滴滴 Redis 异地多活的演进历程
为了更好的做好容灾保障,使业务能够应对机房级别的故障,滴滴的存储服务都在多机房进行部署。本文简要分析了 Redis 实现异地多活的几种思路,以及滴滴 Redis 异地多活架构演进过程中遇到的主要问题和解决方法,抛砖引玉,给小伙伴们一些参考。
Redis 异地多活的主要思路
业界实现 Redis 异地多活通常三种思路:主从架构、Proxy双写架构、数据层双向同步架构。
主从架构
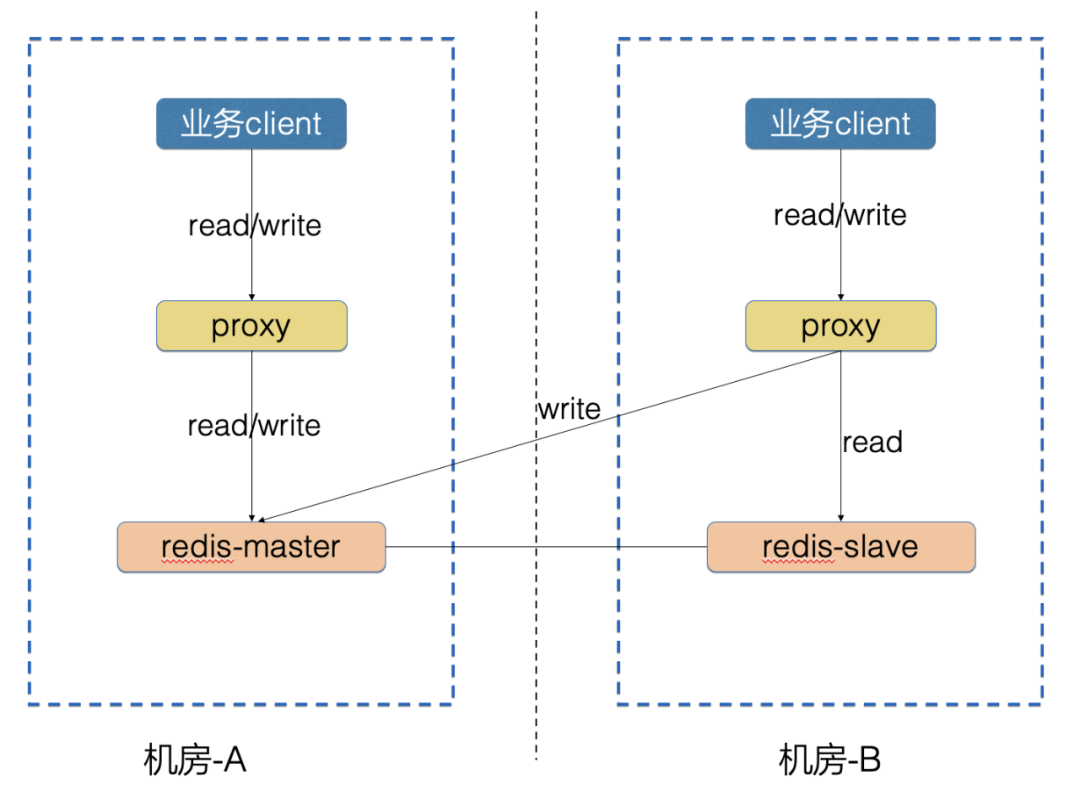
主从架构的思路:
各机房的 Redis 通过 Proxy 对外提供读写服务,业务流量读写本机房的 Redis-proxy
主机房里的 Redis-master 实例承担所有机房的写流量
从机房里的 Redis-slave 实例只读,承担本机房里的读流量
主从架构的优点:
实现简单,在 Proxy 层开发读写分流功能就可以实现
Redis 层使用原生主从复制,可以保证数据一致性
主从架构的缺点:
从机房里的 Redis-proxy 需要跨机房写,受网络延时影响,业务在从机房里的写耗时高于主机房
主机房故障时,从机房的写流量也会失败,需要把从机房切换为主机房,切换 Redis-master
网络故障时,从机房的写流量会全部失败,为了保障数据一致性,这种场景比较难处理
Proxy 双写架构
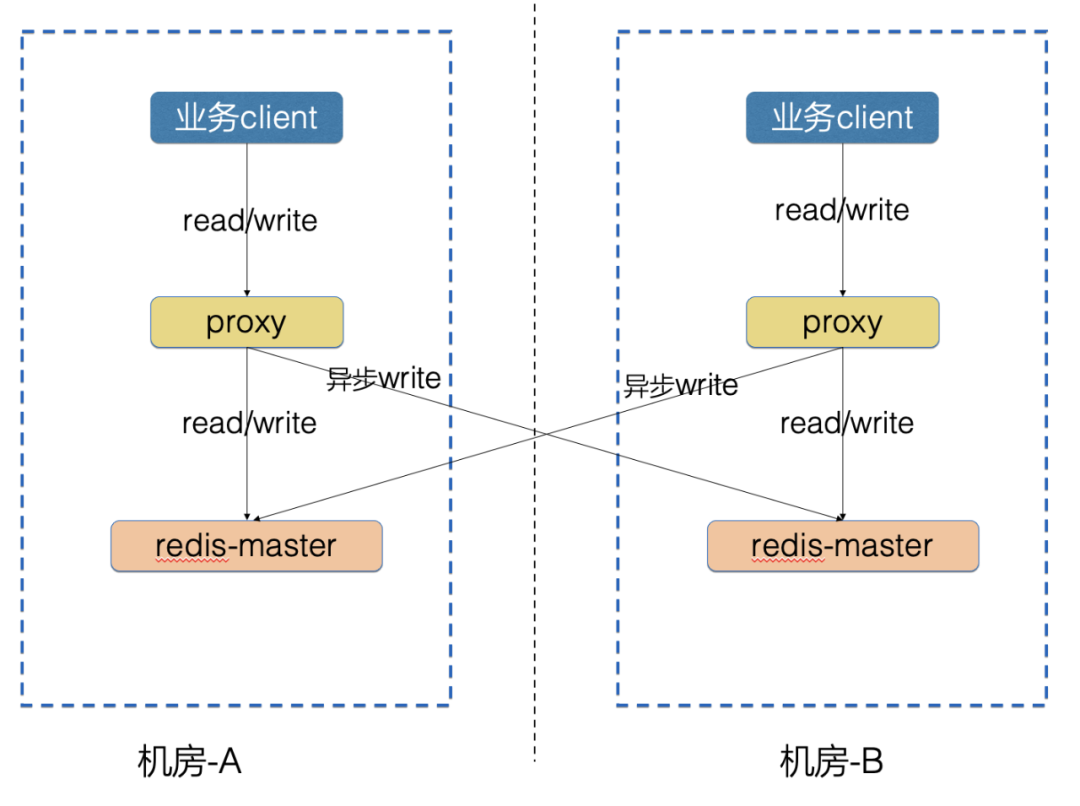
Proxy 双写架构的思路:
各机房的 Redis 通过 Proxy 对外提供读写服务,业务流量读写本机房的 Redis-proxy
不区分主从机房,每个机房都是独立的 Redis 集群
各机房的读写流量都是访问本机房的 Redis 集群
Proxy 层在写本机房成功后,将写请求异步发送到对端机房
Proxy 双写架构的优点:
实现简单,在 Proxy 层开发双写功能就可以实现
一个机房故障时,其他机房的流量不受影响
网络故障时,各机房内部的流量也不受影响
Proxy 双写架构的缺点:
不能保证数据一致性,Proxy 异步 write 请求可能会失败,失败丢弃请求后,导致双机房数据不一致
假设机房-A的集群先上线,机房-B 后上线,Proxy 双写架构不能支持把机房-A的存量数据同步到机房-B
网络故障时,异步 write 会失败后丢弃,网络恢复后,之前失败的数据已经丢弃,导致双机房数据不一致
数据层双向同步架构
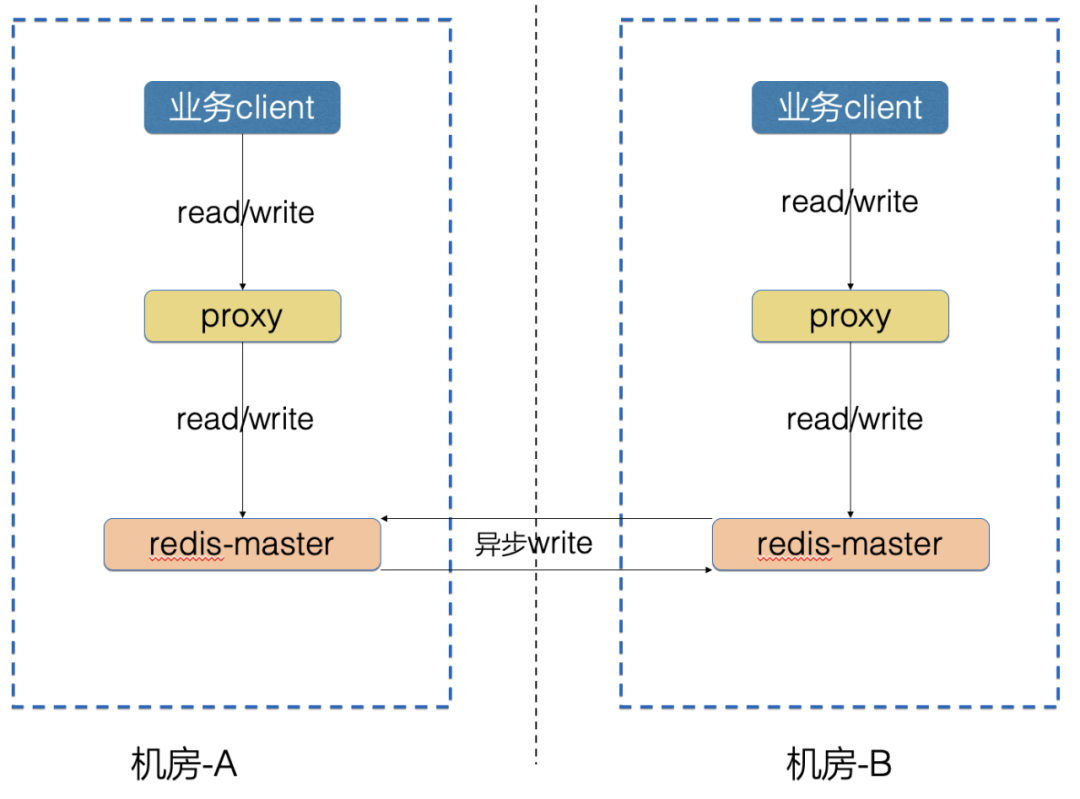
数据层双向同步架构的思路:
Proxy 不关心底层 Redis 数据同步
业务流量只访问本机房里的 Redis 集群
在 RedisServer 层面实现数据同步
数据层双向同步架构的优点:
机房-A故障时,机房-B不受影响,反向如是
网络故障时,本机房流量不受影响,网络恢复后,数据层面可以拉取增量数据继续同步,数据不丢
支持存量数据的同步
业务访问 Redis 延时低,访问链路不受机房间网络延时影响
业务单元化部署时,双机房 Redis 会有较高的数据一致性
数据层双向同步架构的缺点:
实现相对比较复杂,RedisServer 改动比较大
滴滴 Redis 架构
Codis 架构(早期架构,现已废弃)
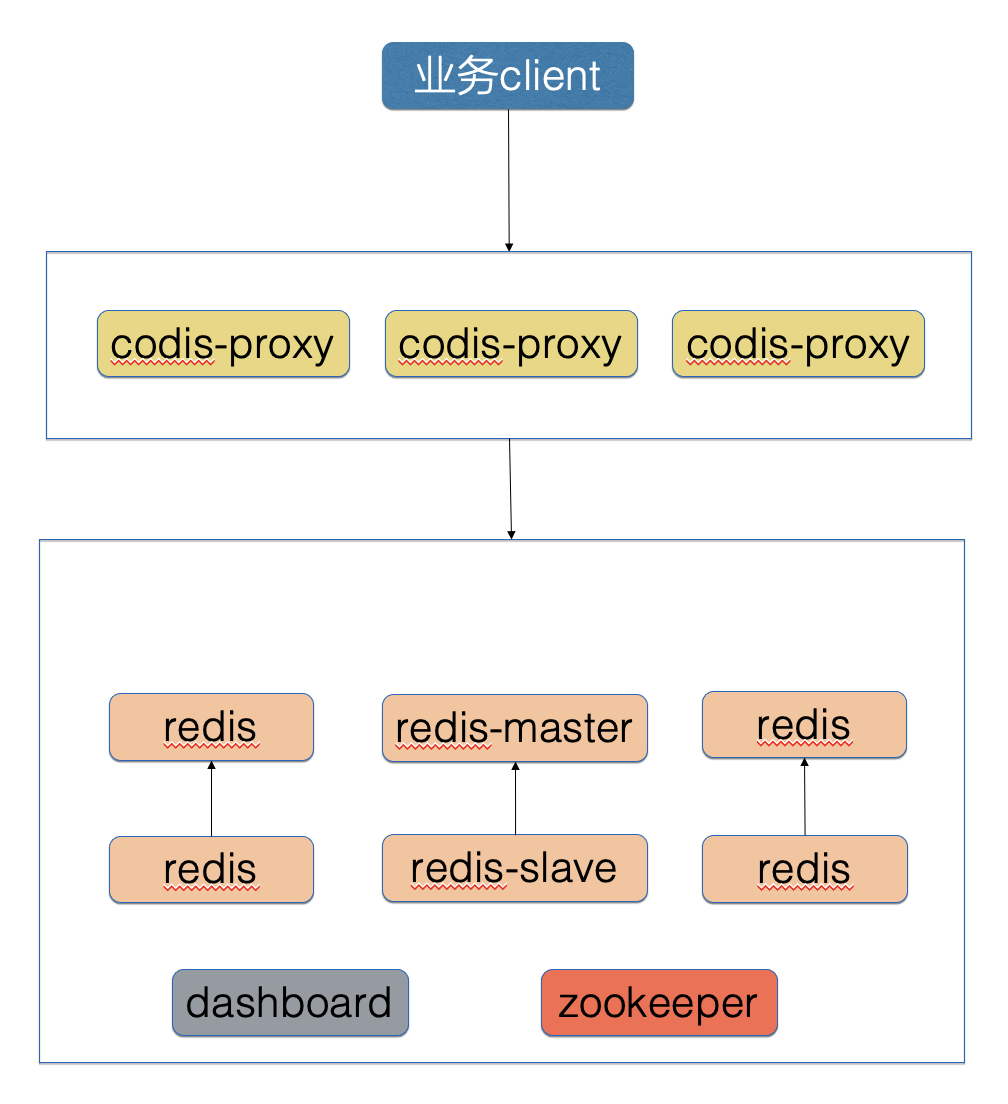
Kedis 架构(线上架构)
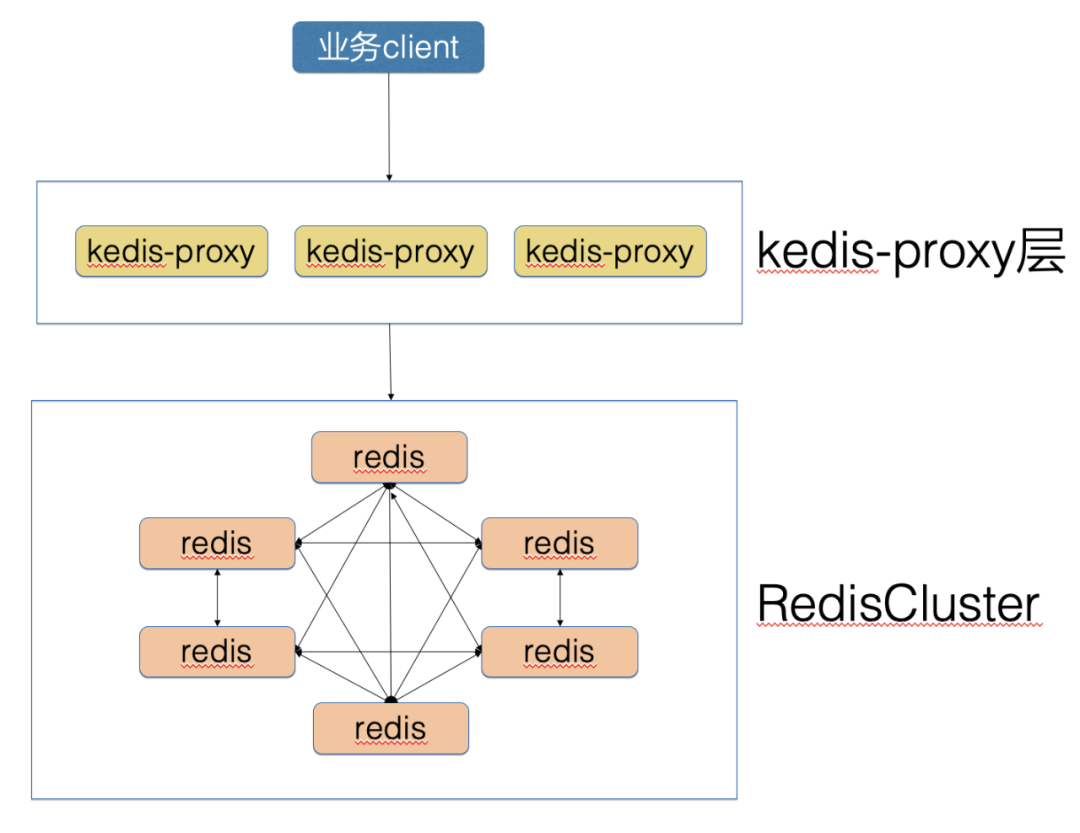
滴滴 Redis 异地多活架构的演进
第一代多活架构
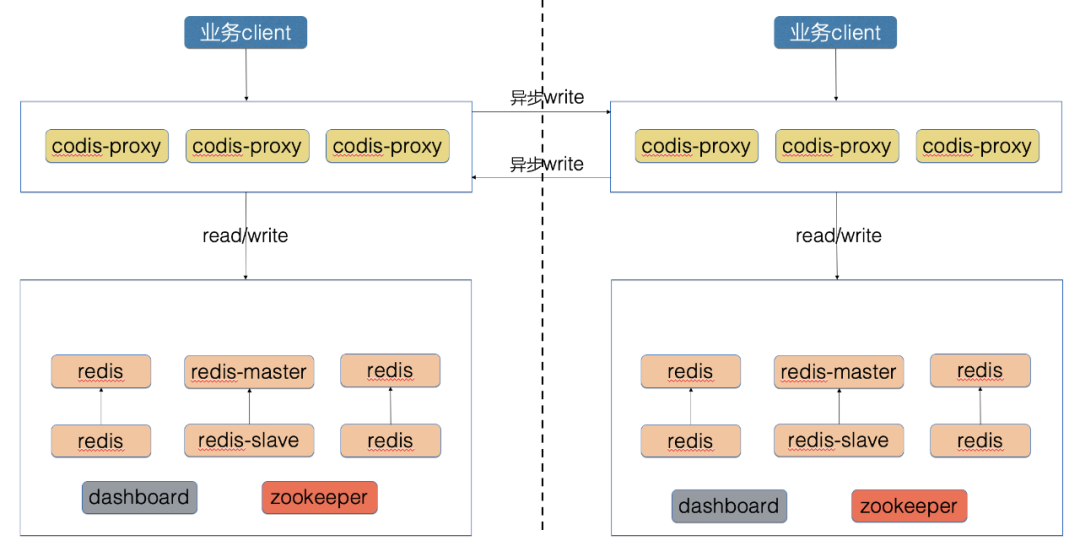
第一代 Redis 多活基于 Codis 架构在 proxy 层实现了双写,即本机房的 Proxy 将写流量转发到对端机房的 Proxy,这个方案的特点是快速实现,尽快满足了业务多机房同步的需求。如前面 Proxy 双向架构思路所讲,本方案还存在着诸多缺点,最主要的是网络故障时,同步数据丢失的问题,为了解决这些问题,我们开发了第二代多活架构。
第二代多活架构
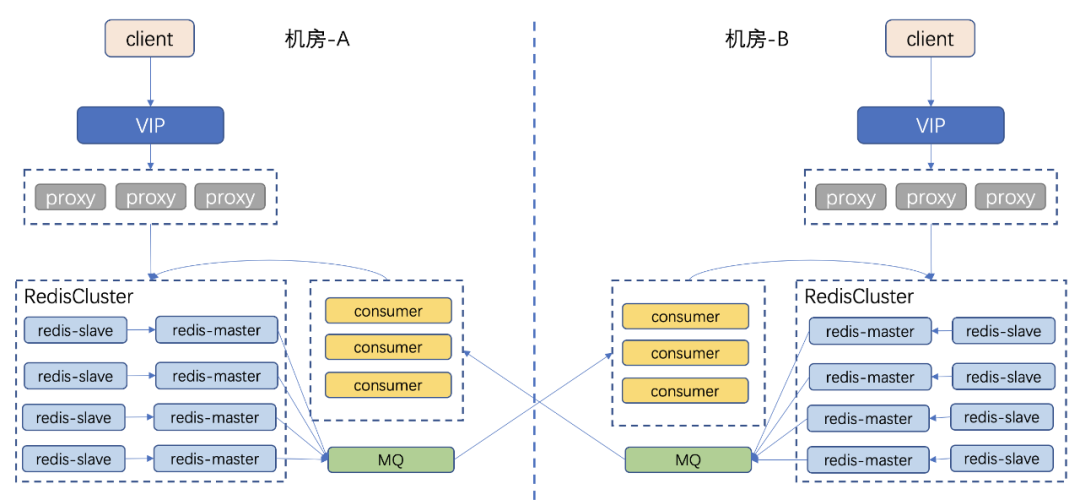
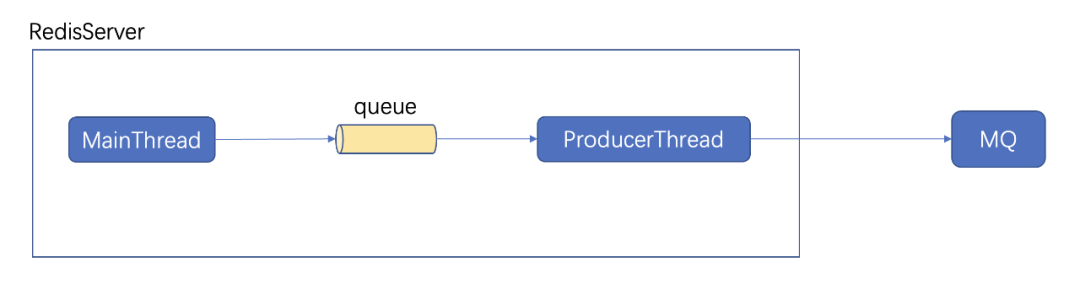
第二代多活基于 Kedis 架构,对 Redis-server 进行改造,可以把增量数据从 Redis 直接写入本机房的 MQ 中,由对端机房的 consumer 来消费 MQ,consumer 将数据写入对端 Redis 中。网络故障时,数据会在 MQ 堆积,待网络恢复后,consumer 可以基于故障前的 offset 继续进行消费,写入对端 Redis,从而保证在网络故障时 Redis 多活不会丢数据。
但这一代架构仍不够完美,存在以下问题:
ProducerThread 把数据写入 MQ 时,如果触发 MQ 限流,数据会被丢掉
RedisServer 内部包含了 ProducerThread,当中间内部 queue 累积数据量超过10000条时,数据会被 MainThread 丢掉
中间同步数据写入 MQ,增加了跨部门依赖,同步链路长,不利于系统稳定性
中间同步链路重试会造成非幂等命令执行多次,例如 incrby 重试可能造成命令执行多次造成数据不一致
对于新建双活链路,不支持同步存量数据,只能从当前增量数据开始同步
Redis 增量数据写入 MQ,导致成本增加
为了解决以上问题,我们开发了第三代架构。
第三代多活架构
在第三代架构中,我们细化了设计目标,主要思路是保证同步链路中的数据不丢不重,同时去掉对 MQ 的依赖,降低多活成本。
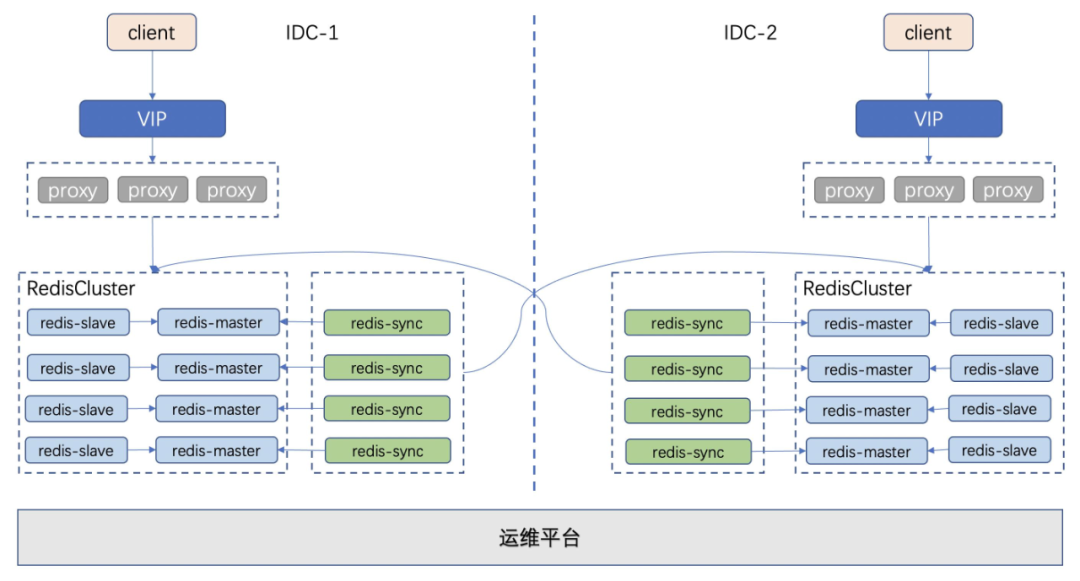
第三代架构中,我们去掉了 MQ 和 consumer,新增了 syncer 组件。syncer 组件模拟 Redis-slave 从 Redis-master 中拉取增量数据,这样把数据同步和 Redis 进行解耦,便于后续多机房扩展。
在第三代架构中,Redis 遇到了回环、重试、数据冲突、增量数据存储和读取等问题,接下来一一介绍我们应对这些问题的解决方案。
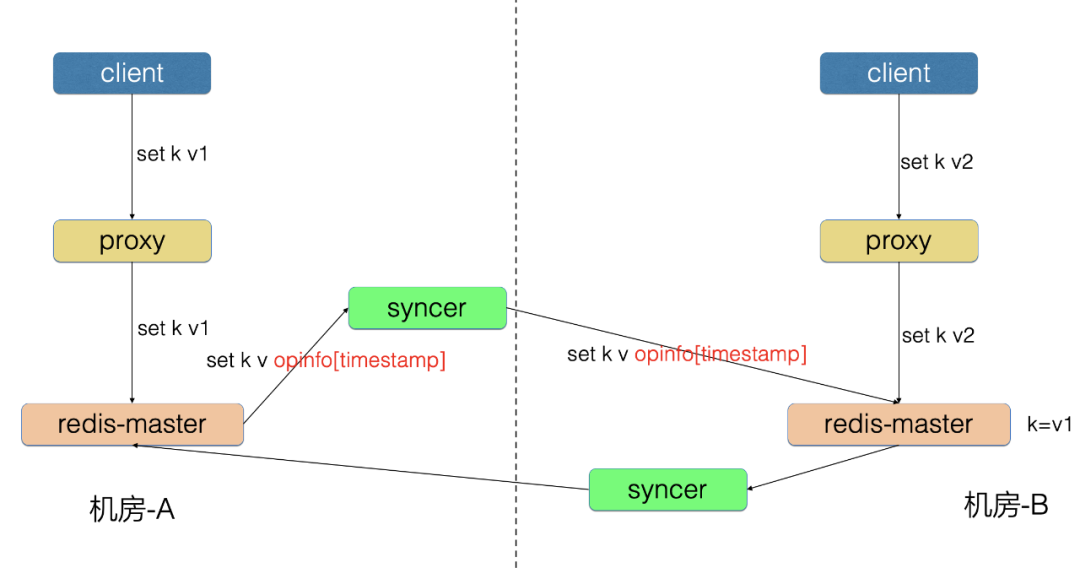
1、回环问题
机房-A 写入的数据同步到机房-B,防止数据再传回机房-A。
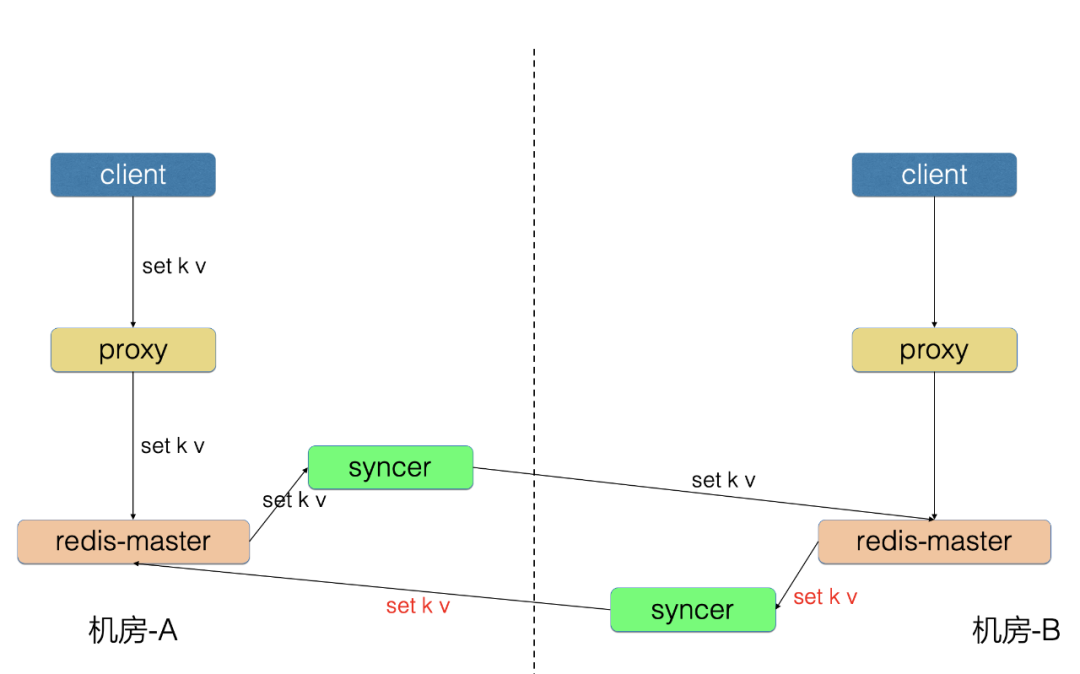
为了解决回环问题,我们开发了防回环机制:
Redis 增加 shardID 配置,标识唯一分片号
Redis 请求中增加 opinfo,记录元信息,包含 shardID
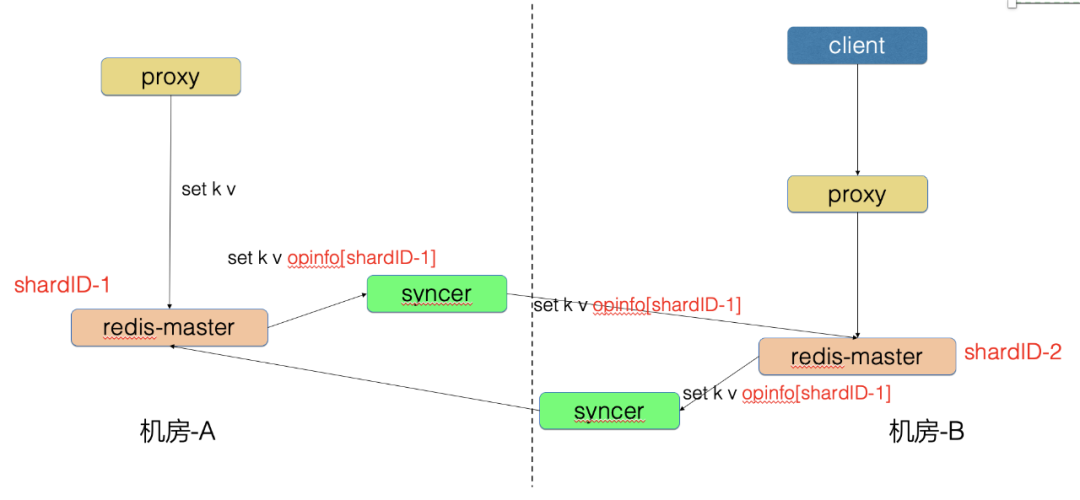
机房-A 的 Proxy 写入了 set k v 请求
机房-A 的 Redis-master 向 syncer 同步 set k v opinfo[shardID-1] 请求
syncer 向机房-B 写入 set k v opinfo[shardID-1] 请求
这样机房-B 根据 shardID-1 识别出这条请求是机房-A 生产的数据,因此不会再向机房-A 同步本条请求
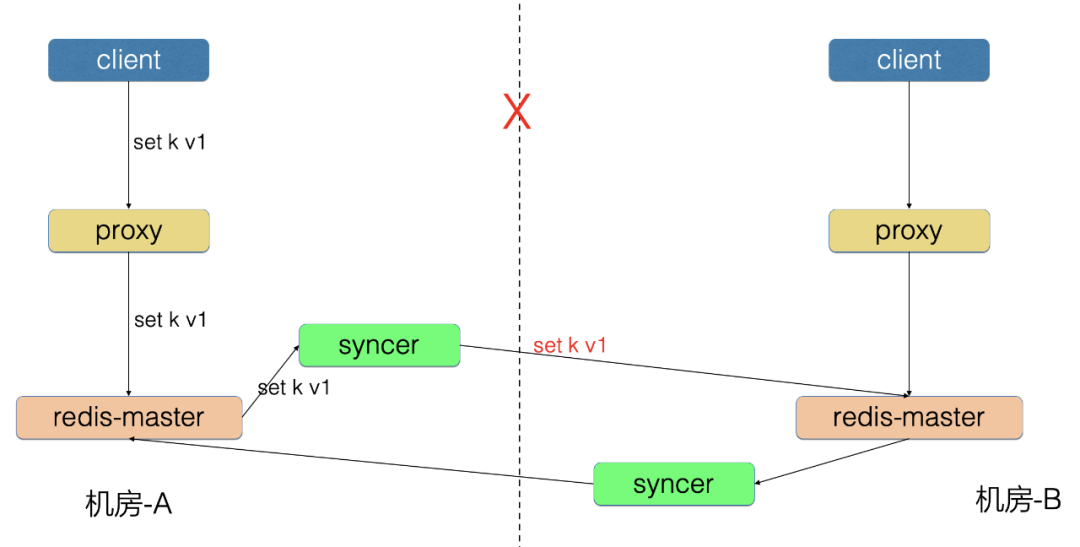
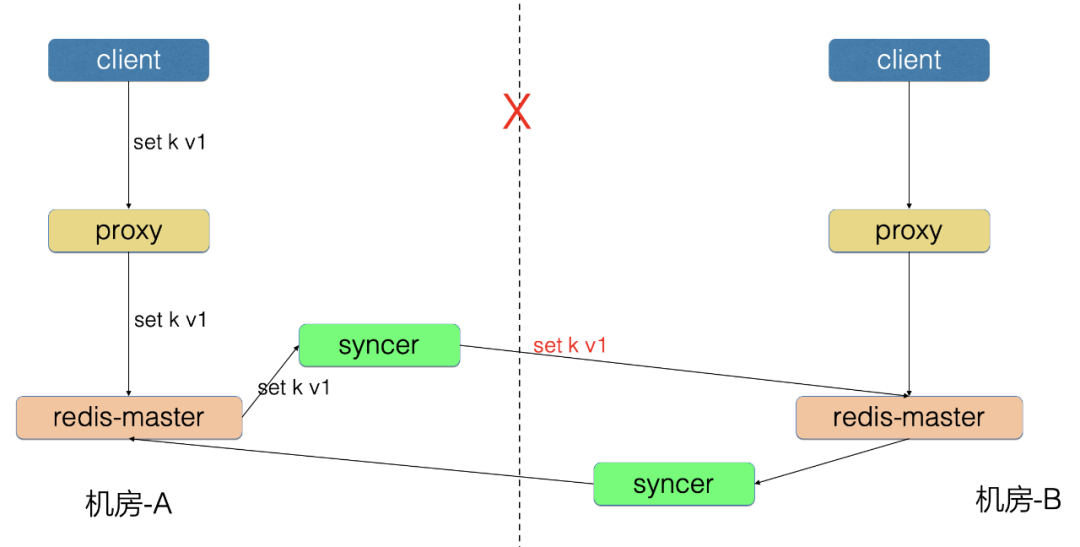
2、重试问题
机房-A 写入的 incrby 请求同步到机房-B,由于中间链路的重试,导致机房-B 可能执行了多次。
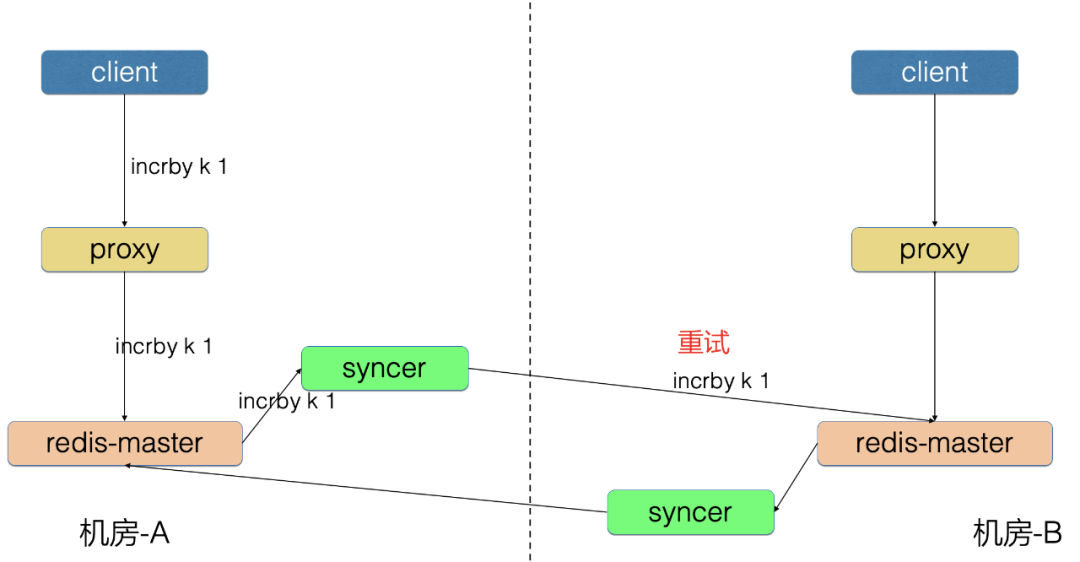
为了解决重试问题,我们开发了防重放机制:
Redis 增加 opid,标识唯一请求号
Redis 请求中增加 opinfo,记录元信息[opid]
机房-A 的 Proxy 写入了 incrby k 1 请求
机房-A 的 Redis-master 向 syncer 同步了 incrby k 1 opinfo[opid=100] 请求, 之前同步的 opid=99 的请求已经成功
syncer 向机房-B 写入 incrby k 1 opinfo[opid=100] 请求
机房-B 的 Redis 里存储了防重放信息 shardID-1->opid[99]
机房-B 的 Redis 发现新请求的 opid=100>本地的99,判断为新请求
机房-B的 Redis 执行这条请求,并把防重放信息更新为shardID-1->opid[100]
假设机房-A 的 syncer 将本条请求进行了重试,又执行了一遍 incrby k 1 opinfo[opid=100]
机房-B 的 Redis 发现新请求 opid=100 等于本地的100,判断为重复请求
机房-B 的 Redis 忽略掉本地请求,不执行
3、数据冲突问题
双机房同时修改同一个 key 导致数据不一致
对于数据冲突,不同数据类型的不同操作的数据合并,如果单从存储层解决,是一个非常复杂的话题。如果业务层做了单元化部署,则不会出现这种问题。如果业务层没有做单元化,我们开发了冲突检测功能,来帮助业务及时发现数据冲突,最后数据以哪边为准来修正,需要业务同学来决策。
冲突检测机制:
Redis 记录 key 的最后 write 时间
Redis 请求中增加 opinfo,记录元信息 [timestamp]
如果 opinfo.timestamp<=key_write_time,则记录冲突 key
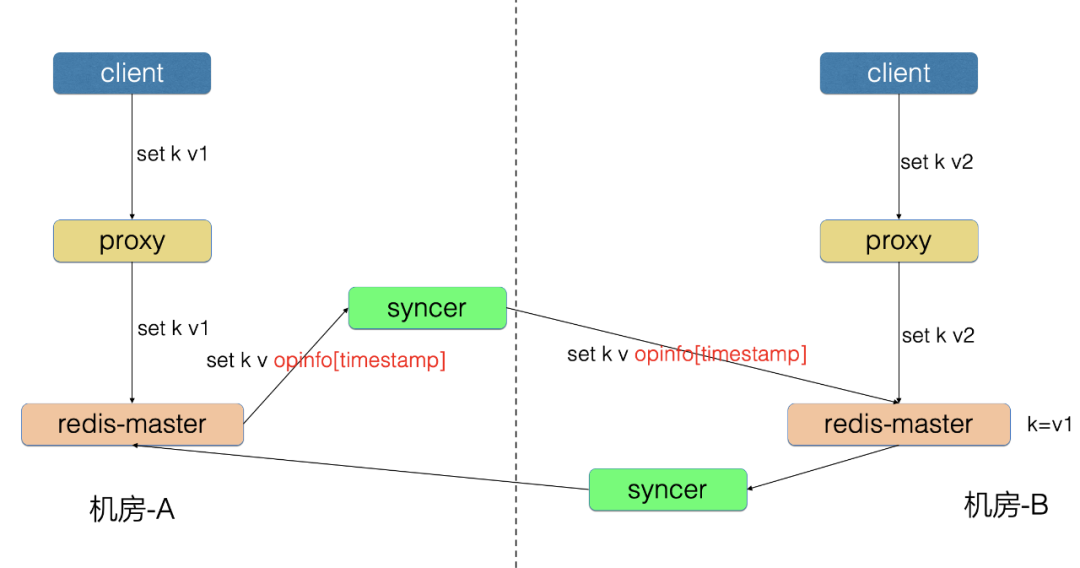
时间T1<T2<T3
T1时间,用户在机房-A 写入请求 set k v1
T2时间,用户在机房-B 写入请求 set k v2,并记录k的最后修改时间为T2
由于网络同步延时,T3时间,syncer 把T1时间写入的 set k v1请求发送到了机房-B
机房-B 的 Redis 执行 set k v1 时发现 timestamp 为T1,但 k 的最后修改时间为T2
由于T1<T2,机房-B 的 Redis 判断这是一次冲突,并记录下来,然后执行该条请求
以上是冲突检测的基本原理,这是一个旁路统计,帮助用户发现一些潜在冲突数据。
4、增量数据存储和读取问题
因为 syncer 只是同步组件,不会存储数据,所以需要考虑当网络故障时,增量数据的存储和读取问题。
为了解决这个问题,我们对 Redis 的 aof 机制进行了改造,可以在网络故障时,增量数据都堆积在 Redis 的磁盘上,在网络恢复后,syncer 从 Redis 里拉取增量 aof 数据发送到对端机房,避免数据丢失。
aof 机制改造有:aof 文件切分、aof 增量复制、aof 异步写盘
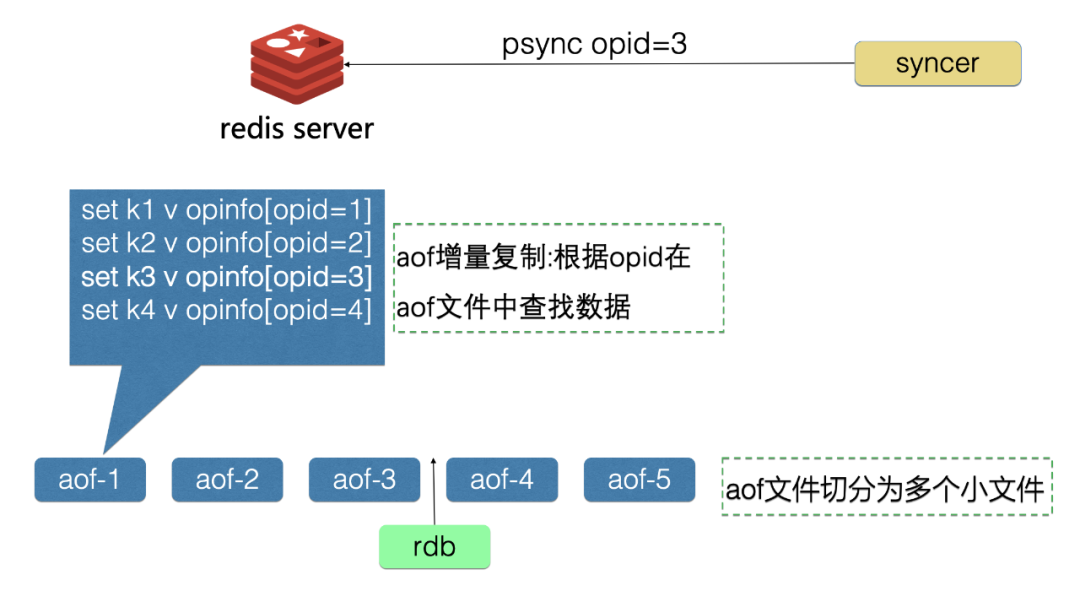
将 aof 文件切分为多个小文件,保存增量数据
当增量数据超过配置的阈值时,Redis 自动删除最旧的 aof 文件
当 Redis 重启时,加载 rdb 文件和 rdb 之后的 aof 文件,可以恢复全部数据
当网络故障恢复后,syncer 根据故障前的 opid 向 Redis 请求拉取增量数据,发送到对端机房
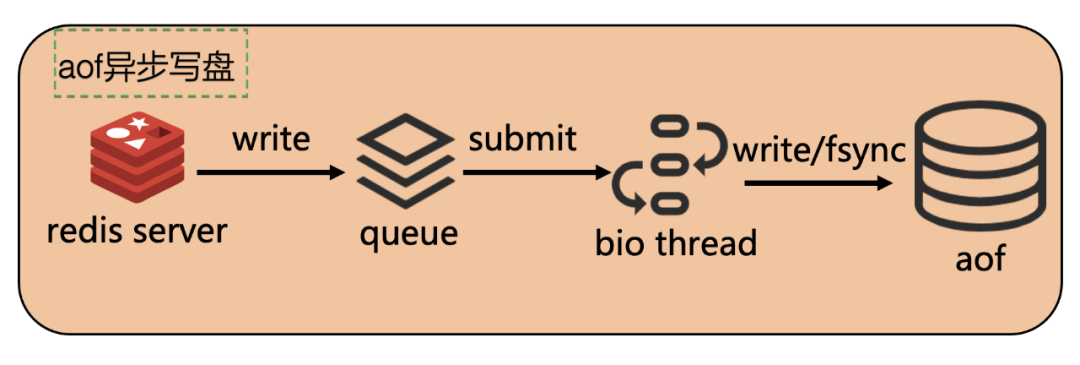
开源 Redis 是在主线程中进行 aof 写盘,当磁盘 IO 过高时,Redis 写盘可能造成业务访问 Redis 耗时抖动。因此我们开发了 aof 异步写盘机制:
Redis 的主线程将 aof 数据写入 queue 中
bio 线程来消费 queue
bio 线程将 aof 数据写入磁盘
这样 Redis 的访问耗时不受磁盘 IO 的影响,更好的保证稳定性。
相关文章:
滴滴 Redis 异地多活的演进历程
为了更好的做好容灾保障,使业务能够应对机房级别的故障,滴滴的存储服务都在多机房进行部署。本文简要分析了 Redis 实现异地多活的几种思路,以及滴滴 Redis 异地多活架构演进过程中遇到的主要问题和解决方法,抛砖引玉,…...
前端实现页面内容的截图与下载(html2canvas)
今天是一个发文的好日子😀~ 👇👇👇 一个需求,要截取页面中的内容并截图保存,来看一看我是怎么实现的吧: 这里需要使用到插件--html2canvas 1.安装并引入html2canvas npm install html2canv…...
VS2017 IDE 编译时的 X86、x64位 是干什么的
指定编译出的程序是x86架构下的32位程序还是64位程序 VS2017项目配置X86改配置x64位_winform:把项目由x86改为x64-CSDN博客 vs平台选项:Any CPU,x86,x64_vs anycpu-CSDN博客...
微信小程序 解决tab页切换过快 数据出错问题
具体问题:切换tab页切换过快时,上一个列表接口未响应完和当前列表数据冲突 出现数据错误 具体效果如下: 解决方式:原理 通过判断是否存在request 存在中断 并发送新请求 不存在新请求 let shouldAbort false; // 添加一个中断标志 let re…...

Taro编译警告解决方案:Error: chunk common [mini-css-extract-plugin]
文章目录 1. 背景2. 问题分析3. 解决方案3.1 更新 Taro 版本3.2 更新相关依赖3.3 调整 webpack 配置3.4 检查依赖版本 4. 拓展与分析4.1 拓展4.2 避免不必要的依赖4.3 查阅 Taro GitHub 仓库 5. 总结 🎉欢迎来到Java学习路线专栏~Taro编译警告解决方案:E…...

基于JavaWeb+SpringBoot+Vue电子商城微信小程序系统的设计和实现
基于JavaWebSpringBootVue电子商城微信小程序系统的设计和实现 源码获取入口前言系统设计功能截图Lun文目录订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 源码获取入口 前言 身处互联网时代,互联网无形中影响着人们的吃穿住行,人们享受着不…...
JS进阶——作用域、解构、箭头函数
1、作用域 作用域(scope)规定了变量能够被访问的“范围”,离开了这个“范围”变量便不能被访问。 1.1 局部作用域 局部作用域可分为函数作用域和块作用域。 1.1.1 函数作用域 在函数内部声明的变量只能在函数内部被访问,外部无…...

centos下安装mysql8版本
1、如果服务器没有wget,先下载wget工具 sudo yum install wget 2、下载指定mysql版本的tar包 sudo wget https://downloads.mysql.com/archives/get/p/23/file/mysql-8.0.21-1.el7.x86_64.rpm-bundle.tar 3、解压tar包 sudo tar -xvf mysql-8.0.21-1.el7.x86_64.rpm…...

C++面试常考手写题目
C面试常考手写题目 vectorstringauto_ptrshared_ptrunique_ptrweak_ptrsingleton快排非递归heapheap_sortmerge_sort vector #include <bits/stdc.h> using namespace std;template<typename T> class vector {public:typedef T value_type;typedef T* iterator;p…...

LLM建模了什么,为什么需要RAG
LLM近期研究是井喷式产出,如此多的文章该处何处下手,他们到底又在介绍些什么、解决什么问题呢?“为学日增,为道日损”,我们该如何从如此多的论文中找到可以“损之又损以至于无”的更本质道或者说是这个方向的核心模型。…...

为开发GPT-5,OpenAI向微软寻求新融资
11月14日,金融时报消息,OpenAI正在向微软寻求新一轮融资,用于开发超级智能向AGI(通用人工智能)迈进,包括最新模型GPT-5。 最近,OpenAI召开了首届开发者大会,推出了GPT-4 Turbo、自定…...

创邻科技亮相ISWC 2023,国际舞台见证知识图谱领域研究突破
近日,第22届国际语义网大会 ISWC 2023 在雅典希腊召开,通过线上线下的形式,聚集了全球的顶级研究人员、从业人员和行业专家,讨论、发展和塑造语义网和知识图谱技术的未来。创邻科技CEO张晨博士作为知识图谱行业专家受邀参会&#…...
开源博客项目Blog .NET Core源码学习(6:雪花算法)
Blog .NET项目中有多种数据类生成对象实例时需要唯一标识,一般做法要么使用GUID,也可以保存到数据库时使用数据库表的自增长ID,也可以自定义规则以确保产生不重复的唯一标识,而在Blog .NET项目中使用雪花算法生成唯一标识。 关…...

【Python】集合与字典
按照输入顺序输出 将输入的名字去重,同时按照输入顺序输出 sinput().split(,) blist(set(s)) bsorted(b,keys.index) print(b) 删除集合元素、更新集合 根据操作删除更新集合 update括号里可以是一个集合,add只能是一个元素 discard用于删除元素&#x…...

【LeetCode】88. 合并两个有序数组
88. 合并两个有序数组 难度:简单 题目 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 …...

Linux文件权限
R 代表可读 W 代表可写 X 代表可执行 文档类型有如下表示方法: d - 目录,例如上表档名为『.gconf』的那一行; - - 文档,例如上表档名为『install.log』那一行; l - 链接档(link file); b …...
〖大前端 - 基础入门三大核心之JS篇㉟〗- JavaScript 的DOM简介
说明:该文属于 大前端全栈架构白宝书专栏,目前阶段免费,如需要项目实战或者是体系化资源,文末名片加V!作者:不渴望力量的哈士奇(哈哥),十余年工作经验, 从事过全栈研发、产品经理等工作…...

CentOS中安装常用环境
一、CentOS安装 redis ①:更新yum sudo yum update②:安装 EPEL 存储库 Redis 通常位于 EPEL 存储库中。运行以下命令安装 EPEL 存储库 sudo yum install epel-release③:安装 Redis sudo yum install redis④:启动 Redis 服…...

python时间变化与字符串替换技术及读JSON文件等实践笔记
1. 需求描述 根据预测出结果发出指令的秒级时间,使用时间戳,也就是设定时间(字符串)转为数字时间戳。时间计算转换过程中,出现单个整数(例如8点),按字符串格式补齐两位“08”。字符…...
leetcode刷题日记:141. Linked List Cycle(环形链表)
这一题是给我们一个链表让我们判断这是否是一个环形链表,我们知道如果一个链表中有环的话这一个链表是没有办法访问到尾的, 假若有如图所示的带环链表: 我们从图示中很容易看出来这一个链表在访问的时候会在里面转圈,我们再来看看…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

Linux安全加固:从攻防视角构建系统免疫
Linux安全加固:从攻防视角构建系统免疫 构建坚不可摧的数字堡垒 引言:攻防对抗的新纪元 在日益复杂的网络威胁环境中,Linux系统安全已从被动防御转向主动免疫。2023年全球网络安全报告显示,高级持续性威胁(APT)攻击同比增长65%,平均入侵停留时间缩短至48小时。本章将从…...