【Shell脚本入门】
Shell中的特殊符号
1.$
美元符号,用来表示变量的值。
如变量NAME的值为Mike,则使用$NAME就可以得到“Mike”这个值。2.#
井号,除了做为超级用户的提示符之外,还可以在脚本中做为注释的开头字母,每一行语句中,从#号开始的部分就不执行了。3.“”
双引号,shell不会将一对双引号之间的文本中的大多数特殊字符进行解释。
如#不再是注释的开头,它只表示一个井号“#”。但$仍然保持特殊含义。
双引号对于某些特殊符号是不起作用的, 例如:”,$,\,`(反引号)
双引号和单引号不能嵌套。即:echo ‘””’ 输出””, echo “’’” 输出’’4.‘’
单引号,shell不会将一对单引号之间的任何字符做特殊解释。5.``
倒引号,命令替换。在倒引号内部的shell命令首先被执行,其结果输出代替用倒引号括起来的文本,不过特殊字符会被shell解释。6.\
斜杠,用来去掉在shell解释中字符的特殊含义。在文本中,跟在\后面的一个字符不会被shell特殊解释,但其余的不受影响。7.{}
大括号,主要是和$符号配合,作为字符串连接来使用echo ${HOME}ismydir
/home/qzkismydir
shell中的表达式
1.shell 输出/输入重定向
命令 说明
command > file 将输出重定向到 file。
command < file 将输入重定向到file。
command >> file 将输出以追加的方式重定向到 file。
n >file 将文件描述符为n的文件重定向到file。
n>> file 将文件描述符为n的文件以追加的方式重定向到file。
n>&m 将输出文件m和n合并
n<&m 将输出文件m和n合并
<< tag 将开始标记tag 和结束标记tag 之间的内容作为输入。输出 >
将右尖括号前的命令的输入重定向到尖括号后的文件中。ls *.sh > list.txt
将当前目录下所有末尾名为sh的文件的列表写入到list.txt如果要将新内容添加在文件末尾,请使用>>操作符。输入 <
将左箭头后面的文件作为左箭头前的命令的输入。grep “a” < test.sh
将test.sh中找到所有包含a的行command < infile > outfile
同时替换输入和输出,执行command,从文件infile读取内容,然后将输出写入到outfile中。
错误输出重定向
默认bash有3个标准输入输出设备。0 标准输入
1 标准输出
2 错误输出
如果执行脚本的时候发生错误,会输出到2上。
要想就将错误的输出也输出在标准输出上,需要重定向。./test.sh > a.log 2>&1
后面2>&1就是将标准错误的输出重定向到标准输出上。3.tee
将此命令的输入分叉,一支输出到屏幕一支可以重定向到其他位置。./test.sh | tee >a.txt 2>&1
运行test.sh,通过tee输出到a.txt,同时屏幕上可以看到输出。并且将错误输出重定向到标准输出( 2>&1 )3.exec
将此命令后的参数作为命令在当前的shell中执行,当前的shell或者脚本不在执行。
脚本格式
脚本以#!/bin/bash 开头(指定解析器)
Shell中的变量
1.常用系统变量
$HOME、$PWD、$SHELL、$USER等echo $USER
xinghe
2.自定义变量
1、基本语法
(1)定义变量:变量=值
(2)撤销变量:unset 变量
(3)声明静态变量:readonly 变量,注意:不能 unset
2、变量定义规则
(1)变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量名建议大写。
(2)等号两侧不能有空格
(3)在 bash 中,变量默认类型都是字符串类型,无法直接进行数值运算。
(4)变量的值如果有空格,需要使用双引号或单引号括起来。
(1)定义变量 A
$ A=5
$ echo $A
5
(2)给变量 A 重新赋值
$ A=8
$ echo $A
8
(3)撤销变量 A
unset A
$ echo $A(4)声明静态的变量 B=2,不能 unset
$ readonly B=2
$ echo $B
2
$ B=9
-bash: B: readonly variable
(5)在 bash 中,变量默认类型都是字符串类型,无法直接进行数值运算
$ C=1+2
$ echo $C
1+2
(6)变量的值如果有空格,需要使用双引号或单引号括起来
$ D=hello world
-bash: world: command not found
$ D="hello world"
$ echo $D
hello world
(7)可把变量提升为全局环境变量,可供其他 Shell 程序使用 export 变量名。
3.特殊变量
$n、$#、$*、$@、$?
$n (功能描述:n 为数字,$0 代表该脚本名称,$1-$9 代表第一到第九个参数,十以上的参数需要用大括号包含,如${10})$# (功能描述:获取所有输入参数个数,常用于循环)。$* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体(一个字符串))
$@ (功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待)$? (功能描述:最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。)**
4、Shell 数组
数组中可以存放多个值。Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小,数组元素的下标由 0 开始。
Shell 数组用括号来表示,元素用"空格"符号分割开,语法格式如下:
array_name=(value1 value2 ... valuen)
也可以使用下标来定义数组:
array_name[0]=value0 array_name[1]=value1 array_name[2]=value2
读取数组
读取数组元素值的一般格式是:
${array_name[index]}
获取数组中的所有元素
使用@ 或 * 可以获取数组中的所有元素
${array_name[*]}
${array_name[@]}
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
#!/bin/bash
my_array[0]=A
my_array[1]=B
my_array[2]=C
my_array[3]=D
echo "数组元素个数为: ${#my_array[*]}"
echo "数组元素个数为: ${#my_array[@]}"
执行脚本,输出结果如下所示:
$ chmod +x test.sh
$ ./test.sh
数组元素个数为: 4
数组元素个数为: 4
运算符
1.基本语法
(1)expr + , - , * , / , % 加,减,乘,除,取余
(2)“ ( ( 运算式 ) ) ”或“ ((运算式))”或“ ((运算式))”或“[运算式]”
注意:expr 运算符间要有空格
(1)计算 3+2 的值
expr 2 + 3
5
(2)计算(2+3)X4 的值
(a)expr 一步完成计算
expr `expr 2 + 3` \* 4
20
(b)采用$[运算式]方式
res=$((2+3))
res=$[((2+3)*4)]
条件判断
1.基本语法
[ condition ](注意 condition 前后要有空格)
注意:条件非空即为 true,[ qiuzhi ]返回 true,[] 返回 false。
2.常用判断条件
(1)两个整数之间比较
= 字符串比较
-lt 小于(less than)
-le 小于等于(less equal)
-gt 大于(greater than)
-ne 不等于(Not equal)
-eq 等于(equal)
-ge 大于等于(greater equal)
(2)按照文件权限进行判断
-r 有读的权限(read)
-x 有执行的权限(execute)
-w 有写的权限(write)
(3)按照文件类型进行判断
-f 文件存在并且是一个常规的文件(file)
-e 文件存在(existence)
-d 文件存在并是一个目录(directory)(1)23 是否大于等于 22
[ 23 -ge 22 ]
echo $?
0
(2)helloworld.sh 是否具有写权限
[ -w helloworld.sh ]
echo $?
0
(3)/home/atguigu/cls.txt 目录中的文件是否存在
[ -e /home/qiuzhi/cls.txt ]
echo $?
1
(4)多条件判断(&& 表示前一条命令执行成功时,才执行后一条命令,|| 表示上一条命令执行失 败后,才执行下一条命令)
[ -w helloworld.sh ] && echo OK || echo notok
OK
[ -w helloworld1.sh ] && [ ] || echo notok
notok
流程控制
1.if 判断
基本语法if [条件判断式]
then程序
fi
或者
if [条件判断式]
then 程序
elif [ 条件判断式 ]
then 程序
else 程序
fi
注意事项:
(1)[ 条件判断式 ],中括号和条件判断式之间必须有空格
(2)if 后要有空格
2.case 语句
基本语法case $变量名 in
"值 1")如果变量的值等于值 1,则执行程序 1
;;
"值 2")如果变量的值等于值 2,则执行程序 2
;;
...省略其他分支...
*)如果变量的值都不是以上的值,则执行此程序
;;
esac
注意事项:
case 行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。
双分号“;;”表示命令序列结束,相当于 java 中的 break。
最后的“*)”表示默认模式,相当于 java 中的 default,*不可以加双引号。
3.for 循环
基本语法 1for ((初始值;循环控制条件;变量变化))
do 程序
done
基本语法 2for 变量 in 值 1 值 2 值 3...
do 程序
done
比较 ∗ 和 *和 ∗和@区别
(a) ∗ 和 *和 ∗和@都表示传递给函数或脚本的所有参数,不被双引号“”包含时,都以$1 2 … 2 … 2…n 的形式输出所有参数。
(b)当它们被双引号“”包含时,“$*”会将所有的参数作为一个整体,以“$1 2 … 2 … 2…n”的形式输出所有参数;“$@”会将各个参数分开,以“$1” “ 2 ” … ” 2”…” 2”…”n” 的形式输出所有参数。
4.while 循环
基本语法while [ 条件判断式 ]
do程序
done
注意事项:
while 后面需要有空格
read 读取控制台输入
基本语法
read(选项)(参数)
选项:-p:指定读取值时的提示符;
-t:指定读取值时等待的时间(秒)。参数变量:指定读取值的变量名
函数
1.系统函数
1、basename 基本语法
basename [string / pathname] [suffix]
basename 命令会删掉所有的前缀包括最后一个(‘/’)字符,然后将字符串显示出来。
选项:
suffix 为后缀,如果 suffix 被指定确定的后缀值了,basename 会将 pathname 或 string 中的后缀去掉。2、dirname 基本语法dirname 文件绝对路径
从给定的包含绝对路径的文件名中去除文件名 (非目录的部分),然后返回剩下的路径(目录的部分)
自定义函数
基本语法
[ function ] funname[()]
{Action;[return int;]
}
funname
经验技巧
(1)必须在调用函数地方之前,先声明函数,shell 脚本是逐行运行。不会像其它语言一 样先编译。
(2)函数返回值,只能通过$?(代表了上个命令的退出状态,或函数的返回值)系统变量获得,可以显示加 return 返回,如果不加,将以最后一条命令运行结果,作为返回值。
Shell 工具
1.cut
cut 的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。
基本用法cut [选项参数] filename
说明:默认分隔符是制表符
选项参数说明
- -f: 列号,提取第几列
- -d: 分隔符,按照指定分隔符分割列
- -c: 指定具体的字符
[admin@ datas]$ vim words
hello world !!
hadoop spark hive
张三 李四 王五
(1)根据" "切割 words 第一、三列
[admin@ datas]$ cut -d " " -f 1,3 words
(2)根据" "切割,获取 words 第 2 行第 1 列
[admin@ datas]$ cat words | head -n 2 | tail -n 1 | cut -d " " -f 1
(3)选取系统 PATH 变量值
[admin@ datas]$ echo $PATH
选取系统 PATH 变量值,第 2 个“:”开始后的所有路径:
[admin@ datas]$ echo $PATH | cut -d : -f 2-
选取系统 PATH 变量值,第 4 列(包括第 4 列)之前的所有路径:
[admin@ datas]$ echo $PATH | cut -d : -f -4
选取系统 PATH 变量值,第 2 到 4 列(包括第 2 到 4 列)之间的所有路径:
[admin@mc datas]$ echo $PATH | cut -d : -f 2-4
(4)切割 ifconfig 后打印的 IP 地址
[admin@ ~]$ ifconfig
获取 ip 地址
[admin@ ~]$ ifconfig | grep "inet" | tail -n 1 | cut -d " " -f 9- | cut -d " " -f 2
2.sed
sed 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用 sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变, 除非你使用重定向存储输出。
基本用法sed [选项参数] ‘command’ filename
选项参数说明-e: 直接在指令列模式上进行 sed 的动作编辑
-i: 直接编辑文件
命令功能描述
- a: 新增,a 的后面可以接字串,在下一行出现
- d: 删除
- s: 查找并替换
(0)数据准备
[admin@ datas]$ vim words
hello world !!
hadoop spark hive
张三 李四 王五
(1)将“lucy 1234 www”这个单词插入到 words 第二行下,打印。
[admin@ datas]$ sed "2a lucy 1234 www" words
(2)删除 words 文件所有包含 h 字母的行
[admin@ datas]$ sed "/h/d" words
(3)将 words 文件中 h 字母替换为 H 字母
[admin@ datas]$ sed "s/h/H/g" words
注意:‘g’表示 global,全部替换
(4)将 words 文件中的第二行删除并将 h 字母替换为 H 字母
[admin@ datas]$ sed -e "2d" -e "s/h/H/g" words
3.awk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
基本用法awk [选项参数] ‘pattern1{action1} pattern2{action2}...’ filename
- pattern:表示 AWK 在数据中查找的内容,就是匹配模式
- action:在找到匹配内容时所执行的一系列命令
选项参数说明
- -F: 指定输入文件折分隔符
- -v(小写): 赋值一个用户定义变量
(1)awk+action 简单示例
数据准备
[admin@ datas]$ vim words
hello world !!
hadoop spark hive
张三 李四 王五
找到 words 文件的第 1 列
[admin@ datas]$ awk '{print $1}' words
(2)awk+pattern+action 示例
awk 可以使用正则
搜索 passwd 文件,以:分隔,输出以 a 字母开头的所有行
[admin@ datas]$ awk -F ':' '/^a/{print $0}' passwd
搜索 passwd 文件,以:分隔,输出以 a 字母开头的所有行的第 1 列和第 6 列,两列之间加上--字符
[admin@ datas]$ awk -F ':' '/^a/{print $1"--"$6}' passwd
注意:有正则的时候,只有匹配了 pattern 的行才会执行 action
搜索 passwd 文件,输出以 a 字母开头的所有行的第 1 列和第 6 列,以--分割,且在开头第一行的上面添加一行列名“1 列”“6 列”,以--分隔,在最后一行的下面添加一行内容"这是所有的以 a 开头的行的 1、6 两列"。
[admin@ datas]$ awk -F ':' 'BEGIN{print "1 列--6 列"} /^a/{print $1"--"$6} END {print "这是所有的以 a 开头的行的 1、6 两列"}' passwd
注意:BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。
搜索 passwd 文件,输出以 a 字母开头的所有行的第 1 列和第 6 列,以空格分割,且在开头第一行的上面添加一行列名“行号”“1 列”“6 列”,以空格分隔,在最后一行的下面添加一行内容"这是所有的以 a 开头的行的 1、6 两列",并且给每一行一个行号(从 1 开始,以此类推,不包括开始和结束行)
[admin@ datas]$ awk -v i=0 -F ':' \
'BEGIN{print "行号","1 列","6 列"} \
/^a/{print ++i,$1,$6} \
END {print "这是所有的以 a 头的行的 1、6 两列"}' \
passwd
运算符
= += -= *= /= %= ^= **= 赋值
?: C 条件表达式
|| 逻辑或
&& 逻辑与
~ 和 !~ 匹配正则表达式和不匹配正则表达式
< <= > >= != == 关系运算符
空格 连接
+- 加,减
* / % 乘,除与求余
+ - ! 一元加,减和逻辑非
^ *** 求幂
++ -- 增加或减少,作为前缀或后缀 $ 字段引用
in 数组成员搜索 passwd 文件,输出以 a 字母开头的第 2、3 行的第 1 列和第 6 列,以空格分割,且在开头第一行的上面添加一行列名“行号”“1 列”“6 列”,以空格分隔,在最后一行的下面添加一行内容"这是所有的以 a 开头的行的 1、6 两列",并且给每一行一个行号 (从 1 开始,以此类推,不包括开始和结束行)
[admin@ datas]$ awk -v i=0 -F ':' '/^a/{print ++i,$1,$6}' passwd | awk 'BEGIN{print "行号","1 列","6 列"} $1>=2&&$1<=3 {print $0} END {print "这是 所有的以a 头的行的1、6两列"}'
print 和 printf
[admin@ datas]$ vim person
张三 男 13
想要把上面 person 的内容输出为以下这样:
姓名:张三
性别:男
年龄:13
使用 print,print 输出字符串,直接拼接
[admin@ datas]$ awk '{print "姓名:"$1"\n 性别:"$2"\n 年龄:"$3}' person
使用 printf,printf 是格式化输出,语法格式为 printf 格式 参数
[admin@ datas]$ awk '{printf ("姓名:%s\n 性别:%s\n 年龄:%d\n",$1,$2,$3)}' person
注意:printf 可以直接在命令行使用,但是在命令行中使用和在 awk 中有些区别直接使用是这样写
[admin@ datas]$ printf "姓名:%s\n 性别:%s\n 年龄:%d\n" "张三" "男" 11
常用转义字符
\" - 转义后的双引号 \\ - 转义后的反斜杠\b - 退格符 \n - 换行符\r - 回车符\t - 水平制表符 \v - 垂直制表符%% - 单个%符号
格式化常用的类型转换符
%d - 将参数打印为十进制整数%f - 将参数打印为浮点数 %s - 将参数打印为字符串%x - 将参数打印为十六进制整数%o - 将参数打印为八进制整数
awk 的内置变量
$n 当前记录的第 n 个字段,字段间由 FS 分隔
$0 完整的输入记录
ARGC 命令行参数的数目
ARGIND 命令行中当前文件的位置(从 0 开始算)
ARGV 包含命令行参数的数组
CONVFMT 数字转换格式(默认值为%.6g)
ENVIRON 环境变量关联数组
ERRNO 最后一个系统错误的描述
FIELDWIDTHS 字段宽度列表(用空格键分隔)
FILENAME 当前文件名
FNR 各文件分别计数的行号
FS 字段分隔符(默认是任何空格)
IGNORECASE 如果为真,则进行忽略大小写的匹配
NF 一条记录的字段的数目
NR 已经读出的记录数,就是行号,从 1 开始
OFMT 数字的输出格式(默认值是%.6g)
OFS 输出字段分隔符,默认值与输入字段分隔符一致。ORS 输出记录分隔符(默认值是一个换行符)
RLENGTH 由 match 函数所匹配的字符串的长度
RS 记录分隔符(默认是一个换行符)
RSTART 由 match 函数所匹配的字符串的第一个位置 SUBSEP 数组下标分隔符(默认值是/034)(1)统计 passwd 文件名,每行的行号,每行的列数
[admin@ datas]$ awk -F ':' '{printf ("文件名:%s,第%d 行有%d 列 \n",FILENAME,NR,NF)}' passwd
(2)切割 IP(awk 有去空格)
[admin@ datas]$ ifconfig | grep "inet" | head -n 1 | awk '{print $2}'
(3)查询一个文件中所有空行所在的行号 数据准备
[admin@ datas]$ vim space.txt
[admin@ datas]$ awk '/^$/ {print NR}' space.txt
(4)统计单词数
[admin@mc datas]$ vim wordcount
hello world hello world
hello hadoop spark hive hadoop
hive 李四
使用 awk 统计查询 wordcount
[admin@ datas]$ awk '{for(i=1;i<=NF;i++){arr[$i]++}} END{for(i in arr){print i,arr[i]}}' wordcount
注意:
我们这里使用了 for 和 if,在命令行执行 awk 命令时,for 和 if 这些的写法基本上就与 java 很相似了。
awk 中不用特意声明变量,第一次使用变量的地方就相当于声明。
我们使用了数组,awk 中的数组除了数字做索引之外,也可以使用字符串做索引,我们这里就是使用的字符串做索引(这样就相当于 java 中的 map 集合了),数组元素如果是 null 也可以直接使用++计算。
awk脚本
awk 脚本中是要执行的 awk 逻辑,脚本以后缀为.awk,脚本开头是#!/bin/awk -f。
awk 脚本执行是 awk -f 脚本 查询的目标文件
使用 awkdemo.awk 脚本查询 words 文件
[admin@ datas]$ awk -f awkdemo.awk words之前使用 awk 命令行统计查询 wordcount
[admin@ datas]$ awk '{for(i=1;i<=NF;i++){arr[$i]++}} END{for(i in arr){print i,arr[i]}}' wordcount
把这个改成 awk 脚本执行
[admin@ datas]$ vim count.awk
#!/bin/awk -f
#遍历文件前
#BEGIN{
# 如果遍历前有逻辑,就在这里写
#}
#遍历文件每一行时的逻辑
{for(i=1;i<=NF;i++){ arr[$i]++}
}
#遍历文件后
END{
#如果遍历后有逻辑,在这里写
#我这里是输出汇总结果for(i in arr){ print i,arr[i]}
}
执行这个脚本,统计 wordcount 文件的单词
[admin@ datas]$ awk -f count.awk wordcount
awk 内置函数
算数函数
atan2( y, x ) 返回 y/x 的反正切。
cos( x ) 返回 x 的余弦;x 是弧度。
exp( x ) 返回 x 幂函数。
log( x ) 返回 x 的自然对数。
sqrt( x ) 返回 x 平方根。
int( x ) 返回 x 的截断至整数的值。
rand( ) 返回任意数字 n,其中 0 <= n < 1。
srand( [Expr] ) 将 rand 函数的种子值设置为 Expr 参数的值,或如果省略 Expr 参数则使用某天的时间。返回先前的种子值。srand()括号内没有表达式的话,它会采用当前时间作为随机计数器的种子,这样以秒为间隔,rand()随机数就能滚动随机生成了
生成 3 次 10 以内的随机数
[admin@ datas]$ vim demo.awk
#!/bin/awk -f
BEGIN{srand() for(i=0;i<3;i++){print int(rand()*10) }
}
字符串函数
sub( Ere, Repl, [ In ] )
字符串替换,只替换第一次匹配的
参数 1:被替换的字符串(具体的值或正则)
参数 2:替换的新的字符串
参数 3:被替换的字符串所属的变量(不填默认是 awk 的$0)
gsub( Ere, Repl, [ In ] )
替换所有匹配的字符串
参数含义与sub相同
index( String1, String2 )
返回参数 2 作为参数 1 子串出现在参数 1 的哪个索引位置,从 1 开始。如果参数 2 不是参数 1 的子串,则返回 0。
length [(String)]
返回 String 参数指定的字符串的长度(字符形式)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。
blength [(String)]
返回 String 参数指定的字符串的长度(以字节为单位)。如果未给出 String 参数,则返回整个记录的长度($0 记录变 量)。
substr( String, M, [N])
字符串截取
参数 1:被截取的字符串
参数 2:截取的子串开始位置索引值,从 1 开始
参数 3:截取的子串的结束位置索引值,不填就是截取到结尾 返回值:截取的字符串,从 M 到 N 位置,不包括 N
match( String, Ere )
在 String 参数指定的字符串(Ere 参数指定的扩展正则表达式 出现在其中)中返回位置(字符形式),从 1 开始编号,如果 Ere 不存在,则返回 0(零)。
split( String, A, [Ere] )
分割为数组
参数 1:被分割的字符串
参数 2:接收分隔的字符串数组
参数 3:分隔的字符(固定值或者正则)
tolower( String )
返回 String 参数指定的字符串,字符串中每个大写字符将更改 为小写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。
toupper( String )
返回 String 参数指定的字符串,字符串中每个小写字符将更改 为大写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。
sprintf(Format, Expr, Expr, . . . )
根据 Format 参数指定的 printf 子例程格式字符串来格式化 Expr 参数指定的表达式并返回最后生成的字符串。
(1)substr 字符串截取 [admin@mc datas]$ vim words
hello world !!
hadoop spark hive
张三 李四 王五
截取输出 words 每一行的第 1 列的前 2 个字符
[admin@ datas]$ awk '{print substr($1,1,2)}' words
awk 做大数据查询的简单应用
[admin@ datas]$ vim grade.txt
#学号 科目 成绩
1 语文 90
1 数学 40
1 英语 59
2 语文 95
2 数学 80
2 英语 52
3 语文 89
4 数学 29
(1)使用 awk 命令行,根据学号汇总查询每个学生的总成绩
[admin@ datas]$ cat grade.txt | grep -v "#" | awk '{arr[$1]+=$3} END{for(i in arr){printf("学号为%d 的学生的成绩是:%d\n",i,arr[i])}}'
(2)使用 awk 脚本,根据学号查询学生的总成绩,学号参数由外部输入,可以同时查询 多个学号
可以使用 awk -f xxx.awk -v 参数名=参数值 参数名=参数值 查询的目标文件这样的方式 给 awk 脚本传参[admin@ datas]$ vim grade-no.awk
#!/bin/awk -f
{ arr[$1]+=$3
}
END{
#接收参数名为 no 的外部参数,参数 no 的值是学号,可以多个
#多个值时用英文逗号分隔
#使用 split 函数切割 no 的字符串,分隔符是英文逗号,
#用变量 nos 接收切割后的数组
split(no,nos,",")
for(i in nos){cno=nos[i]printf("学号为%d 的学生的成绩是:%d\n",cno,arr[cno])}
}
执行 awk 脚本,查询学号为 2 和 4 的学生的总成绩
[admin@ datas]$ awk -f grade-no.awk -v no="2,4" grade.txt
相关文章:

【Shell脚本入门】
Shell中的特殊符号 1.$ 美元符号,用来表示变量的值。 如变量NAME的值为Mike,则使用$NAME就可以得到“Mike”这个值。2.# 井号,除了做为超级用户的提示符之外,还可以在脚本中做为注释的开头字母,每一行语句中ÿ…...

redis大全
redis-cli 常用命令 redis常用命令 redis数据结构 redis数据结构 redis持久化存储 持久化存储 redis事务 redis事务 redis管道 管道 redis7集群搭建 集群 redis常见问题以及解决方案 常见问题以及解决方案 redis面试题 面试题 redis高级案列case 高级case sp…...

linux rsyslog日志采集格式设定五
linux rsyslog日志采集格式设定五 1.创建日志接收模板 打开/etc/rsyslog.conf文件,在GLOBAL DIRECTIVES模块下任意位置添加以下内容 命令: vim /etc/rsyslog.conf 测试:rsyslog.conf文件结尾添加以下内容 $template ztj,"%fromhost-ip% %app-name% %syslogseveri…...
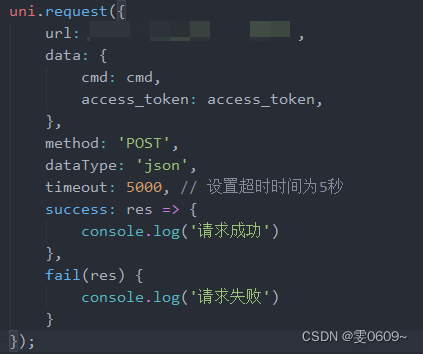
uni-app:如何配置uni.request请求的超时响应时间(全局+局部)
方法一:全局配置响应时间 一、进入项目的manifest.json的代码视图模块 二、写入代码 "networkTimeout": {"request": 5000 }, 表示现在request请求响应时间最多位5秒 方法二:局部设置响应时间 一、直接在uni.request中写入属性…...
AI中文版怎么用,版本分享,GPT官网入口
网页版上线啦,在线助力大学生、上班族的高效生活! GPT4.0是OpenAI最新推出的聊天模型,它的语言理解和生成能力比以前的版本更强大。对于忙碌的上班族来说,GPT4.0能帮助你高效处理工作中的大部分写作任务,比如撰写报告…...

mysql数据库通过binlog恢复数据
1:通过命令查询是否开启 show variables like log_bin2:查看binlog文件存放目录 show variables like %datadir%3:通过positon恢复 mysqlbinlog --start-position219 --stop-position636 --databasetest "/data/binlog.00001" …...

【unity插件】UGUI的粒子效果(UI粒子)—— Particle Effect For UGUI (UI Particle)
文章目录 前言插件地址描述特征Demo 演示如何玩演示对于 Unity 2019.1 或更高版本对于 Unity 2018.4 或更早版本 用法基本上是用法使用您现有的 ParticleSystem 预制件带 Mask 或 RectMask2D 组件脚本用法UIParticleAttractor 组件开发说明常见问题解答:为什么我的粒…...
(中))
高教社杯数模竞赛特辑论文篇-2023年C题:基于历史数据的蔬菜类商品定价与补货决策模型(附获奖论文及R语言和Python代码实现)(中)
目录 六、 问题三模型建立与求解 6.1 问题三求解思路 6.2 问题三模型建立 6.2.1 模型假定和预处理...

element-ui plus 文件上传组件,设置单选,并支持替换和回显
遇到的坑: 1、设置limit属性为1后,on-change属性不生效 2、on-exceed属性虽然值改变,但是回显没有随之变化 3、由于element-ui plus版本file-list值出现问题 最后的解决方案决定不设置 limit 属性,通过 on-change 中的判断来控制数…...
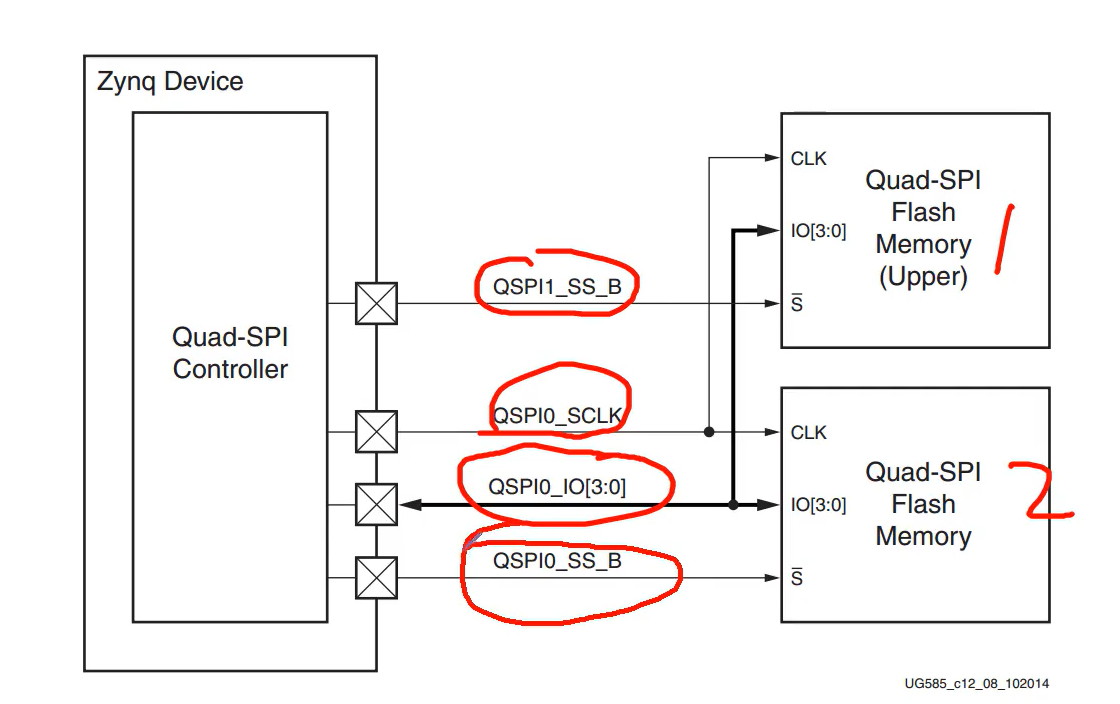
ZYNQ7000---FLASH读写
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Flash是什么?二、Flash的分类1、内部结构(接口)区分:2、外部接口区分:SPIQPSI Flash: QSPI 控制…...

SpringMVC log4j1升级log4j2
整个升级过程耗时5个小时,中间耗时最长的是找合适的包和升级后日志无法打印以及无法控制日志输出位置,完成后感觉其实很简单,如果一开始就能看到我现在写的笔记,可能几分钟就搞定了。 第一步:首先上log4j2所需要的包 …...
(十一))
MATLAB算法实战应用案例精讲-【图像处理】机器视觉(基础篇)(十一)
目录 几个相关概念 1、焦点(focus) 2、弥散圆(circle of confusion) 3、景深(depth of field) 知识储备 线阵相机...
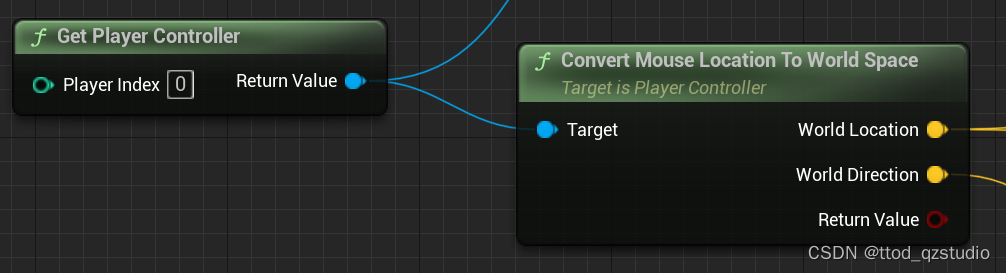
UE的PlayerController方法Convert Mouse Location To World Space
先上图: Convert Mouse Location To World这是PlayerController对象中很重要的方法。 需要说明的是两个输出值。 第一个是World Location,这是个基于世界空间的位置值,一开始我以为这个值和当前摄像机的位置是重叠的,但是打印出来…...
【Qt之QStandardItemModel】使用,tableview、listview、treeview设置模型
1. 引入 QStandardItemModel类提供了一个通用的模型,用于存储自定义数据。 以下是其用法:该类属于gui模块,因此在.pro中,需添加QT gui,如果已存在,则无需重复添加。 首先,引入头文件ÿ…...

mongodb 6/7的 windows安装问题
https://cloud.tencent.com/developer/article/2205068...

网站建设所需要的主要资源相关介绍
人力资源: 网站开发人员:前端开发、后端开发、UI/UX设计师等。 内容创作者:负责编写网站内容,包括文章、图片和视频。 项目经理:协调团队工作,确保项目按计划进行。 数字营销:帮助推广和市场…...
互联网上门预约洗衣洗鞋店小程序;
拽牛科技干洗店洗鞋店软件,方便快捷,让你轻松洗衣。只需在线预约洗衣洗鞋服务,附近的门店立即上门取送,省心省力。轻松了解品牌线下门店,通过列表形式展示周围门店信息,自动选择最近门店为你服务。简单填写…...

OSPF开放最短路径优先(Open Shortest Path First)协议
OSPF开放最短路径优先(Open Shortest Path First)协议 为克服RIP的缺点(限制网络规模,坏消息传得慢)在1989年开发出来的原理很简单,但实现很复杂使用了Dijkstra提出的最短路径算法SPF(Shortest Path First)采用分布式的链路状态协议(link state protoco…...
 字符串操作)
数据结构(c语言版本) 字符串操作
作业要求 创建字符串插入、字符串、字符定位、求字串、删除某个字符、替换某个字符串、合并两个字符串 代码实现 #include <stdio.h> #include <string.h> #define MAXSIZE 100//定义结构体 struct SeqString{char data[MAXSIZE];int charlen; };//初始化 void …...

【Pyqt5】windows和linux安装Pyqt5+designer
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 一、windows安装二、linux安裝linux 安装pyqt5 designer 一、windows安装 PyCharm安装PyQt5及其工具(Qt Designer、PyUIC、PyRcc…...

SenseVoice-small部署教程:Nginx反向代理+HTTPS加密访问WebUI安全配置
SenseVoice-small部署教程:Nginx反向代理HTTPS加密访问WebUI安全配置 1. 为什么需要安全配置? 当你把SenseVoice-small语音识别服务部署到服务器上,默认的访问方式是通过 http://服务器IP:7860 来使用。这种方式虽然简单,但存在…...

解决终端开发效率瓶颈的AI编程助手技术方案
解决终端开发效率瓶颈的AI编程助手技术方案 【免费下载链接】opencode 一个专为终端打造的开源AI编程助手,模型灵活可选,可远程驱动。 项目地址: https://gitcode.com/GitHub_Trending/openc/opencode 在当前的软件开发实践中,开发者面…...

阿里通义Z-Image-Turbo WebUI图像生成:一键部署,开箱即用
阿里通义Z-Image-Turbo WebUI图像生成:一键部署,开箱即用 1. 快速部署指南 1.1 环境准备与启动 阿里通义Z-Image-Turbo WebUI提供了极简的部署方案,无需复杂配置即可快速启动服务。以下是两种启动方式: 推荐方式:使…...
,主芯片LP3798ESM)
全压过认证36W碳化硅方案(24V1.5A/12V3A),主芯片LP3798ESM
LP3798ESM是芯茂微推出的一款原边反馈控制内置SiC功率管二合一芯片,采用ASOP-6封装,内置750V/1.0Ω的SiC MOSFET。配合同步整流芯片LP15R060S(或LP10R060SD),可轻松实现12V3A(36W)或24V1.5A输出…...

多目标点路径规划——蚁群+A*算法融合算法 解决室内旅行商问题 1 A*算法规划两两之间的路径...
多目标点路径规划——蚁群A*算法融合算法 解决室内旅行商问题 1 A*算法规划两两之间的路径,并计算路径长度; 2 蚁群算法依据两点之间路径长度,规划多个目标点的先后到达顺序; 3 自定义地图,起点,终点&#…...

如何快速部署Duix.Avatar开源数字人:5个步骤打造本地AI视频制作平台
如何快速部署Duix.Avatar开源数字人:5个步骤打造本地AI视频制作平台 【免费下载链接】Duix-Avatar 项目地址: https://gitcode.com/GitHub_Trending/he/Duix-Avatar 在数字化内容创作的新时代,开源数字人制作工具正成为内容创作者、教育工作者和…...

Comsol 岩石损伤模型:探索膨胀剂作用下岩石损伤奥秘
comsol岩石损伤模型 模拟了岩石在膨胀剂水化作用下,产生膨胀压力,随着压力的增大,损伤产生以及不同时间点的损伤部位的发展情况。在岩土工程等众多领域,研究岩石在不同条件下的损伤特性至关重要。今天咱就来唠唠利用 Comsol 构建岩…...

嵌入式极简状态机:零动态内存的FSM实现
1. 项目概述 “Minimalistic State Machine”(极简状态机)是一个面向嵌入式系统的轻量级、类封装的有限状态机(Finite State Machine, FSM)实现。它不依赖任何操作系统抽象层(如FreeRTOS内核服务)、标准C运…...

比迪丽WebUI实战:用负向提示词精准去除多余肢体与背景干扰
比迪丽WebUI实战:用负向提示词精准去除多余肢体与背景干扰 1. 引言:当AI画图“画蛇添足”时 如果你用过AI绘画工具,一定遇到过这样的烦恼:明明只想画一个角色,结果AI给你画出了三只手;想要一个干净的背景…...

2024年最受欢迎的免费开源图片数据集与下载平台推荐
1. 2024年最受欢迎的免费开源图片数据集 在计算机视觉和机器学习领域,高质量的开源图片数据集是算法开发和模型训练的基础。2024年,随着AI技术的快速发展,一批新的开源数据集脱颖而出,同时一些经典数据集也持续更新迭代。这些数据…...