MySQl总结
文章目录
- MySQL数据库的常见考点
- 1、ACID
- 事务原理
- 事务持久性
- 事务原子性
- MVCC基本概念
- MVCC基本原理
- undo log
- undo log版本链
- readview
- MVCC实现原理
- RC读已提交
- RR可重复读
- MVCC实现原理
- 总结
- 2、并发事务引发的问题
- 3、事务隔离级别
- 4、索引
- 索引结构
- B+Tree
- Hash
- 面试题
- 索引分类
- 思考题
- 语法
- 性能分析
- 查看执行频次
- 慢查询日志
- profile
- explain
- 使用规则
- 最左前缀法则
- 索引失效情况
- SQL 提示
- 覆盖索引&回表查询
- 前缀索引
- 单列索引&联合索引
- 注意事项
- 设计原则
- 总结:
- 5、SQL 优化
MySQL数据库的常见考点
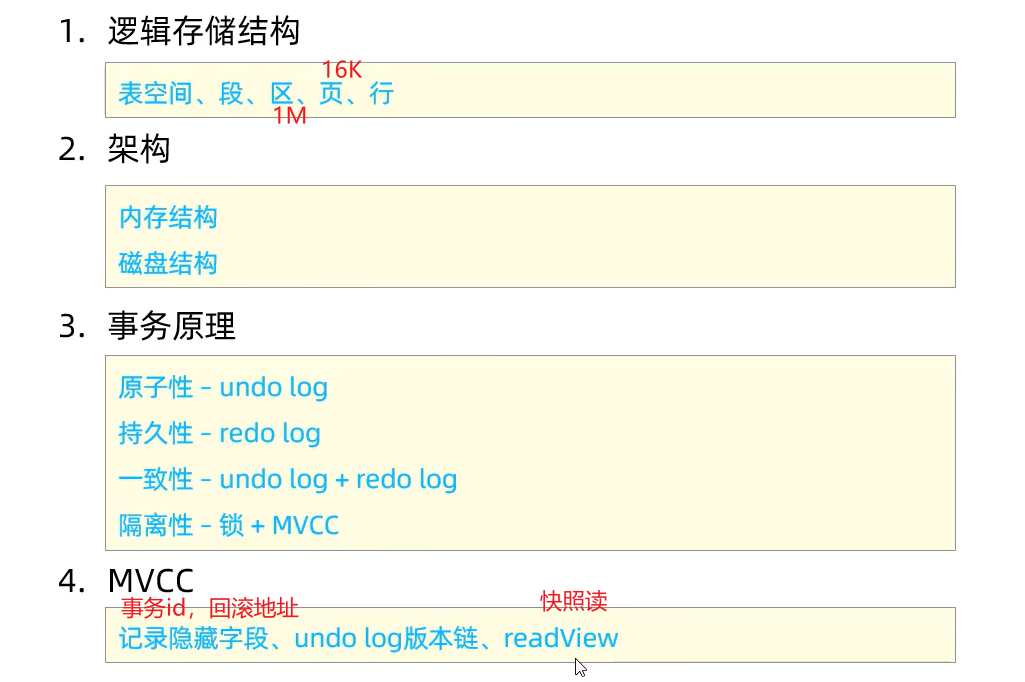
1、ACID
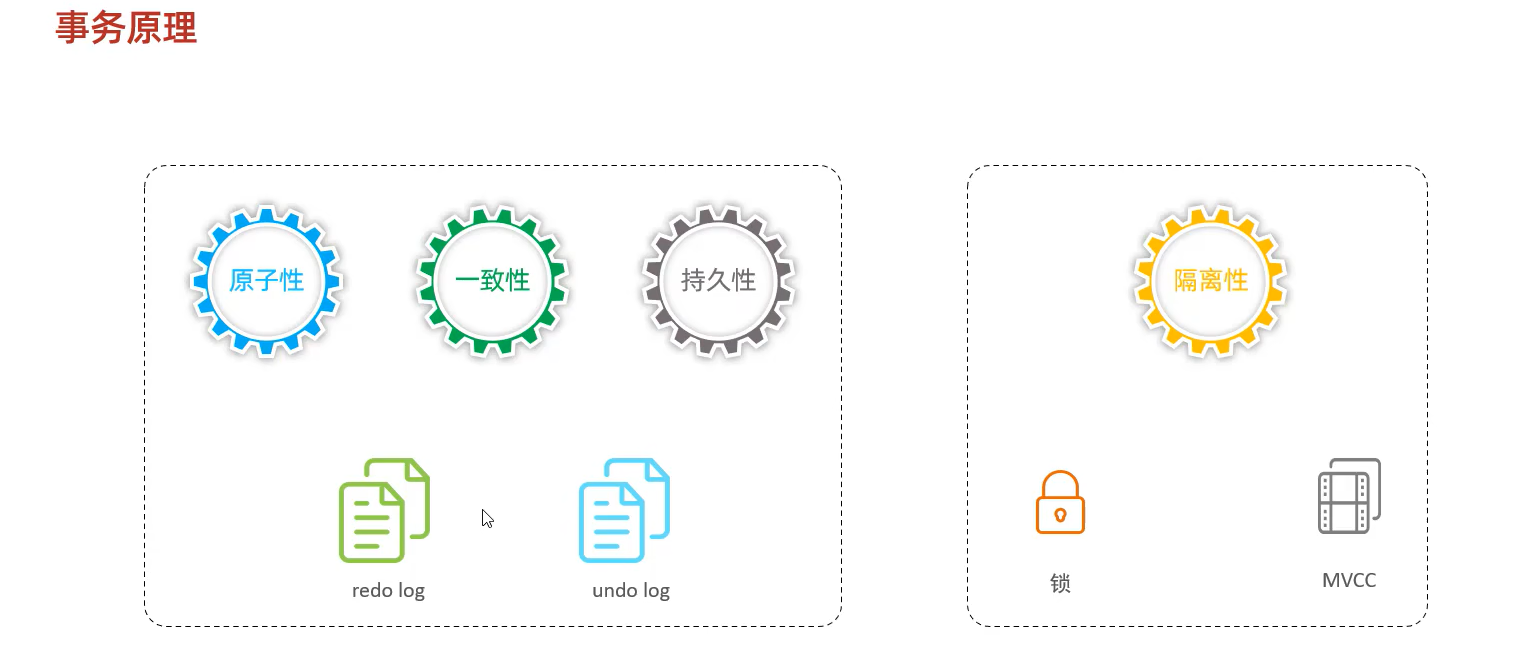
事务原理
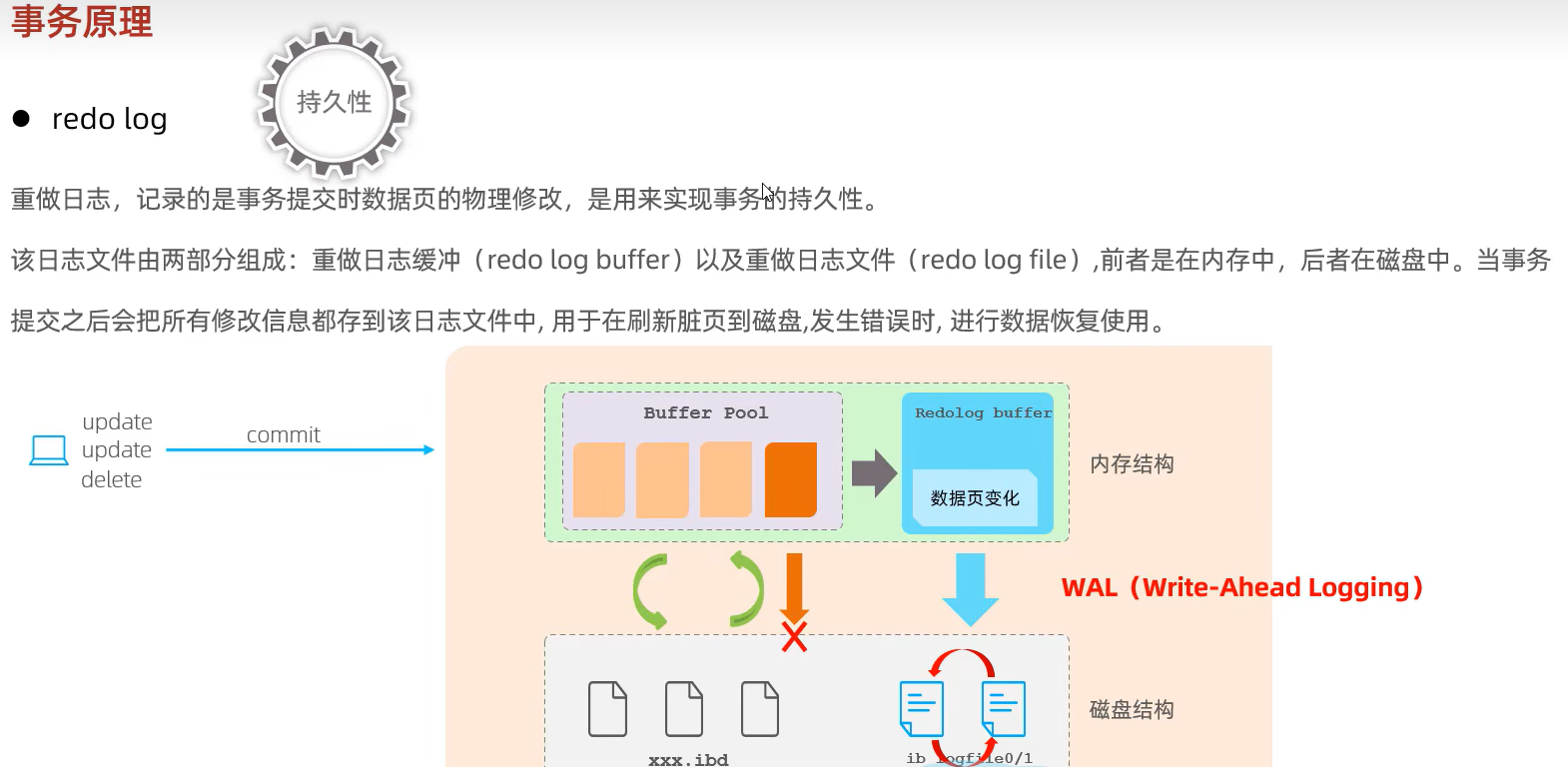
事务持久性
事务原子性

MVCC基本概念

MVCC基本原理

undo log

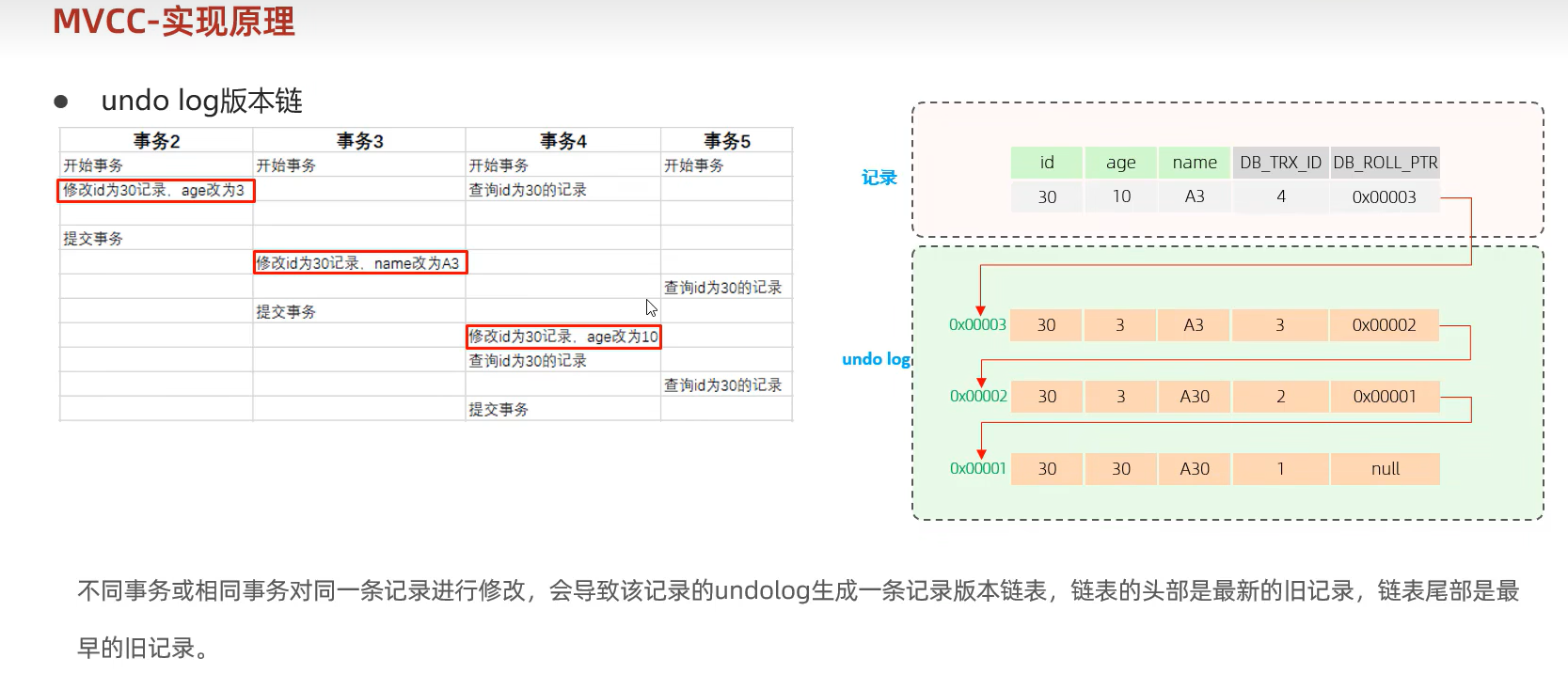
undo log版本链
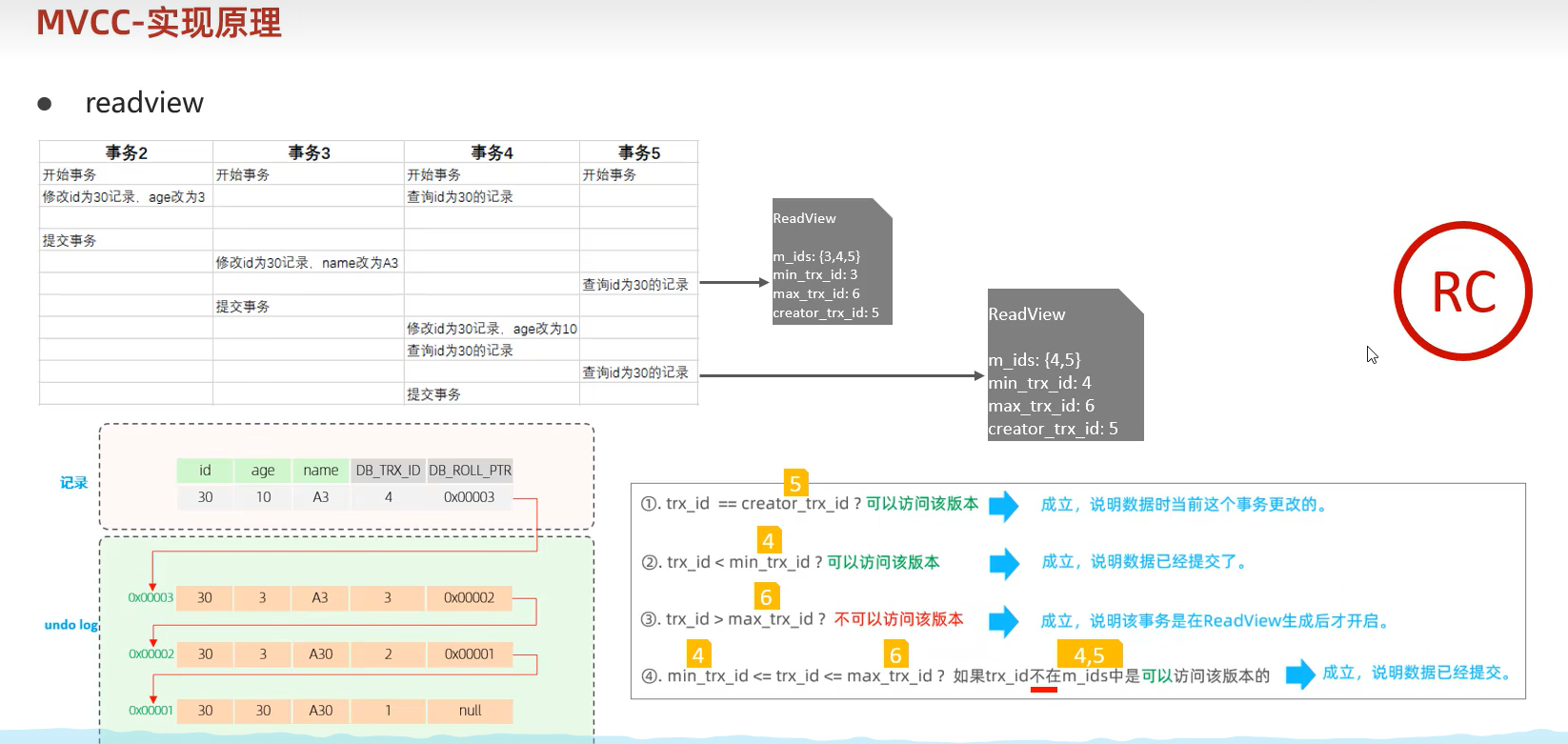
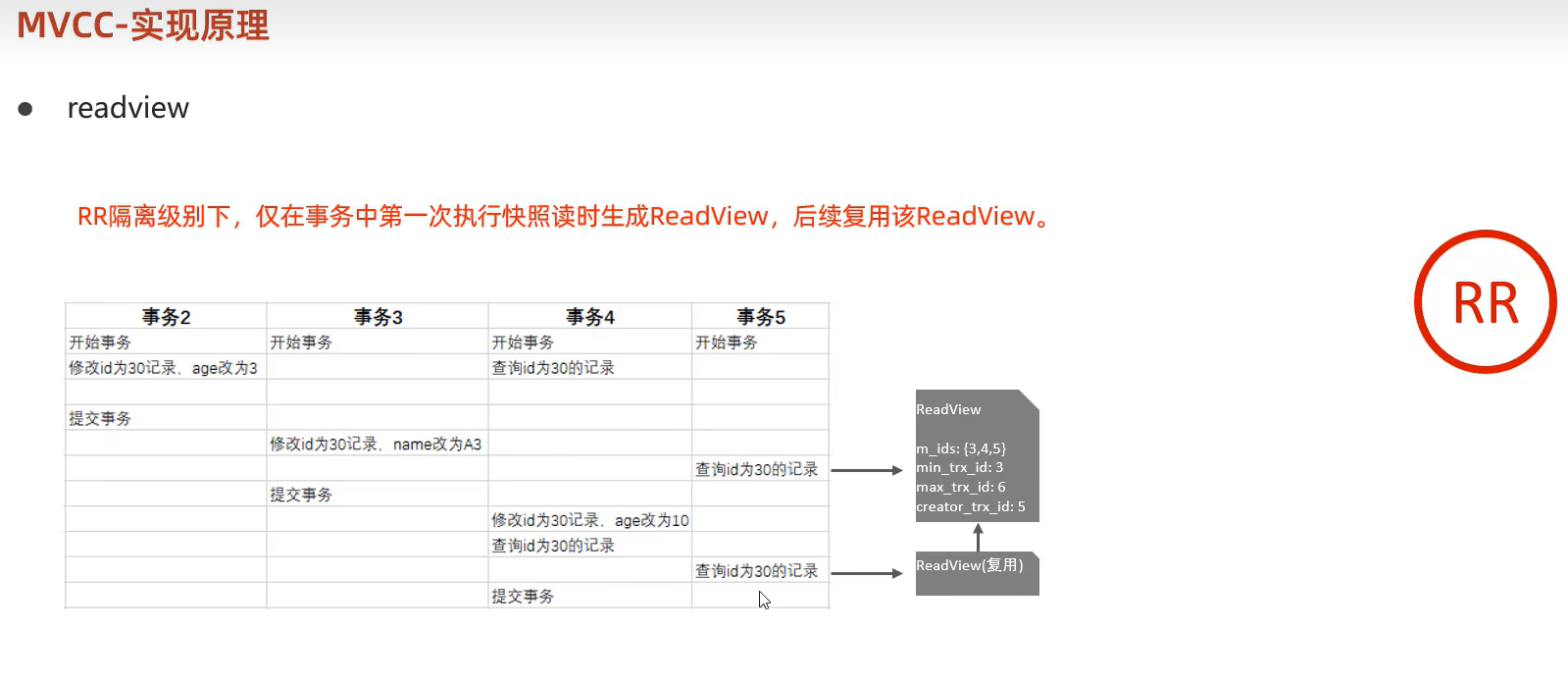
readview

MVCC实现原理

RC读已提交
RR可重复读
MVCC实现原理
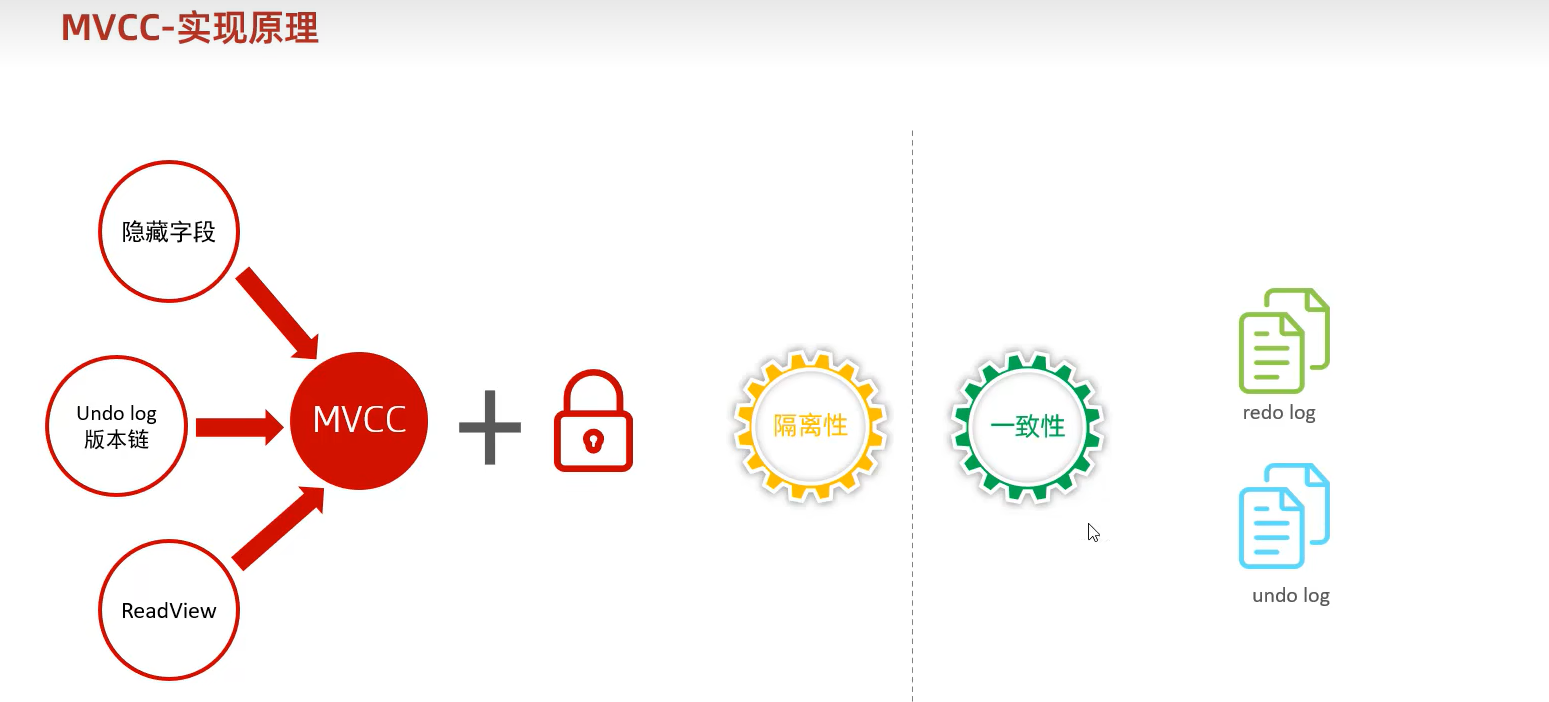
总结
2、并发事务引发的问题
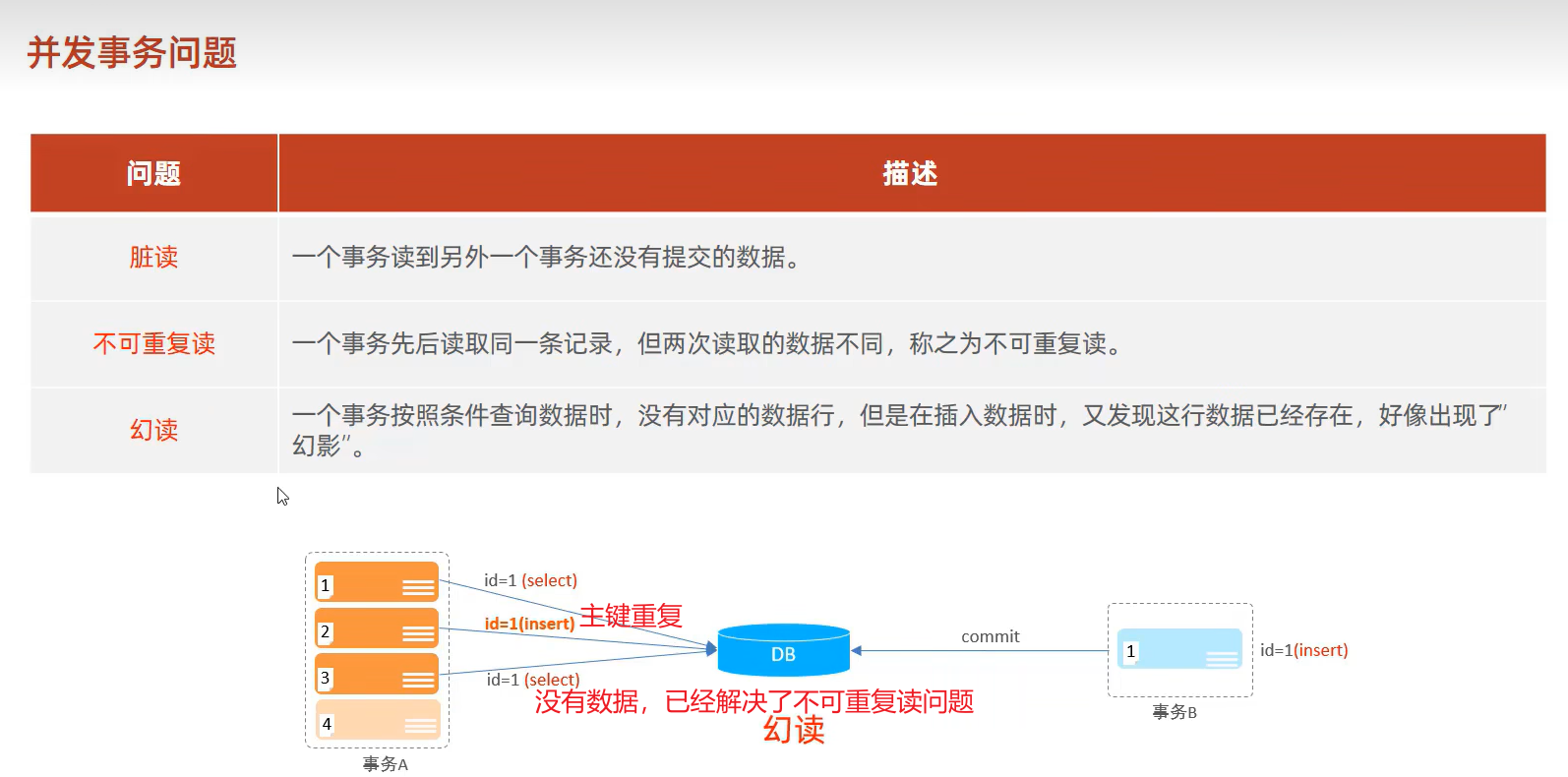
3、事务隔离级别
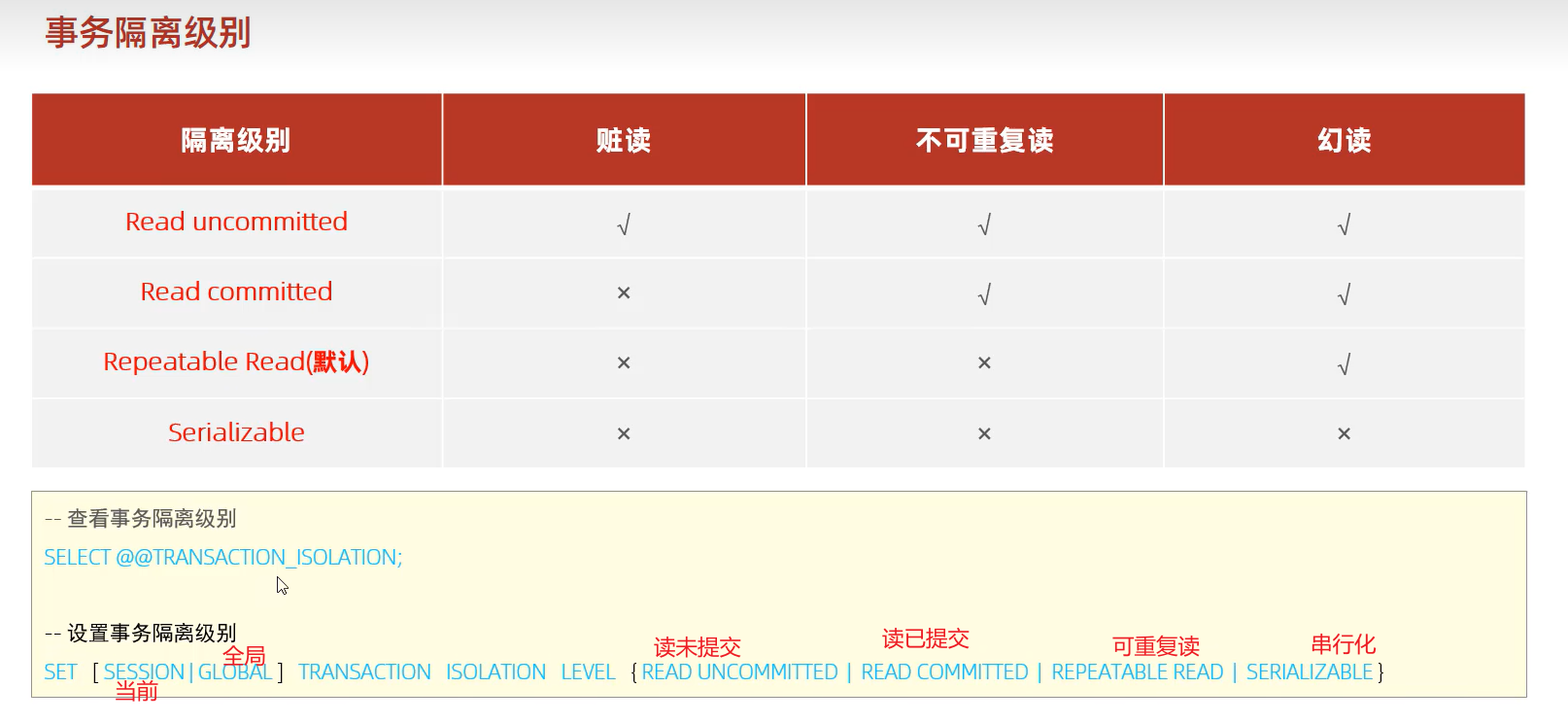
注意:事务隔离级别越高,数据越安全,但性能越低

4、索引
索引是帮助 MySQL 高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查询算法,这种数据结构就是索引。
优缺点:
优点:
- 提高数据检索效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点:
- 索引列也是要占用空间的
- 索引大大提高了查询效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
索引结构
| 索引结构 | 描述 |
|---|---|
| B+Tree | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash | 底层数据结构是用哈希表实现,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-Tree(空间索引) | 空间索引是 MyISAM 引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-Text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式,类似于 Lucene, Solr, ES |
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本后支持 | 支持 | 不支持 |
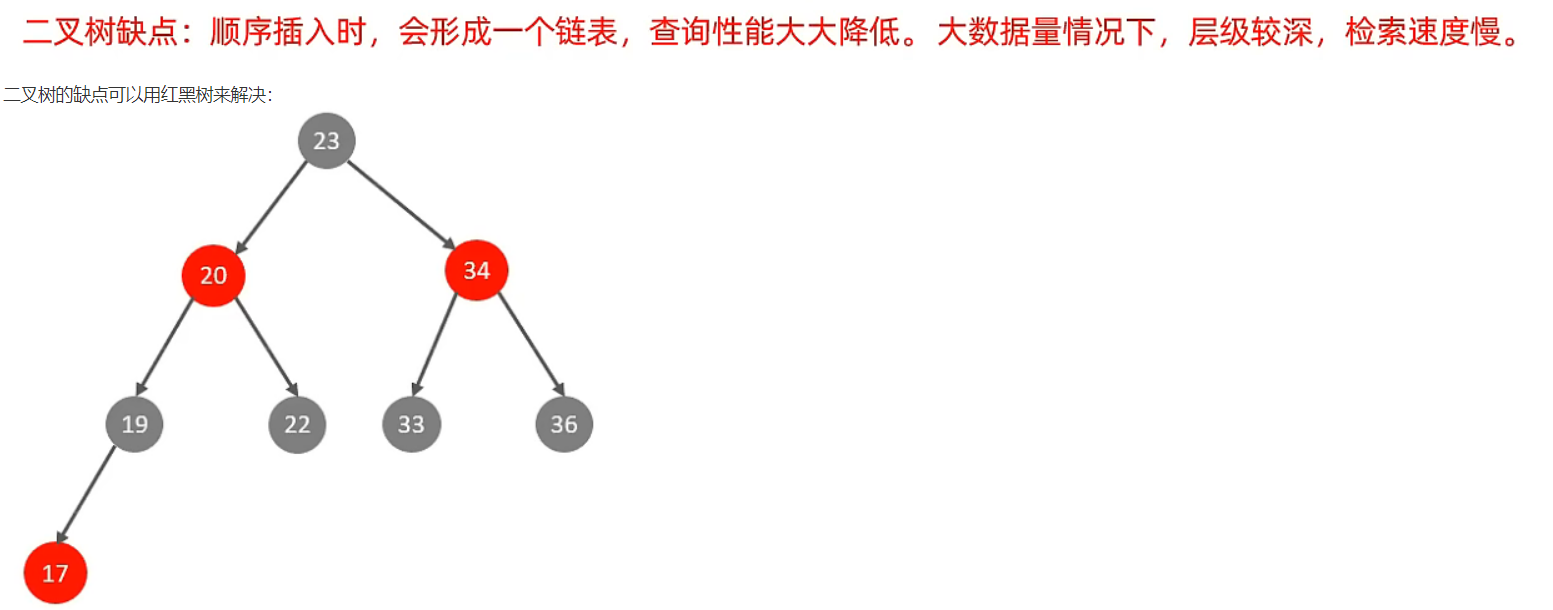
红黑树也存在大数据量情况下,层级较深,检索速度慢的问题。
为了解决上述问题,可以使用 B-Tree 结构。
B-Tree (多路平衡查找树) 以一棵最大度数(max-degree,指一个节点的子节点个数)为5(5阶)的 b-tree 为例(每个节点最多存储4个key,5个指针)
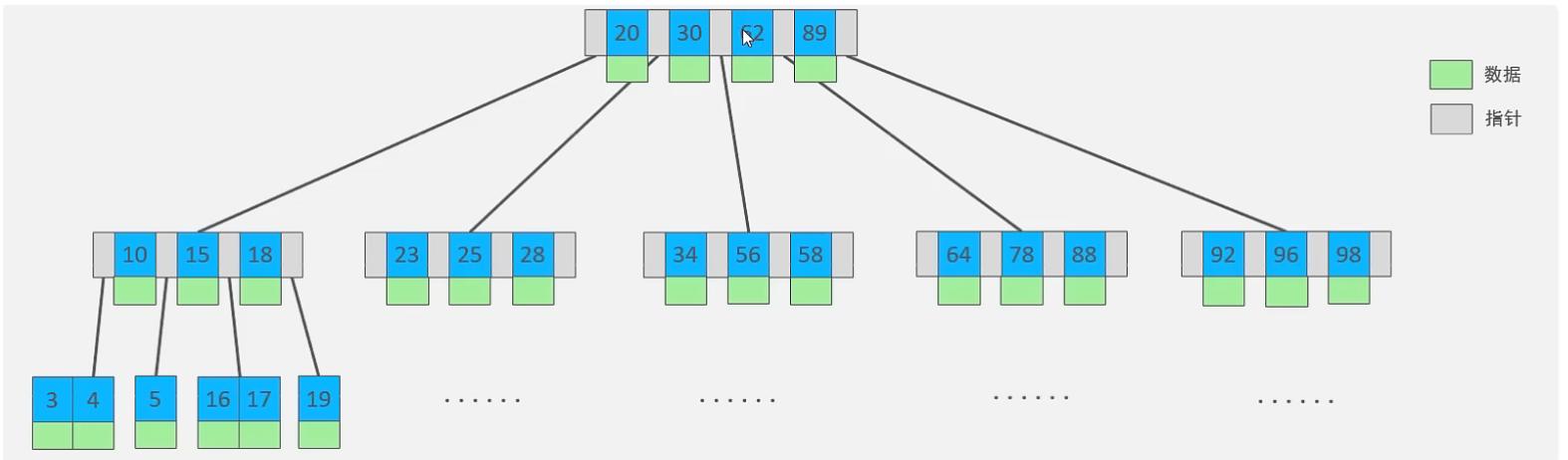
B-Tree 的数据插入过程动画参照:https://www.bilibili.com/video/BV1Kr4y1i7ru?p=68
演示地址:https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+Tree
结构图:
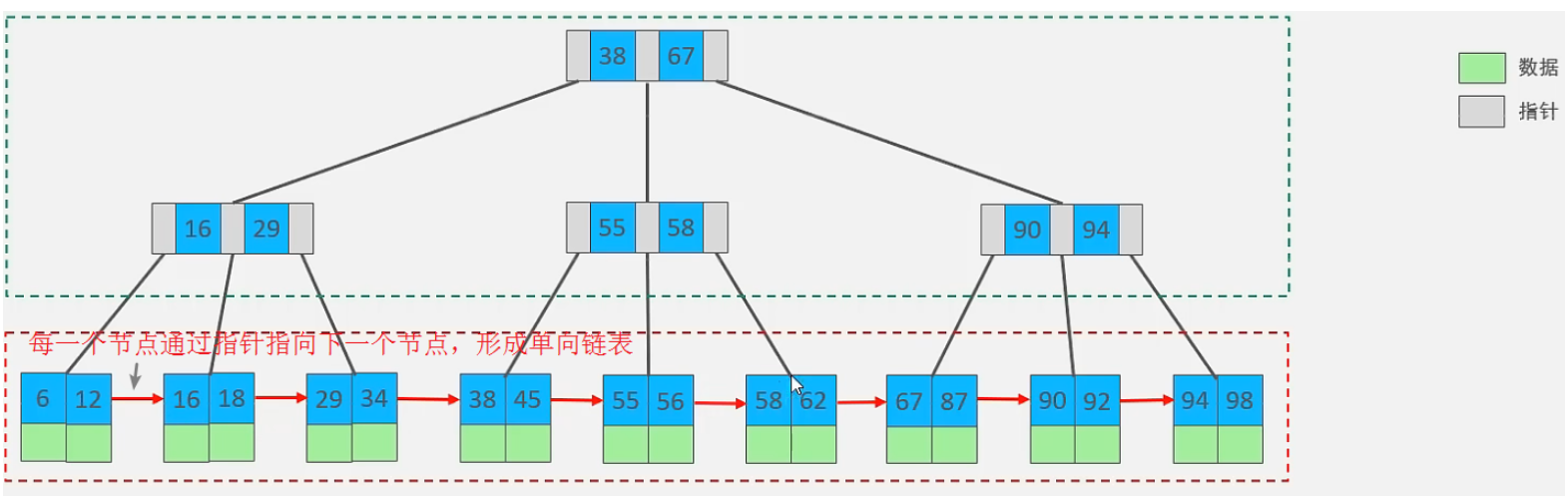
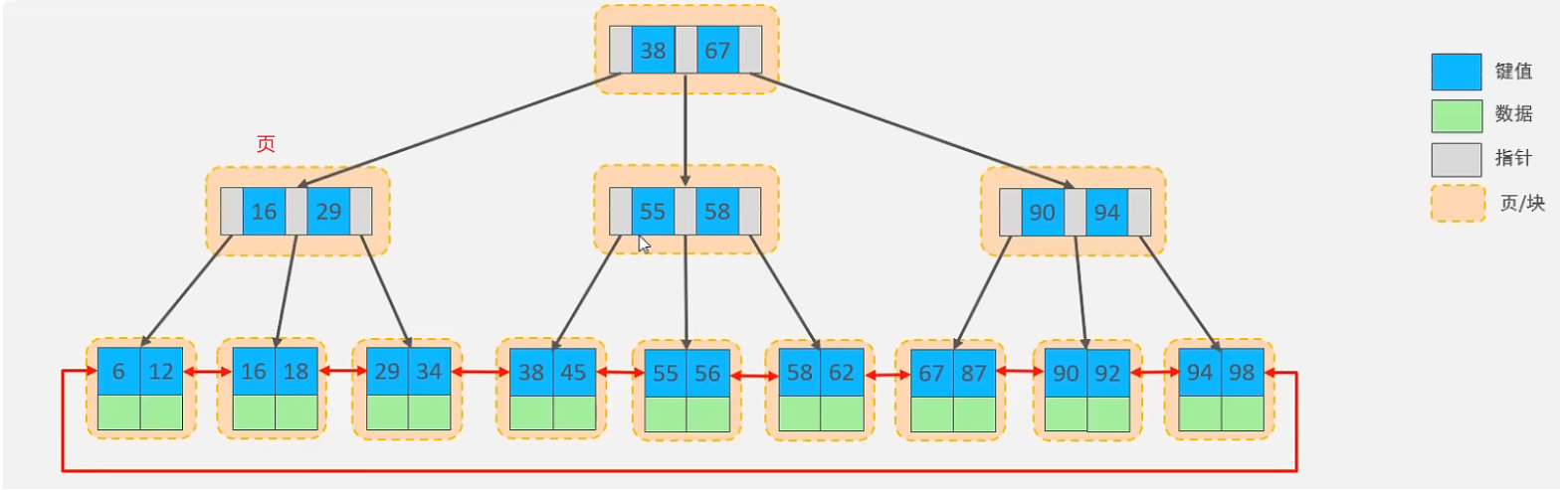
演示地址:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
与 B-Tree 的区别:
- 所有的数据都会出现在叶子节点
- 叶子节点形成一个单向链表
MySQL 索引数据结构对经典的 B+Tree 进行了优化。在原 B+Tree 的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的 B+Tree,提高区间访问的性能。
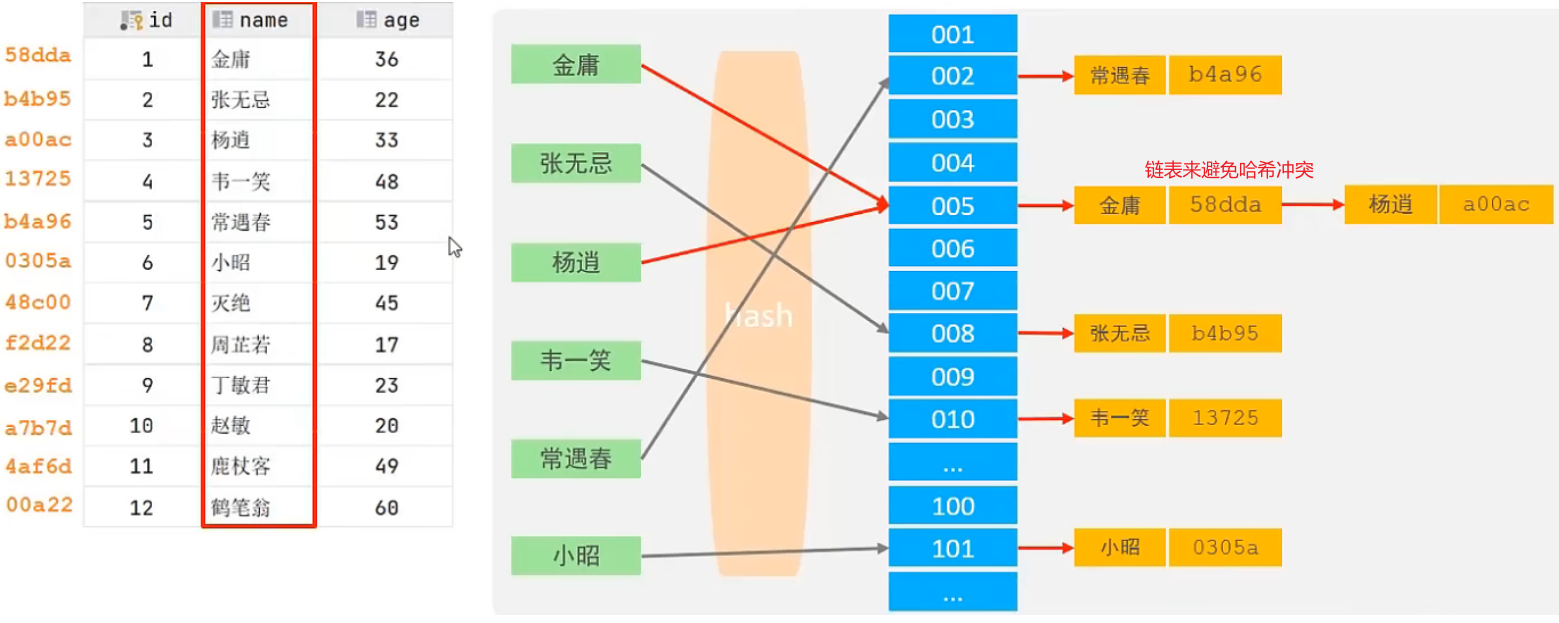
Hash
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
特点:
- Hash索引只能用于对等比较(=、in),不支持范围查询(betwwn、>、<、…)
- 无法利用索引完成排序操作
- 查询效率高,通常只需要一次检索就可以了,效率通常要高于 B+Tree 索引
存储引擎支持:
- Memory
- InnoDB: 具有自适应hash功能,hash索引是存储引擎根据 B+Tree 索引在指定条件下自动构建的
面试题
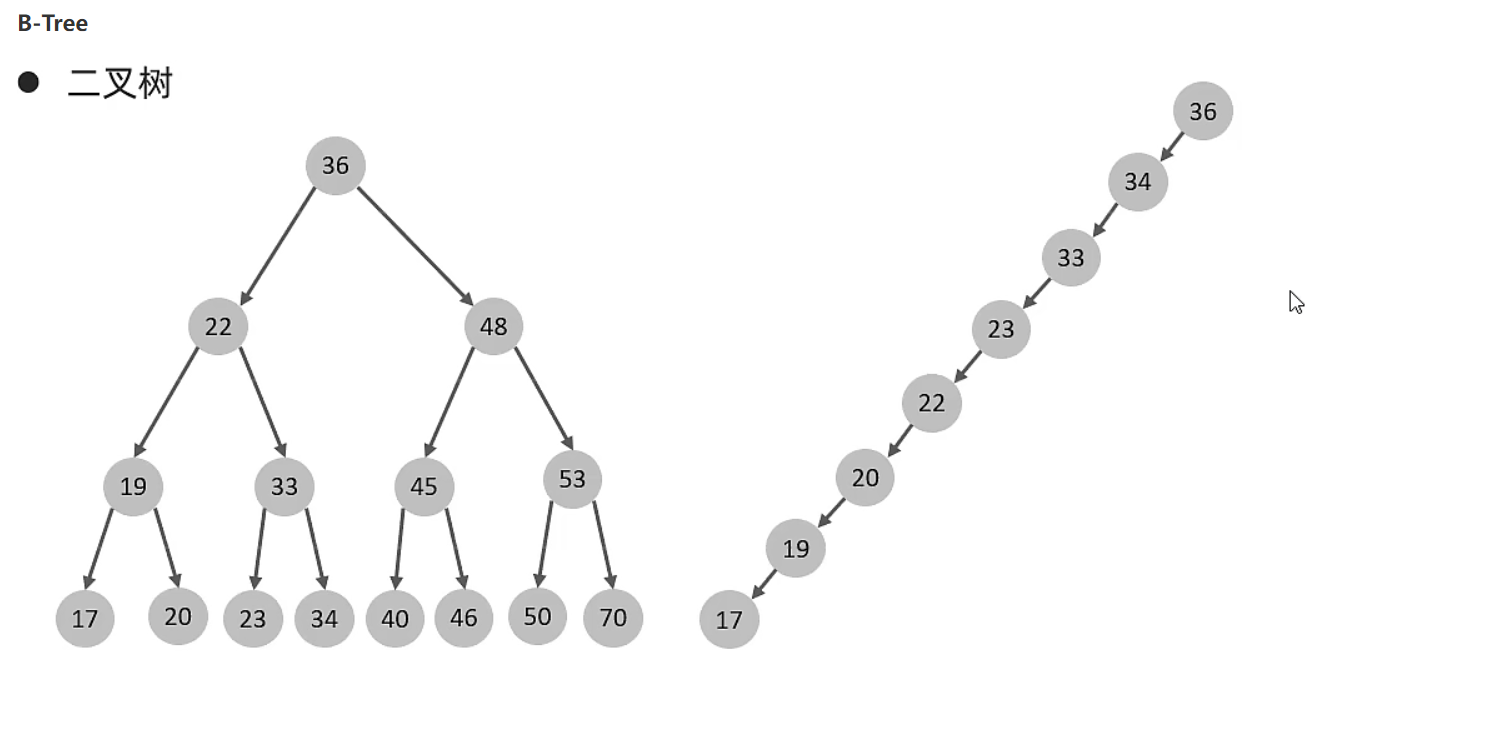
- 为什么 InnoDB 存储引擎选择使用 B+Tree 索引结构?
- 相对于二叉树,层级更少,搜索效率高
- 对于 B-Tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针也跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低
- 相对于 Hash 索引,B+Tree 支持范围匹配及排序操作
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在 InnoDB 存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
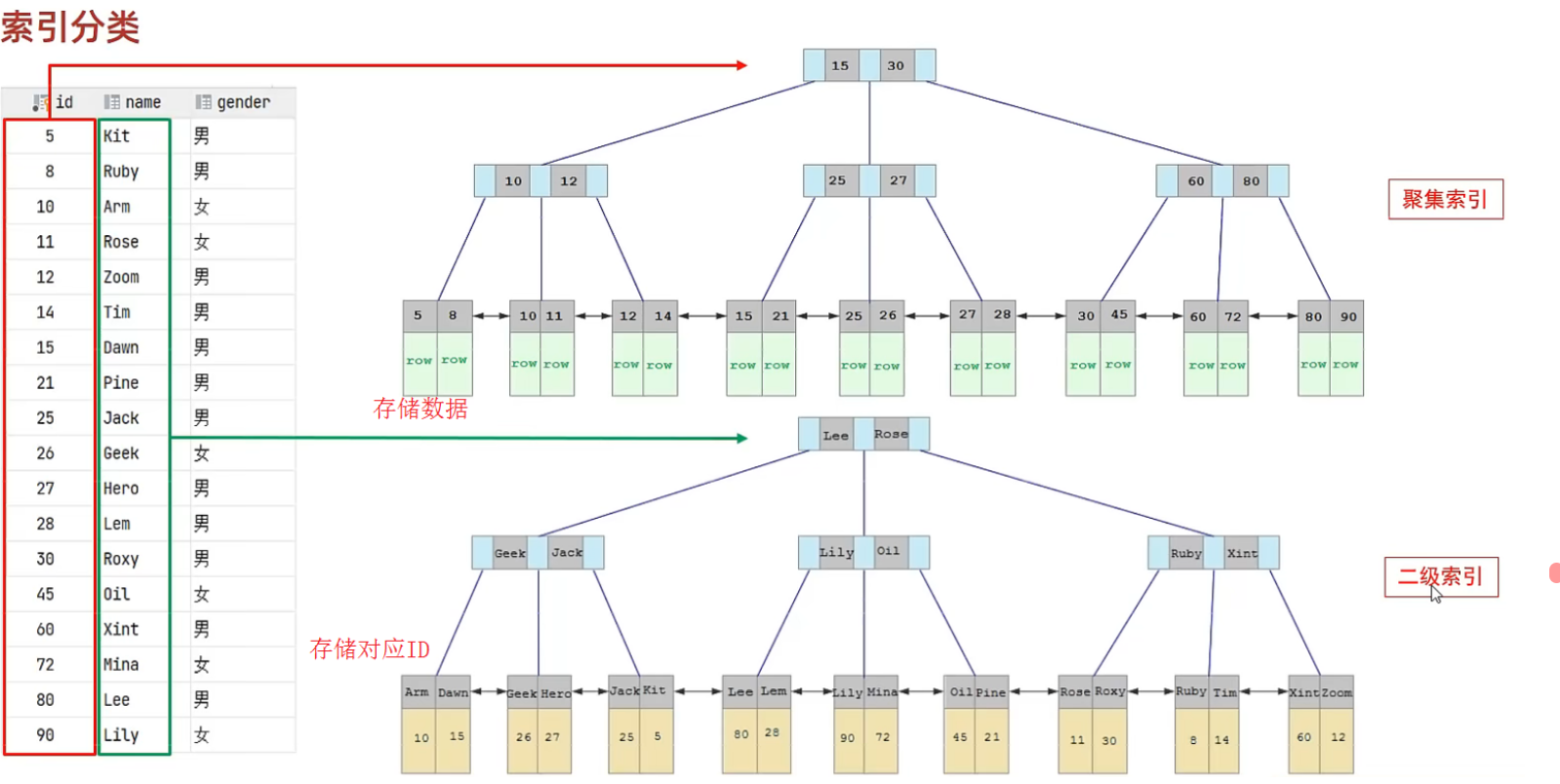
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有主键或没有合适的唯一索引,则 InnoDB 会自动生成一个 rowid 作为隐藏的聚集索引
思考题
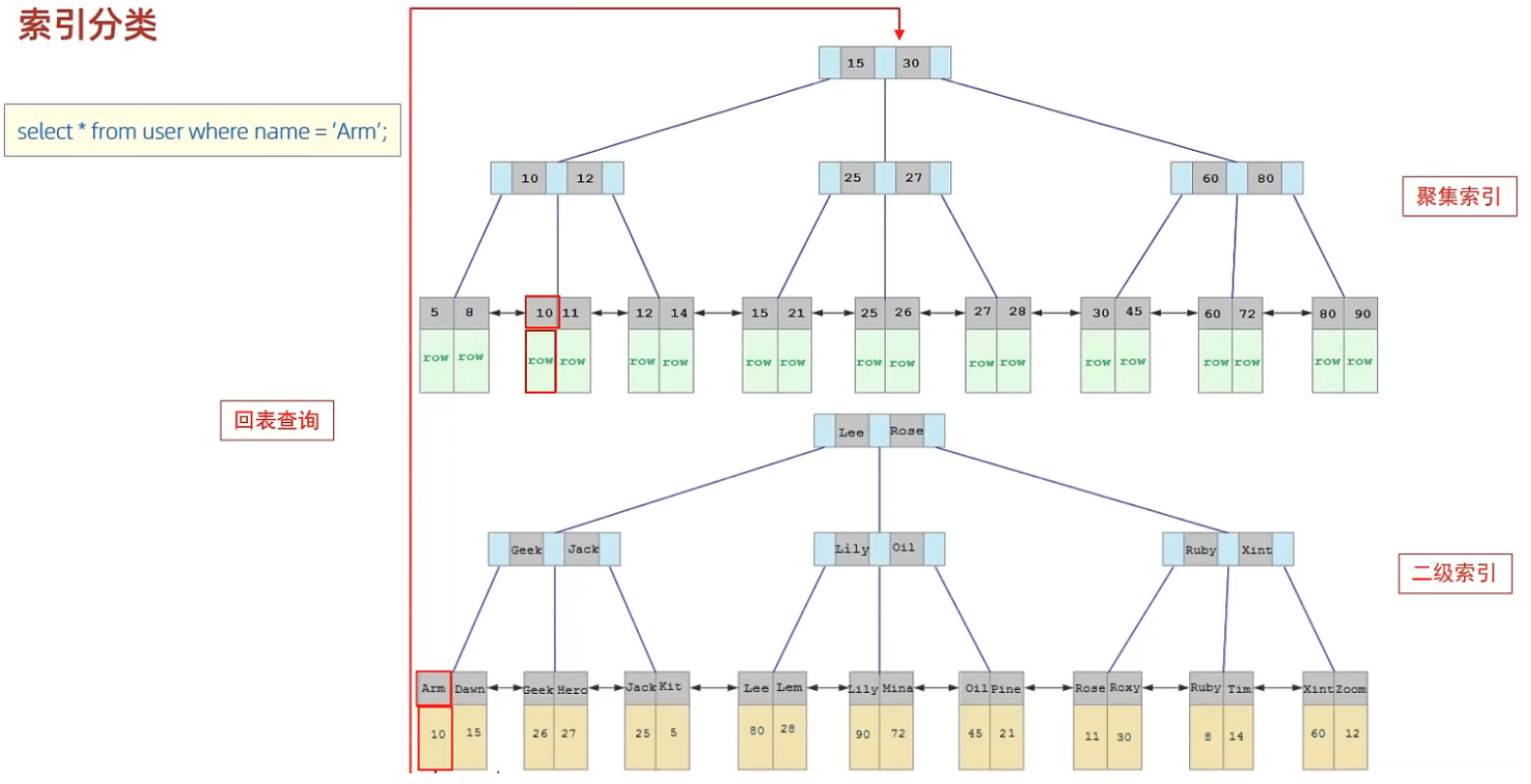
\1. 以下 SQL 语句,哪个执行效率高?为什么?
select * from user where id = 10;
select * from user where name = 'Arm';-- 备注:id为主键,name字段创建的有索引
答:第一条语句,因为第二条需要回表查询,相当于两个步骤。
\2. InnoDB 主键索引的 B+Tree 高度为多少?
答:假设一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB 的指针占用6个字节的空间,主键假设为bigint,占用字节数为8.
可得公式:n * 8 + (n + 1) * 6 = 16 * 1024,其中 8 表示 bigint 占用的字节数,n 表示当前节点存储的key的数量,(n + 1) 表示指针数量(比key多一个)。算出n约为1170。
如果树的高度为2,那么他能存储的数据量大概为:1171 * 16 = 18736;
如果树的高度为3,那么他能存储的数据量大概为:1171 * 1171 * 16 = 21939856。
另外,如果有成千上万的数据,那么就要考虑分表,涉及运维篇知识。
语法
创建索引:
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name, ...);
如果不加 CREATE 后面不加索引类型参数,则创建的是常规索引
查看索引:
SHOW INDEX FROM table_name;
删除索引:
DROP INDEX index_name ON table_name;
案例:
-- name字段为姓名字段,该字段的值可能会重复,为该字段创建索引create index idx_user_name on tb_user(name);-- phone手机号字段的值非空,且唯一,为该字段创建唯一索引create unique index idx_user_phone on tb_user (phone);-- 为profession, age, status创建联合索引create index idx_user_pro_age_stat on tb_user(profession, age, status);-- 为email建立合适的索引来提升查询效率create index idx_user_email on tb_user(email);-- 删除索引drop index idx_user_email on tb_user;
性能分析
查看执行频次
查看当前数据库的 INSERT, UPDATE, DELETE, SELECT 访问频次:
SHOW GLOBAL STATUS LIKE 'Com_______'; 或者 SHOW SESSION STATUS LIKE 'Com_______';
例:show global status like 'Com_______'
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
# 开启慢查询日志开关slow_query_log=1# 设置慢查询日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志long_query_time=2
更改后记得重启MySQL服务,日志文件位置:/var/lib/mysql/localhost-slow.log
查看慢查询日志开关状态:
show variables like 'slow_query_log';

profile
show profile 能在做SQL优化时帮我们了解时间都耗费在哪里。通过 have_profiling 参数,能看到当前 MySQL 是否支持 profile 操作:
SELECT @@have_profiling;
profiling 默认关闭,可以通过set语句在session/global级别开启 profiling:
SET profiling = 1;
查看所有语句的耗时:
show profiles;
查看指定query_id的SQL语句各个阶段的耗时:
show profile for query query_id;
查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
explain
EXPLAIN 或者 DESC 命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
语法:
# 直接在select语句之前加上关键字 explain / descEXPLAIN SELECT 字段列表 FROM 表名 HWERE 条件;
EXPLAIN 各字段含义:
-
id:select 查询的序列号,表示查询中执行 select 子句或者操作表的顺序(id相同,执行顺序从上到下;id不同,值越大越先执行)
-
select_type:表示 SELECT 的类型,常见取值有 SIMPLE(简单表,即不适用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等
-
type:表示连接类型,性能由好到差的连接类型为 NULL、system、const、eq_ref、ref、range、index、all
-
possible_key:可能应用在这张表上的索引,一个或多个
-
Key:实际使用的索引,如果为 NULL,则没有使用索引
-
Key_len:表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好
-
rows:MySQL认为必须要执行的行数,在InnoDB引擎的表中,是一个估计值,可能并不总是准确的
-
filtered:表示返回结果的行数占需读取行数的百分比,filtered的值越大越好


使用规则
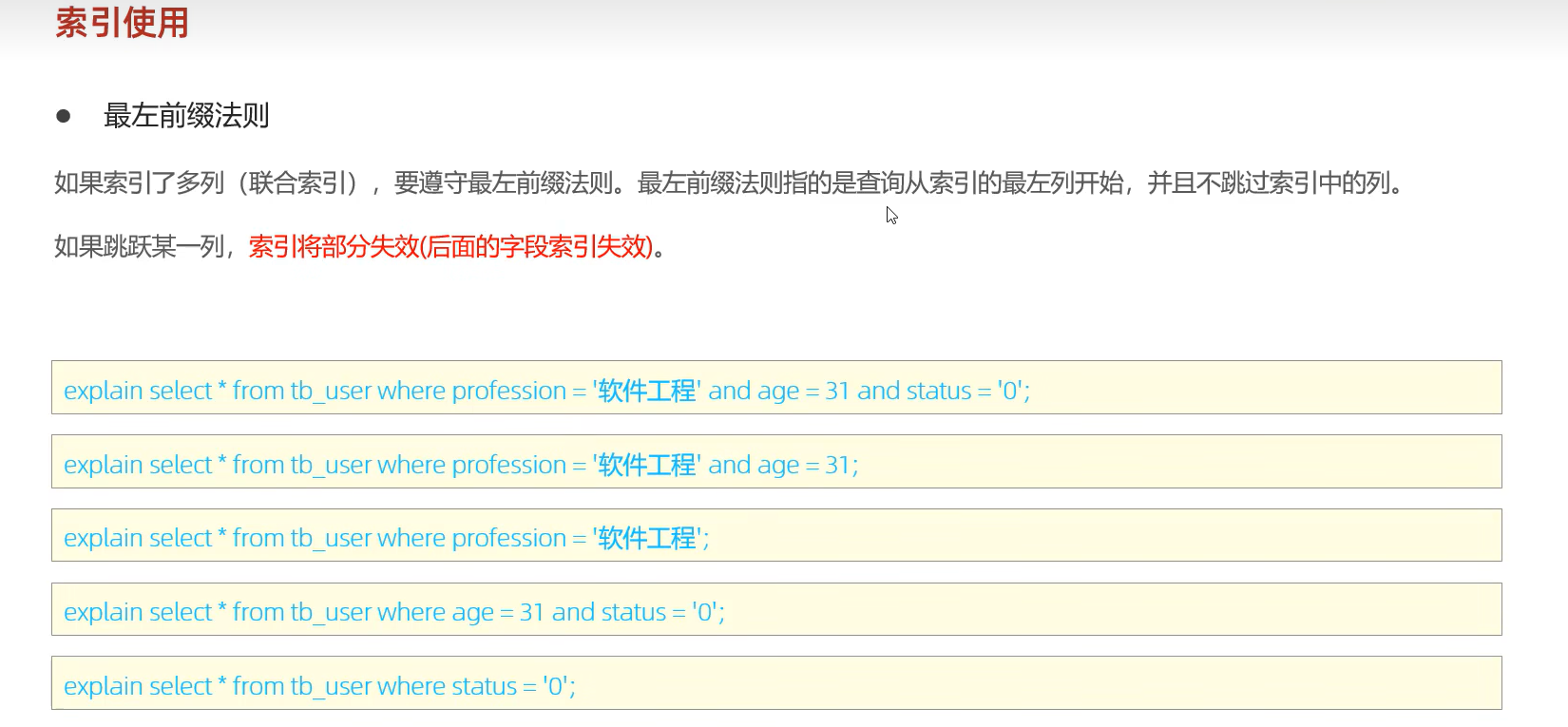
最左前缀法则
如果索引关联了多列(联合索引),要遵守最左前缀法则,最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。
如果跳跃某一列,索引将部分失效(后面的字段索引失效)。
联合索引中,出现范围查询(<, >),范围查询右侧的列索引失效。可以用>=或者<=来规避索引失效问题。
索引失效情况
- 在索引列上进行运算操作,索引将失效。如:
explain select * from tb_user where substring(phone, 10, 2) = '15'; - 字符串类型字段使用时,不加引号,索引将失效。如:
explain select * from tb_user where phone = 17799990015;,此处phone的值没有加引号 - 模糊查询中,如果仅仅是尾部模糊匹配,索引不会是失效;如果是头部模糊匹配,索引失效。如:
explain select * from tb_user where profession like '%工程';,前后都有 % 也会失效。 - 用 or 分割开的条件,如果 or 其中一个条件的列没有索引,那么涉及的索引都不会被用到。
- 如果 MySQL 评估使用索引比全表更慢,则不使用索引。
SQL 提示
是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
例如,使用索引:
explain select * from tb_user use index(idx_user_pro) where profession="软件工程";
不使用哪个索引:
explain select * from tb_user ignore index(idx_user_pro) where profession="软件工程";
必须使用哪个索引:
explain select * from tb_user force index(idx_user_pro) where profession="软件工程";
use 是建议,实际使用哪个索引 MySQL 还会自己权衡运行速度去更改,force就是无论如何都强制使用该索引。

覆盖索引&回表查询
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能找到),减少 select *。

2、覆盖索引的使用
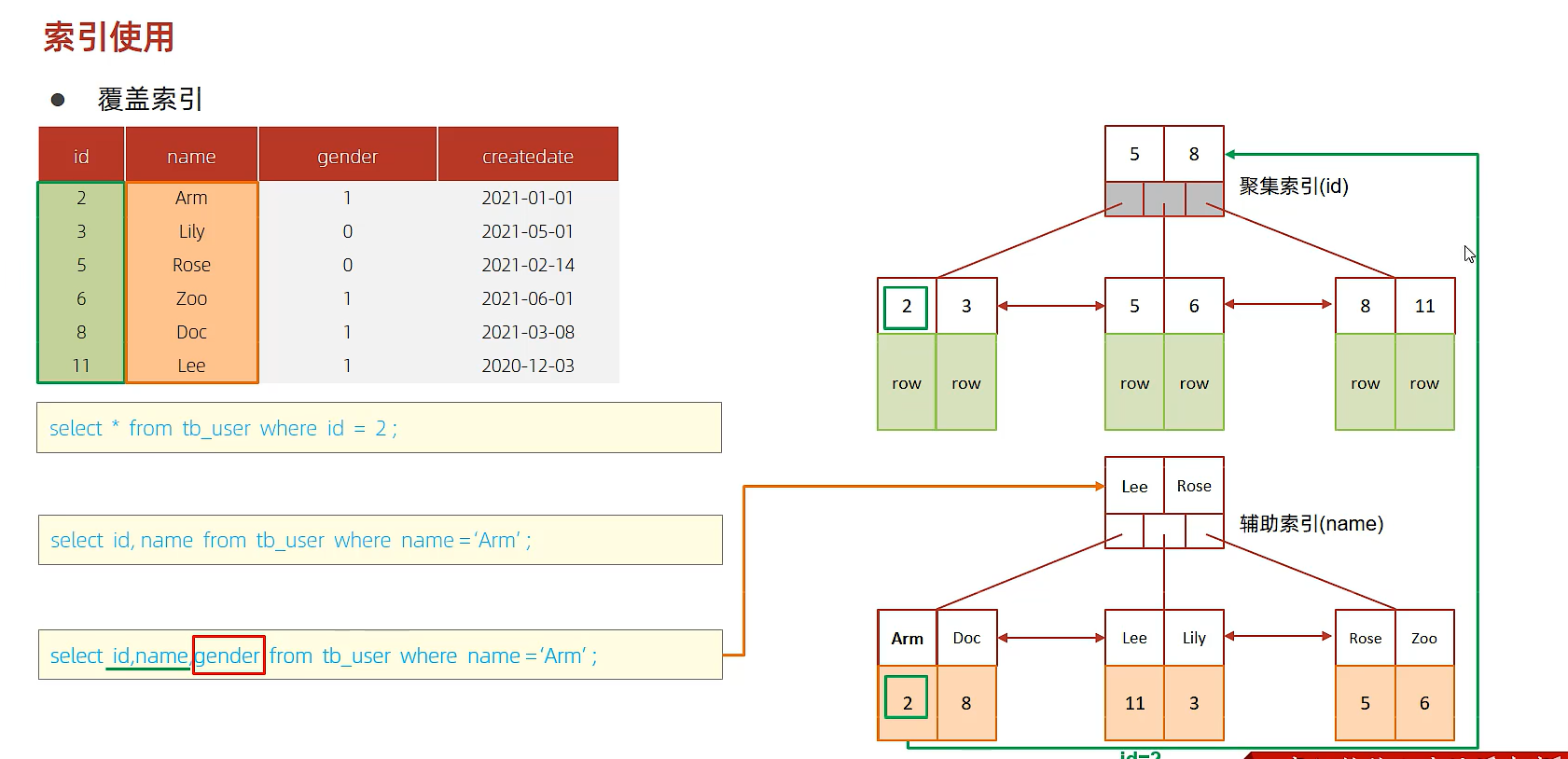
explain 中 extra 字段含义:
using index condition:查找使用了索引,但是需要回表查询数据
using where; using index;:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询
如果在聚集索引中直接能找到对应的行,则直接返回行数据,只需要一次查询,哪怕是select *;如果在辅助索引中找聚集索引,如select id, name from xxx where name='xxx';,也只需要通过辅助索引(name)查找到对应的id,返回name和name索引对应的id即可,只需要一次查询;如果是通过辅助索引查找其他字段,则需要回表查询,如select id, name, gender from xxx where name='xxx';
所以尽量不要用select *,容易出现回表查询,降低效率,除非有联合索引包含了所有字段
==面试题:==一张表,有四个字段(id, username, password, status),由于数据量大,需要对以下SQL语句进行优化,该如何进行才是最优方案:
select id, username, password from tb_user where username='itcast';
解:给username和password字段建立联合索引,则不需要回表查询,直接覆盖索引
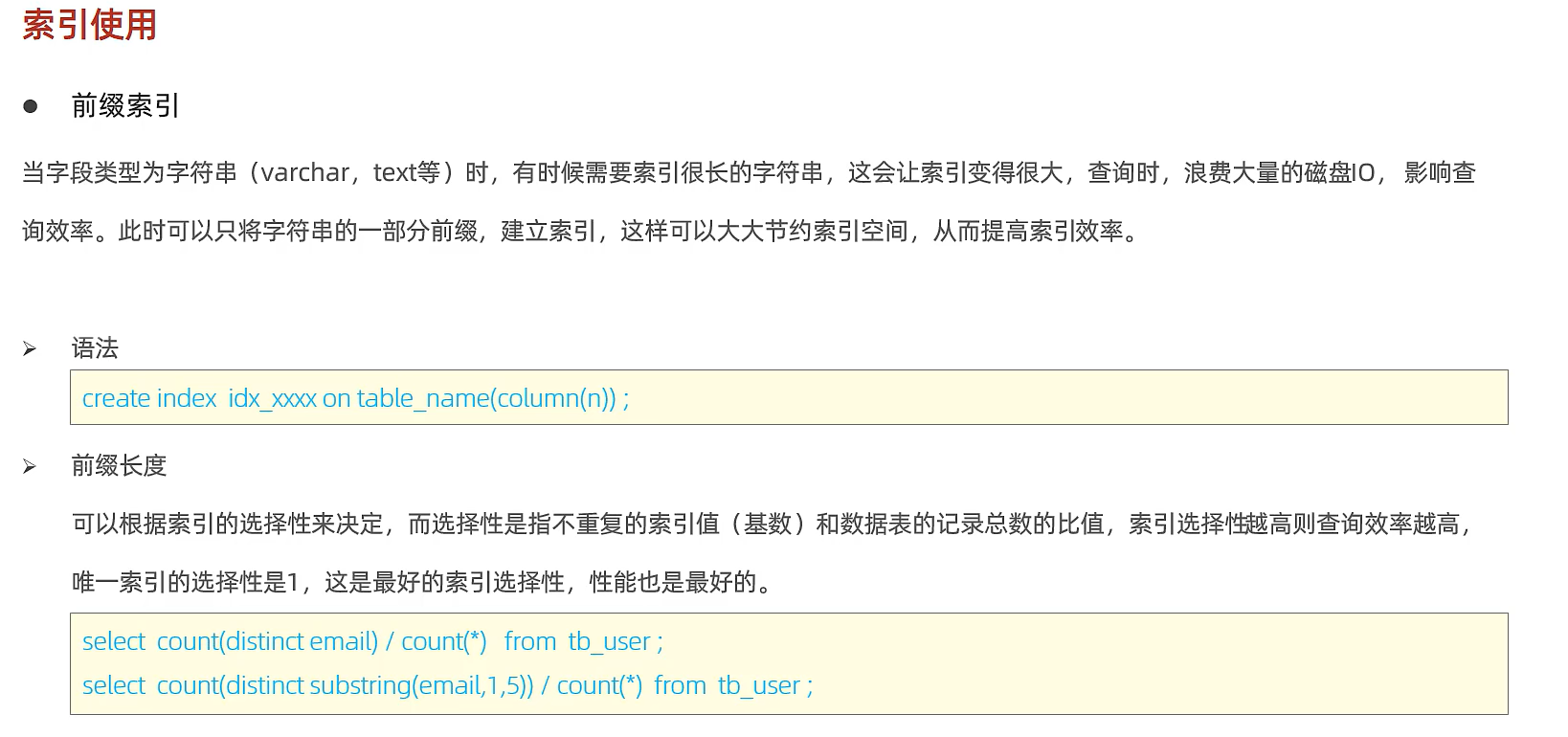
前缀索引
当字段类型为字符串(varchar, text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率,此时可以只降字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
语法:create index idx_xxxx on table_name(columnn(n));
前缀长度:可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
求选择性公式:
select count(distinct email) / count(*) from tb_user;select count(distinct substring(email, 1, 5)) / count(*) from tb_user;
show index 里面的sub_part可以看到接取的长度
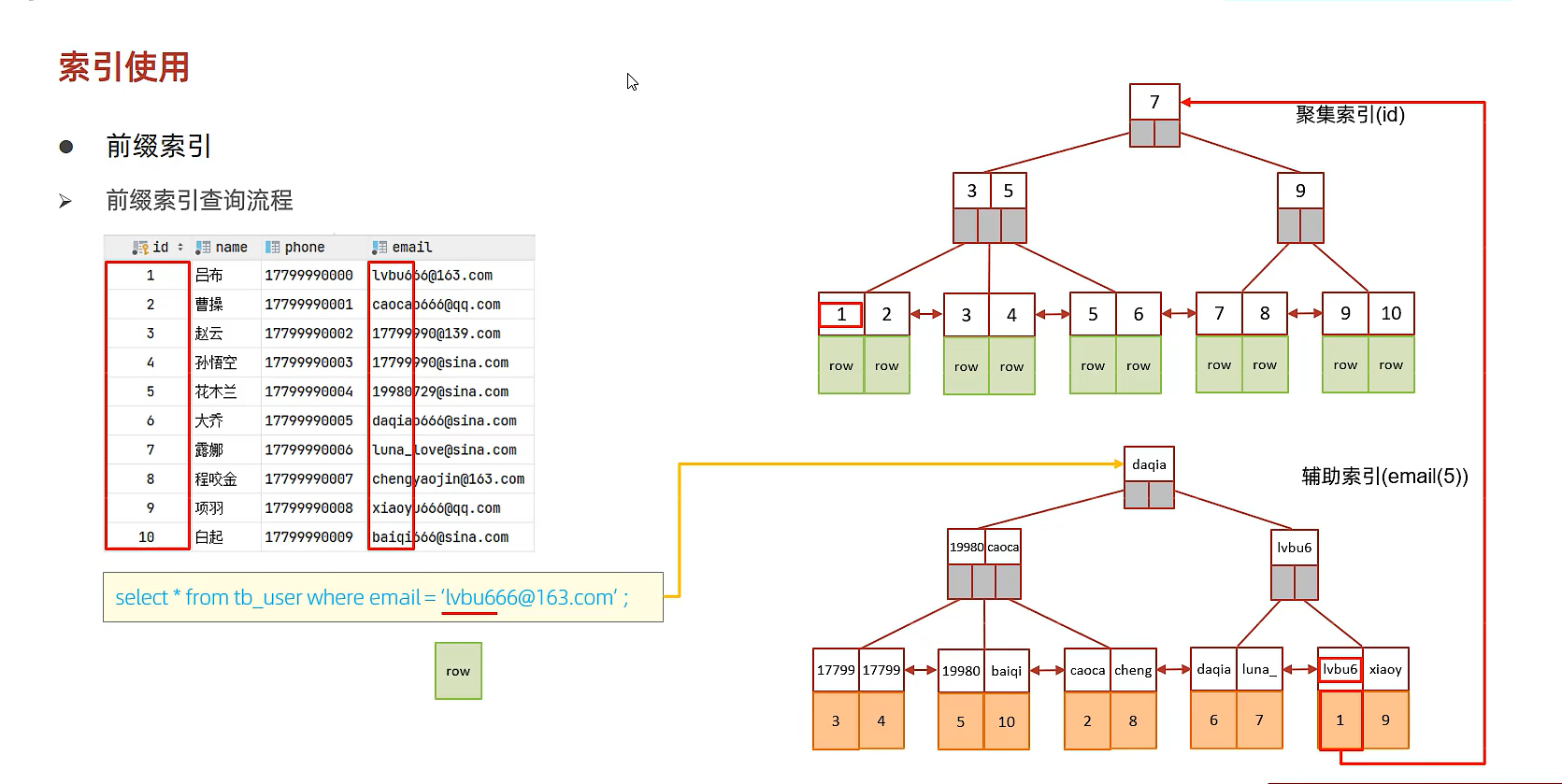
前缀索引的执行流程:
根据前缀查询到之后,还应该进行比对后面的字符串,如果能匹配成功,就返回。匹配不成功,就不返回。返回之后还应该看前缀索引后边的是否满足,如果满足重新执行上述流程。不满足则结束。
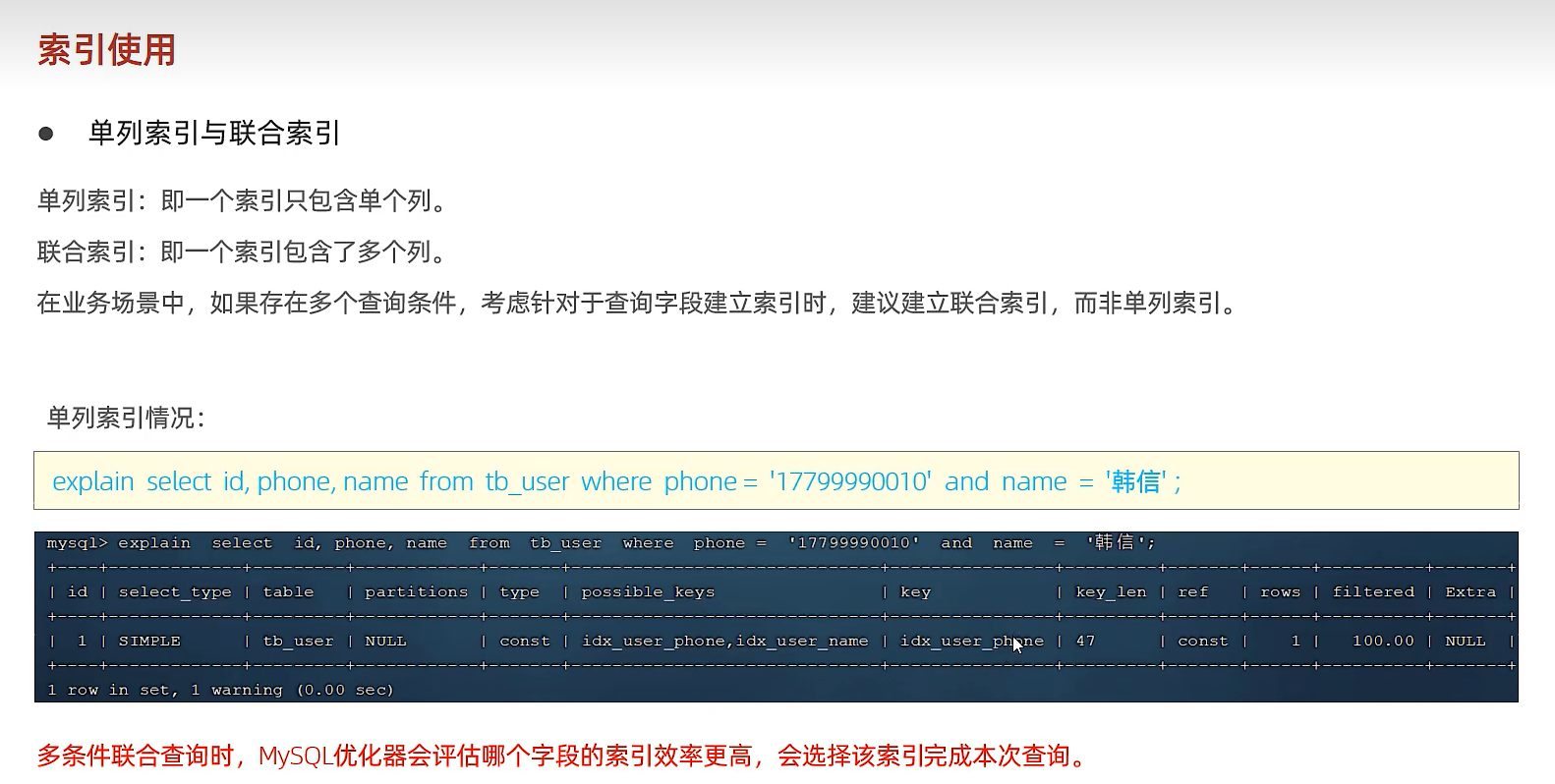
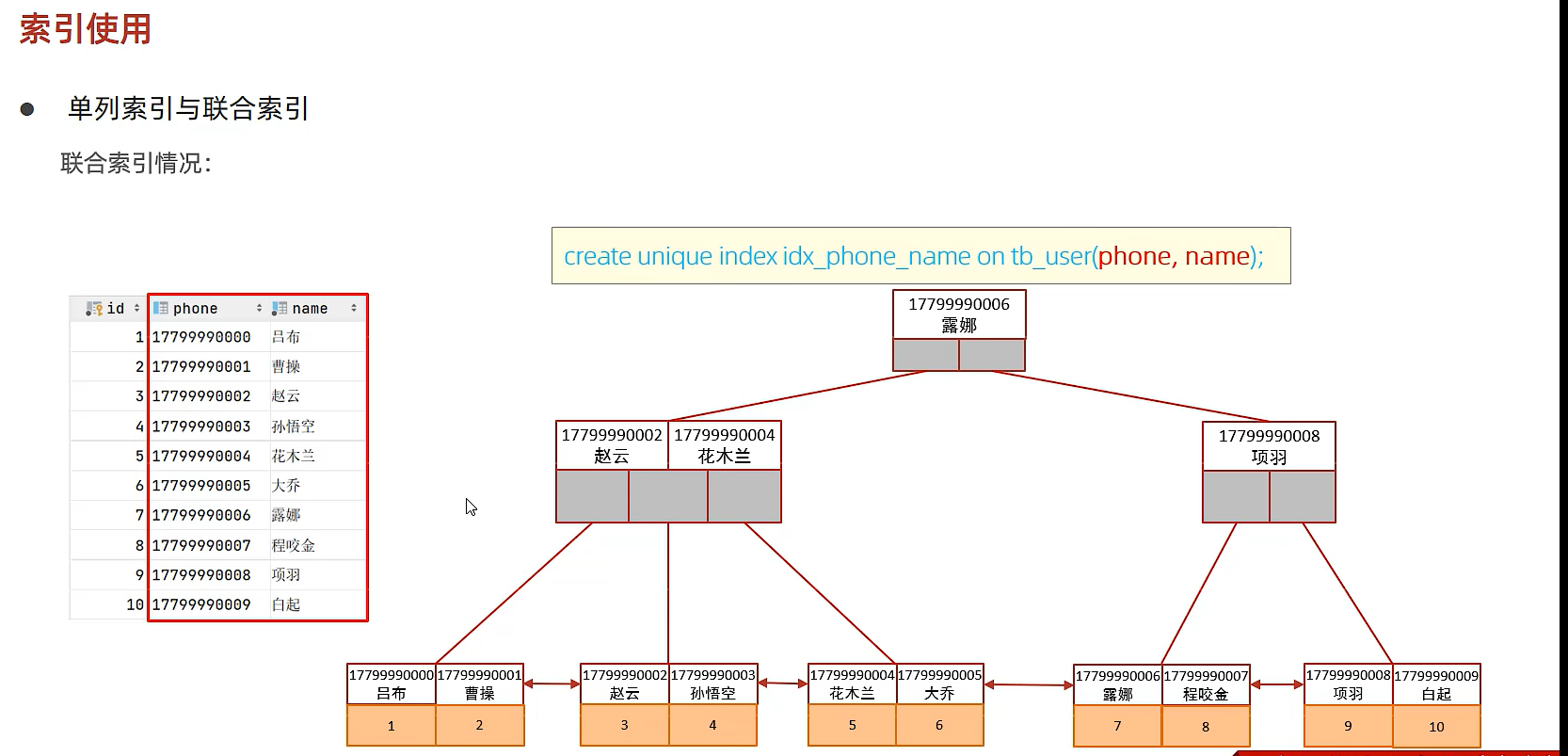
单列索引&联合索引
单列索引:即一个索引只包含单个列
联合索引:即一个索引包含了多个列
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
单列索引情况:
explain select id, phone, name from tb_user where phone = '17799990010' and name = '韩信';
这句只会用到phone索引字段
联合索引和单列索引(尽量使用联合索引)
注意事项
- 多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询
设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
- 如果是字符串类型的字段,字段长度较长,可以针对于字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价就越大,会影响增删改的效率
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询

总结:
1、索引概述:索引是高效获取数据的数据结构
2、索引结构:B+tree Hash
3、索引分类:主键索引、唯一索引、常规索引、全文索引
聚集索引、二级索引
4、索引语法:
create[unique]index ××× on ×××;
show index from ×××;
drop index ××× on ×××;
5、SQL 优化
插入数据
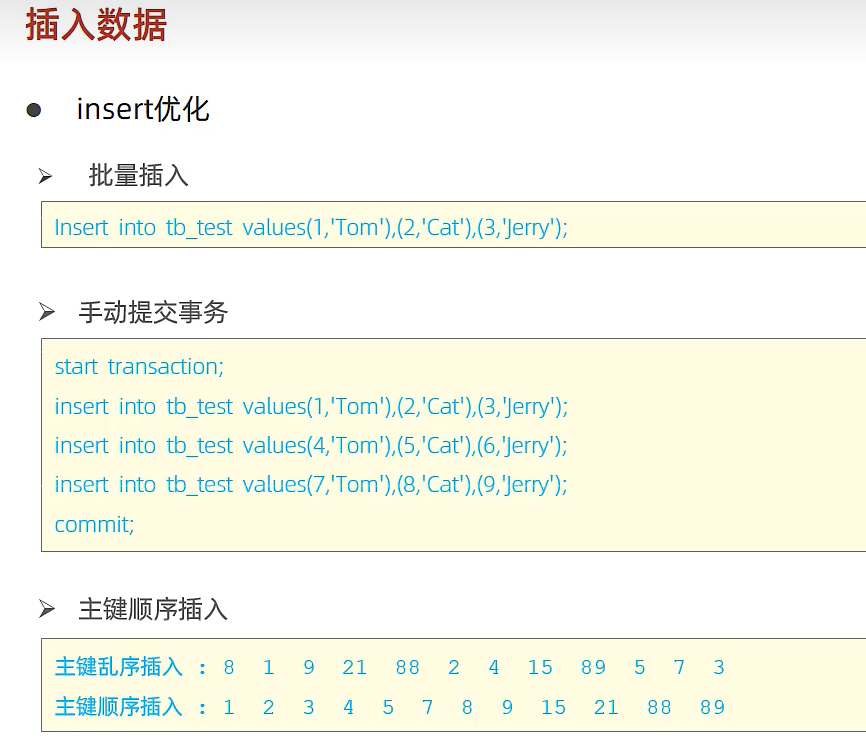
普通插入:
- 采用批量插入(一次插入的数据不建议超过1000条)
- 手动提交事务
- 主键顺序插入
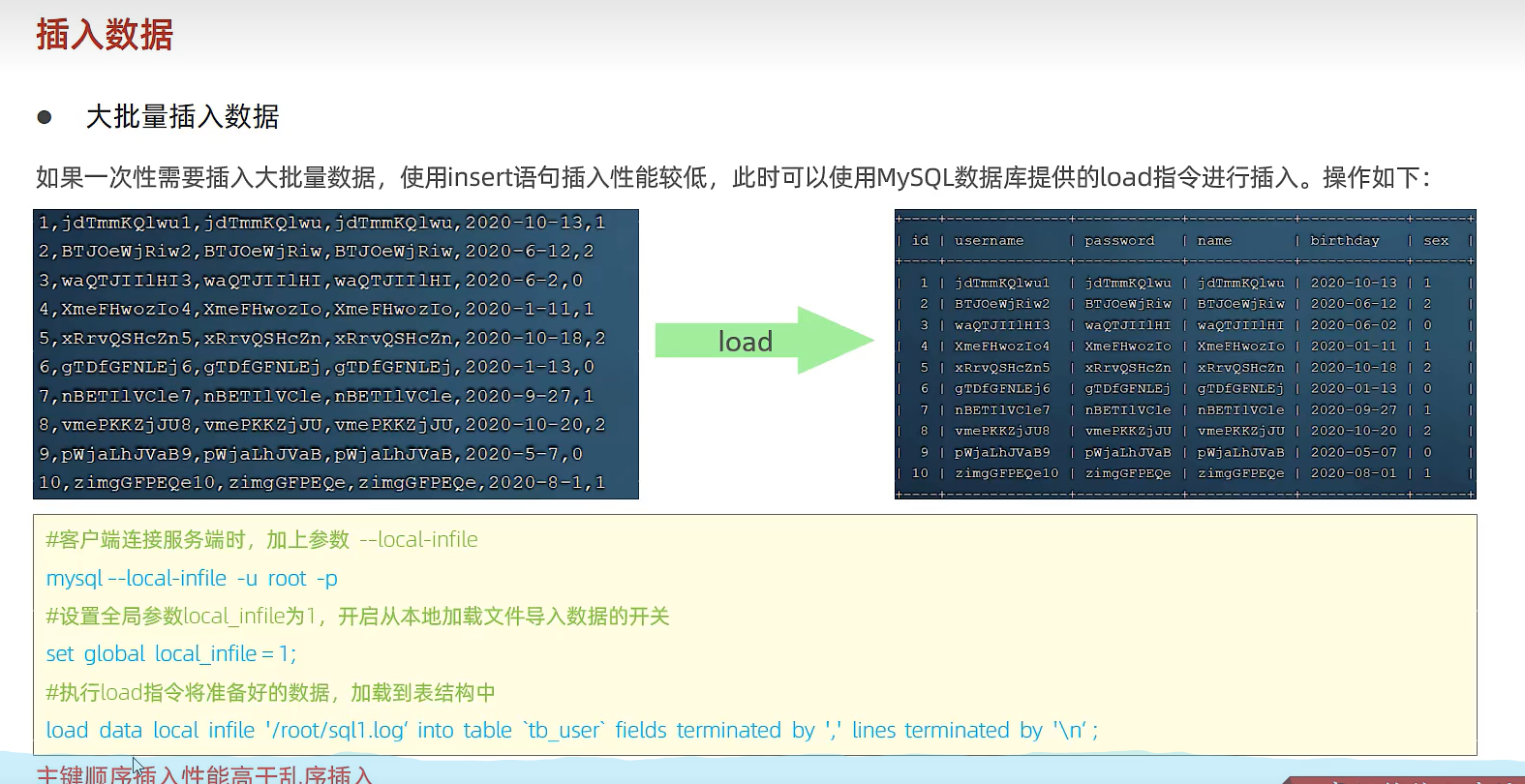
大批量插入:
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令插入。
主键优化
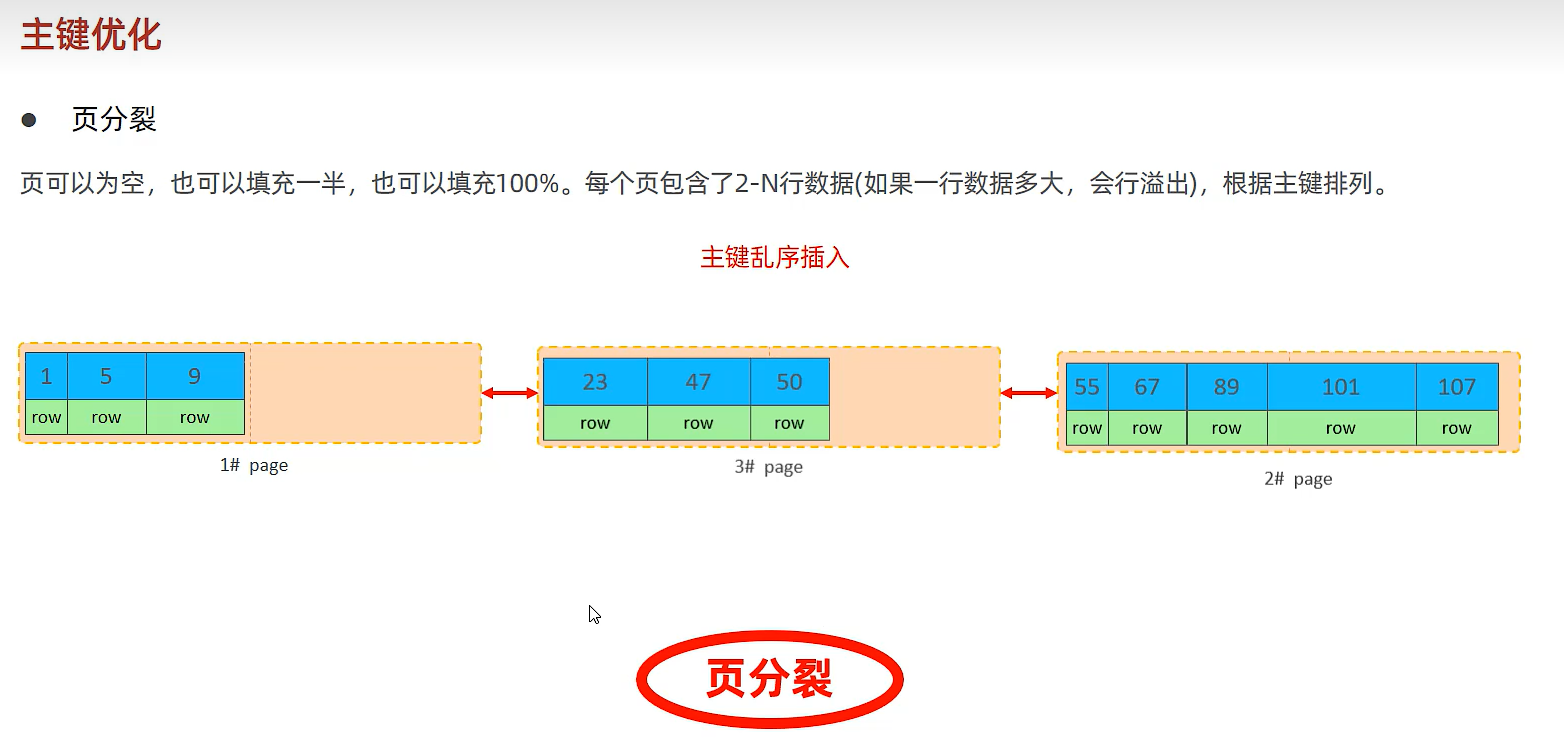
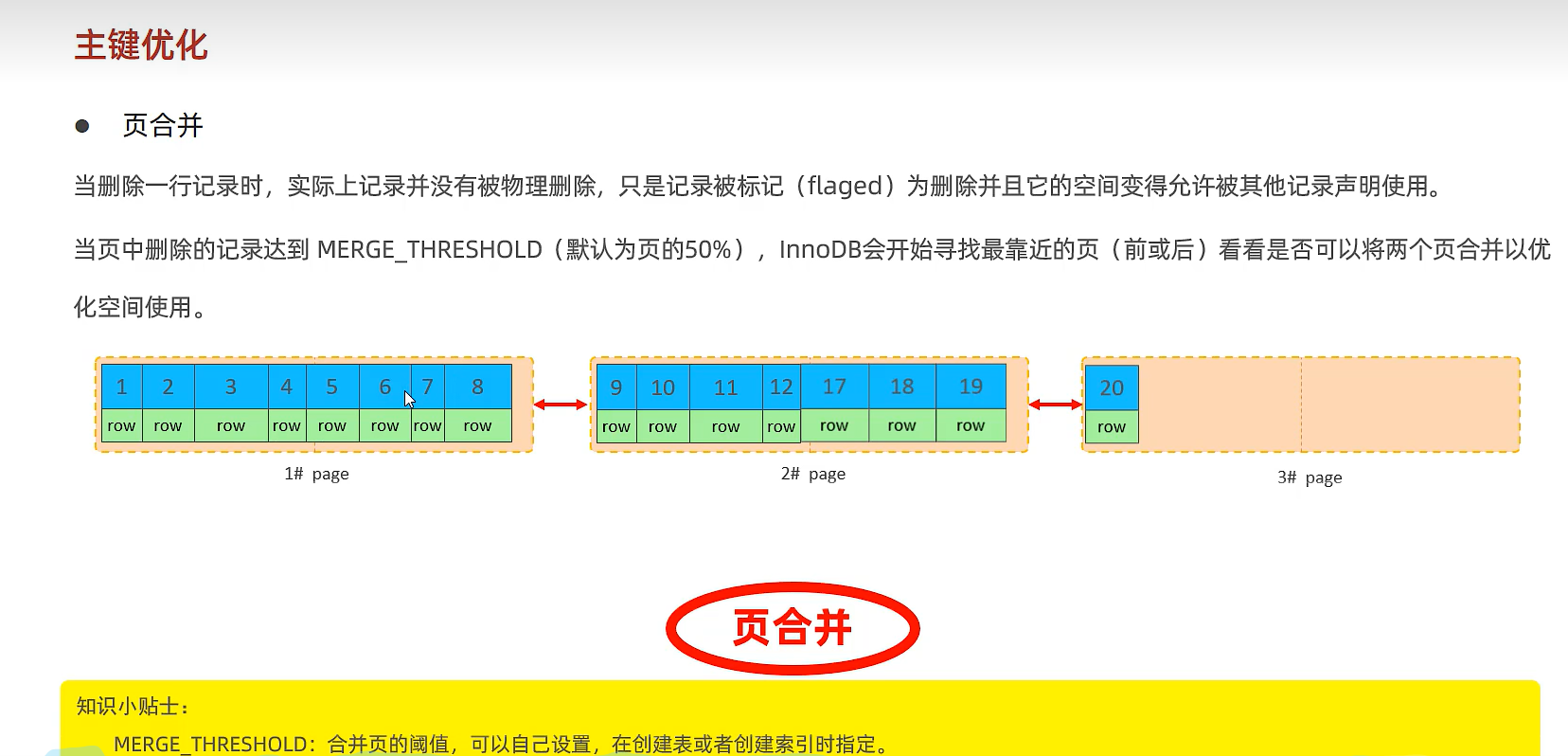
数据组织方式:在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(Index organized table, IOT)
页分裂:页可以为空,也可以填充一般,也可以填充100%,每个页包含了2-N行数据(如果一行数据过大,会行溢出),根据主键排列。尽量顺序插入
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或创建索引时指定
页合并:当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。当页中删除的记录到达 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前后)看看是否可以将这两个页合并以优化空间使用。
主键设计原则:
- 满足业务需求的情况下,尽量降低主键的长度
- 插入数据时,尽量选择顺序插入,选择使用 AUTO_INCREMENT 自增主键
- 尽量不要使用 UUID 做主键或者是其他的自然主键,如身份证号
- 业务操作时,避免对主键的修改
order by优化
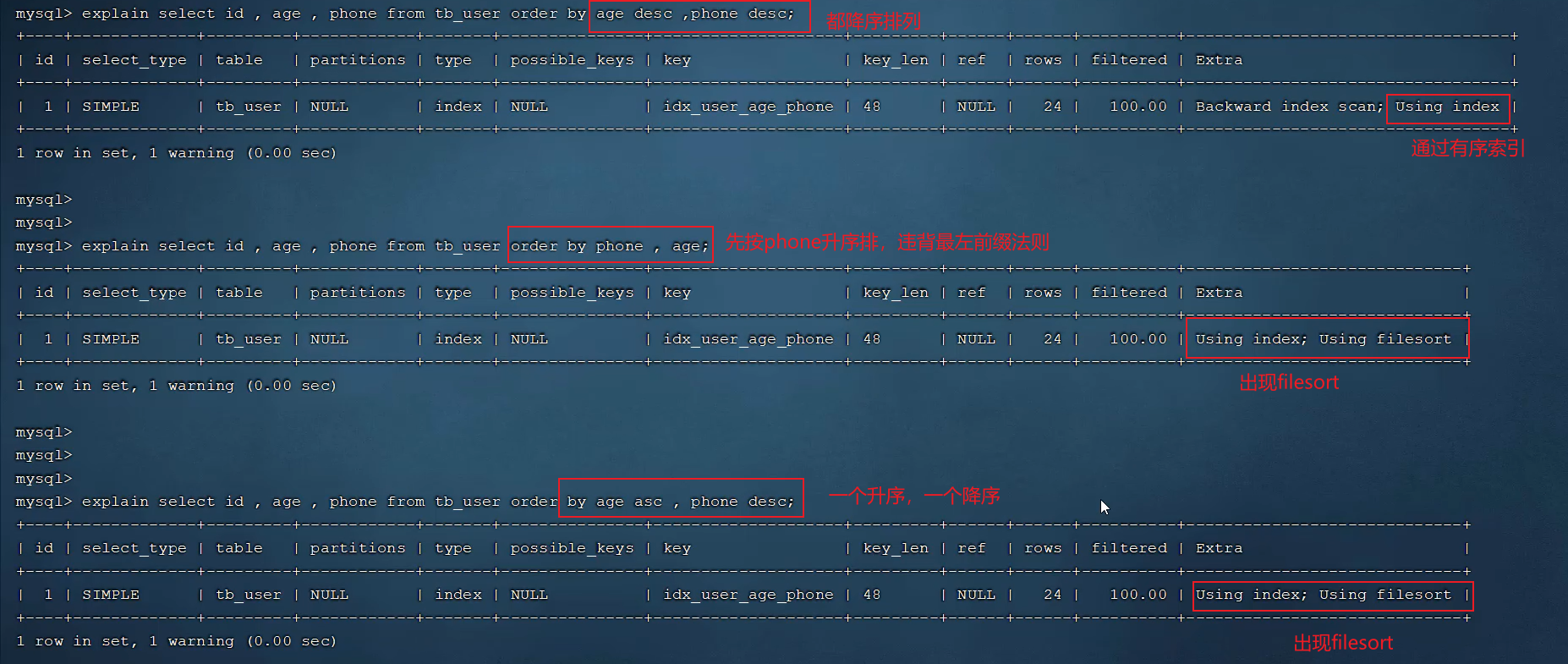
- Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区 sort buffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序
- Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为 using in dex,不需要额外排序,操作效率高
如果order by字段全部使用升序排序或者降序排序,则都会走索引,但是如果一个字段升序排序,另一个字段降序排序,则不会走索引,explain的extra信息显示的是Using index, Using filesort,如果要优化掉Using filesort,则需要另外再创建一个索引,如:create index idx_user_age_phone_ad on tb_user(age asc, phone desc);,此时使用select id, age, phone from tb_user order by age asc, phone desc;会全部走索引**(数据库建立索引默认是升序排列)**
前提是使用覆盖索引

总结:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则
- 尽量使用覆盖索引
- 多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)
- 如果不可避免出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)
group by优化
总结:
- 在分组操作时,可以通过索引来提高效率
- 分组操作时,索引的使用也是满足最左前缀法则的
如索引为idx_user_pro_age_stat,则句式可以是select ... where profession order by age,这样也符合最左前缀法则
limit优化
常见的问题如limit 2000000, 10,此时需要 MySQL 排序前2000000条记录,但仅仅返回2000000 - 2000010的记录,其他记录丢弃,查询排序的代价非常大。
优化方案:一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
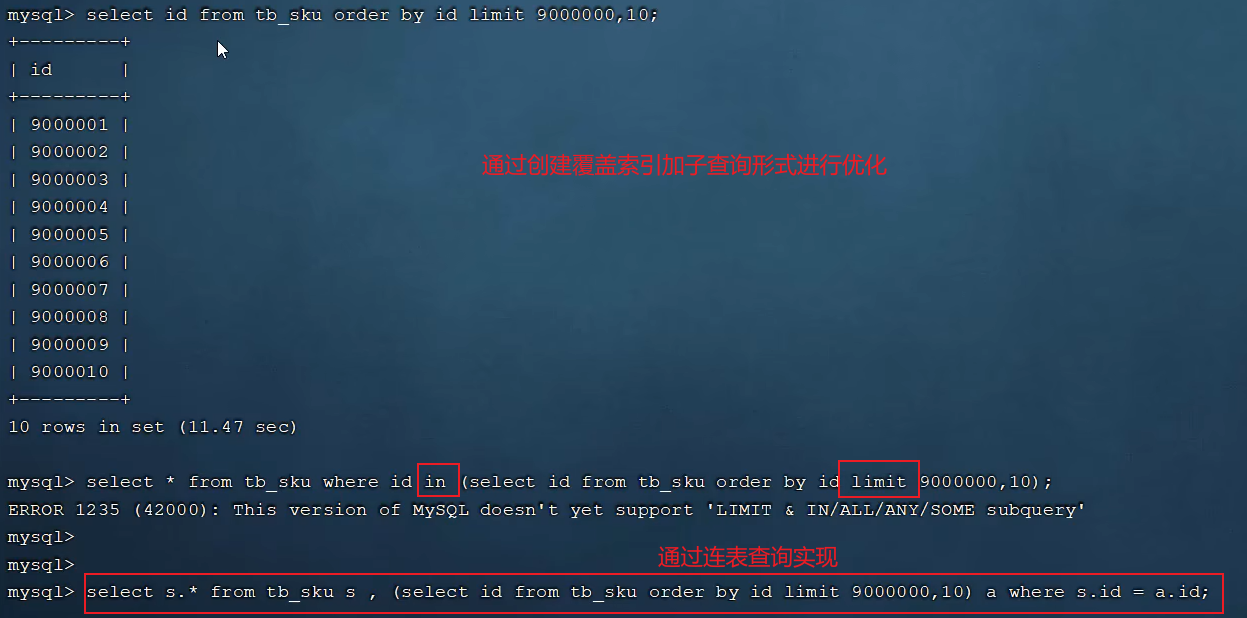
例如:
-- 此语句耗时很长select * from tb_sku limit 9000000, 10;
-- 通过覆盖索引加快速度,直接通过主键索引进行排序及查询select id from tb_sku order by id limit 9000000, 10;-- 下面的语句是错误的,因为 MySQL 不支持 in 里面使用 limit
-- select * from tb_sku where id in (select id from tb_sku order by id limit 9000000, 10);-- 通过连表查询即可实现第一句的效果,并且能达到第二句的速度
select * from tb_sku as s, (select id from tb_sku order by id limit 9000000, 10) as a where s.id = a.id;
count优化
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高(前提是不适用where);
InnoDB 在执行 count(*) 时,需要把数据一行一行地从引擎里面读出来,然后累计计数。
优化方案:自己计数,如创建key-value表存储在内存或硬盘,或者是用redis
count的几种用法:
- 如果count函数的参数(count里面写的那个字段)不是NULL(字段值不为NULL),累计值就加一,最后返回累计值
- 用法:count(*)、count(主键)、count(字段)、count(1)
- count(主键)跟count()一样,因为主键不能为空;count(字段)只计算字段值不为NULL的行;count(1)引擎会为每行添加一个1,然后就count这个1,返回结果也跟count()一样;count(null)返回0
各种用法的性能:
- count(主键):InnoDB引擎会遍历整张表,把每行的主键id值都取出来,返回给服务层,服务层拿到主键后,直接按行进行累加(主键不可能为空)
- count(字段):没有not null约束的话,InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加;有not null约束的话,InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加
- count(1):InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一层,放一个数字 1 进去,直接按行进行累加
- count(*):InnoDB 引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加
按效率排序:count(字段) < count(主键) < count(1) < count(),所以尽量使用 count()
update优化(避免行锁升级为表锁)
InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。
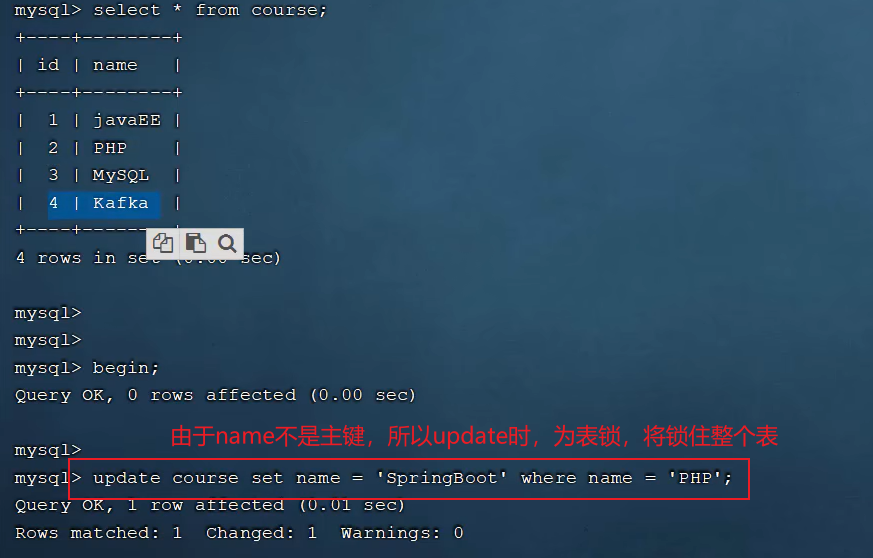
如以下两条语句:
update student set no = '123' where id = 1;,这句由于id有主键索引,所以只会锁这一行;
update student set no = '123' where name = 'test';,这句由于name没有索引,所以会把整张表都锁住进行数据更新,释放锁才可以成功解决方法是给name字段添加索引
SQL优化总结
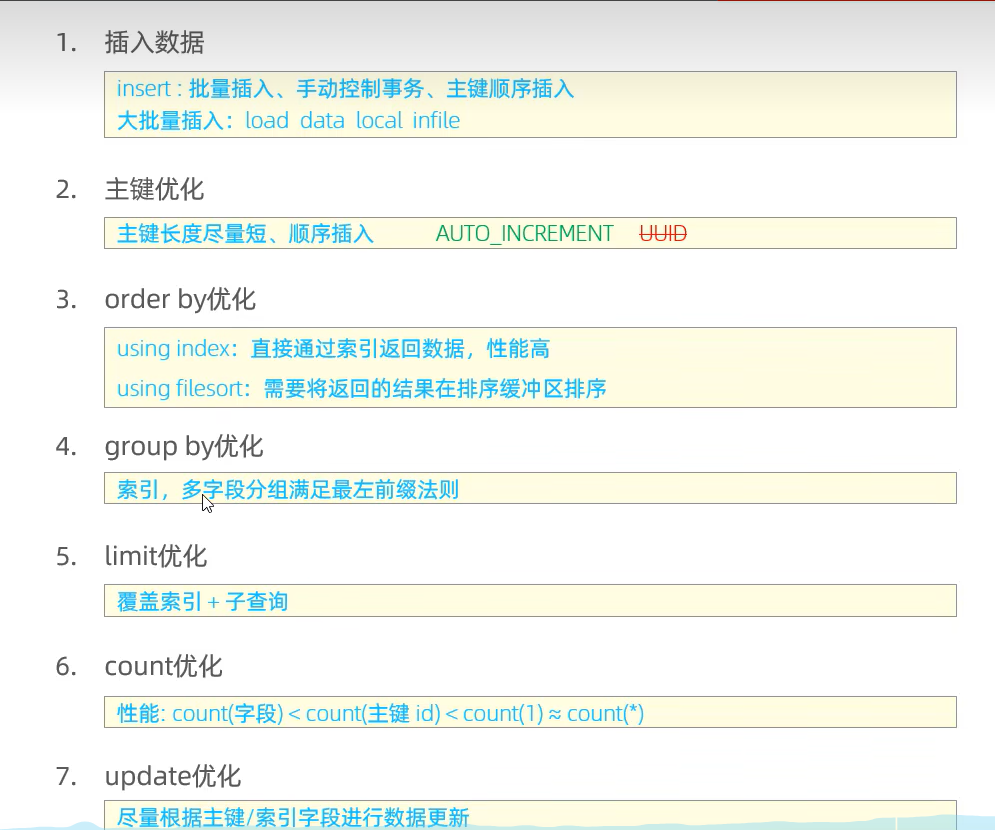
- 插入数据
insert:批量插入、手动控制事务、主键顺序插入
大批量插入:load data local infile
- 主键优化
主键长度尽量短、顺序插入 AUTO_INCREMENT(主键自增)
- order by优化
using index:直接通过索引返回数据,性能高
using filesort:需要将返回的结果在排序缓冲区排序
- group by优化
索引,多字段满足最左前缀法则
- limit优化
覆盖索引+子查询
- count优化
性能:count(字段)<count(主键id)<count(1)<count(*)
- update优化
尽量根据主键/索引字段进行数据更新
相关文章:
MySQl总结
文章目录MySQL数据库的常见考点1、ACID事务原理事务持久性事务原子性MVCC基本概念MVCC基本原理undo logundo log版本链readviewMVCC实现原理RC读已提交RR可重复读MVCC实现原理总结2、并发事务引发的问题3、事务隔离级别4、索引索引结构BTreeHash面试题索引分类思考题语法性能分…...

【学习笔记】NOIP爆零赛7
结论专场,结果被踩暴了 青鱼和序列 赛时的做法是,维护∑aii\sum a_i\times i∑aii的取值,发现只和最后一次操作222的位置有关,于是递推O(n)O(n)O(n)解决。 赛后发现还有更神奇的结论 第二个结论是,第一次进行操作…...

一文读懂账号体系产品设计
一、账号体系的概念及价值账号体系是用户在各平台上的通行证。平台给与用户可持续的服务,用户在平台上获取价值,中间的媒介,便是账号体系。阿境将其理解为维系用户与平台之间的枢纽。注:本文中,账号账户,二…...
从“入门”到“专家”,一份3000字完整的性能测试体系的知识分享
随着科技的飞速发展,软件产品广泛应用于各个行业领域,人们对计算机和网络的依赖性越来越大,对新奇事物也越来越感兴趣,成千上万的用户活跃在庞大的网络系统中,这给提供服务的系统带来严重的负荷,"高并…...

构建对话机器人:Rasa3安装和基础入门
在开源对话机器人中,Rasa社区很活跃,在国内很多企业也在使用Rasa做对话机器人,有rasa开发经验的往往是加分项。 当年实习的时候接触到了Rasa,现在工作中也使用Rasa,因此,写写一些经验文档,有助后…...
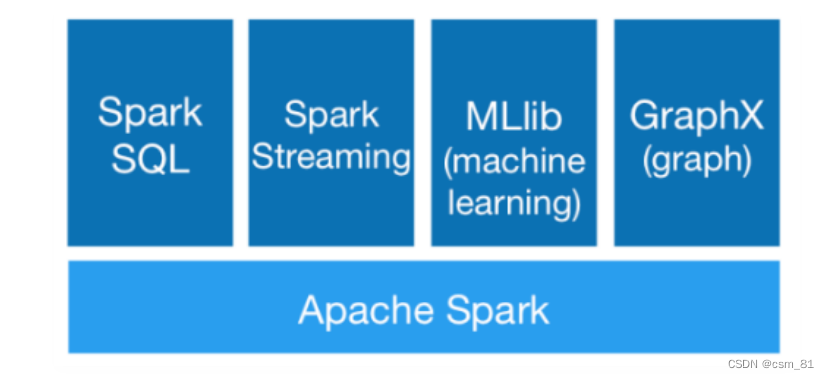
Spark计算框架入门笔记
Spark是一个用于大规模数据处理的统一计算引擎 注意:Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,等等,所以说它是一个统一的计算引擎 既然说到了Spar…...

入职数据分析公认的好书|建议收藏
众所周知,数据分析经常出现在我们的日常生活中,各行各业都需要数据分析。可你知道什么是数据分析?它在企业里到底扮演什么角色?以及如果我们自己也想拥有数据分析的能力,以便更好的满足数据分析的需求,我们…...

Linux查找文件和目录,重定向输出 ,系统默认运行级别的查看和设置理论和练习
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...

Redis源码---键值对中字符串的实现,用char*还是结构体
目录 前言 为什么 Redis 不用 char*? char* 的结构设计 操作函数复杂度 SDS 的设计思想 SDS 结构设计 SDS 操作效率 紧凑型字符串结构的编程技巧 小结 前言 对于 Redis 来说,键值对中的键是字符串,值有时也是字符串在 Redis 中写入一…...

算法 - 剑指Offer 表示数值的字符串
题目 请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。 数值(按顺序)可以分成以下几个部分: 若干空格 一个 小数 或者 整数 (可选)一个 ‘e’ 或 ‘E’ ,后面跟着一个 …...
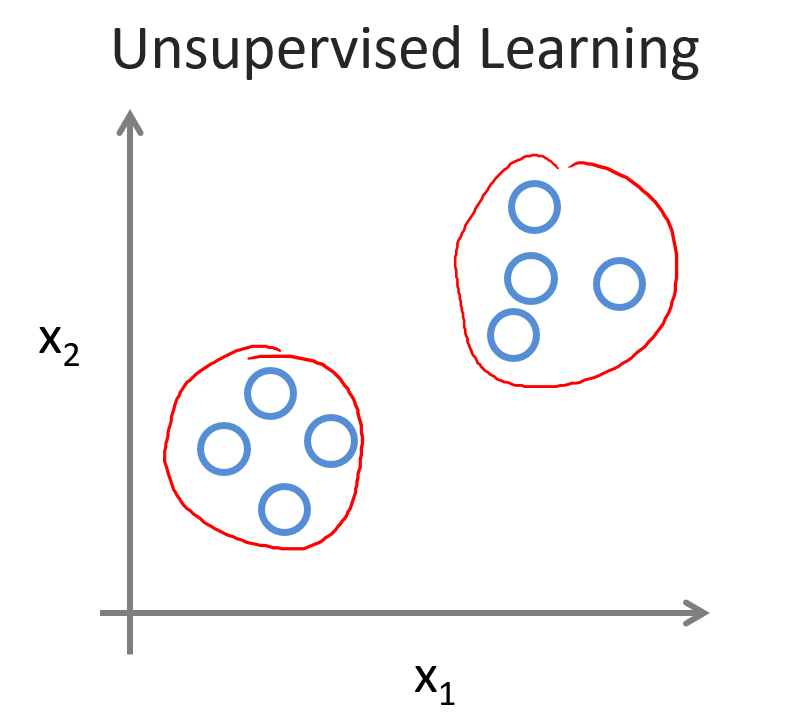
初识机器学习
监督学习与无监督学习supervised learning:监督学习,给出的训练集中有输入也有输出(标签)(也可以说既有特征又有目标),在此基础上让计算机进行学习。学习后通过测试集测试给相应的事物打上标签。…...
VsCode安装PlatformIO 开发ESP arduino,买的板子或者随便ESP,PlatformIO添加Board(不是自定义Board)
这次主要记录怎么给新建选板子的时候没有的板子下程序 我这里是一块 WiFi Kit 32 (V3) PlatformIO里面只有到V2 先从头开始,安装PlatformIO 安装PlatformIO 直接搜索安装 安装有时候会比较慢,左侧出现蚂蚁图标之后点击会显示 右下角会提示正在安…...

golang 复杂数据结构解析
[{"key":"15275771","pack":{"1":[{"name":"消息配置","id":15275771,"version":1,"createUser":"molaifeng","data":"test"}]},"callback&qu…...

不怕被AirTag跟踪?苹果Find My技术越来越普及
苹果的 AirTag 自推出以来,如何有效遏制用户用其进行非法跟踪,是摆在苹果面前的一大难题。一家为执法部门制造无线扫描设备的公司近日通过 KickStarter 平台,众筹了一款消费级产品,可帮助用户检测周围是否存在追踪的 AirTag 等设备…...
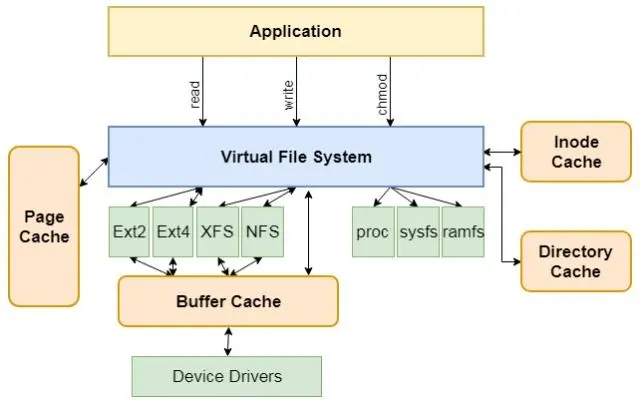
Linux驱动中的open函数是如何从软件打通硬件呢?
一、前言 打开文件是Linux系统中最基本的操作之一,open函数可以实现打开文件的功能。下面我将为您介绍open函数打通上层到底层硬件的详细过程。 二、open函数打通软硬件介绍 open函数是系统调用中的一种,其原型定义在头文件unistd.h中: #…...

Java 基础语法
Java 是一门广泛使用的编程语言,由于其简单易学和可移植性,已成为开发 Web 应用程序、移动应用程序、桌面应用程序以及企业级应用程序的首选语言之一。在本文中,我们将探讨 Java 的基础语法,包括变量、数据类型、运算符、控制流等…...
python下如何安装并使用matplotlib(画图模块)
在搜索命令中输入cmd,以管理员身份运行。 输入以下命令,先对pip安装工具进行升级 pip install --upgrade pip 升级完成 之后使用pip安装matplotlib pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple 也可以使用pycharm来安装matp…...

系统分析师---计算机网络思维导图
TCP、IP协议簇(4星) 传输协议:TCP有连接、可靠、有回应机制、三次握手基于TCP的应用层协议:POP3:邮件收取,默认端口110SMTP:邮件发送,默认端口25FTP:文件传输协议&#…...

算法练习(七)数据分类处理
一、数据分类处理 1、题目描述: 信息社会,有海量的数据需要分析处理,比如公安局分析身份证号码、 QQ 用户、手机号码、银行帐号等信息及活动记录。采集输入大数据和分类规则,通过大数据分类处理程序,将大数据分类输出…...

nohup ./startWebLogic.sh >out.log 2>1 解析
在启动weblogic的时候我们经常看到如下的命令: nohup ./startWebLogic.sh >out.log 2>&1 & 从09年开始用weblogic到现在已经过去3年多了 ,今天终于将该命令理解清楚了。 其中 0、1、2分别代表如下含义: 0 – stdin (standa…...

嵌入式GPIO边沿中断消抖增强库
1. 项目概述interruptin_mod是一个面向嵌入式微控制器(MCU)的 GPIO 引脚电平变化中断扩展库,其核心设计目标是在标准 HAL 或 LL 库提供的基础 EXTI(External Interrupt)功能之上,构建更灵活、更鲁棒、更易集…...

OpenClaw+GLM-4.7-Flash创意生成:自动化设计海报与营销文案
OpenClawGLM-4.7-Flash创意生成:自动化设计海报与营销文案 1. 为什么需要自动化创意生成 作为一名独立设计师,我经常面临一个典型困境:客户给出一段产品描述后,需要在极短时间内产出多版海报设计方案和配套文案。传统工作流中&a…...
)
工业4.0必备:如何用PDPS优化汽车焊接生产线(附真实案例参数)
工业4.0实战:用PDPS重构汽车焊接产线的5个关键步骤 当某德系车企的焊装车间主管第一次将产线OEE数据导入Process Simulate时,虚拟环境中立刻跳出了17处潜在碰撞点——这个数字让整个技术团队倒吸一口冷气。这正是工业4.0时代数字化双胞胎技术的魔力所在&…...

KeePassXC浏览器扩展:本地化密码管理的安全实践指南
KeePassXC浏览器扩展:本地化密码管理的安全实践指南 【免费下载链接】keepassxc-browser KeePassXC Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ke/keepassxc-browser 从零开始搭建个人密码安全体系 在数字身份日益重要的今天,…...

Wiley期刊投稿返修实战:手把手教你搞定Response Letter和Graphical Abstract
Wiley期刊投稿返修实战:手把手教你搞定Response Letter和Graphical Abstract 收到Wiley期刊的大修通知时,那种既兴奋又焦虑的复杂心情,每个科研工作者都深有体会。兴奋的是论文没有被直接拒稿,说明研究有价值;焦虑的是…...

AI虚拟房地产架构技术选型:云服务 vs 自建,架构师该怎么选?
AI虚拟房地产架构技术选型:云服务 vs 自建的第一性原理决策框架 元数据框架 标题 AI虚拟房地产架构技术选型:云服务 vs 自建的第一性原理决策框架 关键词 AI虚拟房地产、云服务架构、自建IDC、技术选型、弹性计算、实时渲染、成本优化 摘要 AI虚拟…...

一键部署:nanobot轻量级AI助手快速体验,QQ聊天机器人搭建不求人
一键部署:nanobot轻量级AI助手快速体验,QQ聊天机器人搭建不求人 1. 开箱即用:你的第一个AI助手,5分钟就能跑起来 想拥有一个属于自己的AI助手,但又觉得技术门槛太高、部署太麻烦?今天,我来带你…...

OpenClaw环境迁移指南:QwQ-32B配置从云端到本地的无缝转移
OpenClaw环境迁移指南:QwQ-32B配置从云端到本地的无缝转移 1. 为什么需要环境迁移? 去年夏天,我在星图平台体验了OpenClaw与QwQ-32B的组合方案。云端沙盒环境确实方便,但随着使用深入,我发现两个痛点:一是…...

学习周报三十七
文章目录摘要abstract一、mclip的论文-Multilingual CLIP via Cross-lingual Transfer-23.二、实践总结摘要 围绕多语言图文检索模型mCLIP论文展开学习,论文提出了一种多语言视觉-语言预训练模型。核心创新在于通过三角形跨模态知识蒸馏(TriKDÿ…...

ollama-QwQ-32B模型融合实践:提升OpenClaw多任务泛化能力
ollama-QwQ-32B模型融合实践:提升OpenClaw多任务泛化能力 1. 为什么需要模型融合 去年冬天,当我第一次尝试用OpenClaw自动化处理日常工作时,发现单一模型在面对复杂任务时总有些力不从心。比如让模型帮我整理技术文档时,它在文本…...