hadoop 集群常用命令(学习笔记) —— 筑梦之路
概念介绍
#HDFS 概述Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。 (2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。 (3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。#YARN 概述Yet Another Resource Negotiator 简称YARN ,另一种资源协调者,是Hadoop 的资源管理器。ResourceManager(RM):整个集群资源(内存、CPU等)的管理者 NodeManager(NM):单个节点服务器资源的管理者。ApplicationMaster(AM):单个任务运行的管理者。Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。#MapReduce 概述MapReduce 将计算过程分为两个阶段:Map 和 Reduce(1)Map 阶段并行处理输入数据 (2)Reduce 阶段对Map 结果进行汇总各组件和对应服务名
| 组件名 | 服务名 | 进程名 |
|---|---|---|
| NameNode | hadoop-hdfs-namenode | NameNode |
| DataNode | hadoop-hdfs-datanode | DataNode |
| ResourceManager | hadoop-yarn-resourcemanager | ResourceManager |
| NodeManager | hadoop-yarn-nodemanager | NodeManager |
| JobHistory | hadoop-mapreduce-historyserver | JobHistoryServer |
| JournalNode | hadoop-hdfs-journalnode | JournalNode |
| zkfc | hadoop-hdfs-zfkc | DFSZKFailoverController |
hadoop服务启停流程
#启动过程1、启动所有zookeeper2、启动所有的JournalNode3、启动两台NameNode及zkfc ,---这里可以通过查看namenode的web页面,查看两台机器的状态---一台为active ,另一台为standby4、启动所有的DataNode5、启动两台ResourceManager ,这里可以通过查看resourceManager的web页面6、启动所有的NodeManager7、启动JobHistory-------------------------------------------------------------------------------# 关闭过程1、停止JobHistory2、停止所有的NodeManager3、停止两台ResourceManager4、停止所有的DataNode5、停止两台NameNode及ZKFC6、停止所有的JournalNode7、停止所有的zookeeper整合为脚本
#启停脚步包含hdfs、yarn、historyserver#!/bin/bash
#启停脚本if [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
ficase $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.3.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.3.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop103 "/opt/module/hadoop-3.3.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop103 "/opt/module/hadoop-3.3.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.3.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.3.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac启停验证
>web端查看HDFS的NameNode
http://hadoop101:9870>web端查看yarn的ResourceManager
http://hadoop102:8088>历史服务器地址
http://hadoop103:19888/jobhistohadoop服务单独启停
#命令启动hdfs ---namenode节点上执行cd /opt/module/hadoop-3.3.3/sbin/
./start-dfs.sh#命令停止hdfs ---namenode节点上执行cd /opt/module/hadoop-3.3.3/sbin/
./stop-dfs.sh#验证web端查看HDFS的NameNodehttp://hadoop101:9870yarn启停
#在resourcemanager节点上执行,先启动hdfs,再启动yarncd /opt/module/hadoop-3.3.3/sbin/
./start-yarn.sh#yarn停止---在resourcemanager节点上执行cd /opt/module/hadoop-3.3.3/sbin/
./stop-yarn.sh#验证web端查看yarn的ResourceManagerhttp://hadoop102:8088# 启动hdfs、yarncd /opt/module/hadoop-3.3.3/sbin/
./start-all.sh#停止hdfs、yarncd /opt/module/hadoop-3.3.3/sbin/
./stop-all.sh单独启停某个服务进程
# hdfs --daemon start 单独启动⼀个进程
hdfs --daemon start namenode # 只开启NameNode
hdfs --daemon start datanode # 只开启DataNode
hdfs --daemon start secondarynamenode # 只开启SecondaryNameNode# hdfs --daemon stop 单独停⽌⼀个进程
hdfs --daemon stop namenode # 只停⽌NameNode
hdfs --daemon stop datanode # 只停⽌DataNode
hdfs --daemon stop secondarynamenode # 只停⽌SecondaryNameNode# hdfs --workers --daemon start 启动所有的指定进程
hdfs --workers --daemon start namenode
hdfs --workers --daemon start datanode # 开启所有节点上的DataNode
hdfs --workers --daemon start secondarynamenode # hdfs --workers --daemon stop 停止所有的指定进程
hdfs --workers --daemon stop namenode
hdfs --workers --daemon stop datanode # 停⽌所有节点上的DataNode
hdfs --workers --daemon stop secondarynamenode常用命令# 修改hdfs文件的备份数hdfs dfs -setrep -R 副本数 dir备注:dfs.replication 这个参数其实只在文件被写入dfs时起作用
虽然更改了配置文件,但是不会改变之前写入的文件的备份数# 检查hdfs block健康状态hdfs fsck /# 删除坏的block块hdfs fsck / -delete 坏块路径(hdfs上的文件路径)---
若出现坏块,即报告中Missing Blocks有值,
尝试重启hdfs服务 ./stop-dfs.sh ./start-dfs.sh
重启后观察(重启时间较长,10-20分钟之后再去查看)是否还有坏块若重启HDFS服务不能修复,可通过手动检查坏块并删除坏块
hdfs fsck / --扫描坏块
hdfs fsck -delete 坏块地址
#扫描坏块后查看,坏块地址为”:MISSING“之前的地址再重新检查坏块情况和坏块告警情况
---启动负载均衡datanode之间出现数据存储大小不均衡时,比如磁盘损坏或者新增加,需要做负载均衡。尽量不要在namenode节点使用cd /opt/module/hadoop-3.3.3/sbin/
./start-balancer.sh -t 10%
datanode存储使用率/集群总存储使用率>10%就触发负载均衡格式化文件系统
注意:格式化namenode后集群的数据会全部丢失,格式化之前需做好数据备份工作1、格式化之前,首先需删除Hadoop系统日志,默认路径为${HADOOP_HOME}/logs。2、然后删除主节点目录以及数据节点目录,默认路径分别为${hadoop.tmp.dir}/dfs/name
和${hadoop.tmp.dir}/dfs/data。hadoop.tmp.dir默认值是/tmp/hadoop-${user.name},
可以在core-site.xml配置文件中的hadoop.tmp.dir属性设置。而上面的主节点目录和数据节点目录也可以在hdfs-site.xml配置文件中的dfs.namenode.name.dir和dfs.namenode.data.dir属性中设置。(在dfs/name/current目录下的VERSION文件中记录集群的版本信息,其中clusterID是集群版本标识,每次format都会生成不同的ID。在dfs/data/current目录下的VERSION文件中记录datanode的版本相关信息,其中clusterID标识它是属于哪个集群的,namenode 和 datanode的这两个值一致时,才会认为是同一个集群。格式化后,namenode的clusterID会改变,但datanode节点目录dfs/data/current如果在格式化时仍存在,则datanode的clusterID不会变化。这种情况下,启动集群,datanode进程虽然也会启动,但与namenode确认clusterID后,发现不一致,就会自动退出了。)
格式化NameNode,命令为hdfs namenode -format。3、格式化NameNode,命令为hdfs namenode -format。
----------------------------------------------------------------------升级、回滚、持久化、checkpoint#分发新的hdfs版本之后,namenode应以upgrade 选项启动hdfs namenode -upgrade#将namenode回滚到前一版本,这个选项要在停止集群,分发老的hdfs版本之后执行hdfs namenode -rollback#finalize 会删除文件系统的前一状态。最近的升级会被持久化,rollback选项将不再可用,升级终结操作之后,它会停掉namenode,分发老的hdfs版本后使用hdfs namenode -finalize#从检查点目录装载镜像并保存到当前检查点目录,检查点目录由fs.checkpoint.dir 指定hdfs namenode importCheckpointhdfs 系统检查#移动受损文件到/lost+found
hdfs fsck <path> -move #删除受损文件
hdfs fsck <path> -delete #打印出写打开的文件
hdfs fsck <path> -openforwrite #打印出正被检查的文件
hdfs fsck <path> -files #打印出块信息报告
hdfs fsck <path> -blocks#打印出每个块的位置信息
hdfs fsck <path> -locations #打印出datanode的网络拓扑结构
hdfs fsck <path> -racksyarn常用命令在集群部署中,yarn的各个组件是和hadoop集群中的其他组件进行同一部署的。yarn中的容器(动态资源分配单位)代表了cpu、内存、磁盘、网络等计算资源,可限定每个应用程序使用的资源量yarn 组件ResourceManager处理客户端请求、启动、监控ApplicationMaster、监控NodeManager、资源分配与调度ApplicationMaster为应用程序申请资源,并分配给内部任务、任务的调度监控与容错NodeManager单个节点上的资源管理、处理ResourceManager的命令、处理来自ApplicationMaster 的命令yarn工作流程在yarn中执行1个MapReduce程序,从提交到完成需要经历8个步骤①用户编写客户端应用程序, 向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。②YARN 中的ResourceManager负责接收和处理来自客户端的请求。接到客户端应用程序请求后,ResourceManager里面的调度器会为应用程序分配一个容器。同时, ResourceManager的应用程序管理器会与该容器所在NodeManager 通信,为该应用程序在该容器中启动一个ApplicationMaster。③ApplicationMaster 被创建后会首先向ResourceManager 注册,从而使得用户可以通过ResourceManager来直接查看应用程序的运行状态。接下来的步骤4~7是具体的应用程序执行步骤。④ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请资源。⑤ResourceManager 以“容器”的形式向提出申请的ApplicationMaster 分配资源,一旦ApplicationMaster申请到资源后,就会与该容器所在的NodeManager 进行通信,要求它启动任务。⑥当ApplicationMaster要求容器启动任务时,它会为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)然后将任务启动命令写到一个脚本中, 最后通过在容器中运行该脚本来启动任务。⑦各个任务通过某个RPC 协议向ApplicationMaster汇报自己的状态和进度,让ApplicationMaster可以随时掌握各 个任务的运行状态,从而可以在任务失败时重新启动任务。⑧应用程序运行完成后,ApplicationMaster向ResourceManager的应用程序管理器注销并关闭自己,若ApplicationMaster因故失败,ResourceManager中的应用程序管理器会监测到失败的情形,然后将其重新启动,直到所有的任务执行完毕。yarn调度算法三种调度算法#1、先进先出 (FIFO Scheduler)优点:简单易懂缺点:不支持多队列,生产环境很少使用#2、容量调度器(capacity scheduler)Capacity Scheduler是Yahoo开发的多用户调度器。 特点: (1)多队列:每个队列配置一定资源量,每个队列采用FIFO调度策略 (2)容量保证:管理员可为队列设置资源最低保证和资源使用上限 (3)灵活性:如果一个队列资源有余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列 (4)多租户:支持多用户共享集群和多应用程序同时运行。 为了防止同一个用户的作业独占队列中的资源,**该调度器会对同一用户提交的作业所占资源量进行限定。1、队列资源分配从root开始,使用深度优先算法,优先选择“资源占用率最低”的队列分配资源2、作业资源分配默认按照提交作业的优先级和提交时间顺序分配资源3、容器资源分配按照容器的优先级 分配资源按照优先级相同,按照数据的本地性原则 :(1)任务和数据在同一节点(2)任务和数据在同一机架(3)任务和数据不在同一节点,也不在同一机架3、公平调度器(Fair Scheduler)Fair Scheduler 是 Facebook开发的多用户调度器同队列所有任务共享资源,在时间尺度上获得公平的资源与容量调度器相同点:(1) 多队列:支持(2)容量保证:管理员可为队列设置资源最低保证和资源使用上限(3)灵活性:如果一个队列资源有余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列 (4)多租户:支持多用户共享集群和多应用程序同时运行。 为了防止同一个用户的作业独占队列中的资源,**该调度器会对同一用户提交的作业所占资源量进行限定。与容量调度器不同点:(1) 核心调度策略不同容量调度器:优先选择 资源利用率低的队列公平调度器:优先选择对资源的缺额比较大的(2)每个队列可以单独设置资源分配方式容量调度器:FIFO、DRF公平调度器:FIFO、FAIR、DRF#分配方式(1)FIFO策略公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。(2)Fair策略公平的策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。 具体资源分配流程和容量调度器一致;(1)选择队列 (2)选择作业 (3)选择容器。此三步,每一步都是按照公平策略分配资源实际最小资源份额:mindshare = Min(资源需求量,配置的最小资源)是否饥饿:isNeedy = 资源使用量 < mindshare(实际最小资源份额) 资源分配比:minShareRatio = 资源使用量 / Max (minshare,1) 资源使用权重比:useToWeightRatio = 资源使用量 / 权重DRF策略 DRF(Doninant Resouree Fairmess),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。 DRF调度:假设集群一共有100 CPU和10T内存,而应用A需要(2CPU,300GB),应用B需要(6 CPU,100GB )。则两个应用分别需要A(2%CPU,3%内存)和B(6%CPU,1%内存)的资源,这就意味着A是内存主导的,B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。yarn常用命令和核心参数yarn application查看任务#列出所有的applicationyarn application -list#根据application状态过滤yarn application -list -appStates XXX(XXX - ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)#杀死程序yarn application -kill application-idyarn logs查看日志#查询application日志yarn logs -applicationId <ApplicationId>#查询container 日志yarn logs -applicationId <ApplicationId> -containerId <ContainerId>yarn applicationattempt查看尝试运行的任务#列出所有Application尝试的列表yarn applicationattempt -list <ApplicationId>#打印ApplicationAttemp状态yarn applicationattempt -status <ApplicationAttemptId>yarn container查看容器#列出所有Containeryarn container -list <ApplicationAttemptId>#打印Container状态yarn container -status <ContainerId>
备注:只有在任务跑的途中才能看到container的状态yarn node查看节点状态#列出所有节点yarn node -list -allyarn rmadmin更新配置#加载队列配置yarn rmadmin -refreshQueuesyarn queue查看队列#打印队列信息yarn queue -status <QueueName>#yarn核心参数配置1、ResourceManager相关#配置调度器,默认容量yarn.resourcemanager.scheduler.class#ResourceManager处理器请求的线程数量,默认50yarn.resourcemanager.scheduler.clinent.thread-count2、NodeManager相关#是否让yarn自己检测硬件进行配置,默认falseyarn.nodemanager.resource.detect-hardware-capabilities#是否将虚拟核数当做cpu核数,默认falseyarn.nodemanager.resource.count-logical-processors-as-cores#虚拟核数和物理核数乘数,默认为1.0yarn.nodemanager.resource.pcores-vcores-multiplier#NodeManager使用内存,默认8Gyarn.nodemanager.resource.memory-mb#NodeManager 为系统保留多少内存yarn.nodemanager.resource.system-reserved-memory-mb备注:改参数和上个参数有一定的关系#NodeManager 使用cpu核数,默认8个yarn.nodemanager.resource.cpu-vcores#是否开启物理内存检查限制container,默认打开yarn.nodemanager.pmem-check-enabled#是否开启虚拟内存检查限制container,默认打开yarn.nodemanager.vmem-check-enabled#虚拟内存和真实物理内存的比率,默认2.1yarn.nodemanager.vmem-pmem-ratio3、Container相关#容器最小内存,默认1Gyarn.scheduler.minimum-allocation-mb
#容器最大内存,默认8Gyarn.scheduler.maximum-allocation-mb#容器最小CPU核数,默认1个yarn.scheduler.minimum-allocation-vcores#容器最大CPU核数,默认4个yarn.scheduler.maximum-allocation-vcores按照上边的参数进行配置下我们的yarn-site.xml文件#设置参考意见container:内存和cpu的虚拟概念内存cpu资源预留20%给系统一个计算任务至少需要1core 。core越多,计算的并发就越多内存:计算时所需的空间oom-killer机制cpu:决定并发任务cloudera公司经过生产实践,推荐1个container的vcore最好不要超过5,就设置4个4.3、mapreduce常用命令4.3.1、mapreduce相关参数
资源相关参数以下参数是在用户自己的 MapReduce 应用程序中配置就可以生效:mapreduce.map.memory.mb:一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。mapreduce.reduce.memory.mb:一个ReduceTask可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。mapreduce.map.cpu.vcores:每个MapTask可使用的最多cpu core数目,默认值: 1mapreduce.reduce.cpu.vcores:每个ReduceTask可使用的最多cpu core数目,默认值: 1mapreduce.map.java.opts: MapTask的JVM参数,你可以在此配置默认的java heap size等参数, 比如:"-Xmx2048m -verbose:gc -Xloggc:/tmp/@taskid@.gc",默认值是:""mapreduce.reduce.java.opts: ReduceTask的JVM参数,你可以在此配置默认的java heap size等参数以下参数应该在yarn启动之前就配置在服务器的配置文件中才能生效:yarn.scheduler.minimum-allocation-mb=1024 给应用程序container分配的最小内存yarn.scheduler.maximum-allocation-mb=8192 给应用程序container分配的最大内存yarn.scheduler.minimum-allocation-vcores=1 yarn.scheduler.maximum-allocation-vcores=32 yarn.nodemanager.resource.memory-mb=8192 mapreduce.task.io.sort.mb=256 (HDFSv3.0) shuffle的环形缓冲区大小,默认256m mapreduce.map.sort.spill.percent=0.8 环形缓冲区溢出的阈值,默认80% MapReduce程序进行flush操作的阀值,默认0.80。mapreduce.reduce.shuffle.parallelcopies MapReduce程序reducer copy数据的线程数,默认10 (HDFSv3.0)。mapreduce.reduce.shuffle.input.buffer.percent reduce复制map数据的时候指定的内存堆大小百分比,默认为0.70 适当的增加该值可以减少map数据的磁盘溢出,能够提高系统能。mapreduce.reduce.shuffle.merge.percentreduce reduce进行shuffle的时候,用于启动合并输出和磁盘溢写的过程的阀值,默认为0.66。如果允许,适当增大其比例能够减少磁盘溢写次数,提高系统性能。同mapreduce.reduce.shuffle.input.buffer.percent一起使用 mapreduce.task.timeout mr程序的task执行情况汇报过期时间,默认600000(10分钟) 设置为0表示不进行该值的判断。容错相关参数mapreduce.map.maxattempts=4 每个MapTask最大重试次数,一旦重试参数超过该值,则认为MapTask运行失败 mapreduce.reduce.maxattempts=4:每个ReduceTask最大重试次数,一旦重试参数超过该值,则认为MapTask运行失败 mapreduce.task.timeout=600000:Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该task处于block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远block住不退出,则强制设置了一个该超时时间(单位毫秒),老版本默认是300000。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大=====================================================================================
mapreduce常用命令#执行jar包程序
hdfs jar file.jar #杀死正在执行的jar包程序
hdfs job -kill job_202222xxxx#提交作业
hdfs job -submit <job-file>#打印map和reduce完成百分比和所有计数器
hdfs job -status <job-id>#打印计数器的值
hdfs job -counter <job-id> <group-name> <counter-name>#杀死指定作业
hdfs job -kill <job-id>#打印给定范围内jobtracker接收到的事件细节
hdfs job -events <job-id> <from-event-#><#-of-events>#打印作业的细节、失败及被杀死原因的细节。
更多的关于一个作业的细节比如成功的任务,做过的任务尝试等信息可以通过
all选项查看。
hdfs job -history [all] <jobOutputDir>
hdfs job -history <jobOutputDir>#显示所有的作业。-list 只显示将要完成的作业
hdfs job -list [all]#杀死任务,被杀死的任务不会不利于失败尝试
hdfs job -kill -task <task-id>#使任务失败。被失败的任务会对失败尝试不利
hdfs job -fail -task <task-id>
相关文章:
 —— 筑梦之路)
hadoop 集群常用命令(学习笔记) —— 筑梦之路
概念介绍 #HDFS 概述Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性&…...

ARC142D Deterministic Placing
ARC142D Deterministic Placing 题目大意 有一棵nnn个顶点的树,每个点上最多放一张卡片,你可以做如下操作: 同时将所有的卡片移到它所在顶点的相邻的一个顶点上 一个操作我们说它是好的,当下列条件满足: 每条边最…...

阶段八:服务框架高级(第二章:分布式事务)
阶段八:服务框架高级(第二章:分布式事务)Day-分布式事务0.学习目标1.分布式事务问题1.1.本地事务1.2.分布式事务1.3.演示分布式事务问题2.理论基础2.1.CAP定理2.1.1.一致性2.1.2.可用性2.1.3.分区容错2.1.4.矛盾2.2.BASE理论2.3.解…...
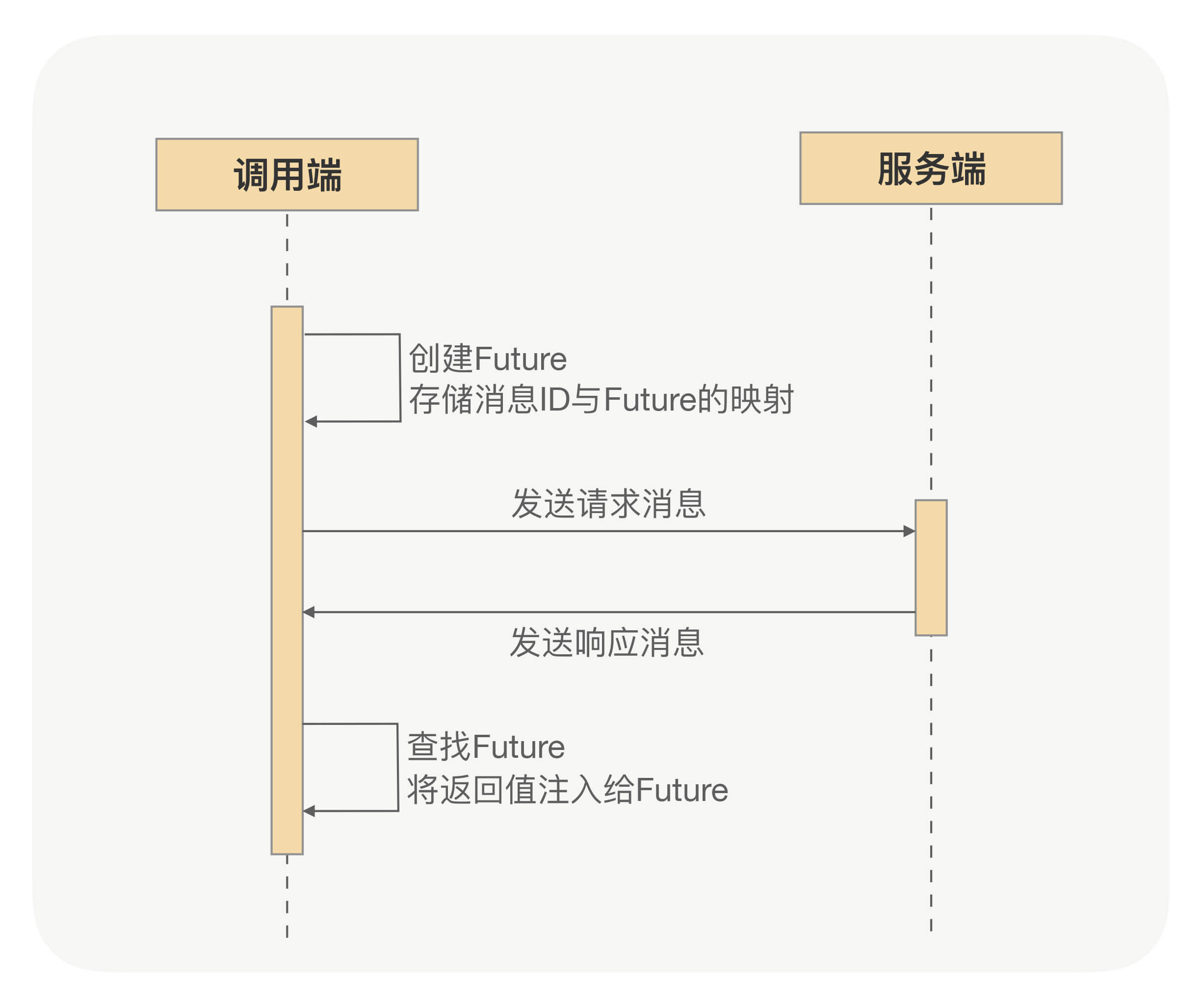
RPC异步化原理
深入RPC,更好使用RPC,须从RPC框架整体性能考虑问题。得知道如何提升RPC框架的性能、稳定性、安全性、吞吐量及如何在分布式下快速定位问题。RPC框架如何压榨单机吞吐量? 1 前言 TPS一直上不去,压测时CPU压到40%~50%就…...

C# 多窗口切换的实现
1、目的在主窗口中根据不同的按钮选择不同的子窗口显示。2、实现(1)、创建Winform窗体程序,放入SplitContainer控件splitContainer1将窗体分成左右2部分;(2)、在左侧splitContainer1.panel1中放入3个Button…...
【深度学习】RNN
1. 什么是RNN 循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递…...

招聘岗位,机会难得
岗位需求 费话不多说,直接上JD: 嵌入式开发工程师: 17:411.计算机、通信等相关专业。 2.熟悉网络基础知识,熟悉802.11a/b/g/n/ac协议,能通过抓包等分析手段排查定位各种wifi相关问题。 3.熟悉路由器主要功能及实现原…...
)
web打印的几种方法(2023)
在工作中出现web打印的情况是非常多的,其实这也是一个比较烦人的问题,这篇博客整理一下关于Web打印的一些方法或者方式。 1. window.print() 这个方法是用来打印网页的,页面上的其他的元素也会被打印处理,在打印的时候页眉页脚是…...
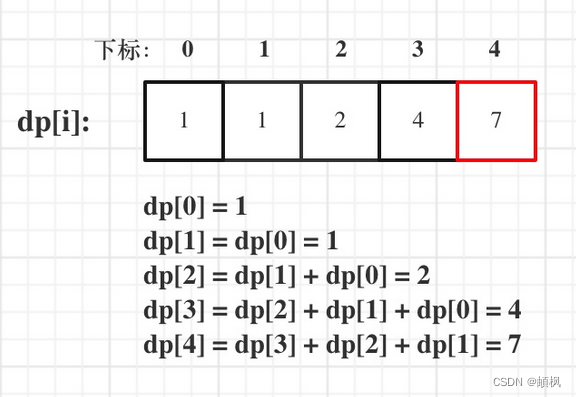
代码随想录算法训练营day44 | 动态规划之完全背包 518. 零钱兑换 II 377. 组合总和 Ⅳ
day44完全背包基础知识问题描述举个栗子518. 零钱兑换 II1.确定dp数组以及下标的含义2.确定递推公式3.dp数组如何初始化4.确定遍历顺序5.举例推导dp数组377. 组合总和 Ⅳ1.确定dp数组以及下标的含义2.确定递推公式3.dp数组如何初始化4.确定遍历顺序5.举例来推导dp数组完全背包基…...
IntelliJ IDEA 实用插件推荐(包含使用教程)
IntelliJ IDEA 实用插件推荐 背景:电脑重装了,重新下载了最新版的IntelliJ IDEA,感觉默认模式有点枯燥,于是决定从网上下载一些实用美观的插件优化自己以后吃饭的工具,现在推荐的都是目前还能用的(亲身实践…...

WideDeep模型
google提出的Wide&deep模型,将线性模型与DNN很好的结合起来,在提高模型泛化能力的同时,兼顾模型的记忆性。wide&deep这种将线性模型与DNN的并行连接模式,后来称为推荐领域的经典模式,奠定了后面深度学习模型的…...
nacos集群模式+keepalived搭建高可用服务
实际工作中如果nacos这样的核心服务停掉了或者整个服务器宕机了,那整个系统也就gg了,所以像这样的核心服务我们必须要搞个3个或者3个以上的nacos集群部署,实现高可用; 部署高可用版本之前,首先你要会部署单机版的naco…...

吉利「银河」负重突围
吉利控股集团最新公布的数据显示,2022年,吉利控股集团汽车总销量超230万辆,同比增长4.3%。其中,新能源汽车销量超64万辆,同比增长100.3%。 在中国本土市场,2022年吉利集团旗下品牌乘用车总交付量为135.84万…...

QT之图形视图框架概述——Graphics View Framework
QT之图形视图框架概述——Graphics View Framework1. 概述2. 核心类3. 事件传递4. Graphics View 坐标系统5. 参考1. 概述 Graphics View Framework是子Qt 4.2引入的,用来取代之前版本中的QCanvas。Graphics View Framework提拱了用于大量2D图形项的管理和交互的能…...
:数仓报表场景(上) 从分析函数效率一定快吗聊一聊结果集分页和隔行抽样实现方式)
【SQL开发实战技巧】系列(二十二):数仓报表场景(上) 从分析函数效率一定快吗聊一聊结果集分页和隔行抽样实现方式
系列文章目录 【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事 【SQL开发实战技巧】系列(二):简单单表查询 【SQL开发实战技巧】系列(三):SQL排序的那些事 【SQL开发实战技巧…...

小米无线AR眼镜探索版细节汇总
在MWC 2023期间,小米正式发布了一款无线AR眼镜,虽然还没看过实机,但XDA提前上手体验,我们从中进行总结。首先我要说的是,小米这款眼镜和高通无线AR眼镜参考设计高度重叠,产品卖点几乎一致,只是增…...

Web3中文|Litra:简洁而优美的NFT流动性协议,能给NFT市场带来什么?
2021年,NFT元年2021年,无疑是 NFT 的“元年”。这一年推特创始人的首条推特被拍出250万美元,加密艺术家Beeple的数字作品“First 5000 Days”在佳士得以6900万美元价格成交,无聊猿最高上涨了1800倍。2021年11月,在Goog…...

SSL证书对虚拟主机的用处有哪些?
虚拟主机是指在同一台服务器上,通过不同的域名或IP地址为多个网站提供服务的一种网络主机。而SSL证书则是一种数字证书,它用于加密网站与用户之间的通信,确保数据传输的安全性和完整性。在虚拟主机上,SSL证书有以下几个用处&#…...
SpringCloud之MQ笔记分享
MQ异步通信 初始MQ 同步通信 优点:时效性较强,可以以及得到结果 Feign就属于同步方式–问题: 耦合问题性能下降(中间的等待时间)资源浪费级联失败 异步通信 优点 耦合度低性能提升,吞吐量高故障隔离…...
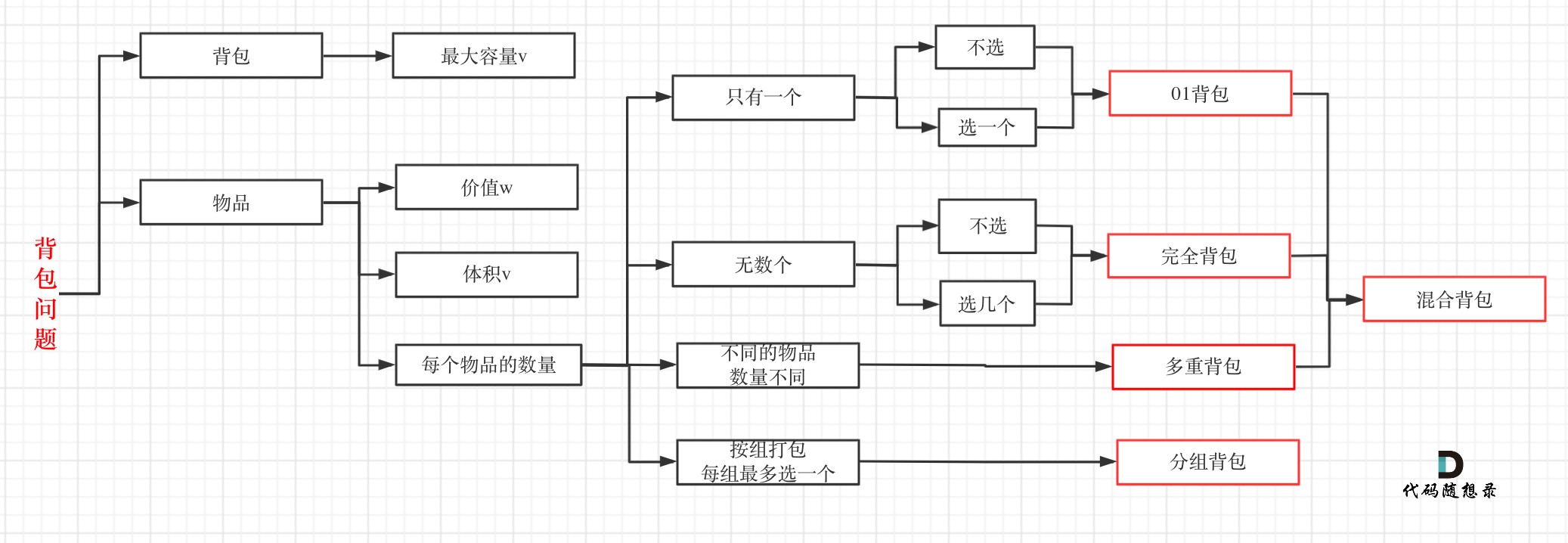
动态规划背包问题
背包问题的分类 拿到背包问题,最重要的是会归类到哪一种背包问题中,常见的考题里主要是01背包和完全背包,leetcode上连多重背包的题目都没有。实际完全背包问题就是01背包的一种。 对一和零这道题,很多人容易把m看成一个背包,n看成另一个背包,从而当做多重背包。然而这…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里
写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里 脚本1 #!/bin/bash #定义变量 ip10.1.1 #循环去ping主机的IP for ((i1;i<10;i)) doping -c1 $ip.$i &>/dev/null[ $? -eq 0 ] &&am…...

CTF show 数学不及格
拿到题目先查一下壳,看一下信息 发现是一个ELF文件,64位的 用IDA Pro 64 打开这个文件 然后点击F5进行伪代码转换 可以看到有五个if判断,第一个argc ! 5这个判断并没有起太大作用,主要是下面四个if判断 根据题目…...
李沐--动手学深度学习--GRU
1.GRU从零开始实现 #9.1.2GRU从零开始实现 import torch from torch import nn from d2l import torch as d2l#首先读取 8.5节中使用的时间机器数据集 batch_size,num_steps 32,35 train_iter,vocab d2l.load_data_time_machine(batch_size,num_steps) #初始化模型参数 def …...
RabbitMQ 各类交换机
为什么要用交换机? 交换机用来路由消息。如果直发队列,这个消息就被处理消失了,那别的队列也需要这个消息怎么办?那就要用到交换机 交换机类型 1,fanout:广播 特点 广播所有消息:将消息…...

AWS vs 阿里云:功能、服务与性能对比指南
在云计算领域,Amazon Web Services (AWS) 和阿里云 (Alibaba Cloud) 是全球领先的提供商,各自在功能范围、服务生态系统、性能表现和适用场景上具有独特优势。基于提供的引用[1]-[5],我将从功能、服务和性能三个方面进行结构化对比分析&#…...