百亿数据,毫秒级返回查询优化
近年来公司业务迅猛发展,数据量爆炸式增长,随之而来的的是海量数据查询等带来的挑战,我们需要数据量在十亿,甚至百亿级别的规模时依然能以秒级甚至毫秒级的速度返回,这样的话显然离不开搜索引擎的帮助,在搜索引擎中,ES(ElasticSearch)毫无疑问是其中的佼佼者,连续多年在 DBRanking 的搜索引擎中评测中排名第一,也是绝大多数大公司的首选,那么它与传统的 DB 如 MySQL 相比有啥优势呢,ES 的数据又是如何生成的,数据达到 PB 时又是如何保证 ES 索引数据的实时性以更好地满足业务的需求的呢。
本文会结合我司在 ES 上的实践经验与大家谈谈如何构建准实时索引的一些思路,希望对大家有所启发。本文目录如下
-
为什么要用搜索引擎,传统 DB 如 MySQL 不香吗
-
- MySQL 的不足
- ES 简介
-
ES 索引数据构建
-
PB 级的 ES 准实时索引数据构建之道
为什么要用搜索引擎,传统 DB 如 MySQL 不香吗
MySQL 的不足
MySQL 架构天生不适合海量数据查询,它只适合海量数据存储,但无法应对海量数据下各种复杂条件的查询,有人说加索引不是可以避免全表扫描,提升查询速度吗,为啥说它不适合海量数据查询呢,有两个原因:
*1、*加索引确实可以提升查询速度,但在 MySQL 中加多个索引最终在执行 SQL 的时候它只会选择成本最低的那个索引,如果没有索引满足搜索条件,就会触发全表扫描,而且即便你使用了组合索引,也要符合最左前缀原则才能命中索引,但在海量数据多种查询条件下很有可能不符合最左前缀原则而导致索引失效,而且我们知道存储都是需要成本的,如果你针对每一种情况都加索引,以 innoDB 为例,每加一个索引,就会创建一颗 B+ 树,如果是海量数据,将会增加很大的存储成本,之前就有人反馈说他们公司的某个表实际内容的大小才 10G, 而索引大小却有 30G!这是多么巨大的成本!所以千万不要觉得索引建得越多越好。
*2、*有些查询条件是 MySQL 加索引都解决不了的,比如我要查询商品中所有 title 带有「格力空调」的关键词,如果你用 MySQL 写,会写出如下代码
SELECT * FROM product WHERE title like '%格力空调%'
这样的话无法命中任何索引,会触发全表扫描,而且你不能指望所有人都能输对他想要的商品,是人就会犯错误,我们经常会犯类似把「格力空调」记成「格空间」的错误,那么 SQL 语句就会变成:
SELECT * FROM product WHERE title like '%格空调%'
这种情况下就算你触发了全表扫描也无法查询到任何商品,综上所述,MySQL 的查询确实能力有限。
ES 简介
与其说上面列的这些点是 MySQL 的不足,倒不如说 MySQL 本身就不是为海量数据查询而设计的,术业有专攻,海量数据查询还得用专门的搜索引擎,这其中 ES 是其中当之无愧的王者,它是基于 Lucene 引擎构建的开源分布式搜索分析引擎,可以提供针对 PB 数据的近实时查询,广泛用在全文检索、日志分析、监控分析等场景。
它主要有以下三个特点:
轻松支持各种复杂的查询条件: 它是分布式实时文件存储,会把每一个字段都编入索引(倒排索引),利用高效的倒排索引,以及自定义打分、排序能力与丰富的分词插件等,能实现任意复杂查询条件下的全文检索需求可扩展性强:天然支持分布式存储,通过极其简单的配置实现几百上千台服务器的分布式横向扩容,轻松处理 PB 级别的结构化或非结构化数据。高可用,容灾性能好:通过使用主备节点,以及故障的自动探测与恢复,有力地保障了高可用
我们先用与 MySQL 类比的形式来理解 ES 的一些重要概念

通过类比的形式不难看出 ES 的以下几个概念
1、 MySQL 的数据库(DataBase)相当于 Index(索引),数据的逻辑集合,ES 的工作主要也是创建索引,查询索引。
2、 一个数据库里会有多个表,同样的一个 Index 也会有多个 type
3、 一个表会有多行(Row),同样的一个 Type 也会有多个 Document。
4、 Schema 指定表名,表字段,是否建立索引等,同样的 Mapping 也指定了 Type 字段的处理规则,即索引如何建立,是否分词,分词规则等
5、 在 MySQL 中索引是需要手动创建的,而在 ES 一切字段皆可被索引,只要在 Mapping 在指定即可
那么 ES 中的索引为何如此高效,能在海量数据下达到秒级的效果呢?它采用了多种优化手段,最主要的原因是它采用了一种叫做倒排索引的方式来生成索引,避免了全文档扫描,那么什么是倒排索引呢,通过文档来查找关键词等数据的我们称为正排索引,返之,通过关键词来查找文档的形式我们称之为倒排索引,假设有以下三个文档(Document)
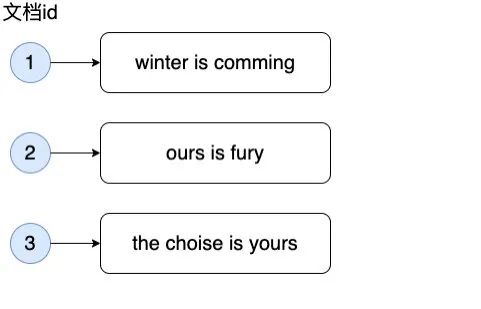
要在其中找到含有 comming 的文档,如果要正排索引,那么要把每个文档的内容拿出来查找是否有此单词,毫无疑问这样的话会导致全表扫描,那么用倒排索引会怎么查找呢,它首先会将每个文档内容进行分词,小写化等,然后建立每个分词与包含有此分词的文档之前的映射关系,如果有多个文档包含此分词,那么就会按重要程度即文档的权重(通常是用 TF-IDF 给文档打分)将文档进行排序,于是我们可以得到如下关系
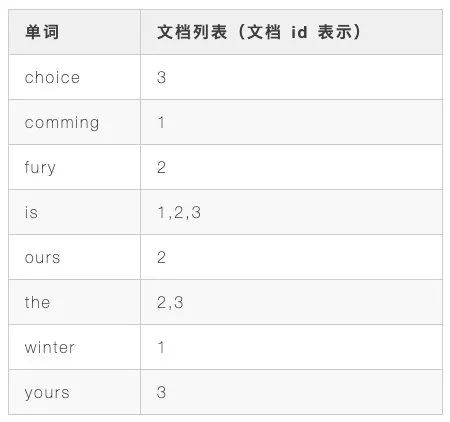
这样的话我们我要查找所有带有 comming 的文档,就只需查一次,而且这种情况下查询多个单词性能也是很好的,只要查询多个条件对应的文档列表,再取交集即可,极大地提升了查询效率。
画外音:这里简化了一些流程,实际上还要先根据单词表来定位单词等,不过这些流程都很快,可以忽略,有兴趣的读者可以查阅相关资料了解。
除了倒排索引外,ES 的分布式架构也天然适合海量数据查询,来看下 ES 的架构
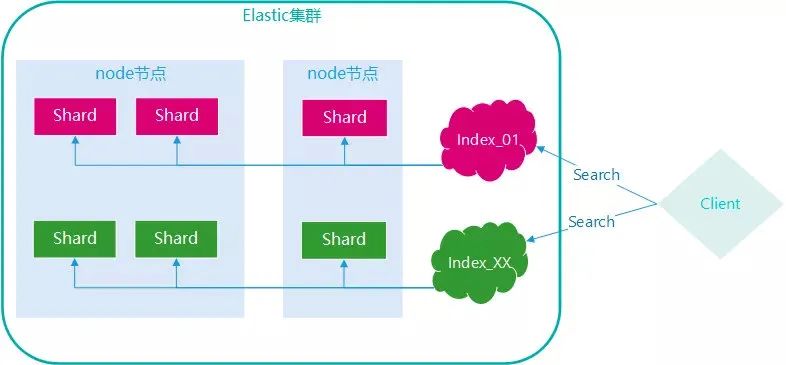
一个 ES 集群由多个 node 节点组成,每个 index 是以分片(Shard,index 子集)的数据存在于多个 node 节点上的,这样的话当一个查询请求进来,分别在各个 node 查询相应的结果并整合后即可,将查询压力分散到多个节点,避免了单个节点 CPU,磁盘,内存等处理能力的不足。
另外当新节点加入后,会自动迁移部分分片至新节点,实现负载均衡,这个功能是 ES 自动完成的,对比一个下 MySQL 的分库分表需要开发人员引入 Mycat 等中间件并指定分库分表规则等繁琐的流程是不是一个巨大的进步?这也就意味着 ES 有非常强大的水平扩展的能力,集群可轻松扩展致几百上千个节点,轻松支持 PB 级的数据查询。
当然 ES 的强大不止于此,它还采用了比如主备分片提升搜索吞率,使用节点故障探测,Raft 选主机制等提升了容灾能力等等,这些不是本文重点,读者可自行查阅,总之经过上面的简单总结大家只需要明白一点:ES 的分布式架构设计天生支持海量数据查询。
那么 ES 的索引数据(index)如何生成的呢,接下来我们一起来看看本文的重点
如何构建 ES 索引
要构建 ES 索引数据,首先得有数据源,一般我们会使用 MySQL 作为数据源,你可以直接从 MySQL 中取数据然后再写入 ES,但这种方式由于直接调用了线上的数据库查询,可能会对线上业务造成影响,比如考虑这样的一个场景:
在电商 APP 里用的最多的业务场景想必是用户输入关键词来查询相对应的商品了,那么商品会有哪些信息呢,一个商品会有多个 sku(sku 即同一个商品下不同规格的品类,比如苹果手机有 iPhone 6, iPhone 6s等),会有其基本属性如价格,标题等,商品会有分类(居家,服饰等),品牌,库存等,为了保证表设计的合理性,我们会设计几张表来存储这些属性,假设有 product_sku(sku 表), product_property(基本属性表),sku_stock(库存表),product_category(分类表)这几张表,那么为了在商品展示列表中展示所有这些信息,就必须把这些表进行 join,然后再写入 ES,这样查询的时候就会在 ES 中获取所有的商品信息了。
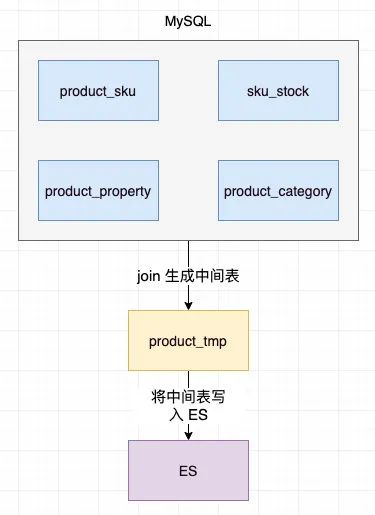
这种方案由于直接在 MySQL 中执行 join 操作,在商品达到千万级时会对线上的 DB 服务产生极大的性能影响,所以显然不可行,那该怎么生成中间表呢,既然直接在 MySQL 中操作不可行,能否把 MySQL 中的数据同步到另一个地方再做生成中间表的操作呢,也就是加一个中间层进行处理,这样就避免了对线上 DB 的直接操作,说到这相信大家又会对计算机界的名言有进一步的体会:没有什么是加一个中间层不能解决的,如果有,那就再加一层。
这个中间层就是 hive
什么是 hive
hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制,它的意义就是把好写的 hive 的 sql 转换为复杂难写的 map-reduce 程序(map-reduce 是专门用于用于大规模数据集(大于1TB)的并行运算编程模型),也就是说如果数据量大的话通过把 MySQL 的数据同步到 hive,再由 hive 来生成上述的 product_tmp 中间表,能极大的提升性能。hive 生成临时表存储在 hbase(一个分布式的、面向列的开源数据库) 中,生成后会定时触发 dump task 调用索引程序,然后索引程序主要从 hbase 中读入全量数据,进行业务数据处理,并刷新到 es 索引中,整个流程如下

这样构建索引看似很美好,但我们需要知道的是首先 hive 执行 join 任务是非常耗时的,在我们的生产场景上,由于数据量高达几千万,执行 join 任务通常需要几十分钟,从执行 join 任务到最终更新至 ES 整个流程常常需要至少半小时以上,如果这期间商品的价格,库存,上线状态(如被下架)等重要字段发生了变更,索引是无法更新的,这样会对用户体验产生极大影响,优化前我们经常会看到通过 ES 搜索出的中有状态是上线但实际是下架的产品,严重影响用户体验,那么怎么解决呢,有一种可行的方案:建立宽表
既然我们发现 hive join 是性能的主要瓶颈,那么能否规避掉这个流程呢,能否在 MySQL 中将 product_sku,product_property,sku_stock 等表组合成一个大表(我们称其为宽表)
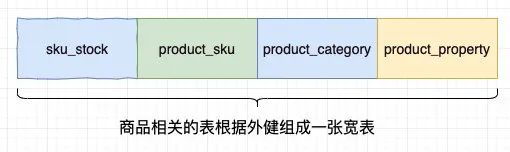
这样在每一行中商品涉及到的的数据都有了,所以将 MySQL 同步到 hive 后,hive 就不需要再执行耗时的 join 操作了,极大的提升了整体的处理时间,从 hive 同步 MySQL 再到 dump 到 ES 索引中从原来的半小时以上降低到了几分钟以内,看起来确实不错,但几分钟的索引延迟依然是无法接受的。
为什么 hive 无法做到实时导入索引
因为 hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,hive 并不能够在大规模数据集上实现低延迟快速的查询等操作,再且千万级别的数据全量从索引程序导入到 ES 集群至少也是分钟级。
另外引入了宽表,它的维护也成了一个新问题,设想 sku 库存变了,产品下架了,价格调整了,那么除了修改原表(sku_stock,product_categry 等表)记录之外,还要将所有原表变更到的记录对应到宽表中的所有记录也都更新一遍,这对代码的维护是个噩梦,因为你需要在所有商品相关的表变更的地方紧接着着变更宽表的逻辑,与宽表的变更逻辑变更紧藕合!
PB 级的 ES 准实时索引构建之道
该如何解决呢?仔细观察上面两个问题,其实都是同一个问题,如果我们能实时监听到 db 的字段变更,再将变更的内容实时同步到 ES 和宽表中不就解决了我们的问题了。
怎么才能实时监听到表字段的变更呢?
答案:binlog
来一起复习下 MySQL 的主从同步原理
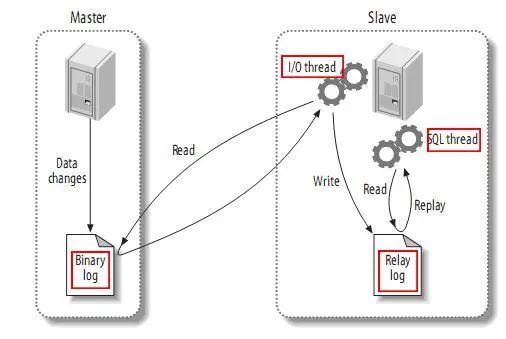
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
可以看到主从复制的原理关键是 Master 和 Slave 遵循了一套协议才能实时监听 binlog 日志来更新 slave 的表数据,那我们能不能也开发一个遵循这套协议的组件,当组件作为 Slave 来获取 binlog 日志进而实时监听表字段变更呢?阿里的开源项目 Canal 就是这个干的,它的工作原理如下:
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
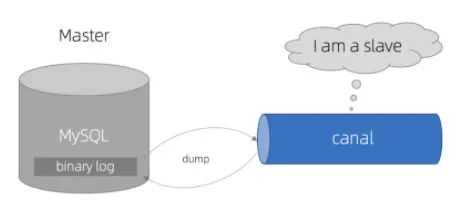
这样的话通过 canal 就能获取 binlog 日志了,当然 canal 只是获取接收了 master 过来的 binlog,还要对 binlog 进行解析过滤处理等,另外如果我们只对某些表的字段感兴趣,该如何配置,获取到 binlog 后要传给谁? 这些都需要一个统一的管理组件,阿里的 otter 就是干这件事的。
什么是 otter
Otter 是由阿里提供的基于数据库增量日志解析,准实时同步到本机房或异地机房 MySQL 数据库的一个分布式数据库同步系统,它的整体架构如下:
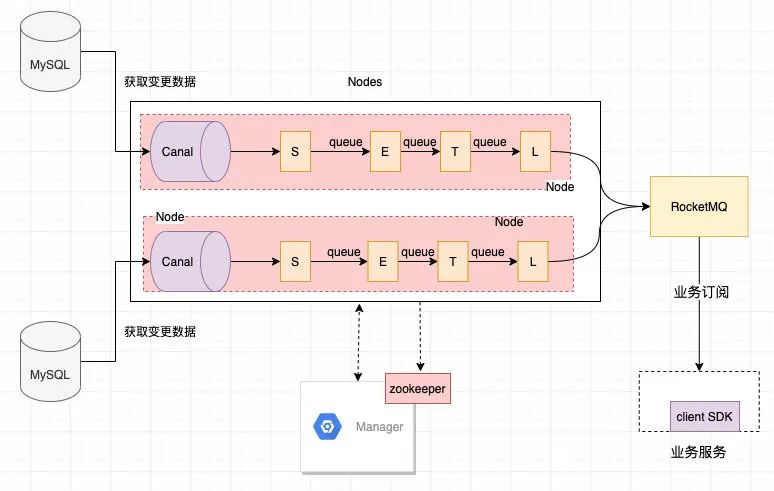
注:以上是我司根据 otter 改造后的业务架构,与原版 otter 稍有不同,不过大同小异
主要工作流程如下
- 在 Manager 配置好 zk,要监听的表 ,负责监听表的节点,然后将配置同步到 Nodes 中
- node 启动后则其 canal 会监听 binlog,然后经过 S(select),E(extract),T(transform),L(load) 四个阶段后数据发送到 MQ
- 然后业务就可以订阅 MQ 消息来做相关的逻辑处理了
画外音:zookeeper 主要协调节点间的工作,如在跨机房数据同步时,可能要从 A 机房的节点将数据同步到 B 机房的节点,要用 zookeeper 来协调,
大家应该注意到了node 中有 S,E,T,L 四个阶段,它们的主要作用如下
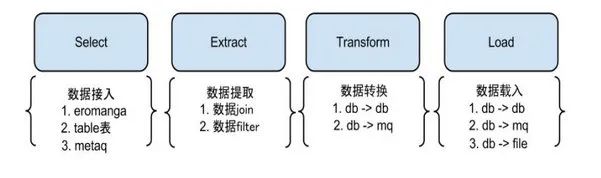
Select 阶段: 为解决数据来源的差异性,比如接入 canal 获取增量数据,也可以接入其他系统获取其他数据等。Extract阶段: 组装数据,针对多种数据来源,mysql,oracle,store,file等,进行数据组装和过滤。Transform 阶段: 数据提取转换过程,把数据转换成目标数据源要求的类型Load 阶段: 数据载入,把数据载入到目标端,如写入迁移后的数据库, MQ,ES 等
以上这套基于阿里 otter 改造后的数据服务我们将它称为 DTS(Data Transfer Service),即数据传输服务。
搭建这套服务后我们就可以通过订阅 MQ 来实时写入 ES 让索引实时更新了,而且也可以通过订阅 MQ 来实现宽表字段的更新,解决了上文中所说的宽表字段更新与原表紧藕合的问题,基于 DTS 服务的索引改进架构如下:
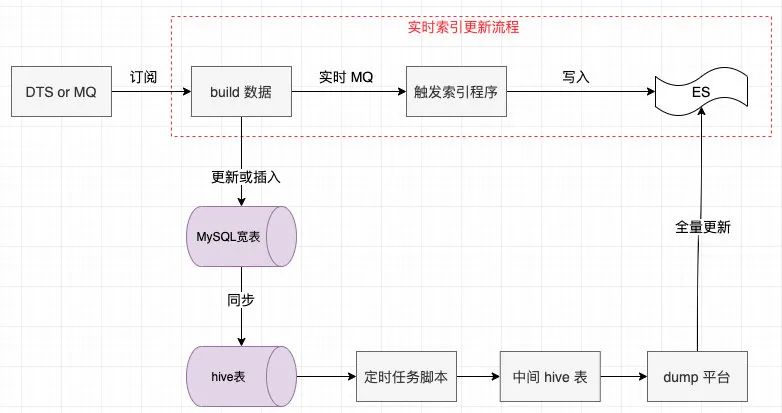
注意:「build 数据」这一模块对实时索引更新是透明的,这个模块主要用在更新或插入 MySQL 宽表,因为对于宽表来说,它是几个表数据的并集,所以并不是监听到哪个字段变更就更新哪个,它要把所有商品涉及到的所有表数据拉回来再更新到宽表中。
于是,通过 MySQL 宽表全量更新+基于 DTS 的实时索引更新我们很好地解决了索引延迟的问题,能达到秒级的 ES 索引更新!
这里有几个问题可能大家比较关心,我简单列一下
需要订阅哪些字段
对于 MySQL 宽表来说由于它要保存商品的完整信息,所以它需要订阅所有字段,但是对于红框中的实时索引更新而言,它只需要订阅库存,价格等字段,因为这些字段如果不及时更新,会对销量产生极大的影响,所以我们实时索引只关注这些敏感字段即可。
有了实时索引更新,还需要全量索引更新吗
需要,主要有两个原因:
- 实时更新依赖消息机制,无法百分百保证数据完整性,需要全量更新来支持,这种情况很少,而且消息积压等会有告警,所以我们一天只会执行一次全量索引更新
- 索引集群异常或崩溃后能快速重建索引
全量索引更新的数据会覆盖实时索引吗
会,设想这样一种场景,你在某一时刻触发了实时索引,然后此时全量索引还在执行中,还未执行到实时索引更新的那条记录,这样在的话当全量索引执行完之后就会把之前实时索引更新的数据给覆盖掉,针对这种情况一种可行的处理方式是如果全量索引是在构建中,实时索引更新消息可以延迟处理,等全量更新结束后再消费。也正因为这个原因,全量索引我们一般会在凌晨执行,由于是业务低峰期,最大可能规避了此类问题。
总结
本文简单总结了我司在 PB 级数据下构建实时 ES 索引的一些思路,希望对大家有所帮助,文章只是简单提到了 ES,canal,otter 等阿里中间件的应用,但未对这些中间件的详细配置,原理等未作过多介绍,这些中间件的设计非常值得我们好好研究下,比如 ES 为了提高搜索效率、优化存储空间做了很多工作,再比如 canal 如何做高可用,otter 实现异地跨机房同步的原理等,建议感兴趣的读者可以之后好好研究一番,相信你会受益匪浅。
巨人的肩膀
- Elasticsearch简介及与MySQL查询原理对比:https://www.jianshu.com/p/116cdf5836f2
- https://www.cnblogs.com/zhjh256/p/9261725.html
- otter安装之otter-node安装(单机多节点安装):https://blog.csdn.net/u014642915/article/details/96500957
- MySQL和Lucene索引对比分析: https://developer.aliyun.com/article/50481
- 10 分钟快速入门海量数据搜索分析引擎 Elasticearch: https://www.modb.pro/db/29806
- ElasticSearch和Mysql查询原理分析与对比:https://www.pianshen.com/article/4254917942/
- 带你走进神一样的Elasticsearch索引机制:https://zhuanlan.zhihu.com/p/137574234
相关文章:
百亿数据,毫秒级返回查询优化
近年来公司业务迅猛发展,数据量爆炸式增长,随之而来的的是海量数据查询等带来的挑战,我们需要数据量在十亿,甚至百亿级别的规模时依然能以秒级甚至毫秒级的速度返回,这样的话显然离不开搜索引擎的帮助,在搜…...
cpp之STL
STL原理 STL ⼀共提供六⼤组件,包括容器,算法,迭代器,仿函数,适配器和空间配置器,彼此可以组合套⽤。容器通过配置器取得数据存储空间,算法通过迭代器存取容器内容,仿函数可以协助算…...

基于Spring Boot开发的资产管理系统
文章目录 项目介绍主要功能截图:登录首页信息软件管理服务器管理网络设备固定资产明细硬件管理部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目…...

Markdown总结
文字的着重标记与段落的层次划分 Tab键可以缩进列表; shift Tab:取消缩进列表 加粗(****)、斜体(**)高亮:xxx$$:特殊标记删除:~~xxx~~多级标题:######无序列…...
字节跳动软件测试岗4轮面经(已拿34K+ offer)...
没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2021年10月,我有幸成为了字节跳动的一名测试工程师,从外包辞职了历…...

docker - 搭建redis集群和Etcd
概述 由于业务需要,需要把之前的分布式架构调整成微服务,把老项目迁移到k8s的服务中,再开始编码之前,需要再本地环境里做相应的准备工作,使用docker搭建redis集群,Etcd主要是注册本地的rpc服务。 Liunx O…...
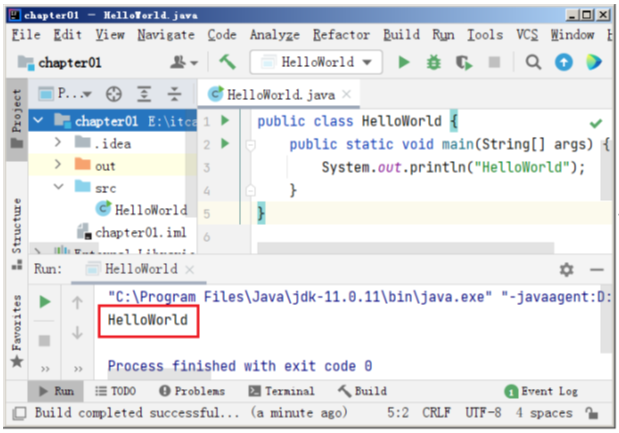
Java程序开发中如何使用lntelliJ IDEA?
完成了IDEA的安装与启动,下面使用IDEA创建一个Java程序,实现在控制台上打印HelloWorld!的功能,具体步骤如下。 1.创建Java项目 进入New Project界面后,单击New Project选项按钮创建新项目,弹出New Project对话框&…...
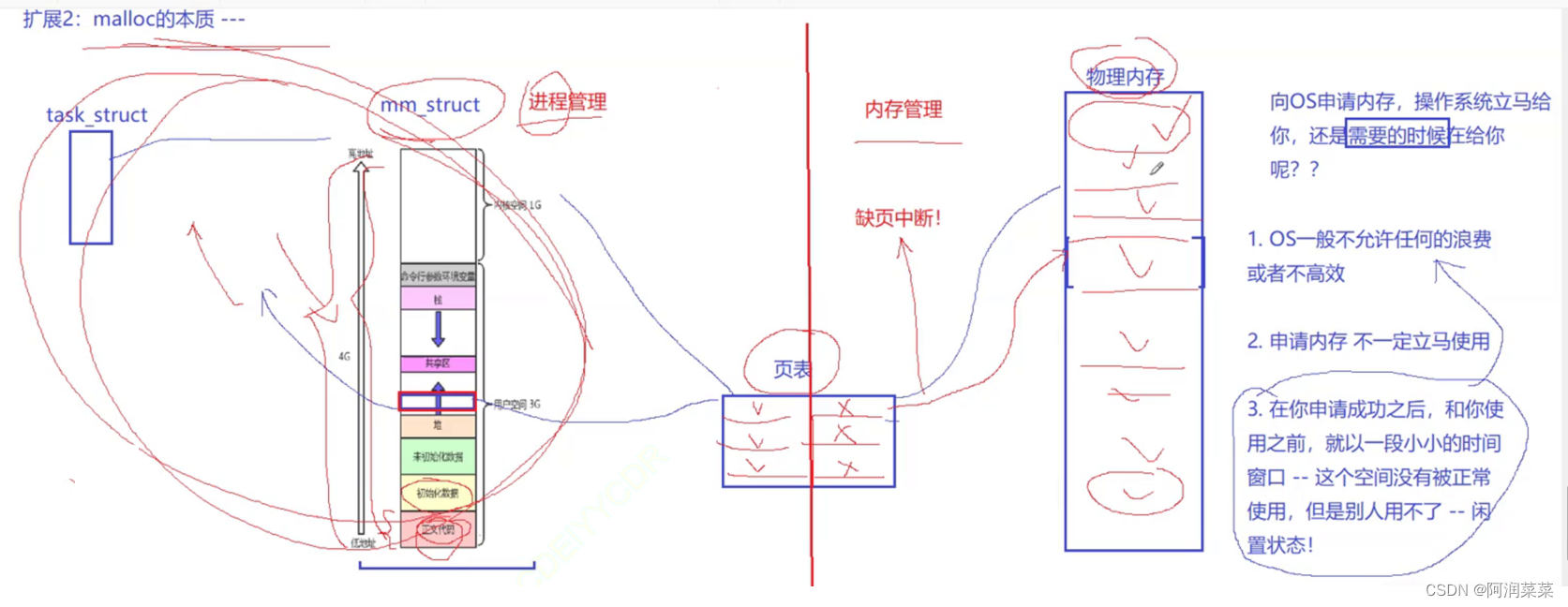
【Linux】理解进程地址空间
🍎作者:阿润菜菜 📖专栏:Linux系统编程 我们在学习C语言的时候,都学过内存区域的划分如栈、堆、代码区、数据区这些。但我们其实并不真正理解内存 — 我们之前一直说的内存是物理上的内存吗? 前言 我们…...

Unity脚本 --- 常用API(类)--- GameObject类 和
第一部分 --- GameObject类 1.在Hierarchy 层级面板中添加游戏物体其实就相当于在场景中添加游戏物体 2.每一个场景都有一个自己的Hierarchy层级面板,用来管理场景中的所有游戏物体 3.是的,我们可以创建多个场景 1.首先上面这两个变量都是布尔变量&am…...

HTML标签——表格标签
HTML标签——表格标签 目录HTML标签——表格标签一、表格标题和表头单元格标签场景:注意点:案例实操小结二、表格的结构标签场景:注意点:案例实操:三、合并单元格思路场景:代码实现一、表格标题和表头单元格…...

Telerik JustMock 2023 R1 Crack
Telerik JustMock 2023 R1 Crack 制作单元测试的最快、最灵活和模拟选项。 Telerik JustLock也很简单,可以使用一个模拟工具来帮助您更快地生成更好的单元测试。JustLock使您更容易创建对象并建立对依赖关系的期望,例如,互联网服务需求、数据…...

筑基八层 —— 问题思考分析并解决
目录 零:移步 一.修炼必备 二.问题思考(先思考) 三.问题解答 零:移步 CSDN由于我的排版不怎么好看,我的有道云笔记相当的美观,请移步有道云笔记 一.修炼必备 1.入门必备:VS2019社区版&#x…...

【面试题】当面试官问 Vue2与Vue3的区别,你该怎么回答?
大厂面试题分享 面试题库后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库被问到 《vue2 与 vue3 的区别》应该怎么回答Vue 内部根据功能可以被分为三个大的模块:响应性 reactivite、运行时 runtime、编辑器…...

使用Python对excel中的数据进行处理
一、读取excel中的数据首先引入pandas库,没有的话使用控制台安装 —— pip install pandas 。import pandas as pd #引入pandas库,别名为pd#read_excel用于读取excel中的数据,这里只列举常用的两个参数(文件所在路径ÿ…...
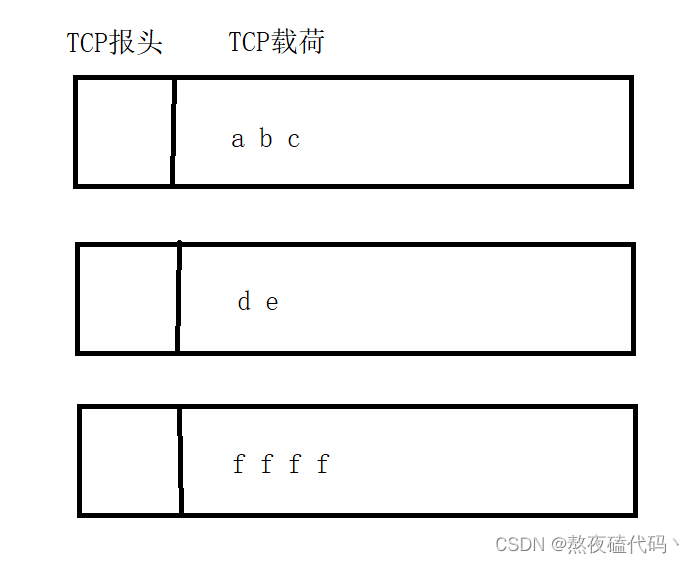
TCP协议原理三
文章目录七、延时应答八、捎带应答九、面向字节流粘包问题十、TCP异常情况总结七、延时应答 如果说滑动窗口的关键是让窗口大一些,传输速度就快一些。那么延时应答就是在接收方能够处理的前提下,尽可能把ack返回的窗口大小尽可能大一些。 如果在接受数据…...
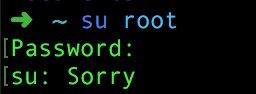
mac在命令行里获取root权限
1、为什么要获取root权限? 答:一些命令在正常状态下没有权限会报错,只有获取了root权限才能正常操作。 比如我们想修改一些系统的文件: vim /etc/shells 1 修改后保存,发现没权限,报错了。如下图…...
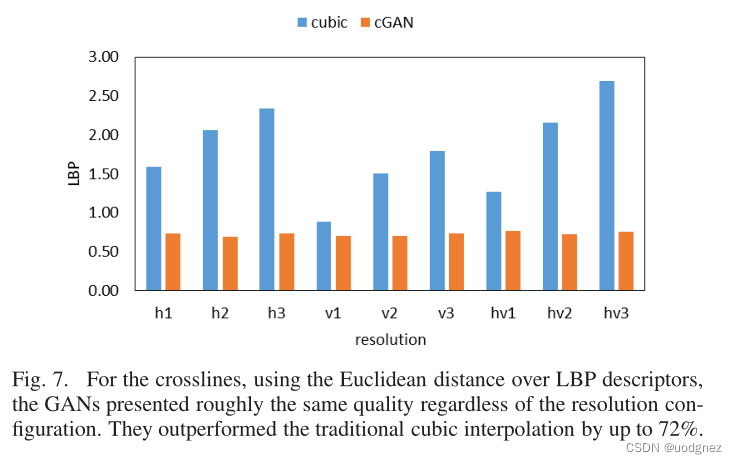
文献阅读 Improving Seismic Data Resolution with Deep Generative Networks
题目 Improving Seismic Data Resolution with Deep Generative Networks 使用深度生成网络提高地震数据分辨率 摘要 叠前数据的使用,通常可以来解决噪声迹线、覆盖间隙或不规则/不适当的迹线间距等问题。但叠前数据并不总是可用的。作为替代方案,叠后…...

mysql数据库之子查询练习
1、查询员工的姓名、年龄、职位、部门信息(隐式内连接)。 #emp、dept #连接条件:emp.dept_iddept.id select e.name,e.age,e.job,d.name from emp e,dept d where e.dept_idd.id; 2、查询年龄小于30岁的员工姓名、年龄、职位、部…...

西电计算机通信与网络(计网)简答题计算题核心考点汇总(期末真题+核心考点)
文章目录前言一、简答计算题真题概览二、网桥,交换机和路由器三、ARQ协议四、曼彻斯特编码和差分曼彻斯特编码五、CRC六、ARP协议七、LAN相关协议计算前言 主要针对西安电子科技大学《计算机通信与网络》的核心考点进行汇总,包含总共26章的核心简答。 【…...
【博学谷学习记录】超强总结,用心分享丨人工智能 Python基础 个人学习总结之列表排序
目录前言简述list.sort()语法返回值实例无参参数key参数reversesorted()语法返回值实例无参参数key参数reverseoperator.itemgetter功能简述实例List.sort与sored区别sorted原理:Timsort算法扩展list原理数据结构心得前言 经过一周的学习,对Python基础部…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...