Python编写GUI界面案例:实现免费下载器
前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

本次网站:
本文所有模块\环境\源码\教程皆可点击文章下方名片获取此处跳转
开发环境:
-
python 3.8 运行代码
-
pycharm 2022.3 辅助敲代码
模块使用:
-
import parsel >>> pip install parsel
-
import requests >>> pip install requests
如何安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
思路
一、数据来源分析
-
明确需求:
采集的网站是什么?
采集的数据是什么?
标题/内容
-
分析 标题/内容 是从哪里来的
通过浏览器自带工具: 开发者工具抓包分析
打开开发者工具: F12 / 鼠标右键点击检查选择network
刷新网页
搜索数据, 找到数据包

二. 代码实现
-
发送请求, 模拟浏览器对于url地址发送请求
-
获取数据, 获取服务器返回响应数据内容
开发者工具: response
-
解析数据, 提取我们想要的数据内容
标题/内容
-
保存数据, 把数据保存本地文件

代码实现
有个视频教程给大家录好啦,但是C站放不上来
源码资料电子书: 点击此处跳转文末名片获取
一、单章小说下载
-
发送请求
-
获取数据
import requests
url = '网站链接'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response)
# print(response.text)
- 解析数据
import re
import parsel selector = parsel.Selector(response.text)
title = selector.xpath('//*[@class="bookname"]/h1/text()').get()
content = '\n'.join(selector.xpath('//*[@id="content"]/text()').getall())
print(title)
print(content)
- 保存数据
with open(title + '.txt', mode='a', encoding='utf-8') as f:
"""
第一章 标题小说内容
第二章 标题小说内容
"""
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')

二、整本小说下载
import requests
import re
import parsel
import oslist_url = ''
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
html_data = requests.get(url=list_url, headers=headers).text
name = re.findall('<h1>(.*?)</h1>', html_data)[0]
file = f'{name}\\'
if not os.path.exists(file):os.mkdir(file)url_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)
for url in url_list:index_url = '网址' + urlprint(index_url)headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}response = requests.get(url=index_url, headers=headers)print(response)selector = parsel.Selector(response.text)title = selector.xpath('//*[@class="bookname"]/h1/text()').get()content = '\n'.join(selector.xpath('//*[@id="content"]/text()').getall())print(title)
with open(file + title + '.txt', mode='a', encoding='utf-8') as f:
"""第一章 标题小说内容第二章 标题小说内容"""
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
三、多线程采集
import requests
import re
import parsel
import os
import concurrent.futures
def get_response(html_url):
"""
发送请求函数
:param html_url: 请求链接
:return: response响应对象
"""
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
return response
def get_list_url(html_url):
"""
获取章节url/小说名
:param html_url: 小说目录页
:return:
"""
html_data = get_response(html_url).text
name = re.findall('<h1>(.*?)</h1>', html_data)[0]
url_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)
return name, url_list
def get_content(html_url):
"""
获取小说内容/小说标题
:param html_url: 小说章节url
:return:
"""
html_data = get_response(html_url).text
title = re.findall('<h1>(.*?)</h1>', html_data)[0]
content = re.findall('<div id="content">(.*?)<p>', html_data, re.S)[0].replace('<br/><br/>', '\n')
return title, content
def save(name, title, content):
"""
保存数据函数
:param name: 小说名
:param title: 章节名
:param content: 内容
:return:
"""
file = f'{name}\\'
if not os.path.exists(file):os.mkdir(file)
with open(file + title + '.txt', mode='a', encoding='utf-8') as f:
"""第一章 标题小说内容第二章 标题小说内容"""
f.write(title)f.write('\n')f.write(content)f.write('\n')print(title, '已经保存')def main(home_url):title, content = get_content(html_url=home_url)save(name, title, content)if __name__ == '__main__':url = ''name, url_list = get_list_url(html_url=url)exe = concurrent.futures.ThreadPoolExecutor(max_workers=7)for url in url_list:index_url = '网址' + urlexe.submit(main, index_url)exe.shutdown()
四、采集排行榜所有小说
import requests
import re
import parsel
import os
def get_response(html_url):
"""
发送请求函数
:param html_url: 请求链接
:return: response响应对象
"""
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
return response
def get_list_url(html_url):
"""
获取章节url/小说名
:param html_url: 小说目录页
:return:
"""
html_data = get_response(html_url).textname = re.findall('<h1>(.*?)</h1>', html_data)[0]url_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)return name, url_listdef get_content(html_url):
"""
获取小说内容/小说标题
:param html_url: 小说章节url
:return:
"""
html_data = get_response(html_url).text
title = re.findall('<h1>(.*?)</h1>', html_data)[0]
content = re.findall('<div id="content">(.*?)<p>', html_data, re.S)[0].replace('<br/><br/>', '\n')
return title, content
def save(name, title, content):
"""
保存数据函数
:param name: 小说名
:param title: 章节名
:param content: 内容
:return:
"""
file = f'{name}\\'
if not os.path.exists(file):os.mkdir(file)
with open(file + title + '.txt', mode='a', encoding='utf-8') as f:
"""第一章 标题小说内容第二章 标题小说内容"""
f.write(title)f.write('\n')f.write(content)f.write('\n')
print(title, '已经保存')
"""
获取小说ID
:param html_url: 某分类的链接
:return:
"""
def get_novel_id(html_url):novel_data = get_response(html_url=html_url).textselector = parsel.Selector(novel_data)href = selector.css('.l .s2 a::attr(href)').getall()href = [i.replace('/', '') for i in href]return hrefdef main(home_url):href = get_novel_id(html_url=home_url)for novel_id in href:novel_url = f'网址/{novel_id}/'name, url_list = get_list_url(html_url=novel_url)print(name, url_list)for url in url_list:index_url = '' + urltitle, content = get_content(html_url=index_url)save(name, title, content)breakif __name__ == '__main__':html_url = ''main(html_url)
五、搜索小说功能
- 模块
import requests
import re
import parsel
import os
import prettytable as pt
- 发送请求函数
def get_response(html_url):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}response = requests.get(url=html_url, headers=headers)return response
- 获取章节url/小说名
def get_list_url(html_url):html_data = get_response(html_url).textname = re.findall('<h1>(.*?)</h1>', html_data)[0]url_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)return name, url_list
- 获取小说内容/小说标题
def get_content(html_url):html_data = get_response(html_url).texttitle = re.findall('<h1>(.*?)</h1>', html_data)[0]content = re.findall('<div id="content">(.*?)<p>', html_data, re.S)[0].replace('<br/><br/>', '\n')return title, content
- 保存数据函数
def save(name, title, content):file = f'{name}\\'if not os.path.exists(file):os.mkdir(file)with open(file + name + '.txt', mode='a', encoding='utf-8') as f:f.write(title)f.write('\n')f.write(content)f.write('\n')print(title, '已经保存')
- 获取小说ID
def get_novel_id(html_url):novel_data = get_response(html_url=html_url).textselector = parsel.Selector(novel_data)href = selector.css('.l .s2 a::attr(href)').getall()href = [i.replace('/', '') for i in href]return href
- 搜索功能
def search(word):search_url = f'网址/searchbook.php?keyword={word}'search_data = get_response(html_url=search_url).textselector = parsel.Selector(search_data)lis = selector.css('.novelslist2 li')novel_info = []tb = pt.PrettyTable()tb.field_names = ['序号', '书名', '作者', '书ID']num = 0for li in lis[1:]:name = li.css('.s2 a::text').get()novel_id = li.css('.s2 a::attr(href)').get().replace('/', '')writer = li.css('.s4::text').get()dit = {'name': name,'writer': writer,'novel_id': novel_id,}tb.add_row([num, name, writer, novel_id])num += 1novel_info.append(dit)print('你搜索的结果如下:')print(tb)novel_num = input('请输入你想要下载的小说序号: ')novel_id = novel_info[int(novel_num)]['novel_id']return novel_id
- 主函数
def main(word):novel_id = search(word)novel_url = f'网址/{novel_id}/'name, url_list = get_list_url(html_url=novel_url)print(name, url_list)for url in url_list:index_url = '网址' + urltitle, content = get_content(html_url=index_url)save(name, title, content)if __name__ == '__main__':word = input('请输入你搜索小说名: ')main(word)
六、GUI界面
import tkinter as tk
from tkinter import ttkdef show():name = name_va.get()print('输入的名字是:', name)def download():name = num_va.get()print('输入的序号:', name)root = tk.Tk()
root.title('完整代码添加VX:python5180 ')
root.geometry('500x500+200+200')
name_va = tk.StringVar()search_frame = tk.Frame(root)
search_frame.pack(pady=10)tk.Label(search_frame, text='书名 作者', font=('微软雅黑', 15)).pack(side=tk.LEFT, padx=10)
tk.Entry(search_frame, relief='flat', textvariable=name_va).pack(side=tk.LEFT)num_va = tk.StringVar()download_frame = tk.Frame(root)
download_frame.pack(pady=10)
tk.Label(download_frame, text='小说 序号', font=('微软雅黑', 15)).pack(side=tk.LEFT, padx=10)
tk.Entry(download_frame, relief='flat', textvariable=num_va).pack(side=tk.LEFT)
button_frame = tk.Frame(root)
button_frame.pack(pady=10)
tk.Button(button_frame, text='查询', font=('微软雅黑', 10), relief='flat', bg='#88e2d6', width=10, command=show).pack(side=tk.LEFT, padx=10)
tk.Button(button_frame, text='下载', font=('微软雅黑', 10), relief='flat', bg='#88e2d6', width=10, command=download).pack(side=tk.LEFT, padx=10)columns = ('num', 'writer', 'name', 'novel_id')
columns_value = ('序号', '作者', '书名', '书ID')
tree_view = ttk.Treeview(root, height=18, show='headings', columns=columns)
tree_view.column('num', width=40, anchor='center')
tree_view.column('writer', width=40, anchor='center')
tree_view.column('name', width=40, anchor='center')
tree_view.column('novel_id', width=40, anchor='center')
tree_view.heading('num', text='序号')
tree_view.heading('writer', text='作者')
tree_view.heading('name', text='书名')
tree_view.heading('novel_id', text='书ID')
tree_view.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
root.mainloop()
效果展示

尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝

相关文章:
Python编写GUI界面案例:实现免费下载器
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本次网站: 本文所有模块\环境\源码\教程皆可点击文章下方名片获取此处跳转 开发环境: python 3.8 运行代码 pycharm 2022.3 辅助敲代码 模块使用: import parsel >>> pip install parsel…...
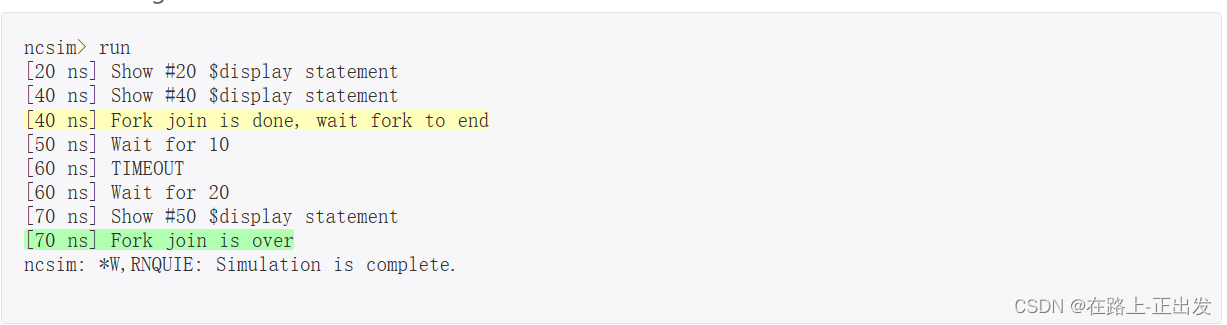
我的 System Verilog 学习记录(6)
引言 本文简单介绍 SystemVerilog 语言的 线程。 前文链接: 我的 System Verilog 学习记录(1) 我的 System Verilog 学习记录(2) 我的 System Verilog 学习记录(3) 我的 System Verilog 学…...

SAP 常见问题大全及问题解决大全
1.A:在公司代码分配折旧表时报错? 在公司代码分配折旧表时报错,提示是“3000 的公司代码分录不完全-参见长文本” 希望各位大侠帮我看看。 3000 的公司代码分录不完全-参见长文本 R: a.你把零进项税的代码分配给这个公司代码就可以了 …...

10.Quartz实现定时打分 热帖排行
1.Spring Quartz(1)简介核心组件scheduler 接口:核心调度工具,所有任务由这一接口调用job:定义任务,重写execute方法JobDetail接口:配置描述Trigger接口:什么时候运行,以什么样的频率运行(2)Spr…...

pandas 读取Excel 批量转换时间戳
一、安装 pip install pandas 如果出报错,不能运行,可以安装 pip install xlrd 二、 代码如下 import pandas as pd import time,datetimefile_path rC:\Users\Administrator\Desktop\携号转网测试\admin_log.xls df pd.read_excel(file_path, sheet_n…...

绕过检测之Executor内存马浅析(内存马系列篇五)
写在前面 前面已经从代码层面讲解了Tomcat的架构,这是内存马系列文章的第五篇,带来的是Tomcat Executor类型的内存马实现。有了前面第四篇中的了解,才能更好的看懂内存马的构造。 前置 什么是Executor Executor是一种可以在Tomcat组件之间…...
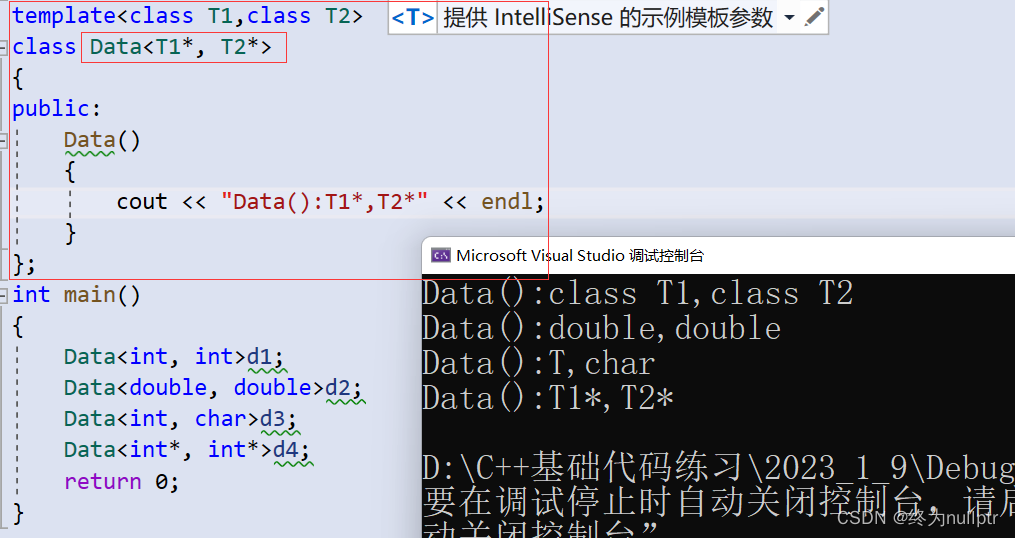
《C++模板进阶》
致前行的人: 要努力,但不要着急,繁花锦簇,硕果累累都需要过程! 目录 前言: 1.非类型模板参数 1.1.概念: 1.2.使用注意事项 2.模板特化 2.1函数模板特化 2.2类模板特化 3.模板的分离编译 3.1什么…...

【项目管理】项目进度管理中的逻辑关系
项目的进度管理是项目核心管理之一,通过合理的进度安排,制定出科学可行的分项工期表,并条理清晰的显示出项目进度之间的逻辑关系。 1、目标是计划的灵魂 进度计划必须按照确定的项目总进度要求进行编制,了解项目总目标和整体安…...

ARM的汇编指令集
一、汇编指令 1.1 指令与伪指令 汇编的指令 指令是CPU机器指令的助记符,编译后会得到一串二进制机器码,由CPU执行 汇编的伪指令 伪指令本质上不是指令,它是编译器环境提供用来指导编译过程,编译后伪指令不会生成机器码 伪指令…...
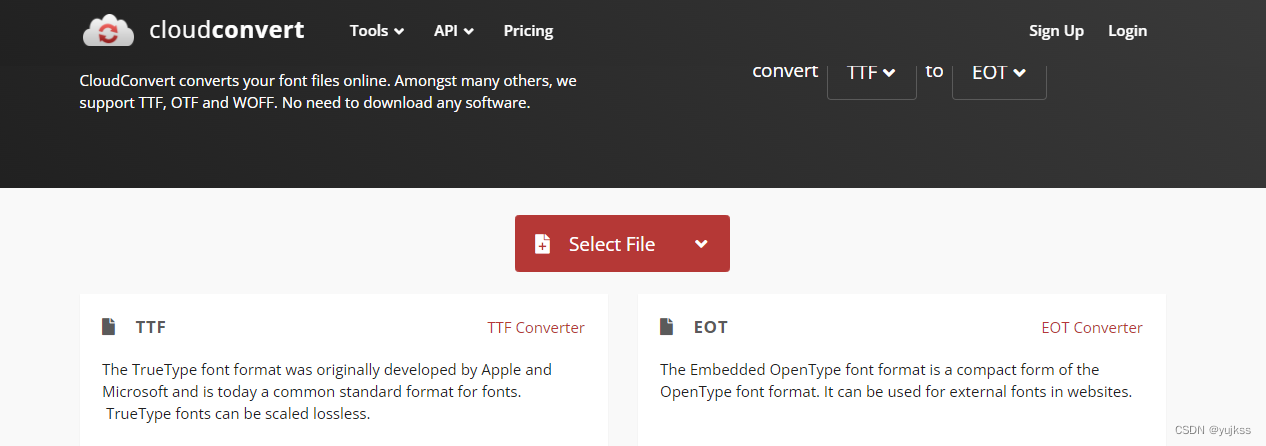
@font-face用法超详细讲解
文章目录font-face是什么font-face基本语法urlTTFOTFEOTWOFFSVGformatfont-face用法示例font字体下载ttf-to-eot 字体转换器https://blog.csdn.net/qq_37417446/article/details/106728725 https://developer.mozilla.org/zh-CN/docs/Web/CSS/font-face font-face是什么 font-…...
[oeasy]python0095_乔布斯求职_雅达利_atari_breakout_打砖块_布什内尔_游戏机_Jobs
编码进化 回忆上次内容 上次 我们回顾了 电子游戏的历史 从 电子游戏鼻祖 双人网球到 视频游戏 PingPong再到 街机游戏 Pong 雅达利 公司 来了 嬉皮士 捣乱?🤔 布什内尔 会如何 应对 呢?🤔 布什内尔 布什内尔 本身就有点 …...

全景极简印度史
转自:印度简史 - 知乎 (zhihu.com)印度是世界上最早出现文明的地区之一,印度河是其文明的发源地。古印度文明的疆域曾包括今印度共和国、巴基斯坦、孟加拉国、阿富汗斯坦南部部分地区和尼泊尔。史前时代200万年前,巴基斯坦北部的希瓦利克遗址…...

《设计模式》模板方法
《设计模式》模板方法 模板方法是一种行为型设计模式,用于定义一个算法的框架,而将一些步骤的实现留给子类来完成。模板方法在基类中定义了一个模板方法,该方法确定了算法的基本结构,然后将一些步骤的实现交给子类去完成。这个模…...

Linux环境内存管理——链表
我是荔园微风,作为一名在IT界整整25年的老兵,今天我们来重新审视一下Windows程序员如何学习Linux环境内存管理。由于很多程序在Windows环境下开发好后,还要部署到Linux服务器上去,所以作为Windows程序员有必要学习Linux环境的内存…...

String、StringBuffer、StringBuilder类
String类 由多个字符组成的一串数据,值一旦创建不可改变 private final char value[]; 一旦值改变,就会创建新的对象 String s "abc"; //char[] c {a,b,c}s"def"; // 并不是String的值改变,而是创建了一个新的对象s"gh";s"aaa"…...

在VScode中添加Linux中的Docker容器中的Python解释器
VScode编辑器在安装好Python插件之后会自动选择环境变量中排序最高的那一个解释器作为默认解释器,而想要额外添加新的Python解释器就需要自己设置。 VScode编辑器安装在本地电脑 支持Python的docker安装在远程服务器 第一步,在/usr/local/下新建pytho…...
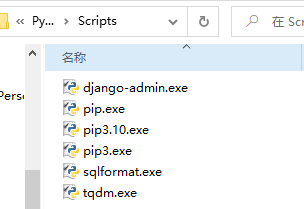
无法将“django-admin”项识别为cmdlet,函数,脚本文件或可运行程序的名称问题
无法将“django admin”项识别为cmdlet,函数,脚本文件或可运行程序的名称问题 小提示:首先检查一下有没有拼写错误!!!没有的话请继续 我们要知道django装到哪里去了 pip show django 注意:3.0…...
乐友商城学习笔记(十五)
无状态登陆原理 在服务器端保存session 无状态不需要session,把登陆状态保存在cookie中 jwtrsa token:登陆时, jwt oath2 jwt:头信息(jwt) 载荷(用户信息,签发人,签发时…...

目标检测论文阅读:CBNet算法笔记
标题:CBNet: A Composite Backbone Network Architecture for Object Detection 期刊:TIP2022 论文地址:https://ieeexplore.ieee.org/document/9932281/ 官方代码:https://github.com/VDIGPKU/CBNetV2 作者单位:北京大…...

vue前端与Java后端进行跨域交互
1.后端的几种解决方法 1.在Controller上面加上CrossOrigin 2.写一个配置文件并且在Controller层加上注解CORSConfig package com.wolwo.langyage.base.util;import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configurat…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...