Python爬虫教程:从入门到实战

更多Python学习内容:ipengtao.com
大家好,我是涛哥,今天为大家分享 Python爬虫教程:从入门到实战,文章3800字,阅读大约15分钟,大家enjoy~~
网络上的信息浩如烟海,而爬虫(Web Scraping)是获取和提取互联网信息的强大工具。Python作为一门强大而灵活的编程语言,拥有丰富的库和工具,使得编写爬虫变得更加容易。本文将从基础的爬虫原理和库介绍开始,逐步深入,通过实际示例代码,带领读者学习Python爬虫的使用和技巧,掌握从简单到复杂的爬虫实现。
1. 基础知识
1.1 HTTP请求
在开始爬虫之前,了解HTTP请求是至关重要的。Python中有许多库可以发送HTTP请求,其中requests库是一个简单而强大的选择。
import requestsresponse = requests.get("https://www.example.com")
print(response.text)1.2 HTML解析
使用BeautifulSoup库可以方便地解析HTML文档,提取所需信息。
from bs4 import BeautifulSouphtml = """
<html><body><p>Example Page</p><a href="https://www.example.com">Link</a></body>
</html>
"""soup = BeautifulSoup(html, 'html.parser')
print(soup.get_text())2. 静态网页爬取
2.1 简单示例
爬取静态网页的基本步骤包括发送HTTP请求、解析HTML并提取信息。
import requests
from bs4 import BeautifulSoupurl = "https://www.example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')# 提取标题
title = soup.title.text
print(f"Title: {title}")# 提取所有链接
links = soup.find_all('a')
for link in links:print(link['href'])2.2 处理动态内容
对于使用JavaScript渲染的网页,可以使用Selenium库模拟浏览器行为。
from selenium import webdriver
from selenium.webdriver.common.keys import Keysurl = "https://www.example.com"
driver = webdriver.Chrome()
driver.get(url)# 模拟滚动
driver.find_element_by_tag_name('body').send_keys(Keys.END)# 提取渲染后的内容
rendered_html = driver.page_source
soup = BeautifulSoup(rendered_html, 'html.parser')
# 进一步处理渲染后的内容3. 数据存储
3.1 存储到文件
将爬取的数据存储到本地文件是一种简单有效的方法。
import requestsurl = "https://www.example.com"
response = requests.get(url)
with open('example.html', 'w', encoding='utf-8') as file:file.write(response.text)3.2 存储到数据库
使用数据库存储爬取的数据,例如使用SQLite。
import sqlite3conn = sqlite3.connect('example.db')
cursor = conn.cursor()# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS pages (id INTEGER PRIMARY KEY, url TEXT, content TEXT)''')# 插入数据
url = "https://www.example.com"
content = response.text
cursor.execute('''INSERT INTO pages (url, content) VALUES (?, ?)''', (url, content))# 提交并关闭连接
conn.commit()
conn.close()4. 处理动态网页
4.1 使用API
有些网站提供API接口,直接请求API可以获得数据,而无需解析HTML。
import requestsurl = "https://api.example.com/data"
response = requests.get(url)
data = response.json()
print(data)4.2 使用无头浏览器
使用Selenium库模拟无头浏览器,适用于需要JavaScript渲染的网页。
from selenium import webdriverurl = "https://www.example.com"
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
driver = webdriver.Chrome(options=options)
driver.get(url)# 处理渲染后的内容5. 高级主题
5.1 多线程和异步
使用多线程或异步操作可以提高爬虫的效率,特别是在爬取大量数据时。
import requests
from concurrent.futures import ThreadPoolExecutordef fetch_data(url):response = requests.get(url)return response.texturls = ["https://www.example.com/1", "https://www.example.com/2", "https://www.example.com/3"]
with ThreadPoolExecutor(max_workers=5) as executor:results = list(executor.map(fetch_data, urls))for result in results:print(result)5.2 使用代理
为了防止被网站封禁IP,可以使用代理服务器。
import requestsurl = "https://www.example.com"
proxy = {'http': 'http://your_proxy_here','https': 'https://your_proxy_here'
}
response = requests.get(url, proxies=proxy)
print(response.text)6. 防反爬虫策略
6.1 限制请求频率
设置适当的请求间隔,模拟人类操作,避免过快爬取。
import timeurl = "https://www.example.com"
for _ in range(5):response = requests.get(url)print(response.text)time.sleep(2) # 2秒间隔6.2 使用随机User-Agent
随机更换User-Agent头部,降低被识别为爬虫的概率。
import requests
from fake_useragent import UserAgentua = UserAgent()
headers = {'User-Agent': ua.random}
url = "https://www.example.com"
response = requests.get(url, headers=headers)
print(response.text)总结
这篇文章全面涵盖了Python爬虫的核心概念和实际操作,提供了从基础知识到高级技巧的全面指南。深入剖析了HTTP请求、HTML解析,以及静态和动态网页爬取的基本原理。通过requests、BeautifulSoup和Selenium等库的灵活运用,大家能够轻松获取和处理网页数据。数据存储方面,介绍了将数据保存到文件和数据库的方法,帮助大家有效管理爬取到的信息。高级主题涵盖了多线程、异步操作、使用代理、防反爬虫策略等内容,能够更高效地进行爬虫操作,并规避反爬虫机制。最后,提供了良好的实践建议,包括设置请求频率、使用随机User-Agent等,以确保爬虫操作的合法性和可持续性。
总体而言,本教程通过生动的示例代码和详实的解释,为学习和实践Python爬虫的读者提供了一份全面而实用的指南。希望大家通过学习本文,能够在实际应用中灵活驾驭爬虫技术,更深入地探索网络世界的无限可能。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
更多Python学习内容:ipengtao.com
干货笔记整理
100个爬虫常见问题.pdf ,太全了!
Python 自动化运维 100个常见问题.pdf
Python Web 开发常见的100个问题.pdf
124个Python案例,完整源代码!
PYTHON 3.10中文版官方文档
耗时三个月整理的《Python之路2.0.pdf》开放下载
最经典的编程教材《Think Python》开源中文版.PDF下载

点击“阅读原文”,获取更多学习内容
相关文章:
Python爬虫教程:从入门到实战
更多Python学习内容:ipengtao.com 大家好,我是涛哥,今天为大家分享 Python爬虫教程:从入门到实战,文章3800字,阅读大约15分钟,大家enjoy~~ 网络上的信息浩如烟海,而爬虫(…...
C++实现高频设计模式
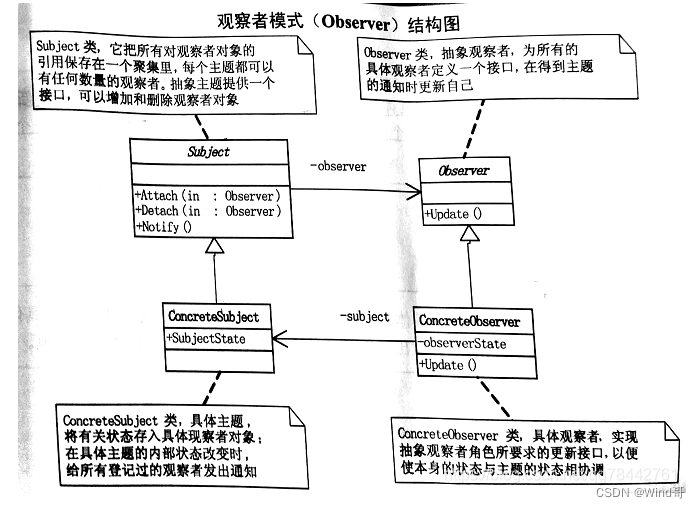
面试能说出这几种常用的设计模式即可 1.策略模式 1.1 业务场景 大数据系统把文件推送过来,根据不同类型采取不同的解析方式。多数的小伙伴就会写出以下的代码: if(type"A"){//按照A格式解析 }else if(type"B"){//按照B格式解析 …...
opencv(2): 视频采集和录制
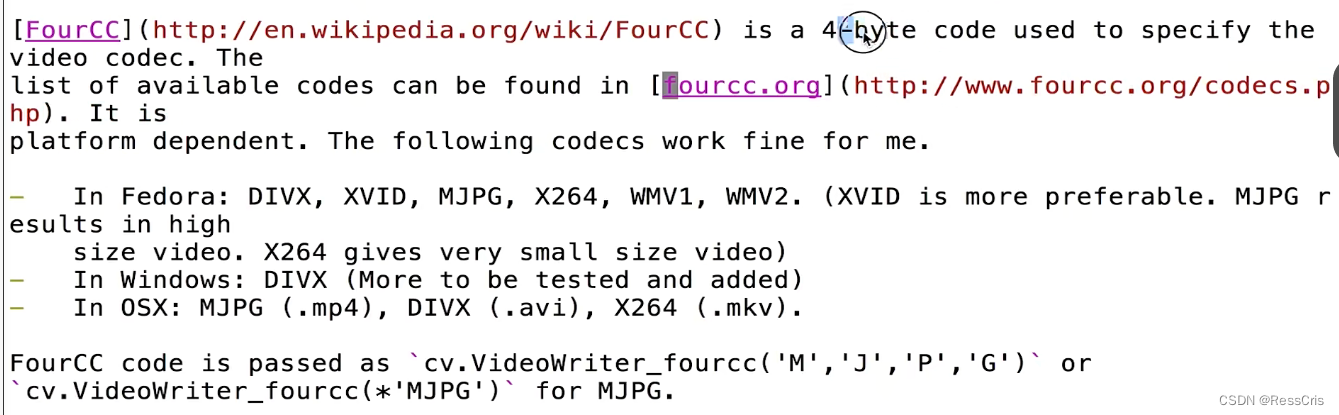
视频采集 相关API VideoCapture()cap.read(): 返回两个值,第一个参数,如果读到frame,返回 True. 第二个参数为相应的图像帧。cap.release() VideoCapture cv2.VideoCapture(0) 0 表示自动检测,如果在笔记本上运行&…...

SpringBoot+EasyExcel设置excel样式
方式一:使用注解方式设置样式 模板可通过HeadFontStyle、HeadStyle、ContentFontStyle、ContentStyle、HeadRowHeight ContentRowHeight等注解设置excel单元格样式; //字体样式及字体大小 HeadFontStyle(fontName "宋体",fontHeightInPoints…...
)
自定义View之Measure(二)
measure 用来测量 View 的宽和高,它的流程分为 View 的 measure 流程和 ViewGroup 的measure流程,只不过ViewGroup的measure流程除了要完成自己的测量,还要遍历地调用子元素的measure()方法。 上一回说到performMeasur…...
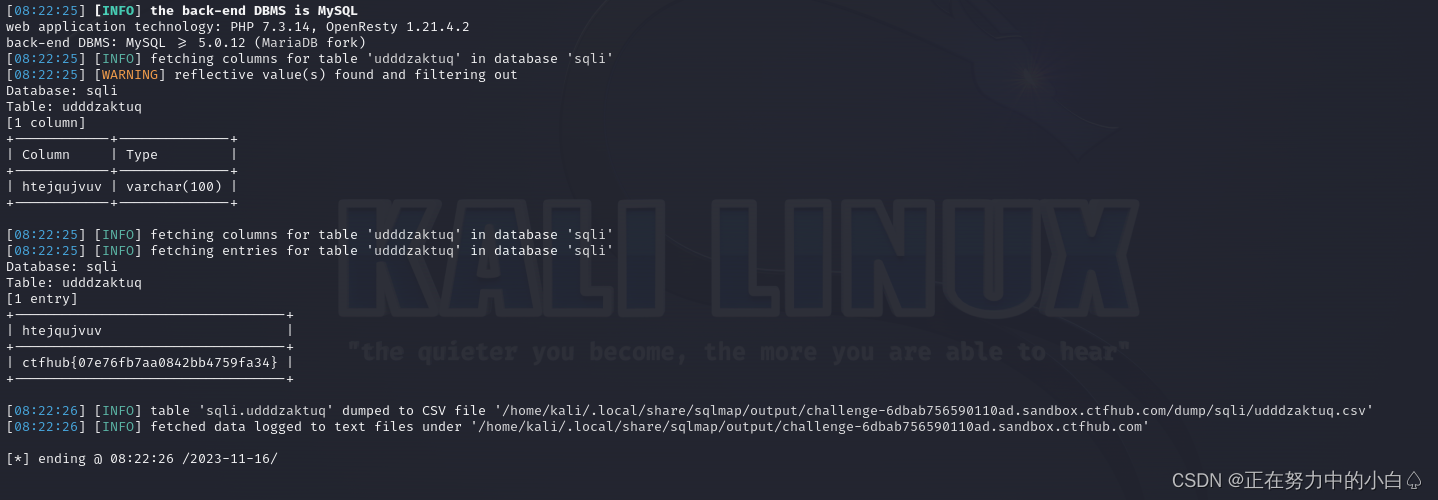
SQL注入学习--GTFHub(布尔盲注+时间盲注+MySQL结构)
目录 布尔盲注 手工注入 笔记 Boolean注入 # 使用脚本注入 sqlmap注入 使用Burpsuite进行半自动注入 时间盲注 手工注入 使用脚本注入 sqlmap注入 使用Burpsuite进行半自动注入 MySQL结构 手工注入 sqlmap注入 笔记 union 联合注入,手工注入的一般步骤 …...

Kubernetes学习-概念2
参考:关于 cgroup v2 | Kubernetes 关于 cgroup v2 在 Linux 上,控制组约束分配给进程的资源。 kubelet 和底层容器运行时都需要对接 cgroup 来强制执行为 Pod 和容器管理资源, 这包括为容器化工作负载配置 CPU/内存请求和限制。 Linux 中…...
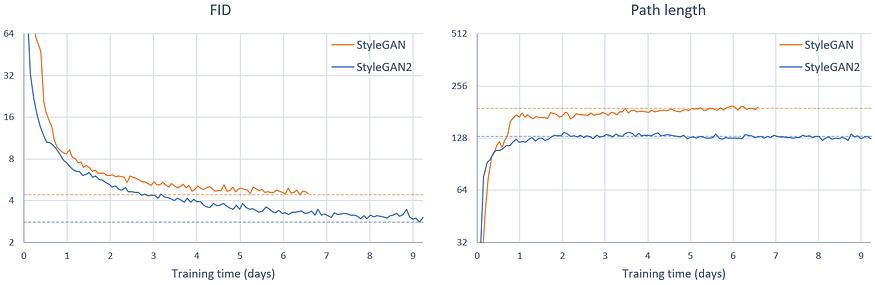
StyleGAN:彻底改变生成对抗网络的艺术
一、介绍 多年来,人工智能领域取得了显着的进步,其中最令人兴奋的领域之一是生成模型的发展。这些模型旨在生成与人类创作没有区别的内容,例如图像和文本。其中,StyleGAN(即风格生成对抗网络)因其创建高度逼…...

黑马程序员微服务第四天课程 分布式搜索引擎1
分布式搜索引擎01 – elasticsearch基础 0.学习目标 1.初识elasticsearch 1.1.了解ES 1.1.1.elasticsearch的作用 elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容 例如: …...

向量以及矩阵
0.前言 好了那我们新的征程也即将开始,那么在此呢我也先啰嗦两句,本篇文章介绍数学基础的部分,因为个人精力有限我不可能没一字一句都讲得非常清楚明白,像矩阵乘法之类的一些基础知识我都是默认你会了(还不会的同学推…...
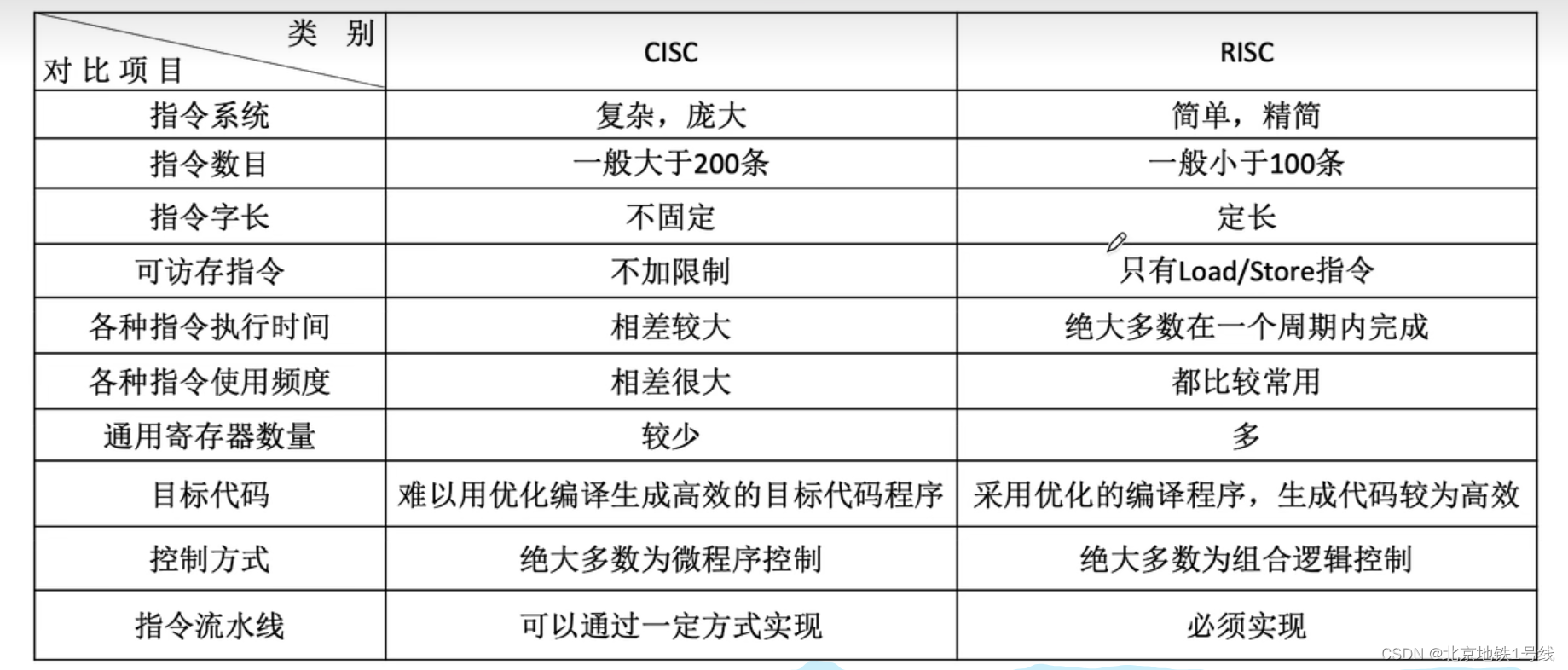
9.程序的机器级代码表示,CISC和RISC
目录 一. x86汇遍语言基础(Intel格式) 二. AT&T格式汇编语言 三. 程序的机器级代码表示 (1)选择语句 (2)循环语句 (3)函数调用 1.函数调用命令 2.栈帧及其访问 3.栈帧的…...

《硅基物语.AI写作高手:从零开始用ChatGPT学会写作》《从零开始读懂相对论》
文章目录 《硅基物语.AI写作高手:从零开始用ChatGPT学会写作》内容简介核心精华使用ChatGPT可以高效搞定写作的好处如下 《从零开始读懂相对论》内容简介关键点书摘最后 《硅基物语.AI写作高手:从零开始用ChatGPT学会写作》 内容简介 本书从写作与ChatG…...

【2016年数据结构真题】
已知由n(M>2)个正整数构成的集合A{a<k<n},将其划分为两个不相交的子集A1 和A2,元素个数分别是n1和n2,A1和A2中的元素之和分别为S1和S2。设计一个尽可能高效的划分算法,满足|n1-n2|最小且|s1-s2|最大。要求…...
创作者等级终于升到4级了
写了两个月的文章,终于等到4级了。发文纪念一下:...
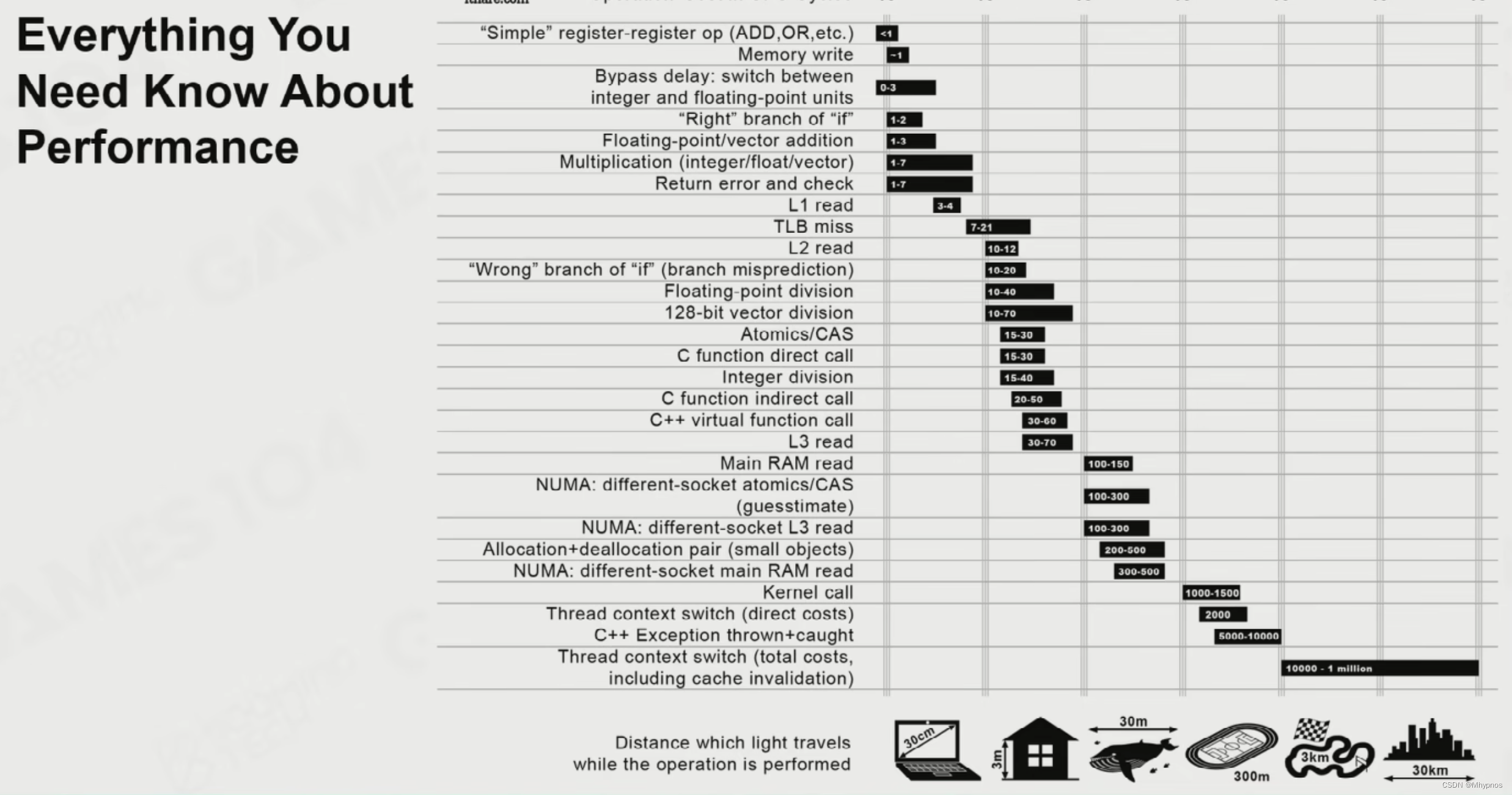
Games104现代游戏引擎笔记 面向数据编程与任务系统
Basics of Parallel Programming 并行编程的基础 核达到了上限,无法越做越快,只能通过更多的核来解决问题 Process 进程 有独立的存储单元,系统去管理,需要通过特殊机制去交换信息 Thread 线程 在进程之内,共享了内存…...
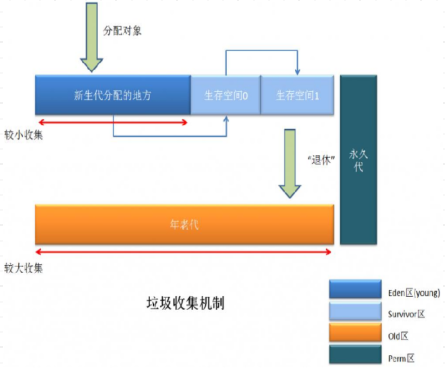
系列三、GC垃圾回收【总体概览】
一、GC垃圾回收【总体概览】 JVM进行GC时,并非每次都对上面的三个内存区域(新生区、养老区、元空间/永久代)一起回收,大部分回收的是新生区里边的垃圾,因此GC按照回收的区域又分为了两种类型,一种是发生在新…...
WPA破解-创建Hash-table加速并用Cowpatty破解)
无线WiFi安全渗透与攻防(N.3)WPA破解-创建Hash-table加速并用Cowpatty破解
WPA破解-创建Hash-table加速并用Cowpatty破解 WPA破解-创建Hash-table加速并用Cowpatty破解1.Cowpatty 软件介绍2.渗透流程1.安装CoWPAtty2.抓握手包1.查看网卡2.开启监听模式3.扫描wifi4.抓握手包5.进行冲突模式攻击3.STA重新连接wifi4.渗透WPA wifi5.使用大字典破解3.hash-ta…...

golang 动态库
目录 1. golang 动态库2. golang 语言使用动态库、调用动态链接库2.1. Go 插件系统2.2. 动态加载的优劣2.3. Go 的插件系统:Plugin2.4. 插件开发原则2.4.1. 插件独立2.4.2. 使用接口类型作为边界2.4.3. Unix 模块化原则2.4.4. 版本控制 2.5. 插件开发示例2.5.1. 编写…...

Python的2042小游戏及其详解
源码: import random import os# 游戏界面尺寸 SIZE 4# 游戏结束标志 GAME_OVER False# 初始化游戏界面 board [[0] * SIZE for _ in range(SIZE)]# 随机生成一个初始方块 def add_random_tile():empty_tiles [(i, j) for i in range(SIZE) for j in range(SIZ…...
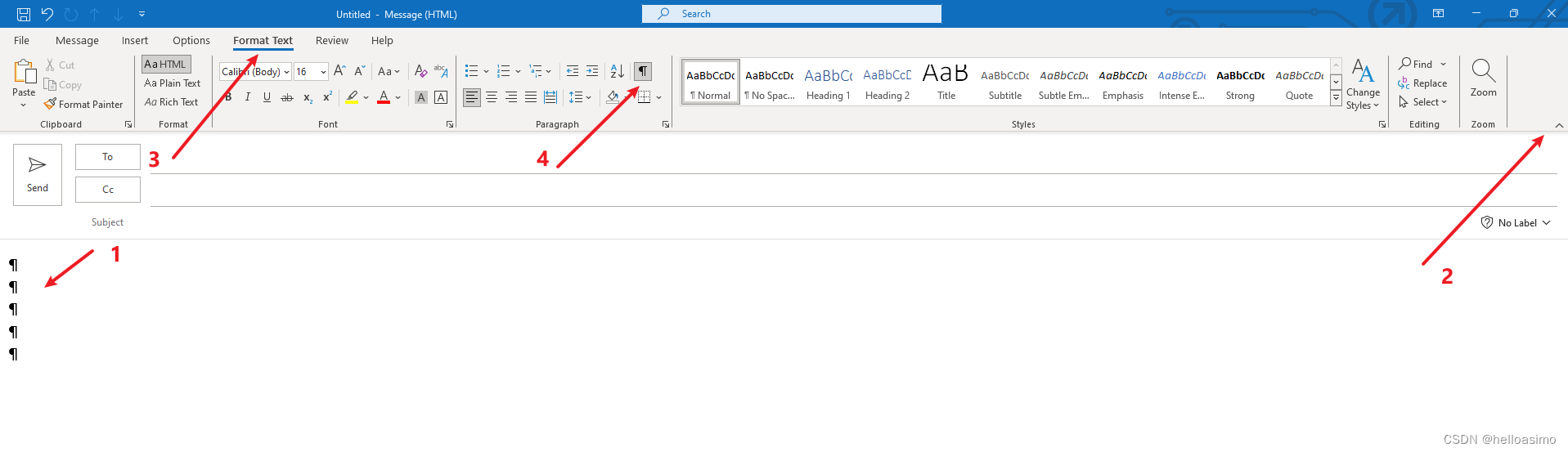
怎么去掉邮件内容中的回车符
上图是Outlook 截图,可见1指向的总有回车符; 故障原因: 不小心误按了箭头4这个选项; 解决方法: 点击2箭头确保tab展开; 点击3以找到箭头4. 取消勾选或者多次点击,即可解决。...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...
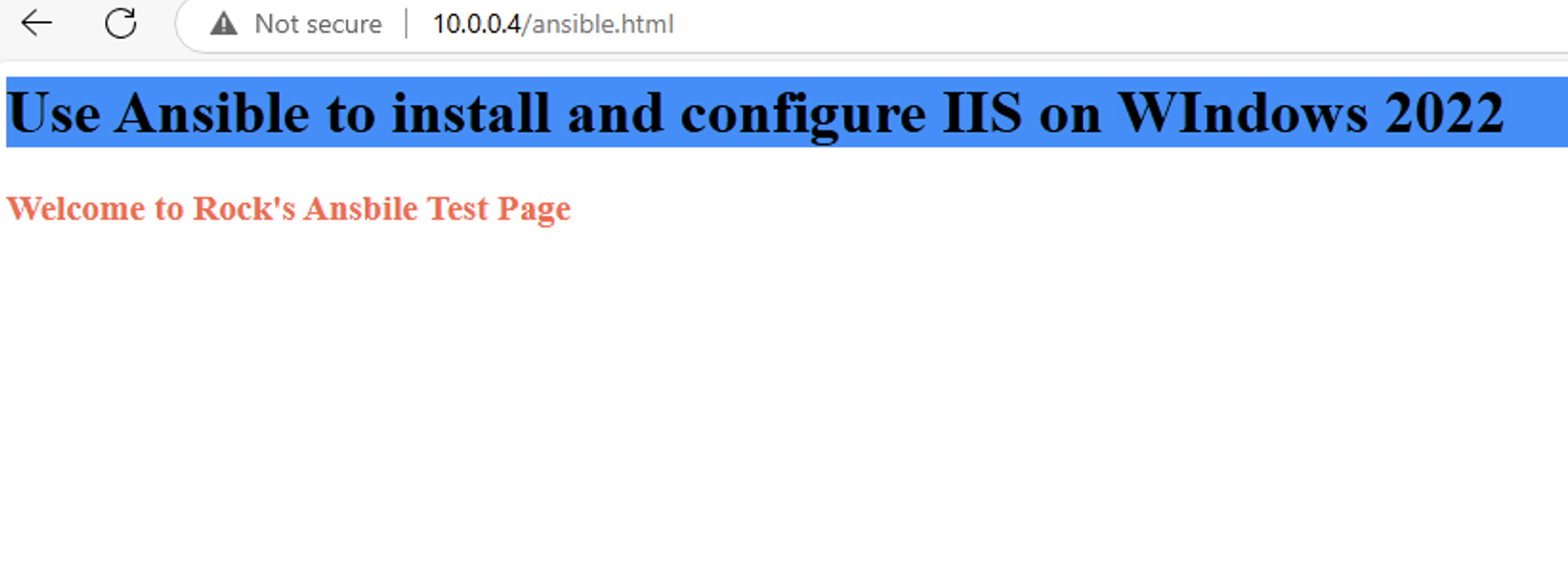
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...
麒麟系统使用-进行.NET开发
文章目录 前言一、搭建dotnet环境1.获取相关资源2.配置dotnet 二、使用dotnet三、其他说明总结 前言 麒麟系统的内核是基于linux的,如果需要进行.NET开发,则需要安装特定的应用。由于NET Framework 是仅适用于 Windows 版本的 .NET,所以要进…...
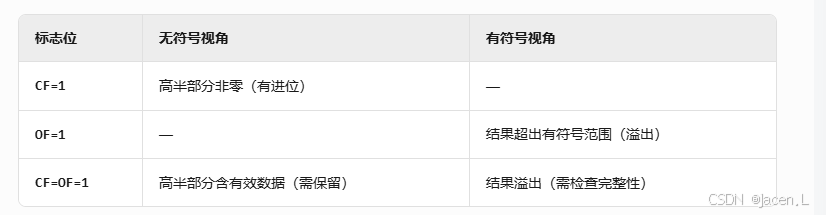
【汇编逆向系列】六、函数调用包含多个参数之多个整型-参数压栈顺序,rcx,rdx,r8,r9寄存器
从本章节开始,进入到函数有多个参数的情况,前面几个章节中介绍了整型和浮点型使用了不同的寄存器在进行函数传参,ECX是整型的第一个参数的寄存器,那么多个参数的情况下函数如何传参,下面展开介绍参数为整型时候的几种情…...

C#最佳实践:为何优先使用as或is而非强制转换
C#最佳实践:为何优先使用as或is而非强制转换 在 C# 的编程世界里,类型转换是我们经常会遇到的操作。就像在现实生活中,我们可能需要把不同形状的物品重新整理归类一样,在代码里,我们也常常需要将一个数据类型转换为另…...
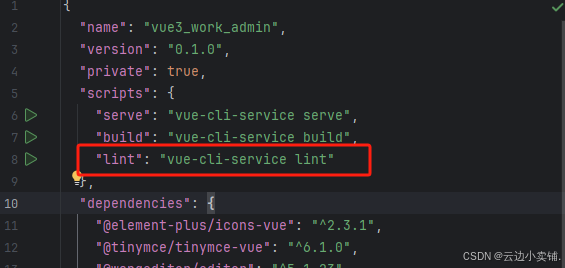
运行vue项目报错 errors and 0 warnings potentially fixable with the `--fix` option.
报错 找到package.json文件 找到这个修改成 "lint": "eslint --fix --ext .js,.vue src" 为elsint有配置结尾换行符,最后运行:npm run lint --fix...