21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
21、Flink 的table API与DataStream API 集成(3)- changelog流处理、管道示例、类型转换和老版本转换示例
21、Flink 的table API与DataStream API 集成(完整版)
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
25、Flink 的table api与sql之函数(自定义函数示例)
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
33、Flink 的Table API 和 SQL 中的时区
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、Table API 与 DataStream API集成
- 4、批处理模式
- 1)、Changelog Unification
- 5、Handling of (Insert-Only) Streams 处理(仅插入)流
- 1)、fromDataStream 示例
- 2)、createTemporaryView 示例
- 3)、toDataStream示例
本文是Flink table api 与 datastream api的集成的第二篇,主要批处理模式下的集成和insert-only处理,并以具体的示例进行说明。
本文依赖flink、kafka集群能正常使用。
本文分为2个部分,即批处理模式下的集成和insert-only处理。
本文的示例是在Flink 1.17版本中运行。
一、Table API 与 DataStream API集成
4、批处理模式
批处理运行时模式是有界Flink程序的专用执行模式。
一般来说,有界性是数据源的一个属性,它告诉我们来自该源的所有记录在执行之前是否已知,或者新数据是否会显示,可能是无限期的。反过来,如果作业的所有源都有界,则作业是有界的,否则作业是无界的。
另一方面,流运行时模式可用于有界作业和无界作业。
有关不同执行模式的更多信息,请参阅相应的DataStream API部分。
Table API和SQL计划器为这两种模式中的任何一种提供了一组专门的优化器规则和运行时运算符。
截至Flink 版本 1.17,运行时模式不是从源自动派生的,因此,在实例化StreamTableEnvironment时,必须显式设置或将从StreamExecutionEnvironment采用运行时模式:
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;// adopt mode from StreamExecutionEnvironment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// or// set mode explicitly for StreamTableEnvironment
// it will be propagated to StreamExecutionEnvironment during planning
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, EnvironmentSettings.inBatchMode());
在将运行时模式设置为BATCH之前,必须满足以下先决条件:
- 所有源都必须声明自己是有界的。
- 截至Flink 版本 1.17,表源必须发出仅插入更改。
- 运算符需要足够的堆外内存用于排序和其他中间结果。
- 所有表操作必须在批处理模式下可用。截至Flink 版本 1.17,其中一些仅在流媒体模式下可用。请查看相应的表API和SQL页面。
批处理执行具有以下含义(以及其他含义):
- 渐进水印(Progressive watermarks)既不会生成,也不会在运算符中使用。但是,源在关闭之前会发出最大水印(maximum watermark)。
- 根据execution.batch-shuffle-mode,任务之间的交换可能会被阻塞。这也意味着与在流模式下执行相同管道相比,可能会减少资源需求。
- 检查点已禁用。插入了人工状态后端。
- 表操作不会产生增量更新,而只会产生一个完整的最终结果,该结果将转换为仅插入的变更日志流。
由于批处理可以被视为流处理的特殊情况,因此我们建议首先实现流管道,因为它是有界和无界数据的最通用实现。
理论上,流管道可以执行所有操作符。然而,在实践中,一些操作可能没有多大意义,因为它们将导致不断增长的状态,因此不受支持。全局排序是一个仅在批处理模式下可用的示例。简单地说:应该可以在批处理模式下运行工作流管道,但不一定相反。
下面的示例演示如何使用DataGen表源处理批处理模式。许多源提供了隐式使连接器有界的选项,例如,通过定义终止偏移量或时间戳。在我们的示例中,我们使用number-of-rows选项限制行数。
public static void test5() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);//建表Table table =tenv.from(TableDescriptor.forConnector("datagen").option("number-of-rows", "5") // make the source bounded.schema(Schema.newBuilder().column("uid", DataTypes.TINYINT()).column("payload", DataTypes.STRING()).build()).build());//转datastream,并输出tenv.toDataStream(table).keyBy(r -> r.<Byte>getFieldAs("uid")).map(r -> "alan_payload: " + r.<String>getFieldAs("payload")).executeAndCollect().forEachRemaining(System.out::println);env.execute();}
- 输出
alan_payload: 143dc81ed1cf71d9b7a4f8088cae78b5fd919f0ba2bc57e24828c18dea47fb9e84f4ce6a74d0f18285c8c66b9587947a81b1
alan_payload: c3bc0a98d286c9db33a02896bca16ac327f267183e16bc42c813741297ed3f51b998dc45d23231d2ca06677072c21b222369
alan_payload: ce3bae6e08c4dbef6b4d4517b426c76792b788126747c494110a48e6b4909920602643e37323e64038e64cc2d359476e7495
alan_payload: b22c2ac79d2e9be20caf3c311d12637dc42422f7d25132750b4afbb8e8dd341d0f767e42e70874f7207cf5a24c7d1caea713
alan_payload: d1bb8a7fe2077efaa61dc4befe8fef884c257c5c201c62bbac11787a222b70df021e16cba32d5cfc42527589af45dc968c7f
1)、Changelog Unification
在大多数情况下,当从流模式切换到批处理模式时,管道定义本身在Table API和DataStream API中都可以保持不变,反之亦然。然而,如前所述,由于避免了批处理模式中的增量操作,因此产生的变更日志流(changelog streams)可能会不同。
依赖于事件时间并利用水印作为完整性标记的基于时间的操作(Time-based operations)能够生成独立于运行时模式的仅插入变更日志流(insert-only changelog stream)。
下面的Java示例演示了一个Flink程序,该程序不仅在API级别上统一,而且在生成的changelog流中统一。
该示例使用基于两个表(ts)中的时间属性的 interval join来联接SQL中的两个表,即UserTable和OrderTable。
它使用DataStream API实现自定义运算符,该运算符使用KeyedProcessFunction和值状态(value state)对用户名进行重复数据消除。
运行结果见输出注释部分。
public static void test6() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.BATCH);StreamTableEnvironment tenv = StreamTableEnvironment.create(env);//数据源 userStreamDataStream<Row> userStream = env.fromElements(Row.of(LocalDateTime.parse("2023-11-13T17:50:00"), 1, "alan"),Row.of(LocalDateTime.parse("2023-11-13T17:55:00"), 2, "alanchan"),Row.of(LocalDateTime.parse("2023-11-13T18:00:00"), 2, "alanchanchn")).returns(Types.ROW_NAMED(new String[] {"ts", "uid", "name"},Types.LOCAL_DATE_TIME, Types.INT, Types.STRING));//数据源 orderStream DataStream<Row> orderStream = env.fromElements(Row.of(LocalDateTime.parse("2023-11-13T17:52:00"), 1, 122),Row.of(LocalDateTime.parse("2023-11-13T17:57:00"), 2, 239),Row.of(LocalDateTime.parse("2023-11-13T18:01:00"), 2, 999)).returns(Types.ROW_NAMED(new String[] {"ts", "uid", "amount"},Types.LOCAL_DATE_TIME, Types.INT, Types.INT));//创建视图 UserTabletenv.createTemporaryView("UserTable",userStream,Schema.newBuilder().column("ts", DataTypes.TIMESTAMP(3)).column("uid", DataTypes.INT()).column("name", DataTypes.STRING()).watermark("ts", "ts - INTERVAL '1' SECOND").build());//创建视图 OrderTabletenv.createTemporaryView("OrderTable",orderStream,Schema.newBuilder().column("ts", DataTypes.TIMESTAMP(3)).column("uid", DataTypes.INT()).column("amount", DataTypes.INT()).watermark("ts", "ts - INTERVAL '1' SECOND").build());// 建立OrderTable 和 UserTable 关联关系Table joinedTable =tenv.sqlQuery("SELECT U.name, O.amount " +"FROM UserTable U, OrderTable O " +"WHERE U.uid = O.uid AND O.ts BETWEEN U.ts AND U.ts + INTERVAL '5' MINUTES");//将table转成datastreamDataStream<Row> joinedStream = tenv.toDataStream(joinedTable);joinedStream.print();
// +I[alanchan, 239]
// +I[alanchanchn, 999]
// +I[alan, 122]env.execute();}- 使用ProcessFunction和ValueState现自定义运算符
在上面的例子中,加入下面的代码即可,运行结果是将姓名输出
// 使用ProcessFunction和值状态实现自定义运算符joinedStream.keyBy(r -> r.<String>getFieldAs("name")).process(new KeyedProcessFunction<String, Row, String>() {ValueState<String> seen;@Overridepublic void open(Configuration parameters) {seen = getRuntimeContext().getState(new ValueStateDescriptor<>("seen", String.class));}@Overridepublic void processElement(Row row, Context ctx, Collector<String> out)throws Exception {String name = row.getFieldAs("name");if (seen.value() == null) {seen.update(name);out.collect(name);}}}).print();
// alan
// alanchan
// alanchanchn5、Handling of (Insert-Only) Streams 处理(仅插入)流
StreamTableEnvironment提供了以下方法进行datastream的转换API:
- fromDataStream(DataStream):将仅插入更改和任意类型的流解释为表。默认情况下,不会传播事件时间和水印。
- fromDataStream(DataStream, Schema):将仅插入更改和任意类型的流解释为表。可选模式允许丰富列数据类型,并添加时间属性、水印策略、其他计算列或主键。
- createTemporaryView(String, DataStream):注册一个可以在sql中访问的流名称(虚表、视图)。它是createTemporaryView(String,fromDataStream(DataStream))的快捷方式。
- createTemporaryView(String, DataStream, Schema):注册一个可以在sql中访问的流名称(虚表、视图)。 它是createTemporaryView(String,fromDataStream(DataStream,Schema))的快捷方式。
- toDataStream(Table):将表转换为仅插入更改的流。默认的流记录类型为org.apache.flink.types.Row。将单个rowtime属性列写回DataStream API的记录中。水印也会传播。
- toDataStream(Table, AbstractDataType):将表转换为仅插入更改的流。该方法接受数据类型来表示所需的流记录类型。planner 可以插入隐式转换和重新排序列,以将列映射到(可能是嵌套的)数据类型的字段。
- toDataStream(Table, Class):toDataStream(Table,DataTypes.of(Class))的快捷方式,用于反射地快速创建所需的数据类型。
从Table API的角度来看,和DataStream API的转换类似于读取或写入在SQL中使用CREATE Table DDL定义的虚拟表连接器。
虚拟CREATE TABLE name(schema)WITH(options)语句中的模式部分可以自动从DataStream的类型信息中派生、丰富或完全使用org.apache.flink.table.api.Schema手动定义。
The virtual DataStream table connector exposes the following metadata for every row:
虚拟DataStream table 连接器为每一行暴露以下元数据:
| Key | Data Type | Description | R/W |
|---|---|---|---|
| rowtime | TIMESTAMP_LTZ(3) NOT NULL | Stream record’s timestamp. | R/W |
虚拟DataStream table source实现SupportsSourceWatermark,因此允许调用source_WATERMARK()内置函数作为水印策略,以采用来自DataStream API的水印。
1)、fromDataStream 示例
下面的代码展示了如何将fromDataStream用于不同的场景。其输出结果均在每个步骤的输出注释部分。
import java.time.Instant;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
public class TestFromDataStreamDemo {@NoArgsConstructor@AllArgsConstructor@Datapublic static class User {public String name;public Integer score;public Instant event_time;}public static void test1() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 2、创建数据源DataStream<User> dataStream =env.fromElements(new User("alan", 4, Instant.ofEpochMilli(1000)),new User("alanchan", 6, Instant.ofEpochMilli(1001)),new User("alanchanchn", 10, Instant.ofEpochMilli(1002)));// 示例1、显示table的数据类型// 说明了不需要基于时间的操作时的简单用例。Table table = tenv.fromDataStream(dataStream);
// table.printSchema();
// (
// `name` STRING,
// `score` INT,
// `event_time` TIMESTAMP_LTZ(9)
// )// 示例2、增加一列,并显示table的数据类型// 这些基于时间的操作应在处理时间内工作的最常见用例。Table table2 = tenv.fromDataStream(dataStream,Schema.newBuilder().columnByExpression("proc_time", "PROCTIME()").build());
// table2.printSchema();
// (
// `name` STRING,
// `score` INT,
// `event_time` TIMESTAMP_LTZ(9),
// `proc_time` TIMESTAMP_LTZ(3) NOT NULL *PROCTIME* AS PROCTIME()
// )// 示例3、增加rowtime列,并增加watermarkTable table3 =tenv.fromDataStream(dataStream,Schema.newBuilder().columnByExpression("rowtime", "CAST(event_time AS TIMESTAMP_LTZ(3))").watermark("rowtime", "rowtime - INTERVAL '10' SECOND").build());
// table3.printSchema();
// (
// `name` STRING,
// `score` INT,
// `event_time` TIMESTAMP_LTZ(9),
// `rowtime` TIMESTAMP_LTZ(3) *ROWTIME* AS CAST(event_time AS TIMESTAMP_LTZ(3)),
// WATERMARK FOR `rowtime`: TIMESTAMP_LTZ(3) AS rowtime - INTERVAL '10' SECOND
// )// 示例4、增加rowtime列,并增加watermark(SOURCE_WATERMARK()水印策略假设已经实现了,本部分仅仅是展示用法)// 基于时间的操作(如窗口或间隔联接)应成为管道的一部分时最常见的用例。Table table4 =tenv.fromDataStream(dataStream,Schema.newBuilder().columnByMetadata("rowtime", "TIMESTAMP_LTZ(3)").watermark("rowtime", "SOURCE_WATERMARK()").build());
// table4.printSchema();
// (
// `name` STRING,
// `score` INT,
// `event_time` TIMESTAMP_LTZ(9),
// `rowtime` TIMESTAMP_LTZ(3) *ROWTIME* METADATA,
// WATERMARK FOR `rowtime`: TIMESTAMP_LTZ(3) AS SOURCE_WATERMARK()
// ) // 示例5、修改event_time类型长度,增加event_time的水印策略(SOURCE_WATERMARK()水印策略假设已经实现了,本部分仅仅是展示用法)// 完全依赖于用户的声明。这对于用适当的数据类型替换DataStream API中的泛型类型(在Table API中是RAW)很有用。Table table5 =tenv.fromDataStream(dataStream,Schema.newBuilder().column("event_time", "TIMESTAMP_LTZ(3)").column("name", "STRING").column("score", "INT").watermark("event_time", "SOURCE_WATERMARK()").build());table5.printSchema();
// (
// `event_time` TIMESTAMP_LTZ(3) *ROWTIME*,
// `name` STRING,
// `score` INT
// )env.execute();}public static void main(String[] args) throws Exception {test1() ;}}由于DataType比TypeInformation更丰富,我们可以轻松地启用不可变POJO和其他复杂的数据结构。
下面的Java示例显示了可能的情况。
另请检查DataStream API的“数据类型和序列化”页面,以获取有关那里支持的类型的更多信息。
package org.tablesql.convert;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
public class TestFromDataStreamDemo {// user2的属性都加上了final修饰符public static class User2 {public final String name;public final Integer score;public User2(String name, Integer score) {this.name = name;this.score = score;}}public static void test2() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);//the DataStream API does not support immutable POJOs yet, the class will result in a generic type that is a RAW type in Table API by defaul//DataStream API尚不支持不可变POJO,该类的结果默认情况下将是一个Table API中是RAW类型的泛型。// 2、创建数据源DataStream<User2> dataStream = env.fromElements(new User2("Alice", 4),new User2("Bob", 6),new User2("Alice", 10));// 示例1:输出表结构Table table = tenv.fromDataStream(dataStream);
// table.printSchema();
// (
// `f0` RAW('org.tablesql.convert.TestFromDataStreamDemo$User2', '...')
// )// 示例2:声明式输出表结构// 在自定义模式中使用table API的类型系统为列声明更有用的数据类型,并在下面的“as”投影中重命名列Table table2 = tenv.fromDataStream(dataStream,Schema.newBuilder().column("f0", DataTypes.of(User2.class)).build()).as("user");
// table2.printSchema();
// (
// `user` *org.tablesql.convert.TestFromDataStreamDemo$User2<`name` STRING, `score` INT>*
// )//示例3:数据类型可以如上所述反射地提取或显式定义//Table table3 = tenv.fromDataStream(dataStream,Schema.newBuilder().column("f0",DataTypes.STRUCTURED(User2.class,DataTypes.FIELD("name", DataTypes.STRING()),DataTypes.FIELD("score", DataTypes.INT()))).build()).as("user");table3.printSchema();
// (
// `user` *org.tablesql.convert.TestFromDataStreamDemo$User2<`name` STRING, `score` INT>*
// ) env.execute();}public static void main(String[] args) throws Exception {test2();}}
2)、createTemporaryView 示例
DataStream可以直接注册为视图。
从DataStream 创建的视图只能注册为临时视图。由于它们的内联/匿名性质,无法在永久目录(permanent catalog)中注册它们。
下面的代码展示了如何对不同的场景使用createTemporaryView。每个示例中的运行结果均在输出部分以注释展示。
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/*** @author alanchan**/
public class TestCreateTemporaryViewDemo {public static void test1() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 2、创建数据源DataStream<Tuple2<Long, String>> dataStream = env.fromElements(Tuple2.of(12L, "alan"), Tuple2.of(0L, "alanchan"));// 示例1:创建视图、输出表结构tenv.createTemporaryView("MyView", dataStream);tenv.from("MyView").printSchema();
// (
// `f0` BIGINT NOT NULL,
// `f1` STRING
// )// 示例2:创建视图、输出表结构,使用Schema显示定义列,类似于fromDataStream的定义//在这个例子中,输出的NOT NULL没有定义tenv.createTemporaryView("MyView",dataStream,Schema.newBuilder().column("f0", "BIGINT").column("f1", "STRING").build());tenv.from("MyView").printSchema();
// (
// `f0` BIGINT,
// `f1` STRING
// )// 示例3:创建视图,并输出表结构// 在创建视图前修改(或定义)列名称,as一般是指重命名,原名称是f0、f1tenv.createTemporaryView("MyView",tenv.fromDataStream(dataStream).as("id", "name"));tenv.from("MyView").printSchema();
// (
// `id` BIGINT NOT NULL,
// `name` STRING
// )env.execute();}/*** @param args* @throws Exception */public static void main(String[] args) throws Exception {test1();}}3)、toDataStream示例
下面的代码展示了如何在不同的场景中使用toDataStream。每个示例中的运行结果均在输出部分以注释展示。
import java.time.Instant;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
public class TestToDataStreamDemo {@NoArgsConstructor@AllArgsConstructor@Datapublic static class User {public String name;public Integer score;public Instant event_time;}static final String SQL = "CREATE TABLE GeneratedTable "+ "("+ " name STRING,"+ " score INT,"+ " event_time TIMESTAMP_LTZ(3),"+ " WATERMARK FOR event_time AS event_time - INTERVAL '10' SECOND"+ ")"+ "WITH ('connector'='datagen')";public static void test1() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 2、建表tenv.executeSql(SQL);Table table = tenv.from("GeneratedTable");// 示例1:table 转 datastream// 使用默认的Row实例转换// 由于`event_time`是单个行时间属性,因此它被插入到DataStream元数据中,并传播水印
// DataStream<Row> dataStream = tenv.toDataStream(table);
// dataStream.print();
// 以下是示例性输出,实际上是连续的数据
// 10> +I[9b979ecef142c06746ff2be0f79f4afe7ef7089f60f267184e052c12ef5f2c2a144c73d3653bee51b351ed5b20ecaf0673ec, -1424631858, 2023-11-14T02:58:56.071Z]
// 1> +I[444998c8992accc54e2c10cac4f4a976cda516d84817a8fd728c9d013da3d87e91d28537a564f09fb07308142ca83c2548e9, -1240938499, 2023-11-14T02:58:56.071Z]
// 12> +I[fa42df01fe1f789535df26f81c2e58c02feaeba60338e4cfb7c8fdb06ed96c69b46e9a966d93d0cf811b24dd9434a8ef2253, 2039663083, 2023-11-14T02:58:56.070Z]
// 1> +I[25aa121a0d656a5355c32148a0c68cc39ac05443bd7de6a0c499a2daae85868422dd024c6803598133dc26a607cd1e60e747, 1912789884, 2023-11-14T02:58:56.071Z]// 示例2:table 转 datastream// 从类“User”中提取数据类型,planner重新排序字段,并在可能的情况下插入隐式转换,以将内部数据结构转换为所需的结构化类型// 由于`event_time`是单个行时间属性,因此它被插入到DataStream元数据中,并传播水印DataStream<User> dataStream2 = tenv.toDataStream(table, User.class);
// dataStream2.print();
// 以下是示例性输出,实际上是连续的数据
// 4> TestToDataStreamDemo.User(name=e80b612e48443a292c11e28159c73475b9ef9531b91d5712420753d5d6041a06f5de634348210b151f4fc220b4ec91ed5c72, score=2146560121, event_time=2023-11-14T03:01:17.657Z)
// 14> TestToDataStreamDemo.User(name=290b48dea62368bdb35567f31e5e2690ad8b5dd50c1c0f7184f15d2e85b24ea84155f1edef875f4c96e3a2133a320fcb6e41, score=2062379192, event_time=2023-11-14T03:01:17.657Z)
// 12> TestToDataStreamDemo.User(name=a0b31a03ad951b53876445001bbc74178c9818ece7d5e53166635d40cb8ef07980eabd7463ca6be38b34b1f0fbd4e2251df0, score=16953697, event_time=2023-11-14T03:01:17.657Z)// 示例3:table 转 datastream// 数据类型可以如上所述反射地提取或显式定义DataStream<User> dataStream3 =tenv.toDataStream(table,DataTypes.STRUCTURED(User.class,DataTypes.FIELD("name", DataTypes.STRING()),DataTypes.FIELD("score", DataTypes.INT()),DataTypes.FIELD("event_time", DataTypes.TIMESTAMP_LTZ(3))));dataStream3.print();
// 以下是示例性输出,实际上是连续的数据
// 9> TestToDataStreamDemo.User(name=49550693e3cb3a41cd785504c699684bf2015f0ebff5918dbdea454291c265d316773f2d9507ce73dd18f91a2f5fdbd6e500, score=744771891, event_time=2023-11-14T03:06:13.010Z)
// 2> TestToDataStreamDemo.User(name=60589709fe41decb647fcf4e2f91d45c82961bbe64469f3ea8a9a12b0cac071481ec9cfd65a9c218e3799986dd72ab80e457, score=-1056249244, event_time=2023-11-14T03:06:13.010Z)
// 15> TestToDataStreamDemo.User(name=d0a179f075c8b521bf5ecb08a32f6c715b5f2c616f815f8173c0a1c2961c53774faf396ddf55a44db49abe8085772f35d75c, score=862651361, event_time=2023-11-14T03:06:13.010Z) env.execute();}public static void main(String[] args) throws Exception {test1() ;}}
toDataStream仅支持非更新表。通常,基于时间的操作(如windows, interval joins或MATCH_RECOGNIZE子句)非常适合于在 insert-only pipelines的简单操作(如投影(projections )和过滤)。
具有生成更新的操作的管道可以使用toChangelogStream。
以上,本文是Flink table api 与 datastream api的集成的第二篇,主要批处理模式下的集成和insert-only处理,并以具体的示例进行说明。
相关文章:
- 批处理模式和inser-only流处理)
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

051-第三代软件开发-日志容量时间限制
第三代软件开发-日志容量时间限制 文章目录 第三代软件开发-日志容量时间限制项目介绍日志容量时间限制 关键字: Qt、 Qml、 Time、 容量、 大小 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Object Language…...
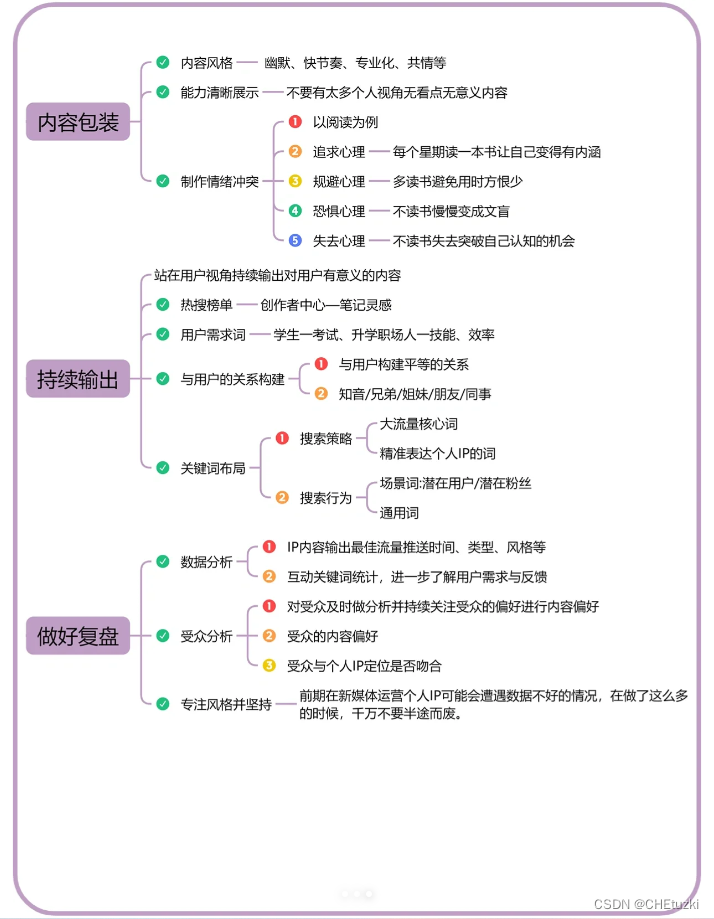
9步打造个人ip
什么是个人IP? 就是一个人创造出来的属于自己的有个性有价值的,能让他人记住你,信任你,认可你的东西。 如何强化个人IP呢? 需要一些必要的条件如专业性、耐心、勤奋等等要知道,打造IP是一个见效慢的过程&am…...

【深度学习】吴恩达课程笔记(四)——优化算法
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 【吴恩达课程笔记专栏】 【深度学习】吴恩达课程笔记(一)——深度学习概论、神经网络基础 【深度学习】吴恩达课程笔记(二)——浅层神经网络、深层神经网络 【深度学习】吴恩达课程笔记(三)——参数VS超参数、深度…...

MyBatis-plus 代码生成器配置
数据库配置(DataSourceConfig) 基础配置 属性说明示例urljdbc 路径jdbc:mysql://127.0.0.1:3306/mybatis-plususername数据库账号rootpassword数据库密码123456 new DataSourceConfig.Builder("jdbc:mysql://127.0.0.1:3306/mybatis-plus","root","…...
框架设计的核心要素
我们的框架应该给用户提供哪些构建产物?产物的模块格式如何?当用户没有以预期的方式使用框架时,是否应该打印合适的警告信息从而提供更好的开发体验,让用户快速定位问题?开发版本的构建和生产版本的构建有何区别&#…...
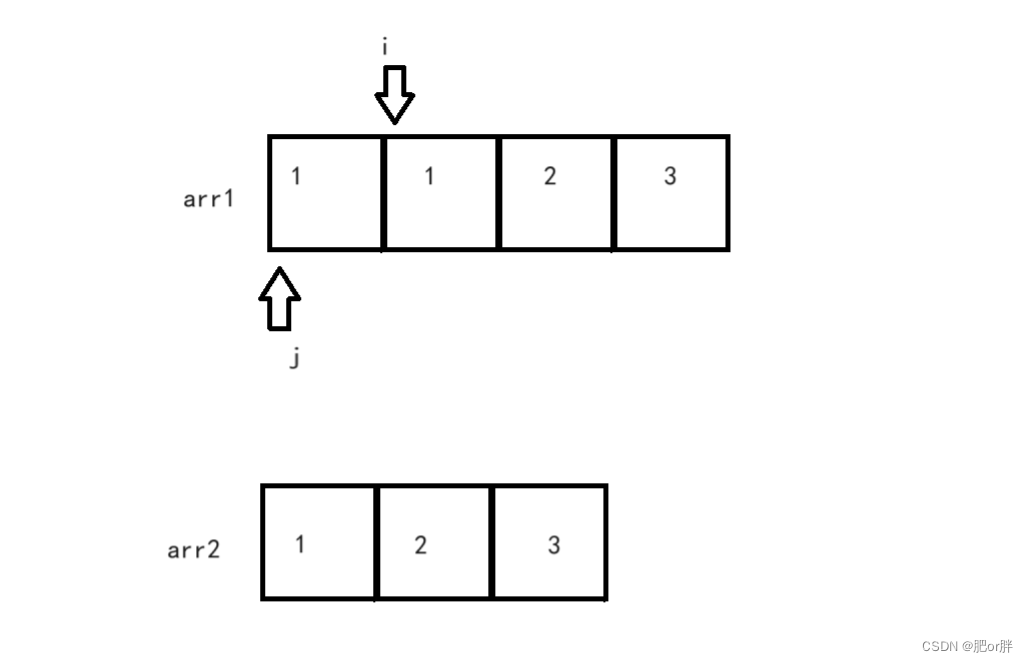
LeetCode - 26. 删除有序数组中的重复项 (C语言,快慢指针,配图)
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 思路一:快慢指针 在数组中,快慢指针就是两个整数下标,定义 fast 和 slow 这里我们从下标1开始(下标0的数据就1个,没有重复项)&…...

C#不安全代码
在C#中,“不安全代码”(unsafe code)通常指的是那些直接操作内存地址的代码。它允许开发者使用指针等低级别的数据结构,这些在通常的安全代码(safe code)中是不允许的。C# 的不安全代码提供了一种方式&…...

《C++避坑神器·二十二》VS能正常运行程序,但运行exe程序无响应解决办法
原因是某个文件只是放在了项目路径下,没有放在exe路径下,比如Json文件原来只放在了mlx项目下,导致VS可以运行,但运行exe无响应或报错如下: 两种方式修改: 1、把Json文件拷贝一份放到exe路径下 2、利用生成…...

lua调用C/C++的函数,十分钟快速掌握
系列文章目录 lua调用C\C动态库函数 系列文章目录摘要环境使用步骤你需要有个lua环境引入库码代码lua代码 摘要 在现代软件开发中,Lua作为一种轻量级脚本语言,在游戏开发、嵌入式系统等领域广泛应用。Lua与C/C的高度集成使得开发者能够借助其灵活性和高…...

自定义GPT已经出现,并将影响人工智能的一切,做好被挑战的准备了吗?
原创 | 文 BFT机器人 OpenAI凭借最新突破:定制GPT站在创新的最前沿。预示着个性化数字协助的新时代到来,ChatGPT以前所未有的精度来满足个人需求和专业需求。 从本质上讲,自定义GPT是之前的ChatGPT的高度专业化版本或代理,但自定…...
vue中一个页面引入多个相同组件重复请求的问题?
⚠️!!!此内容需要了解一下内容!!! 1、会使用promise??? 2、 promise跟 async 的区别??? async 会终止后面的执行,后续…...

Uniapp连接iBeacon设备——实现无线定位与互动体验(实现篇)
export default { data() { return { iBeaconDevices: [], // 存储搜索到的iBeacon设备 deviceId: [], data: [], url: getApp().globalData.url, innerAudioContext: n…...

【ceph】ceph集群删除pool报错: “EPERM: pool deletion is disabled“
本站以分享各种运维经验和运维所需要的技能为主 《python零基础入门》:python零基础入门学习 《python运维脚本》: python运维脚本实践 《shell》:shell学习 《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战 《k8…...

【微信小程序】使用npm包
1、小程序对npm的支持与限制2、Vant Weapp通过 npm 安装修改 app.json修改 project.config.json构建 npm 包 3、使用4、定制全局主题样式5、API Promise化 1、小程序对npm的支持与限制 目前,小程序中已经支持使用npm安装第三方包, 从而来提高小程序的开发…...

【开发记录篇】第二篇:SQL创建分区表
实现分区表注意事项 分区字段必须在主键中存在 使用时间分区时,字段类型不支持 timestamp,需改为 datetime 年分区示例 下表中使用 insert_time 时间进行分区 CREATE TABLE t_log (id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 日志ID,inse…...

vue 使用 this.$router.push 传参数,接参数的 query或params 两种方法示例
背景:vue项目 使用this.$router.push进行路由跳转时,可以通过query或params参数传递和接收参数。 通过query参数传递参数: // 传递参数 this.$router.push({path: /target,query: {id: 1,name: John} }); // 接收参数 this.$route.query.id …...

rk3588 usb网络共享连接
出门在外总会遇到傻 X 地方 没有能连接公网的 网口给香橙派连网 而我的香橙派5plus 没有wifi模块。。。话不多说 在手机上看一眼手机的mac地址, 在rk3588 上执行以下命令: sudo ifconfig usb0 down sudo ifconfig usb0 hw ether 58:F2:FC:5D:D4:7A //该m…...

shell 拒绝恶意连接脚本 centos7.x拒绝恶意连接脚本
1. crontab -l 脚本频率: */2 * * * * /bin/bash /home/shell/deny.sh 2. 脚本: rm -rf /home/shell/ip_list cat /var/log/secure | grep "Failed password for" | awk {print$(NF-3)} | sort | uniq -c > /home/shell/ip_list #cat /va…...

【系统架构设计】计算机公共基础知识: 2 计算机系统基础知识
目录 一 计算机系统组成 二 操作系统 三 文件系统 四 系统性能 一 计算机系统组成...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...