LLM(四)| Chinese-LLaMA-Alpaca:包含中文 LLaMA 模型和经过指令微调的 Alpaca 大型模型

论文题目:《EFFICIENT AND EFFECTIVE TEXT ENCODING FOR CHINESE LL AMA AND ALPACA》
论文地址:https://arxiv.org/pdf/2304.08177v1.pdf
Github地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca
一、项目介绍
- 通过在原有的LLaMA词汇中增加20,000个中文符号来提高中文编码和解码的效率,并提高LLaMA的中文理解能力;
- 采用低秩适应(LoRA)的方法来有效地训练和部署中文的LLaMA和Alpaca模型,使研究人员能够在不产生过多计算成本的情况下使用这些模型;
- 评估了中文羊驼7B和13B模型在各种自然语言理解(NLU)和自然语言生成( NLG)任务中的表现,表明在中文语言任务中比原来的LLaMA对应模型有明显的改进;
- 公开了研究资源和结果,促进了NLP社区的进一步研究和合作,并鼓励将LLaMA和Alpaca模型改编为其他语言。
二、Chinese LLaMA
对于中文而言,LLaMA存在的问题:
- LLaMA tokenizer的原始词汇中只有不到一千个中文字符。尽管LLaMA tokenizer通过回退到byte来支持所有的中文字符,但这种回退策略大大增加了序列的长度,降低了中文文本的处理效率;
- byte tokens并不是专门用来表示汉字的,因为它们也被用来表示其他UTF-8令牌,这使得字节令牌很难学习汉字的语义。
为了解决这些问题,作者建议用额外的中文标记来扩展LLaMA tokenizer,并为新的tokenizer适配模型:
- 为了加强tokenizer对中文文本的支持,作者首先用SentencePiece在中文语料库上训练一个中文tokenizer,使用的词汇量为20,000。然后通过组合它们的词汇,将中文tokenizer合并到原始的LLaMA tokenizer中。最终得到了 一个合并的tokenizer,称之为中文LLaMA tokenizer,其词汇量为49,953;
- 为了适应中文LLaMA tokenizer的模型,作者将词嵌入和语言模型头的大小从形状V×H调整为V′×H,其中V=32,000代表原始词汇量,V′=49,953是中文LLaMA tokenizer的词汇量。新的行被附加到原始嵌入矩阵的末尾,以确保原始词汇中的标记的嵌入仍然不受影响。
实验表明,中文LLaMA tokenizer产生的tokens数量大约是原始LLaMA tokenizer的一半,如表1所示。正如我们所看到的,使用中文LLaMA tokenizer大大减少了编码长度,在固定的语境长度下,模型可以容纳大约两倍的信息,而且生成速度比原来的LLaMA tokenizer快两倍。

在完成上述适应步骤后,作者在标准的休闲语言建模(CLM)任务中使用中文-LLaMA tokenizer对中文-LLaMA模型进行了预训练。
三、Chinese Alpaca
在获得预训练的中文LLaMA模型后,作者按照斯坦福大学Alpaca中使用的方法,应用self-instructed微调来训练指令跟随模型。每个例子由一条指令和一个输出组成,将指令输入模型,并提示模型自动生成输出。这个过程类似于普通的语言建模任务。作者采用以下来自斯坦福大学Alpaca的提示模板,用于自我指导的微调,这也是在推理过程中使用的:

模型的loss只会技术输出部分,公式如下所示:

作者的方法和Stanford Alpaca的一个关键区别是,作者只使用了没有Input字段的例子设计的提示模板,而Stanford Alpaca为有Input字段和没有Input字段的例子分别采用了两个模板。如果例子中包含一个非空的Input字段,作者使用一个"/n "将指令和输入连接起来,形成新的指令。
PS:Alpaca模型有一个额外的填充标记,导致词汇量为49,954。
四、使用LoRA进行微调
Low-Rank Adaptation (LoRA)是一种参数高效的训练方法,它在预训练模型层旁支引入了可训练A、B矩阵,通过调整秩r来控制训练参数和模型效果,冻结大模型参数,只训练这两个A、B矩阵,这种方法大大减少了可训练参数的数量,LoRA形式如下图所示:
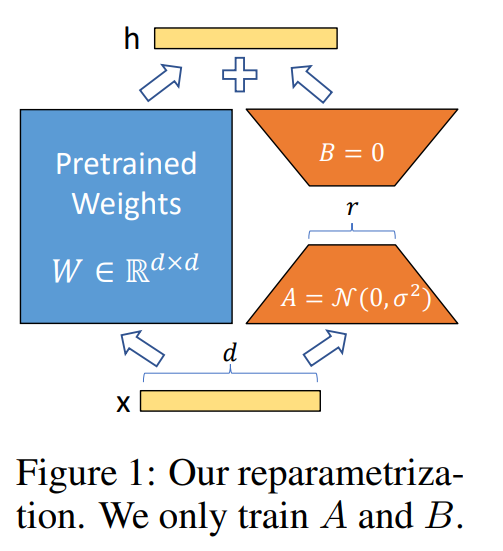
LoRA的一般公式如下,其中r是预先确定的秩,d是隐藏的大小,A和B是分解的可训练矩阵:
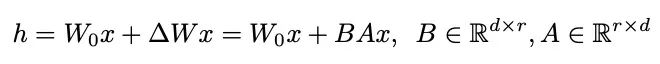
为控制预算,作者在chinese-LalaMA/Alpaca模型的实验中都讲应用LoRA,包括预训练和微调阶段。作者主要将LoRA引入注意力模块的权重中,实验效果请参考下一节和表2。
五、实验设置
5.1、用于预训练和微调的实验设置
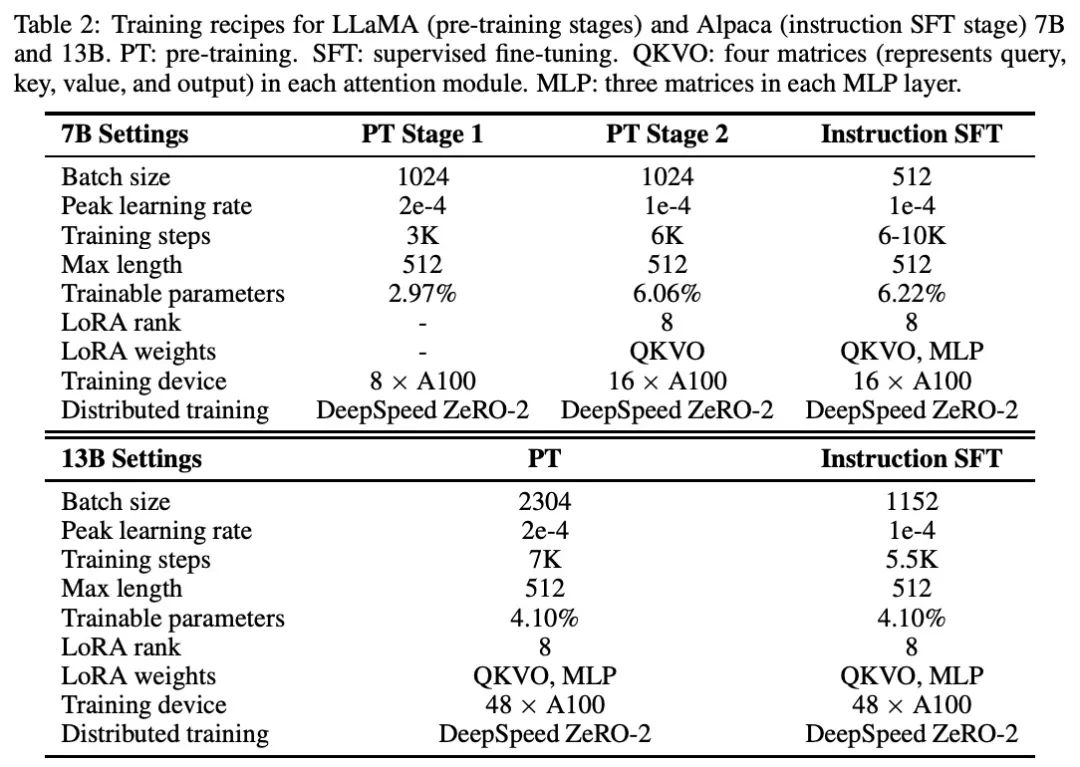
7B版本
预训练:作者用原始的LLaMA权重初始化中文-LLaMA模型,收集中文BERT-wwm、MacBERT、LERT等模型使用的语料(大概20GB)进行预训练。预训练过程包括两个阶段:
- 第一阶段:冻结transformer编码器的参数,只训练embeddings来适应新增加的中文词向量,同时尽量减少对原始模型的干扰;
- 第二阶段:将LoRA权重(适配器)添加到注意力机制中,并训练embeddings、LM头和新增加的LoRA参数;
指令微调:在得到预训练的模型后,作者在MLP层添加LoRA适配器来增加可训练参数的数量。微调数据包括翻译、pCLUE3 , Stanford Alpaca,以及爬虫的SFT数据。对于抓取的数据,作者采用从ChatGPT(gpt-3.5-turboAPI)中自动获取数据的self-instruction方法。超参数可以参考表2,微调数据的详细信息可以在表3中查阅。
13B版本
预训练:13B模型的预训练过程与7B模型的预训练过程基本相同,作者跳过了预训练的第1阶段,直接将LoRA应用于注意力和MLPs的训练,同时将嵌入和LM头设置为可训练。
指令微调:LoRA设置和可训练参数与预训练阶段保持一致。作者在13B模型的微调中使用了额外的100万个爬行的self-instruction的数据,使得13B模型的总数据量为3M,超参数可以参考表2。
5.2、解码的设置
LLMs的解码过程在决定生成文本的质量和多样性方面起着关键作用。在实验中,作者设置的解码超参数如下表所示:
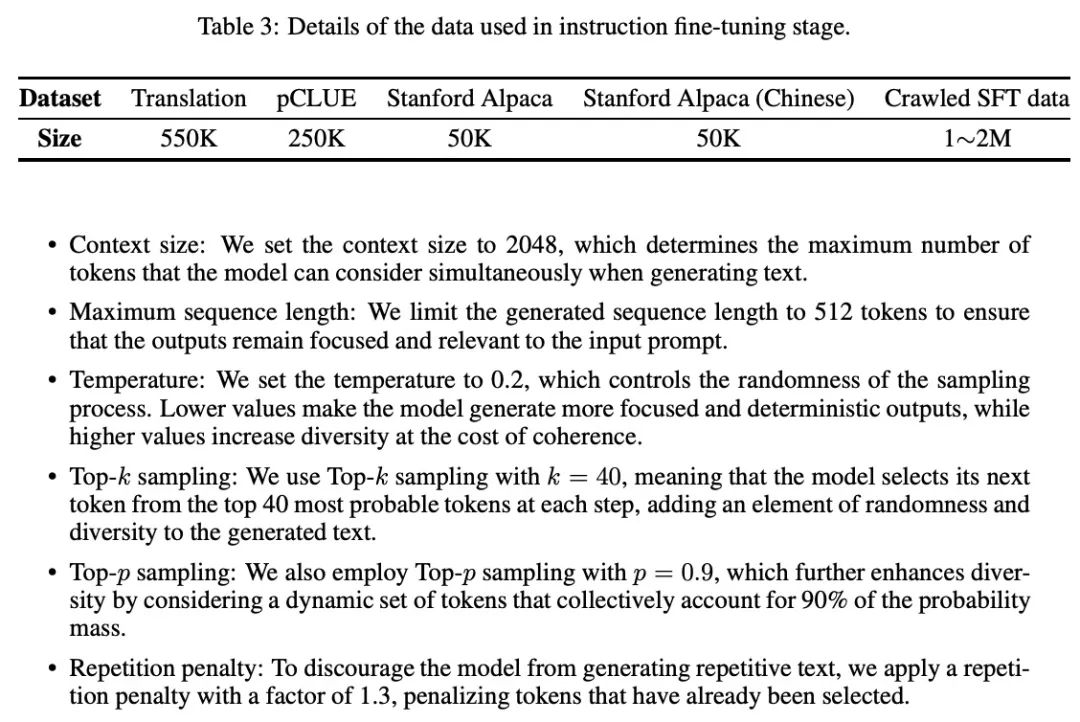
- 上下文大小:上下文大小设置为2048,这决定了模型在生成文本时可以同时考虑的最大数量的标记;
-
最大的序列长度:生成的序列长度限制在512个标记,以确保输出结果保持重点,并与输入提示相关;
-
温度:温度设置为0.2,控制采样过程的随机性。较低的值使模型产生更集中和确定的输出,而较高的值则以一致性为代价增加多样性;
-
Top-k抽样:使用k=40的Top-k抽样,这意味着模型在每一步从最有可能的40个标记中选择其下一个标记,为生成的文本添加随机性和多样性元素;
-
Top-p抽样:采用了p=0.9的Top-p抽样,通过考虑集体占概率质量90%的动态标记集,进一步提高了分歧度;
-
重复性惩罚:为了阻止模型生成重复的文本,应用了一个系数为1.3的重复惩罚,惩罚那些已经被选中的标记。
PS:这些值对于每个应用场景来说可能都不是最佳的。作者没有对每个任务的这些超参数进行进一步的调整,以保持一个平衡的观点。
5.3、在CPU上部署
在个人电脑上部署大型语言模型,特别是在CPU上部署,由于其巨大的计算需求,历来都是一个挑战。然而,在许多社区努力的帮助下,如llama.cpp,用户可以有效地将LLM量化为4bit形式,大大减少内存使用和计算需求,使LLM更容易部署在个人电脑上,这也使得与模型的互动更加快速,并有利于本地数据处理。量化LLM并将其部署在个人电脑上,有几个好处。首先,它帮助用户保护数据隐私,确保敏感信息留在他们的本地环境中,而不是被传输到外部服务器。其次,它通过使计算资源有限的用户更容易接触到LLMs,实现了对它们的民主化访问。最后,它促进了利用本地LLM部署的新应用和研究方向的发展。总的来说,使用llama.cpp(或类似的)在个人电脑上部署LLM的能力,为在各种领域中更多地利用LLM和关注隐私铺平了道路。
在下面的章节中,作者将使用4bitRTN量化的中文羊驼进行评估,从用户的角度来看,这比面向研究的观点更现实。通常来说,4bit量化的模型一般比FP16或FP32模型的表现要差。
5.4、评价和任务设置
评估文本生成任务的性能可能具有挑战性,因为它们的形式有很大的不同,这与自然语言理解任务(如文本分类和提取式机器阅读理解)不同。继以前利用GPT-4作为评分方法的工作之后,作者也采用GPT-4为每个样本提供一个总分(10分制),这比人工评估更有效。然而,GPT-4可能并不总是提供准确的分数,所以作者对其评分进行人工检查,必要时进行调整。人工检查确保了评分的一致性,并反映了被评估模型的真实性能。作者使用以下提示模板对系统的输出进行评分:

通过采用GPT-4作为评分方法,结合人工检查,作者建立了一个可靠的评估框架,有效地衡量了中文羊驼模型在一系列自然语言理解和生成任务中的表现。评估集由160个样本组成,涵盖10个不同的任务,包括问题回答、推理、文学、娱乐、翻译、多轮对话、编码和伦理等。一项具体任务的总分是通过将该任务中所有样本的分数相加,并将总分归一化为100分来计算的。这种方法确保了评价集反映了模型在各种任务中的能力,为其性能提供了一个平衡而有力的衡量。
六、实验结果分析
在这一节中,作者介绍并分析了4bit量化的中文Alpaca-7B和Alpaca-13B模型进行实验的结果,如表4所示。
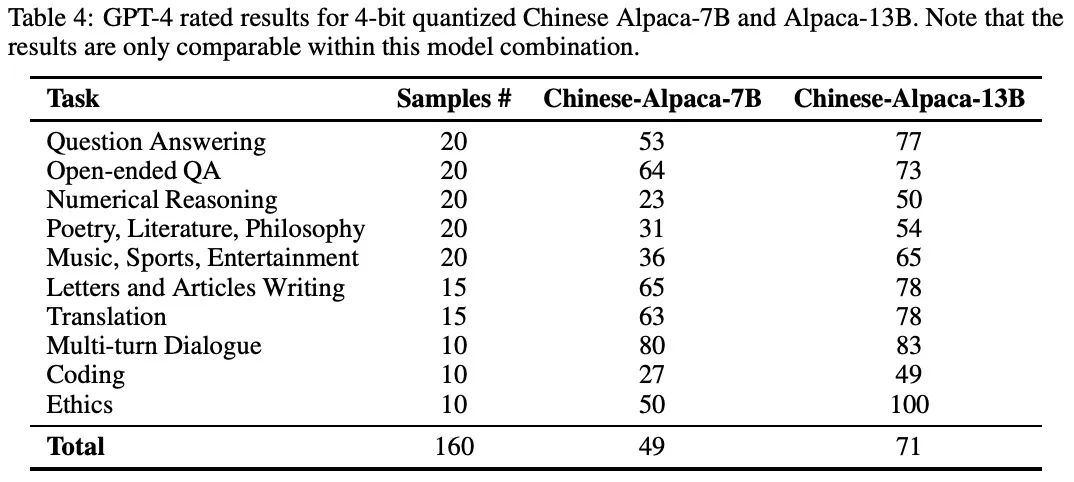
基于GPT-4在10个不同的NLP任务中的评分结果,共包括160个样本。值得注意的是,所提出的分数只可以相互比较,而不能与其他模型比较,这就需要对系统重新评分。
中文的Alpaca-7B和Alpaca-13B模型的性能都显示出比原来的LLaMA模型有明显的提高。中文的Alpaca-13B模型的性能一直优于7B变体,突出了增加模型容量的好处。
对于问题回答任务,中文的Alpaca-13B获得了77分,而7B模型为53分。在开放式问答中也可以看到类似的改进,13B和7B模型的得分分别为73和64。数字推理显示出更大的改进,13B模型的得分是50,而7B模型的得分是23。
在诗歌、文学、哲学、音乐、体育和娱乐等领域,13B模型的表现继续优于7B模型,其得分分别为54和65,而7B模型为31和36。在涉及信件和文章、翻译和多轮对话的任务中,性能差距仍然很大,13B模型一直取得较高的分数。有趣的是,即使作者没有使用任何多轮对话数据来调整系统,中文羊驼仍然有能力跟踪对话历史,并以连续的方式遵循用户指令。
编码任务表现出明显的改进,中文的Alpaca-13B模型得到49分,而7B模型得到27分。最显著的性能差异可以在伦理学任务中观察到,13B模型获得了100分的满分,而7B模型的得分是50分,这表明在拒绝任何不道德的用户输入方面表现出色。
总之,实验结果表明,中文的Alpaca-7B和Alpaca-13B模型都比原来的LLaMA模型有明显的改进,其中13B模型在所有任务中的表现一直优于7B模型。这强调了作者的方法在提高LLaMA和Alpaca模型的中文理解和生成能力方面的有效性。


七、结论
在这份技术报告中,作者提出了一种方法来提高LLaMA模型的中文理解和生成能力。认识到原来的LLaMA中文词汇的局限性,通过加入2万个额外的中文符号来扩展它,极大地提高了它对中文的编码效率。在中文LLaMA的基础上,用指令数据进行了监督性的微调,从而开发出了中文羊驼模型,它表现出了更好的指令跟随能力。
为了有效地评估模型,在10种不同的任务类型中注释了160个样本,并使用GPT-4进行评估。实验表明,所提出的模型在中文理解和生成任务中明显优于原LLaMA,与7B变体相比,13B变体一直取得更大的改进。
展望未来,作者计划探索从人类反馈中强化学习(RLHF)或从人工智能指导的反馈中再强化学习(RLAIF),以进一步使模型的输出与人类的偏好一致。此外,作者打算采用更先进和有效的量化方法,如GPTQ等。此外,作者还打算研究LoRA的替代方法,以便更有效地对大型语言模型进行预训练和微调,最终提高它们在中文NLP社区各种任务中的性能和适用性。
限制条件
虽然这个项目成功地加强了对LLaMA和Alpaca模型的中文理解和生成能力,但必须承认有几个局限性:
- 有害的和不可预知的内容:结果表明,13B版本比7B版本有更好的能力来拒绝不道德的查询。然而,这些模型仍然可能产生有害的或与人类偏好和价值观不一致的内容。这个问题可能来自于训练数据中存在的偏见,或者模型在某些情况下无法辨别适当的输出;
- 训练不充分:由于计算能力和数据可用性的限制,模型的训练可能不足以达到最佳性能。因此,模型的中文理解能力仍有改进的余地;
- 缺少稳健性:在某些情况下,模型可能会表现出脆性,在面对对抗性输入或罕见的语 言现象时产生不一致或无意义的输出;
- 可扩展性和效率:尽管应用了LoRA和4bit量化,使模型更容易被更多的人接受, 但当与原来的LLaMA相结合时,模型的大尺寸和复杂性会导致部署上的困难,特别是对于计算资源有限的用户。这个问题可能会阻碍这些模型在各种应用中的可及性和广泛采用。
参考文献:
[1] https://arxiv.org/pdf/2304.08177v1.pdf
相关文章:
LLM(四)| Chinese-LLaMA-Alpaca:包含中文 LLaMA 模型和经过指令微调的 Alpaca 大型模型
论文题目:《EFFICIENT AND EFFECTIVE TEXT ENCODING FOR CHINESE LL AMA AND ALPACA》 论文地址:https://arxiv.org/pdf/2304.08177v1.pdf Github地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca 一、项目介绍 通过在原有的LLaMA词…...

虚拟机CentOS 8 重启后不能上网
情况说明:原本虚拟机是可以上网的,然后嘚一下,重启后,连接不上网络,完了,上网查找一堆质料,我的连接方式是桥接模式(复制物理网络连接状态)。 好,有人说是vmn…...

让AI拥有人类的价值观,和让AI拥有人类智能同样重要
编者按:2023年是微软亚洲研究院建院25周年。25年来,微软亚洲研究院探索并实践了一种独特且有效的企业研究院的新模式,并以此为基础产出了诸多对微软公司和全球社会都有积极影响的创新成果。一直以来,微软亚洲研究院致力于创造具有…...

《C++避坑神器·十七》找到程序崩溃Bug的一个实用方法:dump调试
在检查程序报错除了断点调试,生成log日志,还有种直接的方法,调试dump文件,该调试方法可以在运行exe程序崩溃时进行调试。文章末尾有下载链接。 头文件 #include "crashdump.h"在mainWindow或主程序最开始处加下面代码…...
ROS stm32 CAN通信
文章目录 运行环境:原理1.1 ros中的代码1)socketcan_bridge2)测试的ros-python包3)keil5中数据解析4)USB-CAN连接5)启动指令 运行环境: ubuntu18.04.melodic STM32:DJI Robomaster C板 ROS:18.04 硬件:USB-CAN&#x…...
简单地聊一聊Spring Boot的构架
前言 本文小编将详细解析Spring Boot框架,并通过代码举例说明每个层的作用。我们将深入探讨Spring Boot的整体架构,包括展示层、业务逻辑层和数据访问层。通过这些例子,读者将更加清晰地了解每个层在应用程序中的具体作用。通过代码实例&…...
【算法】复习搜索与图论
🍎 博客主页:🌙披星戴月的贾维斯 🍎 欢迎关注:👍点赞🍃收藏🔥留言 🍇系列专栏:🌙 蓝桥杯 🌙请不要相信胜利就像山坡上的蒲公英一样唾手…...

【KCC@南京】KCC南京数字经济-开源行
一场数字经济与开源的视听盛宴,即将于11月26日,在南京举办。本次参与活动的有: 庄表伟(开源社理事执行长、天工开物开源基金会执行副秘书长)、林旅强Richard(开源社联合创始人、前华为开源专家)…...
苍穹外卖-day11
苍穹外卖-day11 课程内容 Apache ECharts营业额统计用户统计订单统计销量排名Top10 功能实现:数据统计 数据统计效果图: 1. Apache ECharts 1.1 介绍 Apache ECharts 是一款基于 Javascript 的数据可视化图表库,提供直观,生…...

git_07_协同开发
1.作业回复 干的什么事?动了哪些东西? 文档作业xxx文档已编写完成,相关svn目录:xxx/xxx/xxx代码作业(Git代码提交规范)具体什么问题,影响范围,是否已经解决: feat(xxx):改动描述 perf(xxx):改动…...
对比国内主流开源 SQL 审核平台 Yearning vs Archery
Yearning, Archery 和 Bytebase 是目前国内最主流的三个开源 SQL 审核平台。其中 Yearning 和 Archery 是社区性质的项目,而 Bytebase 则是商业化产品。通常调研 Bytebase 的用户也会同时比较 Yearning 和 Archery。 下面我们就来展开对比一下 Yearning 和 Archery…...

Mistral 7B 比Llama 2更好的开源大模型 (三)
Mistral 7B 比Llama 2更好的开源大模型 Mistral 7B是一个70亿参数的语言模型,旨在获得卓越的性能和效率。Mistral 7B在所有评估的基准测试中都优于最好的开放13B模型(Llama 2),在推理、数学和代码生成方面也优于最好的发布34B模型(Llama 1)。Mistral 7B模型利用分组查询注…...
关于 Git 你了解多少?
1. 什么是Git? Git 是一个版本控制系统,由林纳斯托瓦兹创建。它旨在管理项目代码的更改,以便团队成员可以协作开发和维护代码库。Git 可以让用户跟踪代码的更改、回滚错误的更改、合并代码等。Git 还具有分支和标签的功能,使得团队成员可以在…...

关于Elasticsearch的自动补全、数据同步和集群,以下是相关的知识点
1. 自动补全:Elasticsearch可以通过自动补全功能帮助用户快速查找相关的内容。它使用了一种称为“completion suggester”的功能来实现自动补全,是一种基于前缀的建议查询,可以在用户输入时提供实时建议。 2. 数据同步:Elasticse…...
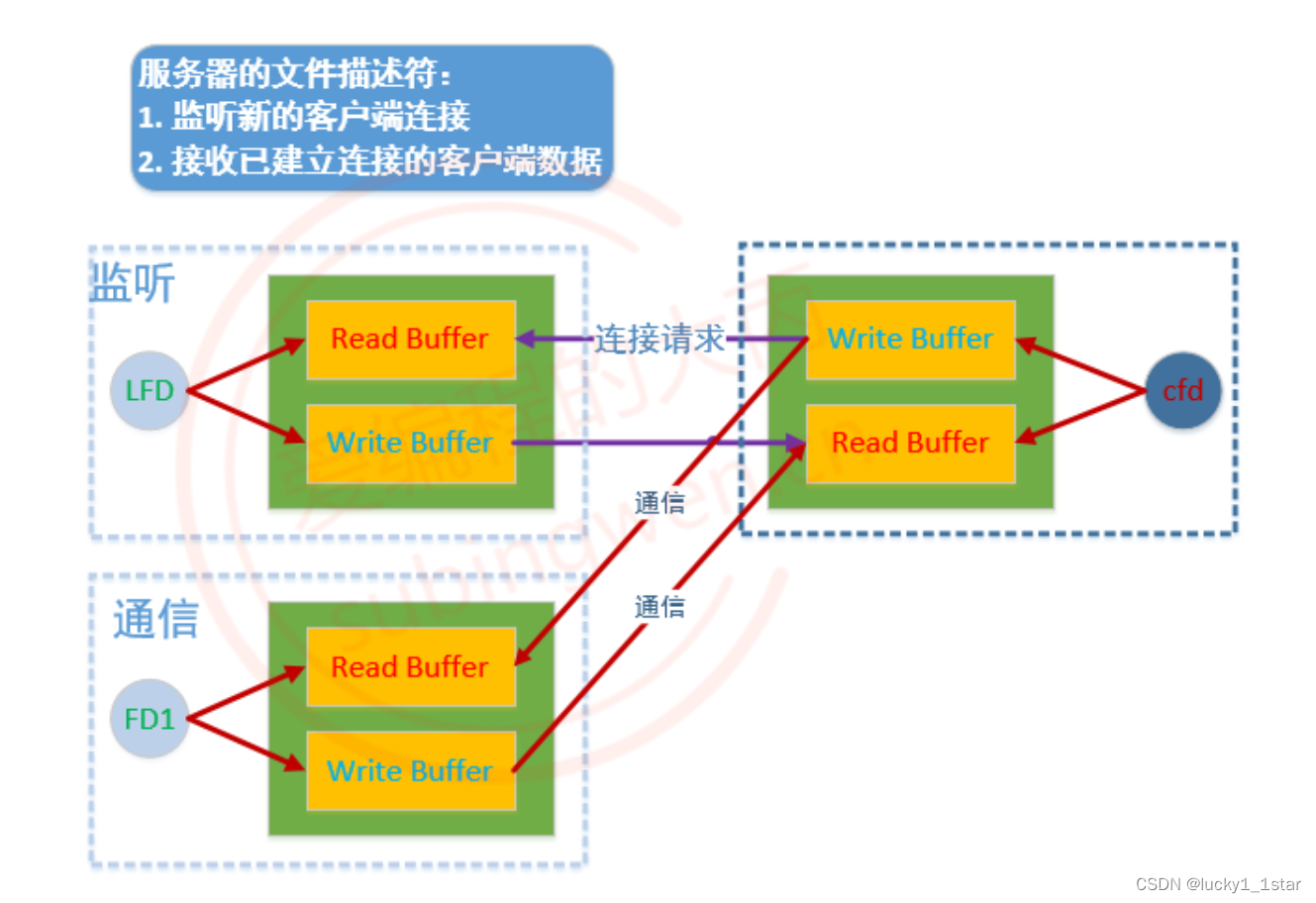
linux套接字-Socket
1.概念 局域网和广域网 局域网:局域网将一定区域内的各种计算机、外部设备和数据库连接起来形成计算机通信的私有网络。广域网:又称广域网、外网、公网。是连接不同地区局域网或城域网计算机通信的远程公共网络。IPInternet Protocol)&#…...
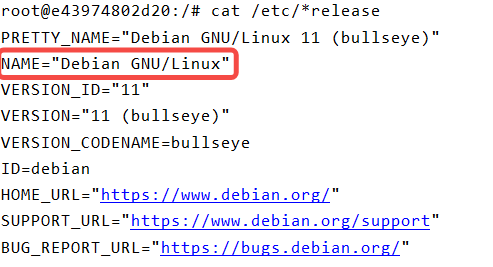
debian 修改镜像源为阿里云【详细步骤】
文章目录 修改步骤第 1 步:安装 vim 软件第 2 步:备份源第 3 步:修改为阿里云镜像参考👉 背景:在 Docker 中安装了 jenkins 容器。查看系统,发现是 debian 11(bullseye)。 👉 目标:修改 debian bullseye 的镜像为阿里云镜像,加速软件安装。 修改步骤 第 1 步:…...

从0到0.01入门React | 004.精选 React 面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...
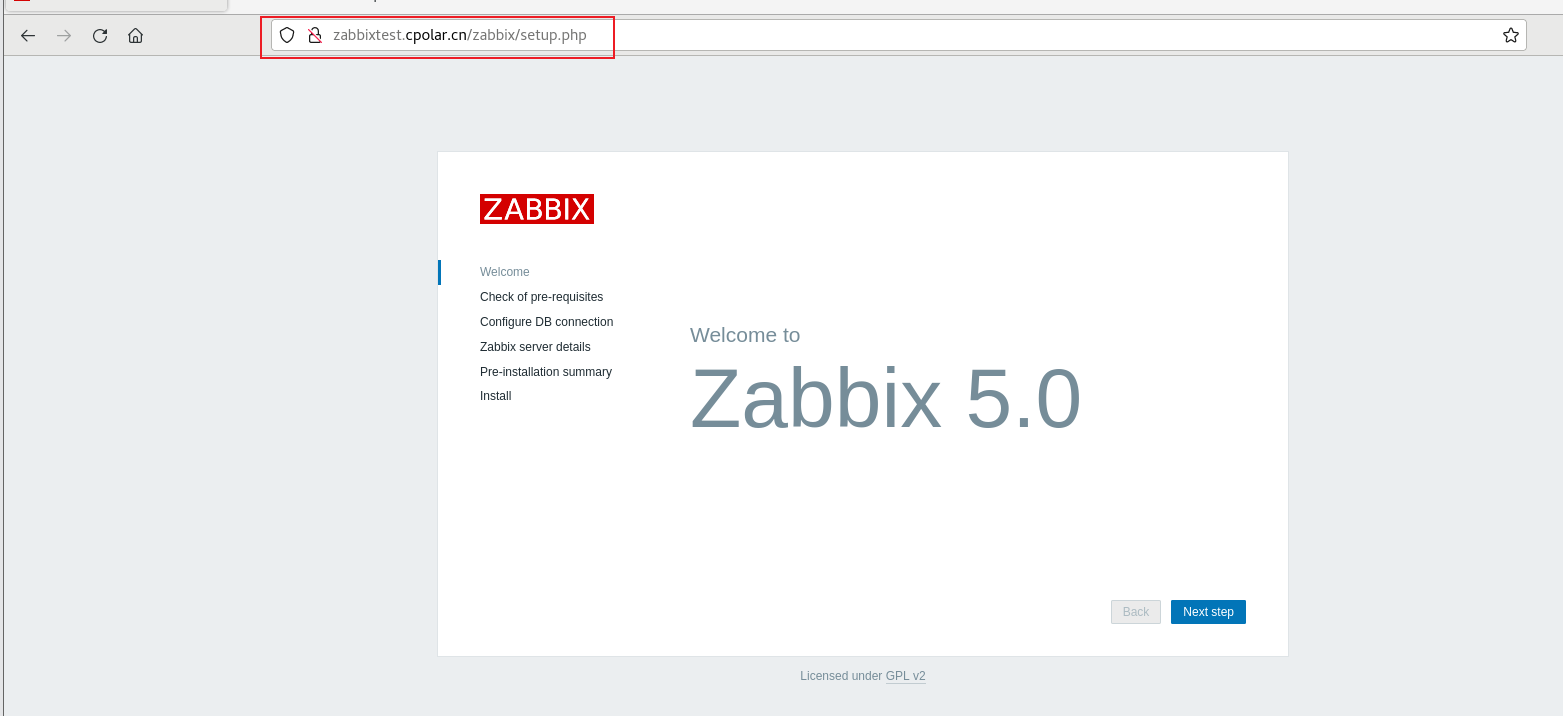
Linux 本地zabbix结合内网穿透工具实现安全远程访问浏览器
前言 Zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题。 本地zabbix web管理界面限制在只能局域…...
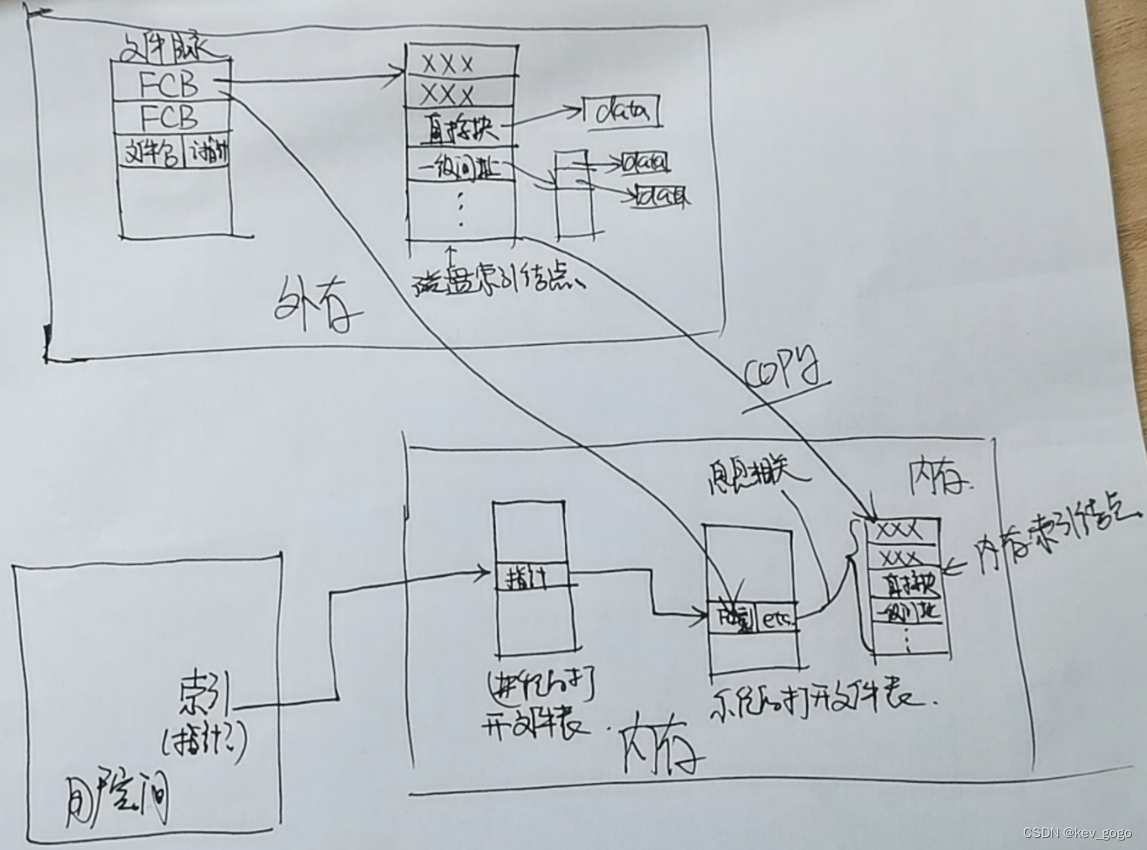
【以图会意】文件系统从外存到内存到用户空间
首先,在文件目录中,装有很多块FCB,由文件名和i指针两部分构成,指针指向文件所在的索引结点,包含了例如:文件存储权限,文件长度等一系列文件的信息,最重要的当然是物理地址࿰…...

一、交换配置
2.SW1、SW2、SW3启用MSTP,实现网络二层负载均衡和冗余备份,创建实例Instance10和Instance20,名称为skills,修订版本为1,其中Instance10关联Vlan60和Vlan70,Instance20关联Vlan80和Vlan90。SW1为Instance0和Instance10的根交换机,为Instance20备份根交换机;SW2为Instanc…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
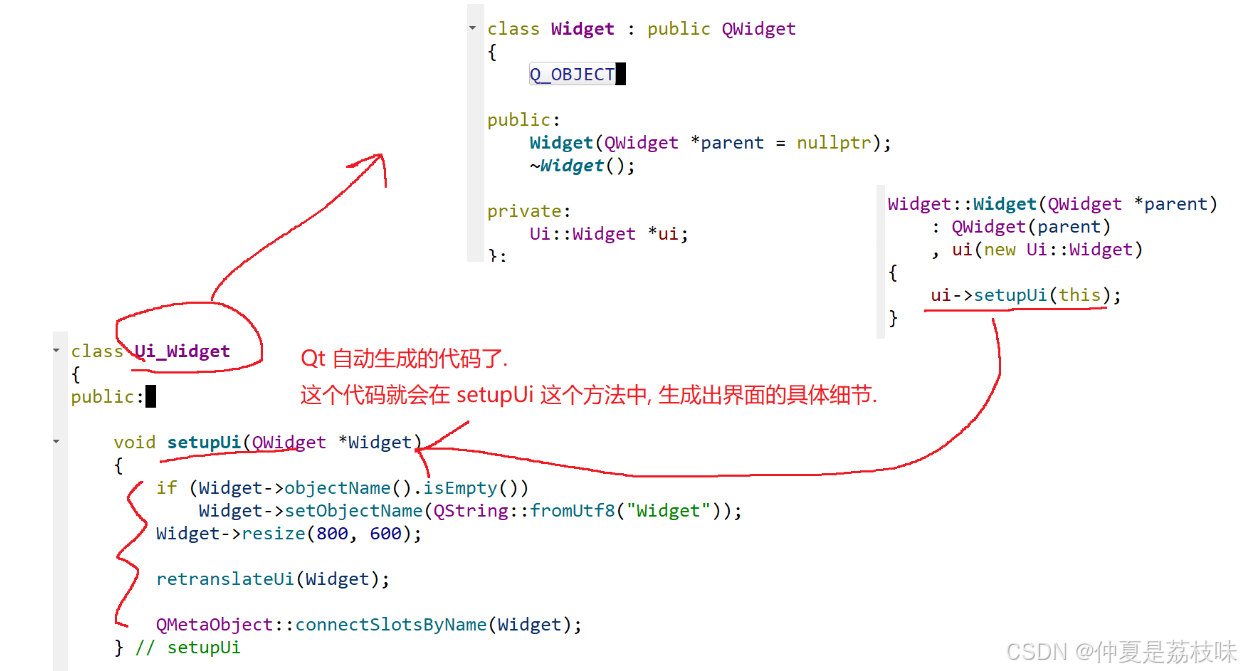
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...

Easy Excel
Easy Excel 一、依赖引入二、基本使用1. 定义实体类(导入/导出共用)2. 写 Excel3. 读 Excel 三、常用注解说明(完整列表)四、进阶:自定义转换器(Converter) 其它自定义转换器没生效 Easy Excel在…...