Elasticsearch:通过摄取管道加上嵌套向量对大型文档进行分块轻松地实现段落搜索
作者:VECTOR SEARCH

向量搜索是一种基于含义而不是精确或不精确的 token 匹配技术来搜索数据的强大方法。 然而,强大的向量搜索的文本嵌入模型只能按几个句子的顺序处理短文本段落,而不是可以处理任意大量文本的基于 BM25 的技术。 现在,Elasticsearch 可以将大型文档与向量搜索无缝结合。
简单地说,它是如何在发挥作用的呢?
Elasticsearch 功能(例如摄取管道、脚本处理器的灵活性以及对使用密集向量的嵌套文档的新支持)的组合允许以一种简单的方式在摄取时将大文档分成足够小的段落,然后由文本嵌入模型处理这些段落以生成表示大型文档的全部含义所需的所有向量。
像平常一样摄取文档数据,并向摄取管道添加一个脚本处理器,将大型文本数据分解为句子数组或其他类型的块,然后添加一个 for_each 处理器,对每个块运行推理处理器。 索引的映射被定义为使得块数组被设置为嵌套对象,其中以密集向量映射作为子对象,然后该子对象将正确索引每个向量并使它们可搜索。
让我们详细了解一下:
加载文本嵌入模型
你需要的第一件事是一个模型,用于从块中创建文本嵌入,你可以使用任何你想要的东西,但此示例将在 all-distilroberta-v1 模型上端到端运行。 创建 Elastic Cloud 集群或准备另一个 Elasticsearch 集群后,我们可以使用 eland 库上传文本嵌入模型。
MODEL_ID = "sentence-transformers/all-MiniLM-L6-v2"
ELASTIC_PASSWORD = "YOURPASSWORD"
CLOUD_ID = "YOURCLOUDID"eland_import_hub_model \--cloud-id $CLOUD_ID \--es-username elastic \--es-password $ELASTIC_PASSWORD \--hub-model-id $MODEL_ID \--task-type text_embedding \--start映射示例
下一步是准备映射以处理将在摄取管道期间创建的句子数组和向量对象。 对于这个特定的文本嵌入模型,维度为 384,dot_product 相似度将用于最近邻计算:
PUT chunker
{"mappings": {"dynamic": "true","properties": {"passages": {"type": "nested","properties": {"vector": {"properties": {"predicted_value": {"type": "dense_vector","index": true,"dims": 384,"similarity": "dot_product"}}}}}}}
}摄取管道示例
最后的准备步骤是定义一个摄取管道,将 body_content 字段分解为存储在 passages 字段中的文本块。 该管道有两个处理器,第一个脚本处理器将 body_content 字段分解为通过正则表达式存储在 passages 字段中的句子数组。 要进一步研究,请阅读正则表达式的高级功能,例如负向后查找和正向后查找,以了解它如何尝试在句子边界上正确分割,而不是在 Mr. 或 Mrs. 或 Ms. 上分割,并保留句子中的标点符号。 只要总字符串长度低于传递给脚本的参数,它还会尝试将句子块连接在一起。 接下来每个处理器通过推理处理器在每个句子上运行文本嵌入模型:
PUT _ingest/pipeline/chunker
{"processors": [{"script": {"description": "Chunk body_content into sentences by looking for . followed by a space","lang": "painless","source": """String[] envSplit = /((?<!M(r|s|rs)\.)(?<=\.) |(?<=\!) |(?<=\?) )/.split(ctx['body_content']);ctx['passages'] = new ArrayList();int i = 0;boolean remaining = true;if (envSplit.length == 0) {return} else if (envSplit.length == 1) {Map passage = ['text': envSplit[0]];ctx['passages'].add(passage)} else {while (remaining) {Map passage = ['text': envSplit[i++]];while (i < envSplit.length && passage.text.length() + envSplit[i].length() < params.model_limit) {passage.text = passage.text + ' ' + envSplit[i++]}if (i == envSplit.length) {remaining = false}ctx['passages'].add(passage)}}""","params": {"model_limit": 400}}},{"foreach": {"field": "passages","processor": {"inference": {"field_map": {"_ingest._value.text": "text_field"},"model_id": "sentence-transformers__all-minilm-l6-v2","target_field": "_ingest._value.vector","on_failure": [{"append": {"field": "_source._ingest.inference_errors","value": [{"message": "Processor 'inference' in pipeline 'ml-inference-title-vector' failed with message '{{ _ingest.on_failure_message }}'","pipeline": "ml-inference-title-vector","timestamp": "{{{ _ingest.timestamp }}}"}]}}]}}}}]
}添加一些文档
现在我们可以在 body_content 中添加包含大量文本的文档,并自动将它们分块,并将每个块文本通过模型嵌入到向量中:
PUT chunker/_doc/1?pipeline=chunker
{
"title": "Adding passage vector search to Lucene",
"body_content": "Vector search is a powerful tool in the information retrieval tool box. Using vectors alongside lexical search like BM25 is quickly becoming commonplace. But there are still a few pain points within vector search that need to be addressed. A major one is text embedding models and handling larger text input. Where lexical search like BM25 is already designed for long documents, text embedding models are not. All embedding models have limitations on the number of tokens they can embed. So, for longer text input it must be chunked into passages shorter than the model’s limit. Now instead of having one document with all its metadata, you have multiple passages and embeddings. And if you want to preserve your metadata, it must be added to every new document. A way to address this is with Lucene's “join” functionality. This is an integral part of Elasticsearch’s nested field type. It makes it possible to have a top-level document with multiple nested documents, allowing you to search over nested documents and join back against their parent documents. This sounds perfect for multiple passages and vectors belonging to a single top-level document! This is all awesome! But, wait, Elasticsearch® doesn’t support vectors in nested fields. Why not, and what needs to change? The key issue is how Lucene can join back to the parent documents when searching child vector passages. Like with kNN pre-filtering versus post-filtering, when the joining occurs determines the result quality and quantity. If a user searches for the top four nearest parent documents (not passages) to a query vector, they usually expect four documents. But what if they are searching over child vector passages and all four of the nearest vectors are from the same parent document? This would end up returning just one parent document, which would be surprising. This same kind of issue occurs with post-filtering."
}PUT chunker/_doc/3?pipeline=chunker
{
"title": "Automatic Byte Quantization in Lucene",
"body_content": "While HNSW is a powerful and flexible way to store and search vectors, it does require a significant amount of memory to run quickly. For example, querying 1MM float32 vectors of 768 dimensions requires roughly 1,000,000∗4∗(768+12)=3120000000≈31,000,000∗4∗(768+12)=3120000000bytes≈3GB of ram. Once you start searching a significant number of vectors, this gets expensive. One way to use around 75% less memory is through byte quantization. Lucene and consequently Elasticsearch has supported indexing byte vectors for some time, but building these vectors has been the user's responsibility. This is about to change, as we have introduced int8 scalar quantization in Lucene. All quantization techniques are considered lossy transformations of the raw data. Meaning some information is lost for the sake of space. For an in depth explanation of scalar quantization, see: Scalar Quantization 101. At a high level, scalar quantization is a lossy compression technique. Some simple math gives significant space savings with very little impact on recall. Those used to working with Elasticsearch may be familiar with these concepts already, but here is a quick overview of the distribution of documents for search. Each Elasticsearch index is composed of multiple shards. While each shard can only be assigned to a single node, multiple shards per index gives you compute parallelism across nodes. Each shard is composed as a single Lucene Index. A Lucene index consists of multiple read-only segments. During indexing, documents are buffered and periodically flushed into a read-only segment. When certain conditions are met, these segments can be merged in the background into a larger segment. All of this is configurable and has its own set of complexities. But, when we talk about segments and merging, we are talking about read-only Lucene segments and the automatic periodic merging of these segments. Here is a deeper dive into segment merging and design decisions."
}PUT chunker/_doc/2?pipeline=chunker
{
"title": "Use a Japanese language NLP model in Elasticsearch to enable semantic searches",
"body_content": "Quickly finding necessary documents from among the large volume of internal documents and product information generated every day is an extremely important task in both work and daily life. However, if there is a high volume of documents to search through, it can be a time-consuming process even for computers to re-read all of the documents in real time and find the target file. That is what led to the appearance of Elasticsearch® and other search engine software. When a search engine is used, search index data is first created so that key search terms included in documents can be used to quickly find those documents. However, even if the user has a general idea of what type of information they are searching for, they may not be able to recall a suitable keyword or they may search for another expression that has the same meaning. Elasticsearch enables synonyms and similar terms to be defined to handle such situations, but in some cases it can be difficult to simply use a correspondence table to convert a search query into a more suitable one. To address this need, Elasticsearch 8.0 released the vector search feature, which searches by the semantic content of a phrase. Alongside that, we also have a blog series on how to use Elasticsearch to perform vector searches and other NLP tasks. However, up through the 8.8 release, it was not able to correctly analyze text in languages other than English. With the 8.9 release, Elastic added functionality for properly analyzing Japanese in text analysis processing. This functionality enables Elasticsearch to perform semantic searches like vector search on Japanese text, as well as natural language processing tasks such as sentiment analysis in Japanese. In this article, we will provide specific step-by-step instructions on how to use these features."
}PUT chunker/_doc/5?pipeline=chunker
{
"title": "We can chunk whatever we want now basically to the limits of a document ingest",
"body_content": """Chonk is an internet slang term used to describe overweight cats that grew popular in the late summer of 2018 after a photoshopped chart of cat body-fat indexes renamed the "Chonk" scale grew popular on Twitter and Reddit. Additionally, "Oh Lawd He Comin'," the final level of the Chonk Chart, was adopted as an online catchphrase used to describe large objects, animals or people. It is not to be confused with the Saturday Night Live sketch of the same name. The term "Chonk" was popularized in a photoshopped edit of a chart illustrating cat body-fat indexes and the risk of health problems for each class (original chart shown below). The first known post of the "Chonk" photoshop, which classifies each cat to a certain level of "chonk"-ness ranging from "A fine boi" to "OH LAWD HE COMIN," was posted to Facebook group THIS CAT IS C H O N K Y on August 2nd, 2018 by Emilie Chang (shown below). The chart surged in popularity after it was tweeted by @dreamlandtea[1] on August 10th, 2018, gaining over 37,000 retweets and 94,000 likes (shown below). After the chart was posted there, it began growing popular on Reddit. It was reposted to /r/Delighfullychubby[2] on August 13th, 2018, and /r/fatcats on August 16th.[3] Additionally, cats were shared with variations on the phrase "Chonk." In @dreamlandtea's Twitter thread, she rated several cats on the Chonk scale (example, shown below, left). On /r/tumblr, a screenshot of a post featuring a "good luck cat" titled "Lucky Chonk" gained over 27,000 points (shown below, right). The popularity of the phrase led to the creation of a subreddit, /r/chonkers,[4] that gained nearly 400 subscribers in less than a month. Some photoshops of the chonk chart also spread on Reddit. For example, an edit showing various versions of Pikachu on the chart posted to /r/me_irl gained over 1,200 points (shown below, left). The chart gained further popularity when it was posted to /r/pics[5] September 29th, 2018."""
}搜索那些文档
要搜索数据并返回与查询最匹配的块,你可以使用 inner_hits 和 knn 子句,以在查询的命中输出中返回文档的最佳匹配块:
GET chunker/_search
{"_source": false,"fields": ["title"],"knn": {"inner_hits": {"_source": false,"fields": ["passages.text"]},"field": "passages.vector.predicted_value","k": 1,"num_candidates": 100,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-minilm-l6-v2","model_text": "Can I use multiple vectors per document now?"}}}
}将返回最佳文档和较大文档文本的相关部分:
{"took": 4,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0.75261426,"hits": [{"_index": "chunker","_id": "1","_score": 0.75261426,"_ignored": ["body_content.keyword","passages.text.keyword"],"fields": {"title": ["Adding passage vector search to Lucene"]},"inner_hits": {"passages": {"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0.75261426,"hits": [{"_index": "chunker","_id": "1","_nested": {"field": "passages","offset": 3},"_score": 0.75261426,"fields": {"passages": [{"text": ["This sounds perfect for multiple passages and vectors belonging to a single top-level document! This is all awesome! But, wait, Elasticsearch® doesn’t support vectors in nested fields. Why not, and what needs to change? The key issue is how Lucene can join back to the parent documents when searching child vector passages."]}]}}]}}}}]}
}回顾一下
这里使用的方法展示了利用 Elasticsearch 的不同功能来解决更大问题的力量。
摄取管道允许你在索引之前对文档进行预处理,虽然有许多处理器可以执行特定的目标任务,但有时你需要脚本语言的强大功能才能执行诸如将文本分解为句子数组之类的操作。 因为你可以在对文档建立索引之前访问该文档,所以只要所有信息都在文档本身中,你就可以以几乎任何你能想象到的方式重新创建数据。 foreach 处理器允许我们包装一些可能运行零到 N 次的东西,而无需事先知道它需要执行多少次。 在本例中,我们使用它来运行与提取的句子一样多的句子,以运行推断处理器来生成向量。
索引的映射准备好处理原始文档中不存在的文本和向量的现在的对象数组,并使用嵌套对象来索引数据,以便我们可以正确搜索文档。
使用带有向量嵌套支持的 knn 允许使用 inner_hits 来呈现文档的最佳评分部分,这可以替代通常通过在 BM25 查询中使用 highlight 显示来完成的操作。
原文:Chunking Large Documents via Ingest pipelines plus nested vectors equals easy passage search — Elastic Search Labs
相关文章:
Elasticsearch:通过摄取管道加上嵌套向量对大型文档进行分块轻松地实现段落搜索
作者:VECTOR SEARCH 向量搜索是一种基于含义而不是精确或不精确的 token 匹配技术来搜索数据的强大方法。 然而,强大的向量搜索的文本嵌入模型只能按几个句子的顺序处理短文本段落,而不是可以处理任意大量文本的基于 BM25 的技术。 现在&…...
OpenCV图像纹理
LBP描述 LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。它是首先由T. Ojala, M.Pietikinen, 和D. Harwood 在1994年提出,用于纹理特征提取…...

自媒体写手提问常用的ChatGPT通用提示词模板
如何撰写一篇具有吸引力和可读性的自媒体文章? 如何确定自媒体文章的主题和受众群体? 如何为自媒体文章取一个引人入胜的标题? 如何让自媒体文章的开头更加吸引人? 如何为自媒体文章构建一个清晰、逻辑严谨的框架?…...

分类预测 | Matlab实现PSO-LSTM-Attention粒子群算法优化长短期记忆神经网络融合注意力机制多特征分类预测
分类预测 | Matlab实现PSO-LSTM-Attention粒子群算法优化长短期记忆神经网络融合注意力机制多特征分类预测 目录 分类预测 | Matlab实现PSO-LSTM-Attention粒子群算法优化长短期记忆神经网络融合注意力机制多特征分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1…...
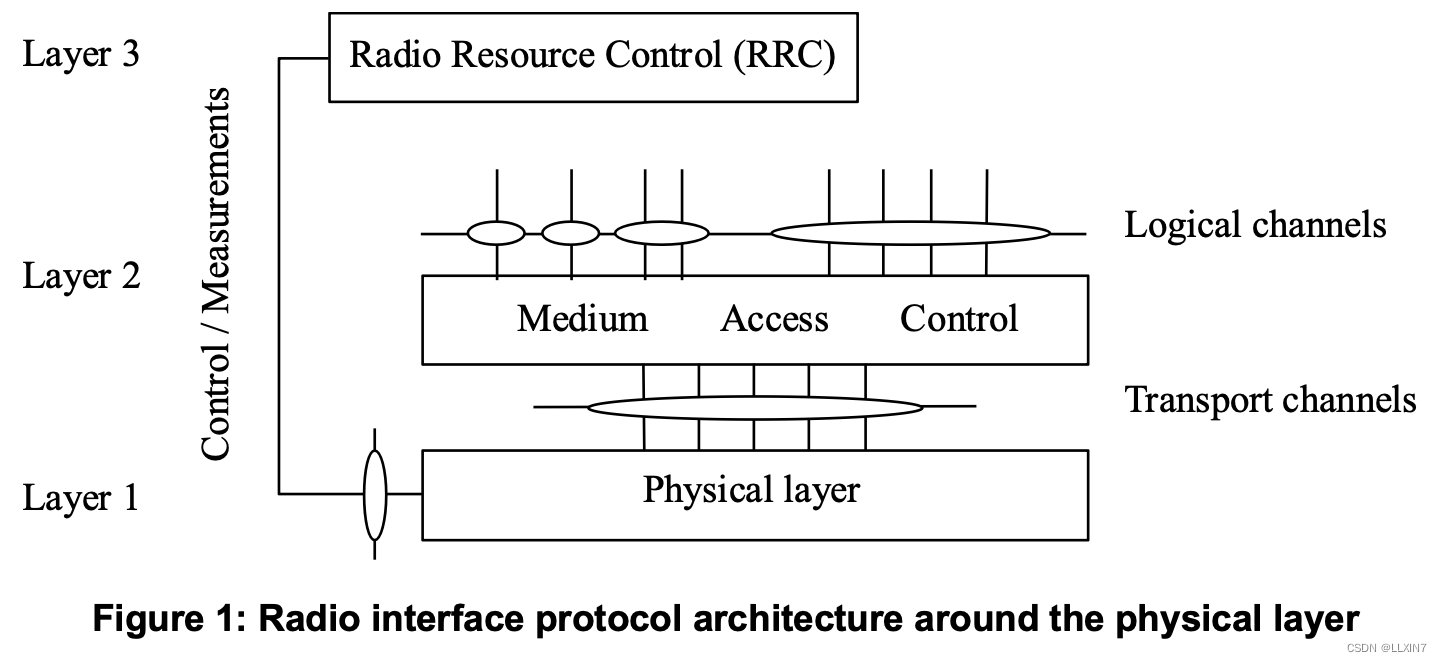
3GPP TS38.201 NR; Physical layer; General description (Release 18)
TS38.201是介绍性的标准,简单介绍了RAN的信道组成和PHY层承担的功能,下图是PHY层相关标准的关系。 文章目录 结构信道类型调制方式PHY层支持的过程物理层测量其他标准TS 38.202: Physical layer services provided by the physical layerTS 38.211: Ph…...
【GitLab】-HTTP 500 curl 22 The requested URL returned error: 500~SSH解决
写在前面 本文主要介绍通过SSH的方式拉取GitLab代码。 目录 写在前面一、场景描述二、具体步骤1.环境说明2.生成秘钥3.GitLab添加秘钥4.验证SSH方式4.更改原有HTTP方式为SSH 三、参考资料写在后面系列文章 一、场景描述 之前笔者是通过 HTTP Personal access token 的方式拉取…...

【如何学习Python自动化测试】—— 自动化测试环境搭建
1、 自动化测试环境搭建 1.1 为什么选择 Python 什么是python,引用python官方的说法就是“一种解释型的、面向对象、带有励志语义的高级程序设计语言”,对于很多测试人员来说,这段话包含了很多术语,而测试人员大多是希望利用编程…...
在通用jar包中引入其他spring boot starter,并在通用jar包中直接配置这些starter的yml相关属性
场景 我在通用jar包中引入 spring-boot-starter-actuator 这样希望引用通用jar的所有服务都可以直接使用 actuator 中的功能, 问题在于,正常情况下,actuator的配置都写在每个项目的yml文件中,这就意味着,虽然每个项目…...

Seaborn 回归(Regression)及矩阵(Matrix)绘图
Seaborn中的回归包括回归拟合曲线图以及回归误差图。Matrix图主要是热度图。 1. 回归及矩阵绘图API概述 seaborn中“回归”绘图函数共3个: lmplot(回归统计绘图):figure级regplot函数,绘图同regplot完全相同。(lm指lin…...
nginx学习(1)
一、下载安装NGINX: 先安装gcc-c编译器 yum install gcc-c yum install -y openssl openssl-devel(1)下载pcre-8.3.7.tar.gz 直接访问:http://downloads.sourceforge.net/project/pcre/pcre/8.37/pcre-8.37.tar.gz,就…...
CLEARTEXT communication to XX not permitted by network security policy 报错
在进行网络请求时,日志中打印 CLEARTEXT communication to XX not permitted by network security policy 原因: Android P系统网络访问安全策略升级,限制了非加密的流量请求 Android P系统限制了明文流量的网络请求,之下的版本…...

91.移动零(力扣)
问题描述 代码解决以及思想 class Solution { public:void moveZeroes(vector<int>& nums) {int left 0; // 左指针,用于指向当前非零元素应该放置的位置int right 0; // 右指针,用于遍历数组int len nums.size(); // 数组长度while …...
PatchMatchNet笔记
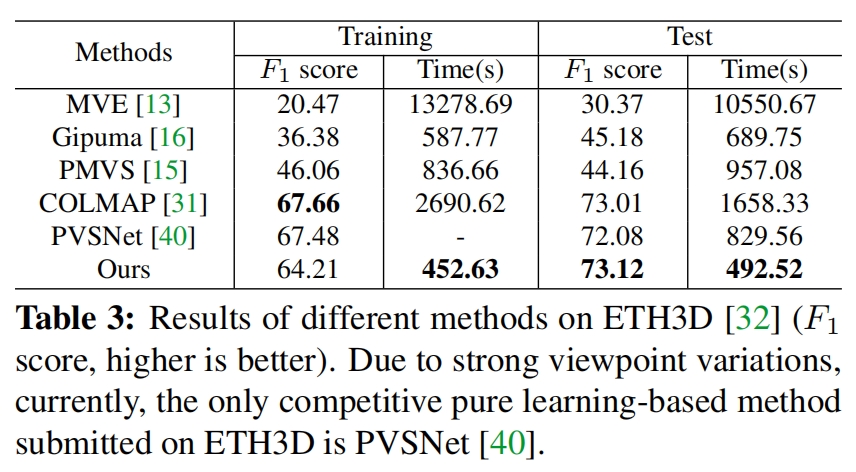
PatchMatchNet笔记 1 概述2 PatchmatchNet网络结构图2.1 多尺度特征提取2.2 基于学习的补丁匹配 3 性能评价 PatchmatchNet: Learned Multi-View Patchmatch Stereo:基于学习的多视角补丁匹配立体算法 1 概述 特点 高速,低内存,可以处理…...

实时人眼追踪、内置3D引擎,联想ThinkVision裸眼3D显示器创新四大应用场景
11月17日,在以“因思而变 智领未来”为主题的Think Centre和ThinkVision 20周年纪念活动上,联想正式发布了业内首款2D/3D 可切换裸眼3D显示器——联想ThinkVision 27 3D。该产品首次将裸眼2D、3D可切换技术应用在显示器领域,并拓展了3D技术多…...
)
SELinux零知识学习十四、SELinux策略语言之客体类别和许可(8)
接前一篇文章:SELinux零知识学习十三、SELinux策略语言之客体类别和许可(7) 一、SELinux策略语言之客体类别和许可 4. 客体类别许可实例 (2)文件客体类别许可 文件客体类别有三类许可:直接映像到标准Lin…...
Unity——URP相机详解
2021版本URP项目下的相机,一般新建一个相机有如下组件 1:Render Type(渲染类型) 有Base和Overlay两种选项,默认是Base选项 Base:主相机使用该种渲染方式,负责渲染场景中的主要图形元素 Overlay(叠加):使用了Oveylay的…...

CRUD-SQL
文章目录 前置insertSelective和upsertSelective使用姿势手写sql,有两种方式 一、增当导入的数据不存在时则进行添加,有则更新 1.1 唯一键,先查,后插1.2 批量插1.2.1 批次一200、批次二200、批次三200,有一条数据写入失…...

【C语言 | 数组】C语言数组详解(经典,超详细)
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

第三十三节——组合式API生命周期
一、基本使用 组合式api生命周期几乎和选项式一致。注意组合式api是从挂载阶段开始 <template><div></div> </template> <script setup> import {onBeforeMount, onMounted,onBeforeUpdate, onUpdated, onBeforeUnmount, onUnmounted, } from …...

【Linux】Alibaba Cloud Linux 3 安装 PHP8.1
一、系统安装 请参考 【Linux】Alibaba Cloud Linux 3 中第二硬盘、MySQL8.、MySQL7.、Redis、Nginx、Java 系统安装 二、安装源 rpm -ivh --nodeps https://rpms.remirepo.net/enterprise/remi-release-8.rpm sed -i s/PLATFORM_ID"platform:al8"/PLATFORM_ID&q…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...

DAY 26 函数专题1
函数定义与参数知识点回顾:1. 函数的定义2. 变量作用域:局部变量和全局变量3. 函数的参数类型:位置参数、默认参数、不定参数4. 传递参数的手段:关键词参数5 题目1:计算圆的面积 任务: 编写一…...
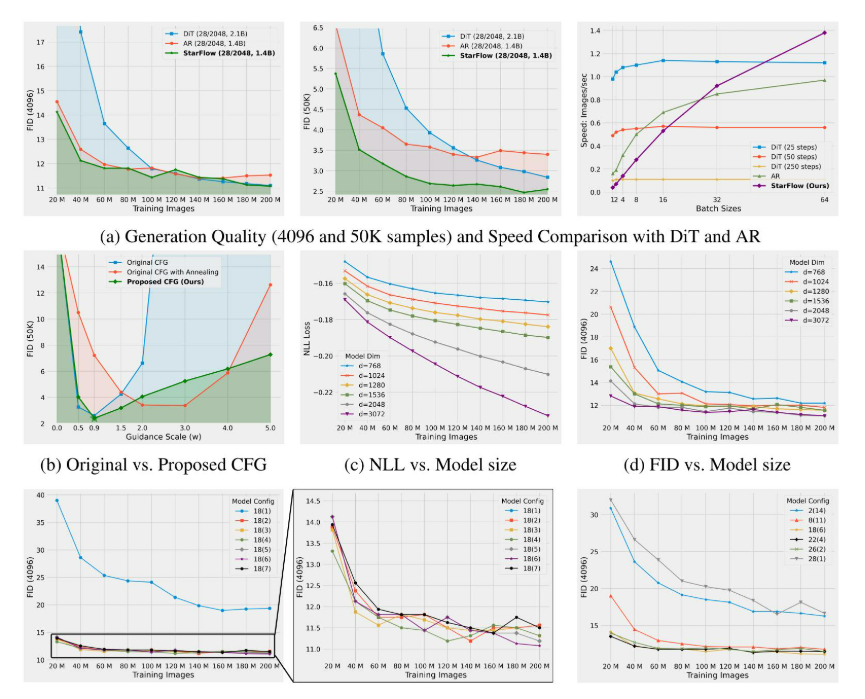
高分辨率图像合成归一化流扩展
大家读完觉得有帮助记得关注和点赞!!! 1 摘要 我们提出了STARFlow,一种基于归一化流的可扩展生成模型,它在高分辨率图像合成方面取得了强大的性能。STARFlow的主要构建块是Transformer自回归流(TARFlow&am…...

SQL进阶之旅 Day 22:批处理与游标优化
【SQL进阶之旅 Day 22】批处理与游标优化 文章简述(300字左右) 在数据库开发中,面对大量数据的处理任务时,单条SQL语句往往无法满足性能需求。本篇文章聚焦“批处理与游标优化”,深入探讨如何通过批量操作和游标技术提…...
性能优化中,多面体模型基本原理
1)多面体编译技术是一种基于多面体模型的程序分析和优化技术,它将程序 中的语句实例、访问关系、依赖关系和调度等信息映射到多维空间中的几何对 象,通过对这些几何对象进行几何操作和线性代数计算来进行程序的分析和优 化。 其中࿰…...

链结构与工作量证明7️⃣:用 Go 实现比特币的核心机制
链结构与工作量证明:用 Go 实现比特币的核心机制 如果你用 Go 写过区块、算过哈希,也大致理解了非对称加密、数据序列化这些“硬核知识”,那么恭喜你,现在我们终于可以把这些拼成一条完整的“区块链”。 不过别急,这一节我们重点搞懂两件事: 区块之间是怎么连接成“链”…...