如何基于OpenCV和Sklearn算法库开展机器学习算法研究
大家在做机器学习或深度学习研究过程中,不可避免都会涉及到对各种算法的研究使用,目前比较有名的机器学习算法库主要有OpenCV和Scikit-learn(简称Sklearn),二者都支持各种机器学习算法,主要有监督学习、无监督学习、数据降维等,OpenCV的所有机器学习相关函数都在OpenCV ML里面描述,OpenCV对图像处理方面有比较大的优势,后续在单独说明,Sklearn是目前机器学习领域最完整、同时也是最具影响力的算法库,基于Numpy, Scipy和matplotlib,包含了大量的机器学习算法实现,相关机器学习算法可通过sklearn.__all__进行查看,同时,Sklearn包含了非常多的已建设规范好的数据集,如波士顿数据集、mnist数据集等。
一般所说的机器学习或深度学习解决的问题主要有分类、回归、聚类和降维等。
一、十大经典机器学习算法
- 线性回归 (Linear Regression)
- 逻辑回归 (Logistic Regression)
- 决策树 (Decision Tree)
- 支持向量机(SVM)
- 朴素贝叶斯 (Naive Bayes)
- K邻近算法(KNN)
- K-均值算法(K-means)
- 随机森林 (Random Forest),集成算法
- 降低维度算法(Dimensionality Reduction Algorithms),主成分分析(即PCA)降维算法
- Gradient Boost和Adaboost集成算法
二、常见机器学习算法示例
以下是利用OpenCV或Sklearn实现的各种数据加载和分类回归问题示例,OpenCV对回归问题支持的不是太好,回归问题主要采用Sklearn实现了。完整代码如下。
import cv2
import numpy as np
import sklearn
print(dir(cv2.ml)) # 查看opencv支持的所有算法函数,如cv2.ml.KNearest_create()
print(sklearn.__all__) # 查看sklearn支持的所有算法分类等,如sklearn.linear_model.LogisticRegression()
# 1.加载本地数据集
print('###1.加载本地数据,访问mnist数据集','#'*50)
from scipy.io import loadmat
mnist = loadmat("./data/mnist-original.mat") #获取本地数据集
print(mnist["data"].shape) #70000张图像,每张图像为28*28=784个像素
print(mnist["label"].shape) #70000个标签,为每张图像设置一个标签
print(np.unique(mnist["label"])) #标签分类总共有10,及0~9
X=mnist["data"].T # 对数据进行转置,行为照片数,列为28*28=784特征数
y=mnist["label"].T
print('###拆分训练集和测试集','#'*50)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] #拆分数据集为训练集和测试集
# mnist分类模型训练和预测
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import SGDClassifier
from sklearn import metrics
# model = SGDClassifier(random_state=42)
model = KNeighborsClassifier()
model.fit(X_train, y_train.ravel())
y_pred=model.predict(X_test)
accuracyError=metrics.mean_squared_error(y_test.ravel(), y_pred) #计算均方误差
print('均方误差 =',accuracyError)# 2.加载digits数据,访问sklearn数据
print('###2.加载sklearn的digits数据集','#'*50)
from sklearn import datasets
import matplotlib.pyplot as plt
digits = datasets.load_digits()
print(digits.data.shape) #1797张图像,每张图像为8*8=64个像素
print(digits.images.shape)
img = digits.images[0, :, :] #获取第一张图像的像素数据
plt.imshow(img, cmap='gray') #显示出来
plt.savefig('./notebooks/figures/02.04-digit0.png')
plt.show()
# 获取前10张图像并显示
plt.figure(figsize=(14, 4)) #设置绘图区域大小,14行,4列
for image_index in range(10): # images are 0-indexed, subplots are 1-indexed subplot_index = image_index + 1 plt.subplot(2, 5, subplot_index) plt.imshow(digits.images[image_index, :, :], cmap='gray')
plt.show() # 3.加载boston数据,测试回归预测
print('###3.加载sklearn的boston数据集','#'*50)
from sklearn import datasets
from sklearn import metrics
from sklearn import model_selection
from sklearn import linear_model
import matplotlib.pyplot as plt
boston = datasets.load_boston()
print(dir(boston))
linreg = linear_model.LinearRegression() #线性回归
# linreg= linear_model.Ridge() #ridge回归
# linreg= linear_model.Lasso() #Lasso回归
X_train, X_test, y_train, y_test = model_selection.train_test_split(
boston.data, boston.target, test_size=0.1, random_state=42)
linreg.fit(X_train, y_train)
metrics.mean_squared_error(y_train, linreg.predict(X_train)) #计算均方误差
linreg.score(X_train, y_train) #计算确定系数(R方值)
#计算测试集的预测情况
y_pred = linreg.predict(X_test)
metrics.mean_squared_error(y_test, y_pred) #计算均方误差
#绘图显示预测结果
plt.style.use('ggplot')
plt.rcParams.update({'font.size': 16})
plt.figure(figsize=(10, 6))
plt.plot(y_test, linewidth=3, label='ground truth')
plt.plot(y_pred, linewidth=3, label='predicted')
plt.legend(loc='best')
plt.xlabel('test data points')
plt.ylabel('target value')
plt.show() # 4.加载Iris数据,测试分类问题
print('###4.加载sklearn的Iris数据集','#'*50)
import numpy as np
import cv2
from sklearn import datasets
from sklearn import model_selection
from sklearn import metrics
import matplotlib.pyplot as plt
iris = datasets.load_iris()
print(dir(iris))
print(np.unique(iris.target))
# 过滤数据,去掉分类2,变为二分类问题
idx = iris.target != 2
data = iris.data[idx].astype(np.float32)
target = iris.target[idx].astype(np.float32)
X_train, X_test, y_train, y_test = model_selection.train_test_split(
data, target, test_size=0.1, random_state=42)
# # (1) 利用opencv进行分类预测
# lr = cv2.ml.LogisticRegression_create()
# lr.setTrainMethod(cv2.ml.LogisticRegression_MINI_BATCH)
# lr.setMiniBatchSize(1)
# lr.setIterations(100) #设置迭代次数
# lr.train(X_train, cv2.ml.ROW_SAMPLE, y_train)
# lr.get_learnt_thetas() #获的权重参数
# (2) 利用sklearn进行分类预测
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn import svm
from sklearn.tree import DecisionTreeClassifier
# lr = KNeighborsClassifier(n_neighbors=1)
# lr = svm.SVC()
# lr = LogisticRegression()
lr=DecisionTreeClassifier()
lr.fit(X_train, y_train)
#训练集预测
# ret, y_pred = lr.predict(X_train) # opencv写法
y_pred = lr.predict(X_train) # sklearn写法
metrics.accuracy_score(y_train, y_pred)
#测试集预测
# ret, y_pred = lr.predict(X_test) # opencv写法
y_pred = lr.predict(X_test) # sklearn写法
metrics.accuracy_score(y_test, y_pred)
# 显示过滤后的数据
plt.figure(figsize=(10, 6))
plt.scatter(data[:, 0], data[:, 1], c=target, cmap=plt.cm.Paired, s=100)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.show()相关文章:

如何基于OpenCV和Sklearn算法库开展机器学习算法研究
大家在做机器学习或深度学习研究过程中,不可避免都会涉及到对各种算法的研究使用,目前比较有名的机器学习算法库主要有OpenCV和Scikit-learn(简称Sklearn),二者都支持各种机器学习算法,主要有监督学习、无监…...

在 Node.js 中发出 HTTP 请求的 5 种方法
在 Node.js 中发出 HTTP 请求的 5 种方法 学习如何在 Node.js 中发出 HTTP 请求可能会让人感到不知所措,因为有数十个可用的库,每个解决方案都声称比上一个更高效。一些库提供跨平台支持,而另一些库则关注捆绑包大小或开发人员体验。 在这篇…...
pipeline agent分布式构建
开启 agent rootjenkins:~/learning-jenkins-cicd/07-jenkins-agents# docker-compose -f docker-compose-inbound-agent.yml up -d Jenkins配置添加 pipeline { agent { label docker-jnlp-agent }parameters {booleanParam(name:pushImage, defaultValue: true, descript…...

MySQL(17):触发器
概述 MySQL从 5.0.2 版本开始支持触发器。MySQL的触发器和存储过程一样,都是嵌入到MySQL服务器的一段程序。 触发器是由 事件来触发 某个操作,这些事件包括 INSERT 、 UPDATE 、 DELETE 事件。 所谓事件就是指用户的动作或者触发某项行为。 如果定义了触…...
挖掘PostgreSQL事务的“中间态”----更加严谨的数据一致性?
1.问题 今天在上班途中,中心的妹纸突然找我,非常温柔的找我帮忙看个数据库的报错。当然以我的性格,妹子找我的事情对我来说优先级肯定是最高的,所以立马放下手中的“小事”,转身向妹子走去。具体是一个什么样的问题呢…...

多种方法实现conda环境迁移
Conda 为包管理器和虚拟环境管理器。在配置完项目环境,进行了编写和测试代码,需要大量数据测试运行时,需要将其移至另一台主机上。Conda 提供了多种保存和移动环境的方法。 方法1: scp拷贝法,直接将envs的环境文件夹…...
C++ string类(一)
1.C语言中的字符串 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符 OOP(Object Oriented Programming)的思想,而且…...

系统时间和JVM的Date时间不一致问题解决
通过Java得到的时间与操作系统时间不一致,如何修改Java虚拟机时间? 造成这种问题的原因可能是:你的操作系统时区跟你JVM的时区不一致。 你的操作系统应该是中国的时区吧,而JVM的时区不一定是中国时区,你在应用服务器…...
23111701[含文档+PPT+源码等]计算机毕业设计javaweb点餐系统全套餐饮就餐订餐餐厅
文章目录 **项目功能简介:****点餐系统分为前台和后台****前台功能介绍:****后台功能介绍:** **论文截图:****实现:****代码片段:** 编程技术交流、源码分享、模板分享、网课教程 🐧裙:77687156…...
RabbitMQ 部署及配置详解(集群部署)
单机部署请移步: RabbitMQ 部署及配置详解 (单机) RabbitMQ 集群是一个或 多个节点,每个节点共享用户、虚拟主机、 队列、交换、绑定、运行时参数和其他分布式状态。 一、RabbitMQ 集群可以通过多种方式形成: 通过在配置文件中列出群集节点以…...
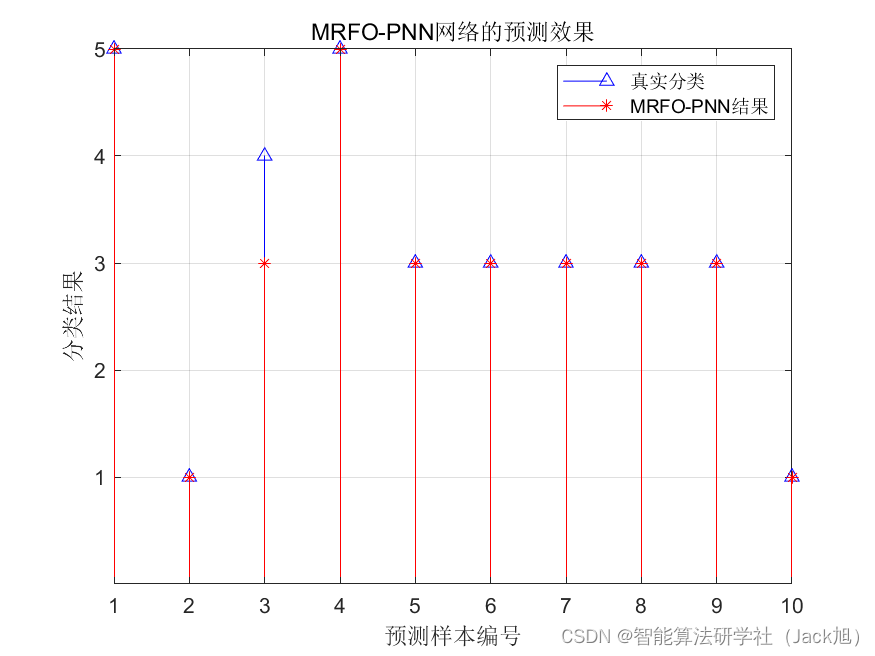
基于蝠鲼觅食算法优化概率神经网络PNN的分类预测 - 附代码
基于蝠鲼觅食算法优化概率神经网络PNN的分类预测 - 附代码 文章目录 基于蝠鲼觅食算法优化概率神经网络PNN的分类预测 - 附代码1.PNN网络概述2.变压器故障诊街系统相关背景2.1 模型建立 3.基于蝠鲼觅食优化的PNN网络5.测试结果6.参考文献7.Matlab代码 摘要:针对PNN神…...

「分享学习」SpringCloudAlibaba高并发仿斗鱼直播平台实战完结
[分享学习]SpringCloudAlibaba高并发仿斗鱼直播平台实战完结 第一段:简介 Spring Cloud Alibaba是基于Spring Cloud和阿里巴巴开源技术的微效劳框架,普遍应用于大范围高并发的互联网应用系统。本文将引见如何运用Spring Cloud Alibaba构建一个高并发的仿…...
Vue|props配置
props是Vue中用于传递数据的属性。通过在子组件的选项中定义props属性,可以指定子组件可以接收的数据以及其他配置选项。父组件可以通过在子组件上使用特定的属性来传递数据。 目录 目录 App.vue 什么是App.vue 组件引用 props配置 组件复用 案例1:…...
使用Microsoft Dynamics AX 2012 - 2. 入门:导航和常规选项
Microsoft Dynamics AX的核心原则之一是为习惯于Microsoft软件的用户提供熟悉的外观和感觉。然而,业务软件必须适应业务流程,这可能相当复杂。 用户界面和常见任务 在我们开始进行业务流程和案例研究之前,我们想了解一下本章中的常见功能。…...
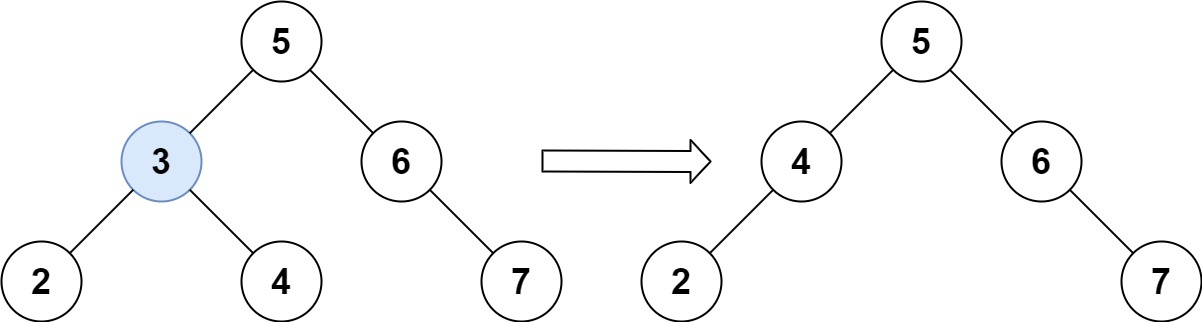
【代码随想录】算法训练计划21、22
day 21 1、530. 二叉搜索树的最小绝对差 题目: 给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。 差值是一个正数,其数值等于两值之差的绝对值。 思路: 利用了二叉搜索树的中序遍历特性用了双指…...
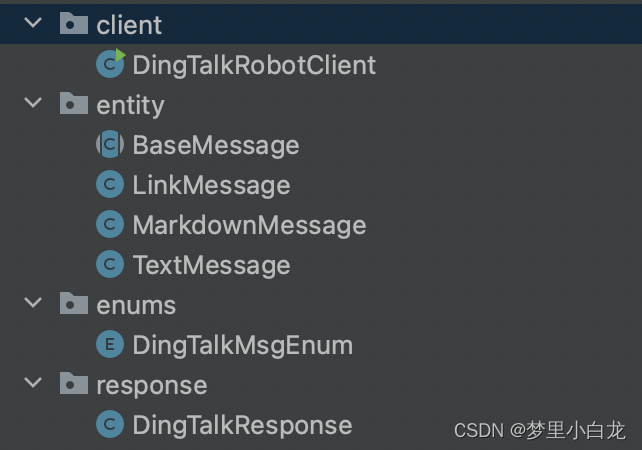
java实现钉钉机器人消息推送
项目开发中需要用到钉钉机器人发送任务状态,本来想单独做一个功能就好,但是想着公司用到钉钉机器人发送项目挺多的。所以把这个钉钉机器人抽离成一个组件发布到企业maven仓库,这样可以给其他同事用提高工作效率。 1.目录结构 2.用抽象类&…...
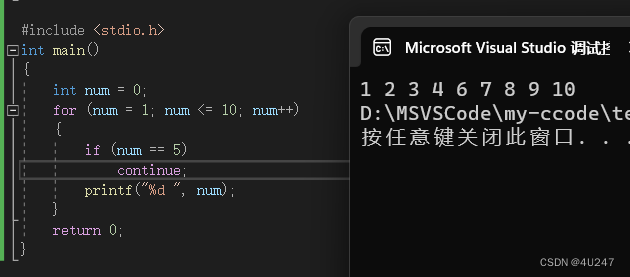
C语言之break continue详解
C语言之break continue 文章目录 C语言之break continue1. break 和 continue2. while语句中的break和continue2.1break和continue举例 3. for语句中的break和continue3.1break和continue举例 1. break 和 continue 循环中break和continue 在循环语句中,如果我达到…...

mysql group by 执行原理及千万级别count 查询优化
大家好,我是蓝胖子,前段时间mysql经常碰到慢查询报警,我们线上的慢sql阈值是1s,出现报警的表数据有 7000多万,经常出现报警的是一个group by的count查询,于是便开始着手优化这块,遂有此篇,记录下…...

Linux的几个常用基本指令
目录 1. ls 指令2.pwd命令3.cd 指令4. touch指令5.mkdir指令6.rmdir指令 && rm 指令7.man指令8.cp指令9.mv指令10.cat指令 1. ls 指令 语法: ls [选项][目录或文件] 功能:对于目录,该命令列出该目录下的所有子目录与文件。对于文件&…...
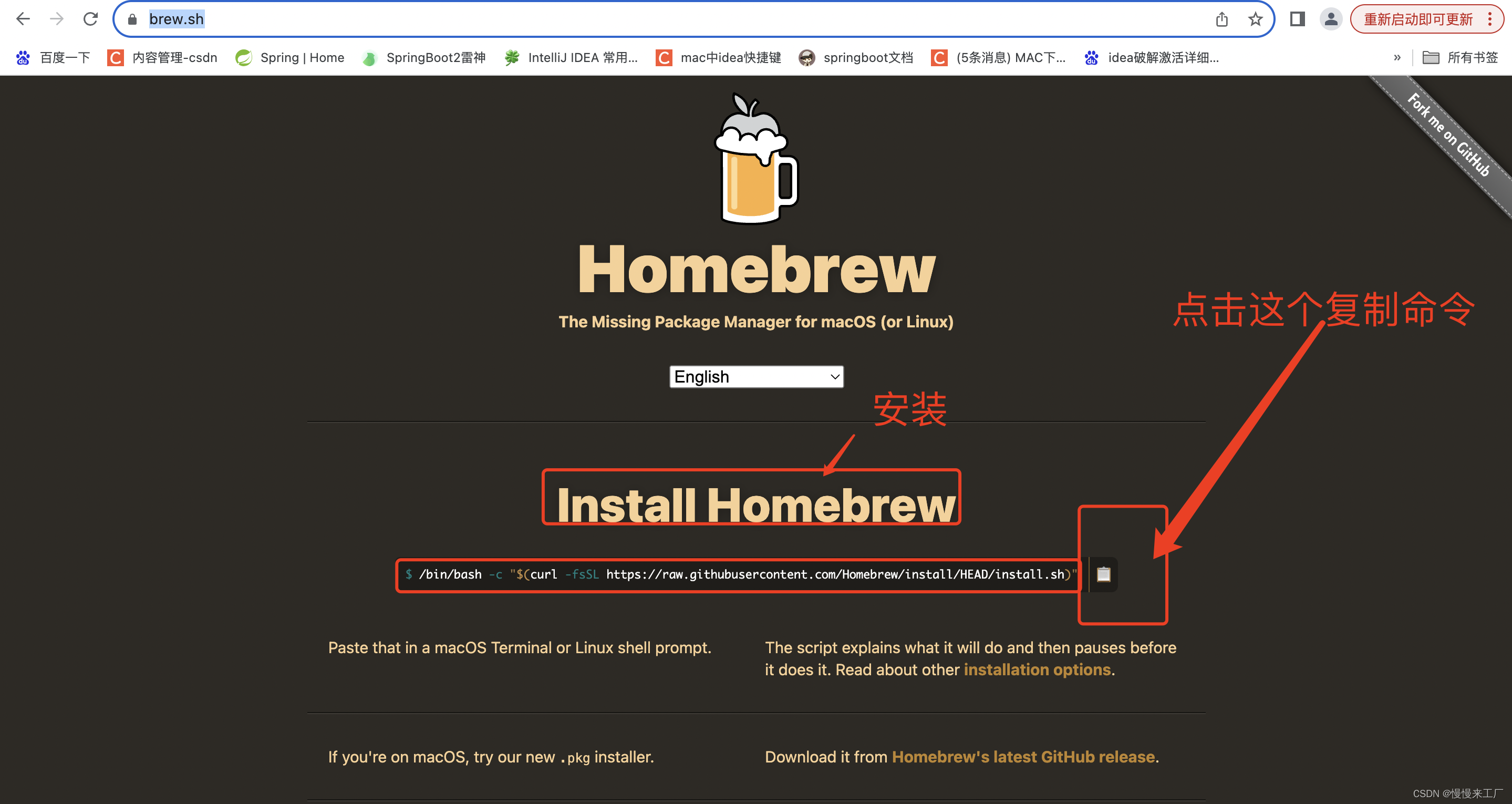
mac中安装Homebrew
1、Homebrew是什么? 软件安装管理工具 2、先检查电脑中是否已经安装了Homebrew 打开终端输入:brew 提示命令没有找到,说明电脑没有安装Homebrew 如果提示上述图片说明Homebrew已经安装成功 3、安装Homebrew 进入https://brew.sh/ 复制的命…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...