Kafka学习笔记(二)
目录
- 第3章 Kafka架构深入
- 3.3 Kafka消费者
- 3.3.1 消费方式
- 3.3.2 分区分配策略
- 3.3.3 offset的维护
- 3.4 Kafka高效读写数据
- 3.5 Zookeeper在Kafka中的作用
- 3.6 Kafka事务
- 3.6.1 Producer事务
- 3.6.2 Consumer事务(精准一次性消费)
- 第4章 Kafka API
- 4.1 Producer API
- 4.1.1 消息发送流程
- 4.1.2 异步发送API
- 4.1.3 同步发送API
- 4.2 Consumer API
- 4.2.1 自动提交offset
- 4.2.2 手动提交offset
第3章 Kafka架构深入
3.3 Kafka消费者
3.3.1 消费方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。
它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
3.3.2 分区分配策略
一个consumer group中有多个consumer,一个 topic有多个partition,所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer来消费。
Kafka有两种分配策略,一是roundrobin,一是range。
-
roundrobin

-
range

3.3.3 offset的维护
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。
3.4 Kafka高效读写数据
- 顺序写磁盘
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到到600M/s,而随机写只有100k/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。 - 应用Pagecache
Kafka数据持久化是直接持久化到Pagecache中,这样会产生以下几个好处:
- I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能
- I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
- 充分利用所有空闲内存(非 JVM 内存)。如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担
- 读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据
- 如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用
尽管持久化到Pagecache上可能会造成宕机丢失数据的情况,但这可以被Kafka的Replication机制解决。如果为了保证这种情况下数据不丢失而强制将 Page Cache 中的数据 Flush 到磁盘,反而会降低性能。
- 零复制技术
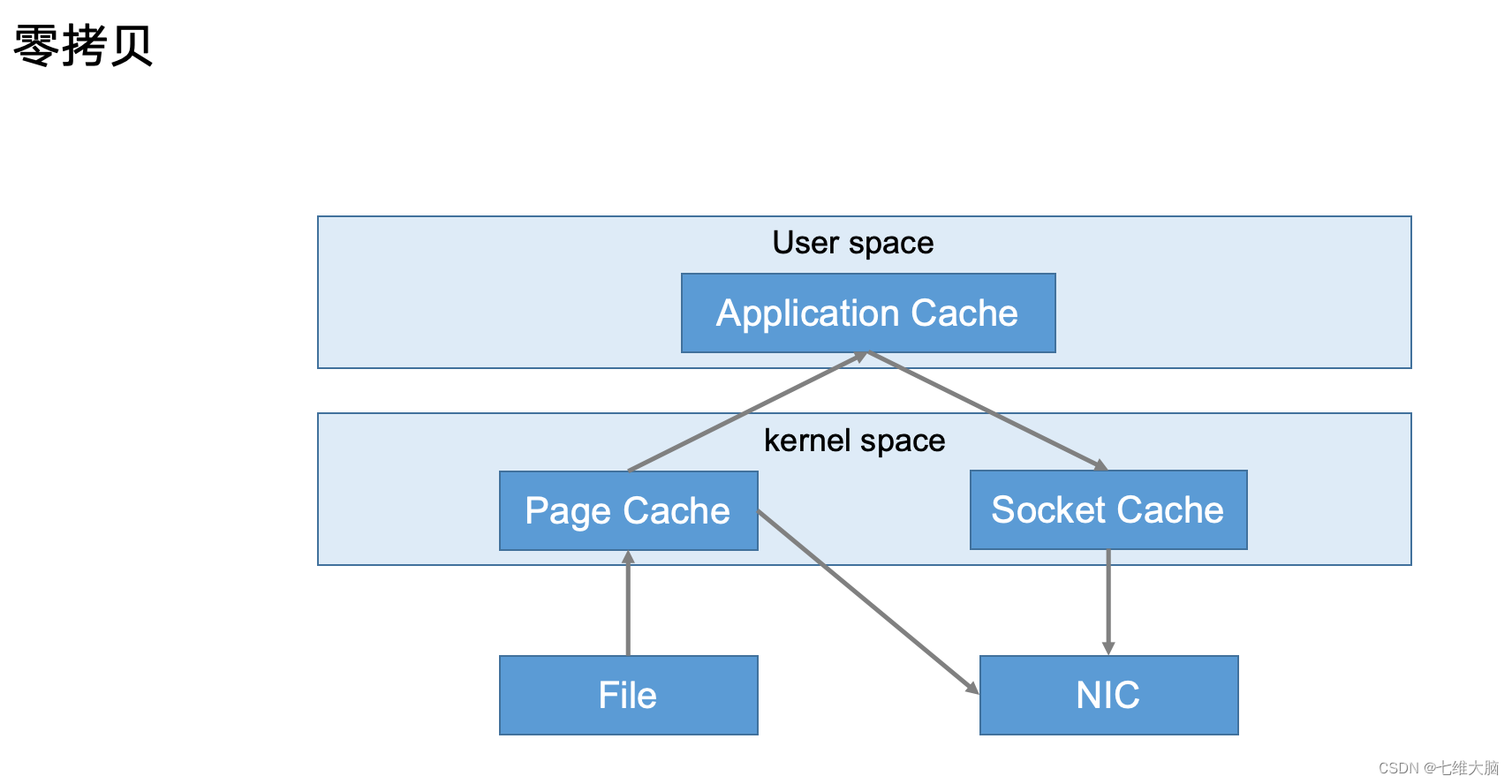
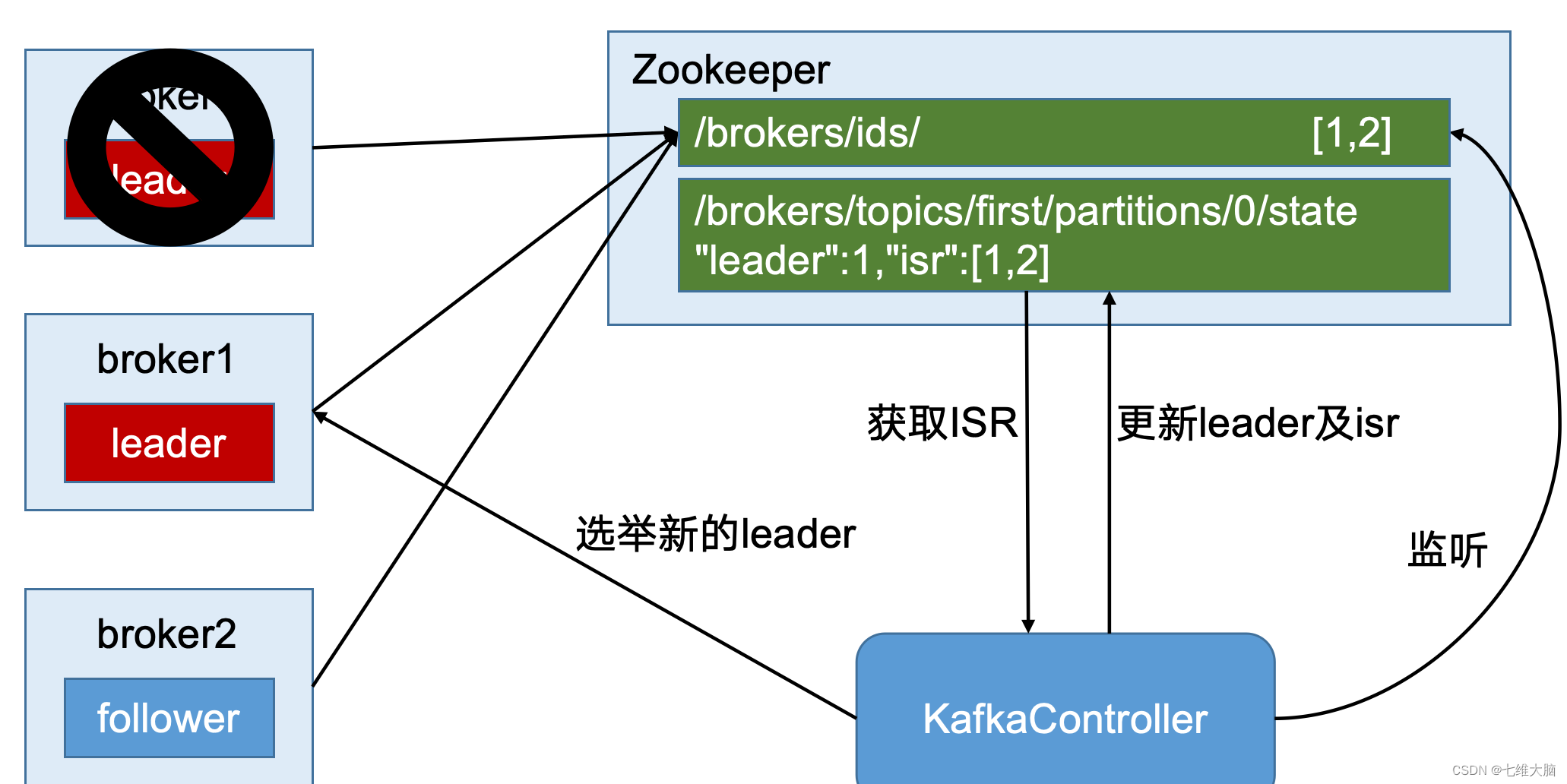
3.5 Zookeeper在Kafka中的作用
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
Controller的管理工作都是依赖于Zookeeper的。
以下为partition的leader选举过程:
3.6 Kafka事务
Kafka从0.11版本开始引入了事务支持。事务可以保证Kafka在Exactly Once语义的基础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败。
3.6.1 Producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transaction,Kafka引入了一个新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态。Transaction Coordinator还负责将事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
3.6.2 Consumer事务(精准一次性消费)
上述事务机制主要是从Producer方面考虑,对于Consumer而言,事务的保证就会相对较弱,尤其时无法保证Commit的信息被精确消费。这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事务的消息可能会出现重启后被删除的情况。
如果想完成Consumer端的精准一次性消费,那么需要kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将kafka的offset保存到支持事务的自定义介质中(比如mysql)。这部分知识会在后续项目部分涉及。
第4章 Kafka API
4.1 Producer API
4.1.1 消息发送流程
Kafka的Producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量——RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
KafkaProducer 发送消息流程:
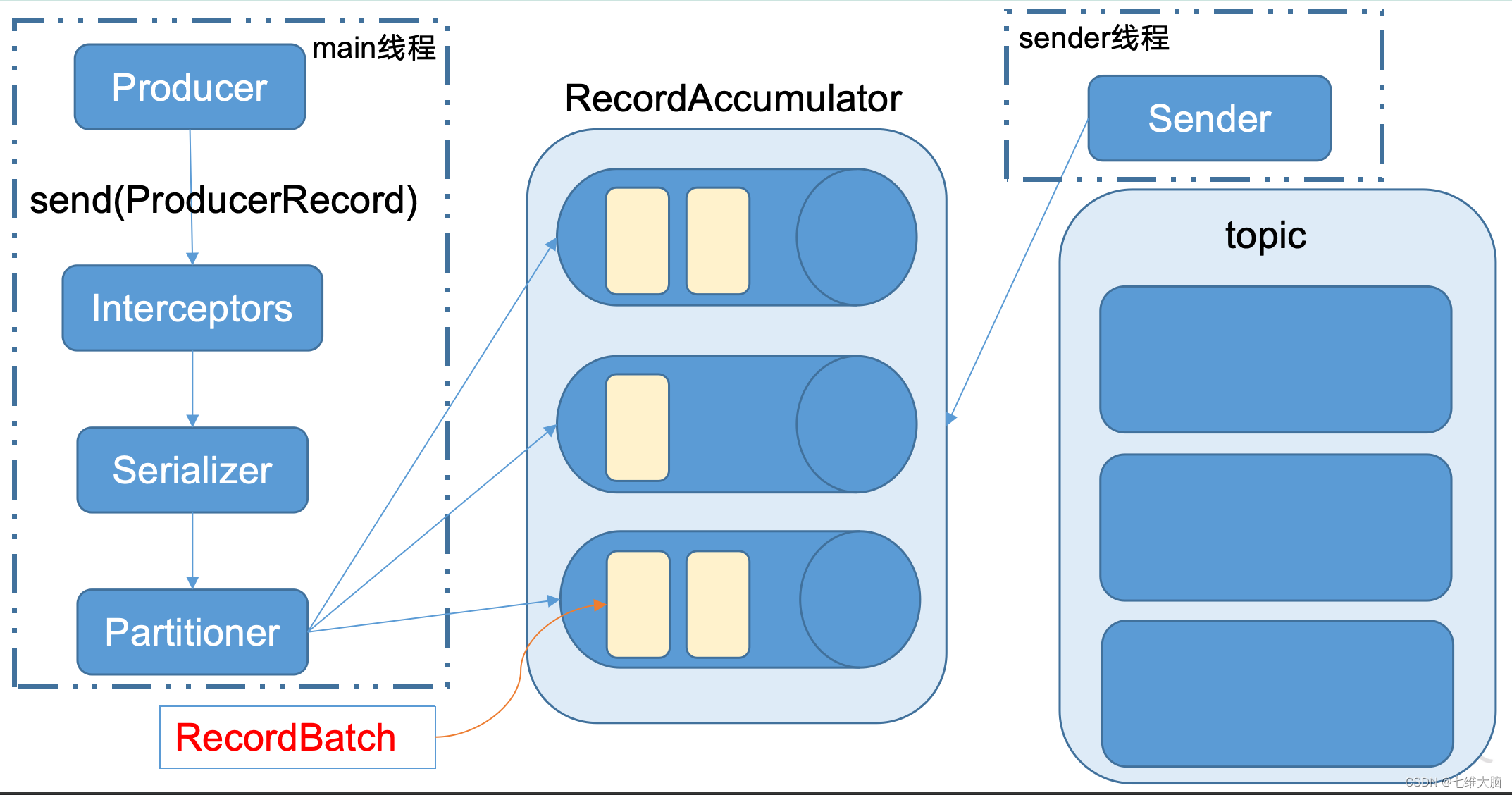
相关参数:
- batch.size:只有数据积累到batch.size之后,sender才会发送数据。
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。
4.1.2 异步发送API
- 导入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.4.1</version>
</dependency>
- 编写代码
需要用到的类:
- KafkaProducer:需要创建一个生产者对象,用来发送数据
- ProducerConfig:获取所需的一系列配置参数
- ProducerRecord:每条数据都要封装成一个ProducerRecord对象
不带回调函数的API:
package com.atguigu.kafka;import org.apache.kafka.clients.producer.*;import java.util.Properties;
import java.util.concurrent.ExecutionException;public class CustomProducer {public static void main(String[] args) throws ExecutionException, InterruptedException {Properties props = new Properties();props.put("bootstrap.servers", "hadoop102:9092");//kafka集群,broker-listprops.put("acks", "all");props.put("retries", 1);//重试次数props.put("batch.size", 16384);//批次大小props.put("linger.ms", 1);//等待时间props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 100; i++) {producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i)));}producer.close();}
}
带回调函数的API:
回调函数会在producer收到ack时调用,为异步调用,该方法有两个参数,分别是RecordMetadata和Exception,如果Exception为null,说明消息发送成功,如果Exception不为null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
package com.atguigu.kafka;import org.apache.kafka.clients.producer.*;import java.util.Properties;
import java.util.concurrent.ExecutionException;public class CustomProducer {public static void main(String[] args) throws ExecutionException, InterruptedException {Properties props = new Properties();props.put("bootstrap.servers", "hadoop102:9092");//kafka集群,broker-listprops.put("acks", "all");props.put("retries", 1);//重试次数props.put("batch.size", 16384);//批次大小props.put("linger.ms", 1);//等待时间props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 100; i++) {producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i)), new Callback() {//回调函数,该方法会在Producer收到ack时调用,为异步调用@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null) {System.out.println("success->" + metadata.offset());} else {exception.printStackTrace();}}});}producer.close();}
}
4.1.3 同步发送API
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回ack。
由于send方法返回的是一个Future对象,根据Futrue对象的特点,我们也可以实现同步发送的效果,只需在调用Future对象的get方发即可。
package com.atguigu.kafka;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;
import java.util.concurrent.ExecutionException;public class CustomProducer {public static void main(String[] args) throws ExecutionException, InterruptedException {Properties props = new Properties();props.put("bootstrap.servers", "hadoop102:9092");//kafka集群,broker-listprops.put("acks", "all");props.put("retries", 1);//重试次数props.put("batch.size", 16384);//批次大小props.put("linger.ms", 1);//等待时间props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 100; i++) {producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i))).get();}producer.close();}
}
4.2 Consumer API
Consumer消费数据时的可靠性是很容易保证的,因为数据在Kafka中是持久化的,故不用担心数据丢失问题。
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
所以offset的维护是Consumer消费数据是必须考虑的问题。
4.2.1 自动提交offset
- 导入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.4.1</version>
</dependency>
- 编写代码
需要用到的类:
- KafkaConsumer:需要创建一个消费者对象,用来消费数据
- ConsumerConfig:获取所需的一系列配置参数
- ConsuemrRecord:每条数据都要封装成一个ConsumerRecord对象
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
enable.auto.commit:是否开启自动提交offset功能
auto.commit.interval.ms:自动提交offset的时间间隔
以下为自动提交offset的代码:
package com.atguigu.kafka;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.util.Arrays;
import java.util.Properties;public class CustomConsumer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "hadoop102:9092");props.put("group.id", "test");props.put("enable.auto.commit", "true");props.put("auto.commit.interval.ms", "1000");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList("first"));while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records)System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}}
}
4.2.2 手动提交offset
虽然自动提交offset十分简介便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而commitAsync则没有失败重试机制,故有可能提交失败。
- 同步提交offset
由于同步提交offset有失败重试机制,故更加可靠,以下为同步提交offset的示例。
package com.atguigu.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.util.Arrays;
import java.util.Properties;/*** @author liubo*/
public class CustomComsumer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "hadoop102:9092");//Kafka集群props.put("group.id", "test");//消费者组,只要group.id相同,就属于同一个消费者组props.put("enable.auto.commit", "false");//关闭自动提交offsetprops.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList("first"));//消费者订阅主题while (true) {ConsumerRecords<String, String> records = consumer.poll(100);//消费者拉取数据for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}consumer.commitSync();//同步提交,当前线程会阻塞知道offset提交成功}}
}
- 异步提交offset
虽然同步提交offset更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会收到很大的影响。因此更多的情况下,会选用异步提交offset的方式。
以下为异步提交offset的示例:
package com.atguigu.kafka.consumer;import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;import java.util.Arrays;
import java.util.Map;
import java.util.Properties;/*** @author liubo*/
public class CustomConsumer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "hadoop102:9092");//Kafka集群props.put("group.id", "test");//消费者组,只要group.id相同,就属于同一个消费者组props.put("enable.auto.commit", "false");//关闭自动提交offsetprops.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList("first"));//消费者订阅主题while (true) {ConsumerRecords<String, String> records = consumer.poll(100);//消费者拉取数据for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {if (exception != null) {System.err.println("Commit failed for" + offsets);}}});//异步提交}}
}
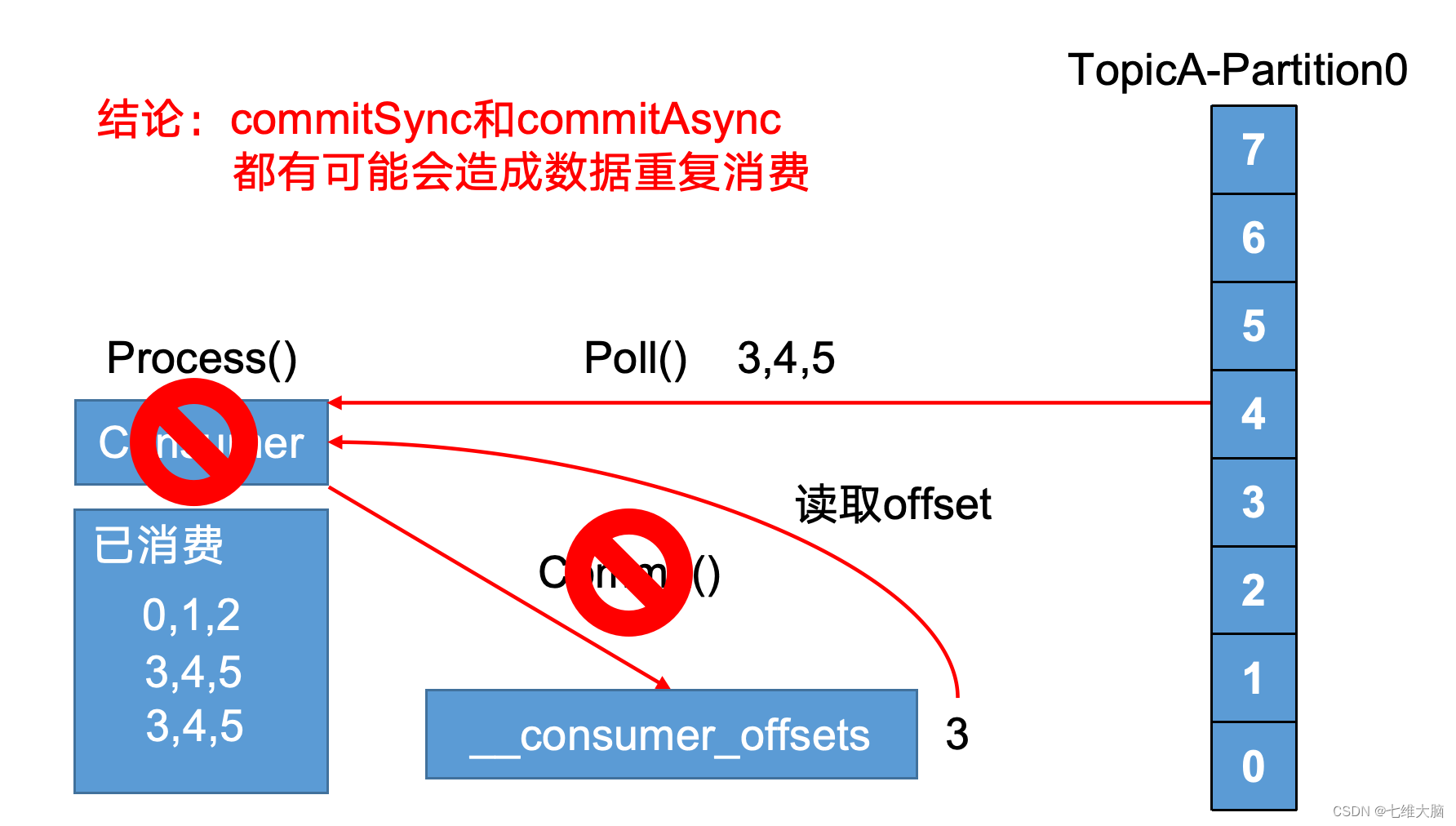
- 数据漏消费和重复消费分析
无论是同步提交还是异步提交offset,都有可能会造成数据的漏消费或者重复消费。先提交offset后消费,有可能造成数据的漏消费;而先消费后提交offset,有可能会造成数据的重复消费。
数据重复消费问题:
相关文章:
Kafka学习笔记(二)
目录 第3章 Kafka架构深入3.3 Kafka消费者3.3.1 消费方式3.3.2 分区分配策略3.3.3 offset的维护 3.4 Kafka高效读写数据3.5 Zookeeper在Kafka中的作用3.6 Kafka事务3.6.1 Producer事务3.6.2 Consumer事务(精准一次性消费) 第4章 Kafka API4.1 Producer A…...
Typora for Mac:打造全新文本编辑体验
Typora for Mac是一款与众不同的文本编辑器,它不仅拥有直观易用的界面,还融合了Markdown语法和富文本编辑的功能,为用户带来了前所未有的写作和编辑体验。 一、简洁明了的界面设计 Typora for Mac的界面简洁明了,让用户可以专注…...

TikTok与媒体素养:如何辨别虚假信息?
在当今数字时代,社交媒体平台如TikTok已经成为信息传播和社交互动的主要渠道之一。然而,随之而来的是虚假信息的泛滥,这对用户的媒体素养提出了严峻的挑战。本文将探讨TikTok平台上虚假信息的现象,以及如何提高媒体素养࿰…...
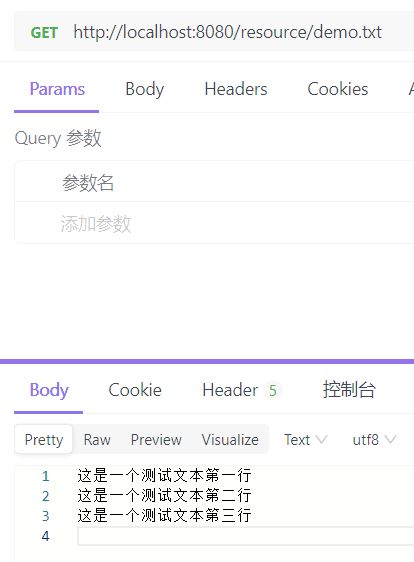
Spring Boot 中使用 ResourceLoader 加载资源的完整示例
ResourceLoader 是 Spring 框架中用于加载资源的接口。它定义了一系列用于获取资源的方法,可以处理各种资源,包括类路径资源、文件系统资源、URL 资源等。 以下是 ResourceLoader 接口的主要方法: Resource getResource(String location)&am…...
1688往微信小程序自营商城铺货商品采集API接口
一、背景介绍 随着移动互联网的快速发展,微信小程序作为一种新型的电商形态,正逐渐成为广大商家拓展销售渠道、提升品牌影响力的重要平台。然而,对于许多传统企业而言,如何将商品信息快速、准确地铺货到微信小程序自营商城是一个…...

QStatusBar开发详解
一、QStatusBar接口说明 QStatusBar 类是 Qt 中用于创建和管理状态栏的类。它继承自 QFrame 类,提供了在主窗口底部显示消息、进度等信息的功能。以下是一些 QStatusBar 类的重要接口: 1.1 QStatusBar构造函数 QStatusBar(QWidget *parent nullptr);…...

后端接口性能优化分析-程序结构优化
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码🔥如果感觉博主的文章还不错的话,请👍三连支持&…...
【SpringBoot3+Vue3】三【实战篇】-后端(优化)
目录 一、登录优化-redis 1、SpringBoot集成redis 1.1 pom 1.2 yml 1.3 测试程序(非必须) 1.4 启动redis,执行测试程序 2、令牌主动失效(代码优化) 2.1 UserController设置token到redis 2.2 登录拦截器Log…...
DevExpress中文教程 - 如何在macOS和Linux (CTP)上创建、修改报表(上)
DevExpress Reporting是.NET Framework下功能完善的报表平台,它附带了易于使用的Visual Studio报表设计器和丰富的报表控件集,包括数据透视表、图表,因此您可以构建无与伦比、信息清晰的报表。 DevExpress Reports — 跨平台报表组件&#x…...
一个iOS tableView 滚动标题联动效果的实现
效果图 情景 tableview 是从屏幕顶部开始的,现在有导航栏,和栏目标题视图将tableView的顶部覆盖了 分析 我们为了达到滚动到某个分区选中标题的效果,就得知道 展示最顶部的cell或者区头在哪个分区范围内 所以我们必须首先获取顶部的位置 …...

代码执行相关函数以及简单例题
代码/命令 执行系列 相关函数 (代码注入)...
大数据爬虫分析基于Python+Django旅游大数据分析系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 基于Python和Django的旅游大数据分析系统是一种使用Python编程语言和Django框架开发的系统,用于处理和分…...

C# 结构体介绍
文章目录 定义结构体实例化结构体结构体的值类型特性结构体和类的区别限制 C# 中的结构体(Struct)是一种值类型数据结构,用于封装不同或相同类型的数据成一个单一的实体。结构体非常适合用来表示轻量级的对象,比如坐标点、颜色值或…...
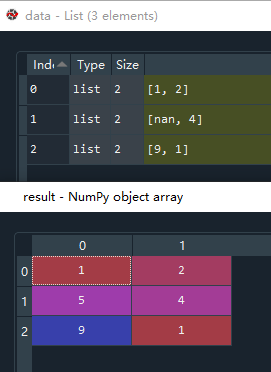
【机器学习】特征工程:特征预处理,归一化、标准化、处理缺失值
特征预处理采用的是特定的统计方法(数学方法)将数据转化为算法要求的数字 1. 数值型数据 归一化,将原始数据变换到[0,1]之间 标准化,数据转化到均值为0,方差为1的范围内 缺失值,缺失值处理成均值、中…...

Pytorch torch.norm函数详解用法
torch.norm参数定义 torch版本1.6 def norm(input, p"fro", dimNone, keepdimFalse, outNone, dtypeNone)input input (Tensor): the input tensor 输入为tensorp p (int, float, inf, -inf, fro, nuc, optional): the order of norm. Default: froThe following …...

【DevOps】Git 图文详解(二):Git 安装及配置
Git 图文详解(二):Git 安装及配置 1.Git 的配置文件2.配置 - 初始化用户3.配置 - 忽略.gitignore Git 官网:https://www.git-scm.com/ 下载安装包进行安装。Git 的使用有两种方式: 命令行:Git 的命令通过系…...

亚马逊美国站CPC认证ASTM F963测试项目要求有哪些?
ASTM F963是美国材料和试验联合会(ASTM)制定的儿童玩具安全性的标准规范,专门针对儿童玩具产品的安全性进行了规定和要求。 ASTM F963标准的内容和要求包括: 1、物理机械性能:规定了玩具的物理机械性能要求࿰…...
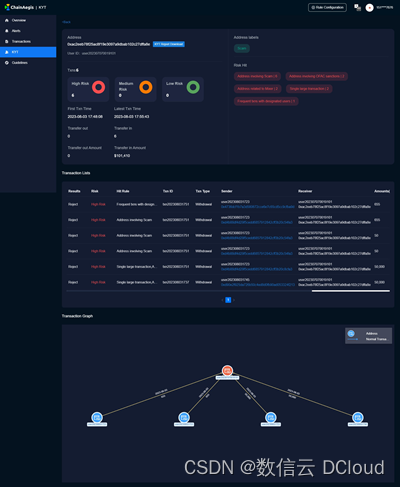
通付盾Web3专题 | KYT/AML:Web3合规展业的必要条件
与传统证券一样,基于区块链技术发展出来的虚拟资产交易所经历了快速发展而缺乏有效监管的行业早期。除了科技光环加持的各种区块链项目方、造富神话之外,交易所遭到黑客攻击、内部偷窃作恶、甚至经营主体异常而致使投资人血本无归的案例亦令人触目惊心。…...
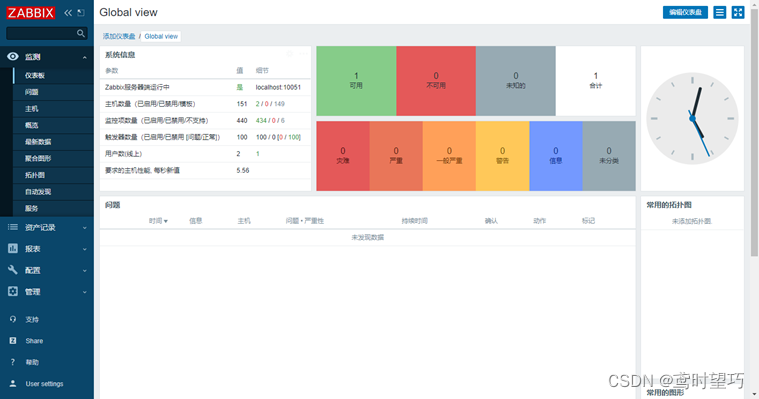
Centos8配置Zabbix5.0中文汉化
1.点击【Sign in】按钮,输入用户名和密码进入Zabbix的首页,结果如图。 2.点击左边导航栏的【User settings】链接,进入用户个性化设置界面,结果如图。 3.在搭建Zabbix的虚拟机上使用yum命令下载中文包。 yum install glibc-langpa…...
元数据管理,数字化时代企业的基础建设
随着新一代信息化、数字化技术的应用,众多领域通过科技革命和产业革命实现了深度化的数字改造,进入到以数据为核心驱动力的,全新的数据处理时代,并通过业务系统、商业智能BI等数字化技术和应用实现了数据价值,从数字经…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...