓解通信的压力。
2.4 Relation to Hogwild/ASGD
异步更新能够增加并行度,但是并没有改变基础性的东西。
3 1-Bit SGD with Error Feedback
将需要交换的数据进行压缩,将其压缩为一位的数据,这样能够减少数据的交换量,从而减少通信的瓶颈。
不过如果只是简单的将数据压缩成一位,然后任由SGDSGDSGD进行缺失数据的修正,那么这是很容易导致模型发散的。
为了防止模型的发散提出了错误反馈机制,该机制并不会将丢失的精度给丢弃掉,而是会对其进行记录下一次更新的时候需要同时考虑之前丢失的精度。
整个过程可以用下面的公式来表述:
Gquant(t)=Q(G(t)+Δ(t−N))Δ(t)=G(t)−Q−1(Gquant(t))\begin{aligned} &G^{quant}(t) = Q(G(t)+\Delta(t-N))\\ &\Delta(t)=G(t)-Q^{-1}(G^{quant}(t)) \end{aligned} Gquant(t)=Q(G(t)+Δ(t−N))Δ(t)=G(t)−Q−1(Gquant(t))
参数说明:
- GGG:本轮计算出来的梯度。
- QQQ:量化函数,具体的,如果输入大于000,则量化成111,输出小于000,则量化成000,这样就可以将原本需要用323232位表示的梯度只用111位进行表示。
- GquantG^{quant}Gquant:量化后的梯度。
- Q−1Q^{-1}Q−1:反量化函数,输入只能是000或者111,当输入是111的时候输出是111,当输入是000的时候,输出是−1-1−1。
- Δ\DeltaΔ:梯度误差。
上述的过程就是压缩之后会记录压缩误差,压缩误差在下一轮的时候继续参与压缩。
3.1 Aggregating the Gradients
本文使用的聚合算法的复杂度关于结点个数是O(1)O(1)O(1)(这里的描述有一点奇怪,但是大概的意思就是每个结点聚合的数据量为所有梯度的一部分)。
具体的过程如下:
- 如果有KKK个结点,那么每个结点会处理1K\frac 1 KK1的梯度。
- 每个结点会从其他的K−1K-1K−1个结点接收属于自己处理的梯度部分。
- 收到后结点聚合自己负责的这一部分梯度。
- 聚合完成后分发给其他所有结点。
4 System Description
根据最佳节点个数的计算公式,至少存在三种方法能够提升并行度:(也就是通过改变变量让公式的结果变大)
- 提升NNN:增加每轮处理的批量个数。
- 增加ZZZ:增加压缩度。
- 减少固定计算时间(固定计算时间减少意味着相同的计算时间中有更多的时间用于了梯度的计算)
本文的压缩算法属于第二种方法。
对于方法一本文的实验发现NNN的增加是有一个限制的,当增大的太多时,整个模型可能会发散。同时本文发现一个成熟的模型能够处理的NNN的值要大一些。
为了防止模型发散的情况,本文后面的实验会隔一定的时间增大NNN而不是一开始就将NNN设置的很大,这样能够防止模型发散或是准确率下降严重。
除了这些之外,学习率也是采用递减的方式。
最后使用了AdaGradAdaGradAdaGrad进行优化,这样模型会收敛的更快,同时这也使得批量大小能够进一步的增加。
本文的系统可以在三个不同的地方使用AdaGradAdaGradAdaGrad:
- 在本地梯度量化之前;(可能会导致不一致性,但是可能对量化有益)
- 聚合结束后的数据交换期间;(可能会与量化冲突)
- 使用动量平滑后;(可以减少内存的使用和固定计算时间但是效果不好,因为峰值被动量磨平了)
作者发现AdaGradAdaGradAdaGrad在量化后动量平滑前使用效果最好。
为了也利用方法333,本文在使用数据并行的同时,在多GPUGPUGPU上做了模型并行。
5 Experimental Results
实验的细节可以在原文中找到。
论文的实验做的都是语音识别相关的,所以并没有证明所有方面都适合该方法。
5.1 Cost Measurements
这一部分主要测量几个耗时。
TcommfloatT^{float}_{comm}Tcommfloat大约为3−10ms3-10ms3−10ms$。
Tcalcpost+Tcalcupd=18.2msT^{post}_{calc}+T^{upd}_{calc}=18.2msTcalcpost+Tcalcupd=18.2ms。
Tcalcupd≈9T^{upd}_{calc}\approx9Tcalcupd≈9。
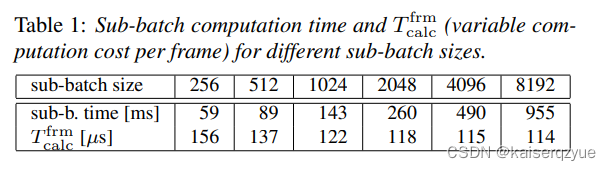
Table1Table\ 1Table 1给出了TcalcfrmT^{frm}_{calc}Tcalcfrm与批量大小的关系。
5.2 Effect of 1-Bit Quantization
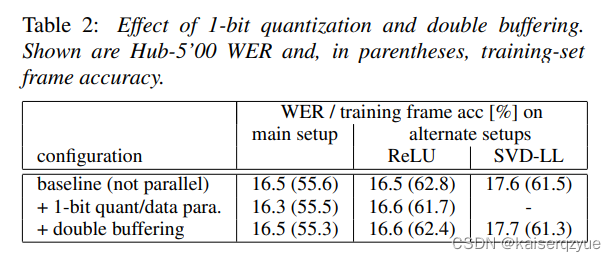
Table2Table\ 2Table 2展示了不同的模式下的三种方式的对比,可以看出1−bit1-bit1−bit的效果并没有受到太大的影响。
5.3 When to do AdaGrad?
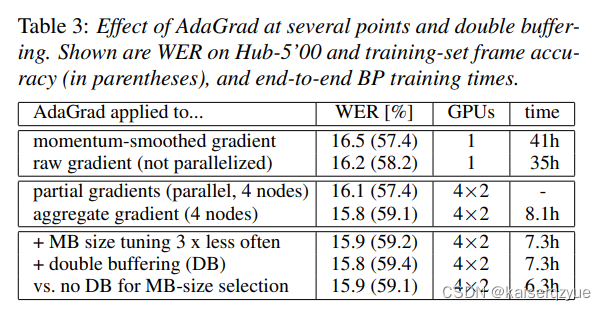
Table3Table\ 3Table 3展示了在不同环节使用AdaGradAdaGradAdaGrad进行优化对于准确率的影响,可以看出应该在动量平衡之前使用错误率会更低,作者指出这可能是因为动量平滑减少了梯度的标准差从而导致AdaGradAdaGradAdaGrad的效果不好。
partialgradientspartial\ gradientspartial gradients代表量化前各个结点自身的梯度,aggregategradientaggregate\ gradientaggregate gradient代表量化后聚合的梯度。
5.4 Impact of MB-Size Selection and Double Buffering
这一部分讲的是选取特别大的批量的时间耗时。从Table3Table\ 3Table 3中每一栏花费的时间可以得到一些信息。
第二行的时间比第一行小主要是因为:第一行的实验选取了较大的批量大小。
第四行增加到了四个结点进行数据进行,同时每个结点进行两个GPUGPUGPU的模型并行导致整个的时间下降到8.1h8.1h8.1h.
第五行相比于第四行的下降则是因为第四行的实验每24h24h24h选择一次新的批量大小,而第五行每72h72h72h选择一次。
第六行与第五行对比可以发现在这种情况下并没有进一步带来速度的提升,不过当使用双重缓冲区了之后自动选择的批量大小将会有所下降。
第七行代表的是什么意思本人并没有看懂。
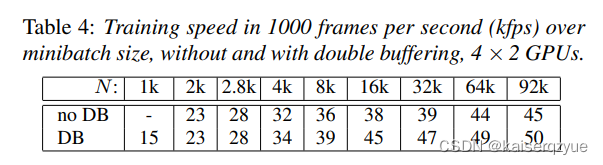
Table4Table\ 4Table 4展示了固定不同的批量大小下双重缓冲对于速度的影响。
5.5 Combination with Model Parallelism
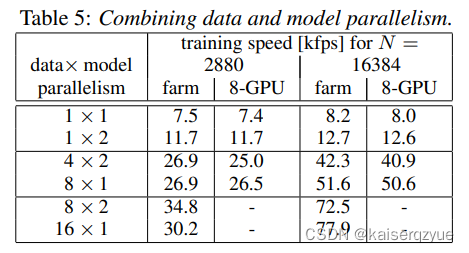
下图展示了不同的数据并行与模型并行的速率,可以发现在显卡数量相同的情况下,只有8×28\times28×2的时候模型并行提升了速率,在大多数情况下模型并并没有提升速率,这代表着在大多数情况下模型并行没有数据并行高效,这是因为如果使用模型并行则不能很好的利用缓存机制,模型并行的时候,每交换一次数据缓冲就会失效,而如果是更多的使用数据并行,那么就会减少一定缓存失效的次数。
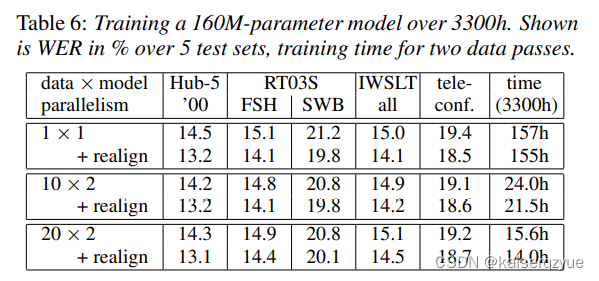
5.6 Training a Production-Scale Model
表格中的realignrealignrealign代表将数据进行对齐。
6 Conclusion
将通信传播的通信量从323232位降为111位,同时提出误差反馈机制保证模型的收敛。
一位的量化能够大大降低通信量从而减少通信所带来的瓶颈。
相关文章:
超出认知的数据压缩 用1-bit数据来表示32-bit的梯度 语音识别分布式机器学习 梯度压缩 论文精读
说明 介绍1−bit1-bit1−bit论文内容。 原文链接:1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs | Semantic Scholar ABS 实验证明在分布式机器学习的过程中能够通过将同步所传递的梯度进行量化…...

深度剖析指针(上)——“C”
各位CSDN的uu们你们好呀,今天,小雅兰的内容是指针噢,在学习C语言的过程中,指针算是一个比较重要的内容,当然,难度也是比较大的,那么现在就让小雅兰来带大家进入指针的世界吧 字符指针 数组指针…...

学习 Python 之 Pygame 开发魂斗罗(六)
学习 Python 之 Pygame 开发魂斗罗(六)继续编写魂斗罗1. 创建碰撞类2. 给地图添加碰撞体3. 让人物可以掉下去4. 实现人物向下跳跃5. 完整的代码继续编写魂斗罗 在上次的博客学习 Python 之 Pygame 开发魂斗罗(五)中,我…...

LeetCode题解:1238. 循环码排列,归纳法,详细注释
原题链接: https://leetcode.cn/problems/circular-permutation-in-binary-representation/ 前置条件: 在解题之前,请先一定要阅读89.格雷编码的题解格雷编码可以满足题目的条件“p[i] 和 p[i1] 的二进制表示形式只有一位不同”,…...

全新后门文件Nev-3.exe分析
一、 样本发现: 蜜罐 二、 内容简介: 通过公司的蜜罐告警发现一个Nev-3.exe可执行文件文件,对该样本文件进行分析发现,该可执行程序执行后会从远程服务器http://194.146.84.2:4395/下载一个名为“3”的压缩包,解压后…...

线性回归系数解释
线性回归系数解释线性回归系数1、R2R^2R2(R方,R-Square)2、Adj−R2Adj-R^2Adj−R2(调整后的 R 方)3、标准误差4、FFF 值5、FFF 显著度6、置信区间7、PPP 值线性回归系数 回归模型得到后会有多个系数,这些系…...
 A~D)
22.2.27打卡 Codeforces Round #852 (Div. 2) A~D
A Yet Another Promotion 题面翻译 题目描述 共 ttt 组数据,每组数据中,你需要买 nnn 公斤苹果,第一天单价为 aaa ,但每买 mmm 公斤赠送一公斤;第二天单价为 bbb 。求最小花费。 输入输出格式 第一行一个正整数 …...
如何查看Spring Boot各版本的变化
目录 1.版本 2.基础特性和使用 3.新增特性和Bug修复 1.版本 打开Spring官网,点进Spring Boot项目我们会发现在不同版本后面会跟着不同的标签: 这些标签对应不同的版本,其意思如下: GA正式版本,通常意味着该版本已…...

程序员是否要加入创业公司?
我从1月份入职到2月份离职,历时一个半月。短暂的体验了一段创业生活,更准确的说是一段“待在”创业团队的生活,因为我发现创业本身跟我关系不大。一个半月的就业经历,对任何人来说都不是一个好选择,当然也不是我所期望…...
2023软件测试工程师全新技术栈,吃透这些,起薪就是25k~
相信每个准备软件测试面试的同学,不管你是大学刚毕业,满心憧憬着进入公司实习、非计算机行业转行软件测试、自学测试就业还是培训后就业,都会面临着众多的疑问和不解,那就是该怎么走出着第一步,今天本文一次性告诉你&a…...

【ChatGPT情商大考验】ChatGPT教我谈恋爱
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

C++类内存结构模型
内存分区 内存全局数据区,代码区,栈区,堆区。 定义一个类 类的成员函数被放在代码区 类的静态成员变量被放在全局数据区(不占用类的存储空间) 非静态成员在类的实例内,实例在栈区或者堆区 虚函数指针&…...
HTML#4超链接标签,列表标签,表格标签和布局标签
一. 超链接标签介绍<a> 定义超链接,用于连接到另一个资源herf: 指定访问资源的URLtarget: 指定打开资源的方式代码<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>超链接标签</title> <…...

本科课程【数字图像处理】实验汇总
文章目录 实验1 - 腐蚀与膨胀实验2 - 图像增强实验3 - 图像的几何变换实验4 - 图像的蒙纱效果实验5 - 空洞填充实验6 - 取阈值的邻域平均算法实验7 - 图像的平移与伸缩变换实验1 - 腐蚀与膨胀 实验目的 分析掌握腐蚀与膨胀的基本原理,编写腐蚀与膨胀的算法,并掌握开闭运算的规…...

nginx安装lua、jwt模块,通过lua验证jwt实现蓝绿发布样例
文章目录前言一、基础组件下载二、组件安装1.luajit安装2.lua-nginx-module安装3.lua-resty-core安装4.lua-resty-lrucache安装5.ngx_devel_kit安装6.nginx加载lua模块7.lua-cjson安装8.lua-resty-string安装9.lua-resty-jwt安装10.lua-resty-hmac安装三、验证jwt中属性实现蓝绿…...

【redis的几种数据结构及在Java里的应用案例】
Redis是一款高性能的key-value存储系统,支持多种数据结构,包括字符串、列表、哈希表、集合和有序集合等。下面是Redis的几种数据结构及在Java中的应用案例: string 字符串(String) 字符串是Redis中最基本的数据类型,用于存储字符…...

【mybatis】 01- mybatis快速入门
数据库创建(注意:最好先创建好数据库设置utf8再进行表创建) create database mybatis; use mybatis;drop table if exists tb_user;create table tb_user(id int primary key auto_increment,username varchar(20),password varchar(20),gender char(1),addr varch…...

【C语言每日一题】杨氏矩阵(源码以及改进源码)
【C语言每日一题】—— 杨氏矩阵😎😎😎 目录 💡前言🌞: 💛杨氏矩阵题目💛 💪 解题思路的分享💪 😊题目源码的分享😊 Ǵ…...

JavaScript 面向对象【快速掌握知识点】
目录 类和对象 属性和方法 继承 多态 封装 类和对象 类是用于定义对象的模板或蓝图;它包含对象的属性和方法,我们可以使用class关键字来定义类。 class Person {constructor(name, age) {this.name name;this.age age;}sayHello() {console.log(H…...
Qt——自定义Model
众所周知,Qt提供了一套Model/View框架供开发者使用,Model用来提供数据, View则用来提供视觉层的显示。实际上这是一套遵循MVC设计模式的GUI框架,因为Qt还提供了默认的Delegate作为Controller来作为控制器。 MVC的好处这里就不多说…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...